Google’s Gary Illyes confirmed that AI content is fine as long as the quality is high. He said that “human created” isn’t precisely the right way to describe their AI content policy, and that a more accurate description would be “human curated.”
The questions were asked by Kenichi Suzuki in the context of an exclusive interview with Illyes.
AI Overviews and AI Mode Models
Kenichi asked about the AI models used for AI Overviews and AI Mode, and he answered that they are custom Gemini models.
Illyes answered:
“So as you noted, the the model that we use for AIO (for AI Overviews) and for AI mode is a custom Gemini model and that might mean that it was trained differently. I don’t know the exact details, how it was trained, but it’s definitely a custom model.”
Kenichi then asked if AI Overviews (AIO) and AI Mode use separate indexes for grounding.
Grounding is where an LLM will connect answers to a database or a search index so that answers are more reliable, truthful, and based on verifiable facts, helping to cut down on hallucinations. In the context of AIO and AI Mode, grounding generally happens with web-based data from Google’s index.
Suzuki asked:
“So, does that mean that AI Overviews and AI Mode use separate indexes for grounding?”
Google’s Illyes answered:
“As far as I know, Gemini, AI Overview and AI Mode all use Google search for grounding. So basically they issue multiple queries to Google Search and then Google Search returns results for that those particular queries.”
Kenichi was trying to get an answer regarding the Google Extended crawler, and Illyes’s response was to explain when the Google Extended crawler comes into play.
“So does that mean that the training data are used by AIO and AI Mode collected by regular Google and not Google Extended?”
And Illyes answered:
“You have to remember that when grounding happens, there’s no AI involved. So basically it’s the generation that is affected by the Google extended. But also if you disallow Google Extended then Gemini is not going to ground for your site.”
AI Content In LLMs And Search Index
The next question that Illyes answered was about whether AI content published online is polluting LLMs. Illyes said that this is not a problem with the search index, but it may be an issue for LLMs.
Kenichi’s question:
“As more content is created by AI, and LLMs learn from that content. What are your thoughts on this trend and what are its potential drawbacks?”
Illyes answered:
“I’m not worried about the search index, but model training definitely needs to figure out how to exclude content that was generated by AI. Otherwise you end up in a training loop which is really not great for for training. I’m not sure how much of a problem this is right now, or maybe because how we select the documents that we train on.”
Content Quality And AI-Generated Content
Suzuki then followed up with a question about content quality and AI.
He asked:
“So you don’t care how the content is created… so as long as the quality is high?”
Illyes confirmed that a leading consideration for LLM training data is content quality, regardless of how it was generated. He specifically cited the factual accuracy of the content as an important factor. Another factor he mentioned is that content similarity is problematic, saying that “extremely” similar content shouldn’t be in the search index.
He also said that Google essentially doesn’t care how the content is created, but with some caveats:
“Sure, but if you can maintain the quality of the content and the accuracy of the content and ensure that it’s of high quality, then technically it doesn’t really matter.
The problem starts to arise when the content is either extremely similar to something that was already created, which hopefully we are not going to have in our index to train on anyway.
And then the second problem is when you are training on inaccurate data and that is probably the riskier one because then you start introducing biases and they start introducing counterfactual data in your models.
As long as the content quality is high, which typically nowadays requires that the human reviews the generated content, it is fine for model training.”
Human Reviewed AI-Generated Content
Illyes continued his answer, this time focusing on AI-generated content that is reviewed by a human. He emphasizes human review not as something that publishers need to signal in their content, but as something that publishers should do before publishing the content.
Again, “human reviewed” does not mean adding wording on a web page that the content is human reviewed; that is not a trustworthy signal, and it is not what he suggested.
Here’s what Illyes said:
“I don’t think that we are going to change our guidance any time soon about whether you need to review it or not.
So basically when we say that it’s human, I think the word human created is wrong. Basically, it should be human curated. So basically someone had some editorial oversight over their content and validated that it’s actually correct and accurate.”
Takeaways
Google’s policy, as loosely summarized by Gary Illyes, is that AI-generated content is fine for search and model training if it is factually accurate, original, and reviewed by humans. This means that publishers should apply editorial oversight to validate the factual accuracy of content and to ensure that it is not “extremely” similar to existing content.
Google’s Gary Illyes recently answered the question of whether AI-generated images used together with “legit” content can impact rankings. Gary discussed whether it had an impact on SEO and called attention to a technical issue involving server resources that is a possible outcome.
Does Google Penalize for AI-Generated Content?
How does Google react to AI image content when it’s encountered in the context of a web page? Google’s Gary Illyes answered that question within the context of a Q&A and offered some follow-up observations about how it could lead to extra traffic from Google Image Search. The question was asked at about the ten-minute mark of the interview conducted by Kenichi Suzuki and published on YouTube.
This is the question that was asked:
“Say if there’s a content that the content itself is legit, the sentences are legit but and also there are a lot of images which are relevant to the content itself, but all of them, let’s say all of them are generated by AI. Will that content or the overall site, is it going to be penalized or not?”
This is an important and reasonable question because Google ran an update about a year ago that appeared to de-rank low quality AI-generated content.
Google’s Gary Ilyes’ answer was clear that AI-generated content will not result in penalization and that it has no direct impact on SEO.
He answered:
“No, no. So AI generated image doesn’t impact the SEO. Not direct.
So obviously when you put images on your site, you will have to sacrifice some resources to those images… But otherwise you are not going to, I don’t think that you’re going to see any negative impact from that.
If anything, you might get some traffic out of image search or video search or whatever, but otherwise it should just be fine.”
AI-Generated Content
Gary Illyes did not discuss authenticity; however it’s a good thing to consider in the context of using AI-generated content. Authenticity is an important quality for users, especially in contexts where there is an expectation that an illustration is a faithful depiction of an actual outcome or product. For example, users expect product illustrations to accurately reflect the products they are purchasing and screenshots of food to reasonably represent the completed dishes after following the recipe instructions.
Google often says that content should be created for users and that many questions about SEO are adequately answered by the context of how users will react to it. Illyes did not reflect on any of that, but it is something that publishers should consider if they care about how content resonates with users.
Gary’s answer makes it clear that AI-generated content will not have a negative impact on SEO.
For decades, the digital world has been defined by hyperlinks, a simple, powerful way to connect documents across a vast, unstructured library. Yet, the foundational vision for the web was always more ambitious.
It was a vision of a Semantic Web, a web where the relationships between concepts are as important as the links between pages, allowing machines to understand the context and meaning of information, not just index its text.
With its latest Search Labs experiment, Web Guide (that got me so excited), Google is taking an important step in this direction.
Google’s Web Guide is designed to make it easier to find the information, not just webpages. It is optimized as an alternative to AI Mode and AI Overview for tackling complex, multi-part questions or to explore a topic from multiple angles.
Built using a customized version of the Gemini AI model, Web Guide organizes search results into helpful, easy-to-browse groups.
This is a pivotal moment. It signals that the core infrastructure of search is now evolving to natively support the principle of semantic understanding.
Web Guide represents a shift away from a web of pages and average rankings and toward a web of understanding and hyper-personalization.
This article will deconstruct the technology behind Web Guide, analyzing its dual impact on publishers and refining a possibly new playbook for the era of SEO or Generative Engine Optimization (GEO) if you like.
I personally don’t see Web Guide as just another feature; I see it as a glimpse into the future of how knowledge shall be discovered and consumed.
How Google’s Web Guide Works: The Technology Behind The Hyper-Personalized SERP
At its surface, Google Web Guide is a visual redesign of the search results page. It replaces the traditional, linear list of “10 blue links” with a structured mosaic of thematic content.
For an exploratory search like [how to solo travel in Japan], a user might see distinct, expandable clusters for “comprehensive guides,” “personal experiences,” and “safety recommendations.”
This allows users to immediately drill down into the facet of their query that is most relevant to them.
But, the real revolution is happening behind the scenes. This curation is powered by a custom version of Google’s Gemini model, but the key to its effectiveness is a technique known as “query fan-out.”
When a user enters a query, the AI doesn’t just search for that exact phrase. Instead, it deconstructs the user’s likely intent into a series of implicit, more specific sub-queries, “fanning out” to search for them in parallel.
For the “solo travel in Japan” query, the fan-out might generate internal searches for “Japan travel safety for solo women,” “best blogs for Japan travel,” and “using the Japan Rail Pass.”
By casting this wider net, the AI gathers a richer, more diverse set of results. It then analyzes and organizes these results into the thematic clusters presented to the user. This is the engine of hyper-personalization.
The SERP is no longer a one-size-fits-all list; it’s a dynamically generated, personalized guide built to match the multiple, often unstated, intents of a specific user’s query. (Here is the early analysis I did by analyzing the network traffic – HAR file – behind a request.)
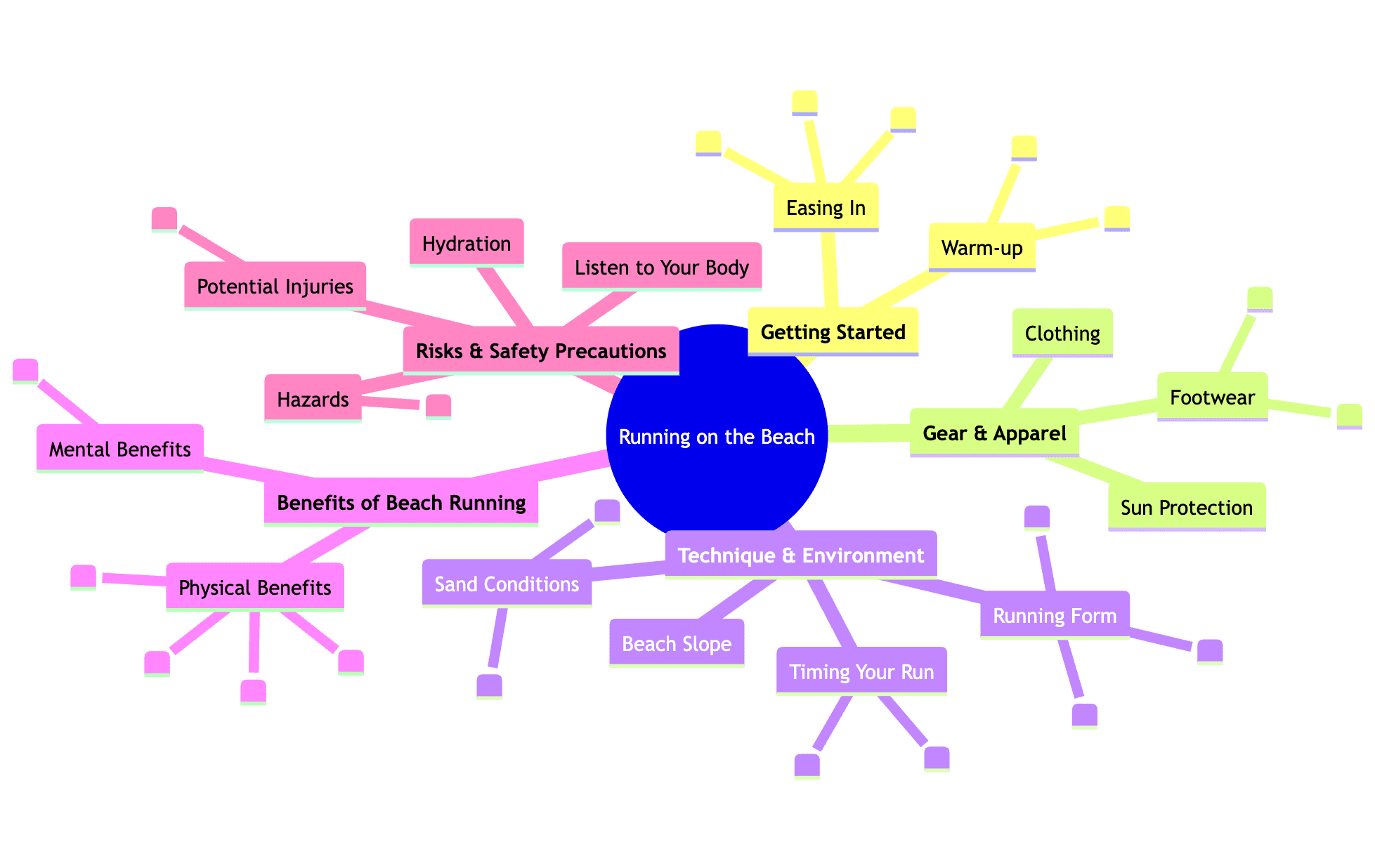
To visualize how this works in semantic terms, let’s consider the query “things to know about running on the beach,” which the AI breaks down into the following facets:
Screenshot from search for [things to know about running on the beach], Google, August 2025
Image from author, August 2025
The WebGuide UI is composed of several elements designed to provide a comprehensive and personalized experience:
Main Topic: The central theme or query that the user has entered.
Branches: The main categories of information generated in response to the user’s query. These branches are derived from various online sources to provide a well-rounded overview.
Sites: The specific websites from which the information is sourced. Each piece of information within the branches is attributed to its original source, including the entity name and a direct URL.
Let’s review Web Guide in the context of Google’s other AI initiatives.
Feature
Primary Function
Core Technology
Impact on Web Links
AI Overviews
Generate a direct, synthesized answer at the top of the SERP.
Generative AI, Retrieval-Augmented Generation.
High negative impact. Designed to reduce clicks by providing the answer directly. It is replacing featured snippets, as recently demonstrated by Sistrix for the UK market.
AI Mode
Provide a conversational, interactive, generative AI experience.
Custom version of Gemini, query fan-out, chat history.
High negative impact. Replaces traditional results with a generated response and mentions.
Web Guide
Organize and categorize traditional web link results.
Custom version of Gemini, query fan-out.
Moderate/Uncertain impact. Aims to guide clicks to more relevant sources.
Web Guide’s unique role is that of an AI-powered curator or librarian.
It adds a layer of AI organization while preserving the fundamental link-clicking experience, making it a strategically distinct and potentially less contentious implementation of AI in search.
The Publisher’s Conundrum: Threat Or Opportunity?
The central concern surrounding any AI-driven search feature is the potential for a severe loss of organic traffic, the economic lifeblood of most content creators. This anxiety is not speculative.
Cloudflare’s CEO has publicly criticized these moves as another step in “breaking publishers’ business models,” a sentiment that reflects deep apprehension across the digital content landscape.
This fear is contextualized by the well-documented impact of Web Guide’s sibling feature, AI Overviews.
A critical study by the Pew Research Center revealed that the presence of an AI summary at the top of a SERP dramatically reduces the likelihood that a user will click on an organic link, a nearly 50% relative drop in click-through rate in its analysis.
Google has mounted a vigorous defense, claiming it has “not observed significant drops in aggregate web traffic” and that the clicks that do come from pages with AI Overviews are of “higher quality.”
Amid this, Web Guide presents a more nuanced picture. There is a credible argument that, by preserving the link-clicking paradigm, it could be a more publisher-friendly application of AI.
Its “query fan-out” technique could benefit high-quality, specialized content that has struggled to rank for broad keywords.
In this optimistic view, Web Guide acts as a helpful librarian, guiding users to the right shelf in the library rather than just reading them a summary at the front desk.
However, even this more “link-friendly” approach cedes immense editorial control to an opaque algorithm, making the ultimate impact on net traffic uncertain to say the least.
The New Playbook: Building For The “Query Fan-Out”
The traditional goal of securing the No. 1 ranking for a specific keyword is rapidly becoming an outdated and insufficient goal.
In this new landscape, visibility is defined by contextual relevance and presence within AI-generated clusters. This requires a new strategic discipline: Generative Engine Optimization (GEO).
GEO expands the focus from optimizing for crawlers to optimizing for discoverability within AI-driven ecosystems.
The key to success in this new paradigm lies in understanding and aligning with the “query fan-out” mechanism.
Pillar 1: Build For The “Query Fan-Out” With Topical Authority
The most effective strategy is to pre-emptively build content that maps directly to the AI’s likely “fan-out” queries.
This means deconstructing your areas of expertise into core topics and constituent subtopics, and then building comprehensive content clusters that cover every facet of a subject.
This involves creating a central “pillar” page for a broad topic, which then links out to a “constellation” of highly detailed, dedicated articles that cover every conceivable sub-topic.
For “things to know about running on the beach,” (the example above) a publisher should create a central guide that links to individual, in-depth articles such as “The Benefits and Risks of Running on Wet vs. Dry Sand,” “What Shoes (If Any) Are Best for Beach Running?,” “Hydration and Sun Protection Tips for Beach Runners,” and “How to Improve Your Technique for Softer Surfaces.”
By creating and intelligently interlinking this content constellation, a publisher signals to the AI that their domain possesses comprehensive authority on the entire topic.
This dramatically increases the probability that when the AI “fans out” its queries, it will find multiple high-quality results from that single domain, making it a prime candidate to be featured across several of Web Guide’s curated clusters.
This strategy must be built upon Google’s established E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) principles, which are amplified in an AI-driven environment.
Pillar 2: Master Technical & Semantic SEO For An AI Audience
While Google states there are no new technical requirements for AI features, the shift to AI curation elevates the importance of existing best practices.
Structured Data (Schema Markup): This is now more critical than ever. Structured data acts as a direct line of communication to AI models, explicitly defining the entities, properties, and relationships within your content. It makes content “AI-readable,” helping the system understand context with greater precision. This could mean the difference between being correctly identified as a “how-to guide” versus a “personal experience blog,” and thus being placed in the appropriate cluster.
Foundational Site Health: The AI model needs to see a page the same way a user does. A well-organized site architecture, with clean URL structures that group similar topics into directories, provides strong signals to the AI about your site’s topical structure. Crawlability, a good page experience, and mobile usability are essential prerequisites for competing effectively.
Write with semiotics in mind: As Gianluca Fiorelli would say, focus on the signals behind the message. AI systems now rely on hybrid chunking; they break content into meaning-rich segments that combine text, structure, visuals, and metadata. The clearer your semiotic signals (headings, entities, structured data, images, and relationships), the easier it is for AI to interpret the purpose and context of your content. In this AI-gated search environment, meaning and context have become your new keywords.
The Unseen Risks: Bias In The Black Box
A significant criticism of AI-driven systems like Web Guide lies in their inherent opacity. These “black boxes” pose a formidable challenge to accountability and fairness.
The criteria by which the Gemini model decides which categories to generate and which pages to include are not public, raising profound questions about the equity of the curation process.
There is a significant risk that the AI will not only reflect but also amplify existing societal and brand biases. A compelling example is to review complex issues to test the fairness of the Web Guide.
Screenshot from search for [Are women more likely to be prescribed antidepressants for physical symptoms?], Google, August 2025
Medical diagnostic queries are complex and can easily reveal biases.
Screenshot from search for [Will AI eliminate most white-collar jobs?], Google, July 2025
Once again, UGC is used and might not always bring the right nuance between doom narratives and overly optimistic positions.
Since the feature is built upon these same core systems of traditional Search, it is highly probable that it will perpetuate existing biases.
Conclusion: The Age Of The Semantic AI-Curated Web
Google’s Web Guide is not a temporary UI update; it is a manifestation of a deeper, irreversible transformation in information discovery.
It represents Google’s attempt to navigate the passage between the old world of the open, link-based web and the new world of generative, answer-based AI.
The “query fan-out” mechanism is the key to understanding its impact and the new strategic direction. For all stakeholders, adaptation is not optional.
The strategies that guaranteed success in the past are no longer sufficient. The core imperatives are clear: Embrace topical authority as a direct response to the AI’s mechanics, master the principles of Semantic SEO, and prioritize the diversification of traffic sources. The era of the 10 blue links is over.
The era of the AI-curated “chunks” has begun, and success will belong to those who build a deep, semantic repository of expertise that AI can reliably understand, trust, and surface.
I’ve had this post in drafts for a while, mostly as a container for me to drop bits into for when I get time to expand it into a proper newsletter.
Then, my good friend Jono Alderson published his excellent piece on semantic HTML, and for a few weeks, I lost the will to complete mine.
But, I thought I should finish my version anyway, as my focus is slightly different and perhaps a bit more practical than Jono’s.
You should still definitely read Jono’s blog; it says all I want to say and more.
Semantic HTML
Let’s start with a quick overview of what semantic HTML is.
As the language upon which the web is built, HTML is a markup that surrounds text to provide it with structure.
The
tag around a block of content indicates that it is a paragraph of text.
The
tag around a sentence shows that it is the page’s main heading.
The
tag indicates the start of an ordered (usually numbered) list.
The tag indicates you’ll be loading an image onto the webpage. And so forth.
Semantic HTML was used to code every webpage.
Content was surrounded by specific tags that indicated what each bit of content was meant for, and then CSS was applied to make it look good. It wasn’t perfect by any means, but it worked.
It also meant that you could look at the raw HTML source of a webpage and see what the page was trying to deliver, and how. The HTML signposted the structure and meaning of each bit of content on the page. You could see the purpose of the page just by looking at its code.
Then WYSIWYG editors and later JavaScript frameworks arrived on the scene, and HTML took a backseat. Instead of
and
, we got endless nestings of
and tags.
The end result is webpage HTML that lacks structure and has no meaning, until it is completely rendered in the browser and visually painted onto a screen. Only then will the user (and a machine system trying to emulate a user) understand what the page’s purpose is.
It’s why Google goes through the effort of rendering pages as part of its indexing process (even though it really doesn’t want to).
We know Google doesn’t usually have the time to render a news article before it needs to rank it in Top Stories and elsewhere. The raw HTML is therefore immensely important for news publishers.
Good HTML allows Google to effortlessly extract your article content and rank your story where it deserves in Google’s ecosystem.
Semantic HTML is a key factor here. This is the reason why SEOs like me insist that an article’s headline is wrapped in the
heading tag, and that this is the only instance of
on an article page.
The H1 headline indicates a webpage’s primary headline. It signposts where the article begins, so that Google can find the article content easily.
Which HTML Tags Are Semantic?
Beyond the
heading tag, there are many other semantic HTML elements you can implement that allow Google to more easily extract and index your article content.
In no particular order, the elements you should be using are:
Paragraphs: Don’t use
and tags to format the article into paragraphs. There’s been a tag for that for as long as HTML has existed, and it’s the
tag. Use it.
Subheadings: Use
/
/
subheading tags to give your page structure. Use subheadings in an article to preface specific sections of content in your article. Use subheadings for the headers above concrete structural elements, such as recommended articles.
Images: Always use the tag if you want to show an image that you’d like Google to see as well. Google explicitly recommends this.
Relational Links: The tag allows you to create a relationship between the current URL and another URL. This can be a canonical page, a stylesheet, an alternative language version of the current page, etc.
Lists: Bullet lists should use the
tag, and numbered lists should use
tag. You can make them look however you want with CSS, but do use the list tags as the foundation.
Emphasis: When you want to highlight a specific word or phrase, there are semantic HTML tags you should use for that: for italics, and for bold.
All the above tags, with the exception of , are intended for the content of the webpage, providing structure and meaning to the text.
There are additional semantic HTML tags that are intended to provide structure and meaning to the code of the page.
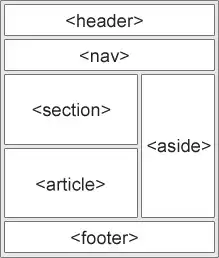
These tags allow Google to identify different elements on the page, such as the navigation vs. a sidebar, and process them accordingly.
Semantic HTML image from W3Schools.com (Image Credit: Barry Adams)
The and tags exist to separate the page’s metadata (in the ) from the actual content (in the ). Every HTML page starts with those two.
can be used to wrap around the head section of the page, where the logo, navigation, and other stylistic elements sit.
should be used for your site’s main navigation. Mega menus, hamburger menus, top navigation links, whatever form your navigation takes, you should wrap it in the
You can use tags to divide your page into multiple sections. One section could be the article; another could be the comments below the article.
is the tag that shows where the page’s actual main article text begins (including the headline). This is a very valuable tag for news publishers.
With you can indicate blocks of content like a sidebar of trending stories, recommended articles, or the latest news.
is used for, you guessed it, the footer of the webpage.
These structural semantic tags help search engines understand the purpose and value of each section of HTML.
It enables Google to rapidly index your content and process the different elements of your pages appropriately.
There are many more semantic HTML tags at your disposal, for various different purposes. Chances are, there’s an HTML element for every imaginable use case.
Rather than cram your code full of
tags to make something happen, first see if there’s a proper HTML element that does the trick.
How Does It Help AI?
We know that LLMs like ChatGPT and Perplexity crawl the open web for training data, as well as for specific user queries that require content from the web.
What some of you may not know is that LLMs do not render JavaScript when they process webpages.
Google is the exception to the rule, as it has devoted a great deal of resources to rendering webpages as part of indexing.
Because Google’s Gemini is the only LLM built on Google’s index, Gemini is the only LLM that uses content from fully rendered webpages.
So, if you want to have any chance of showing up as a cited source in ChatGPT or Perplexity, you’d do well to ensure your complete page content is available in your raw, unrendered HTML.
Using semantic HTML to structure your code and provide meaning also helps these LLMs easily identify your core content.
It’s much simpler for ChatGPT to parse a few dozen semantic HTML tags rather than several hundred (or even thousand) nested
tags to find a webpage’s main content.
If and when the “agentic web” comes to life (I’m skeptical), semantic HTML is likely a crucial aspect of success.
With meaningless
and tags, it’s much easier for an AI agent to misunderstand what actions it should perform.
When you use semantic HTML for things like buttons, links, and forms, the chances of an AI agent failing its task are much lower.
The meaning inherent in proper HTML tags will tell the AI agent where to go and what to do.
What About Structured Data?
You may think that structured data has made semantic HTML obsolete.
After all, with structured data, you can provide machine systems with the necessary information about a page’s content and purpose in a simple machine-readable format.
This is true to an extent. However, structured data was never intended to replace semantic HTML. It serves an entirely different purpose.
Structured data has limitations that semantic HTML doesn’t have.
Structured data won’t tell a machine which button adds a product to a cart, what subheading precedes a critical paragraph of text, and which links the reader should click on for more information.
By all means, use structured data to enrich your pages and help machines understand your content. But you should also use semantic HTML for the same reasons.
Used together, semantic HTML and structured data are an unbeatable combination.
Build Websites, Not Web Apps
I could go off on a 2,500-word rant about why we should be building websites instead of web apps and how the appification of the web is anathema to the principles on which the World Wide Web was founded, but I’ll spare you that particular polemic.
Suffice it to say that web apps for content-delivery websites (like news sites) are almost always inferior to plain old-fashioned websites.
And websites are built, or should be, on HTML. Make use of all that HTML has to offer, and you’re avoiding 90% of the technical SEO pitfalls that web apps tend to faceplant themselves into.
That’s it for another edition. Thanks for reading and subscribing, and I’ll see you at the next one!
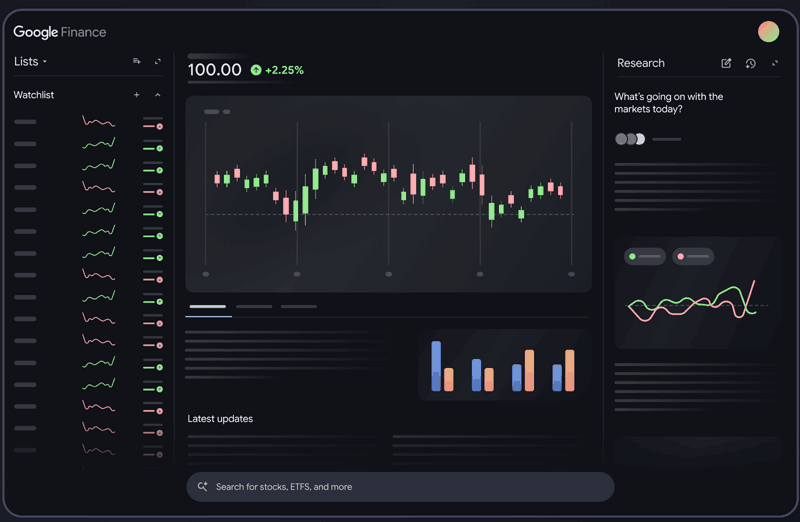
Google announced that they’re testing a new AI-powered Google Finance tool. The new tool enables users to ask natural language questions about finance and stocks, get real-time information about financial and cryptocurrency topics, and access new charting tools that visualize the data.
Three Ways To Access Data
Google’s AI finance page offers three ways to explore financial data:
Research
Charting Tools
Real-Time Data And News
Screenshot Of Google Finance
The screenshot above shows a watchlist panel on the left, a chart in the middle, a “latest updates” section beneath that, and a “research” section on the right hand panel.
Research
The new finance page enables users to ask natural language questions about finance, including the stock market, and the AI will return comprehensive answers, plus links to the websites where the relevant answers can be found.
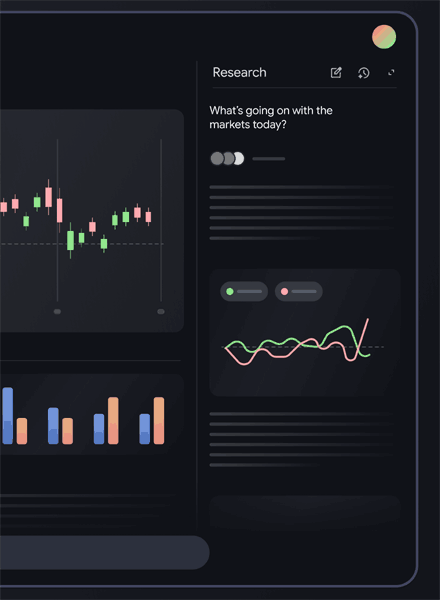
Closeup Screenshot Of Research Section
Charting Tools
Google’s finance page also features charting tools that enable users to visualize financial data.
According to Google:
“New, powerful charting tools will help you visualize financial data beyond simple asset performance. You can view technical indicators, like moving average envelopes, or adjust the display to see candlestick charts and more.”
Real-Time Data
The new finance page also provides real-time data and tools, enabling users to explore finance news, including cryptocurrency information. This part features a live news feed.
The AI-powered page will roll out over the next few weeks on Google.com/finance/.
Google’s John Mueller says small businesses may be hurting their search visibility by choosing generic keyword domains instead of building distinctive brand names.
Speaking on a recent episode of Search Off the Record, Mueller and fellow Search Advocate Martin Splitt discussed common challenges for photography websites.
During the conversation, Mueller noted that many small business owners fall into a “generic domain” trap that can make it harder to connect the business name with its work.
Why Keyword Domains Can Be a Problem
The topic came up when Splitt mentioned that his photography site uses a German term for “underwater photo” as its domain. Mueller responded:
“I see a lot of small businesses make the mistake of taking a generic term and calling it their brand.”
He explained that businesses choosing keyword-rich domains often end up competing with directories, aggregators, and other established sites targeting the same phrases.
Even if the domain name exactly matches a service, there’s little room to stand out in search.
The Advantage Of A Distinct Brand
Mueller contrasted this with using a unique business name:
“If your brand were Martin Splitt Photos then people would be able to find you immediately.”
When customers search for a brand they remember, competition drops. Mentions and links from other websites also become clearer signals to search engines, reducing the chance of confusion with similarly named businesses.
Lost Opportunities For Word-of-Mouth
Relying on a generic keyword domain can also make offline marketing less effective.
If a potential client hears about a business at an event but can’t remember its exact generic name, finding it later becomes more difficult.
Mueller noted:
“If you’ve built up a reputation as being kind of this underwater photography guy and they remember your name, it’s a lot easier to find you with a clear brand name.”
Why This Matters
For service providers like photographers, event planners, or contractors, including the service and location in a domain name can feel like a shortcut to local rankings.
Mueller’s advice suggests otherwise: location targeting can be achieved through content, structured data, and Google Business Profile optimization, without giving up a distinctive brand.
Looking Ahead
While Mueller didn’t recommend immediate rebrands for existing sites, he made it clear that unique, brandable domains give small businesses a defensible advantage in search and marketing.
For those still choosing a domain, the long-term benefits of memorability and differentiation can outweigh any short-term keyword gains.
Join Wayne Cichanski on August 20, 2025 for an exclusive webinar sponsored by iQuanti. Learn how to adapt your SEO strategy and site architecture for AI-driven queries and remain competitive in this new search era.
In this session, you’ll discover:
Why user experience, schema, and site architecture are now just as important as keywords
How to position your brand for discovery in AI-driven queries, not just rankings
Why this session is essential:
With generative AI reshaping search results across platforms like Google, Bing, and ChatGPT, it is crucial to rethink how your content is structured and how people interact with your brand in AI search. Do not get left behind. Optimize for AI-driven search now.
Register today for actionable insights and a roadmap to success in the AI search era. If you cannot attend live, do not worry. Sign up anyway and we will send you the full recording.
Marketers spent decades perfecting the funnel: awareness, consideration, conversion. We built personas. We mapped content to stages. We watched users click, scroll, bounce, convert. Everything was visible.
But GenAI doesn’t show its hand.
The funnel still exists, it’s just hidden inside the model. Every time someone prompts ChatGPT or Perplexity, they reveal their place in a decision journey.
Not by filling out a form or triggering a pixel, but through the prompt fingerprint embedded in their question.
That’s the new funnel. You’re still being evaluated. Still being chosen. But the targeting is now invisible, inferred, and dynamic.
And most marketers have no idea it’s happening. In fairness, I think only the cohort portion of this is actively happening today.
The ad system I explore here is purely theoretical (though Google appears to be working in a similar direction currently, and its rollout could be realistic, soon – links below).
TL;DR: This article doesn’t just explain how I think GenAI is reshaping audience targeting; it introduces three new concepts I think you’ll need to understand the next evolution of paid media: Prompt Fingerprints, Embedding Fingerprints, and Intent Vector Bidding.
The funnel isn’t gone. It’s embedded. And it’s about to start building and placing ads on its own.
About the terminology:
Prompt Fingerprint and Intent Vector Bidding, I believe, are net-new terms for our industry, coined here to describe how future LLM-based systems could group users and auction ad space.
Conceptually, Intent Vector Bidding aligns with work already being done behind the scenes at Google (and I’m sure elsewhere), though I don’t believe they use this phrase.
Embedding Fingerprint draws from AI research but is reframed here as a brand-side construct to power targeting and retrieval inside GenAI systems.
This article was written over the last three weeks of July, and I was happy to find an article on August 4 talking about the concepts I’m exploring for a future paid ads bidding system.
Coincidental, but validating. The link to that article is below.
Image credit: Duane Forrester
What Cohort Targeting Used To Be
In the pre-AI era, cohort targeting was built around observable behaviors.
Retargeting audiences built from cookies and pixels.
Segments shaped by demographics, location, and device.
Lookalikes trained on customer traits and CRM lists.
We mapped campaigns to persona types and funnel stages. A 42-year-old dad in Ohio was mid-funnel if he clicked a product video. An 18-year-old in Mumbai was top-funnel if he downloaded an ebook.
These were guesses, good ones, often, but still blunt instruments. And they were built on identifiers that don’t necessarily survive the GenAI shift.
Prompts Are The New Personas
Large language models don’t need to know who you are. They don’t really need to track you. They don’t care where you came from. They only care what you ask, and how you ask it.
Every prompt is vectorized. That means it’s turned into a mathematical representation of meaning, called an embedding. These vectors capture everything the model can glean from your input:
Topical domain.
Familiarity and depth.
Sentiment and urgency.
Stage of intent.
LLMs use this signal to group prompts with similar meaning, even if they come from completely different types of people.
And that’s how new cohorts can form. Not from identity. From intent.
Right now, most marketers are still optimizing for keywords, and missing the bigger picture. Keywords describe what someone is searching for. Prompt fingerprints describe why and how.
Someone asking “quietest portable generator for camping” isn’t just looking for a product, they’re signaling lifestyle priorities (minimal noise, portability, outdoor use) and stage (comparison shopping).
That single prompt tells the model far more than any demographic profile ever could.
And crucially, that person is joining a cohort of other prompters asking similar questions in similar ways. If your content isn’t semantically aligned with that group, it’s not just less visible. It’s excluded.
New Concept: Prompt Fingerprint
A unique embedding signature derived from a user’s language, structure, and inferred intent within a prompt. This fingerprint is your new persona.
It’s what the model actually sees and what it uses to determine which answers (and potentially which ads) you receive. (More on those ads later!)
When Context Creates The Cohort
Let’s say the Toronto Maple Leafs just won the Stanley Cup (hey, a guy can dream, right?!). Across the city, thousands of people start prompting:
“Where to celebrate in Toronto tonight?”
“Best bars near Scotiabank Arena open late?”
“Leaf’s victory parade time and location?”
None of these users knows each other. Some are teenagers, others are retirees. Some are local, others are visiting. Some are hardcore fans, some just like to party. But to the model, they’re now a momentary cohort; a group connected by real-time context, not long-term traits.
This is a fundamental break from everything digital marketers are used to. We’ve always grouped people by identity: age, interests, behavior, psychographics. But LLMs group people by situational similarity.
That creates new marketing opportunities and new blind spots.
Imagine you sell travel gear. A major snowstorm is forecast to slam into the Northeast U.S.
Within hours, prompts spike around early departures, snowproof duffel bags, and waterproof boots. A travel-stress cohort forms: people trying to escape before the storm hits. They’re not a segment you planned for. They’re a moment the system saw before you did.
If your content or product is aligned with that moment, you need a system that detects, matches, and delivers immediately. That’s what makes system-embedded ad tech essential.
You’re not buying audiences anymore. You’re buying alignment with the now, with a moment in time.
And this part is real today.
While the inner workings of commercial GenAI systems remain opaque, cluster-like behavior is often visible within a single platform session.
When you ask a string of similar questions in one ChatGPT or Gemini session, you may encounter repeated phrasing, brand mentions, or answer structure. That consistency suggests the model is grouping prompts by embedded meaning, not demographics or declared traits.
I cannot find studies or examples of this behavior being recorded, so please drop a comment if you have a source for such data. I keep hearing about it, but cannot find dedicated data.
Looking Forward
Entire classes of micro-cohorts may form and disappear within hours. To reach them, you’ll need AI-powered, system-embedded ad systems that can:
Detect the cohort’s emergence through real-time prompt patterns.
Generate ads aligned with the cohort’s immediate need.
Place and optimize those ads before the window closes.
Humans can’t move at that speed. AI can. And it has to because the opportunity vanishes with the context.
Sidebar: What I Think Is Real Vs. What I Think Is Coming
Prompt Fingerprints – Live Today: Every GenAI system turns your prompt into a vector embedding. It’s already the foundation of how models interpret meaning.
Cohort Clustering by Prompt Similarity – Active Now: You can observe this in tools like ChatGPT and Gemini. Similar prompts return similar answers, meaning the system is clustering users based on shared intent.
Embedding Fingerprints – Possible Today: If brands structure their content for vectorization, they can create an embedding signature that aligns with relevant prompts. Most don’t yet.
Intent Vector Bidding – Emerging Theory: Almost in the market today. Given current ad platform trends, this kind of bidding system is likely being explored widely across platforms.
Why Old-School Personas Will Work Less Effectively
Age. Income. ZIP code. None of that maps cleanly in vector space.
In the GenAI era, two people with radically different demographics might prompt in nearly identical ways and be served the same answers as a result.
It’s not about who you are. It’s about how your question fits into the model’s understanding of the world.
The classic marketing persona is much less reliable as a targeting unit. I’m suggesting the new unit is the Prompt Fingerprint, and marketers who ignore that shift may find themselves omitted from the conversation entirely.
The Funnel Is Still There — You Just Can’t See It
Here’s the thing: LLMs do understand funnel stages.
They just don’t label them the way marketers do. They infer them from phrasing, specificity, and structure.
TOFU: “Best folding kayaks for beginners”
MOFU: “Oru Inlet vs. Tucktec comparison”
BOFU: “Oru kayak discount codes July 2025”
These are prompt-level indicators of funnel stage. And if your content doesn’t align with how those prompts are formed, it likely won’t get retrieved.
Want to stay visible? Start mapping your content to the language patterns of funnel-stage prompts, not just to topics or keywords.
Embedding Fingerprints: The New Targeting Payload
It’s not just prompts that get vectorized. Your content does, too.
Every product page, blog post, or ad you write forms its own Embedding Fingerprint, a vector signature that reflects what your message actually means in the model’s understanding.
Repurposed Concept: Embedding Fingerprint
Originally used in machine learning to describe the vector signature of a piece of data, this concept is reframed here for content strategy.
An embedding fingerprint becomes the reusable vector signature tied to a brand, product, or message – a semantic identity that determines cohort alignment in GenAI systems.
If your content’s fingerprint aligns closely with a user’s prompt fingerprint, it’s more likely to be retrieved. If not, it’s effectively invisible, no matter how “optimized” it may be in traditional terms.
Intent Vector Bidding: A Possible New Advertising Paradigm
So, what happens when GenAI systems all start monetizing this behavior?
You could get a new kind of auction. One where the bid isn’t for a keyword or a user profile, per se, but for alignment.
New Concept: Intent Vector Bidding
A real-time ad bidding mechanism where placement is determined by alignment between a user’s prompt intent vector and an advertiser’s content vector.
To be clear: this is not live today in any public, commercial ad platform that I am aware of. But I think it’s well within reach. Models already understand alignment. Prompt clustering is already happening.
What’s missing is the infrastructure to let advertisers fully plug in. And you can bet the major players (OpenAI, Google, Meta, Microsoft, Amazon, etc.) are already thinking this way. Google is already looking at this openly.
We’ve Been Heading Here All Along
The shift toward LLM-native ad platforms might sound radical, but in reality, we’ve been headed this way for over a decade.
Step by step, platform by platform, advertisers have been ceding control to automation, often without realizing they were walking toward full autonomy.
Before we trace the path, please keep in mind that while I do have some background in the paid ad world, it’s much less than many of you.
I’m attempting to keep my date ranges and tech evolutions accurate, and I believe they are, but others may have a different view.
My point here isn’t historical accuracy, it’s to demonstrate a continual, directional progression, not nail down on which day of which year did Google do X.
And, I’ll add, maybe I’m entirely off base with my thinking here, but it’s still been interesting to map all this out, especially since Google has already been digging in on a similar concept.
1. From Manual Control To Rule-Based Efficiency
Early 2000s – 2015
In the early days of search and display, marketers controlled everything: keyword targeting, match types, ad copy, placements, and bidding.
Power users lived inside tools like AdWords Editor, manually optimizing bids by time of day, device type, and conversion rate.
Automation started small, with rule-based scripts for bid adjustments, budget caps, and geo-targeting refinements. You were still the pilot, just with some helpful instruments.
2. From Rule-Based Logic To AI-Guided Bidding
2015 – 2018
Then came Smart Bidding.
Google introduced Target CPA, Target ROAS, and Enhanced CPC: bid strategies powered by machine learning models that ingested real-time auction data (device, time, location, conversion likelihood) and made granular decisions on your behalf.
Marketers set the goal, but the system chose the path. Control shifted from how to what result you want. This was a foundational step toward AI-defined outcomes.
3. From AI-Guided Bidding To Creative Automation
2018 – 2023
Next came the automation of the message itself.
Responsive Search Ads let advertisers upload multiple headlines and descriptions and Google handled the permutations and combinations.
Meta and TikTok adopted similar dynamic creative formats.
Then Google launched Performance Max (2021), a turning point that eliminated keywords entirely.
You provide assets and conversion goals.
The system decides where and when to show your ads, whether across Search, YouTube, Display, Gmail, Maps, and more.
Targeting becomes opaque. Placement is more invisible. Strategy becomes trust.
You’re no longer steering the vehicle. You’re defining the destination and expecting the algorithm gets you there efficiently.
4. From Creative Automation To Generative Execution
2023–2025
The model doesn’t just optimize messages anymore; it writes them.
Meta’s AI Sandbox generates headlines and CTAs from a prompt.
TikTok’s Creative Assistant produces hook-driven video scripts on demand.
Third-party tools and GPT-based agents build full ad campaigns, including copy and targeting.
Google’s Veo 3 and Veo 3 Fast now live on Vertex AI, generate polished ads and social clips from text or image-to-video inputs, optimized for rapid iteration and programmatic use.
This isn’t sci-fi. It’s what’s coming to market today.
5. What Comes Next – And Why It’s Inevitable
The final leap is where you don’t submit an ad, you instead submit your business.
A fully LLM-native ad platform would:
Accept your brand’s value propositions, certifications, product specs, creative assets, brand guidelines, company vision statements, and guardrails.
Monitor emergent cohorts in real time based on prompt clusters and conversation spikes.
Inject your brand into those moments if, and only if, your business’s vector aligns with the cohort’s intent.
Charge you automatically for participation in that alignment.
You wouldn’t target. You wouldn’t build campaigns. You’d just feed the system and monitor how well it performs as a semantic extension of your business.
The ad platform becomes a meaning-based proxy for your company, an intent-aware agent acting on your behalf.
That’s not speculative science fiction. It’s a natural endpoint of the road we’re already on, I believe. Performance Max removed the steering wheel. Generative AI threw out the copywriter. Prompt-aligned retrieval will take care of the rest.
Building The LLM-Native Ad Platform
This is a theoretical suggestion of what could be our future for paid ads within AI-generated answer systems.
To make Intent Vector Bidding real at scale, the underlying ad platform will have to evolve dramatically. I don’t see this as a plug-in bolted onto legacy PPC infrastructure.
It will be a fully native layer inside LLM-based systems, one that replaces both creative generation and ad placement management.
Here’s how it could work:
1. Advertiser Input Shifts From Campaigns To Data Feeds
Instead of building ads manually, businesses upload:
Targeted keywords, concepts, and product entities.
Business limitations: geography, availability, compliance.
Structured value props and pricing tiers.
2. The System Becomes The Creative + Placement Engine
The LLM:
Detects emerging prompt cohorts.
Matches intent vectors to advertiser fingerprints.
Constructs and injects ads on the fly, using aligned assets and messaging.
Adjusts tone and detail based on prompt stage (TOFU vs BOFU).
3. Billing Becomes Automated And Embedded
Accounts are pre-funded or credit-card linked.
Ad spend is triggered by real-time participation in retrieval or output injection.
No ad reps. No auctions you manage. Just vector-aligned outcomes billed per engagement, view, or inclusion.
Ad creation and placement become a single-price-point item as the system manages all, in real time.
If you want some more thoughts on this concept, or one that’s closely related, Cindy Krum was recently on Shelley Walsh’s IMHO show, where she talked about whether she thinks Google will put ads inside Gemini’s answers, and it was an interesting discussion.
Marketers and ad teams won’t be eliminated. Instead, they’ll become the data stewards and strategic interpreters of the system.
Expectation setting: Clients will need help understanding why their content shows up (or doesn’t) in GenAI outputs.
Data maintenance: The system is only as good as the assets you feed it, and relevance and freshness matter.
Governance and constraints: Humans will define ethical limits, messaging boundaries, and exclusions.
Training and iteration: AI ad visibility will rely on live outputs and observed responses, not static dashboards. You’ll tune prompts, inputs, and outputs based on what the system retrieves and how often it surfaces your content.
In this model, the ad strategist becomes part translator, part data curator, part retrieval mechanic.
And the ad platform? It becomes autonomous, context-driven, and functionally invisible, until you realize your product’s already been included in the buyer’s decision … and you’ve been billed accordingly.
A Closer Look: Intent Vector Bidding In Action
Imagine you’re an outdoor gear brand and there’s a sudden heatwave hitting the Pacific Northwest. Across Oregon and Washington, people begin prompting:
“Best ultralight tents for summer hiking”
“Camping gear for extreme heat”
“Stay cool while backpacking in July”
The model recognizes a spike in semantically similar prompts and data from news sources, etc. A heatwave cohort forms.
At the same time, your brand has a product page and ad copy about breathable mesh tents and high-vent airflow systems.
If your content has been vectorized (or if your system embeds an ad payload with a strong Embedding Fingerprint), it’s eligible to enter the auction.
But this isn’t a bid based on demographic data or historical retargeting. It’s based on how closely your product vector aligns with the live cohort’s prompt vectors.
The LLM chooses the most semantically aligned match. The better your alignment, the more likely your product is included in the AI’s answer, or inserted into the contextual ad slot within the response.
No campaign setup. No segmented audience targeting. Just semantic match at machine speed. This is where creative, product, and performance converge, and that convergence rewrites what it means to “win” in modern advertising.
What Marketers Can Do Right Now
There’s no dashboard that will tell you which Prompt Fingerprints you’re aligned with. That’s the hard part.
But you can start by thinking like a model until tools start to develop features that allow you to model your Prompt Fingerprint.
Start with:
Simulated prompt testing: Use GPT-4 (or Gemini or any other) to generate sample queries by funnel stage and see what brands get retrieved.
Create content for multi-cohort resonance: for example, a camping blog that aligns with both eco-conscious minimalists and adventure-seeking parents.
Build your own prompt libraries: Classify by intent stage, specificity, and phrasing. Use these to guide creative briefs, content chunking, and SEO.
Track AI summaries: In platforms like Perplexity, Gemini, and ChatGPT, your brand might influence answers even when you’re not explicitly mentioned. Your goal is to become the attributed source, not just a silent contributor.
In this new, genAI version of search, you’re no longer optimizing for page views. You’re optimizing for retrievability by semantic proximity.
The Rise Of The Prompt-Native Brand
Some brands will begin designing entire messaging strategies around prompt behavior. These prompt-native brands won’t wait for traffic to arrive. They’ll engineer their content to surf the wave of prompt clusters as they form.
Product copy structured to match MOFU queries.
Comparison pages written in prompt-first language.
AI ad copy tuned by cohort spike detection.
And eventually, new brands will emerge that never even needed a traditional website. Their entire presence will exist in AI conversations.
Built, tuned, and served directly into LLMs via vector-aligned content and Intent Vector Bids.
Wrapping Up
This is the next funnel, and it’s not a page. It’s a probability field. The funnel didn’t disappear. It just went invisible.
In traditional marketing, we mapped clear stages (awareness, interest, decision) and built content to match. That funnel still exists. But now it lives inside the model. It’s inferred, not declared. It’s shaped by prompts, not click paths.
And if your content doesn’t align with what the model sees in that moment, you’re missing in the retrieval.
Over the past decade, digital marketers have witnessed a dramatic shift in how search budgets are allocated.
In the past decade, companies were funding SEO teams alongside PPC teams. However, a shift towards PPC-first has dominated the inbound marketing space.
Where Have SEO Budgets Gone?
Today, more than $150 billion is spent annually on paid search in the United States alone, while only $50 billion is invested in SEO.
With Google Ads, every dollar has a direct, reportable outcome:
Impressions.
Clicks.
Conversions.
SEO, by contrast, has long been:
A black box.
As a result, agencies and the clients that hire them followed the money, even when SEO’s results were higher.
PPC’s Direct Attribution Makes PPC Look More Important, But SEO Still Dominates
Hard facts:
SEO drives 5x more traffic than PPC.
Companies pay 3x more on PPC than SEO.
Image created by MarketBrew, August 2025
You Can Now Trace ROI Back To SEO
As a result, many SEO professionals and agencies want a way back to organic. Now, there is one, and it’s powered by attribution.
Attribution Is the Key to Measurable SEO Performance
Instead of sitting on the edge of the search engine’s black box, guessing what might happen, we can now go inside the SEO black box, to simulate how the algorithms behave, factor by factor, and observe exactly how rankings react to each change.
With this model in place, you are no longer stuck saying “trust us.”
You can say, “Here’s what we changed. Here’s how rankings moved. Here’s the value of that movement.” Whether the change was a new internal link structure or a content improvement, it’s now visible, measurable, and attributable.
For the first time, SEO teams have a way to communicate performance in terms executives understand: cause, effect, and value.
This transparency is changing the way agencies operate. It turns SEO into a predictable system, not a gamble. And it arms client-facing teams with the evidence they need to justify the budget, or win it back.
How Agencies Are Replacing PPC With Measurable Organic SEO
For agencies, attribution opens the door to something much bigger than better reporting; it enables a completely new kind of offering: performance-based SEO.
Traditionally, SEO services have been sold as retainers or hourly engagements. Clients pay for effort, not outcomes. With attribution, agencies can now flip that model and say: You only pay when results happen.
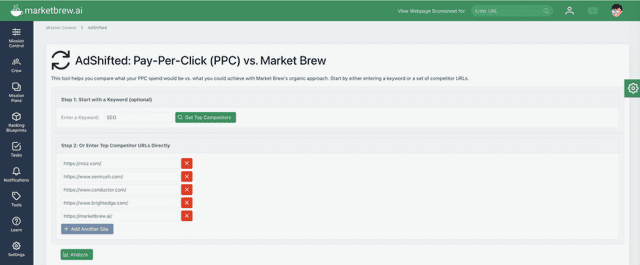
Enter Market Brew’s AdShifted feature to model this value and success as shown here:
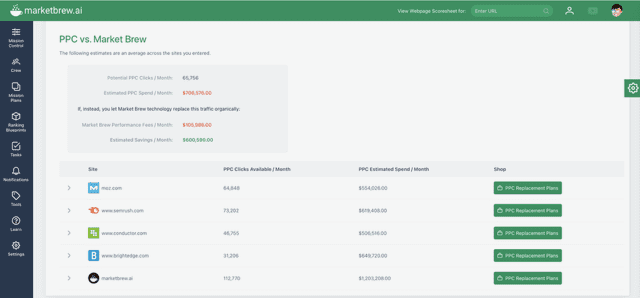
Screenshot from a video by MarketBrew, August 2025
The AdShift tool starts by entering a keyword to discover up to 4* competitive URLs for the Keyword’s Top Clustered Similarities. (*including your own website plus 4 top-ranking competitors)
Screenshot of PPC vs. MarketBrew comparison dashboard by Marketbrew, August 2025
AdShift averages CPC and search volume across all keywords and URLs, giving you a reliable market-wide estimate and details for your brand towards a monthly PPC investment to rank #1.
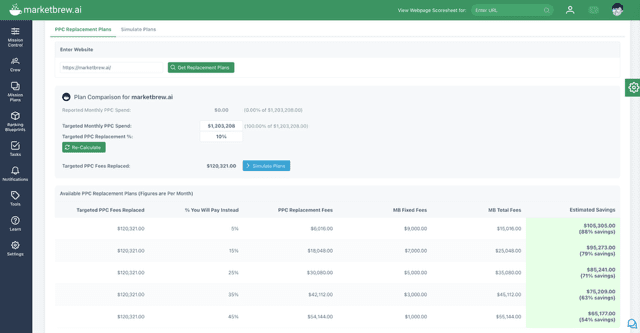
Screenshot of a dashboard by Marketbrew, August 2025
AdShift then calculates YOUR percentage of replacement for PPC to fund SEO.
This allows you to model your own Performance Plan with variable discounts available to the Market Brew license fees with an always less than 50% of PPC Fee for clicks replaced by new SEO traffic.
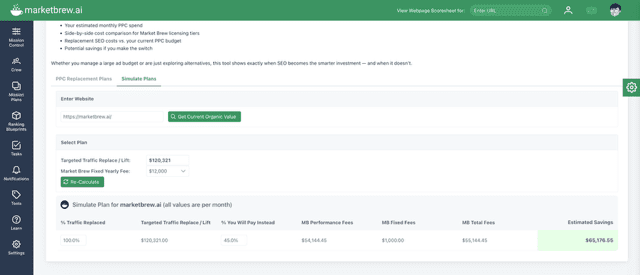
Screenshot of a dashboard by Marketbrew, August 2025
AdShift simulates a PPC replacement plan option selected based on its keywords footprint to instantly see savings from the associated Performance Plans.
That’s the heart of the PPC replacement plan: a strategy you can use to gradually shift a clients’ paid search budgets into measurable performance-based SEO.
What Is A PPC Replacement Plan? Trackable SEO.
A PPC replacement plan is a strategy in which agencies gradually shift their clients’ paid search budgets into organic investments, with measurable outcomes and shared performance incentives.
Here’s how it works:
Benchmark Paid Spend: Identify the current Google Ads budget, i.e., $10,000 per month or $120,000 per year.
Forecast Organic Value: Use search engine modeling to predict the lift in organic traffic from specific SEO tasks.
Execute & Attribute: Complete tasks and monitor real-time changes in rankings and traffic.
Charge on Impact: Instead of billing for time, bill for results, often at a fraction of the client’s former ad spend.
This is not about replacing all paid spend.
Branded queries and some high-value targets may remain in PPC. But for the large, expensive middle of the keyword funnel, agencies can now offer a smarter path: predictable, attributable organic results, at a lower cost-per-click, with better margins.
And most importantly, instead of lining Google’s pockets with PPC revenue, your investments begin to fuel both organic and LLM searches!
Real-World Proof That SEO Attribution Works
Agencies exploring this new attribution-powered model aren’t just intrigued … they’re energized. For many, it’s the first time in years that SEO feels like a strategic growth engine, not just a checklist of deliverables.
“We’ve pitched performance SEO to three clients this month alone,” said one digital strategy lead. “The ability to tie ranking improvements to specific tasks changed the entire conversation.”
“Instead of walking into meetings looking to justify an SEO retainer, we enter with a blueprint representing a SEO/GEO/AEO Search Engine’s ‘digital twin’ with the AI-driven tasks that show exactly what needs to be changed and the rankings it produces. Clients don’t question the value … they ask what’s next.”
Several agencies report that new business wins are increasing simply because they offer something different. While competitors stick to vague SEO promises or expensive PPC management, partners leveraging attribution offer clarity, accountability, and control.
And when the client sees that they’re paying less and getting more, it’s not a hard sell, it’s a long-term relationship.
A Smarter, More Profitable Model for Agencies and SEOs
The traditional agency model in search has become a maze of expectations.
Managing paid search may deliver short-term wins, but it comes to a bidding war with only those with the biggest budgets winning. SEO, meanwhile, has often felt like a thankless task … necessary but underappreciated, valuable but difficult to prove.
Attribution changes that.
For agencies, this is a path back to profitability and positioning. With attribution, you’re not just selling effort … you’re selling outcomes. And because the work is modeled and measured in advance, you can confidently offer performance plans that are both client-friendly and agency-profitable.
For SEOs, this is about getting the credit they deserve. Attribution allows practitioners to demonstrate their impact in concrete terms. Rankings don’t just move, … they move because of you. Traffic increases aren’t vague, … they’re connected to your specific strategies.
Now, you can show this.
Most importantly, this approach rebuilds trust.
Clients no longer have to guess what’s working. They see it. In dashboards, in forecasts, in side-by-side comparisons of where they were and where they are now. It restores SEO to a place of clarity and control where value is obvious, and investment is earned.
The industry has been waiting for this. And now, it’s here.
From PPC Dependence to Organic Dominance — Now Backed by Data
Search budgets have long been upside down, pouring billions into paid clicks that capture a mere fraction of user attention, while underfunding the organic channel that delivers lasting value.
Why? Because SEO lacked attribution.
That’s no longer the case.
Today, agencies and SEO professionals have the tools to prove what works, forecast what’s next, and get paid for the real value they deliver. It’s a shift that empowers agencies to move beyond bidding-war PPC management and into a lower cost & higher ROAS, performance-based SEO.
This isn’t just a new service mode it’s a rebalancing of power in search.
Organic is back. It’s measurable. It’s profitable. And it’s ready to take center stage again.
The only question is: will you be the agency or brand that leads the shift or watch as others do it first?
Generative AI platforms such as ChatGPT, Perplexity, and Claude now execute live web searches with all prompts. Ensuring a site is crawlable by AI bots is therefore essential for mentions and citations on those platforms.
Here’s how to optimize a website for AI crawlers.
Disable JavaScript
Make sure your pages are readable with JavaScript disabled.
Unlike Google’s crawler, AI bots are immature. Many tests from industry practitioners confirm AI crawlers cannot always render JavaScript.
Most publishers and businesses no longer worry about JavaScript crawlability since Google has rendered those pages for years. Hence there’s a huge number of JavaScript-heavy sites.
The Chrome browser can render a site without JavaScript. To activate:
Go to your site using Chrome.
Open Web Developer tools at View > Developer > Developer Tools.
Click Settings (behind the gear icon) on the right side of the panel.
Scroll down and check the option “Disable JavaScript” under “Debugger.”
Disable JavaScript in Chrome’s Developer Tools panel.
Now browse your site, making sure:
All essential content is visible, especially behind tabs and drop-down menus.
The navigation menu and other links are clickable.
For video embeds, there’s an option to click to the original video, access a transcript, or both.
You can use Aiso, an AI optimization platform, to ensure AI bots can access and crawl your site. With a free trial, the platform allows a few free checks. Go to the “Website crawlability” section and enter your URL.
The tool will conduct a thorough review with suggestions on improving access for AI crawlers and even show the appearance of pages with JavaScript disabled.
Aiso can review a site’s use of JavaScript and suggest improvements for AI bot access.
Ensure AI Access
Make sure your site allows access for AI bots. Some content management platforms and plugins disallow AI access by default — site owners are often unaware.
To check, review your robots.txt file at [yoursite.com]/robots.txt.
The AI platforms themselves can interpret the file to ensure it allows access. Paste your robots.text URL into a ChatGPT prompt, for example, and request an analysis.
Schema markup makes it easier for AI bots to extract essential information from a page (or bypass a block) without crawling it in full.
For example, many website FAQ sections have collapsible elements that prevent access to AI bots. Schema’s FAQPage Type replicates all questions and answers, enabling bot visibility.
Similarly, Schema’s Article Type can communicate context and authorship of content.