Just four years ago, the movement to ban police departments from using face recognition in the US was riding high. By the end of 2020, around 18 cities had enacted laws forbidding the police from adopting the technology. US lawmakers proposed a pause on the federal government’s use of the tech.
In the years since, that effort has slowed to a halt. Five municipal bans on police and government use passed in 2021, but none in 2022 or in 2023 so far, according to a database from the digital rights group Fight for the Future. Some local bans have even been partially repealed, and today, few seriously believe that a federal ban on police use of face recognition could pass in the foreseeable future. In the meantime, without legal limits on its use, the technology has only grown more ingrained in people’s day-to-day lives.
However, in Massachusetts there is hope for those who want to restrict police access to face recognition. The state’s lawmakers are currently thrashing out a bipartisan state bill that seeks to limit police use of the technology. Although it’s not a full ban, it would mean that only state police could use it, not all law enforcement agencies.
The bill, which could come to a vote imminently, may represent an unsatisfying compromise, both to police who want more freedom to use the technology and to activists who want it completely banned. But it represents a vital test of the prevailing mood around police use of these controversial tools.
That’s because when it comes to regulating face recognition, few states are as important as Massachusetts. It has more municipal bans on the technology than any other state, and it’s an epicenter for civil liberty advocates, academics, and tech companies. For a movement in need of a breakthrough, a lot rides on whether this law gets passed.
Right now in the US, regulations on police use of face recognition are trapped in political gridlock. If a leader like Massachusetts can pass its bill, that could usher in a new age of compromise. It would be one of the strictest pieces of statewide legislation in the country and could set the standard for how face recognition is regulated elsewhere.
On the other hand, if a vote is delayed or fails, it would be yet another sign that the movement is waning as the country moves on to other policy issues.
A history of advocacy
Privacy advocates and public interest groups have long had concerns about the invasiveness of face recognition, which is pivotal to a growing suite of high-tech police surveillance tools. Many of those fears revolve around privacy: live video-based face recognition is seen as riskier than retroactive photo-based recognition because it can track people in real time.
Those worries reached a fever pitch in 2018 with the arrival of a bombshell: a privacy-shredding new product from a small company called Clearview AI.
Clearview AI’s powerful technology dramatically changed privacy and policing in the US. The company quietly gave free trials of the product to hundreds of law enforcement agencies across the country. Suddenly, police officers looking to identify someone could quickly comb through vastly more images than they’d ever had access to before—billions of public photos available on the internet.
The very same year, evidence started to mount that the accuracy of face recognition tools varied by race and gender. A groundbreaking study out of MIT by Joy Buolamwini and Timnit Gebru, called Gender Shades, showed that the technology is far less accurate at identifying people of color and women than white men.
The US government corroborated the results in a 2019 study by the National Institute of Science and Technology, which found that many commercial face recognition algorithms were 10 to 100 times more inaccurate in identifying Asian and Black faces than white ones.
Politicians started to wake up to the risks. In May 2019, San Francisco became the first city in the US to ban police use of face recognition. One month later, the ACLU of Massachusetts announced a groundbreaking campaign called “Press Pause,” which called for a temporary ban on the technology’s use by police in cities across the state. Somerville, Massachusetts, became the second city in the United States to ban it.
Over the next year, six more Massachusetts cities, including Boston, Cambridge, and Springfield, approved bans on police and government use of face recognition. Some cities even did so preemptively; in Boston, for example, police say they were not using the technology when it was banned. Major tech companies, including Amazon, Microsoft, and IBM pulled the technology from their shelves, and civil liberties advocates were pushing for a nationwide ban on its police use.
“Everyone who lives in Massachusetts deserves these protections; it’s time for the Massachusetts legislature to press pause on this technology by passing a statewide moratorium on government use of face surveillance,” Carol Rose, the executive director of the ACLU’s Massachusetts chapter, said in a statement after Boston passed its ban in June 2020.
That moratorium would never happen.
Is your face private?
At first, momentum was on the side of those who supported a statewide ban. The murder of George Floyd in Minneapolis in May 2020 had sent shock waves through the country and reinvigorated public outcry about abuses in the policing system. In the search for something tangible to fix, activists both locally and nationwide alighted on face recognition.
At the beginning of December 2020, the Massachusetts legislature passed a bill that would have dramatically restricted police agencies in the state from using face recognition, but Governor Charlie Baker refused to sign it, saying it was too limiting for police. He said he would never sign a ban into law.
In response, the legislature passed another, more toned-down bill several weeks later. It was still a landmark achievement, restricting most government agencies in the state from using the technology. It also created a commission that would be tasked with investigating further laws specific to face recognition. The commission included representatives from the state police, the Boston police, the Massachusetts Chiefs of Police Association, the ACLU of Massachusetts, several academic experts, the Massachusetts Department of Public Safety, and various lawmakers from both political parties, among others.
Law enforcement agencies in the state were now permitted access only to face recognition systems owned and operated by the Registry of Motor Vehicles (RMV), the state police, or the FBI. As a result, the universe of photos that police could query was much more limited than what was available through a system like Clearview, which gives users access to all public photos on the internet.
To hunt for someone’s image, police had to submit a written request and obtain a court order. That’s a lower bar than a warrant, but previously, they’d just been able to ask by emailing over a photo to search for suspects in misdemeanor and felony offenses including fraud, burglary, and identity theft.
At the time, critics felt the bill was lacking. “They passed some initial regulations that don’t go nearly far enough but were an improvement over the status quo, which was nothing,” says Kade Crockford of the ACLU of Massachusetts, a commission member.
Still, the impetus toward a national ban was building. Just as the commission began meeting in June 2021, Senator Ed Markey of Massachusetts and seven other members of Congress introduced a bill to ban federal government agencies, including law enforcement, from using face recognition technology. All these legislators were left-leaning, but at the time, stricter regulation had bipartisan support.
The Massachusetts commission met regularly for a year, according to its website, with a mandate to draft recommendations for the state legislature about further legal limits on face recognition.
As debate ensued, police groups argued that the technology was essential for modern policing.
“The sort of constant rhetoric of many of the appointees who were from law enforcement was that they did not want to tie the hands of law enforcement if the X, Y, Z worst situation happened—a terrorist or other extremely violent activity,” said Jamie Eldridge, a Massachusetts state senator who cochaired the commission, in an interview with MIT Technology Review.
Despite that lobbying, in March 2022 the commission voted to issue a strict set of recommendations for the legal use of face recognition. It suggested that only the state police be allowed to use the RMV database for face matching during a felony investigation, and only with a warrant. The state police would also be able to request that the FBI run a face recognition search.
Of the commission’s 21 members, 15 approved the recommendations, including Crockford. Two abstained, and four dissented. Most of the police members of the commission voted no.
One of them, Norwood Police Chief William Brooks, told MIT Technology Review there were three major things he disagreed with in the recommendations: requiring a warrant, restricting use of the technology to felonies only, and preventing police from accessing face recognition databases outside those of the RMV and the FBI.
Brooks says the warrant requirement “makes no sense” and “would protect no one,” given that the law already requires a court order to use face recognition technology.
“A search warrant is obtained when the police want to search in a place where a person has an expectation of privacy. We’re not talking about that here. We’re just talking about what their face looks like,” he says.
Other police groups and officers serving on the commission, including the Massachusetts public safety office, the Boston Police Patrolmen’s Association, and the Gloucester Police Department, have not responded to our multiple requests for comment.
An unsatisfying compromise
After years of discussion, debate, and compromise, in July 2022 the Massachusetts commission’s recommendations were codified into an amendment that has already been passed in the state house of representatives and may come to a vote via a bill in the state senate any day.
The bill allows image matching, which looks to retroactively identify a face by finding it in a database of images, in certain cases. But it bans two other types of face recognition: face surveillance, which seeks to identify a face in videos and moving images, and emotion recognition, which tries to assign emotions to different facial expressions.
This more subtle approach is reminiscent of the path that EU lawmakers have taken when evaluating the use of AI in public applications. That system uses risk tiers; the higher the risks associated with a particular technology, the stricter the regulation. Under the proposed AI Act in Europe, for example, live face recognition on video surveillance systems in public spaces would be regulated more harshly than more limited, non-real-time applications, such as an image search for in an investigation of a missing child.
Eldridge says he expects resistance from prosecutors and law enforcement groups, though he is “cautiously optimistic” that the bill will pass. He also says that many tech companies lobbied during the commission hearings, claiming that the technology is accurate and unbiased, and warning of an industry slowdown if the restrictions pass. Hoan Ton-That, CEO of Clearview, told the commission in his written testimony that “Clearview AI’s bias-free algorithm can accurately find any face out of over 3 billion images it has collected from the public internet.”
Crockford and Eldridge say they are hopeful the bill will be called to a vote in this session, which lasts until July 2024, but so far, no such vote has been scheduled. In Massachusetts, like everywhere else, other priorities like economic and education bills have been getting more attention.
Nevertheless, the bill has been influential already. Earlier this month, the Montana state legislature passed a law that echoes many of the Massachusetts requirements. Montana will outlaw police use of face recognition on videos and moving images, and require a warrant for face matching.
The real costs of compromise
Not everyone is thrilled with the Massachusetts standard. Police groups remain opposed to the bill. Some activists don’t think such regulations are enough. Meanwhile, the sweeping face recognition laws that some anticipated on a national scale in 2020 have not been passed.
So what happened between 2020 and 2023? During the three years that Massachusetts spent debating, lobbying, and drafting, the national debate moved from police reform to rising crime, triggering political whiplash. As the pendulum of public opinion swung, face recognition became a bargaining chip between policymakers, police, tech companies, and advocates. Perhaps importantly, we also got accustomed to face recognition technology in our lives and public spaces.
Law enforcement groups nationally are becoming increasingly vocal about the value of face recognition to their work. For example, in Austin, Texas, which has banned the technology, Police Chief Joseph Chacon wishes he had access to it in order to make up for staffing shortages, he told MIT Technology Review in an interview.
Some activists, including Caitlin Seeley George, director of campaigns and operations at Fight for the Future, say that police groups across the country have used similar arguments in an effort to limit face recognition bans.
“This narrative about [an] increase in crime that was used to fight the defund movement has also been used to fight efforts to take away technologies that police argue they can use to address their alleged increasing crime stats,” she says.
Nationally, face recognition bans in certain contexts, and even federal regulation, might be on the table again as lawmakers grapple with recent advances in AI and the attendant public frenzy about the technology. In March, Senator Markey and colleagues reintroduced the proposal to limit face recognition at a federal level.
But some advocacy groups still disagree with any amount of political compromise, such as the concessions in the Montana and Massachusetts bills.
“We think that advocating for and supporting these regulatory bills really drains any opportunity to move forward in the future with actual bans,” says Seeley George. “Again, we’ve seen that regulations don’t stop a lot of use cases and don’t do enough to limit the use cases where police are still using this technology.”
Crockford wishes a ban had been politically feasible: “Obviously the ACLU’s preference is that this technology is banned entirely, but we get it … We think that this is a very, very, very compromised common-sense set of regulations.”
Meanwhile, some experts think that some activists’ “ban or nothing” approach is at least partly responsible for the current lack of regulations restricting face recognition. Andrew Guthrie Ferguson, a law professor at American University Washington College of Law who specializes in policing and tech, says outright bans face significant opposition, and that’s allowed continued growth of the technology without any guardrails or limits.
Face recognition abolitionists fear that any regulation of the technology will legitimize it, but the inability to find agreement on first principles has meant regulation that might actually do some good has languished.
Yet throughout all this debate, facial recognition technology has only grown more ubiquitous and more accurate.
In an email to MIT Technology Review, Ferguson said, “In pushing for the gold standard of a ban against the political forces aligned to give police more power, the inability to compromise to some regulation has a real cost.”
When computer science students and faculty at Carnegie Mellon University’s Institute for Software Research returned to campus in the summer of 2020, there was a lot to adjust to.
Beyond the inevitable strangeness of being around colleagues again after months of social distancing, the department was also moving into a brand-new building: the 90,000-square-foot, state-of-the-art TCS Hall.
The hall’s futuristic features included carbon dioxide sensors that automatically pipe in fresh air, a rain garden, a yard for robots and drones, and experimental super-sensing devices called Mites. Mounted in more than 300 locations throughout the building, these light-switch-size devices can measure 12 types of data—including motion and sound. Mites were embedded on the walls and ceilings of hallways, in conference rooms, and in private offices, all as part of a research project on smart buildings led by CMU professor Yuvraj Agarwal and PhD student Sudershan Boovaraghavan and including another professor, Chris Harrison.
“The overall goal of this project,” Agarwal explained at an April 2021 town hall meeting for students and faculty, is to “build a safe, secure, and easy-to-use IoT [Internet of Things] infrastructure,” referring to a network of sensor-equipped physical objects like smart light bulbs, thermostats, and TVs that can connect to the internet and share information wirelessly.
Not everyone was pleased to find the building full of Mites. Some in the department felt that the project violated their privacy rather than protected it. In particular, students and faculty whose research focused more on the social impacts of technology felt that the device’s microphone, infrared sensor, thermometer, and six other sensors, which together could at least sense when a space was occupied, would subject them to experimental surveillance without their consent.
“It’s not okay to install these by default,” says David Widder, a final-year PhD candidate in software engineering, who became one of the department’s most vocal voices against Mites. “I don’t want to live in a world where one’s employer installing networked sensors in your office without asking you first is a model for other organizations to follow.”
Students pass by the Walk to the Sky monument on Carnegie Mellon’s campus.
GETTY IMAGES
All technology users face similar questions about how and where to draw a personal line when it comes to privacy. But outside of our own homes (and sometimes within them), we increasingly lack autonomy over these decisions. Instead, our privacy is determined by the choices of the people around us. Walking into a friend’s house, a retail store, or just down a public street leaves us open to many different types of surveillance over which we have little control.
Voices on both sides of the issue were aware that the Mites project could have an impact far beyond TCS Hall. After all, Carnegie Mellon is a top-tier research university in science, technology, and engineering, and how it handles this research may influence how sensors will be deployed elsewhere. “When we do something, companies … [and] other universities listen,” says Widder.
Indeed, the Mites researchers hoped that the process they’d gone through “could actually be a blueprint for smaller universities” looking to do similar research, says Agarwal, an associate professor in computer science who has been developing and testing machine learning for IoT devices for a decade.
But the crucial question is what happens if—or when—the super-sensors graduate from Carnegie Mellon, are commercialized, and make their way into smart buildings the world over.
The conflict is, in essence, an attempt by one of the world’s top computer science departments to litigate thorny questions around privacy, anonymity, and consent. But it has deteriorated from an academic discussion into a bitter dispute, complete with accusations of bullying, vandalism, misinformation, and workplace retaliation. As in so many conversations about privacy, the two sides have been talking past each other, with seemingly incompatible conceptions of what privacy means and when consent should be required.
Ultimately, if the people whose research sets the agenda for technology choices are unable to come to a consensus on privacy, where does that leave the rest of us?
The future, according to Mites
The Mites project was based on two basic premises: First, that buildings everywhere are already collecting data without standard privacy protections and will continue to do so. And second, that the best solution is to build better sensors—more useful, more efficient, more secure, and better-intentioned.
In other words, Mites.
“What we really need,” Agarwal explains, is to “build out security-, privacy-, safety-first systems … make sure that users have trust in these systems and understand the clear value proposition.”
“I would rather [we] be leading it than Google or ExxonMobil,” adds Harrison, an associate professor of human-computer interaction and a faculty collaborator on the project, referring to sensor research. (Google funded early iterations of the research that led to Mites, while JPMorgan Chase is providing “generous support of smart building research at TCS Hall,” as noted on plaques hung around the building.)
Mites—the name refers to both the individual devices and the overall platform—are all-in-one sensors supported by a hardware stack and on-device data processing. While Agarwal says they were not named after the tiny creature, the logo on the project’s website depicts a bug.
According to the researchers, Mites represent a significant improvement over current building sensors, whichtypically have a singular purpose—like motion detectors or thermometers. In addition, many smart devices today often only working in isolation or with specific platforms like Google’s Nest or Amazon’s Alexa; they can’t interact with each other.
A Mites sensor installed in a wall panel in TCS Hall.
Additionally, current IoT systems offer little transparency about exactly what data is being collected, how it is being transmitted, and what security protocols are in place—while erring on the side of over-collection.
The researchers hoped Mites would address these shortcomings and facilitate new uses and applications for IoT sensors. For example, microphones on Mites could help students find a quiet room to study, they said—and Agarwal suggested at the town hall meeting in April 2021 that the motion sensor could tell an office occupant whether custodial staff were actually cleaning offices each night. (The researchers have since said this was a suggested use case specific to covid-19 protocols and that it could help cleaning staff focus on high-traffic areas—but they have moved away from the possibility.)
The researchers also believe that in the long term, Mites—and building sensors more generally—are key to environmental sustainability. They see other, more ambitious use cases too. A university write-up describes this scenario: In 2050, a woman starts experiencing memory loss. Her doctor suggests installing Mites around her home to “connect to … smart speakers and tell her when her laundry is done and when she’s left the oven on” or to evaluate her sleep by noting the sound of sheets ruffling or nighttime trips to the bathroom. “They are helpful to Emily, but even more helpful to her doctor,” the article claims.
As multipurpose devices integrated with a platform, Mites were supposed to solve all sorts of problems without going overboard on data collection. Each device contains nine sensors that can pick up all sorts of ambient information about a room, including sound, light, vibrations, motion, temperature, and humidity—a dozen different types of data in all. To protect privacy, it does not capture video or photos.
The CMU researchers are not the first to attempt such a project. An IoT research initiative out of the Massachusetts Institute of Technology, similarly called MITes, designed portable sensors to collect environmental data like movement and temperature. It ran from 2005 to 2016, primarily as part of PlaceLab, a experimental laboratory modeled after an apartment in which carefully vetted volunteers consented to live and have their interactions studied. The MIT and CMU projects are unrelated. (MIT Technology Review is funded in part by MIT but maintains editorial independence.)
The Carnegie Mellon researchers say the Mites system extracts only some of the data the devices collect, through a technical process called “featurization.” This should make it more difficult to trace, say, a voice back to an individual.
Machine learning—which, through a technique called edge computing, would eventually take place on the device rather than on a centralized server—then recognizes the incoming data as the result of certain activities. The hope is that a particular set of vibrations could be translated in real time into, for example, a train passing by.
The researchers say that featurization and other types of edge computing will make Mites more privacy-protecting, since these technologies minimize the amount of data that must be sent, processed, and stored in the cloud. (At the moment, machine learning is still taking place on a separate server on campus.)
“Our vision is that there’s one sensor to rule them all, if you’ve seen Lord of the Rings. The idea is rather than this heterogeneous collection of sensors, you have one sensor that’s in a two-inch-by-two-inch package,” Agarwal explained in the April 2021 town hall, according to a recording of the meeting shared with MIT Technology Review.
But if the departmental response is any indication, maybe a ring of power that let its wearer achieve domination over others wasn’t the best analogy.
A tense town hall
Unless you are looking for them, you might not know that the bright and airy TCS Hall, on the western edge of Carnegie Mellon’s Pittsburgh campus, is covered in Mites devices—314 of them as of February 2023, according to Agarwal.
But look closely, and they are there: small square circuit boards encased in plastic and mounted onto standard light switch plates. They’re situated inside the entrances of common rooms and offices, by the thermostats and light controls, and in the ceilings.
The only locations in TCS Hall that are Mites-free, in fact, are the bathrooms—and the fifth floor, where Tata Consultancy Services, the Indian multinational IT company that donated $35 million to fund the building bearing its name, runs a research and innovation center. (A spokesperson said, “TCS is not involved in the Mites project.”)
Widder, whose PhD thesis focuses on how to help AI developers think about their responsibility for the harm their work could cause, remembers finding out about the Mites sensors in his office sometime in fall of 2020. And once he noticed them, he couldn’t unsee the blinking devices mounted on his wall and ceiling, or the two on the hallway ceiling just outside his door.
A Mites sensor installed on the ceiling in TCS Hall
Nor was Widder immediately aware of how to turn the devices off; they did not have an on-off switch. (Ultimately, his attempts to force that opt-out would threaten to derail his career.)
This was a problem for the budding tech ethicist. Widder’s academic work explores how software developers think about the ethical implications of the products that they build; he’s particularly interested in helping computer scientists understand the social consequences of technology. And so Mites was of both professional and personal concern. The same issues of surveillance and informed consent that he helped computer scientists grapple with had found their way into his very office.
CMU isn’t the only university to test out new technologies on campus before sending them into the wider world. University campuses have long been a hotbed for research—with sometimes questionable policies around consent. Timnit Gebru, a tech ethicist and the founder of the Distributed AI Research Institute, cites early research on facial recognition that was built on surveillance data collected by academic researchers. “So many of the problematic data practices we see in industry were first done in the research world, and they then get transported to industry,” she says.
It was through that lens that Widder viewed Mites. “I think nonconsensual data collection for research … is usually unethical. Pervasive sensors installed in private and public spaces make increasingly pervasive surveillance normal, and that is a future that I don’t want to make easier,” he says.
Hevoiced his concerns in the department’s Slack channel, in emails, and in conversations with other students and faculty members—and discovered that he wasn’t alone. Many other people were surprised to learn about the project, he says, and many shared his questions about what the sensor data would be used for and when collection would start.
“I haven’t been to TCS Hall yet, but I feel the same way … about the Mites,” another department member wrote on Slack in April 2021. “I know I would feel most comfortable if I could unplug the one in my office.”
The researchers say that they followed the university’s required processes for data collection and received sign-off after a review by its institutional review board (IRB) and lawyers. The IRB—which oversees research in which human subjects are involved, as required by US federal regulation—had provided feedback on the Mites research proposal before ultimately approving the project in March. According to a public FAQ about the project, the board determined that simply installing Mites and collecting data about the environment did not require IRB approval or prior consent from occupants of TCS Hall—with an exception for audio data collection in private offices, which would be based on an “opt-in” consent process. Approval and consent would be required for later stages of the project, when office occupants would use a mobile app allowing them to interact with Mites data.
The Mites researchers also ran the project by the university’s general counsel to review whether the use of microphones in the sensors violated Pennsylvania state law, which mandates two-party consent in audio recording. “We have had extensive discussions with the CMU-Office of the General Counsel and they have verified that we are not violating the PA wiretap law,” the project’s FAQ reads.
Overall, the Institute for Software Research, since renamed Software and Societal Systems, was split. Some of its most powerful voices, including the department chair (and Widder’s thesis co-advisor), James Herbsleb, encouraged department members to support the research. “I want to repeat that this is a very important project … if you want to avoid a future where surveillance is routine and unavoidable!” he wrote in an email shortly after the town hall.
“The initial step was to … see how these things behave,” says Herbsleb, comparing the Mites sensors to motion detectors that people might want to test out. “It’s purely just, ‘How well does it work as a motion detector?’ And, you know, nobody’s asked to consent. It’s just trying out a piece of hardware.”
Of course, the system’s advanced capabilities meant that Mites were not just motion detectors—and other department members saw things differently. “It’s a lot to ask of people to have a sensor with a microphone that is running in their office,” says Jonathan Aldrich, a computer science professor, even if “I trust my coworkers as a general principle and I believe they deserve that trust.” He adds, “Trusting someone to be a good colleague is not the same as giving them a key to your office or having them install something in your office that can record private things.” Allowing someone else to control a microphone in your office, he says, is “very much like giving someone else a key.”
As the debate built over the next year, it pitted students against their advisors and academic heroes as well—although many objected in private, fearing the consequences of speaking out against a well-funded, university-backed project.
In the video recording of the town hall obtained by MIT Technology Review, attendees asked how researchers planned to notify building occupants and visitors about data collection. Jessica Colnago, then a PhD student, was concerned about how the Mites’ mere presence would affect studies she was conducting on privacy. “As a privacy researcher, I would feel morally obligated to tell my participant about the technology in the room,” she said in the meeting. While “we are all colleagues here” and “trust each other,” she added, “outside participants might not.”
Attendees also wanted to know whether the sensors could track how often they came into their offices and at what time. “I’m in office [X],” Widder said. “The Mite knows that it’s recording something from office [X], and therefore identifies me as an occupant of the office.” Agarwal responded that none of the analysis on the raw data would attempt to match that data with specific people.
At one point, Agarwal also mentioned that he had gotten buy-in on the idea of using Mites sensors to monitor cleaning staff—which some people in the audience interpreted as facilitating algorithmic surveillance or, at the very least, clearly demonstrating the unequal power dynamics at play.
A sensor system that could be used to surveil workers concerned Jay Aronson, a professor of science, technology, and society in the history department and the founder of the Center for Human Rights Science, who became aware of Mites after Widder brought the project to his attention. University staff like administrative and facilities workers are more likely to be negatively impacted and less likely to reap any benefits, said Aronson. “The harms and the benefits are not equally distributed,” he added.
A sign reading “Privacy is NOT dead, Carnegie Mellon University Privacy Engineering” is displayed on the wall a few feet from a Mites sensor.
Similarly, students and nontenured faculty seemingly had very little to directly gain from the Mites project and faced potential repercussions both from the data collection itself and, they feared, from speaking up against it. We spoke with five students in addition to Widder who felt uncomfortable both with the research project and with voicing their concerns.
One of those students was part of a small cohort of 45 undergraduates who spent time at TCS Hall in 2021 as part of a summer program meant to introduce them to the department as they considered applying for graduate programs. The town hall meeting was the first time some of them learned about the Mites. Some became upset, concerned they were being captured on video or recorded.
But the Mites weren’t actually recording any video. And any audio captured by the microphones was scrambled so that it could not be reconstructed.
In fact, the researchers say that the Mites were not—and are not yet—capturing any usable data at all.
For the researchers, this “misinformation” about the data being collected, as Boovaraghavan described it in an interview with MIT Technology Review, was one of the project’s biggest frustrations.
But if the town hall was meant to clarify details about the project, it exacerbated some of that confusion instead. Although a previous interdepartment email thread had made clear that the sensors were not yet collecting data, that was lost in the tense discussion. At some points, the researchers indicated that no data was or would be collected without IRB approval (which had been received the previous month), and at other points they said that the sensors were only collecting “telemetry data” (basically to ensure they were powered up and connected) and that the microphone “is off in all private offices.” (In an emailed statement to MIT Technology Review, Boovaraghavan clarified that “data has been captured in the research teams’ own private or public spaces but never in other occupants’ spaces.”)
For some who were unhappy, exactly what data the sensors were currently capturing was beside the point. It didn’t matter that the project was not yet fully operational. Instead, the concern was that sensors more powerful than anything previously available had been installed in offices without consent. Sure, the Mites were not collecting data at that moment. But at some date still unspecified by the researchers, they could be. And those affected might not get a say.
Widder says the town hall—and follow-up one-on-one meetings with the researchers—actually made him “more concerned.” He grabbed his Phillips screwdriver. He unplugged the Mites in his office, unscrewed the sensors from the wall and ceiling, and removed the ethernet cables from their jacks.
He put his Mite in a plexiglass box on his shelf and sent an email to the research team, his advisors, and the department’s leadership letting them know he’d unplugged the sensors, kept them intact, and wanted to give them back. With others in the department, he penned an anonymous open letter that detailed more of his concerns.
Is it possible to clearly define “privacy”?
The conflict at TCS Hall illustrates what makes privacy so hard to grapple with: it’s subjective. There isn’t one agreed-upon standard for what privacy means or when exactly consent should be required for personal data to be collected—or what even counts as personal data. People have different conceptions of what is acceptable. The Mites debate highlighted the discrepancies between technical approaches to collecting data in a more privacy-preserving way and the “larger philosophical and social science side of privacy,” as Kyle Jones, a professor of library and information science at Indiana University who studies student privacy in higher education, puts it.
Some key issues in the broader debates about privacy were particularly potent throughout the Mites dispute. What does informed consent mean, and under what circumstances is it necessary? What data can actually identify someone, even if it does not meet the most common definitions of “personally identifiable data”? And is building privacy-protecting technology and processes adequate if they’re not communicated clearly enough to users?
For the researchers, these questions had a straightforward answer: “My privacy can’t be invaded if, literally, there’s no data collected about me,” says Harrison.
Even so, the researchers say, consent mechanisms were in place. “The ability to power off the sensor by requesting it was built in from the start. Similarly, the ability to turn on/off any individual sensor on any Mites board was also built in from the get-go,” they wrote in an email.
But though the functionality may have existed, it wasn’t well communicated to the department, as an internal Slack exchange showed. “The one general email that was sent did not provide a procedure to turn them off,” noted Aldrich.
Students we spoke with highlighted the reality that requiring them to opt out of a high-profile research project, rather than giving them the chance to opt in, fails to account for university power dynamics. In an email to MIT Technology Review, Widder said he doesn’t believe that the option to opt out via email request was valid, because many building occupants were not aware of it and because opting out would identify anyone who essentially disagreed with the research.
Aldrich was additionally concerned about the technology itself.
“Can you … reconstruct speech from what they’ve done? There’s enough bits that it’s theoretically possible,” he says. “The [research team] thinks it’s impossible, but we don’t have proof of this, right?”
But a second concern was social: Aldrich says he didn’t mind the project until a colleague outside the department asked not to meet in TCS Hall because of the sensors. That changed his mind. “Do I really want to have something in my office that is going to keep a colleague from coming and meeting with me in my office? The answer was pretty clearly no. However I felt about it, I didn’t want it to be a deterrent for someone else to meet with me in my office, or to [make them] feel uncomfortable,” he says.
The Mites team posted signs around the building—in hallways, common areas, stairwells, and some rooms—explaining what the devices were and what they would collect. Eventually, the researchers added a QR code linking to the project’s 20-page FAQ document. The signs were small, laminated letter-size papers that some visitors said were easy to miss and hard to understand.
“When I saw that, I was just thinking, wow, that’s a very small description of what’s going on,” noted one such visitor, Se A Kim, an undergraduate student who made multiple visits to TCS Hall in the spring of 2022 for a design school assignment to explore how to make visitors aware of data collection in TCS’s public spaces. When she interviewed a number of them, she was surprised by how many were still unaware of the sensors.
One concern repeated by Mites opponents is that even if the current Mites deployment is not set up to collect the most sensitive data, like photos or videos, and is not meant to identify individuals, this says little about what data it might collect—or what that data might be combined with—in the future. Privacy researchers have repeatedlyshown that aggregated, anonymized data can easily be de-anonymized.
ARI LILOAN
This is most often the case with far larger data sets—collected, for example, by smartphones. Apps and websites might not have the phone number or the name of the phone’s owner, but they often have access to location data that makes it easy to reverse-engineer those identifying details. (Mites researchers have since changed how they handle data collection in private offices by grouping multiple offices together. This makes it harder to ascertain the behavior of individual occupants.)
The Mites research team was aware of these well-known privacy issues and security breaches, but unlike their critics, who saw these precedents as a reason not to trust the installation of even more powerful IoT devices, Agarwal, Boovaraghavan, and Harrison saw them as motivation to create something better. “Alexa and Google Homes are really interesting technology, but some people refuse to have them because that trust is broken,” Harrison says. He felt the researchers’ job was to figure out how to build a new device that was trustworthy from the start.
Unlike the devices that came before, theirs would be privacy-protecting.
Tampering and bullying claims
In the spring of 2021, Widder received a letter informing him he was being investigated for alleged misconduct for tampering with university computing equipment. It also warned him that the way he had acted could be seen as bullying.
Department-wide email threads, shared with MIT Technology Review, hint at just how personal the Mites debate had become—and how Widder had, in the eyes of some of his colleagues, become the bad guy. “People taking out sensors on their own (what’s the point of these deep conversations if we are going to just literally take matters in our hands?) and others posting on social media is *not ethical*,” one professor wrote. (Though the professor did not name Widder, it was widely known that he had done both.)
“I do believe some people felt bullied here, and I take that to heart,” Widder says, though he also wonders, “What does it say about our field if we’re not used to having these kinds of discussions and … when we do, they’re either not taken seriously or … received as bullying?” (The researchers did not respond to questions about the bullying allegations.)
The disciplinary action was dropped after Widder plugged the sensors back in and apologized, but to Aldrich, “the letter functions as a way to punish David for speaking up about an issue that is inconvenient to the faculty, and to silence criticism from him and others in the future,” as he wrote in an official response to Widder’s doctoral review.
Herbsleb, the department chair and Widder’s advisor, declined to comment on what he called a “private internal document,” citing student privacy.
While Widder believes that he was punished for his criticisms, the researchers had taken into account some of those critiques already. For example, the researchers offered to let building occupants turn off the Mites sensors in their offices by asking to opt out via email. But this remained impossible in public spaces, in part because “there’s no way for us to even know who’s in the public space,” the researchers told us.
By February 2023, occupants in nine offices out of 110 had written to the researchers to disable the Mites sensors in their own offices—including Widder and Aldrich.
The researchers point to this small number as proof that most people are okay with Mites. But Widder disagrees; all it proves, he says, is that people saw how he was retaliated against for removing his own Mites sensors and were dissuaded from asking to have theirs turned off. “Whether or not this was intended to be coercive, I think it has that effect,” he says.
“The high-water mark”
On a rainy day last October, in a glass conference room on the fourth floor of TCS Hall, the Mites research team argued that the simmering tensions over their project—the heated and sometimes personal all-department emails, Slack exchanges, and town halls—were a normal part of the research process.
“You may see this discord … through a negative lens; we don’t,” Harrison said.
“I think it’s great that we’ve been able to foster a project where people can legitimately … raise issues with it … That’s a good thing,” he added.
“I’m hoping that we become the high-water mark for how to do this [sensor research] in a very deliberate way,” said Agarwal.
Other faculty members—even those who have become staunch supporters of the Mites project, like Lorrie Cranor, a professor of privacy engineering and a renowned privacy expert—say things could have been done differently. “In hindsight, there should have been more communication upfront,” Cranor acknowledges—and those conversations should have been ongoing so that current students could be part of them. Because of the natural turnover in academia, she says, many of them had never had a chance to participate in these discussions, even though long-standing faculty were informed about the project years ago.
She also has suggestions for how the project could improve. “Maybe we need a Mites sensor in a public area that’s hooked up to a display that gives you a livestream, and you can jump up and down and whistle and do all sorts of stuff in front of it and see what data is coming through,” she says. Or let people download the data and figure out, “What can you reconstruct from this? … If it’s possible to reverse-engineer it and figure something out, someone here probably will.” And if not, people might be more inclined to trust the project.
Widder’s disabled Mites sensors, which he placed in a plexiglass box on his shelf after unscrewing the device
The devices could also have an on-off switch, Herbsleb, the department chair, acknowledges: “I think if those concerns had been recognized earlier, I’m sure Yuvraj [Agarwal] would have designed it that way.” (Widder still thinks the devices should have an off switch.)
But still, for critics, these actual and suggested improvements do not change the fact that “the public conversation is happening because of a controversy, rather than before,” Aronson says.
Nor do the research improvements take away what Widder experienced. “When I raised concerns, especially early on,” he says, “I was treated as an attention seeker … as a bully, a vandal. And so if now people are suggesting that this has made the process better?” He pauses in frustration. “Okay.”
Besides, beyond any improvements made in the research process at CMU, there is still the question of how the technology might be used in the real world. That commercialized version of the technology might have “higher-quality cameras and higher-quality microphones and more sensors and … more information being sucked in,” notes Aronson. Before something like Mites rolls out to the public, “we need to have this big conversation” about whether it is necessary or desired, he says.
“The big picture is, can we trust employers or the companies that produce these devices not to use them to spy on us?” adds Aldrich. “Some employers have proved they don’t deserve such trust.”
The researchers, however, believe that worrying about commercial applications may be premature. “This is research, not a commercial product,” they wrote in an emailed statement. “Conducting this kind of research in a highly controlled environment enables us to learn and advance discovery and innovation. The Mites project is still in its early phases.”
But there’s a problem with that framing, says Aronson. “The experimental location is not a lab or a petri dish. It’s not a simulation. It’s a building that real human beings go into every day and live their lives.”
Widder, the project’s most vocal critic, can imagine an alternative scenario where perhaps he could have felt differently about Mites, had it been more participatory and “collaborative.” Perhaps, he suggests, the researchers could have left the devices, along with an introduction and instruction booklet, on department members’ desks so they could decide if they wanted to participate. That would have ensured that the research was done “based on the principle of opt-in consent to even have these in the office in the first place.” In other words, he doesn’t think technical features like encryption and edge computing can replace meaningful consent.
Even these sorts of adjustments wouldn’t fundamentally change how Widder feels, however. “I’m not willing to accept the premise of … a future where there are all of these kinds of sensors everywhere,” he says.
The 314 Mites that remain in the walls and ceilings of TCS Hall are, at this point, unlikely to be ripped out. But if the fight over this project may well have wound down, debates about privacy are really just beginning.
China Report is MIT Technology Review’s newsletter about technology developments in China. Sign up to receive it in your inbox every Tuesday.
China’s annual, week-long parliamentary meeting just ended on Monday. Apart from confirming President Xi Jinping for a historic third term and appointing a new batch of other top leaders, the government also approved a restructuring plan for national ministries, as it typically does every five years.
Among all the changes, there’s one that the tech world is avidly watching: the creation of a new regulatory body named the National Data Administration.
According to official documents, the NDA will be in charge of “advancing the development of data-related fundamental institutions, coordinating the integration, sharing, development and application of data resources, and pushing forward the planning and building of a Digital China, the digital economy and a digital society, among others.”
In plain words, the NDA will help build smart cities in China, digitize government services, improve internet infrastructure, and make government agencies share data with each other.
The big question mark is how much regulatory authority it will exert. At the moment, many different governmental groups in China have a hand in data regulation (last year, one political representative counted 15), and there is no government body that has an explicit mission to protect data privacy. The closest the country has is the Cyberspace Administration of China, which was originally created to police online content and promote party propaganda.
“It makes sense to set something [like NDA] up, given how important data is,” says Jamie Horsley, a senior fellow at the Paul Tsai China Center at Yale Law School, who studies regulatory reforms in China. “But the problem anytime you try to streamline government is that you realize every issue impacts other issues. It’s very hard to just carve out something that’s only going to be regulated by this one entity.”
For now, it seems this new department is part of an ongoing effort by the Chinese government to drum up a “digital economy” around collecting, sharing, and trading data.
In fact, the new national administration greatly resembles the Big Data Bureaus that Chinese provinces have been setting up since 2014. These local bureaus have built data centers across China and set up data exchanges that can trade data sets like stocks. The content of the data is as varied as cell phone locations and results from remote sensing of the ocean floor. The bureaus have even embraced and invested in the questionable concept of the metaverse.
Those bureaus tend to view data as a promising economic resource rather than a Pandora’s box full of privacy concerns. Now, these local experiments are being integrated and elevated to a national-level agency. And that explains why the new NDA is set up under China’s National Development and Reform Commission, an office mostly responsible for drawing broad economic blueprints for the country.
We may not get clarity on NDA’s full scope of authority until the summer, when its organizational structure, personnel, and regulatory responsibilities are expected to be put down in writing. But analysts think that it’s not likely to replace the Cyberspace Administration of China, which has risen up in recent years to become the “super regulator” of the tech industry.
“Although CAC will lose a few things, its core power has not been significantly undermined,” wrote Tom Nunlist, a senior analyst on tech and data policy at the analytical firm Trivium China. Likely, it will keep exerting control in many of the areas it has been regulating for years: keeping big tech companies in check, ramping up internet censorship, and scrutinizing multinational companies for security issues related to data transfer.
But the creation of the NDA could mean CAC won’t have total reign over China’s internet. That could be a boon for transparency. Because CAC is a branch of the Chinese Communist Party rather than the government, it is subject to fewer disclosure requirements when it comes to its budgets, duties, and rule-making processes. It’s also likely to focus on policies around ideological governance and national security rather than on economic development.
Making the NDA a government agency is a big move, given how party-centric China’s leadership is today, Horsley says: “[China is] a party-state, but the state piece of it is still very important … Of course, it’s supposed to be loyal to the party, but it’s also supposed to deliver [on economic development goals].”
What impact do you think the new National Data Administration will have on the Chinese tech world? Let me know your thoughts at zeyi@technologyreview.com.
Catch up with China
1. Silicon Valley Bank, which collapsed last week, was among the first financial institutions to cater to Chinese startups and connect them with US investors. (The Information $)
2. China has brokered an agreement between Iran and Saudi Arabia to reestablish diplomatic relations, filling a diplomatic vacuum left by the United States. (Vox)
3. Hundreds of Baidu employees are working around the clock and borrowing computer chips from other departments to get ready for the launch of Ernie Bot, Baidu’s answer to ChatGPT, this coming Thursday. (Wall Street Journal $)
4. Shou Zi Chew, TikTok’s CEO, has sought closed-door meetings with at least half a dozen lawmakers in Washington, DC. He is scheduled to appear before a congressional hearing regarding privacy and national security concerns about TikTok later this month. (Forbes $)
5. China may control 32% of the world’s lithium mining capacity by 2025, the investment bank UBS AG estimates. (Bloomberg $)
6. China reappointed Yi Gang as the head of the central bank, signaling continuity in its monetary policies. (AP)
7. The “996” overwork culture in China, embraced by tech companies a few years ago, is not going away easily. An executive at a Chinese auto company recently asked its legal department to figure out “how to avoid legal risks” in asking employees to work on Saturdays. (Sixth Tone)
Lost in translation
In central China, a young entrepreneur is reimagining retirement homes by teaching the senior residents how to play e-sports. As Chinese gaming publication ChuApp reports, Fan Jinlin, a 25-year-old in Henan province, took over his family’s retirement home business after college. He started creating video content about the lives of the residents and quickly attracted millions of followers on Douyin, the Chinese version of TikTok.
In February 2022, he began building an e-sports room in his fifth retirement home and recruiting seniors who are interested in video games. Zhang Fengqin, a 68-year-old retired bank clerk, is one of them. She saw the news on Douyin and applied. Soon, she grew from someone who didn’t even know how to use a mouse to a proficient player of Teamfight Tactics, a popular game that doesn’t require quick reflexes as much as strategic thinking. Ultimately, Fan wants to build a professional team to play in tournaments, but to achieve that, he would need at least seven participants like Zhang. Right now he only has three.
One more thing
The number 2,952 has disappeared from China’s social media platform Weibo. Why? Because President Xi Jinping extended his rule for another five years last week, having received 2,952 votes approving the extension—with zero opposed and zero abstaining—in China’s ceremonial legislative body, the National People’s Congress. While everyone knew Xi would get a third term, the fact that there was not a single opposition vote still got people talking about how pointless the procedure was. Just a few days later, Weibo blocked search results on the number.
And China loses another number…
On Weibo, you can look up 2951.
Searching for 2953 is also no problem.
But 2952?
“According to the relevant laws, regulations and policies, the page is not found.”
China Report is MIT Technology Review’s newsletter about technology developments in China. Sign up to receive it in your inbox every Tuesday.
As I often say, the American people and the Chinese people have much more in common than either side likes to admit. For example, take the shared concern about how much time children and teenagers are spending on TikTok (or its Chinese domestic version, Douyin).
On March 1, TikTok announced that it’s setting a 60-minute default time limit per day for users under 18. Those under 13 would need a code entered by their parents to have an additional 30 minutes, while those between 13 and 18 can make that decision for themselves.
While the effectiveness of this measure remains to be seen (it’s certainly possible, for example, to lie about your age when registering for the app), TikTok is clearly responding to popular requests from parents and policymakers who are concerned that kids are overly addicted to it and other social media platforms. In 2022, teens spent on average 103 minutes per day on TikTok, beating Snapchat (72 minutes) and YouTube (67). The app has also been found to promote content about eating disorders and self-harm to young users.
Lawmakers are taking notice: several US senators have pushed for bills that would restrict underage users’ access to apps like TikTok.
But ByteDance, the parent company of TikTok, is no stranger to those requests.In fact, it has been dealing with similar government pressures in China since at least 2018.
That year, Douyin introduced in-app parental controls, banned underage users from appearing in livestreams, and released a “teenager mode” that only shows whitelisted content, much like YouTube Kids. In 2019, Douyin limited users in teenager mode to 40 minutes per day, accessible only between the hours of 6 a.m. and 10 p.m. Then, in 2021, it made the use of teenager mode mandatory for users under 14. So a lot of the measures that ByteDance is now starting to introduce outside China with TikTok have already been tested aggressively with Douyin.
Why has it taken so long for TikTok to impose screen-time limits? Some right-wing politicians and commentators are alleging actual malice from ByteDance and the Chinese government (“It’s almost like they recognize that technology is influencing kids’ development, and they make their domestic version a spinach version of TikTok, while they ship the opium version to the rest of the world,” Tristan Harris, cofounder of the Center for Humane Technology and a former Google employee, told 60 Minutes.) But I don’t think that the difference between the two platforms is the result of some sort of conspiracy. Douyin would probably look very similar to TikTok were it not for how quickly and forcefully the Chinese government regulates digital platforms.
The Chinese political system allows the government to react swiftly to the consequences of new tech platforms. Sometimes it’s in response to a widespread concern, such as teen addiction to social media. Other times it’s more about the government’s interests, like clamping down on a new product that makes censorship harder. But the shared result is that the state is able to ask platforms to make changes quickly without much pushback.
You can see that clearly in the Chinese government’s approach to another tech product commonly accused of causing teen addiction: video games. After denouncing the games for many years, the government implemented strict restrictions in 2021: people under 18 in China are allowed to play video games only between 8 and 9 p.m. on weekends and holidays; they are supposed to be blocked from using them outside those hours. Gaming companies are punished for violations, and many have had to build or license costly identity verification systems to enforce the rule.
When the crackdown on video games happened in 2021, the social media industry was definitely spooked, because many Chinese people were already comparing short-video apps like Douyin to video games in terms of addictiveness. It seemed as though the sword of Damocles could drop at any time.
That possibility seems even more certain now. On February 27, the National Radio and Television Administration, China’s top authority on media production and consumption, said it had convened a meeting to work on “enforcing the regulation of short videos and preventing underage users from becoming addicted.” News of the meeting sent a clear signal to Chinese social media platforms that the government is not pleased with the current measures and needs them to come up with new ones.
What could those new measures look like? It could mean even stricter rules around screen time and content. But the announcement also mentioned some other interesting directions, like requiring creators to obtain a license to provide content for teenagers and developing ways for the government to regulate the algorithms themselves. As the situation develops, we should expect to see more innovative measures taken in China to impose limits on Douyin and similar platforms.
As for the US, even getting to the level of China’s existing regulations around social media would require some big changes.
To ensure that no teens in China are using their parents’ accounts to watch or post to Douyin, every account is linked to the user’s real identity, and the company says facial recognition tech is used to monitor the creation of livestream content. Sure, those measures help prevent teens from finding workarounds, but they also have privacy implications for all users, and I don’t believe everyone will decide to sacrifice those rights just to make sure they can control what children get to see.
We can see how the control vs. privacy trade-off has previously played out in China. Before 2019, the gaming industry had a theoretical daily play-time limit for underage gamers, but it couldn’t be enforced in real time. Now there is a central database created for gamers, tied to facial recognition systems developed by big gaming publishers like Tencent and NetEase, that can verify everyone’s identity in seconds.
On the content side of things, Douyin’s teenager mode bans a slew of content types from being shown, including videos of pranks, “superstitions,” or “entertainment venues”—places like dance or karaoke clubs that teenagers are not supposed to enter. While the content is likely selected by ByteDance employees, social media companies in China are regularly punished by the government for failing to conduct thorough censorship, and that means decisions about what is suitable for teens to watch are ultimately made by the state. Even the normal version of Douyin regularly takes down pro-LGBTQ content on the basis that they present “unhealthy and non-mainstream views on marriage and love.”
There is a dangerously thin line between content moderation and cultural censorship. As people lobby for more protection for their children, we’ll have to answer some hard questions about what those social media limits should look like—and what we’re willing to trade for them.
Do you think a mandatory daily TikTok time limit for teenagers is necessary? Let me know what you think at zeyi@technologyreview.com.
Catch up with China
1. Over the weekend, the Chinese government held its “two sessions”—an annual political gathering that often signals government plans for the next year. Li Keqiang, China’s outgoing premier, set the annual GDP growth target as 5%, the lowest in nearly 30 years. (New York Times $)
Because the government is often cryptic about its policy priorities, it becomes an annual tradition to analyze what words are mentioned the most in the premier’s report. This year, “stability,” “food,” and “energy” took center stage. (Nikkei Asia $)
Some political representatives come from the tech industry, and it’s common (and permissible) for them to make policy recommendations that are favorable to their own business interests. I called it “the Chinese style of lobbying” in a report last year. (Protocol)
2. Wuxi, a second-tier city in eastern China, announced that it has deliberately destroyed a billion pieces of personal data, as part of its process of decommissioning pandemic surveillance systems. (CNN)
3. Diversifying from manufacturing in China, Foxconn plans to increase production in India from 6 million iPhones a year to 20 million, and to triple the number of workers to 100,000 by 2024. (Wall Street Journal $)
4. Chinese diplomats are being idolized like pop-culture celebrities by young fans on social media. (What’s on Weibo $)
5. China is planning on creating a new government agency that has concentrated authority on various data-related issues, anonymous sources said. (Wall Street Journal $)
6. Activists and investors are criticizing Volkswagen after its CEO toured the company’s factories in Xinjiang and said he didn’t see any sign of forced labor. (Reuters $)
7. Wuling, the Chinese tiny-EV brand that outsold Tesla in 2021, has found its first overseas market in Indonesia, and its cars have become the most popular choice of EV there. (Rest of World)
8. The US government added 37 more Chinese companies, some in genetics research and cloud computing, to its trade blacklist. (Reuters $)
Lost in translation
As startups swarm to develop the Chinese version of ChatGPT, Chinese publication Leiphone made an infographic comparing celebrity founders in China to determine who’s most likely to win the race. The analysis takes into consideration four dimensions: academic reputation and influence, experience working with corporate engineers, resourcefulness within the Chinese political and business ecosystem, and proclaimed interest in joining the AI chatbot arms race.
The two winners of the analysis are Wang Xiaochuan, the CEO of Chinese search engine Sogou, and Lu Qi, a former executive at Microsoft and Baidu. Wang has embedded himself deeply in the circles of Tsinghua University (China’s top engineering school) and Tencent, making it possible for him to assemble a star team quickly. Meanwhile, Lu’s experience working on Microsoft’s Bing and Baidu’s self-driving unit makes him extremely relevant. Plus, Lu is now the head of Y Combinator China and has personal connections to Sam Altman, the CEO of OpenAI and the former president of Y Combinator.
One more thing
Recently, a video went viral in China that shows a driver kneeling in front of his electric vehicle to scan his face. An app in the car system required the driver to verify his identity through facial recognition, and since there’s no camera within the car, the exterior camera on the front of the car was the only option.
China Report is MIT Technology Review’s newsletter about technology developments in China. Sign up to receive it in your inbox every Tuesday.
First of all, I’m still processing the whole “Chinese spy balloon” saga, which, from start to finish, took over everyone’s brains for just about 72 hours and has been one of the weirdest recent events in US-China relations. There are still so many mysteries around it that I don’t want to jump to any conclusions, but I will link to some helpful analyses in the next section. For now, I just want to say: RIP The Balloon.
On a wholly different note, I’ve been preoccupied by the many Chinese individuals who remain in police custody after going into the streets in Beijing late last year to protest zero-covid policies. While action happened in many Chinese cities, it’s the Beijing police who have been consistently making new arrests, as recently as mid-January. According to a Twitter account that’s been following what’s happened with the protesters, over 20 people have been detained in Beijing since December 18, four of them formally charged with the crime of “picking quarrels.” As the Wall Street Journal has reported, many of those arrested have been young women.
For the younger generation in China, the movement last year was an introduction to participating in civil disobedience. But many of these young people lack the technical knowledge to protect themselves when organizing or participating in public events. As the Chinese government’s surveillance capability grows, activists are forced to become tech experts to avoid being monitored. It’s an evolving lesson that every new activist will have to learn.
To better understand what has happened over the past two months and what lies ahead, I reached out to Lü Pin, a feminist activist and scholar currently based in the US. As one of the most prominent voices in China’s current feminist movement, Lü is still involved in activist efforts inside China and the longtime cat-and-mouse game between protesters and police. Even though their work is peaceful and legal, she and her fellow activists often worry that their communications are being intercepted by the government. When we talked last week about the aftermath of the “White Paper Protests,” she explained how she thinks protesters were potentially identified through their communications, why many Chinese protesters continue to use Telegram, and the different methods China’s traditional police force and state security agents use to infiltrate group chats.
The following interview has been translated, lightly edited, and rearranged for clarity.
How did the Chinese police figure out the identity of protesters and arrest them over a month after it happened?
In the beginning, the police likely got access to a Telegram group. Later on, officers could have used facial recognition [to identify people in video footage]. Many people, when participating in the White Paper Protests, were filmed with their faces visible. It’s possible that the police are now working on identifying more faces in these videos.
Those who were arrested have no way of confirming this, but their friends [suspect that facial recognition was used] and spread the message.
And, as you said, it was reported that the police did have information on some protesters’ involvement in a Telegram group. What exactly happened there?
When [these protesters in Beijing] decided to use a Telegram group, they didn’t realize they needed to protect the information on the event. Their Telegram group became very public in the end. Some of them even screenshotted it and posted it on their WeChat timelines.
Even when they were on the streets in Liangma River [where the November 27 protest in Beijing took place], this group chat was still active. What could easily have happened was that when the police arrested them, they didn’t have time to delete the group chat from their phone. If that happened, nothing [about the group] would be secure anymore.
Could there be undercover police in the Telegram group?
It’s inevitable that there were government people in the Telegram group. When we were organizing the feminist movement inside China, there were always state security officials [in the group]. They would use fake identities to talk to organizers and say: I’m a student interested in feminism. I want to attend your event, join your WeChat group, and know when’s the next gathering. They joined countless WeChat groups to monitor the events. It’s not just limited to feminist activists. They are going to join every group chat about civil society groups, no matter if you are [advocating for] LGBTQ rights or environmental protection.
What do they want to achieve by infiltrating these group chats?
Different Chinese ministries have different jobs. The people collecting information [undercover] are mostly from the Ministry of State Security [Editor’s note: this is the agency responsible for foreign intelligence and counterintelligence work]. It operates on a long-term basis, so it would be doing more information collection; it has no responsibility to call off an event.
But the purpose of the Ministry of Public Security [Editor’s note: this is the rank-and-file police force] is to stop our events immediately. It works on a more short-term basis. According to my experience, the technology know-how of the police is relatively [basic]. They mostly work with WeChat and don’t use any VPN. And they are also only responsible for one locality, so it’s easier to tell who they are. For example, if they work for the city of Guangzhuo, they will only care about what’s going to happen in Guangzhou. And people may realize who they are because of that.
I’m also seeing people question whether some Twitter accounts, like the one belonging to “Teacher Li,” were undercover police. Is there any merit to that thinking?
It used to be less complicated. Previously, the government could use censorship mechanisms to control [what people posted] within China, so they didn’t need to [establish phishing accounts on foreign platforms]. But one characteristic of the White Paper Revolution is that it leveraged foreign platforms more than ever before.
But my personal opinion is that the chance of a public [Twitter] account phishing information for the government is relatively small. The government operations don’t necessarily have intricate planning. When we talk about phishing, we are talking about setting up an account, accepting user submissions, monitoring your submissions remotely, and then monitoring your activities. It requires a lot of investment to operate a [public] account. It’s far less efficient than infiltrating a WeChat group or Telegram group to obtain information.
But I don’t think the anxiety is unwarranted. The government’s tools evolve rapidly. Every time the government has learned about our organizing or the information of our members, we try to analyze how it happened. It used to be that we could often find out why, but now we can hardly figure out how the police found us. It means their data investigation skills have modernized. So I think the suspicion [of phishing accounts’ existence] is understandable.
And there is a dilemma here: On one hand, we need to be alert. On the other hand, if we are consumed by fears, the Chinese government will have won. That’s the situation we are in today.
When did people start to use Telegram instead of WeChat?
I started around 2014 or 2015. In 2015, we organized some rescue operations [for five feminist activists detained by the state] through Telegram. Before that, people didn’t realize WeChat was not secure. [Editor’s note: WeChat messages are not end-to-end encrypted and have been used by the police for prosecution.] Afterwards, when people were looking for a secure messaging app, the first option was Telegram. At the time, it was both secure and accessible in China. Later, Telegram was blocked, but the habit [of using it] remained. But I don’t use Telegram now.
It does feel like Telegram has gained this reputation of “the protest app of choice” even though it’s not necessarily the most secure one. Why is that?
If you are just a small underground circle, there are a lot of software options you can use. But if you also want other people to join your group, then it has to be something people already know and use widely. That’s how Telegram became the choice.
But in my opinion, if you are already getting out of the Great Firewall, you can use Signal, or you can use WhatsApp. But many Chinese people don’t know about WhatsApp, so they choose to stay on Telegram. It has a lot to do with the reputation of Telegram. There’s a user stickiness issue with any software you use. Every time you migrate to new software, you will lose a great number of users. That’s a serious problem.
So what apps are you using now to communicate with protesters in China?
The app we use now? That’s a secret [laughs]. The reason why Telegram was monitored and blocked in the first place was because there was lots of media reporting on Telegram use back in 2015.
What do you think about the security protocols taken by Telegram and other communication apps? Let me know at zeyi@technologyreview.com.
Catch up with China
1. The balloon fiasco caused US Secretary of State Antony Blinken to postpone his meeting with President Xi Jinping of China, which was originally planned for this week. (CNN)
While the specific goals of the balloon’s trip are unclear, an expert said the termination mechanism likely failed to function. (Ars Technica)
Since the balloon was shot down over the weekend, the US Coast Guard has been searching for debris in the Atlantic, which US officials hope to use to reconstruct Chinese intelligence-gathering methods. (Reuters $)
The balloon itself didn’t necessarily pose many risks, but the way the situation escalated makes clear that military officials in the two countries do not currently have good communication. (New York Times $)
2. TikTok finally opened a transparency center in LA, three years after it first announced it’d build new sites where people could examine how the app conducts moderation. A Forbes journalist who was allowed to tour the center wasn’t impressed. (Forbes)
3. Baidu, China’s leading search engine and AI company, is planning to release its own version of ChatGPT in March. (Bloomberg $)
4. The past three months should have been the busiest season for Foxconn’s iPhone assembly factory in China. Instead, it was disrupted by mass covid-19 infections and intense labor protests. (Rest of World)
5. A new decentralized social media platform called Damus had its five minutes (actually, two days) of fame in China before Apple swiftly removed it from China’s App Store for violating domestic cybersecurity laws. (South China Morning Post $)
6. Taiwan decided to shut down all nuclear power plants by 2025. But its renewable-energy industry is not ready to fill in the gap, and now new fossil-fuel plants are being built to secure the energy supply. (HuffPost)
7. The US Department of Justice suspects that executives of the San Diego–based self-driving-truck company TuSimple have improperly transferred technology to China, anonymous sources said. (Wall Street Journal $)
Lost in translation
Renting smartphones is becoming a popular alternative to purchasing them in China, according to the Chinese publication Shenran Caijing. With 19 billion RMB ($2.79 billion) spent on smartphone rentals in 2021, it is a niche but growing market in the country. Many people opt for rentals to be able to brag about having the latest model, or as a temporary solution when, for example, their phone breaks down and the new iPhone doesn’t come out for a few months.
But this isn’t exactly saving people cash. While renting a phone costs only one or two bucks a day, the fees build up over time, and many platforms require leases to be at least six months long. In the end, it may not be as cost-effective as buying a phone outright.
The high costs and lack of regulation have led some individuals to exploit the system. Some people use it as a form of cash loan: they rent a high-end phone, immediately sell it for cash, and slowly pay back the rental and buyout fees. There are also cases of scams where people use someone else’s identity to rent a phone, only to disappear once they obtain the device.
One more thing
Born in Wuhan, I grew up eating freshwater fish like Prussian carp. They taste divine, but the popular kinds often have more small bones than saltwater fish, which can make the eating experience laborious and annoying. Last week, a team of Chinese hydrobiologists based in Wuhan (duh) announced that they had used CRISPR-Cas9 gene-editing technology to create a Prussian carp mutant that is free of the small bones. Not gonna lie, this is true innovation to me.
When Greg unboxed a new Roomba robot vacuum cleaner in December 2019, he thought he knew what he was getting into.
He would allow the preproduction test version of iRobot’s Roomba J series device to roam around his house, let it collect all sorts of data to help improve its artificial intelligence, and provide feedback to iRobot about his user experience.
He had done this all before. Outside of his day job as an engineer at a software company, Greg had been beta-testing products for the past decade. He estimates that he’s tested over 50 products in that time—everything from sneakers to smart home cameras.
“I really enjoy it,” he says. “The whole idea is that you get to learn about something new, and hopefully be involved in shaping the product, whether it’s making a better-quality release or actually defining features and functionality.”
But what Greg didn’t know—and does not believe he consented to—was that iRobot would share test users’ data in a sprawling, global data supply chain, where everything (and every person) captured by the devices’ front-facing cameras could be seen, and perhaps annotated, by low-paid contractors outside the United States who could screenshot and share images at their will.
Greg, who asked that we identify him only by his first name because he signed a nondisclosure agreement with iRobot, is not the only test user who feels dismayed and betrayed.
Nearly a dozen people who participated in iRobot’s data collection efforts between 2019 and 2022 have come forward in the weeks since MIT Technology Review published an investigation into how the company uses images captured from inside real homes to train its artificial intelligence. The participants have shared similar concerns about how iRobot handled their data—and whether those practices conform with the company’s own data protection promises. After all, the agreements go both ways, and whether or not the company legally violated its promises, the participants feel misled.
“There is a real concern about whether the company is being deceptive if people are signing up for this sort of highly invasive type of surveillance and never fully understand … what they’re agreeing to,” says Albert Fox Cahn, the executive director of the Surveillance Technology Oversight Project.
The company’s failure to adequately protect test user data feels like “a clear breach of the agreement on their side,” Greg says. It’s “a failure … [and] also a violation of trust.”
Now, he wonders, “where is the accountability?”
The blurry line between testers and consumers
Last month MIT Technology Review revealed how iRobot collects photos and videos from the homes of test users and employees and shares them with data annotation companies, including San Francisco–based Scale AI, which hire far-flung contractors to label the data that trains the company’s artificial-intelligence algorithms.
We found that in one 2020 project, gig workers in Venezuela were asked to label objects in a series of images of home interiors, some of which included individuals—their faces visible to the data annotators. These workers then shared at least 15 images—including shots of a minor and of a woman sitting on the toilet—to social media groups where they gathered to talk shop. We know about these particular images because the screenshots were subsequently shared with us, but our interviews with data annotators and researchers who study data annotation suggest they are unlikely to be the only ones that made their way online; it’s not uncommon for sensitive images, videos, and audio to be shared with labelers.
Shortly after MIT Technology Review contacted iRobot for comment on the photos last fall, the company terminated its contract with Scale AI.
Nevertheless, in a LinkedIn post in response to our story, iRobot CEO Colin Angle did not acknowledge the mere fact that these images, and the faces of test users, were visible to human gig workers was a reason for concern. Rather, he wrote, making such images available was actually necessary to train iRobot’s object recognition algorithms: “How do our robots get so smart? It starts during the development process, and as part of that, through the collection of data to train machine learning algorithms.” Besides, he pointed out, the images came not from customers but from “paid data collectors and employees” who had signed consent agreements.
In the LinkedIn post and in statements to MIT Technology Review, Angle and iRobot have repeatedly emphasized that no customer data was shared and that “participants are informed and acknowledge how the data will be collected.”
This attempt to clearly delineate between customers and beta testers—and how those people’s data will be treated—has been confounding to many testers, who say they consider themselves part of iRobot’s broader community and feel that the company’s comments are dismissive. Greg and the other testers who reached out also strongly dispute any implication that by volunteering to test a product, they have signed away all their privacy.
What’s more, the line between tester and consumer is not so clear cut. At least one of the testers we spoke with enjoyed his test Roomba so much that he later purchased the device.
This is not an anomaly; rather, converting beta testers to customers and evangelists for the product is something Centercode, the company that recruited the participants on behalf of iRobot, actively tries to promote: “It’s hard to find better potential brand ambassadors than in your beta tester community. They’re a great pool of free, authentic voices that can talk about your launched product to the world, and their (likely techie) friends,” it wrote in a marketing blog post.
To Greg, iRobot has “failed spectacularly” in its treatment of the testing community, particularly in its silence over the privacy breach. iRobot says it has notified individuals whose photos appeared in the set of 15 images, but it did not respond to a question about whether it would notify other individuals who had taken part in its data collection. The participants who reached out to us said they have not received any kind of notice from the company.
“If your credit card information … was stolen at Target, Target doesn’t notify the one person who has the breach,” he adds. “They send out a notification that there was a breach, this is what happened, [and] this is how they’re handling it.”
Inside the world of beta testing
The journey of iRobot’s AI-powering data points starts on testing platforms like Betabound, which is run by Centercode. The technology company, based in Laguna Hills, California, recruits volunteers to test out products and services for its clients—primarily consumer tech companies. (iRobot spokespersonJames Baussmannconfirmed that the company has used Betabound but said that “not all of the paid data collectors were recruited via Betabound.” Centercode did not respond to multiple requests for comment.)
“If your credit card information … was stolen at Target, Target doesn’t notify the one person who has the breach.”
As early adopters, beta testers are often more tech savvy than the average consumer. They are enthusiastic about gadgets and, like Greg, sometimes work in the technology sector themselves—so they are often well aware of the standards around data protection.
A review of all 6,200 test opportunities listed on Betabound’s website as of late December shows that iRobot has been testing on the platform since at least 2017. The latest project, which is specifically recruiting German testers, started just last month.
Need some help with your household chores? Our friends at iRobot have a new opportunity for German testers to try out a robotic cleaning device. To sign up with iRobot and apply, click here: https://t.co/YJbVoeSKPp#newbetatest#testing#irobot#smarthome
iRobot’s vacuums are far from the only devices in its category. There are over 300 tests listed for other “smart” devices powered by AI, including “a smart microwave with Alexa support,” as well as multipleother robot vacuums.
The first step for potential testers is to fill out a profile on the Betabound website. They can then apply for specific opportunities as they’re announced. If accepted by the company running the test, testers sign numerous agreements before they are sent the devices.
Betabound testers are not paid, as the platform’s FAQ for testers notes: “Companies cannot expect your feedback to be honest and reliable if you’re being paid to give it.” Rather, testers might receive gift cards, a chance to keep their test devices free of charge, or complimentary production versions delivered after the device they tested goes to market.
iRobot, however, did not allow testers to keep their devices, nor did they receive final products. Instead, the beta testers told us that they received gift cards in amounts ranging from $30 to $120 for running the robot vacuums multiple times a week over multiple weeks. (Baussmann says that “with respect to the amount paid to participants, it varies depending upon the work involved.”)
For some testers, this compensation was disappointing—“even before considering … my naked ass could now be on the Internet,” as B, a tester we’re identifying only by his first initial, wrote in an email. He called iRobot “cheap bastards” for the $30 gift card that he received for his data, collected daily over three months.
What users are really agreeing to
When MIT Technology Review reached out to iRobot for comment on the set of 15 images last fall, the company emphasized that each image had a corresponding consent agreement. It would not, however, share the agreements with us, citing “legal reasons.” Instead, the company said the agreement required an “acknowledgment that video and images are being captured during cleaning jobs” and that “the agreement encourages paid data collectors to remove anything they deem sensitive from any space the robot operates in, including children.”
Test users have since shared with MIT Technology Review copies of their agreement with iRobot. These include several different forms—including a general Betabound agreement and a “global test agreement for development robots,” as well as agreements onnondisclosure, test participation, and product loan. There are also agreements for some of the specific tests being run.
The text of iRobot’s global test agreement from 2019, copied into a new document to protect the identity of test users.
The forms do contain the language iRobot previously laid out, while also spelling out the company’s own commitments on data protection for test users. But they provide little clarity on what exactly that means, especially how the company will handle user data after it’s collected and whom the data will be shared with.
The “global test agreement for development robots,” similar versions of which were independently shared by a half-dozen individuals who signed them between 2019 and 2022, contains the bulk of the information on privacy and consent.
In the short document of roughly 1,300 words, iRobot notes that it is the controller of information, which comes with legal responsibilities under the EU’s GDPR to ensure that data is collected for legitimate purposes and securely stored and processed. Additionally, it states, “iRobot agrees that third-party vendors and service providers selected to process [personal information] will be vetted for privacy and data security, will be bound by strict confidentiality, and will be governed by the terms of a Data Processing Agreement,” and that users “may be entitled to additional rights under applicable privacy laws where [they] reside.”
It’s this section of the agreement that Greg believes iRobot breached. “Where in that statement is the accountability that iRobot is proposing to the testers?” he asks. “I completely disagree with how offhandedly this is being responded to.”
“A lot of this language seems to be designed to exempt the company from applicable privacy laws, but none of it reflects the reality of how the product operates.”
What’s more, all test participants had to agree that their data could be used for machine learning and object detection training. Specifically, the global test agreement’s section on “use of research information” required an acknowledgment that “text, video, images, or audio … may be used by iRobot to analyze statistics and usage data, diagnose technology problems, enhance product performance, product and feature innovation, market research, trade presentations, and internal training, including machine learning and object detection.”
What isn’t spelled out here is that iRobot carries out the machine-learning training through human data labelers who teach the algorithms, click by click, to recognize the individual elements captured in the raw data. In other words, the agreements shared with us never explicitly mention that personal images will be seen and analyzed by other humans.
Baussmann, iRobot’s spokesperson, said that the language we highlighted “covers a variety of testing scenarios” and is not specific to images sent for data annotation. “For example, sometimes testers are asked to take photos or videos of a robot’s behavior, such as when it gets stuck on a certain object or won’t completely dock itself, and send those photos or videos to iRobot,” he wrote, adding that “for tests in which images will be captured for annotation purposes, there are specific terms that are outlined in the agreement pertaining to that test.”
He also wrote that “we cannot be sure the people you have spoken with were part of the development work that related to your article,” though he notably did not dispute the veracity of the global test agreement, which ultimately allows all test users’ data to be collected and used for machine learning.
What users really understand
When we asked privacy lawyers and scholars to review the consent agreements and shared with them the test users’ concerns, they saw the documents and the privacy violations that ensued as emblematic of a broken consent framework that affects us all—whether we are beta testers or regular consumers.
Experts say companies are well aware that people rarely read privacy policies closely, if we read them at all. But what iRobot’s global test agreement attests to, says Ben Winters, a lawyer with the Electronic Privacy Information Center who focuses on AI and human rights, is that “even if you do read it, you still don’t get clarity.”
Rather, “a lot of this language seems to be designed to exempt the company from applicable privacy laws, but none of it reflects the reality of how the product operates,” says Cahn, pointing to the robot vacuums’ mobility and the impossibility of controlling where potentially sensitive people or objects—in particular children—are at all times in their own home.
Ultimately, that “place[s] much of the responsibility … on the end user,” notes Jessica Vitak, an information scientist at the University of Maryland’s College of Information Studies who studies best practices in research and consent policies. Yet it doesn’t give them a true accounting of “how things might go wrong,” she says—“which would be very valuable information when deciding whether to participate.”
Not only does it put the onus on the user; it also leaves it to that single person to “unilaterally affirm the consent of every person within the home,” explains Cahn, even though “everyone who lives in a house that uses one of these devices will potentially be put at risk.”
All of this lets the company shirk its true responsibility as a data controller, adds Deirdre Mulligan, a professor in the School of Information at UC Berkeley. “A device manufacturer that is a data controller” can’t simply “offload all responsibility for the privacy implications of the device’s presence in the home to an employee” or other volunteer data collectors.
Some participants did admit that they hadn’t read the consent agreement closely. “I skimmed the [terms and conditions] but didn’t notice the part about sharing *video and images* with a third party—that would’ve given me pause,” one tester, who used the vacuum for three months last year, wrote in an email.
Before testing his Roomba, B said, he had “perused” the consent agreement and “figured it was a standard boilerplate: ‘We can do whatever the hell we want with what we collect, and if you don’t like that, don’t participate [or] use our product.’” He added, “Admittedly, I just wanted a free product.”
Still, B expected that iRobot would offer some level of data protection—not that the “company that made us swear up and down with NDAs that we wouldn’t share any information” about the tests would “basically subcontract their most intimate work to the lowest bidder.”
Notably, many of the test users who reached out—even those who say they did read the full global test agreement, as well as myriad other agreements, including ones applicable to all consumers—still say they lacked a clear understanding of what collecting their data actually meant or how exactly that data would be processed and used.
What they did understand often depended more on their own awareness of how artificial intelligence is trained than on anything communicated by iRobot.
One tester, Igor, who asked to be identified only by his first name, works in IT for a bank; he considers himself to have “above average training in cybersecurity” and has built his own internet infrastructure at home, allowing him to self-host sensitive information on his own servers and monitor network traffic. He said he did understand that videos would be taken from inside his home and that they would be tagged.“I felt that the company handled the disclosure of the data collection responsibly,” he wrote in an email, pointing to both the consent agreement and the device’s prominently placed sticker reading “video recording in process.” But, he emphasized, “I’m not an average internet user.”
Photo of iRobot’s preproduction Roomba J series device.
COURTESY OF IROBOT
For many testers, the greatest shock from our story was how the data would be handled after collection—including just how much humans would be involved. “I assumed it [the video recording] was only for internal validation if there was an issue as is common practice (I thought),” another tester who asked to be anonymous wrote in an email. And as B put it, “It definitely crossed my mind that these photos would probably be viewed for tagging within a company, but the idea that they were leaked online is disconcerting.”
“Human review didn’t surprise me,” Greg adds, but “the level of human review did … the idea, generally, is that AI should be able to improve the system 80% of the way … and the remainder of it, I think, is just on the exception … that [humans] have to look at it.”
Even the participants who were comfortable with having their images viewed and annotated, like Igor, said they were uncomfortable with how iRobot processed the data after the fact. The consent agreement, Igor wrote, “doesn’t excusethe poor data handling” and “the overall storage and control that allowed a contractor to export the data.”
Multiple US-based participants, meanwhile, expressed concerns about their data being transferred out of the country. The global agreement, they noted, had language for participants “based outside of the US” saying that “iRobot may process Research Data on servers not in my home country … including those whose laws may not offer the same level of data protection as my home country”—but the agreement did not have any corresponding information for US-based participants on how their data would be processed.
“I had no idea that the data was going overseas,” one US-based participant wrote to MIT Technology Review—a sentiment repeated by many.
Once data is collected, whether from test users or from customers, people ultimately have little to no control over what the company does with it next—including, for US users, sharing their data overseas.
US users, in fact, have few privacy protections even in their home country, notes Cahn, which is why the EU has laws to protect data from being transferred outside the EU—and to the US specifically. “Member states have to take such extensive steps to protect data being stored in that country. Whereas in the US, it’s largely the Wild West,” he says. “Americans have no equivalent protection against their data being stored in other countries.”
For some testers, this compensation was disappointing—“even before considering … my naked ass could now be on the Internet.”
Many testers themselves are aware of the broader issues around data protection in the US, which is why they chose to speak out.
“Outside of regulated industries like banking and health care, the best thing we can probably do is create significant liability for data protection failure, as only hard economic incentives will make companies focus on this,” wrote Igor, the tester who works in IT at a bank. “Sadly the political climate doesn’t seem like anything could pass here in the US. The best we have is the public shaming … but that is often only reactionary and catches just a small percentage of what’s out there.”
In the meantime, in the absence of change and accountability—whether from iRobot itself or pushed by regulators—Greg has a message for potential Roomba buyers. “I just wouldn’t buy one, flat out,” he says, because he feels “iRobot is not handling their data security model well.”
And on top of that, he warns, they’re “really dismissing their responsibility as vendors to … notify [or] protect customers—which in this case include the testers of these products.”
Lam Thuy Vo contributed research.
Correction: This piece has been updated to clarify what iRobot CEO Colin Angle wrote in a LinkedIn post in response to faces appearing in data collection.
In the fall of 2020, gig workers in Venezuela posted a series of images to online forums where they gathered to talk shop. The photos were mundane, if sometimes intimate, household scenes captured from low angles—including some you really wouldn’t want shared on the Internet.
In one particularly revealing shot, a young woman in a lavender T-shirt sits on the toilet, her shorts pulled down to mid-thigh.
The images were not taken by a person, but by development versions of iRobot’s Roomba J7 series robot vacuum. They were then sent to Scale AI, a startup that contracts workers around the world to label audio, photo, and video data used to train artificial intelligence.
They were the sorts of scenes that internet-connected devices regularly capture and send back to the cloud—though usually with stricter storage and access controls. Yet earlier this year, MIT Technology Review obtained 15 screenshots of these private photos, which had been posted to closed social media groups.
The photos vary in type and in sensitivity. The most intimate image wesaw was the series of video stills featuring the young woman on the toilet, her face blocked in the lead image but unobscured in the grainy scroll of shots below. In another image, a boy who appears to be eight or nine years old, and whose face is clearly visible, is sprawled on his stomach across a hallway floor. A triangular flop of hair spills across his forehead as he stares, with apparent amusement, at the object recording him from just below eye level.
The other shots show rooms from homes around the world, some occupied by humans, one by a dog. Furniture, décor, and objects located high on the walls and ceilings are outlined by rectangular boxes and accompanied by labels like “tv,” “plant_or_flower,” and “ceiling light.”
iRobot—the world’s largest vendor of robotic vacuums, which Amazon recently acquired for $1.7 billion in a pending deal—confirmed that these images were captured by its Roombas in 2020. All of them came from “special development robots with hardware and software modifications that are not and never were present on iRobot consumer products for purchase,” the company said in a statement. They were given to “paid collectors and employees” who signed written agreements acknowledging that they were sending data streams, including video, back to the company for training purposes. According to iRobot, the devices were labeled with a bright green sticker that read “video recording in progress,” and it was up to those paid data collectors to “remove anything they deem sensitive from any space the robot operates in, including children.”
In other words, by iRobot’s estimation, anyone whose photos or video appeared in the streams had agreed to let their Roombas monitor them. iRobot declined to let MIT Technology Review view the consent agreements and did not make any of its paid collectors or employees available to discuss their understanding of the terms.
While the images shared with us did not come from iRobot customers, consumers regularly consent to having our data monitored to varying degrees on devices ranging from iPhones to washing machines. It’s a practice that has only grown more common over the past decade, as data-hungry artificial intelligence has been increasingly integrated into a whole new array of products and services. Much of this technology is based on machine learning, a technique that uses large troves of data—including our voices, faces, homes, and other personal information—to train algorithms to recognize patterns. The most useful data sets are the most realistic, making data sourced from real environments, like homes, especially valuable. Often, we opt in simply by using the product, as noted in privacy policies with vague language that gives companies broad discretion in how they disseminate and analyze consumer information.
Did you participate in iRobot’s data collection efforts? We’d love to hear from you. Please reach out at tips@technologyreview.com.
The data collected by robot vacuums can be particularly invasive. They have “powerful hardware, powerful sensors,” says Dennis Giese, a PhD candidate at Northeastern University who studies the security vulnerabilities of Internet of Things devices, including robot vacuums. “And they can drive around in your home—and you have no way to control that.” This is especially true, he adds, of devices with advanced cameras and artificial intelligence—like iRobot’s Roomba J7 series.
This data is then used to build smarter robots whose purpose may one day go far beyond vacuuming. But to make these data sets useful for machine learning, individual humans must first view, categorize, label, and otherwise add context to each bit of data. This process is called data annotation.
“There’s always a group of humans sitting somewhere—usually in a windowless room, just doing a bunch of point-and-click: ‘Yes, that is an object or not an object,’” explains Matt Beane, an assistant professor in the technology management program at the University of California, Santa Barbara, who studies the human work behind robotics.
The 15 images shared with MIT Technology Review are just a tiny slice of a sweeping data ecosystem. iRobot has said that it has shared over 2 million images with Scale AI and an unknown quantity more with other data annotation platforms; the company has confirmed that Scale is just one of the data annotators it has used.
James Baussmann, iRobot’s spokesperson, said in an email the company had “taken every precaution to ensure that personal data is processed securely and in accordance with applicable law,” and that the images shared with MIT Technology Review were “shared in violation of a written non-disclosure agreement between iRobot and an image annotation service provider.” In an emailed statement a few weeks after we shared the images with the company, iRobot CEO Colin Angle said that “iRobot is terminating its relationship with the service provider who leaked the images, is actively investigating the matter, and [is] taking measures to help prevent a similar leak by any service provider in the future.” The company did not respond to additional questions about what those measures were.
Ultimately, though, this set of images represents something bigger than any one individual company’s actions. They speak to the widespread, and growing, practice of sharing potentially sensitive data to train algorithms, as well as the surprising, globe-spanning journey that a single image can take—in this case, from homes in North America, Europe, and Asia to the servers of Massachusetts-based iRobot, from there to San Francisco–based Scale AI, and finally to Scale’s contracted data workers around the world (including, in this instance, Venezuelan gig workers who posted the images to private groups on Facebook, Discord, and elsewhere).
Together, the images reveal a whole data supply chain—and new points where personal information could leak out—that few consumers are even aware of.
“It’s not expected that human beings are going to be reviewing the raw footage,” emphasizes Justin Brookman, director of tech policy at Consumer Reports and former policy director of the Federal Trade Commission’s Office of Technology Research and Investigation. iRobot would not say whether data collectors were aware that humans, in particular, would be viewing these images, though the company said the consent form made clear that “service providers” would be.
“It’s not expected that human beings are going to be reviewing the raw footage.”
“We literally treat machines differently than we treat humans,” adds Jessica Vitak, an information scientist and professor at the University of Maryland’s communication department and its College of Information Studies. “It’s much easier for me to accept a cute little vacuum, you know, moving around my space [than] somebody walking around my house with a camera.”
And yet, that’s essentially what is happening. It’s not just a robot vacuum watching you on the toilet—a person may be looking too.
The robot vacuum revolution
Robot vacuums weren’t always so smart.
The earliest model, the Swiss-made Electrolux Trilobite, came to market in 2001. It used ultrasonic sensors to locate walls and plot cleaning patterns; additional bump sensors on its sides and cliff sensors at the bottom helped it avoid running into objects or falling off stairs. But these sensors were glitchy, leading the robot to miss certain areas or repeat others. The result was unfinished and unsatisfactory cleaning jobs.
The next year, iRobot released the first-generation Roomba, which relied on similar basic bump sensors and turn sensors. Much cheaper than its competitor, it became the first commercially successful robot vacuum.
The most basic models today still operate similarly, while midrange cleaners incorporate better sensors and other navigational techniques like simultaneous localization and mapping to find their place in a room and chart out better cleaning paths.
Higher-end devices have moved on to computer vision, a subset of artificial intelligence that approximates human sight by training algorithms to extract information from images and videos, and/or lidar, a laser-based sensing technique used by NASA and widely considered the most accurate—but most expensive—navigational technology on the market today.
Computer vision depends on high-definition cameras, and by our count, around a dozencompanieshave incorporated front-facing cameras into their robot vacuums for navigation and object recognition—as well as, increasingly, home monitoring. This includes the top three robot vacuum makers by market share: iRobot, which has 30% of the market and has sold over 40 million devices since 2002; Ecovacs, with about 15%; and Roborock, which has about another 15%, according to the market intelligence firm Strategy Analytics. It also includes familiar household appliance makers like Samsung, LG, and Dyson, among others. In all, some 23.4 million robot vacuums were sold in Europe and the Americas in 2021 alone, according to Strategy Analytics.
From the start, iRobot went all in on computer vision, and its first device with such capabilities, the Roomba 980, debuted in 2015. It was also the first of iRobot’s Wi-Fi-enabled devices, as well as its first that could map a home, adjust its cleaning strategy on the basis of room size, and identify basic obstacles to avoid.
Computer vision “allows the robot to … see the full richness of the world around it,” says Chris Jones, iRobot’s chief technology officer. It allows iRobot’s devices to “avoid cords on the floor or understand that that’s a couch.”
But for computer vision in robot vacuums to truly work as intended, manufacturers need to train it on high-quality, diverse data sets that reflect the huge range of what they might see. “The variety of the home environment is a very difficult task,” says Wu Erqi, the senior R&D director of Beijing-based Roborock.Road systems “are quite standard,” he says, so for makers of self-driving cars, “you’ll know how the lane looks … [and] how the traffic sign looks.” But each home interior is vastly different.
“The furniture is not standardized,” he adds. “You cannot expect what will be on your ground. Sometimes there’s a sock there, maybe some cables”—and the cables may look different in the US and China.
MATTHIEU BOUREL
MIT Technology Review spoke with or sent questions to 12 companies selling robot vacuums and found that they respond to the challenge of gathering training data differently.
In iRobot’s case, over 95% of its image data set comes from real homes, whose residents are either iRobot employees or volunteers recruited by third-party data vendors (which iRobot declined to identify). People using development devices agree to allow iRobot to collect data, including video streams, as the devices are running, often in exchange for “incentives for participation,” according to a statement from iRobot.The company declined to specify what these incentives were, saying only that they varied “based on the length and complexity of the data collection.”
The remaining training data comes from what iRobot calls “staged data collection,” in which the company builds models that it then records.
iRobot has also begun offering regular consumers the opportunity to opt in to contributing training data through its app, where people can choose to send specific images of obstacles to company servers to improve its algorithms. iRobot says that if a customer participates in this “user-in-the-loop” training, as it is known, the company receives only these specific images, and no others. Baussmann, the company representative, said in an email that such images have not yet been used to train any algorithms.
In contrast to iRobot, Roborock said that it either “produce[s] [its] own images in [its] labs” or “work[s] with third-party vendors in China who are specifically asked to capture & provide images of objects on floors for our training purposes.” Meanwhile, Dyson, which sells two high-end robot vacuum models, said that it gathers data from two main sources: “home trialists within Dyson’s research & development department with a security clearance” and, increasingly, synthetic, or AI-generated, training data.
Most robot vacuum companies MIT Technology Review spoke with explicitly said they don’t use customer data to train their machine-learning algorithms. Samsung did not respond to questions about how it sources its data (though it wrote that it does not use Scale AI for data annotation), while Ecovacs calls the source of its training data “confidential.” LG and Bosch did not respond to requests for comment.
“You have to assume that people … ask each other for help. The policy always says that you’re not supposed to, but it’s very hard to control.”
Some clues about other methods of data collection come from Giese, the IoT hacker, whose office at Northeastern is piled high with robot vacuums that he has reverse-engineered, giving him access to their machine-learning models. Some are produced by Dreame, a relatively new Chinese company based in Shenzhen that sells affordable, feature-rich devices.
Giese found that Dreame vacuums have a folder labeled “AI server,” as well as image upload functions. Companies often say that “camera data is never sent to the cloud and whatever,” Giese says, but “when I had access to the device, I was basically able to prove that it’s not true.” Even if they didn’t actually upload any photos, he adds, “[the function] is always there.”
Dreame manufactures robot vacuums that are also rebranded and sold by other companies—an indication that this practice could be employed by other brands as well, says Giese.
Dreame did not respond to emailed questions about the data collected from customer devices, but in the days following MIT Technology Review’s initial outreach, the company began changing its privacy policies, including those related to how it collects personal information, and pushing out multiple firmware updates.
But without either an explanation from companies themselves or a way, besides hacking, to test their assertions, it’s hard to know for sure what they’re collecting from customers for training purposes.
How and why our data ends up halfway around the world
With the raw data required for machine-learning algorithms comes the need for labor, and lots of it. That’s where data annotation comes in. A young but growing industry, data annotation is projected to reach $13.3 billion in market value by 2030.
The field took off largely to meet the huge need for labeled data to train the algorithms used in self-driving vehicles. Today, data labelers, who are often low-paid contract workers in the developing world, help power much of what we take for granted as “automated” online. They keep the worst of the Internet out of our social media feeds by manually categorizing and flagging posts, improve voice recognition software by transcribing low-quality audio, and help robot vacuums recognize objects in their environments by tagging photos and videos.
Among the myriad companies that have popped up over the past decade,Scale AI has become the market leader. Founded in 2016, it built a business model around contracting with remote workers in less-wealthy nations at cheap project- or task-based rates on Remotasks, its proprietary crowdsourcing platform.
In 2020, Scale posted a new assignment there: Project IO. It featured images captured from the ground and angled upwards at roughly 45 degrees, and showed the walls, ceilings, and floors of homes around the world, as well as whatever happened to be in or on them—including people, whose faces were clearly visible to the labelers.
Labelers discussed Project IO in Facebook, Discord, and other groups that they had set up to share advice on handling delayed payments, talk about the best-paying assignments, or request assistance in labeling tricky objects.
iRobot confirmed that the 15 images posted in these groups and subsequently sent to MIT Technology Review came from its devices, sharing a spreadsheet listing the specific dates they were made (between June and November 2020), the countries they came from (the United States, Japan, France, Germany, and Spain), and the serial numbers of the devices that produced the images, as well as a column indicating that a consent form had been signed by each device’s user. (Scale AI confirmed that 13 of the 15 images came from “an R&D project [it] worked on with iRobot over two years ago,” though it declined to clarify the origins of or offer additional information on the other two images.)
iRobot says that sharing images in social media groups violates Scale’s agreements with it, and Scale says that contract workers sharing these images breached their own agreements.
“The underlying problem is that your face is like a password you can’t change. Once somebody has recorded the ‘signature’ of your face, they can use it forever to find you in photos or video.”
But such actions are nearly impossible to police on crowdsourcing platforms.
When I ask Kevin Guo, the CEO of Hive, a Scale competitor that also depends on contract workers, if he is aware of data labelers sharing content on social media, he is blunt. “These are distributed workers,” he says. “You have to assume that people … ask each other for help. The policy always says that you’re not supposed to, but it’s very hard to control.”
That means that it’s up to the service provider to decide whether or not to take on certain work. For Hive, Guo says, “we don’t think we have the right controls in place given our workforce” to effectively protect sensitive data. Hive does not work with any robot vacuum companies, he adds.
“It’s sort of surprising to me that [the images] got shared on a crowdsourcing platform,” says Olga Russakovsky, the principal investigator at Princeton University’s Visual AI Lab and a cofounder of the group AI4All. Keeping the labeling in house, where “folks are under strict NDAs” and “on company computers,” would keep the data far more secure, she points out.
In other words, relying on far-flung data annotators is simply not a secure way to protect data. “When you have data that you’ve gotten from customers, it would normally reside in a database with access protection,” says Pete Warden, a leading computer vision researcher and a PhD student at Stanford University. But with machine-learning training, customer data is all combined “in a big batch,” widening the “circle of people” who get access to it.
Screenshots shared with MIT Technology Review of data annotation in progress
For its part, iRobot says that it shares only a subset of training images with data annotation partners, flags any image with sensitive information, and notifies the company’s chief privacy officer if sensitive information is detected. Baussmann calls this situation “rare,” and adds that when it does happen, “the entire video log, including the image, is deleted from iRobot servers.”
The company specified, “When an image is discovered where a user is in a compromising position, including nudity, partial nudity, or sexual interaction, it is deleted—in addition to ALL other images from that log.” It did not clarify whether this flagging would be done automatically by algorithm or manually by a person, or why that did not happen in the case of the woman on the toilet.
iRobot policy, however, does not deem faces sensitive, even if the people are minors.
“In order to teach the robots to avoid humans and images of humans”—a feature that it has promoted to privacy-wary customers—the company “first needs to teach the robot what a human is,” Baussmann explained. “In this sense, it is necessary to first collect data of humans to train a model.” The implication is that faces must be part of that data.
But facial images may not actually be necessary for algorithms to detect humans, according to William Beksi, a computer science professor who runs the Robotic Vision Laboratory at the University of Texas at Arlington: human detector models can recognize people based “just [on] the outline (silhouette) of a human.”
“If you were a big company, and you were concerned about privacy, you could preprocess these images,” Beksi says. For example, you could blur human faces before they even leave the device and “before giving them to someone to annotate.”
“It does seem to be a bit sloppy,” he concludes, “especially to have minors recorded in the videos.”
In the case of the woman on the toilet, a data labeler made an effort to preserve her privacy, by placing a black circle over her face. But in no other images featuring people were identities obscured, either by the data labelers themselves, by Scale AI, or by iRobot. That includes the image of the young boy sprawled on the floor.
Baussmann explained that iRobot protected “the identity of these humans” by “decoupling all identifying information from the images … so if an image is acquired by a bad actor, they cannot map backwards to identify the person in the image.”
But capturing faces is inherently privacy-violating, argues Warden. “The underlying problem is that your face is like a password you can’t change,” he says. “Once somebody has recorded the ‘signature’ of your face, they can use it forever to find you in photos or video.”
MATTHIEU BOUREL
Additionally, “lawmakers and enforcers in privacy would view biometrics, including faces, as sensitive information,” says Jessica Rich, a privacy lawyer who served as director of the FTC’s Bureau of Consumer Protection between 2013 and 2017. This is especially the case if any minors are captured on camera, she adds: “Getting consent from the employee [or testers] isn’t the same as getting consent from the child. The employee doesn’t have the capacity to consent to data collection about other individuals—let alone the children that appear to be implicated.” Rich says she wasn’t referring to any specific company in these comments.
In the end, the real problem is arguably not that the data labelers shared the images on social media. Rather, it’s that this type of AI training set—specifically, one depicting faces—is far more common than most people understand, notes Milagros Miceli, a sociologist and computer scientist who has been interviewing distributed workers contracted by data annotation companies for years. Miceli has spoken to multiple labelers who have seen similar images, taken from the same low vantage points and sometimes showing people in various stages of undress.
The data labelers found this work “really uncomfortable,” she adds.
Surprise: you may have agreed to this
Robot vacuum manufacturers themselves recognize the heightened privacy risks presented by on-device cameras. “When you’ve made the decision to invest in computer vision, you do have to be very careful with privacy and security,” says Jones, iRobot’s CTO. “You’re giving this benefit to the product and the consumer, but you also have to be treating privacy and security as a top-order priority.”
In fact, iRobot tells MIT Technology Review it has implemented many privacy- and security-protecting measures in its customer devices, including using encryption, regularly patching security vulnerabilities, limiting and monitoring internal employee access to information, and providing customers with detailed information on the data that it collects.
But there is a wide gap between the way companies talk about privacy and the way consumers understand it.
It’s easy, for instance, to conflate privacy with security, says Jen Caltrider, the lead researcher behind Mozilla’s “*Privacy Not Included” project, which reviews consumer devices for both privacy and security. Data security refers to a product’s physical and cyber security, or how vulnerable it is to a hack or intrusion, while data privacy is about transparency—knowing and being able to control the data that companies have, how it is used, why it is shared, whether and for how long it’s retained, and how much a company is collecting to start with.
Conflating the two is convenient, Caltrider adds, because “security has gotten better, while privacy has gotten way worse” since she began tracking products in 2017. “The devices and apps now collect so much more personal information,” she says.
Company representatives also sometimes use subtle differences, like the distinction between “sharing” data and selling it, that make how they handle privacy particularly hard for non-experts to parse. When a company says it will never sell your data, that doesn’t mean it won’t use it or share it with others for analysis.
These expansive definitions of data collection are often acceptable under companies’ vaguely worded privacy policies, virtually all of which contain some language permitting the use of data for the purposes of “improving products and services”—language that Rich calls so broad as to “permit basically anything.”
“Developers are not traditionally very good [at] security stuff.” Their attitude becomes “Try to get the functionality, and if the functionality is working, ship the product. And then the scandals come out.”
Indeed, MIT Technology Review reviewed 12 robot vacuum privacy policies, and all ofthem, including iRobot’s, contained similar language on “improving products and services.” Most of the companies to which MIT Technology Review reached out for comment did not respond to questions on whether “product improvement” would include machine-learning algorithms. But Roborock and iRobot say it would.
And because the United States lacks a comprehensive data privacy law—instead relying on a mishmash of state laws, most notably the California Consumer Privacy Act—these privacy policies are what shape companies’ legal responsibilities, says Brookman. “A lot of privacy policies will say, you know, we reserve the right to share your data with select partners or service providers,” he notes. That means consumers are likely agreeing to have their data shared with additional companies, whether they are familiar with them or not.
Brookman explains that the legal barriers companies must clear to collect data directly from consumers are fairly low. The FTC, or state attorneys general, may step in if there are either “unfair” or “deceptive” practices, he notes, but these are narrowly defined: unless a privacy policy specifically says “Hey, we’re not going to let contractors look at your data” and they share it anyway, Brookman says, companies are “probably okay on deception, which is the main way” for the FTC to “enforce privacy historically.” Proving that a practice is unfair, meanwhile, carries additional burdens—including proving harm. “The courts have never really ruled on it,” he adds.
Most companies’ privacy policies do not even mention the audiovisual data being captured, with a few exceptions. iRobot’s privacy policy notes that it collects audiovisual data only if an individual shares images via its mobile app. LG’s privacy policy for the camera- and AI-enabled Hom-Bot Turbo+ explains that its app collects audiovisual data, including “audio, electronic, visual, or similar information, such as profile photos, voice recordings, and video recordings.” And the privacy policy for Samsung’s Jet Bot AI+ Robot Vacuum with lidar and Powerbot R7070, both of which have cameras, will collect “information you store on your device, such as photos, contacts, text logs, touch interactions, settings, and calendar information” and “recordings of your voice when you use voice commands to control a Service or contact our Customer Service team.” Meanwhile, Roborock’s privacy policy makes no mention of audiovisual data, though company representatives tell MIT Technology Review that consumers in China have the option to share it.
iRobot cofounder Helen Greiner, who now runs a startup called Tertill that sells a garden-weeding robot, emphasizes that in collecting all this data, companies are not trying to violate their customers’ privacy. They’re just trying to build better products—or, in iRobot’s case, “make a better clean,” she says.
Still, even the best efforts of companies like iRobot clearly leave gaps in privacy protection. “It’s less like a maliciousness thing, but just incompetence,” says Giese, the IoT hacker. “Developers are not traditionally very good [at] security stuff.” Their attitude becomes “Try to get the functionality, and if the functionality is working, ship the product.”
“And then the scandals come out,” he adds.
Robot vacuums are just the beginning
The appetite for data will only increase in the years ahead. Vacuums are just a tiny subset of the connected devices that are proliferating across our lives, and the biggest names in robot vacuums—including iRobot, Samsung, Roborock, and Dyson—are vocal about ambitions much grander than automated floor cleaning. Robotics, including home robotics, has long been the real prize.
Consider how Mario Munich, then the senior vice president of technology at iRobot, explained the company’s goals back in 2018. In a presentation on the Roomba 980, the company’s first computer-vision vacuum, he showed images from the device’s vantage point—including one of a kitchen with a table, chairs, and stools—next to how they would be labeled and perceived by the robot’s algorithms. “The challenge is not with the vacuuming. The challenge is with the robot,” Munich explained. “We would like to know the environment so we can change the operation of the robot.”
This bigger mission is evident in what Scale’s data annotators were asked to label—not items on the floor that should be avoided (a feature that iRobot promotes), but items like “cabinet,” “kitchen countertop,” and “shelf,” which together help the Roomba J series device recognize the entire space in which it operates.
The companies making robot vacuums are already investing in other features and devices that will bring us closer to a robotics-enabled future. The latest Roombas can be voice controlled through Nest and Alexa, and they recognize over 80 different objects around the home. Meanwhile, Ecovacs’s Deebot X1 robot vacuum has integrated the company’s proprietary voice assistance, while Samsung is one of several companies developing “companion robots” to keep humans company. Miele, which sells the RX2 Scout Home Vision, has turned its focus toward other smart appliances, like its camera-enabled smart oven.
And if iRobot’s $1.7 billion acquisition by Amazon moves forward—pending approval by the FTC, which is considering the merger’s effect on competition in the smart-home marketplace—Roombas are likely to become even more integrated into Amazon’s vision for the always-on smart home of the future.
Perhaps unsurprisingly, public policy is starting to reflect the growing public concern with data privacy. From 2018 to 2022, there has been a marked increase in states considering and passing privacy protections, such as the California Consumer Privacy Act and the Illinois Biometric Information Privacy Act. At the federal level, the FTC is considering new rules to crack down on harmful commercial surveillance and lax data security practices—including those used in training data. In two cases, the FTC has taken action against the undisclosed use of customer data to train artificial intelligence, ultimately forcing the companies, Weight Watchers International and the photo app developer Everalbum, to delete both the data collected and the algorithms built from it.
Still, none of these piecemeal efforts address the growing data annotation market and its proliferation of companies based around the world or contracting with global gig workers, who operate with little oversight, often in countries with even fewer data protection laws.
When I spoke this summer to Greiner, she said that she personally was not worried about iRobot’s implications for privacy—though she understood why some people might feel differently. Ultimately, she framed privacy in terms of consumer choice: anyone with real concerns could simply not buy that device.
“Everybody needs to make their own privacy decisions,” she told me. “And I can tell you, overwhelmingly, people make the decision to have the features as long as they are delivered at a cost-effective price point.”
But not everyone agrees with this framework, in part because it is so challenging for consumers to make fully informed choices. Consent should be more than just “a piece of paper” to sign or a privacy policy to glance through, says Vitak, the University of Maryland information scientist.
True informed consent means “that the person fully understands the procedure, they fully understand the risks … how those risks will be mitigated, and … what their rights are,” she explains. But this rarely happens in a comprehensive way—especially when companies market adorable robot helpers promising clean floors at the click of a button.
Do you have more information about how companies collect data to train AI? Did you participate in data collection efforts by iRobot or other robot vacuum companies? We’d love to hear from you and will respect requests for anonymity. Please reach out at tips@technologyreview.com or securely on Signal at 626.765.5489.
China Report is MIT Technology Review’s newsletter about what’s happening in China. Sign up to receive it in your inbox every Tuesday.
Welcome back to China Report!
I recently had a very interesting conversation with Wall Street Journal reporters Josh Chin and Liza Lin. They wrote a new book called Surveillance State, whichexplores how China is leading the global experiment in using surveillance tech.
We covered a lot of important topics: how covid offered the ideal context to justify expanding government surveillance, how the world should respond to China, and even philosophical questions about how people perceive privacy. You can read the takeaways in full here.
But in this newsletter, I want to share a few extra snippets from our conversation that have really stuck with me.
Chin and Lin are very clearheaded about the fact that the emergence of the surveillance state is not just a problem in China. Countries with democratic institutions can be and have already been attracted to surveillance tech for its (often artificial) promises. Singapore, where Lin is from, is a great example.
When Lin was living in Shanghai in 2018, she used to count the number of surveillance cameras she would see every day. As she told me:
I remember one day walking from my apartment to Lao Xi Men station in Shanghai, and there were 17 cameras just from the entrance of that subway station to where you scan your tickets. Seventeen cameras! All owned by various safety departments, and maybe the metro department as well.
She thought this phenomenon would be unique to China—but when she later moved back to Singapore, she found out she was wrong.
Once I started going back [to Singapore] in 2019 and 2020, it [had] started to embrace the same ideas that China had in terms of a “safe city.” I saw cameras popping up at road intersections that catch cars that are speeding, and then you saw cameras popping up at the subway.
Even her son has picked up her habit, but this time in Singapore.
He “is now counting the number of cameras when we walk through the subway tunnel just to get to the station,” Lin says. “He’s like, ‘Mommy, that’s the police.’”
We also talked about the impact of the pandemic on surveillance tech. In China, tracing the virus’s spread became another justification for the government to collect data on its citizens, and it further normalized the presence of mass surveillance infrastructure.
Lin told me that the same kind of tracking, if to a lesser extent, happened in Singapore. In March 2020 the country launched an app called TraceTogether, which uses Bluetooth to identify close contacts of people who tested positive for covid. In addition to the mobile app, there were even Apple Watch–size gadgets given to people who don’t use smartphones.
Over 92% of the population in Singapore eventually used the app. “They didn’t say it was compulsory,” Lin told me. “But just like in China, you couldn’t enter public places if you didn’t have that contact tracing app.”
And once the pandemic surveillance infrastructure was in place, the police wasted no time in taking advantage of it.
Chin: I thought this was really telling. Initially, when they rolled it out, they were like, “This will be strictly for health monitoring. No other government agencies are going to have access to the data.” That includes the police. And they made an explicit promise to get people to buy in. And then, I can’t remember how much longer …
Lin: Within that same year.
Chin: Yeah, within the same year, the police were using that technology to track suspects, and they basically openly said: “Well, we changed our minds.”
Lin: And there was a public pushback to that. And now they stopped doing it. It’s just an example of how easily one use can lead to another.
The pushback led the Singaporean parliament to pass a bill in February 2021 to restrict police use of TraceTogether data. State forces are still able to access the data now, but they need to go through a stricter process to get permission.
It’s easy to imagine that not all countries will respond the same way. Several Asian countries were at the forefront of adopting covid tracing apps, and it’s not yet clear how the relevant authorities will deal with the data they collected along the way. So it was a pleasant surprise when I read that Thailand, which pushed for its own covid app, named MorChana, announced in June that it would close down the app and delete all relevant data.
Since our conversation, I keep thinking about what the pandemic has meant for surveillance tech. For one thing, I think it helped illustrate that surveillance is not an abstract “evil” that all “good” societies would naturally object to. Rather, there’s a nuanced balance between privacy and social needs like public health. And it’s precisely for this reason that we should expect to see governments around the world, including democracies, keep citing new reasons to justify using surveillance tech. There will always be some sort of crisis to respond to, right?
Instead of relying on governments to be responsible with data and self-correct when it makes mistakes, Chin and Lin argued, it’s important to start recognizing the harm of surveillance tech early, and to craft regulations that safeguard against those dangers.
How do you think countries should approach surveillance tech? Let me know your thoughts at zeyi@technologyreview.com
Catch up with China
1. Using the medical records of Li Wenliang, the Chinese doctor and covid whistleblower who died in Wuhan in February 2020, reporters were able to reconstruct his final days. They confirmed that doctors were pushed to use excessive resuscitation measures in order to show that his care was not compromised. (The New York Times $)
2. The Biden administration will block international companies, not just American ones, from selling advanced chips and relevant tools to certain Chinese companies. (Reuters $)
Of course, Chinese companies will look for workarounds: already, a startup run by a former Huawei executive is building a semiconductor manufacturing factory in Shenzhen. It may help Huawei circumvent US chip export controls. (Bloomberg $)
On Monday, $240 billion in Asian chip companies’ stock market value was wiped out as traders predicted the new controls will hurt their sales. (Bloomberg $)
The chip export control is the latest in a series of administrative actions intended to restrict China’s efforts to advance in critical technologies. I wrote a primer last month to help you understand them. (MIT Technology Review)
3. Chinese electric-vehicle companies are hungry for lithium mines and spending big bucks around the world to secure supply. (Tech Crunch)
4. Social media influencers are persuading young parents in China to take drastic measures to ensure that their babies conform to traditional beauty standards. (Sixth Tone)
5. The almighty algorithms of Douyin, China’s domestic version of TikTok, are failing to understand audio in Cantonese and suspending live streams for “unrecognized languages.” (South China Morning Post $)
6. To reduce its dependence on China for manufacturing, Apple wants to make its flagship iPhones in India. (BBC)
Lost in translation
Since 2015, banks and fintech platforms have popularized the use of facial verification to make payments faster and more convenient. But that’s also come with a high risk that facial recognition data could be hacked or leaked.
So it’s probably to no one’s surprise that “paying with your face” has already gone quite wrong in China. The Chinese publication Caijing recently reported on a mysterious scam case in which criminals were able to bypass the bank’s facial recognition verification process and withdraw money from a victim’s account, even though she didn’t provide her face. Experts concluded that the criminals likely tricked the bank’s security system through a combination of illegally obtained biometric data and other technical tools. According to local court documents, identity documents, bank account information, and facial recognition data are sometimes sold on the black market at the price of just $7 to $14 per individual account.
It’s no surprise that last week, when the Biden administration updated its list of Chinese military companies blocked from accessing US technologies, it added Dahua. The second-largest surveillance camera company in the world, just after Hikvision, Dahua sells to over 180 countries. It exemplifies how Chinese companies have leapfrogged to the front of the video surveillance industry and have driven the world, especially China, to adopt more surveillance tech.
Over the past decade, the US—and the world more generally—have watched with a growing sense of alarm as China has emerged as a global leader in this space. Indeed, the Chinese government has been at the forefront of exploring ways to apply cutting-edge research in computer vision, the Internet of Things, and hardware manufacturing in day-to-day governance. This has led to a slew of human rights abuses—notably, and perhaps most brutally, in monitoring Muslim ethnic minorities in the Western region of Xinjiang. At the same time, the state has also used surveillance tech for good: to find abducted children, for example, and to improve traffic control and trash management in populous cities.
As Wall Street Journalreporters Josh Chin and Liza Lin argue in their new book Surveillance State, out last month, the Chinese government has managed to build a new social contract with its citizens: they give up their data in exchange for more precise governance that, ideally, makes their lives safer and easier (even if it doesn’t always work out so simply in reality).
MIT Technology Review recently spoke with Chin and Lin about the five years of reporting that culminated in the book, exploring the misconception that privacy is not valued in China.
“A lot of the foreign media coverage, when they encountered that [question], would just brush it off as ‘Oh, Chinese people just don’t have the concept of privacy … they’re brainwashed into accepting it,’” says Chin. “And we felt it was too easy of a conclusion for us, so we wanted to dig into it.” When they did, they realized that the perception of privacy is actually more pliable than it often appears.
We also spoke about how the pandemic has accelerated the use of surveillance tech in China, whether the technology itself can stay neutral, and the extent to which other countries are following China’s lead.
How the world should respond to the rise of surveillance states “might be one of the most important questions facing global politics at the moment,” Chin says, “because these technologies … really do have the potential to completely alter the way governments interact with and control people.”
Here are the key takeaways from our conversation with Josh Chin and Liza Lin.
China has rewritten the definition of privacy to sell a new social contract
After decades of double-digit GDP growth, China’s economic boom has slowed down over the past three years and is expected to face even stronger headwinds. (The World Bank currently estimates that China’s 2022 annual GDP growth will decrease to 2.8%.) So the old social contract, which promised better returns from an economy steered by an authoritarian government, is strained—and a new one is needed.
As Chin and Lin observe, the Chinese government is now proposing that by collecting every Chinese citizen’s data extensively, it can find out what the people want (without giving them votes) and build a society that meets their needs.
But to sell this to its people—who, like others around the world, are increasingly aware of the importance of privacy—China has had to cleverly redefine that concept, moving from an individualistic understanding to a collectivist one.
The idea of privacy itself is “an incredibly confusing and malleable concept,” says Chin. “In US law, there’s a dozen, if not more, definitions of privacy. And I think the Chinese government grasped that and sensed an opportunity to define privacy in ways that not only didn’t undermine the surveillance state but actually reinforced it.”
What the Chinese government has done is position the state and citizens on the same side of the privacy battle against private companies. Consider recent Chinese legislation like the Personal Information Protection Law (in effect since November 2021) and the Data Security Law (since September 2021), under which private companies face harsh penalties for allowing security breaches or failing to get user consent for data collection. State actors, however, largely get a pass under these laws.
“Cybersecurity hacks and data leaks happen not just to companies. They happen to government agencies, too,” says Lin. “But with something like that, you never hear state media play it up at all.” Enabled by its censorship machine, the Chinese government has often successfully directed people’s fury over privacy violations away from the government and entirely toward private companies.
The pandemic was the perfect excuse to expand surveillance tech
When Chin and Lin were planning the book, they envisioned ending with a thought experiment about what would happen to surveillance tech if something like 9/11 happened again. Then the pandemic came.
And just like 9/11, the coronavirus fast-tracked the global surveillance industry, the authors saw—particularly in China.
Chin and Lin report on the striking parallels between the way China used societal security to justify the surveillance regime it built in Xinjiang and the way it used physical safety to justify the overreaching pandemic control tools. “In the past, it was always a metaphorical virus: ‘someone was infected with terrorist ideas,’” says Lin. In Xinjiang, before the pandemic, the term “virus” was used in internal government documents to describe what the state deemed “Islamic radicalism.” “But with covid,” she says, “we saw China really turn the whole state surveillance apparatus against its entire population and against a virus that was completely invisible and contagious.”
Going back to the idea that the perception of privacy can change greatly depending on the circumstances, the pandemic has also provided the exact context in which ordinary citizens may agree to give up more of their privacy in the name of safety. “In the field of public health, disease surveillance has never been controversial, because of course you would want to track a disease in the way it spreads. Otherwise how do you control it?” says Chin.
“They probably saved millions of lives by using those technologies,” he says, “and the result is that sold [the necessity of] state surveillance to a lot of Chinese people.”
Does “good” surveillance tech exist?
Once someone (or some entity) starts using surveillance tech, the downward slope is extremely slippery: no matter how noble the motive for developing and deploying it, the tech can always be used for more malicious purposes. For Chin and Lin, China shows how the “good” and “bad” uses of surveillance tech are always intertwined.
They report extensively on how a surveillance system in Hangzhou, the city that’s home to Alibaba, Hikvision, Dahua, and many other tech companies, was built on the benevolent premise of improving city management. Here, with a dense network of cameras on the street and a cloud-based “city brain” processing data and giving out orders, the “smart city” system is being used to monitor disasters and enable quick emergency responses. In one notable example, the authors talk to a man who accompanied his mother to the hospital in an ambulance in 2019 after she nearly drowned. The city was able to turn all the traffic lights on their path to reduce the time it took to reach the hospital. It’s impossible to argue this isn’t a good use of the technology.
But at the same time, it has come to a point where the “smart city” technologies are almost indistinguishable from “safe city” technologies, which aim to enhance police forces and track down alleged criminals. The surveillance company Hikvision, which partly powers the lifesaving system in Hangzhou, is the same one that facilitated the massive incarceration of Muslim minorities in Xinjiang.
China is far from the only country where police are leaning on a growing number of cameras. Chin and Lin highlight how police in New York City have used and abused cameras to build a facial recognition database and identify suspects, sometimes with legally questionable tactics. (MIT Technology Review also reported earlier this year on how the police in Minnesota built a database to surveil protesters and journalists.)
Chin argues that given this track record, the tech itself can no longer be considered neutral. “Certain technologies by their nature lend themselves to harmful uses. Particularly with AI applied to surveillance, they lend themselves to authoritarian outcomes,” he says. And just like nuclear researchers, for instance, scientists and engineers in these areas should be more careful about the technology’s potential harm.
It’s still possible to disrupt the global supply chain of surveillance tech
There is a sense of pessimism when talking about how surveillance tech will advance in China, because the invasive implementation has become so widespread that it’s hard to imagine the country reversing course.
But that doesn’t mean people should give up. One key way to intervene, Chin and Lin argue, is to cut off the global supply chain of surveillance tech (a network MIT Technology Review wrote about just last month).
The development of surveillance technology has always been a global effort, with many American companies participating. The authors recount how American companies like Intel and Cisco were essential in building the bedrock of China’s surveillance system. And they were able to disclaim their own responsibility by saying they simply didn’t know what the end use of their products would be.
That kind of excuse won’t work as easily in the future, because global tech companies are being held to higher standards. Whether they contributed to human rights violations on the opposite side of the globe “has become a thing that companies are worried about and planning around,” Chin says. “That’s a really interesting shift that we haven’t seen in decades.”
Some of these companies have stopped working with China or have been replaced by Chinese firms that have developed similar technologies, but that doesn’t mean China has a self-sufficient surveillance system now. The supply chain for surveillance technology is still distributed around the world, and Chinese tech companies require parts from the US or other Western countries to continue building their products.
The main example here is the GPU, a type of processor originally produced to run better-quality video games that has since been used to power mass surveillance systems. China still relies for these on foreign companies like Nvidia, which is headquartered in California.
“In the last two years, there’s been a huge push to substitute foreign technology with domestic technology, [but] these are the areas [where] they still can’t achieve independence,” Lin says.
This means the West can still try to slow the development of the Chinese surveillance state by putting pressure on industry. But results will depend on how much political will there is to uncover the key links in surveillance supply chains, and to come up with effective responses.
“The other really important thing is just to strengthen your own democratic institutions … like a free press and a strong and vibrant civil society space,” says Lin. Because China won’t be the only country with the potential to become a surveillance state. It can happen anywhere, they warn, including countries with democratic institutions.







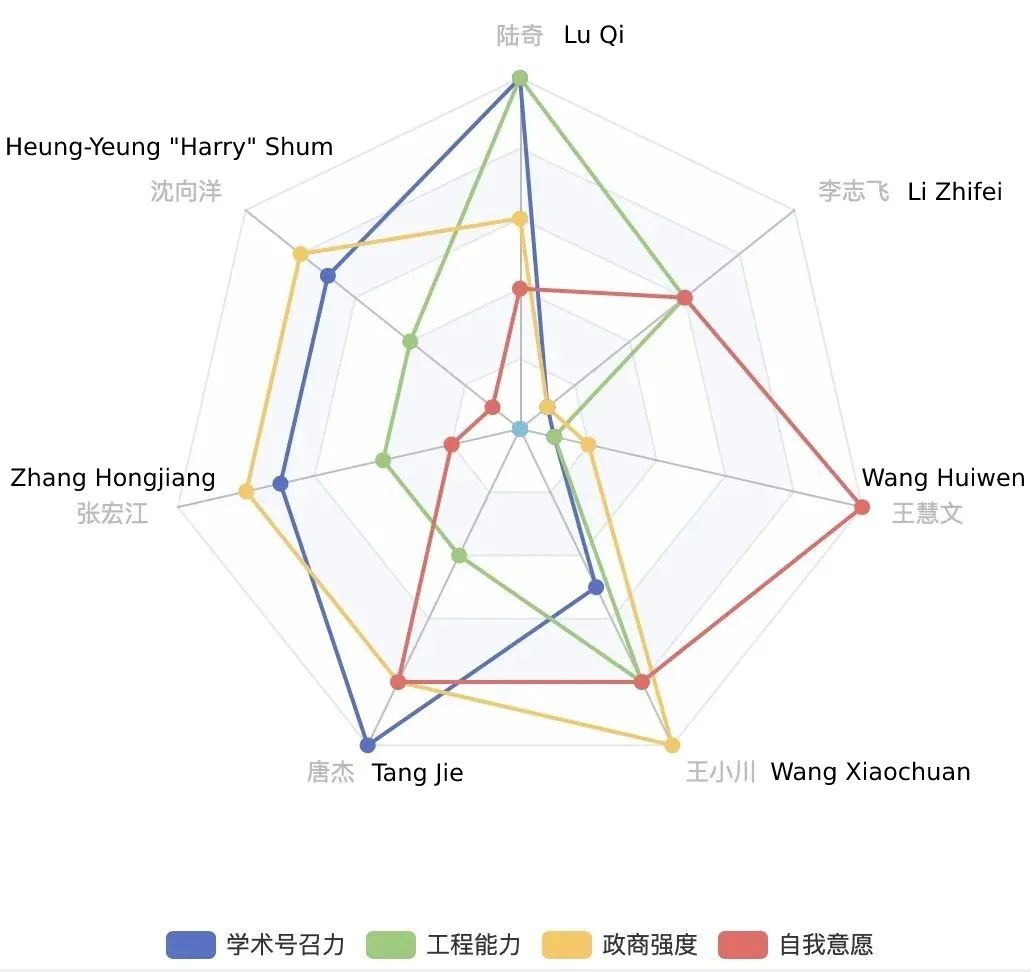


 (@betabound)
(@betabound)