Keyword research has an expanded purpose in the world of local SEO. The keyword intent you’re already building for clients can now feed the trust signal layer that drives local AI recommendations, but only if it’s deployed in the right places.
When AI tools recommend a local business, they’re not just reading the website. They’re weighing a layer of activity around the business: how often it’s reviewed, how those reviews are responded to, how its Google Business Profile is updated, and what language is showing up across all of it. That activity is the trust signal layer, and on-page SEO alone doesn’t generate it.
Local AI recommendations pull from that activity: keyword-rich, consistent engagement tied to a business’s local presence. Reviews, review responses, and GBP posts are where the keyword intent you’ve already built needs to land. The terms your clients want to be known for have to show up on the surfaces AI is actively reading, at a cadence that signals the business is current. Most agencies finish the keyword research and stop at the website. The intent is sitting in a doc instead of working across the places AI is actually pulling from.
The research is already done. What’s missing is the deployment plan for keyword-driven trust signals: where to place each term by signal type, how to format it so it reads as natural engagement, and how to keep that activity running across every client account without burning hours on manual work.
What You’ll Learn in This Local SEO & AI Search Webinar
Where AI is pulling keyword-rich signals from: The specific sources keyword research needs to feed: reviews, responses, and GBP activity. Plus how placement inside each one influences local AI recommendations.
How to build keyword-driven trust signals from scratch: Keyword selection, placement by signal type, and the response cadence that tells AI a business is active and relevant.
How to automate that activity across your full client roster: Review response automation, keyword refresh intervals, and GBP activity scheduling on a consistent weekly cadence so every account runs the same play.
What Reviewly.ai Has Learned Running This Across Local Client Rosters
The session is led by Jeff “Herschy” Schwerdt, founder and CEO of Reviewly.ai, the platform built to deploy and automate keyword-driven trust signals across local SEO accounts.
He’s not teaching this from a research lens; he’s teaching the workflow Reviewly.ai actually runs to keep review responses, GBP activity, and keyword placement on a consistent weekly cadence for every client. Expect specific signal placements, the automation cadences that are working, and the patterns showing up in local AI recommendations right now.
Search engines were designed to do several things at once: Rank a field of options, route the user to one of them, and keep the human inside the decision so the engine never owned the choice. That last part was not an accident. It was the liability architecture. Large language models were built without any of it. They were built to answer the question directly, which is a different job entirely, and the design choices that follow from it change what visibility looks like, what risk looks like, and what the word ROI can honestly mean when the thing sending you traffic was never built to send traffic in the first place.
Two Systems, Two Jobs
A search engine’s job description is long. It crawls the web, indexes it, ranks a pool of candidate results against a query, presents them as a ranked list, and then waits for the human to make a click decision. The SERP itself has been drifting toward retention for years now, with galleries, rich snippets, answer boxes, local maps, video carousels, and AI Overviews all layering in features that keep the user on the page longer and route fewer of them to third-party sites. But the underlying contract was always the same. The engine offers options. The user selects one. The user owns the choice.
An LLM does not offer options. It produces an answer. The citation, when it appears, is not functioning as a routing instrument. It is closer to a grounding artifact produced by a retrieval pipeline, or in some framings, a confidence hedge, or both at the same time. Whichever read you prefer, none of them describe a system designed to send traffic somewhere else. The system was designed to resolve the question in place.
That distinction sits beneath every metric conversation in this space. When practitioners ask what the LLM referral rate is, what the attributed traffic number looks like, what the click-through from an AI answer is, they are asking questions that assume a routing mechanism that is not actually part of the architecture. Whatever traffic does come through is a byproduct, not a design goal, and confusing the two is the first mistake in almost every conversation about AI visibility ROI.
The Liability Surface Moved
The human in the click decision was the SERP’s shield. If the link the user selected led somewhere harmful, misleading, or defamatory, the engine could point to the list of options and the user’s own agency in choosing one. The engine had not published the claim. It had surfaced 10 candidate sources, the user had chosen one, and whatever happened next was not the engine’s editorial output. That is not a small feature. That is the reason Section 230 protections were structured the way they were, and why algorithmic ranking has traditionally been treated as something other than direct speech.
LLMs have no equivalent shield to stand behind. The system is producing the answer directly, in its own voice, without a field of options or a user-selected source. The liability surface that the SERP was designed to offload sits with the model producing the output, and the cases that have already moved through courts are starting to sketch the edges of that surface.
Walters v. OpenAI was dismissed on summary judgment in May 2025, and the decision leaned heavily on OpenAI’s disclaimers and a sophisticated reader who reasonably knew the chatbot could hallucinate. That reading protects general-purpose consumer chatbots in a very specific kind of case. It does not protect every product that uses a language model. In a separate matter, Air Canada was held liable for its customer service chatbot’s false statements about its own bereavement fare policy, because a customer could reasonably rely on an airline’s branded support agent for accurate information about that airline’s policies. Reasonable reliance is the key legal term, and the more specialized and authoritative the chatbot appears, the harder the disclaimer defense becomes to run.
The active litigation is still mapping the frontier. OpenAI is currently facing multiple lawsuits tied to allegations that ChatGPT drove users toward suicide or harmful delusions, several involving minors. The New York Times copyright case against OpenAI was allowed to proceed by a federal judge in March 2025, and Anthropic settled with book authors in August 2025 for a reported sum well into the billions. European GDPR complaints continue to move through Noyb. Battle v. Microsoft is still live. None of these outcomes are settled, and some will be dismissed on the same disclaimer grounds that resolved Walters. The point is not that LLM operators will lose every case. The point is that the liability surface now sits with the system producing the output, whether the individual plaintiff wins or loses, and every brand building against an LLM inherits some version of that surface when it uses the system’s output in its own customer-facing work.
The Denominator Problem
The most common argument against investing in AI visibility work sounds decisive until you look closely at what it is measuring. The argument runs roughly: ChatGPT and the others send a tiny sliver of referral traffic, somewhere in the low single digits of total inbound, so why reallocate budget toward a channel that barely moves the needle? Conductor’s research pegs the combined AI referral share at about 1% of publisher traffic. That number is real. At first read, it seems to close the ROI question cleanly.
It closes nothing. The problem is the denominator.
Read against that backdrop, a stable percentage share of a shrinking pie is not stable. It is a loss. The skeptics who point at the 1% number are measuring relative share of a traffic base that is contracting underneath them, and they are treating a falling absolute as if it were a steady state. The real question is not whether LLMs are sending meaningful traffic yet. The real question is whether the channel that used to send meaningful traffic is still doing what it used to do, and the answer is visibly no. The denominator is moving, and any ROI calculation anchored to the old denominator is a calculation of the previous environment, not the current one.
What The Billions Say
If the design-intent and liability and denominator arguments still leave room for doubt, the last place to look is revealed preference. What are the companies with the most complete internal data on user behavior actually doing with their capital?
That is not the shape of a defensive hedge. A hedge is a fraction of the cash flow, deployed to avoid being caught flat-footed if a competitor’s bet pays off. Companies do not put 94% of operating cash flow into a category for two consecutive years unless the leadership genuinely believes the category is the business. And those leadership teams have access to data that the rest of us do not. They can see inside their own products, their own user behavior shifts, their own cohort analyses, their own enterprise pipeline conversations. They are legally bound to deploy shareholder capital in a way that reflects what they actually see, and what they are deploying it toward is the architecture that produces direct answers rather than ranked lists of options. To believe search-as-we-knew-it remains the gold standard, you have to believe that dozens of CEOs, boards, and senior leadership teams with decades of internal-only data are reading their own numbers wrong, while an external industry with none of that data is reading the market correctly. That does not pencil.
The human-behavior side of the equation makes the same point in a different register. Every labor-saving technology that has ever been introduced has reshaped the status quo faster than its skeptics predicted, because cognitive efficiency is not a preference. It is a survival behavior, wired in through long periods when calories were scarce, and shortcuts mattered. When a new tool appears that makes some task meaningfully easier, adoption is not a matter of whether. It is a matter of how fast and along what curve. ChatGPT is now at roughly 900 million weekly active users, up from 200 million 18 months earlier, and the full category is past a billion active users across platforms. The behavior has already shifted. The money has already shifted. The only thing that has not fully shifted is the measurement frame most practitioners are still using to evaluate the channel.
Which brings the question back to the one that is actually worth asking. What do you do if there is no ROI by the old definition, and you still cannot ignore the channel? The honest answer is that brands will need to invest in visibility work whose return is not expressed in clicks or referral traffic, because clicks and referral traffic are artifacts of the previous design. Being the cited source, the grounded source, the trusted source inside the answer is a different kind of visibility, and it will need a different kind of measurement. The teams that figure that out first will not be doing it because they found an ROI case that convinced their CFO. They will be doing it because they looked at the capex curves, the behavioral curves, and the liability curves, and concluded that the channel is the future, regardless of whether the spreadsheet knows how to score it yet.
If this lands somewhere real in your work, or if it reads wrong from where you are sitting, I would like to hear about it. The shift happening right now is too large for any one practitioner’s vantage point, and the best signal I get comes from the conversations that start after the article ends.
Since we’ve been able to produce content at scale through AI, there have been graph screenshots littering X and LinkedIn, usually case studies or as part of sales materials.
An SEO I know well, Martin Sean Fennon, shared an example of an ongoing brand case study, scaling content through AI, and how the content is being received (through third-party traffic measurement).
Screenshot from LinkedIn, May 2026
The issue isn’t always that the content has been produced by AI; that’s always been a good differentiator to hang the blame on, as there are a lot more factors that go into whether or not content is being indexed, let alone served.
The real problem lies in the fact that scaling content production, regardless of the method, often introduces a raft of quality control issues. AI is simply the latest, and easiest, scapegoat for a fundamental breakdown in the content pipeline, which includes everything from keyword strategy and topic selection to editing, internal linking, and distribution.
This allocation, however, is not a guarantee of sustained performance.
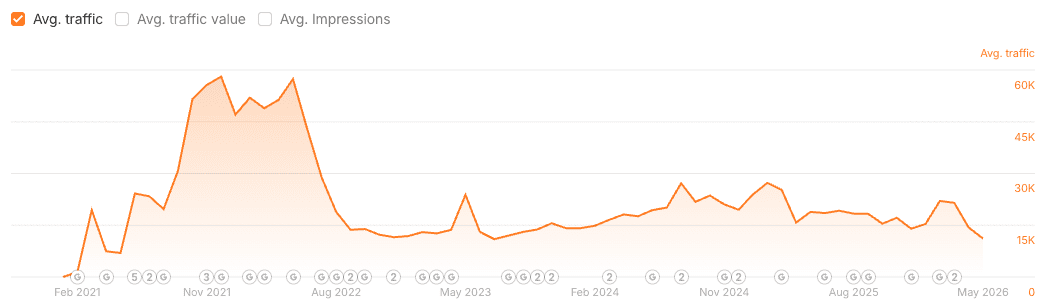
A new brand launch in January 2021, and the initial “boost” subsides after a few months. Not AI content. (Image from author, May 2026)
The initial surge is often the result of Google’s systems efficiently processing new or novel content, meaning it benefits from a “freshness boost.” A similar freshness boost is applied when you submit a URL through Google Search Console for indexing.
The threshold we are currently facing is maintaining that quality and relevance at scale, once the initial novelty wears off and the “Mt. AI” effect subsides, leaving behind the underlying content-quality challenges.
When you introduce a lot of new URLs to your website, you’re asking Google to increase resources to your website, and how Google allocates these resources is well documented.
As their perceived inventory now no longer matches your actual inventory, Google has to choose how much of the new URL batch to invest in, or whether or not to invest in a representative sample of the new URLs (potentially based on a URL pattern, e.g., a subfolder) and then see how users react to and engage with the content.
This process determines if, minus the initial freshness boost, the URL (and content) is justified in remaining in the index and being served.
This concept ties directly into crawl budget and Google’s Quality Threshold. If the sample URLs perform poorly or fail to meet a certain quality bar after the initial novelty wears off, the remainder of the scaled content often struggles to gain traction.
AI-generated content leading to an initial traffic surge, quickly followed by a plateau or decline, makes for a good social post, but it also highlights a key understanding that the problem is not AI itself, but a fundamental failure in content strategy and quality control at scale.
AI simply amplifies existing weaknesses. The “freshness boost” that new URLs receive masks these underlying issues, creating a temporary illusion of success.
The real hurdle is Google’s Quality Threshold, as Google needs to manage resources and become stricter with what it crawls (and how frequently), and what is retained in the index ready to serve.
By assessing a sample of new URLs to see if they genuinely engage users and maintain relevance, it avoids wasting resources. If this sample, or the wider-scaled content, falls short of the current quality threshold, then resources will be retracted, and we will witness more “Mt. AI” scenarios.
Shift From Production Scale To Quality Maintenance At Scale
This matters because relying solely on AI for volume is a vanity metric that guarantees long-term resource waste.
The focus must shift from production scale to quality maintenance at scale.
Brands must invest in robust editorial processes, human-led strategy, and meticulous quality assurance (including internal linking and distribution) to ensure that every piece of content, whether AI-assisted or not, consistently surpasses Google’s evolving threshold. This has most recently been described by Google in Toronto as non-commodity content.
Not doing so means constantly chasing fleeting traffic boosts instead of building durable, authoritative organic performance.
Google’s John Mueller answered a question about whether Google’s Preferred Sources feature can override standard ranking signals in Top Stories. His answer offers some clarity about how user preference can influence visibility without giving preferred sites a free pass around Google’s quality systems.
Google’s Preferred Sources
Google Preferred Sources is a Search feature that enables users to choose specific websites and news outlets they want to see more often in Top Stories. Search queries that trigger news results will then show the preferred sites for those users in the Top Stories feature.
Preferred Sources gives users some control over which publishers appear more frequently when relevant news results are shown. Google expanded Preferred Sources globally on April 30, 2026, making it available in all languages supported by Google Search.
The phrase, Google’s Preferred Sources, inadvertently can lead to the belief that these sites are the sites that Google itself chooses to trust but that’s not what it is. Google’s Preferred Sources are the sites that users trust.
Google’s official documentation explains what Preferred Sources is:
“If you’re a website owner, you can help your audience find your publication as a preferred source in Google Search. When a user selects your site as a preferred source, your content is more likely to appear for them during relevant news queries in “Top Stories”.”
The phrase “more likely to appear” implies a weighting effect. The signal is also implied to be limited to the audience that selected it. A preferred source may have a better chance of appearing for relevant news queries to the audience that selected it. There’s nothing in the official documentation that says it will help the site rank in the Top Stories news feature for anyone else.
That distinction is important for publishers and SEOs because it keeps the feature in perspective as a way to strengthen the connection between a publication and its loyal readers.
But, as you’ll see a little further below, there’s a curious similarity to the Preferred Sources feature and a Google patent for trusted websites algorithm.
Question About Preferred Sources And Ranking Signals
An SEO asked on Bluesky whether Google’s Preferred Sources feature can override standard ranking signals. The question focused on whether a followed site could appear in Top Stories even if its content had low helpful content scores or was AI-generated.
It’s a valid question that provides a little insight into how Google’s ranking algorithms work. What takes precedence, a user’s express desire to see an algorithmically determined low quality site or Google’s algorithm?
On one hand, how likely is it that a user will want to see an unhelpful and spammy website?
But on the other hand, how likely is it that Google’s determination that a site is unhelpful is wrong, even when users clearly want to see it?
So the question that was asked is more than theoretical and the answer may shed a little light on the inner workings of Google’s search algorithms.
“Do “Preferred Sources” override standard ranking signals? If a user follows a site, will it appear in Top Stories even if its content has low “helpful content” scores or is AI-generated, effectively letting user preference “win” over the general algorithm? Thanks!”
What would you do in the case of a spammy site, give the user what they want, ignore their preference, or flag the spammy site as possibly not spammy?
Does a user preference outweigh other ranking and quality signals?
Is the Preferred Sources trigger limited to just Top Stories or can it be used as an external signal of trustworthiness?
Is Google’s Preferred Sources A Trust Signal?
I think there is a small possibility that Google’s Preferred Sources feature could be a user trust signal because there are patents that talk about “trust buttons” that users can click to express their opinion that they trust a particular website.
“The user visits sites that they trust and click a “trust button” that tells the search engine that this is a trusted site.
The trusted site “labels” other sites as trusted for certain topics (the label could be a topic like “symptoms”).
A user asks a question at a search engine (a query) and uses a label (like “symptoms”).
The search engine ranks websites according to the usual manner then it looks for sites that users trust and sees if any of those sites have used labels about other sites.
Google ranks those other sites that have had labels assigned to them by the trusted sites.”
Does that sound a little bit like Google’s Preferred Sources to you?
John Mueller’s Answer
Mueller’s answer is ambiguous because he states that it doesn’t make sense to show a spammy site but that it’s also helpful to show users sites that they want to see.
He responded:
“We document it as ‘When a user selects your site as a preferred source, your content is more likely to appear for them during relevant news queries in “Top Stories”.’ I don’t think it makes sense to show spam to users just because of that, but it does help a user to see their preferred sources more.”
What he did there was to rely on Google’s official documentation and repeated what it said there, likely because that’s the canonical external source for Preferred Sources.
The person who asked the question responded to Mueller to note that sometimes Google ranks low quality sites.
They wrote:
“However, Google sometimes considers content to be good when it actually isn’t…
Thanks anyway!”
Google’s Preferred Sources is an interesting feature because it’s one of the few ways that an SEO and site publishers can encourage users to send a positive signal to Google that will have a definite ranking change.
Semrush put out an infographic last week. The kind built to be screenshotted into LinkedIn carousels and pasted into webinar decks. Four pillars. The fourth one is called “Technical GEO”: schema, structured data, clean architecture. The line that justifies it: “Ensures AI engines can parse and connect your content.”
That is the entire piece in one word. The architecture of large language models is, by design, the opposite of ensured. And schema has nothing to do with whether an LLM can parse text. LLMs parse text by reading text.
Semrush is far from alone. Every SaaS vendor with skin in this game is running variations of the same play. SEO-era controllability, repackaged under a new acronym. The same percentages, pillars, and pyramids. All dressed for a system that was built specifically not to work this way.
I have made the strategic version of this case before, in “Your AI Strategy Isn’t a Strategy.” This piece is the technical floor underneath it.
Built To Read Whatever’s There
Language models exist because the web is a mess. Forums, Wikipedia stubs, blog posts written at 2 A.M., scraped product copy, machine-translated junk, code comments, half-formed sentences, typos, contradictions, every register from journal article to subreddit shitpost. Pre-training data is the public web, and the public web has never been structured.
The transformer architecture handles this by treating language as sequences of tokens. There is no parser inside the model looking for tags. There is no preference for FAQ markup. The model reads the words. That is the mechanism.
At inference time, the model generates more tokens conditioned on the input. None of that pipeline is reading microdata.
Schema.org has real jobs. It feeds rich results in classical search. It supports entity disambiguation in the knowledge graph. It helps voice assistants pull structured fields. These are well-defined functions inside specific systems. They are not the mechanism by which an LLM understands a sentence.
So when a vendor claims structured data “ensures AI engines can parse and connect your content,” there is nothing to ensure. The parsing layer they are imagining is not there. The model already parsed your sentence. It did so by reading the sentence.
One Trick, Three Brand Colors
Look at the biggest GEO and AEO explainers in the market right now, and you find the same SEO-era playbook with the acronym swapped.
Semrush is already covered. The fourth pillar of its “Technical GEO” presents schema and structured data as ensuring something that the architecture cannot ensure.
AirOps published a graphic titled “15 Ways to Get Cited by ChatGPT, Perplexity, & Google.” It is the most numbers-heavy specimen of the genre I have seen this year. Schema markup increases citation likelihood by 13%. Sequential H2 to H4 tags double your chances. Short paragraphs make content 49% more likely to appear in AI answers. Perplexity cites UGC in 91% of answers, versus Gemini’s 7. Read the source notes and the methodology trail comes home. The numbers in the graphic trace back to AirOps’s own “2026 State of AI Search Report.” AirOps is citing AirOps on the question of whether AirOps’s prescriptions work.
Peec AI does a more honest job in places. Its complete guide to GEO acknowledges the probabilistic nature of the system and concedes that foundation models are already trained, so optimization focuses on the retrieval layer. Then it lands the same prescriptions: heading hierarchy, bullet lists, FAQ markup, multiple schema types layered on each page, summaries at the top of sections – all built on the chunking claim that long paragraphs lose out because the engine extracts fragments rather than full articles.
Profound, citing Aleyda Solis’s checklist, is the most explicit in its piece: “Optimize for Chunk-Level Retrieval.” Each section, a standalone snippet. Each page, a buffet from which the engine takes what it wants. The engine, in this telling, is a polite guest who only takes what’s been laid out.
Three vendors. Same operating assumption: a controllable, prescriptive technical discipline sits between a publisher and a citation, and it occupies roughly the same shape as classical SEO. Schema, headings, structure, freshness, machine-readable formats. Familiar. Billable. Reportable up to a chief marketing officer.
What Schema Actually Does
Schema is not the target here. Schema has real, well-defined uses. Classical Google search uses it for rich results: prices, ratings, event times, the structured fields that drive search engine results page features. The knowledge graph uses it for entity disambiguation. Voice assistants pull structured fields out of it.
None of that goes away. If you’re responsible for technical SEO, keep implementing schema where it earns its keep.
Schema cannot reach into a transformer and improve its comprehension of your prose. The model isn’t architected to read schema as schema. It receives whatever text the engine fetched and chose to include, and processes that text as language tokens. The entire GEO/AEO marketing layer rests on conflating two distinct claims: that schema is useful in classical search, and that schema feeds the LLM. The first is true. The second is a category error.
Chunking Is Not Yours To Optimize
Image Credit: Pedro Dias
The chunking advice keeps reappearing because it sounds technical, sits neatly inside a flowchart, and gives a content team something concrete to do on Monday morning. It is also incoherent.
Chunking happens at retrieval time. Perplexity, ChatGPT, and Gemini each run a retriever over candidate documents, split them according to their own configurations (length, overlap, embedding model, sometimes semantic boundaries), and feed the top-k chunks into the model’s context. Those configurations belong to the engine. They get tuned differently across systems and retuned on schedules no publisher is privy to. The publisher’s view of the chunker is the publisher’s view of the model: black box, results only.
So when a vendor says “optimize for chunk-level retrieval,” what is actually being recommended is good writing. Short, self-contained paragraphs. Clear definitions near the top of sections. Internal logical structure. These are recognizable disciplines: information architecture, technical writing, readability. They have been recognizable disciplines since long before the transformer was invented. They are not a new technical layer.
A more honest version of the pitch would be: Hire someone competent at writing for the web. That sentence does not fit on a pricing page.
The Paper They Don’t Read
There is an actual academic paper called “GEO.” Aggarwal and co-authors, KDD 2024. It is the closest thing to a citable source the SaaS layer has when it sells generative engine optimization as a discipline. It is also, as papers go, easy to skim. Nine “optimization methods” are tested on a 10,000-query benchmark, with results.
What did the paper find worked?
Adding citations from credible sources. Adding quotations from relevant sources. Adding statistics. Improving fluency. Making prose easier to understand. The methods that produced the largest visibility lifts were essentially: write content with more evidence in cleaner prose.
What did the paper test and find did not work?
Keyword stuffing, the closest analogue in the paper to the SEO-era playbook the current GEO and AEO vendors have repackaged. Result: below baseline. The paper’s authors note in plain terms that techniques effective in search engines “may not translate to success in this new paradigm.”
Notice what is not in the list of nine methods. Schema. Structured data. FAQ markup. Heading hierarchy. Machine-readable formats. None of these are tested in the paper, because none of them are the optimization surface the paper studies. The paper is studying content-level interventions: what you put in the words, not metadata layered around the words.
The SaaS layer borrowed the acronym. The findings stayed in the paper. “Technical GEO” is the SEO playbook with different stickers on the same boxes, sold against research that points the other way.
The Assumption Smuggled In
The SaaS pitch only makes sense if you smuggle in one assumption: that the system you’re optimizing for has the same shape as the one that’s been billing SEO clients for a quarter-century. Inputs you control. Outputs that respond. A retrievable causal chain between the two.
That model was always a simplification of how search worked. It was close enough to keep the industry running, and close enough to keep the invoices going out.
None of that simplification survives contact with generative systems. The same prompt produces different answers across sessions, users, temperatures, model versions, and days. Observed behavior across the major engines, not a clean property of any single one. The retrieval layer in front of the model also moves: candidate sources shift, ranking shifts, freshness windows shift. No causal chain runs between “I added FAQ schema” and “the model cited my page.” What runs between them is a probability distribution, and the things you control affect that distribution in ways nobody can cleanly attribute. Not even the people who created these systems.
This is the established line on AI visibility tools, repeated here because it applies to the whole prescriptive layer. Statistically unverifiable data drawn from non-deterministic systems. A 13% citation lift, measured how, against what counterfactual, with what reproducibility? The methodological questions aren’t what those numbers are designed to answer. The numbers are the answer. They land in a graphic, get rendered as ROI in a board deck, and the conversation moves on.
Something To Say In The Meeting
Here is the part that the architecture argument and the methodology argument do not, on their own, explain. Why does the entire SaaS layer keep successfully selling this stuff to people who are not stupid?
The honest version of the answer goes something like: We are operating with reduced visibility into a system that does not expose its mechanics, that returns different outputs to different people for the same query, that is changing month by month, and that has folded a substantial chunk of the funnel into a black box. We can keep doing the work that has always been the work: writing well, being useful, building authority, maintaining the site. We can monitor what shows up where. The deterministic dashboard we used to have is not coming back.
That sentence is unsayable in a marketing meeting. It admits the lever is not connected. It tells leadership that the budget line they approved does not have a corresponding action. It gives the team nothing to put in next quarter’s plan.
So the SaaS layer fills the gap. It manufactures levers. Pillars, frameworks, percentage lifts, schema audits, chunking optimization, machine-readable formats. Reportable activity. Defensible expenditure. Something to say in the meeting. None of this gets you visibility. The engine decides that. What is on offer is the appearance of control, sold to people who would rather pay than concede that control left the room.
Once the lever is bought, it has to be operated. Schema audits get scheduled. Chunking checklists get reviewed. Citation likelihoods get tracked, refreshed, and compared. The dashboard the team paid for becomes the dashboard the team optimizes against, and the dashboard quietly replaces the actual problem with the part of the problem it can see. By the time anyone notices, the SaaS layer is writing the brief.
None of this is a moral failure on the buyer’s side. What you are watching is what happens when an industry has been organized for a quarter-century around the premise that you can pull a lever and watch the meter move, and the meter quietly disconnects from the lever. The vendors aren’t running a con. They are filling demand for the only thing the buyer can no longer afford to do without: an answer that fits in a slide.
Rank And Tank, All Over Again
I keep coming back to a phrase that fits this whole moment: dancing to the rank-and-tank tunes (I borrowed it from David McSweeney). The cycle goes: Vendor sells the controllable-discipline frame, agencies adopt it, content teams scale production around the prescriptions, AI-generated articles get pumped out at volume because the prescriptions are easy to template. Some of it ranks for a while. Most of it eventually tanks because the prescriptions were never the mechanism, and the engine adjusts, or the freshness window closes, or the system simply moves on.
The SEO industry has done this before. Spinning. Mass programmatic pages. Doorway content. Each cycle followed the same shape: a controllable input dressed as a discipline, sold at scale, briefly effective, eventually punished by the engine, replaced by the next controllable input dressed as a discipline.
GEO and AEO are the current cycle. The pillars and percentages and pyramids are this cycle’s templates. Underneath them, the strategies bifurcate.
One path is brand presence exploitation. Plant your name where the engines look. Reddit threads, top-X listicles, the same citation surfaces over and over. The cycle feeds itself: engines cite the surfaces, brands work the surfaces, surfaces feed the engines. I have written about this loop before; I called it the Ouroboros pattern. The short version is that the loop is less stable than the strategy assumes.
The other path is content at scale. Produce variations, pump out volume, treat the templated output as content that could earn a citation. I have written about this approach before, in the “Scaling Disappointment” piece. The short version is that uniqueness is not value, and at the pace these prescriptions enable, qualitative review stops being possible. The volume of AI-generated copy produced under this path is this cycle’s externality.
Forget for a second whether your “Technical GEO” is set up correctly. Ask whether the thing you are putting on the page is worth reading. Large language models were designed to read whatever is there. If what is there is good, it will be read. If what is there is templated, low-utility content optimized against a chunking heuristic that does not exist, it will eventually be filtered out: by the engine, by the user, or by the next academic paper showing that retrieval quality is degraded by exactly this kind of slop.
The advantage, when it accrues, will accrue to the people who do not get distracted. Who do not subscribe to the dashboard. Who keep working on product-driven SEO and the foundations that have always connected content to people. There are early signs of this on the timelines I read. Practitioners openly questioning whether optimizing against a non-deterministic surface makes sense at all, and asking whether their attention belongs back on classical search; which, at the end of the chain, is what feeds these systems anyway.
The mess was always the point. The architecture handles it. The industry just needs to stop pretending the mess is the problem.
More Resources:
This post was originally published on The Inference.
A recent Linkedin post by Jim Yu flagged that BrightEdge’s AI Catalyst team analyzed citation and brand mention patterns from prompts across Finance, Healthcare, Education, and B2B Tech in five AI search engines: ChatGPT, Perplexity, Gemini, Google AI Mode, and Google AI Overviews. The finding that mattered most was buried in the data. Despite wildly different source preferences, every engine tends to surface the same brands. Source overlap across engine pairs runs from 16% to 59%. Brand overlap lands in a much tighter band, 35% to 55%. The engines wander far on what they cite. They hold fast to who they recommend.
“Review sites, comparison content, trade press, retailer listings, and finance data are the sources AI most frequently reaches for. Investment in PR, trade coverage, review site visibility, and category comparison content translates into visibility across every engine, not just one.”
I sent that takeaway to Katie Delahaye Paine, as I have watched her track the collision points between data and communications longer than most people in this industry have been alive. She sent back a link to a press release that looks like a Yahoo Finance story with one question: “What do you think of this?”
In the link, Zen Media argued that AI tools are giving PR teams measurable citation data for the first time – a genuine breakthrough for a profession that has historically struggled to tie its work to business outcomes. I told her I thought PR had a new opportunity, if there were communications professionals brave enough to seize it. Unfortunately, too many are so service-oriented that they have become servile.
She responded, “Sad, but true.”
The Opportunity Is Real
The data backing this shift is not subtle. According to new Stacker research, earned media distribution can increase AI citations by a median lift of 239%. Brands with review profiles on platforms like Trustpilot, G2, and Capterra are three times more likely to be cited by ChatGPT than brands without them.
Lily Ray, while vice president of SEO Strategy & Research at Amsive, found that digital PR and YouTube optimization have become essential tactics for AI discovery. Amsive’s research showed ChatGPT most frequently cites Wikipedia, Perplexity leans on Reddit and YouTube, and Microsoft Copilot gravitates toward Forbes and Gartner. The implication is that being discussed in credible third-party sources, exactly what good PR has always produced, now feeds directly into the sources AI trusts most.
Research from Muck Rack’s Generative Pulse platform found that earned media still accounts for 25% of all AI citations. Press coverage, authoritative reviews, third-party writeups. The raw material of traditional PR. Being mentioned in a Wirecutter roundup or a TechCrunch feature, their team noted, does more for AI visibility than almost anything a brand publishes on its own site.
PR Has The Raw Material. It Lacks The Ambition
Here is the maddening part. Everything that matters for AI citation, third-party credibility, trade press coverage, review site presence, expert mentions, is work that PR professionals are already positioned to do. They understand how to cultivate relationships with the publications and journalists that AI engines trust. They know how to place stories in the outlets that show up as authoritative sources. What they have lacked, historically, is a measurable link between that activity and business outcomes.
That link now exists. AI engines create a citation trail. Brand visibility in AI responses can be tracked, measured, and attributed. Katie has spent her career making the case that PR’s contribution to business value must be expressed in persuasion, trust, and credibility, which are all imminently measurable, she has argued for decades, if the profession would simply demand better tools. The tools now exist. The measurement imperative is sharper than ever.
So, why isn’t the initiative to combine SEO and PR coming from PR? Because far too many practitioners remain reactive. They wait to be briefed, execute campaigns, report outputs, and repeat. The organizations most likely to move first on this are the ones where someone outside the PR function, such as an SEO professional who understands earned media, a digital marketer watching their traffic erode from AI Overviews, a content strategist, or an entrepreneur tracking every conversion, recognizes that the citation graph and the PR strategy map are now the same document.
What A Unified Strategy Actually Looks Like
BrightEdge made the point clearly: Build for three source layers, not five LLM playbooks. Every AI engine draws from authoritative sources, commercial and editorial content, and user-generated content. They weigh the mix differently, Perplexity and Gemini lean toward authority, Google AI Overviews lean toward UGC, ChatGPT and AI Mode lean toward commercial content, but all three layers matter in every engine.
That means the practical work is, earn placement in trade press and analyst reports that are relevant to your category. Generate real customer reviews at scale. Produce comparison and category content that review aggregators and editorial sources want to reference. Get on the podcasts and YouTube channels that AI engines are already pulling from. None of this requires a new discipline. It requires PR and SEO professionals to stop treating their work as separate and start treating the citation graph as shared territory.
The brands that establish citation authority now are building something that compounds. Entity authority is slow to build and slow to decay. Early movers in AI visibility are capturing ground that late movers will find increasingly expensive to reclaim.
AI has handed PR the measurement framework it never had and the strategic mandate it always deserved. The question is whether the profession will recognize the moment, or wait for someone else in the organization to seize it first.
Google is testing Web Bot Auth, an experimental protocol designed to help websites verify that automated traffic is really coming from the bot or service it claims to represent. The new protocol could give site owners a dependable way to separate legitimate automated traffic from bots that hide or misrepresent who they are.
A new developer support page was published provide information on how to verify requests with the Web Bot Auth protocol, which is currently in an experimental phase.
What Google’s Web Bot Auth Is Based On
The new protocol is technically called the HTTP Message Signatures Directory. It’s a proposed technical standard designed to automate trust between web services. It helps websites recognize verified automated services without requiring each side to manually exchange security keys beforehand.
The basic idea is similar to giving verified automated services a standardized way to present credentials. Instead of relying only on names, user-agent strings, or private setup between companies, the protocol gives websites a repeatable way to check whether an automated request can be verified. That matters because many bots can claim to be something they are not. Web Bot Auth does not decide whether a bot is good or bad, but it can give site owners a stronger signal about whether the bot is really the service it claims to be.
A Reliable Way To Identify Bots
The cryptographic part is important because it makes identity harder to fake. Today, a rogue bot can claim to be a legitimate crawler by copying a name or user-agent string. Web Bot Auth is designed to move beyond that kind of self-identification by giving websites a way to check whether an automated request matches the service’s cryptographic credentials.
Under this protocol, a bot would need more than a label saying who it is. It would need to prove that identity in a way that a website can validate. That could give site owners a secure basis for allowing verified automated services while blocking bots that cannot prove who they are. The protocol does not automatically decide which bots should be allowed or blocked, but it could give websites a more dependable signal for making that decision.
Cryptographic verification is what makes Web Bot Auth better than current bot identification methods. Instead of relying on signals that can be misrepresented, it gives websites a way to verify automated requests. That means recognition is based less on what a bot says about itself and more on whether its identity can be confirmed by cryptographic credentials.
Caveat: It’s In An Experimental Phase
The proposed protocol will make it possible to distinguish between rogue bots that are impersonating trusted crawlers from the genuine bots from trusted services. This protocol is like a whitelist of what’s allowed which may make it easier to isolate untrusted crawlers.
However, because this is an experimental phase, the “whitelist” currently only applies to a subset of traffic, such as the Google-Agent . Google is “not yet signing every request,” so a missing signature does not automatically mean a bot is rogue. Site owners are advised to continue using IP addresses and reverse DNS alongside the protocol to avoid accidentally blocking legitimate traffic that hasn’t migrated yet.
What It Does
The new standard replaces manual setup between websites and bots, crawlers, and other automated services with a three-step discovery process:
Standardized Key Files: Keys are stored in a common format, JSON Web Key Set (JWKS), that all servers can read.
Well-Known Addresses: It defines a specific “home” on a website (/.well-known/) where these keys are always kept.
Self-Identifying Requests: It adds a new header, Signature-Agent, to HTTP requests that acts like a digital business card, pointing the receiver directly to the sender’s key directory.
Benefits For Automated Services And Websites
Web Bot Auth could make bot verification easier to scale by reducing the need for manual setup between each website and automated service. It also gives automated services a more consistent way to stay recognizable when their security details change, which can help avoid broken verification over time.
Web Bot Auth Is Experimental
Google stresses that users should continue using existing standards such as user-agent IP-based bot verification, stressing that the standard itself is a proposal that is subject to change.
The new documentation provides the following warning:
“The experimental status means that:
Not all Google user agents are using Web Bot Auth.
Google is not yet signing every request of agents using the protocol.
We recommend that in addition to Web Bot Auth you continue relying on IP addresses, reverse DNS, and user-agent strings as we gradually roll out signed traffic.
If you’re a developer or system administrator looking to allowlist our experimental AI agents, you can implement verification through the Web Bot Auth protocol:
Using a product or service that supports Web Bot Auth
Verifying requests yourself”
Nevertheless, the standard does aim to simplify bot identification and controlling bot traffic by using a cryptographic protocol that a rogue agent can’t spoof, provide insights into how bots are interacting with your traffic, and to build a better way to control the currently out of control situation with bot crawling.
Google encourages users interested in the protocol to contact their web hosting providers to see if they intend to support the experimental protocol, keep up to date with the latest changes published by the Web Bot Auth Working Group and to send feedback through Google’s official Web Bot Auth feedback form.
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Am I still an advisor? Or a builder? I’m having an existential moment.
My work has forever changed in a way I’m still trying to understand. Six months ago, agentic vibe coding crossed a threshold. Since then, I have used AI to raise my impact by a magnitude.
I designed landing pages end-to-end for a major travel brand that made it into production.
I built an array of useful applications for myself, from automating the SSI (SEO Site Index found in the bimonthly Growth Intelligence Briefs) to Openclaw agents that help me with research and charts.
The work I shipped improved, while it also became harder to define. But when the cost of building collapses due to AI, judgment is the only thing that doesn’t compress. Meanwhile, most operators are still hiring, budgeting, and measuring as if execution is the constraint.
A screenshot of the keyword universe I built for my clients. One example of several tools I built to make my work more efficient. (Image Credit: Kevin Indig)
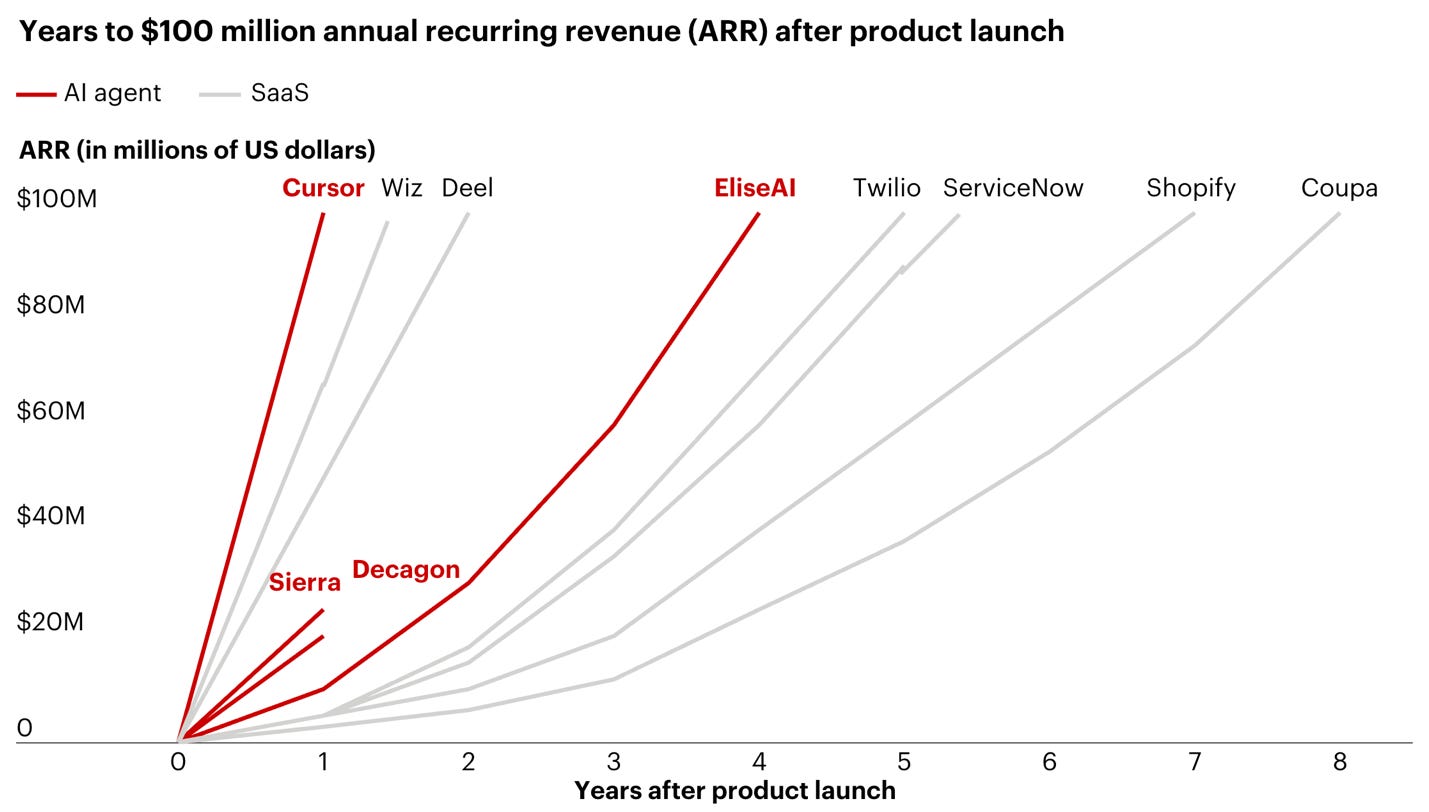
I’m not alone: AI companies are reaching $100 million ARR faster than ever, in large part because they’re AI native. Their whole product development philosophy is fundamentally different. Heck, Anthropic went from $9 to $30 billion USD in six months and is now worth about as much as Starbucks, Mastercard, or McDonald’s.
AI companies grow faster than anything before (source: Bain) – Image Credit: Kevin Indig
So, I want to take a beat from publishing research this week and take measure of how agentic coding changes software, distribution, and people.
The Effect On Software
In 2024, I made a bold prediction that AI agents would hit 100 million users in 2025. I was off by about a year. Agents didn’t hit 100 million users in 2025, but they did hit production in 2026, and the gains are measurable:
METR found 1.5 to 13x (!) time savings when technical staff used Claude Code.
A 40% reduction in cost and 60% reduction in time from agentic AI is not unrealistic.
Bain & Co estimates a 30-50% gain in productivity from deploying AI agents and automation.
Study from METR showing time savings between ~1.5x and ~13x (Image Credit: Kevin Indig)
What happens to software when non-engineers can ship code?
After the iShares software ETF (IGV) cratered 24% in Q1 2026 (steepest quarterly drop since Q4 2008), you could sense a panic in the air that AI would make software companies redundant. But software is more than code.
Enterprise software has strong guards against AI redundancy. Anyone who has ever purchased a CRM or migrated to another vendor knows how hard this is and how much is involved.
Enterprise software is more than code. It’s code plus integration, security, uptime, sales, and support … all wrapped up in procurement cycles, IT review, and legal sign-off.
AI can chip away at any one of those pieces. For example, an agent can handle an integration, run a security audit, even book a demo. But no agent shows up to get sued when a mission-critical system goes down at 3 A.M. Accountability is the part that doesn’t unbundle. Enterprise companies don’t replace this stack; they build their own agents and AI workflows on top of it.
Self-serve software is a different beast. Anyone can now spin up a simple task tracker in a Kanban format. I personally would rather pay a few dollars a month and spare myself the hassle of bug fixing, but it’s possible and quick. Self-serve products need to move upmarket. The playbook shows up in Notion’s, Figma’s, and Canva’s moves into enterprise.
In this shift, two archetypes stand out:
Data providers.
System of records.
1. Data providers provide value by making data that the market could not otherwise access. These companies lose leverage from their user interfaces but gain it from their data. For example, let’s say a data provider gives you app store rankings. The user interface for that company is slowly turning into friction as more people can code their own dashboards. But their data becomes much more interesting. The durable levers for APIs/MCPs in this world are data completeness, uniqueness, stability, and cost. The logical move is to shift to a headless experience for early adopters and keep the user interface for legacy users.
2. Systems of record (SOR) are the canonical place where a company’s own data lives. Salesforce, Workday, or Coupa are the bane of existence for many people, but they’re billion-dollar companies because they’re extremely hard to replace. The moat is the tangle of permissions, audit trails, integrations, compliance posture, and decades of workflow conventions built around that data. An agent can generate a CRM in an afternoon; replacing Salesforce at a Fortune 500 is a multi-year change-management project. These companies have already started and will continue to use AI more to provide better user experiences. But their levers are depth of integrations, compliance and audit posture, switching cost, and the quality of their agents. The winners in the SOR space are the ones whose agents make the existing system of record more useful, not the ones trying to replace it.
The Effect On Distribution
Distribution is more important than product, or so the saying goes, but getting it in 2026 is hard. Platforms are closing (by reducing clickouts and keeping users inside), and they’re taking opportunities away to convert or build direct relationships with visitors outside of the platform.
AI Overviews and AI Mode make more than 50% of clicks redundant and keep users on the Google platform.
Cost per visit climbed 9.4% in 2025 alone, adding to a 30% cumulative increase over 3 years. Conversion rates fell 5.1%.
How do you get distributionin this AI-first world? Two levers compound:
Velocity.
Product.
1. Velocity means you execute faster (and better) than your competitors. When all distribution channels decline, and no alternatives open up, the only way to grow is to leverage them better. Play the game better than the competition. Fast shipping speed becomes table stakes, and ideas + compute become the differentiators.
PwC found AI speeds content production up by 3-10x. In plain words, we need to automate more. But not at the cost of trust. When you lose trust, you lose the game.
2. Product is the marketing now, with two distinct effects:
AI sees through marketing gloss. Agents can read ingredient lists, parse reviews, compare specs. “We’re the best X in the world” doesn’t survive an agent that actually checks. But strong products get chosen consistently.
Free product is the new top of the funnel. Standalone tools that solve a real problem are easier to build than ever, and they acquire better than ads. Ramp Sheets routes users toward Ramp’s core product without a marketing budget.
When product is the marketing, the emphasis shifts to product growth: onboarding, engagement, retention. The fastest-growing products these days all have product-led growth motions. So, marketing and product development melt together.
The Effect On People
AI capability is racing ahead, but human cognition … isn’t. Until we reach AGI (God knows when; I hope not any time soon), human cognition is what limits AI productivity. We can only ship as much as we can review.
AI tools can take in more input than ever before, while our own human attention span is declining: AI’s context windows grew 3,906x (!) over the last 10 years, from 512 to 2 million tokens, while human attention has shrunk. We’re outsourcing thinking faster than we’re learning to check it.
Image Credit: Kevin Indig
Two cost curves are racing each other: the Cost to Automate (exponential decay) versus the Cost to Verify (biologically bottlenecked). In “Some Simple Economics of AI,” Catalini et al., argues that tasks with a verifiable output will be automated the fastest. Work that requires a human to check it compounds slower, so we’ll automate work that’s easy to measure faster. I feel it whenever I’m running four terminal windows at once: the focus drain is as high as the throughput. At scale, what holds us back is how much we can proofread and direct.
When anyone can build anything, the ways we’re limited change: Skill and tools matter less. But judgment, ideas, and time decide whether you run in the right direction or in circles. It’s very easy to get distracted with AI because the cost to build is now so low.
Judgment is the part that doesn’t compress. I can ask Claude Cowork for a contract review, but I have to know what it missed. Claude will happily write me a Q4 plan, but it’s only as good as my read on which market to attack and what my competitors are about to do.
Over the last six months, I implemented more agentic and automated systems than I’ve done hands-on work. My clients now have access to unique software they can’t get anywhere else that solves their unique problems.
Three things are now compressing toward zero: the cost to build software, the cost to produce content, the cost to spin up a tool. But another cost is trending far away from zero: The cost to know whether any of it is right.
I’m not directly “doing” the work anymore in a traditional sense. I’m now building the thing that does the work, then checking it. The work that matters now is the part I can’t hand to an agent … knowing what to build, what to kill, and what the agent missed. And I’m here to figure out what that means – with you.
More Resources:
Featured Image: Fit Ztudio/Shutterstock; Paulo Bobita/Search Engine Journal
Google’s Martin Splitt and Nikola Todorovic discussed the impact of AI on search, revealing that there’s a new wave of people that are doing things with Google search that is markedly different than in the past and that this is an upward trend.
Martin Splitt noted that AI in search is not new and that it had always been there behind the scenes assisting in the organic search results. It’s only recently that it’s been moved to the forefront where it is now assisting users with increasingly complex multimodal search queries. Funny thing about AI search is that whereas AI plays a role in the background of organic, organic search plays a role in the background of AI search.
Martin asked if AI Search is evolutionary or a revolutionary change:
“Yeah, because I think everyone is talking about AI in search as if it’s a new thing, but it has been there behind the scenes, so to speak, before that.
So what makes these AI features that people are using now and that are progressively enhancing the search experience for them so different from the features we had before?
Would you consider these new features revolutionary and completely different from what we’ve been doing so far?
Or is it more like an evolution of what we have been doing in the past?”
Google’s Nikola Todorovic, Director of Software Engineering at Google Search, answered that it’s revolutionary and that search today is very different from what it was ten years ago. he also noted that current AI-driven search behavior is changing because users are becoming increasingly confident about the kinds of questions that Google is able to answer.
Todorovic replied:
“I think the way they are being used, and I think it is a revolution that they’re speaking of right now. But clearly in the whole process, there’s like small steps. But if you compare search now and search 10 years ago, it’s a very different product. So I would say yes, this is like a big step change and it is absolutely changing the way the users are searching.
So if you think about it, any feature is changing in some way. For example, if you bring like more images, videos, etc, then it is bringing this kind of experience. So people are going more to image search. For example, when we added what we call the image universal blocks on the main page. Now that this new wave is also changing the way the users are searching because they are uncovering that search can actually answer to more complex questions.
And for that reason, we do see that user queries or you call them prompts now, so they’re getting longer. They become more detailed and the average query length is growing.
So we do see the new traffic and this new wave of traffic is a consequence of users being able to see, aha, there is something new I can do over here. That’s from that perspective, it is revolution, but it is obviously a bunch of steps in between that happened and have been improving search all the time.”
Key insights about search behavior today:
User queries are becoming longer and more detailed.
Users are discovering new things they can do with search.
That last one is important and may partially explain where some of the traffic is going. People are doing more complex searches, plus as noted in a podcast interview of Liz Reid, people are using multiple AI chat services.
While some SEOs say that AI Search is longtail now, that’s not really what’s happening behind the scenes because Classic Search is still happening behind the scenes because the AI is splitting complex queries into simpler fan-out queries. “Keyword-ese” queries are still happening to a certain extent but now they’re components of a larger query that itself is longtail.
Takeaways
AI in search is not new, but AI at the front of the search experience is changing how people use Google.
Google says search today is a different product than it was ten years ago because users are asking longer, more detailed, and more complex questions.
Users are discovering that search can handle questions they may not have tried before, which is creating new search behavior.
AI Search may look like longtail search on the surface, but Google can break complex prompts into simpler fan-out queries behind the scenes.
Classic Search still matters because AI Search depends on retrieval. Organic search has not disappeared. It has moved into the background of the AI experience.
Keywords are not dead. They may now function as smaller pieces inside larger prompts and more complex search sessions.
Content has to work at two levels: retrievable for classic search and useful for more complex AI Search behavior.
The important insight is not that users are writing longer queries, but that users are learning what search can do now. As AI Search solves more complex queries, SEO begins to feel more uncertain. It may be useful to consider that simpler fan-out queries are what is being optimized for. But also see the insights about Browsy Queries.
A recent Search Off The Record episode featuring Martin Splitt and Nikola Todorovic, Director of Software Engineering at Google Search, explored the revolutionary aspect of AI and how a new wave of users are crafting longer conversational queries. They pointed out that while AI has democratized access to information it has made experience-based insights more valuable, implying that this is a key to standing out in the AI search.
AI Makes Human Experience And Opinions More Important
While AI is making information more accessible, it’s making basic information less important because it’s something that AI can do. Something like the specs of Texas Instruments OPA1656 op-amps is something that is provided by Texas Instruments and data sheets available from sites like electronics warehouses like DigiKey and Mouser.
What AI can’t provide are opinions and experience with those electronic parts, like what is the sonic difference between using an OPA1656 and something else that is six times more expensive? This is something that an AI can’t provide and as a consequence human experience and opinion is the thing that is variously referred to as the “value” that makes one site useful and another site not useful.
Martin Splitt made this case in talking about how AI can bridge human experience and the basic type of information that’s found “on the box.”
Splitt explained:
“Some people have misunderstood whatever it was that they’re trying to accomplish or to provide to be these cumbersome bits and only these cumbersome bits, right?
But eventually that turned into…, how do I put this nicely, putting words around spec sheets from manufacturers. And that wasn’t really the value that I was looking for. I’m not interested in knowing how many gigahertz a certain new processor has because I can read that basically on the box. It says it on the box. You don’t have to tell me that this is now a 3 gigahertz processor. It says it on the box.
And I had a key moment when I was buying a joystick back in the days for a computer game. And I didn’t know what force feedback was. And that’s effectively you have a different resistance. And it might move and vibrate the device if there’s any shaking happening in the surroundings. And I didn’t know what that was. And it said on the box, it has force feedback.
And so I went to someone who worked at the shop, and I anticipated them to be like an expert on the topic. So I’m like, so this says force feedback. What does that mean? And he literally said to me, that means that this joystick has force feedback.
And this is funny, but I’m seeing this a lot in articles and on websites that they’re effectively not giving me any context. They’re just explaining what I can kind of glimpse and gather from the information that is right in front of me. And I think AI makes that easier. You don’t have to spend as much time to rattle off the spec sheets into a more readable human conversational form. But chat bots do that.”
Splitt followed up by saying that it’s no longer necessary for websites to focus on providing commonly available information. That’s still important but there is a higher level of information that based on human experience that websites can provide, even if it’s something as small as explaining what “force feedback” on a gaming joystick is.
Paradoxically, while information is now more widely available than at any point in human history, it’s also made human judgement and opinion more valuable because that’s something that an AI system cannot do. And while there are many ways to approach content, it’s the subjective information that can be said to be the value add.
Splitt explained:
“So I think there is still enough space online for different outlets and people and opinions and experiences, but I think we have to increase the level of our content to be useful and interesting for humans, from humans to humans. And I don’t think AI is going to take that away. I think AI is going to bridge that.”
Martin Splitt insists that basic content is no substitute for expertise. He suggests that judgment and insights earned through experience are superior to surface-level content that can be found anywhere. Human experience is a key ingredient of high-value content.”
Content that only repeats widely available facts now has a weaker claim on attention because AI can make that same baseline information easier to reach. The stronger opportunity is content built from what a person notices, tests, prefers, questions, compares, and learns through use. That is where experience becomes editorial value, not as a decorative personal angle but as the part of the page that changes what the reader understands.
Facts explain commonly known information.
Experience explains what it means to a human.
What it means turns information into guidance.
Guidance is the value-add that makes a web page worth visiting.
What this means for SEO is that these kinds of considerations can be used for evaluating content and identifying reasons why it’s not being indexed, why it’s underperforming in search. And I know that for beginners a step-by-step approach feels useful but in real-life, optimizing for search engines, a checklist approach to optimizing only gets you to a shallow level of content and not to the higher standards necessary to stand out.