For offshore wind power in the US, the new year is bringing new legal battles.
On December 22, the Trump administration announced it would pause the leases of five wind farms currently under construction off the US East Coast. Developers were ordered to stop work immediately.
The cited reason? National security, specifically concerns that turbines can cause radar interference. But that’s a known issue, and developers have worked with the government to deal with it for years.
Companies have been quick to file lawsuits, and the court battles could begin as soon as this week. Here’s what the latest kerfuffle might mean for the struggling offshore wind industry in the US.
This pause affects $25 billion in investment in five wind farms: Vineyard Wind 1 off Massachusetts, Revolution Wind off Rhode Island, Sunrise Wind and Empire Wind off New York, and Coastal Virginia Offshore Wind off Virginia. Together, those projects had been expected to create 10,000 jobs and power more than 2.5 million homes and businesses.
In a statement announcing the move, the Department of the Interior said that “recently completed classified reports” revealed national security risks, and that the pause would give the government time to work through concerns with developers. The statement specifically says that turbines can create radar interference (more on the technical details here in a moment).
Three of the companies involved have already filed lawsuits, and they’re seeking preliminary injunctions that would allow construction to continue. Orsted and Equinor (the developers for Revolution Wind and Empire Wind, respectively) told the New York Times that their projects went through lengthy federal reviews, which did address concerns about national security.
This is just the latest salvo from the Trump administration against offshore wind. On Trump’s first day in office, he signed an executive order stopping all new lease approvals for offshore wind farms. (That order was struck down by a judge in December.)
The administration previously ordered Revolution Wind to stop work last year, also citing national security concerns. A federal judge lifted the stop-work order weeks later, after the developer showed that the financial stakes were high, and that government agencies had previously found no national security issues with the project.
There are real challenges that wind farms introduce for radar systems, which are used in everything from air traffic control to weather forecasting to national defense operations. A wind turbine’s spinning can create complex signatures on radar, resulting in so-called clutter.
Previous government reports, including one 2024 report from the Department of Energy and a 2025 report from the Government Accountability Office (an independent government watchdog), have pointed out this issue in the past.
“To date, no mitigation technology has been able to fully restore the technical performance of impacted radars,” as the DOE report puts it. However, there are techniques that can help, including software that acts to remove the signatures of wind turbines. (Think of this as similar to how noise-canceling headphones work, but more complicated, as one expert told TechCrunch.)
But the most widespread and helpful tactic, according to the DOE report, is collaboration between developers and the government. By working together to site and design wind farms strategically, the groups can ensure that the projects don’t interfere with government or military operations. The 2025 GAO report found that government officials, researchers, and offshore wind companies were collaborating effectively, and any concerns could be raised and addressed in the permitting process.
This and other challenges threaten an industry that could be a major boon for the grid. On the East Coast where these projects are located, and in New England specifically, winter can bring tight supplies of fossil fuels and spiking prices because of high demand. It just so happens that offshore winds blow strongest in the winter, so new projects, including the five wrapped up in this fight, could be a major help during the grid’s greatest time of need.
One 2025 study found that if 3.5 gigawatts’ worth of offshore wind had been operational during the 2024-2025 winter, it would have lowered energy prices by 11%. (That’s the combined capacity of Revolution Wind and Vineyard Wind, two of the paused projects, plus two future projects in the pipeline.) Ratepayers would have saved $400 million.
Before Donald Trump was elected, the energy consultancy BloombergNEF projected that the US would build 39 gigawatts of offshore wind by 2035. Today, that expectation has dropped to just 6 gigawatts. These legal battles could push it lower still.
What’s hardest to wrap my head around is that some of the projects being challenged are nearly finished. The developers of Revolution Wind have installed all the foundations and 58 of 65 turbines, and they say the project is over 87% complete. Empire Wind is over 60% done and is slated to deliver electricity to the grid next year.
To hit the pause button so close to the finish line is chilling, not just for current projects but for future offshore wind efforts in the US. Even if these legal battles clear up and more developers can technically enter the queue, why would they want to? Billions of dollars are at stake, and if there’s one word to describe the current state of the offshore wind industry in the US, it’s “unpredictable.”
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
Enterprises are sitting on vast quantities of unstructured data, from call records and video footage to customer complaint histories and supply chain signals. Yet this invaluable business intelligence, estimated to make up as much as 90% of the data generated by organizations, historically remained dormant because its unstructured nature makes analysis extremely difficult.
But if managed and centralized effectively, this messy and often voluminous data is not only a precious asset for training and optimizing next-generation AI systems, enhancing their accuracy, context, and adaptability, it can also deliver profound insights that drive real business outcomes.
A compelling example of this can be seen in the US NBA basketball team the Charlotte Hornets who successfully leveraged untapped video footage of gameplay—previously too copious to watch and too unstructured to analyze—to identify a new competition-winning recruit. However, before that data could deliver results, analysts working for the team first had to overcome the critical challenge of preparing the raw, unstructured footage for interpretation.
The challenges of organizing and contextualizing unstructured data
Unstructured data presents inherent difficulties due to its widely varying format, quality, and reliability, requiring specialized tools like natural language processing and AI to make sense of it.
Every organization’s pool of unstructured data also contains domain-specific characteristics and terminology that generic AI models may not automatically understand. A financial services firm, for example, cannot simply use a general language model for fraud detection. Instead, it needs to adapt the model to understand regulatory language, transaction patterns, industry-specific risk indicators, and unique company context like data policies.
The challenge intensifies when integrating multiple data sources with varying structures and quality standards, as teams may struggle to distinguish valuable data from noise.
How computer vision gave the Charlotte Hornets an edge
When the Charlotte Hornets set out to identify a new draft pick for their team, they turned to AI tools including computer vision to analyze raw game footage from smaller leagues, which exist outside the tiers of the game normally visible to NBA scouts and, therefore, are not as readily available for analysis.
“Computer vision is a tool that has existed for some time, but I think the applicability in this age of AI is increasing rapidly,” says Jordan Cealey, senior vice president at AI company Invisible Technologies, which worked with the Charlotte Hornets on this project. “You can now take data sources that you’ve never been able to consume, and provide an analytical layer that’s never existed before.”
By deploying a variety of computer vision techniques, including object and player tracking, movement pattern analysis, and geometrically mapping points on the court, the team was able to extract kinematic data, such as the coordinates of players during movement, and generate metrics like speed and explosiveness to acceleration.
This provided the team with rich, data-driven insights about individual players, helping them to identify and select a new draft whose skill and techniques filled a hole in the Charlotte Hornets’ own capabilities. The chosen athlete went on to be named the most valuable player at the 2025 NBA Summer League and helped the team win their first summer championship title.
Annotation of a basketball match
Before data from game footage can be used, it needs to be labeled so the model can interpret it. The x and y coordinates of the individual players, seen here in bounding boxes, as well as other features in the scene, are annotated so the model can identify individuals and track their movements through time.
Taking AI pilot programs into production
From this successful example, several lessons can be learned. First, unstructured data must be prepared for AI models through intuitive forms of collection, and the right data pipelines and management records. “You can only utilize unstructured data once your structured data is consumable and ready for AI,” says Cealey. “You cannot just throw AI at a problem without doing the prep work.”
For many organizations, this might mean they need to find partners that offer the technical support to fine-tune models to the context of the business. The traditional technology consulting approach, in which an external vendor leads a digital transformation plan over a lengthy timeframe, is not fit for purpose here as AI is moving too fast and solutions need to be configured to a company’s current business reality.
Forward-deployed engineers (FDEs) are an emerging partnership model better suited to the AI era. Initially popularized by Palantir, the FDE model connects product and engineering capabilities directly to the customer’s operational environment. FDEs work closely with customers on-site to understand the context behind a technology initiative before a solution is built.
“We couldn’t do what we do without our FDEs,” says Cealey. “They go out and fine-tune the models, working with our human annotation team to generate a ground truth dataset that can be used to validate or improve the performance of the model in production.”
Second, data needs to be understood within its own context, which requires models to be carefully calibrated to the use case. “You can’t assume that an out-of-the-box computer vision model is going to give you better inventory management, for example, by taking that open source model and applying it to whatever your unstructured data feeds are,” says Cealey. “You need to fine-tune it so it gives you the data exports in the format you want and helps your aims. That’s where you start to see high-performative models that can then actually generate useful data insights.”
For the Hornets, Invisible used five foundation models, which the team fine-tuned to context-specific data. This included teaching the models to understand that they were “looking at” a basketball court as opposed to, say, a football field; to understand how a game of basketball works differently from any other sport the model might have knowledge of (including how many players are on each team); and to understand how to spot rules like “out of bounds.” Once fine-tuned, the models were able to capture subtle and complex visual scenarios, including highly accurate object detection, tracking, postures, and spatial mapping.
Lastly, while the AI technology mix available to companies changes by the day, they cannot eschew old-fashioned commercial metrics: clear goals. Without clarity on the business purpose, AI pilot programs can easily turn into open-ended, meandering research projects that prove expensive in terms of compute, data costs, and staffing.
“The best engagements we have seen are when people know what they want,” Cealey observes. “The worst is when people say ‘we want AI’ but have no direction. In these situations, they are on an endless pursuit without a map.”
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Researchers are getting organoids pregnant with human embryos
At first glance, it looks like the start of a human pregnancy: A ball-shaped embryo presses into the lining of the uterus then grips tight, burrowing in as the first tendrils of a future placenta appear. This is implantation—the moment that pregnancy officially begins.
Only none of it is happening inside a body. These images were captured in a Beijing laboratory, inside a microfluidic chip, as scientists watched the scene unfold.
In three recent papers published by Cell Press, scientists report what they call the most accurate efforts yet to mimic the first moments of pregnancy in the lab. They’ve taken human embryos from IVF centers and let these merge with “organoids” made of endometrial cells, which form the lining of the uterus. Read our story about their work, and what might come next.
—Antonio Regalado
LLMs contain a LOT of parameters. But what’s a parameter?
A large language model’s parameters are often said to be the dials and levers that control how it behaves. Think of a planet-size pinball machine that sends its balls pinging from one end to the other via billions of paddles and bumpers set just so. Tweak those settings and the balls will behave in a different way.
OpenAI’s GPT-3, released in 2020, had 175 billion parameters. Google DeepMind’s latest LLM, Gemini 3, may have at least a trillion—some think it’s probably more like 7 trillion—but the company isn’t saying. (With competition now fierce, AI firms no longer share information about how their models are built.)
But the basics of what parameters are and how they make LLMs do the remarkable things that they do are the same across different models. Ever wondered what makes an LLM really tick—what’s behind the colorful pinball-machine metaphors? Let’s dive in.
—Will Douglas Heaven
What new legal challenges mean for the future of US offshore wind
For offshore wind power in the US, the new year is bringing new legal battles.
On December 22, the Trump administration announced it would pause the leases of five wind farms currently under construction off the US East Coast. Developers were ordered to stop work immediately.
The cited reason? Concerns that turbines can cause radar interference. But that’s a known issue, and developers have worked with the government to deal with it for years.
Companies have been quick to file lawsuits, and the court battles could begin as soon as this week. Here’s what the latest kerfuffle might mean for the US’s struggling offshore wind industry.
—Casey Crownhart
This story is from The Spark, our weekly newsletter that explains the tech that could combat the climate crisis. Sign up to receive it in your inbox every Wednesday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1Google and Character.AI have agreed to settle a lawsuit over a teenager’s death It’s one of five lawsuits the companies have settled linked to young people’s deaths this week. (NYT $) + AI companions are the final stage of digital addiction, and lawmakers are taking aim. (MIT Technology Review)
2 The Trump administration’s chief output is online trolling Witness the Maduro memes. (The Atlantic $)
3 OpenAI has created a new ChatGPT Health feature It’s dedicated to analyzing medical results and answering health queries. (Axios) + AI chatbots fail to give adequate advice for most questions relating to women’s health. (New Scientist $) + AI companies have stopped warning you that their chatbots aren’t doctors. (MIT Technology Review)
4 Meta’s acquisition of Manus is being probed by China Holding up the purchase gives it another bargaining chip in its dealings with the US. (CNBC) + What happened when we put Manus to the test. (MIT Technology Review)
5 China is building humanoid robot training centers To address a major shortage of the data needed to make them more competent. (Rest of World) + The robot race is fueling a fight for training data. (MIT Technology Review)
6 AI still isn’t close to automating our jobs The technology just fundamentally isn’t good enough yet—for now. (WP $)
7 Weight regain seems to happen within two years of quitting the jabs That’s the conclusion of a review of more than 40 studies. But dig into the details, and it’s not all bad news. (New Scientist $)
8 This Silicon Valley community is betting on algorithms to find love Which feels like a bit of a fool’s errand. (NYT $)
9 Hearing aids are about to get really good You can—of course—thank advances in AI. (IEEE Spectrum)
10 The first 100% AI-generated movie will hit our screen within three years That’s according to Roku’s founder Anthony Wood. (Variety $) + How do AI models generate videos? (MIT Technology Review)
Quote of the day
“I’ve seen the video. Don’t believe this propaganda machine. ”
—Minnesota’s governor Tim Walz responds on X to Homeland Security’s claim that ICE’s shooting of a woman in Minneapolis was justified.
One more thing
Inside the strange limbo facing millions of IVF embryos
Millions of embryos created through IVF sit frozen in time, stored in cryopreservation tanks around the world. The number is only growing thanks to advances in technology, the rising popularity of IVF, and improvements in its success rates.
At a basic level, an embryo is simply a tiny ball of a hundred or so cells. But unlike other types of body tissue, it holds the potential for life. Many argue that this endows embryos with a special moral status, one that requires special protections.
The problem is that no one can really agree on what that status is. So while these embryos persist in suspended animation, patients, clinicians, embryologists, and legislators must grapple with the essential question of what we should do with them. What do these embryos mean to us? Who should be responsible for them? Read the full story.
—Jessica Hamzelou
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ I love hearing about musicians’ favorite songs + Here are some top tips for making the most of travelling on your own. + Check out just some of the excellent-sounding new books due for publication this year. + I could play this spherical version of Snake forever (thanks Rachel!)
The new year has barely begun, but the first days of 2026 have brought big news for health. On Monday, the US’s federal health agency upended its recommendations for routine childhood vaccinations—a move that healthassociations worry puts children at unnecessary risk of preventable disease.
There was more news from the federal government on Wednesday, when health secretary Robert F. Kennedy Jr. and his colleagues at the Departments of Health and Human Services and Agriculture unveiled new dietary guidelines for Americans. And they are causing a bit of a stir.
That’s partly because they recommend products like red meat, butter, and beef tallow—foods that have been linked to cardiovascular disease, and that nutrition experts have been recommending people limit in their diets.
These guidelines are a big deal—they influence food assistance programs and school lunches, for example. So this week let’s look at the good, the bad, and the ugly advice being dished up to Americans by their government.
The government dietary guidelines have been around since the 1980s. They are updated every five years, in a process that typically involves a team of nutrition scientists who have combed over scientific research for years. That team will first publish its findings in a scientific report, and, around a year later, the finalized Dietary Guidelines for Americans are published.
The last guidelines covered the period 2020 to 2025, and new guidelines were expected in the summer of 2025. Work had already been underway for years; the scientific report intended to inform them was published back in 2024. But the publication of the guidelines was delayed by last year’s government shutdown, Kennedy said last year. They were finally published yesterday.
Nutrition experts had been waiting with bated breath. Nutrition science has evolved slightly over the last five years, and some were expecting to see new recommendations. Research now suggests, for example, that there is no “safe” level of alcohol consumption.
We are also beginning to learn more about health risks associated with some ultraprocessed foods (although we still don’t have a good understanding of what they might be, or what even counts as “ultraprocessed”.) And some scientists were expecting to see the new guidelines factor in environmental sustainability, says Gabby Headrick, the associate director of food and nutrition policy at George Washington University’s Institute for Food Safety & Nutrition Security in Washington DC.
They didn’t.
Many of the recommendations are sensible. The guidelines recommend a diet rich in whole foods, particularly fresh fruits and vegetables. They recommend avoiding highly processed foods and added sugars. They also highlight the importance of dietary protein, whole grains, and “healthy” fats.
But not all of them are, says Headrick. The guidelines open with a “new pyramid” of foods. This inverted triangle is topped with “protein, dairy, and healthy fats” on one side and “vegetables and fruits” on the other.
USDA
There are a few problems with this image. For starters, its shape—nutrition scientists have long moved on from the food pyramids of the 1990s, says Headrick. They’re confusing and make it difficult for people to understand what the contents of their plate should look like. That’s why scientists now use an image of a plate to depict a healthy diet.
“We’ve been using MyPlate to describe the dietary guidelines in a very consumer-friendly, nutrition-education-friendly way for over the last decade now,” says Headrick. (The UK’s National Health Service takes a similar approach.)
And then there’s the content of that food pyramid. It puts a significant focus on meat and whole-fat dairy produce. The top left image—the one most viewers will probably see first—is of a steak. Smack in the middle of the pyramid is a stick of butter. That’s new. And it’s not a good thing.
While both red meat and whole-fat dairy can certainly form part of a healthy diet, nutrition scientists have long been recommending that most people try to limit their consumption of these foods. Both can be high in saturated fat, which can increase the risk of cardiovascular disease—the leading cause of death in the US. In 2015, on the basis of limited evidence, the World Health Organization classified red meat as “probably carcinogenic to humans.”
Also concerning is the document’s definition of “healthy fats,” which includes butter and beef tallow (a MAHA favorite). Neither food is generally considered to be as healthy as olive oil, for example. While olive oil contains around two grams of saturated fat per tablespoon, a tablespoon of beef tallow has around six grams of saturated fat, and the same amount of butter contains around seven grams of saturated fat, says Headrick.
“I think these are pretty harmful dietary recommendations to be making when we have established that those specific foods likely do not have health-promoting benefits,” she adds.
Red meat is not exactly a sustainable food, and neither are dairy products. And the advice on alcohol is relatively vague, recommending that people “consume less alcohol for better overall health” (which might leave you wondering: Less than what?).
There are other questionable recommendations in the guidelines. Americans are advised to include more protein in their diets—at levels between 1.2 and 1.6 grams daily per kilo of body weight, 50% to 100% more than recommended in previous guidelines. There’s a risk that increasing protein consumption to such levels could raise a person’s intake of both calories and saturated fats to unhealthy levels, says José Ordovás, a senior nutrition scientist at Tufts University. “I would err on the low side,” he says.
Some nutrition scientists are questioning why these changes have been made. It’s not as though the new recommendations were in the 2024 scientific report. And the evidence on red meat and saturated fat hasn’t changed, says Headrick.
In reporting this piece, I contacted many contributors to the previous guidelines, and some who had led research for 2024’s scientific report. None of them agreed to comment on the new guidelines on the record. Some seemed disgruntled. One merely told me that the process by which the new guidelines had been created was “opaque.”
“These people invested a lot of their time, and they did a thorough job [over] a couple of years, identifying [relevant scientific studies],” says Ordovás. “I’m not surprised that when they see that [their] work was ignored and replaced with something [put together] quickly, that they feel a little bit disappointed,” he says.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Acquiring new customers versus targeting existing ones is a common goal of advertisers. Google Ads offers account and bid settings to help. It starts with a feature called “New Customer Acquisition” in customer lifecycle optimization, located in the account-level goals section.
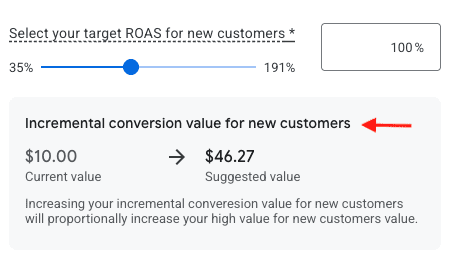
Advertisers can set an incremental conversion value for new customers. For example, if converting a repeat customer is worth $20, an incremental value could be $10, elevating new customers to $30.
Google provides a tool to calculate an incremental value based on average order value. To use, set a target return on ad spend for new customers. Say an advertiser wants a 100% customer acquisition ROAS — a 1:1 return. In the screen capture below, Google suggested a $46.27 value for new customers based on a given AOV and a $10 current value.
Google suggests a $46.27 value for new customers based on a given AOV, 100% ROAS, and a $10 current value.
The next step is to provide existing audience segments via Customer Match lists, either by specific category or overall. Google uses the lists (of at least 1,000 customers) to identify new prospects, much like how it uses first-party data to build lookalike audiences in Demand Gen campaigns.
Advertisers can deviate from Google’s suggested new-customer value and assign a higher amount. The option is often relevant for an audience segment of high-ticket buyers, provided there are 1,000 members. But a higher value is not critical in my experience, especially if the goal is to acquire any customer.
Having assigned an incremental value and uploaded a match list(s), the New Customer Acquisition feature is complete at the account level. Implement for each campaign by selecting the box labeled “Adjust your bidding to help acquire new customers.”
For each campaign, implement account-level acquisition settings by selecting the box labeled “Adjust your bidding to help acquire new customers.”
Google Ads will now bid higher within the target ROAS to acquire new customers, with lower bids for existing ones.
Yet advertisers can opt to bid only for new customers, such as for free trials or samples. Be careful, however, as this option will limit traffic. An alternative tactic is uploading an audience exclusion list of consumers who signed up for the free offer.
To activate New Customer Acquisition, advertisers must first set up value-based bidding. The system can’t bid higher for new customers without a base conversion value. Use a maximize conversion value bid strategy (with or without a target ROAS). Additionally, confirm the conversion classification is “purchase.”
Reporting
It’s worthwhile for reporting purposes to set a nominal new-customer conversion value (even $0.01) regardless of the bid strategy. Absent an incremental value, you can’t see the number of conversions from new vs. returning customers in the segment option view of “Conversions > New vs. returning customers.”
Even a nominal incremental value is worthwhile for distinguishing conversions between new and returning customers.
AI Overviews don’t show up consistently across Google Search because the system learns where they’re useful and pulls them back when people don’t engage.
Robby Stein, Vice President of Product at Google Search, described in a CNN interview how Google tests the summaries, measures interaction, and reduces their appearance for certain kinds of searches where they don’t help.
How Google Decides When To Show AI Overviews
Stein explained that AI Overviews appear based on learned usefulness rather than showing up by default.
“The system actually learns where they’re helpful and will only show them if users have engaged with that and find them useful,” Stein said. “For many questions, people just ask like a short question or they’re looking for very specific website, they won’t show up because they’re not actually helpful in many many cases.”
He gave a concrete example. When someone searches for an athlete’s name, they typically want photos, biographical details, and social media links. The system learned people didn’t engage with an AI Overview for those queries.
“The system will learn that if it tried to do an AI overview, no one really clicked on it or engaged with it or valued it,” Stein said. “We have lots of metrics we look at that and then it won’t show up.”
What “Under The Hood” Queries Mean For Visibility
Stein described the system as sometimes expanding a search beyond what you type. Google “in many cases actually issues additional Google queries under the hood to expand your search and then brings you the most relevant information for a given question,” he said.
That may help explain why pages sometimes show up in AI Overview citations even when they don’t match your exact query wording. The system pulls in content answering related sub-questions or providing context.
For image-focused queries, AI Overviews integrate with image results. For shopping queries, they connect to product information. The system adapts based on what serves the question.
Where AI Mode Fits In
Stein described AI Mode as the next step for complicated questions that need follow-up conversation. The design assumes you start in traditional Search, get an Overview if it helps, then go deeper into AI Mode when you need more.
“We really designed AI Mode to really help you go deeper with a pretty complicated question,” Stein said, citing examples like comparing cars or researching backup power options.
During AI Mode testing, Google saw “like a two to three … full increase in the query length” compared to typical Search queries. Users also started asking follow-up questions in a conversational pattern.
The longer AI Mode queries included more specificity. Stein’s example: instead of “things to do in Nashville,” users asked “restaurants to go to in Nashville if one friend has an allergy and we have dogs and we want to sit outside.”
Personalization Exists But Is Limited
Some personalization in AI Mode already exists. Users who regularly click video results might see videos ranked higher, for example.
“We are personalizing some of these experiences,” Stein said. “But right now that’s a smaller adjustment probably to the experience because we want to keep it as consistent as possible overall.”
Google’s focus is on maintaining consistency across users while allowing for individual preferences where it makes sense.
If you’re tracking AIO presence week to week, the fluctuations may reflect user behavior patterns for different question types rather than algorithm changes.
The “under the hood” query expansion means content can appear in citations even without matching your exact phrasing. That matters when you’re explaining CTR drops internally or planning content for complex queries where Overviews are more likely to surface.
Looking Ahead
Google’s AI Overviews earn placement based on usefulness rather than appearing by default.
Personalization is limited today, but the direction is moving toward more tailored experiences that maintain overall consistency.
ChatGPT accounted for 64% of worldwide traffic share among gen AI chatbot websites as of January, while Google’s Gemini reached 21%, according to Similarweb’s Global AI Tracker.
Similarweb’s tracker (PDF link) measures total visits at the domain level, so it reflects people who go to these tools directly on the web. It doesn’t capture API usage, embedded assistants, or other integrations where much of the AI usage occurs now.
ChatGPT Down, Gemini Up In A Year Of Share Gains
The share movement is easiest to see year-over-year.
A year ago, Similarweb estimated ChatGPT accounted for 86% of worldwide traffic among tracked chatbot sites. Now, that figure is 64%. Over the same period, Gemini rose from 5% to 21%.
Other tools are much smaller by this measure. DeepSeek was at 3.7%, Grok at 3.4%, and Perplexity and Claude both at 2.0%.
Google has been promoting Gemini through products like Android and Workspace, which may help explain why it’s gaining share among users who access these tools directly.
Winter Break Pulled Down Total Visits
Similarweb pointed to seasonality during the holiday period:
“Driven by the winter break, the daily average visits to all tools dropped to August-September levels.”
That context matters because it helps distinguish overall category softness from shifts in market share.
Writing Tool Domain Traffic Declines
Writing and content generation sites were down 10% over the most recent 12-week window in Similarweb’s category view.
At the individual tool level, Similarweb’s table shows steep drops for several writing platforms. Growthbarseo was down 100%, while Jasper fell 16%, Writesonic dropped 17%, and Rytr declined 9%. Originality was up 17%.
These are still domain-level visit counts, so the clearest takeaway is that fewer people are going directly to specialized writing sites online. That can happen for several reasons, including users relying more on general assistants, switching to apps, or using these models through integrations.
Code Completion Shows Mixed Results
The developer tools category looked more mixed than the writing tools.
Similarweb’s code completion table shows Bolt down 39% over 12 weeks, while Cursor (up 8%), Replit (up 2%), and Base44 (up 49%) moved in different directions.
Traditional Search Looks Close To Flat
In Similarweb’s “disrupted sectors” view, traditional search traffic is down roughly 1% to 3% year-over-year across recent periods, which doesn’t indicate a sharp drop in overall search usage in this dataset.
The same table shows Reddit up 12% year-over-year and Quora down 53%, consistent with the idea that some Q&A behavior is being redistributed even as overall search remains relatively steady.
Why This Matters
When making sense of how AI is changing discovery and demand, these numbers can help you understand where direct, web-based attention is concentrating. That can influence which assistants you monitor for brand mentions, citations, and referral behavior.
Though you should treat this a snapshot, not the full picture. If your audience is interacting with AI through browsers, apps, or embedded assistants, your own analytics will be a better barometer than any domain-level tracker.
Looking Ahead
The next report should clarify whether category traffic rebounds after the holiday period and whether Gemini continues to gain share at the same pace. It will also be a useful read on whether writing tools stabilize or whether more of that usage continues to consolidate into general assistants and bundled experiences.
When most people hear the phrase “AI bias,” their mind jumps to ethics, politics, or fairness. They think about whether systems lean left or right, whether certain groups are represented properly, or whether models reflect human prejudice. That conversation matters. But it is not the conversation reshaping search, visibility, and digital work right now.
The bias that is quietly changing outcomes is not ideological. It is structural, and operational. It emerges from how AI systems are built, trained, how they retrieve and weight information, and how they are rewarded. It exists even when everyone involved is acting in good faith. And it affects who gets seen, cited, and summarized long before anyone argues about intent.
This article is about that bias. Not as a flaw or as a scandal. But as a predictable consequence of machine systems designed to operate at scale under uncertainty.
To talk about it clearly, we need a name. We need language that practitioners can use without drifting into moral debate or academic abstraction. This behavior has been studied, but what hasn’t existed is a single term that explains how it manifests as visibility bias in AI-mediated discovery. I’m calling it Machine Comfort Bias.
Image Credit: Duane Forrester
Why AI Answers Cannot Be Neutral
To understand why this bias exists, we need to be precise about how modern AI answers are produced.
AI systems do not search the web the way people do. They do not evaluate pages one by one, weigh arguments, or reason toward a conclusion. What they do instead is retrieve information, weight it, compress it, and generate a response that is statistically likely to be acceptable given what they have seen before, a process openly described in modern retrieval-augmented generation architectures such as those outlined by Microsoft Research.
That process introduces bias before a single word is generated.
First comes retrieval. Content is selected based on relevance signals, semantic similarity, and trust indicators. If something is not retrieved, it cannot influence the answer at all.
Then comes weighting. Retrieved material is not treated equally. Some sources carry more authority. Some phrasing patterns are considered safer. Some structures are easier to compress without distortion.
Finally comes generation. The model produces an answer that optimizes for probability, coherence, and risk minimization. It does not aim for novelty. It does not aim for sharp differentiation. It aims to sound right, a behavior explicitly acknowledged in system-level discussions of large models such as OpenAI’s GPT-4 overview.
At no point in this pipeline does neutrality exist in the way humans usually mean it. What exists instead is preference. Preference for what is familiar. Preference for what has been validated before. Preference for what fits established patterns.
Introducing Machine Comfort Bias
Machine Comfort Bias describes the tendency of AI retrieval and answer systems to favor information that is structurally familiar, historically validated, semantically aligned with prior training, and low-risk to reproduce, regardless of whether it represents the most accurate, current, or original insight.
This is not a new behavior. The underlying components have been studied for years under different labels. Training data bias. Exposure bias. Authority bias. Consensus bias. Risk minimization. Mode collapse.
What is new is the surface on which these behaviors now operate. Instead of influencing rankings, they influence answers. Instead of pushing a page down the results, they erase it entirely.
Machine Comfort Bias is not a scientific replacement term. It is a unifying lens. It brings together behaviors that are already documented but rarely discussed as a single system shaping visibility.
Where Bias Enters The System, Layer By Layer
To understand why Machine Comfort Bias is so persistent, it helps to see where it enters the system.
Training Data And Exposure Bias
Language models learn from large collections of text. Those collections reflect what has been written, linked, cited, and repeated over time. High-frequency patterns become foundational. Widely cited sources become anchors.
This means that models are deeply shaped by past visibility. They learn what has already been successful, not what is emerging now. New ideas are underrepresented by definition. Niche expertise appears less often. Minority viewpoints show up with lower frequency, a limitation openly discussed in platform documentation about model training and data distribution.
This is not an oversight. It is a mathematical reality.
Authority And Popularity Bias
When systems are trained or tuned using signals of quality, they tend to overweight sources that already have strong reputations. Large publishers, government sites, encyclopedic resources, and widely referenced brands appear more often in training data and are more frequently retrieved later.
The result is a reinforcement loop. Authority increases retrieval. Retrieval increases citation. Citation increases perceived trust. Trust increases future retrieval. And this loop does not require intent. It emerges naturally from how large-scale AI systems reinforce signals that have already proven reliable.
Structural And Formatting Bias
Machines are sensitive to structure in ways humans often underestimate. Clear headings, definitional language, explanatory tone, and predictable formatting are easier to parse, chunk, and retrieve, a reality long acknowledged in how search and retrieval systems process content, including Google’s own explanations of machine interpretation.
Content that is conversational, opinionated, or stylistically unusual may be valuable to humans but harder for systems to integrate confidently. When in doubt, the system leans toward content that looks like what it has successfully used before. That is comfort expressed through structure.
Semantic Similarity And Embedding Gravity
Modern retrieval relies heavily on embeddings. These are mathematical representations of meaning that allow systems to compare content based on similarity rather than keywords.
Embedding systems naturally cluster around centroids. Content that sits close to established semantic centers is easier to retrieve. Content that introduces new language, new metaphors, or new framing sits farther away, a dynamic visible in production systems such as Azure’s vector search implementation.
This creates a form of gravity. Established ways of talking about a topic pull answers toward themselves. New ways struggle to break in.
Safety And Risk Minimization Bias
AI systems are designed to avoid harmful, misleading, or controversial outputs. This is necessary. But it also shapes answers in subtle ways.
Sharp claims are riskier than neutral ones. Nuance is riskier than consensus. Strong opinions are riskier than balanced summaries.
When faced with uncertainty, systems tend to choose language that feels safest to reproduce. Over time, this favors blandness, caution, and repetition, a trade-off described directly in Anthropic’s work on Constitutional AI as far back as 2023.
Why Familiarity Wins Over Accuracy
One of the most uncomfortable truths for practitioners is that accuracy alone is not enough.
Two pages can be equally correct. One may even be more current or better researched. But if one aligns more closely with what the system already understands and trusts, that one is more likely to be retrieved and cited.
This is why AI answers often feel similar. It is not laziness. It is system optimization. Familiar language reduces the chance of error. Familiar sources reduce the chance of controversy. Familiar structure reduces the chance of misinterpretation, a phenomenon widely observed in mainstream analysis showing that LLM-generated outputs are significantly more homogeneous than human-generated one.
From the system’s perspective, familiarity is a proxy for safety.
The Shift From Ranking Bias To Existence Bias
Traditional search has long grappled with bias. That work has been explicit and deliberate. Engineers measure it, debate it, and attempt to mitigate it through ranking adjustments, audits, and policy changes.
Most importantly, traditional search bias has historically been visible. You could see where you ranked. You could see who outranked you. You could test changes and observe movement.
AI answers change the nature of the problem.
When an AI system produces a single synthesized response, there is no ranking list to inspect. There is no second page of results. There is only inclusion or omission. This is a shift from ranking bias to existence bias.
If you are not retrieved, you do not exist in the answer. If you are not cited, you do not contribute to the narrative. If you are not summarized, you are invisible to the user.
That is a fundamentally different visibility challenge.
Machine Comfort Bias In The Wild
You do not need to run thousands of prompts to see this behavior. It has already been observed, measured, and documented.
Studies and audits consistently show that AI answers disproportionately mirror encyclopedic tone and structure, even when multiple valid explanations exist, a pattern widely discussed.
Independent analyses also reveal high overlap in phrasing across answers to similar questions. Change the prompt slightly, and the structure remains. The language remains. The sources remain.
These are not isolated quirks. They are consistent patterns.
What This Changes About SEO, For Real
This is where the conversation gets uncomfortable for the industry.
SEO has always involved bias management. Understanding how systems evaluate relevance, authority, and quality has been the job. But the feedback loops were visible. You could measure impact, and you could test hypotheses. Machine Comfort Bias now complicates that work.
When outcomes depend on retrieval confidence and generation comfort, feedback becomes opaque. You may not know why you were excluded. You may not know which signal mattered. You may not even know that an opportunity existed.
This shifts the role of the SEO. From optimizer to interpreter. From ranking tactician to system translator, which reshapes career value. The people who understand how machine comfort forms, how trust accumulates, and how retrieval systems behave under uncertainty become critical. Not because they can game the system, but because they can explain it.
What Can Be Influenced, And What Cannot
It is important to be honest here. You cannot remove Machine Comfort Bias, nor can you force a system to prefer novelty. You cannot demand inclusion.
What you can do is work within the boundaries. You can make structure explicit without flattening voice, and you can align language with established concepts without parroting them. You can demonstrate expertise across multiple trusted surfaces so that familiarity accumulates over time. You can also reduce friction for retrieval and increase confidence for citation. The bottom line here is that you can design content that machines can safely use without misinterpretation. This shift is not about conformity; it’s about translation.
How To Explain This To Leadership Without Losing The Room
One of the hardest parts of this shift is communication. Telling an executive that “the AI is biased against us” rarely lands well. It sounds defensive and speculative.
I will suggest that a better framing is this. AI systems favor what they already understand and trust. Our risk is not being wrong. Our risk is being unfamiliar. That is our new, biggest business risk. It affects visibility, and it affects brand inclusion as well as how markets learn about new ideas.
Once framed that way, the conversation changes. This is no longer about influencing algorithms. It is about ensuring the system can recognize and confidently represent the business.
Bias Literacy As A Core Skill For 2026
As AI intermediaries become more common, bias literacy becomes a professional requirement. This does not mean memorizing research papers, but instead it means understanding where preference forms, how comfort manifests, and why omission happens. It means being able to look at an AI answer and ask not just “is this right,” but “why did this version of ‘right’ win.” That is an enhanced skill, and it will define who thrives in the next phase of digital work.
Naming The Invisible Changes
Machine Comfort Bias is not an accusation. It is a description, and by naming it, we make it discussable. By understanding it, we make it predictable. And anything predictable can be planned for.
This is not a story about loss of control. It is a story about adaptation, about learning how systems see the world and designing visibility accordingly.
Bias has not disappeared. It has changed shape, and now that we can see it, we can work with it.
“Is there any difference between how AI systems handle JavaScript-rendered or interactively hidden content compared to traditional Google indexing? What technical checks can SEOs do to confirm that all page critical information is available to machines?”
For several years now, SEOs have been fairly encouraged by Googlebot’s improvements in being able to crawl and render JavaScript-heavy pages. However, with the new AI crawlers, this might not be the case.
In this article, we’ll look at the differences between the two crawler types, and how to ensure your critical webpage content is accessible to both.
How Does Googlebot Render JavaScript Content?
Googlebot processes JavaScript in three main stages: crawling, rendering, and indexing. In a basic and simple explanation, this is how each stage works:
Crawling
Googlebot will queue pages to be crawled when it discovers them on the web. Not every page that gets queued will be crawled, however, as Googlebot will check to see if crawling is allowed. For example, it will see if the page is blocked from crawling via a disallow command in the robots.txt.
If the page is not eligible to be crawled, then Googlebot will skip it, forgoing an HTTP request. If a page is eligible to be crawled, it will move to render the content.
Rendering
Googlebot will check if the page is eligible to be indexed by ensuring there are no requests to keep it from the index, for example, via a noindex meta tag. Googlebot will queue the page to be rendered. The rendering may happen within seconds, or it may remain in the queue for a longer period of time. Rendering is a resource-intensive process, and as such, it may not be instantaneous.
In the meantime, the bot will receive the DOM response; this is the content that is rendered before JavaScript is executed. This typically is the page HTML, which will be available as soon as the page is crawled.
Once the JavaScript is executed, Googlebot will receive the fully constructed page, the “browser render.”
Indexing
Eligible pages and information will be stored in the Google index and made available to serve as search results at the point of user query.
How Does Googlebot Handle Interactively Hidden Content?
Not all content is available to users when they first land on a page. For example, you may need to click through tabs to find supplementary content, or expand an accordion to see all of the information.
Googlebot doesn’t have the ability to switch between tabs, or to click open an accordion. So, making sure it can parse all the page’s information is important.
The way to do this is to make sure that the information is contained within the DOM on the first load of the page. Meaning, content may be “hidden from view” on the front end before clicking a button, but it’s not hidden in the code.
Think of it like this: The HTML content is “hidden in a box”; the JavaScript is the key to open the box. If Googlebot has to open the box, it may not see that content straightaway. However, if the server has opened the box before Googlebot requests it, then it should be able to get to that content via the DOM.
How To Improve The Likelihood That Googlebot Will Be Able To Read Your Content
The key to ensuring that content can be parsed by Googlebot is making it accessible without the need for the bot to render the JavaScript. One way of doing this is by forcing the rendering to happen on the server itself.
Server-side rendering is the process by which a webpage is rendered on the server rather than by the browser. This means an HTML file is prepared and sent to the user’s browser (or the search engine bot), and the content of the page is accessible to them without waiting for the JavaScript to load. This is because the server has essentially created a file that has rendered content in it already; the HTML and CSS are accessible immediately. Meanwhile, JavaScript files that are stored on the server can be downloaded by the browser.
This is opposed to client-side rendering, which requires the browser to fetch and compile the JavaScript before content is accessible on the webpage. This is a much lower lift for the server, which is why it is often favored by website developers, but it does mean that bots struggle to see the content on the page without rendering the JavaScript first.
How Do LLM Bots Render JavaScript?
Given what we now know about how Googlebot renders JavaScript, how does that differ from AI bots?
The most important element to understand about the following is that, unlike Googlebot, there is no “one” governing body that represents all the bots that might be encompassed under “LLM bots.” That is, what one bot might be capable of doing won’t necessarily be the standard for all.
The bots that scrape the web to power the knowledge bases of the LLMs are not the same as the bots that visit a page to bring back timely information to a user via a search engine.
And Claude’s bots do not have the same capability as OpenAI’s.
When we are considering how to ensure that AI bots can access our content, we have to cater to the lowest-capability bots.
Less is known about how LLM bots render JavaScript, mainly because, unlike Google, the AI bots are not sharing that information. However, some very smart people have been running tests to identify how each of the main LLM bots handles it.
Back in 2024, Vercel published an investigation into the JavaScript rendering capabilities of the main LLM bots, including OpenAI’s, Anthropic’s, Meta’s, ByteDance’s, and Perplexity’s. According to their study, none of those bots were able to render JavaScript. The only ones that were, were Gemini (leveraging Googlebot’s infrastructure), Applebot, and CommonCrawl’s CCbot.
More recently, Glenn Gabe reconfirmed Vercel’s findings through his own in-depth analysis of how ChatGPT, Perplexity, and Claude handle JavaScript. He also runs through how to test your own website in the LLMs to see how they handle your content.
These are the most well-known bots, from some of the most heavily funded AI companies in this space. It stands to reason that if they are struggling with JavaScript, lesser-funded or more niche ones will be also.
How Do AI Bots Handle Interactively Hidden Content?
Not well. That is, if the interactive content requires some execution of JavaScript, they may struggle to parse it.
To ensure the bots are able to see content hidden behind tabs, or in accordions, it is prudent to ensure the content loads fully in the DOM without the need to execute JavaScript. Human visitors can still interact with the content to reveal it, but the bots won’t need to.
How To Check For JavaScript Rendering Issues
There are two very easy ways to check if Googlebot is able to render all the content on your page:
Check The DOM Through Developer Tools
The DOM (Document Object Model) is an interface for a webpage that represents the HTML page as a series of “nodes” and “objects.” It essentially links a webpage’s HTML source code to JavaScript, which enables the functionality of the webpage to work. In simple terms, think of a webpage as a family tree. Each element on a webpage is a “node” on the tree. So, a header tag
, a paragraph
, and the body of the page itself
are all nodes on the family tree.
When a browser loads a webpage, it reads the HTML and turns it into the family tree (the DOM).
How To Check It
I’ll take you through this using Chrome’s Developer Tools as an example.
You can check the DOM of a page by going to your browser. Using Chrome, right-click and select “Inspect.” From there, make sure you’re in the “Elements” tab.
To see if content is visible on your webpage without having to execute JavaScript, you can search for it here. If you find the content fully within the DOM when you first load the page (and don’t interact with it further), then it should be visible to Googlebot and LLM bots.
Use Google Search Console
To check if the content is visible specifically to Googlebot, you can use Google Search Console.
Choose the page you want to test and paste it into the “Inspect any URL” field. Search Console will then take you to another page where you can “Test live URL.” When you test a live page, you will be presented with another screen where you can opt to “View tested page.”
How To Check If An LLM Bot Can See Your Content
As per Glenn Gabe’s experiments, you can ask the LLMs themselves what they can read from a specific webpage. For example, you can prompt them to read the text of an article. They will respond with an explanation if they cannot due to JavaScript.
Viewing The Source HTML
If we are working to the lowest common denominator, it is prudent to assume, at this point, LLMs can’t read content in JavaScript. To make sure that your content is available in the HTML of a webpage so that the bots can definitely access it, be absolutely sure that the content of your page is readable to these bots. Make sure it is in the source HTML. To check this, you can go to Chrome and right click on the page. From the menu, select “View page source.” If you can “find” the text in this code, you know it’s in the source HTML of the page.
What Does This Mean For Your Website?
Essentially, Googlebot has been developed over the years to be much better at handling JavaScript than the newer LLM bots. However, it’s really important to understand that the LLM bots are not trying to crawl and render the web in the same way as Googlebot. Don’t assume that they will ever try to mimic Googlebot’s behavior. Don’t consider them “behind” Googlebot. They are a different beast altogether.
For your website, this means you need to check if your page loads all the pertinent information in the DOM on the first load of the page to satisfy Googlebot’s needs. For the LLM bots, to be very sure the content is available to them, check your static HTML.
More Resources:
Featured Image: Paulo Bobita/Search Engine Journal
Your future customers are relying on answer engines to surface a single recommendation, not a list of options.
Yet most small businesses remain invisible to AI because their Google Business Profile information is incomplete, inconsistent, or structured in ways these AI chat systems cannot confidently interpret. The result is fewer calls, missed bookings, and lost revenue.
In this upcoming webinar session, Raj Madhavni, Co-Founder, Alpha SEO Pros at Thryv, will explain how AI assistants evaluate local businesses today and which signals most influence recommendations. He will also identify the common gaps that prevent businesses from being selected and outline how to address them before 2026.
The ranking signals AI assistants use to select local businesses
A practical roadmap to increase AI driven visibility, trust, and conversions in 2026
Why Attend?
This webinar gives small business owners and marketers a clear framework for competing in an AI driven local search environment. You will leave with actionable guidance to close visibility gaps, strengthen trust signals, and position your business as the one AI assistants recommend when customers ask.
Register now to prepare your business for local AI search in 2026.
🛑 Can’t attend live? Register anyway, and we’ll send you the on demand recording after the session.