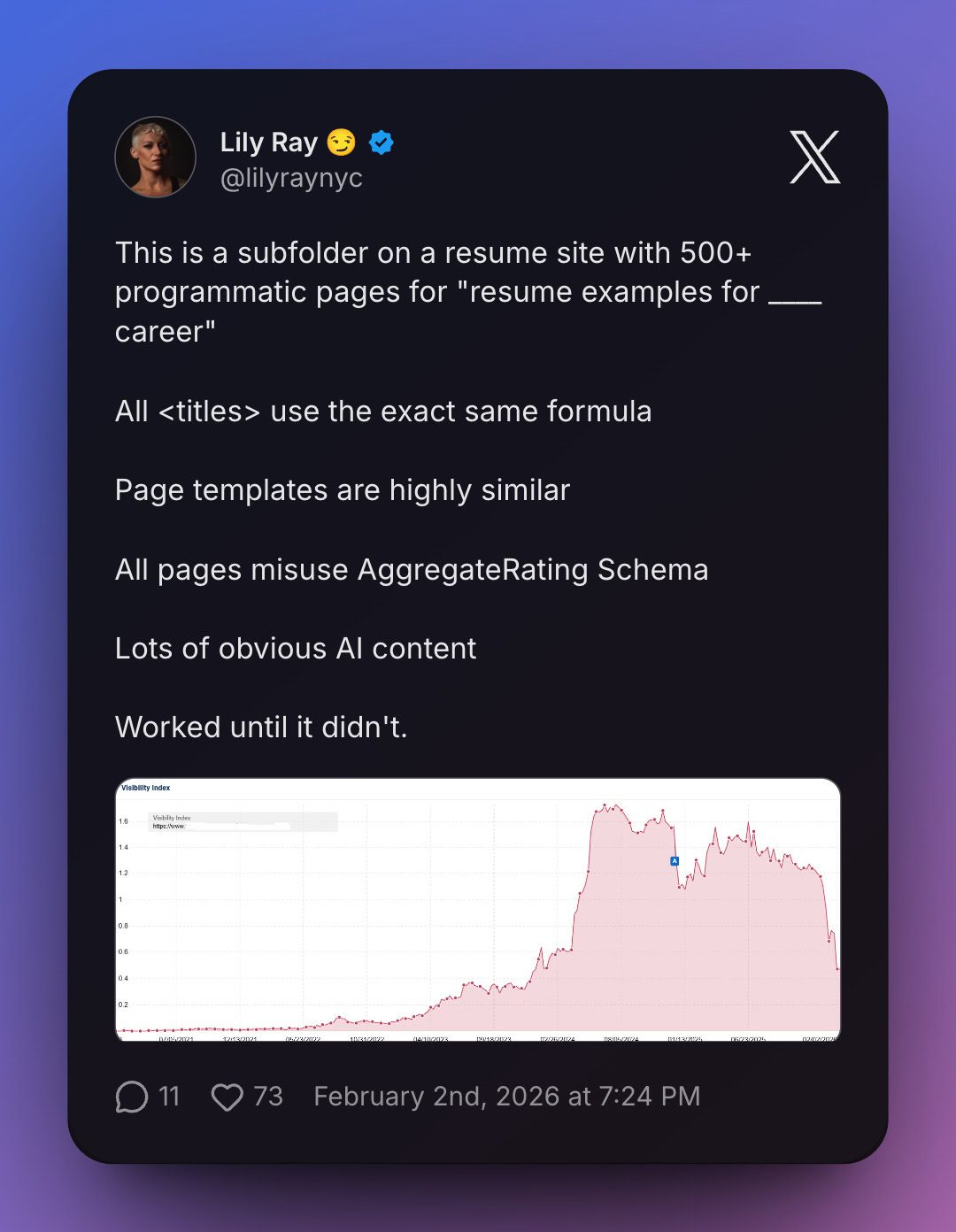
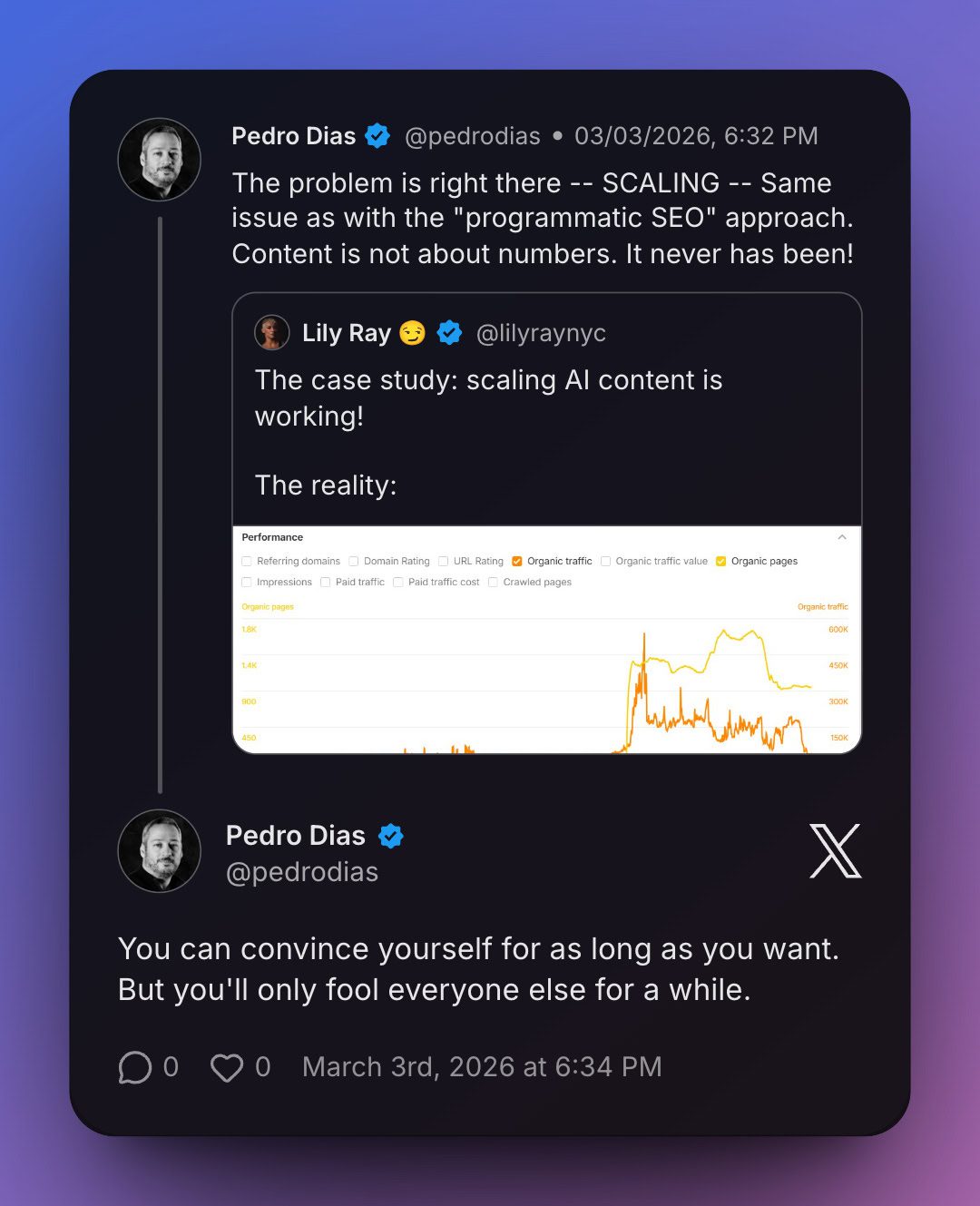
For 25 years, we’ve built websites for humans who click, scroll, and browse. That era is ending. I’ve been in website optimization for 15+ years, and this is the biggest shift I’ve seen since mobile. And honestly, I think it’s way bigger than that.
The internet is undergoing its most significant transformation since it began. Your website now has two audiences: humans and AI agents. The agents are already here, shopping, researching, booking, and making decisions. The question is whether your website can serve them.
This is the first article in a five-part series on optimizing websites for the agentic web. We’ll cover discovery, citation, technical implementation, and the new commerce protocols that let AI complete purchases on your behalf. Throughout this series, we’ll draw exclusively from official documentation, research papers, and announcements from the companies building this infrastructure.
But first, we need to understand how we got here and why December 2025 changed everything.
The Evolution: SEO To AEO To GEO To AAIO
The alphabet soup of optimization acronyms tells a story about how the web has changed.
SEO (Search Engine Optimization) dominated from the mid-1990s through the 2010s. The goal was simple: rank higher on Google. You optimized keywords, built backlinks, and structured your site so crawlers could index it. Success meant appearing on page one when someone searched for your topic.
AEO (Answer Engine Optimization) emerged as AI systems started answering questions directly. When Google introduced featured snippets, then AI Overviews, the game changed. Ranking wasn’t enough anymore. You needed to be the source that AI systems cited when generating answers. AEO focuses on structuring content so it gets selected and quoted, becoming the definitive answer rather than just a search result.
GEO (Generative Engine Optimization) expanded this further. Systems like ChatGPT, Claude, and Perplexity don’t just cite sources. They synthesize information from multiple places into comprehensive responses. GEO ensures your content appears in these synthesized answers, ensuring your expertise gets woven into the AI’s response even when you’re not the primary citation.
AAIO (Agentic AI Optimization) is the latest evolution, and it represents a fundamental shift. AAIO isn’t about being found or cited. It’s about being usable by AI agents that act autonomously on behalf of humans.
A research paper published in April 2025 by Luciano Floridi and colleagues formalized this distinction. As they put it, AAIO “explicitly optimises content for autonomous artificial agents, simultaneously addressing both human and machine interpretability.” Unlike SEO, which enhanced discoverability for humans through search engines, AAIO prepares websites for AI systems that initiate digital interactions independently.
Agent Experience Optimization (AXO) is the umbrella term that encompasses all of these practices. Just as UX focuses on human users and SEO focuses on search crawlers, AXO focuses on AI systems that interact with websites. It includes discovery (being found), citation (being referenced), and action (being usable). I cover AXO in depth in What is Agent Experience Optimization.
The progression is straightforward: SEO asks “How do I rank?” AEO asks “How do I get cited?” GEO asks “How do I get included?” AAIO asks “How do I enable agents to complete tasks on my site?”
The relationship between website optimization and AI effectiveness creates a virtuous cycle, similar to what happened with SEO and search engines in the early 2000s. When websites implement AAIO practices, AI agents perform better, which encourages more websites to adopt these practices, which makes agents more useful, which drives adoption further.
December 2025: The HTML Moment For AI
On Dec. 9, 2025, something significant happened. The Linux Foundation announced the Agentic AI Foundation (AAIF), a vendor-neutral governance body for agentic AI standards.
Eight platinum members anchored the foundation: Amazon Web Services, Anthropic, Block, Bloomberg, Cloudflare, Google, Microsoft, and OpenAI. What’s remarkable here isn’t the technology. It’s that OpenAI, Anthropic, Google, and Microsoft are building shared infrastructure instead of competing standards. This is a strong signal that the industry sees agentic AI as foundational, not a feature war.
Three key projects were contributed:
- Model Context Protocol (MCP) from Anthropic: a universal standard for connecting AI systems to tools and data sources, now with over 10,000 published servers and adoption by Claude, ChatGPT, Gemini, VS Code, and Microsoft Copilot
- AGENTS.md from OpenAI: a standardized specification for providing AI coding agents consistent project guidance across repositories
- goose from Block: an open-source, local-first agent framework combining language models with extensible tools
This matters because it mirrors what happened with the early web. In the 1990s, competing browser vendors and incompatible standards fragmented the internet. The W3C brought order by establishing shared protocols like HTML and CSS. The Agentic AI Foundation aims to do the same for AI agents, creating the shared infrastructure that lets agents from different companies work together and interact with websites consistently.
As Linux Foundation Executive Director Jim Zemlin put it, the foundation enables development “with the transparency and stability that only open governance provides.”
We’re watching the TCP/IP moment for agents. The protocols being established now will define how AI interacts with the web for the next decade: MCP for tool integration, A2A for agent-to-agent communication, NLWeb for making websites queryable.
I realize that sounds hyperbolic. It isn’t. We’re in the early months of a decade-long transformation.
Discovery, Citation, And Action
These three concepts form the framework for this entire series:
- Discovery is about being found by AI systems. AI crawlers like GPTBot, ClaudeBot, and PerplexityBot index the web for their respective platforms. If you’re blocking these crawlers, or if your content isn’t accessible to them, you’re invisible to AI systems. Discovery is the foundation. Nothing else matters if agents can’t find you.
- Citation is about being selected as a source. When an AI system generates a response, it chooses which sources to reference. Getting cited requires content that AI systems recognize as authoritative, accurate, and relevant. This involves structured data, clear information hierarchy, and demonstrable expertise. Microsoft has published detailed guidance on what makes content citable.
- Action is about enabling agents to use your site. This is where AAIO diverges from earlier optimization approaches. An agent visiting your site might need to click buttons, fill forms, navigate menus, compare options, and complete transactions. If your site breaks when an agent tries to interact with it, you lose the business to competitors whose websites work.
The stakes escalate at each level. Failing at discovery means invisibility. Failing at citation means your competitors get referenced instead. Failing at action means losing transactions that would have happened on your site.
Why This Matters Now
Two converging trends make 2026 the year to act.
Agentic browsers are reaching consumers.
The first wave of AI browsers launched in 2025, and 2026 is bringing them to mainstream users. For a complete breakdown, see The Agentic Browser Landscape in 2026.
Perplexity’s Comet combines search-focused AI with full browser capabilities. ChatGPT Atlas from OpenAI includes Agent Mode for autonomous multi-step tasks. Chrome’s auto browse feature, powered by Gemini, is shipping to Google AI subscribers.
Chrome alone represents 3 billion potential users. If you’re wondering whether to take this seriously: Google doesn’t ship features to 3 billion users on a whim.
When the world’s most popular browser can autonomously scroll, click, type, and navigate on your behalf, the implications for website owners are profound. Websites that work well with these agents get included in agentic workflows. Websites that don’t get skipped.
As DigitalOcean’s analysis notes, “This shift forces websites to redesign for both human and AI users,” requiring cleaner navigation, API-first strategies, and optimization for agent functionality beyond visual presentation.
Commerce is shifting.
Stripe, Shopify, and OpenAI are building infrastructure for AI agents to complete purchases. The Agentic Commerce Protocol enables secure, agent-initiated transactions. Brands like URBN, Etsy, Glossier, and SKIMS are already implementing these systems.
Checkout is no longer a page. It’s an API endpoint. The agent researches, selects, and purchases on behalf of the user, who never visits your website at all.
What’s Coming In This Series
This article established the “why.” The rest of the series covers the “how”:
Part 2: Answer Engine Optimization dives into getting your content cited in AI responses. How AI systems parse content differently than search engines, the structure that gets cited, which schema markup matters, and how to measure your AI visibility.
Part 3: The Agentic Web Protocols explores MCP, A2A, NLWeb, and AGENTS.md, the standards powering the agentic web. These protocols are complementary, not competing, and together they form the infrastructure layer that enables everything else.
Part 4: How AI Agents See Your Website provides the implementation guide. How agents “see” websites, why semantic HTML matters more than ever, the role of accessibility standards, and what to tell your developers.
Part 5: Selling to AI covers agentic commerce. Stripe’s Agentic Commerce Suite, Shopify’s Universal Commerce Protocol, secure payment tokens, fraud detection for agent traffic, and how to get started.
Key Takeaways
- The web is shifting from pages for humans to content for AI agents. Your website now serves two audiences, and optimizing for both is becoming necessary.
- The evolution runs from SEO to AEO to GEO to AAIO. Each builds on the last: ranking, then citation, then inclusion, then enabling autonomous action.
- December 2025 was the turning point. The Agentic AI Foundation launch established shared standards, moving agentic AI from experimentation to infrastructure.
- Three levels matter: discovery, citation, and action. Being found, being referenced, and being usable by AI agents.
- The business case is concrete. Agentic browsers are reaching billions of users. Commerce protocols are enabling agent-initiated purchases. Websites that work with agents capture this opportunity; those that don’t lose business to competitors.
Traditional SEO asked: “How do I rank on Google?” The new question is: “How do I become the answer, and how do I let AI complete transactions on my site without a human ever visiting?”
I’m writing this series because I believe most websites do and will get this wrong. They’ll treat it as an SEO tweak or a CRO experiment when it’s an architectural shift.
The infrastructure is being built now. The standards are being established. The agents are already browsing.
The question is whether your website is ready for them.
More Resources:
This post was originally published on No Hacks.
Featured Image: Collagery/Shutterstock