Apple May Add AI Search Engines to Safari As Google Use Drops via @sejournal, @MattGSouthern
Apple is reportedly planning to redesign Safari to focus on AI search engines.
According to recent testimony in the Google antitrust case, this comes as the company prepares for possible changes to its profitable Google deal.
Apple Signals Shift In Search Strategy
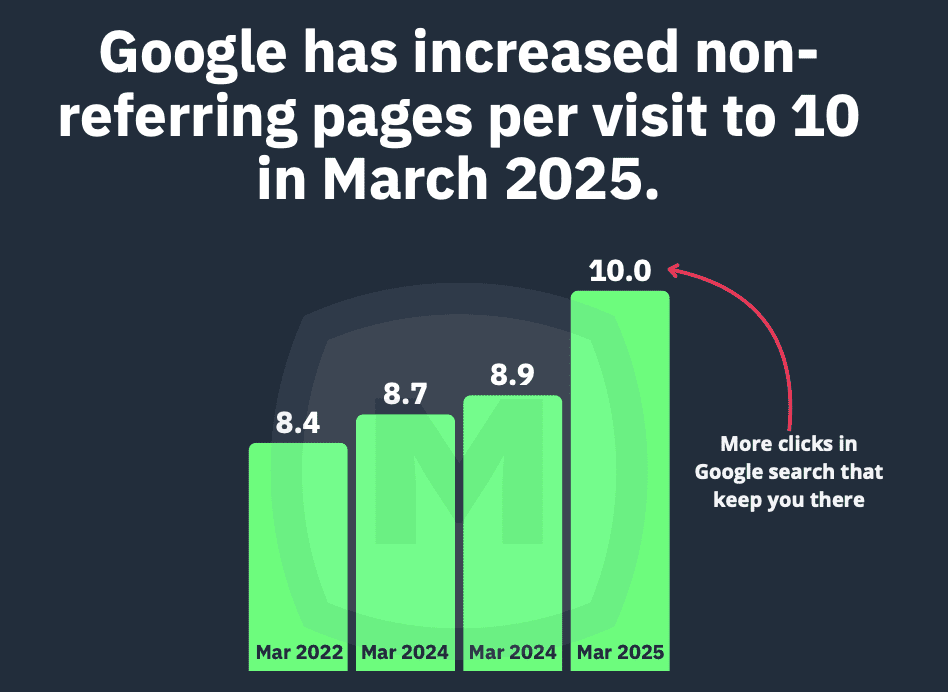
Eddy Cue, Apple’s senior vice president of services, testified that Safari searches dropped for the first time last month.
He believes users are choosing AI tools over regular search engines. This change happens as courts decide what to do after Google lost its antitrust case in August.
Per a report from Bloomberg, Cue testified:
“You may not need an iPhone 10 years from now as crazy as it sounds. The only way you truly have true competition is when you have technology shifts. Technology shifts create these opportunities. AI is a new technology shift, and it’s creating new opportunities for new entrants.”
AI Search Providers May Replace Traditional Search
Cue believes AI search providers such as OpenAI, Perplexity AI, and Anthropic will eventually replace traditional search engines like Google.
“We will add them to the list — they probably won’t be the default,” Cue said, noting Apple has already talked with Perplexity.
Currently, Apple offers ChatGPT as an option in Siri and plans to add Google’s Gemini later this year.
Cue admitted that these AI search tools need to improve their search indexes. However, he said their other features are “so much better that people will switch.”
“There’s enough money now, enough large players, that I don’t see how it doesn’t happen,” he said about the shift from standard search to AI-powered options.
Context: Google’s Antitrust Battle Timeline
This testimony comes during a key moment in the case against Google:
- August 2024: Judge Mehta ruled Google broke antitrust law through exclusive search deals
- October 2024: DOJ proposed remedies targeting search distribution, data usage, search results, and advertising
- December 2024: Google offered counter-proposals to loosen search deals
- March 2025: DOJ filed revised proposals, including possibly forcing Google to sell Chrome
The $20 Billion Question
The core issue is Google’s deal with Apple, worth a reported $20 billion per year, that makes Google the default search engine on Safari.
While expecting changes to this deal, Cue admitted he has “lost sleep over the possibility of losing the revenue share from their agreement.”
We learned about this payment during the trial. In 2022, Google paid Apple $20 billion to be Safari’s default search engine.
Last year, they expanded their partnership to add Google Lens to the Visual Intelligence feature on new iPhones.
Proposed Remedies & Responses
The DOJ’s latest filing suggests several significant changes:
- Making Google sell off Chrome
- Limiting Google’s payments for default search placement
- Stopping Google from favoring its products in search results
- Making Google’s advertising practices more transparent
Google has criticized these proposals, calling them a “radical interventionist agenda” that would “break a range of Google products.”
Instead, Google suggests letting browser companies deal with multiple search engines and giving device makers more freedom about which search options are preloaded.
What This Means
If Apple shifts Safari toward AI, prepare for significant changes in search.
It’s not a stretch to say the outcome could reshape search competition and digital marketing for years.
Featured Image: Bendix M/Shutterstock