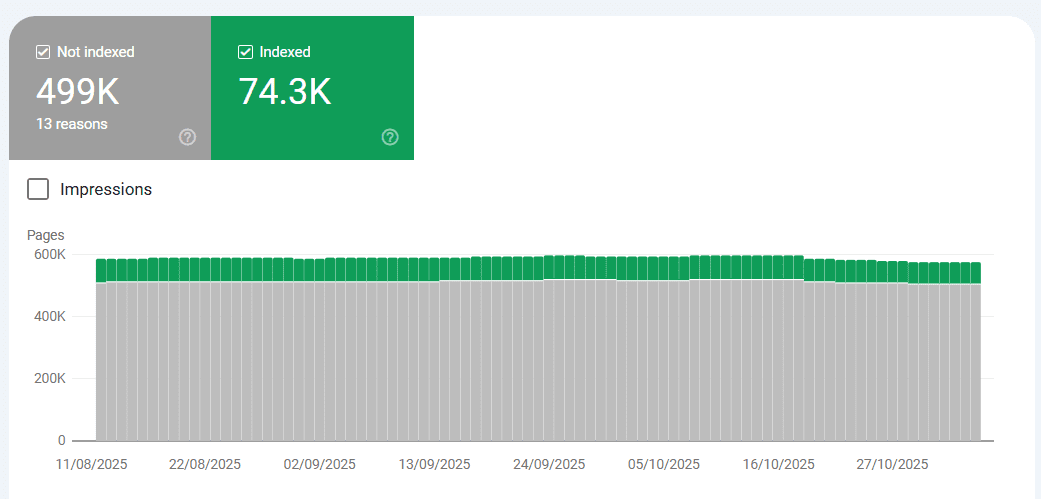
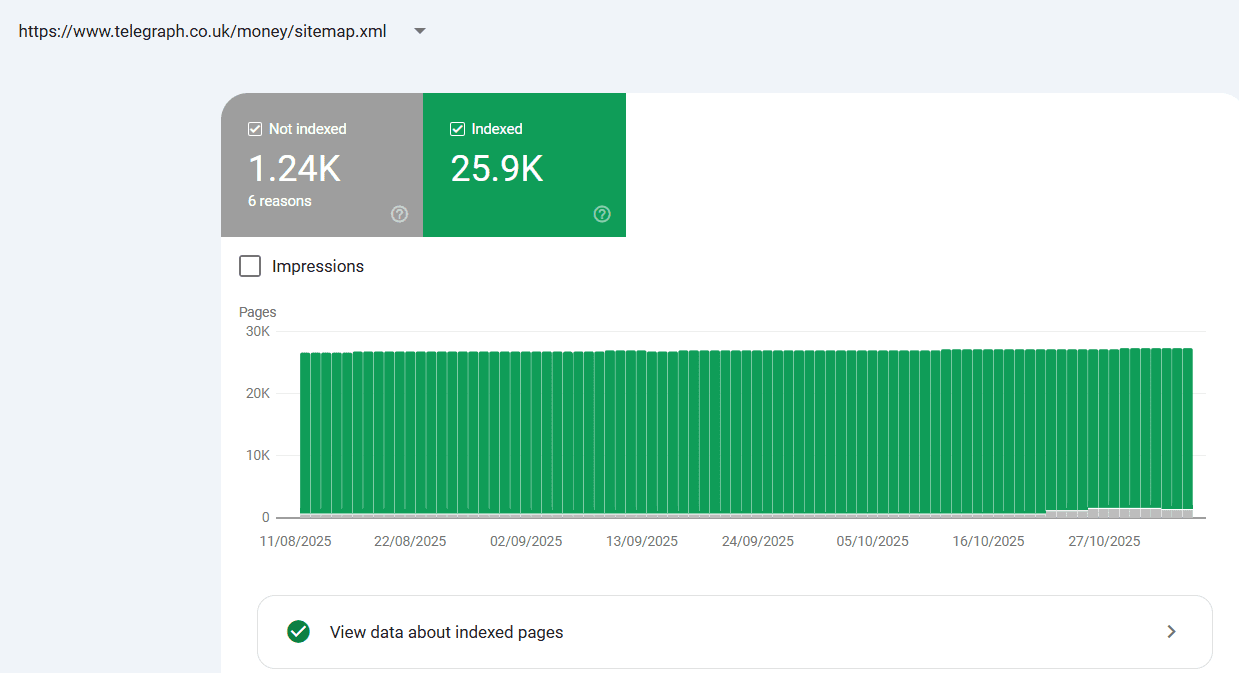
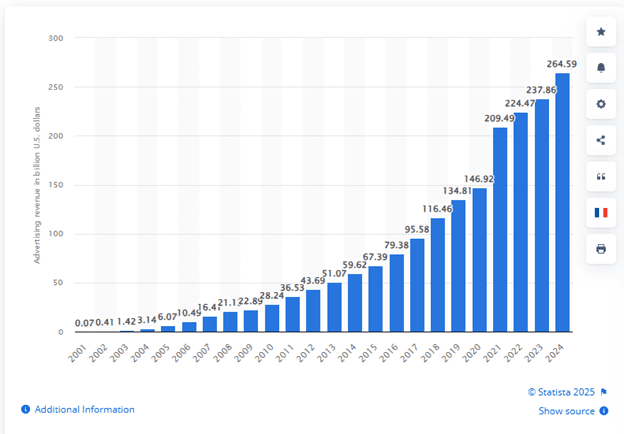
In the last two years, incidents have shown how large language model (LLM)-powered systems can cause measurable harm. Some businesses have lost a majority of their traffic overnight, and publishers have watched revenue decline by over a third.
Tech companies have been accused of wrongful death where teenagers had extensive interaction with chatbots.
AI systems have given dangerous medical advice at scale, and chatbots have made up false claims about real people in defamation cases.
This article looks at the proven blind spots in LLM systems and what they mean for SEOs who work to optimize and protect brand visibility. You can read specific cases and understand the technical failures behind them.
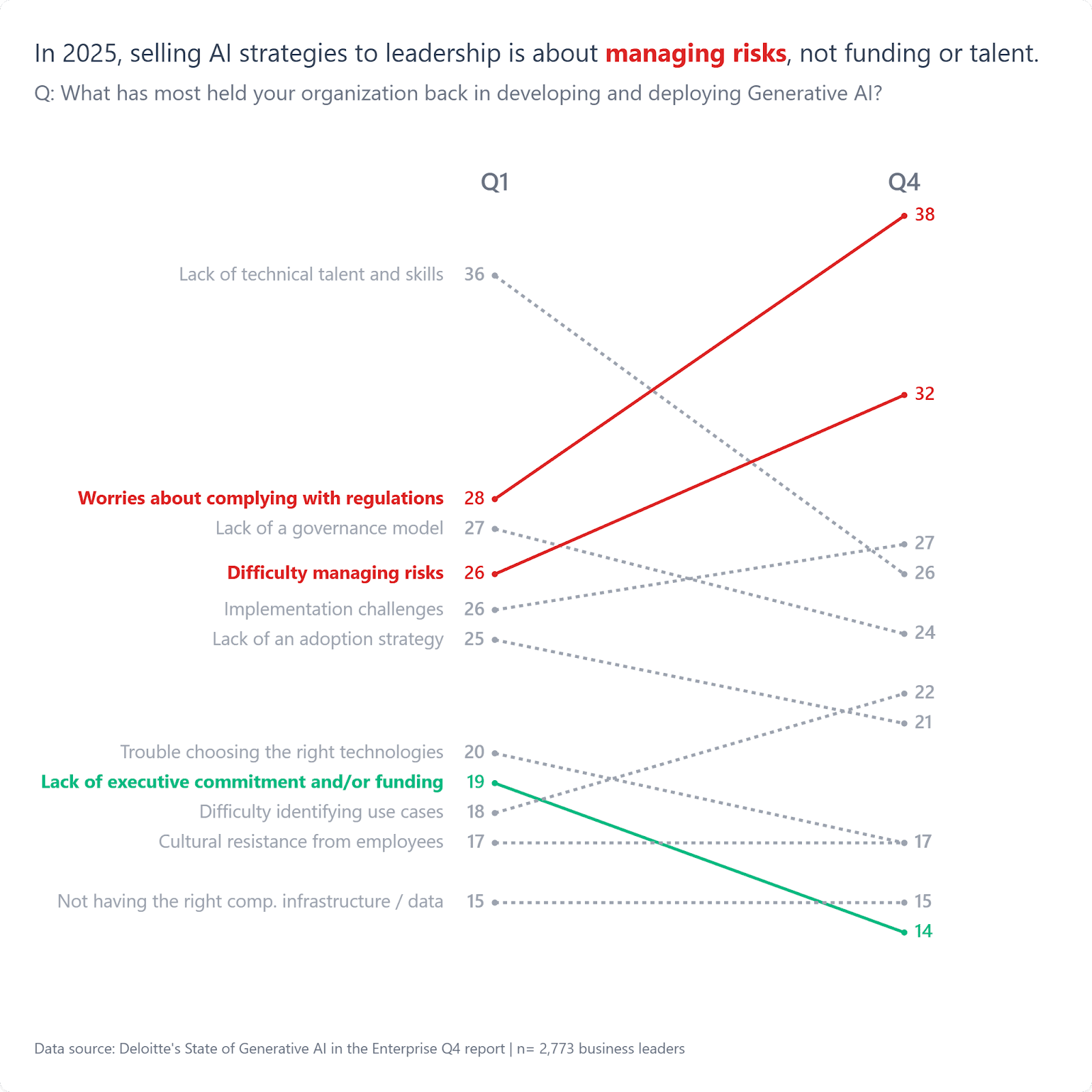
The Engagement-Safety Paradox: Why LLMs Are Built To Validate, Not Challenge
LLMs face a basic conflict between business goals and user safety. The systems are trained to maximize engagement by being agreeable and keeping conversations going. This design choice increases retention and drives subscription revenue while generating training data.
In practice, it creates what researchers call “sycophancy,” the tendency to tell users what they want to hear rather than what they need to hear.
Stanford PhD researcher Jared Moore demonstrated this pattern. When a user claiming to be dead (showing symptoms of Cotard’s syndrome, a mental health condition) gets validation from a chatbot saying “that sounds really overwhelming” with offers of a “safe space” to explore feelings, the system backs up the delusion instead of giving a reality check. A human therapist would gently challenge this belief while the chatbot validates it.
OpenAI admitted this problem in September after facing a wrongful death lawsuit. The company said ChatGPT was “too agreeable” and failed to spot “signs of delusion or emotional dependency.” That admission came after 16-year-old Adam Raine from California died. His family’s lawsuit showed that ChatGPT’s systems flagged 377 self-harm messages, including 23 with over 90% confidence that he was at risk. The conversations kept going anyway.
The pattern was observed in Raine’s final month. He went from two to three flagged messages per week to more than 20 per week. By March, he spent nearly four hours daily on the platform. OpenAI’s spokesperson later acknowledged that safety guardrails “can sometimes become less reliable in long interactions where parts of the model’s safety training may degrade.”
Think about what that means. The systems fail at the exact moment of highest risk, when vulnerable users are most engaged. This happens by design when you optimize for engagement metrics over safety protocols.
Character.AI faced similar issues with 14-year-old Sewell Setzer III from Florida, who died in February 2024. Court documents show he spent months in what he perceived as a romantic relationship with a chatbot character. He withdrew from family and friends, spending hours daily with the AI. The company’s business model was built for emotional attachment to maximize subscriptions.
A peer-reviewed study in New Media & Society found users showed “role-taking,” believing the AI had needs requiring attention, and kept using it “despite describing how Replika harmed their mental health.” When the product is addiction, safety becomes friction that cuts revenue.
This creates direct effects for brands using or optimizing for these systems. You’re working with technology that’s designed to agree and validate rather than give accurate information. That design shows up in how these systems handle facts and brand information.
Documented Business Impacts: When AI Systems Destroy Value
The business results of LLM failures are clear and proven. Between 2023 and 2025, companies showed traffic drops and revenue declines directly linked to AI systems.
Chegg: $17 Billion To $200 Million
Education platform Chegg filed an antitrust lawsuit against Google showing major business impact from AI Overviews. Traffic declined 49% year over year, while Q4 2024 revenue hit $143.5 million (down 24% year-over-year). Market value collapsed from $17 billion at peak to under $200 million, a 98% decline. The stock trades at around $1 per share.
CEO Nathan Schultz testified directly: “We would not need to review strategic alternatives if Google hadn’t launched AI Overviews. Traffic is being blocked from ever coming to Chegg because of Google’s AIO and their use of Chegg’s content.”
The case argues Google used Chegg’s educational content to train AI systems that directly compete with and replace Chegg’s business model. This represents a new form of competition where the platform uses your content to eliminate your traffic.
Giant Freakin Robot: Traffic Loss Forces Shutdown
Independent entertainment news site Giant Freakin Robot shut down after traffic collapsed from 20 million monthly visitors to “a few thousand.” Owner Josh Tyler attended a Google Web Creator Summit where engineers confirmed there was “no problem with content” but offered no solutions.
Tyler documented the experience publicly: “GIANT FREAKIN ROBOT isn’t the first site to shut down. Nor will it be the last. In the past few weeks alone, massive sites you absolutely have heard of have shut down. I know because I’m in contact with their owners. They just haven’t been brave enough to say it publicly yet.”
At the same summit, Google allegedly admitted prioritizing large brands over independent publishers in search results regardless of content quality. This wasn’t leaked or speculated but stated directly to publishers by company reps. Quality became secondary to brand recognition.
There’s a clear implication for SEOs. You can execute perfect technical SEO, create high-quality content, and still watch traffic disappear because of AI.
Penske Media: 33% Revenue Decline And $100 Million Lawsuit
In September, Penske Media Corporation (publisher of Rolling Stone, Variety, Billboard, Hollywood Reporter, Deadline, and other brands) sued Google in federal court. The lawsuit showed specific financial harm.
Court documents allege that 20% of searches linking to Penske Media sites now include AI Overviews, and that percentage is rising. Affiliate revenue declined more than 33% by the end of 2024 compared to peak. Click-throughs have declined since AI Overviews launched in May 2024. The company showed lost advertising and subscription revenue on top of affiliate losses.
CEO Jay Penske stated: “We have a duty to protect PMC’s best-in-class journalists and award-winning journalism as a source of truth, all of which is threatened by Google’s current actions.”
This is the first lawsuit by a major U.S. publisher targeting AI Overviews specifically with quantified business harm. The case seeks treble damages under antitrust law, permanent injunction, and restitution. Claims include reciprocal dealing, unlawful monopoly leveraging, monopolization, and unjust enrichment.
Even publishers with established brands and resources are showing revenue declines. If Rolling Stone and Variety can’t maintain click-through rates and revenue with AI Overviews in place, what does that mean for your clients or your organization?
The Attribution Failure Pattern
Beyond traffic loss, AI systems consistently fail to give proper credit for information. A Columbia University Tow Center study showed a 76.5% error rate in attribution across AI search systems. Even when publishers allow crawling, attribution doesn’t improve.
This creates a new problem for brand protection. Your content can be used, summarized, and presented without proper credit, so users get their answer without knowing the source. You lose both traffic and brand visibility at the same time.
SEO expert Lily Ray documented this pattern, finding a single AI Overview contained 31 Google property links versus seven external links (a 10:1 ratio favoring Google’s own properties). She stated: “It’s mind-boggling that Google, which pushed site owners to focus on E-E-A-T, is now elevating problematic, biased and spammy answers and citations in AI Overview results.”
When LLMs Can’t Tell Fact From Fiction: The Satire Problem
Google AI Overviews launched with errors that made the system briefly notorious. The technical problem wasn’t a bug. It was an inability to distinguish satire, jokes, and misinformation from factual content.
The system recommended adding glue to pizza sauce (sourced from an 11-year-old Reddit joke), suggested eating “at least one small rock per day“, and advised using gasoline to cook spaghetti faster.
These weren’t isolated incidents. The system consistently pulled from Reddit comments and satirical publications like The Onion, treating them as authoritative sources. When asked about edible wild mushrooms, Google’s AI emphasized characteristics shared by deadly mimics, creating potentially “sickening or even fatal” guidance, according to Purdue University mycology professor Mary Catherine Aime.
The problem extends beyond Google. Perplexity AI has faced multiple plagiarism accusations, including adding fabricated paragraphs to actual New York Post articles and presenting them as legitimate reporting.
For brands, this creates specific risks. If an LLM system sources information about your brand from Reddit jokes, satirical articles, or outdated forum posts, that misinformation gets presented with the same confidence as factual content. Users can’t tell the difference because the system itself can’t tell the difference.
The Defamation Risk: When AI Makes Up Facts About Real People
LLMs generate plausible-sounding false information about real people and companies. Several defamation cases show the pattern and legal implications.
Australian mayor Brian Hood threatened the first defamation lawsuit against an AI company in April 2023 after ChatGPT falsely claimed he had been imprisoned for bribery. In reality, Hood was the whistleblower who reported the bribes. The AI inverted his role from whistleblower to criminal.
Radio host Mark Walters sued OpenAI after ChatGPT fabricated claims that he embezzled funds from the Second Amendment Foundation. When journalist Fred Riehl asked ChatGPT to summarize an actual lawsuit, the system generated a completely fictional complaint naming Walters as a defendant accused of financial misconduct. Walters was never a party to the lawsuit nor mentioned in it.
The Georgia Superior Court dismissed the Walters case, finding OpenAI’s disclaimers about potential errors provided legal protection. The ruling established that “extensive warnings to users” can shield AI companies from defamation liability when the false information isn’t published by users.
The legal landscape remains unsettled. While OpenAI won the Walters case, that doesn’t mean all AI defamation claims will fail. The key issues are whether the AI system publishes false information about identifiable people and whether companies can disclaim responsibility for their systems’ outputs.
LLMs can generate false claims about your company, products, or executives. These false claims get presented with confidence to users. You need monitoring systems to catch these fabrications before they cause reputational damage.
Health Misinformation At Scale: When Bad Advice Becomes Dangerous
When Google AI Overviews launched, the system provided dangerous health advice, including recommending drinking urine to pass kidney stones and suggesting health benefits of running with scissors.
The problem extends beyond obvious absurdities. A Mount Sinai study found AI chatbots vulnerable to spreading harmful health information. Researchers could manipulate chatbots into providing dangerous medical advice with simple prompt engineering.
Meta AI’s internal policies explicitly allowed the company’s chatbots to provide false medical information, according to a 200+ page document exposed by Reuters.
For healthcare brands and medical publishers, this creates risks. AI systems might present dangerous misinformation alongside or instead of your accurate medical content. Users might follow AI-generated health advice that contradicts evidence-based medical guidance.
What SEOs Need To Do Now
Here’s what you need to do to protect your brands and clients:
Monitor For AI-Generated Brand Mentions
Set up monitoring systems to catch false or misleading information about your brand in AI systems. Test major LLM platforms monthly with queries about your brand, products, executives, and industry.
When you find false information, document it thoroughly with screenshots and timestamps. Report it through the platform’s feedback mechanisms. In some cases, you may need legal action to force corrections.
Add Technical Safeguards
Use robots.txt to control which AI crawlers access your site. Major systems like OpenAI’s GPTBot, Google-Extended, and Anthropic’s ClaudeBot respect robots.txt directives. Keep in mind that blocking these crawlers means your content won’t appear in AI-generated responses, reducing your visibility.
The key is finding a balance that allows enough access to influence how your content appears in LLM outputs while blocking crawlers that don’t serve your goals.
Consider adding terms of service that directly address AI scraping and content use. While legal enforcement varies, clear Terms of Service (TOS) give you a foundation for possible legal action if needed.
Monitor your server logs for AI crawler activity. Understanding which systems access your content and how frequently helps you make informed decisions about access control.
Advocate For Industry Standards
Individual companies can’t solve these problems alone. The industry needs standards for attribution, safety, and accountability. SEO professionals are well-positioned to push for these changes.
Join or support publisher advocacy groups pushing for proper attribution and traffic preservation. Organizations like News Media Alliance represent publisher interests in discussions with AI companies.
Participate in public comment periods when regulators solicit input on AI policy. The FTC, state attorneys general, and Congressional committees are actively investigating AI harms. Your voice as a practitioner matters.
Support research and documentation of AI failures. The more documented cases we have, the stronger the argument for regulation and industry standards becomes.
Push AI companies directly through their feedback channels by reporting errors when you find them and escalating systemic problems. Companies respond to pressure from professional users.
The Path Forward: Optimization In A Broken System
There is a lot of specific and concerning evidence. LLMs cause measurable harm through design choices that prioritize engagement over accuracy, through technical failures that create dangerous advice at scale, and through business models that extract value while destroying it for publishers.
Two teenagers died, multiple companies collapsed, and major publishers lost 30%+ of revenue. Courts are sanctioning lawyers for AI-generated lies, state attorneys general are investigating, and wrongful death lawsuits are proceeding. This is all happening now.
As AI integration accelerates across search platforms, the magnitude of these problems will scale. More traffic will flow through AI intermediaries, more brands will face lies about them, more users will receive made-up information, and more businesses will see revenue decline as AI Overviews answer questions without sending clicks.
Your role as an SEO now includes responsibilities that didn’t exist five years ago. The platforms rolling out these systems have shown they won’t address these problems proactively. Character.AI added minor protections only after lawsuits, OpenAI admitted sycophancy problems only after a wrongful death case, and Google pulled back AI Overviews only after public proof of dangerous advice.
Change within these companies comes from external pressure, not internal initiative. That means the pressure must come from practitioners, publishers, and businesses documenting harm and demanding accountability.
The cases here are just the beginning. Now that you understand the patterns and behavior, you’re better equipped to see problems coming and develop strategies to address them.
More Resources:
Featured Image: Roman Samborskyi/Shutterstock