The AI Convergence Problem
There’s a particular flavor of panic in our industry at the moment. It’s the panic of the digital marketer who has been told, repeatedly and loudly, that if they aren’t piping every decision through an LLM by the end of the quarter, they will be replaced by a more obedient colleague who is. The pitch is always the same: AI is thinking now. AI is reasoning. AI is strategizing. Hand the wheel over, sit back, and enjoy a fully optimized, hyper-personalized, infinitely scalable future.
Allow me to gently push back, armed with the classic MSPaint.exe.
There are two problems with the “let the robot decide” school of marketing, and they are mirror images of each other. Where LLMs are weak, they are very stupid in ways that should disqualify them from strategic work. And where they are strong, they are even more dangerous, because they will quietly drag your strategy towards the average, which, in marketing, is the single worst place you can possibly be.
LLMs Don’t Think, They Predict The Next Token
Let’s start with the bit that the AI labs would rather you didn’t dwell on. Large language models do not “think” in any meaningful sense. Under the bonnet, they are statistical machines that predict the most probable next token given the sequence so far. That is the entire trick. There is no inner monologue, no model of the world, no quiet moment where the model goes “hang on, that doesn’t add up.” There is only, “Given these tokens, what tokens usually come next?”
This is not a hot take from a skeptic on Substack. Apple’s research team published a paper with the gloriously blunt title “The Illusion of Thinking,” in which frontier “reasoning” models hit a complete accuracy collapse once puzzle complexity rose beyond a certain threshold and, even more damningly, started using fewer tokens as problems got harder, as though giving up. Apple researchers had previously shown in GSM-Symbolic that simply adding a clause to a maths problem that didn’t even change the answer could drop performance by up to 65%, suggesting that what looks like reasoning is mostly pattern-matching against training data. A more recent taxonomy of LLM failures groups these into things like the “reversal curse” (knowing “A is B” but failing on “B is A”) and “compositional collapse” (solving each step individually but failing to chain them), all flowing from the next-token prediction objective prioritizing statistical pattern completion over deliberate reasoning.
This basically means if your problem looks like something the model has seen a million times, it will appear brilliant. The moment your problem is even slightly novel, the wheels can come off in spectacular fashion.
Exhibit A: The Car Wash
The cleanest demonstration of this in the wild is the now-infamous car wash prompt:
“I want to get my car washed. The nearest car wash is 100 metres away. Should I walk or drive there?”
We’re hovering around Ralph Wiggum levels of reasoning here, a question most 5-year-olds would not struggle with. You need the car to be at the car wash, because the car is the thing being washed. The car cannot be washed in absentia while you stroll there on foot, no matter how good your intentions.
When this prompt went viral, ChatGPT, Claude, and Grok all confidently advised the user to walk. It’s only 100 meters, they reasoned (or “reasoned”). Save the planet. Get some steps in. They had clearly seen a great deal of training data along the lines of “should I drive or walk to [short distance]?” and dutifully predicted the tokens that usually follow: a polite lecture about exercise and emissions. The actual point of the question – that the car is the object of the verb – sailed past them at altitude.

Gemini, to Google’s credit, got it right out of the gate. Suspicious, I thought. And it was. The prompt had gone viral, which meant the correct answer was already being written about, posted about, and dunked on across the internet. Google, helpfully sitting on top of the index of that internet, was first to hoover up the new “knowledge.” A fortnight later, Grok also produced the correct answer, not because it had had a Damascene conversion to logic, but because the answer was now in its training data.
The models didn’t learn to think. They learned the answer.
This is the key thing to internalize before we go any further. When an LLM appears to “reason,” what you’re often watching is it reciting the consensus answer to a problem that lots of people have already solved on the internet. Which is fine when you want the consensus. It is catastrophic when you don’t.
And Now The Worse Problem
Here is where most “AI in marketing” posts stop. They wag a finger at the car wash, suggest you keep “a human in the loop,” and head off to write a LinkedIn post about it (probably with ChatGPT).
But the failure modes are the comfortable bit. The dangerous bit is what happens when the LLM is good at the task you’ve given it.
Because if a model is “good” at a task, it means there is a great deal of training data showing it how the task is normally solved. And if it has consumed all of that training data – alongside every other frontier model, all trained on roughly the same scrape of the internet then the output it produces will, almost by definition, sit somewhere very close to the mean of what everyone else is already doing.
In marketing, that is the worst sin you can commit. The whole job is to stand out. To be chosen. To be remembered. The instant your brand voice, your campaign idea, your headline, or your “10 SEO tips for 2026” article is indistinguishable from your competitor’s, you have stopped doing marketing and started doing wallpaper.
Jeremy Daly summarized the underlying mechanic neatly: Convergence is a function of shared data, shared incentives, and fast iteration loops. When three companies pour the same training data into the same model, optimizing for the same engagement metrics, on iteration cycles tight enough to sand the rough edges off any deviation, you don’t get differentiated strategies – you get the same strategy in three brand colors.
This is not just a vibe. Researchers from Columbia and MIT found that handing identity-defining choices to LLM agents shifts people’s choices toward more popular options, reducing the distinctiveness of their behaviors and preferences. They called it, with admirable honesty, “The Basic B*** Effect.” A separate study published in Science Advances showed that generative AI enhances individual creativity but reduces the collective diversity of novel content – each writer’s story got a little better, but across the population, the stories started to look the same. And work on LLM “mode collapse” has documented the same homogenization pattern at the level of the model itself: the same few completions, again and again, even when many valid answers exist.
Put plainly: The very thing LLMs reward you for: speed, fluency, consistency, “best practice” is the thing that will quietly turn your marketing into beige.
Exhibit B: Parliament Has Been LinkedIn-ified
If you want to see what convergence looks like in the wild, look no further than the House of Commons.
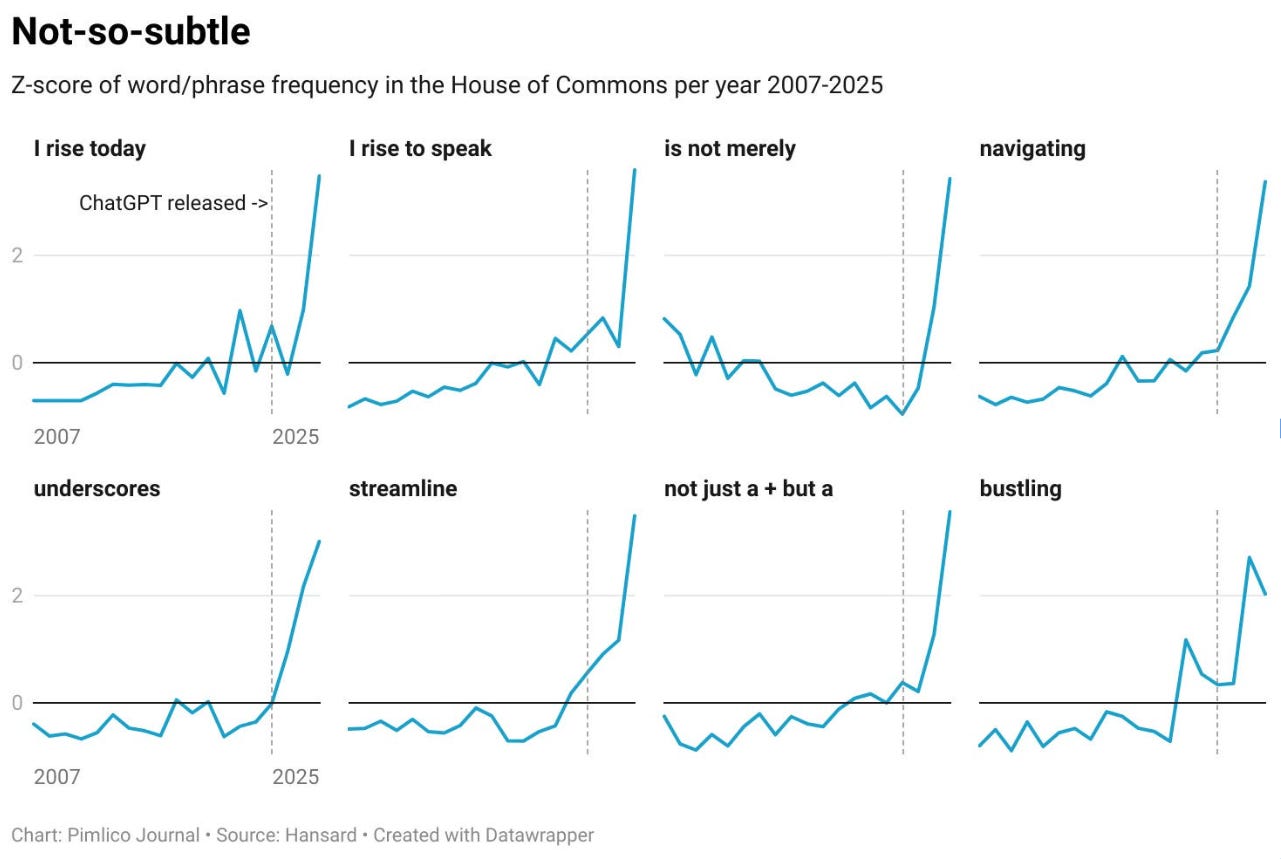
The Pimlico Journal analyzed every word spoken in Hansard from 2007 to 2025 and tracked the Z-score frequency of phrases that are tell-tale ChatGPT tics. “I rise to speak.” “Is not merely.” “Navigating.” “Underscores.” “Streamline.” “Not just a [X], but a [Y].” “Bustling.” Phrases that pootled along the baseline for 15 years and then, almost to the week of ChatGPT’s release in late 2022, shot vertically off the chart. “I rise to speak” alone hit a Z-score of 3.60 by 2025. The Telegraph picked the story up under the headline “ChatGPT triggers surge in MPs using AI-written speeches”.
Set aside the democratic implications for a moment (they are not good). Look at it purely as marketers. These are 650 individuals, each with their own constituency, their own pet causes, their own carefully cultivated personal brand, each ostensibly trying to be memorable enough to stay employed at the next election. And after handing the drafting work to an LLM, they have started to sound like the same person. The same person who, incidentally, also writes every other LinkedIn post you’ve ever scrolled past.
That is convergence. It does not require a conspiracy. It does not require anyone to be lazy or stupid. It just requires the inputs (the same training data), the incentives (the same metrics), and the loops (publish, see what works, repeat) to be roughly similar across users. Which, in marketing, they almost always are.
Now imagine the same chart for your category page H1s. Your meta descriptions. Your blog intros. Your campaign concepts. Your tone-of-voice guidelines. Your “thought leadership.” Your client pitch decks. Then ask yourself, honestly, what is left for the customer to choose between.
Exhibit C: Tactical MSPaint.exe On LinkedIn
I have, by accident, run my own counter-experiment.
For the past while, I have been posting unsolicited #SEO tips and Core Updates round-ups on LinkedIn, accompanied by absolutely terrible MS Paint drawings. Not stylized “playful illustrations” produced by some agency. Genuinely bad pictures of a stick-man labeled “SEO” pointing at a robot labeled “GSC,” drawn in MSPaint.exe by someone who should not be allowed near a graphics tablet.
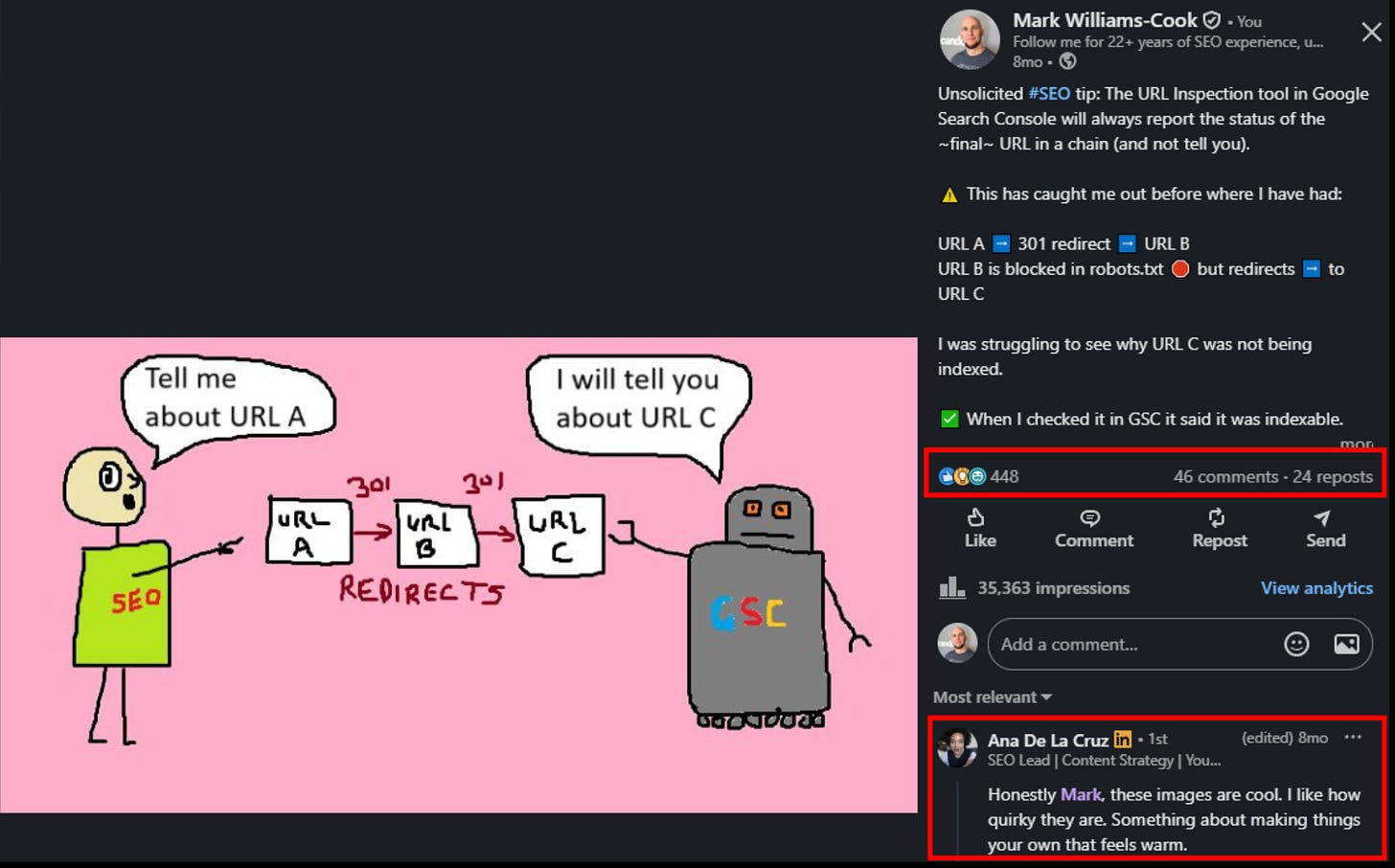
The post above did 35,363 impressions, 448 reactions, 46 comments, and 24 reposts. Not because the drawing is good – it is, objectively, not – but because it is unmistakably handmade on a platform that has been carpet-bombed by AI-generated hero images, all of which appear to depict the same diverse team of smiling professionals high-fiving in front of a holographic dashboard.
One of the most common comments I get is some version of “I love these images, they feel warm,” or “something about making things your own.” Which is exactly the point. There is a growing, almost feral hunger for content that is demonstrably human-made; content that signals “an actual person sat down and did this, on purpose, for you.”
Or, as Tyler Durden put it in Fight Club:
“The glass dishes with tiny bubbles and imperfections, proof they were crafted by the honest, simple, hard-working indigenous peoples of wherever”
That line was originally a joke about middle-class consumerism. It is now, somehow, a viable LinkedIn content strategy.
What This Means For Digital Marketing
Right. So what do you actually do with this, beyond nodding sagely and going back to prompting?
Use LLMs where they are good, on purpose, and accept the mean. For commodity work: fixing alt text at scale, summarizing a meeting, drafting a polite reply to that client who is technically wrong. LLMs are excellent here, and the cost of being average is zero. Nobody is going to choose your brand based on the quality of your internal Slack summary. Use the tool, save the time, move on.
Refuse to use LLMs where average is fatal. Brand positioning. Headlines. Hooks. Campaign concepts. Tone of voice. Editorial angles. Anywhere a human is going to make a choice between you and a competitor. If you let the model decide, you are explicitly choosing to be the average of everyone in your training corpus. There is no universe in which “be the average of your competitors” is the right strategy.
Treat LLM outputs as a baseline to deliberately diverge from. A useful exercise: Ask the model for its first answer, then ask, “What would the opposite of this look like?” Then ask, “What would only my brand do here?”. The model’s first instinct is the consensus. Your job is to know what the consensus is so you can choose not to be it.
Invest in inputs the model does not have. Proprietary data. First-hand customer interviews. Your own experiments. Internal opinions that haven’t been blogged about. These are the moats. If your “insight” is anything a competitor can extract from a public scrape, it is not an insight; it is wallpaper. (Jeremy Daly’s convergence map makes the same point from the software side: convergence pressure is weakest where inputs are asymmetric and feedback loops are slow.)
Put visible human fingerprints on the output. A drawing. A specific anecdote. A weird turn of phrase. A genuinely held opinion that might lose you a follower. The bubbles in the glass. People are now actively scanning content for evidence that a person made it, and the bar for “evidence” is low, but it has to be there.
Stop confusing fluency with intelligence. An LLM that produces a paragraph faster than you can read it is not smarter than you. It is faster than you. Those are different things. The car wash question is the canary in the coal mine: anything novel, anything that requires actually modeling the world, anything where the right answer is not the popular answer, is where you need to switch the machine off and use your own head.
TL;DR
LLMs are token predictors with excellent diction. Where they are weak, they fail in ways a child wouldn’t, and confidently tell you to walk to the car wash, because that’s what the words usually say. Where they are strong, they fail in a quieter and more expensive way: they pull every user gently towards the same mean answer, which in marketing is the one thing you cannot afford to be.
This is the AI Convergence Problem. Shared data plus shared incentives plus fast feedback loops equals everyone sounding like everyone else. We can already see it creeping into our very government. We will see it in your category. The question is whether your strategy is the one being averaged out, or the one people are reaching for because they can no longer stand the beige.
Don’t think like a robot.
More Resources:
This post was originally published on Mark Williams-Cook SubStack.
Featured Image: Raziya Athar/Shutterstock