You live in a house you designed and built yourself. You rely on the sun for power, heat your home with a woodstove, and farm your own fish and vegetables. The year is 2025.
This is the life of Marcin Jakubowski, the 53-year-old founder of Open Source Ecology, an open collaborative of engineers, producers, and builders developing what they call the Global Village Construction Set (GVCS). It’s a set of 50 machines—everything from a tractor to an oven to a circuit maker—that are capable of building civilization from scratch and can be reconfigured however you see fit.
Jakubowski immigrated to the US from Slupca, Poland, as a child. His first encounter with what he describes as the “prosperity of technology” was the vastness of the American grocery store. Seeing the sheer quantity and variety of perfectly ripe produce cemented his belief that abundant, sustainable living was within reach in the United States.
With a bachelor’s degree from Princeton and a doctorate in physics from the University of Wisconsin, Jakubowski had spent most of his life in school. While his peers kick-started their shiny new corporate careers, he followed a different path after he finished his degree in 2003: He bought a tractor to start a farm in Maysville, Missouri, eager to prove his ideas about abundance. “It was a clear decision to give up the office cubicle or high-level research job, which is so focused on tiny issues that one never gets to work on the big picture,” he says. But in just a short few months, his tractor broke down—and he soon went broke.
Every time his tractor malfunctioned, he had no choice but to pay John Deere for repairs—even if he knew how to fix the problem on his own. John Deere, the world’s largest manufacturer of agricultural equipment, continues to prohibit farmers from repairing their own tractors (except in Colorado, where farmers were granted a right to repair by state law in 2023). Fixing your own tractor voids any insurance or warranty, much like jailbreaking your iPhone.
Today, large agricultural manufacturers have centralized control over the market, and most commercial tractors are built with proprietary parts. Every year, farmers pay $1.2 billion in repair costs and lose an estimated $3 billion whenever their tractors break down, entirely because large agricultural manufacturers have lobbied against the right to repair since the ’90s. Currently there are class action lawsuits involving hundreds of farmers fighting for their right to do so.
“The machines own farmers. The farmers don’t own [the machines],” Jakubowski says. He grew certain that self-sufficiency relied on agricultural autonomy, which could be achieved only through free access to technology. So he set out to apply the principles of open-source software to hardware. He figured that if farmers could have access to the instructions and materials required to build their own tractors, not only would they be able to repair them, but they’d also be able to customize the vehicles for their needs. Life-changing technology should be available to all, he thought, not controlled by a select few. So, with an understanding of mechanical engineering, Jakubowski built his own tractor and put all his schematics online on his platform Open Source Ecology.
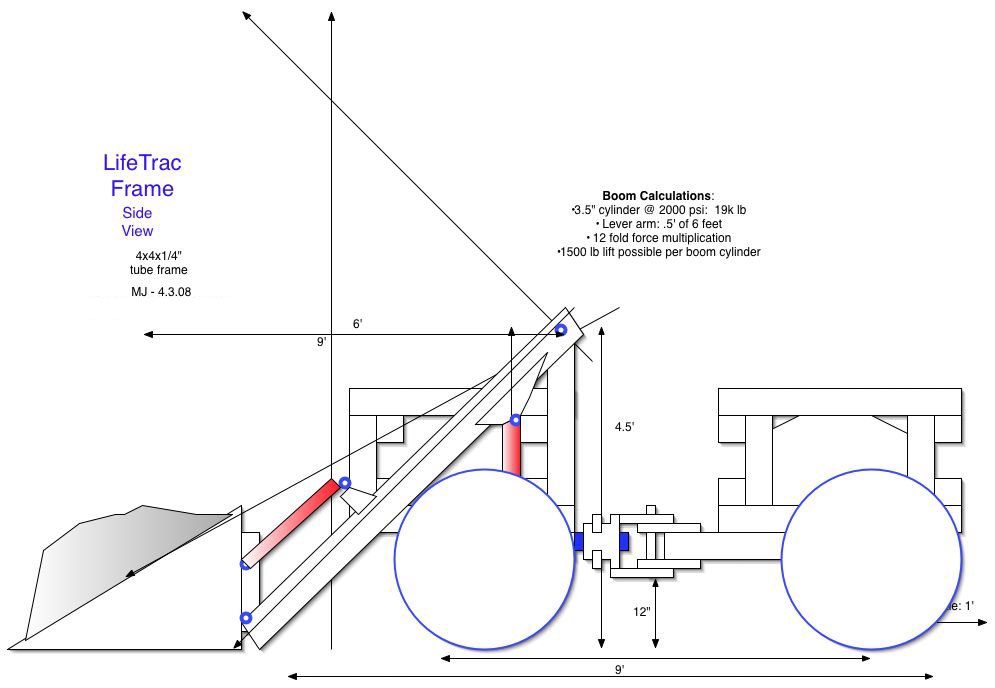
That tractor Jakubowski built is designed to be taken apart. It’s a critical part of the GVCS, a collection of plug-and-play machines that can “build a thriving economy anywhere in the world … from scratch.” The GVCS includes a 3D printer, a self-contained hydraulic power unit called the Power Cube, and more, each designed to be reconfigured for multiple purposes. There’s even a GVCS micro-home. You can use the Power Cube to power a brick press, a sawmill, a car, a CNC mill, or a bioplastic extruder, and you can build wind turbines with the frames that are used in the home.
Jakubowski compares the GVCS to Lego blocks and cites the Linux ecosystem as his inspiration. In the same way that Linux’s source code is free to inspect, modify, and redistribute, all the instructions you need to build and repurpose a GVCS machine are freely accessible online. Jakubowski envisions a future in which the GVCS parallels the Linux infrastructure, with custom tools built to optimize agriculture, construction, and material fabrication in localized contexts. “The [final form of the GVCS] must be proven to allow efficient production of food, shelter, consumer goods, cars, fuel, and other goods—except for exotic imports (coffee, bananas, advanced semiconductors),” he wrote on his Open Source Ecology wiki.
The ethos of GVCS is reminiscent of the Whole Earth Catalog, a countercultural publication that offered a combination of reviews, DIY manuals, and survival guides between 1968 and 1972. Founded by Stewart Brand, the publication had the slogan “Access to tools” and was famous for promoting self-sufficiency. It heavily featured the work of R. Buckminster Fuller, an American architect known for his geodesic domes (lightweight structures that can be built using recycled materials) and for coining the term “ephemeralization,” which refers to the ability of technology to let us do more with less material, energy, and effort.
The schematics for Marcin Jakubowski’s designs are all available online.
COURTESY OF OPEN SOURCE ECOLOGY
Jakubowski owns the publication’s entire printed output, but he offers a sharp critique of its legacy in our current culture of tech utopianism. “The first structures we built were domes. Good ideas. But the open-source part of that was not really there yet—Fuller patented his stuff,” he says. Fuller and the Whole Earth Catalog may have popularized an important philosophy of self-reliance, but to Jakubowski, their failure to advocate for open collaboration stopped the ultimate vision of sustainability from coming to fruition. “The failure of the techno-utopians to organize into a larger movement of collaborative, open, distributed production resulted in a miscarriage of techno-utopia,” he says.
With a background in physics and an understanding of mechanical engineering, Marcin Jakubowski built his own tractor.
COURTESY OF OPEN SOURCE ECOLOGY
Unlike software, hardware can’t be infinitely reproduced or instantly tested. It requires manufacturing infrastructure and specific materials, not to mention exhaustive documentation. There are physical constraints—different port standards, fluctuations in availability of materials, and more. And now that production chains are so globalized that manufacturing a hot tub can require parts from seven different countries and 14 states, how can we expect anything to be replicable in our backyard? The solution, according to Jakubowski, is to make technology “appropriate.”
Appropriate technology is technology that’s designed to be affordable and sustainable for a specific local context. The idea comes from Gandhi’s philosophy of swadeshi (self-reliance) and sarvodaya (upliftment of all) and was popularized by the economist Ernst Friedrich “Fritz” Schumacher’s book Small Is Beautiful, which discussed the concept of “intermediate technology”: “Any intelligent fool can make things bigger, more complex, and more violent. It takes a touch of genius—and a lot of courage—to move in the opposite direction.” Because different environments operate at different scales and with different resources, it only makes sense to tailor technology for those conditions. Solar lamps, bikes, hand-powered water pumps—anything that can be built using local materials and maintained by the local community—are among the most widely cited examples of appropriate technology.
This concept has historically been discussed in the context of facilitating economic growth in developing nations and adapting capital-intensive technology to their needs. But Jakubowski hopes to make it universal. He believes technology needs to be appropriate even in suburban and urban places with access to supermarkets, hardware stores, Amazon deliveries, and other forms of infrastructure. If technology is designed specifically for these contexts, he says, end-to-end reproduction will be possible, making more space for collaboration and innovation.
What makes Jakubowski’s technology “appropriate” is his use of reclaimed materials and off-the-shelf parts to build his machines. By using local materials and widely available components, he’s able to bypass the complex global supply chains that proprietary technology often requires. He also structures his schematics around concepts already familiar to most people who are interested in hardware, making his building instructions easier to follow.
Everything you need to build Jakubowski’s machines should be available around you, just as everything you need to know about how to repair or operate the machine is online—from blueprints to lists of materials to assembly instructions and testing protocols. “If you’ve got a wrench, you’ve got a tractor,” his manual reads.
This spirit dates back to the ’70s, when the idea of building things “moved out of the retired person’s garage and into the young person’s relationship with the Volkswagen,” says Brand. He references John Muir’s 1969 book How to Keep Your Volkswagen Alive: A Manual of Step-by-Step Procedures for the Compleat Idiot and fondly recalls how the Beetle’s simple design and easily swapped parts made it common for owners to rebody their cars, combining the chassis of one with the body of another. He also mentions the impact of the Ford Model T cars that, with a few extra parts, were made into tractors during the Great Depression.
For Brand, the focus on repairability is critical in the modern context. There was a time when John Deere tractors were “appropriate” in Jakubowski’s terms, Brand says: “A century earlier, John Deere took great care to make sure that his plowshares could be taken apart and bolted together, that you can undo and redo them, replace parts, and so on.” The company “attracted insanely loyal customers because they looked out for the farmers so much,” Brand says, but “they’ve really reversed the orientation.” Echoing Jakubowski’s initial motivation for starting OSE, Brand insists that technology is appropriate to the extent that it is repairable.
Even if you can find all the parts you need from Lowe’s, building your own tractor is still intimidating. But for some, the staggering price advantage is reason enough to take on the challenge: A GVCS tractor costs $12,000 to build, whereas a commercial tractor averages around $120,000 to buy, not including the individual repairs that might be necessary over its lifetime at a cost of $500 to $20,000 each. And gargantuan though it may seem, the task of building a GVCS tractor or other machine is doable: Just a few years after the project launched in 2008, more than 110 machines had been built by enthusiasts from Chile, Nicaragua, Guatemala, China, India, Italy, and Turkey, just to name a few places.
Of the many machines developed, what’s drawn the most interest from GVCS enthusiasts is the one nicknamed “The Liberator,” which presses local soil into compressed earth blocks, or CEBs—a type of cost- and energy-efficient brick that can withstand extreme weather conditions. It’s been especially popular among those looking to build their own homes: A man named Aurélien Bielsa replicated the brick press in a small village in the south of France to build a house for his family in 2018, and in 2020 a group of volunteers helped a member of the Open Source Ecology community build a tiny home using blocks from one of these presses in a fishing village near northern Belize.
The CEB press, nicknamed “The Liberator,” turns local soil into energy-efficient compressed earth blocks.
COURTESY OF OPEN SOURCE ECOLOGY
Jakubowski recalls receiving an email about one of the first complete reproductions of the CEB press, built by a Texan named James Slate, who ended up starting a business selling the bricks: “When [James] sent me a picture [of our brick press], I thought it was a Photoshopped copy of our machine, but it was his. He just downloaded the plans off the internet. I knew nothing about it.” Slate described having a very limited background in engineering before building the brick press. “I had taken some mechanics classes back in high school. I mostly come from an IT computer world,” he said in an interview with Open Source Ecology. “Pretty much anyone can build one, if they put in the effort.”
Andrew Spina, an early GVCS enthusiast, agrees. Spina spent five years building versions of the GVCS tractor and Power Cube, eager to create means of self-sufficiency at an individual scale. “I’m building my own tractor because I want to understand it and be able to maintain it,” he wrote in his blog, Machining Independence. Spina’s curiosity gestures toward the broader issue of technological literacy: The more we outsource to proprietary tech, the less we understand how things work—further entrenching our need for that proprietary tech. Transparency is critical to the open-source philosophy precisely because it helps us become self-sufficient.
Since starting Open Source Ecology, Jakubowski has been the main architect behind the dozens of machines available on his platform, testing and refining his designs on a plot of land he calls the Factor e Farm in Maysville. Most GVCS enthusiasts reproduce Jakubowski’s machines for personal use; only a few have contributed to the set themselves. Of those select few, many made dedicated visits to the farm for weeks at a time to learn how to build Jakubowski’s GVCS collection. James Wise, one of the earliest and longest-term GVCS contributors, recalls setting up tents and camping out in his car to attend sessions at Jakubowski’s workshop, where visiting enthusiasts would gather to iterate on designs: “We’d have a screen on the wall of our current best idea. Then we’d talk about it.” Wise doesn’t consider himself particularly experienced on the engineering front, but after working with other visiting participants, he felt more emboldened to contribute. “Most of [my] knowledge came from [my] peers,” he says.
Jakubowski’s goal of bolstering collaboration hinges on a degree of collective proficiency. Without a community skilled with hardware, the organic innovation that the open-source approach promises will struggle to bear fruit, even if Jakubowski’s designs are perfectly appropriate and thoroughly documented.
“That’s why we’re starting a school!” said Jakubowski, when asked about his plan to build hardware literacy. Earlier this year, he announced the Future Builders Academy, an apprenticeship program where participants will be taught all the necessary skills to develop and build the affordable, self-sustaining homes that are his newest venture. Seed Eco Homes, as Jakubowski calls them, are “human-sized, panelized” modular houses complete with a biodigester, a thermal battery, a geothermal cooling system, and solar electricity. Each house is entirely energy independent and can be built in five days, at a cost of around $40,000. Over eight of these houses have been built across the country, and Jakubowski himself lives in the earliest version of the design. Seed Eco Homes are the culmination of his work on the GVCS: The structure of each house combines parts from the collection and embodies its modular philosophy. The venture represents Jakubowski’s larger goal of making everyday technology accessible. “Housing [is the] single largest cost in one’s life—and a key to so much more,” he says.
The final goal of Open Source Ecology is a “zero marginal cost” society, where producing an additional unit of a good or service costs little to nothing. Jakubowski’s interpretation of the concept (popularized by the American economist and social theorist Jeremy Rifkin) assumes that by eradicating licensing fees, decentralizing manufacturing, and fostering collaboration through education, we can develop truly equitable technology that allows us to be self-sufficient. Open-source hardware isn’t just about helping farmers build their own tractors; in Jakubowski’s view, it’s a complete reorientation of our relationship to technology.
In the first issue of the Whole Earth Catalog, a key piece of inspiration for Jakubowski’s project, Brand wrote: “We are as gods and we might as well get good at it.” In 2007, in a book Brand wrote about the publication, he corrected himself: “We are as gods and have to get good at it.” Today, Jakubowski elaborates: “We’re becoming gods with technology. Yet technology has badly failed us. We’ve seen great progress with civilization. But how free are people today compared to other times?” Cautioning against our reliance on the proprietary technology we use daily, he offers a new approach: Progress should mean not just achieving technological breakthroughs but also making everyday technology equitable.
“We don’t need more technology,” he says. “We just need to collaborate with what we have now.”
Tiffany Ng is a freelance writer exploring the relationship between art, tech, and culture. She writes Cyber Celibate, a neo-Luddite newsletter on Substack.
Consider, if you will, the translucent blob in the eye of a microscope: a human blastocyst, the biological specimen that emerges just five days or so after a fateful encounter between egg and sperm. This bundle of cells, about the size of a grain of sand pulled from a powdery white Caribbean beach, contains the coiled potential of a future life: 46 chromosomes, thousands of genes, and roughly six billion base pairs of DNA—an instruction manual to assemble a one-of-a-kind human.
Now imagine a laser pulse snipping a hole in the blastocyst’s outermost shell so a handful of cells can be suctioned up by a microscopic pipette. This is the moment, thanks to advances in genetic sequencing technology, when it becomes possible to read virtually that entire instruction manual.
An emerging field of science seeks to use the analysis pulled from that procedure to predict what kind of a person that embryo might become. Some parents turn to these tests to avoid passing on devastating genetic disorders that run in their families. A much smaller group, driven by dreams of Ivy League diplomas or attractive, well-behaved offspring, are willing to pay tens of thousands of dollars to optimize for intelligence, appearance, and personality. Some of the most eager early boosters of this technology are members of the Silicon Valley elite, including tech billionaires like Elon Musk, Peter Thiel, and Coinbase CEO Brian Armstrong.
Embryo selection is less like a build-a-baby workshop and more akin to a store where parents can shop for their future children from several available models—complete with stat cards.
But customers of the companies emerging to provide it to the public may not be getting what they’re paying for. Genetics experts have been highlighting the potential deficiencies of this testing for years. A 2021 paper by members of the European Society of Human Genetics said, “No clinical research has been performed to assess its diagnostic effectiveness in embryos. Patients need to be properly informed on the limitations of this use.” And a paper published this May in the Journal of Clinical Medicine echoed this concern and expressed particular reservations about screening for psychiatric disorders and non-disease-related traits: “Unfortunately, no clinical research has to date been published comprehensively evaluating the effectiveness of this strategy [of predictive testing]. Patient awareness regarding the limitations of this procedure is paramount.”
Moreover, the assumptions underlying some of this work—that how a person turns out is the product not of privilege or circumstance but of innate biology—have made these companies a political lightning rod.
SELMAN DESIGN
As this niche technology begins to make its way toward the mainstream, scientists and ethicists are racing to confront the implications—for our social contract, for future generations, and for our very understanding of what it means to be human.
Preimplantation genetic testing (PGT), while still relatively rare, is not new. Since the 1990s, parents undergoing in vitro fertilization have been able to access a number of genetic tests before choosing which embryo to use. A type known as PGT-M can detect single-gene disorders like cystic fibrosis, sickle cell anemia, and Huntington’s disease. PGT-A can ascertain the sex of an embryo and identify chromosomal abnormalities that can lead to conditions like Down syndrome or reduce the chances that an embryo will implant successfully in the uterus. PGT-SR helps parents avoid embryos with issues such as duplicated or missing segments of the chromosome.
Those tests all identify clear-cut genetic problems that are relatively easy to detect, but most of the genetic instruction manual included in an embryo is written in far more nuanced code. In recent years, a fledgling market has sprung up around a new, more advanced version of the testing process called PGT-P: preimplantation genetic testing for polygenic disorders (and, some claim, traits)—that is, outcomes determined by the elaborate interaction of hundreds or thousands of genetic variants.
In 2020, the first baby selected using PGT-P was born. While the exact figure is unknown, estimates put the number of children who have now been born with the aid of this technology in the hundreds. As the technology is commercialized, that number is likely to grow.
Embryo selection is less like a build-a-baby workshop and more akin to a store where parents can shop for their future children from several available models—complete with stat cards indicating their predispositions.
A handful of startups, armed with tens of millions of dollars of Silicon Valley cash, have developed proprietary algorithms to compute these stats—analyzing vast numbers of genetic variants and producing a “polygenic risk score” that shows the probability of an embryo developing a variety of complex traits.
For the last five years or so, two companies—Genomic Prediction and Orchid—have dominated this small landscape, focusing their efforts on disease prevention. But more recently, two splashy new competitors have emerged: Nucleus Genomics and Herasight, which have rejected the more cautious approach of their predecessors and waded into the controversial territory of genetic testing for intelligence. (Nucleus also offers tests for a wide variety of other behavioral and appearance-related traits.)
The practical limitations of polygenic risk scores are substantial. For starters, there is still a lot we don’t understand about the complex gene interactions driving polygenic traits and disorders. And the biobank data sets they are based on tend to overwhelmingly represent individuals with Western European ancestry, making it more difficult to generate reliable scores for patients from other backgrounds. These scores also lack the full context of environment, lifestyle, and the myriad other factors that can influence a person’s characteristics. And while polygenic risk scores can be effective at detecting large, population-level trends, their predictive abilities drop significantly when the sample size is as tiny as a single batch of embryos that share much of the same DNA.
But beyond questions of whether evidence supports the technology’s effectiveness, critics of the companies selling it accuse them of reviving a disturbing ideology: eugenics, or the belief that selective breeding can be used to improve humanity. Indeed, some of the voices who have been most confident that these methods can successfully predict nondisease traits have made startling claims about natural genetic hierarchies and innate racial differences.
What everyone can agree on, though, is that this new wave of technology is helping to inflame a centuries-old debate over nature versus nurture.
The term “eugenics” was coined in 1883 by a British anthropologist and statistician named Sir Francis Galton, inspired in part by the work of his cousin Charles Darwin. He derived it from a Greek word meaning “good in stock, hereditarily endowed with noble qualities.”
Some of modern history’s darkest chapters have been built on Galton’s legacy, from the Holocaust to the forced sterilization laws that affected certain groups in the United States well into the 20th century. Modern science has demonstrated the many logical and empirical problems with Galton’s methodology. (For starters, he counted vague concepts like “eminence”—as well as infections like syphilis and tuberculosis—as heritable phenotypes, meaning characteristics that result from the interaction of genes and environment.)
Yet even today, Galton’s influence lives on in the field of behavioral genetics, which investigates the genetic roots of psychological traits. Starting in the 1960s, researchers in the US began to revisit one of Galton’s favorite methods: twin studies. Many of these studies, which analyzed pairs of identical and fraternal twins to try to determine which traits were heritable and which resulted from socialization, were funded by the US government. The most well-known of these, the Minnesota Twin Study, also accepted grants from the Pioneer Fund, a now defunct nonprofit that had promoted eugenics and “race betterment” since its founding in 1937.
The nature-versus-nurture debate hit a major inflection point in 2003, when the Human Genome Project was declared complete. After 13 years and at a cost of nearly $3 billion, an international consortium of thousands of researchers had sequenced 92% of the human genome for the first time.
Today, the cost of sequencing a genome can be as low as $600, and one company says it will soon drop even further. This dramatic reduction has made it possible to build massive DNA databases like the UK Biobank and the National Institutes of Health’s All of Us, each containing genetic data from more than half a million volunteers. Resources like these have enabled researchers to conduct genome-wide association studies, or GWASs, which identify correlations between genetic variants and human traits by analyzing single-nucleotide polymorphisms (SNPs)—the most common form of genetic variation between individuals. The findings from these studies serve as a reference point for developing polygenic risk scores.
Most GWASs have focused on disease prevention and personalized medicine. But in 2011, a group of medical researchers, social scientists, and economists launched the Social Science Genetic Association Consortium (SSGAC) to investigate the genetic basis of complex social and behavioral outcomes. One of the phenotypes they focused on was the level of education people reached.
“It was a bit of a phenotype of convenience,” explains Patrick Turley, an economist and member of the steering committee at SSGAC, given that educational attainment is routinely recorded in surveys when genetic data is collected. Still, it was “clear that genes play some role,” he says. “And trying to understand what that role is, I think, is really interesting.” He adds that social scientists can also use genetic data to try to better “understand the role that is due to nongenetic pathways.”
Many on the left are generally willing to allow that any number of traits, from addiction to obesity, are genetically influenced. Yet heritable cognitive ability seems to be “beyond the pale for us to integrate as a source of difference.”
The work immediately stirred feelings of discomfort—not least among the consortium’s own members, who feared that they might unintentionally help reinforce racism, inequality, and genetic determinism.
It’s also created quite a bit of discomfort in some political circles, says Kathryn Paige Harden, a psychologist and behavioral geneticist at the University of Texas in Austin, who says she has spent much of her career making the unpopular argument to fellow liberals that genes are relevant predictors of social outcomes.
Harden thinks a strength of those on the left is their ability to recognize “that bodies are different from each other in a way that matters.” Many are generally willing to allow that any number of traits, from addiction to obesity, are genetically influenced. Yet, she says, heritable cognitive ability seems to be “beyond the pale for us to integrate as a source of difference that impacts our life.”
Harden believes that genes matter for our understanding of traits like intelligence, and that this should help shape progressive policymaking. She gives the example of an education department seeking policy interventions to improve math scores in a given school district. If a polygenic risk score is “as strongly correlated with their school grades” as family income is, she says of the students in such a district, then “does deliberately not collecting that [genetic] information, or not knowing about it, make your research harder [and] your inferences worse?”
To Harden, persisting with this strategy of avoidance for fear of encouraging eugenicists is a mistake. If “insisting that IQ is a myth and genes have nothing to do with it was going to be successful at neutralizing eugenics,” she says, “it would’ve won by now.”
Part of the reason these ideas are so taboo in many circles is that today’s debate around genetic determinism is still deeply infused with Galton’s ideas—and has become a particular fixation among the online right.
SELMAN DESIGN
After Elon Musk took over Twitter (now X) in 2022 and loosened its restrictions on hate speech, a flood of accounts started sharing racist posts, some speculating about the genetic origins of inequality while arguing against immigration and racial integration. Musk himself frequently reposts and engages with accounts like Crémieux Recueil, the pen name of independent researcher Jordan Lasker, who has written about the “Black-White IQ gap,” and i/o, an anonymous account that once praised Musk for “acknowledging data on race and crime,” saying it “has done more to raise awareness of the disproportionalities observed in these data than anything I can remember.” (In response to allegations that his research encourages eugenics, Lasker wrote to MIT Technology Review, “The popular understanding of eugenics is about coercion and cutting people cast as ‘undesirable’ out of the breeding pool. This is nothing like that, so it doesn’t qualify as eugenics by that popular understanding of the term.” After going to print, i/o wrote in an email, “Just because differences in intelligence at the individual level are largely heritable, it does not mean that group differences in measured intelligence … are due to genetic differences between groups,” but that the latter is not “scientifically settled” and “an extremely important (and necessary) research area that should be funded rather than made taboo.” He added, “I’ve never made any argument against racial integration or intermarriage or whatever.”X and Musk did not respond to requests for comment.)
Harden, though, warns against discounting the work of an entire field because of a few noisy neoreactionaries. “I think there can be this idea that technology is giving rise to the terrible racism,” she says. The truth, she believes, is that “the racism has preexisted any of this technology.”
In 2019, a company called Genomic Prediction began to offer the first preimplantation polygenic testing that had ever been made commercially available. With its LifeView Embryo Health Score, prospective parents are able to assess their embryos’ predisposition to genetically complex health problems like cancer, diabetes, and heart disease. Pricing for the service starts at $3,500. Genomic Prediction uses a technique called an SNP array, which targets specific sites in the genome where common variants occur. The results are then cross-checked against GWASs that show correlations between genetic variants and certain diseases.
Four years later, a company named Orchid began offering a competing test. Orchid’s Whole Genome Embryo Report distinguished itself by claiming to sequence more than 99% of an embryo’s genome, allowing it to detect novel mutations and, the company says, diagnose rare diseases more accurately. For $2,500 per embryo, parents can access polygenic risk scores for 12 disorders, including schizophrenia, breast cancer, and hypothyroidism.
Orchid was founded by a woman named Noor Siddiqui. Before getting undergraduate and graduate degrees from Stanford, she was awarded the Thiel fellowship—a $200,000 grant given to young entrepreneurs willing to work on their ideas instead of going to college—back when she was a teenager, in 2012. This set her up to attract attention from members of the tech elite as both customers and financial backers. Her company has raised $16.5 million to date from investors like Ethereum founder Vitalik Buterin, former Coinbase CTO Balaji Srinivasan, and Armstrong, the Coinbase CEO.
In August Siddiqui made the controversial suggestion that parents who choose not to use genetic testing might be considered irresponsible. “Just be honest: you’re okay with your kid potentially suffering for life so you can feel morally superior …” she wrote on X.
Americans have varied opinions on the emerging technology. In 2024, a group of bioethicists surveyed 1,627 US adults to determine attitudes toward a variety of polygenic testing criteria. A large majority approved of testing for physical health conditions like cancer, heart disease, and diabetes. Screening for mental health disorders, like depression, OCD, and ADHD, drew a more mixed—but still positive—response. Appearance-related traits, like skin color, baldness, and height, received less approval as something to test for.
Intelligence was among the most contentious traits—unsurprising given the way it has been weaponized throughout history and the lack of cultural consensus on how it should even be defined. (In many countries, intelligence testing for embryos is heavily regulated; in the UK, the practice is banned outright.) In the 2024 survey, 36.9% of respondents approved of preimplantation genetic testing for intelligence, 40.5% disapproved, and 22.6% said they were uncertain.
Despite the disagreement, intelligence has been among the traits most talked about as targets for testing. From early on, Genomic Prediction says, it began receiving inquiries “from all over the world” about testing for intelligence, according to Diego Marin, the company’s head of global business development and scientific affairs.
At one time, the company offered a predictor for what it called “intellectual disability.” After some backlash questioning both the predictive capacity and the ethics of these scores, the company discontinued the feature. “Our mission and vision of this company is not to improve [a baby], but to reduce risk for disease,” Marin told me. “When it comes to traits about IQ or skin color or height or something that’s cosmetic and doesn’t really have a connotation of a disease, then we just don’t invest in it.”
Orchid, on the other hand, does test for genetic markers associated with intellectual disability and developmental delay. But that may not be all. According to one employee of the company, who spoke on the condition of anonymity, intelligence testing is also offered to “high-roller” clients. According to this employee, another source close to the company, and reporting in the Washington Post, Musk used Orchid’s services in the conception of at least one of the children he shares with the tech executive Shivon Zilis. (Orchid, Musk, and Zilis did not respond to requests for comment.)
I met Kian Sadeghi, the 25-year-old founder of New York–based Nucleus Genomics, on a sweltering July afternoon in his SoHo office. Slight and kinetic, Sadeghi spoke at a machine-gun pace, pausing only occasionally to ask if I was keeping up.
Sadeghi had modified his first organism—a sample of brewer’s yeast—at the age of 16. As a high schooler in 2016, he was taking a course on CRISPR-Cas9 at a Brooklyn laboratory when he fell in love with the “beautiful depth” of genetics. Just a few years later, he dropped out of college to build “a better 23andMe.”
His company targets what you might call the application layer of PGT-P, accepting data from IVF clinics—and even from the competitors mentioned in this story—and running its own computational analysis.
“Unlike a lot of the other testing companies, we’re software first, and we’re consumer first,” Sadeghi told me. “It’s not enough to give someone a polygenic score. What does that mean? How do you compare them? There’s so many really hard design problems.”
Like its competitors, Nucleus calculates its polygenic risk scores by comparing an individual’s genetic data with trait-associated variants identified in large GWASs, providing statistically informed predictions.
Nucleus provides two displays of a patient’s results: a Z-score, plotted from –4 to 4, which explains the risk of a certain trait relative to a population with similar genetic ancestry (for example, if Embryo #3 has a 2.1 Z-score for breast cancer, its risk is higher than average), and an absolute risk score, which includes relevant clinical factors (Embryo #3 has a minuscule actual risk of breast cancer, given that it is male).
The real difference between Nucleus and its competitors lies in the breadth of what it claims to offer clients. On its sleek website, prospective parents can sort through more than 2,000 possible diseases, as well as traits from eye color to IQ. Access to the Nucleus Embryo platform costs $8,999, while the company’s new IVF+ offering—which includes one IVF cycle with a partner clinic, embryo screening for up to 20 embryos, and concierge services throughout the process—starts at $24,999.
“Maybe you want your baby to have blue eyes versus green eyes,” Nucleus founder Kian Sadeghi said at a June event. “That is up to the liberty of the parents.”
Its promises are remarkably bold. The company claims to be able to forecast a propensity for anxiety, ADHD, insomnia, and other mental issues. It says you can see which of your embryos are more likely to have alcohol dependence, which are more likely to be left-handed, and which might end up with severe acne or seasonal allergies. (Nevertheless, at the time of writing, the embryo-screening platform provided this disclaimer: “DNA is not destiny. Genetics can be a helpful tool for choosing an embryo, but it’s not a guarantee. Genetic research is still in it’s [sic] infancy, and there’s still a lot we don’t know about how DNA shapes who we are.”)
To people accustomed to sleep trackers, biohacking supplements, and glucose monitoring, taking advantage of Nucleus’s options might seem like a no-brainer. To anyone who welcomes a bit of serendipity in their life, this level of perceived control may be disconcerting to say the least.
Sadeghi likes to frame his arguments in terms of personal choice. “Maybe you want your baby to have blue eyes versus green eyes,” he told a small audience at Nucleus Embryo’s June launch event. “That is up to the liberty of the parents.”
On the official launch day, Sadeghi spent hours gleefully sparring with X users who accused him of practicing eugenics. He rejects the term, favoring instead “genetic optimization”—though it seems he wasn’t too upset about the free viral marketing. “This week we got five million impressions on Twitter,” he told a crowd at the launch event, to a smattering of applause. (In an email to MIT Technology Review, Sadeghi wrote, “The history of eugenics is one of coercion and discrimination by states and institutions; what Nucleus does is the opposite—genetic forecasting that empowers individuals to make informed decisions.”)
Nucleus has raised more than $36 million from investors like Srinivasan, Alexis Ohanian’s venture capital firm Seven Seven Six, and Thiel’s Founders Fund. (Like Siddiqui, Sadeghi was a recipient of a Thiel fellowship when he dropped out of college; a representative for Thiel did not respond to a request for comment for this story.) Sadeghi has even poached Genomic Prediction’s cofounder Nathan Treff, who is now Nucleus’s chief clinical officer.
Sadeghi’s real goal is to build a one-stop shop for every possible application of genetic sequencing technology, from genealogy to precision medicine to genetic engineering. He names a handful of companies providing these services, with a combined market cap in the billions. “Nucleus is collapsing all five of these companies into one,” he says. “We are not an IVF testing company. We are a genetic stack.”
This spring, I elbowed my way into a packed hotel bar in the Flatiron district, where over a hundred people had gathered to hear a talk called “How to create SUPERBABIES.” The event was part of New York’s Deep Tech Week, so I expected to meet a smattering of biotech professionals and investors. Instead, I was surprised to encounter a diverse and curious group of creatives, software engineers, students, and prospective parents—many of whom had come with no previous knowledge of the subject.
The speaker that evening was Jonathan Anomaly, a soft-spoken political philosopher whose didactic tone betrays his years as a university professor.
Some of Anomaly’s academic work has focused on developing theories of rational behavior. At Duke and the University of Pennsylvania, he led introductory courses on game theory, ethics, and collective action problems as well as bioethics, digging into thorny questions about abortion, vaccines, and euthanasia. But perhaps no topic has interested him so much as the emerging field of genetic enhancement.
In 2018, in a bioethics journal, Anomaly published a paper with the intentionally provocative title “Defending Eugenics.” He sought to distinguish what he called “positive eugenics”—noncoercive methods aimed at increasing traits that “promote individual and social welfare”—from the so-called “negative eugenics” we know from our history books.
Anomaly likes to argue that embryo selection isn’t all that different from practices we already take for granted. Don’t believe two cousins should be allowed to have children? Perhaps you’re a eugenicist, he contends. Your friend who picked out a six-foot-two Harvard grad from a binder of potential sperm donors? Same logic.
His hiring at the University of Pennsylvania in 2019 caused outrage among some students, who accused him of “racial essentialism.” In 2020, Anomaly left academia, lamenting that “American universities had become an intellectual prison.”
A few years later, Anomaly joined a nascent PGT-P company named Herasight, which was promising to screen for IQ.
At the end of July, the company officially emerged from stealth mode. A representative told me that most of the money raised so far is from angel investors, including Srinivasan, who also invested in Orchid and Nucleus. According to the launch announcement on X, Herasight has screened “hundreds of embryos” for private customers and is beginning to offer its first publicly available consumer product, a polygenic assessment that claims to detect an embryo’s likelihood of developing 17 diseases.
Their marketing materials boast predictive abilities 122% better than Orchid’s and 193% better than Genomic Prediction’s for this set of diseases. (“Herasight is comparing their current predictor to models we published over five years ago,” Genomic Prediction responded in a statement. “Our team is confident our predictors are world-class and are not exceeded in quality by any other lab.”)
The company did not include comparisons with Nucleus, pointing to the “absence of published performance validations” by that company and claiming it represented a case where “marketing outpaces science.” (“Nucleus is known for world-class science and marketing, and we understand why that’s frustrating to our competitors,” a representative from the company responded in a comment.)
Herasight also emphasized new advances in “within-family validation” (making sure that the scores are not merely picking up shared environmental factors by comparing their performance between unrelated people to their performance between siblings) and “cross-ancestry accuracy” (improving the accuracy of scores for people outside the European ancestry groups where most of the biobank data is concentrated). The representative explained that pricing varies by customer and the number of embryos tested, but it can reach $50,000.
When it comes to traits that Jonathan Anomaly believes are genetically encoded, intelligence is just the tip of the iceberg. He has also spoken about the heritability of empathy, violence, religiosity, and political leanings.
Herasight tests for just one non-disease-related trait: intelligence. For a couple who produce 10 embryos, it claims it can detect an IQ spread of about 15 points, from the lowest-scoring embryo to the highest. The representative says the company plans to release a detailed white paper on its IQ predictor in the future.
The day of Herasight’s launch, Musk responded to the company announcement: “Cool.” Meanwhile, a Danish researcher named Emil Kirkegaard, whose research has largely focused on IQ differences between racial groups, boosted the company to his nearly 45,000 followers on X (as well as in a Substack blog), writing, “Proper embryo selection just landed.” Kirkegaard has in fact supported Anomaly’s work for years; he’s posted about him on X and recommended his 2020 book Creating Future People, which he called a “biotech eugenics advocacy book,” adding: “Naturally, I agree with this stuff!”
When it comes to traits that Anomaly believes are genetically encoded, intelligence—which he claimed in his talk is about 75% heritable—is just the tip of the iceberg. He has also spoken about the heritability of empathy, impulse control, violence, passivity, religiosity, and political leanings.
Anomaly concedes there are limitations to the kinds of relative predictions that can be made from a small batch of embryos. But he believes we’re only at the dawn of what he likes to call the “reproductive revolution.” At his talk, he pointed to a technology currently in development at a handful of startups: in vitro gametogenesis. IVG aims to create sperm or egg cells in a laboratory using adult stem cells, genetically reprogrammed from cells found in a sample of skin or blood. In theory, this process could allow a couple to quickly produce a practically unlimited number of embryos to analyze for preferred traits. Anomaly predicted this technology could be ready to use on humans within eight years.
SELMAN DESIGN
“I doubt the FDA will allow it immediately. That’s what places like Próspera are for,” he said, referring to the so-called “startup city” in Honduras, where scientists and entrepreneurs can conduct medicalexperiments free from the kinds of regulatory oversight they’d encounter in the US.
“You might have a moral intuition that this is wrong,” said Anomaly, “but when it’s discovered that elites are doing it privately … the dominoes are going to fall very, very quickly.” The coming “evolutionary arms race,” he claimed, will “change the moral landscape.”
He added that some of those elites are his own customers: “I could already name names, but I won’t do it.”
After Anomaly’s talk was over, I spoke with a young photographer who told me he was hoping to pursue a master’s degree in theology. He came to the event, he told me, to reckon with the ethical implications of playing God. “Technology is sending us toward an Old-to-New-Testament transition moment, where we have to decide what parts of religion still serve us,” he said soberly.
Criticisms of polygenic testing tend to fall into two camps: skepticism about the tests’ effectiveness and concerns about their ethics. “On one hand,” says Turley from the Social Science Genetic Association Consortium, “you have arguments saying ‘This isn’t going to work anyway, and the reason it’s bad is because we’re tricking parents, which would be a problem.’ And on the other hand, they say, ‘Oh, this is going to work so well that it’s going to lead to enormous inequalities in society.’ It’s just funny to see. Sometimes these arguments are being made by the same people.”
One of those people is Sasha Gusev, who runs a quantitative genetics lab at the Dana-Farber Cancer Institute. A vocal critic of PGT-P for embryo selection, he also often engages in online debates with the far-right accounts promoting race science on X.
Gusev is one of many professionals in his field who believe that because of numerous confounding socioeconomic factors—for example, childhood nutrition, geography, personal networks, and parenting styles—there isn’t much point in trying to trace outcomes like educational attainment back to genetics, particularly not as a way to prove that there’s a genetic basis for IQ.
He adds, “I think there’s a real risk in moving toward a society where you see genetics and ‘genetic endowments’ as the drivers of people’s behavior and as a ceiling on their outcomes and their capabilities.”
Gusev thinks there is real promise for this technology in clinical settings among specific adult populations. For adults identified as having high polygenic risk scores for cancer and cardiovascular disease, he argues, a combination of early screening and intervention could be lifesaving. But when it comes to the preimplantation testing currently on the market, he thinks there are significant limitations—and few regulatory measures or long-term validation methods to check the promises companies are making. He fears that giving these services too much attention could backfire.
“These reckless, overpromised, and oftentimes just straight-up manipulative embryo selection applications are a risk for the credibility and the utility of these clinical tools,” he says.
Many IVF patients have also had strong reactions to publicity around PGT-P. When the New York Timespublished an opinion piece about Orchid in the spring, angry parents took to Reddit to rant. One user posted, “For people who dont [sic] know why other types of testing are necessary or needed this just makes IVF people sound like we want to create ‘perfect’ babies, while we just want (our) healthy babies.”
Still, others defended the need for a conversation. “When could technologies like this change the mission from helping infertile people have healthy babies to eugenics?” one Redditor posted. “It’s a fine line to walk and an important discussion to have.”
Some PGT-P proponents, like Kirkegaard and Anomaly, have argued that policy decisions should more explicitly account for genetic differences. In a series of blog posts following the 2024 presidential election, under the header “Make science great again,” Kirkegaard called for ending affirmative action laws, legalizing race-based hiring discrimination, and removing restrictions on data sets like the NIH’s All of Us biobank that prevent researchers like him from using the data for race science. Anomaly has criticized social welfare policies for putting a finger on the scale to “punish the high-IQ people.”
Indeed, the notion of genetic determinism has gained some traction among loyalists to President Donald Trump.
In October 2024, Trump himself made a campaign stop on the conservative radio program The Hugh Hewitt Show. He began a rambling answer about immigration and homicide statistics. “A murderer, I believe this, it’s in their genes. And we got a lot of bad genes in our country right now,” he told the host.
Gusev believes that while embryo selection won’t have much impact on individual outcomes, the intellectual framework endorsed by many PGT-P advocates could have dire social consequences.
“If you just think of the differences that we observe in society as being cultural, then you help people out. You give them better schooling, you give them better nutrition and education, and they’re able to excel,” he says. “If you think of these differences as being strongly innate, then you can fool yourself into thinking that there’s nothing that can be done and people just are what they are at birth.”
For the time being, there are no plans for longitudinal studies to track actual outcomes for the humans these companies have helped bring into the world. Harden, the behavioral geneticist from UT Austin, suspects that 25 years down the line, adults who were once embryos selected on the basis of polygenic risk scores are “going to end up with the same question that we all have.” They will look at their life and wonder, “What would’ve had to change for it to be different?”
Julia Black is a Brooklyn-based features writer and a reporter in residence at Omidyar Network. She has previously worked for Business Insider, Vox, The Information, and Esquire.
Sucking carbon pollution out of the atmosphere is becoming a big business—companies are paying top dollar for technologies that can cancel out their own emissions.
Today, nearly 70% of announced carbon removal contracts are for one technology: bioenergy with carbon capture and storage (BECCS). Basically, the idea is to use trees or some other types of biomass for energy, and then capture the emissions when you burn it.
While corporations, including tech giants like Microsoft, are betting big on this technology, there are a few potential problems with BECCS, as my colleague James Temple laid out in a new story. And some of the concerns echo similar problems with other climate technologies we cover, like carbon offsets and alternative jet fuels.
Carbon math can be complicated.
To illustrate one of the biggest issues with BECCS, we need to run through the logic on its carbon accounting. (And while this tech can use many different forms of biomass, let’s assume we’re talking about trees.)
When trees grow, they suck up carbon dioxide from the atmosphere. Those trees can be harvested and used for some intended purpose, like making paper. The leftover material, which might otherwise be waste, is then processed and burned for energy.
This cycle is, in theory, carbon neutral. The emissions from burning the biomass are canceled out by what was removed from the atmosphere during plants’ growth. (Assuming those trees are replaced after they’re harvested.)
So now imagine that carbon-scrubbing equipment is added to the facility that burns the biomass, capturing emissions. If the cycle was logically carbon neutral before, now it’s carbon negative: On net, emissions are removed from the atmosphere. Sounds great, no notes.
There are a few problems with this math, though. For one, it leaves out the emissions that might be produced while harvesting, transporting, and processing wood. And if projects require clearing land to plant trees or grow crops, that transformation can wind up releasing emissions too.
Issues with carbon math might sound a little familiar if you’ve read any of James’s reporting on carbon offsets, programs where people pay for others to avoid emissions. In particular, his 2021 investigation with ProPublica’s Lisa Song laid out how this so-called solution was actually adding millions of tons of carbon dioxide into the atmosphere.
Carbon capture may entrench polluting facilities.
One of the big benefits of BECCS is that it can be added to existing facilities. There’s less building involved than there might be in something like a facility that vacuums carbon directly out of air. That helps keep costs down, so BECCS is currently much cheaper than direct air capture and other forms of carbon removal.
But keeping legacy equipment running might not be a great thing for emissions or local communities in the long run.
Carbon dioxide is far from the only pollutant spewing out of these facilities. Burning biomass or biofuels can release emissions that harm human health, like particulate matter, sulfur dioxide, and carbon monoxide. Carbon capture equipment might trap some of these pollutants, like sulfur dioxide, but not all.
Assuming that waste material wouldn’t be used for something else might not be right.
It sounds great to use waste, but there’s a major asterisk lurking here, as James lays out in the story:
But the critical question that emerges with waste is: Would it otherwise have been burned or allowed to decompose, or might some of it have been used in some other way that kept the carbon out of the atmosphere?
Biomass can be used for other things, like making plastic, building material, or even soil additives that can help crops get more nutrients. So the assumption that it’s BECCS or nothing is flawed.
Moreover, a weird thing happens when you start making waste valuable: There’s an incentive to produce more of it. Some experts are concerned that companies could wind up trimming more trees or clearing more forests than what’s needed to make more material for BECCS.
These waste issues remind me of conversations around sustainable aviation fuels. These alternative fuels can be made from a huge range of materials, including crop waste or even used cooking oil. But as demand for these clean fuels has ballooned, things have gotten a little wonky—there are even some reports of fraud, where scammers try to pass off newly made oil from crops as used cooking oil.
BECCS is a potentially useful technology, but like many things in climate tech, it can quickly get complicated.
James has been reporting on carbon offsets and carbon removal for years. As he put it to me this week when we were chatting about this story: “Just cut emissions and stop messing around.”
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The race to make the perfect baby is creating an ethical mess
An emerging field of science is seeking to use cell analysis to predict what kind of a person an embryo might eventually become.
Some parents turn to these tests to avoid passing on devastating genetic disorders that run in their families. A much smaller group, driven by dreams of Ivy League diplomas or attractive, well-behaved offspring, are willing to pay tens of thousands of dollars to optimize for intelligence, appearance, and personality.
But customers of the companies emerging to provide it to the public may not be getting what they’re paying for.Read the full story.
—Julia Black
This story is from our forthcoming print issue, which is all about the body. If you haven’t already, subscribe now to receive future issues once they land. Plus, you’ll also receive a free digital report on nuclear power.
The problem with Big Tech’s favorite carbon removal tech
Sucking carbon pollution out of the atmosphere is becoming a big business—companies are paying top dollar for technologies that can cancel out their own emissions.
Tech giants like Microsoft are betting big on one technology: bioenergy with carbon capture and storage (BECCS). But there are a few potential problems with BECCS, as my colleague James Temple laid out in a new story. And some of the concerns echo similar problems with other climate technologies we cover, like carbon offsets and alternative jet fuels. Read the full story.
—Casey Crownhart
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
2025 climate tech companies to watch: Fervo Energy and its advanced geothermal power plants
Some places on Earth hit the geological jackpot for generating electricity. In those spots, three conditions naturally align: high temperatures, plentiful water, and rock that’s permeable enough for fluids to circulate through.
Enhanced geothermal systems aim to replicate those conditions in far more places—producing a steady supply of renewable energy wherever they’re deployed. Fervo Energy uses fracking techniques to create geothermal reservoirs capable of delivering enough electricity to power massive data centers and hundreds of thousands of homes. Read the full story.
—Celina Zhao
Fervo Energy is one of our 10 climate tech companies to watch—our annual list of some of the most promising climate tech firms on the planet. Check out the rest of the list here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Meta removed a Facebook group that shared ICE agent sightings It’s the latest tech company to acquiesce to US government pressure. (NYT $) + Meta says the group violates its policies against “coordinated harm.” (NBC News) + Another effort to track ICE raids was just taken offline. (MIT Technology Review)
2 Loss-making AI startups are still soaring in value If it looks like a bubble, and sounds like a bubble… (FT $) + AI-backed energy firms have also ballooned in value. (WSJ $) + Scaling isn’t always the answer, y’know. (Wired $)
3 Facial recognition is failing people with facial differences Yet it’s being embedded in everything from phone unlocking systems to public services. (Wired $)
4 Tech billionaires are backing a startup that treats tumors with sound waves It’s being touted as a less-invasive alternative to chemotherapy. (Bloomberg $)
5 Scam texts are a billion-dollar criminal enterprise And we’re being inundated with more of them than ever before. (WSJ $) + The people using humor to troll their spam texts. (MIT Technology Review)
6 South Korea has rolled back an AI textbook program for schools Turns out it was riddled with inaccuracies and added to teachers’ workloads. (Rest of World) + The country is considering allowing Google and Apple to make hi-res maps. (TechCrunch)
7 YouTube is setting its sights on sports Which makes sense, given that it’s conquered pretty much all the other TV genres. (Hollywood Reporter $)
8 Job hunting in the age of AI is bleak Even the best candidates are being overlooked. (The Atlantic $) + The job market is a mess too. (Slate $)
9 A new channel broadcasts a livestream direct from the ISS If you’ve ever wanted to be an astronaut, watching this is the next best thing. (The Guardian)
10 The end of support for Windows 10 is an e-waste disaster Up to 400 million machines could be heading to the scrap heap. (404 Media) + The US government has cut funding for a battery-metals recycler. (Bloomberg $) + AI will add to the e-waste problem. Here’s what we can do about it. (MIT Technology Review)
Quote of the day
“We are not the elected moral police of the world.”
—OpenAI CEO Sam Altman reacts to the outcry sparked by his company’s decision to relax its rules to let adults hold erotic conversations with ChatGPT, CNBC reports.
One more thing
Inside India’s scramble for AI independence
Despite its status as a global tech hub, India lags far behind the likes of the US and China when it comes to homegrown AI.
That gap has opened largely because India has chronically underinvested in R&D, institutions, and invention. Meanwhile, since no one native language is spoken by the majority of the population, training language models is far more complicated than it is elsewhere.
So when the open-source foundation model DeepSeek-R1 suddenly outperformed many global peers, it struck a nerve. This launch by a Chinese startup prompted Indian policymakers to confront just how far behind the country was in AI infrastructure—and how urgently it needed to respond. Read the full story.
—Shadma Shaikh
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
Used in aviation, book and claim offers companies the ability to financially support the use of SAF even when it is not physically available at their locations.
As companies that ship goods by air or provide air freight related services address a range of climate goals aiming to reduce emissions, the importance of sustainable aviation fuel (SAF) couldn’t be more pronounced. In its neat form, SAF has the potential to reduce life cycle GHG emissions by up to 80% compared to conventional jet fuel.
In this exclusive webcast, leaders discuss the urgency for reducing air freight emissions for freight forwarders and shippers, and reasons why companies should use SAF. They also explain how companies can best make use of the book and claim model to support their emissions reduction strategies.
Learn from the leaders
What book and claim is and how companies can use it
Why SAF use is so important
How freight-forwarders and shippers can both potentially utilise and contribute to the benefits of SAF
Featured speakers
Raman Ojha, President, Shell Aviation. Raman is responsible for Shell’s global aviation business, which supplies fuels, lubricants, and lower carbon solutions, and offers a range of technical services globally. During almost 20 years at Shell, Raman has held leadership positions across a variety of industry sectors, including energy, lubricants, construction, and fertilisers. He has broad experience across both matured markets in the Americas and Europe, as well as developing markets including China, India, and Southeast Asia.
Bettina Paschke, VP ESG Accounting, Reporting & Controlling, DHL Express. Bettina Paschke leads ESG Accounting, Reporting & Controlling, at DHL Express a division of DHL Group. In her role, she is responsible for ESG, including, EU Taxonomy Reporting, and Carbon Accounting. She has more than 20 years’ experience in Finance. In her role she is driving the Sustainable Aviation Fuel agenda at DHL Express and is engaged in various industry initiatives to allow reliable book and claim transactions.
Christoph Wolff, Chief Executive Officer at Smart Freight Centre. Christoph Wolff is currently the Chief Executive Officer at Smart Freight Centre, leading programs focused on sustainability in freight transport. Prior to this role, Christoph served as the Senior Advisor and Director at ACME Group, a global leader in green energy solutions. With a background in various industries, Christoph has held positions such as Managing Director at European Climate Foundation and Senior Board Advisor at Ferrostaal GmbH. Christoph has also worked at Novatec, Solar Millennium AG, DB Schenker, McKinsey & Company, and served as an Assistant Professor at Northwestern University – Kellogg School of Management. Christoph holds multiple degrees from RWTH Aachen University and ETH Zürich, along with ongoing executive education at the University of Michigan.
This discussion is presented by MIT Technology Review Insights in association with Avelia. Avelia is a Shell owned solution and brand that was developed with support from Amex GBT, Accenture and Energy Web Foundation. The views from individuals not affiliated with Shell are their own and not those of Shell PLC or its affiliates. Cautionary note | Shell Global
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
Not all offerings are available in all jurisdictions. Depending on jurisdiction and local laws, Shell may offer the sale of Environmental Attributes (for which subject to applicable law and consultation with own advisors, buyers might be able to use such Environmental Attributes for their own emission reduction purposes) and/or Environmental Attribute Information (pursuant to which buyers are helping subsidize the use of SAF and lower overall aviation emissions at designated airports but no emission reduction claims may be made by buyers for their own emissions reduction purposes). Different offerings have different forms of contracts, and no assumptions should be made about a particular offering without reading the specific contractual language applicable to such offering.
This week we had some terrifying news from the World Health Organization: Antibiotics are failing us. A growing number of bacterial infections aren’t responding to these medicines—including common ones that affect the blood, gut, and urinary tract. Get infected with one of these bugs, and there’s a fair chance antibiotics won’t help.
The scary truth is that a growing number of harmful bacteria and fungi are becoming resistant to drugs. Just a few weeks ago, the US Centers for Disease Control and Prevention published a report finding a sharp rise in infections caused by a dangerous type of bacteria that are resistant to some of the strongest antibiotics. Now, the WHO report shows that the problem is surging around the world.
In this week’s Checkup, we’re trying something a bit different—a little quiz. You’ve probably heard about antimicrobial resistance (AMR) before, but how much do you know about microbes, antibiotics, and the scale of the problem? Here’s our attempt to put the “fun” in “fundamental threat to modern medicine.” Test your knowledge below!
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
The resale economy is no longer a niche. As the 2025 Christmas shopping season approaches, the sale of pre-owned, refurbished, or overstock goods is impacting how merchants attract consumers and clear excess inventory.
Salesforce predicts that U.S. resale transactions — peer-to-peer, marketplaces, other channels — will account for $64 billion in holiday revenue this year. Fashion resale alone could top $26 billion in 2025.
Recommerce is fast becoming both a profitable sales channel and a discount strategy that avoids brand erosion.
Nearly every recommerce survey this year points to growth. Deloitte reported that some 150 U.S. fashion brands now offer in-house resale programs, up more than 300% since 2021.
Tariffs, inflation, and changing consumer values all push shoppers toward pre-owned goods.
Lululemon Like New is the company’s dedicated resale site.
The Resale Consumer
The resale shopper, however, is not only a bargain hunter.
Recommerce’s new appeal could stem from taste, value, and access. Consumers want products that feel distinct and attainable, and if those products happen to be cheaper than first-run items, all the better.
Consider Pinterest’s Autumn Trend Report 2025, released in August. The platform reported a 550% increase in searches for “dream thrift finds” and more than a 1,000% increase in searches related to a “vintage autumn aesthetic.”
This apparent combination of thrift and taste may explain why even relatively expensive brands such as Lululemon, Madewell, and Nike sell their own used, reconditioned, or overstock products at steep discounts.
Strategic Resale
For ecommerce operators, recommerce isn’t merely a revenue opportunity. It is a strategic pricing tool.
Instead of relying on blanket markdowns that dilute brand equity, merchants can move open-box returns, refurbished goods, and aged or seasonal inventory into a “pre-owned” or “like-new” category.
This approach reframes discounting as value-driven and appeals to new customer segments, especially Gen Zs and Millennials who associate thrift with intelligence and authenticity.
Holiday Execution
The imminent Christmas shopping season is an excellent time to test recommerce.
New inventory. Recommerce can begin with overstock and slow-moving products, not just used items. Instead of markdowns, list products in a “like new” category that frames savings as smart and value-driven.
Merchants can also A/B test results. Offer the same SKU twice — one discounted, one recommerce — and compare performance. Many shops find the “like new” label maintains value while attracting price-conscious buyers.
Returned. Don’t forget returned and reconditioned items. These often sit idle during the holidays. Try creating a dedicated section for open-box or lightly used goods that meet resale standards.
Early returns from Black Friday and Cyber Monday can become new listings within days. Build a fast intake process: inspect, relabel, and relist within 72 hours. Every extra day in storage is a lost chance to capture demand.
After Christmas. Present post-holiday campaigns as “Smart Finds” or “Returned Favorites.” Turn liquidation into a recommerce story. The approach converts returns into marketing and signals that the retailer values reuse and efficiency.
Recommerce Tech
With planning and organization, the resale channel is an option for nearly any ecommerce site.
Nonetheless, several apps and add-ons make reselling relatively easier.
Archive and Trove integrate with Shopify and other platforms for resale logistics.
B-Stock provides liquidation options for bulk or unsellable items.
Tracking resale margins separately in Google Analytics or ecommerce dashboards can quantify whether recommerce cannibalizes or complements sales.
Holiday Testing
Recommerce increasingly contributes to U.S. retail growth. For merchants, it is a margin and retention strategy that redefines how inventory flows through the business.
Testing recommerce during the 2025 holiday shopping season allows retailers to gauge sales without committing to a full-scale effort. If it performs well, the channel can become permanent.
Google’s John Mueller answered a question about removing hacked URLs that are showing in the index. He explained how to remove the sites from appearing in the search results and then discussed the nuances involved in dealing with this specific situation.
Removing Hacked Pages From Google’s SERPs
The person asking the question was the victim of the Japanese hacking attack, so-called because the attackers create hundreds or even thousands of rogue Japanese language web pages. The person had dealt with the issue and removed the spammy infected web pages, leaving them with 404 pages that are still referenced in Google’s search results.
They now want to remove them from Google’s search index so that the site is no longer associated with those pages.
“My site recently got a Japanese attack. However, I shifted that site to a new hosting provider and have removed all data from there.
However, the fact is that many Japanese URLs have been indexed.
So how do I deindex those thousands of URLs from my website?”
The question reflects a common problem in the aftermath of a Japanese hack attack, where hacked pages stubbornly remain indexed long after the pages were removed. This shows that site recovery is not complete once the malicious content is removed; Google’s search index needs to clear the pages, and that can take a frustratingly long time.
How To Remove Japanese Hack Attack Pages From Google
Google’s John Mueller recommended using the URL Removals Tool found in Search Console. Contrary to the implication inherent in the name of the tool, it doesn’t remove a URL from the search index; it just removes it from showing in Google’s search results faster if the content has already been removed from the site or blocked from Google’s crawler. Under normal circumstances, Google will remove a page from the search results after the page is crawled and noted to be blocked or gone (404 error response).
Three Prerequisites For URL Removals Tool
The page is removed and returns a 404 or 410 server response code.
The URL is blocked from indexing by a robots meta tag:
The URL is prevented from being crawled by a robots.txt file.
Google’s Mueller responded:
“You can use the URL removal tool in search console for individual URLs (also if the URLs all start with the same thing). I’d use that for any which are particularly visible (check the performance report, 24 hours).
This doesn’t remove them from the index, but it hides them within a day. If the pages are invalid / 404 now, they’ll also drop out over time, but the removal tool means you can stop them from being visible “immediately”. (Redirecting o 404 are both ok, technically a 404 is the right response code)”
Mueller clarified that the URL Removals Tool does not delete URLs from Google’s index but instead hides them from search results, faster than natural recrawling would. His explanation is a reminder that the tool has a temporary search visibility effect and is not a way to permanently remove a URL from Google’s index itself. The actual removal from the search index happens after Google verifies that the page is actually gone or blocked from crawling or indexing.
Google Business Profile appears to be testing a feature that lets managers share the same update across multiple locations from a single dialog.
Tim Capper reported seeing the option. After publishing an update, a “Copy post” dialog appears with the prompt: “Copy the update to other profiles you manage.”
You can now post an update across multiple Google Business Profiles
After posting this pop up appears if you want to add to other profiles, nice ! pic.twitter.com/tlXHlrxYie
The interface displays a list of business locations with checkboxes so you can choose which profiles receive the same update.
We’ve asked Google for comment on availability and eligibility requirements and will update this article if we receive a response.
What’s New
From what’s visible in the screenshots, the workflow streamlines cross-posting for multi-location accounts.
You publish an update to one profile, then immediately see a pop-up listing other profiles you manage.
You can select one or many locations and post the same update without repeating the process.
Why It Matters
If you manage multiple locations, this could save time by reducing repetitive posting. It may also help keep messaging consistent across locations.
Make sure updates remain locally relevant before copying them everywhere.
How To Check If You Have Access
If you manage more than one profile in the same account, publish a standard update to one location.
If your account is in the test, you should see a “Copy post” dialog immediately after posting, with a list of other profiles you manage.
If You Don’t See It
Not all accounts will have access during tests. Keep posting as usual and check again periodically. If you manage many locations, confirm that all profiles are grouped under the same account with the correct permissions.
Looking Ahead
If Google proceeds with a wider launch, expect details on supported post types, scheduling, and limits. We’ll update this story if Google confirms the feature or publishes documentation.
Search has never stood still. Every few years, a new layer gets added to how people find and evaluate information. Generative AI systems like ChatGPT, Copilot Search, and Perplexity haven’t replaced Google or Bing. They’ve added a new surface where discovery happens earlier, and where your visibility may never show up in analytics.
Call it Generative Engine Optimization, call it AI visibility work, or just call it the next evolution of SEO. Whatever the label, the work is already happening. SEO practitioners are already tracking citations, analyzing which content gets pulled into AI responses, and adapting strategies as these platforms evolve weekly.
This work doesn’t replace SEO, rather it builds on top of it. Think of it as the “answer layer” above the traditional search layer. You still need structured content, clean markup, and good backlinks, among the other usual aspects of SEO. That’s the foundation assistants learn from. The difference is that assistants now re-present that information to users directly inside conversations, sidebars, and app interfaces.
If your work stops at traditional rankings, you’ll miss the visibility forming in this new layer. Tracking when and how assistants mention, cite, and act on your content is how you start measuring that visibility.
Your brand can appear in multiple generative answers without you knowing. These citations don’t show up in any analytics tool until someone actually clicks.
Image Credi: Duane Forrester
Perplexity explains that every answer it gives includes numbered citations linking to the original sources. OpenAI’s ChatGPT Search rollout confirms that answers now include links to relevant sites and supporting sources. Microsoft’s Copilot Search does the same, pulling from multiple sources and citing them inside a summarized response. And Google’s own documentation for AI overviews makes it clear that eligible content can be surfaced inside generative results.
Each of these systems now has its own idea of what a “citation” looks like. None of them report it back to you in analytics.
That’s the gap. Your brand can appear in multiple generative answers without you knowing. These are the modern zero-click impressions that don’t register in Search Console. If we want to understand brand visibility today, we need to measure mentions, impressions, and actions inside these systems.
But there’s yet another layer of complexity here: content licensing deals. OpenAI has struck partnerships with publishers including the Associated Press, Axel Springer, and others, which may influence citation preferences in ways we can’t directly observe. Understanding the competitive landscape, not just what you’re doing, but who else is being cited and why, becomes essential strategic intelligence in this environment.
In traditional SEO, impressions and clicks tell you how often you appeared and how often someone acted. Inside assistants, we get a similar dynamic, but without official reporting.
Mentions are when your domain, name, or brand is referenced in a generative answer.
Impressions are when that mention appears in front of a user, even if they don’t click.
Actions are when someone clicks, expands, or copies the reference to your content.
These are not replacements for your SEO metrics. They’re early indicators that your content is trusted enough to power assistant answers.
If you read last week’s piece, where I discussed how 2026 is going to be an inflection year for SEOs, you’ll remember the adoption curve. During 2026, assistants are projected to reach around 1 billion daily active users, embedding themselves into phones, browsers, and productivity tools. But that doesn’t mean they’re replacing search. It means discovery is happening before the click. Measuring assistant mentions is about seeing those first interactions before the analytics data ever arrives.
Let’s be clear. Traditional search is still the main driver of traffic. Google handles over 3.5 billion searches per day. In May 2025, Perplexity processed 780 million queries in a full month. That’s roughly what Google handles in about five hours.
The data is unambiguous. AI assistants are a small, fast-growing complement, not a replacement (yet).
But if your content already shows up in Google, it’s also being indexed and processed by the systems that train and quote inside these assistants. That means your optimization work already supports both surfaces. You’re not starting over. You’re expanding what you measure.
Ranking is an output-aligned process. The system already knows what it’s trying to show and chooses the best available page to match that intent. Retrieval, on the other hand, is pre-answer-aligned. The system is still assembling the information that will become the answer and that difference can change everything.
When you optimize for ranking, you’re trying to win a slot among visible competitors. When you optimize for retrieval, you’re trying to be included in the model’s working set before the answer even exists. You’re not fighting for position as much as you’re fighting for participation.
That’s why clarity, attribution, and structure matter so much more in this environment. Assistants pull only what they can quote cleanly, verify confidently, and synthesize quickly.
When an assistant cites your site, it’s doing so because your content met three conditions:
It answered the question directly, without filler.
It was machine-readable and easy to quote or summarize.
It carried provenance signals the model trusted: clear authorship, timestamps, and linked references.
Those aren’t new ideas. They’re the same best practices SEOs have worked with for years, just tested earlier in the decision chain. You used to optimize for the visible result. Now you’re optimizing for the material that builds the result.
One critical reality to understand: citation behavior is highly volatile. Content cited today for a specific query may not appear tomorrow for that same query. Assistant responses can shift based on model updates, competing content entering the index, or weighting adjustments happening behind the scenes. This instability means you’re tracking trends and patterns, not guarantees (not that ranking was guaranteed, but they are typically more stable). Set expectations accordingly.
Not all content has equal citation potential, and understanding this helps you allocate resources wisely. Assistants excel at informational queries (”how does X work?” or “what are the benefits of Y?”). They’re less relevant for transactional queries like “buy shoes online” or navigational queries like “Facebook login.”
If your content serves primarily transactional or branded navigational intent, assistant visibility may matter less than traditional search rankings. Focus your measurement efforts where assistant behavior actually impacts your audience and where you can realistically influence outcomes.
The simplest way to start is manual testing.
Run prompts that align with your brand or product, such as:
“What is the best guide on [topic]?”
“Who explains [concept] most clearly?”
“Which companies provide tools for [task]?”
Use the same query across ChatGPT Search, Perplexity, and Copilot Search. Document when your brand or URL appears in their citations or answers.
Log the results. Record the assistant used, the prompt, the date, and the citation link if available. Take screenshots. You’re not building a scientific study here; you’re building a visibility baseline.
Once you’ve got a handful of examples, start running the same queries weekly or monthly to track change over time.
You can even automate part of this. Some platforms now offer API access for programmatic querying, though costs and rate limits apply. Tools like n8n or Zapier can capture assistant outputs and push them to a Google Sheet. Each row becomes a record of when and where you were cited. (To be fair, it’s more complicated than 2 short sentences make it sound, but it’s doable by most folks, if they’re willing to learn some new things.)
This is how you can create your first “ai-citation baseline“ report if you’re willing to just stay manual in your approach.
But don’t stop at tracking yourself. Competitive citation analysis is equally important. Who else appears for your key queries? What content formats do they use? What structural patterns do their cited pages share? Are they using specific schema markup or content organization that assistants favor? This intelligence reveals what assistants currently value and where gaps exist in the coverage landscape.
We don’t have official impression data yet, but we can infer visibility.
Look at the types of queries where you appear in assistants. Are they broad, informational, or niche?
Use Google Trends to gauge search interest for those same queries. The higher the volume, the more likely users are seeing AI answers for them.
Track assistant responses for consistency. If you appear across multiple assistants for similar prompts, you can reasonably assume high impression potential.
Impressions here don’t mean analytics views. They mean assistant-level exposure: your content seen in an answer window, even if the user never visits your site.
Actions are the most difficult layer to observe, but not because assistant ecosystems hide all referrer data. The tracking reality is more nuanced than that.
Most AI assistants (Perplexity, Copilot, Gemini, and paid ChatGPT users) do send referrer data that appears in Google Analytics 4 as perplexity.ai / referral or chatgpt.com / referral. You can see these sources in your standard GA4 Traffic Acquisition reports. (useful article)
The real challenges are:
Free-tier users don’t send referrers. Free ChatGPT traffic arrives as “Direct” in your analytics, making it impossible to distinguish from bookmark visits, typed URLs, or other referrer-less traffic sources. (useful article)
No query visibility. Even when you see the referrer source, you don’t know what question the user asked the AI that led them to your site. Traditional search gives you some query data through Search Console. AI assistants don’t provide this.
Volume is still small but growing. AI referral traffic typically represents 0.5% to 3% of total website traffic as of 2025, making patterns harder to spot in the noise of your overall analytics. (useful article)
Here’s how to improve tracking and build a clearer picture of AI-driven actions:
Set up dedicated AI traffic tracking in GA4. Create a custom exploration or channel group using regex filters to isolate all AI referral sources in one view. Use a pattern like the excellent example in this Orbit Media article to capture traffic from major platforms ( ^https://(www.meta.ai|www.perplexity.ai|chat.openai.com|claude.ai|gemini.google.com|chatgpt.com|copilot.microsoft.com)(/.*)?$ ). This separates AI referrals from generic referral traffic and makes trends visible.
Add identifiable UTM parameters when you control link placement. In content you share to AI platforms, in citations you can influence, or in public-facing URLs. Even platforms that send referrer data can benefit from UTM tagging for additional attribution clarity. (useful article)
Monitor “Direct” traffic patterns. Unexplained spikes in direct traffic, especially to specific landing pages that assistants commonly cite, may indicate free-tier AI users clicking through without referrer data. (useful article)
Track which landing pages receive AI traffic. In your AI traffic exploration, add “Landing page + query string” as a dimension to see which specific pages assistants are citing. This reveals what content AI systems find valuable enough to reference.
Watch for copy-paste patterns in social media, forums, or support tickets that match your content language exactly. That’s a proxy for text copied from an assistant summary and shared elsewhere.
Each of these tactics helps you build a more complete picture of AI-driven actions, even without perfect attribution. The key is recognizing that some AI traffic is visible (paid tiers, most platforms), some is hidden (free ChatGPT), and your job is to capture as much signal as possible from both.
Machine-Validated Authority (MVA) isn’t visible to us as it’s an internal trust signal used by AI systems to decide which sources to quote. What we can measure are the breadcrumbs that correlate with it:
Frequency of citation
Presence across multiple assistants
Stability of the citation source (consistent URLs, canonical versions, structured markup)
When you see repeat citations or multi-assistant consistency, you’re seeing a proxy for MVA. That consistency is what tells you the systems are beginning to recognize your content as reliable.
Perplexity reports almost 10 billion queries a year across its user base. That’s meaningful visibility potential even if it’s small compared to search.
Microsoft’s Copilot Search is embedded in Windows, Edge, and Microsoft 365. That means millions of daily users see summarized, cited answers without leaving their workflow.
Google’s rollout of AI Overviews adds yet another surface where your content can appear, even when no one clicks through. Their own documentation describes how structured data helps make content eligible for inclusion.
Each of these reinforces a simple truth: SEO still matters, but it now extends beyond your own site.
Start small. A basic spreadsheet is enough.
Columns:
Date.
Assistant (ChatGPT Search, Perplexity, Copilot).
Prompt used.
Citation found (yes/no).
URL cited.
Competitor citations observed.
Notes on phrasing or ranking position.
Add screenshots and links to the full answers for evidence. Over time, you’ll start to see which content themes or formats surface most often.
If you want to automate, set up a workflow in n8n that runs a controlled set of prompts weekly and logs outputs to your sheet. Even partial automation will save time and let you focus on interpretation, not collection. Use this sheet and its data to augment what you can track in sources like GA4.
Before investing heavily in assistant monitoring, consider resource allocation carefully. If assistants represent less than 1% of your traffic and you’re a small team, extensive tracking may be premature optimization. Focus on high-value queries where assistant visibility could materially impact brand perception or capture early-stage research traffic that traditional search might miss.
Manual quarterly audits may suffice until the channel grows to meaningful scale. This is about building baseline understanding now so you’re prepared when adoption accelerates, not about obsessive daily tracking of negligible traffic sources.
Executives understand and prefer dashboards, not debates about visibility layers, so show them real-world examples. Put screenshots of your brand cited inside ChatGPT or Copilot next to your Search Console data. Explain that this is not a new algorithm update but a new front end for existing content. It’s up to you to help them understand this critical difference.
Frame it as additive reach. You’re showing leadership that the company’s expertise is now visible in new interfaces before clicks happen. That reframing keeps support for SEO strong and positions you as the one tracking the next wave.
It’s worth noting that citation practices exist within a shifting legal landscape. Publishers and content creators have raised concerns about copyright and fair use as AI systems train on and reproduce web content. Some platforms have responded with licensing agreements, while legal challenges continue to work through courts.
This environment may influence how aggressively platforms cite sources, which sources they prioritize, and how they balance attribution with user experience. The frameworks we build today should remain flexible as these dynamics evolve and as the industry establishes clearer norms around content usage and attribution.
AI assistant visibility is not yet a major traffic source. It’s a small but growing signal of trust.
By measuring mentions and citations now, you build an early-warning system. You’ll see when your content starts appearing in assistants long before any of your analytics tools do. This means that when 2026 arrives and assistants become a daily habit, you won’t be reacting to the curve. You’ll already have data on how your brand performs inside these new systems.
If you extend the concept here of “data” to a more meta level, you could say it’s already telling us that the growth is starting, it’s explosive, and it’s about to have an impact in consumer’s behaviors. So now is the moment to take that knowledge and focus it on the more day-to-day work you do and start to plan for how those changes impact that daily work.
Traditional SEO remains your base layer. Generative visibility sits above it. Machine-Validated Authority lives inside the systems. Watching mentions, impressions, and actions is how we start making what’s in the shadows measurable.
We used to measure rankings because that’s what we could see. Today, we can measure retrieval for the same reason. This is just the next evolution of evidence-based SEO. Ultimately, you can’t fix what you can’t see. We cannot see how trust is assigned inside the system, but we can see the outputs of each system.
The assistants aren’t replacing search (yet). They’re simply showing you how visibility behaves when the click disappears. If you can measure where you appear in those layers now, you’ll know when the slope starts to change and you’ll already be ahead of it.