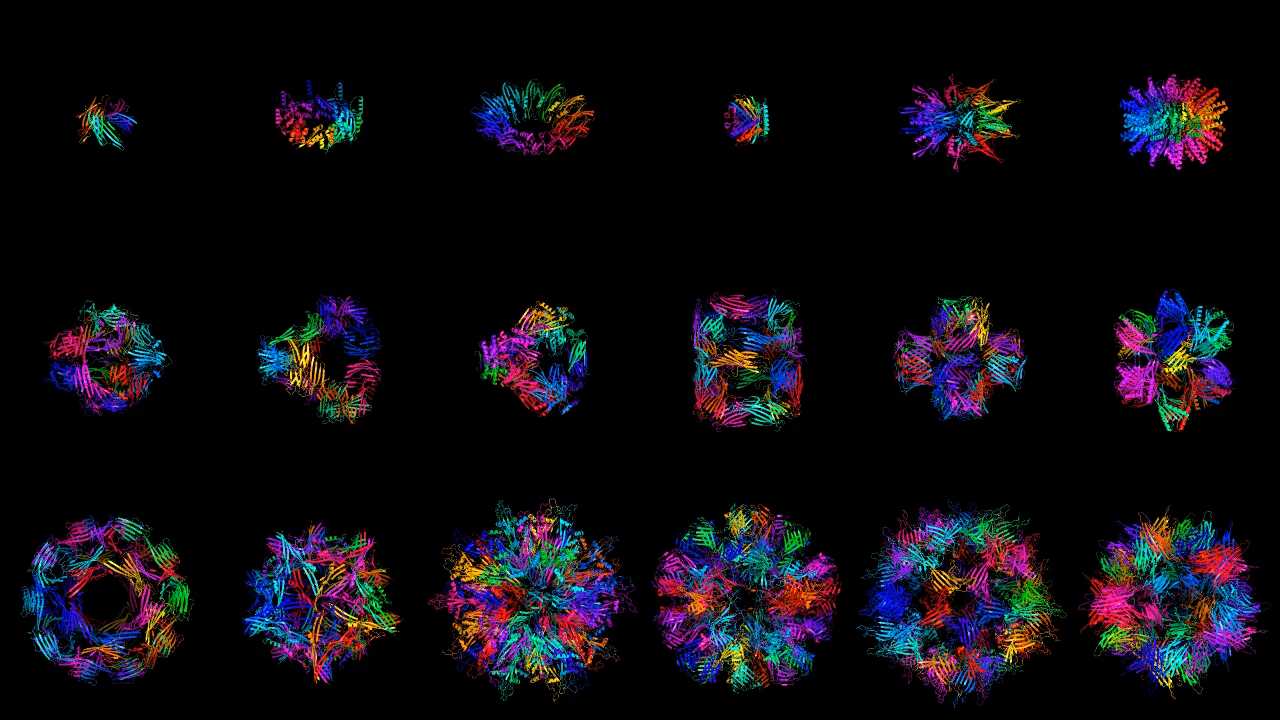Does the IP address of your website’s server affect your rankings in search results? According to some sources around the internet, your IP address is a ranking signal used by Google.
But does your IP address have the potential to help or harm your rankings in search? Continue reading to learn whether IP addresses are a Google ranking factor.
The Claim: IP Address As A Ranking Factor
Articles on the internet from reputable marketing sites claim that Google has over 200 “known” ranking factors.
These lists often include statements about flagged IP addresses affecting rankings or higher-value links because they are from separate C-class IP addresses.
Screenshot from HubSpot.com, June 2022
Fortunately, these lists sparked numerous conversations with Google employees about the validity of IP addresses as ranking factors in Google’s algorithm.
The Evidence Against IP Address As A Ranking Factor
In 2010, Matt Cutts, former head of Google’s webspam team, was asked if the ranking of a client’s website would be affected by spammy websites on the same server.
His response:
“On the list of things that I worry about, that would not be near the top. So I understand, and Google understands that shared web hosting happens. You can’t really control who else is on that IP address or class c subnet.”
Ultimately, Google decided if they took action on an IP address or Class C subnet, the spammers would just move to another IP address. Therefore, it wouldn’t be the most efficient way to tackle the issue.
Cutts did note a specific exception, where an IP address had 26,000 spam sites and one non-spammy site that invited more scrutiny but reiterated that this was an exceptional outlier.
In 2011, a tweet from Kaspar Szymanski, another former member of Google’s webspam team, noted that Google has the right to take action when free hosts have been massively spammed.
In 2016, during a Google Webmaster Central Office Hours, John Mueller, Search Advocate at Google, was asked if having all of a group’s websites on the same c block of IP addresses was a problem.
He answered:
“No, that’s perfectly fine. So that’s not something where you artificially need to buy IP address blocks to just shuffle things around.
And especially if you are on a CDN, then maybe you’ll end up on an IP address block that’s used by other companies. Or if you’re on shared hosting, then these things happen. That’s not something you need to artificially move around.”
In March 2018, Mueller was asked if an IP change with a different geo-location would affect SEO. He responded:
“If you move to a server in a different location? Usually not. We get enough geotargeting information otherwise, e.g., from the TLD & geotargeting settings in Search Console.”
A few months later, Mueller replied to a tweet asking if Google still counted bad neighborhoods as a ranking signal and if a dedicated IP was necessary.
“Shared IP addresses are fine for search! Lots of hosting / CDN environments use them.”
In October 2018, Mueller was asked if the IP address location mattered for a site’s rankings. His response was simply, “Nope.”
A few tweets later, within the same Twitter thread, another user commented that IP addresses mattered regarding backlinks. Mueller again responded with a simple “Nope.”
In June 2019, Mueller received a question about Google Search Console showing a website’s IP address instead of a domain name. His answer:
“Usually, getting your IP addresses indexed is a bad idea. IP addresses are often temporary.”
He suggested that the user ensure the IP address redirects to their domain.
A few months later, when asked if links from IP addresses were bad, Mueller tweeted:
“Links from IP addresses are absolutely fine. Most of the time, it means the server wasn’t set up well (we canonicalized to the IP address rather than the hostname, easy to fix with redirects & rel=canonical), but that’s just a technical detail. It doesn’t mean they’re bad.”
In early 2020, when asked about getting links from different IP addresses, Mueller said that the bad part was the user was making the backlinks themselves – not the IP addresses.
Then, in June, Mueller was asked what happens if a website on an IP address bought links. Would there be an IP-level action taken?
“Shared hosting & CDNs on a single IP is really common. Having some bad sites on an IP doesn’t make everything on that IP bad.”
In September, during a discussion about bad neighborhoods affecting search rankings, Mueller stated:
“I’m not aware of any ranking algorithm that would take IPs like that into account. Look at Blogger. There are great sites that do well (ignoring on-page limitations, etc.), and there are terrible sites hosted there. It’s all the same infrastructure, the same IP addresses.”
In November, Gary Illyes, Chief of Sunshine and Happiness at Google, shared a fun fact.
“Fun fact: changing a site’s underlaying infrastructure like servers, IPs, you name it, can change how fast and often Googlebot crawls from said site. That’s because it actually detects that something changed, which prompts it to relearn how fast and often it can crawl.”
While it’s interesting information, it seems to impact crawling and not ranking. Crawling is, of course, required to rank, but crawling is not a ranking factor.
In 2021, a Twitter user asked if IP canonicalization could positively affect SEO. Meuller replied:
“Unless folks are linking to your site’s IP address (which would be unexpected), this wouldn’t have any effect on SEO.”
Later in December, when asked if an IP address instead of a hostname looks unusual when Google evaluates a link’s quality, Meuller stated, “Ip addresses are fine. The internet has tons of them.”
If you’re worried about your IP address or hosting company, the consensus seems to be: Don’t worry.
Our Verdict: IP Address Is Not A Ranking Factor Anymore
Maybe in the past, Google experimented with IP-level actions against spammy websites.
But it must have found this ineffective because we are not seeing any confirmation from Google representatives that IP addresses, shared hosting, and bad neighborhoods are a part of the algorithm.
Therefore, we can conclude for now that IP addresses are not a ranking factor.
Featured Image: Paulo Bobita/Search Engine Journal
Many law firms are simply leasing space when it comes to their online marketing.
Whether it’s Google pay-per-click (PPC) ads, Facebook Ads, or social media, these channels often yield only temporary wins. Once you pull the investment, your results go away entirely.
Your website, on the other hand, can be a 24/7 selling tool for your law firm practice. It can effectively become your greatest asset, getting leads and cases while you sleep.
In this guide, we’ll talk about how to turn your website into the ultimate marketing tool for your law firm practice and generate seven figures in revenue for your business.
A Well-Optimized Law Firm Website Can Yield Huge Results
With your law firm’s website, you can use content marketing to your advantage to generate lucrative results for your business. Content and SEO allow you to attract users organically and convert traffic passively into new cases for your law firm.
As an example, a high-ranking webpage in a competitive market getting 1,000 users per month can get huge results:
Convert visitors at 2-5% = 20-50 leads.
Convert even 10-20% of leads = 2-10 cases.
Average $8000 revenue per case = $16,000-$80,000 monthly revenue from one page.
Over the course of a year, this could lead to high six-figures to seven-figures in revenue!
The Foundations Of A Revenue-Generating Law Firm Website
At its core, your law firm website should serve to speak to the needs, struggles, and interests of your target audience. It should be laser-focused on your practice area, who you serve, and what you have to offer.
With this in mind, a well-crafted website content strategy should define:
Your business goals (the cases you want).
What competitors are doing.
What pages to write and keywords to target.
How to use your content budget.
Your editorial calendar.
The purpose/intent of each page.
PR and backlink strategy.
Below, we’ll dive deeper into how to develop this strategy, build out amazing content, and achieve your seven-figure revenue goals.
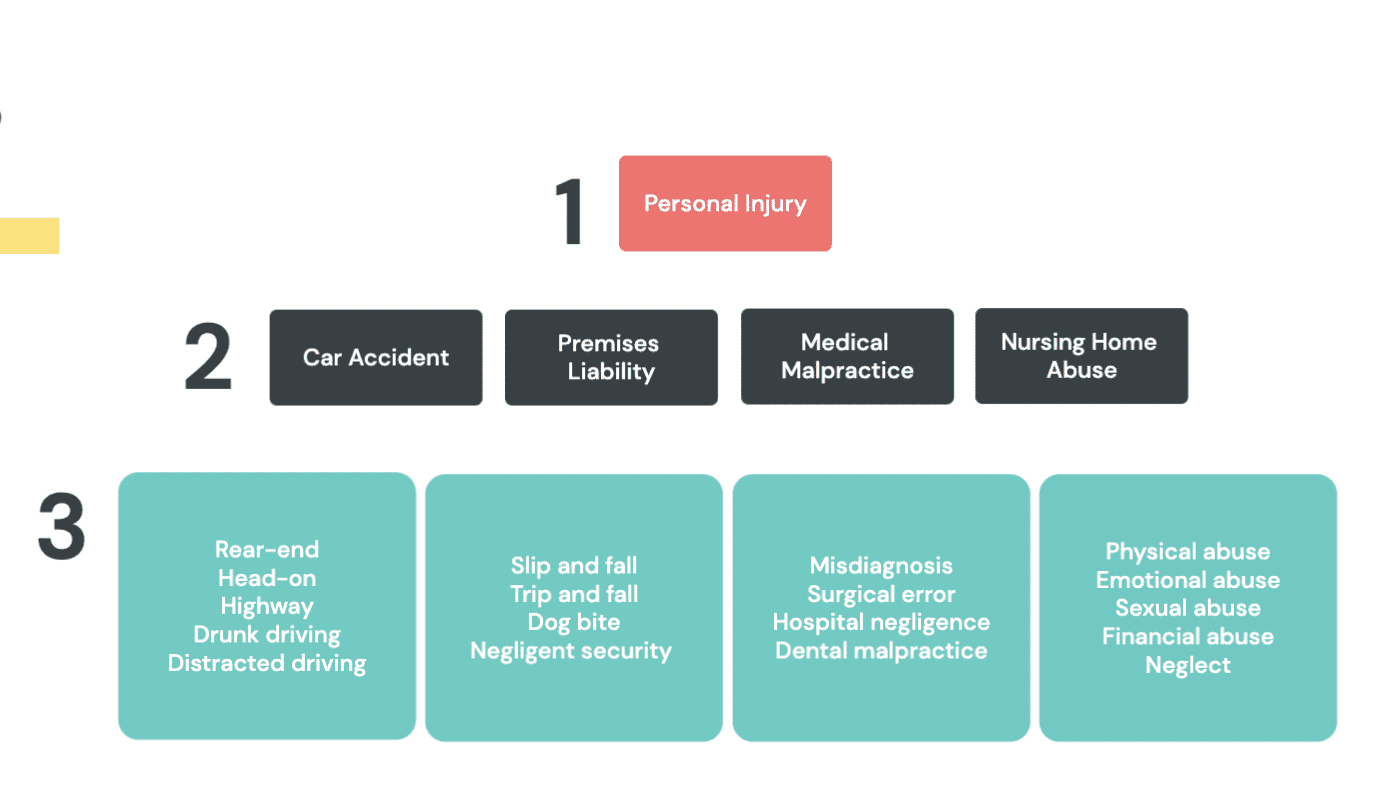
1. Define The Cases You Want
The first step to developing a successful website marketing strategy is to define the types of legal cases you want.
This activity will help you determine the types of people you want to reach, the type of content you should create, and the types of SEO keywords you need to target.
That way, you end up marketing to a more specific subset of potential clients, rather than a broad range of users.
Not sure where to set your focus? Here are a few questions that might help:
Which of your cases are the most profitable?
What types of cases are you not getting enough of?
In what markets are you strongest?
In which markets do you want to improve?
Are there any practice areas you want to explore?
At the end of this activity, you might decide that you want to attract more family law cases, foreclosure law cases, or DUI cases – whatever it is, getting hyper-focused on the types of cases you want to attract will only make your website marketing even stronger.
2. Identify Your Top Competitors
One of the best ways to “hack” your website marketing strategy is to figure out what’s working for your competitors.
By “competitors” we mean law firms that are working to attract the types of cases you’re trying to attract, at the same level at which your law firm is currently operating.
I say this because I see many law firms trying to out beat and outrank the “big” fish and this can feel like a losing battle. You want to set your sights on your closest competitors, rise above them, and then get more competitive with your strategy.
Here are a few ways to identify your closest competitors:
Conduct a Google search of your legal practice area + your service area (e.g., “family law Kirkland”, “DUI lawyer LA”, “Denver probate attorney” etc.). Take note of the top-ranking domains (i.e., websites).
Use SEO tools like Semrush or Ahrefs to search your domain name. These tools will often surface close competitors to your domain.
Using the same tools above, conduct organic research on your domain to see what keywords you are already ranking for. Search these keywords in Google and see what other domains come up.
Use these tools to determine the domain authority (DA) of your domain. Compare this to the other top-ranking domains to see which domains have an authority score that’s similar to your own.
Be sure to look at your known business competitors as well.
These may or may not be ranking well in Google Search, but it’s still worth a peek to see if they are targeting any high-priority keywords that your website should be targeting.
3. Conduct A Content Audit Of Your Website
Your next step is to conduct an audit of your current website. This will allow you to take stock of what content is performing well, and what content requires improvement.
First, start with your main service pages.
Use SEO tools like Semrush or Ahrefs again to review the rank (position), performance, and keywords of each page. Identify any pages that are ranking low, or not at all.
Then, find “low-hanging fruit” pages. These are the pages that are ranking around position 5-10. They require less effort to optimize to reach those higher rank positions – compared to pages ranking at, say, position 59.
This compares your website’s performance to that of your closest competitors. It will show you a list of keywords that your competitors are ranking for that your website is not ranking for at all.
Finally, create an inventory of what pages you already have, which need to be revised, and which you need to create. Doing so will help you stay organized and stay on task when developing your content strategy.
4. Plan Your Content Silos
By this step, you will have a pretty good idea of what pages you already have, and which pages are “missing” from your strategy (based on the list of keywords you are not yet targeting).
From here, you will plan what’s called “content silos”.
Here is the basic process:
Review an existing service page (if you have one) and optimize it as best you can. Ideally, this is a page that’s already performing well and is otherwise a “low-hanging fruit” page.
If you don’t have any existing service pages, create one based on one of your high-priority keywords. Again, these should be a keyword that is meant to attract your preferred type of cases.
Next, build a “silo” of content around your main page. In other words, create new pages that are topically related to your main service page, but that target slightly different keywords (ideally, “long-tail”, lower competition keywords).
Add internal links between these pages and your primary service page.
Over time, build backlinks to these pages (through guest posting, PR, content marketing, etc.)
Below is an example of a content silo approach for “personal injury:”
Image from author, November 2022
5. Identify Supporting Topics
As part of your website content strategy, you’ll then want to create other supporting content pieces. This should be content that provides value to your potential clients.
FAQs, blogs, and other service pages can support your main pages.
For example, if you are a DUI lawyer, you might want to publish an FAQ page that addresses the main questions clients have about DUI law, or a blog post titled “What to Do When You Get a DUI.”
There are a few tools you can use to research supporting topics:
Semrush – Use this tool to identify untapped keywords, content topics, and more.
AlsoAsked – Identify other questions people have searched for relevant to your primary topic.
Answer the Public – Use this search listening tool to identify topics and questions related to your practice area.
Below is an example of how the full content silo can come together for “Los Angeles Car Accident Lawyer:”
Image from author, November 2022
6. Build An Editorial Calendar
Once you have all of your content ideas down on paper, it’s time to develop your editorial calendar.
This is essentially a plan of what content you need to create when you want to publish it, and what keywords you plan to target.
This can be as simple as a Google Sheet or as fancy as a project management tool (like Monday.com or Asana).
Here are a few tips to get you started:
Always prioritize main pages. These should be the first content pieces you create on your website.
Create or revise your main pages and monitor their performance.Use Google Analytics and other SEO tools to keep your eye on how your content is performing.
Depending on budget and urgency, you might start with all main pages, or go silo by silo. Determine which service pages are most important to you. You can create all of your main pages at once, or develop the entire silo as you go.
Keep a record of your target keywords. Just because you “optimize” for them doesn’t mean your content will automatically rank for your target keywords. In your editorial calendar, keep track of the keywords you wish to target – by page – so you have a record of your original SEO strategy.
What Makes A Winning Law Firm Website Strategy?
The key to achieving seven figures with your law firm website is content.
Content allows you to target your ideal clients, attract your preferred cases, engage your audience, and so much more.
A well-thought-out content strategy will empower your website to achieve more for your business than any other marketing channel could!
Above, I outline a few steps to developing this type of winning strategy. But, achieving excellence takes time.
I recommend keeping your eye on the prize, monitoring performance, and making updates as you go along.
Learning to code, whether with Python, JavaScript, or another programming language, has a whole host of benefits, including the ability to work with larger datasets and automate repetitive tasks.
But despite the benefits, many SEO professionals are yet to make the transition – and I completely understand why! It isn’t an essential skill for SEO, and we’re all busy people.
If you’re pressed for time, and you already know how to accomplish a task within Excel or Google Sheets, then changing tack can feel like reinventing the wheel.
When I first started coding, I initially only used Python for tasks that I couldn’t accomplish in Excel – and it’s taken several years to get to the point where it’s my defacto choice for data processing.
Looking back, I’m incredibly glad that I persisted, but at times it was a frustrating experience, with many an hour spent scanning threads on Stack Overflow.
This post is designed to spare other SEO pros the same fate.
Within it, we’ll cover the Python equivalents of the most commonly used Excel formulas and features for SEO data analysis – all of which are available within a Google Colab notebook linked in the summary.
Specifically, you’ll learn the equivalents of:
LEN.
Drop Duplicates.
Text to Columns.
SEARCH/FIND.
CONCATENATE.
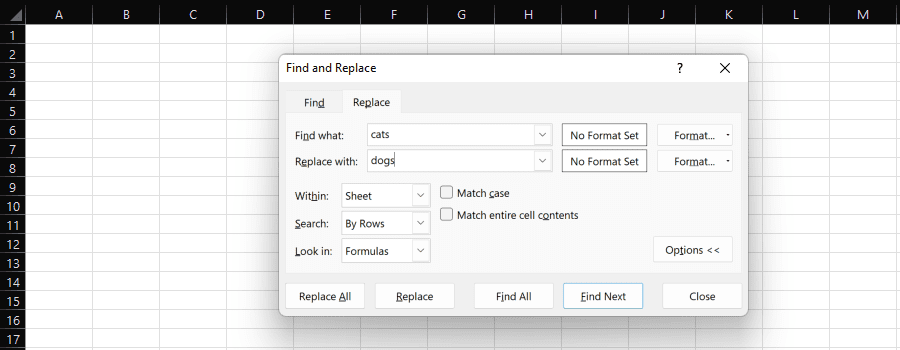
Find and Replace.
LEFT/MID/RIGHT.
IF.
IFS.
VLOOKUP.
COUNTIF/SUMIF/AVERAGEIF.
Pivot Tables.
Amazingly, to accomplish all of this, we’ll primarily be using a singular library – Pandas – with a little help in places from its big brother, NumPy.
Prerequisites
For the sake of brevity, there are a few things we won’t be covering today, including:
Installing Python.
Basic Pandas, like importing CSVs, filtering, and previewing dataframes.
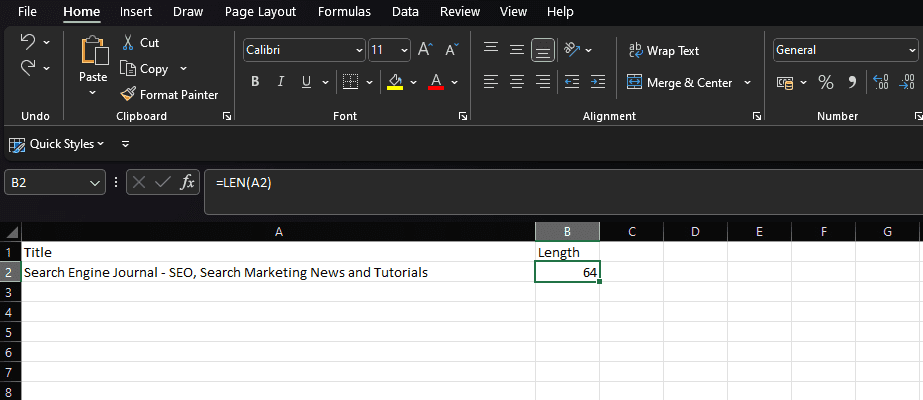
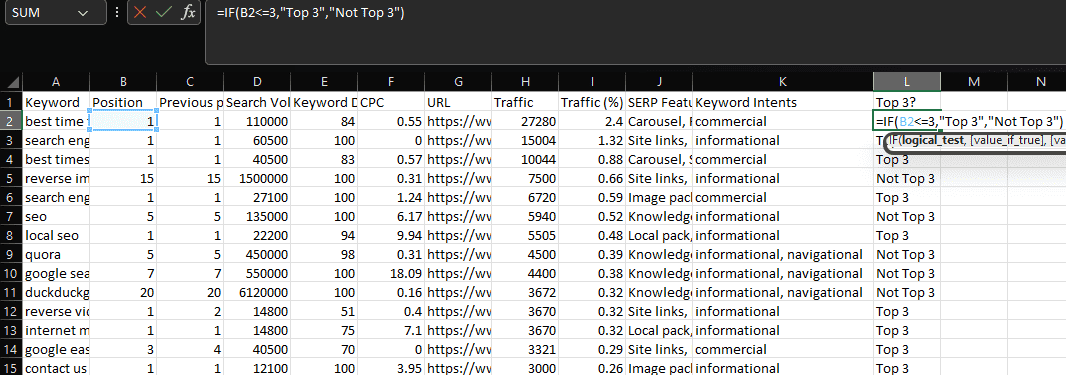
LEN provides a count of the number of characters within a string of text.
For SEO specifically, a common use case is to measure the length of title tags or meta descriptions to determine whether they’ll be truncated in search results.
Within Excel, if we wanted to count the second cell of column A, we’d enter:
=LEN(A2)
Screenshot from Microsoft Excel, November 2022
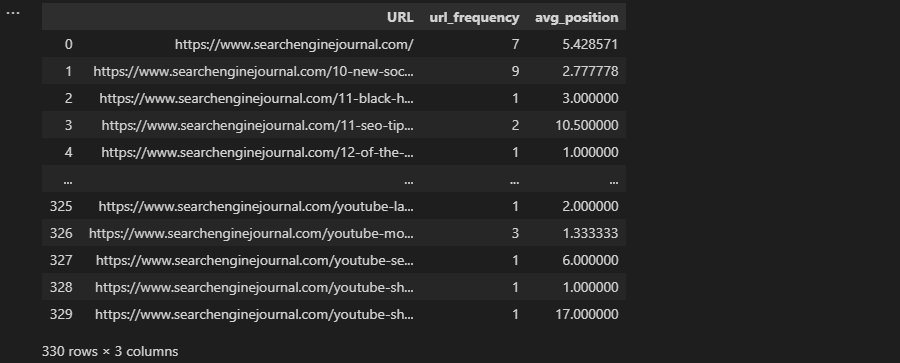
Python isn’t too dissimilar, as we can rely on the inbuilt len function, which can be combined with Pandas’ loc[] to access a specific row of data within a column:
len(df['Title'].loc[0])
In this example, we’re getting the length of the first row in the “Title” column of our dataframe.
Screenshot of VS Code, November, 2022
Finding the length of a cell isn’t that useful for SEO, though. Normally, we’d want to apply a function to an entire column!
In Excel, this would be achieved by selecting the formula cell on the bottom right-hand corner and either dragging it down or double-clicking.
When working with a Pandas dataframe, we can use str.len to calculate the length of rows within a series, then store the results in a new column:
df['Length'] = df['Title'].str.len()
Str.len is a ‘vectorized’ operation, which is designed to be applied simultaneously to a series of values. We’ll use these operations extensively throughout this article, as they almost universally end up being faster than a loop.
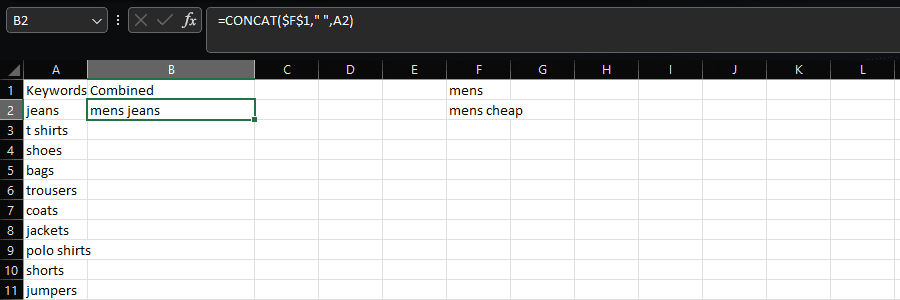
Another common application of LEN is to combine it with SUBSTITUTE to count the number of words in a cell:
=LEN(TRIM(A2))-LEN(SUBSTITUTE(A2," ",""))+1
In Pandas, we can achieve this by combining the str.split and str.len functions together:
We’ll cover str.split in more detail later, but essentially, what we’re doing is splitting our data based upon whitespaces within the string, then counting the number of component parts.
Screenshot from VS Code, November 2022
Dropping Duplicates
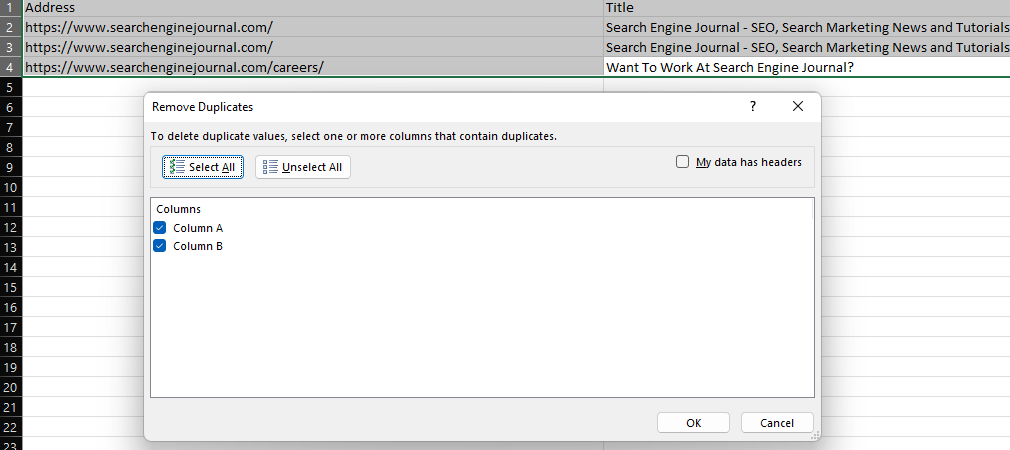
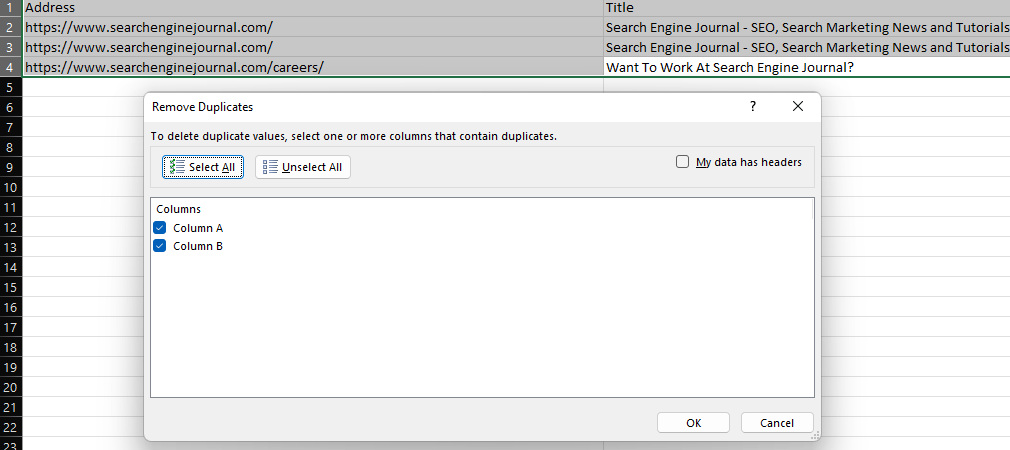
Excel’s ‘Remove Duplicates’ feature provides an easy way to remove duplicate values within a dataset, either by deleting entirely duplicate rows (when all columns are selected) or removing rows with the same values in specific columns.
Screenshot from Microsoft Excel, November 2022
In Pandas, this functionality is provided by drop_duplicates.
To drop duplicate rows within a dataframe type:
df.drop_duplicates(inplace=True)
To drop rows based on duplicates within a singular column, include the subset parameter:
One addition above that’s worth calling out is the presence of the inplace parameter. Including inplace=True allows us to overwrite our existing dataframe without needing to create a new one.
There are, of course, times when we want to preserve our raw data. In this case, we can assign our deduped dataframe to a different variable:
df2 = df.drop_duplicates(subset='column')
Text To Columns
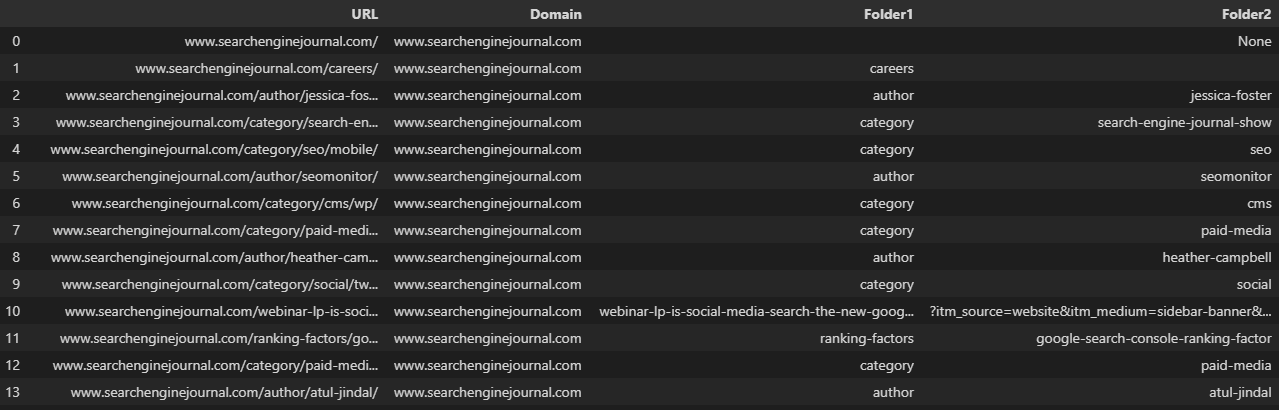
Another everyday essential, the ‘text to columns’ feature can be used to split a text string based on a delimiter, such as a slash, comma, or whitespace.
As an example, splitting a URL into its domain and individual subfolders.
Screenshot from Microsoft Excel, November 2022
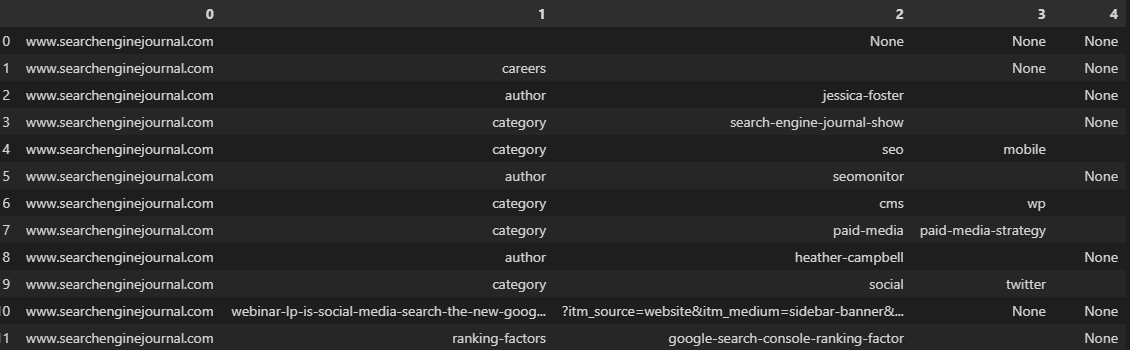
When dealing with a dataframe, we can use the str.split function, which creates a list for each entry within a series. This can be converted into multiple columns by setting the expand parameter to True:
df['URL'].str.split(pat='/', expand=True)
Screenshot from VS Code, November 2022
As is often the case, our URLs in the image above have been broken up into inconsistent columns, because they don’t feature the same number of folders.
This can make things tricky when we want to save our data within an existing dataframe.
Specifying the n parameter limits the number of splits, allowing us to create a specific number of columns:
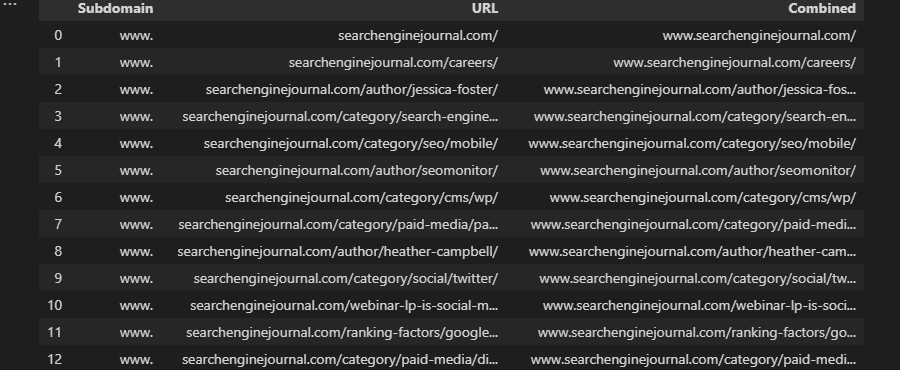
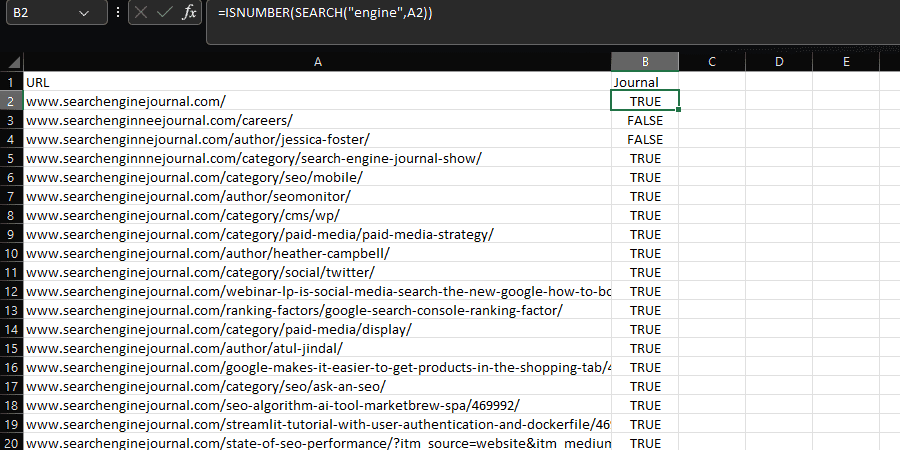
The SEARCH and FIND formulas provide a way of locating a substring within a text string.
These commands are commonly combined with ISNUMBER to create a Boolean column that helps filter down a dataset, which can be extremely helpful when performing tasks like log file analysis, as explained in this guide. E.g.:
=ISNUMBER(SEARCH("searchthis",A2)
Screenshot from Microsoft Excel, November 2022
The difference between SEARCH and FIND is that find is case-sensitive.
The equivalent Pandas function, str.contains, is case-sensitive by default:
In either scenario, including na=False will prevent null values from being returned within the Boolean column.
One massive advantage of using Pandas here is that, unlike Excel, regex is natively supported by this function – as it is in Google sheets via REGEXMATCH.
Chain together multiple substrings by using the pipe character, also known as the OR operator:
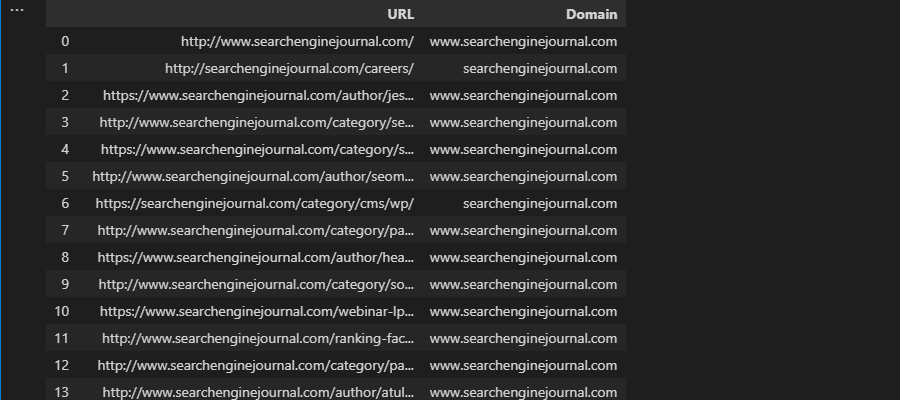
Extracting a substring within Excel requires the usage of the LEFT, MID, or RIGHT functions, depending on where the substring is located within a cell.
Let’s say we want to extract the root domain and subdomain from a URL:
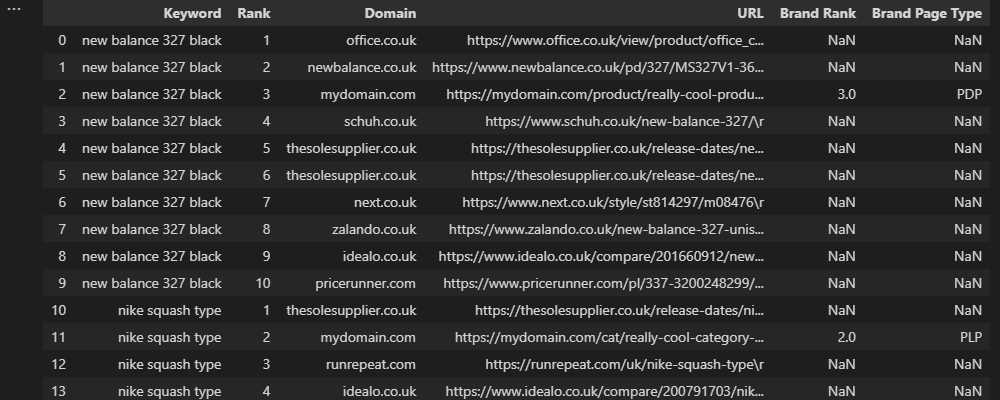
Above, we’re using str.contains to evaluate whether or not a URL in the top 10 matches our brand’s pattern, then using the “Brand Rank” column to exclude any competitors.
In this example, the tilde sign (~) indicates a negative match. In other words, we’re saying we want every brand URL that doesn’t match the pattern for a “PDP” or “PLP” to match the criteria for ‘Other.’
Lastly, None is included because we want non-brand results to return a null value.
Screenshot from VS Code, November 2022
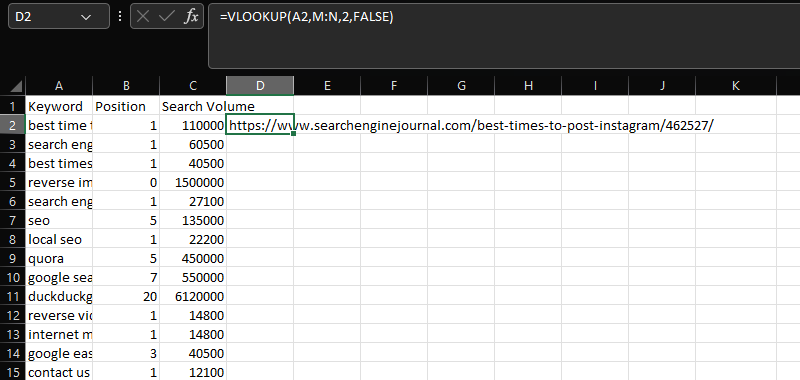
VLOOKUP
VLOOKUP is an essential tool for joining together two distinct datasets on a common column.
In this case, adding the URLs within column N to the keyword, position, and search volume data in columns A-C, using the shared “Keyword” column:
=VLOOKUP(A2,M:N,2,FALSE)
Screenshot from Microsoft Excel, November 2022
To do something similar with Pandas, we can use merge.
Replicating the functionality of an SQL join, merge is an incredibly powerful function that supports a variety of different join types.
For our purposes, we want to use a left join, which will maintain our first dataframe and only merge in matching values from our second dataframe:
One added advantage of performing a merge over a VLOOKUP, is that you don’t have to have the shared data in the first column of the second dataset, as with the newer XLOOKUP.
It will also pull in multiple rows of data rather than the first match in finds.
One common issue when using the function is for unwanted columns to be duplicated. This occurs when multiple shared columns exist, but you attempt to match using one.
To prevent this – and improve the accuracy of your matches – you can specify a list of columns:
The above code snippet executes two merges to join together three dataframes with the same columns – which are our rankings for November, October, and September.
By labeling the months within the suffix parameters, we end up with a much cleaner dataframe that clearly displays the month, as opposed to the defaults of _x and _y seen in the earlier example.
Screenshot from VS Code, November 2022
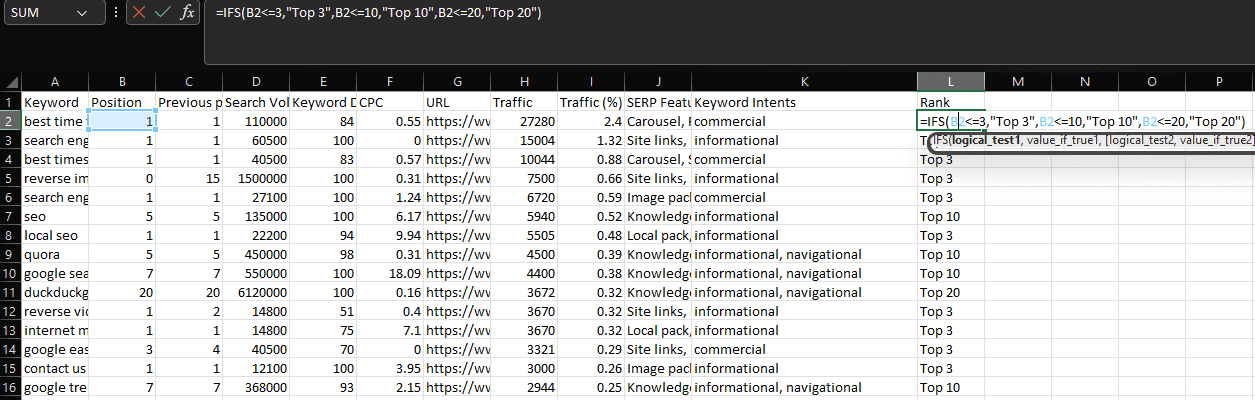
COUNTIF/SUMIF/AVERAGEIF
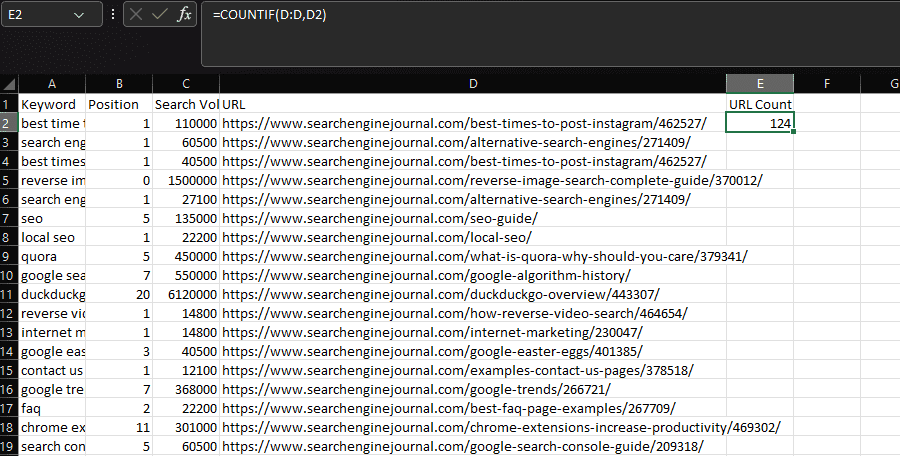
In Excel, if you want to perform a statistical function based on a condition, you’re likely to use either COUNTIF, SUMIF, or AVERAGEIF.
Commonly, COUNTIF is used to determine how many times a specific string appears within a dataset, such as a URL.
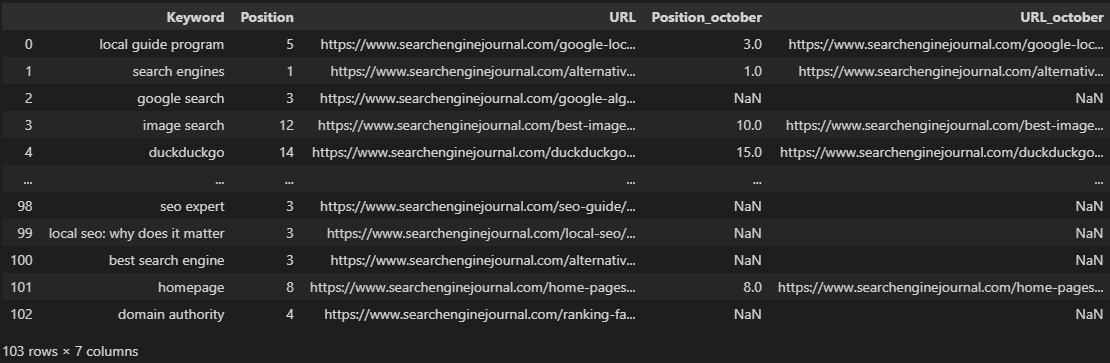
We can accomplish this by declaring the ‘URL’ column as our range, then the URL within an individual cell as our criteria:
=COUNTIF(D:D,D2)
Screenshot from Microsoft Excel, November 2022
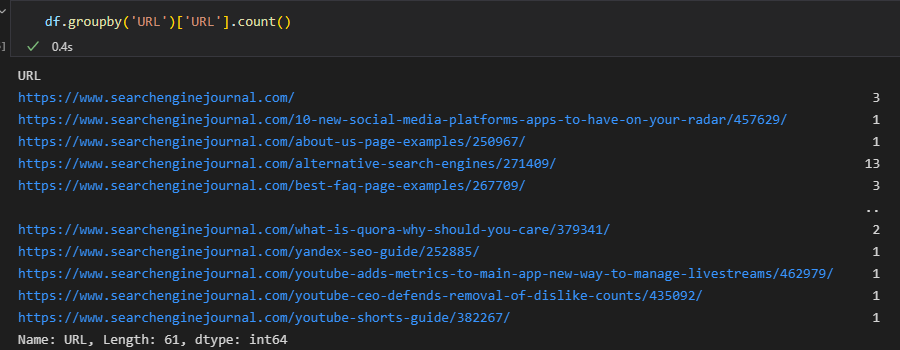
In Pandas, we can achieve the same outcome by using the groupby function:
df.groupby('URL')['URL'].count()
Screenshot from VS Code, November 2022
Here, the column declared within the round brackets indicates the individual groups, and the column listed in the square brackets is where the aggregation (i.e., the count) is performed.
The output we’re receiving isn’t perfect for this use case, though, because it’s consolidated the data.
Typically, when using Excel, we’d have the URL count inline within our dataset. Then we can use it to filter to the most frequently listed URLs.
To do this, use transform and store the output in a column:
In our examples so far, we’ve been using the same column for our grouping and aggregations, but we don’t have to. Similarly to COUNTIFS/SUMIFS/AVERAGEIFS in Excel, it’s possible to group using one column, then apply our statistical function to another.
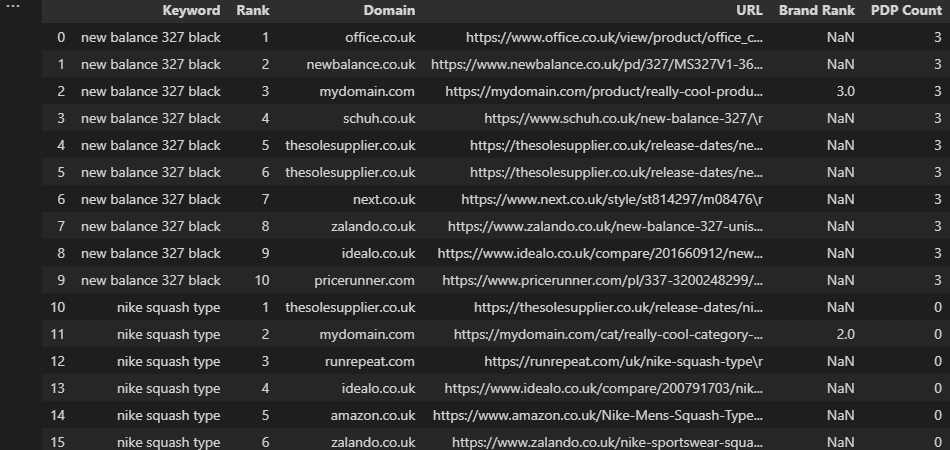
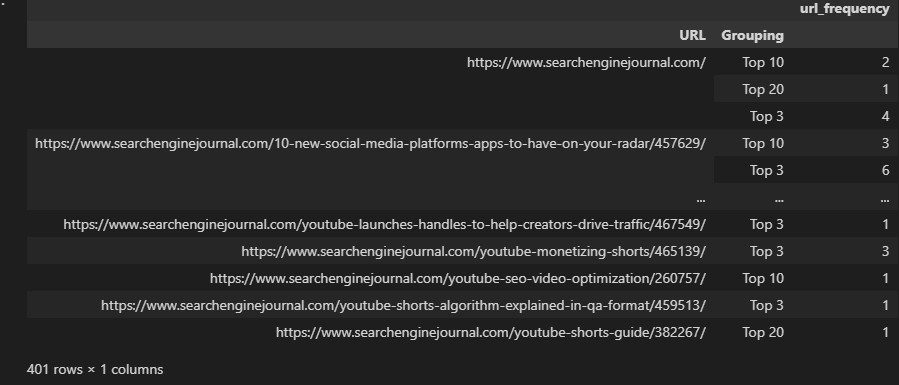
Going back to the earlier search engine results page (SERP) example, we may want to count all ranking PDPs on a per-keyword basis and return this number alongside our existing data:
Last, but by no means least, it’s time to talk pivot tables.
In Excel, a pivot table is likely to be our first port of call if we want to summarise a large dataset.
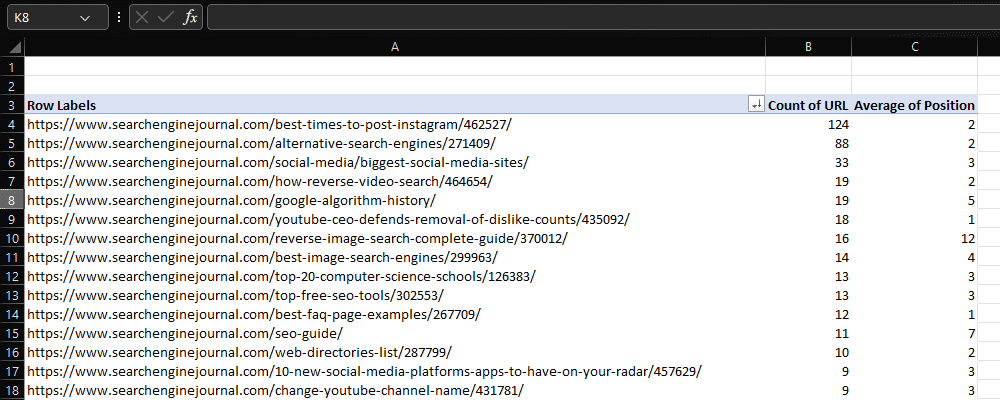
For instance, when working with ranking data, we may want to identify which URLs appear most frequently, and their average ranking position.
Screenshot from Microsoft Excel, November 2022
Again, Pandas has its own pivot tables equivalent – but if all you want is a count of unique values within a column, this can be accomplished using the value_counts function:
count = df['URL'].value_counts()
Using groupby is also an option.
Earlier in the article, performing a groupby that aggregated our data wasn’t what we wanted – but it’s precisely what’s required here:
Two aggregate functions have been applied in the example above, but this could easily be expanded upon, and 13 different types are available.
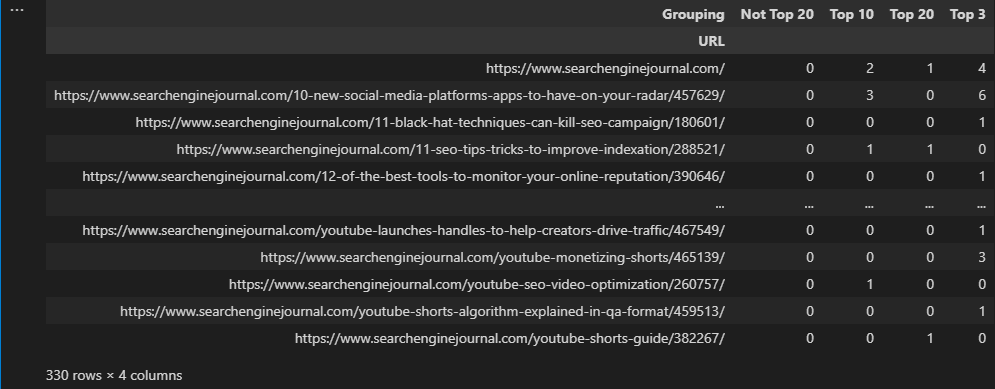
There are, of course, times when we do want to use pivot_table, such as when performing multi-dimensional operations.
To illustrate what this means, let’s reuse the ranking groupings we made using conditional statements and attempt to display the number of times a URL ranks within each group.
Whether you’re looking for inspiration to start learning Python, or are already leveraging it in your SEO workflows, I hope that the above examples help you along on your journey.
As promised, you can find a Google Colab notebook with all of the code snippets here.
In truth, we’ve barely scratched the surface of what’s possible, but understanding the basics of Python data analysis will give you a solid base upon which to build.
Have you ever felt overwhelmed by Google’s seemingly constant algorithm updates? If so, you’re certainly not alone.
Many SEO professionals are reeling from Google’s whirlwind of a year, with eight confirmed and several unconfirmed updates that have dropped in 2022.
And with so much volatility in search this past year, it can often feel like you’re scrambling to keep up.
But what does the chaos of 2022 mean for 2023? Can we expect more updates? Will we see more testing?
How can you get on the front end of Google’s new rollouts and make sure you’re prepared for the changes to come?
How can you adapt your SEO strategy to keep it fresh and relevant?
For SEO pros looking to get ahead of the curve, our next webinar focuses on how to handle frequent algorithm changes and market shifts.
Join Pat Reinhart, VP of Customer Success at Conductor, for an in-depth recap of this year’s biggest SEO insights, as well as expert predictions for what 2023 may hold.
Key Takeaways From This Upcoming Google Algorithm Webinar
What a crazy 2022 for Google means for 2023.
How the growth of social media search will impact strategy next year.
What the popularity of visual search will mean going forward.
As technology continues to evolve and new digital trends emerge, the SEO community must quickly adapt.
With image search becoming more prominent and Google starting to prioritize short-form videos on mobile SERPs, visual content is predicted to make a major impact on search rankings, going forward.
Between the rise of social media and the explosion of short-form video content, there are several factors expected to have a major impact on SEO in 2023.
Not only are people sharing more on social platforms now, but an increasing amount of people are relying on social media search to find what they’re looking for online.
This trend, plus the growing popularity of visual search, should be key considerations in your SEO strategy for next year.
Discover more insights on how these trends could affect SEO next year by signing up for this webinar.
Optimize Your SEO Strategy
If you struggled to keep up with this year’s frequent search engine updates, the SEO predictions you’ll discover in this webinar could be a game-changer for your business.
If you want to stay competitive in 2023, it’s time to take action and start optimizing your SEO strategy.
A mere day after Elon Musk reactivated Rep. Marjorie Taylor Greene’s Twitter account, she tweeted that I’m a “communist groomer,” presumably because I’m a gay Jewish Democratic elected official from San Francisco.
Greene’s tweet also promoted her proposed federal law to ban gender-affirming care for transgender youth and to make it effectively impossible for adult transgender people to receive that care. In the past when Greene has gone after me with homophobic or transphobic tropes, I’ve received increased abuse on social media, but this was an escalation beyond what I’m used to. And that escalation, which was especially pronounced after the Club Q massacre, was due less to Greene than to Twitter’s new owner, Elon Musk.
Since finalizing his purchase of Twitter, Musk has brought some of the platform’s most notorious banned users back to the flock. Shortly before he restored Greene’s account, he reactivated the accounts of Donald Trump and Kanye West (of “death con 3 on Jewish people” fame). He’s also reinstated the accounts of Project Veritas, which had engaged in severe doxxing; James Lindsay, who popularized the “OK groomer” hashtag, opined that Joe McCarthy hadn’t gone far enough, and referred to a Jewish person as “Dr. Lampshades” (a Holocaust myth that holds that Jewish skin was used to make lampshades); and Andrew Tate, who said that rape victims bear responsibility for getting raped.
Musk is now promising—based on a Twitter “poll” that was reportedly mobbed with extremist 4chan users—to reactivate any suspended account that didn’t violate the law or generate egregious spam. That could be quite the motley crew: for example, Nick Fuentes, a white supremacist who said “the Jews had better start being nice to people like us, because what comes out of this is going to be a lot uglier and a lot worse for them”; Milo Yiannopoulos, who worked closely with Nazi and white supremacist leaders, was Sieg Heil saluted by Nazis, used antisemitic words as passwords, and recently posted about the “Jewish powers that be who hate Jesus Christ, hate our country, and see us all as disposable cattle according to their ‘holy’ book” (Yiannopoulos interns for Greene); and an endless cast of lesser-known insurrectionists, bigots, and online harassers. And given that Trump absolutely broke the law by inciting people to violent insurrection, Musk’s “violate the law” exclusion appears to be quite limited.
While Twitter is a small platform compared with other major social media, this shift matters tremendously. Twitter punches way above its weight class. It is an incredibly important platform for our democracy—a place where ideas and information germinate, spread, and break out of Twitter itself into broader media and public perception. Whether for politics, media, science, medicine, history, or pretty much any other subject area, Twitter has become an epicenter of public discourse in American life.
Make no mistake: the reinstatement of these accounts will make Twitter far more toxic than it was before. The people previously banned from Twitter are not just benign trolls. Many have engaged in aggressive antisemitic, homophobic, transphobic, or racist harassment campaigns; are doxxers; are egregious purveyors of misinformation that risks violence or promotes vaccine lies; or have incited or continue to incite insurrection. Bringing them back not only forgives their past behavior, it validates and enshrines their rhetoric as pillars of Twitter’s platform going forward.
Musk’s reinstatement effort appears to stem from his assertion that he is a “free speech absolutist.” Putting aside that he’s banned multiple progressive accounts that parodied him—parody being one of the most powerful and essential forms of free speech—his free speech absolutism is actually about free hate speech, free harassment speech, and free incitement speech. Combined with his decimation of Twitter’s content moderation staff, Twitter will quickly become the free-for-all hellscape Musk insists he wants to avoid.
If Twitter becomes a right-wing cesspool—even if it’s just a more benign version of 4chan—its role as a democratizing host to global conversations will quickly collapse, as people who don’t think Fuentes or other white supremacists and Nazis are awesome flee the platform.
More tangibly for Twitter users—and for those who are not on Twitter but are nevertheless targeted on the increasingly unmoderated platform—an antisemitic, racist, homophobic, transphobic, xenophobic, threatening Twitter cesspool puts a lot of people in actual physical danger. I say this based on personal experience, as that gay Jewish Democrat from San Francisco.
Over the past several years, I’ve received thousands of death threats, overwhelmingly on or stemming from social media, largely in response to my work advancing LGBTQ+ civil rights, with a secondary source being my work to expand vaccine access.
The threats and harassment started when I wrote a law to repeal several felonies that singled out people living with HIV for harsh criminal treatment (felonies that didn’t apply to people with any other serious infectious diseases). The social media threats and harassment then exploded when I authored a law—supported by law enforcement, civil rights organizations, and victim advocacy groups—to end discrimination against LGBTQ+ young people when determining who should be included on California’s sex offender registry. That bill started the QAnon slander campaign tidal wave against me, describing me as a “pedophile” and “groomer.” The threats and harassment flared up again when I drafted legislation to allow transgender kids and their families to seek refuge in California if they are being criminalized in states that seek to ban gender-affirming care for trans youth, like Texas and Alabama, and when I pursued legislation to allow teenagers to get vaccinated without parental consent and protect their own health.
The threats and harassment directed at me on social media have been breathtaking. I’ve been doxxed. I’ve been repeatedly threatened with decapitation and rape. I’ve been told that the sender would come find me with a gun. I received a bomb threat that led to the police sweeping my home with a bomb-sniffing dog. Several threats, either from or almost certainly inspired by social media, resulted in criminal prosecutions and convictions for those who issued them. For the first time in my life, I had to testify before a jury—against a man who was threatening my very existence.
As I received these waves of death threats, I learned a lot about the various social media platforms and how they handle the problem. YouTube was the slowest to address the threats and harassment. Meta (mostly Instagram but also Facebook) was initially quite slow to take action but got better over time. Twitter was the most responsive and proactive, but I’m confident that, going forward, it won’t be any better than the other platforms. It’ll likely be much worse for people like me.
Yet as bad as it’s been for me, I’m one of the lucky ones. I’m privileged because I have resources. I have a platform and a role where I can highlight this issue, as I’m doing in this piece.
The same can’t be said about the vast majority of people who are threatened, stalked, harassed, or doxxed on Twitter and other platforms and whose lives will get worse as Musk empties out the Twitter equivalent of the Phantom Zone, allowing vicious, bigoted, and even violent harassers, Nazis, and white supremacists to return.
School board members, teachers, and librarians are being targeted by extremists claiming these educators are “grooming” their kids to be transgender or teaching them critical race theory. Progressive activists’ home addresses are being posted online, as are pictures of community leaders’ families. Public health leaders are viciously harassed and threatened by anti-vaxxers, and physicians are harassed and threatened by elements of the anti-choice movement.
Suffice it to say that for every prominent public figure like me who’s getting harassed and threatened, thousands of people are suffering in silence.
Elon Musk owns Twitter, and he has the power to shape and change it. Yet Twitter is so much more than a private asset. It matters to our democracy and public discourse. And it matters in terms of whether people are safe. Musk lives in a rarefied world. He is, in fact, the richest man in the world. He has access to every conceivable resource—security, investigators, or whatever else he needs.
Most of us don’t have those resources. As Musk plays his chaotic Twitter game, we’re the ones left suffering the consequences.
Scott Wiener is a California state senator who represents San Francisco and northern San Mateo County.
China Report is MIT Technology Review’s newsletter about technology developments in China. Sign up to receive it in your inbox every Tuesday.
The past week has meant many sleepless nights for people in China, and for people like me who are intently watching from afar.
You may have seen that nearly three years after the pandemic started, protests have erupted across the country. In Beijing, Shanghai, Urumqi, Guangzhou, Wuhan, Chengdu, and more cities and towns, hundreds of people have taken to the streets to mourn the lives lost in an apartment fire in Urumqi and to demand that the government roll back its strict pandemic policies, which many blame for trapping those who died.
It’s remarkable. It’s likely the largest grassroots protest in China in decades, and it’s happening at a time when the Chinese government is better than ever at monitoring and suppressing dissent.
Videos of these protests have been shared in real time on social media—on both Chinese and American platforms, even though the latter are technically blocked in the country—and they have quickly become international front-page news. However, discussions among foreigners have too often reduced the protests to the most sensational clips, particularly ones in which protesters directly criticize President Xi Jinping or the ruling party.
The reality is more complicated. As in any spontaneous protest, different people want different things. Some only want to abolish the zero-covid policies, while others have made direct calls for freedom of speech or a change of leadership.
I talked to two Shanghai residents who attended the protests to understand what they experienced firsthand, why they went, and what’s making them anxious about the thought of going again. Both have requested we use only their surnames, to avoid political retribution.
Zhang, who went to the first protest in Shanghai after midnight on Saturday, told me he was motivated by a desire to let people know his discontent. “Not everyone can silently suffer from your actions,” he told me, referring to government officials. “No. People’s lives have been really rough, and you should reflect on yourself.”
In the hour that he was there, Zhang said, protesters were mostly chanting slogans that stayed close to opposing zero-covid policies—like the now-famous line “Say no to covid tests, yes to food. No to lockdowns, yes to freedom,” which came from a protest by one Chinese citizen, Peng Lifa, right before China’s heavily guarded party congress meeting last month.
While Peng hasn’t been seen in public since, his slogans have been heard and seen everywhere in China over the past week. Relaxing China’s strict pandemic control measures, which often don’t reflect a scientific understanding of the virus, is the most essential—and most agreed-upon—demand.
It was really only later that night (or, more accurately, early the next morning, around 3 a.m.), that the chants got more radical and more political, when some people directly called for the Chinese Communist Party and Xi to step down. Zhang had already left by then, but from home he saw videos on social media.
Chen, another Shanghai resident, went to the second protest on Sunday afternoon in the same location and heard much of the same as Zhang. She said that while everyone echoed the demands for relaxing the testing system and increasing freedom, there were some chants explicitly mentioning Xi or the Communist Party. These, she said, were noticeably less loud.
Chen agreed that people have the right to say whatever they want, but she worried that it may divert the public’s attention from what she sees as the core message: “It’s unnecessary to shout out too radical political slogans from the beginning. It’s too radical.”
The people protesting are clearly not a monolith. And, to be fair, it is the first time many of them are participating in a protest in real life; they are just learning how it works. They came out of their homes because they have been genuinely disturbed by the increased covid control measures. Even after the Chinese government announced a policy to loosen restrictions in early November, the reality on the ground hasn’t really changed. In some cities, local government officials have doubled down on controls. When people hit the streets, they might be thinking of the things that are closest to their lives and not what that means on a higher political level.
It’s understandable that the rare direct criticism of China’s top leadership has raised more eyebrows overseas and made it into newspaper headlines. But it has also stirred worries that this organic, homegrown movement will be painted as foreign interference. In fact, that’s already happening. Some Chinese pro-government influencers have highlighted the anti-Xi slogans to claim that foreign actors are pushing a “color revolution.”
(Other protesters argue that the legitimacy of the protests would be doubted regardless of whether the slogans were radical or not. Smearing protesters as foreign actors is an old rule in the Chinese information-control playbook.)
So what’s going to happen next? We don’t know how long the protests are going to continue, but they have become much harder to organize and attend since the Chinese police gradually reacted to the events and increased their enforcement activities.
While Zhang has friends who worry that protesters are being pushed to become more radical as the demonstrations continue, that in particular does not trouble him. He told me he thinks it’s perfectly fine for people to have a range of thoughts and feelings. “[If you don’t agree], you can just choose not to say it,” Zhang said. “In protests, there are always going to be slogans that are too radical. You can either choose peaceful demonstrations and not say anything; or if you are speaking out, then don’t be afraid.”
What does worry him is how China’s well-oiled state surveillance system can be easily deployed against these protesters—an important part of the risk calculation for anyone who has participated and who still wants to go. Zhang read on social media that protesters in Beijing suspect their health code data has been used against them to determine who showed up. There are also reports of police checking people’s phones in Shanghai, which deeply concerned Chen and made her take a different route to work on Monday to avoid the police presence.
Chen said she worries about going to a protest again and ending up alone and falling victim to the police. But she would go if enough people showed up; she wants to, because the experience of the past days has taught her that protests really matter.
Back in October, when Peng Lifa staged that single-person protest, Chen thought it would go unnoticed. But seeing so many people in different cities chanting the same words that Peng wrote has convinced her that protests, no matter how small, can get the message across in today’s China. “These fights have meaningful results,” she said. “The [results] may not show up the next day, but they will.”
1. What else you need to know about the protests in China:
A Uyghur living in exile confirmed that five of his relatives died in the Urumqi fire, which inspired the nationwide protests. (AP)
Twitter, with its massively reduced anti-propaganda team, is struggling with the rise of porn spam that has obscured search results on what’s happening in Chinese cities. (Washington Post $)
Blank sheets of white paper have become the new protest symbol. (Wall Street Journal $)
Last week, in a separate but related protest, workers in a Foxconn factory in China clashed, sometimes violently, with security forces over salary changes and covid-infection concerns. (CNN)
2. China plans to revise its antitrust law, adding many new rules targeting tech platforms. (South China Morning Post $)
3. Four Chinese immigrants working on a marijuana farm in Oklahoma were recently killed. (NBC News)
While it’s too early to know if it was the case in this incident, during the pandemic thousands of Chinese immigrants living on the West Coast were lured and trafficked to cannabis farms in New Mexico, Oklahoma, and the Navajo Nation. (Searchlight New Mexico)
4. The Vatican was taken by surprise by the installation of a bishop in China in a diocese that the church does not recognize. (Vatican News)
5. Serbian police bought and used Huawei-made surveillance equipment to identify fugitives and record videos of protesters. (Radio Free Europe)
6. Chinese company Sino Biopharm announced it has successfully developed three mRNA vaccines to prevent monkeypox. (News Medical)
7. Popular video games like World of Warcraft and Overwatch will no longer be playable in China after a deal between Activision Blizzard and the Chinese company NetEase fell through. (BBC)
8. China may be the biggest climate polluter today, but data shows the US is responsible for the most emissions throughout history. (MIT Technology Review)
Lost in translation
When three Chinese artists found themselves in a centralized quarantine facility in Sichuan, they decided to turn eight days in solitary into an art experiment.
As Chinese publication Bingdian Weekly reported, Meng Lichao, Chen Yu, and Yang Yang were supposed to attend an art festival in early November, but a last-minute covid case in the hotel where they were staying meant all three artists had to be transferred to a quarantine facility. Since they were missing the festival, they decided to put up art exhibitions in their individual rooms instead. Meng drew doodles over every inch of the walls and made an audio installation mixing EDM music and audio samples that say “You are being monitored.” Chen printed out surveillance camera footage of fellow residents opening their doors without management’s approval that had been shared in an attempt to publicly shame them. Yang made a collage on the wall with medical waste trash bags, cotton swabs, and food packaging from his quarantine meals.
In the end, since it’s a quarantine facility, no one could come in to see the art in their rooms except for the next batch of residents, who arrived just hours after they left.
One more thing
Who says you can’t find peace and serenity in your phone? Young Chinese people are using apps that simulate “wooden fish”—a special woodblock that Buddhist monks knock rhythmically in ceremonies—to purify themselves of sins and acquire “merit scores.” Well, most of the time it’s more of a tongue-in-cheek joke for these people than a serious religious practice. But app developers have since come up with different variations of digital wooden fish, sometimes gamifying the practice and allowing users to compete with friends for the highest merit score.
We tend to lump all plastics into one category, but water bottles, milk jugs, egg cartons, and credit cards are actually made from different materials, as you’ve probably noticed while trying to figure out what can go in your recycling bin.
Once they’ve reached a recycling facility, the plastic must be separated, a process that can be slow and costly, and ultimately limits which materials, and how much of them, are recycled.
Now researchers have developed a new process that can transform a mixture of several types of plastics into propane, a simple chemical building block that can be used as fuel or converted into new plastics or other products. The process works because, although their exact chemistry can differ, many plastics share a similar basic recipe: they are made of long chains of mostly carbon and hydrogen.
Over 400 million metric tons of plastic are produced each year worldwide. Of that, less than 10% is recycled, about 30% remains in use for some time, and the rest either finds its way to landfills or the environment, or is incinerated. Plastics are also a significant driver of climate change: their production accounted for 3.4% of global greenhouse gas emissions in 2019. Not only does recycling keep plastics out of landfills and oceans, new ways to produce building blocks for plastics could help cut emissions as well.
“What we’re really trying to do is think about ways that we can see these waste plastic materials as a valuable feedstock,” says Julie Rorrer, a postdoctoral fellow in chemical engineering at MIT and one of the lead authors of the recent research.
A major benefit of the new approach Rorrer and her colleagues developed is that it works on the two most common plastics used today: polyethylene and polypropylene. Into the reactor goes a mixture of the plastics that make bottles and milk jugs, and out comes propane. The approach has high selectivity, with propane making up about 80% of the final product gases.
“This is really exciting because it’s a step toward this idea of circularity,” Rorrer says.
To lower the energy needed to break down plastics, the process uses a catalyst with two parts: cobalt and porous sand-like material called zeolites. Researchers still aren’t sure exactly how the combination works, but Rorrer says the selectivity likely comes from the pores in the zeolite, which limit where the long molecular chains in plastics react, while the cobalt helps keep the zeolite from being deactivated.
The process is still far from being ready for industrial use. Right now, the reaction is done in small batches, and it would likely need to be continuous to be economical.
Rorrer says the researchers are also considering what materials they should use. Cobalt is more common and less expensive than some other catalysts they’ve tried, like ruthenium and platinum, but they are still searching for other options. Better understanding how the catalysts work could allow them to replace cobalt with cheaper, more abundant catalysts, Rorrer says.
The ultimate goal would be a fully mixed-feed plastic recycling system, Rorrer says, “and that framework is not completely far-fetched.”
Still, achieving that vision will take some tweaks. Polyethylene and polypropylene are simple chains of carbon and hydrogen, while some other plastics contain other elements, like oxygen and chlorine, that could pose a challenge to chemical recycling methods.
For example, if polyvinyl chloride (PVC), widely used in bottles and pipes, winds up in this system, it could deactivate or poison the catalyst while producing toxic gas side products, so researchers still need to figure out other ways to handle that plastic.
Scientists are also pursuing other ways to accomplish mixed-feed plastic recycling. In a study published in Science in October, researchers used a chemical process alongside genetically engineered bacteria to break down a mixture of three common plastics.
The first step, involving chemical oxidation, cuts up long chains, creating smaller molecules that have oxygen tacked on. The approach is effective because oxidation is “quite promiscuous,” working on a range of materials, explains Shannon Stahl, a lead author of the research and a chemist at the University of Wisconsin.
Oxidizing the plastics generates products that can then be gobbled up by soil bacteria that have been tweaked to feast on them. By altering the metabolism of the bacteria, researchers could eventually make novel plastics, like new forms of nylon.
The research is still a work in progress, says Alli Werner, a biologist at the National Renewable Energy Laboratory and one of the authors of the Science study. In particular, the team is working to better understand the metabolic pathways bacteria are using to make the products so that they can speed up the process and produce larger amounts of useful materials.
This approach could likely be used on a larger scale, as both oxidation and genetically engineered bacteria are already widespread: the petrochemical industry relies on oxidation to make millions of tons of material every year, and microorganisms are used in industries like drug development and food processing.
As biologists like Werner and chemical engineers like Rorrer turn their attention to new plastic recycling methods, they open up opportunities to rethink how we deal with the vast amounts of plastic waste.
“This is a challenge that the community is well suited to tackle,” Rorrer says. And she’s noticed a significant influx of new researchers starting to work on plastics: “It seems like everyone and their sister is getting into plastic upcycling.”
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
I’m coming in with a hot take this week: plastics might just be the most useful inventions of the 20th century.
Before you get out the pitchforks, let me take you on a tour of just a few of the ways that people’s lives are better because of plastics.
Plastics are instrumental in medicine, from syringes to IV bags to glasses lenses. They’re integral in electronics, making possible today’s cheap and light-weight phones and computers. Plastics have even had a hand in making electric vehicles more practical, because cutting weight helps extend how far they can go with the charge in their batteries.
Plastics have brought down costs across industries and saved lives. That helps explain why they’re absolutely everywhere.
Now, I’m sure you’re probably guessing where I’m going next, but it needs to be said: plastics are an environmental, climate, and public health disaster.
Add all that up and what do we get? A large part of society that’s fully come to depend on plastics for a wide range of uses, and a lot of people that are severely and consistently harmed by their use.
Where the heck do we go from here?
Honestly, we’re not getting rid of plastics anytime soon. They’re everywhere, truly ingrained in our lives.
It will probably take until 2024 for the treaty to be completed, and we don’t know all the details yet, though there’s been talk of production limits, as well as more restrictions on what can go into plastics. But limits on how much plastic nations produce probably won’t be enough to solve the problem.
Finding ways to reinvent plastic recycling could also play a huge role in cutting down on plastic’s negative impacts.
Most plastic recycling today relies on thermal and mechanical techniques—basically melting down plastics and reforming them. This works well in some cases, but can lead to a lower-quality product than what you started with.
That’s why almost no plastic water bottles that do get collected for recycling are made into new water bottles.Instead, the small fraction that do end up getting recycled are typically used to make other products, like carpets.
New approaches like chemical and biological recycling could fix some of these problems. For example, last year I wrote about a French company called Carbios, which is working on using microbes to recycle the plastic in water bottles, PET. If the method winds up being economical, it could help more bottles get recycled back into bottles.
But that process won’t work for all plastics. That brings us to chemical recycling, a huge umbrella term for a variety of different recycling approaches.
One of the most interesting areas in chemical recycling to me is mixed-feed recycling: where different plastics might be handled with one process. Plastics that go to a recycling facility today are separated before going through processing, because your water bottle needs a different treatment from your milk jug.
If it were economical, a mixed-feed recycling system could help recycling make a more significant dent in our plastics problem.
Chemists are trying to do just that, as I wrote about in a new story. Using chemical tools like oxidation and catalysis, or biological tools like genetic engineering, researchers are trying to create a truly circular system for plastics, where old materials create the building blocks for new ones.
A caveat here: details matter when it comes to chemical recycling. The term can refer to a wide range of practices that includes burning plastics, and there are concerns about how these facilities will run and how they’ll affect communities around them. And some of the processes produce chemicals that won’t actually go into new plastics, or be particularly useful to anyone.
But some chemical recycling methods can actually produce useful products, and if handled right, they may help to realize the vision of a circular plastics economy.
There’s still a long road ahead of these efforts to reach commercialization. Improvements to the lab process will be needed to accommodate the wide range of plastics used today and to work at a large scale. But if chemical recycling can safely and economically make useful building blocks for new materials, they could help chip away at the mountain of our plastics problem.
Massive floodgates have helped Venice avert disaster. But just moderate sea-level rise could threaten the multi-decade, multi-billion dollar project by midcentury. (Washington Post)
Offshore wind in Scotland is bringing new energy and jobs to communities that previously relied on oil and gas production. (New York Times)
Satellites show offset sites in California don’t end up with more forest biomass, meaning they’re not actually capturing the carbon they advertise. (Los Angeles Times)
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Elon Musk’s Neuralink hopes to test its brain implant in a human next year
Elon Musk’s brain-computer interface company Neuralink is planning to test a brain implant in humans in six months, the company has announced.
At a ‘show and tell’ event yesterday, Musk said that the company was in the process of submitting paperwork to the US Food and Drug Administration, which has the power to approve or deny the company’s application to start clinical trials in humans.
When Musk launched Neuralink in 2017, he outlined plans for “a high-bandwidth, long-lasting, biocompatible, bidirectional” brain implant. This brain modem, he claimed, could somehow allow humans to keep pace with artificial intelligence. Now, after years of delays and experiments on monkeys, he’s hoping to prove it can be safely implanted in humans.
Musk also announced that the company is working on repurposing the implant for two further parts of the body: the spinal cord, to potentially help to restore movement in someone who is paralysed, and an ocular implant to restore vision in people with sight loss. He demonstrated the latter product with a video explaining how a Neuralink implant had stimulated a flash of light in a monkey’s brain.
Antonio Regalado, our senior biomedicine editor, correctly predicted that a vision implant capable of generating images in an animal’s brain would make its way into the company’s presentation. Read why that matters—and what, in theory, it could mean for humans.
While everyone waits for GPT-4, OpenAI is still fixing its predecessor
Buzz around GPT-4, the anticipated but as-yet-unannounced follow-up to OpenAI’s groundbreaking large language model, GPT-3, is growing by the week. But OpenAI is not yet done tinkering with the previous version.
The San Francisco-based company has released a demo of a new model called ChatGPT, a spin-off of GPT-3 that is geared toward answering questions via back-and-forth dialogue. But while the conversational format allows ChatGPT to admit its mistakes, and reject inappropriate requests, it’s still far from perfect. Read the full story.
—Will Douglas Heaven
In defense of plastic (sort of)
Plastics have a bad reputation, there’s no denying it. They’re an environmental, climate, and public health disaster. But, simultaneously, they’ve brought down costs across industries and saved lives, thanks to their use in everything from medical equipment to electronics.
The question is, where do we go from here? Taking steps to cut down on gratuitous plastic use is a start, and finding ways to reinvent plastic recycling could also play a huge role in cutting down on its negative impacts. Among the most promising of these is chemical recycling, which, if chemists successfully pull it off, could allow us to handle different plastics using a single process. Read the full story.
Casey’s story is from The Spark, her weekly climate and energy newsletter. Sign up to receive it in your inbox every Wednesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 The European Central Bank thinks bitcoin is on its last gasp It says the cryptocurrency is on “the road to irrelevance.” (The Guardian) + Sam Bankman-Fried has given another disastrous interview. (NYT $) + Unsurprisingly, he said his lawyers had advised him against speaking publicly. (Vox) + Times aren’t great for NFT artists right now. (New Yorker $) + It’s okay to opt out of the crypto revolution. (MIT Technology Review)
2 Chinese protests could be the beginning of the end for zero covid It is damaging the country’s economy, and much of the population has had enough. (Vox) + Xi Jinping has painted himself into a corner. (The Atlantic $) + Simply lifting the restrictions won’t magically return life to normal, though. (Wired $)
3 An American journalist is suing NSO Group He and his colleagues allege they were surveilled using the company’s Pegasus spyware. (New Yorker $) + Password manager LastPass says some user data was exposed in a hack. (The Verge) + The war in Ukraine has shifted cybercriminals’ focus away from stealing money. (Economist $) + Google has blocked a Spanish hacking tool. (Wired $) + The hacking industry faces the end of an era. (MIT Technology Review)
4 San Francisco police can now deploy killer robots They can kill someone in order to save the life of a civilian or an officer. (TechCrunch) + The policy could easily end up harming the city’s most vulnerable people. (Wired $)
5 Children are still dying from TikTok’s blackout challenge Parents feel the platform’s not doing enough to prevent other minors from copying the videos. (Bloomberg $)
6 California wants to punish doctors who spread covid misinformation But two legal challenges claim the new law is unconstitutional. (NYT $)
7 Gasoline consumption in the US barely fell last year Despite more electric vehicles hitting the roads, gas use fell by just 0.54%. (Wired $) + Electric vehicle startups are struggling to survive. (The Information $) + Where are those superbatteries we were promised? (IEEE Spectrum)
8 A Singapore therapy chatbot has been accused of gaslighting The government-backed bot is designed to help teachers, but seems to be doing anything but. (Rest of World)
9 Gen Z really doesn’t like Instagram Its cringey pivot to video isn’t cutting through. (The Atlantic $) + Social networks in general are shrinking. (Slate $)
10 You can still poke someone on Facebook Why not brighten up a friend’s day? (BuzzFeed News)
Quote of the day
“If you look at all the major competing platforms that have existed — iOS, Android, Windows — Apple stands out. It is the only one where one company can control what apps get on the device. I don’t think it’s sustainable or good.”
—Meta CEO Mark Zuckerberg (no stranger to accusations of monopolistic behavior himself) joins Elon Musk in criticizing Apple’s power as a gatekeeper for apps in comments made at a New York Times conference.
The big story
Finding homes for the waste that will (probably) outlive humanity
October 2020
Since 2013, when regulators decided to shut California’s San Onofre Nuclear Generating Station down, teams of scientists, engineers, and policymakers have been hard at work to make sure it could be safely decommissioned.
The big question is: what to do with all the spent nuclear fuel? Its radioactive waste could outlast the human race, and is being kept in storage holes buried along the seismically active California coastline.
They are sitting ducks for the next big earthquake, which is likely to hit within the next century. If the nuclear waste somehow got out, the results would be devastating. And the fact the problem exists at all highlights how the US government has so far been unable to fulfill its legal duty to find a long-term home for America’s radioactive waste. Read the full story.
+ How to maintain a healthy, nutritious diet when everything’s so expensive. + I’d be pretty happy with any one of these robot presents, to be honest. + While Christine McVie gave us so many amazing songs, Songbird may just be the best. + Leftovers aren’t just tasty—they’re literal works of art. + There’s a group of tens of thousands of manta rays just vibing off the coast of Ecuador.
The explosion in text-to-image AI models like OpenAI’s DALL-E 2—programs trained to generate pictures of almost anything you ask for—has sent ripples through the creative industries, from fashion to filmmaking, by providing weird and wonderful images on demand.
The same technology behind these programs is also making a splash in biotech labs, which are increasingly using this type of generative AI, known as a diffusion model, to conjure up designs for new types of protein never seen in nature.
Today, two labs separately announced programs that use diffusion models to generate designs for novel proteins with more precision than ever before. Generate Biomedicines, a Boston-based startup, revealed a program called Chroma, which the company describes as the “DALL-E 2 of biology.”
At the same time, a team at the University of Washington led by biologist David Baker has built a similar program called RoseTTAFold Diffusion. In a preprint paper posted online today, Baker and his colleagues show that their model can generate precise designs for novel proteins that can then be brought to life in the lab. “We’re generating proteins with really no similarity to existing ones,” says Brian Trippe, one of the co-developers of RoseTTAFold.
These protein generators can be directed to produce designs for proteins with specific properties, such as shape or size or function. In effect, this makes it possible to come up with new proteins to do particular jobs on demand. Researchers hope that this will eventually lead to the development of new and more effective drugs. “We can discover in minutes what took evolution millions of years,” says Gevorg Grigoryan, CEO of Generate Biomedicines.
“What is notable about this work is the generation of proteins according to desired constraints,” says Ava Amini, a biophysicist at Microsoft Research in Cambridge, Massachusetts.
Symmetrical protein structures generated by Chroma
GENERATE BIOMEDICINES
Proteins are the fundamental building blocks of living systems. In animals, they digest food, contract muscles, detect light, drive the immune system, and so much more. When people get sick, proteins play a part.
Proteins are thus prime targets for drugs. And many of today’s newest drugs are protein based themselves. “Nature uses proteins for essentially everything,” says Grigoryan. “The promise that offers for therapeutic interventions is really immense.”
But drug designers currently have to draw on an ingredient list made up of natural proteins. The goal of protein generation is to extend that list with a nearly infinite pool of computer-designed ones.
Computational techniques for designing proteins are not new. But previous approaches have been slow and not great at designing large proteins or protein complexes—molecular machines made up of multiple proteins coupled together. And such proteins are often crucial for treating diseases.
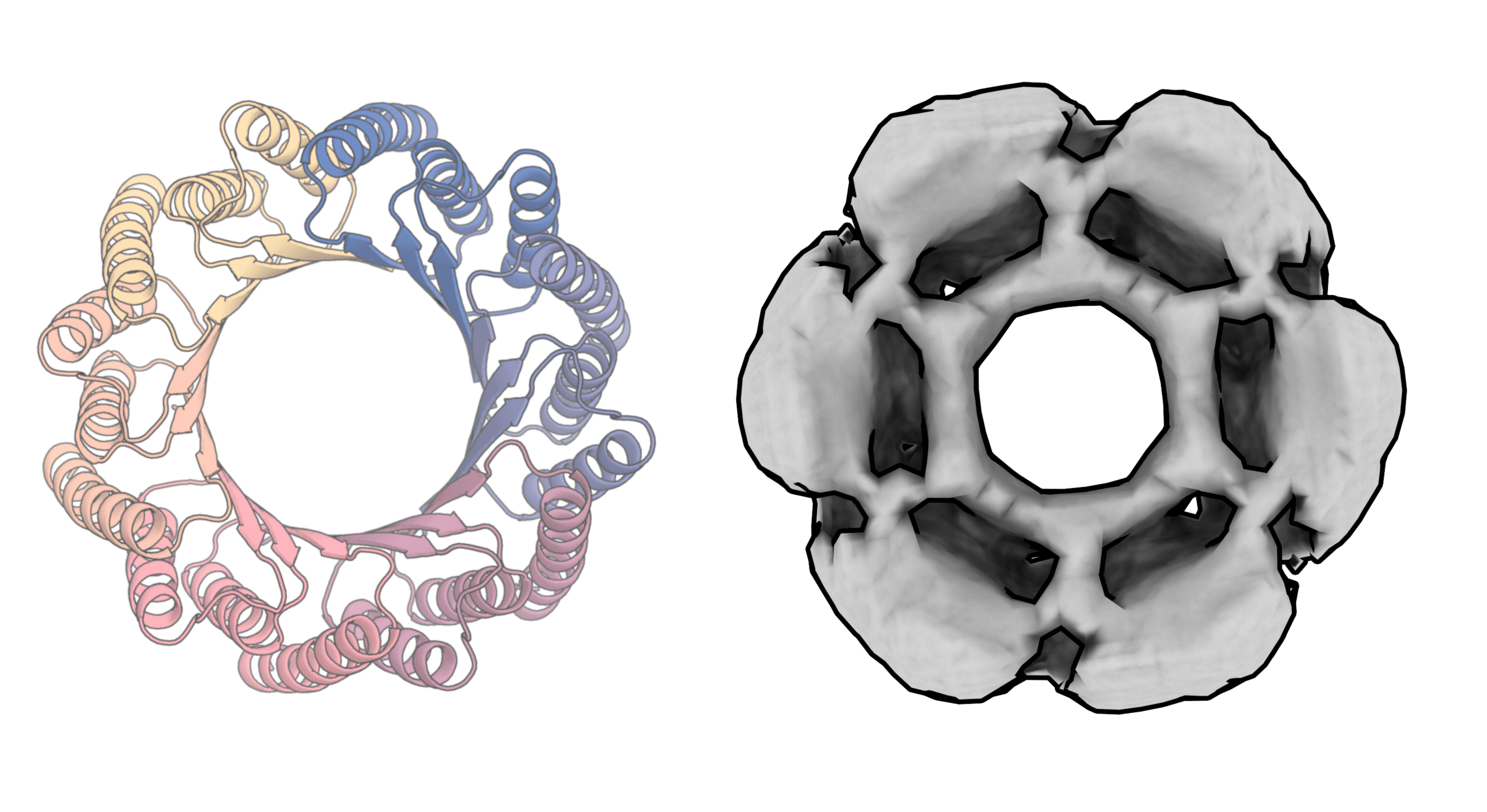
A protein structure generated by RoseTTAFold Diffusion (left) and the same structure created in the lab (right)
IAN C HAYDON / UW INSTITUTE FOR PROTEIN DESIGN
The two programs announced today are also not the first use of diffusion models for protein generation. A handful of studies in the last few months from Amini and others have shown that diffusion models are a promising technique, but these were proof-of-concept prototypes. Chroma and RoseTTAFold Diffusion build on this work and are the first full-fledged programs that can produce precise designs for a wide variety of proteins.
Namrata Anand, who co-developed one of the first diffusion models for protein generation in May 2022, thinks the big significance of Chroma and RoseTTAFold Diffusion is that they have taken the technique and supersized it, training on more data and more computers. “It may be fair to say that this is more like DALL-E because of how they’ve scaled things up,” she says.
Diffusion models are neural networks trained to remove “noise”—random perturbations added to data—from their input. Given a random mess of pixels, a diffusion model will try to turn it into a recognizable image.
In Chroma, noise is added by unraveling the amino acid chains that a protein is made from. Given a random clump of these chains, Chroma tries to put them together to form a protein. Guided by specified constraints on what the result should look like, Chroma can generate novel proteins with specific properties.
Baker’s team takes a different approach, though the end results are similar. Its diffusion model starts with an even more scrambled structure. Another key difference is that RoseTTAFold Diffusion uses information about how the pieces of a protein fit together provided by a separate neural network trained to predict protein structure (as DeepMind’s AlphaFold does). This guides the overall generative process.
Generate Biomedicines and Baker’s team both show off an impressive array of results. They are able to generate proteins with multiple degrees of symmetry, including proteins that are circular, triangular, or hexagonal. To illustrate the versatility of their program, Generate Biomedicines generated proteins shaped like the 26 letters of the Latin alphabet and the numerals 0 to 10. Both teams can also generate pieces of proteins, matching new parts to existing structures.
Most of these demonstrated structures would serve no purpose in practice. But because a protein’s function is determined by its shape, being able to generate different structures on demand is crucial.
Generating strange designs on a computer is one thing. But the goal is to turn these designs into real proteins. To test whether Chroma produced designs that could be made, Generate Biomedicines took the sequences for some of its designs—the amino acid strings that make up the protein—and ran them through another AI program. They found that 55% of them would be predicted to fold into the structure generated by Chroma, which suggests that these are designs for viable proteins.
Baker’s team ran a similar test. But Baker and his colleagues have gone a lot further than Generate Biomedicines in evaluating their model. They have created some of RoseTTAFold Diffusion’s designs in their lab. (Generate Biomedicines says that it is also doing lab tests but is not yet ready to share results.) “This is more than just proof of concept,” says Trippe. “We’re actually using this to make really great proteins.”
A protein structure generated by RoseTTAFold Diffusion that binds to the SARS-CoV-2 spike protein
IAN C HAYDON / UW INSTITUTE FOR PROTEIN DESIGN
For Baker, the headline result is the generation of a new protein that attaches to the parathyroid hormone, which controls calcium levels in the blood. “We basically gave the model the hormone and nothing else and told it to make a protein that binds to it,” he says. When they tested the novel protein in the lab, they found that it attached to the hormone more tightly than anything that could have been generated using other computational methods—and more tightly than existing drugs. “It came up with this protein design out of thin air,” says Baker.
Grigoryan acknowledges that inventing new proteins is just the first step of many. We’re a drug company, he says. “At the end of the day what matters is whether we can make medicines that work or not.” Protein based drugs need to be manufactured in large numbers, then tested in the lab and finally in humans. This can take years. But he thinks that his company and others will find ways for AI to speed up those steps up as well.
“The rate of scientific progress comes in fits and starts,” says Baker. “But right now we’re in the middle of what can only be called a technological revolution.”

 Screenshot from HubSpot.com, June 2022
Screenshot from HubSpot.com, June 2022
![Ranking Factors: Fact Or Fiction? Let’s Bust Some Myths! [Ebook]](https://ecommerceedu.com/wp-content/uploads/2022/10/rf-ebook-download-banner-62e8c6126ffe8-sej.jpg)