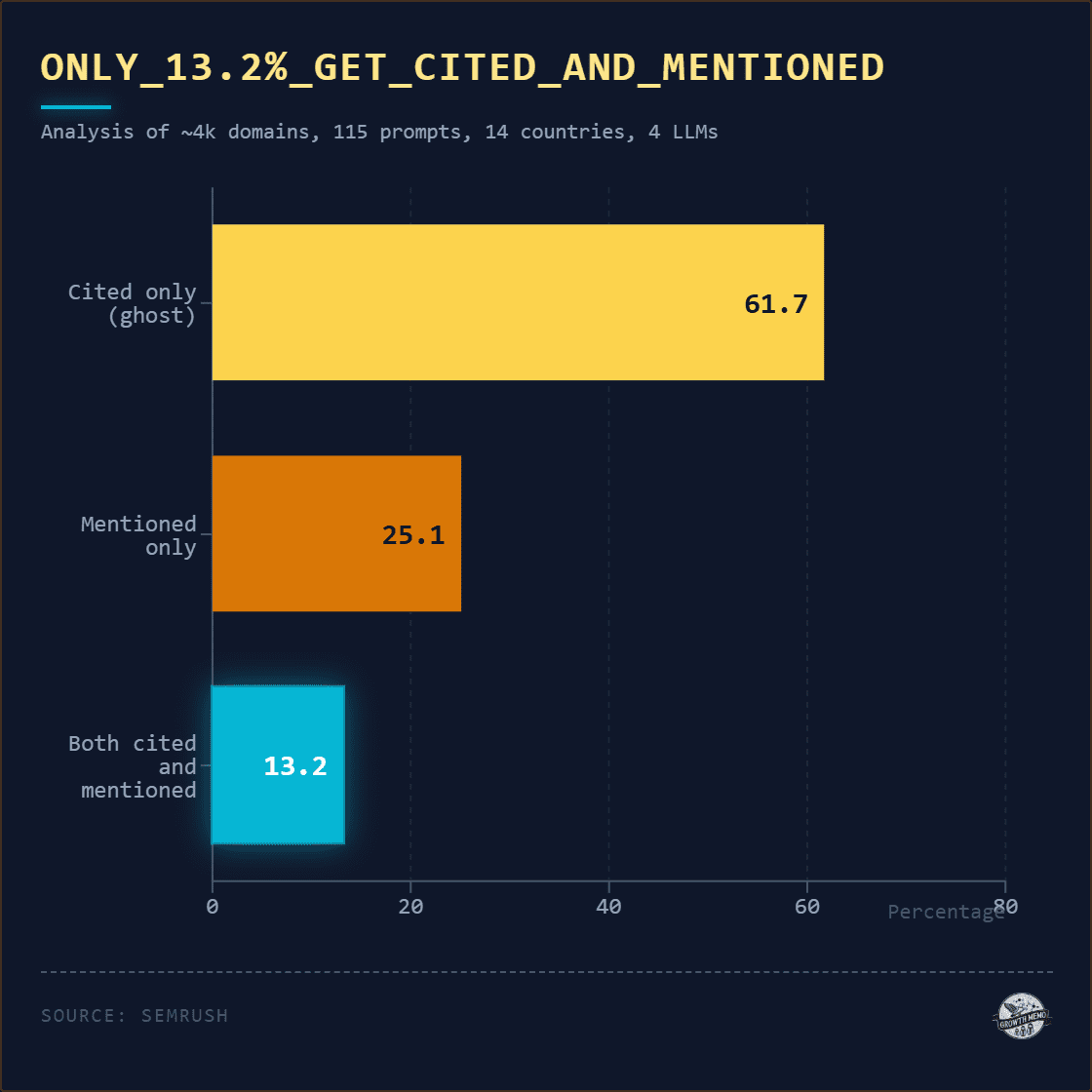
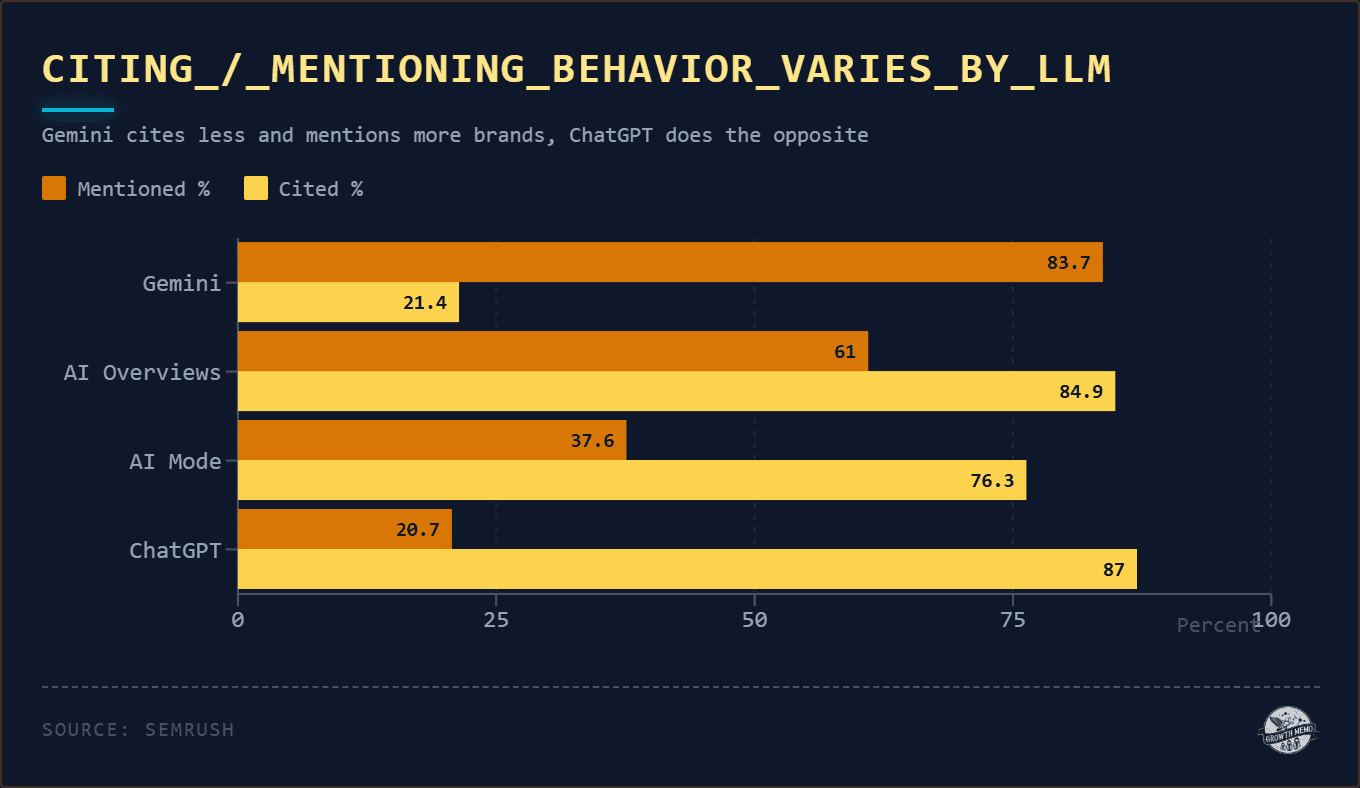
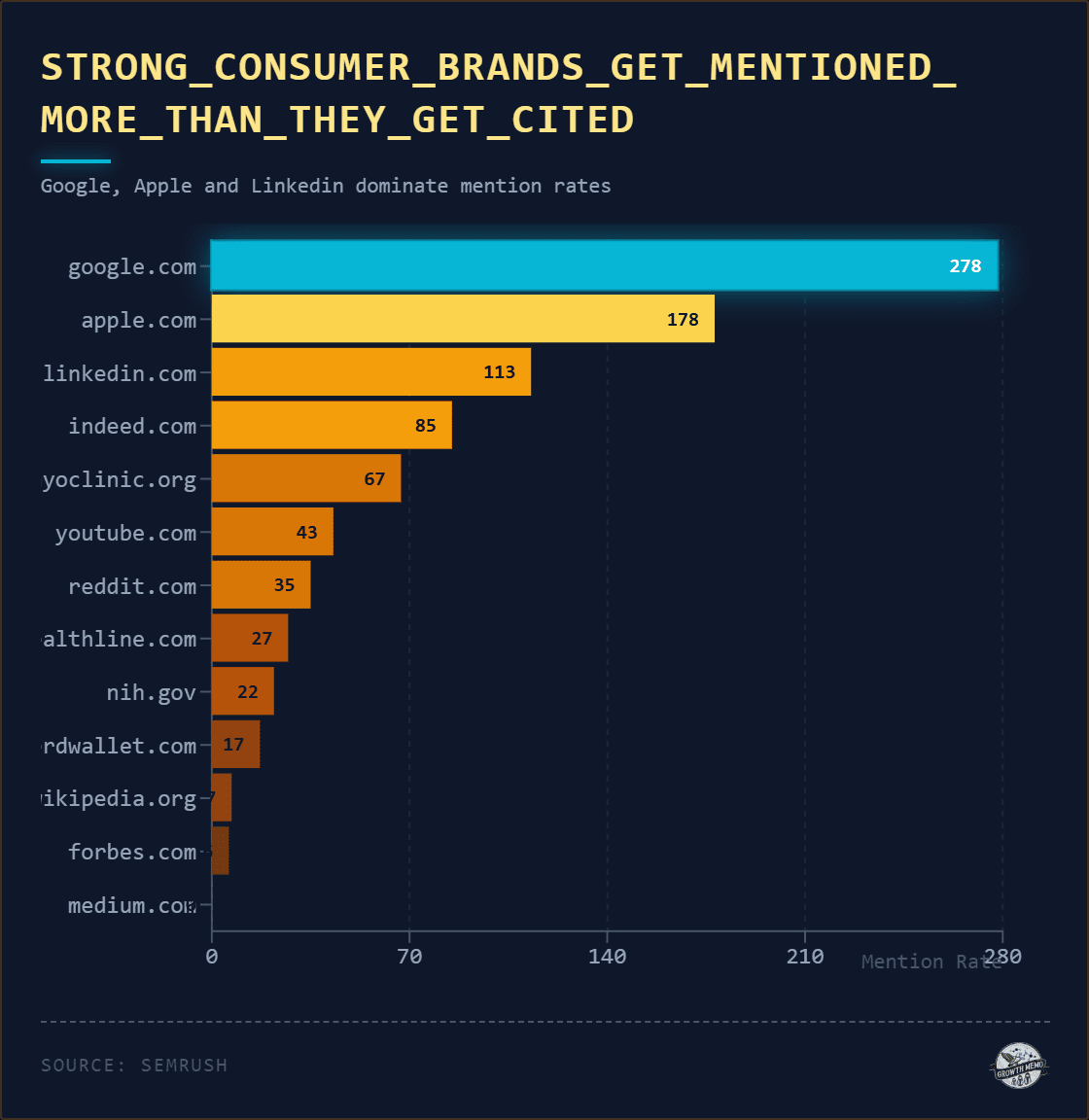
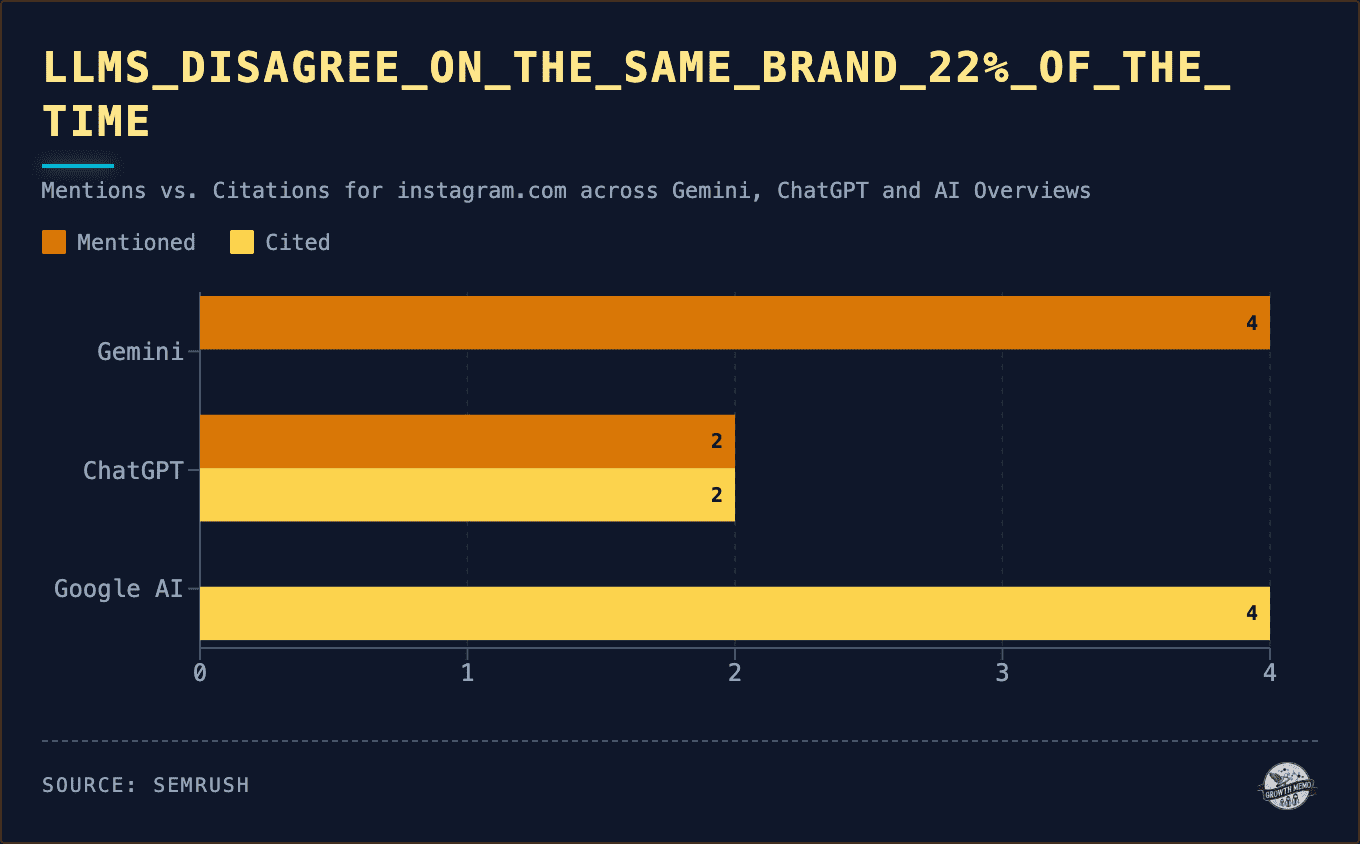
If you want to capture something wolflike, it’s best to embark before dawn.
So on a morning this January, with the eastern horizon still pink-hued, I drove with two young scientists into a blanket of fog. Forty miles to the west, the industrial sprawl of Houston spawned a golden glow. Tanner Broussard’s old Toyota Tacoma bumped over the levee-top roads as killdeer, flushed from their rest, flew across the beams of his headlights.
Broussard peered into the darkness, looking for traps. “I have one over here,” he said, slowing slightly. A master’s student at McNeese State University, he was quiet and contemplative, his bearded face half-hidden under a black ball cap. “Nothing on it,” he said, blandly. The truck rolled on.
Wolves and their relations—dogs, jackals, coyotes, and so on—are classed in the family Canidae, and the canid that dominated this landscape in eastern Texas was once the red wolf. But as soon as white settlers arrived on the continent, Canis rufus found itself under siege. The war on wolves “lasted 200 years,” federal researchers once put it, in a surprisingly evocative report. “The wolf lost.” By 1980, the red wolf was declared extinct in the wild, its population reduced to a small captive breeding population.
Still, for decades afterward, people noted that strange wolflike creatures persisted along the Gulf Coast. Finally, in 2018, scientists confirmed that some local coyotes were more than coyotes: They were taller, long-legged, their coats shaded with hints of cinnamon. These animals contained relict red wolf genes. They became known as the ghost wolves.
Broussard grew up in southwest Louisiana, watching coyotes trot across his parents’ ranch. The thrilling fact that these might have been not just coyotes but something more? That reset a rambling academic career. In 2023, Broussard had recently returned to college after a seven-year pause, and his budding obsession with wolves narrowed his focus. Before he finished his bachelor’s degree, he began to supply field data to a prominent conservation nonprofit.
Then, last year, just before he began his master’s studies, he woke to disconcerting news. A startup called Colossal Biosciences claimed to have resuscitated the dire wolf, a large canid that went extinct more than 10,000 years ago. Pundits debated the utility of the project and whether the clones—technically, gray wolves with some genetic tweaks—could really be called dire wolves. But what mattered to Broussard was Colossal’s simultaneous announcement that it had cloned four red wolves.
“That surprised pretty much everybody in the wolf community,” Broussard said as we toured the wildlife refuge where he’d set his traps. The Association of Zoos and Aquariums runs a program that sustains red wolves through captive breeding; its leadership had no idea a cloning project was underway. Nor did ecologist Joey Hinton, one of Broussard’s advisors, who had trapped the canids Colossal used to source the DNA for its clones. Some of Hinton’s former partners were collaborating with the company, but he didn’t know that clones were on the table.
There was already disagreement among scientists about the entire idea of de-extinction. Now Colossal had made these mystery clones, whose location was kept secret. Even the purpose of the clones was murky to some scientists; just how they might restore red wolf populations was unclear.
Red wolves had always been a contentious species, hard for scientists to pin down. The red wolf research community was already marked by the inevitable interpersonal tensions of a small and passionate group. Now Colossal’s clones became one more lightning rod. Perhaps the most curious question, though, was whether the company had cloned red wolves at all.
You can think of the red wolf as the wolf of the East—an apex predator that once roamed the forests and grasslands and marshes everywhere from Texas to Illinois to New York. Smaller than a gray wolf (though a good bit larger than a coyote), this was a sleek beast, with, according to one old field guide, a “cunning fox-like appearance”: long body, long legs; clearly built to run across long distances. Its coat was smooth and flat and came in many colors: a reddish tone that comes out in the right light, yes, but also, despite the name, white and gray and, in certain regions and populations, an ominous all black.
We know these details thanks to a few notes from early naturalists. As writer Andrew Moore writes in his new book, The Beasts of the East, by the time a mammalogist decided to class these eastern wolves as a standalone species in the 1930s, the red wolf had been extirpated from the East Coast and was rapidly dwindling across its range. Working with remnant skulls and other specimens, the mammalogist chose the name red wolf—which was later enshrined with the Latinate Canis rufus—because that’s what these wolves were called in the last place they survived.
The looming extinction of the red wolf turned out to be a good thing for coyotes. Canis latrans is a distant relative of wolves that split away from a common ancestor thousands of years ago and might be considered, as one canid biologist put it to me, the “wolf of the Anthropocene.” Their smaller size means they need less food and can survive in smaller and more fragmented territory, the kind that modern humans tend to build.
The last red wolves, which lived in Louisiana and Texas, decided a strange and smaller mate was preferable to no mate at all.
Red wolves had kept coyotes out of eastern America, outcompeting them for prey. Now, as the wolves declined, the coyotes began to slip in. The last red wolves, which lived in Louisiana and Texas, decided a strange and smaller mate was preferable to no mate at all. Soon the territory became a genetic jumble, home to both wolves and coyotes and hybrids that, after several generations of intermixing, came in every shade between. Scientists call such a population a “hybrid swarm,” and it poses a genetic threat to the declining species: As more coyotes poured east, and as all the canids kept interbreeding, there would be nothing that was “purely” wolf.
For years, no one seemed to notice. Perhaps trappers in the region mistook the new hybrids for wolves—or were happy to take the higher bounty that a wolf pelt earned. Finally, though, by the 1960s, as the concept of endangered species first emerged, biologists began to worry for the disappearing wolf.
The best solution they could come up with was a program of mass extermination. Over several years, trappers rounded up hundreds of canids in Texas and Louisiana. Those deemed true red wolves (on the basis of their howls and skull shape) were whisked away to breed in captivity. Most of the rest were euthanized. In 1980, the red wolf was declared extinct in the wild. To put it plainly: The red wolf was wiped out intentionally, in a roundabout effort to keep it alive.
Just 14 individuals survived this gauntlet; today’s wolves descend from 12 of those. They became the ark, the source material for the few hundred red wolves that live today. There are about 280 in the “Species Survival Plan” population, living in captivity, and another 30 or so that roam a federal refuge in coastal North Carolina, and that the government deems “nonessential” and “experimental.” According to the US Fish and Wildlife Service, to be classified as a representative of the protected entity known as Canis rufus, an animal must trace at least 87.5% of its lineage to the 12 founders.
The scientist who led this trapping-and-breeding program understood that the federal government would be narrowing the red wolf’s gene pool precipitously—so much so that the result could be an entirely new species. None of those notably black wolves persisted in the new population, for example. But what other choice existed? A new kind of wolf, free of the taint of the invading coyote, seemed better than no wolf at all.
After I learned about Colossal’s clones, I decided to travel to eastern Texas. The clones were hidden away on an unnamed refuge, but on this coastline, I might be able to at least see the animals that provided their genetic material. I arrived in the small town of Winnie on a balmy afternoon in January and met up with Broussard and another graduate student, Patrick Cunningham, at a Tex-Mex joint to discuss the challenges of studying red wolves.
“We don’t have a good reference genome,” Cunningham said. We can collect DNA from the descendants of the 12 founders, but not from the countless wolves that had been killed. It’s difficult to extract usable DNA from old samples. So our picture of what the species used to look like is limited.
Studies of the genes we do have, meanwhile, have proved controversial. When a Princeton geneticist named Bridgett vonHoldt dug into the genome of the Species Survival Plan population, she found little about their DNA that could set them apart from other wolflike American canids. In 2016, in a paper in Science Advances, vonHoldt and her coauthors wondered if there ever really was a separate southern wolf species. Perhaps the 12 founders were just coyotes injected with some smaller portion of wolf.
It’s long been clear that North America’s soup of Canis genes is something less like a family tree and more like a river—one that’s broken by islands and sandbars into many braided channels that split and merge and re-split.
Her paper called for complex new interpretations of the Endangered Species Act. We should, she wrote, focus less on species and more on the function a group of animals performs. The red wolves deserved protection, then, as creatures that filled the same role as truly endangered wolves and carried some of their genetics. Nonetheless, for Canis rufus, the timing of the paper was bad news.
The red wolves roaming that federal reserve in North Carolina are supposed to be a first step toward the species’ return to the wild. But some locals never liked the idea of living alongside wolves. By 2016, state officials had turned against the recovery program and were requesting its termination. The wild population, which had included as many as 120 a few years earlier, was falling. But the US Fish and Wildlife Service had paused further releases of wolves. Now a group of scientists, led by vonHoldt, was saying that the red wolf showed “a lack of unique ancestry.” Why spend money, some people wondered, on a species that does not exist?
Part of the problem was that the concept of a “species” is less sturdy than your high school biology teacher might have led you to believe. The most familiar definition is that a species consists of animals that can produce fertile offspring. But that’s a rule various species of canids violate all the time; it’s long been clear that North America’s soup of Canis genes is something less like a family tree and more like a river—one that’s broken by islands and sandbars into many braided channels that split and merge and re-split.
VonHoldt suggested that the modern red wolf is a channel in that river, part wolf and part coyote, that appeared surprisingly recently. But a year after her study came out, other researchers claimed that her data, if interpreted differently, could suggest that the red wolf braid had emerged tens of thousands of years ago, meaning this was a species that had long been on its own evolutionary journey.
These nuances were confusing for the policymakers who oversaw actual, living animals. “Congress was just like, ‘What is going on?’” Cunningham said. “‘Why is there not just a simple explanation for what this thing is?’”
Given the policy implications, the National Academies of Science, Engineering, and Medicine tasked a panel of scientists with finding that simple answer. Their report, published in 2019, declared that the red wolf is, by virtue of its appearance and seemingly long-standing isolated population, a species. As their study got underway, though, a new question was arising: What to make of the strange canids on the Gulf Coast, those today called the ghost wolves?
The path to that name began in 2008, when a photographer from Galveston Island, Texas, grew obsessed with the oversized local coyotes. He began to take photos of the packs, which he distributed to scientists, seeking answers: What were they? By 2016, the photos had reached Joey Hinton, then a postdoctoral researcher at the University of Georgia.
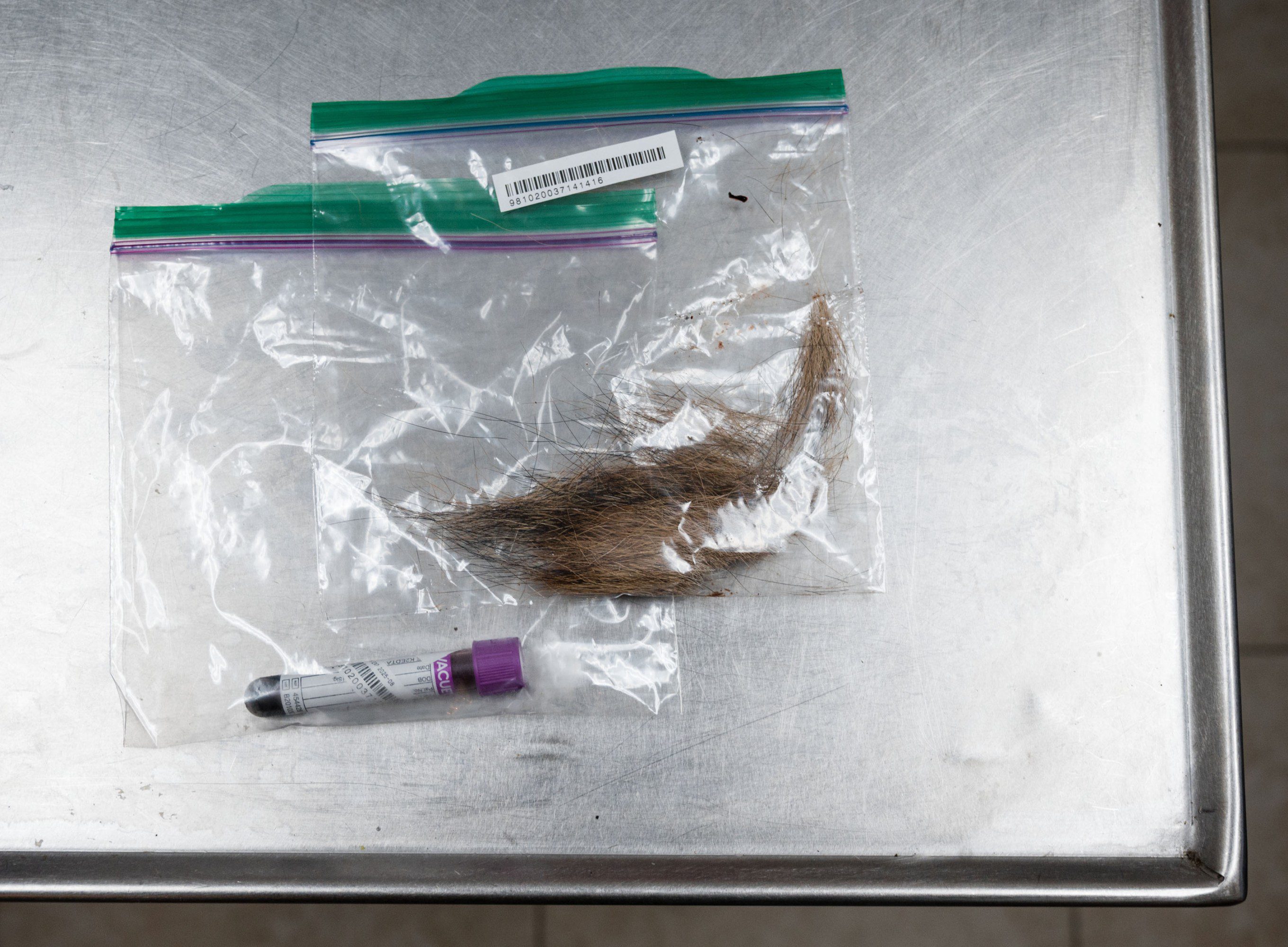
Hinton had spent more than a decade trapping wolves and coyotes in North Carolina, and his work has always focused on live animals, especially visual ways to distinguish red wolves and coyotes. So he was a good choice for helping the photographer, Ron Wooten, figure out the status of the canids. In his freezer Wooten also had tissue samples he’d collected from road-killed coyotes. These could be used by a geneticist to give a fuller picture of the canids’ ancestry. So vonHoldt was brought in too. The result was a 2018 paper, with Hinton as a coauthor, that identified the Galveston Island canids as at least part red wolf.
These canids were not, to be clear, actual red wolves; no canid on the Gulf Coast is descended from the government’s 12 canonical founders, so under current policy, none can be officially classified as a wolf. Subsequent studies have found that, on average, the ancestry of the region’s canids is less than half red wolf, and often far less. In scientific terms, the red wolf had introgressed into the Gulf Coast population—its genes had leaked across the species boundary and lodged themselves in a different population.
Hinton, vonHoldt, and their coauthors also noted the presence of what they called “ghost alleles”—DNA sequences unknown in any other named species. The Occam’s razor assumption was that, in these already wolfy coyotes, these sequences likely represented Canis rufus genetics that had not been captured in the sweep of the marsh that yielded the Species Survival Plan population. Since so much of the red wolf gene pool had been lost, these genes seemed to be a potential resource for the species—a way to expand its diversity. When the New York Times covered this discovery a few years later, the headline popularized the “ghost wolf” moniker that has proved so indelible.
As it happened, a separate team, focused on canids in and around federally protected marsh in Louisiana, published a similar paper in 2018, at nearly the same time. The twin discoveries raised new questions—What should we make of these creatures, the latest branch in the canid river? What do they mean for the wolves in North Carolina?—and helped researchers secure new funding.
In 2020, vonHoldt and Kristin Brzeski, a former postdoc under vonHoldt and now a professor at Michigan Technological University, launched what they called the Gulf Coast Canine Project. Brzeski, who led the field work, hired Hinton to do much of the canid trapping and sample collection. In 2022, vonHoldt, Hinton, and Brzeski were all coauthors of another paper that identified even more red-wolf-descended canids in Louisiana and noted a positive correlation between red wolf ancestry and body mass—the more red wolf genes, the bigger the animal. The paper also suggested that given this newly discovered reservoir of red wolf DNA, “genomic technologies” could prove useful in the long-term survival of the species.
VonHoldt and Brzeski eventually conceived of an ambitious project. They hoped that by carefully matching the most wolf-descended canids and breeding them together, over three generations they’d increase the proportion of red wolf genes—de-introgression. “I’m expecting, based on these pairings of animals, that I can stitch together the puzzle pieces,” vonHoldt told me recently. “We are very likely to get puppies each generation that are higher and higher red wolf content”—enough wolf content, she hopes, to eventually win her permission to breed the resulting animals with the Species Survival Plan population of red wolves. They’d essentially be adding a new founder to the limited lineage.
Hinton told me he felt he’d been kept in the dark about the de-introgression idea. He was also worried, he says, to learn that Colossal Biosciences hovered in the background. (In a draft proposal for the project, vonHoldt indicated that Colossal would be in charge of “live capture.”) Hinton says he was not comfortable collecting materials for a for-profit company that has to keep its shareholders happy.
Hinton says he reached out to state and federal officials and found they knew little about the project. (The US Fish and Wildlife Service declined to make anyone available for an interview for this story, and the Louisiana Department of Wildlife and Fisheries did not reply to requests for comment.) He knew the group’s next phone call would be difficult, and indeed it was. He wound up speaking one-on-one with vonHoldt for at least half an hour.
“We didn’t reach an agreement,” he says. After the call, he sent her a text: He was exiting the project. He believes that had Colossal not been involved, they’d all still be working as a team. Both vonHoldt and Brzeski declined to comment on what felt to them like a matter of interpersonal relationships rather than a scientific dispute. “There were challenges over time, and the tone and manner of the interactions became increasingly difficult to navigate productively,” Brzeski said in an email.
Colossal was cofounded in 2021 by George Church, an eminent Harvard geneticist who, thanks to investors, could finally embark on a long-discussed dream. He wanted to make de-extinction a reality—using CRISPR gene-editing technology to, say, turn a modern elephant into something like the extinct woolly mammoth. The concept has drawn skepticism from the beginning—at best it would only be possible to make something like a woolly mammoth. Was there any point to that? Some scientists note that genes alone do not teach an animal how to exist in the world; indeed, since social structures affect how genes are expressed, an animal without parents may not effectively fill its ecological niche.
Less reproachable, though, was Colossal’s interest in partnering with scientists who, like vonHoldt and Brzeski, focus on extant species that are endangered. This gave more heft to Colossal’s gee-whiz de-extinction projects: They would, along the way, supply technology that could save our natural world.
For red wolves, such technologies could offer a quick way to expand the limited gene pool. Through genetic engineering, Colossal could take clones of the Gulf Coast canids and tune up the wolf, tune down the coyote. It would be a high-tech shortcut past vonHoldt and Brzeski’s careful breeding program. “You can do the same thing much more precisely, much more quickly, much more efficiently, in vitro,” says Matt James, Colossal’s chief animal officer and the executive director of the Colossal Foundation, the company’s nonprofit arm. VonHoldt notes that the old-fashioned approach, with breeding, means she has to take a few individual canids out of the wild, into captivity—never ideal but, in her view, a worthwhile price for progress. The advantage of cloning, which Colossal has managed to do with blood samples alone, is that the wild canid populations can be kept intact.
VonHoldt has always been an advocate for wolves. Indeed, when she hypothesized that the red wolf had hybrid origins, in 2016, she’d framed it as an argument for protecting the gray wolf, which the federal government was considering removing from the Endangered Species List. (In short: If all wolves were one wolf, then it was undeniable that the species’ range had contracted precipitously.) But she’d grown frustrated with the federal government’s efforts to restore the red wolf, which after half a century had seen few meaningful successes, she says.
VonHoldt joined Colossal’s scientific advisory board in 2023. “I love the bold, the shock and awe,” she told me, explaining her decision. She saw the fact that Colossal sparked controversy as an asset, given the problems she sees in conservation: “Get something out there. Start pushing buttons and start forcing these conversations,” she says. The red wolf was akin to a terminal patient who was ready to accept any and all therapies, however experimental. Why not embrace biotech?
She also notes that the federal budget for endangered species conservation is incredibly limited. Rely only on that money and “we can kiss our world goodbye,” she said in an e-mail. The $100 million raised by the Colossal Foundation is essential, then, she says. As for the samples the team had collected on the Gulf Coast, she says, limited freezer space is often devoted to animals that are officially categorized as threatened or endangered, which the Gulf Coast canids are not. Colossal could take the samples, and the team passed them along to the company.
It was Hinton—a source for a former story—who first alerted me to Colossal’s work on red wolves; he described vonHoldt and Brzeski’s de-introgression project, which won federal funding in late 2024, as nefarious-sounding work to “disappear” canids off the Gulf Coast. But he did not have all the details of the project, which had changed after he left the team. He suggested they’d be “just throwing animals together,” whereas vonHoldt described a careful program of observing the canids in the wild so she could determine which acted most wolflike, findings she’d cross-reference with their genetic data.
Colossal did not wind up participating in the de-introgression project. But the company is doing work on the red wolf that vonHoldt views as complementary: Its scientists are assembling a “pangenome” of North American canids by studying samples pulled from museums, universities, zoos, and other institutions. This data set is expected to clarify both what genetic sequences are shared across the entire canid family and what snippets differ in certain populations. The hope is that this will provide a clearer picture of the red wolf in its early days, before the coyotes arrived and the gene pool narrowed. That might shift what Colossal’s James calls the government’s arbitrary definition of the red wolf, to encompass more of the species’ full former diversity.
The pangenome, then, might allow vonHoldt’s de-introgressed canids, descended from the Gulf coast canids, to qualify as actual red wolves. Indeed, James suggested to me that more information about historic red wolves might force the government to take a new look at the Gulf Coast canids; some individuals might have high enough red wolf ancestry to be classified as red wolves. (“That has management implications that terrify state and federal government,” he added.)
The purpose of vonHoldt’s de-introgression project is to bring back certain lost red wolf genes—to create a whole new wolf lineage. But she has also pushed against the idea of “genetic purity,” which she thinks limits what we protect with conservation laws; she told me emphasizing it reminds her of the human history of eugenics and “makes every part of my soul hurt.” She cares less about what species are out there, in the landscape, than what ecological function the animals play, and she sees coyotes and red wolves as closely related animals that may have a role to play in one another’s future survival.
As for Colossal’s clones, even vonHoldt seems to describe them as something less than a conservation breakthrough. They are a “proof of principle that we, collectively, as a scientific community, know how to do it,” she told me. If an urgent need arises to clone red wolves, the groundwork has been laid.
Hinton, meanwhile, is one of several scientists I spoke with who were skeptical Colossal was doing good science, given that so much is conducted behind closed doors. He implied that the clones were nothing but an empty showpiece, a way to earn headlines and attract funders. “The work is anything but symbolic,” James responded via e-mail. “It expands the genetic toolkit available for critically endangered species, demonstrates scalable approaches to biodiversity restoration, and contributes directly to preserving imperiled lineages.” He noted that Colossal had intentionally decided to avoid the “snail’s pace” of the peer review process and suggested that the skepticism from scientists may actually be a “panicked response to being outpaced.”
Until some evidence confirms that the Gulf Coast canids—the source material for the clones—are red wolves, they can’t legally be classified as such for federal conservation purposes. Nonetheless, Colossal’s press release claimed that the company had “birthed two litters of cloned red wolves, the most critically endangered wolf in the world.” On the same day that press release dropped, Colossal’s CEO and cofounder, Ben Lamm, appeared on The Joe Rogan Experience and claimed that he had offered to create hundreds of red wolves for the federal government to use in recovery—for free! He was miffed when the government, under the Biden administration, replied that it wanted to spend several years and many millions of dollars to study the potential for cloning before it would take any action. (The company has gotten more traction with the Trump administration, Lamm said.)
When I first spoke to James at Colossal, he said that he was “cognizant” of the concerns over the names and labels and that the company’s own materials described the clones as “red ‘ghost’ wolves.” He suggested that if anyone assumed the clones were actual red wolves, that was because journalists had failed to grasp the nuances of the science. But this phrase appears so late in a long document that it was cut off in some versions. Later, over email, James indicated that further analysis had convinced him that what the company had created were red wolves, and that anyone who disagreed either could not grasp the science or is “so ideologically opposed to Colossal’s conservation revolution that they are willing to compromise their scientific integrity.”
VonHoldt has had her own issues with the company’s communications; she told me it was “stressful” when Lamm described the clones as red wolves—which, she notes, “federally, they’re not.” But she values the company’s work, she says, and “the thing that I value the most is shaking things up.” People are paying attention to red wolves. If it’s hard to decide what to call the animals on the Gulf Coast—where some heavily wolfy animals live alongside others that are more coyote—that’s just proof that our concept of a “species” does not capture the complex realities on the ground.
In 2025, the same year as Colossal’s wolf announcement, Hinton launched the Texas-Louisiana Canid Project. He’s working in partnership with Broussard, the master’s student at McNeese, in slightly different territory from vonHoldt and Brzeski—and focusing more on the animals’ appearance and behavior than their genes. The Gulf Coast canids are stable and faring better than the North Carolina red wolves, and his hope is that if we learn why they’ve been successful for so many years, we might be able to help the official red wolf population, which is only just limping along.
I had planned to join Hinton in the field, but by the time I was able to visit, he’d had to go home to his family. So I joined Broussard on his last days trapping in Texas that season. Before I’d left for Winnie, I’d told my friends I’d be out chasing the last surviving red wolves. But there, on the Gulf Coast, I came to understand that this was just as much a story about coyotes.
That’s what Broussard and Cunningham both called the creatures. Hinton does too; he considers the animals to be a specific “ecotype” of coyote, featuring an injection of wolf DNA that has helped them adapt to the local marshes.
At vonHoldt’s behest, I drove an hour down the coast to Galveston Island, where she and Brzeski began working with the island’s animal control department; when locals find a coyote, the animal is captured so its blood can be collected and a GPS collar fitted on its neck. A small group of locals who support the project have come to call themselves the “ghost wolf team.” They hoped that the presence of these remarkable creatures might rein in the rapid development of the island’s last stands of green. Still, the people I spoke to in Galveston conceded that the animals were, if special, nonetheless a form of coyote.
VonHoldt describes Galveston Island as a potential model for what conservation could look like in the future. Top-down recovery hasn’t been working, but helping more places fall in love with their local animals might. And for that to happen, we need to stop obsessing over whether or not something is a “pure” wolf. What matters, she argues, is that an animal is doing what a larger predator does in an ecosystem. She embraces the “ghost wolf” name because, more than “Gulf Coast canid,” it makes clear that there’s something special on the coast—something worth protecting.
Her vision is enticing: Focus on function over purity. Let evolution proceed. Stop protecting the wolf of the past and consider the wolf of the future. Such rapid genetic exchange may be necessary to help predators adapt to a hotter, increasingly shattered world, she says.
If we throw out the concept of “endangered species,” will we really protect “endangered functions” instead?
Then again, we already know what’s adapted to the world we’re building: coyotes. The argument against genetic purity can sound like giving up on wolves entirely, with the possible exception of whatever specimens we produce in cloning facilities. And there is the matter of politics: If we throw out the concept of “endangered species,” will we really protect “endangered functions” instead? Under an administration already rolling back environmental protections, the likeliest outcome may be protecting nothing at all.
I tried in Galveston, too, to see the coyotes. Ron Wooten, the local resident who helped alert scientists to this population, dropped some pins on a map, pointing me toward several likely spots. That evening, after the sun set, I chose a quiet road that passed through marshes until it reached the island’s eastern beach. It was mating season, Wooten had noted. The animals should be on the move, he said; look to the bushes. As I drove up and down the road, my headlights revealed only empty darkness. No coyote. No wolf. Fitting, perhaps—isn’t absence the essence of a ghost? But whether this was a good omen was less clear. As individuals, these animals do best by avoiding us humans. As a group, their survival—like the survival of the red wolves—depends on our knowing that they are here, and were here, and deciding that is reason enough to care.
In Winnie the next morning, I went out one last time with Broussard, and we struck out again. With no coyotes in his traps and the new semester looming, he decided to take down his game cameras. Back at the hotel, I caught at least an image of what I’d been chasing: In black and white, the animals were appropriately silver, spectral, dashing across the midnight fields. In one clip, a canid paused and howled. “That’s super cool,” Broussard said quietly, as an echoing, interweaving chorus responded from somewhere deeper in the marsh.
Boyce Upholt is a journalist based in New Orleans and founding editor of Southlands, a magazine about Southern nature.