These systems retrieve and synthesize information differently from traditional search crawlers, and if your URL architecture isn’t built with that in mind, you are increasing your chances of not being cited by LLMs.
In the new age of search, we need to extend those SEO fundamentals to also align with AI bots and how they crawl URLs.
Why AI Systems Read URLs Differently
Search engines have spent decades developing sophisticated crawling and indexing infrastructure. They follow redirects, resolve canonicals, parse JavaScript (sometimes…), and can infer context from a page when the URL is a string of random characters.
The input prompt is converted into a vector embedding
Relevant passages are then retrieved from indexed URLs, documents and knowledge graphs in traditional search results like Google and Bing.
An LLM like ChatGPT or similar will then process this information and generate a refined response.
A developer-built RAG system will essentially use data sources from URLs to extract content – they will crawl the URL, convert the web content into searchable “chunks” and store them as numerical vectors for later retrieval.
This is now also evolving into a realm of URL context grounding, which is specific to Gemini. The aim for URL context grounding is to help Gemini (and presumably AI Overviews / AI Mode) to better understand and answer questions about content and data in individual URLs without performing traditional RAG processing.
The aim here is for the LLM to specifically pull direct information from multiple URLs, analyze multiple reports and combine information from several sources to generate more accurate summaries. This should, in theory, help to improve AI factual accuracy and reduce hallucinations.
Then there’s zero shot classification – a technique that enables models to categorize the purpose of a webpage without any task-specific training data.
This works by drawing on the model’s pre-trained language knowledge to infer a page’s likely function, while also detecting distinct patterns in the words and phrasing that signal what type of content the page contains.
This has been particularly useful in identifying phishing links and other malicious links based solely on their URL patterns but also indicates how LLMs could begin to leverage zero-shot classification to rely solely on URLs to infer semantic relevance.
A URL that communicates nothing forces LLM models to work harder and introduces ambiguity in how the content gets categorized.
More practically, when an AI system cites a source in a response, it often surfaces the URL alongside the excerpt. That URL becomes visible to real users, in the same way it does in a search result, and they’re going to make real decisions about whether or not to click.
A clean, descriptive path builds trust in a way that something like /p?id-4821 never will.
The Core Principle Of URLs As Semantic Signals
Think of your URL structure as a secondary content layer – one that communicates hierarchy, topic, and specificity independently to the page title or H1, or other metadata.
A URL like /resources/seo/url-structure-ai-retrieval/ tells a retrieval system several things at once: This lives under a resources hub, it’s within an SEO category, and it covers a specific subtopic at a granular level.
That’s a useful signal. It maps to how AI systems try to understand content provenance and relevance before surfacing it in a response.
This matters especially for:
Long-tail and question-based queries, where AI systems are looking for precise matches to specific information needs.
Citation quality, where a descriptive URL increases the likelihood an AI agent references your content over a competitor’s near-identical page.
Practical Architecture Principles
There are a number of practical architecture principles that you should consider for both traditional search as well as AI search.
Use A Logical, Shallow Hierarchy
Deep nesting (i.e., /blog/category/subcategory/year/month/post-title/) creates noise, and your content is multiple steps away from the homepage. A structure three levels deep is almost always sufficient, i.e., domain > category > specific page. There are some CMS setups, like Shopify, where you are forced into four or five, depending on your theme (i.e., domain/blog/name-of-blog/blog-post-title/), but as long as you’re adding meaningful context and not administrative clutter, your structure will be aligned with the principle.
Make Every Segment Human-Readable And Descriptive
Avoid abbreviations, internal jargon, or ID numbers in public-facing URLs. A URL like /ai-search-optimization communicates the topic directly, whereas a URL like /aso-v2 communicates nothing without prior knowledge.
Align URL Slugs With The Actual Search Intent, Not Just The Keyword
There’s a big difference between /email-marketing and /email-marketing-best-practices-b2b. The second one signals specificity. It’s more likely to surface when an AI system is generating a response to a precise question, because the URL itself narrows the relevance scope before the content is even parsed.
Be Consistent With Category Naming Across Your Site
If your content strategy uses /guides/ for long-form education content and /blog/ for shorter commentary, maintain that consistently. It’s likely that AI retrieval systems build a model of your site structure over time. Inconsistency blurs the signal about what type of content lives where.
Avoid Keyword Stuffing In URLs
This is old SEO advice, but it also applies here. A URL crammed with keywords looks spammy to human users who see it cited in an AI response, which undermines the trust benefit you’re trying to build. One primary keyword or phrase per segment is the right call.
What Does This Look Like In Practice
If two different marketers are writing about the same topic, the URL structure could be key for RAG systems to better understand the context of the page as part of content retrieval.
An example:
Marketer A publishes /blog/2024/03/email-tips-part-4.
Marketer B publishes /resources/email-marketing/b2b-deliverability-guide.
Marketer B’s URL structure properly communicates hierarchy (resources hub), category (email marketing), and a specific focus (B2B deliverability) before a single word of body copy is processed.
Users are also more likely to benefit from this URL being cited because they can make sense of it immediately.
It can be argued that this type of clarity and specificity could compound as your URL structure and site’s information architecture can dictate the entire topical structure of your site, also helping to communicate both expertise and relevance.
The Redirect & Consolidation Problem
This is more relevant to enterprise sites that have accumulated URL debt like redirects, duplicate paths, and inconsistent slugs due to historical content management system migrations.
A practical fix will be to prioritize your website’s URLs. Audit your highest traffic and highest value pages, and confirm that their canonical URLs are clean, accessible, and structured in line with your current taxonomy.
Then work backward.
You don’t need to restructure the entire site for the chance of being cited in AI responses, but especially for your highest value pages, you should ensure that you’re offering the best possible URL signals.
What You Should Avoid Changing
It’s important not to always chase the big and shiny, so don’t completely restructure your entire site’s URL architecture just for marginal AI retrieval gains.
URL restructuring carries real SEO risk and time to recover link equity if 301 redirects are put in place – and there have been many web migration horror stories that can attest to what can happen when they’re not implemented correctly.
The goal is to apply these principles to new content and flag structural problems in existing high-value pages where the case to remediate these issues is clear and lower risk.
If your current URL structure already follows clean, descriptive, hierarchical conventions (which is all a standard part of SEO best practice), then congratulations! You’ve been optimizing for AI retrieval without even knowing.
In Summary
URL structure has always been a relatively small signal, but as AI assistants become more of a meaningful discovery channel, URL structures have the potential to be cited in more places than just Google and Bing.
They can help you to appear in AI-generated answers, they can shape citation quality, and they can contribute to how retrieval systems will categorize your content before anything else.
Simply build URLs that tell the story of your content clearly, before the user clicks on it.
The standard technical SEO audit checks crawlability, indexability, website speed, mobile-friendliness, and structured data. That checklist was designed for one consumer: Googlebot.
This is how it’s always been.
In 2026, your website has, at least, a dozen additional non-human consumers. AI crawlers like GPTBot, ClaudeBot, and PerplexityBot train models and power AI search results. User-triggered agents like the newly announced Google-Agent, or its “siblings” Claude-User and ChatGPT-User, browse websites on behalf of specific humans in real time. A Q1 2026 analysis across Cloudflare’s network found that 30.6% of all web traffic now comes from now bots, with AI crawlers and agents making up a growing share. Your technical audit needs to account for all of them.
Here are the five layers to add to your existing technical SEO audit.
Layer 1: AI Crawler Access
Your robots.txt was probably written for Googlebot, Bingbot, and maybe a few scrapers. AI crawlers need their own robots.txt rules, and they need to be separate from Googlebot and Bingbot.
What To Check
Review your robots.txt for rules targeting AI-specific user agents: GPTBot, ClaudeBot, PerplexityBot, Google-Extended, Bytespider, AppleBot-Extended, CCBot, and ChatGPT-User. If none of these appear, you’re running on defaults, and those defaults might not reflect what you actually want. Never accept the defaults unless you know they are exactly what you need.
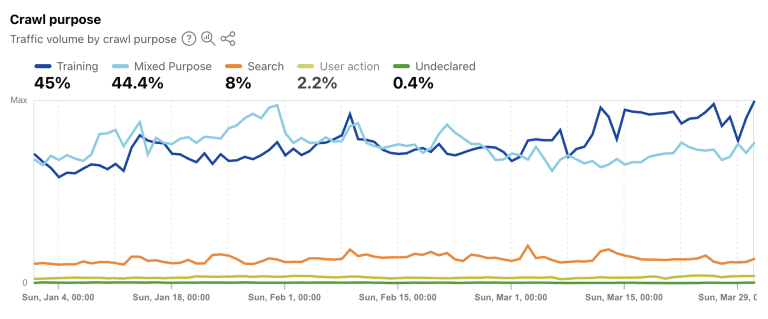
The key is making a conscious decision per crawler rather than blanket allowing or blocking everything. Not all AI crawlers serve the same purpose. AI crawler traffic can be split into three categories: training crawlers that collect data for model training (89.4% of AI crawler traffic according to Cloudflare data), search crawlers that power AI search results (8%), and user-triggered agents like Google-Agent and ChatGPT-User that browse on behalf of a specific human in real time (2.2%). Each category warrants a different robots.txt decision.
Cloudflare Radar data showing traffic volume by crawl purpose (Q1 2026); Screenshot by author, April 2026
The crawl-to-referral ratios from Cloudflare’s Radar report can make this an informed decision for you. Anthropic’s ClaudeBot crawls 20.6 thousand pages for every single referral it returns. OpenAI’s ratio is 1,300:1. Meta sends no referrals. Blocking OpenAI’s OAI-SearchBot or PerplexityBot reduces your visibility in ChatGPT Search and Perplexity’s AI answers. Blocking training-focused crawlers like CCBot or Meta’s crawler prevents data extraction from a provider that sends zero traffic back. The crawl-to-referral ratios tell you who is taking without giving.
There is one crawler that requires special attention. Google added Google-Agent to its official list of user-triggered fetchers on March 20, 2026. Google-Agent identifies requests from AI systems running on Google infrastructure that browse websites on behalf of users. Unlike traditional crawlers, Google-Agent ignores robots.txt. Google’s position is that since a human initiated the request, the agent acts as a user proxy rather than an autonomous crawler. Blocking Google-Agent requires server-side authentication, not robots.txt rules. This is both interesting, and important for the future, even if it’s not within the scope of this article.
AppleBot (which uses a WebKit-based renderer) and Googlebot are the only major crawlers that render JavaScript. Four of the six major web crawlers (GPTBot, ClaudeBot, PerplexityBot, and CCBot) fetch static HTML only, making server-side rendering a requirement for AI search visibility, not an optimization. If your content lives in client-side JavaScript, it is invisible to the crawlers training OpenAI, Anthropic, and Perplexity’s models and powering their AI search products.
What To Check
Run curl -s [URL] on your critical pages and search the output for key content like product names, prices, or service descriptions. If that content isn’t in the curl response, GPTBot, ClaudeBot, and PerplexityBot can’t see it either. Alternatively, use View Source in your browser (not Inspect Element, which shows the rendered DOM after JavaScript execution) and check whether the important information is present in the raw HTML.
Curl fetch of No Hacks homepage (Image from author, April 2026)
Single-page applications (SPAs) built with React, Vue, or Angular are particularly at risk unless they use server-side rendering (SSR) or static site generation (SSG). A React SPA that renders product descriptions, pricing, or key claims entirely on the client side is sending AI crawlers a blank page with a link to the JavaScript bundle.
The fix isn’t complicated. Server-side rendering (SSR), static site generation (SSG), or pre-rendering solves this for every major framework. Next.js supports SSR and SSG natively for React, Nuxt provides the same for Vue, and Angular Universal handles server rendering for Angular applications. The audit just needs to flag which pages depend on client-side JavaScript for critical content.
Layer 3: Structured Data For AI
Structured data has been part of technical SEO audits for years, but the evaluation criteria need updating. The question is no longer just “does this page have schema markup?” It’s “does this markup help AI systems understand and cite this content?”
What To Check
JSON-LD implementation (preferred over Microdata and RDFa for AI parsing).
Schema types that go beyond the basics: Organization, Article, Product, FAQ, HowTo, Person.
Entity relationships: sameAs, author, publisher connections that link your content to known entities.
Completeness: are all relevant properties populated, or are you just checking a box using skeleton schemas with name and URL?
Why This Matters Now
Microsoft’s Bing principal product manager Fabrice Canel confirmed in March 2025 that schema markup helps LLMs understand content for Copilot. The Google Search team stated in April 2025 that structured data gives an advantage in search results.
No, you can’t win with schema alone. Yes, it can help.
The data density angle matters too. The GEO research paper by Princeton, Georgia Tech, the Allen Institute for AI, and IIT Delhi (presented at ACM KDD 2024, first to publicly use the term “GEO”) found that adding statistics to content improved AI visibility by 41%. Yext’s analysis found that data-rich websites earn 4.3x more AI citations than directory-style listings. Structured data contributes to data density by giving AI systems machine-readable facts rather than requiring them to extract meaning from prose.
An important caveat: No peer-reviewed academic studies exist yet on schema’s impact on AI citation rates specifically. The industry data is promising and consistent, but treat these numbers as indicators rather than guarantees.
W3Techs reports that approximately 53% of the top 10 million websites use JSON-LD as of early 2026. If your website isn’t among them, you’re missing signals that both traditional and AI search systems use to understand your content.
Duane Forrester, who helped build Bing Webmaster Tools and co-launched Schema.org, argues that schema markup is only step one. As AI agents continue moving from simply interpreting pages to making decisions, brands will also need to publish operational truth (pricing, policies, constraints) in machine-verifiable formats with versioning and cryptographic signatures. Publishing machine-verifiable source packs is beyond the scope of a standard audit today, but auditing structured data completeness and accuracy is the foundation verified source packs build on.
Layer 4: Semantic HTML And The Accessibility Tree
The first three layers of the AI-readiness audit cover crawler access (robots.txt), JavaScript rendering, and structured data. The final two address how AI agents actually read your pages and what signals help them discover and evaluate your content.
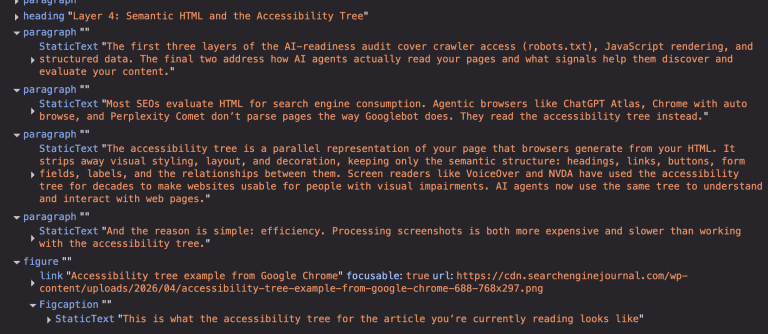
Most SEOs evaluate HTML for search engine consumption. Agentic browsers like ChatGPT Atlas, Chrome with auto browse, and Perplexity Comet don’t parse pages the way Googlebot does. They read the accessibility tree instead.
The accessibility tree is a parallel representation of your page that browsers generate from your HTML. It strips away visual styling, layout, and decoration, keeping only the semantic structure: headings, links, buttons, form fields, labels, and the relationships between them. Screen readers like VoiceOver and NVDA have used the accessibility tree for decades to make websites usable for people with visual impairments. AI agents now use the same tree to understand and interact with web pages.
And the reason is simple: efficiency. Processing screenshots is both more expensive and slower than working with the accessibility tree.
This is what an accessibility tree looks like in Google Chrome (Image from author, April 2026)
This matters because the accessibility tree exposes what your HTML actually communicates, not what your CSS (or JS) makes it look like. A
styled to look like a button doesn’t appear as a button in the accessibility tree. An image without alt text means nothing. A heading hierarchy that skips from H1 to H4 creates a broken structure that both screen readers and AI agents will struggle to navigate.
Microsoft’s Playwright MCP, the standard tool for connecting AI models to browser automation, uses accessibility snapshots rather than raw HTML or screenshots. Playwright MCP’s browser_snapshot function returns an accessibility tree representation because it’s more compact and semantically meaningful for LLMs. OpenAI’s documentation states that ChatGPT Atlas uses ARIA tags to interpret page structure when browsing websites.
Web accessibility and AI agent compatibility are now the same discipline. Proper heading hierarchy (H1-H6) creates meaningful sections that AI systems use for content extraction. Semantic elements like
, ,
, and
tell machines what role each content block plays. Form labels and descriptive button text make interactive elements understandable to agents that parse the accessibility tree instead of rendering visual design.
What To Check
Heading hierarchy: logical H1-H6 structure that machines can use to understand content relationships.
Form inputs: every input has a label, every button has descriptive text.
Interactive elements: clickable things use or , not .
Accessibility tree: run a Playwright MCP snapshot or test with VoiceOver/NVDA to see what agents actually see.
Somehow, things are getting worse on this front. The WebAIM Million 2026 report found that the average web page now has 56.1 accessibility errors, up 10.1% from 2025.
ARIA (Accessible Rich Internet Applications) usage increased 27% in a single year. ARIA is a set of HTML attributes that add extra semantic information to elements, telling screen readers and AI agents things like “this div is actually a dialog” or “this list functions as a menu.” But what’s critical is this: pages with ARIA present had significantly more errors (59.1 on average) than pages without ARIA (42 on average). Adding ARIA without understanding it makes things worse, not better, because incorrect ARIA overrides the browser’s default accessibility tree interpretation with wrong information. Start with proper semantic HTML. Add ARIA only when native elements aren’t sufficient.
Technical SEOs do not need to become accessibility experts. But treating accessibility as someone else’s problem is no longer viable when the same tree that screen readers parse is now the primary interface between AI agents and your website.
Sidenote: The Markdown Shortcut Doesn’t Work
Serving raw markdown files to AI crawlers instead of HTML can result in a 95% reduction in token usage per page. However, Google Search Advocate John Mueller called this “a stupid idea” in February 2026 on Bluesky. Mueller’s argument was this: “Meaning lives in structure, hierarchy and context. Flatten it and you don’t make it machine-friendly, you make it meaningless.” LLMs were trained on normal HTML pages from the beginning and have no problems processing them. The answer isn’t to create a flat, simplified version for machines. It’s to make the HTML itself properly structured. Well-written semantic HTML already is the machine-readable format. Besides, that simplified version already exists in the accessibility tree, and it is what AI agents already use.
Layer 5: AI Discoverability Signals
The final layer covers signals that don’t fit neatly into traditional audit categories but directly affect how AI systems discover and evaluate your website.
llms.txt (dis-honourable mention). Listed first for one reason only, ask any LLM what you should do to make your website more visible to AI systems, and llms.txt will be at or near the top of the list. It’s their world, I guess. The llms.txt specification provides a simple markdown file that helps AI agents understand your website’s purpose, structure, and key content. No large-scale adoption data has been published yet, and its actual impact on AI citations is unproven. But LLMs consistently recommend it, which means AI-powered audit tools and consultants will flag its absence. It takes minutes to create and costs nothing to maintain.
OK, now that we’ve got that out of the way, let’s look at what might really matter.
AI crawler analytics. Are you monitoring AI bot traffic? Cloudflare’s AI Audit dashboard shows which AI crawlers visit, how often, and which pages they hit. If you’re not on Cloudflare, check server logs for Google-Agent, ChatGPT-User, and ClaudeBot user agent strings. Google publishes a user-triggered-agents.json file containing IP ranges that Google-Agent uses, so you can verify whether incoming requests are genuinely from Google rather than spoofed user agent strings.
Entity definition. Does your website clearly define what the business is, who runs it, and what it does? Not in marketing copy, but in structured, machine-parseable markup. Organization schema should include name, URL, logo, founding date, and sameAs links to verified profiles on LinkedIn, Crunchbase, and Wikipedia. Person schema for key people should connect them to the organization via author and employee properties. AI systems need to resolve your identity as a distinct entity before they can confidently recommend you over competitors with similar names or offerings. Don’t slap this on top of your website when your designer is done with their work. Start here; it will make your life easier.
Content position. Where you place information on the page directly affects whether AI systems cite it. Kevin Indig’s analysis of 98,000 ChatGPT citation rows across 1.2 million responses found that 44.2% of all AI citations come from the top 30% of a page. The bottom 10% earns only 2.4-4.4% of citations regardless of industry. Duane Forrester calls this “dog-bone thinking”: strong at the beginning and end, weak in the middle, a pattern Stanford researchers have confirmed as the “lost in the middle” phenomenon. Audit your key pages: are the most important claims and data points in the first 30%, or buried in the middle?
Content extractability. Pull any key claim from your page and read it in isolation. Does it still make sense without the surrounding paragraphs? AI retrieval systems, like ChatGPT, Perplexity, and Google AI Overviews, extract and cite individual passages and sentences that rely on “this,” “it,” or “the above” for meaning, become unusable when extracted from their original context. Ramon Eijkemans’ excellent utility-writing framework maps these principles to documented retrieval mechanisms: self-contained sentences, explicit entity relationships, and quotable anchor statements that AI systems can confidently cite without additional inference.
The Audit Checklist
Check
Tool/Method
What You’re Looking For
AI crawler robots.txt
Manual review
Conscious per-crawler decisions
JavaScript rendering
curl, View Source, Lynx browser
Critical content in static HTML
Structured data
Schema validator, Rich Results Test
Complete, connected JSON-LD
Semantic HTML
axe DevTools, Lighthouse
Proper elements, heading hierarchy
Accessibility tree
Playwright MCP snapshot, screen reader
What agents actually see
AI bot traffic
Cloudflare, server logs
Volume, pages hit, patterns
From Audit To Action
This audit identifies gaps. Fixing them requires a sequence, because some fixes depend on others. Optimizing content structure before establishing a machine-readable identity means agents can extract your information, but can’t confidently attribute it to your brand. I wrote Machine-First Architecture to provide that sequence: identity, structure, content, interaction, each pillar building on the previous one.
Why Technical SEO Audit Is Where This Belongs
None of this is technically SEO. Robots.txt rules for AI crawlers don’t affect Google rankings. Accessibility tree optimization doesn’t move keyword positions. Content position scoring has nothing to do with search indexing.
But most of it did grow out of technical SEO. Crawl management, structured data, semantic HTML, JavaScript rendering, server log analysis: these are skills technical SEOs already have. The audit methodology transfers directly. The consumer it serves is what changed.
The websites that get cited in AI responses, that work when Chrome auto browse visits them, that show up when someone asks ChatGPT for a recommendation, they won’t be the ones with the best content alone. They’ll be the ones whose technical foundation made that content accessible to machines. Technical SEOs are the people best equipped to build that foundation. The old audit template just needs a new section to reflect it.
Google may expand the list of unsupported robots.txt rules in its documentation based on analysis of real-world robots.txt data collected through HTTP Archive.
Illyes explained why the team broadened the scope beyond the two tags in the PR:
“We tried to not do things arbitrarily, but rather collect data.”
Rather than add only the two tags proposed, the team decided to look at the top 10 or 15 most-used unsupported rules. Illyes said the goal was “a decent starting point, a decent baseline” for documenting the most common unsupported tags in the wild.
How The Research Worked
The team used HTTP Archive to study what rules websites use in their robots.txt files. HTTP Archive runs monthly crawls across millions of URLs using WebPageTest and stores the results in Google BigQuery.
The first attempt hit a wall. The team “quickly figured out that no one is actually requesting robots.txt files” during the default crawl, meaning the HTTP Archive datasets don’t typically include robots.txt content.
After consulting with Barry Pollard and the HTTP Archive community, the team wrote a custom JavaScript parser that extracts robots.txt rules line by line. The custom metric was merged before the February crawl, and the resulting data is now available in the custom_metrics dataset in BigQuery.
What The Data Shows
The parser extracted every line that matched a field-colon-value pattern. Illyes described the resulting distribution:
“After allow and disallow and user agent, the drop is extremely drastic.”
Beyond those three fields, rule usage falls into a long tail of less common directives, plus junk data from broken files that return HTML instead of plain text.
Google currently supports four fields in robots.txt. Those fields are user-agent, allow, disallow, and sitemap. The documentation says other fields “aren’t supported” without listing which unsupported fields are most common in the wild.
Google has clarified that unsupported fields are ignored. The current project extends that work by identifying specific rules Google plans to document.
The top 10 to 15 most-used rules beyond the four supported fields are expected to be added to Google’s unsupported rules list. Illyes did not name specific rules that would be included.
Typo Tolerance May Expand
Illyes said the analysis also surfaced common misspellings of the disallow rule:
“I’m probably going to expand the typos that we accept.”
His phrasing implies the parser already accepts some misspellings. Illyes didn’t commit to a timeline or name specific typos.
Why This Matters
Search Console already surfaces some unrecognized robots.txt tags. If Google documents more unsupported directives, that could make its public documentation more closely reflect the unrecognized tags people already see surfaced in Search Console.
Looking Ahead
The planned update would affect Google’s public documentation and how disallow typos are handled. Anyone maintaining a robots.txt file with rules beyond user-agent, allow, disallow, and sitemap should audit for directives that have never worked for Google.
Google updated its snippet documentation today with a new section on “Read more” deep links in Search results. The section outlines three best practices for increasing the likelihood that a page appears with these deep links.
What A Read More Deep Link Is
Google defines the feature as “a link within a snippet that leads users to a specific section on that page.”
The examples in the documentation show the link appearing inside the snippet area of a standard Search result.
Screenshot from: developers.google.com/search/docs/appearance/snippet, April 2026.
The Three Best Practices
Google lists three best practices that can increase the likelihood of these links appearing.
First, content must be immediately visible to a human on page load. Content hidden behind expandable sections or tabbed interfaces can reduce that likelihood, per Google’s guidance.
Second, avoid using JavaScript to control the user’s scroll position on page load. One example Google gives is forcing the user’s scroll to the top of the page.
Third, if the page uses history API calls or window.location.hash modifications on page load, keep the hash fragment in the URL. Removing it breaks deep linking behavior.
More Context
Read more deep links are one type of anchor URL that appears in Search Console performance reports. John Mueller previously addressed those hashtag URLs, confirming that they come from Google and link to page sections.
Before today’s addition, the documentation was last revised in 2024. That change clarified page content, not the meta description, as the primary source of search snippets.
Why This Matters
For websites, the new guidance outlines what can increase the likelihood that a Read more deep link will appear.
Pages using accordion UI patterns, tabbed content, or forced-scroll JavaScript may reduce that likelihood. Teams working with single-page applications should ensure that hash fragments remain in URLs during page loads.
Looking Ahead
This is a documentation clarification, not a new SERP feature. Read more deep links have appeared in Search for some time. What’s new is the written guidance on how to increase that likelihood.
Developers working on JavaScript-heavy sites should test how their pages handle scroll position and hash fragments on initial load. Today’s update provides clearer signals on what can reduce the likelihood of a “Read more” link appearing.
AI agents are already here. Not as a concept, not as a demo, but shipping inside browsers used by billions of people. Every major tech company has launched either a browser with AI built in or an extension that acts on your behalf.
Anthropic’s Claude for Chrome can navigate websites, fill forms, and perform multi-step operations on your behalf. Google announced Gemini in Chrome with agentic browsing capabilities, including auto browse, which can act on webpages for you. OpenClaw, the open-source AI agent, connects large language models directly to browsers, messaging apps, and system tools to execute tasks autonomously.
For more understanding about optimizing for agents, I spoke to Slobodan Manic, who recently wrote a five-part series on optimizing websites for AI agents. His perspective sits at the intersection of technical web performance and where AI agent interaction is actually heading.
From Slobodan Manic’s testing, almost every website is structurally broken for this shift.
“It started with us going to AI and asking questions. And now AI is coming to us and meeting us where we are. From my testing, I noticed that websites are nowhere near being ready for this shift because structurally almost every website is broken.”
The Single Biggest Thing That’s Changed
I started by asking Slobodan what’s changed in the last six to nine months that means SEOs need to pay attention to AI agents right now.
“Every major tech company has launched either a browser that has AI in it that can do things for you or some kind of extension that gets into Chrome. Claude has a plugin for Chrome that can do things for you, not just analyze web pages, summarize web pages, but actually perform operations.”
When ChatGPT first launched in 2023, making AI widely accessible, in parallel with how we started typing basic queries in search engines 25 years ago, we asked AI questions. We are now becoming more sophisticated and fluid with our prompting as we realize that AI can do so much more than [write me an email to politely decline an invitation].
Agents represent an even bigger shift to a different dynamic, where AI can complete tasks on our behalf and run complex systems. [Check my emails and delete any that are spam, sort them into a priority group, and surface what needs my immediate attention and provide a qualified response to anything on a basic query, plus make appointments in my calendar for any meeting invites].
I have a theory that brand websites are becoming hubs, the central point that connects all of your content assets online. But Slobodan has gone further. He’s written about websites becoming optional for the end user, with pages built by machines for machines and the interaction happening through closed system interfaces. I asked him to expand on that vision and what kind of timeframe we’re realistically looking at.
“First I’ll say that this is not fully happening today. This is still near to mid future. This is not March 2026,” he clarified. But the signals are concrete.
He was careful not to overstate it. People still like to browse, read, and compare things. Websites aren’t disappearing.
“Just the same way as mobile traffic has not killed desktop traffic even if it’s taken a bigger share of traffic overall, higher percentage of overall traffic while the desktop traffic is staying flat in terms of absolute numbers, I think this is another lane that will open where things will be happening without a human being involved in every step.”
His timeline for this: “Within a year we can have this become a reality. Not majority, but if Google starts rewriting landing pages using AI, we will see this happening probably 2027, if not sooner.”
When Checkout Becomes A Protocol
Slobodan has written that checkout is becoming a protocol, not a page. If an AI agent can buy on your behalf without ever loading a brand’s website, I asked, “What does that mean for how brands build trust and differentiate when the customer never sees their site?”
“If you’re building trust in a checkout page, you’re doing it wrong. Let’s start there. That I firmly believe. This is not to do with AI. This was never the right place to build trust,” he responded.
Slobodan pointed to every Shopify checkout page that looks identical. “There’s no trust built there. It’s just a machine-readable page that looks the same for everyone, for every brand. You’re supposed to be doing your job before the user needs to pay you.”
This is where he referenced Jono Alderson, and the concept of upstream engineering. “Moving upstream and doing work there and not on the website is the only way to move forward for anyone whose job is optimizing websites. That’s SEO, that’s CRO, that’s content, that’s anyone doing any kind of website work.”
He best summarized by saying “Your website is a part of the equation. Your website is not the equation. And that’s the biggest structural shift that people need to make to survive moving forward.”
What SEOs And Brands Should Actually Do Now
I asked what SEOs and brands can practically start doing to transition over the next year. His answer reframed how we should think about the website itself.
“If your website was your storefront, and it was for decades, people come to you, people do business there. It needs to be a warehouse and a storefront moving forward or you’re not going to survive. Simple as that.”
“We had all those bookstores that were selling books in the ’90s and then Amazon shows up and then you need to be a warehouse. You need to exist in two planes at the same time for the near future at least. So focusing only on your website is the most wrong thing you can do moving forward.”
His main area of focus right now is what he calls machine-first architecture. The principle is to build for machines before you build for humans.
“You don’t build your website for humans until you’ve built it for machines. When you’re working on a product page, there’s no Figma, there’s no design, there’s no copy. You start with your schema. What is your schema supposed to say? What is the meaning of the page? You start with the meaning and then from that build into a web page as it’s built for humans.”
He compared it directly to the mobile-first shift. “That did not mean no desktop. That meant do the more difficult version of it first and then do the easy thing. Trust me, it’s a lot more complicated to add meaning and structure to a page that’s already been designed than to do it the other way.”
And it extends beyond the website. “If you’re saying something on your website, you better check all of your profiles everywhere online, what people are saying about you. It’s everything everywhere all at once. But this is what optimization has become and what it needs to be.”
I also put to him the argument that optimizing for LLMs is fundamentally different from SEO. His response was unequivocal.
“Hard disagree. The hardest possible disagree. If you were doing things the right way, working on the foundations and checking every box that has to be checked, it’s not different at all.”
Where he sees a difference is in the speed of consequences. “With AI in the mix, you just get exposed much faster and the consequences are much greater. There’s nothing different other than those two things.”
This echoed something I’ve felt strongly. The cycle is moving more quickly, but there’s so much similarity with what happened at the foundation of this industry 25 to 30 years ago, which I raised in my SEO Pioneers series. We’re feeling our way through in the same way. And Slobodan agreed.
“They figured this out once and maybe we should ask them how to figure it out again.”
Vibe Coding Is A Trap, Deep Work Is The Moat
For my last question, I put it to Slobodan that he’s said vibe coding is a trap and deep work is the only moat left. For the SEO practitioner feeling overwhelmed, what’s the one thing they should actually do this week?
“It’s really the foundations. I hate to give the boring answer, but it’s really fixing every single foundational thing that you have on your website or your website presence.”
He’s watched the industry chase one shiny tool after another. “There’s always a new shiny toy to work on while your website doesn’t work with JavaScript disabled. Just ignore all of that until you’ve fixed every single broken foundation you have on your website.”
On vibe coding specifically, he was precise: “I don’t like the term vibe coding. It just suggests that you have no idea what you’re doing and you’re happy about it. That’s the way that sounds to me. The concept of AI-assisted coding, it’s there. It’s great. It’s not going away.”
“But just focus on what you should be doing first before you use AI to do it faster.”
What resonated with me is how well this applies to writing, too. AI is brilliant at confidently producing a draft that, at first glance, looks great. But when you actually read it, you realize it’s just somebody confidently talking nonsense.
Slobodan nailed the core problem: “You need to know what good is and what good looks like. Because AI will always give you something. If you don’t know enough about that specific thing, it will always look good from the outside. And there’s a reason why everyone is okay with vibing everything except for their own profession, because they try it and they see that the results are just horrific.”
Build For Machines First, Everything Else Follows
The one thing to take away from this conversation is to build for machines first, then humans. Not because human user experience won’t matter, but because getting the machine layer right first makes the human layer better.
Your website is no longer the only version of your business that people, or agents, will encounter. The brands that treat it as part of a wider ecosystem rather than the whole ecosystem are the ones that will come through this transition in the strongest position.
Watch the full video interview with Slobodan Manic here, or on YouTube.
Thank you to Slobodan for sharing his insights and being my guest on IMHO.
This post was sponsored by Alli AI. The opinions expressed in this article are the sponsor’s own.
Everyone assumes Googlebot is the dominant crawler hitting their website. That assumption is now wrong.
We analyzed 24,411,048 proxy requests across 78,000+ pages on 69 customer websites on Alli AI’s crawler enablement platform over a 55-day period (January to March 2026). OpenAI’s ChatGPT-User crawler made 3.6x more requests than Googlebot across our data sample. And that’s not even counting GPTBot, OpenAI’s separate training crawler.
A note on methodology: Crawler identification used user agent string matching, verified against published IP ranges. Request metrics are measured at the proxy/CDN layer. The dataset covers 69 websites across a variety of industries and sizes, predominantly WordPress-based. Full methodology is detailed at the end.
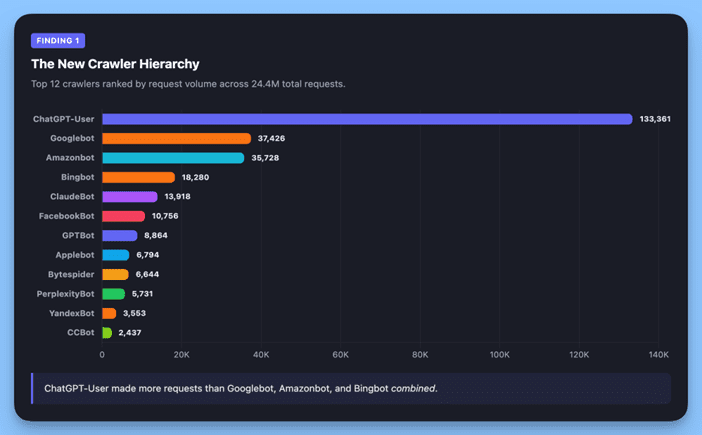
Finding 1: AI Crawlers Now Outpace Google 3.6x & ChatGPT Leads the Pack
Image created by Alli AI, April 2026.
When we ranked every identified crawler by request volume, the results were unambiguous:
Rank
Crawler
Requests
Category
1
ChatGPT-User (OpenAI)
133,361
AI Search
2
Googlebot
37,426
Traditional Search
3
Amazonbot
35,728
AI / E-Commerce
4
Bingbot
18,280
Traditional Search
5
ClaudeBot (Anthropic)
13,918
AI Search
6
MetaBot
10,756
Social
7
GPTBot (OpenAI)
8,864
AI Training
8
Applebot
6,794
AI Search
9
Bytespider (ByteDance)
6,644
AI Training
10
PerplexityBot
5,731
AI Search
ChatGPT-User made more requests than Googlebot, Amazonbot, and Bingbot combined.
Image created by Alli AI, April 2026.
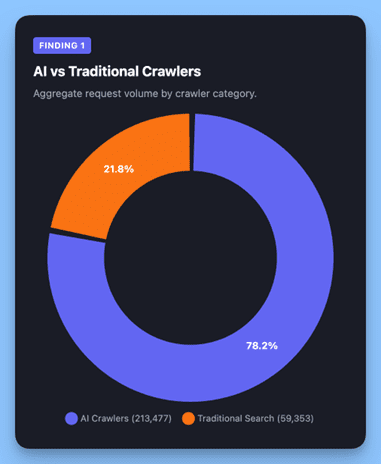
Grouped by purpose, AI-related crawlers (ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, Applebot, Bytespider, PerplexityBot, CCBot) made 213,477 requests versus 59,353 for traditional search crawlers (Googlebot, Bingbot, YandexBot). AI crawlers are now making 3.6x more requests than traditional search crawlers across our network.
Finding 2: OpenAI Uses 2 Crawlers (And Most Sites Don’t Know the Difference)
Image created by Alli AI, April 2026.
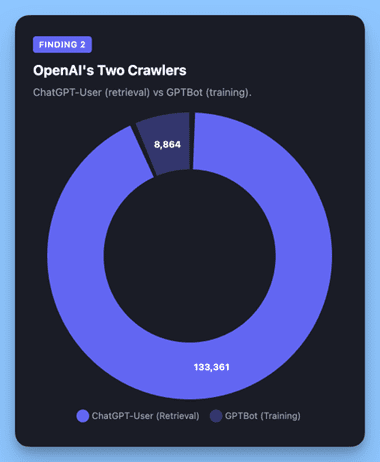
OpenAI operates two distinct crawlers with very different purposes.
ChatGPT-User is the retrieval crawler. It fetches pages in real time when users ask ChatGPT questions that require up-to-date web information. This determines whether your content appears in ChatGPT’s answers.
GPTBot is the training crawler. It collects data to improve OpenAI’s models. Many sites block GPTBot via robots.txt but not ChatGPT-User, or vice versa, without understanding the distinct consequences of each.
Combined, OpenAI’s crawlers made 142,225 requests: 3.8x Googlebot’s volume.
The robots.txt directives are separate:
User-agent: GPTBot # Training crawler — feeds OpenAI's models
User-agent: ChatGPT-User # Retrieval crawler — fetches pages for ChatGPT answers
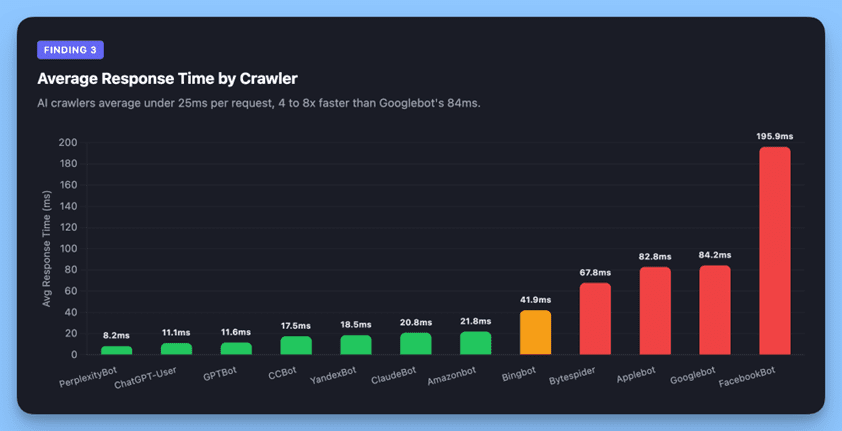
Finding 3: AI Crawlers Are Faster & More Reliable, But Their Volume Adds Up
Image created by Alli AI, April 2026.
AI crawlers are significantly more efficient per request:
Crawler
Avg Response Time
200 Success Rate
PerplexityBot
8ms
100%
ChatGPT-User
11ms
99.99%
GPTBot
12ms
99.9%
ClaudeBot
21ms
99.9%
Bingbot
42ms
98.4%
Googlebot
84ms
96.3%
Two likely reasons. First, AI retrieval crawlers are fetching specific pages in response to user queries, not exhaustively discovering site architecture. They know what they want, they grab it, and they leave. Second, while all crawlers on our infrastructure receive pre-rendered responses, Googlebot’s broader crawl pattern means it requests a wider range of URLs, including stale paths from sitemaps and its own legacy index, which adds latency from redirect chains and error handling that retrieval crawlers avoid entirely.
But there’s a catch: while each individual request is lightweight, the sheer volume means aggregate server load is substantial. ChatGPT-User at 11ms × 133,361 requests is still a real infrastructure cost, just distributed differently than Googlebot’s fewer, heavier requests.
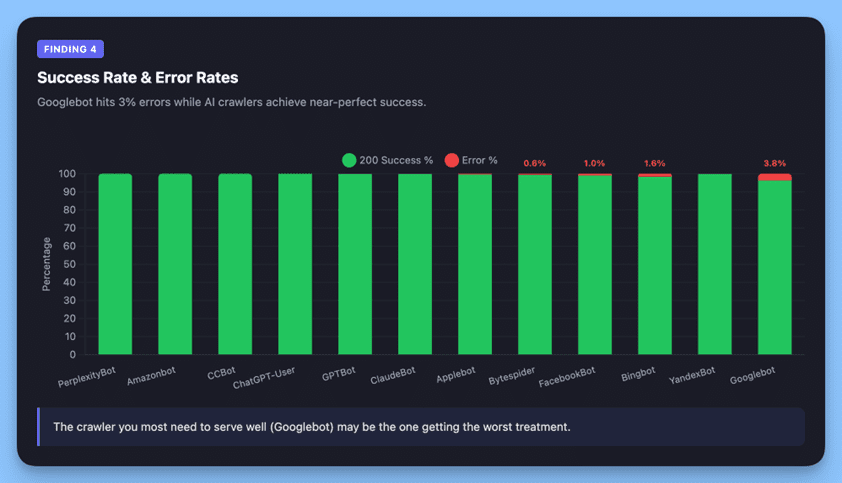
Finding 4: Googlebot Sees a Different (Worse) Version of Your Site
Image created by Alli AI, April 2026.
Googlebot’s 96.3% success rate versus near-perfect rates for AI crawlers reveals an important structural difference.
Googlebot received 624 blocked responses (403) and 480 not found errors (404), accounting for 3% of its requests. Meanwhile, ChatGPT-User achieved 99.99% success. PerplexityBot hit a perfect 100%.
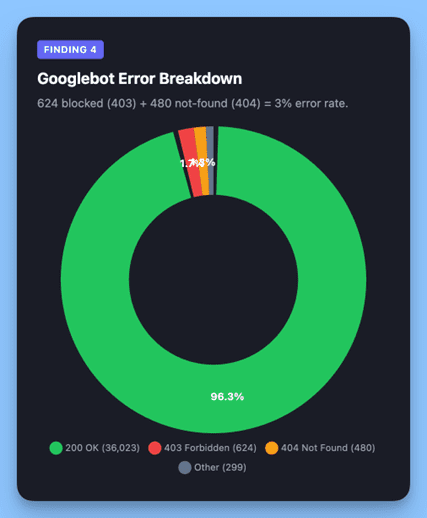
Image created by Alli AI, April 2026.
Why the gap? The most likely explanation is index age and crawl behavior, not site misconfiguration.
Googlebot maintains a massive legacy index built over years of continuous crawling. It routinely re-requests URLs it already knows about — including pages that have since been deleted (404s) or restructured (403s). This is normal behavior for a search engine maintaining an index of this scale, but it means a meaningful percentage of Googlebot’s requests are directed at URLs that no longer exist.
AI crawlers don’t carry that baggage. ChatGPT-User fetches specific pages in response to real-time user queries, targeting content that’s currently relevant and linked. That’s a structural advantage that produces near-perfect success rates.
Industry Reports Confirm AI Crawling Surged 15x in 2025
Our data shows this crossover may already be happening at the site level for properties that actively enable AI crawler access.
Your New SEO Strategy: How To Audit, Clean Up & Optimize For AI Crawlers
1. Audit your robots.txt for AI crawlers today
Most robots.txt files were written for a Googlebot-first world. At minimum, have explicit directives for ChatGPT-User, GPTBot, ClaudeBot, Amazonbot, PerplexityBot, Applebot, Bytespider, CCBot, and Google-Extended.
Our recommendation: Most businesses benefit from allowing both retrieval crawlers (ChatGPT-User, PerplexityBot, ClaudeBot) and training crawlers (GPTBot, CCBot, Bytespider), training data is what teaches these models about your brand, products, and expertise. Blocking training crawlers today means AI models learn less about you tomorrow, which reduces your chances of being cited in AI-generated answers down the line.
The exception: if you have content you specifically need to protect from model training (proprietary research, gated content), use granular Disallow rules for those paths rather than blanket blocks.
2. Clean up stale URLs in Google Search Console
Our data shows Googlebot hits a 3% error rate, mostly 403s and 404s, while AI crawlers achieve near-perfect success rates. That gap likely reflects Googlebot re-crawling legacy URLs that no longer exist. But those failed requests still consume the crawl budget.
Audit your GSC crawl stats for recurring 404s and 403s. Set up proper redirects for restructured URLs and submit updated sitemaps.
3. Treat AI crawler accessibility as a distinct SEO channel
Ranking in ChatGPT’s answers, Perplexity’s results, and Claude’s responses is emerging as a distinct visibility channel. If your content isn’t accessible to these crawlers, particularly if you’re running JavaScript-heavy frameworks, you’re invisible in AI search.
We’ve published a live dashboard showing how AI crawler traffic breaks down across a real site: which platforms are visiting, how often, and their share of total traffic; if you want to see what this looks like in practice.
4. Plan for volume, not just individual request weight
AI crawlers send light, fast requests, but they send many of them. ChatGPT-User alone accounted for more than 133,000 requests in 55 days. The aggregate server load from AI crawlers is now likely exceeding your Googlebot load. Make sure your hosting and CDN can handle it, the low per request response times in our data reflect the fact that Alli AI serves pre-rendered static HTML from the CDN edge, which is exactly the kind of architecture that absorbs this volume without taxing your origin server.
Methodology
This analysis is based on 24,411,048 HTTP proxy requests processed through Alli AI’s crawler enablement platform between January 14 and March 9, 2026, covering 69 customer websites.
Crawler identification used user agent string matching, verified against published IP ranges. For OpenAI crawlers specifically, every request was cross-referenced against OpenAI’s published CIDR ranges. This confirmed 100% of GPTBot requests and 99.76% of ChatGPT-User requests originated from OpenAI’s infrastructure. The remaining 0.24% (requests from spoofed user agents) were excluded.
Limitations: The dataset is scoped to Alli AI customers who have opted into crawler enablement. Crawlers that don’t self-identify via user agent are not captured. Response time measurements are at the proxy layer, not the origin server.
About Alli AI
Alli AI provides server-side rendering infrastructure for AI and search engine crawlers. This analysis was produced using data from our proxy infrastructure to help the SEO community better understand the evolving crawler landscape.
Want to see this data in action? See the breakdown firsthand by visiting our AI visibility dashboard.
Google’s Gary Illyes published a blog post explaining how Googlebot’s crawling systems work. The post covers byte limits, partial fetching behavior, and how Google’s crawling infrastructure is organized.
The post references episode 105 of the Search Off the Record podcast, where Illyes and Martin Splitt discussed the same topics. Illyes adds more details about crawling architecture and byte-level behavior.
What’s New
Googlebot Is One Client Of A Shared Platform
Illyes describes Googlebot as “just a user of something that resembles a centralized crawling platform.”
Google Shopping, AdSense, and other products all send their crawl requests through the same system under different crawler names. Each client sets its own configuration, including user agent string, robots.txt tokens, and byte limits.
When Googlebot appears in server logs, that’s Google Search. Other clients appear under their own crawler names, which Google lists on its crawler documentation site.
How The 2 MB Limit Works In Practice
Googlebot fetches up to 2 MB for any URL, excluding PDFs. PDFs get a 64 MB limit. Crawlers that don’t specify a limit default to 15 MB.
Illyes adds several details about what happens at the byte level.
He says HTTP request headers count toward the 2 MB limit. When a page exceeds 2 MB, Googlebot doesn’t reject it. The crawler stops at the cutoff and sends the truncated content to Google’s indexing systems and the Web Rendering Service (WRS).
Those systems treat the truncated file as if it were complete. Anything past 2 MB is never fetched, rendered, or indexed.
Every external resource referenced in the HTML, such as CSS and JavaScript files, gets fetched with its own separate byte counter. Those files don’t count toward the parent page’s 2 MB. Media files, fonts, and what Google calls “a few exotic files” are not fetched by WRS.
Rendering After The Fetch
The WRS processes JavaScript and executes client-side code to understand a page’s content and structure. It pulls in JavaScript, CSS, and XHR requests but doesn’t request images or videos.
Illyes also notes that the WRS operates statelessly, clearing local storage and session data between requests. Google’s JavaScript troubleshooting documentation covers implications for JavaScript-dependent sites.
Best Practices For Staying Under The Limit
Google recommends moving heavy CSS and JavaScript to external files, since those get their own byte limits. Meta tags, title tags, link elements, canonicals, and structured data should appear higher in the HTML. On large pages, content placed lower in the document risks falling below the cutoff.
Illyes flags inline base64 images, large blocks of inline CSS or JavaScript, and oversized menus as examples of what could push pages past 2 MB.
The 2 MB limit “is not set in stone and may change over time as the web evolves and HTML pages grow in size.”
The platform description explains why different Google crawlers behave differently in server logs and why the 15 MB default differs from Googlebot’s 2 MB limit. These are separate settings for different clients.
HTTP header details matter for pages near the limit. Google states headers consume part of the 2 MB limit alongside HTML data. Most sites won’t be affected, but pages with large headers and bloated markup might hit the limit sooner.
Looking Ahead
Google has now covered Googlebot’s crawl limits in documentation updates, a podcast episode, and a dedicated blog post within a two-month span. Illyes’ note that the limit may change over time suggests these figures aren’t permanent.
For sites with standard HTML pages, the 2 MB limit isn’t a concern. Pages with heavy inline content, embedded data, or oversized navigation should verify that their critical content is within the first 2 MB of the response.
Google’s Gary Illyes and Martin Splitt used a recent episode of the Search Off the Record podcast to discuss whether webpages are getting too large and what that means for both users and crawlers.
The conversation started with a simple question: are websites getting fat? Splitt immediately pushed back on the framing, arguing that website-level size is meaningless. Individual page size is where the discussion belongs.
What The Data Shows
Splitt cited the 2025 Web Almanac from HTTP Archive, which found that the median mobile homepage weighed 845 KB in 2015. By July, that same median page had grown to 2,362 KB. That’s roughly a 3x increase over a decade.
Both agreed the growth was expected, given the complexity of modern web applications. But the numbers still surprised them.
Splitt noted the challenge of even defining “page weight” consistently, since different people interpret the term differently depending on whether they’re thinking about raw HTML, transferred bytes, or everything a browser needs to render a page.
How Google’s Crawl Limits Fit In
Illyes discussed a 15 MB default that applies across Google’s broader crawl infrastructure, where each URL gets its own limit, and referenced resources like CSS, JavaScript, and images are fetched separately.
That’s a different number from what appears in Google’s current Googlebot documentation. Google states that Googlebot for Google Search crawls the first 2 MB of a supported file type and the first 64 MB of a PDF.
Our previous coverage broke down the documentation update that clarified these figures earlier this year. Illyes and Splitt discussed the flexibility of these limits in a previous episode, noting that internal teams can override the defaults depending on what’s being crawled.
The Structured Data Question
One of the more interesting moments came when Illyes raised the topic of structured data and page bloat. He traced it back to a statement from Google co-founder Sergey Brin, who said early in Google’s history that machines should be able to figure out everything they need from text alone.
Illyes noted that structured data exists for machines, not users, and that adding the full range of Google’s supported structured data types to a page can add weight that visitors never see. He framed it as a tension rather than offering a clear answer on whether it’s a problem.
Does It Still Matter?
Splitt said yes. He acknowledged that his home internet connection is fast enough that page weight is irrelevant in his daily experience. But he said the picture changes when traveling to areas with slower connections, and noted that metered satellite internet made him rethink how much data websites transfer.
He suggested that page size growth may have outpaced improvements in median mobile connection speeds, though he said he’d need to verify that against actual data.
Illyes referenced prior studies suggesting that faster websites tend to have better retention and conversion rates, though the episode didn’t cite specific research.
Looking Ahead
Splitt said he plans to address specific techniques for reducing page size in a future episode.
Most pages are still unlikely to hit those limits, with the Web Almanac reporting a median mobile homepage size of 2,362 KB. But the broader trend of growing page weight affects both performance and accessibility for users on slower or metered connections.
Google updated its Discussion Forum and Q&A Page structured data documentation, adding several new supported properties to both markup types.
The most notable addition is digitalSourceType, a property that lets forum and Q&A sites indicate when content was created by a trained AI model or another automated system.
Content Source Labeling Comes To Forum Markup
The new digitalSourceType property uses IPTC digital source enumeration values to indicate how content was created. Google supports two values:
TrainedAlgorithmicMediaDigitalSource for content created by a trained model, such as an LLM.
AlgorithmicMediaDigitalSource for content created by a simpler algorithmic process, such as an automatic reply bot.
The property is listed as recommended, not required, for both the DiscussionForumPosting and Comment types in the Discussion Forum docs, and for Question, Answer, and Comment types in the Q&A Page docs.
Google already uses similar IPTC source type values in its image metadata documentation to identify how images were created. The update extends that concept to text-based forum and Q&A content.
New Comment Count Property
Google added commentCount as a recommended property across both documentation pages. It lets sites declare the total number of comments on a post or answer, even when not all comments appear in the markup.
The Q&A Page documentation includes a new formula: answerCount + commentCount should equal the total number of replies of any type. This gives Google a clearer picture of thread activity on pages where comments are paginated or truncated.
Expanded Shared Content Support
The Discussion Forum documentation expanded its sharedContent property. Previously, sharedContent accepted a generic CreativeWork type. The updated docs now explicitly list four supported subtypes:
WebPage for shared links.
ImageObject for posts where an image is the primary content.
VideoObject for posts where a video is the primary content.
DiscussionForumPosting or Comment for quoted or reposted content from other threads.
The addition of DiscussionForumPosting and Comment as accepted types is new. Google’s updated documentation includes a code example showing how to mark up a referenced comment with its URL, author, date, and text.
The image property description was also updated across both docs with a note about link preview images. Google now recommends placing link preview images inside the sharedContent field’s attached WebPage rather than in the post’s image field.
Why This Matters
For sites that publish a mix of human and machine-generated content, the digitalSourceType addition provides a structured way to communicate that to Google. The new properties are optional, and no existing implementations will break.
Google has not said how it will use the digitalSourceType data in its ranking or display systems. The documentation only describes it as a way to indicate content origin.
Looking Ahead
The update does not include changes to required properties, so existing forum and Q&A structured data implementations remain valid. Sites that want to adopt the new properties can add them incrementally.