According to a report by The Information, Google is working to reduce its reliance on Apple’s Safari browser, but progress has been slower than anticipated.
As Google awaits a ruling on the U.S. Department of Justice’s antitrust lawsuit, its arrangement with Apple is threatened.
The current agreement, which makes Google the default search engine on Safari for iPhones, could be in jeopardy if the judge rules against Google.
To mitigate this risk, Google encourages iPhone users to switch to its Google Search or Chrome apps for browsing. However, these efforts have yielded limited success.
Modest Gains In App Adoption
Over the past five years, Google has increased the percentage of iPhone searches conducted through its apps from 25% to the low 30s.
While this represents progress, it falls short of Google’s internal target of 50% by 2030.
The company has employed various marketing strategies, including campaigns showcasing features like Lens image search and improvements to the Discover feed.
Despite these efforts, Safari’s preinstalled status on iPhones remains an obstacle.
Financial Stakes & Market Dynamics
The financial implications of this struggle are considerable for both Google and Apple.
In 2023, Google reportedly paid over $20 billion to Apple to maintain its status as the default search engine on Safari.
By shifting more users to its apps, Google aims to reduce these payments and gain leverage in future negotiations.
Antitrust Lawsuit & Potential Consequences
The ongoing antitrust lawsuit threatens Google’s business model.
If Google loses the case, it could potentially lose access to approximately 70% of searches conducted on iPhones, which account for about half of the smartphones in the U.S.
This outcome could impact Google’s mobile search advertising revenue, which exceeded $207 billion in 2023.
New Initiatives & Leadership
To address these challenges, Google has brought in new talent, including former Instagram and Yahoo product executive Robby Stein.
Stein is now tasked with leading efforts to shift iPhone users to Google’s mobile apps, exploring ways to make the apps more compelling, including the potential use of generative AI.
Looking Ahead
With the antitrust ruling on the horizon, Google’s ability to attract users to its apps will determine whether it maintains its search market share.
We’ll be watching closely to see how Google navigates these challenges and if it can reduce its reliance on Safari.
Wondering why your carefully crafted content isn’t climbing the search rankings?
You might be overlooking a crucial piece of the puzzle: technical SEO.
It’s easy to get lost in content optimization and on-page SEO, but the real game-changer lies behind the scenes.
Technical SEO is basically the backbone of your website’s performance, ensuring that search engines can find, crawl, and index your pages effectively.
So if your site’s technical foundation hasn’t been a top priority, you could be missing out on major ranking opportunities.
But it’s never too late to pivot – if you’re ready to start maximizing your web performance and outranking your competition, our upcoming webinar is one you won’t want to miss.
Join us live on July 17, as we lay out an actionable framework for auditing and improving your technical SEO across four key pillars:
Discoverability is all about how easily search engines can find your website and its pages.
Crawlability ensures that search engine bots can navigate and access your site without any issues.
Indexability means your pages can be stored in the search engine’s database and shown in search results.
User Experience (UX) focuses on making sure your site is easy for visitors to navigate and enjoyable to use.
Our presenters Steven van Vessum, Director of Organic Marketing at Conductor and Alexandra Dristas, Principal Solutions Consultant at Conductor, will explore ways you can implement core technical SEO best practices.
You’ll also learn which to prioritize based on impact, as well as how to maintain these improvements moving forward.
In this webinar, we’ll cover the following topics:
Optimizing for Discoverability: Learn how creating a clear sitemap and well-organized site architecture helps search engines find and index your pages efficiently.
Improving Crawl Budget: Ensure search engine bots focus on valuable pages rather than getting stuck in loops or wasting resources on low-priority content.
Leveraging Schema and Headings: How using Schema markup and optimizing your heading structure can help improve indexability in search results.
Core Web Vitals and Accessibility: Discover best practices to provide a seamless and satisfying experience for all visitors.
Monitoring Technical SEO: Learn the top tools and processes to continuously identify and fix technical issues, maintaining optimal site performance.
Don’t miss this opportunity to elevate your technical SEO strategy and boost your search visibility.
Plus, if you stick around after the presentation, Steven and Alexandra will be answering questions live in our Q&A session.
Sign up now and get the expert insights you need to rank higher on SERPs.
When working on sites with traffic, there is as much to lose as there is to gain from implementing SEO recommendations.
The downside risk of an SEO implementation gone wrong can be mitigated using machine learning models to pre-test search engine rank factors.
Pre-testing aside, split testing is the most reliable way to validate SEO theories before making the call to roll out the implementation sitewide or not.
We will go through the steps required on how you would use Python to test your SEO theories.
Choose Rank Positions
One of the challenges of testing SEO theories is the large sample sizes required to make the test conclusions statistically valid.
Split tests – popularized by Will Critchlow of SearchPilot – favor traffic-based metrics such as clicks, which is fine if your company is enterprise-level or has copious traffic.
If your site doesn’t have that envious luxury, then traffic as an outcome metric is likely to be a relatively rare event, which means your experiments will take too long to run and test.
Instead, consider rank positions. Quite often, for small- to mid-size companies looking to grow, their pages will often rank for target keywords that don’t yet rank high enough to get traffic.
Over the timeframe of your test, for each data point of time, for example day, week or month, there are likely to be multiple rank position data points for multiple keywords. In comparison to using a metric of traffic (which is likely to have much less data per page per date), which reduces the time period required to reach a minimum sample size if using rank position.
Thus, rank position is great for non-enterprise-sized clients looking to conduct SEO split tests who can attain insights much faster.
Google Search Console Is Your Friend
Deciding to use rank positions in Google makes using the data source a straightforward (and conveniently a low-cost) decision in Google Search Console (GSC), assuming it’s set up.
GSC is a good fit here because it has an API that allows you to extract thousands of data points over time and filter for URL strings.
While the data may not be the gospel truth, it will at least be consistent, which is good enough.
Filling In Missing Data
GSC only reports data for URLs that have pages, so you’ll need to create rows for dates and fill in the missing data.
The Python functions used would be a combination of merge() (think VLOOKUP function in Excel) used to add missing data rows per URL and filling the data you want to be inputed for those missing dates on those URLs.
For traffic metrics, that’ll be zero, whereas for rank positions, that’ll be either the median (if you’re going to assume the URL was ranking when no impressions were generated) or 100 (to assume it wasn’t ranking).
The distribution of any data represents its nature, in terms of where the most popular value (mode) for a given metric, say rank position (in our case the chosen metric) is for a given sample population.
The distribution will also tell us how close the rest of the data points are to the middle (mean or median), i.e., how spread out (or distributed) the rank positions are in the dataset.
This is critical as it will affect the choice of model when evaluating your SEO theory test.
Using Python, this can be done both visually and analytically; visually by executing this code:
The chart above shows that the distribution is positively skewed (think skewer pointing right), meaning most of the keywords rank in the higher-ranked positions (shown towards the left of the red median line).
Now, we know which test statistic to use to discern whether the SEO theory is worth pursuing. In this case, there is a selection of models appropriate for this type of distribution.
Minimum Sample Size
The selected model can also be used to determine the minimum sample size required.
The required minimum sample size ensures that any observed differences between groups (if any) are real and not random luck.
That is, the difference as a result of your SEO experiment or hypothesis is statistically significant, and the probability of the test correctly reporting the difference is high (known as power).
This would be achieved by simulating a number of random distributions fitting the above pattern for both test and control and taking tests.
To break it down, the numbers represent the following using the example below:
(39.333,: proportion of simulation runs or experiments in which significance will be reached, i.e., consistency of reaching significance and robustness.
1.0) : statistical power, the probability the test correctly rejects the null hypothesis, i.e., the experiment is designed in such a way that a difference will be correctly detected at this sample size level.
60000: sample size
The above is interesting and potentially confusing to non-statisticians. On the one hand, it suggests that we’ll need 230,000 data points (made of rank data points during a time period) to have a 92% chance of observing SEO experiments that reach statistical significance. Yet, on the other hand with 10,000 data points, we’ll reach statistical significance – so, what should we do?
Experience has taught me that you can reach significance prematurely, so you’ll want to aim for a sample size that’s likely to hold at least 90% of the time – 220,000 data points are what we’ll need.
This is a really important point because having trained a few enterprise SEO teams, all of them complained of conducting conclusive tests that didn’t produce the desired results when rolling out the winning test changes.
Hence, the above process will avoid all that heartache, wasted time, resources and injured credibility from not knowing the minimum sample size and stopping tests too early.
Assign And Implement
With that in mind, we can now start assigning URLs between test and control to test our SEO theory.
In Python, we’d use the np.where() function (think advanced IF function in Excel), where we have several options to partition our subjects, either on string URL pattern, content type, keywords in title, or other depending on the SEO theory you’re looking to validate.
Strictly speaking, you would run this to collect data going forward as part of a new experiment. But you could test your theory retrospectively, assuming that there were no other changes that could interact with the hypothesis and change the validity of the test.
Something to keep in mind, as that’s a bit of an assumption!
Test
Once the data has been collected, or you’re confident you have the historical data, then you’re ready to run the test.
In our rank position case, we will likely use a model like the Mann-Whitney test due to its distributive properties.
However, if you’re using another metric, such as clicks, which is poisson-distributed, for example, then you’ll need another statistical model entirely.
Once run, you can print the output of the test results:
Mann-Whitney U Test Test Results
MWU Statistic: 6870.0
P-Value: 0.013576443923420183
Additional Summary Statistics:
Test Group: n=122, mean=5.87, std=2.37
Control Group: n=3340, mean=22.58, std=20.59
The above is the output of an experiment I ran, which showed the impact of commercial landing pages with supporting blog guides internally linking to the former versus unsupported landing pages.
In this case, we showed that offer pages supported by content marketing enjoy a higher Google rank by 17 positions (22.58 – 5.87) on average. The difference is significant, too, at 98%!
However, we need more time to get more data – in this case, another 210,000 data points. As with the current sample size, we can only be sure that <10% of the time>
Split Testing Can Demonstrate Skills, Knowledge And Experience
In this article, we walked through the process of testing your SEO hypotheses, covering the thinking and data requirements to conduct a valid SEO test.
By now, you may come to appreciate there is much to unpack and consider when designing, running and evaluating SEO tests. My Data Science for SEO video course goes much deeper (with more code) on the science of SEO tests, including split A/A and split A/B.
As SEO professionals, we may take certain knowledge for granted, such as the impact content marketing has on SEO performance.
Clients, on the other hand, will often challenge our knowledge, so split test methods can be most handy in demonstrating your SEO skills, knowledge, and experience!
The U.S. National Vulnerability Database (NVD) and Wordfence published a security advisory of a high severity Cross Site Request Forgery (CSRF) vulnerability affecting the Nested Pages WordPress plugin affecting up to +100,000 installations. The vulnerability received a Common Vulnerability Scoring System (CVSS) rating of 8.8 on a scale of 1 – 10, with ten representing the highest level severity.
Cross Site Request Forgery (CSRF)
The Cross Site Request Forgery (CSRF) is a type of attack that takes advantage of a security flaw in the Nested Pages plugin that allows unauthenticated attackers to call (execute) PHP files, which are the code level files of WordPress.
There is a missing or incorrect nonce validation, which is a common security feature used in WordPress plugins to secure forms and URLs. A second flaw in the plugin is a missing security feature called sanitization. Sanitization is a method of securing data that’s input or output which is also common to WordPress plugins but in this case is missing.
According to Wordfence:
“This is due to missing or incorrect nonce validation on the ‘settingsPage’ function and missing santization of the ‘tab’ parameter.”
The CSRF attack relies on getting a signed in WordPress user (like an Administrator) to click a link which in turn allows the attacker to complete the attack. This vulnerability is rated 8.8 which makes it a high severity threat. To put that into perspective, a score of 8.9 is a critical level threat which is an even higher level. So at 8.8 it is just short of a critical level threat.
This vulnerability affects all versions of the Nested Pages plugin up to and including version 3.2.7. The developers of the plugin released a security fix in version 3.2.8 and responsibly published the details of the security update in their changelog.
The official changelog documents the security fix:
“Security update addressing CSRF issue in plugin settings”
But as important as those things all are, at the end of the day, there is really just a small set of things that will make most of the difference in your SEO success.
In SEO, there are really just three things – three pillars – that are foundational to achieving your SEO goals.
Authority.
Relevance.
Experience (of the users and bots visiting the site).
Nutritionists tell us our bodies need protein, carbohydrates, and fats in the right proportions to stay healthy. Neglect any of the three, and your body will soon fall into disrepair.
Similarly, a healthy SEO program involves a balanced application of authority, relevance, and experience.
Authority: Do You Matter?
In SEO, authority refers to the importance or weight given to a page relative to other pages that are potential results for a given search query.
Modern search engines such as Google use many factors (or signals) when evaluating the authority of a webpage.
Why does Google care about assessing the authority of a page?
For most queries, there are thousands or even millions of pages available that could be ranked.
Google wants to prioritize the ones that are most likely to satisfy the user with accurate, reliable information that fully answers the intent of the query.
Google cares about serving users the most authoritative pages for their queries because users that are satisfied by the pages they click through to from Google are more likely to use Google again, and thus get more exposure to Google’s ads, the primary source of its revenue.
Authority Came First
Assessing the authority of webpages was the first fundamental problem search engines had to solve.
Some of the earliest search engines relied on human evaluators, but as the World Wide Web exploded, that quickly became impossible to scale.
Google overtook all its rivals because its creators, Larry Page and Sergey Brin, developed the idea of PageRank, using links from other pages on the web as weighed citations to assess the authoritativeness of a page.
Page and Brin realized that links were an already-existing system of constantly evolving polling, in which other authoritative sites “voted” for pages they saw as reliable and relevant to their users.
Search engines use links much like we might treat scholarly citations; the more scholarly papers relevant to a source document that cite it, the better.
The relative authority and trustworthiness of each of the citing sources come into play as well.
So, of our three fundamental categories, authority came first because it was the easiest to crack, given the ubiquity of hyperlinks on the web.
The other two, relevance and user experience, would be tackled later, as machine learning/AI-driven algorithms developed.
Links Still Primary For Authority
The big innovation that made Google the dominant search engine in a short period was that it used an analysis of links on the web as a ranking factor.
The essential insight behind this paper was that the web is built on the notion of documents inter-connected with each other via links.
Since putting a link on your site to a third-party site might cause a user to leave your site, there was little incentive for a publisher to link to another site unless it was really good and of great value to their site’s users.
In other words, linking to a third-party site acts a bit like a “vote” for it, and each vote could be considered an endorsement, endorsing the page the link points to as one of the best resources on the web for a given topic.
Then, in principle, the more votes you get, the better and the more authoritative a search engine would consider you to be, and you should, therefore, rank higher.
Passing PageRank
A significant piece of the initial Google algorithm was based on the concept of PageRank, a system for evaluating which pages are the most important based on scoring the links they receive.
So, a page that has large quantities of valuable links pointing to it will have a higher PageRank and will, in principle, be likely to rank higher in the search results than other pages without as high a PageRank score.
When a page links to another page, it passes a portion of its PageRank to the page it links to.
Thus, pages accumulate more PageRank based on the number and quality of links they receive.
Not All Links Are Created Equal
So, more votes are better, right?
Well, that’s true in theory, but it’s a lot more complicated than that.
PageRank scores range from a base value of one to values that likely exceed trillions.
Higher PageRank pages can have a lot more PageRank to pass than lower PageRank pages. In fact, a link from one page can easily be worth more than one million times a link from another page.
But the PageRank of the source page of a link is not the only factor in play.
Google also looks at the topic of the linking page and the anchor text of the link, but those have to do with relevance and will be referenced in the next section.
The way that links are evaluated has changed in significant ways – some of which we know, and some of which we don’t.
What About Trust?
You may hear many people talk about the role of trust in search rankings and in evaluating link quality.
For the record, Google says it doesn’t have a concept of trust it applies to links (or ranking), so you should take those discussions with many grains of salt.
These discussions began because of a Yahoo patent on the concept of TrustRank.
The idea was that if you started with a seed set of hand-picked, highly trusted sites and then counted the number of clicks it took you to go from those sites to yours, the fewer clicks, the more trusted your site was.
Google has long said it doesn’t use this type of metric.
However, in 2013 Google was granted a patent related to evaluating the trustworthiness of links. We should not though that the existence of a granted patent does not mean it’s used in practice.
For your own purposes, however, if you want to assess a site’s trustworthiness as a link source, using the concept of trusted links is not a bad idea.
If they do any of the following, then it probably isn’t a good source for a link:
Sell links to others.
Have less than great content.
Otherwise, don’t appear reputable.
Google may not be calculating trust the way you do in your analysis, but chances are good that some other aspect of its system will devalue that link anyway.
Fundamentals Of Earning & Attracting Links
Now that you know that obtaining links to your site is critical to SEO success, it’s time to start putting together a plan to get some.
The key to success is understanding that Google wants this entire process to be holistic.
Google actively discourages, and in some cases punishes, schemes to get links in an artificial way. This means certain practices are seen as bad, such as:
Buying links for SEO purposes.
Going to forums and blogs and adding comments with links back to your site.
Hacking people’s sites and injecting links into their content.
Distributing poor-quality infographics or widgets that include links back to your pages.
Offering discount codes or affiliate programs as a way to get links.
And many other schemes where the resulting links are artificial in nature.
What Google really wants is for you to make a fantastic website and promote it effectively, with the result that you earn or attract links.
So, how do you do that?
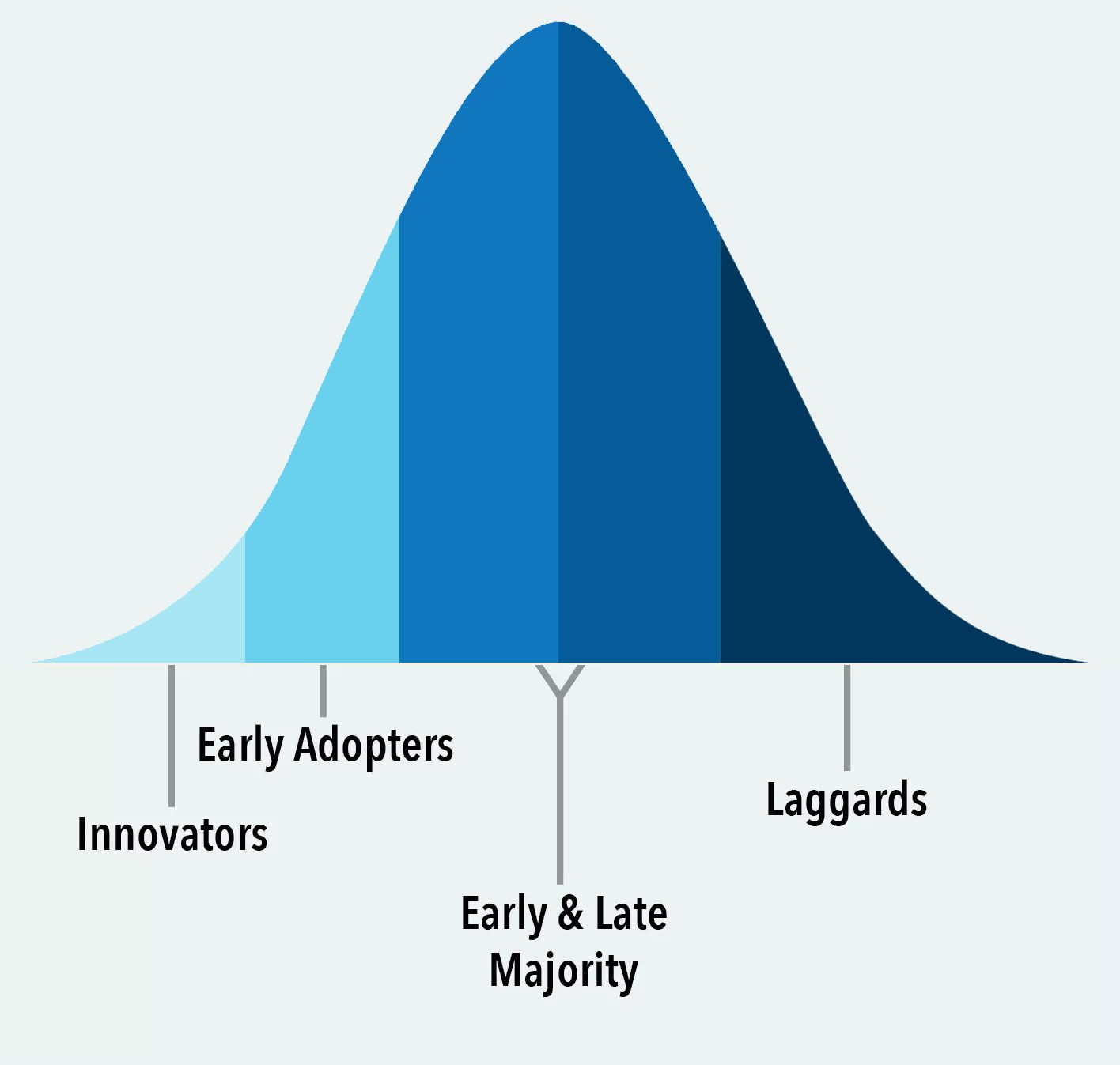
Who Links?
The first key insight is understanding who it is that might link to the content you create.
Who do you think are the people that might implement links?
It’s certainly not the laggards, and it’s also not the early or late majority.
It’s the innovators and early adopters. These are the people who write on media sites or have blogs and might add links to your site.
There are also other sources of links, such as locally-oriented sites, such as the local chamber of commerce or local newspapers.
You might also find some opportunities with colleges and universities if they have pages that relate to some of the things you’re doing in your market space.
Think of every visit to a page as an encounter on a dating app. Will users “swipe right” (thinking, “this looks like a good match!)?
If you have a page about Tupperware, it doesn’t matter how many links you get – you’ll never rank for queries related to used cars.
This defines a limitation on the power of links as a ranking factor, and it shows how relevance also impacts the value of a link.
Consider a page on a site that is selling a used Ford Mustang. Imagine that it gets a link from Car and Driver magazine. That link is highly relevant.
Also, think of this intuitively. Is it likely that Car and Driver magazine has some expertise related to Ford Mustangs? Of course it does.
In contrast, imagine a link to that Ford Mustang from a site that usually writes about sports. Is the link still helpful?
Probably, but not as helpful because there is less evidence to Google that the sports site has a lot of knowledge about used Ford Mustangs.
In short, the relevance of the linking page and the linking site impacts how valuable a link might be considered.
What are some ways that Google evaluates relevance?
The Role Of Anchor Text
Anchor text is another aspect of links that matters to Google.
The anchor text helps Google confirm what the content on the page receiving the link is about.
For example, if the anchor text is the phrase “iron bathtubs” and the page has content on that topic, the anchor text, plus the link, acts as further confirmation that the page is about that topic.
Thus, the links evaluate both the page’s relevance and authority.
Be careful, though, as you don’t want to go aggressively obtaining links to your page that all use your main keyphrase as the anchor text.
Google also looks for signs that you are manually manipulating links for SEO purposes.
One of the simplest indicators is if your anchor text looks manually manipulated.
Properly structured internal links connecting related content are a way of showing Google that you have the topic well-covered, with pages about many different aspects.
By the way, anchor text is as important when creating external links as it is for external, inbound links.
Your overall site structure is related to internal linking.
Think strategically about where your pages fall in your site hierarchy. If it makes sense for users it will probably be useful to search engines.
The Content Itself
Of course, the most important indicator of the relevance of a page has to be the content on that page.
Most SEO professionals know that assessing content’s relevance to a query has become way more sophisticated than merely having the keywords a user is searching for.
Due to advances in natural language processing and machine learning, search engines like Google have vastly increased their competence in being able to assess the content on a page.
What are some things Google likely looks for in determining what queries a page should be relevant for?
Keywords: While the days of keyword stuffing as an effective SEO tactic are (thankfully) way behind us, having certain words on a page still matters. My company has numerous case studies showing that merely adding key terms that are common among top-ranking pages for a topic is often enough to increase organic traffic to a page.
Depth: The top-ranking pages for a topic usually cover the topic at the right depth. That is, they have enough content to satisfy searchers’ queries and/or are linked to/from pages that help flesh out the topic.
Structure: Structural elements like H1, H2, and H3, bolded topic headings, and schema-structured data may help Google better understand a page’s relevance and coverage.
It is the framework of the Search Quality Rater’s Guidelines, a document used to train Google Search Quality Raters.
Search Quality Raters evaluate pages that rank in search for a given topic using defined E-E-A-T criteria to judge how well each page serves the needs of a search user who visits it as an answer to their query.
Those ratings are accumulated in aggregate and used to help tweak the search algorithms. (They are not used to affect the rankings of any individual site or page.)
Of course, Google encourages all site owners to create content that makes a visitor feel that it is authoritative, trustworthy, and written by someone with expertise or experience appropriate to the topic.
The main thing to keep in mind is that the more YMYL (Your Money or Your Life) your site is, the more attention you should pay to E-E-A-T.
YMYL sites are those whose main content addresses things that might have an effect on people’s well-being or finances.
If your site is YMYL, you should go the extra mile in ensuring the accuracy of your content, and displaying that you have qualified experts writing it.
Don’t just suddenly start doing a lot of random stuff.
Take the time to study what your competitors are doing so you can invest your content marketing efforts in a way that’s likely to provide a solid ROI.
One approach to doing that is to pull their backlink profiles using tools that can do that.
With this information, you can see what types of links they’ve been getting and, based on that, figure out what links you need to get to beat them.
Take the time to do this exercise and also to map which links are going to which pages on the competitors’ sites, as well as what each of those pages rank for.
Building out this kind of detailed view will help you scope out your plan of attack and give you some understanding of what keywords you might be able to rank for.
It’s well worth the effort!
In addition, study the competitor’s content plans.
Learn what they are doing and carefully consider what you can do that’s different.
Focus on developing a clear differentiation in your content for topics that are in high demand with your potential customers.
This is another investment of time that will be very well spent.
Experience
As we traced above, Google started by focusing on ranking pages by authority, then found ways to assess relevance.
The third evolution of search was evaluating the site and page experience.
This actually has two separate but related aspects: the technical health of the site and the actual user experience.
We say the two are related because a site that is technically sound is going to create a good experience for both human users and the crawling bots that Google uses to explore, understand a site, and add pages to its index, the first step to qualifying for being ranked in search.
In fact, many SEO pros (and I’m among them) prefer to speak of SEO not as Search Engine Optimization but as Search Experience Optimization.
Let’s talk about the human (user) experience first.
User Experience
Google realized that authoritativeness and relevancy, as important as they are, were not the only things users were looking for when searching.
Users also want a good experience on the pages and sites Google sends them to.
What is a “good user experience”? It includes at least the following:
The page the searcher lands on is what they would expect to see, given their query. No bait and switch.
The content on the landing page is highly relevant to the user’s query.
The content is sufficient to answer the intent of the user’s query but also links to other relevant sources and related topics.
The page loads quickly, the relevant content is immediately apparent, and page elements settle into place quickly (all aspects of Google’s Core Web Vitals).
In addition, many of the suggestions above about creating better content also apply to user experience.
Broken connections or even things that slow down a bot’s progress can drastically affect the number of pages Google will index and, therefore, the potential traffic your site can qualify for from organic search.
The practice of maintaining a technically healthy site is known as technical SEO.
The many aspects of technical SEO are beyond the scope of this article, but you can find many excellent guides on the topic, including Search Engine Journal’s Advanced Technical SEO.
In summary, Google wants to rank pages that it can easily find, that satisfy the query, and that make it as easy as possible for the searcher to identify and understand what they were searching for.
What About the Google Leak?
You’ve probably heard by now about the leak of Google documents containing thousands of labeled API calls and many thousands of attributes for those data buckets.
Many assume that these documents reveal the secrets of the Google algorithms for search. But is that a warranted assumption?
No doubt, perusing the documents is interesting and reveals many types of data that Google may store or may have stored in the past. But some significant unknowns about the leak should give us pause.
As Google has pointed out, we lack context around these documents and how they were used internally by Google, and we don’t know how out of date they may be.
It is a huge leap from “Google may collect and store data point x” to “therefore data point x is a ranking factor.”
Even if we assume the document does reveal some things that are used in search, we have no indication of how they are used or how much weight they are given.
Given those caveats, it is my opinion that while the leaked documents are interesting from an academic point of view, they should not be relied upon for actually forming an SEO strategy.
Putting It All Together
Search engines want happy users who will come back to them again and again when they have a question or need.
They create and sustain happiness by providing the best possible results that satisfy that question or need.
To keep their users happy, search engines must be able to understand and measure the relative authority of webpages for the topics they cover.
When you create content that is highly useful (or engaging or entertaining) to visitors – and when those visitors find your content reliable enough that they would willingly return to your site or even seek you out above others – you’ve gained authority.
Search engines work hard to continually improve their ability to match the human quest for trustworthy authority.
As we explained above, that same kind of quality content is key to earning the kinds of links that assure the search engines you should rank highly for relevant searches.
That can be either content on your site that others want to link to or content that other quality, relevant sites want to publish, with appropriate links back to your site.
Focusing on these three pillars of SEO – authority, relevance, and experience – will increase the opportunities for your content and make link-earning easier.
You now have everything you need to know for SEO success, so get to work!
More resources:
Featured Image: Paulo Bobita/Search Engine Journal
In a sense, Shopify’s financial overview is similar to Amazon’s. Both derive the most profit not from their core products but from complementary services. Amazon’s cloud computing division, an outgrowth of its marketplace infrastructure, accounts for over 60% of gross profit.
Similarly, fees to access Shopify’s core SaaS platform — called “Subscription solutions” — accounted for less than half of gross profit in Q1 2024.
Shopify’s “Merchant solutions” — almost entirely Shopify Payments, its credit card processing service — produced roughly 70% of revenue in Q1 and 56% of gross profit.
Total revenue for Q1 — Subscription solutions plus Merchant solutions — grew by roughly 23% from the prior year, from $1.5 billion to $1.9. In comparison, Amazon’s Q1 2024 revenue was $143.3 billion, with $80.4 million for BigCommerce.
Shopify was an obvious pandemic winner, with its share price hitting an all-time high of $169.21 in November 2021. The stock (NYSE: SHOP) is down by roughly 60% — to $66.73 on July 4, 2024 — amid accelerating revenue but lagging net income.
Shopify Plus, for high-volume sellers, comprised roughly 32% of Subscription solutions in Q1. Example Plus customers include Heinz, FTD, Netflix, Kylie Cosmetics and SKIMS.
Shopify does not disclose the number of its merchant stores. Estimates range from 2 to 4 million.
The company has customers in 175 countries, although over 70% of 2023 revenue came from the U.S. (66%) and Canada (5%).
Notable Shopify board members include Gail Goodman, the former CEO of Constant Contact; Fidji Simo, CEO of Instacart; and, as of 2023, Brett Taylor, the board chair of OpenAI and co-founder of Sierra Technologies, a conversational AI company.
Shopify holds equity investments in three companies: Global-E Online, a cross-border ecommerce facilitator; Affirm, the buy-now-pay-later service; and Klaviyo, the marketing automation platform. The fair value of each, as of March 31, was:
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Can you spot a liar? It’s a question I imagine has been on a lot of minds lately, in the wake of various televised political debates. Research has shown that we’re generally pretty bad at telling a truth from a lie.
Some believe that AI could help improve our odds, and do better than dodgy old fashioned techniques like polygraph tests. AI-based lie detection systems could one day be used to help us sift fact from fake news, evaluate claims, and potentially even spot fibs and exaggerations in job applications. The question is whether we will trust them. And if we should.
In a recent study, Alicia von Schenk and her colleagues developed a tool that was significantly better than people at spotting lies. Von Schenk, an economist at the University of Würzburg in Germany, and her team then ran some experiments to find out how people used it. In some ways, the tool was helpful—the people who made use of it were better at spotting lies. But they also led people to make a lot more accusations.
In their study published in the journal iScience, von Schenk and her colleagues asked volunteers to write statements about their weekend plans. Half the time, people were incentivized to lie; a believable yet untrue statement was rewarded with a small financial payout. In total, the team collected 1,536 statements from 768 people.
They then used 80% of these statements to train an algorithm on lies and truths, using Google’s AI language model BERT. When they tested the resulting tool on the final 20% of statements, they found it could successfully tell whether a statement was true or false 67% of the time. That’s significantly better than a typical human; we usually only get it right around half the time.
To find out how people might make use of AI to help them spot lies, von Schenk and her colleagues split 2,040 other volunteers into smaller groups and ran a series of tests.
One test revealed that when people are given the option to pay a small fee to use an AI tool that can help them detect lies—and earn financial rewards—they still aren’t all that keen on using it. Only a third of the volunteers given that option decided to use the AI tool, possibly because they’re skeptical of the technology, says von Schenk. (They might also be overly optimistic about their own lie-detection skills, she adds.)
But that one-third of people really put their trust in the technology. “When you make the active choice to rely on the technology, we see that people almost always follow the prediction of the AI… they rely very much on its predictions,” says von Schenk.
This reliance can shape our behavior. Normally, people tend to assume others are telling the truth. That was borne out in this study—even though the volunteers knew half of the statements were lies, they only marked out 19% of them as such. But that changed when people chose to make use of the AI tool: the accusation rate rose to 58%.
In some ways, this is a good thing—these tools can help us spot more of the lies we come across in our lives, like the misinformation we might come across on social media.
But it’s not all good. It could also undermine trust, a fundamental aspect of human behavior that helps us form relationships. If the price of accurate judgements is the deterioration of social bonds, is it worth it?
And then there’s the question of accuracy. In their study, von Schenk and her colleagues were only interested in creating a tool that was better than humans at lie detection. That isn’t too difficult, given how terrible we are at it. But she also imagines a tool like hers being used to routinely assess the truthfulness of social media posts, or hunt for fake details in a job hunter’s resume or interview responses. In cases like these, it’s not enough for a technology to just be “better than human” if it’s going to be making more accusations.
Would we be willing to accept an accuracy rate of 80%, where only four out of every five assessed statements would be correctly interpreted as true or false? Would even 99% accuracy suffice? I’m not sure.
It’s worth remembering the fallibility of historical lie detection techniques. The polygraph was designed to measure heart rate and other signs of “arousal” because it was thought some signs of stress were unique to liars. They’re not. And we’ve known that for a long time. That’s why lie detector results are generally not admissible in US court cases. Despite that, polygraph lie detector tests have endured in some settings, and have caused plenty of harm when they’ve been used to hurl accusations at people who fail them on reality TV shows.
Imperfect AI tools stand to have an even greater impact because they are so easy to scale, says von Schenk. You can only polygraph so many people in a day. The scope for AI lie detection is almost limitless by comparison.
“Given that we have so much fake news and disinformation spreading, there is a benefit to these technologies,” says von Schenk. “However, you really need to test them—you need to make sure they are substantially better than humans.” If an AI lie detector is generating a lot of accusations, we might be better off not using it at all, she says.
Now read the rest of The Checkup
Read more from MIT Technology Review’s archive
AI lie detectors have also been developed to look for facial patterns of movement and “microgestures” associated with deception. As Jake Bittle puts it: “the dream of a perfect lie detector just won’t die, especially when glossed over with the sheen of AI.”
On the other hand, AI is also being used to generate plenty of disinformation. As of October last year, generative AI was already being used in at least 16 countries to “sow doubt, smear opponents, or influence public debate,” as Tate Ryan-Mosley reported.
The way AI language models are developed can heavily influence the way that they work. As a result, these models have picked up different political biases, as my colleague Melissa Heikkilä covered last year.
AI, like social media, has the potential for good or ill. In both cases, the regulatory limits we place on these technologies will determine which way the sword falls, argue Nathan E. Sanders and Bruce Schneier. Chatbot answers are all made up. But there’s a tool that can give a reliability score to large language model outputs, helping users work out how trustworthy they are. Or, as Will Douglas Heaven put it in an article published a few months ago, a BS-o-meter for chatbots.
From around the web
Scientists, ethicists and legal experts in the UK have published a new set of guidelines for research on synthetic embryos, or, as they call them, “stem cell-based embryo models (SCBEMs).” There should be limits on how long they are grown in labs, and they should not be transferred into the uterus of a human or animal, the guideline states. They also note that, if, in future, these structures look like they might have the potential to develop into a fetus, we should stop calling them “models” and instead refer to them as “embryos.”
Antimicrobial resistance is already responsible for 700,000 deaths every year, and could claim 10 million lives per year by 2050. Overuse of broad spectrum antibiotics is partly to blame. Is it time to tax these drugs to limit demand? (International Journal of Industrial Organization)
Spaceflight can alter the human brain, reorganizing gray and white matter and causing the brain to shift upwards in the skull. We need to better understand these effects, and the impact of cosmic radiation on our brains, before we send people to Mars. (The Lancet Neurology)
The vagus nerve has become an unlikely star of social media, thanks to influencers who drum up the benefits of stimulating it. Unfortunately, the science doesn’t stack up. (New Scientist)
A hospital in Texas is set to become the first in the country to enable doctors to see their patients via hologram. Crescent Regional Hospital in Lancaster has installed Holobox—a system that projects a life-sized hologram of a doctor for patient consultations. (ABC News)
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next.You can read more from the series here.
When ChatGPT was first released, everyone in AI was talking about the new generation of AI assistants. But over the past year, that excitement has turned to a new target: AI agents.
Agents featured prominently in Google’s annual I/O conference in May, when the company unveiled its new AI agent called Astra, which allows users to interact with it using audio and video. OpenAI’s new GPT-4o model has also been called an AI agent.
And it’s not just hype, although there is definitely some of that too. Tech companies are plowing vast sums into creating AI agents, and their research efforts could usher in the kind of useful AI we have been dreaming about for decades. Many experts, including Sam Altman, say they are the next big thing.
But what are they? And how can we use them?
How are they defined?
It is still early days for research into AI agents, and the field does not have a definitive definition for them. But simply, they are AI models and algorithms that can autonomously make decisions in a dynamic world, says Jim Fan, a senior research scientist at Nvidia who leads the company’s AI agents initiative.
The grand vision for AI agents is a system that can execute a vast range of tasks, much like a human assistant. In the future, it could help you book your vacation, but it will also remember if you prefer swanky hotels, so it will only suggest hotels that have four stars or more and then go ahead and book the one you pick from the range of options it offers you. It will then also suggest flights that work best with your calendar, and plan the itinerary for your trip according to your preferences. It could make a list of things to pack based on that plan and the weather forecast. It might even send your itinerary to any friends it knows live in your destination and invite them along. In the workplace, it could analyze your to-do list and execute tasks from it, such as sending calendar invites, memos, or emails.
One vision for agents is that they are multimodal, meaning they can process language, audio, and video. For example, in Google’s Astra demo, users could point a smartphone camera at things and ask the agent questions. The agent could respond to text, audio, and video inputs.
These agents could also make processes smoother for businesses and public organizations, says David Barber, the director of the University College London Centre for Artificial Intelligence. For example, an AI agent might be able to function as a more sophisticated customer service bot. The current generation of language-model-based assistants can only generate the next likely word in a sentence. But an AI agent would have the ability to act on natural-language commands autonomously and process customer service tasks without supervision. For example, the agent would be able to analyze customer complaint emails and then know to check the customer’s reference number, access databases such as customer relationship management and delivery systems to see whether the complaint is legitimate, and process it according to the company’s policies, Barber says.
Broadly speaking, there are two different categories of agents, says Fan: software agents and embodied agents.
Software agents run on computers or mobile phones and use apps, much as in the travel agent example above. “Those agents are very useful for office work or sending emails or having this chain of events going on,” he says.
Embodied agents are agents that are situated in a 3D world such as a video game, or in a robot. These kinds of agents might make video games more engaging by letting people play with nonplayer characters controlled by AI. These sorts of agents could also help build more useful robots that could help us with everyday tasks at home, such as folding laundry and cooking meals.
Fan was part of a team that built an embodied AI agent called MineDojo in the popular computer game Minecraft. Using a vast trove of data collected from the internet, Fan’s AI agent was able to learn new skills and tasks that allowed it to freely explore the virtual 3D world and complete complex tasks such as encircling llamas with fences or scooping lava into a bucket. Video games are good proxies for the real world, because they require agents to understand physics, reasoning, and common sense.
In a new paper, which has not yet been peer-reviewed, researchers at Princeton say that AI agents tend to have three different characteristics. AI systems are considered “agentic” if they can pursue difficult goals without being instructed in complex environments. They also qualify if they can be instructed in natural language and act autonomously without supervision. And finally, the term “agent” can also apply to systems that are able to use tools, such as web search or programming, or are capable of planning.
Are they a new thing?
The term “AI agents” has been around for years and has meant different things at different times, says Chirag Shah, a computer science professor at the University of Washington.
There have been two waves of agents, says Fan. The current wave is thanks to the language model boom and the rise of systems such as ChatGPT.
The previous wave was in 2016, when Google DeepMind introduced AlphaGo, its AI system that can play—and win—the game Go. AlphaGo was able to make decisions and plan strategies. This relied on reinforcement learning, a technique that rewards AI algorithms for desirable behaviors.
“But these agents were not general,” says Oriol Vinyals, vice president of research at Google DeepMind. They were created for very specific tasks—in this case, playing Go. The new generation of foundation-model-based AI makes agents more universal, as they can learn from the world humans interact with.
“You feel much more that the model is interacting with the world and then giving back to you better answers or better assisted assistance or whatnot,” says Vinyals.
What are the limitations?
There are still many open questions that need to be answered. Kanjun Qiu, CEO and founder of the AI startup Imbue, which is working on agents that can reason and code, likens the state of agents to where self-driving cars were just over a decade ago. They can do stuff, but they’re unreliable and still not really autonomous. For example, a coding agent can generate code, but it sometimes gets it wrong, and it doesn’t know how to test the code it’s creating, says Qiu. So humans still need to be actively involved in the process. AI systems still can’t fully reason, which is a critical step in operating in a complex and ambiguous human world.
“We’re nowhere close to having an agent that can just automate all of these chores for us,” says Fan. Current systems “hallucinate and they also don’t always follow instructions closely,” Fan says. “And that becomes annoying.”
Another limitation is that after a while, AI agents lose track of what they are working on. AI systems are limited by their context windows, meaning the amount of data they can take into account at any given time.
“ChatGPT can do coding, but it’s not able to do long-form content well. But for human developers, we look at an entire GitHub repository that has tens if not hundreds of lines of code, and we have no trouble navigating it,” says Fan.
To tackle this problem, Google has increased its models’ capacity to process data, which allows users to have longer interactions with them in which they remember more about past interactions. The company said it is working on making its context windows infinite in the future.
For embodied agents such as robots, there are even more limitations. There is not enough training data to teach them, and researchers are only just starting to harness the power of foundation models in robotics.
So amid all the hype and excitement, it’s worth bearing in mind that research into AI agents is still in its very early stages, and it will likely take years until we can experience their full potential.
That sounds cool. Can I try an AI agent now?
Sort of. You’ve most likely tried their early prototypes, such as OpenAI’s ChatGPT and GPT-4. “If you’re interacting with software that feels smart, that is kind of an agent,” says Qiu.
Right now the best agents we have are systems with very narrow and specific use cases, such as coding assistants, customer service bots, or workflow automation software like Zapier, she says. But these are a far cry from a universal AI agent that can do complex tasks.
“Today we have these computers and they’re really powerful, but we have to micromanage them,” says Qiu.
OpenAI’s ChatGPT plug-ins, which allow people to create AI-powered assistants for web browsers, were an attempt at agents, says Qiu. But these systems are still clumsy, unreliable, and not capable of reasoning, she says.
Despite that, these systems will one day change the way we interact with technology, Qiu believes, and it is a trend people need to pay attention to.
“It’s not like, ‘Oh my God, all of a sudden we have AGI’ … but more like ‘Oh my God, my computer can do way more than it did five years ago,’” she says.
Lukas Tanasiuk once paid a firm to redesign his Shopify site, which sold electric scooters. The result was slow page loads and his efforts to improve them. What he found, he says, was a lot of false claims.
“I discovered corruption among folks who say they are page-speed optimizers,” he told me.
Page-speed optimization became Tanasiuk’s next opportunity. In 2023 he launched The Nice Agency, focusing on Shopify page loads.
He and I recently discussed his journey from merchant to agency owner, slow Shopify sites, and more. The entire audio of our conversation is embedded below. The transcript is edited for clarity and length.
Eric Bandholz: Tell us what you do.
Lukas Tanasiuk: I’ve been a Shopify store owner since 2015. In 2020, I started a click-and-mortar store in Vancouver, Canada, selling personal electric vehicles, such as e-scooters, e-skates, one-wheels, and electric unicycles.
We grew that very quickly. We paid to get our site redesigned, but the download speed was super slow. In my journey to improve the speed, I discovered corruption among folks who say they are page-speed optimizers. I became passionate about it.
I realized few practitioners in the space were doing good work for a fair price. I decided this was my next opportunity. I started The Nice Agency in 2023 and have been scaling ever since, focusing solely on Shopify site speed optimization.
Clients come to us with non-native Shopify sites that are very slow. They have great functionality, but they load poorly. Shopify acts a lot like Apple. If you work within their tight ecosystems, performance is good. But the second you insert external components, performance suffers.
Every app in the Shopify space is third-party code. You can’t edit it. The developer doesn’t want you messing with it. Certain apps render pages on their own servers and then re-render them on your page.
The easy answer is building something natively into Shopify. If the cost isn’t too insane and the project scope isn’t wild, do it. We build directly into the theme. We don’t build apps.
Bandholz: How much would that cost?
Tanasiuk: It depends on the project. We’ve done jobs for $2,000 that add functionality to an existing rebuild.
The killers are the ones that replace entire components. I advise merchants to remove little-used components rather than replace them. Examples are A/B tests and review widgets. If you’re doing under $5 million in online revenue, you probably don’t need A/B testing.
Use common sense. Buy products from your own site. Browse your site. Keep an eye on conversion rates. Don’t be afraid to make changes without being data-driven. You can measure and analyze over time. You don’t need expensive software.
We’re doing optimization now for a client’s main product page. The primary visual asset is a high-end 45-second video describing the product. In Core Web Vitals, it’s the Largest Contentful Paint metric.
The video is the first thing that loads. The client has six conversion optimization apps attached to the product page, plus an A/B testing app. It takes 25 seconds for the page to load completely, which is terrible. The gold standard Shopify page speed is below three seconds.
In my experience, a static image with good copy and a clear call-to-action typically converts more than a video or a carousel. Download a heat map or a tracking tool. Very few visitors watch the video for more than a few seconds or click on multiple images in a carousel. Most look only at the static image. Plus, an optimized image won’t hurt page speed. So you’re losing on both fronts with videos and carousels.
My background, again, is as an ecommerce operator. An operator’s goal should be to improve the customer experience. A quick-loading website is essential. Many apps do the opposite. Unfortunately, many developers are looking for a quick buck and promising a faster site.
Bandholz: Care to name examples?
Tanasiuk: Here’s one from last fall. I posted a video on my page, which I’ve since removed, of a company making false page-speed promises. I partnered with a brilliant developer, Jake Casto, from Proton Agency in New York City. He provided the technical expertise while I offered the non-technical founder’s perspective.
A client had just installed the company’s app and asked my opinion. I went to the company’s site, and the first thing they’re marketing is an instant Shopify performance score of 90 to 95. That’s impossible. It was a huge red flag.
For weeks I asked colleagues and dug deeper. That’s how I met Jake Casto. He was making comments about them being sheisty.
He asked me to collaborate on an expose of these guys. We had multiple calls with the heads at Shopify. Other people at Shopify consulted directly with the Google performance team, who confirmed that everything we had uncovered was true.
So Jake and I created a report, reached out to the company’s CEO, and said, “We’re doing a report on you guys because we found some pretty weird stuff going on. We’ll send the report to you before we go live with it so you can write a response. We’ll add it to ours.”
Within hours, every mention of performance score improvement was wiped off their website. Their founder deleted every single tweet going back years that related anything to a performance score.
The lesson for merchants is this. Watch for red flags when you’re seeking Shopify site speed optimization. Be wary of big promises or overnight fixes for cheap.