Google’s Search Relations team has explained why their SEO advice often sounds vague or comes with conditions, such as “it depends.”
In a recent Search Off the Record podcast, team members Martin Splitt and Gary Illyes shared the challenges that prevent them from providing clear-cut answers.
The discussion was part of what the team referred to as a “more human episode.”
The Googlers acknowledged they sometimes come across as robotic and used this episode to show a more human side.
The Context Problem
Splitt works as Google’s bridge between developers and SEO professionals. He provided an example of how good advice can be distorted when people overlook the broader context.
At a Tech SEO Summit, he presented a slide with a bold statement about JavaScript performance. To prevent confusion, he added a note stating that the slide lacked context and provided a full explanation during the talk.
But even with that, he said the statement still got pulled out and repeated on its own.
“I had a remark on that slide saying there’s context missing here, and then I gave all that context… The problem with me saying that in general is that people will just take that one sentence and ignore everything else I said before or after.”
He clarified that JavaScript plays an important role in many web experiences, like enabling offline support. But that nuance often gets lost when single lines are quoted in isolation.
Why Google Doesn’t Share Slides
This loss of context is one reason why Google teams don’t typically share their presentation slides.
Illyes confirmed that slides on their own can be misleading:
He stated:
“Our slides without context, they are useless.”
The team sees what happens when advice meant for one specific situation gets used everywhere. This can hurt websites that have different needs.
For example, advice that works for a small local business might be wrong for a global company with websites in multiple languages.
The “It Depends” Situation
Both Google reps know the SEO community gets frustrated with “it depends” answers.
Splitt even called it his “pet peeve.” But they explained why they can’t give simple yes-or-no answers.
Splitt noted:
“Someone who is serving a very specific niche with highly regulated content in a single country in a single language might have very different requirements than a multilanguage multinational brand that sells everything to everyone.”
They try to give more complete answers by explaining what factors matter. But this makes their advice longer and more complex.
The Google team also worries about how people use their quotes. Splitt said people often pick one statement while ignoring other important information.
Splitt explained:
“It often makes things tricky because people might cherry pick and might pick one thing you said, take that out of context and use it as an example why people should follow their agenda rather than ours.”
While they know public statements can be quoted freely, both reps feel bad when selective quoting gets out of control.
What This Means
The Google team’s openness about their struggles affirms the experience of many SEO professionals.
Google’s guidance often feels cautious because it needs to account for a wide range of use cases.
Instead of seeking simple answers, focus on the factors that influence Google’s recommendations.
Understanding the “why” behind Google’s advice is more useful than chasing one-size-fits-all solutions.
The new AI Mode is rewriting the rules of search. Are you ready?
Google’s AI-generated answers are starting to dominate the SERPs, pushing traditional results further down the page. If your business relies on organic traffic, you can’t afford to ignore this shift.
Join us on June 25, 2025, for an expert-led webinar sponsored by Conductor. Get actionable strategies from Nick Gallagher, SEO Lead at Conductor, to help you adapt fast and stay ahead of the curve.
Traditional SEO tactics are no longer enough. Understanding how AI Mode works and knowing how to respond could be the difference between steady growth and a sharp drop in traffic.
Don’t let AI Mode catch you off guard.
Register today to secure your spot. Can’t make it live? Sign up anyway, and we’ll send you the full recording.
The new AI Mode tab in Google’s results, currently only active in the U.S., enables users to get an AI-generated answer to their query.
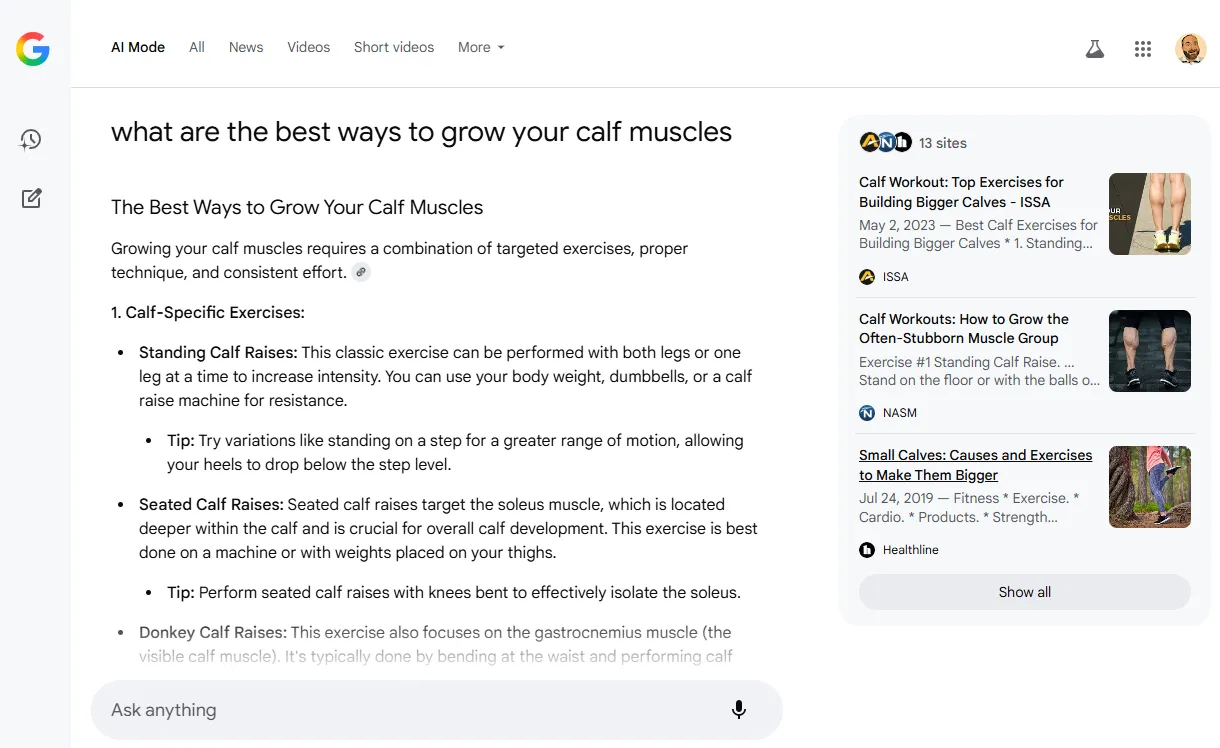
You can ask a detailed question in AI Mode, and Google will provide a summarized answer.
Google AI Mode answer for the question [what are the best ways to grow your calf muscles], providing a detailed summary of exercises and tips (Image Credit: Barry Adams)
The critical process is what Google calls a “query fan-out” technique, where many related queries are performed in the background.
The results from these related queries are collected, summarized, and integrated into the AI-generated response to provide more detail, accuracy, and usefulness.
Having played with AI Mode since its launch, I have to admit it’s pretty good. I get useful answers, often with detailed explanations that give me the information I am looking for. It also means I have less need to click through to cited source websites.
I have to admit that, in many cases, I find myself reluctant to click on a source webpage, even when I want additional information. It’s simpler to ask AI Mode a follow-up question rather than click to a webpage.
Much of the web has become quite challenging to navigate. Clicking on an unknown website for the first time means having to brave a potential gauntlet of cookie-consent forms, email signup pop-ups, app install overlays, autoplay videos, and a barrage of intrusive ads.
The content you came to the page for is frequently hidden behind several barriers-to-entry that the average user will only persist with if they really want to read that content.
And then in many cases, the content isn’t actually there, or is incomplete and not quite what the user was looking for.
AI Mode removes that friction. You get most of the content directly in the AI-generated answer.
You can still click to a webpage, but often it’s easier to simply ask the AI a more specific follow-up question. No need to brave unusable website experiences and risk incomplete content after all.
AI Mode & News
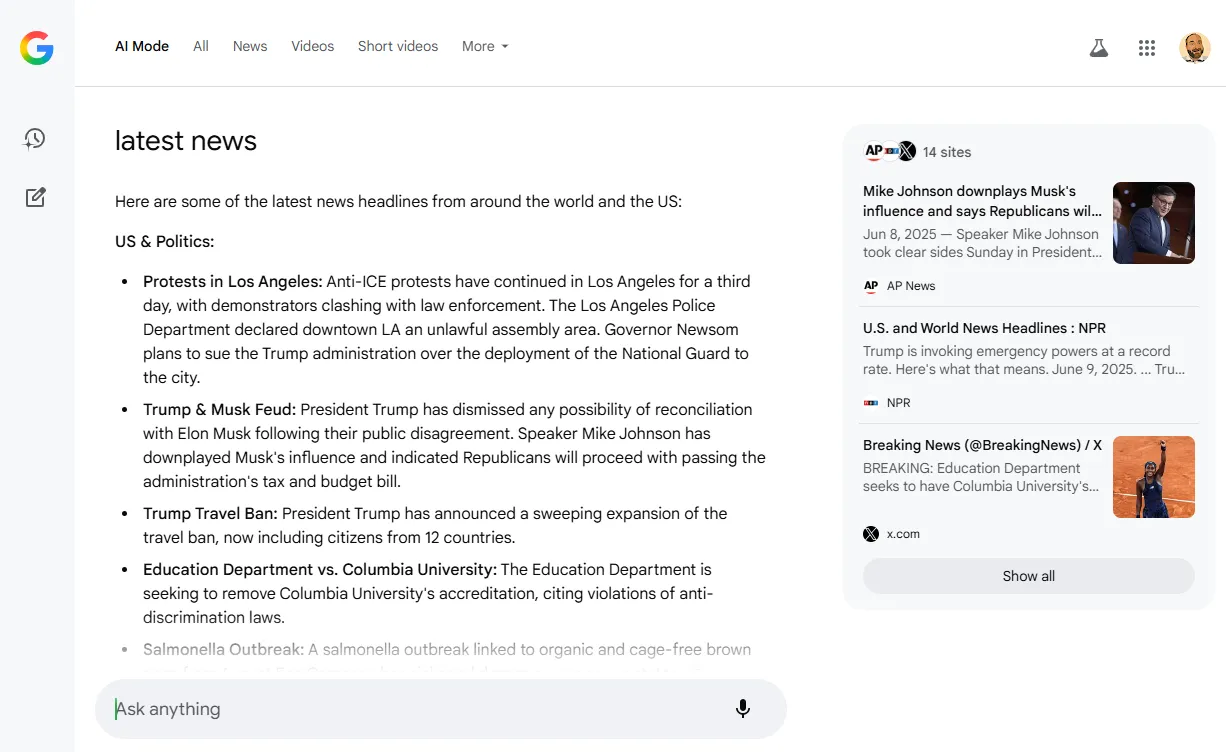
Contrary to AI Overviews, AI Mode will provide summaries for almost any query, including news-specific queries:
AI Mode answer for the [latest news] query (Image Credit: Barry Adams)
Playing with AI Mode, I’ve seen some answers to news-specific queries that don’t even cite news sources, but link only to Wikipedia.
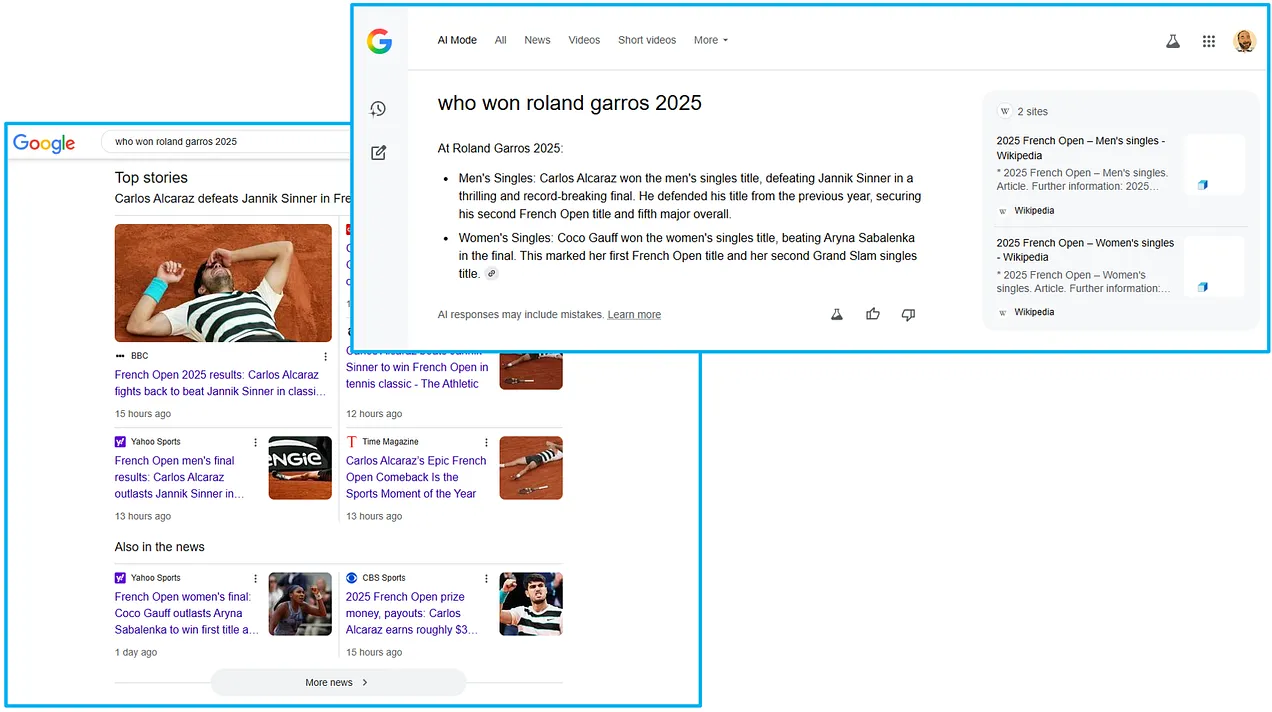
For contrast, the regular Google SERP for the same query features a rich Top Stories box with seven news stories.
With these types of results in AI Mode, the shelf life of news is reduced even further.
Where in search, you can rely on a Top Stories news box to persist for a few days after a major news event, in AI Mode, news sources can be rapidly replaced by Wikipedia links. This further reduces the traffic potential to news publishers.
A Google SERP for [who won roland garros 2025] with a rich Top Stories box vs. the AI Mode answer linking only to Wikipedia (Image Credit: Barry Adams)
There is some uncertainty about AI Mode’s traffic impact. I’ve seen examples of AI Mode answers that provide direct links to webpages in-line with the response, which could help drive clicks.
Google is certainly not done experimenting with AI Mode. We haven’t seen the final product yet, and because it’s an experimental feature that most users aren’t engaged with (see below), there’s not much data on CTR.
As an educated guess, the click-through rate from AI Mode answers to their cited sources is expected to be at least as low, and probably lower, as the CTR from AI Overviews.
This means publishers could potentially see their traffic from Google search decline by 50% or more.
AI Mode User Adoption
The good news is that user adoption of AI Mode appears to be low.
The latest data from Similarweb shows that after an initial growth, usage of the AI Mode tab on Google.com in the U.S. has slightly dipped and now sits at just over 1%.
This makes it about half as popular as the News tab, which is not a particularly popular tab within Google’s search results to begin with.
It could be that Google’s users are satisfied with AI Overviews and don’t need expanded answers in AI Mode, or that Google hasn’t given enough visual emphasis to AI Mode to drive a lot of usage.
I suspect that Google may try to make AI Mode more prominent, with perhaps allowing users to click from an AI Overview into AI Mode (the same way you can click from a Top Stories box to the News tab), or integrate it more prominently into their default SERP.
When user adoption of AI Mode increases, the impact will be keenly felt by publishers. Google’s CEO has reiterated their commitment to sending traffic to the web, but the reality appears to contradict that.
In some of their newest documentation about AI, Google strongly hints at diminished traffic and encourages publishers to “[c]onsider looking at various indicators of conversion on your site, be it sales, signups, a more engaged audience, or information lookups about your business.”.
AI Mode Survival Strategies
Broad adoption of AI Mode, whatever form that may take, can have several impactful consequences for web publishers.
Worst case scenario, most Google search traffic to websites will disappear. If AI Mode becomes the new default Google result, expect to see a collapse of clicks from search results to websites.
Focusing heavily on optimizing for visibility in AI answers will not save your traffic, as the CTR for cited sources is likely to be very low.
In my view, publishers have roughly three strategies for survival:
1. Google Discover
Google’s Discover feed may soften the blow somewhat, especially with the rollout onto desktop Chrome browsers.
Expanded presence of Discover on all devices with a Chrome browser gives more opportunities for publishers to be visible and drive traffic.
However, a reliance on Discover as a traffic source can encourage bad habits. Disregarding Discover’s inherent volatility, the unfortunate truth is that clickbait headlines and cheap churnalism do well in the Discover feed.
Reducing reliance on search in favor of Discover is not a strategy that lends itself well to quality journalism.
There’s a real risk that, in order to survive a search apocalypse, publishers will chase after Discover clicks at any cost. I doubt this will result in a victory for content quality.
2. Traffic & Revenue Diversification
Publishers need to grow traffic and income from more channels than just search. Due to Google’s enormous monopoly in search, diversified traffic acquisition has been a challenge.
Google is the gatekeeper of most of the web’s traffic, so of course we’ve been focused on maximising that channel.
With the risk of a greatly diminished traffic potential from Google search, other channels need to pick up the slack.
We already mentioned Discover and its risks, but there are more opportunities for publishing brands to drive readers and growth.
Paywalls seem inevitable for many publishers. While I’m a fan of freemium models, publishers will have to decide for themselves what kind of subscription model they want to implement.
A key consideration is whether your output is objectively worth paying for. This is a question few publishers can honestly answer, so unbiased external opinions will be required to make the right business decision.
Podcasts have become a cornerstone of many publishers’ audience strategies, and for good reason. They’re easy to produce, and you don’t need that many subscribers to make a podcast economically feasible.
Another content format that can drive meaningful growth is video, especially short-form video that has multiplatform potential (YouTube, TikTok, Instagram, Discover).
Email newsletters are a popular channel, and I suspect this will only grow. The way many journalists have managed to grow loyal audiences on Substack is testament to this channel’s potential.
And while social media hasn’t been a key traffic driver for many years, it can still send significant visitor numbers. Don’t sleep on those Facebook open graph headlines (also valuable for Discover).
3. Direct Brand Visits
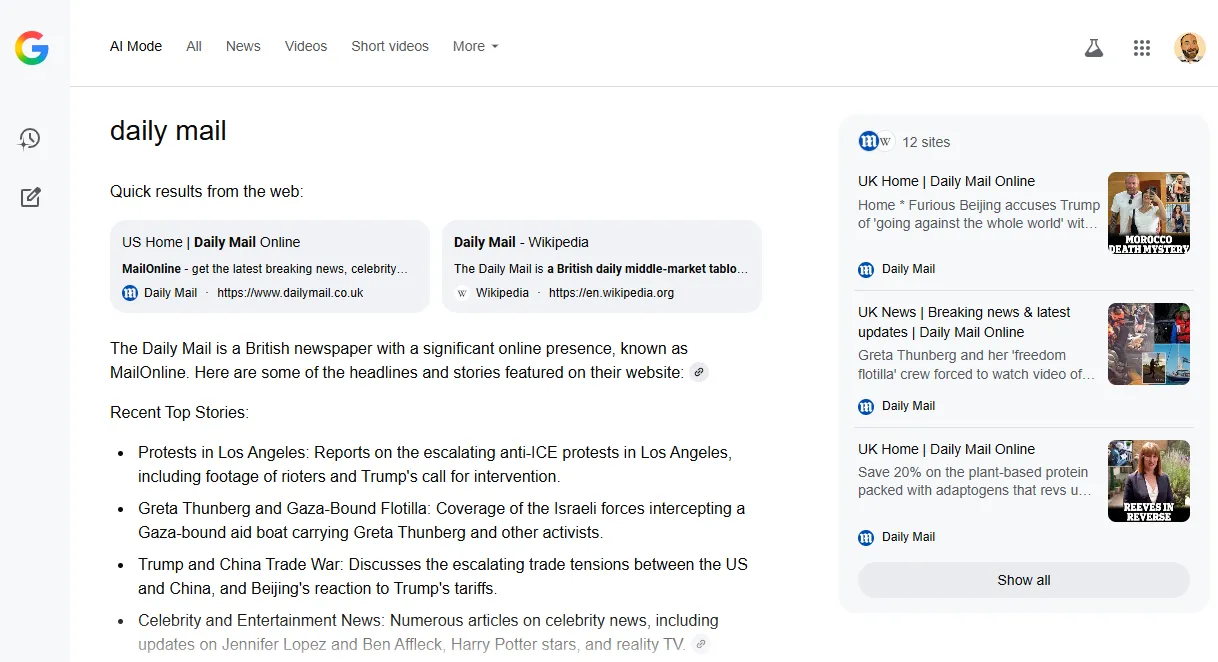
The third strategy, and probably the most important one, is to build a strong publishing brand that is actively sought out by your audience.
No matter the features that Google or any other tech intermediary rolls out, when someone wants to visit your website, they will come to you directly. Not even Google’s AI Mode would prevent you from visiting a site you specifically ask for.
A brand search for [daily mail] in Google AI Mode provides a link to the site’s homepage at the top of the response (Image credit: Barry Adams)
Brand strength translates into audience loyalty.
A recognizable publisher will find it easier to convince its readers to install their dedicated app, subscribe to their newsletters, watch their videos, and listen to their podcasts.
A strong brand presence on the web is also, ironically, a cornerstone of AI visibility optimization.
LLMs are, after all, regurgitators of the web’s content, so if your brand is mentioned frequently on the web (i.e., in LLMs’ training data), you are more likely to be cited as a source in LLM-generated answers.
Exactly how to build a strong online publishing brand is the real question. Without going into specifics, I’ll repeat what I’ve said many times before: You need to have something that people are willing to actively seek out.
If you’re just another publisher writing the same news that others are also writing, without anything that makes you unique and worthwhile, you’re going to have a very bad time. The worst thing you can be as a publisher is forgettable.
There is a risk here, too. In an effort to cater to a specific target segment, a publisher could fall victim to “audience capture“: Feeding your audience what they want to hear rather than what’s true. We already see many examples of this, to the detriment of factual journalism.
It’s a dangerous pitfall that even the biggest news brands find difficult to navigate.
Optimizing For AI
In my previous article, I wrote a bit about how to optimize for AI Overviews.
I’ll expand on this in future articles with more tips, both technical and editorial, for optimizing for AI visibility.
Google is offering voluntary buyouts to employees across several of its core U.S.-based teams, including Search, Ads, engineering, marketing, and research.
The offer provides eligible employees with at least 14 weeks of severance and is available through July 1, according to reporting from The Verge and The Information.
The buyouts are limited to employees in the U.S. who report into Google’s Core Systems division, and exclude staff at DeepMind, Google Cloud, YouTube, and central ad sales.
An Exit Path, Not a Layoff
While Google has conducted layoffs in other departments earlier this year, the current program is being positioned differently.
It’s entirely voluntary and framed as an opportunity for employees to step away if their goals or performance no longer align with Google’s direction.
In a memo obtained by Business Insider, Jen Fitzpatrick, the Senior Vice President of Core Systems, explained the reasoning behind the move:
“The Voluntary Exit Program may be a fit for Core Googlers who aren’t feeling excited about and aligned with Core’s mission and goals, or those who are having difficulty meeting the demands of their role.”
Fitzpatrick added:
“This isn’t about reducing the number of people in Core. We will use this opportunity to create internal mobility and fresh growth opportunities.”
While the message downplays the idea of forced exits, this move bears a resemblance to earlier reorganizations.
In January, Google began with internal reshuffling in its Platforms and Devices division, which later led to confirmed layoffs affecting Pixel, Nest, Android, and Assistant teams. Whether the current buyouts will lead to further cuts remains to be seen.
New Return-to-Office Rules
Alongside the exit program, Google is updating its hybrid work policy.
All U.S.-based Core employees who live within 50 miles of an approved return site are being asked to transfer back to an office and follow the standard three-day in-office schedule.
Fitzpatrick noted that while remote flexibility is still supported, in-person presence is viewed as critical to collaboration and innovation.
Fitzpatrick wrote:
“When it comes to connection, collaboration, and moving quickly to innovate together, there’s just no substitute for coming together in person.”
These changes are positioned as part of a cultural shift toward spending more time in the office and aligning around shared goals.
Tied to Google’s Broader AI Push
This move comes as Google deploys its AI strategy across multiple business units. Over the past year, the company has:
This shows AI is driving changes both internally and externally.
Fitzpatrick’s memo opens by framing the current moment as a “transformational” shift for Google:
“AI is reshaping everything—our products, our tools, the way we work, how we innovate, and so on.”
Looking Ahead
While Google insists this isn’t about cutting jobs, the voluntary exit program and mandatory RTO policies make a couple of things clear. Google is fine-tuning who builds its products and how they do it.
Google wants its teams engaged, in-office, and ready to build the next generation of AI-driven tools.
For marketers and SEO professionals, this restructuring could foreshadow faster product rollouts, rapidly evolving search experiences, and continued automation in advertising tools.
Google’s John Mueller used a clever technique to show the publisher of an educational site how to diagnose their search performance issues, which were apparently triggered by a domain migration but were actually caused by the content.
Site With Ranking Issues
Someone posted a plea for help on the Bluesky social network to help their site recover from a site migration gone wrong. The person associated with the website attributed the de-indexing directly to the site migration because there was a direct correlation between the two events.
SEO Insight An interesting point to highlight is that the site migration preceded the de-indexing by Google but it’s not the cause. The site migration is not the cause for the de-indexing. The migration is what set a chain of events into action that led to the real cause, which as you’ll see later on is low quality content. A common error that SEOs and publishers make is to stop investigating upon discovering the most obvious reason for why something is happening. But the most obvious reason is not always the actual reason, as you’ll see further on.
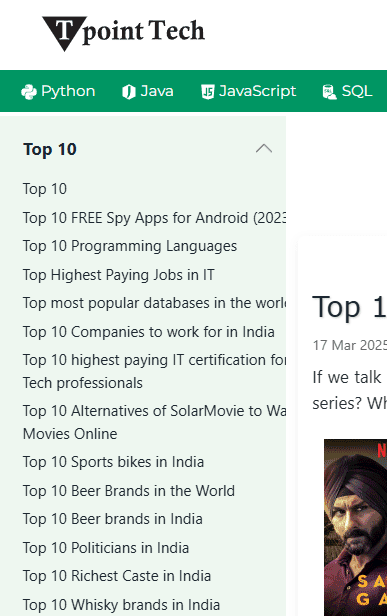
Sudden Deindexing & Traffic Drop after Domain Migration (from javatpoint.com to tpointtech.com) – Need Help”
Google’s John Mueller answered their plea and suggested they do a site search on Bing with their new domain, like this:
site:tpointtech.com sexy
And when you do that Bing shows “top ten list” articles about various Indian celebrities.
Google’s John Mueller also suggested doing a site search for “watch online” and “top ten list” which revealed that the site is host to scores of low quality web pages that are irrelevant to their topic.
A screenshot of one of the pages shows how abundant the off-topic web pages are on that website:
Where Did Irrelevant Pages Come From?
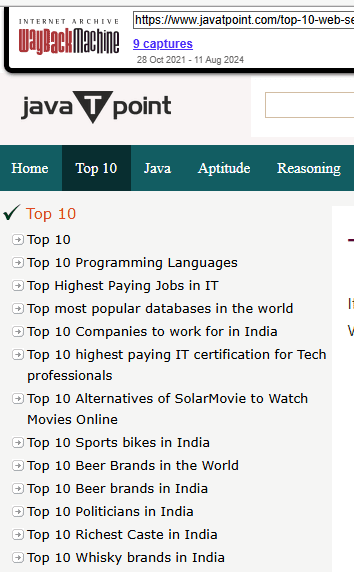
The irrelevant pages originated from the original domain, Javatpoint.com, from which they migrated. When they migrated to Tpointtech they also brought along all of that low quality irrelevant content as well.
Here’s a screenshot of the original domain, demonstrating that the off-topic content originated on the old domain:
Google’s John Mueller posted:
“One of the things I noticed is that there’s a lot of totally unrelated content on the site. Is that by design? If you go to Bing and use [site:tpointtech.com watch online], [site:tpointtech.com sexy], [site:tpointtech.com top 10] , similarly probably in your Search Console, it looks really weird.”
Takeaways
Bing Is Useful For Site Searches Google’s John Mueller showed that Bing can be useful for identifying pages that Google is not indexing which could then indicate a content problem.
SEO Insight The fact that Bing continues to index the off topic content may highlight a difference between Google and Bing. The domain migration might be showing one of the ways that Google identifies the motivation for content, whether the intent is to rank and monetize rather than create something useful to site visitors. An argument could be made that the wildly off-topic nature of the content betrays the “made-for-search-engines” motivation that Google cautions against.
Irrelevant Content A site generally has a main topic, with branching related subtopics. But in general the main topic and subtopics relate to each other in a way that makes sense for the user. Adding wildly off-topic content low quality content betrays an intent to create content for traffic, something that Google explicitly prohibits.
Past Performance Doesn’t Predict Future Performance There’s a tendency on the part of site publishers to shrug about their content quality because it seems to them that Google likes it just fine. But that doesn’t mean the content is fine, it means that it hasn’t become an issue yet. Some problems are dormant and when I see this in site reviews and generally say that this may not be a problem now but it could become a problem later so it’s best to be proactive about it now.
Given that the search performance issues occurred after the site migration but the irrelevant content was pre-existing it appears that the effects of the irrelevant content were muted by the standing the original content had. Nevertheless the irrelevant content was still an issue, it just hadn’t hatched into an issue yet. Migrating the site to a new domain forced Google to re-evaluate the entire site and that’s when the low quality content became an issue.
Content Quality Versus Content Intent It’s possible for someone to make a case that the content, although irrelevant, was high quality and shouldn’t have made a difference. What calls attention to me is that the topics appear to signal an intent to create content for ranking and monetization purposes. It’s hard to argue that the content is useful for site visitors to an educational site.
Expansion Of Content Topics Lastly there’s the issue of whether it’s a good idea to expand the range of topics that a site is relevant for. A television review site can expand to include reviews of other electronics like headphones and keyboards and it’s especially smoother if the domain name doesn’t set up the wrong expectation. That’s why domains with the product types in them are so limiting because they presume the publisher will never achieve so much success that they’ll have to expand the range of topics.
Last week, I sent out an update on my marketplace SEO issue, and it would be a complete miss if I didn’t do the same for the topic of product-led SEO, because they’re directly related.
In this issue, you’ll get:
A thorough look at what product-led SEO is, what it isn’t, and where it’s valuable.
Three primary modalities of product-led SEO.
Three real-world current examples, with notes about why they’re working in the current search landscape.
The top watch-outs for product-led SEO programs based on modality.
And premium subscribers will get access to:
My guiding checklist for product-led SEO and
An interactive assessment landing in your inbox this week that will guide you in creating a high-level plan to refine your product-led approach. Sign up for full access so you don’t miss out.
Also, a quick thanks to Amanda Johnson, who partnered with me on this one. Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
Some companies, not all, can take a hyperscalable approach to organic growth: product-led SEO.
While most sites drive SEO traffic through company-generated content (i.e., content libraries), product-led SEO allows certain sites to scale landing pages with content that comes out of the product.
In this post, I highlight five different examples and types of product-led SEO.
Guidance here has also been fully updated to reflect the recent changes in search, including the impact of AIOs, AI Mode, and LLMs, as well as how these changes affect a product-led SEO approach.
The term product-led SEO (or PLSEO for short) was first coined by Eli Schwartz in his book of the same name.
PLSEO is an organic growth strategy where your SEO practices are focused on improving the discoverability, adoption, and user experience of your product itself within search results, instead of focusing on growing organic visibility through traditional content marketing efforts.
In plain terms, the content comes from your product instead of writers.
A few examples:
TripAdvisor: millions of programmatic pages supported by reviews (UGC).
Uber Eats: millions of programmatic pages supported by restaurants (inventory).
Zillow: millions of programmatic pages supported by properties (inventory).
The key distinction from marketing-led SEO is that a product or growth team considers SEO in the development of the product itself, surfacing user-generated content or other inventory directly into (Google) Search.
Unlike company-generated content, product-led SEO leverages user interactions, integrations, or data to create content.
It’s an aggregator strategy, meaning it only works for companies that “aggregate” (think: collect and group) goods like reviews, suppliers, locations, and more.
Product-led SEO has been quite the buzz, especially amongst SaaS companies, but it often gets misunderstood.
Product-led SEO is not:
Dependent on manually crafting every landing or content page: Unlike traditional SEO approaches, where each landing page is carefully crafted by content teams, product-led SEO often uses programmatic or automated methods to generate large volumes of pages directly from product, inventory, or user data.
Solely focused on targeting queries for marketing angles: While typical SEO practices might start with creating content around keyword research or audience-based query discovery, product-led SEO begins with in-product signals (e.g., what users build or interact with) and surfaces that as content.
Relying on fixed pages: Traditional SEO often involves creating a finite set of cornerstone assets or topic clusters, expanding content from there. Product-led SEO, however, continually scales as the product (or user base) grows – each new UGC, integration, or product addition automatically adds indexable pages.
Some companies carry out a product-led SEO strategy with user-generated content (UGC), while others might use integrations or apps.
Here, I’m going to provide a look into three primary modalities of product-led SEO – and with three real-world, current examples.
UGC-driven PLSEO (like Figma, Traveladvisor, or Cameo): Community members create new assets – design files, shout-out profiles, wikis, etc. – and each submission spawns its own landing page. Over time, these pages accumulate long-tail keyword coverage without editorial teams writing each one.
Supply-driven PLSEO (like Zapier, IMDb): In this model, the product itself “supplies” data – integrations, API endpoints, or statistical datasets – that automatically translate into SEO pages.
Locale-driven PLSEO (like Doordash, Booking.com, or Zillow): As listings go live or update (a new restaurant, a hotel’s availability), a corresponding city- or neighborhood-specific page is generated. These pages capture “near me” and other local keywords.
A site might choose to employ multiple modalities, depending on its offerings, but I’ll also dive into what approach may work best based on your business type or goals.
Important note before you dive in: All marketplaces are product-led SEO plays, but not all product-led SEO plays are marketplaces. For a deep dive into marketplace SEO practices, check out Effective Marketplace SEO is more like Product Growth.
With UGC-based PLSEO, user contributions (templates, profiles, reviews) become the primary SEO fuel.
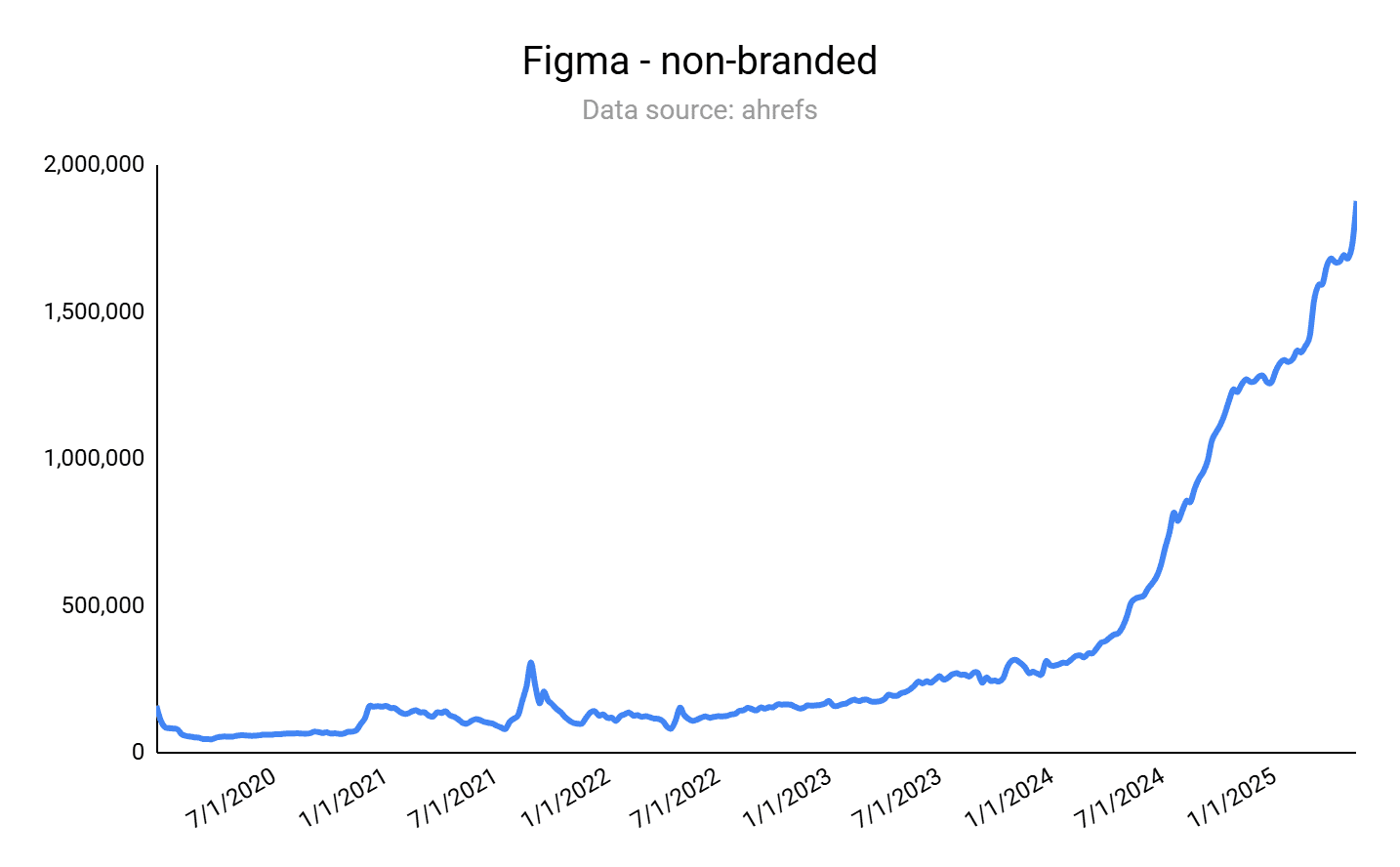
Design tool Figma is an archetypal example of an SEO aggregator that drives product-led SEO through user-generated content.
The scaling mechanism for Figma is the community, where users can upload and sell templates for all sorts of use cases, from mobile app design to GUI templates.
As you can see in the screenshot below, Figma’s organic traffic is exploding.
Image Credit: Kevin Indig
If you do a quick check of Figma in your preferred SEO tool, you’ll notice the following:
The main URL shows that, globally, Figma’s organic rankings and traffic have held or grown slightly since the intense changes across the search landscape.
The organic rankings and traffic of the /community/ and /templates/ subdirectories have either held or increased, depending on the particular country.
The number of total pages on the site has stayed about the same.
What this likely means:
For Figma, its UGC product-led SEO approach is holding strong after the increase of LLM chat use for search, along with Google’s AI Overviews and AI Mode.
This SEO approach is difficult to replicate, which creates a growth loop for Figma that is hard to compete with.
A UGC-driven approach helps overcome current search challenges. Figma has a countless number of helpful kits and templates that AI-driven search and LLMs can rely on in their sourcing and recommendations. (A quick search of “what are the best free UI kits?” in ChatGPT gave me a list of 10 recommendations, and seven were from Figma. In Google’s AI Mode, I received two to three “best of” lists that were just Figma free kits.)
Notion or Typeshare follow the same approach:
With knowledge management software Notion, users can create their own wikis and allow Google to index specific pages, or whole workspaces.
Typeshare is a social posting tool that automatically adds social content to a mini blog that users can decide to index in Search.
Top Use Cases For UGC Product-Led SEO
This type of SEO excels for sites and businesses that can continuously scale content based on what users contribute or interact with, including:
SaaS companies where users can create their own templates, designs, or workflows to share and sell.
Code snippet sharing sites or platforms.
Knowledge-sharing forums or wiki platforms (like the HubSpot Community).
Review and recommendation aggregators – marketplaces like G2 and TripAdvisor.
For supply-driven product-led SEO, remember: The product itself “supplies” data. That’s the content that produces pages for optimization.
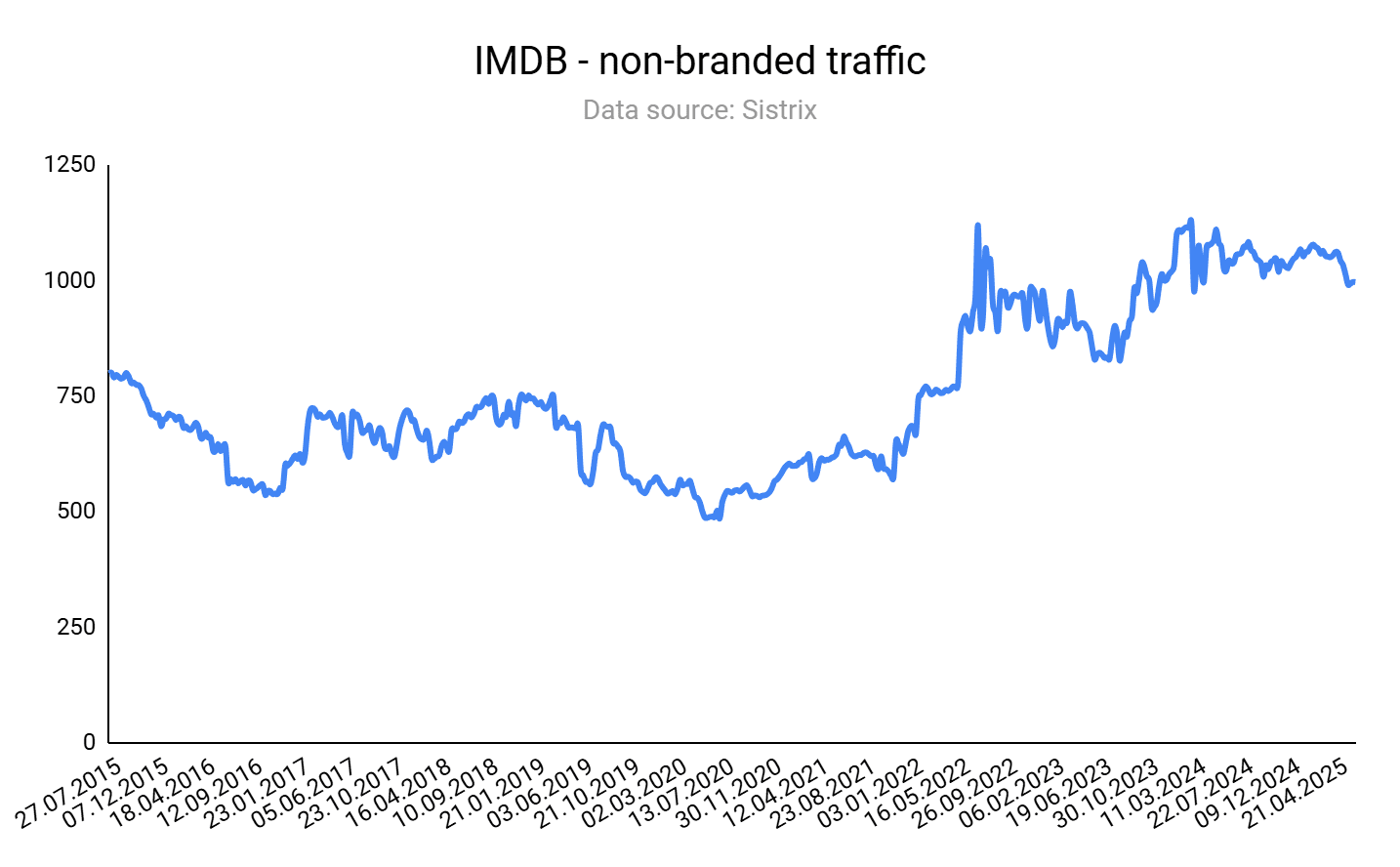
An excellent B2C example of this (and a site that you’re likely familiar with already) is IMDb.
IMDb’s massive repository of movie and TV metadata – cast lists, release dates, ratings, and filming locations – produces SEO pages that rank for film enthusiasts’ long-tail queries.
Whenever new data (e.g., “new Netflix release 2025”) is ingested via AWS Data Exchange or partner feeds, IMDb’s platform auto-generates or updates the corresponding title page, ensuring fresh content for searches like “when is [Movie Title] coming out on streaming?”
Plus, IMDb benefits from a boost with a side of UGC from user ratings and commentary.
This data-supply-driven approach turns product updates into continuous SEO signals.
Image Credit: Kevin Indig
If you do a quick check of IMDb in your preferred SEO tool, you’ll notice:
The main URL shows that, globally, IMDb organic rankings and traffic have held or grown slightly since the intense changes across the search landscape.
The organic rankings and traffic of the /boxoffice/ and /calendar/ subdirectories have either held, increased, or even skyrocketed, depending on the particular country.
The number of total pages on the site has decreased slightly in the last 12 months, by about 23%.
What this likely means:
For IMDb, its supply-driven product-led SEO approach is holding strong after the increase of LLM chat use for search, along with Google’s AI Overviews and AI Mode.
This SEO approach is difficult for other sites to replicate, which creates a growth loop for IMDb that is hard to compete with. IMDb’s global data supply is robust and hard to beat.
A supply-driven approach helps overcome current search challenges. Because IMDb is responsive to date-driven, rating-driven data changes, it provides an excellent source of updated, live information for traditional searching and LLMs to surface in conversation-based searches.
Top Use Cases For Supply-Driven Product-Led SEO
This type of PLSEO excels when you have unique, defensible datasets and a templating system to publish pages at scale, capturing long-tail and high-intent queries without manual content creation.
Examples of orgs that could benefit from this modality include:
Security and vulnerability databases that can auto-publish advisory pages for each newly discovered vulnerability (like Snyk).
Real-time pricing and compensation sites (think Glassdoor or fintech rate comparison sites).
SaaS products that collect user behavior or performance metrics (e.g., “Average page load times for Shopify stores”).
The locale-driven PLSEO modality leverages hyperlocal or geo-specific inventory – restaurants, homes, hotels – to create SEO pages for every location or zip code.
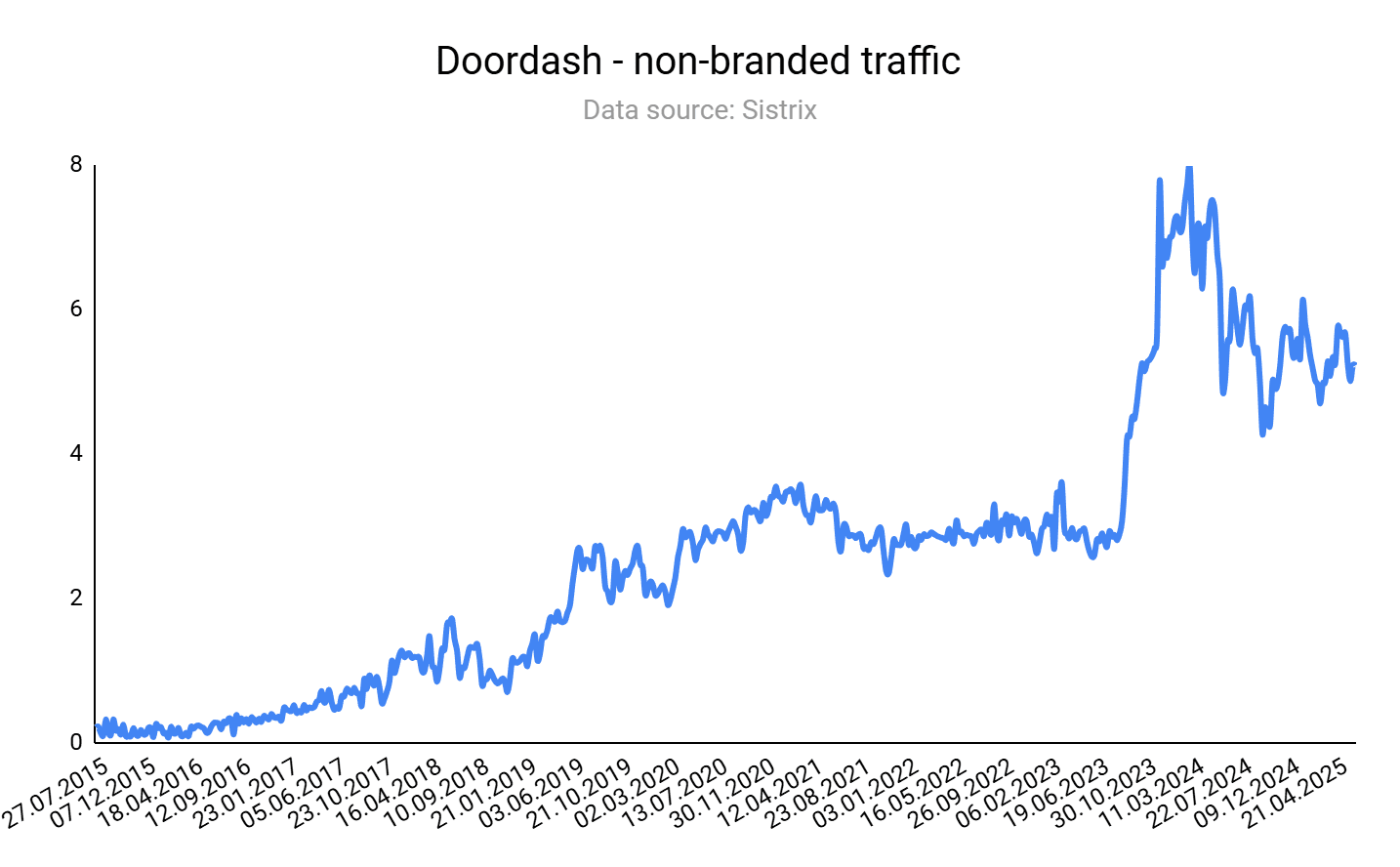
Food delivery service Doordash scales organic traffic by aggregating restaurants and types of food, similar to Uber Eats or Instacart.
Image Credit: Kevin Indig
Since food delivery has a strong local intent, near me queries are essential. Doordash addresses that with an extensive list of city pages.
The right page layout and content are key for sites that scale through product inventory.
Doordash’s city pages contain restaurants, text, and FAQ.
Restaurant pages themselves follow a similar pattern: They cover meals to order, reviews, and FAQ.
Another important factor? Internal linking. City pages link to nearby cities; restaurant pages to restaurants in the same city.
Doordash has also created pages for schools (order near a campus), hotels (order near a hotel), and zip codes to cover all possible user intentions.
Other examples of product inventory-driven sites are real estate site Zillow or coupon code site Retailmenot.
If you do a quick check of Doordash in your preferred SEO tool, you’ll notice:
The main URL shows Doordash’s organic rankings and traffic have declined significantly and then held in the U.S. market, but have grown slightly since January 2025 in some global markets.
It has reduced its total number of pages by ~30%.
What this likely means:
For Doordash, its product inventory, product-led SEO approach is holding strong after the increase of LLM chat use for search, along with Google’s AI Overviews and AI Mode.
Part of this sustained presence (despite a challenging SEO landscape) is likely due to investment in the brand, expanding globally, and reducing unimportant pages and topics to their business.
I predict that search engines and LLMs will continue to give favor to hyperlocal content, which is hard to match.
These product inventory sites that are centered on location (like Doordash, Zillow) or millions of products have the right infrastructure to do it well.
This particular approach to product-led SEO can work well for businesses that can programmatically generate search-ready pages from their product or listing inventory, including:
Food delivery & local ordering platforms.
Real estate marketplaces.
Ecommerce retailers with expansive catalogs.
Travel & accommodation aggregators.
Automotive listing portals.
While product-led SEO can drive the creation of SEO growth loops around your business – ones that are difficult for your competitors to replicate – this approach doesn’t come without some big challenges.
Keep the following in mind:
1. Sites using PLSEO approaches need to watch out for SEO hygiene, spam, and site maintenance issues.
Inventory changes (menus, listings, hours, availability) on the site can keep content fresh – an advantage for both classic SEO and potential LLM training inputs.
However, the hygiene and maintenance required to keep these pages functioning and accurate are significant. Don’t employ this practice without the proper infrastructure in place to maintain it over time.
And if you rely on UGC? It’s mission-critical to have smart QA processes and spam filters in place to ensure content quality.
2. SEO aggregators, especially marketplaces, have been significantly impacted by the rollouts of AI-based search.
PLSEO is not exempt from the impact of Google’s AIOs, AI Mode, and LLM-based search. In actuality, many aggregator marketplaces have been disproportionally affected.
One of the biggest challenges, especially for product-led UGC SEO plays, is that all your hard work may go unclicked.
Creating systems to do this kind of SEO at scale is labor-intensive.
It’s highly likely that AIOs, AI Mode, and LLMs will reference the user generated content without you earning the organic traffic for it.
However, building a strong, trusted brand through community, publication mentions, and shared links can earn more mentions in LLMs.
Because I recently reworked my in-depth guide to marketplace SEO, I’m going to save you some extra scrolling here.
If you’re interested in the best use cases and how to approach marketplace SEO from a product growth mindset, take a leap over here for some great examples and a full framework: Effective Marketplace SEO is more like Product Growth.
3. Don’t cut corners on the depth of information provided in favor of scaling.
For many sites, the key to scaling product-led SEO is deploying a programmatic approach.
But programmatic landing pages should still contain a depth of information, have strong technical SEO, and engaging content with sufficient user value.
If you don’t have these resources and practices in place, along with the proper processes to maintain pages over time, then it’s likely programmatic SEO isn’t for your org.
With the rise of AI-based search, LLMs like ChatGPT, as well as Google’s AI Overviews and AI Mode, are moving toward understanding and presenting information in more conversational and context-rich formats, which programmatic pages often lack.
Another watch-out? If these programmatic pages are highly templated with lots of elements, they’re often a lot for a human reader to take in at once. And that can lead to poor UX if not done correctly.
4. Future challenge: A web surfed by AI agents.
While it’s likely we don’t need to be worried about this today, we need to start brainstorming how to adapt our content creation for what the web could look like tomorrow.
In what ways would your product-led SEO approach need to change to adapt to AI agent traffic, while also prioritizing human UX?
If users start using queries and commands like “order my favorite dish from the Indian food restaurant I went to last month and have it delivered,” or “give me 3 for-sale listings of 2 bed, 2 bath condos in my area that I didn’t review last week,” to send an AI agent to your site, how would your PLSEO practices need to adapt?
What about PLSEO practices that surface unique integrations, templates, and workflows?
If AI agents become users of products and software themselves – and therefore also have the ability to generate their own apps, integrations, and product workflows as needed – humans, and even their AI counterparts, then skip the need for this search entirely. (Brands that solely rely on these types of searches could say goodbye to organic traffic and visibility.)
I don’t have the answers here – I’d argue no one does right now. So, no need for immediate alarm or dramatic changes.
But it’s important to start investing time and testing to consider what your brand may need to change for an AI agent future.
Adopting a product-led SEO strategy can unlock substantial growth – and growth that holds and is sustained despite the increase in AI-based search – but it’s not a one-size-fits-all solution.
When executed well, PLSEO turns your product (or product data) into an ever-expanding library of SEO assets.
Instead of relying solely on a content team to crank out new blog posts or landing pages, you leverage in-product signals – user contributions, integrations, inventory feeds – to automatically spawn indexable pages.
But before starting or reworking your product-led SEO program, you need to have the right motions in place. For this SEO approach, there are many essential moving parts – and each one is important.
Featured Image: Paulo Bobita/Search Engine Journal
Google’s John Mueller answered a question about a site that received millions of Googlebot requests for pages that don’t exist, with one non-existent URL receiving over two million hits, essentially DDoS-level page requests. The publisher’s concerns about crawl budget and rankings seemingly were realized, as the site subsequently experienced a drop in search visibility.
NoIndex Pages Removed And Converted To 410
The 410 Gone server response code belongs to the family 400 response codes that indicate a page is not available. The 404 response means that a page is not available and makes no claims as to whether the URL will return in the future, it simply says the page is not available.
The 410 Gone status code means that the page is gone and likely will never return. Unlike the 404 status code, the 410 signals the browser or crawler that the missing status of the resource is intentional and that any links to the resource should be removed.
The person asking the question was following up on a question they posted three weeks ago on Reddit where they noted that they had about 11 million URLs that should not have been discoverable that they removed entirely and began serving a 410 response code. After a month and a half Googlebot continued to return looking for the missing pages. They shared their concern about crawl budget and subsequent impacts to their rankings as a result.
Mueller at the time forwarded them to a Google support page.
Rankings Loss As Google Continues To Hit Site At DDOS Levels
Three weeks later things have not improved and they posted a follow-up question noting they’ve received over five millions requests for pages that don’t exist. They posted an actual URL in their question but I anonymized it, otherwise it’s verbatim.
The person asked:
“Googlebot continues to aggressively crawl a single URL (with query strings), even though it’s been returning a 410 (Gone) status for about two months now.
In just the past 30 days, we’ve seen approximately 5.4 million requests from Googlebot. Of those, around 2.4 million were directed at this one URL: https://example.net/software/virtual-dj/ with the ?feature query string.
We’ve also seen a significant drop in our visibility on Google during this period, and I can’t help but wonder if there’s a connection — something just feels off. The affected page is: https://example.net/software/virtual-dj/?feature=…
The reason Google discovered all these URLs in the first place is that we unintentionally exposed them in a JSON payload generated by Next.js — they weren’t actual links on the site.
We have changed how our “multiple features” works (using ?mf querystring and that querystring is in robots.txt)
Would it be problematic to add something like this to our robots.txt?
Disallow: /software/virtual-dj/?feature=*
Main goal: to stop this excessive crawling from flooding our logs and potentially triggering unintended side effects.”
Google’s John Mueller confirmed that it’s Google’s normal behavior to keep returning to check if a page that is missing has returned. This is Google’s default behavior based on the experience that publishers can make mistakes and so they will periodically return to verify whether the page has been restored. This is meant to be a helpful feature for publishers who might unintentionally remove a web page.
Mueller responded:
“Google attempts to recrawl pages that once existed for a really long time, and if you have a lot of them, you’ll probably see more of them. This isn’t a problem – it’s fine to have pages be gone, even if it’s tons of them. That said, disallowing crawling with robots.txt is also fine, if the requests annoy you.”
Caution: Technical SEO Ahead
This next part is where the SEO gets technical. Mueller cautions that the proposed solution of adding a robots.txt could inadvertently break rendering for pages that aren’t supposed to be missing.
He’s basically advising the person asking the question to:
Double-check that the ?feature= URLs are not being used at all in any frontend code or JSON payloads that power important pages.
Use Chrome DevTools to simulate what happens if those URLs are blocked — to catch breakage early.
Monitor Search Console for Soft 404s to spot any unintended impact on pages that should be indexed.
John Mueller continued:
“The main thing I’d watch out for is that these are really all returning 404/410, and not that some of them are used by something like JavaScript on pages that you want to have indexed (since you mentioned JSON payload).
It’s really hard to recognize when you’re disallowing crawling of an embedded resource (be it directly embedded in the page, or loaded on demand) – sometimes the page that references it stops rendering and can’t be indexed at all.
If you have JavaScript client-side-rendered pages, I’d try to find out where the URLs used to be referenced (if you can) and block the URLs in Chrome dev tools to see what happens when you load the page.
If you can’t figure out where they were, I’d disallow a part of them, and monitor the Soft-404 errors in Search Console to see if anything visibly happens there.
If you’re not using JavaScript client-side-rendering, you can probably ignore this paragraph :-).”
The Difference Between The Obvious Reason And The Actual Cause
Google’s John Mueller is right to suggest a deeper diagnostic to rule out errors on the part of the publisher. A publisher error started the chain of events that led to the indexing of pages against the publisher’s wishes. So it’s reasonable to ask the publisher to check if there may be a more plausible reason to account for a loss of search visibility. This is a classic situation where an obvious reason is not necessarily the correct reason. There’s a difference between being an obvious reason and being the actual cause. So Mueller’s suggestion to not give up on finding the cause is good advice.
Google published a research paper describing how it extracts “services offered” information from local business sites to add it to business profiles in Google Maps and Search. The algorithm describes specific relevance factors and confirms that the system has been successfully in use for a year.
What makes this research paper especially notable is that one of the authors is Marc Najork, a distinguished research scientist at Google who is associated with many milestones in information retrieval, natural language processing, and artificial intelligence.
The purpose of this system is to make it easier for users to find local businesses that provide the services they are looking for. The paper was published in 2024 (according to the Internet Archive) and is dated 2023.
The research paper explains:
“…to reduce user effort, we developed and deployed a pipeline to automatically extract the job types from business websites. For example, if a web page owned by a plumbing business states: “we provide toilet installation and faucet repair service”, our pipeline outputs toilet installation and faucet repair as the job types for this business.”
Developing A Local Search System
The first step for creating a system for crawling and extracting job type information was to create training data from scratch. They selected billions of home pages that are listed in Google business profiles and extracted job type information from tables and formatted lists on home pages or pages that were one click away from the home pages. This job type data became the seed set of job types.
The extracted job type data was used as search queries, augmented with query expansion (synonyms) to expand the list of job types to include all possible variations of job type keyword phrases.
Second Step: Fixing A Relevance Problem
Google’s researchers applied their system on the billions of pages and it didn’t work as intended because many pages had job type phrases that were not describing services offered.
The research paper explains:
“We found that many pages mention job type names for other purposes like giving life tips. For example, a web page that teaches readers to deal with bed bugs might contain a sentence like a solution is to call home cleaning services if you find bed bugs in your home. They usually provide services like bed bug control. Though this page mentions multiple job type names, the page is not provided by a home cleaning business.”
Limiting the crawling and indexing to identifying job type keyword phrases resulted in false positives. The solution was to incorporate sentences that surrounded the keyword phrases so that they could better understand the context of the job type keyword phrases.
The success of using surrounding text is explained:
“As shown in Table 2, JobModelSurround performs significantly better than JobModel, which suggests that the surrounding words could indeed explain the intent of the seed job type mentions. This successfully improves the semantic understanding without processing the entire text of each page, keeping our models efficient.”
SEO Insight The described local search algorithm is purposely excluding all information on the page and zeroing in on job type keyword phrases and surrounding words and phrases around those keywords. This shows the importance of how the words around important keyword phrases can provide context for the keyword phrases and make it easier for Google’s crawlers to understand what the page is about without having to process the entire web page.
SEO Insight Another insight is that Google is not indexing the entire web page for the limited purpose of identifying job type keyword phrases. The algorithm is hunting for the keyword phrase and surrounding keyword phrases.
SEO Insight The concept of analyzing only a part of a page is similar to Google’s Centerpiece Annotation where a section of content is identified as the main topic of the page. I’m not saying these are related. I’m just pointing out one feature out of many where a Google algorithm zeroes in on just a section of a page.
The System Uses BERT
Google used the BERT language model to classify whether phrases extracted from business websites describe actual job types. BERT was fine-tuned on labeled examples and given additional context such as website structure, URL patterns, and business category to improve precision without sacrificing scalability.
The Extraction System Can Be Generalized To Other Contexts
An interesting finding detailed by the research paper is that the system they developed can be used in areas (domains) other than local businesses, such as “expertise finding, legal and medical information extraction.”
They write:
“The lessons we shared in developing the largescale extraction pipeline from scratch can generalize to other information extraction or machine learning tasks. They have direct applications to domain-specific extraction tasks, exemplified by expertise finding, legal and medical information extraction.
Three most important lessons are:
(1) utilizing the data properties such as structured content could alleviate the cold start problem of data annotation;
(2) formulating the task as a retrieval problem could help researchers and practitioners deal with a large dataset;
(3) the context information could improve the model quality without sacrificing its scalability.”
Job Type Extract Is A Success
The research paper says that their system is a success, it has a high level of precision (accuracy) and that it is scalable. The research paper says that it has already been in use for a year. The research is dated 2023 but according to the Internet Archive (Wayback Machine), it was published sometime in July 2024.
The researchers write:
“Our pipeline is executed periodically to keep the extracted content up-to-date. It is currently deployed in production, and the output job types are surfaced to millions of Google Search and Maps users.”
Takeaways
Google’s Algorithm That Extracts Job Types from Webpages Google developed an algorithm that extracts “job types” (i.e., services offered) from business websites to display in Google Maps and Search.
Pipeline Extracts From Unstructured Content Instead of relying on structured HTML elements, the algorithm reads free-text content, making it effective even when services are buried in paragraphs.
Contextual Relevance Is Important The system evaluates surrounding words to confirm that service-related terms are actually relevant to the business, improving accuracy.
Model Generalization Potential The approach can be applied to other fields like legal or medical information extraction, showing how it can be applied to other kinds of knowledge.
High Accuracy and Scalability The system has been deployed for over a year and delivers scalable, high-precision results across billions of webpages.
Google published a research paper about an algorithm that automatically extracts service descriptions from local business websites by analyzing keyword phrases and their surrounding context, enabling more accurate and up-to-date listings in Google Maps and Search. This technique avoids dependence on HTML structure and can be adapted for use in other industries where extracting information from unstructured text is needed.
Read the research paper abstract and download the PDF version here:
Google updated the Recipe Schema.org structured data documentation to reflect more precise guidance on what the image structured data property affects and where to find additional information about ranking recipe images in the regular organic search results.
Schema.org Structured Data And Rich Results
The SEO and publisher community refers to the text results as the organic search results or the ten blue links. Google refers to them as the text results.
Structured data helps a site’s content become eligible to rank in Google’s rich results but it generally doesn’t help content rank better in the text results.
That’s the concept underlying Google’s update to the Recipe structured data guidance with the addition of two sentences:
“Specifying the image property in Recipe markup has no impact on the image chosen for a text result image. To optimize for a text result image, follow the image SEO best practices.”
Recipe structured data influences the images shown in the Recipe Rich Results. The structured data does not influence the image rankings in the regular text results (aka the organic search results).
Ranking Images In Text Results
Google offers documentation for image best practices which specify normal HTML like the and elements. Google also recommends using an image sitemap, a sitemap that’s specifically for images.
Something to pay particular attention to is to not use images that have blurry qualities to them. Always use sharp images to give your images the best chance for showing up in the search results.
I know that some images may contain slight purposeful blurring for optimization purposes (blurring decreases image size) and to enhance the perspective of foreground and background. But Google recommends using sharp images and to avoid blurring in images. Google doesn’t say it’s an image ranking factor, but it does make that recommendation.
Here’s what Google’s image optimization guidance recommends:
“High-quality photos appeal to users more than blurry, unclear images. Also, sharp images are more appealing to users in the result thumbnail and can increase the likelihood of getting traffic from users.”
In my opinion I think it’s best to avoid excessive use of blurring. I only have my own anecdotal experience with purposely blurred images not showing up in the search results. So, to me it’s interesting to see my experience confirmed that Google treats blurred images as a negative quality and sharp images as a positive quality.
Read Google’s updated Recipe structured data documentation about images here:
BrightEdge Enterprise SEO platform released new data showing distinctive patterns across major AI search and chatbot platforms and also called attention to potential disruption from Apple if it breaks with Google as the default search engine in Safari.
Desktop AI Traffic Dominance
One of the key findings in the BrightEdge data is that traffic to websites from AI chatbots and search engines is highest from desktop users. The exception is Google Search which is reported to send more traffic from mobile devices over desktop.
The report notes that 94% of the traffic from ChatGPT originates from desktop apps with just 6% of referrals coming from mobile apps. BrightEdge speculates that the reason why there’s less mobile traffic is because ChatGPT’s mobile app shows an in-app preview, requiring a user to execute a second click to navigate to an external site. This creates a referral bottleneck that doesn’t exist on the desktop.
But that doesn’t explain why Perplexity, Bing, and Google Gemini also show similar levels of desktop traffic dominance. Could it be a contextual difference where users on desktop are using AI for business and mobile use is less casual? The fact that Google Search sends more mobile referral traffic than desktop could suggest a contextual reason for the disparity in mobile traffic from AI search and chatbots.
BrightEdge shared their insights:
“While Google maintains an overwhelming market share in overall search (89%) and an even stronger position on mobile (93%), its dominance is particularly crucial in mobile web search. BrightEdge data indicates that Apple phones alone account for 57% of Google’s mobile traffic to US and European brand websites. But with Safari being the default for around a billion users, any change to that default could reallocate countless search queries overnight.
Apple’s vendor-agnostic Apple Intelligence also suggests opportunities for seismic shifts in web search. While generative AI tools have surged in popularity through apps on IOS, mobile web search—where the majority of search still occurs—remains largely controlled by Google via Safari defaults. This makes Apple’s control of Safari the most valuable real estate in the mobile search landscape.”
Here are the traffic referral statistics provided by BrightEdge:
Google Search: Only major AI search with mobile majority traffic referrals (53% mobile vs 44% desktop)
ChatGPT: 94% desktop, just 6% mobile referrals
Perplexity: 96.5% desktop, 3.4% mobile
Bing: 94% desktop, 4% mobile
Google Gemini: 91% desktop, 5% mobile
Apple May Play The Kingmaker?
With Apple’s Worldwide Developers Conference (WWDC) nearing, one of the changes that many will be alert to is any announcement relative to the company’s Safari browser which controls the default search settings on nearly a billion devices. A change in search provider in Safari could initiate dramatic changes to who the new winners and losers are in web search.
Perplexity asserts that the outcome of changes to Safari browser defaults may impact search marketing calculations for the following reasons:
“58% of Google’s mobile traffic to brand websites comes from iPhones
Safari remains the default browser for nearly a billion users
Apple has not yet embedded AI-powered search into its mobile web stack”
Takeaways
Desktop Users Of AI Search Account For The Majority Of Referral Traffic Most AI-generated search traffic from from ChatGPT, Perplexity, Bing, and Gemini comes from desktop usage, not mobile.
Google Search Is The Traffic Referral Outlier Unlike other AI search tools, Google Search still delivers a majority of its traffic via mobile devices.
In-App Previews May Limit ChatGPT Mobile AI Referrals ChatGPT’s mobile app requires an extra click to visit external sites, possibly explaining low mobile referral numbers.
Apple’s Position Is Pivotal To Search Marketing Apple devices account for over half of Google’s mobile traffic to brand websites, giving Apple an outsized impact on mobile search traffic.
Safari Default And Greater Market Share With Safari set as the default browser for nearly a billion users, Apple effectively controls the gate to mobile web search.
Perplexity Stands To Gain Market Share If Apple switches Safari’s default search to Perplexity, the resulting shift in traffic could remake the competitive balance in search marketing.
Search Marketers Should Watch WWDC Any change announced at Apple’s WWDC regarding Safari’s search engine could have large-scale impact on search marketing.
BrightEdge data shows that desktop usage is the dominant source of traffic referrals from AI-powered search tools like ChatGPT, Perplexity, Bing, and Gemini, with Google Search as the only major platform that sends more traffic via mobile.
This pattern could suggest a behavioral split between desktop users, who may be performing work-related or research-heavy tasks, and mobile users, who may be browsing more casually. BrightEdge also points to a bottleneck built into the ChatGPT app that creates a one-click barrier to mobile traffic referrals.
BrightEdge’s data further cites Apple’s control over Safari, which is installed on nearly a billion devices, as a potential disruptor due to a possible change in the default search engine away from Google. Such a shift could significantly alter mobile search traffic patterns.