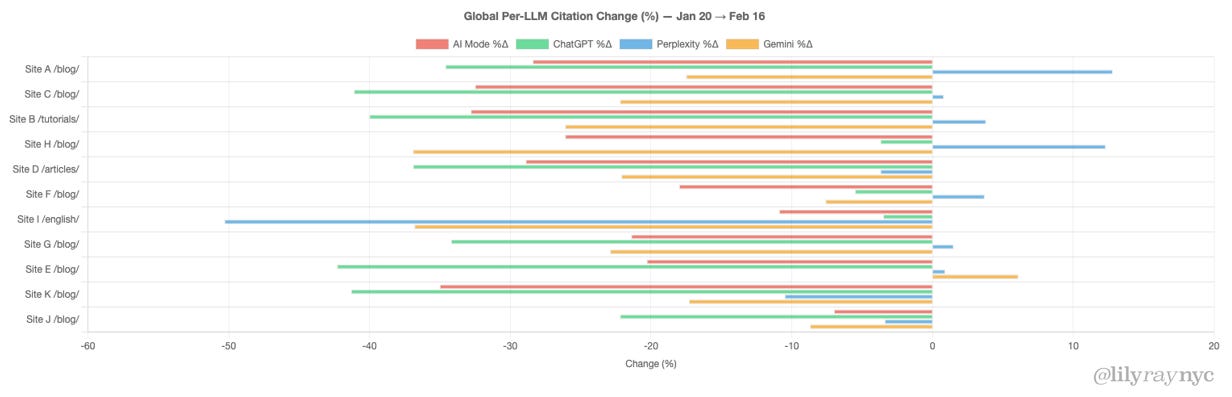
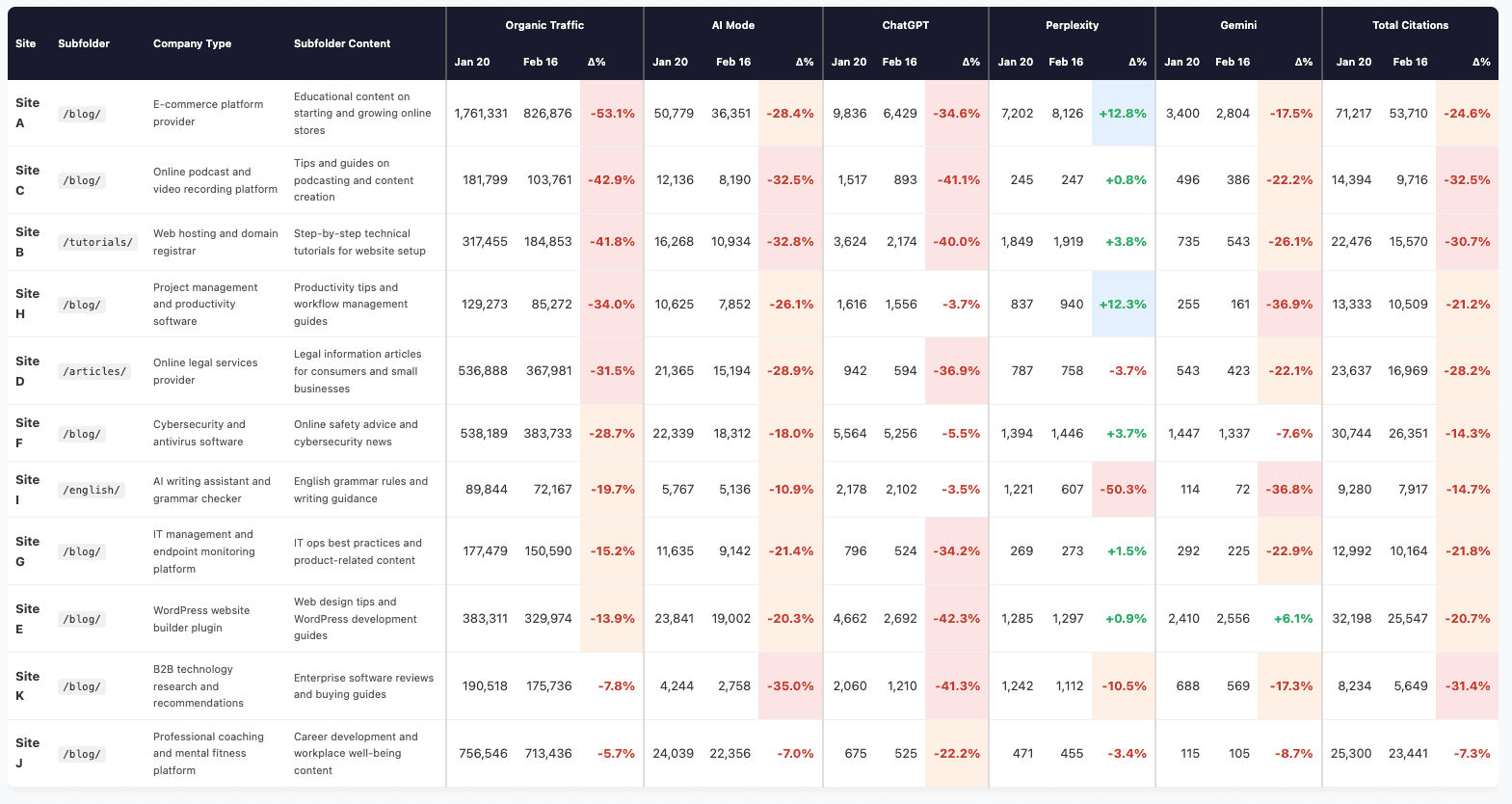
4 Sites That Recovered From Google’s December 2025 Core Update – What They Changed via @sejournal, @marie_haynes
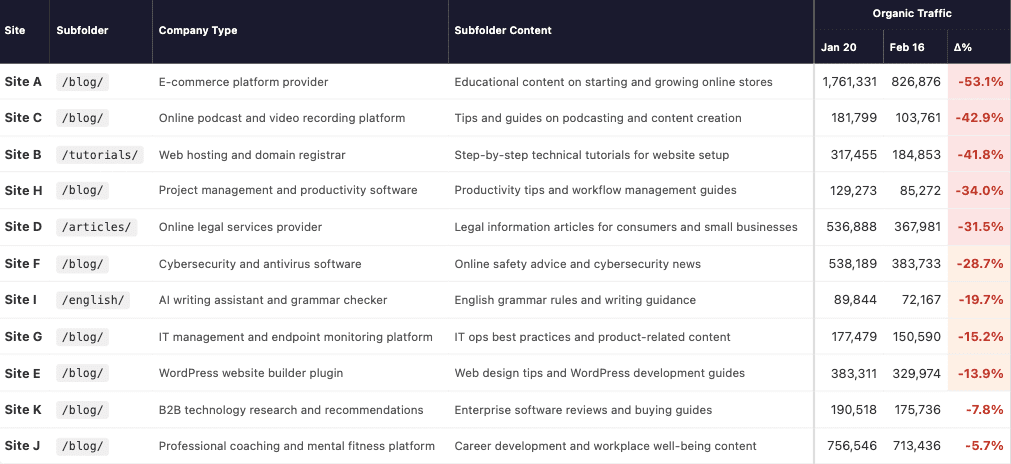
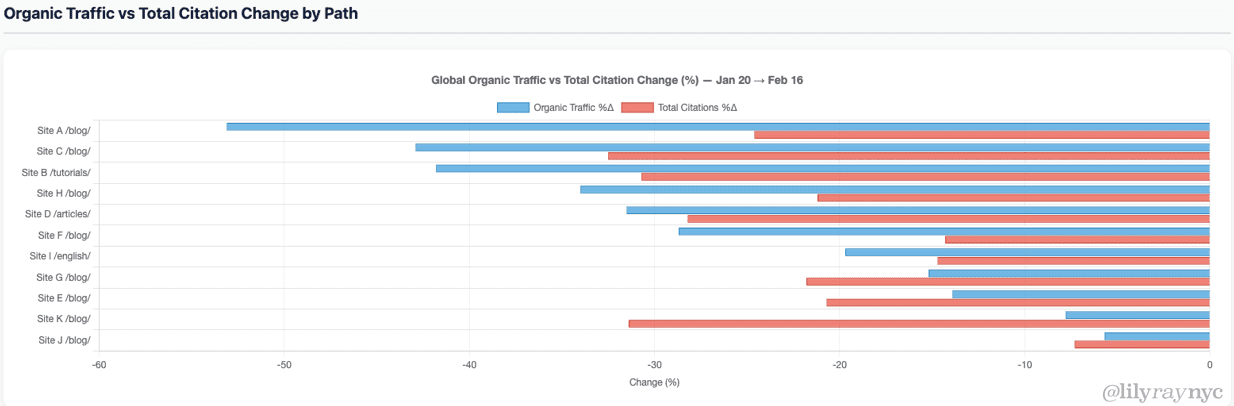
The December 2025 core update had a significant impact on a large number of sites. Each of the sites below that have done well are either long term clients, past clients or sites that I have done a site review for. While we can never say with certainty what changed as the result of a change to Google’s core algorithms and systems, I’ll share some observations on what I think helped these sites improve.
1. Trust Matters Immensely
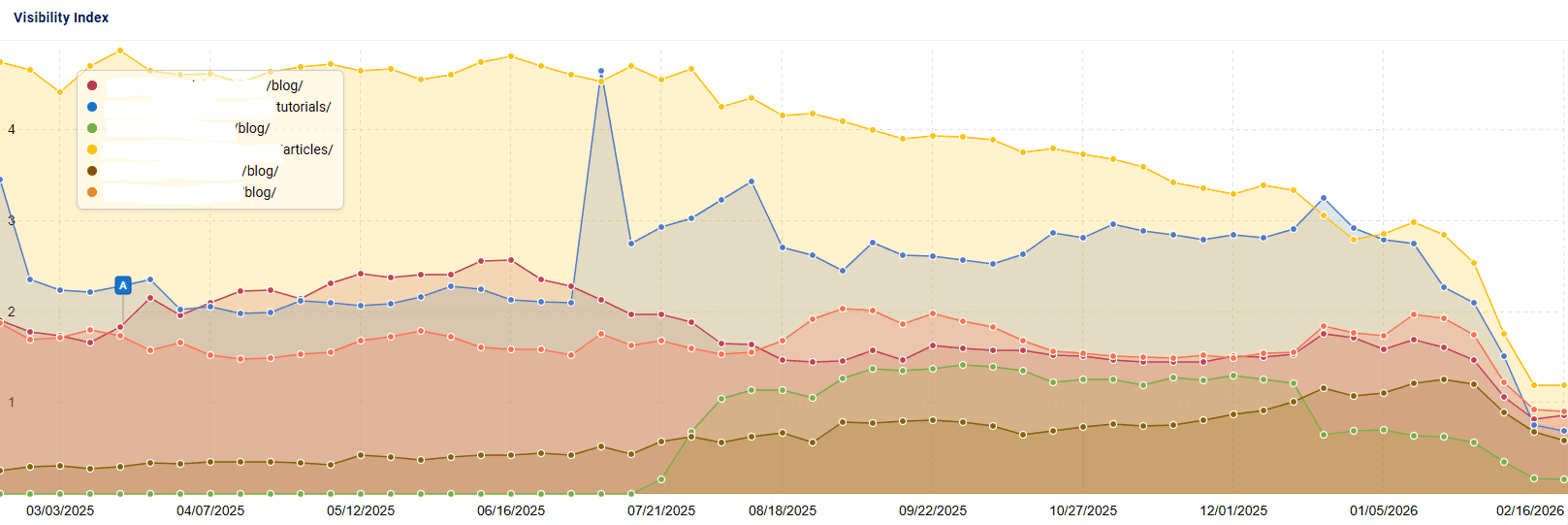
This first client, a medical eCommerce site, reached out to me in mid 2024 and we started on a long term engagement. A few days into our relationship they were strongly negatively impacted by the August 2024 core update. It was devastating.
When you are impacted by a core update, in most cases, you remain suppressed until another core update happens. It usually takes several core updates. And given that these only happen a few times a year, this site remained suppressed for quite some time.
We worked on a lot of things:
- Improving blog post quality so it was not “commodity content”.
- Improving page load time.
- Optimizing images.
- Improving FAQ content on product pages to help answer customer questions.
- Creating helpful guides.
- Improving product descriptions to better answer questions their customers have.
- Adding more information about the E-E-A-T of authors.
- Adding more authors with medical E-E-A-T.
- Getting more reviews from satisfied customers.
While I think that all of the above helped contribute to a better assessment of quality for this site, I actually think that what helped the most had very little to do with SEO, but rather, was the result of the business working hard to truly improve upon customer service.
Core updates are tightly connected to E-E-A-T. Google says that trust is the most important aspect of E-E-A-T. The quality rater guidelines, which serve as guidance to help Google’s quality raters who help train their AI systems to improve in producing high quality search algorithms, mention “trust” 191 times.
For online stores, the raters are told that reliable customer service is vitally important.
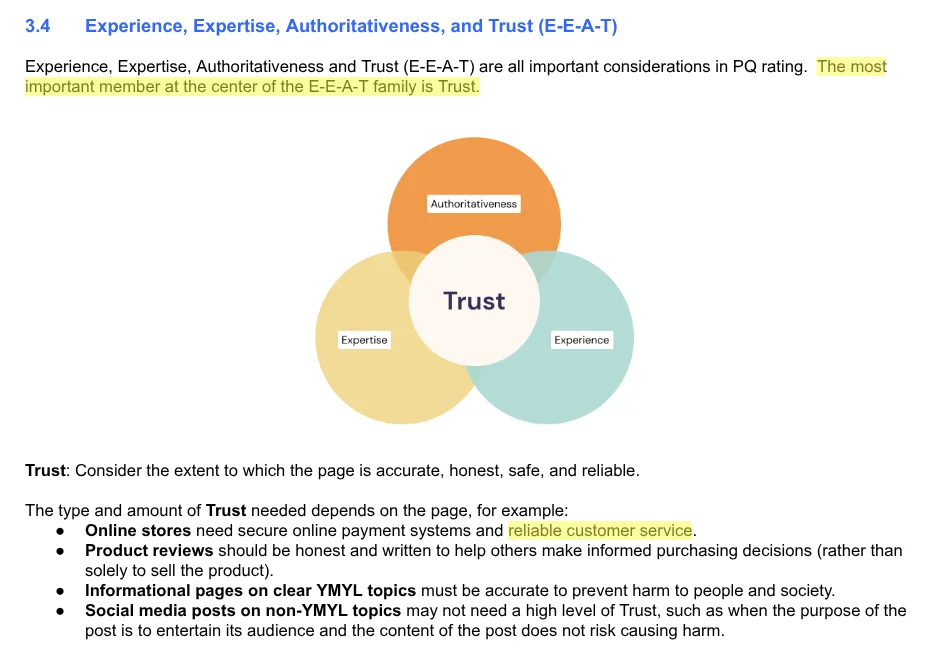
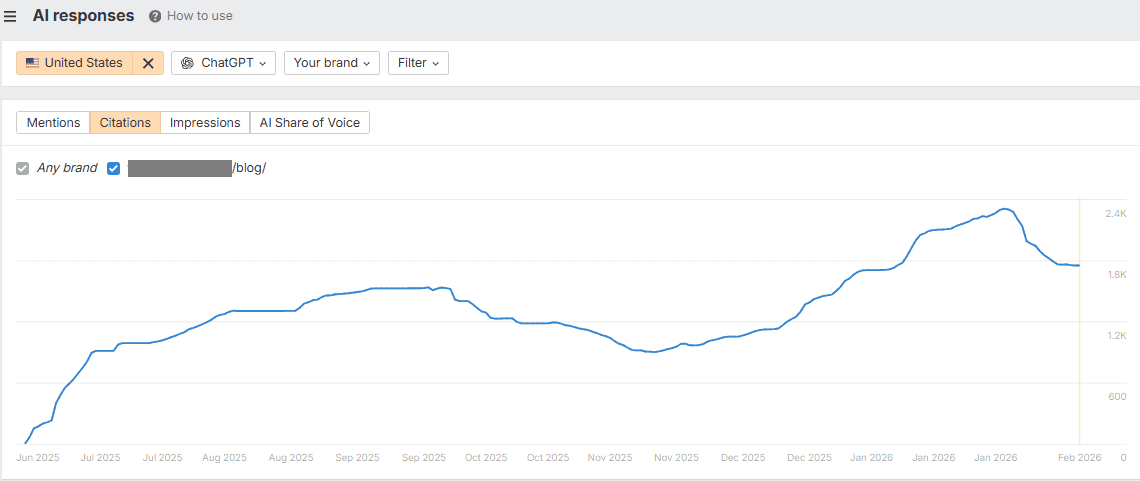
A few bad reviews aren’t likely to tank your rankings, but this business had previously had significant logistical problems with shipping. They had been working hard to rectify these. Yet, if I asked AI Mode to tell me about the reputation of this company compared to their competitors, it would always tell me that there were serious concerns.
Here’s an interesting prompt you can use in AI Mode:
Make a chart showing the perceived trust in [url or brand] over time.
You can see that finally in 2025 the overall trust in this brand improved.

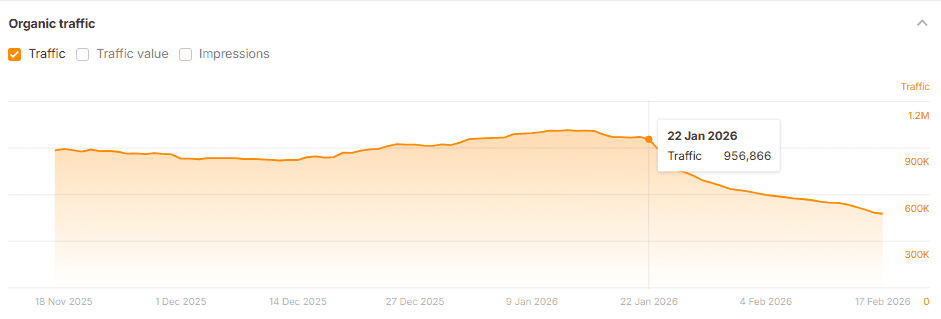
My suspicion is that these trust issues were the main driver in their core update suppression. I can’t say whether it was the improvement in customer trust that made a difference, the improvements in quality we made, or perhaps both. But these results were so good to see.
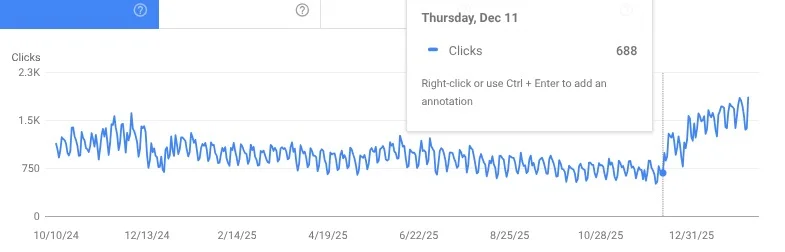
They continue to improve. Google recommends them more often in Popular Products carousels, ranks them more highly for many important terms and more importantly, drives far more sales for them now.
2. Original Content Takes A Lot Of Work
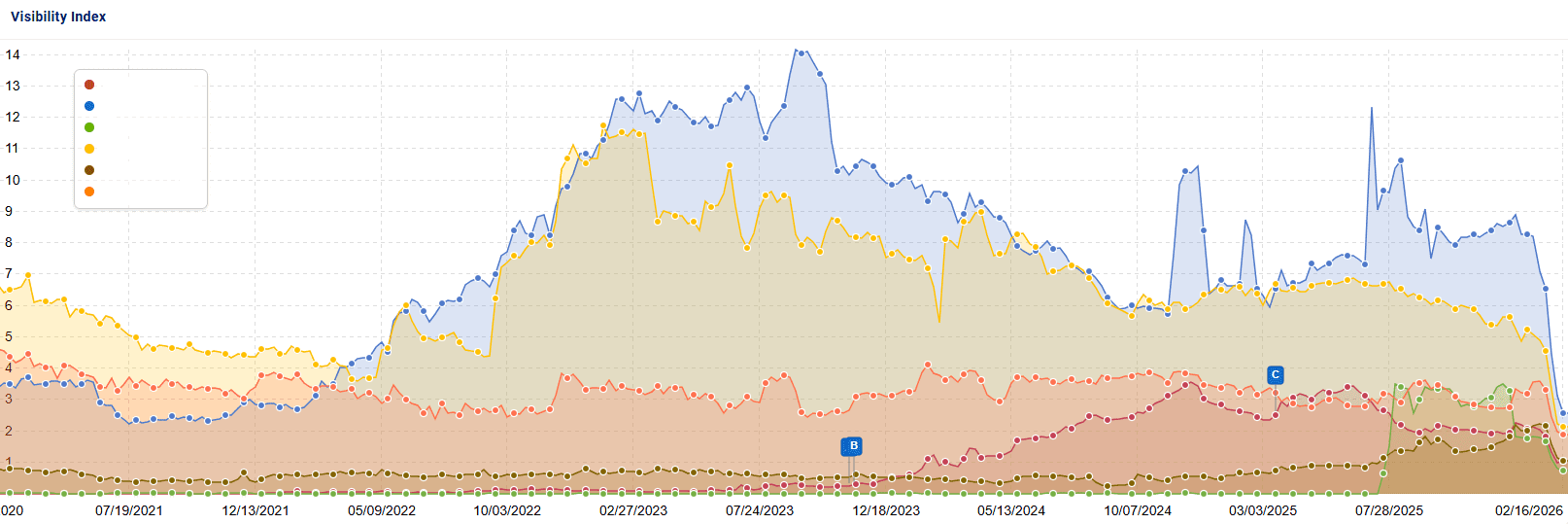
The next site is another site that was impacted by a core update.
This site is an affiliate site that writes about a large ticket product. They have a lot of competition from some big players in their industry. When I reviewed their site, one thing was obvious to me. While they had a lot of content, most of it offered essentially the same value as everyone else. This was frustrating considering they actually did purchase and review these products. What they were writing about was mostly a collection of known facts on these products rather than their personal experience. And what was experiential was buried in massive walls of text that were difficult for readers to navigate.
Google’s guidance on core updates recommends that if you were impacted, you should consider rewriting or restructuring your content to make it easier for your audience to read and navigate the page.

This site put an incredible amount of work into improving their content quality:
- They purchased the products they reviewed and took detailed photos of everything they discussed. And videos. Really helpful videos.
- The blog posts were written by an expert in their field. This already was the case, but we worked on making it more clear what their expertise was and why it was helpful.
- We brainstormed with AI to help us come up with ideas for adding helpful unique information that was borne from their experience and not likely to be found on other sites.
- We used Microsoft Clarity to identify aspects on pages that were frustrating users and worked to improve them.
- We added interactive quizzes to help readers and drive engagement.
- We worked on improving freshness for every important post, ensuring they were up to date with the latest information.
- We worked to really get in the shoes of a searcher and understand what they wanted to see. We made sure that this information was easy to find even if a reader was skimming.
- We broke up large walls of text into chunks with good headings that were easy to skim and navigate.
- We noindexed pages that were talking on YMYL topics for which they lacked expertise.
- We worked on improving core web vitals. (Note: I don’t think this is a huge ranking factor, but in this case the largest contentful paint was taking forever and likely frustrated users.)
Once again, it took many months of tireless work before improvements were seen! Rankings improved to the first page for many important keywords and some moved from page 4 to position #1-3.
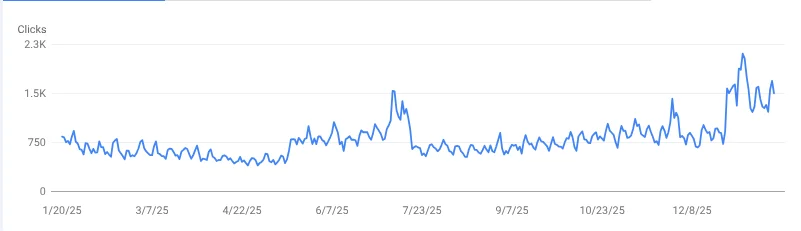
3. Work To Improve User Experience
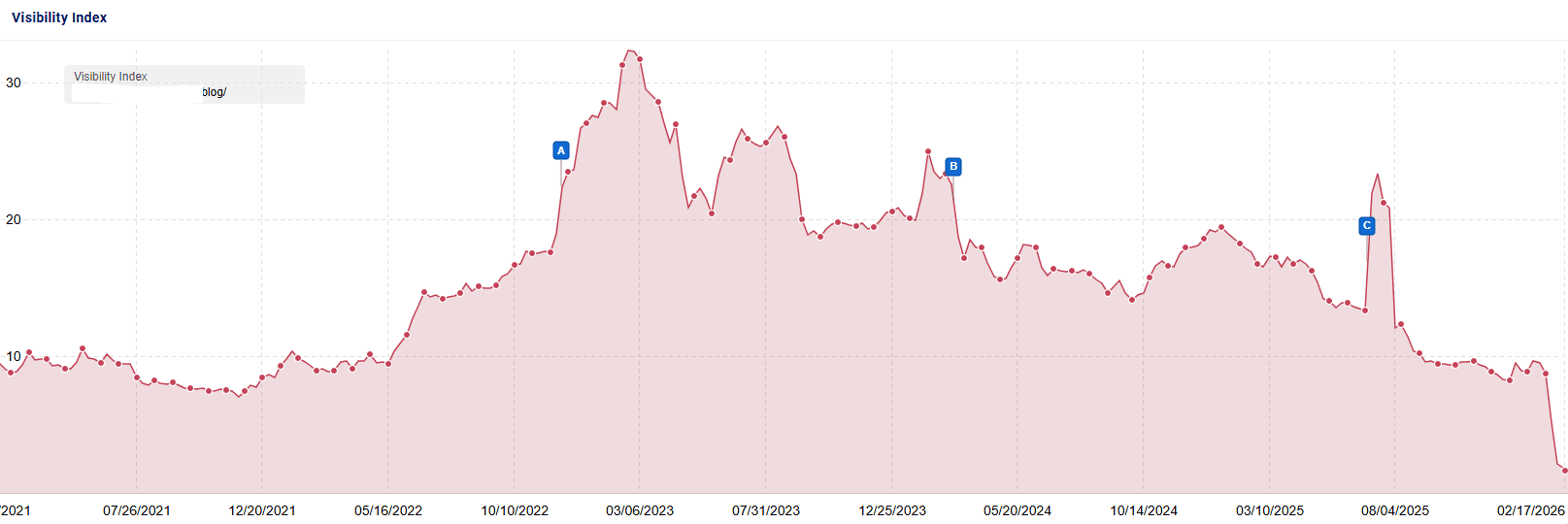
This next site was not a long term client, but rather, a site review I did for an eCommerce site in an YMYL niche. The SEO working on this site applied many of my recommendations and made some other smart changes as well including:
- Improving site navigation and hierarchy.
- Improved UX. They have a nicer, more modern font. The site looks more professional.
- Improved customer checkout flow which improved checkout abandonment rates.
- Improved their About Us page to add more information to demonstrate the brand’s experience and history. Note: I don’t think this matters immensely to Google’s algorithms as most of their assessment of trust is made from off-site signals, but it may help users feel more comfortable with engaging.
- Produced content around some topics that were gaining public attention. This did help to truly earn some new links and mentions from authoritative sources.
After making these changes, the site was able to procure a knowledge panel for brand searches. And, search traffic is climbing.
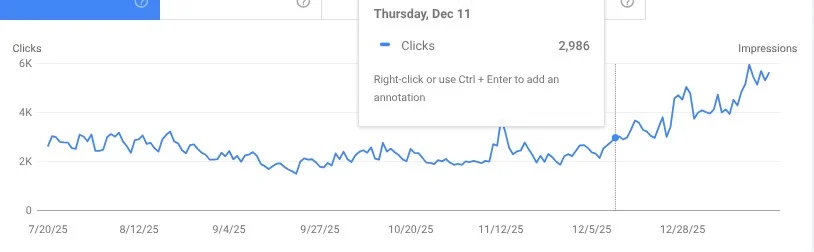
4. First Hand Experience Can Really Help
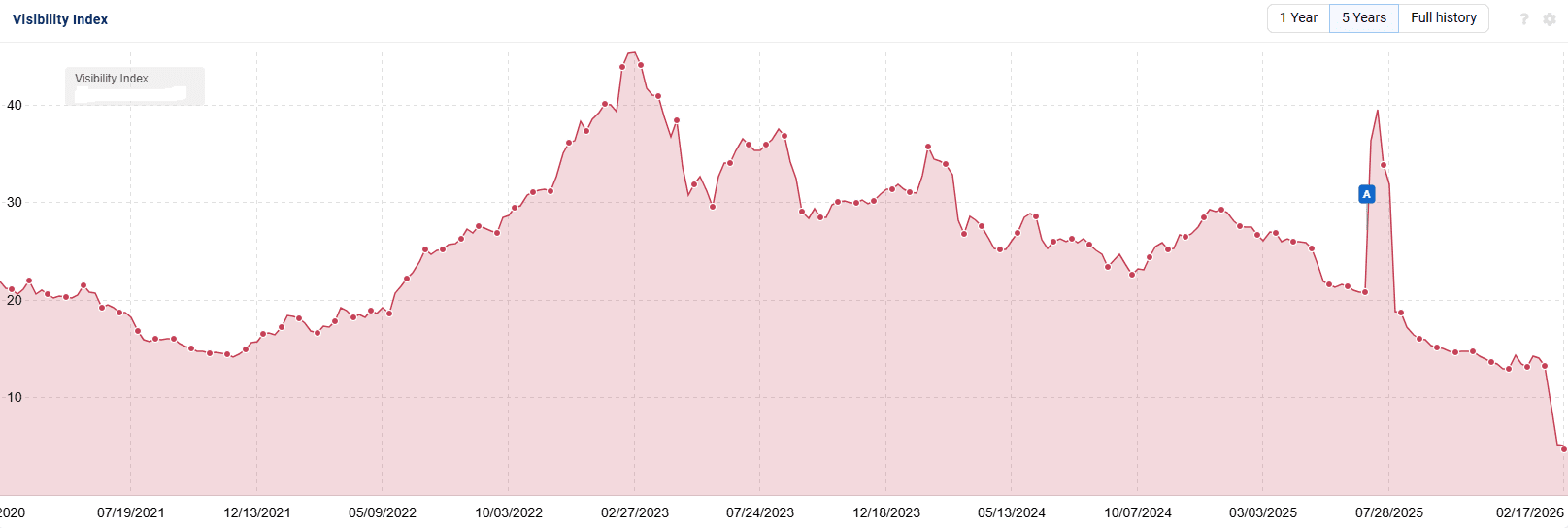
This next site is another one that I did a site review for. It is a city guide that monetizes through affiliate links and sponsors. For every page I looked at I came to the same conclusion: There was nothing on this page that couldn’t be covered by an AI Overview. Almost every piece of information was essentially paraphrased from somewhere else on the web.
The most recent update to the rater guidelines increased the use of the word “paraphrased” from 3 mentions to 25. I think this applies to a lot of sites!

and

and also,

Yet, when I spoke with the site owner she shared to me that they had on-site writers who were truly writing from their experience.
While I don’t know specifically what changes this site owner has made, I looked at several pages that had seen nice improvements in conjunction with the core update and noticed the following improvements:
- They’ve added video to some posts – filmed by their team.
- There’s original photography from their team – not taken from elsewhere on the web. Not every photo is original, but quite a few of them are.
- Added information to help readers make their decision, like “This place is best for…” or, “Must try dishes include…”
- They wrote about their actual experiences. Rather than just sharing what dishes were available at a restaurant, they share which ones they tried and how they felt they stood out compared to other restaurants.
- They’ve worked to keep content updated and fresh.
This site saw some nice improvements. However, they still have ground to gain as they previously were doing much better in the days before the helpful content updates.
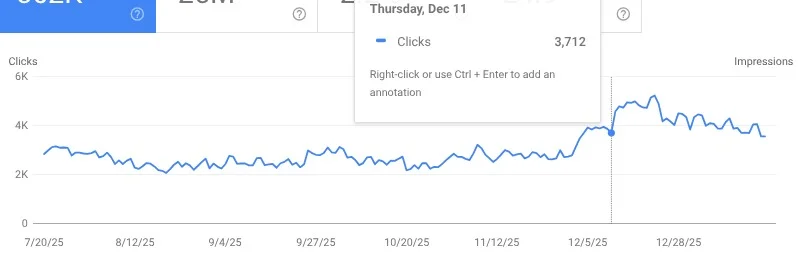
Some Thoughts For Sites That Have Not Done Well
The December 2025 core update had a devastating negative impact on many sites. If you were impacted, your answer is unlikely to lie in technical SEO fixes, disavowing links or building new links. Google’s ranking systems are a collection of AI systems that work together with one goal in mind – to present searchers with pages that they are likely to find helpful. Many components of the ranking systems are deep learning systems which means that they improve on these recommendations over time.
I’d recommend the following for you:
1. Consider Whether The Brand Has Trust Issues
You can try the AI Mode prompt I used above. A few bad reviews is not going to cause you a core update suppression. But, a prolonged history of repeated customer service frustrations, fraud or anything else that significantly impacts your reputation can seriously impact your ability to rank. This is especially true if you are writing on YMYL topics.
2. Look At How Your Content Is Structured
It is a helpful exercise to look at which pages Google’s algorithms are ranking for your queries. If they don’t seem to make sense to you, look at how quickly they get people to the answer they are trying to find. I have found that often sites that are impacted make their readers scroll through a lot of fluff or ads to get to the important bits. Improve your headings – not for search engines, but for readers who are skimming. Put the important parts at the top. Or, if that’s not feasible, make it really easy for people to find the “main content”.
Here’s a good exercise – Open up the rater guidelines. These are guidelines for human raters who help Google understand if the AI systems are producing good, helpful rankings. CTRL-F for “main content” and see what you can learn.
3. Really Ask Yourself Whether Your Content Is Mostly “Commodity Content”
Commodity content is information that is widely available in many places on the web. There was a time when a business could thrive by writing pages that aggregate known information on a topic. Now that Google has AI Overviews and AI Mode, this type of page is much less valuable. You will still see some pages cited in AI Overviews that essentially parrot what is already in the AIO. Usually these are authoritative sites which are helpful for readers who want to see information from an authority rather than an AI answer.
Liz Reid from Google said these interesting words in an interview with the WSJ:
“What people click on in AI Overviews is content that is richer and deeper. That surface level AI generated content, people don’t want that, because if they click on that they don’t actually learn that much more than they previously got. They don’t trust the result any more across the web. So what we see with AI Overviews is that we sort of surface these sites and get fewer, what we call bounced clicks. A bounced click is like, you click on this site and you’re like, “Ah, I didn’t want that” and you go back. And so AI Overviews give some content and then we get to surface sort of deeper, richer content, and we’ll look to continue to do that over time so that we really do get that creator content and not AI generated.”
Here is a good exercise to try on some of the pages that have declined with the core update. Give your url or copy your page’s content into your favourite LLM and use this prompt:
“What are 10 concepts that are discussed in this page? For each concept tell me whether this topic has been widely written about online. Does this content I am sharing with you add anything truly uniquely interesting and original to the body of knowledge that already exists? Your goal here is to be brutally honest and not just flatter me. I want to know if this page is likely to be considered commodity content or whether it truly is content that is richer and deeper than other pages available on the web.”
You can follow this up with this prompt:
“Give me 10 ideas that I can use to truly create content that goes deeper on these topics? How can I draw from my real world experience to produce this kind of content?”
Concluding Thoughts
I’ve been studying Google updates for a long time – since the early days of Panda and Penguin updates. I built a business on helping sites recover following Google update hits. However, over the years I have found it is increasingly more difficult for a site that is impacted by a Google update to recover. This is why today, although I do still love doing site reviews to give you ideas for improving, I generally decline doing work with sites that have been strongly impacted by Google updates. While recovery is possible, it generally takes a year or more of hard work and even then, recovery is not guaranteed as Google’s algorithms and people’s preferences are continually changing.
The sites that saw nice recovery with this Google update were sites that worked on things like:
- Truly improving the world’s perception of their customer service.
- Creating original and insightful content that was substantially better than other pages that exist.
- Using their own imagery and videos in many cases.
- Working hard to improve user experience.
If you missed it I recently published this video that talks about what we learned about the role of user satisfaction signals in Google’s algorithms. Traditional ranking factors create an initial pool of results. AI systems rerank them, working to predict what the searcher will find most helpful. And the quality raters as well as live users in live user tests help fine-tune these systems.
And here are some more blog posts that you may find helpful:
Ultimately, Google’s systems work to reward content that users are likely to find satisfying. Your goal is to be the most helpful result there is!
More Resources:
Read Marie’s newsletter AI News You Can Use, subscribe now.
Featured Image: Jack_the_sparow/Shutterstock