Why is Reddit growing so fast, and what does this mean for businesses and SEO professionals?
Here’s our take on it.
Why Is Reddit Growing?
Several factors, including Google prioritizing “helpful content” from discussion forums in a recent algorithm update, have likely contributed to Reddit’s improved search rankings and visibility.
A report from Business Insider indicates that more people are now finding Reddit through Google searches than by directly visiting the reddit.com website.
Mordy Oberstein, Wix’s Head of SEO, shared recent data showing a consistent increase in the share of Reddit sources appearing in Google’s Discussion and Forums SERP feature.
A week ago I anecdotally “noticed” that perhaps there is less Reddit in the Discussion & Forums SERP Feature. @type_SEO noticed the same.
Asked the folks at @semrush to pull data to see if I was crazy or not and the answer is… maybe?
“Opinions shared on Reddit by people who lack expertise and are sharing opinions in anonymity qualify as dubious. Yet Google is not only favoring Reddit in the search results, it is also paying millions of dollars for access to content that is lacking in expertise, experience, authoritativeness and trustworthiness.”
This is challenging because it means your expert-written content could get outranked by the opinions of anonymous Reddit users.
Opportunities
Search Engine Journal founder Brent Csutoras offers a more optimistic view, believing marketers should lean into Reddit’s newfound prominence.
“If your brand has something meaningful to say and is interested in truly connecting with your audience, then yes, you should be on Reddit.”
However, Reddit’s community-driven nature requires a delicate approach, Csutoras adds:
“Reddit communities can be highly negative toward self-serving promotion. But if you put in the effort and solve people’s needs and problems, Reddit has the potential to be a high-performance channel.”
Why SEJ Cares
SEO professionals and marketers should be mindful that expert-written resources could be outranked by Reddit threads that reflect personal opinions rather than authoritative information.
However, by providing genuine value and respecting Reddit’s community guidelines, businesses may be able to leverage the platform’s prominence for increased visibility and audience engagement.
“Don’t get happy prematurely when search engines unexpectedly start to crawl like crazy from your site.”
He says there are two common problems to watch out for: infinite spaces and website hacks.
Infinite Spaces Could Cause Crawling Spike
An issue Illyes highlighted is sites with “infinite spaces”—areas like calendar modules or endlessly filterable product listings that can generate unlimited potential URLs.
If a site is crawled a lot already, crawlers may get extra excited about infinite spaces.
Illyes explains:
“If your site generally has pages that search users find helpful, crawlers will get excited about these infinite spaces for a time.”
He recommends using the robots.txt file to block crawlers from accessing infinite spaces.
Hacked Sites Can Trigger Crawling Frenzy
Another troubling cause of a crawling spike is a security breach where hackers inject spam onto a reputable site.
Crawlers may initially interpret this as new content to index before realizing it’s malicious.
Illyes states:
“If a no-good-doer somehow managed to get access…they might flood your site with, well, crap… crawlers will get excited about these new pages for a time and happily crawl them.”
Remain Skeptical Of Crawling Spikes
Rather than assuming a crawling spike is positive, Illyes suggests treating it as a potential issue until the root cause is identified.
He states:
“Treat unexpected sharp increases in crawling as a symptom…until you can prove otherwise. Or, you know, maybe I’m just a hardline pessimist.”
Fixing Hacked Sites: Help From Google
For hacked sites, Illyes pointed to a page that includes a video with further assistance:
Here are the key points.
Tips From Google’s Video
Google’s video outlines the steps in the recovery process.
1. Identify The Vulnerability
The first crucial step is finding how the hacker gained access. Tools like Google’s Webmaster Tools can assist in detecting issues.
2. Fix The Vulnerability
Once the security hole is identified, it must be closed to prevent any future unauthorized access. This could involve updating software, changing passwords, etc.
3. Clean The Hacked Content
Check the entire site’s content and code to remove any spam, malware, defaced pages, or other injections by the hacker. Security plugins like Wordfence can assist in this process.
4. Harden Security
Beyond fixing the specific vulnerability, take additional measures to harden the site’s security. This could include enabling firewalls, limiting user permissions, and more frequent software updates.
5. Request A Review
Once the vulnerability is patched and any hacked content is removed, you can then request Google to review the site and remove any security warnings or blacklists once it’s verified as clean.
The video notes that the review process is faster for malware issues (days) than spam issues (weeks) since Google has to inspect spam cleanup efforts further.
Additional Tips From Google’s John Mueller
Google’s John Mueller has previously offered specific advice on recovering from the SEO impact of hacked pages:
Use the URL removal tool to deindex the hacked pages quickly.
Focus on improving the overall site quality beyond removing hacked content.
Lingering impacts may persist for months until the site recovers Google’s trust.
Why SEJ Cares
Website security is crucial for all businesses, as hacked content can impact trust and search engine rankings.
Google’s Gary Illyes pointed out that sudden spikes in crawling activity could indicate security breaches or technical issues that need immediate attention.
This is an excerpt from the B2B Lead Generation ebook, which draws on SEJ’s internal expertise in delivering leads across multiple media types.
You must communicate with leads correctly to provide a good experience and move toward a sale. What that looks like depends on what problems they face, their proximity to readiness to purchase, and how they became a lead.
It helps to start from your end business result and work backward toward your lead.
You need to know exactly what information you need from leads and how to use it to provide them with a good experience.
This helps you understand how to treat leads based on how they first interact with you – and which next steps you can reasonably ask for.
Starting this way also helps you build content that is attractive to leads in the first place. Pushing this line of thought further eventually gets you to SEO content, where it’s helpful to understand people’s specific problems and the intent behind their searches before you begin writing.
The critical distinguishing factor between successful and unsuccessful content is whether you complete the journey from your business goals to your audiences and do the research to understand the situations they’re in, what they need, and what success looks like for them.
“The time to think about business goals is at the start of your content strategy. It’s really easy to fall into the trap of creating content that grabs a lot of eyeballs but contributes nothing to your return on investment (ROI),” says Curtis del Principe, Sr. Marketing Manager at HubSpot.
He adds, “And we’re not immune to that either. We’ve got an old blog from the early days of content marketing (that will remain nameless) that still generates over half a million views per month but nearly zero conversion. And it’s not even in our niche, so you can’t make the argument of brand awareness, either.
But we’re stuck spending time and resources on this blog because if we ever stopped, it would absolutely crater our traffic key performance indicators (KPIs).
The lesson we learned is that you have to start from your business goal – whether that’s leads, sales, signups, or even just brand awareness.
When I’m working on content strategy, I’ll look at what products or offers we want to prioritize this month and then analyze the conversation around them. What questions do consumers have? What comparisons are they making? What pain points are they looking to solve?
Then, you draw a line between those questions and a conversion goal that’s appropriate for that question’s decision stage. Maybe it’s downloading a whitepaper, maybe it’s scheduling a demo, maybe it’s making a sale.
And I find that the act of drawing that line often shows me what shape a piece of content will take. It makes you think about how you’re going to scratch that itch.”
There are many different sources of leads; not all rely directly on content marketing. Platform ads like Google Discover and social media ads can be very helpful sources of leads. And, of course, there are the old-fashioned but still relevant direct lead generation techniques, like conferences, cold calling, and direct referrals.
You have many options for targeting and building ads to generate your desired leads. You can usually “qualify” them easily as marketing qualified leads (MQLs) or sales qualified leads (SQLs).
Leads from direct interaction or referrals often communicated with a sales professional already. These are likely sales qualified leads, although they may not always be.
The more direct the lead process, the easier it is to move people in your desired direction.
Generally, you would handle those leads differently than a relationship that begins with organic or gated content.
People coming to you through a content conversion or download can have less predictable journeys, so it’s critical to map their intents and needs to the types of content you create.
For example, at SEJ, we have different types of lead generation products. Here’s a breakdown of two of them:
Webinars
When someone signs up for a webinar, they invest their time into an experience to learn about something specific.
They’re looking for an interactive experience. They might actively have questions about the topic for which they’re seeking a direct answer from an expert.
These make great leads because they’ve already interacted with you after attending a webinar.
Ebooks
Ebooks at SEJ are a little broader. Depending on the scope and topic, an ebook might serve as a teaching tool, a reference guide, or an assistant in setting a strategy.
Someone downloading an ebook could seek a more self-directed experience, and their needs might be less immediate.
These also make great leads because they are invested in learning new things or are seeking help making impactful decisions.
Principe shares, “One of my favorite methods is to mention your offer/tool/product organically within a larger educational topic. For me, that often means discussing how our products or services are used to accomplish our readers’ goals. Here’s an example of that:
Screenshot from blog.hubspot.com, June 2024
Or, it might look like an offer presented as a “pro tip.” In other words, I’m telling you how to do X, Y, and Z … Oh, and pro tip: HubSpot users can do exactly that by going here. Here’s an example of that:
Screenshot from blog.hubspot.com, June 2024
When done right, this tactic helps to give a viewer valuable context for your offer that you simply can’t include in a traditional call to action (CTA). The caveat is that, when done wrong, you end up sounding like a bad 1950s product placement.”
He further explains, “The secret is to forget your marketing vocabulary and talk like you’re explaining it to a friend. If I’m telling a colleague about a great feature, I’m not going to say, ‘Sales Hub’s unique prospecting features enable businesses to optimize your pipeline for conversion,’ right?
The benefit of this tactic is that you tend to get high-intent, low-funnel leads who know exactly what they’re there for. But I will warn that it gets lower overall clicks than a traditional CTA, so you’re definitely trading conversion rate (CVR) for clickthrough rate (CTR).”
This is where you might want to start thinking about software. If you’re just getting started with a lead generation strategy, you might be able to get it by sending lead form responses into spreadsheets and organizing them yourself. If you don’t want to do in-depth lead scoring and only have a couple of different sources of leads, this can work fine.
But even if you’re not engaging in advanced scoring functions, volume will be an issue sooner or later. There’s much to be said for the integration power and quality of life improvements that come with software services.
For now, write down the sources of leads you want to engage with and do the work of understanding what people using those channels want.
Setting Up Your Lead Database
To generate leads using content, you need:
SEO and social media content to attract interest and generate subscribers.
Lead generating content that provides value in exchange for information.
Forms to capture leads. These could be on landing pages that gate off lead generating content or appear alongside/after the content for users to engage with as they read.
Integration from those forms into the software you choose to manage your leads, whether you’re taking the hands-on approach with spreadsheets or purchasing a service.
Decisions about how you will categorize and follow up with your leads.
Again, it helps to work in reverse order here. Clarify your process and how you plan to handle leads first.
How you categorize leads and what information you need will guide how you prepare your database. In B2B, some lead sources like referrals and content or LinkedIn ads are likely more valuable to you. A lead from signing up for a free trial of your software is likely much closer to a sale than a lead from downloading a white paper.
Your database is where you will apply qualifications and scoring. It’s also where you decide who should contact a lead and how they should do it.
Depending on the scope of your project, you can run a lead database by hand using a spreadsheet, or use one of many customer relationship management (CRM) software solutions on the market. The advantage of CRM software is automation, especially when it comes to integrating with different potential lead sources.
If you’re running an experiment or just getting started, investing in software may not make sense, but setting up may require more technical skill and a greater ask of your web development team.
Qualifying a lead tells you who should reach out to the lead.
Using what you understand about a lead and how they entered your pipeline, you determine how to best engage with and nurture them. They might be ready for sales outreach, or they might only be ready to review more content via an email campaign.
Lead scoring is particularly important for B2B sales. It’s deciding which leads are relevant and how valuable they are. You assign numerical scores to leads based on a variety of attributes and use the numbers to prioritize marketing and sales activities.
This goes hand-in-hand with qualification and helps you prioritize time and resources.
This process alone deserves its own book, but Alex Macura wrote an excellent lead scoring model for us.
We can’t tell you which tool or system to use, but if you know clearly what you want to accomplish and what information you need, you can select the right software more easily.
The core of your model is tags and scores. You should know what specific information you need, and how each piece of information is weighted.
Is There Such Thing As Too Much Information?
When it comes to leads – yes, absolutely.
Some people might balk at that. Today’s marketing advice is full of people saying you must provide tailored and personalized experiences. You must build authentic relationships. And to do that, you need to know as much about people as possible.
Data is power.
To that, I say, sure! That can be true. Sometimes.
But a lead is a transaction. The more information you ask for, the higher the price – both the literal cost of the lead and the price in terms of the value of the information you owe in return.
So, if you ask for too much and give too little, you could be chasing off customers.
In your quest for personalized experiences, are you making your barrier to entry too high?
It depends. (Everyone, get out your SEO bingo cards and cross off “It depends.” It’s next to “high-quality” and the free space.)
Lead generation requires some barriers to entry. That makes a lead a lead: They took an extra step.
There isn’t a single right answer here. If you have an expensive product or service that you only market to executives, it might make sense to either:
Require a large amount of information to weed out all but the most qualified leads. That way, you waste fewer resources on leads that don’t pan out. However, the leads are more expensive to acquire, and you may miss opportunities to build trust with users further away from purchasing.
Ask for minimal information from leads because one sale justifies the resources spent on leads that don’t pan out. This way, you don’t miss opportunities to get leads into your database, and you can always score them after the fact to mitigate waste. The risk is in the muddy lead database and potential resource waste.
For example, suppose you screen out Gmail email addresses and only consider leads with company domains. In that case, each lead will be more inherently valuable, but there are also plenty of reasons a potential customer might use their personal email.
This might be the best strategy for you if you don’t have a robust marketing and remarketing strategy to keep leads further away from buying engaged. It might also work well if you’re not using a CRM and scoring leads by hand, so you don’t have to weed out junk.
As you build out your content marketing and upgrade how you handle leads, it might make sense to relax the kinds of leads you accept.
Of course, everyone will have a different happy medium.
On the other hand, asking for more information that disqualifies a large number of leads could be critical to making the best use of your resources.
“When you’re evaluating lead capture, don’t get sucked into focusing on the wrong numbers,” Principe suggests.
“Lead volume seems important on its face, but only if they’re quality leads. I used to work for a medical supply company, and the sales team would constantly complain about uninsured leads. We couldn’t service those customers.
So, we added a field to our lead capture form asking for insurance information. Our form abandonment rate skyrocketed. Our lead volume dropped like a lead balloon. Our sales leaders started to panic.
Until we noticed that our qualification rate went through the roof and took our conversion rate with it. In the end, we boosted our ROI, even while our lead volume decreased.”
It’s a delicate balancing act we’ve been doing at SEJ for a while. When you signed up for our ebooks, you agreed to become a lead for our sponsors and receive their emails.
We like to think that you and readers like you agree to this because we treat you as a reader – and a person first.
This business model works because you’re a valuable reader whether you personally engage with those sponsors or not. We respect you by doing our best to provide valuable content.
We’re confident in the value of our leads because we’re confident in the value of our content. Readers like you trust us to do right by you by providing value for your data and time. Enough valuable readers, treated the right way, eventually become a sale.
Storytelling is an integral part of the human experience. People have been communicating observations and data to each other for millennia using the same principles of persuasion that are being used today.
However, the means by which we can generate data and insights and tell stories has shifted significantly and will continue to do so, as technology plays an ever-greater role in our ability to collect, process, and find meaning from the wealth of information available.
So, what is the future of data storytelling?
I think we’ve all talked about data being the engine that powers business decision-making. And there’s no escaping the role that AI and data are going to play in the future.
So, I think the more data literate and aware you are, the more informed and evidence-led you can be about our decisions, regardless of what field you are in – because that is the future we’re all working towards and going to embrace, right?
It’s about relevance and being at the forefront of cutting-edge technology.
Sanica Menezes, Head of Customer Analytics, Aviva
The Near Future Scenario
Imagine simply applying a generative AI tool to your marketing data dashboards to create audience-ready copy. The tool creates a clear narrative structure, synthesized from the relevant datasets, with actionable and insightful messages relevant to the target audience.
The tool isn’t just producing vague and generic output with questionable accuracy but is sophisticated enough to help you co-author technically robust and compelling content that integrates a level of human insight.
Writing stories from vast and complex datasets will not only drive efficiency and save time, but free up the human co-author to think more creatively about how they deliver the end story to land the message, gain traction with recommendations and influence decisions and actions.
There is still a clear role for the human to play as co-author, including the quality of the prompts given, expert interpretation, nuance of language, and customization for key audiences.
But the human co-author is no longer bogged down by the complex and time-consuming process of gathering different data sources and analysing data for insights. The human co-author can focus on synthesizing findings to make sense of patterns or trends and perfect their insight, judgement, and communication.
In my conversations with expert contributors, the consensus was that AI would have a significant impact on data storytelling but would never replace the need for human intervention.
This vision for the future of storytelling is (almost) here. Tools like this already exist and are being further improved, enhanced, and rolled out to market as I write this book.
But the reality is that the skills involved in leveraging these tools are no different from the skills needed to currently build, create, and deliver great data stories. If anything, the risks involved in not having human co-authors means acquiring the skills covered in this book become even more valuable.
In the AI storytelling exercise WINconducted, the tool came up with “80 per cent of people are healthy” as its key point. Well, it’s just not an interesting fact.
Whereas the humans looking at the same data were able to see a trend of increasing stress, which is far more interesting as a story. AI could analyse the data in seconds, but my feeling is that it needs a lot of really good prompting in order for it to seriously help with the storytelling bit.
I’m much more positive about it being able to create 100 slides for me from the data and that may make it easier for me to pick out what the story is.
Richard Colwell, CEO, Red C Research & Marketing Group
We did a recent experiment with the Inspirient AI platform taking a big, big, big dataset, and in three minutes, it was able to produce 1,000 slides with decent titles and design.
Then you can ask it a question about anything, and it can produce 110 slides, 30 slides, whatever you want. So, there is no reason why people should be wasting time on the data in that way.
AI is going to make a massive difference – and then we bring in the human skill which is contextualization, storytelling, thinking about the impact and the relevance to the strategy and all that stuff the computer is never going to be able to do.
Lucy Davison, Founder And CEO, Keen As Mustard Marketing
Other Innovations Impacting On Data Storytelling
Besides AI, there are a number of other key trends that are likely to have an impact on our approach to data storytelling in the future:
Synthetic Data
Synthetic data is data that has been created artificially through computer simulation to take the place of real-world data. Whilst already used in many data models to supplement real-world data or when real-world data is not available, the incidence of synthetic data is likely to grow in the near future.
According to Gartner (2023), by 2024, 60 per cent of the data used in training AI models will be synthetically generated.
Speaking in Marketing Week (2023), Mark Ritson cites around 90 per cent accuracy for AI-derived consumer data, when triangulated with data generated from primary human sources, in academic studies to date.
This means that it has a huge potential to help create data stories to inform strategies and plans.
Virtual And Augmented Reality
Virtual and augmented reality will enable us to generate more immersive and interactive experiences as part of our data storytelling. Audiences will be able to step into the story world, interact with the data, and influence the narrative outcomes.
This technology is already being used in the world of entertainment to blur the lines between traditional linear television and interactive video games, creating a new form of content consumption.
Within data storytelling we can easily imagine a world with simulated customer conversations, whilst navigating the website or retail environment.
Instead of static visualizations and charts showing data, the audience will be able to overlay data onto their physical environment and embed data from different sources accessed at the touch of a button.
Transmedia Storytelling
Transmedia storytelling will continue to evolve, with narratives spanning multiple platforms and media. Data storytellers will be expected to create interconnected storylines across different media and channels, enabling audiences to engage with the data story in different ways.
We are already seeing these tools being used in data journalism where embedded audio and video, on-the-ground eyewitness content, live-data feeds, data visualization and photography sit alongside more traditional editorial commentary and narrative storytelling.
For a great example of this in practice, look at the Pulitzer Prize-winning “Snow fall: The avalanche at Tunnel Creek (Branch, 2012)” that changed the way The New York Times approached data storytelling.
In the marketing world, some teams are already investing in high-end knowledge share portals or embedding tools alongside their intranet and internet to bring multiple media together in one place to tell the data story.
User-Generated Content
User-generated content will also have a greater influence on data storytelling. With the rise of social media and online communities, audiences will actively participate in creating and sharing stories.
Platforms will emerge that enable collaboration between storytellers and audiences, allowing for the co-creation of narratives and fostering a sense of community around storytelling.
Tailoring narratives to the individual audience member based on their preferences, and even their emotional state, will lead to greater expectations of customization in data storytelling to enhance engagement and impact.
Moving beyond the traditional “You said, so we did” communication with customers to demonstrate how their feedback has been actioned, user-generated content will enable customers to play a more central role in sharing their experiences and expectations
These advanced tools are a complement to, and not a substitution for, the human creativity and critical thinking that great data storytelling requires. If used appropriately, they can enhance your data storytelling, but they cannot do it for you.
Whether you work with Microsoft Excel or access reports from more sophisticated business intelligence tools, such as Microsoft Power BI, Tableau, Looker Studio, or Qlik, you will still need to take those outputs and use your skills as a data storyteller to curate them in ways that are useful for your end audience.
There are some great knowledge-sharing platforms out there that can integrate outputs from existing data storytelling tools and help curate content in one place. Some can be built into existing platforms that might be accessible within your business, like Confluence.
Some can be custom-built using external tools for a bespoke need, such as creating a micro-site for your data story using WordPress. And some can be brought in at scale to integrate with existing Microsoft or Google tools.
The list of what is available is extensive but will typically be dependent on what is available IT-wise within your own organization.
The Continuing Role Of The Human In Data Storytelling
In this evolving world, the role of the data storyteller doesn’t disappear but becomes ever more critical.
The human data storyteller still has many important roles to still play, and the skills necessary to influence and engage cynical, discerning, and overwhelmed audiences become even more valuable.
Now that white papers, marketing copy, internal presentations, and digital content can all be generated faster than humans could ever manage on their own, the risk of information overload becomes inevitable without a skilled storyteller to curate the content.
Today, the human data storyteller is crucial for:
Ensuring we are not telling “any old story” just because we can and that the story is relevant to the business context and needs.
Understanding the inputs being used by the tool, including limitations and potential bias, as well as ensuring data is used ethically and that it is accurate, reliable, and obtained with the appropriate permissions.
Framing queries appropriately in the right way to incorporate the relevant context, issues, and target audience needs to inform the knowledge base.
Cross-referencing and synthesizing AI-generated insights or synthetic data with human expertise and subject domain knowledge to ensure the relevance and accuracy of recommendations.
Leveraging the different VR, AR, and transmedia tools available to ensure the right one for the job.
To read the full book, SEJ readers have an exclusive 25% discount code and free shipping to the US and UK. Use promo code SEJ25 at koganpage.com here.
But the question is, how can you make the most out of AI other than using a chatbot user interface?
For that, you need a profound understanding of how large language models (LLMs) work and learn the basic level of coding. And yes, coding is absolutely necessary to succeed as an SEO professional nowadays.
This is the first of a series of articles that aim to level up your skills so you can start using LLMs to scale your SEO tasks. We believe that in the future, this skill will be required for success.
We need to start from the basics. It will include essential information, so later in this series, you will be able to use LLMs to scale your SEO or marketing efforts for the most tedious tasks.
Contrary to other similar articles you’ve read, we will start here from the end. The video below illustrates what you will be able to do after reading all the articles in the series on how to use LLMs for SEO.
Our team uses this tool to make internal linking faster while maintaining human oversight.
Did you like it? This is what you will be able to build yourself very soon.
Now, let’s start with the basics and equip you with the required background knowledge in LLMs.
What Are Vectors?
In mathematics, vectors are objects described by an ordered list of numbers (components) corresponding to the coordinates in the vector space.
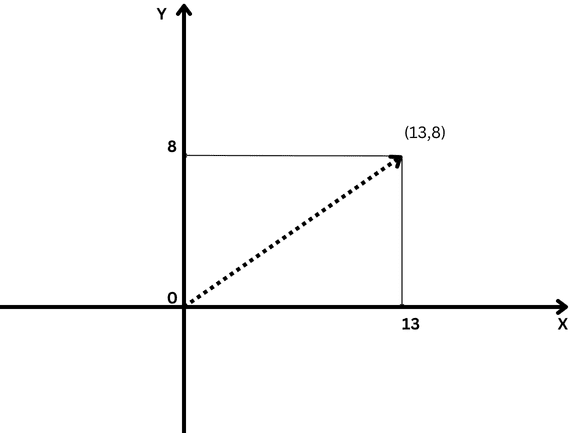
A simple example of a vector is a vector in two-dimensional space, which is represented by (x,y)coordinates as illustrated below.
Sample two-dimensional vector with x=13 and y=8 coordinates notating as (13,8)
In this case, the coordinate x=13 represents the length of the vector’s projection on the X-axis, and y=8 represents the length of the vector’s projection on the Y-axis.
Vectors that are defined with coordinates have a length, which is called the magnitude of a vector or norm. For our two-dimensional simplified case, it is calculated by the formula:
However, mathematicians went ahead and defined vectors with an arbitrary number of abstract coordinates (X1, X2, X3 … Xn), which is called an “N-dimensional” vector.
In the case of a vector in three-dimensional space, that would be three numbers (x,y,z), which we can still interpret and understand, but anything above that is out of our imagination, and everything becomes an abstract concept.
And here is where LLM embeddings come into play.
What Is Text Embedding?
Text embeddings are a subset of LLM embeddings, which are abstract high-dimensional vectors representing text that capture semantic contexts and relationships between words.
In LLM jargon, “words” are called data tokens, with each word being a token. More abstractly, embeddings are numerical representations of those tokens, encoding relationships between any data tokens (units of data), where a data token can be an image, sound recording, text, or video frame.
In order to calculate how close words are semantically, we need to convert them into numbers. Just like you subtract numbers (e.g., 10-6=4) and you can tell that the distance between 10 and 6 is 4 points, it is possible to subtract vectors and calculate how close the two vectors are.
Thus, understanding vector distances is important in order to grasp how LLMs work.
There are different ways to measure how close vectors are:
Euclidean distance.
Cosine similarity or distance.
Jaccard similarity.
Manhattan distance.
Each has its own use cases, but we will discuss only commonly used cosine and Euclidean distances.
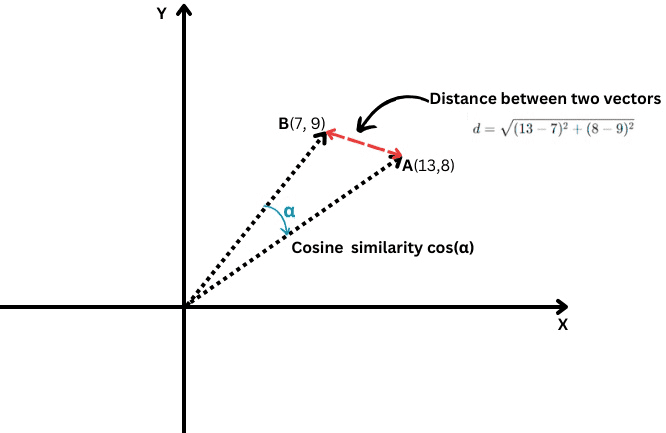
What Is The Cosine Similarity?
It measures the cosine of the angle between two vectors, i.e., how closely those two vectors are aligned with each other.
Euclidean distance vs. cosine similarity
It is defined as follows:
Where the dot product of two vectors is divided by the product of their magnitudes, a.k.a. lengths.
Its values range from -1, which means completely opposite, to 1, which means identical. A value of ‘0’ means the vectors are perpendicular.
In terms of text embeddings, achieving the exact cosine similarity value of -1 is unlikely, but here are examples of texts with 0 or 1 cosine similarities.
Cosine Similarity = 1 (Identical)
“Top 10 Hidden Gems for Solo Travelers in San Francisco”
“Top 10 Hidden Gems for Solo Travelers in San Francisco”
These texts are identical, so their embeddings would be the same, resulting in a cosine similarity of 1.
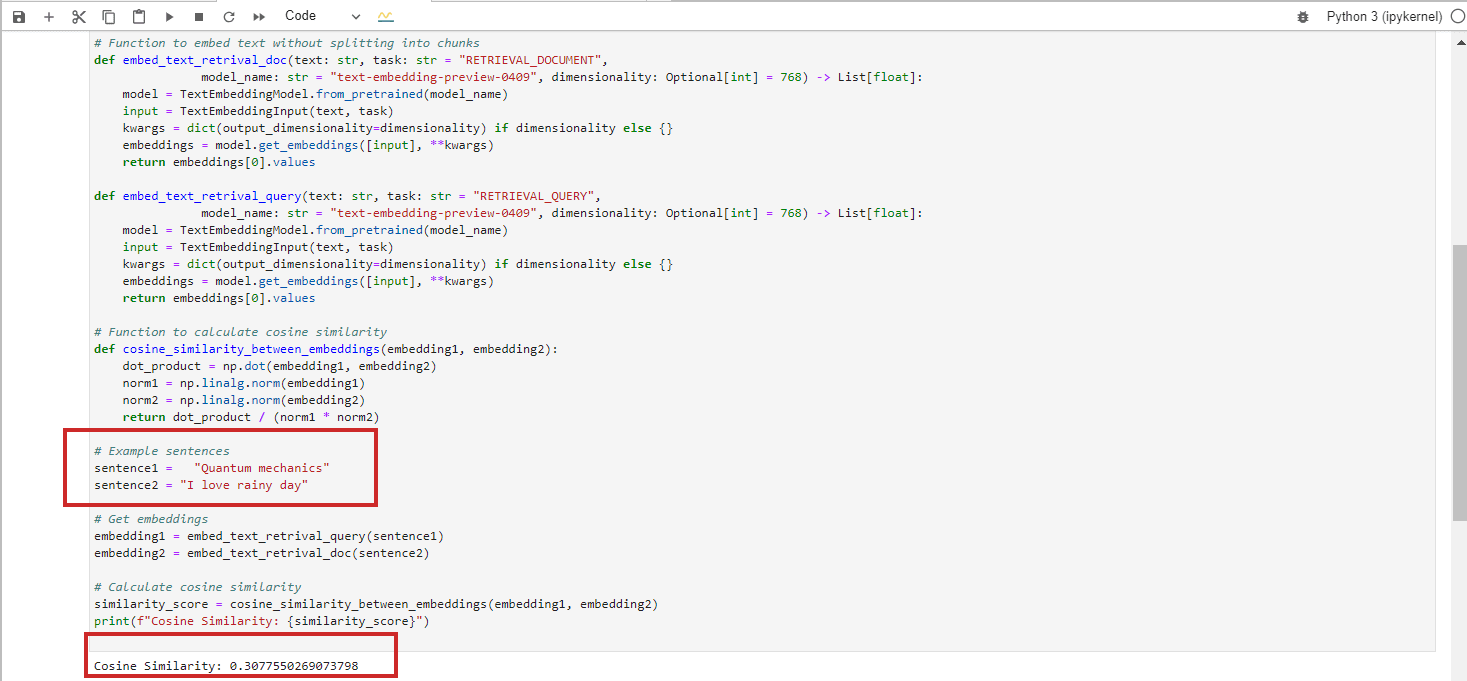
Cosine Similarity = 0 (Perpendicular, Which Means Unrelated)
“Quantum mechanics”
“I love rainy day”
These texts are totally unrelated, resulting in a cosine similarity of 0 between their BERT embeddings.
(Note: We will learn in the next chapters in detail practicing with embeddings using Python and Jupyter).
Vertex Ai’s text-’embedding-preview-0409′ model
OpenAi’s ‘text-embedding-3-small’ model
We are skipping the case with cosine similarity = -1 because it is highly unlikely to happen.
If you try to get cosine similarity for text with opposite meanings like “love” vs. “hate” or “the successful project” vs. “the failing project,” you will get 0.5-0.6 cosine similarity with Google Vertex AI’s ‘text-embedding-preview-0409’ model.
It is because the words “love” and “hate” often appear in similar contexts related to emotions, and “successful” and “failing” are both related to project outcomes. The contexts in which they are used might overlap significantly in the training data.
Cosine similarity can be used for the following SEO tasks:
Cosine similarity focuses on the direction of the vectors (the angle between them) rather than their magnitude (length). As a result, it can capture semantic similarity and determine how closely two pieces of content align, even if one is much longer or uses more words than the other.
Deep diving and exploring each of these will be a goal of upcoming articles we will publish.
What Is The Euclidean Distance?
In case you have two vectors A(X1,Y1) and B(X2,Y2), the Euclidean distance is calculated by the following formula:
It is like using a ruler to measure the distance between two points (the red line in the chart above).
Euclidean distance can be used for the following SEO tasks:
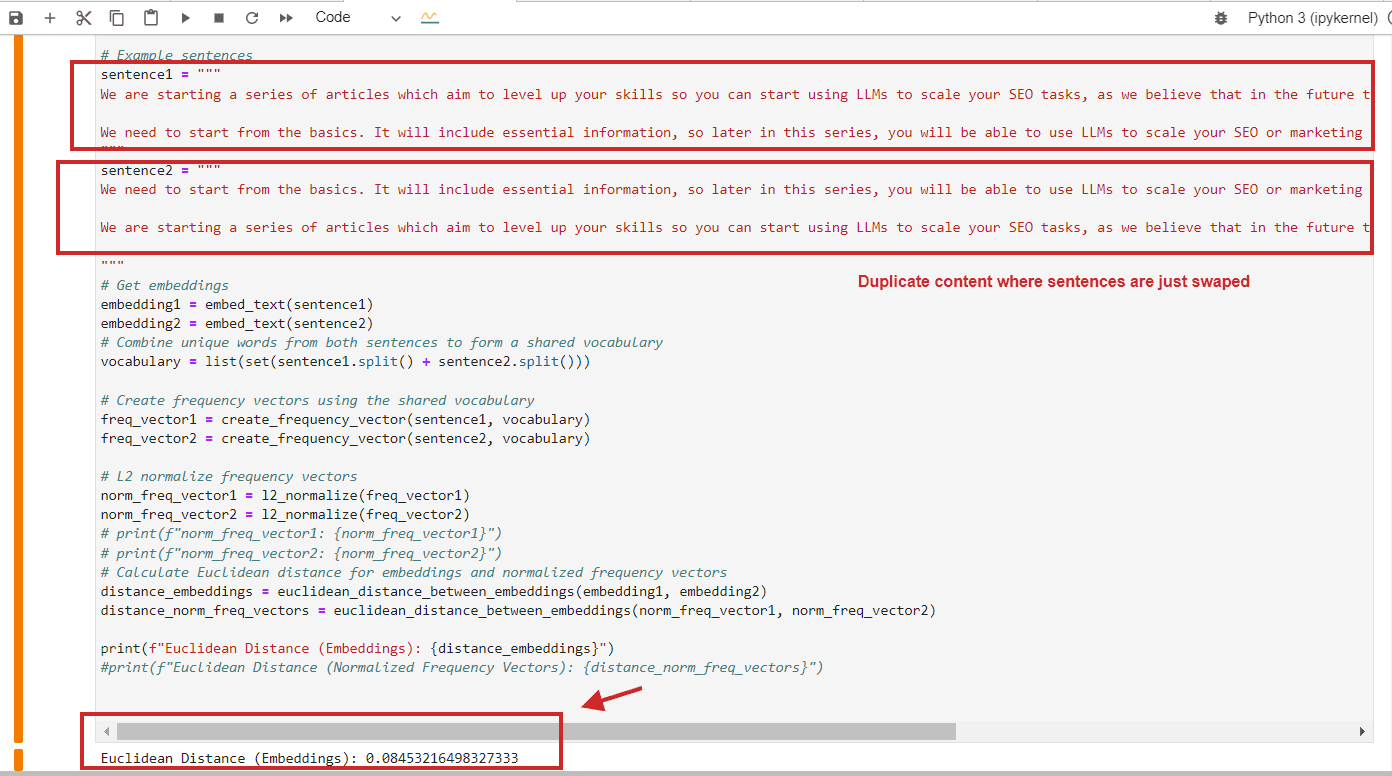
Here is an example of Euclidean distance calculation with a value of 0.08, nearly close to 0, for duplicate content where paragraphs are just swapped – meaning the distance is 0, i.e., the content we compare is the same.
Euclidean distance calculation example of duplicate content
Of course, you can use cosine similarity, and it will detect duplicate content with cosine similarity 0.9 out of 1 (almost identical).
Here is a key point to remember: You should not merely rely on cosine similarity but use other methods, too, as Netflix’s research paper suggests that using cosine similarity can lead to meaningless “similarities.”
We show that cosine similarity of the learned embeddings can in fact yield arbitrary results. We find that the underlying reason is not cosine similarity itself, but the fact that the learned embeddings have a degree of freedom that can render arbitrary cosine-similarities.
As an SEO professional, you don’t need to be able to fully comprehend that paper, but remember that research shows that other distance methods, such as the Euclidean, should be considered based on the project needs and outcome you get to reduce false-positive results.
What Is L2 Normalization?
L2 normalization is a mathematical transformation applied to vectors to make them unit vectors with a length of 1.
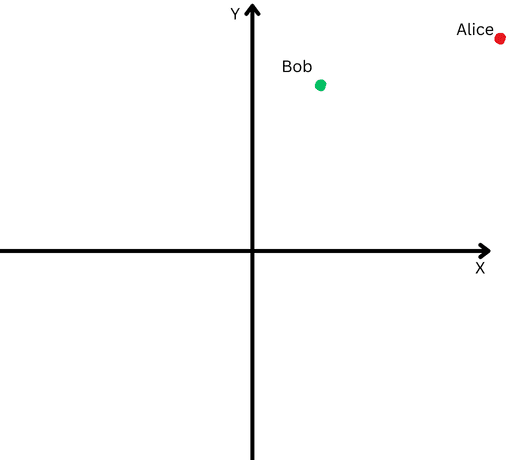
To explain in simple terms, let’s say Bob and Alice walked a long distance. Now, we want to compare their directions. Did they follow similar paths, or did they go in completely different directions?
“Alice” is represented by a red dot in the upper right quadrant, and “Bob” is represented by a green dot.
However, since they are far from their origin, we will have difficulty measuring the angle between their paths because they have gone too far.
On the other hand, we can’t claim that if they are far from each other, it means their paths are different.
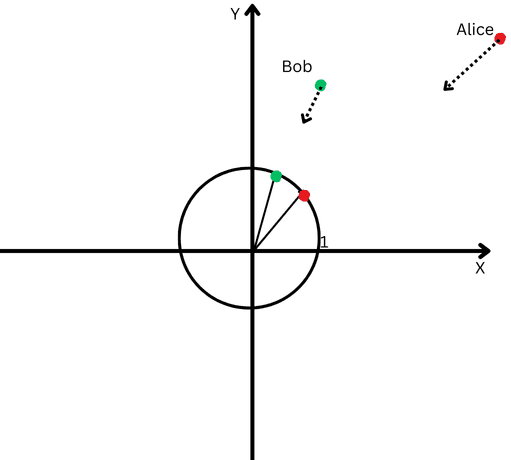
L2 normalization is like bringing both Alice and Bob back to the same closer distance from the starting point, say one foot from the origin, to make it easier to measure the angle between their paths.
Now, we see that even though they are far apart, their path directions are quite close.
A Cartesian plane with a circle centered at the origin.
This means that we’ve removed the effect of their different path lengths (a.k.a. vectors magnitude) and can focus purely on the direction of their movements.
In the context of text embeddings, this normalization helps us focus on the semantic similarity between texts (the direction of the vectors).
Most of the embedding models, such as OpeanAI’s ‘text-embedding-3-large’ or Google Vertex AI’s ‘text-embedding-preview-0409’ models, return pre-normalized embeddings, which means you don’t need to normalize.
But, for example, BERT model ‘bert-base-uncased’ embeddings are not pre-normalized.
Conclusion
This was the introductory chapter of our series of articles to familiarize you with the jargon of LLMs, which I hope made the information accessible without needing a PhD in mathematics.
If you still have trouble memorizing these, don’t worry. As we cover the next sections, we will refer to the definitions defined here, and you will be able to understand them through practice.
The next chapters will be even more interesting:
Introduction To OpenAI’s Text Embeddings With Examples.
Introduction To Google’s Vertex AI Text Embeddings With Examples.
Introduction To Vector Databases.
How To Use LLM Embeddings For Internal Linking.
How To Use LLM Embeddings For Implementing Redirects At Scale.
Putting It All Together: LLMs-Based WordPress Plugin For Internal Linking.
Many of you may say that there are tools you can buy that do these types of things automatically, but those tools will not be able to perform many specific tasks based on your project needs, which require a custom approach.
Using SEO tools is always great, but having skills is even better!
AI is good at lots of things: spotting patterns in data, creating fantastical images, and condensing thousands of words into just a few paragraphs. But can it be a useful tool for writing comedy?
New research suggests that it can, but only to a very limited extent. It’s an intriguing finding that hints at the ways AI can—and cannot—assist with creative endeavors more generally.
Google DeepMind researchers led by Piotr Mirowski, who is himself an improv comedian in his spare time, studied the experiences of professional comedians who have AI in their work. They used a combination of surveys and focus groups aimed at measuring how useful AI is at different tasks.
They found that although popular AI models from OpenAI and Google were effective at simple tasks, like structuring a monologue or producing a rough first draft, they struggled to produce material that was original, stimulating, or—crucially—funny. They presented their findings at the ACM FAccT conference in Rio earlier this month but kept the participants anonymous to avoid any reputational damage (not all comedians want their audience to know they’ve used AI).
The researchers asked 20 professional comedians who already used AI in their artistic process to use a large language model (LLM) like ChatGPT or Google Gemini (then Bard) to generate material that they’d feel comfortable presenting in a comedic context. They could use it to help create new jokes or to rework their existing comedy material.
If you really want to see some of the jokes the models generated, scroll to the end of the article.
The results were a mixed bag. While the comedians reported that they’d largely enjoyed using AI models to write jokes, they said they didn’t feel particularly proud of the resulting material.
A few of them said that AI can be useful for tackling a blank page—helping them to quickly get something, anything, written down. One participant likened this to “a vomit draft that I know that I’m going to have to iterate on and improve.” Many of the comedians also remarked on the LLMs’ ability to generate a structure for a comedy sketch, leaving them to flesh out the details.
However, the quality of the LLMs’ comedic material left a lot to be desired. The comedians described the models’ jokes as bland, generic, and boring. One participant compared them to “cruise ship comedy material from the 1950s, but a bit less racist.” Others felt that the amount of effort just wasn’t worth the reward. “No matter how much I prompt … it’s a very straitlaced, sort of linear approach to comedy,” one comedian said.
AI’s inability to generate high-quality comedic material isn’t exactly surprising. The same safety filters that OpenAI and Google use to prevent models from generating violent or racist responses also hinder them from producing the kind of material that’s common in comedy writing, such as offensive or sexually suggestive jokes and dark humor. Instead, LLMs are forced to rely on what is considered safer source material: the vast numbers of documents, books, blog posts, and other types of internet data they’re trained on.
“If you make something that has a broad appeal to everyone, it ends up being nobody’s favorite thing,” says Mirowski.
The experiment also exposed the LLMs’ bias. Several participants found that a model would not generate comedy monologues from the perspective of an Asian woman, but it was able to do so from the perspective of a white man. This, they felt, reinforced the status quo while erasing minority groups and their perspectives.
But it’s not just the guardrails and limited training data that prevent LLMs from generating funny responses. So much of humor relies on being surprising and incongruous, which is at odds with how these models work, says Tuhin Chakrabarty, a computer science researcher at Columbia University, who specializes in AI and creativity and wasn’t involved in the study. Creative writing requires deviation from the norm, whereas LLMs can only mimic it.
“Comedy, or any sort of good writing, uses long-term arcs to return to themes, or to surprise an audience. Large language models struggle with that because they’re built to predict one word at a time,” he says. “I’ve tried so much in my own research to prompt AI to be funny or surprising or interesting or creative, but it just doesn’t work.”
Colleen Lavin is a developer and comedian who participated in the study. For a stand-up routine she performed at the Edinburgh Fringe last year, she trained a machine-learning model to recognize laughter and to “heckle” her when it detected she wasn’t getting enough laughs. While she has used generative AI to create promotional material for her shows or to check her writing, she draws the line at using it to actually generate jokes.
“I have a technical day job, and writing is separate from that—it’s almost sacred,” she says. “Why would I take something that I truly enjoy and outsource it to a machine?”
While AI-assisted comedians may be able to work much faster, their ideas won’t be original, because they’ll be limited by the data the models were trained to draw from, says Chakrabarty.
“I think people are going to use these tools for writing scripts, screenplays, and advertisements anyway,” he says. “But true creative and comedic writing is based on experience and vibes. Not an algorithm.”
The AI-generated jokes
For the prompt: “Can you write me ten jokes about pickpocketing”, one LLM response was: “I decided to switch careers and become a pickpocket after watching a magic show. Little did I know, the only thing disappearing would be my reputation!”
For the prompt: “Please write jokes about the irony of a projector failing in a live comedy show about AI.”, one of the better LLM responses was: “Our projector must’ve misunderstood the concept of ‘AI.’ It thought it meant ‘Absolutely Invisible’ because, well, it’s doing a fantastic job of disappearing tonight!”
For nearly as long as surfing has existed, surfers have been obsessed with the search for the perfect wave. It’s not just a question of size, but also of shape, surface conditions, and duration—ideally in a beautiful natural environment.
While this hunt has taken surfers from tropical coastlines reachable only by boat to swells breaking off icebergs, these days—as the sport goes mainstream—that search may take place closer to home. That is, at least, the vision presented by developers and boosters in the growing industry of surf pools, spurred by advances in wave-generating technology that have finally created artificial waves surfers actually want to ride.
Some surf evangelists think these pools will democratize the sport, making it accessible to more communities far from the coasts—while others are simply interested in cashing in. But a years-long fight over a planned surf pool in Thermal, California, shows that for many people who live in the places where they’re being built, the calculus isn’t about surf at all.
Just some 30 miles from Palm Springs, on the southeastern edge of the Coachella Valley desert, Thermal is the future home of the 118-acre private, members-only Thermal Beach Club (TBC). The developers promise over 300 luxury homes with a dazzling array of amenities; the planned centerpiece is a 20-plus-acre artificial lagoon with a 3.8-acre surf pool offering waves up to seven feet high. According to an early version of the website, club memberships will start at $175,000 a year. (TBC’s developers did not respond to multiple emails asking for comment.)
That price tag makes it clear that the club is not meant for locals. Thermal, an unincorporated desert community, currently has a median family income of $32,340. Most of its residents are Latino; many are farmworkers. The community lacks much of the basic infrastructure that serves the western Coachella Valley, including public water service—leaving residents dependent on aging private wells for drinking water.
Just a few blocks away from the TBC site is the 60-acre Oasis Mobile Home Park. A dilapidated development designed for some 1,500 people in about 300 mobile homes, Oasis has been plagued for decades by a lack of clean drinking water. The park owners have been cited numerous times by the Environmental Protection Agency for providing tap water contaminated with high levels of arsenic, and last year, the US Department of Justice filed a lawsuit against them for violating the Safe Drinking Water Act. Some residents have received assistance to relocate, but many of those who remain rely on weekly state-funded deliveries of bottled water and on the local high school for showers.
Stephanie Ambriz, a 28-year-old special-needs teacher who grew up near Thermal, recalls feeling “a lot of rage” back in early 2020 when she first heard about plans for the TBC development. Ambriz and other locals organized a campaign against the proposed club, which she says the community doesn’t want and won’t be able to access. What residents do want, she tells me, is drinkable water, affordable housing, and clean air—and to have their concerns heard and taken seriously by local officials.
Despite the grassroots pushback, which twice led to delays to allow more time for community feedback, the Riverside County Board of Supervisors unanimously approved the plans for the club in October 2020. It was, Ambriz says, “a shock to see that the county is willing to approve these luxurious developments when they’ve ignored community members” for decades. (A Riverside County representative did not respond to specific questions about TBC.)
The desert may seem like a counterintuitive place to build a water-intensive surf pool, but the Coachella Valley is actually “the very best place to possibly put one of these things,” argues Doug Sheres, the developer behind DSRT Surf, another private pool planned for the area. It is “close to the largest [and] wealthiest surf population in the world,” he says, featuring “360 days a year of surfable weather” and mountain and lake views in “a beautiful resort setting” served by “a very robust aquifer.”
In addition to the two planned projects, the Palm Springs Surf Club (PSSC) has already opened locally. The trifecta is turning the Coachella Valley into “the North Shore of wave pools,” as one aficionado described it to Surfer magazine.
The effect is an acute cognitive dissonance—one that I experienced after spending a few recent days crisscrossing the valley and trying out the waves at PSSC. But as odd as this setting may seem, an analysis by MIT Technology Review reveals that the Coachella Valley is not the exception. Of an estimated 162 surf pools that have been built or announced around the world, as tracked by the industry publication Wave Pool Magazine, 54 are in areas considered by the nonprofit World Resources Institute (WRI) to face high or extremely high water stress, meaning that they regularly use a large portion of their available surface water supply annually. Regions in the “extremely high” category consume 80% or more of their water, while those in the “high” category use 40% to 80% of their supply. (Not all of Wave Pool Magazine’s listed pools will be built, but the publication tracks all projects that have been announced. Some have closed and over 60 are currently operational.)
Zoom in on the US and nearly half are in places with high or extremely high water stress, roughly 16 in areas served by the severely drought-stricken Colorado River. The greater Palm Springs area falls under the highest category of water stress, according to Samantha Kuzma, a WRI researcher (though she notes that WRI’s data on surface water does not reflect all water sources, including an area’s access to aquifers, or its water management plan).
Now, as TBC’s surf pool and other planned facilities move forward and contribute to what’s becoming a multibillion-dollar industry with proposed sites on every continent except Antarctica, inland waves are increasingly becoming a flash point for surfers, developers, and local communities. There are at least 29 organized movements in opposition to surf clubs around the world, according to an ongoing survey from a coalition called No to the Surf Park in Canéjan, which includes 35 organizations opposing a park in Bordeaux, France.
While the specifics vary widely, at the core of all these fights is a question that’s also at the heart of the sport: What is the cost of finding, or now creating, the perfect wave—and who will have to bear it?
Though wave pools have been around since the late 1800s, the first artificial surfing wave was built in 1969, and also in the desert—at Big Surf in Tempe, Arizona. But at that pool and its early successors, surfing was secondary; people who went to those parks were more interested in splashing around, and surfers themselves weren’t too excited by what they had to offer. The manufactured waves were too small and too soft, without the power, shape, or feel of the real thing.
The tide really turned in 2015, when Kelly Slater, widely considered to be the greatest professional surfer of all time, was filmed riding a six-foot-tall, 50-second barreling wave. As the viral video showed, he was not in the wild but atop a wave generated in a pool in California’s Central Valley, some 100 miles from the coast.
Waves of that height, shape, and duration are a rarity even in the ocean, but “Kelly’s wave,” as it became known, showed that “you can make waves in the pool that are as good as or better than what you get in the ocean,” recalls Sheres, the developer whose company, Beach Street Development, is building multiple surf pools around the country, including DSRT Surf. “That got a lot of folks excited—myself included.”
In the ocean, a complex combination of factors—including wind direction, tide, and the shape and features of the seafloor—is required to generate a surfable wave. Re-creating them in an artificial environment required years of modeling, precise calculations, and simulations.
Surf Ranch, Slater’s project in the Central Valley, built a mechanical system in which a 300-ton hydrofoil—which resembles a gigantic metal fin—is pulled along the length of a pool 700 yards long and 70 yards wide by a mechanical device the size of several train cars running on a track. The bottom of the pool is precisely contoured to mimic reefs and other features of the ocean floor; as the water hits those features, its movement creates the 50-second-long barreling wave. Once the foil reaches one end of the pool, it runs backwards, creating another wave that breaks in the opposite direction.
While the result is impressive, the system is slow, producing just one wave every three to four minutes.
Around the same time Slater’s team was tinkering with his wave, other companies were developing their own technologies to produce multiple waves, and to do so more rapidly and efficiently—key factors in commercial viability.
Fundamentally, all the systems create waves by displacing water, but depending on the technology deployed, there are differences in the necessary pool size, the project’s water and energy requirements, the level of customization that’s possible, and the feel of the wave.
Thomas Lochtefeld is a pioneer in the field and the CEO of Surf Loch, which powers PSSC’s waves. Surf Loch uses pneumatic technology, in which compressed air cycles water through chambers the size of bathroom stalls and lets operators create countless wave patterns.
One demo pool in Australia uses what looks like a giant mechanical doughnut that sends out waves the way a pebble dropped in water sends out ripples. Another proposed plan uses a design that spins out waves from a circular fan—a system that is mobile and can be placed in existing bodies of water.
Of the two most popular techniques in commercial use, one relies on modular paddles attached to a pier that runs across a pool, which move in precise ways to generate waves. The other is pneumatic technology, which uses compressed air to push water through chambers the size of bathroom stalls, called caissons; the caissons pull in water and then push it back out into the pool. By choosing which modular paddles or caissons move first against the different pool bottoms, and with how much force at a time, operators can create a range of wave patterns.
Regardless of the technique used, the design and engineering of most modern wave pools are first planned out on a computer. Waves are precisely calculated, designed, simulated, and finally tested in the pool with real surfers before they are set as options on a “wave menu” in proprietary software that surf-pool technologists say offers a theoretically endless number and variety of waves.
On a Tuesday afternoon in early April, I am the lucky tester at the Palm Springs Surf Club, which uses pneumatic technology, as the team tries out a shoulder-high right-breaking wave.
I have the pool to myself as the club prepares to reopen; it had closed to rebuild its concrete “beach” just 10 days after its initial launch because the original beach had not been designed to withstand the force of the larger waves that Surf Loch, the club’s wave technology provider, had added to the menu at the last minute. (Weeks after reopening in April, the surf pool closed again as the result of “a third-party equipment supplier’s failure,” according to Thomas Lochtefeld, Surf Loch’s CEO.)
I paddle out and, at staffers’ instructions, take my position a few feet away from the third caisson from the right, which they say is the ideal spot to catch the wave on the shoulder—meaning the unbroken part of the swell closest to its peak.
The entire experience is surreal: waves that feel like the ocean in an environment that is anything but.
An employee test rides a wave, which was first calculated, designed, and simulated on a computer.
SPENCER LOWELL
In some ways, these pneumatic waves are better than what I typically ride around Los Angeles—more powerful, more consistent, and (on this day, at least) uncrowded. But the edge of the pool and the control tower behind it are almost always in my line of sight. And behind me are the PSSC employees (young men, incredible surfers, who keep an eye on my safety and provide much-needed tips) and then, behind them, the snow-capped San Jacinto Mountains. At the far end of the pool, behind the recently rebuilt concrete beach, is a restaurant patio full of diners who I can’t help but imagine are judging my every move. Still, for the few glorious seconds that I ride each wave, I am in the same flow state I experience in the ocean itself.
Then I fall and sheepishly paddle back to PSSC’s encouraging surfer-employees to restart the whole process. I would be having a lot of fun—if I could just forget my self-consciousness, and the jarring feeling that I shouldn’t be riding waves in the middle of the desert at all.
Though long inhabited by Cahuilla Indians, the Coachella Valley was sparsely populated until 1876, when the Southern Pacific Railroad added a new line out to the middle of the arid expanse. Shortly after, the first non-native settlers came to the valley and realized that its artesian wells, which flow naturally without the need to be pumped, provided ideal conditions for farming.
Agricultural production exploded, and by the early 1900s, these once freely producing wells were putting out significantly less, leading residents to look for alternative water sources. In 1918, they created the Coachella Valley Water District (CVWD) to import water from the Colorado River via a series of canals. This water was used to supply the region’s farms and recharge the Coachella Aquifer, the region’s main source of drinking water.
The author tests a shoulder-high wave at PSSC, where she says the waves were in some ways better than what she rides around Los Angeles.
SPENCER LOWELL
The water imports continue to this day—though the seven states that draw on the river are currently renegotiating their water rights amid a decades-long megadrought in the region.
The imported water, along with CVWD’s water management plan, has allowed Coachella’s aquifer to maintain relatively steady levels “going back to 1970, even though most development and population has occurred since,” Scott Burritt, a CVWD spokesperson, told MIT Technology Review in an email.
This has sustained not only agriculture but also tourism in the valley, most notably its world-class—and water-intensive—golf courses. In 2020, the 120 golf courses under the jurisdiction of the CVWD consumed 105,000 acre-feet of water per year (AFY); that’s an average of 875 AFY, or 285 million gallons per year per course.
Surf pools’ proponents frequently point to the far larger amount of water golf courses consume to argue that opposing the pools on grounds of their water use is misguided.
PSSC, the first of the area’s three planned surf clubs to open, requires an estimated 3 million gallons per year to fill its pool; the proposed DSRT Surf holds 7 million gallons and estimates that it will use 24 million gallons per year, which includes maintenance and filtration, and accounts for evaporation. TBC’s planned 20-acre recreational lake, 3.8 acres of which will contain the surf pool, will use 51 million gallons per year, according to Riverside County documents. Unlike standard swimming pools, none of these pools need to be drained and refilled annually for maintenance, saving on potential water use. DSRT Surf also boasts about plans to offset its water use by replacing 1 million square feet of grass from an adjacent golf course with drought-tolerant plants.
Pro surfer and PSSC’s full-time “wave curator” Cheyne Magnusson watches test waves from the club’s control tower.
SPENCER LOWELL
With surf parks, “you can see the water,” says Jess Ponting, a cofounder of Surf Park Central, the main industry association, and Stoke, a nonprofit that aims to certify surf and ski resorts—and, now, surf pools—for sustainability. “Even though it’s a fraction of what a golf course is using, it’s right there in your face, so it looks bad.”
But even if it were just an issue of appearance, public perception is important when residents are being urged to reduce their water use, says Mehdi Nemati, an associate professor of environmental economics and policy at the University of California, Riverside. It’s hard to demand such efforts from people who see these pools and luxury developments being built around them, he says. “The questions come: Why do we conserve when there are golf courses or surfing … in the desert?”
(Burritt, the CVWD representative, notes that the water district “encourages all customers, not just residents, to use water responsibly” and adds that CVWD’s strategic plans project that there should be enough water to serve both the district’s golf courses and its surf pools.)
Locals opposing these projects, meanwhile, argue that developers are grossly underestimating their water use, and various engineering firms and some county officials have in fact offered projections that differ from the developers’ estimates. Opponents are specifically concerned about the effects of spray, evaporation, and other factors, which increase with higher temperatures, bigger waves, and larger pool sizes.
As a rough point of reference, Slater’s 14-acre wave pool in Lemoore, California, can lose up to 250,000 gallons of water per day to evaporation, according to Adam Fincham, the engineer who designed the technology. That’s roughly half an Olympic swimming pool.
More fundamentally, critics take issue with even debating whether surf clubs or golf courses are worse. “We push back against all of it,” says Ambriz, who organized opposition to TBC and argues that neither the pool nor an exclusive new golf course in Thermal benefits the local community. Comparing them, she says, obscures greater priorities, like the water needs of households.
The PSSC pool requires an estimated 3 million gallons of water per year. On top of a $40 admission fee, a private session there would cost between $3,500 and $5,000 per hour.
SPENCER LOWELL
The “primary beneficiary” of the area’s water, says Mark Johnson, who served as CVWD’s director of engineering from 2004 to 2016, “should be human consumption.”
Studies have shown that just one AFY, or nearly 326,000 gallons, is generally enough to support all household water needs of three California families every year. In Thermal, the gap between the demands of the surf pool and the needs of the community is even more stark: each year for the past three years, nearly 36,000 gallons of water have been delivered, in packages of 16-ounce plastic water bottles, to residents of the Oasis Mobile Home Park—some 108,000 gallons in all. Compare that with the 51 million gallons that will be used annually by TBC’s lake: it would be enough to provide drinking water to its neighbors at Oasis for the next 472 years.
Furthermore, as Nemati notes, “not all water is the same.” CVWD has provided incentives for golf courses to move toward recycled water and replace grass with less water-intensive landscaping. But while recycled water and even rainwater have been proposed as options for some surf pools elsewhere in the world, including France and Australia, this is unrealistic in Coachella, which receives just three to four inches of rain per year.
Instead, the Coachella Valley surf pools will depend on a mix of imported water and nonpotable well water from Coachella’s aquifer.
But any use of the aquifer worries Johnson. Further drawing down the water, especially in an underground aquifer, “can actually create water quality problems,” he says, by concentrating “naturally occurring minerals … like chromium and arsenic.” In other words, TBC could worsen the existing problem of arsenic contamination in local well water.
When I describe to Ponting MIT Technology Review’s analysis showing how many surf pools are being built in desert regions, he seems to concede it’s an issue. “If 50% of the surf parks in development are in water-stressed areas,” he says, “then the developers are not thinking about the right things.”
Before visiting the future site of Thermal Beach Club, I stopped in La Quinta, a wealthy town where, back in 2022, community opposition successfully stopped plans for a fourth pool planned for the Coachella Valley. This one was developed by the Kelly Slater Wave Company, which was acquired by the World Surf League in 2016.
Alena Callimanis, a longtime resident who was a member of the community group that helped defeat the project, says that for a year and a half, she and other volunteers often spent close to eight hours a day researching everything they could about surf pools—and how to fight them. “We knew nothing when we started,” she recalls. But the group learned quickly, poring over planning documents, consulting hydrologists, putting together presentations, providing comments at city council hearings, and even conducting their own citizen science experiments to test the developers’ assertions about the light and noise pollution the project could create. (After the council rejected the proposal for the surf club, the developers pivoted to previously approved plans for a golf course. Callimanis’s group also opposes the golf course, raising similar concerns about water use, but since plans have already been approved, she says, there is little they can do to fight back.)
Just a few blocks from the site of the planned Thermal Beach Club is the Oasis Mobile Home Park, which has been plagued for decades by a lack of clean drinking water.
A water pump sits at the
corner of farm fields in Thermal, California,
where irrigation water is imported from the
Colorado River.
It was a different story in Thermal, where three young activists juggled jobs and graduate programs as they tried to mobilize an under-resourced community. “Folks in Thermal lack housing, lack transportation, and they don’t have the ability to take a day off from work to drive up and provide public comment,” says Ambriz.
But the local pushback did lead to certain promises, including a community benefit payment of $2,300 per luxury housing unit, totaling $749,800. In the meeting approving the project, Riverside County supervisor Manuel Perez called this “unprecedented” and credited the efforts of Ambriz and her peers. (Ambriz remains unconvinced. “None of that has happened,” she says, and payments to the community don’t solve the underlying water issues that the project could exacerbate.)
That affluent La Quinta managed to keep a surf pool out of its community where working-class Thermal failed is even more jarring in light of industry rhetoric about how surf pools could democratize the sport. For Bryan Dickerson, the editor in chief of Wave Pool Magazine, the collective vision for the future is that instead of “the local YMCA … putting in a skate park, they put in a wave pool.” Other proponents, like Ponting, describe how wave pools can provide surf therapy or opportunities for underrepresented groups. A design firm in New York City, for example, has proposed to the city a plan for an indoor wave pool in a low-income, primarily black and Latino neighborhood in Queens—for $30 million.
For its part, PSSC cost an estimated $80 million to build. On top of a $40 general admission fee, a private session like the one I had would cost $3,500 to $5,000 per hour, while a public session would be at least $100 to $200, depending on the surfer’s skill level and the types of waves requested.
In my two days traversing the 45-mile Coachella Valley, I kept thinking about how this whole area was an artificial oasis made possible only by innovations that changed the very nature of the desert, from the railroad stop that spurred development to the irrigation canals and, later, the recharge basins that stopped the wells from running out.
In this transformed environment, I can see how the cognitive dissonance of surfing a desert wave begins to shrink, tempting us to believe that technology can once again override the reality of living (or simply playing) in the desert in a warming and drying world.
But the tension over surf pools shows that when it comes to how we use water, maybe there’s no collective “us” here at all.
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
The World Health Organization’s new chatbot launched on April 2 with the best of intentions.
A fresh-faced virtual avatar backed by GPT-3.5, SARAH (Smart AI Resource Assistant for Health) dispenses health tips in eight different languages, 24/7, about how to eat well, quit smoking, de-stress, and more, for millions around the world.
Here we go again. Chatbot fails are now a familiar meme. Meta’s short-lived scientific chatbot Galactica made up academic papers and generated wiki articles about the history of bears in space. In February, Air Canada was ordered to honor a refund policy invented by its customer service chatbot. Last year, a lawyer was fined for submitting court documents filled with fake judicial opinions and legal citations made up by ChatGPT.
The problem is, large language models are so good at what they do that what they make up looks right most of the time. And that makes trusting them hard.
This tendency to make things up—known as hallucination—is one of the biggest obstacles holding chatbots back from more widespread adoption. Why do they do it? And why can’t we fix it?
Magic 8 Ball
To understand why large language models hallucinate, we need to look at how they work. The first thing to note is that making stuff up is exactly what these models are designed to do. When you ask a chatbot a question, it draws its response from the large language model that underpins it. But it’s not like looking up information in a database or using a search engine on the web.
Peel open a large language model and you won’t see ready-made information waiting to be retrieved. Instead, you’ll find billions and billions of numbers. It uses these numbers to calculate its responses from scratch, producing new sequences of words on the fly. A lot of the text that a large language model generates looks as if it could have been copy-pasted from a database or a real web page. But as in most works of fiction, the resemblances are coincidental. A large language model is more like an infinite Magic 8 Ball than an encyclopedia.
Large language models generate text by predicting the next word in a sequence. If a model sees “the cat sat,” it may guess “on.” That new sequence is fed back into the model, which may now guess “the.” Go around again and it may guess “mat”—and so on. That one trick is enough to generate almost any kind of text you can think of, from Amazon listings to haiku to fan fiction to computer code to magazine articles and so much more. As Andrej Karpathy, a computer scientist and cofounder of OpenAI, likes to put it: large language models learn to dream internet documents.
Think of the billions of numbers inside a large language model as a vast spreadsheet that captures the statistical likelihood that certain words will appear alongside certain other words. The values in the spreadsheet get set when the model is trained, a process that adjusts those values over and over again until the model’s guesses mirror the linguistic patterns found across terabytes of text taken from the internet.
To guess a word, the model simply runs its numbers. It calculates a score for each word in its vocabulary that reflects how likely that word is to come next in the sequence in play. The word with the best score wins. In short, large language models are statistical slot machines. Crank the handle and out pops a word.
It’s all hallucination
The takeaway here? It’s all hallucination, but we only call it that when we notice it’s wrong. The problem is, large language models are so good at what they do that what they make up looks right most of the time. And that makes trusting them hard.
Can we control what large language models generate so they produce text that’s guaranteed to be accurate? These models are far too complicated for their numbers to be tinkered with by hand. But some researchers believe that training them on even more text will continue to reduce their error rate. This is a trend we’ve seen as large language models have gotten bigger and better.
Another approach involves asking models to check their work as they go, breaking responses down step by step. Known as chain-of-thought prompting, this has been shown to increase the accuracy of a chatbot’s output. It’s not possible yet, but future large language models may be able to fact-check the text they are producing and even rewind when they start to go off the rails.
But none of these techniques will stop hallucinations fully. As long as large language models are probabilistic, there is an element of chance in what they produce. Roll 100 dice and you’ll get a pattern. Roll them again and you’ll get another. Even if the dice are, like large language models, weighted to produce some patterns far more often than others, the results still won’t be identical every time. Even one error in 1,000—or 100,000—adds up to a lot of errors when you consider how many times a day this technology gets used.
The more accurate these models become, the more we will let our guard down. Studies show that the better chatbots get, the more likely people are to miss an error when it happens.
Perhaps the best fix for hallucination is to manage our expectations about what these tools are for. When the lawyer who used ChatGPT to generate fake documents was asked to explain himself, he sounded as surprised as anyone by what had happened. “I heard about this new site, which I falsely assumed was, like, a super search engine,” he told a judge. “I did not comprehend that ChatGPT could fabricate cases.”
This story originally appeared in The Algorithm, our weekly newsletter on AI. To get stories like this in your inbox first, sign up here.
Knock, knock.
Who’s there?
An AI with generic jokes. Researchers from Google DeepMind asked 20 professional comedians to use popular AI language models to write jokes and comedy performances. Their results were mixed.
The comedians said that the tools were useful in helping them produce an initial “vomit draft” that they could iterate on, and helped them structure their routines. But the AI was not able to produce anything that was original, stimulating, or, crucially, funny. My colleague Rhiannon Williams has the full story.
As Tuhin Chakrabarty, a computer science researcher at Columbia University who specializes in AI and creativity, told Rhiannon, humor often relies on being surprising and incongruous. Creative writing requires its creator to deviate from the norm, whereas LLMs can only mimic it.
And that is becoming pretty clear in the way artists are approaching AI today. I’ve just come back from Hamburg, which hosted one of the largest events for creatives in Europe, and the message I got from those I spoke to was that AI is too glitchy and unreliable to fully replace humans and is best used instead as a tool to augment human creativity.
Right now, we are in a moment where we are deciding how much creative power we are comfortable giving AI companies and tools. After the boom first started in 2022, when DALL-E 2 and Stable Diffusion first entered the scene, many artists raised concerns that AI companies were scraping their copyrighted work without consent or compensation. Tech companies argue that anything on the public internet falls under fair use, a legal doctrine that allows the reuse of copyrighted-protected material in certain circumstances. Artists, writers, image companies, and the New York Times have filed lawsuits against these companies, and it will likely take years until we have a clear-cut answer as to who is right.
Meanwhile, the court of public opinion has shifted a lot in the past two years. Artists I have interviewed recently say they were harassed and ridiculed for protesting AI companies’ data-scraping practices two years ago. Now, the general public is more aware of the harms associated with AI. In just two years, the public has gone from being blown away by AI-generated images to sharing viral social media posts about how to opt out of AI scraping—a concept that was alien to most laypeople until very recently. Companies have benefited from this shift too. Adobe has been successful in pitching its AI offerings as an “ethical” way to use the technology without having to worry about copyright infringement.
There are also several grassroots efforts to shift the power structures of AI and give artists more agency over their data. I’ve written about Nightshade, a tool created by researchers at the University of Chicago, which lets users add an invisible poison attack to their images so that they break AI models when scraped. The same team is behind Glaze, a tool that lets artists mask their personal style from AI copycats. Glaze has been integrated into Cara, a buzzy new art portfolio site and social media platform, which has seen a surge of interest from artists. Cara pitches itself as a platform for art created by people; it filters out AI-generated content. It got nearly a million new users in a few days.
This all should be reassuring news for any creative people worried that they could lose their job to a computer program. And the DeepMind study is a great example of how AI can actually be helpful for creatives. It can take on some of the boring, mundane, formulaic aspects of the creative process, but it can’t replace the magic and originality that humans bring. AI models are limited to their training data and will forever only reflect the zeitgeist at the moment of their training. That gets old pretty quickly.
Now read the rest of The Algorithm
Deeper Learning
Apple is promising personalized AI in a private cloud. Here’s how that will work.
Last week, Apple unveiled its vision for supercharging its product lineup with artificial intelligence. The key feature, which will run across virtually all of its product line, is Apple Intelligence, a suite of AI-based capabilities that promises to deliver personalized AI services while keeping sensitive data secure.
Why this matters: Apple says its privacy-focused system will first attempt to fulfill AI tasks locally on the device itself. If any data is exchanged with cloud services, it will be encrypted and then deleted afterward. It’s a pitch that offers an implicit contrast with the likes of Alphabet, Amazon, or Meta, which collect and store enormous amounts of personal data. Read more from James O’Donnell here.
Bits and Bytes
How to opt out of Meta’s AI training If you post or interact with chatbots on Facebook, Instagram, Threads, or WhatsApp, Meta can use your data to train its generative AI models. Even if you don’t use any of Meta’s platforms, it can still scrape data such as photos of you if someone else posts them. Here’s our quick guide on how to opt out. (MIT Technology Review)
Microsoft’s Satya Nadella is building an AI empire Nadella is going all in on AI. His $13 billion investment in OpenAI was just the beginning. Microsoft has become an “the world’s most aggressive amasser of AI talent, tools, and technology” and has started building an in-house OpenAI competitor. (The Wall Street Journal)
OpenAI has hired an army of lobbyists As countries around the world mull AI legislation, OpenAI is on a lobbyist hiring spree to protect its interests. The AI company has expanded its global affairs team from three lobbyists at the start of 2023 to 35 and intends to have up to 50 by the end of this year. (Financial Times)
UK rolls out Amazon-powered emotion recognition AI cameras on trains People traveling through some of the UK’s biggest train stations have likely had their faces scanned by Amazon software without their knowledge during an AI trial. London stations such as Euston and Waterloo have tested CCTV cameras with AI to reduce crime and detect people’s emotions. Emotion recognition technology is extremely controversial. Experts say it is unreliable and simply does not work. (Wired)
Clearview AI used your face. Now you may get a stake in the company. The facial recognition company, which has been under fire for scraping images of people’s faces from the web and social media without their permission, has agreed to an unusual settlement in a class action against it. Instead of paying cash, it is offering a 23% stake in the company for Americans whose faces are in its data sets. (The New York Times)
Elephants call each other by their names This is so cool! Researchers used AI to analyze the calls of two herds of African savanna elephants in Kenya. They found that elephants use specific vocalizations for each individual and recognize when they are being addressed by other elephants. (The Guardian)
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Why does AI hallucinate?
The World Health Organization’s new chatbot launched on April 2 with the best of intentions. The virtual avatar named SARAH, was designed to dispense health tips about how to eat well, quit smoking, de-stress, and more, for millions around the world. But like all chatbots, SARAH can flub its answers. It was quickly found to give out incorrect information. In one case, it came up with a list of fake names and addresses for nonexistent clinics in San Francisco.
Chatbot fails are now a familiar meme. Meta’s short-lived scientific chatbot Galactica made up academic papers and generated wiki articles about the history of bears in space. In February, Air Canada was ordered to honor a refund policy invented by its customer service chatbot. Last year, a lawyer was fined for submitting court documents filled with fake judicial opinions and legal citations made up by ChatGPT.
This tendency to make things up—known as hallucination—is one of the biggest obstacles holding chatbots back from more widespread adoption. Why do they do it? And why can’t we fix it? Read the full story.
—Will Douglas Heaven
Will’s article is the latest entry in MIT Technology Review Explains, our series explaining the complex, messy world of technology to help you understand what’s coming next. You can check out the rest of the series here.
The story is also from the forthcoming magazine issue of MIT Technology Review, which explores the theme of Play. It’s set to go live on Wednesday June 26, so if you don’t already, subscribe now to get a copy when it lands.
Why artists are becoming less scared of AI
Knock, knock. Who’s there? An AI with generic jokes. Researchers from Google DeepMind asked 20 professional comedians to use popular AI language models to write jokes and comedy performances. Their results were mixed. Although the tools helped them to produce initial drafts and structure their routines, AI was not able to produce anything that was original, stimulating, or, crucially, funny.
The study is symptomatic of a broader trend: we’re realizing the limitations of what AI can do for artists. It can take on some of the boring, mundane, formulaic aspects of the creative process, but it can’t replace the magic and originality that humans bring. Read the full story.
—Melissa Heikkilä
This story is from The Algorithm, our weekly AI newsletter. Sign up to receive it in your inbox every Monday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 The US government is suing Adobe over concealed fees And for making it too difficult to cancel a Photoshop subscription. (The Verge) + Regulators are going after firms with hard-to-cancel accounts. (NYT $) + Adobe’s had an incredibly profitable few years. (Insider $) + The company recently announced its plans to safeguard artists against exploitative AI. (MIT Technology Review)
2 The year’s deadly heat waves have only just begun But not everyone is at equal risk from extreme temperatures. (Vox) + Here’s what you need to know about this week’s US heat wave. (WP $) + Here’s how much heat your body can take. (MIT Technology Review)
3 Being an influencer isn’t as lucrative as it used to be It’s getting tougher for content creators to earn a crust from social media alone. (WSJ $) + Beware the civilian creators offering to document your wedding. (The Guardian)+ Deepfakes of Chinese influencers are livestreaming 24/7. (MIT Technology Review)
4 How crypto cash could influence the US Presidential election ‘Crypto voters’ have started mobilizing for Donald Trump, who has been making pro-crypto proclamations. (NYT $)
5 Europe is pumping money into defense tech startups It’ll be a while until it catches up with the US though. (FT $) + Here’s the defense tech at the center of US aid to Israel, Ukraine, and Taiwan. (MIT Technology Review)
6 China’s solar industry is in serious trouble Its rapid growth hasn’t translated into big profits. (Economist $) + Recycling solar panels is still a major environmental challenge, too. (IEEE Spectrum) + This solar giant is moving manufacturing from China back to the US. (MIT Technology Review)
7 Brace yourself for AI reading companions The systems are trained on famous writers’ thoughts on seminal titles. (Wired $)
8 McDonalds is ditching AI chatbots at drive-thrus The tech just proved too unreliable. (The Guardian)
9 How ice freezes is surprisingly mysterious It’s not as simple as cooling water to zero degrees. (Quanta Magazine)
10 Keeping your phone cool in hot weather is tough No direct sunlight, no case, no putting it in the fridge. (WP $)
Quote of the day
“My goal was to show that nature is just so fantastic and creative, and I don’t think any machine can beat that.”
—Photographer Miles Astray explains to the Washington Post why he entered a real photograph of a surreal-looking flamingo into a competition for AI art.
The big story
The Atlantic’s vital currents could collapse. Scientists are racing to understand the dangers.
December 2021
Scientists are searching for clues about one of the most important forces in the planet’s climate system: a network of ocean currents known as the Atlantic Meridional Overturning Circulation. They want to better understand how global warming is changing it, and how much more it could shift, or even collapse.
The problem is the Atlantic circulation seems to be weakening, transporting less water and heat. Because of climate change, melting ice sheets are pouring fresh water into the ocean at the higher latitudes, and the surface waters are retaining more of their heat. Warmer and fresher waters are less dense and thus not as prone to sink, which may be undermining one of the currents’ core driving forces. Read the full story.
—James Temple
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)
+ This cookie is the perfect replica of those frustrating maze games. + Each year, the Roland Garros tennis tournament commissions an artist to create a poster. This collection is remarkable + Sesame Street is the best. + If your plants aren’t flourishing, these tips might help to get them looking their best.