Bing now supports the data-nosnippet HTML attribute, giving websites more precise control over what appears in search snippets and AI-generated answers.
The attribute lets you exclude specific page sections from Bing Search results and Copilot while keeping the page indexed.
Content marked with data-nosnippet remains eligible to rank but will not surface in previews.
What’s New
data-nosnippet can be applied to any HTML element you want to keep out of previews.
When Bing crawls your site, marked sections are discoverable but are omitted from snippet text and AI summaries.
Bing highlights common use cases:
Keep paywalled or premium content out of previews
Reduce exposure of user comments or reviews in AI answers
Hide legal boilerplate, disclaimers, and cookie notices
Suppress outdated notices and expired promotions
Exclude sponsored blurbs and affiliate disclaimers from neutral previews
Avoid A/B test noise by hiding variant copy during experiments
Emphasize high-value content while keeping sensitive parts behind the click
Implementation is straightforward. Add the attribute to any element:
Subscriber Content
This section will not appear in Bing Search or Copilot answers.
After adding it, you can verify changes in Bing Webmaster Tools with URL inspection. Depending on crawl timing, updates may appear within seconds or take up to a week.
How It Compares To Other Directives
data-nosnippet complements page-level directives.
noindex removes a page from the index
nosnippet blocks all text and preview thumbnails
max-snippet, max-image-preview, and max-video-preview cap preview length or size
Unlike those page-wide controls, data-nosnippet targets specific sections for finer control.
Why This Matters
If you run a subscription site, you can keep subscriber-only passages out of previews without sacrificing indexation.
For pages with user-generated content, you can prevent comments or reviews from appearing in AI summaries while leaving your editorial copy visible.
In short, it lets websites exclude specific sections from search snippets and maintain ranking potential.
Looking Ahead
The attribute is available now. Consider adding it to pages where preview control matters most, then confirm behavior in Bing Webmaster Tools.
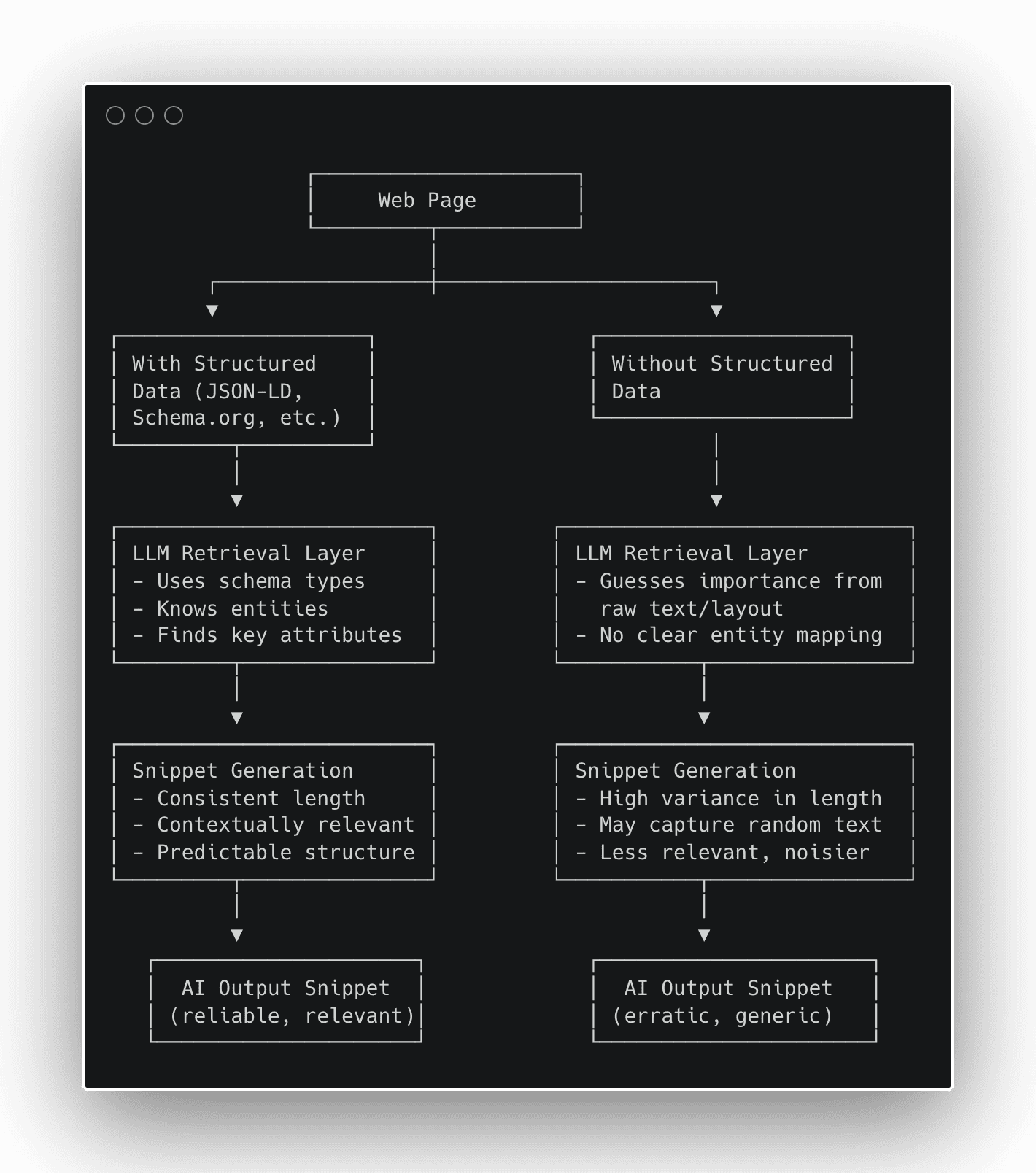
When conversational AIs like ChatGPT, Perplexity, or Google AI Mode generate snippets or answer summaries, they’re not writing from scratch, they’re picking, compressing, and reassembling what webpages offer. If your content isn’t SEO-friendly and indexable, it won’t make it into generative search at all. Search, as we know it, is now a function of artificial intelligence.
But what if your page doesn’t “offer” itself in a machine-readable form? That’s where structured data comes in, not just as an SEO gig, but as a scaffold for AI to reliably pick the “right facts.” There has been some confusion in our community, and in this article, I will:
walk through controlled experiments on 97 webpages showing how structured data improves snippet consistency and contextual relevance,
map those results into our semantic framework.
Many have asked me in recent months if LLMs use structured data, and I’ve been repeating over and over that an LLM doesn’t use structured data as it has no direct access to the world wide web. An LLM uses tools to search the web and fetch webpages. Its tools – in most cases – greatly benefit from indexing structured data.
Image by author, October 2025
In our early results, structured data increases snippet consistency and improves contextual relevance in GPT-5. It also hints at extending the effective wordlim envelope – this is a hidden GPT-5 directive that decides how many words your content gets in a response. Imagine it as a quota on your AI visibility that gets expanded when content is richer and better-typed. You can read more about this concept, which I first outlined on LinkedIn.
Why This Matters Now
Wordlim constraints: AI stacks operate with strict token/character budgets. Ambiguity wastes budget; typed facts conserve it.
Disambiguation & grounding: Schema.org reduces the model’s search space (“this is a Recipe/Product/Article”), making selection safer.
Knowledge graphs (KG): Schema often feeds KGs that AI systems consult when sourcing facts. This is the bridge from web pages to agent reasoning.
My personal thesis is that we want to treat structured data as the instruction layer for AI. It doesn’t “rank for you,” it stabilizes what AI can say about you.
Experiment Design (97 URLs)
While the sample size was small, I wanted to see how ChatGPT’s retrieval layer actually works when used from its own interface, not through the API. To do this, I asked GPT-5 to search and open a batch of URLs from different types of websites and return the raw responses.
You can prompt GPT-5 (or any AI system) to show the verbatim output of its internal tools using a simple meta-prompt. After collecting both the search and fetch responses for each URL, I ran an Agent WordLift workflow [disclaimer, our AI SEO Agent] to analyze every page, checking whether it included structured data and, if so, identifying the specific schema types detected.
These two steps produced a dataset of 97 URLs, annotated with key fields:
has_sd → True/False flag for structured data presence.
schema_classes → the detected type (e.g., Recipe, Product, Article).
search_raw → the “search-style” snippet, representing what the AI search tool showed.
open_raw → a fetcher summary, or structural skim of the page by GPT-5.
Using a “LLM-as-a-Judge” approach powered by Gemini 2.5 Pro, I then analyzed the dataset to extract three main metrics:
Consistency: distribution of search_raw snippet lengths (box plot).
Contextual relevance: keyword and field coverage in open_raw by page type (Recipe, E-comm, Article).
Quality score: a conservative 0–1 index combining keyword presence, basic NER cues (for e-commerce), and schema echoes in the search output.
The Hidden Quota: Unpacking “wordlim”
While running these tests, I noticed another subtle pattern, one that might explain why structured data leads to more consistent and complete snippets. Inside GPT-5’s retrieval pipeline, there’s an internal directive informally known as wordlim: a dynamic quota determining how much text from a single webpage can make it into a generated answer.
At first glance, it acts like a word limit, but it’s adaptive. The richer and better-typed a page’s content, the more room it earns in the model’s synthesis window.
From my ongoing observations:
Unstructured content (e.g., a standard blog post) tends to get about ~200 words.
Structured content (e.g., product markup, feeds) extends to ~500 words.
Dense, authoritative sources (APIs, research papers) can reach 1,000+ words.
This isn’t arbitrary. The limit helps AI systems:
Encourage synthesis across sources rather than copy-pasting.
Avoid copyright issues.
Keep answers concise and readable.
Yet it also introduces a new SEO frontier: your structured data effectively raises your visibility quota. If your data isn’t structured, you’re capped at the minimum; if it is, you grant AI more trust and more space to feature your brand.
While the dataset isn’t yet large enough to be statistically significant across every vertical, the early patterns are already clear – and actionable.
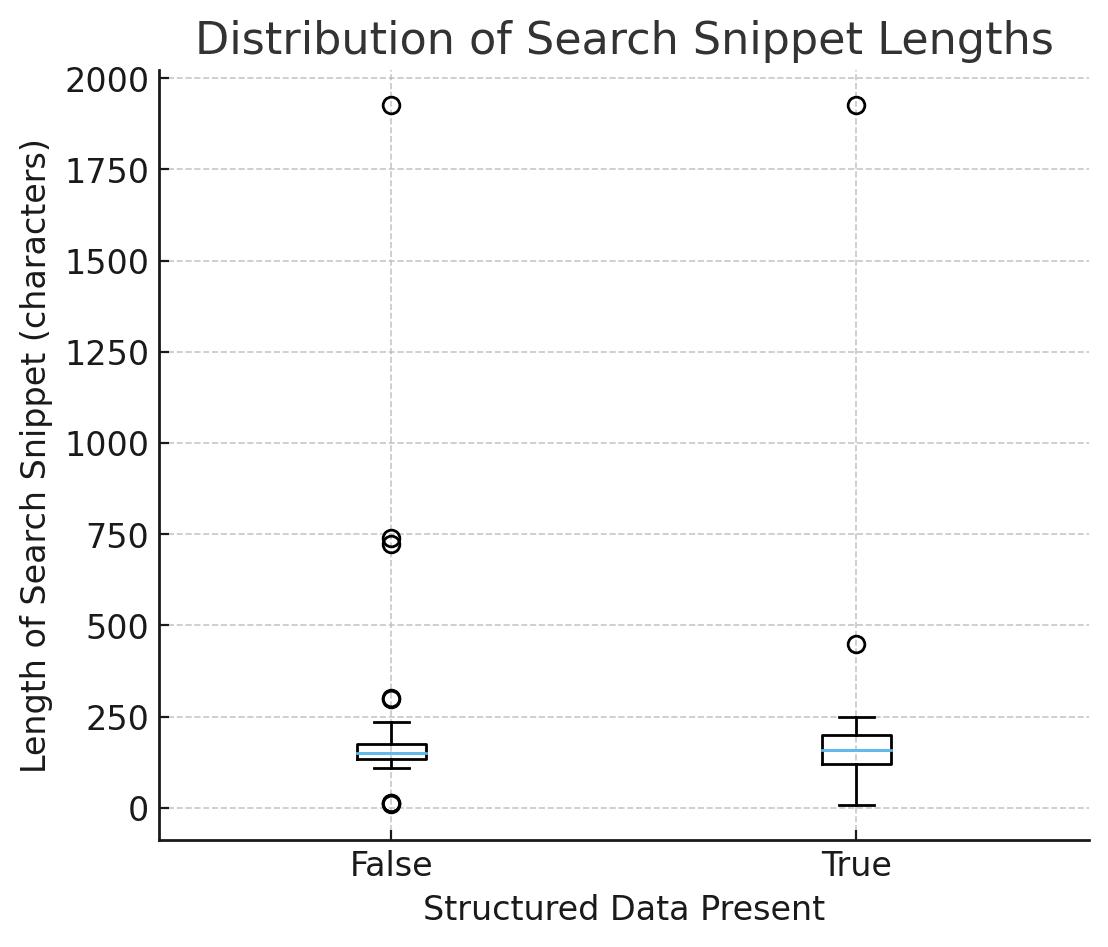
Figure 1 – How Structured Data Affects AI Snippet Generation (Image by author, October 2025)
Results
Figure 2 – Distribution of Search Snippet Lengths (Image by author, October 2025)
1) Consistency: Snippets Are More Predictable With Schema
In the box plot of search snippet lengths (with vs. without structured data):
Medians are similar → schema doesn’t make snippets longer/shorter on average.
Spread (IQR and whiskers) is tighter when has_sd = True → less erratic output, more predictable summaries.
Interpretation: Structured data doesn’t inflate length; it reduces uncertainty. Models default to typed, safe facts instead of guessing from arbitrary HTML.
2) Contextual Relevance: Schema Guides Extraction
Recipes: With Recipe schema, fetch summaries are far likelier to include ingredients and steps. Clear, measurable lift.
Ecommerce: The search tool often echoes JSON‑LD fields (e.g., aggregateRating, offer, brand) evidence that schema is read and surfaced. Fetch summaries skew to exact product names over generic terms like “price,” but the identity anchoring is stronger with schema.
Articles: Small but present gains (author/date/headline more likely to appear).
3) Quality Score (All Pages)
Averaging the 0–1 score across all pages:
No schema → ~0.00
With schema → positive uplift, driven mostly by recipes and some articles.
Even where means look similar, variance collapses with schema. In an AI world constrained by wordlim and retrieval overhead, low variance is a competitive advantage.
Beyond Consistency: Richer Data Extends The Wordlim Envelope (Early Signal)
While the dataset isn’t yet large enough for significance tests, we observed this emerging pattern: Pages with richer, multi‑entity structured data tend to yield slightly longer, denser snippets before truncation.
Hypothesis: Typed, interlinked facts (e.g., Product + Offer + Brand + AggregateRating, or Article + author + datePublished) help models prioritize and compress higher‑value information – effectively extending the usable token budget for that page. Pages without schema more often get prematurely truncated, likely due to uncertainty about relevance.
Next step: We’ll measure the relationship between semantic richness (count of distinct Schema.org entities/attributes) and effective snippet length. If confirmed, structured data not only stabilizes snippets – it increases informational throughput under constant word limits.
Lexical Graph: chunked copy (care instructions, size guides, FAQs) linked back to entities.
Why it works: The entity layer gives AI a safe scaffold; the lexical layer provides reusable, quotable evidence. Together they drive precision under thewordlim constraints.
Here’s how we’re translating these findings into a repeatable SEO playbook for brands working under AI discovery constraints.
Unify entity + lexical Keep specs, FAQs, and policy text chunked and entity‑linked.
Harden snippet surface Facts must be consistent across visible HTML and JSON‑LD; keep critical facts above the fold and stable.
Instrument Track variance, not just averages. Benchmark keyword/field coverage inside machine summaries by template.
Conclusion
Structured data doesn’t change the average size of AI snippets; it changes their certainty. It stabilizes summaries and shapes what they include. In GPT-5, especially under aggressive wordlim conditions, that reliability translates into higher‑quality answers, fewer hallucinations, and greater brand visibility in AI-generated results.
For SEOs and product teams, the takeaway is clear: treat structured data as core infrastructure. If your templates still lack solid HTML semantics, don’t jump straight to JSON-LD: fix the foundations first. Start by cleaning up your markup, then layer structured data on top to build semantic accuracy and long-term discoverability. In AI search, semantics is the new surface area.
For years, technical SEO has been about crawlability, structured data, canonical tags, sitemaps, and speed. All the plumbing that makes pages accessible and indexable. That work still matters. But in the retrieval era, there’s another layer you can’t ignore: vector index hygiene. And while I’d like to claim my usage of vector index hygiene is unique, similar concepts exist in machine learning (ML) circles already. It is unique when applied specifically to our work with content embedding, chunk pollution, and retrieval in SEO/AI pipelines, however.
This isn’t a replacement for crawlability and schema. It’s an addition. If you want visibility in AI-driven answer engines, you now need to understand how your content is dismantled, embedded, and stored in vector indexes and what can go wrong if it isn’t clean.
Traditional Indexing: How Search Engines Break Pages Apart
Google has never stored your page as one giant file. From the beginning, search has dismantled webpages into discrete elements and stored them in separate indexes.
Text is broken into tokens and stored in inverted indexes, which map terms to the documents they appear in. Here, tokenization means traditional IR terms, not LLM sub-word units. This is the backbone of keyword retrieval at scale. (See: Google’s How Search Works overview.)
Images are indexed separately, using filenames, alt text, captions, structured data, and machine-learned visual features. (See: Google Images documentation.)
Video is split into transcripts, thumbnails, and structured data, all stored in a video index. (See: Google’s video indexing docs.)
When you type a query into Google, it queries these indexes in parallel (web, images, video, news) and blends the results into one SERP. This separation exists because handling “an internet’s worth” of text is not the same as handling an internet’s worth of images or video.
For SEOs, the important point is this: you never really ranked “the page.” You ranked the parts of it that were indexed and retrievable.
GenAI Retrieval: From Inverted Indexes To Vector Indexes
AI-driven answer engines like ChatGPT, Gemini, Claude, and Perplexity push this model further. Instead of inverted indexes that map terms to documents, they use vector indexes that store embeddings, essentially mathematical fingerprints of meaning.
Chunks, not pages. Content is split into small blocks. Each block is embedded into a vector. Retrieval happens by finding semantically similar vectors in response to a query. (See: Google Vertex AI Vector Search overview.)
Paraphrased answers replace ranked lists. Instead of showing a SERP, the model paraphrases retrieved chunks into a single answer.
Sometimes, these systems still lean on traditional search as a backstop. Recent reporting showed ChatGPT quietly pulling Google results through SerpApi when it lacked confidence in its own retrieval. (See: Report)
For SEOs, the shift is stark. Retrieval replaces ranking. If your blocks aren’t retrieved, you’re invisible.
What Vector Index Hygiene Means
Vector index hygiene is the discipline of preparing, structuring, embedding, and maintaining content so it remains clean, deduplicated, and easy to retrieve in vector space. Think of it as canonicalization for the retrieval era.
Without hygiene, your content pollutes indexes:
Bloated blocks: If a chunk spans multiple topics, the resulting embedding is muddy and weak.
Boilerplate duplication: Repeated intros or promos create identical vectors that may drown out unique content.
Noise leakage: Sidebars, CTAs, or footers can get chunked and embedded, then retrieved as if they were main content.
Mismatched content types: FAQs, glossaries, blogs, and specs each need different chunk strategies. Treat them the same and you lose precision.
Stale embeddings: Models evolve. If you never re-embed after upgrades, your index contains inconsistencies.
For SEOs, this means hygiene work is no longer optional. It decides whether your content gets surfaced at all.
SEOs can begin treating hygiene the way we once treated crawlability audits. The steps are tactical and measurable.
1. Prep Before Embedding
Strip navigation, boilerplate, CTAs, cookie banners, and repeated blocks. Normalize headings, lists, and code so each block is clean. (Do I need to explain that you still need to keep things human-friendly, too?)
2. Chunking Discipline
Break content into coherent, self-contained units. Right-size chunks by content type. FAQs can be short, guides need more context. Overlap chunks sparingly to avoid duplication.
3. Deduplication
Vary intros and summaries across articles. Don’t let identical blocks generate nearly identical embeddings.
4. Metadata Tagging
Attach content type, language, date, and source URL to every block. Use metadata filters during retrieval to exclude noise. (See: Pinecone research on metadata filtering.)
5. Versioning And Refresh
Track embedding model versions. Re-embed after upgrades. Refresh indexes on a cadence aligned to content changes. (See: Milvus versioning guidance.)
A Note On Cookie Banners (Illustration Of Pollution In Theory)
Cookie consent banners are legally required across much of the web. You’ve seen the text: “We use cookies to improve your experience.” It’s boilerplate, and it repeats across every page of a site.
In large systems like ChatGPT or Gemini, you don’t see this text popping up in answers. That’s almost certainly because they filter it out before embedding. A simple rule like “if text contains ‘we use cookies,’ don’t vectorize it” is enough to prevent most of that noise.
But despite this, cookie banners a still a useful illustration of theory meeting practice. If you’re:
Building your own RAG stack, or
Using third-party SEO tools where you don’t control the preprocessing,
Then cookie banners (or any repeated boilerplate) can slip into embeddings and pollute your index. The result is duplicate, low-value vectors spread across your content, which weakens retrieval. This, in turn, messes with the data you’re collecting, and potentially the decisions you’re about to make from that data.
The banner itself isn’t the problem. It’s a stand-in for how any repeated, non-semantic text can degrade your retrieval if you don’t filter it. Cookie banners just make the concept visible. And if the systems ignore your cookie banner content, etc., is the volume of that content needing to be ignored simply teaching the system that your overall utility is lower than a competitor without similar patterns? Is there enough of that content that the system gets “lost in the middle” trying to reach your useful content?
Old Technical SEO Still Matters
Vector index hygiene doesn’t erase crawlability or schema. It sits beside them.
Canonicalization prevents duplicate URLs from wasting crawl budget. Hygiene prevents duplicate vectors from wasting retrieval opportunities. (See: Google’s canonicalization troubleshooting.)
Structured datastill helps models interpret your content correctly.
Sitemaps still improve discovery.
Page speed still influences rankings where rankings exist.
Think of hygiene as a new pillar, not a replacement. Traditional technical SEO makes content findable. Hygiene makes it retrievable in AI-driven systems.
You don’t need to boil the ocean. Start with one content type and expand.
Audit your FAQs for duplication and block size (chunk size).
Strip noise and re-chunk.
Track retrieval frequency and attribution in AI outputs.
Expand to more content types.
Build a hygiene checklist into your publishing workflow.
Over time, hygiene becomes as routine as schema markup or canonical tags.
Your content is already being chunked, embedded, and retrieved, whether you’ve thought about it or not.
The only question is whether those embeddings are clean and useful, or polluted and ignored.
Vector index hygiene is not THE new technical SEO. But it is A new layer of technical SEO. If crawlability was part of the technical SEO of 2010, hygiene is part of the technical SEO of 2025.
SEOs who treat it that way will still be visible when answer engines, not SERPs, decide what gets seen.
Traditional search engines use bots to crawl webpages and rank them.
LLMs synthesize patterns from massive pre-ingested datasets. LLMs and answer engines don’t index; they use them as their conversational padding.
What Is A Pre-Ingested Data Set?
Pre-ingested datasets are content that is pulled from websites, reviews, directories, forums, and even brand-owned assets.
This means your visibility no longer depends only on keywords
What Do I Need To Do To Show Up In AI Overviews & SERPs?
To increase your visibility in LLMs, your content must be:
Put simply: GEO ensures your brand shows up in the answers themselves as well as in the links beneath them.
How To Optimize For LLMs In GEO
Optimizing for LLMs is about aligning with how these systems select and reuse content.
From our analysis, three core principles stand out in consistently GEO-friendly content:
1. Provide Structure & Clarity
Generative models prioritize content that is well-organized and easy to parse. Clear headings, bullet points, tables, summaries… help engines extract information and recompose it into human-like answers.
2. Include Trust & Reliability Signals
LLMs reward factual accuracy, consistency, and transparency. Contradictions between your site, profiles, and third-party sources weaken credibility. Conversely, quoting sources, citing data, and showcasing expertise increase your chances of being cited!
3. Contextual & Semantic Depth Are Key
Engines rely less on keywords and more on contextual signals (as it has been more and more the case with Google these last years–hello BERT, haven’t heard from you in a while!). Content enriched with synonyms, related terms, and variations is more flexible and better aligned with diverse queries, which is especially important as AI queries are conversational, not just transactional.
3 Tips For Creating GEO-Friendly Content
In the GEO guide we’re sharing with you in this article, 15 tips are delivered–here are 3 of the most important ones:
Cover not just the main query but related terms, variations, and natural follow-ups.
For example, if writing about “content ROI,” anticipate adjacent questions like “How do you measure ROI in SEO?” or “What KPIs prove content ROI?”!
By aligning with user intent, not just keywords, you increase the likelihood of your content being surfaced as the “best available answer” for the LLMs.
And many more opportunities to prove your credibility and authority.
Think of it as content that doesn’t just “read well,” but feels safe to reuse by the LLMs.
3. Optimize format for machine & human readability
Beyond clarity, formats like FAQs, how-tos, comparisons, and lists make your content both user-friendly and machine-friendly. Many SEO techniques are just as powerful and efficient in GEO:
Add alt text for visuals.
Include summaries and key takeaways in long-form content.
Use structured data and schema where relevant.
This dual optimization increases both discoverability and reusability in AI-generated answers.
The risk of ignoring GEO is not just lower traffic—it’s invisibility in the answer layer where trust and decisions are increasingly formed.
By contrast, marketers who embrace GEO can:
Defend brand presence where AI engines consolidate attention.
Create future-forward SEO strategies as search continues to evolve.
Maximize ROI by aligning content with both human expectations and machine logic.
In other words, GEO is not a trend: it’s a structural shift in digital visibility, where SEO remains essential but is no longer sufficient. GEO adds the missing layer: being cited, trusted, and reused by the engines that increasingly mediate how users access information.
GEO As A New Competitive Advantage
The age of GEO is here. For marketing and SEO leaders, the opportunity is to adapt faster than competitors—aligning content with the standards of generative search while continuing to refine SEO.
To win visibility in this environment, prioritize:
Auditing your current content for GEO readiness.
Enhancing clarity, trust signals, and semantic richness.
Monitoring your presence in AI Overviews, ChatGPT, and other generative engines.
Those who invest in GEO today will shape how tomorrow’s answers are written.
This post was sponsored by Cloudways. The opinions expressed in this article are the sponsor’s own.
Wondering why your rankings may be declining?
Just discovered your WooCommerce site has slow load times?
A slow WooCommerce site doesn’t just cost you conversions. It affects search visibility, backend performance, and customer trust.
Whether you’re a developer running your own stack or an agency managing dozens of client stores, understanding how WooCommerce performance scales under load is now considered table stakes.
Today, many WordPress sites are far more dynamic, meaning many things are happening at the same time:
Every action a user takes, from logging in, updating a cart, or initiating checkout, relies on live data from the server. These requests cannot be cached.
Tools like Varnish or CDNs can help with public pages such as the homepage or product listings. But once someone logs in to their account or interacts with their session, caching no longer helps. Each request must be processed in real time.
This article breaks down why that happens and what kind of server setup is helping stores stay fast, stable, and ready to grow.
Why Do WooCommerce Stores Slow Down?
WooCommerce often performs well on the surface. But as traffic grows and users start interacting with the site, speed issues begin to show. These are the most common reasons why stores slow down under pressure:
1. PHP: It Struggles With High User Activity
WooCommerce depends on PHP to process dynamic actions such as cart updates, coupon logic, and checkout steps. Traditional stacks using Apache for PHP handling are slower and less efficient.
Order creation, cart activity, and user actions generate a high number of database writes. During busy times like flash sales, new merchandise arrivals, or course launches, the database struggles to keep up.
Platforms that support optimized query execution and better indexing handle these spikes more smoothly.
3. Caching Issues: Object Caching Is Missing Or Poorly Configured
Without proper object caching, WooCommerce queries the database repeatedly for the same information. That includes product data, imagery, cart contents, and user sessions.
Solutions that include built-in Redis support help move this data to memory, reducing server load and improving site speed.
4. Concurrency Limits Affect Performance During Spikes
Most hosting stacks today, including Apache-based ones, perform well for a wide range of WordPress and WooCommerce sites. They handle typical traffic reliably and have powered many successful stores.
As traffic increases and more users log in and interact with the site at the same time, the load on the server begins to grow. Architecture starts to play a bigger role at that point.
Stacks built on NGINX with event-driven processing can manage higher concurrency more efficiently, especially during unanticipated traffic spikes.
Rather than replacing what already works, this approach extends the performance ceiling for stores that are becoming more dynamic and need consistent responsiveness under heavier load.
5. Your WordPress Admin Slows Down During Sales Seasons
During busy periods like seasonal sales campaigns or new stock availability, stores can often slow down for the team managing the site, too. The WordPress dashboard takes longer to load, which means publishing products, managing orders, or editing pages also becomes slower.
This slowdown happens because both shoppers and staff are using the site’s resources at the same time, and the server has to handle all those requests at once.
How To Architect A Scalable WordPress Setup For Dynamic Workloads?
WooCommerce stores today are built for more than stable traffic. Customers are logging in, updating their carts, taking actions to manage their subscription profile, and as a result, are interacting with your backend in real time.
The traditional WordPress setup, which is primarily designed for static content, cannot handle that kind of demand.
Here’s how a typical setup compares to one built for performance and scale:
Component
Basic Setup
Scalable Setup
Web Server
Apache
NGINX
PHP Handler
mod_php or CGI
PHP-FPM
Object Caching
None or database transients
Redis with Object Cache Pro
Scheduled Tasks
WP-Cron
System cron job
Caching
CDN or full-page caching only
Layered caching, including object cache
.htaccess Handling
Built-in with Apache
Manual rewrite rules in NGINX config
Concurrency Handling
Limited
Event-based, memory-efficient server
How To Manually Setup A Performance-Ready & Scalable WooCommerce Stack
If you’re setting up your own server or tuning an existing one, are the most important components to get right:
1) Use NGINX For Static File Performance
NGINX is often used as a high-performance web server for handling static files and managing concurrent requests efficiently. It is well suited for stores expecting high traffic or looking to fine-tune their infrastructure for speed.
Unlike Apache, NGINX does not use .htaccess files. Rewrite rules, such as permalinks, redirects, and trailing slashes, need to be added manually to the server block. For WordPress, these rules are well-documented and only need to be set once during setup.
This approach gives more control at the server level and can be helpful for teams building out their own environment or optimizing for scale.
2) Enable PHP-FPM For Faster Request Handling
PHP-FPM separates PHP processing from the web server. It gives you more control over memory and CPU usage. Tune values like pm.max_children and pm.max_requests based on your server size to prevent overload during high activity.
3) Install Redis With Object Cache Pro
Redis allows WooCommerce to store frequently used data in memory. This includes cart contents, user sessions, and product metadata.
Pair this with Object Cache Pro to compress cache objects, reduce database load, and improve site responsiveness under load.
4) Replace WP-Cron With A System-Level Cron Job
By default, WordPress checks for scheduled tasks whenever someone visits your site. That includes sending emails, clearing inventory, and syncing data. If you have steady traffic, it works. If not, things get delayed.
You can avoid that by turning off WP-Cron. Just add define(‘DISABLE_WP_CRON’, true); to your wp-config.php file. Then, set up a real cron job at the server level to run wp-cron.php every minute. This keeps those tasks running on time without depending on visitors.
5) Add Rewrite Rules Manually For NGINX
NGINX doesn’t use .htaccess. That means you’ll need to define URL rules directly in the server block.
This includes things like permalinks, redirects, and static file handling. It’s a one-time setup, and most of the rules you need are already available from trusted WordPress documentation. Once you add them, everything works just like it would on Apache.
A Few Tradeoffs To Keep In Mind
This kind of setup brings a real speed boost. But there are some technical changes to keep in mind.
NGINX won’t read .htaccess. All rewrites and redirects need to be added manually.
WordPress Multisite may need extra tweaks, especially if you’re using subdirectory mode.
Security settings like IP bans or rate limits should be handled at the server level, not through plugins.
Most developers won’t find these issues difficult to work with. But if you’re using a modern platform, much of it is already taken care of.
You don’t need overly complex infrastructure to make WooCommerce fast; just a stack that aligns with how modern, dynamic stores operate today.
Next, we’ll look at how that kind of stack performs under traffic, with benchmarks that show what actually changes when the server is built for dynamic sites.
What Happens When You Switch To An Optimized Stack?
Not all performance challenges come from code or plugins. As stores grow and user interactions increase, the type of workload becomes more important, especially when handling live sessions from logged-in users.
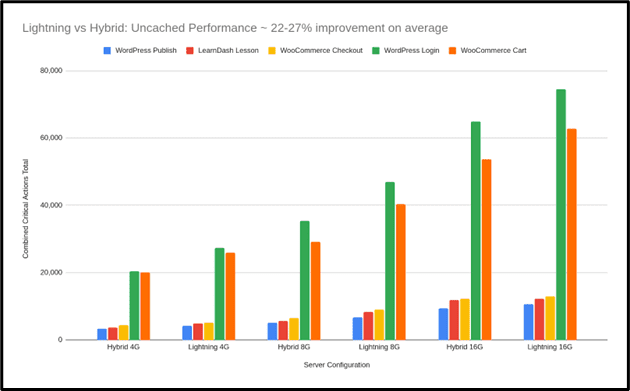
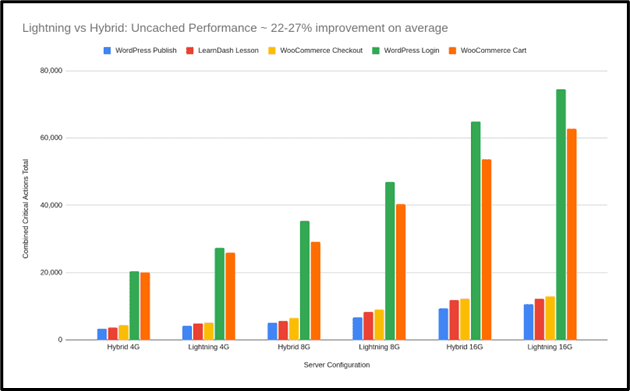
To better understand how different environments respond to this kind of activity, Koddr.io ran an independent benchmark comparing two common production setups:
A hybrid stack using Apache and NGINX.
A stack built on NGINX with PHP-FPM, Redis, and object caching.
Both setups were fully optimized and included tuned components like PHP-FPM and Redis. The purpose of the benchmark was to observe how each performs under specific, real-world conditions.
The tests focused on uncached activity from WooCommerce and LearnDash, where logged-in users trigger dynamic server responses.
In these scenarios, the optimized stack showed higher throughput and consistency during peak loads. This highlights the value of having infrastructure tailored for dynamic, high-concurrency traffic, depending on the use case.
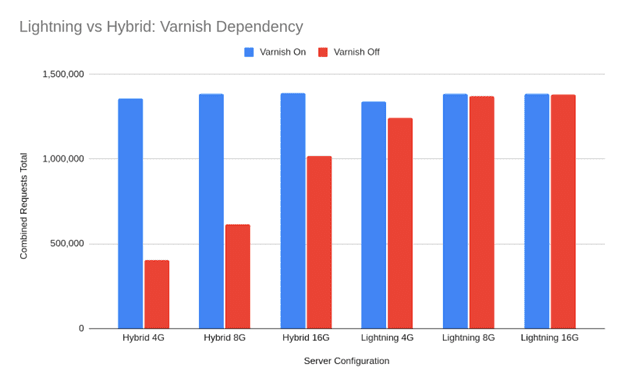
WooCommerce Runs Faster Under Load
One test simulated 80 users checking out at the same time. The difference was clear:
Scenario
Hybrid Stack
Optimized Stack
Gain
WooCommerce Checkout
3,035 actions
4,809 actions
+58%
Screenshot from Koddr.io, August 2025
LMS Platforms Benefit Even More
For LearnDash course browsing—a write-heavy and uncached task, the optimized stack completed 85% more requests:
Scenario
Hybrid Stack
Optimized Stack
Gain
LearnDash Course List View
13,459 actions
25,031 actions
+85%
This shows how optimized stacks handle personalized or dynamic content more efficiently. These types of requests can’t be cached, so the server’s raw efficiency becomes critical.
Screenshot from Koddr.io, August 2025
Backend Speed Improves, Too
The optimized stack wasn’t just faster for customers. It also made the WordPress admin area more responsive:
WordPress login times improved by up to 31%.
Publish actions ran 20% faster, even with high traffic.
This means your team can concurrently manage products, update pages, and respond to sales in real time, without delays or timeouts.
It Handles More Without Relying On Caching
When Koddr turned off Varnish, the hybrid stack experienced a 71% drop in performance. This shows how effectively it handles cached traffic. The optimized stack dropped just 7%, which highlights its ability to maintain speed even during uncached, logged-in sessions.
Both setups have their strengths, but for stores with real-time user activity, reducing reliance on caching can make a measurable difference.
Stack Type
With Caching
Without Caching
Drop
Hybrid Stack
654,000 actions
184,000 actions
-7%
Optimized Stack
619,000 actions
572,000 actions
-7%
Screenshot from Koddr.io, August 2025
Why This Matters?
Static pages are easy to optimize. But WooCommerce stores deal with real-time traffic. Cart updates, login sessions, and checkouts all require live processing. Caching cannot help once a user has signed in.
The Koddr.io results show how an optimized server stack:
Helps scale without complex performance workarounds.
These are the kinds of changes that power newer stacks purpose-built for dynamic workloads like Cloudways Lightning, built for real WooCommerce workloads.
Core Web Vitals Aren’t Just About The Frontend
You can optimize every image. Minify every line of code. Switch to a faster theme. But your Core Web Vitals score will still suffer if the server can’t respond quickly.
That’s what happens when logged-in users interact with WooCommerce or LMS sites.
When a customer hits “Add to Cart,” caching is out of the picture. The server has to process the request live. That’s where TTFB (Time to First Byte) becomes a real problem.
Slow server response means Google waits longer to start rendering the page. And that delay directly affects your Largest Contentful Paint and Interaction to Next Paint metrics.
Frontend tuning gets you part of the way. But if the backend is slow, your scores won’t improve. Especially for logged-in experiences.
Real optimization starts at the server.
How Agencies Are Skipping The Manual Work
Every developer has a checklist for WooCommerce performance. Use NGINX. Set up Redis. Replace WP-Cron. Add a WAF. Test under load. Keep tuning.
But not every team has the bandwidth to maintain all of it.
That’s why more agencies are using pre-optimized stacks that include these upgrades by default. Cloudways Lightning, a managed stack based on NGINX + PHP-FPM, designed for dynamic workloads is a good example of that.
It’s not just about speed. It’s also about backend stability during high traffic. Admin logins stay fast. Product updates don’t hang. Orders keep flowing.
Joe Lackner, founder of Celsius LLC, shared what changed for them:
“Moving our WordPress workloads to the new Cloudways stack has been a game-changer. The console admin experience is snappier, page load times have improved by +20%, and once again Cloudways has proven to be way ahead of the game in terms of reliability and cost-to-performance value at this price point.”
This is what agencies are looking for. A way to scale without getting dragged into infrastructure management every time traffic picks up.
Final Takeaway
WooCommerce performance is no longer just about homepage load speed.
Your site handles real-time activity from both customers and your team. Once a user logs in or reaches checkout, caching no longer applies. Each action hits the server directly.
If the infrastructure isn’t optimized, site speed drops, sales suffer, and backend work slows down.
The foundations matter. A stack that’s built for high concurrency and uncached traffic keeps things fast across the board. That includes cart updates, admin changes, and product publishing.
For teams who don’t want to manage server tuning manually, options like Cloudways Lightning deliver a faster, simpler path to performance at scale.
Use promo code “SUMMER305” and get 30% off for 5 months + 15 free migrations. Signup Now!
In a recent episode of Google’s Search Off the Record podcast, Martin Splitt and John Mueller discussed when lazy loading helps and when it can slow pages.
Splitt used a real-world example on developers.google.com to illustrate a common pattern: making every image lazy by default can delay Largest Contentful Paint (LCP) if it includes above-the-fold visuals.
Splitt said:
“The content management system that we are using for developers.google.com … defaults all images to lazy loading, which is not great.”
Splitt used the example to explain why lazy-loading hero images is risky: you tell the browser to wait on the most visible element, which can push back LCP and cause layout shifts if dimensions aren’t set.
Splitt said:
“If you are using lazy loading on an image that is immediately visible, that is most likely going to have an impact on your largest contentful paint. It’s like almost guaranteed.”
How Lazy Loading Delays LCP
LCP measures the moment the largest text or image in the initial viewport is painted.
Normally, the browser’s preload scanner finds that hero image early and fetches it with high priority so it can paint fast.
When you add loading="lazy" to that same hero, you change the browser’s scheduling:
The image is treated as lower priority, so other resources start first.
The browser waits until layout and other work progress before it requests the hero image.
The hero then competes for bandwidth after scripts, styles, and other assets have already queued.
That delay shifts the paint time of the largest element later, which increases your LCP.
On slow networks or CPU-limited devices, the effect is more noticeable. If width and height are missing, the late image can also nudge layout and feel “jarring.”
SEO Risk With Some Libraries
Browsers now support a built-in loading attribute for images and iframes, which removes the need for heavy JavaScript in standard scenarios. WordPress adopted native lazy loading by default, helping it spread.
Splitt said:
“Browsers got a native attribute for images and iframes, the loading attribute … which makes the browser take care of the lazy loading for you.”
Older or custom lazy-loading libraries can hide image URLs in nonstandard attributes. If the real URL never lands in src or srcset in the HTML Google renders, images may not get picked up for indexing.
Splitt said:
“We’ve seen multiple lazy loading libraries … that use some sort of data-source attribute rather than the source attribute… If it’s not in the source attribute, we won’t pick it up if it’s in some custom attribute.”
How To Check Your Pages
Use Search Console’s URL Inspection to review the rendered HTML and confirm that above-the-fold images and lazy-loaded modules resolve to standard attributes. Avoid relying on the screenshot.
Splitt advised:
“If the rendered HTML looks like it contains all the image URLs in the source attribute of an image tag … then you will be fine.”
Ranking Impact
Splitt framed ranking effects as modest. Core Web Vitals contribute to ranking, but he called it “a tiny minute factor in most cases.”
What You Should Do Next
Keep hero and other above-the-fold images eager with width and height set.
Use native loading="lazy" for below-the-fold images and iframes.
If you rely on a library for previews, videos, or dynamic sections, make sure the final markup exposes real URLs in standard attributes, and confirm in rendered HTML.
Looking Ahead
Lazy loading is useful when applied selectively. Treat it as an opt-in for noncritical content.
Verify your implementation with rendered HTML, and watch how your LCP trends over time.
Featured Image: Screenshot from YouTube.com/GoogleSearchCentral, August 2025.
How to make your content visible in the age of AI search
So, what exactly is LLM Optimization? Well, the answer to that question depends on who you ask. For example, if you ask a machine learning engineer, they’ll tell you it’s all about tweaking prompts and token limits to get better performance from a large language model. In fact, Iguazio actually defines LLM optimization as improving the way models respond, which means smarter, faster, and with more contextual recognition.
If, on the other hand, you are a content strategist or SEO enthusiast, LLM optimization will mean something completely different to you and that is making sure that your content shows up in AI-generated search results. And, that needs to be true no matter whether you’re talking to ChatGPT, searching with Perplexity, or scanning Google’s new AI Mode for answers. Some call this ChatGPT SEO or Generative Engine Optimization.
So, if you fall into the latter of those two groups, ie: the people who want their content and product pages to be seen and clicked, then this article is for you. And, if you’d like to read on, we’ll show you why LLM optimization in an AI-search landscape isn’t some sort of luxury option; it’s an absolute necessity.
What are LLMs and why should you care?
AI engineers train Large Language models on huge amounts of text and data to generate answers, summaries, code, and human-like language. They’ve read everything (not just the Classics) and that includes blogs, news articles and your website.
The reason that’s important is that LLMs don’t crawl your website in real time like Search Engines do. What they do is read it, learn from it and when someone asks them a question, they try to recall what they saw and rephrase it into an answer. If your site shows up as the answer, “Great” but if not, you’ve got a visibility problem.
The new way of searching
Search is not just about Google anymore. Also, it’s not as if just one other thing has come to dominate which means we’re left with a rather messy mix of Perplexity answers, Chat GPT chats, Gemini summaries and voice assistants reading out answers while we try to do two tasks at once.
In short, people aren’t just searching, they’re conversing and if your content can’t hold its own in this environment then you’re missing out on visibility, traffic, and the ability to build trust. We’ll walk you through exactly how to fix that.
SEO vs. GEO vs. AEO vs. LLMO: Are we just rebranding SEO?
If you’ve been wondering whether you now need four different strategies for SEO (Search Engine Optimization), GEO (Generative Engine Optimization), AEO (Answer Engine Optimization), and LLMO (Large Language Model Optimization), relax, it’s not as big a deal as you might think. You see, despite all the buzzwords, the core of optimization hasn’t changed much.
All four terms point to the same central goal: making your content more findable, quotable, and credible in machine-generated output regardless of whether that comes from Google’s AI Overviews, ChatGPT, or an answer box on Bing.
So, should you overhaul your entire content strategy to ‘do LLMO’?
Not really. At least, not yet.
Most of what boosts your presence in LLMs is already what SEO professionals have been doing for years. Structured content, semantic clarity, topical authority, entity association, clean internal linking, it’s all classic SEO.
Where they slightly diverge:
SEO (Search Engine Optimization)
Relies on backlinks and site architecture to establish authority
GEO (Generative Engine Optimization
Puts extra emphasis on unlinked brand mentions and semantic association
AEO (Answer Engine Optimization)
Focuses on being the single best, most concise, and sourceable response to a specific query
LLMO (Large Language Model Optimization)
Leans into optimizing content not just for people or search crawlers but for LLMs reading in chunks, skipping JavaScript, and relying on embeddings and grounding datasets
But the thing is: you don’t need four different playbooks. All you need is one solid SEO foundation. In fact, this point is backed up by Google’s Gary Illyes who confirmed that AI Search does not require specialized optimization, saying that “AI SEO” is not necessary and that standard SEO is all that is needed for both AI Overviews and AI Mode.
Focus more on entity mentions, not just links
Treat your core site pages (home, pricing, about) and PDFs as important LLM fuel.
Remember that AI crawlers don’t render JavaScript, so client-side content might be invisible
Think about how LLMs process structure (chunking, context, citations), not just how humans skim it
So, if you’ve already been investing in foundational SEO, you’re already doing most of what GEO, AEO, and LLMO ae all about. That’s why not every new acronym needs you to have a whole rethink on your efforts. Sometimes, it’s just like SEO.
Key LLM SEO optimization techniques
Now that we know LLMs aren’t crawling our site but are understanding it, we need to think a little differently about how we create and construct content and for more on this, you may find this article extremely insightful. This is not about cramming in keywords or trying to play the algorithm, it’s about clarity, structure and credibility because these are the things LLMs care about when deciding what to quote, summarize or ignore. Below are some techniques that will help your content stay visible now that people are using generative search.
The bar has been raised on the quality of content
LLMs love clarity. The more natural and specific your language is, the easier it is for them to understand and reuse your content. That means not using jargon, avoiding ambiguity and instead, focusing on writing like you’re explaining something to a colleague.
To give an exact example:
Don’t Say:
“Our innovative tool revolutionizes the digital landscape for modern businesses.”
Instead Say:
“The Yoast SEO plugin for WordPress helps businesses to improve their website’s visibility and appear inn search results
Use Structure, Chunked Formatting
Chunked formatting means breaking your content into small pieces (chunks) of informatin that are easy to understand and remember. LLMs tend to prioritize the most easily digestible content construction – which means your headings, bullet points, and clearly defined sections must do a lot of heavy lifting. Not only does organizing your content like this help people to skim read, but it also helps machines understand what each section is about.
Structuring your content like this will help:
Write clear, descriptive H2s and 3s
Use bullet points that can provide standalone value
Include summaries and tables to give quick overviews
Be Factual, Transparent, and Authoritative
Just like Google, LLMs need to trust that your content is reliable before they start taking you seriously. This means you need to show your working out, quote sources, reveal authors, and follow the principles of E-E-A-T. Experience, Expertise, Authority, and Trust.
Include an author bio and credentials if possible (include a link to actual author bios and social profiles)
Name your sources when you use claims or statistics
Share real experiences if possible “As a small business owner…”
The more real, relatable and trustworthy your content looks, the more AI will like it.
Optimize for Summarization
LLMs won’t quote your entire blog post; they’ll only use snippets. Your job is to make those snippets irresistible. Start with strong lead sentences so that each paragraph begins with a clear point followed by context. Also, it’s a good idea to front-load your content. Don’t save your best bits for the end.
As a reminder:
Start each section with what you want the key takeaway to be
Keep paragraphs short and self-contained
Create standalone summary paragraphs as these often get quoted in AI generated answers
Use Schema
Behind every great summary is a structured content model. That’s where Schema markup comes in and to help the AI understand your content, you need to speak in a certain way.
Once you’ve got the basics completed, like clear writing, structure and trust signals, there’s still more you can do to give your content the best shot at visibility. These bonus strategies focus on how to make your site even more AI-friendly by anticipating how LLMs interpret and reuse information.
Use Explicit Context and Clear language
Humans have an incredible ability to be able to ‘fill in the blanks’ and still ‘get the message’ even if the information they got was vague or unclear. One of the biggest differences between humans and LLMs? Humans can infer meaning from vague references. LLMs on the other hand… well, let’s just say that it doesn’t come naturally to them.
In any case, the point is that if your article mentions “this tool” or “our product” without any context, an LLM might miss the connection entirely. The result? You’re left out of the answer, even if you’re the best source.
So, to give your content the clarity it deserves:
Use the full product or brand name, like “Yoast SEO plugin for WordPress,” not just “Yoast”
Define technical or niche terms before using them
Avoid vague language (“this page,” “the above section,” “click here”)
You don’t need to be repetitive, but you do need to be explicit rather than implicit.
Leverage FAQs and Conversational Formats
LLMs love FAQs because they’re direct, predictable, and easy to quote. They closely match real user intent and provide high-value snippets that tools like Perplexity and Gemini can pull from without much guesswork.
That said, there’s an important limitation to keep in mind if you’re using the Yoast SEO FAQ block in Gutenberg:
You cannot use H2 or H3 heading tags inside the FAQ block. The block creates its own question-answer formatting using custom HTML, which is great for structured data (FAQ Page schema), but it doesn’t support native heading tags which limits your ability to optimize AI readability and skimmability.
So, if your goal is to appear in AI-generated summaries or answer boxes, where headings like “What is LLM SEO?” make it easy for AI to quote your content, you might be better off using manual formatting.
Here’s how to get the best of both worlds:
STEP 1: Use H2 or H3 tags for each question (e.g., “What is llms.txt?”) and write a clear, short answer beneath it. This improves LLM visibility but doesn’t generate structured FAQ schema.
Step 2: Use the Yoast FAQ block for schema support but know that it won’t give you a proper heading structure.
Ultimately, the more your FAQs resemble natural, searchable questions — and are structured in a way that both humans and AI can easily parse — the more likely they are to be featured in answers.
Enhance Trust with Freshness Signals
Just like search engines, some LLMs give preference to newer content, but remember that we need to talk to them in a certain way to get the best out of them.
Older content can be overlooked. Worse, it can be quoted incorrectly if something has changed since you last hit publish.
Make sure your pages include:
A clear “last updated” timestamp (can we get a picture of what one would look like for clarification?)
Regular reviews for accuracy
Changelogs or update notes if applicable (especially for software or plugin content)
It doesn’t have to be complicated, even a simple “Last updated: June 2025” can help both readers and AI systems trust that your content is current.
Today, we’re entering a phase where who wrote your content is just as important as what it says. That means you need to highlight author visibility and put effort into signaling real-world experience.
Use Person schema to formally associate the content with a specific individual
Weave in relevant experience (“As an SEO consultant who works with SaaS brands…”)
Remember, LLMs are more likely to trust, quote, and amplify expert-authored content.
Use Internal Linking Strategically
Think of internal linking as your site’s nervous system. It helps both humans and LLMs understand what’s important, how topics relate, and where to go next.
But internal linking isn’t just about SEO hygiene anymore — it’s also a way to establish topic authority and help LLMs build a map of your expertise.
Do:
Cluster related articles together (e.g., link from “LLM Optimization” to “Schema Markup for SEO”)
Use descriptive anchor text like “read our full guide to Schema markup,” not just “click here”
Ensure every piece of content supports a broader narrative
The role of llms.txt. Giving AI search all the right signals
Now let’s talk about one of the most recent developments in LLM visibility; a little file called llms.txt.
Think of it as a sibling to robots.txt, but instead of guiding search engines, it tells AI tools how they’re allowed to interact with your content. Note: llms.txt is still an evolving standard, and support across AI tools may vary, but it’s a smart step toward asserting control
With llms.txt, you can:
Define how your content may be reused or summarized
Set clear expectations around attribution, licensing
It’s not just about protection, it’s about being proactive as AI usage accelerates.
LLM Optimization and SEO are part of the same family, but they serve different functions and require slightly different thinking.
Let’s compare:
Traditional SEO
LLM Optimization
Crawled and ranked by bots
Read, remembered, and reused by AIs
Emphasizes keywords
Emphasizes context and clarity
Optimizes for SERPs
Optimizes for AI-generated summaries and answers
The takeaway? You can’t ignore either. One brings traffic; the other boosts brand visibility within AI responses.
And considering that 42% of users now start their research with an LLM (not Google), you’ll want to be found in both places.
Common Mistakes to Avoid
Even well-meaning content creators fall into holes. So, take a look at the tips below to avoid any mishaps that could damage your LLM visibility:
Writing like a robot or allowing a robot to write for you (ironically, not appreciated by robots)
Leaving your content undated and unchanged for years
Publishing posts without any author information or editorial standards
Ignoring internal links or leaving orphaned pages
Using vague headings or anchor text like “read more” or “this article”
If your content looks generic, outdated, or anonymous, it won’t earn any trust. And, without trust, it won’t get quoted.
Tools and Resources to Get Started
Search used to be about visibility within SERPs. But now, it’s also about being seen in summaries, answers, snippets, and chats. LLMs aren’t just shaping the future of search; they’re shaping how your brand is perceived to both humans and robots alike.
To stand out:
Write with clarity and context
Structure for humans and machines
Cite your expertise and show your authors
Use tools like Yoast and llms.txt to signal your intent
Future-proof your visibility with Yoast SEO. From llms.txt integration to schema support, Yoast gives you all the tools you need to speak AI’s language and dominate both generative answers and search engines. Get started with Yoast SEO Premium nowand make it easy for AI to say something accurate, useful, and… ideally, about you.
Brendan Reid
Brendan is a seasoned writer with a particular interest in SMEs. What he really enjoys is being able to provide real, actionable steps that can be taken today to start making business better for everyone.
Over the past decade, digital marketers have witnessed a dramatic shift in how search budgets are allocated.
In the past decade, companies were funding SEO teams alongside PPC teams. However, a shift towards PPC-first has dominated the inbound marketing space.
Where Have SEO Budgets Gone?
Today, more than $150 billion is spent annually on paid search in the United States alone, while only $50 billion is invested in SEO.
With Google Ads, every dollar has a direct, reportable outcome:
Impressions.
Clicks.
Conversions.
SEO, by contrast, has long been:
A black box.
As a result, agencies and the clients that hire them followed the money, even when SEO’s results were higher.
PPC’s Direct Attribution Makes PPC Look More Important, But SEO Still Dominates
Hard facts:
SEO drives 5x more traffic than PPC.
Companies pay 3x more on PPC than SEO.
Image created by MarketBrew, August 2025
You Can Now Trace ROI Back To SEO
As a result, many SEO professionals and agencies want a way back to organic. Now, there is one, and it’s powered by attribution.
Attribution Is the Key to Measurable SEO Performance
Instead of sitting on the edge of the search engine’s black box, guessing what might happen, we can now go inside the SEO black box, to simulate how the algorithms behave, factor by factor, and observe exactly how rankings react to each change.
With this model in place, you are no longer stuck saying “trust us.”
You can say, “Here’s what we changed. Here’s how rankings moved. Here’s the value of that movement.” Whether the change was a new internal link structure or a content improvement, it’s now visible, measurable, and attributable.
For the first time, SEO teams have a way to communicate performance in terms executives understand: cause, effect, and value.
This transparency is changing the way agencies operate. It turns SEO into a predictable system, not a gamble. And it arms client-facing teams with the evidence they need to justify the budget, or win it back.
How Agencies Are Replacing PPC With Measurable Organic SEO
For agencies, attribution opens the door to something much bigger than better reporting; it enables a completely new kind of offering: performance-based SEO.
Traditionally, SEO services have been sold as retainers or hourly engagements. Clients pay for effort, not outcomes. With attribution, agencies can now flip that model and say: You only pay when results happen.
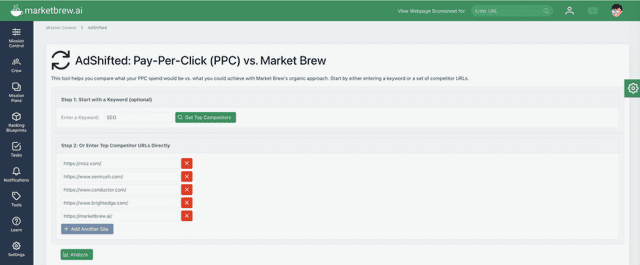
Enter Market Brew’s AdShifted feature to model this value and success as shown here:
Screenshot from a video by MarketBrew, August 2025
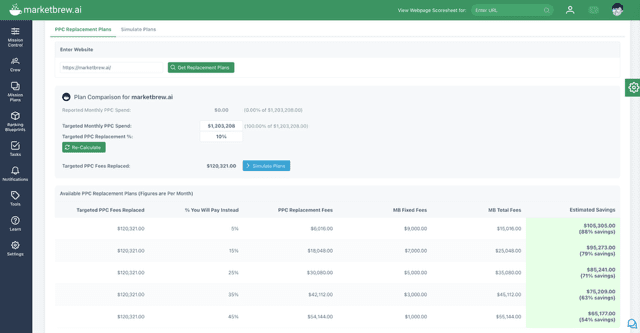
The AdShift tool starts by entering a keyword to discover up to 4* competitive URLs for the Keyword’s Top Clustered Similarities. (*including your own website plus 4 top-ranking competitors)
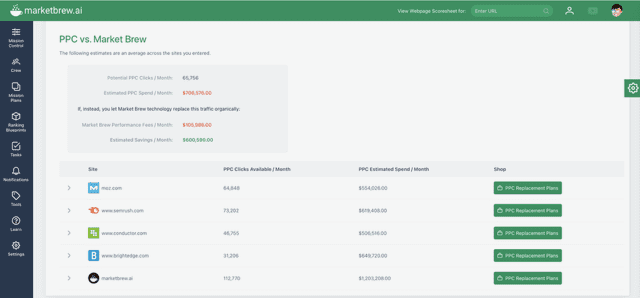
Screenshot of PPC vs. MarketBrew comparison dashboard by Marketbrew, August 2025
AdShift averages CPC and search volume across all keywords and URLs, giving you a reliable market-wide estimate and details for your brand towards a monthly PPC investment to rank #1.
Screenshot of a dashboard by Marketbrew, August 2025
AdShift then calculates YOUR percentage of replacement for PPC to fund SEO.
This allows you to model your own Performance Plan with variable discounts available to the Market Brew license fees with an always less than 50% of PPC Fee for clicks replaced by new SEO traffic.
Screenshot of a dashboard by Marketbrew, August 2025
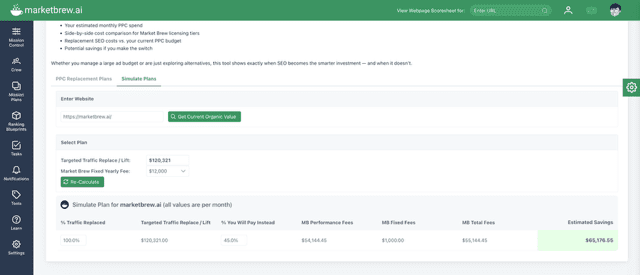
AdShift simulates a PPC replacement plan option selected based on its keywords footprint to instantly see savings from the associated Performance Plans.
That’s the heart of the PPC replacement plan: a strategy you can use to gradually shift a clients’ paid search budgets into measurable performance-based SEO.
What Is A PPC Replacement Plan? Trackable SEO.
A PPC replacement plan is a strategy in which agencies gradually shift their clients’ paid search budgets into organic investments, with measurable outcomes and shared performance incentives.
Here’s how it works:
Benchmark Paid Spend: Identify the current Google Ads budget, i.e., $10,000 per month or $120,000 per year.
Forecast Organic Value: Use search engine modeling to predict the lift in organic traffic from specific SEO tasks.
Execute & Attribute: Complete tasks and monitor real-time changes in rankings and traffic.
Charge on Impact: Instead of billing for time, bill for results, often at a fraction of the client’s former ad spend.
This is not about replacing all paid spend.
Branded queries and some high-value targets may remain in PPC. But for the large, expensive middle of the keyword funnel, agencies can now offer a smarter path: predictable, attributable organic results, at a lower cost-per-click, with better margins.
And most importantly, instead of lining Google’s pockets with PPC revenue, your investments begin to fuel both organic and LLM searches!
Real-World Proof That SEO Attribution Works
Agencies exploring this new attribution-powered model aren’t just intrigued … they’re energized. For many, it’s the first time in years that SEO feels like a strategic growth engine, not just a checklist of deliverables.
“We’ve pitched performance SEO to three clients this month alone,” said one digital strategy lead. “The ability to tie ranking improvements to specific tasks changed the entire conversation.”
“Instead of walking into meetings looking to justify an SEO retainer, we enter with a blueprint representing a SEO/GEO/AEO Search Engine’s ‘digital twin’ with the AI-driven tasks that show exactly what needs to be changed and the rankings it produces. Clients don’t question the value … they ask what’s next.”
Several agencies report that new business wins are increasing simply because they offer something different. While competitors stick to vague SEO promises or expensive PPC management, partners leveraging attribution offer clarity, accountability, and control.
And when the client sees that they’re paying less and getting more, it’s not a hard sell, it’s a long-term relationship.
A Smarter, More Profitable Model for Agencies and SEOs
The traditional agency model in search has become a maze of expectations.
Managing paid search may deliver short-term wins, but it comes to a bidding war with only those with the biggest budgets winning. SEO, meanwhile, has often felt like a thankless task … necessary but underappreciated, valuable but difficult to prove.
Attribution changes that.
For agencies, this is a path back to profitability and positioning. With attribution, you’re not just selling effort … you’re selling outcomes. And because the work is modeled and measured in advance, you can confidently offer performance plans that are both client-friendly and agency-profitable.
For SEOs, this is about getting the credit they deserve. Attribution allows practitioners to demonstrate their impact in concrete terms. Rankings don’t just move, … they move because of you. Traffic increases aren’t vague, … they’re connected to your specific strategies.
Now, you can show this.
Most importantly, this approach rebuilds trust.
Clients no longer have to guess what’s working. They see it. In dashboards, in forecasts, in side-by-side comparisons of where they were and where they are now. It restores SEO to a place of clarity and control where value is obvious, and investment is earned.
The industry has been waiting for this. And now, it’s here.
From PPC Dependence to Organic Dominance — Now Backed by Data
Search budgets have long been upside down, pouring billions into paid clicks that capture a mere fraction of user attention, while underfunding the organic channel that delivers lasting value.
Why? Because SEO lacked attribution.
That’s no longer the case.
Today, agencies and SEO professionals have the tools to prove what works, forecast what’s next, and get paid for the real value they deliver. It’s a shift that empowers agencies to move beyond bidding-war PPC management and into a lower cost & higher ROAS, performance-based SEO.
This isn’t just a new service mode it’s a rebalancing of power in search.
Organic is back. It’s measurable. It’s profitable. And it’s ready to take center stage again.
The only question is: will you be the agency or brand that leads the shift or watch as others do it first?
Bing has updated its sitemap guidance with a renewed focus on the lastmod tag, highlighting its role in AI-powered search to determine which pages need to be recrawled.
While real-time tools like IndexNow offer faster updates, Bing says accurate lastmod values help keep content discoverable, especially on frequently updated or large-scale sites.
Bing Prioritizes lastmod For Recrawling
Bing says the lastmod field in your sitemap is a top signal for AI-driven indexing. It helps determine whether a page needs to be recrawled or can be skipped.
To make it work effectively, use ISO 8601 format with both date and time (e.g. 2004-10-01T18:23:17+00:00). That level of precision helps Bing prioritize crawl activity based on actual content changes.
Avoid setting lastmod to the time your sitemap was generated, unless the page was truly updated.
Bing also confirmed that changefreq and priority tags are ignored and no longer affect crawling or ranking.
Submission & Verification Tips
Bing recommends submitting your sitemap in one of two ways:
Reference it in your robots.txt file
Submit it via Bing Webmaster Tools
Once submitted, Bing fetches the sitemap immediately and rechecks it daily.
You can verify whether it’s working by checking the submission status, last read date, and any processing errors in Bing Webmaster Tools.
Combine With IndexNow For Better Coverage
To increase the chances of timely indexing, Bing suggests combining sitemaps with IndexNow.
While sitemaps give Bing a full picture of your site, IndexNow allows real-time URL-level updates—useful when content changes frequently.
The Bing team states:
“By combining sitemaps for comprehensive site coverage with IndexNow for fast, URL-level submission, you provide the strongest foundation for keeping your content fresh, discoverable, and visible.”
Sitemaps at Massive Scale
If you manage a large website, Bing’s sitemap capacity limits are worth your attention:
Up to 50,000 URLs per sitemap
50,000 sitemaps per index file
2.5 billion URLs per index
Multiple index files support indexing up to 2.5 trillion URLs
That makes the standard sitemap protocol scalable enough even for enterprise-level ecommerce or publishing platforms.
Fabrice Canel and Krishna Madhavan of Microsoft AI, Bing, noted that using these limits to their full extent helps ensure content remains discoverable in AI search.
Why This Matters
As search becomes more AI-driven, accurate crawl signals matter more.
Bing’s reliance on sitemaps, especially the lastmod field, shows that basic technical SEO practices still matter, even as AI reshapes how content is surfaced.
For large sites, Bing’s support for trillions of URLs offers scalability. For everyone else, the message is simpler: keep your sitemaps clean, accurate, and updated in real-time. This gives your content the best shot at visibility in AI search.