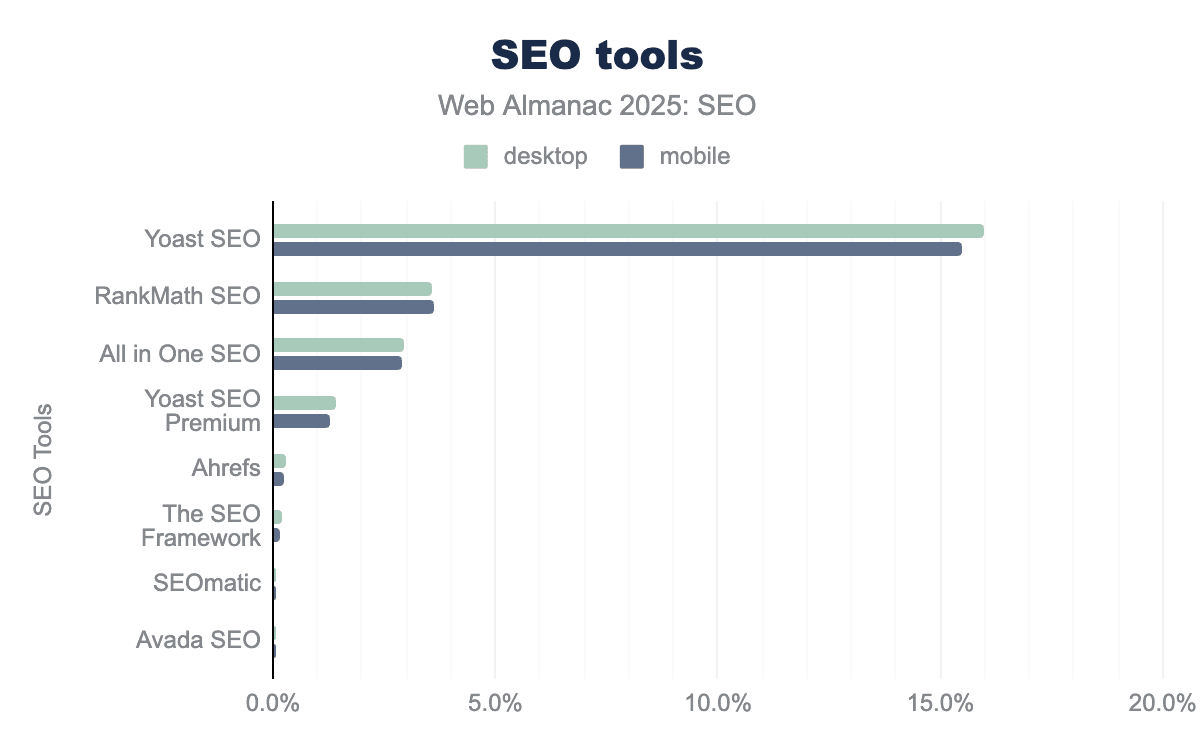
What is an XML sitemap and why should you have one?
A good XML sitemap serves as a roadmap for your website, guiding Google to all your important pages. XML sitemaps can be beneficial for SEO, helping Google find your essential pages quickly, even if your internal linking isn’t perfect. This post explains what they are and how they help you rank better and get surfaced by AI agents.
Key takeaways
- An XML sitemap is crucial for SEO, as it guides search engines to your important pages, improving crawl efficiency
- XML sitemaps list essential URLs and provide metadata, helping search engines understand content and prioritize crawling
- With Yoast SEO, you can automatically generate and manage XML sitemaps, keeping them up to date
- XML sitemaps support faster indexing of new content and help discover orphan pages that aren’t linked elsewhere
- Add your XML sitemap to Google Search Console to help Google find it quickly and monitor indexing status
What are XML sitemaps?
An XML sitemap is a file that lists a website’s essential pages, ensuring Google can find and crawl them. It also helps search engines understand your website structure and prioritize important content.
💡 Fun fact:
XML is not the only type of sitemap; there are several sitemap formats, each serving a slightly different purpose:
- RSS, mRSS, and Atom 1.0 feeds: These are typically used for content that changes frequently, such as blogs or news sites. They automatically highlight recently updated content
- Text sitemaps: The simplest format. These contain a plain list of URLs, one per line, without additional metadata
These are HTML sitemaps that are created for visitors, not search engines. They list and link to important pages in a clear, hierarchical structure to improve user navigation. An XML sitemap, however, is specifically designed for search engines.
XML sitemaps include additional metadata about each URL, helping search engines better understand your content. For example, it can indicate:
- When a page was last meaningfully updated
- How important is a URL relative to other URLs
- Whether the page includes images or videos, using sitemap extensions
Search engines use this information to crawl your site more intelligently and efficiently, especially if your website is large, new, or has complex navigation.
Looking to expand your knowledge of technical SEO? We have a course in the Yoast SEO Academy focusing on crawlability and indexability. One of the topics we tackle is how to use XML sitemaps properly.
What does an XML sitemap look like?
An XML sitemap follows a standardized format. It is a text file written in Extensible Markup Language (XML) that search engines can easily read and process. As it follows a structured format, search engines like Google can quickly understand which URLs exist on your website and when they were last updated.
Here is a very simple example of an XML sitemap that contains a single URL:
https://www.yoast.com/wordpress-seo/
2024-01-01
Each URL in a sitemap is wrapped in specific XML tags that provide information about that page. Some of these tags are required, while others are optional but helpful for search engines.
Below is a breakdown of the most common XML sitemap tags:
| Tag | Requirement | Description |
<?xml> |
Mandatory | Declares the XML version and character encoding used in the file. |
|
Mandatory | The container for the entire sitemap. It defines the sitemap protocol and holds all listed URLs. |
|
Mandatory | Represents a single URL entry in the sitemap. Each page must be enclosed within its own |
|
Mandatory | Specifies the full canonical URL of the page you want search engines to crawl and index. |
|
Optional | Indicates the date when the page was last meaningfully updated, helping search engines know when to re-crawl the page. |
|
Optional | Suggests how frequently the content on the page is expected to change, such as daily, weekly, or monthly. |
|
Optional | Suggests the relative importance of a page compared to other pages on the same site, using a scale from 0.0 to 1.0. |
Note: While sitemaps.org supports optional tags like
What is an XML sitemap index?
A sitemap index is a file that lists multiple XML sitemap files. Instead of containing individual page URLs, it acts as a directory that points search engines to several separate sitemaps.
This becomes useful when a website has a large number of URLs or when the site owner wants to organize sitemaps by content type. For example, a site may have separate sitemaps for pages, blog posts, products, or categories.
Here’s a breakdown of how XML sitemap and XML sitemap index differ:
| Feature | XML Sitemap | XML Sitemap Index |
| Purpose | Lists individual URLs on a website | Lists multiple sitemap files |
| Content | Contains page URLs and optional metadata | Contains links to sitemap files |
| Use case | Suitable for small or medium-sized sites | Useful when a site has multiple sitemaps |
| Structure | Uses |
Uses |
Search engines support sitemap limits. A single sitemap can contain up to 50,000 URLs or be up to 50 MB in size. If your website exceeds these limits, you can create multiple sitemaps and group them together using a sitemap index.
Submitting a sitemap index to search engines allows them to discover and process all your sitemaps from a single file.
In short, an XML sitemap helps search engines discover pages, while a sitemap index helps search engines discover multiple sitemaps.
Below is a simple example of what a sitemap index file looks like:
?xml version="1.0" encoding="UTF-8"?>
https://www.example.com/sitemap-pages.xml
2025-12-11
https://www.example.com/sitemap-products.xml
2025-12-11
In this example, the sitemap index references two separate sitemaps. Each one can contain thousands of URLs. This structure helps search engines efficiently discover and crawl large websites.
Why do you need an XML sitemap?
Technically, you don’t need an XML sitemap. Search engines can often discover your pages through internal links and backlinks from other websites. However, having an XML sitemap is highly recommended because it helps search engines crawl and understand your site more efficiently.
Here are some key benefits of using an XML sitemap:
Improved crawl efficiency
Sitemaps help search engines like Google and Bing crawl large or complex websites more efficiently. By listing your important URLs in one place, you make it easier for crawlers to find and prioritize valuable pages.
Faster indexing of new content
When you update or add new pages to your site, including them in your sitemap helps search engines discover them sooner. This can lead to faster indexing, especially for websites that publish content frequently, such as blogs, news sites, or e-commerce stores with changing product listings.
Discovery of orphan pages
Orphan pages are pages that are not linked from other parts of your website. Because crawlers typically follow links to discover content, these pages can sometimes be missed. An XML sitemap can help ensure these pages are still discovered.
Additional metadata signals
XML sitemaps can include additional metadata about each URL, such as the
Support for specialized content
Sitemaps can also be extended to include specific types of content, such as images or videos. These specialized sitemaps help search engines better understand and surface media content in results like Google Images or video search.
Better understanding of site structure
A well-organized sitemap gives search engines a clearer overview of your website’s structure and the relationship between different sections or content types.
Indexing insights through Search Console
When you submit your sitemap to tools like Google Search Console, you can monitor how many URLs are discovered and indexed. This also helps you identify crawl issues or indexing errors.
Support for multilingual websites
For websites targeting multiple languages or regions, XML sitemaps can include alternate language versions of pages using hreflang annotations. This helps search engines serve the correct language version to users in different locations.
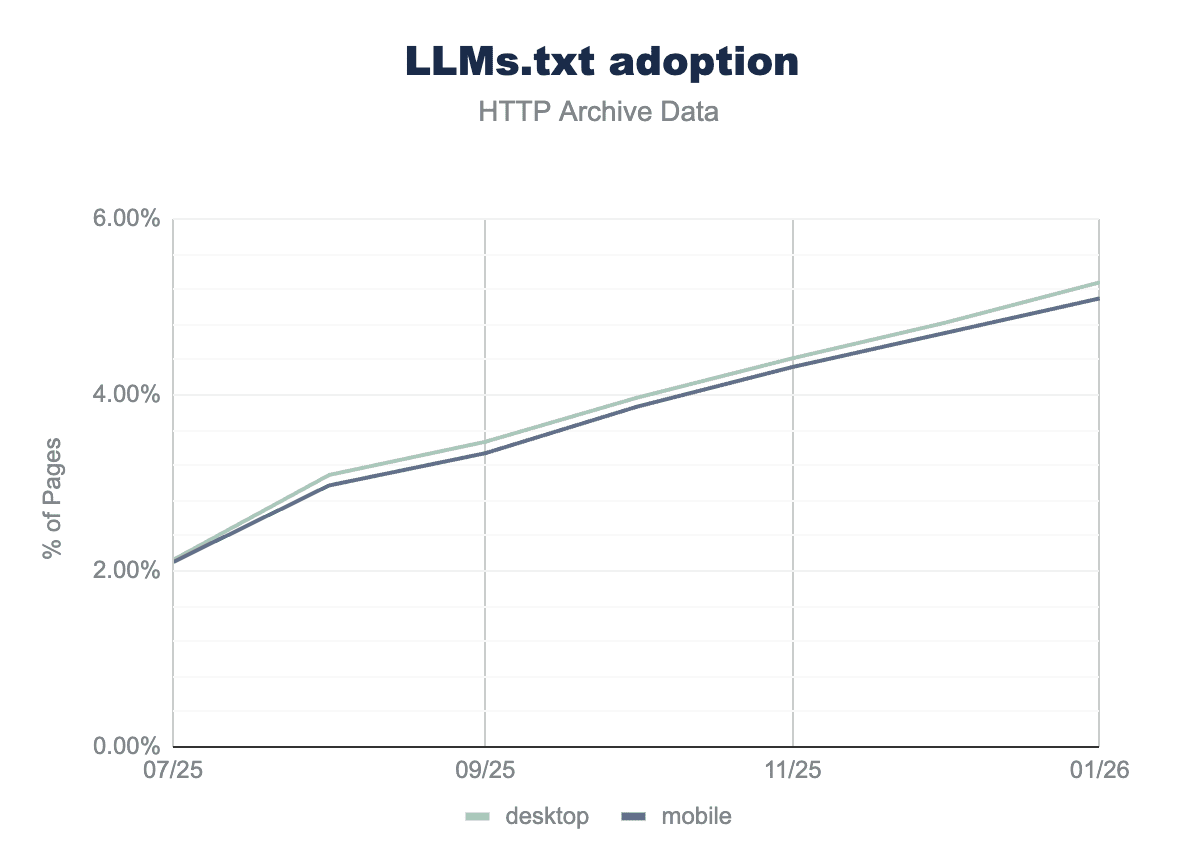
Do XML sitemaps matter for AI search?
Yes, but indirectly. AI-powered search experiences like AI Overviews or Bing Copilot still rely on the traditional search index to discover and retrieve content. That means your pages usually need to be crawled and indexed first before they can appear in AI-generated answers.
This is where XML sitemaps still help. By listing your important URLs in one place, a sitemap makes it easier for search engines to discover and index your content. Keeping the
In short, a sitemap won’t make your content appear in AI answers by itself. But it helps ensure your pages are discoverable, indexed, and up to date, which increases their chances of being used in AI-powered search results.
Adding XML sitemaps to your site with Yoast
Because XML sitemaps play an important role in helping search engines discover and crawl your content, Yoast SEO automatically generates XML sitemaps for your website. This feature is available in both the free and premium versions (Yoast SEO Premium, Yoast WooCommerce SEO, and Yoast SEO AI+) of the plugin.
A smarter analysis in Yoast SEO Premium
Yoast SEO Premium has a smart content analysis that helps you take your content to the next level!
Instead of requiring you to manually create or maintain sitemap files, Yoast SEO handles everything automatically. As you publish, update, or remove content, the plugin updates your sitemap index and the individual sitemaps in real time. This ensures search engines always have an up-to-date overview of the pages you want them to crawl and index.
Yoast SEO also organizes your sitemaps intelligently. Rather than placing every URL in a single file, the plugin creates a sitemap index that groups separate sitemaps for different content types, such as posts, pages, and other public content types, with just one click.
Read more: XML sitemaps in the Yoast SEO plugin
Another important advantage is that Yoast SEO only includes content that should actually appear in search results. Pages set to noindex are automatically excluded from the XML sitemap. This helps keep your sitemap clean and focused on the URLs that matter for SEO.
Controlling what appears in your sitemap
While the plugin automatically manages sitemaps, you still have full control over which content is included.
For example, if you don’t want a specific post or page to appear in search results, you can change the setting “Allow search engines to show this content in search results?” in the Yoast SEO sidebar under the Advanced tab. When this option is set to No, the content will be marked as noindex and automatically excluded from the XML sitemap. When set to Yes, the content remains eligible to appear in search results and is included in the sitemap.
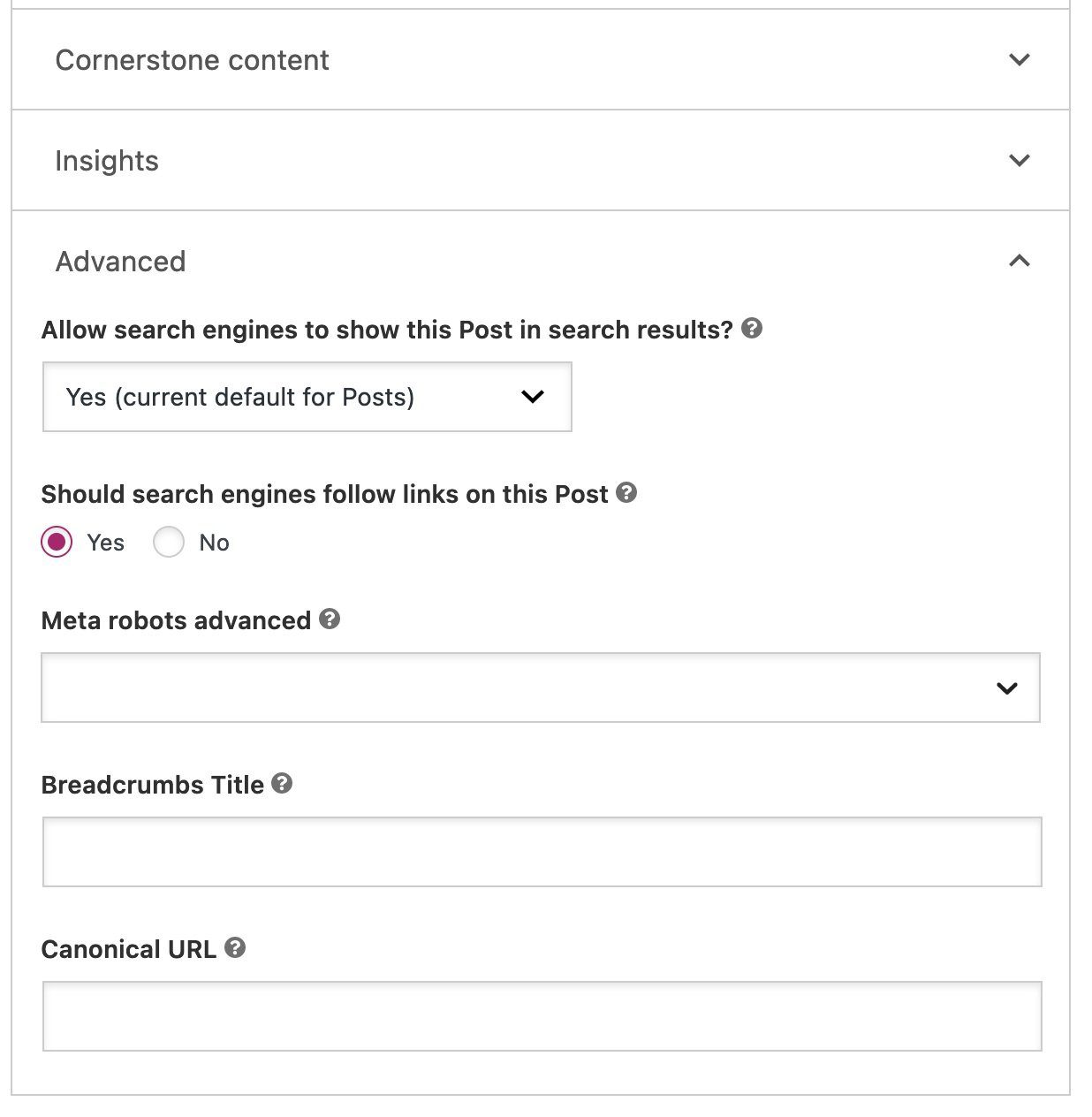
This makes it easy to keep your sitemap focused on the pages you actually want search engines to crawl and index. In some cases, developers can further customize sitemap behavior. For example, filters can be used to limit the number of URLs per sitemap or to programmatically exclude certain content types.
Because all of this happens automatically, most website owners never need to manage sitemap files manually. Yoast SEO keeps your XML sitemap clean, up to date, and optimized for search engines as your site grows.
Read more: How to exclude content from the sitemap
Make Google find your sitemap
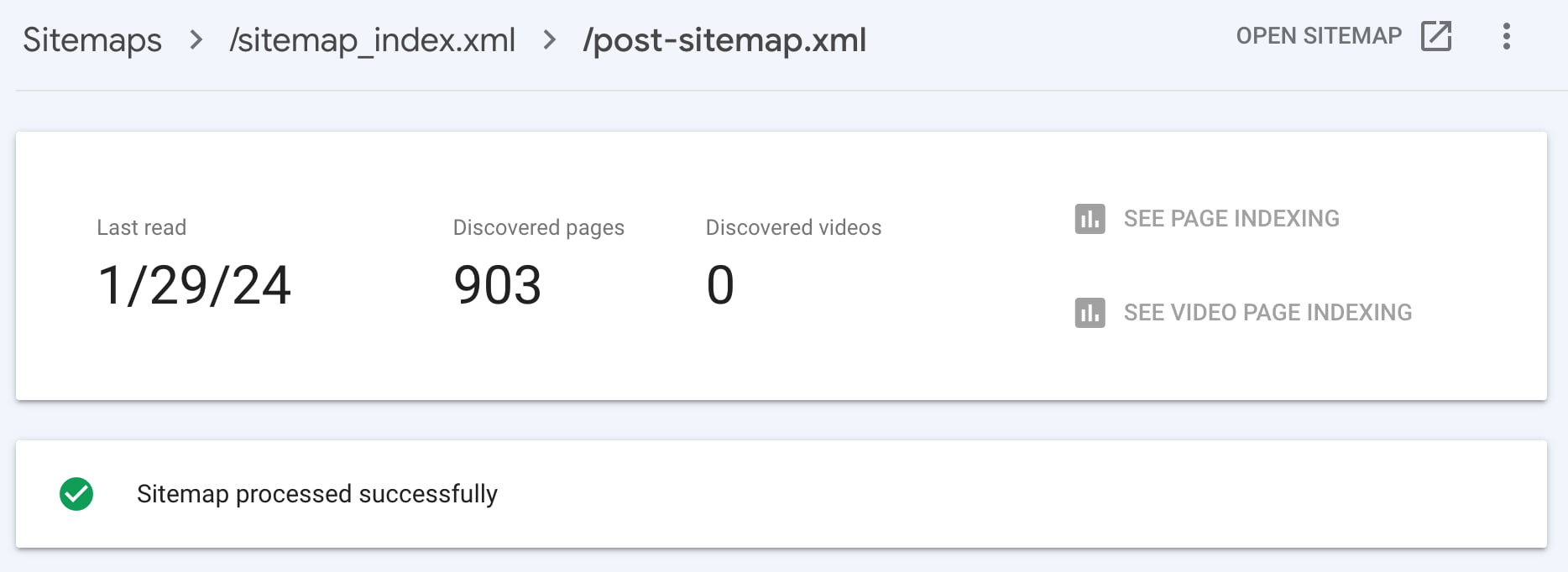
If you want Google to find your XML sitemap quicker, you’ll need to add it to your Google Search Console account. You can find your sitemaps in the ‘Sitemaps’ section. If not, you can add your sitemap at the top of the page.
Adding your sitemap helps check whether Google has indexed all pages in it. We recommend investigating this further if there is a significant difference between the ‘submitted’ and ‘indexed’ counts for a particular sitemap. Maybe there’s an error that prevents some pages from indexing? Another option is to add more links pointing to content that has not yet been indexed.
What websites need an XML sitemap?
Google’s documentation says sitemaps are beneficial for “really large websites,” “websites with large archives,” “new websites with just a few external links to them,” and “websites which use rich media content.” According to Google, proper internal linking should allow it to find all your content easily. Unfortunately, many sites do not properly link their content logically.
While we agree that these websites will benefit the most from having one, at Yoast, we think XML sitemaps benefit every website. As the web grows, it’s getting harder and harder to index sites properly. That’s why you should provide search engines with every available option to have it found. In addition, XML sitemaps make search engine crawling more efficient.
Every website needs Google to find essential pages easily and know when they were last updated. That’s why this feature is included in the Yoast SEO plugin.
Which pages should be in your XML sitemap?
How do you decide which pages to include in your XML sitemap? Always start by thinking of the relevance of a URL: when a visitor lands on a particular URL, is it a good result? Do you want visitors to land on that URL? If not, it probably shouldn’t be in it. However, if you don’t want that URL to appear in the search results, you must add a ‘noindex’ tag. Leaving it out of your sitemap doesn’t mean Google won’t index the URL. If Google can find it by following links, Google can index the URL.
Example: A new blog
For example, you are starting a new blog. Of course, you want to ensure your target audience can find your blog posts in the search results. So, it’s a good idea to immediately include your posts in your XML sitemap. It’s safe to assume that most of your pages will also be relevant results for your visitors. However, a thank you page that people will see after they’ve subscribed to your newsletter is not something you want to appear in the search results. In this case, you don’t want to exclude all pages from your sitemap, only this one.
Let’s stay with the example of the new blog. In addition to your blog posts, you create some categories and tags. These categories and tags will have archive pages that list all posts in that specific category or tag. However, initially, there might not be enough content to fill these archive pages, making them ‘thin content’.
For example, tag archives that show just one post are not that valuable to visitors yet. You can exclude them from the sitemap when starting your blog and include them once you have enough posts. You can even exclude all your tag pages or category pages simultaneously using Yoast SEO.
However, this kind of page could also be excellent ranking material. So, if you think: well, yes, this tag page is a bit ‘thin’ right now, but it could be a great landing page, then enrich it with additional information and images. And don’t exclude it from your sitemap in this case.
Frequently asked questions about XML sitemaps
There are a lot of questions regarding XML sitemaps, so we’ve answered a couple in the FAQ below:
An invalid or improperly read XML sitemap usually indicates a specific error that needs investigation. Check the reported issue to understand what is causing the problem. Make sure the sitemap has been submitted through the search engine’s webmaster tools. When the sitemap is marked as invalid, review the listed errors and apply the appropriate fixes for each one.
In most cases, you can find out if sites have an XML sitemap by adding sitemap.xml to the root domain. So, that would be example.com/sitemap.xml. If a site has Yoast SEO installed, you’ll notice that it’s redirected to example.com/sitemap_index.xml. sitemap_index.xml is the base sitemap that collects all the sitemaps on your site into a single page.
There are ways to create and update your sitemaps by hand, but you shouldn’t. Also, there are static generators that let you generate a sitemap whenever you want. But, again, this process would need to repeat itself every time you add or update content. The best way to do this is by simply using Yoast SEO. Turn on the XML sitemap in Yoast SEO, and all your updates will be applied automatically.
In the past, people believed that adding the
Check your own XML sitemap!
Now you know how important it is to have an XML sitemap: it can help your site’s SEO. If you add the correct URLs, Google can easily access your most important pages and posts. Google will also find updated content easily, so it knows when a URL needs to be crawled again. Lastly, adding your XML sitemap to Google Search Console helps Google find it quickly and lets you check for sitemap errors.
So check your XML sitemap and find out if you’re doing it right!