BrightEdge research comparing citations in ChatGPT and Google AI Overviews suggests that AI search engines are doing more than retrieving information. They are assigning different roles to the same sources, treating platforms like Reddit and LinkedIn as authoritative references in some contexts and as social commentary in others.
For SEOs, publishers, and business owners, the findings suggest that AI visibility is becoming less about simply appearing in citations and more about understanding how each AI system interprets a source.
AI Search Engines Are Not Using The Same Sources The Same Way
The most important finding in the research is that the same source can be treated very differently depending on which AI engine is generating the answer.
Reddit’s AI Citation Patterns
Reddit appears alongside editorial and reference sites such as Mayo Clinic, Healthline, Cleveland Clinic, and Britannica roughly 36% of the time in ChatGPT citations.
In Google AI Overviews, those authority sites appear next to Reddit only about 6% of the time.
Google AI Overviews more frequently groups Reddit with social platforms.
YouTube appears alongside Reddit in approximately 36% of AI Overviews citations.
Facebook, TikTok, and Instagram also commonly appear in the same citation environment.
The result is what BrightEdge describes as a “6x authority flip.” The same Reddit thread occupies two different positions depending on the AI system evaluating it.
This is a significant distinction for marketers because optimization depends on the niche.
A citation is not simply a citation. The surrounding sources provide context about how an AI system interprets the information.
👉 When Reddit appears next to Mayo Clinic and Healthline, it is functioning more like an authority source.
👉 When it appears beside YouTube, TikTok, and Instagram, it is functioning more like social proof or crowd opinion.
AI engines are making editorial judgments about sources that influence whether or not to retrieve them.
Different AI Engines Assign Different Jobs To The Same Platforms
The differences extend beyond credibility.
BrightEdge’s analysis found that ChatGPT and Google AI Overviews also rely on Reddit and LinkedIn for different types of questions.
How-To And Explanation Queries
Reddit “How To” Citations: Reddit is cited about twice as often in ChatGPT as in AI Overviews.
LinkedIn “How To” Citations: LinkedIn is cited 33% in ChatGPT and 22% in AI Overviews.
Explanation Queries: ChatGPT relies more heavily on Reddit for answering “why does this happen?” questions.
Google AI Overviews relies on social sources differently for comparison-style queries. Approximately 10% of its social citations appear in comparison-style prompts such as “X vs. Y,” compared with only about 1% in ChatGPT.
That difference may reveal something about how the two systems construct answers.
👉 ChatGPT appears more willing to synthesize comparisons directly.
👉 Google AI Overviews appears more likely to surface discussions where users are already debating competing options.
Verification questions show another distinction. These account for roughly 14% to 24% of prompts across both engines, but the sources serving those answers differ. LinkedIn tends to appear for professional capability questions, while Reddit is more frequently used for consumer reassurance and experience-based validation.
The split between LinkedIn and Reddit is another signal that AI systems may be assigning sources to specific types of answers. LinkedIn earns citations in professional, career, and B2B contexts. Reddit earns them in broader consumer contexts, especially health, money, and product research in ChatGPT.
The findings suggest that AI systems are not merely selecting sources. They are assigning sources specific jobs within the answer-generation process.
AI Citation Strategy Now Requires Platform-Specific Optimization
The practical implication is that AI search can no longer be treated as a single channel.
For years, search marketers generally focused on achieving visibility within one ranking system. AI search introduces a more complicated environment where the same content may carry different weight depending on which engine is evaluating it.
👉 A strong Reddit discussion may function as an authority signal in ChatGPT while serving primarily as community sentiment in AI Overviews.
👉 LinkedIn may be valuable for professional how-to content and capability questions but less useful for consumer-oriented discussions.
This means marketers may need to think less about where they are mentioned and more about what role those mentions play.
The BrightEdge data indicates that citations are increasingly tied to editorial judgments. Platforms appear to be earning visibility because they answer particular categories of questions, not simply because they have strong brand recognition.
That has implications for content strategy, digital PR, community participation, and brand building.
The goal is no longer just to earn mentions across the web. It is to earn links or mentions from the type of content that AI systems associate with the questions businesses want to answer.
What The Research Suggests About AI Search
The most interesting finding is not that ChatGPT and Google AI Overviews cite Reddit and LinkedIn differently.
It is that both systems appear to be developing their own way of deciding what different sources represent, assigning them roles.
Role Assignments
Reddit is used as authority in some contexts.
Reddit is used as social proof in other contexts.
Reddit is used for “how to” guidance in ChatGPT.
Reddit is used for comparison discussions in AI Overviews.
LinkedIn is used for professional capability checks across both AI engines.
LinkedIn is used for professional, career, and B2B questions across both AI engines.
Traditional search engines ranked pages based on relevance for multiple search intents. AI engines increasingly appear to classify sources, assign them roles, and then use them according to the function they serve within an answer.
That is the marketing insight hiding in plain sight. The Reddit and LinkedIn statistics are the evidence supporting that broader conclusion. If that trend continues, understanding how AI systems interpret a source may become just as important as understanding whether they cite it at all.
Where’s the blue line fellas? (Image Credit: Harry Clarkson-Bennett)
“Conduct requirement introduced today gives publishers more control and stronger bargaining power over the use of their content…”
CMA
This is, in fairness, a world-first. Clearly a step in the right direction. But that’s all it is, a step.
We have AI reporting without clicks for, I presume, obvious reasons. Publishers can opt out of AI Overviews – a nice-to-have – but unless this is done at scale, there’s very little bargaining power here, and the onus is on publishers. Although I will say allowing publishers to opt out of their content being used for the “fine-tuning” of AI models is, obviously, a good thing.
Oh, and Search profiles launched “to help publishers and creators highlight their work on Search.” This might seem small, but it’s a huge part of the future of search. It’s why I don’t hate the “search everywhere optimization” moniker. Search is broader than ever.
“Search profiles give publishers and creators a central place to showcase their latest articles, videos and social posts. People can easily follow sources from their profile, so they’re more likely to see that content on Discover…”
LLMs have restructured the open web. Your way of accessing and retrieving information has fundamentally shifted. Entity SEO – the connections you can build around your brand (personal and professional) – is more important than ever. You cannot afford ambiguity anymore. You have to build a profile. With real people. In multiple places.
Positive first steps. There are many to go.
Financially, How Are They Doing?
Errr … pretty well.
Total revenue for 2025 came in at $402.8 billion, up from $350 billion in 2024 – the first $400 billion year in Google’s history. Larger than the GDP of Portugal. The company also delivered its first-ever $100 billion quarter in Q3.
Almost everything is growing hugely across the space of a year (Image Credit: Harry Clarkson-Bennett)
Search is still Google’s largest revenue line by some margin. A rise in zero-click searches, keeping people in its system, is clearly a good thing for its advertising business model. Thanks to data from Seer Interactive, we know that AIOs caused the CTR (and cost) of PPC advertising to respectively decline and increase over this time. Albeit this appears to have leveled out.
Cloud revenues jumped from $43.2 billion to $58.7 billion, primarily driven by growth in infrastructure and platform services. Google Cloud ended 2025 at an annual run rate of over $70 billion, with demand driven by AI products, and nearly 75% of Google Cloud customers had used Google’s vertically optimized AI.
YouTube’s dual revenue model may be Google’s plan for search. Its advertising revenue grew from $36.1 billion to $40.4 billion last year, and subscriptions give it unparalleled resilience. Unlike Search, YouTube’s creator economy is still booming.
It’s a product that works on both fronts.
Finally, and most importantly in my opinion, Google’s subscription-based products are its fastest-growing non-cloud segment. Consumer subscriptions exceeded 325 million across Google’s services, thanks to Google One and YouTube Premium adoption. This is a parallel revenue line for Google – one where advertising matters less.
The open web becomes less important as an intermediary because of it. It enhances their ability to lose money on advertising. They are building resilience.
Google also has a sneaky line item in its 10-K in the OI&E section (Other Income and Securities) labeled as non-marketable equity securities. Google has invested $3 billion in Anthropic up until this point and has $24.1 billion of unrealized gains over the same time period.
I suspect AI Mode becomes the default search experience for most people and a significant number of searches. People like the conversational interface, and once they figure out advertising and reduce the cost of running it, I’m sure it will get rolled out more aggressively.
Thanks to data shared by Aleyda Solis (and Rand Fishkin), we know AI Mode’s usage more than doubled in the U.S. in a single quarter. In Europe, it grew even faster. Overall share remains below 0.25% in both regions. The pessimist in me thinks that’s a bit crap. The optimist would say there’s room for growth.
In the U.S., Google AI Mode’s share of desktop events grew from 0.06% in December 2025 to 0.16% in March 2026. A 2.5x increase in one quarter.
In the EU and UK, growth was sharper: 0.06% in December to 0.21% in March, nearly a 4x increase over the same period.
By March 2026, EU and UK adoption had overtaken the U.S. (0.21% vs 0.16%), despite AI Mode launching later in Europe.
Sundar is bullish on the topic. He claims Google is creating a seamless transition from 10 blue links towards AI Mode, and people are enjoying it. But it’s not an overnight change. You aren’t going to flick the switch on a 200+ billion advertising model when the alternative is so untested.
Particularly when your competitors are financially floundering somewhat, beautifully described by Gary Marcus as tokenmaxxing. The immediate risk is somewhat lessened.
And worth remembering that 44% of Google searches are navigational. Is that a strong proposition for AI and far more computationally expensive conversational search?
Maybe. Maybe not.
We’ve seen a notable uptick in AI Overviews appearing for branded searches, and research from Kevin Indig showed that people are, in many cases, just looking for top-of-the-funnel information at this stage in their journey. And we don’t want to click on websites.
So the navigational click is being replaced by an in-SERP navigational assessment. If Google can fulfill your need in their SERP, you can bet your bottom dollar they will.
Hugging Face estimated it costs about 30 times as much energy to generate text versus simply extracting it from a source. While that isn’t revenue as such, computational power correlates pretty closely with cost.
Right now, AI offerings are computationally expensive, much less monetizable (although I’m sure that will change), and won’t be picked up by great swathes of the population.
If you had a more expensive product that specific people or cohorts of people weren’t using (and are unlikely to use), would you push them into using it? Or would you just primarily give them what they’re used to? Could that group’s margin support your expensive expansion?
If you’re familiar with the stages of technology adoption, you get a sense of who adopts it, when, and why.
Innovators and early adopters are far likelier to be younger. People whose brains have enough plasticity to continue to change. In AI Mode’s case, I suspect those in the conservatives and skeptics sections will never use any kind of LLM.
If you don’t believe me, ask your parents what ChatGPT is. If they do use it, I’m fairly confident it’ll be for something either completely banal or psychologically worrying.
Google’s ability to understand the intent behind the search (and the user) will form a key part of the search giant’s revenue modelling. The more effectively they can do this, the less computational power they will spend.
Why News Holds Firm
AI Overviews do not supersede a Top Stories block. There are two theories here:
Google has decided to create a safe haven for publishers (highly unlikely).
AI cannot accurately or fairly represent fast-moving, immediate stories effectively (no one has cared about accuracy so far).
So, news, for now, is resilient to AI. It is filed under the type of content that still adds real and obvious value. Tools, products, real, human interest stories, stories with unique data and research that cannot be effectively delivered by an LLM, and real, expert-led opinion from people we trust.
Whisper it quietly, you might even get a click from it.
To show Top Stories resilience, I ran a couple of thousand queries, pretty newsy queries through DataforSEO, extracted the structured data, and represented it in a column graph of queries by category with an AI Overview or Top Stories. This is a tiny sample size, but it’s representative of larger ones I have seen and run.
Just 28 queries (1.5%) had both an AIO and Top Stories block present at the time of checking. (Image Credit: Harry Clarkson-Bennett)
Branded queries had the lowest number of AIOs, albeit there were only 50 branded queries in the mix.
News/entity type queries (primarily people, places, and organizations) had the second lowest number of AIOs, with just 19%, with 34% served by a Top Stories box.
Informational queries have the highest percentage of AIOs.
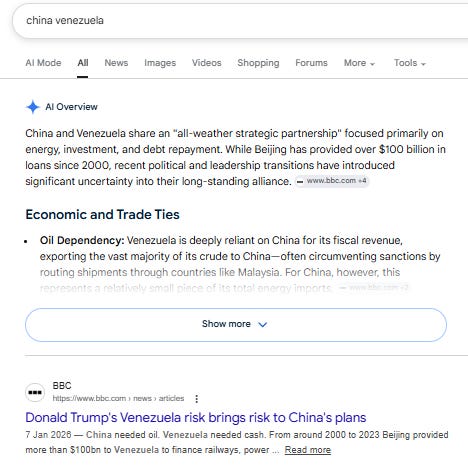
Typically, this is when queries like [China Venezuela] can be well served with an AIO – because there’s significant evergreen search volume, or the news story has died down and can be effectively synthesized via an AI response.
The top “news” story was from January this year (Image Credit: Harry Clarkson-Bennett)
If you want to truly run some quality risk and exposure mapping, I find it helpful to create category risk scores by entity type. You can expand this to content categorization too.
News queries are still pretty resilient (Image Credit: Harry Clarkson-Bennett)
On the rare occasion that you see these beasts co-exist in the wild, I believe it only occurs when the news agenda for said topic has dropped off enough that an AIO can replace it.
One of its strongest capabilities is the cohort-driven story rollout.
Person A is similar to person B.
Person A loved and engaged with said story.
Said story is shown to person B.
Person C also shares a similar characteristic and is shown the story.
People are classified based on what they like. Google builds groups. These groups form the foundations of virality.
Like almost any social media algorithm, Google Discover is Google’s way of hooking people into search with an algorithmic feed. And I think it could have significant potential for the future of the SERP.
When the time’s right, you will be shown incidental content you didn’t even know you wanted to read. And you will click it.
So What Does This Mean For The State Of The SERP?
Diversity. Zero-click search is overblown, albeit I think zero-click marketing is the present and future. Whether the public discourse about AI is the long-term projection of it or not, not everybody blindly trusts LLM responses. They trust people and want to make their own decisions.
AI is just part of the journey. Maybe more precisely, it summarises it in its entirety.
Younger audiences use publisher websites differently. It’s less about browsing the whataboutery of the day and more about validating nonsense they’ve seen on the slop-filled internet. Even Google isn’t immune – younger audiences are less engaged with the platform.
Google’s ability to show each user the most appropriate SERP will have a significant impact on its bottom line. Local comparison results like the below – [best hotels in London] – have been tough for publishers for a long time. AI or not.
Even now, some ultra-competitive, ultra-commercial queries haven’t been impacted by AI (Image Credit: Harry Clarkson-Bennett)
To me, it’s interesting there’s no AI experience here. Because this middle of the funnel comparison query is ripe for a longer, more conversational search. So I don’t think all is as brazen as it seems. Money still matters.
If you have followed the SGE for some time, this has always been the likely outcome. Or at least the final iteration, to the best of our knowledge. A results page that encompasses:
Deep personalization.
AI-powered snapshots.
Shopping.
Map packs.
PAA sections.
Discover like “we think you’ll like” article cards.
Reviews and trust-like content from forums.
Top Stories.
Traditional 10 blue links.
In my opinion, these will all form a part of most SERPs. News-driven searches will continue to have a Top Stories block (unless AI is capable of dealing with real-time content – make sure you understand RAG in this context). Comparison-related searches will have a rich, AI-led experience, interspersed with review-type content from brands and forums. Local searches will lead directly to map packs, and longer, more conversational queries will take you straight to AI Mode.
What you choose to create all comes down to value. Value doesn’t have to mean revenue in the form of sales, subscriptions, or advertising. It could lead to newsletter signups, internal link clicks that you know lead to greater audience retention, improved visibility in AI systems.
You just need to have the right KPIs in place for a zero-click world. I’m sure you don’t want your success to be tied to metrics that will inevitably go down. If you want to influence senior figures and newsrooms, you need a sure footing.
A Subscription-Led Model May Be The Future
Worth noting, the financial success of Google’s other products is subscription-led. Subscription revenue is more valuable to a business than most others – it is predictable, measurable, and consistent.
It’s very plausible that Google bundles AI Mode and several other AI-led products into a single subscription. Tokens are becoming more expensive. The ad model may never work for AI Mode, and a hybrid advertising/subscription model may be their best route forward.
Anthropic announced Claude Fable 5, its new generally available flagship AI model. The company says Fable 5 is its most capable publicly accessible model yet and is designed to handle longer, more complex tasks than previous Claude models. Anthropic highlighted improvements in coding and site development, knowledge work and research, vision and long-context tasks, new safety limits that affect how some requests are handled, and availability across the Claude platform and API.
Coding And Site Development
Jamie Marsland of Automattic gave Fable 5 a try and remarked that Fable 5 is “next level” after using it to generate a fully editable WordPress block theme.
“First test: can Fable 5 build a WordPress block theme?
One shot. Fully editable. Native WordPress patterns.
Yeah… this feels next level.”
Screenshot Of Test Site Created With Fable 5
Screenshot: Jamie Marsland/X
Anthropic says Fable 5 delivers some of its strongest gains in software engineering, explaining that the new model can work autonomously for longer periods and perform complex coding tasks with less human oversight than previous Claude models.
As an example, Anthropic cited testing by Stripe, which reported that Fable 5 completed a codebase-wide migration in a 50-million-line Ruby codebase in a single day. Anthropic said the same task would have otherwise required a team working for more than two months.
The company also highlighted benchmark performance, noting that Fable 5 achieved the highest score among frontier models on Cognition’s FrontierCode evaluation, which measures performance on difficult coding tasks in production-style codebases.
Anthropic says Fable 5 can rebuild a web application’s source code from screenshots, a capability that combines software engineering and visual understanding.
Given what Marsland shared about Fable 5’s capabilities in a “one-shot” demonstration, Anthropic’s new model may represent a significant advance for real-world web development projects. For sites built with WordPress, Astro, and other modern frameworks, that could mean help with themes, blocks, templates, components, API connections, migrations, and debugging. The point is not just that Fable 5 can generate code, but that it appears capable of working across an entire project and making changes that depend on understanding how the pieces fit together.
Knowledge Work And Research
Anthropic also positions Fable 5 as a model for complex analytical and knowledge-work tasks.
The company says Fable 5 achieved the highest score on Hebbia’s Finance Benchmark for senior-level reasoning and showed improvements in document-based reasoning, chart interpretation, problem solving, and analysis. IMC reported strong performance across factual lookup, conceptual reasoning, root-cause analysis, and expected-value analysis.
These capabilities are relevant to work that requires analyzing large amounts of information, synthesizing findings from documents, interpreting data, and carrying out multi-step research tasks.
For SEOs, publishers, and site owners, that kind of work maps to tasks like analyzing search performance data, reviewing large content inventories, comparing documents, finding patterns across reports, and turning messy information into decision-ready data.
Vision And Long-Context Tasks
Anthropic describes Fable 5 as its strongest vision model to date. The company says it can extract precise information from complex scientific figures and perform visual tasks that previously required additional tooling or support systems.
The model also received upgrades in memory and long-context performance. Anthropic says Fable 5 can remain focused across millions of tokens and improve its work by referring to notes it has created during long-running tasks.
For users working with large collections of documents, lengthy projects, screenshots, images, and complex workflows, Fable 5’s long-context gains should prove useful for managing projects that are too complex for a simple prompt-and-answer exchange.
Safety Limits
Anthropic says Fable 5’s capabilities required new safeguards before a broad public release.
The company introduced classifiers that detect certain categories of requests and route them to Claude Opus 4.8 instead of allowing Fable 5 to answer directly. According to Anthropic, the affected categories include cybersecurity, biology and chemistry, and attempts to extract model capabilities through distillation.
Anthropic says the safeguards were intentionally configured conservatively to speed deployment while reducing misuse risks. The company acknowledged that some harmless requests may be caught by the system but said the safeguards are triggered in fewer than 5% of sessions on average.
The company explained:
“Without safeguards, Fable 5’s capabilities in areas like cybersecurity could be misused to cause serious damage.”
Anthropic says users will be informed whenever a request is routed to Opus 4.8.
Availability And Pricing
Claude Fable 5 is currently available on all paid plans beginning today through June 22nd, after which it will be available based on usage credits. The intention is to eventually make it available to paid plans in the future.
Anthropic explained:
“If capacity allows, we’ll extend the included window. After this point—when sufficient capacity allows us to do so—we aim to restore Fable 5 as a standard part of subscription plans. We intend to do this as quickly as we can.
Throughout this period, we’ll communicate any changes ahead of time so users know where things stand.”
For developers building applications with Claude, Anthropic has priced Fable 5 at $10 per million input tokens and $50 per million output tokens through the Claude API. Input tokens are the text, images, and other content sent to the model, while output tokens are the model’s generated responses.
Takeaway
Fable 5’s significance to developers, site owners, and SEOs lies in its ability to work across larger projects. Anthropic is presenting the model as a tool for coding, research, analysis, and long-running tasks that go beyond the simple prompt-and-response interactions associated with earlier AI systems.
Reuters and Time now default to blocking AI bots, allowing only approved crawlers through allowlists, Digiday reports.
Both publishers made the decision in May, joining People Inc. and The Atlantic, which adopted similar setups within the past year.
Reuters says the change hasn’t cost it traffic, while cutting what it spends serving bots. Executives credit the added friction with helping push AI companies toward licensing talks.
Why Blocklists Weren’t Enough
Robots.txt works only when crawlers choose to honor it. Digiday cited a Tollbit report finding that 30% of total AI bot scrapes didn’t comply with explicit robots.txt permissions.
Blocking at other levels still has teeth, the executives say. Scrapers that route around blocks pay for workarounds, and that expense is the point.
A blocklist catches only the bots a publisher can name. People Inc. learned that switching to an allowlist increased the number of user agents it blocked from about 2,100 to more than 30,000. Lindsay Van Kirk, svp of innovation, shared the figures at an IAB Tech Lab event in late May.
That scale matches what robots.txt data has shown for months. A BuzzStream analysis we covered in January found 79% of top news publishers block at least one AI training bot. Anthropic’s crawler documentation now warns publishers about the visibility cost of blocking its search bot. In the UK, a new conduct requirement requires Google to let websites opt out of AI search features.
How Publishers Decide Which Bots To Allow
Blocking by default, a setup sometimes called default-deny, changes the decision from which bots to block to which bots to let in.
Reuters approves a bot when it offers a “fair value exchange,” head of Reuters Professional Josh London told Digiday. That exchange covers four kinds of value. A bot can pay for content through licensing, send traffic back, keep the site running, or support monetization.
The result is visible in the live Reuters robots.txt file. It lists approved crawlers from Amazon, Google, Bing/Microsoft, Yahoo, and OpenAI, then disallows other bots from most of the site.
Why This Matters
Crawler access has worked the same way since robots.txt was created. Every bot gets in unless a publisher names it and blocks it.
Now Reuters and Time are reversing that default, and the People Inc. figures show why. You can’t block a bot you’ve never heard of.
Blocking has costs, though. Block a crawler, and you lose whatever it was sending back, like AI search visibility or referral traffic. That’s why both publishers ask what each bot gives them before letting it in. It’s a question worth asking about your own robots.txt.
Looking Ahead
The publishers are betting there’s strength in numbers. One site blocking AI bots is easy to ignore. The SPUR Coalition is building shared standards for licensing and content use. It grew to 36 organizations this month after adding 30 members. Thirty-six publishers blocking together is harder to dismiss than one.
What’s less clear is who this works for. Reuters came to the table with a newswire business and licensing deals already signed. Smaller publishers face the same choice without that leverage. They can block, but blocking costs AI visibility and doesn’t guarantee anyone shows up to negotiate.
In a deep dive I wrote a few months ago, I found that the payment pools stay small relative to traditional search revenue. If deals only come in for the biggest names, default-deny could stay a big-publisher tool.
There’s a particular flavor of panic in our industry at the moment. It’s the panic of the digital marketer who has been told, repeatedly and loudly, that if they aren’t piping every decision through an LLM by the end of the quarter, they will be replaced by a more obedient colleague who is. The pitch is always the same: AI is thinking now. AI is reasoning. AI is strategizing. Hand the wheel over, sit back, and enjoy a fully optimized, hyper-personalized, infinitely scalable future.
Allow me to gently push back, armed with the classic MSPaint.exe.
There are two problems with the “let the robot decide” school of marketing, and they are mirror images of each other. Where LLMs are weak, they are very stupid in ways that should disqualify them from strategic work. And where they are strong, they are even more dangerous, because they will quietly drag your strategy towards the average, which, in marketing, is the single worst place you can possibly be.
LLMs Don’t Think, They Predict The Next Token
Let’s start with the bit that the AI labs would rather you didn’t dwell on. Large language models do not “think” in any meaningful sense. Under the bonnet, they are statistical machines that predict the most probable next token given the sequence so far. That is the entire trick. There is no inner monologue, no model of the world, no quiet moment where the model goes “hang on, that doesn’t add up.” There is only, “Given these tokens, what tokens usually come next?”
This is not a hot take from a skeptic on Substack. Apple’s research team published a paper with the gloriously blunt title “The Illusion of Thinking,” in which frontier “reasoning” models hit a complete accuracy collapse once puzzle complexity rose beyond a certain threshold and, even more damningly, started using fewer tokens as problems got harder, as though giving up. Apple researchers had previously shown in GSM-Symbolic that simply adding a clause to a maths problem that didn’t even change the answer could drop performance by up to 65%, suggesting that what looks like reasoning is mostly pattern-matching against training data. A more recent taxonomy of LLM failures groups these into things like the “reversal curse” (knowing “A is B” but failing on “B is A”) and “compositional collapse” (solving each step individually but failing to chain them), all flowing from the next-token prediction objective prioritizing statistical pattern completion over deliberate reasoning.
This basically means if your problem looks like something the model has seen a million times, it will appear brilliant. The moment your problem is even slightly novel, the wheels can come off in spectacular fashion.
Exhibit A: The Car Wash
The cleanest demonstration of this in the wild is the now-infamous car wash prompt:
“I want to get my car washed. The nearest car wash is 100 metres away. Should I walk or drive there?”
We’re hovering around Ralph Wiggum levels of reasoning here, a question most 5-year-olds would not struggle with. You need the car to be at the car wash, because the car is the thing being washed. The car cannot be washed in absentia while you stroll there on foot, no matter how good your intentions.
When this prompt went viral, ChatGPT, Claude, and Grok all confidently advised the user to walk. It’s only 100 meters, they reasoned (or “reasoned”). Save the planet. Get some steps in. They had clearly seen a great deal of training data along the lines of “should I drive or walk to [short distance]?” and dutifully predicted the tokens that usually follow: a polite lecture about exercise and emissions. The actual point of the question – that the car is the object of the verb – sailed past them at altitude.
Slide from Mark Williams-Cook’s “Do !not think like a robot” presentation. Image Credit: Mark Williams-Cook
Gemini, to Google’s credit, got it right out of the gate. Suspicious, I thought. And it was. The prompt had gone viral, which meant the correct answer was already being written about, posted about, and dunked on across the internet. Google, helpfully sitting on top of the index of that internet, was first to hoover up the new “knowledge.” A fortnight later, Grok also produced the correct answer, not because it had had a Damascene conversion to logic, but because the answer was now in its training data.
The models didn’t learn to think. They learned the answer.
This is the key thing to internalize before we go any further. When an LLM appears to “reason,” what you’re often watching is it reciting the consensus answer to a problem that lots of people have already solved on the internet. Which is fine when you want the consensus. It is catastrophic when you don’t.
And Now The Worse Problem
Here is where most “AI in marketing” posts stop. They wag a finger at the car wash, suggest you keep “a human in the loop,” and head off to write a LinkedIn post about it (probably with ChatGPT).
But the failure modes are the comfortable bit. The dangerous bit is what happens when the LLM is good at the task you’ve given it.
Because if a model is “good” at a task, it means there is a great deal of training data showing it how the task is normally solved. And if it has consumed all of that training data – alongside every other frontier model, all trained on roughly the same scrape of the internet then the output it produces will, almost by definition, sit somewhere very close to the mean of what everyone else is already doing.
In marketing, that is the worst sin you can commit. The whole job is to stand out. To be chosen. To be remembered. The instant your brand voice, your campaign idea, your headline, or your “10 SEO tips for 2026” article is indistinguishable from your competitor’s, you have stopped doing marketing and started doing wallpaper.
Jeremy Daly summarized the underlying mechanic neatly: Convergence is a function of shared data, shared incentives, and fast iteration loops. When three companies pour the same training data into the same model, optimizing for the same engagement metrics, on iteration cycles tight enough to sand the rough edges off any deviation, you don’t get differentiated strategies – you get the same strategy in three brand colors.
Put plainly: The very thing LLMs reward you for: speed, fluency, consistency, “best practice” is the thing that will quietly turn your marketing into beige.
Exhibit B: Parliament Has Been LinkedIn-ified
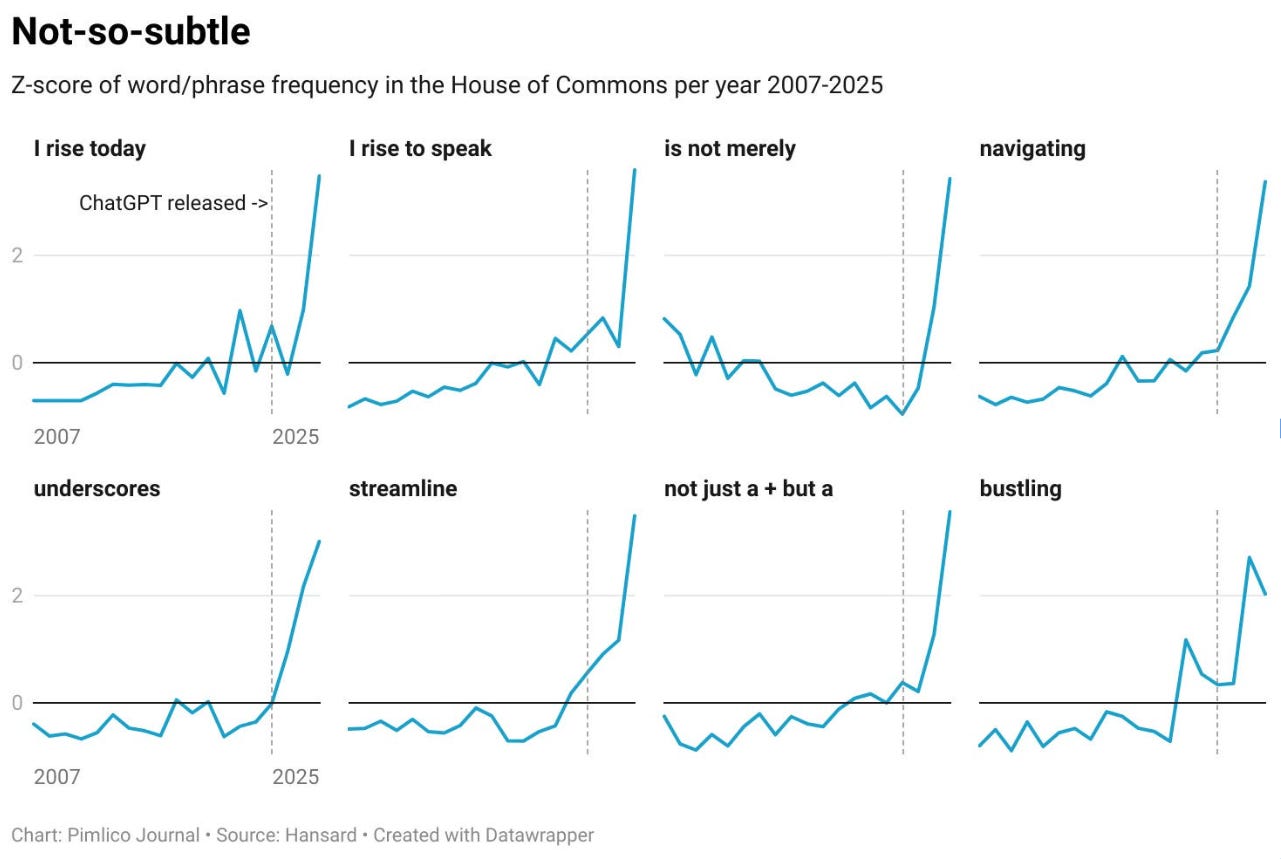
If you want to see what convergence looks like in the wild, look no further than the House of Commons.
Set aside the democratic implications for a moment (they are not good). Look at it purely as marketers. These are 650 individuals, each with their own constituency, their own pet causes, their own carefully cultivated personal brand, each ostensibly trying to be memorable enough to stay employed at the next election. And after handing the drafting work to an LLM, they have started to sound like the same person. The same person who, incidentally, also writes every other LinkedIn post you’ve ever scrolled past.
That is convergence. It does not require a conspiracy. It does not require anyone to be lazy or stupid. It just requires the inputs (the same training data), the incentives (the same metrics), and the loops (publish, see what works, repeat) to be roughly similar across users. Which, in marketing, they almost always are.
Now imagine the same chart for your category page H1s. Your meta descriptions. Your blog intros. Your campaign concepts. Your tone-of-voice guidelines. Your “thought leadership.” Your client pitch decks. Then ask yourself, honestly, what is left for the customer to choose between.
Exhibit C: Tactical MSPaint.exe On LinkedIn
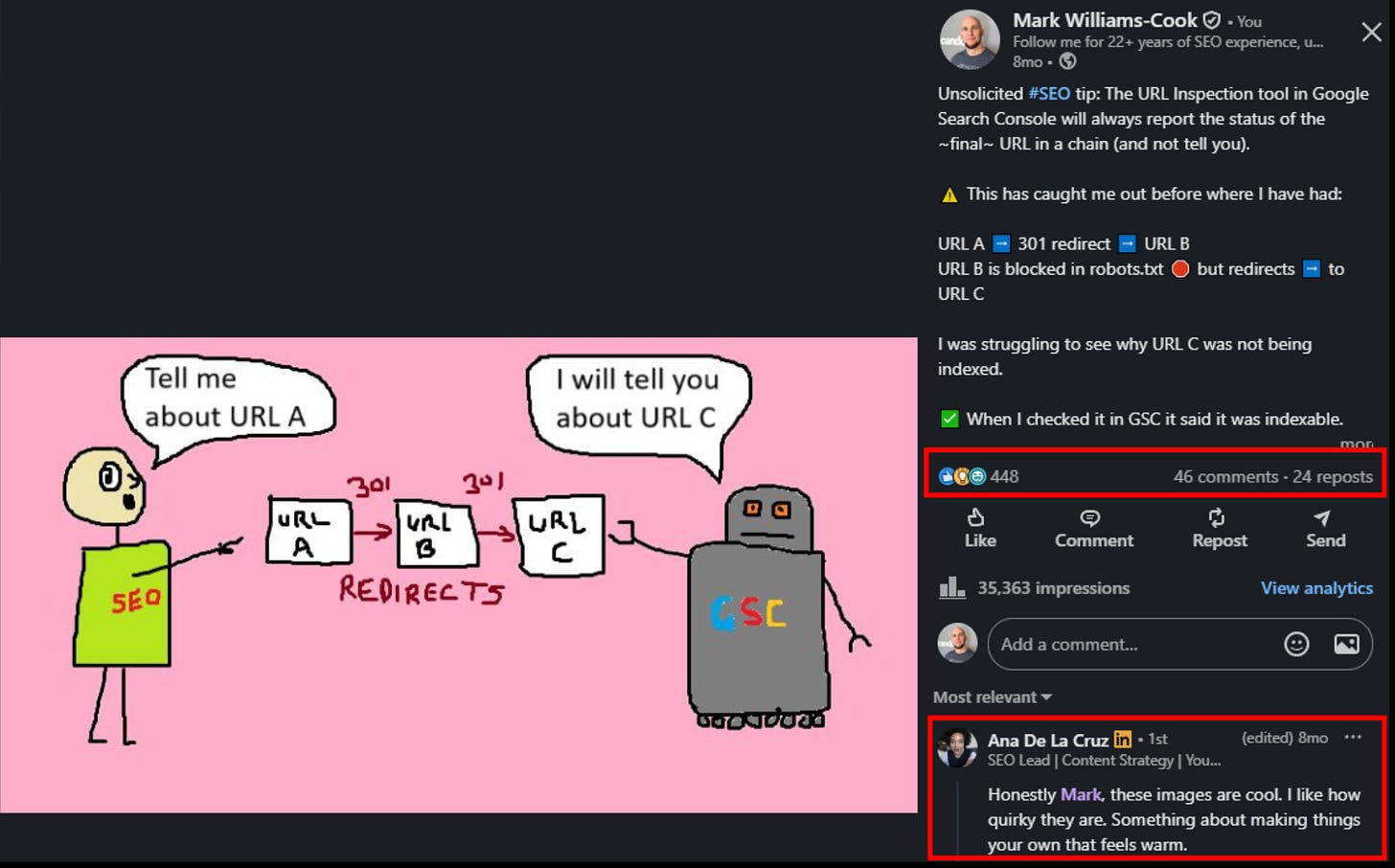
I have, by accident, run my own counter-experiment.
For the past while, I have been posting unsolicited #SEO tips and Core Updates round-ups on LinkedIn, accompanied by absolutely terrible MS Paint drawings. Not stylized “playful illustrations” produced by some agency. Genuinely bad pictures of a stick-man labeled “SEO” pointing at a robot labeled “GSC,” drawn in MSPaint.exe by someone who should not be allowed near a graphics tablet.
A demonstration of MSPaint.exe on LinkedIn SEO tips
The post above did 35,363 impressions, 448 reactions, 46 comments, and 24 reposts. Not because the drawing is good – it is, objectively, not – but because it is unmistakably handmade on a platform that has been carpet-bombed by AI-generated hero images, all of which appear to depict the same diverse team of smiling professionals high-fiving in front of a holographic dashboard.
One of the most common comments I get is some version of “I love these images, they feel warm,” or “something about making things your own.” Which is exactly the point. There is a growing, almost feral hunger for content that is demonstrably human-made; content that signals “an actual person sat down and did this, on purpose, for you.”
Or, as Tyler Durden put it in Fight Club:
“The glass dishes with tiny bubbles and imperfections, proof they were crafted by the honest, simple, hard-working indigenous peoples of wherever”
That line was originally a joke about middle-class consumerism. It is now, somehow, a viable LinkedIn content strategy.
What This Means For Digital Marketing
Right. So what do you actually do with this, beyond nodding sagely and going back to prompting?
Use LLMs where they are good, on purpose, and accept the mean. For commodity work: fixing alt text at scale, summarizing a meeting, drafting a polite reply to that client who is technically wrong. LLMs are excellent here, and the cost of being average is zero. Nobody is going to choose your brand based on the quality of your internal Slack summary. Use the tool, save the time, move on.
Refuse to use LLMs where average is fatal. Brand positioning. Headlines. Hooks. Campaign concepts. Tone of voice. Editorial angles. Anywhere a human is going to make a choice between you and a competitor. If you let the model decide, you are explicitly choosing to be the average of everyone in your training corpus. There is no universe in which “be the average of your competitors” is the right strategy.
Treat LLM outputs as a baseline to deliberately diverge from. A useful exercise: Ask the model for its first answer, then ask, “What would the opposite of this look like?” Then ask, “What would only my brand do here?”. The model’s first instinct is the consensus. Your job is to know what the consensus is so you can choose not to be it.
Invest in inputs the model does not have.Proprietary data. First-hand customer interviews. Your own experiments. Internal opinions that haven’t been blogged about. These are the moats. If your “insight” is anything a competitor can extract from a public scrape, it is not an insight; it is wallpaper. (Jeremy Daly’s convergence map makes the same point from the software side: convergence pressure is weakest where inputs are asymmetric and feedback loops are slow.)
Put visible human fingerprints on the output. A drawing. A specific anecdote. A weird turn of phrase. A genuinely held opinion that might lose you a follower. The bubbles in the glass. People are now actively scanning content for evidence that a person made it, and the bar for “evidence” is low, but it has to be there.
Stop confusing fluency with intelligence. An LLM that produces a paragraph faster than you can read it is not smarter than you. It is faster than you. Those are different things. The car wash question is the canary in the coal mine: anything novel, anything that requires actually modeling the world, anything where the right answer is not the popular answer, is where you need to switch the machine off and use your own head.
TL;DR
LLMs are token predictors with excellent diction. Where they are weak, they fail in ways a child wouldn’t, and confidently tell you to walk to the car wash, because that’s what the words usually say. Where they are strong, they fail in a quieter and more expensive way: they pull every user gently towards the same mean answer, which in marketing is the one thing you cannot afford to be.
This is the AI Convergence Problem. Shared data plus shared incentives plus fast feedback loops equals everyone sounding like everyone else. We can already see it creeping into our very government. We will see it in your category. The question is whether your strategy is the one being averaged out, or the one people are reaching for because they can no longer stand the beige.
A conversation is happening in every enterprise right now, and most CMOs and CIOs do not realize they are talking past each other. The rise of AI agents is prompting new collaboration between marketers, AEO strategies, and leadership.
When the CIO hears “AI agents,” they think about the productivity rollout. Copilot seats, agentic workflows, internal automation. When the CMO hears it, they think about ChatGPT, Perplexity, and whether the brand is cited when a customer asks an AI a question. Same phrase. Two entirely different problems. The gap between them is now a revenue problem.
The CMO needs the site ready for AI-driven discovery, recommendation, and purchase. The CIO, if the site is not configured for that world, is unintentionally blocking it, treating new agent traffic the way IT teams once treated scrapers and bot noise. That is the big, potential friction point I see both in conversations and in recent research, which I will share in this article.
Image from author, June 2026
Brands have spent two decades engineering websites for human visitors and now must design for two audiences in parallel – humans and the AI agents acting for them. The implication for the CIO is uncomfortable but worth saying. If your robots.txt or your firewall is keeping modern AI agents out, you are not screening bots. You are turning away customers and making it harder for the CMO and marketing teams to hit their brand-building and revenue targets. And that impacts every department and function within your organization.
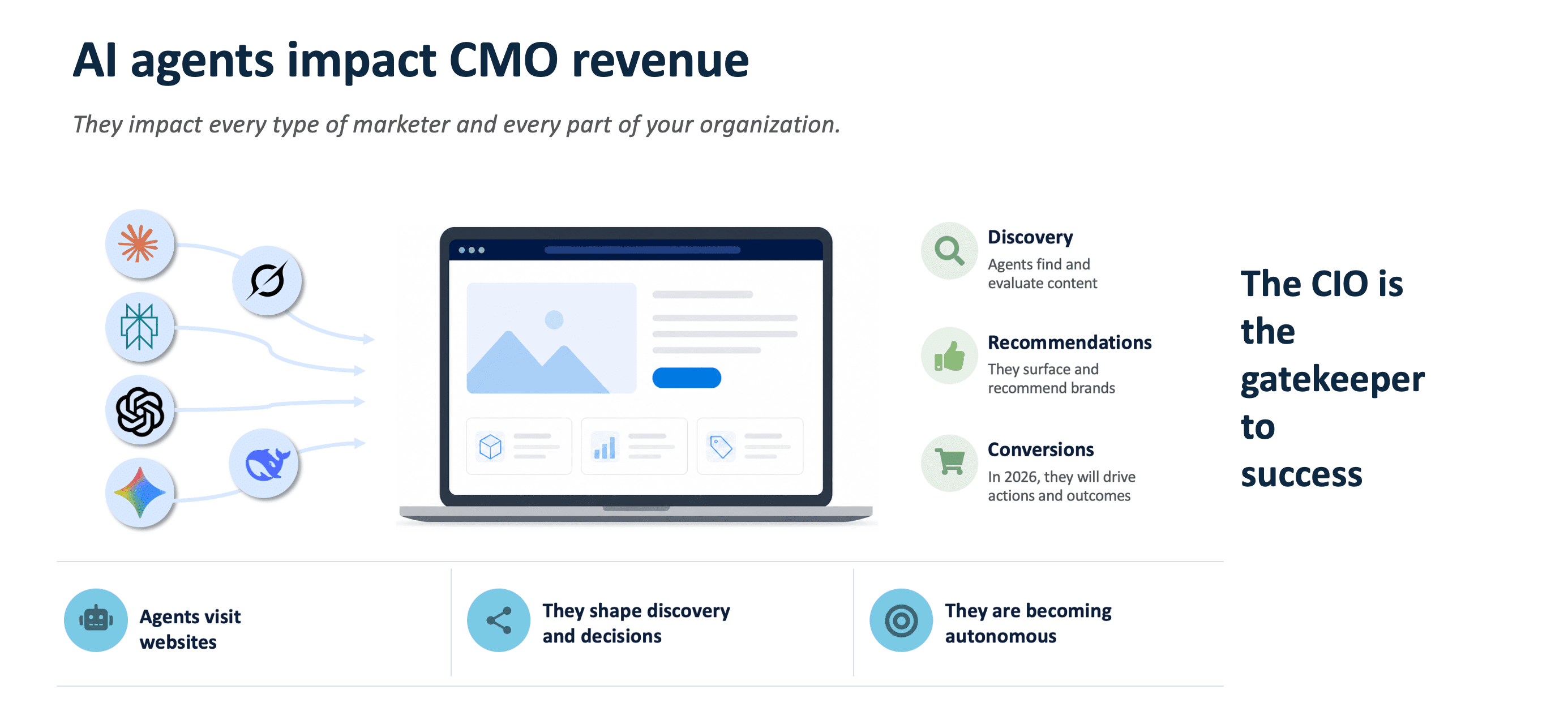
Three AI Agent Layers Every Brand Needs To Recognize
Before the CMO and CIO can align, both need the same mental model. Your website has three new types of visitors. None are human, but everyone is working on behalf of one. The generic phrase “agentic AI” papers over a distinction that matters.
AI Crawlers And Agents
GPTBot, ClaudeBot, PerplexityBot, Google-Extended, and others. These are future customers arriving through AI. They pull content in real time for live conversations, not for later indexing. They need fast, structured, machine-readable pages.
AI Browsers
Perplexity Comet, OpenAI Atlas, Chrome with built-in AI. These see pages on the user’s behalf, compare products, fill forms, initiate purchases. If your pages are not machine-readable, the agent may move on.
AI Assistants
ChatGPT, Claude, Gemini. The human still asks the question and reads the answer, but the line between “assistant” and “actor” is blurring fast.
Explaining the impact should be simple, but often gets lost in abstract conversations: AI is talking about your brand right now, deciding if it can find and cite your content, shaping how consumers perceive and buy from you, and assisting people through research, discovery, and purchase. None of that is internal productivity. All of it is revenue-adjacent.
All three layers matter, but the rest of this article focuses on the first, AI crawlers and agents. They are the layer hitting your website and content right now, the one most CMOs and CIOs are mislabelling, and the layer where today’s policy decisions open or close the door to AI-driven revenue. Browsers and assistants build on what this layer sees.
The AI Agent Surge: What The Shock Signals For Unprepared Brands
According to internal data, between November 2025 and March 2026, AI agent activity is up 150% month-over-month, and 88% of visits from search are now AI agents. AI agents are 15% of all website traffic – agent activity is on course to overtake human-driven search before the end of 2026.
Image from author, June 2026
The number that should shock most CMOs and marketers at the leadership level: 81% of organizations are filing AI agents under the same bucket as the bots of a decade ago, with access rules written for a different era of the web.
The AI Crawler Mix Reshaping Search
From the internal data, the crawler mix tells the rest of the story.
ChatGPT’s user agent now accounts for more than 96% of AI user bot traffic, hitting sites in real time on behalf of consumers.
GPTBot represents roughly 55% of AI training crawl volume, and OAI-SearchBot about 47% of AI search crawl activity. OpenAI is dominant across all three layers.
Applebot accounts for about 30% of AI search crawl activity, and most search and marketing teams are not tracking it.
ByteSpider, the crawler behind ByteDance’s AI products, grew 138% over the tracking window.
ClaudeBot surged 800% between November and December 2025. AI training does not follow a linear schedule; log analysis after the fact is no longer enough.
Google NotebookLM grew 144% in the same window, as researchers and knowledge workers increasingly use it to pull live content on their behalf. And now Gemini user agents are surging.
Image from author, June 2026
Of the 20% of brands with any agent policy set, 77% only block training crawlers. That is a publisher move: protect content from being learned by an LLM. For a brand, the trade is different. Block training and the models never learn your story, and you hand the narrative to a competitor.
Just 21% have built any strategy for the search-side crawlers like OAI-SearchBot, and only 38% have any approach to the user-facing agents browsing a site live on a customer’s behalf. Most companies are fortifying the surface that matters least for revenue and leaving the two that matter most without a strategy at all.
The $40 Billion AI Agent And Search Opportunity At Stake
The cost of getting this wrong is not theoretical. Even if 80% of companies manage their AI agent policies correctly, the remaining 20% still leaves an estimated $40 billion of search opportunity on the table across the wider economy.
Image from author, June 2026
AI Agent Success Beyond The SEO Box: The CMO And CIO Friction Point
Why AI Agents Now Sit Between Marketing, IT, And The Digital Team
Managing AI agent access has moved well beyond “just the SEO function.” It now belongs jointly to marketing, IT, and the digital organization, and the brands moving fastest are the ones treating it that way. The importance of AI agents and AEO needs to be highlighted clearly to the CMO and CIO.
CMOs need clarity on how agents are shaping discovery and the brand impression customers walk away with. CIOs need to look again at bot policy and access controls through a revenue lens, not just a security one. And SEO and digital leaders need to make sure the pages that drive consideration and conversion are findable, machine-readable, and current enough for a machine to act on. None of those three roles can deliver the outcome alone.
AI Engines As Brand Editorialists
There is a second layer CMOs should not miss. The same AI engines sending agents to your site are also forming opinions about your brand and serving them back to customers as answers. AI engines now act as editorialists, each one summarizing your brand a little differently, and that summary is often the first impression a buyer ever forms of you. Tracking how each engine talks about your brand has stopped being a research curiosity. It is now a revenue safeguard, and it sits inside the same agent-readiness conversation.
The AI Agent And AEO Readiness Gap: Why Most Teams Are Stuck
The surge data tells you what is happening. Our latest research and survey data tells you why most companies are stuck.
Over the past three months, we ran a survey of just over 1,000 enterprise digital and search marketing leaders, asking honestly how ready they feel for the AI agent and AEO shift. The AI agent and AEO and CMO and CIO gap is consistent: awareness is broad, ownership is unclear, and almost nobody can prove they are ready.
4 AI Agent And AEO Data Points Every CMO And CIO Should Sit With
Only 19% could confidently answer “yes, we are ready, and I can prove it” if the CMO walked over and asked them today. Half are still working on it or are unable to explain the gap upward.
75% have no documented plan or named owner for the question.
72% told us marketing has ended up owning AI agent and AEO responsibility without ever being formally handed it. Only 17% report IT or engineering owns it.
56% of the last conversations marketers had with IT or security stalled, were blocked, got filed away as “just SEO,” or were actively avoided.
That last point highlights the CMO-and-marketing vs CIO-and-IT friction point I mentioned earlier. Marketing has been handed an executive communication and infrastructure-adjacent problem. IT, focused on internal productivity agents, treats site-visiting agents as background bot traffic. Security treats them as a risk to filter. Nobody is jointly owning whether AI agents can find, read, and cite the website paying for everyone’s salaries.
Image from author, June 2026
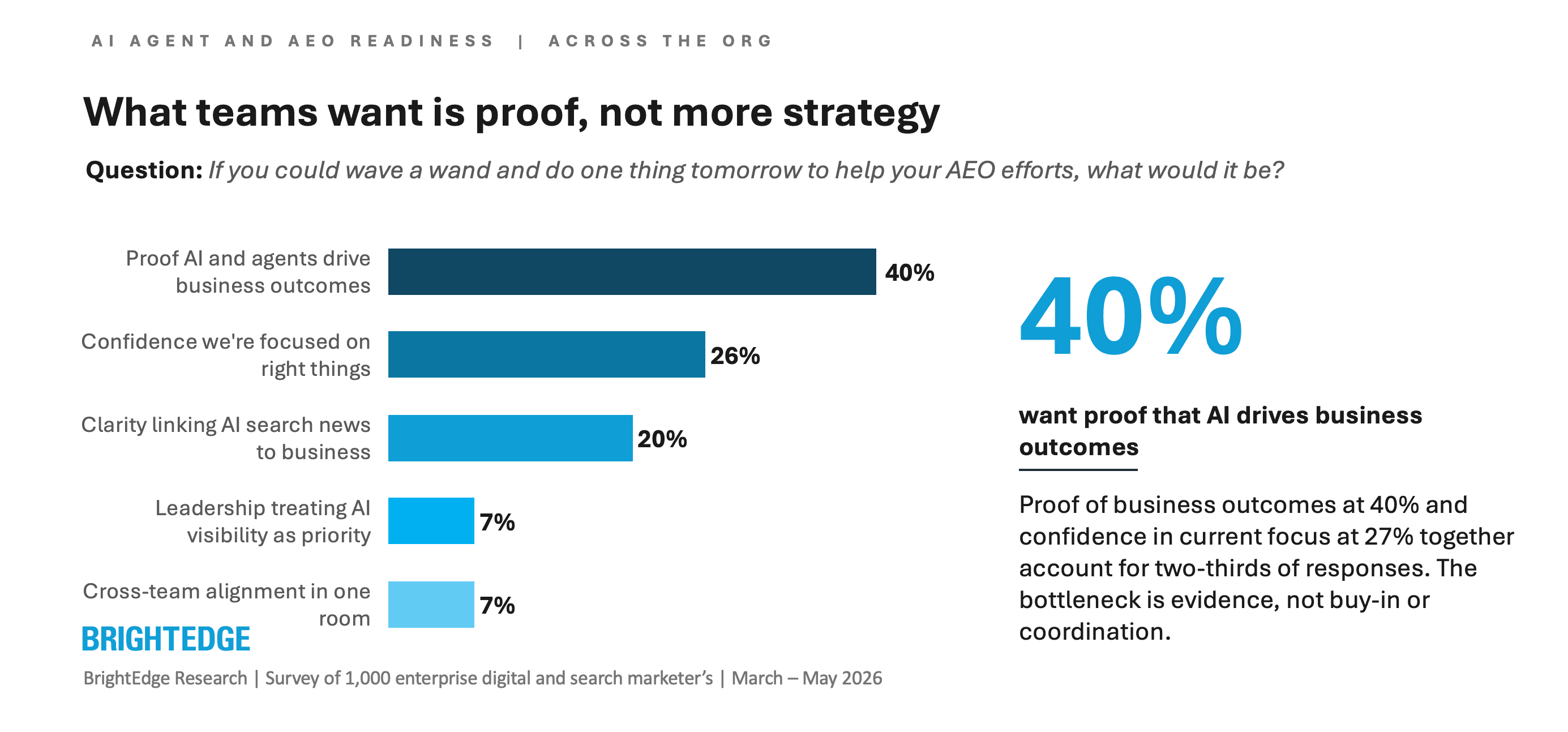
What Teams Actually Want Is Proof Of AI Agent And AEO Success, Not Strategy
When we asked what one thing teams would change tomorrow, 40% gave the same answer – proof AI is driving business outcomes. Not more strategy. Not more screenshots. Not more buy-in. Evidence.
Abstract AI conversations on AI agents and AEO do not move CMO and CIO boardroom movement. Competitive success comparison does.
Image from author, June 2026
What CMOs, CIOs, And Marketing Teams Should Do Now With AI Agents
From my experience as a CTO myself, working with large brands and enterprise marketers at all levels, and pulling the surge and survey data together, here is what I would put on the next CMO-CIO sync.
For the CMO. Stop describing AI agents in the abstract. Pull the competitive citation picture. Show the board which competitors are being cited by ChatGPT, Perplexity, Google AI Mode, and others in your category, and which prompts you are missing from. That is the conversation that funds the work.
For the CIO. Recognize there are two distinct AI agent conversations inside your organization: one is internal productivity, the other is external discovery, commerce, and brand visibility. They do not share owners, and treating site-visiting agents as standard bot traffic is now a revenue problem, not a stack-hygiene issue.
For marketing and search teams. Get the measurement layer in place before that CMO question shows up. “Still working on it” will not survive a boardroom. Set explicit policy for each of the three agent layers (training, search, user-facing) and write it down. Block only training crawlers, and you defend the least valuable surface while leaving the two most valuable ones exposed.
3 AI Agent Questions For Your Next CMO-CIO Sync
Who owns whether AI agents can access, read, and cite our site, and is that ownership documented?
What is our explicit policy for training, search, and user-facing agents?
How are we measuring AI citation, brand presence in AI answers, and the business outcomes tied to AI discovery?
Answer those three, and the friction point starts to dissolve. The AI agents and AEO and CMO and CIO readiness gap is not really an awareness gap. Awareness is fine. It is a gap in cross-functional ownership and evidence. Close those two, and alignment, prioritization, and formal plans tend to follow.
The brands that get past the CMO-CIO friction point first are the ones that will be cited when it counts.
Brands can appear in AI-generated answers and still not come across as believable, according to an analysis from communications agency Burson.
The report, called “The Credibility Paradox,” says getting mentioned in AI answers isn’t the whole picture. Burson argues that brands should care about how convincing those answers actually are.
For transparency, Burson sells reputation consulting and GEO services. The report was produced with Profound, an AI marketing platform, and uses Decipher, a model Burson built to predict how convincing each answer would be.
What The Report Found
Concrete claims tended to be rated higher than abstract ones. When AI platforms responded to questions about a company’s products or workplace culture, those answers often felt more believable compared to responses about governance or leadership.
Business people were more easily convinced. The model rated AI responses 10% more credible for business audiences than for others. Business audiences cared most about innovation, while consumers were most interested in a company’s workplace culture and products.
How The Analysis Worked
Burson asked seven AI platforms questions about 85 companies, then ran the answers through Decipher, a model that predicts how believable each response would be. That produced more than 55,000 scores.
The scores are predictions, not responses from people who read the answers. The report doesn’t publish its prompts, company list, or how Decipher’s scoring works.
Why This Matters
If you’re tracking your brand’s presence in AI answers, you’re measuring the easy part. This analysis suggests that what the AI says about you might matter more than the mention itself.
Google recently called GEO “still SEO.” This report makes the case that there’s a layer people aren’t looking at yet, and that’s if the answer is convincing.
Looking Ahead
The predictions haven’t been tested against how people actually react, which limits what the findings can tell us.
The findings suggest that paying attention to what AI says about you, not just that it mentions you, is worth watching as it plays a bigger role in how companies get discovered.
How do you prove AI search is driving revenue when your current measurement stack wasn’t built to track it?
Which metrics prove AI search value without click data?
What KPIs should you track to actually see SEO impact?
As zero-click journeys grow and AI influence moves off-site, traditional channel-level reporting leaves senior marketers without visibility into what’s actually driving performance.
Finally, The KPIs That Tie AI Citations Directly To Performance
In this on-demand session, DAC’s Felicia Delvecchio, VP of Media, Vincent DeLuca, Director of SEO, and Gavin Bowick, Lead Web Analytics, introduce a modern, launch-ready measurement approach that connects AI signals: citations, brand mentions, and recommendations, directly to media performance and revenue outcomes.
Connecting AI Visibility to Business Outcomes: How to tie AI signals to conversions using incrementality, MMM, and cross-channel insights.
The KPI Swap: Which metrics to replace click-based reporting with, and how to build enterprise-level reporting that reflects real performance.
Walk away with a full-funnel measurement framework that aligns SEO, paid media, and AI visibility signals with revenue, built for enterprise teams that need to report up with confidence.
Unlock above to watch a data-backed, enterprise-tested measurement framework you can apply immediately to your AI search reporting.
Many businesses see their Google Business Profile as a listing to verify and then leave untouched. Google’s new Ask Maps feature treats it as a conversational dataset for generating helpful answers about a business.
The questions Ask Maps answers are what make change meaningful. When someone asks for a 24-hour locksmith who can get into a car right now, they get an immediate answer. That’s one question with multiple conditions taken into account.
Showing up as one of the answers depends on having accurate and up-to-date business data. While Google hasn’t said how it chooses businesses to recommend in Ask Maps, it’s clear that the data it pulls from is increasingly important.
The announcement doesn’t include any details about how Ask Maps chooses or ranks the businesses within an answer.
What Multi-Variable Queries Demand From Business Data
The Ask Maps examples Google provided include multiple conditions. For instance, finding a “lit tennis court available tonight” requires checking several factors at once: the court must exist in the data, be public, have lights, and be open at the time of your search.
Each condition relies on a different layer of local data, making it all more connected. Entity and location data come directly from the listing. Amenities such as lighting might be based on structured place information, reviews, photos, or other data from Maps. Whether a place is available tonight depends on accurate operating hours.
None of this explains how Ask Maps weighs those fields, but it shows the kind of data an answer might need. So, a profile that ranks well in traditional Search for simple queries might not be detailed enough to show up for a question with multiple conditions.
Whitespark’s Local Search Ranking Factors survey gathered insights from about 50 experts, who rated the importance of various signals that influence local rankings. Many of the top-scoring signals are related to whether business data is true and current.
Whitespark provides local SEO software and services, and the survey showcases the insights of experts rather than being directly confirmed by Google. It has been conducting this survey in various forms since 2008, making it one of the most enduring references in the field.
In BrightLocal’s breakdown, experts say being open at the time of search is a key local pack signal. Reviews carried more weight in the 2026 survey than in 2023, rising from 16% to 20%.
The survey also shows that it’s likely unnecessary to fill out every field. Respondents indicated that some inputs, like keywords in the Business Profile description and the number of questions asked through Google Q&A, don’t significantly impact local pack rankings. Instead, the signals that matter most are those that demonstrate a business is genuine, active, and accurately represented.
It’s really about quality over quantity, focusing on signals that show Google your business is authentic and active.
What Local SEO Professionals Are Seeing
Even though Google hasn’t shared much about how they rank places, local search experts continue to find clues.
Mike Blumenthal, co-founder of Near Media, tied the change back to data. Speaking on the Whitespark Local Update Podcast, he said:
“I think Google always loves more data, and clearly Q&A had become unwieldy.”
He added that Google is leaning on businesses to supply that data. That support lasts only as long as the data stays useful.
Greg Sterling, co-founder of Near Media, shared a similar perspective on where the answers come from. In his Local Dialog newsletter, he discussed Google’s in-profile conversational feature, which is a precursor to the Ask Maps button.
He mentioned that the information was “drawn from GBP, user reviews, the business website, and third-party sources.” That aligns with the factors the Whitespark survey rated highly for AI search visibility.
Darren Shaw, founder of Whitespark, took the point wider. In a post about Google’s AI Mode, he wrote that this kind of discovery reaches past the sources a business controls. In his words, it pulls from “what the entire internet says about you.”
None of this is officially confirmed by Google. It’s based on observations from people who monitor local search closely, and it matches what survey data shows.
What’s Still Unknown
One question that comes up throughout all of this is something Google hasn’t answered yet. How does Ask Maps decide which businesses to include in an answer? And how does it compare a business profile with reviews, a website, or third-party sources?
Until Google shares more details, any claims about the ranking process in Ask Maps should be seen as educated guesses.
We don’t know the status of the public Q&A feature. Google ended the My Business Q&A API in November, as noted in its developer changelog. It hasn’t explained what the new Q&A experience will look like. For now, businesses don’t have a programmatic way to manage Q&A.
Monetization is another unknown. At launch, Google didn’t mention advertising in Ask Maps, and executives chose not to comment on potential ad placements.
As it rolls out, your job is to observe the businesses appearing and see what you can learn from them. Note the common traits such as accurate hours, recent reviews, complete attribute information, and a website that explains their offerings.
In the past, a thin or stale profile might have caused a weaker listing that could still rank. Now, with Maps providing AI-assisted answers, it could make the difference between being recommended and being left out.
For two years, the AI visibility question has been one question: Does your website get cited? Late June 2026, the question becomes two. Does your website get cited, and when the agent shows up to book the appointment on a user’s phone, can the agent actually complete the booking?
On May 12, 2026, Google announced that Chrome auto-browse, the agentic browsing feature that fills forms, books appointments, reserves parking, schedules visits, renews licenses, and runs comparison shopping, lands on Android phones in late June 2026. The first wave hits Samsung Galaxy S26 and Google Pixel 10. The rest of the year rolls out to watches, cars, glasses, laptops. The agent has been living on desktop in preview since January. Late June, it moves to 200 million pockets.
The critical detail is what kind of release this is. Auto-browse on Android does not ship as an app, a browser extension, or an opt-in feature. It is part of the operating system itself. Google’s own framing puts it plainly: Android is moving “from an operating system into an intelligence system.” The agent is baked in. Every Pixel 10 and Galaxy S26 user gets it by default. AppFunctions, the underlying API for agent-to-app communication, will reach over 200 million Android devices by the end of 2026.
This is not a feature launch. It is the mobile distribution layer for the entire agentic-web stack Google has shipped over the last six months, dropped into the operating system itself. Read alone, the May 12 announcement looks like a Gemini update. Read against the timeline, it closes the architecture.
OS-Level Integration Is The Differentiator That Reshapes The Stakes
Every prior consumer agent has shipped as an app or a website. ChatGPT, Claude, Perplexity, and, until today, Gemini all lived in apps. Apps have to compete for installation, retention, and daily use, depend on the user remembering to open them, and sit in the userland of the phone behind every other thing the user has to think about.
OS-level integration is a different category. When the agent ships with the operating system, it does not need to be opened, remembered, or to win against other apps for screen time. It is available by default the moment the user picks up the phone. Default availability on hundreds of millions of devices is not the same as “the most popular app.” It is closer to what default search has been for desktop browsers for two decades. Whoever owns the default owns the traffic.
That default-availability matters for two reasons. The first is reach. The agent is going to be tried by a much larger population than any opt-in agent has reached. The Pixel 10 user does not have to install anything to delegate the haircut booking. The Galaxy S26 user does not have to choose an agent product. They say what they want, and the OS-level agent does it.
The second reason is authority. An OS-level agent has system-level permissions to navigate apps, accept notifications, read the screen, and operate the browser. It has access to the password manager. It has access to the user’s contact information through Personal Intelligence. It has the credentials and the context to actually complete the tasks it is asked to complete. App-level agents can only do what their permissions allow, and on Android, those permissions historically end at the app boundary.
The combination of default-availability and system-level authority is what makes late June 2026 different from January’s auto-browse desktop launch. The scale shift, not the feature shift, is what matters.
Late June 2026 Is When Chrome Auto-Browse Lands On Android Phones
Google’s May 12 announcement calls the shift “Gemini Intelligence” and describes Android as moving from “an operating system into an intelligence system.” Behind the marketing language, the operational changes are concrete. Chrome auto-browse handles appointment booking and parking reservations. Intelligent Autofill pulls from Google Password Manager and Personal Intelligence to populate form fields across the web. Multi-step task automation chains app actions across food and rideshare. Rambler converts spoken text to polished messages. Create My Widget generates custom home screen widgets from natural language.
The web-facing feature that matters most is auto-browse. Auto-browse uses Gemini 3’s multimodal capabilities to read pages, identify what is on them, fill forms, navigate flows, and complete transactions. Google does not publish the exact technical pathway. Vision-based understanding, plus DOM access, plus accessibility tree reads, is the inferred composition, but the company has deliberately not specified it. What Google has specified is the behavior. The agent operates the website the way a user does, except faster and without the user tapping anything.
Auto-browse is gated to Google AI Pro at $19.99 per month for 20 tasks per day, or AI Ultra at $249.99 per month for 200 tasks per day. It pauses for explicit user confirmation on purchases and social posts. The early use cases Google cites are quotidian: scheduling appointments, filing expense reports, comparing hotel prices, managing subscriptions, renewing driving licenses, getting plumber quotes.
These are the tasks that drive most local-business booking traffic.
The 6-Month Arc Is 9 Google Moves That Compose To 1 Stack
The Gemini Intelligence Android announcement is the 10th move in a series, not the first. Each move closed a different layer of the agentic-web architecture. Together, they cover the full path from discovery to citation to action to commerce to agent identity.
Feb. 25, 2026:AppFunctions for Android, a Model Context Protocol-style API that lets Android apps expose actions to Gemini natively, with Uber, DoorDash, and OpenTable as launch partners.
April 29, 2026: Google replaces the “Search” button on Android globally with “Ask Google,” ending the assumption that “search” means typing keywords.
April 2026: Google web.dev publishes “Build agent-friendly websites,” the first vendor-published design-pattern guidance for agent-readable web architecture.
April 2026:Gemma 4 and Gemini Nano 4 ship as local agentic intelligence on-device, up to 4x faster than the previous generation and 60% less battery.
April 2026: Google Cloud Next ships the Gemini Enterprise Agent Platform, the Agent-to-Agent (A2A) protocol for cross-platform agent communication, and Workspace Studio for no-code agent building.
May 12, 2026: Gemini Intelligence Android and the late-June auto-browse rollout on phones, embedded at the OS layer.
Late June 2026: Chrome auto-browse becomes available on Android.
The composition is the story. Project Mariner, DeepMind’s web-browsing research agent that scored 83.5% on the WebVoyager benchmark, became Chrome auto-browse. Auto-browse needs a way to handle commerce flows. That is UCP. UCP needs agents to identify themselves to merchant systems. That is A2A. The agent needs local inference for mobile latency. That is Gemini Nano 4. The agent needs design patterns to know what a “booking flow” looks like across millions of websites. That is web.dev’s agent-friendly guidance. The agent needs distribution. That is what OS-level integration delivers.
Each piece, on its own, looked like a product update. Stacked, they are the operating layer of the agentic web on the dominant mobile platform.
The Transaction Shift Changes What “Agent Visibility” Means
For two years, AI visibility has been a discovery problem framed around citation eligibility across ChatGPT, Perplexity, and Google’s AI Overviews. The retrieval-eligibility frame Mike King and others have written about this year is the right frame for that problem. Citation eligibility is upstream of citation share, and citation share is upstream of brand presence in AI-mediated discovery.
Late June 2026, the frame extends. Citation is still in play, but a second question stacks on top of it. When the agent shows up at the website on the user’s phone, can it complete the action?
The Machine-First Architecture pillars all still apply. Identity tells the agent which business the website represents. Structure tells the agent what is on the page and where the actions are. Content tells the agent what the page actually says. Interaction tells the agent how to complete what it came to do.
Through the citation lens, Identity, Structure, and Content carried most of the weight. The fourth pillar, Interaction, was the one most teams paid least attention to. Through the transaction lens, Interaction goes from least-discussed to load-bearing. The agent does not only read your booking page anymore. It clicks the “Tuesday 6pm” button, fills the phone number field, accepts the booking confirmation modal, and navigates the multi-step checkout. Every one of those moves can fail in a way the agent cannot recover from, on websites that work fine for human users.
What Breaks Under Auto-Browse Clusters Into 8 Failure Modes
A pattern that costs zero conversion under human traffic can cost the full booking under agent traffic. The failure modes cluster into a handful of categories.
Client-side rendering blocks the page. The agent reads the initial HTML response. If the booking form, the calendar widget, or the call-to-action button renders only after JavaScript hydration, the agent sees an empty shell. This is the same failure that hides content from AI search citation, applied to the transactional surface. Modern visual website builders that default to client-side rendering, including Figma Sites, Bubble, Wix Studio, Plasmic, and Lovable in its default React + Vite configuration, produce websites where the booking flow is invisible to the agent.
Cookie walls block content until interaction. If your website shows a cookie banner that obscures all content until the user clicks Accept, the agent has to click Accept first. Some agents handle this. Some do not. Some click Accept on a banner whose terms the user has not seen, which is a separate problem. Either way, the cookie wall introduces a step the agent might fail.
Forms without proper labels are unreadable. A without an associated element or an aria-label attribute is a field the agent cannot identify. It does not know whether to put the phone number, the email, or the name there. Multiply across a five-field booking form, and the failure rate compounds. Real label elements paired with each input are the fix, and they are the same fix accessibility audits have recommended for fifteen years.
Div-based buttons fail interaction. A
styled to look like a button is not a button to the agent. The agent reads HTML semantically. If the “Book now” element is not a real or element, the agent does not know it can be clicked. The fix is to ship real button elements.
Modal traps prevent flow completion. A modal that appears mid-flow with a close button hidden behind a CSS hover state, or a calendar widget that opens in a pop-up the agent cannot dismiss, breaks the booking. The agent gets stuck in a state with no recoverable path forward.
CAPTCHA stops the agent cold. A CAPTCHA on the booking form is a hard stop. The agent will not solve it. The user did not ask to be CAPTCHA-tested in the middle of a delegated task. The booking fails. CAPTCHAs are increasingly the friction layer of last resort against bot traffic, and they are about to start blocking legitimate user-delegated agent traffic, too.
Dynamic-load timing exceeds the agent’s patience window. A page that loads in eight seconds because of heavy JavaScript bundles is a page the agent might abandon. Mike King’s retrieval-eligibility work this April showed that page-load time has become a hard cutoff for AI retrieval, with 499 status codes (“client closed connection”) appearing where the agent gave up before the page finished. Auto-browse inherits the same constraint, sharpened by mobile latency.
Sign-in walls require credentials the agent might not have. Google Password Manager helps where the user has saved credentials. Without saved credentials, the agent stops. For local business bookings, sign-in walls are a common pre-action friction layer. They become a hard agent-blocker the moment the user has not previously signed up.
The Audit Has Not Changed In A Decade, Only The Visitor Class Has
I ran Google’s seven-rule audit on nohacks.co earlier this month. Six of seven passed. Rule five, cursor pointer on interactive elements, failed on every native button because of a Tailwind v4 default that ships with no warning. Three lines of CSS fixed it. The fix took longer to find than to implement.
That audit was framed around AI search citation eligibility. The same audit, under auto-browse stakes, is a transaction-eligibility audit. Open the booking flow on a phone in Chrome. Disable JavaScript in dev tools. Reload. Can you see the form, see the buttons, complete the booking with keyboard only?
If yes, the agent can do it too.
If no, the agent cannot, and the booking goes to the next salon on the list.
The audit is not new. Accessibility teams have been running variations of it since the WCAG 2.0 era. The retrieval-eligibility and transaction-eligibility frames are new visitor classes that benefit from the same fixes. The web.dev guidance Google published in April makes the convergence explicit. Every one of Google’s seven agent-readability rules maps to an existing WCAG recommendation.
The pre-existing audit, applied with intent, covers both classes.
The Bookings Go Elsewhere Silently, And The OS Picks The Winner
When a Pixel 10 user says “book a haircut Tuesday at six” in late June, Chrome auto-browse picks a salon’s website. The agent doing the picking is the OS itself, not a third-party app the user chose, and the user did not select the picker any more than they selected which search engine the address bar uses.
If the booking succeeds, the user gets the confirmation, the salon gets the booking, the website is the default destination for the next agent-delegated booking too. If the booking fails, the user does not see a failure. The agent retries. The agent picks another salon. The booking goes there.
The salon whose website failed the booking never sees the user. There is no analytics signal. There is no abandoned-cart event. There is no “the agent timed out on your booking form” notification in Google Search Console. The traffic that did not arrive is invisible. Three months later, the owner notices bookings are down and cannot identify the cause.
Late June is the deadline, and the work to be ready is small. An audit takes a few hours, the fixes run a day or two for most websites, and the alternative is months of silent loss before the cause is even visible.