Meta is reportedly developing a search engine index for its AI chatbot to reduce reliance on Google for AI-generated summaries of current events. Meta AI appears to be evolving to the next stage of becoming a fully independent AI search engine.
Meta-ExternalAgent
Meta has been crawling the Internet since at least this past summer from a user agent called, Meta-ExternalAgent. There have been multiple reports in various forums about excessive amounts of crawling with one person on Hacker News reporting having received 50,000 hits by the bot. A post in the WebmasterWorld bot crawling forum notes that although the documentation for Meta-ExternalAgent says it respects robots.txt it wouldn’t have made a difference because the bot never visited the file.
It may be that the bot wasn’t fully ready earlier this year and that it’s poor behavior has settled down.
The purpose of the bot is to summarize search results and according to the results it’s to reduce reliance on Google and Bing for search results.
Is This A Challenge To Google?
It may be possible that this is indeed a the prelude to a challenge to Google (and other search engines) in AI search. The information at this time supports that this is about creating a search index to complement their Meta AI. As reported in The Verge, Meta is crawling sites for search summaries to be used within the Meta AI Chatbot:
“The search engine would reportedly provide AI-generated search summaries of current events within the Meta AI chatbot.”
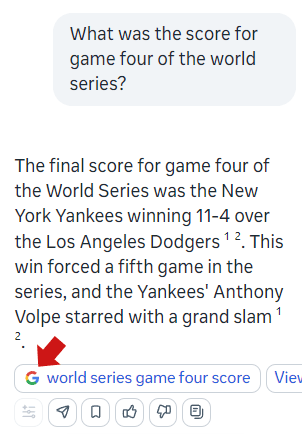
The Meta AI chatbot looks like a search engine and it’s clear that it’s still using Google’s search index.
For example, a search t Meta AI about the recent game four of the World Series showed a summary with an accurate answer that had a link to Google.
Screenshot Of Meta AI With Link To Google Search
Here’s a close up showing the link to Google search results and a link to the sources:
Screenshot Of Close-Up Of Meta AI Results
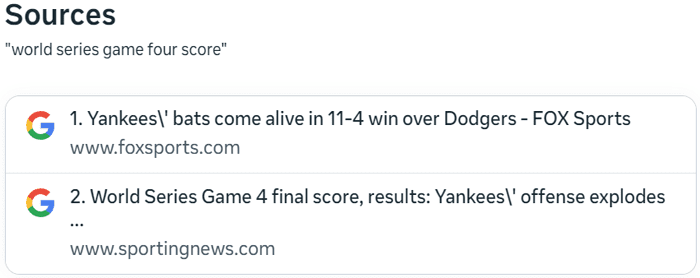
Clicking on the View Sources button spawns a popup with links to Google Search.
This post was sponsored by Kinsta. The opinions expressed in this article are the sponsor’s own.
Managing client sites can quickly become costly in terms of time, money, and expertise, especially as your agency grows.
You’re constantly busy fixing slow WordPress performance, handling downtime, or regularly updating and backing up ecommerce sites and small blogs.
The solution to these challenges might lie in fully managed hosting for WordPress sites.
Opting for a fully managed hosting provider that specializes in WordPress and understands agency needs can save you both time and money. By making the switch, you can focus on what truly matters: serving your current clients and driving new business into your sales funnel.
WordPress Worries & How To Keep Clients Happy
For SEO agencies managing multiple client sites, ensuring consistently fast performance across the board is essential. Websites with poor performance metrics are more likely to see a dip in traffic, increased bounce rates, and lost conversion opportunities.
Managed hosting, especially hosting that specializes and is optimized for WordPress, offers agencies a way to deliver high-speed, well-performing sites without constantly battling technical issues.
Clients expect seamless performance, but handling these technical requirements for numerous websites can be a time-consuming process. While WordPress is versatile and user-friendly, it does come with performance challenges.
SEO agencies must deal with frequent updates, plugin management, security vulnerabilities, and optimization issues.
Challenges like bloated themes, inefficient plugins, and poor hosting infrastructure can lead to slow load times. You also need to ensure that client WordPress sites are secured against malware and hackers, which requires regular monitoring and updates.
With managed hosting, many of these tasks are automated, significantly reducing the workload on your team.
Managed hosting for WordPress simplifies the process by providing a full suite of performance, security, and maintenance services.
Instead of spending valuable time on manual updates, backups, and troubleshooting, you can rely on your hosting provider to handle these tasks automatically, resulting in reduced downtime, improved site performance, and a more efficient use of resources.
Ultimately, you can focus your energy on SEO strategies that drive results for your clients.
Basics Of Managed Hosting For WordPress
Managed hosting providers like Kinsta take care of all the technical aspects of running WordPress websites, including performance optimization, security, updates, backups, and server management.
We take over the responsibilities ensure the platform runs smoothly and securely without the constant need for manual intervention.
Kinsta also eliminates common performance bottlenecks in WordPress include slow-loading themes, outdated plugins, inefficient database queries, and suboptimal server configurations.
Key Benefits Of Efficient Managed Hosting For SEO
1. Performance & Speed
Core Web Vitals, Google’s user experience metrics, play a significant role in determining search rankings. Managed hosting improves metrics like LCP, FID, and CLS by offering high-performance servers and built-in caching solutions.
CDNs reduce latency by serving your website’s static files from servers closest to the user, significantly improving load times.
Kinsta, for example, uses Google Cloud’s premium tier network and C2 virtual machines, ensuring the fastest possible load times for WordPress sites. We also provide integrated CDN services, along with advanced caching configurations, which ensure that even resource-heavy WordPress sites load quickly.
And the benefits are instantly noticeable.
Before the switch, Torro Media faced performance issues, frequent downtimes, and difficulties scaling their websites to handle traffic growth. These issues negatively affected their clients’ user experience and SEO results.
After migrating to Kinsta, Torro Media saw noteable improvements:
Faster website performance – Site load times significantly improved, contributing to better SEO rankings and overall user experience.
Expert support – Our support team helped Torro Media resolve technical issues efficiently, allowing the agency to focus on growth rather than troubleshooting.
Security is a critical component of managed hosting. Platforms like Kinsta offer automatic security patches, malware scanning, and firewalls tailored specifically for WordPress.
These features are vital to protecting your clients’ sites from cyber threats, which, if left unchecked, can lead to ranking drops due to blacklisting by search engines.
Downtime and security breaches negatively impact SEO. Google devalues sites that experience frequent downtime or security vulnerabilities.
Managed hosting providers minimize these risks by maintaining secure, stable environments with 24/7 monitoring, helping ensure that your clients’ sites remain online and safe from attacks.
3. Automatic Backups & Recovery
Automatic daily backups are a standard feature of managed hosting, protecting against data loss due to server crashes or website errors. For agencies, this means peace of mind, knowing that they can restore their clients’ sites quickly in case of a problem. The ability to quickly recover from an issue helps maintain SEO rankings, as prolonged downtime can hurt search performance.
Managed hosting providers often include advanced tools such as one-click restore points and robust disaster recovery systems. Additionally, having specialized support means that you have access to experts who understand WordPress and can help troubleshoot complex issues that affect performance and SEO.
Importance Of An Agency-Focused Managed WordPress Hosting Provider
For SEO agencies, uptime guarantees are essential to maintaining site availability. Managed hosting providers, like Kinsta, who specialize in serving agencies, offer a 99.9% uptime SLA and multiple data center locations, ensuring that websites remain accessible to users across the globe.
Scalability and flexibility matter, too. As your agency grows, your clients’ hosting needs may evolve. Managed hosting platforms designed for agencies offer scalability, allowing you to easily add resources as your client portfolio expands.
With scalable solutions, you can handle traffic surges without worrying about site downtime or slowdowns.
1. The Right Dashboards
A user-friendly dashboard is crucial for managing multiple client sites efficiently. Kinsta’s MyKinsta dashboard, for example, allows agencies to monitor performance, uptime, and traffic across all sites in one centralized location, providing full visibility into each client’s website performance.
Hosting dashboards like Kinsta’s MyKinsta provide real-time insights into key performance metrics such as server response times, resource usage, and traffic spikes. These metrics are essential for ensuring that sites remain optimized for SEO.
2. Balance Costs With Performance Benefits
For agencies, managing hosting costs is always a consideration. While managed hosting may come with a higher price tag than traditional shared hosting, the benefits, such as faster performance, reduced downtime, and enhanced security, translate into better client results and long-term cost savings.
Kinsta offers flexible pricing based on traffic, resources, and features, making it easier for agencies to align their hosting solutions with client budgets.
By automating tasks like backups, updates, and security management, managed hosting allows agencies to significantly reduce the time and resources spent on day-to-day maintenance. This frees up your team to focus on delivering SEO results, ultimately improving efficiency and client satisfaction.
Don’t think it makes that big of a difference? Think again.
Improved site speed – Load times dropped by over 50%, which enhanced user experience and SEO performance.
Better support – Kinsta’s specialized support team helped troubleshoot issues quickly and provided expert-level advice.
Streamlined management – With our user-friendly dashboard and automated features, 5Tales reduced the time spent on maintenance and troubleshooting.
Overall, 5Tales saw an increase in both client satisfaction and SEO rankings after moving to Kinsta.
3. Managed Hosting & Page Speed Optimization
Tools like Kinsta’s Application Performance Monitoring (APM) provide detailed insights into website performance, helping agencies identify slow-loading elements and optimize them. This level of transparency enables faster troubleshooting and more precise optimization efforts, which are critical for maintaining fast page speeds.
It’s also easy to integrate managed hosting platforms with your existing tech stack. Kinsta works seamlessly with SEO tools like Google Analytics, DebugBear, and others, allowing agencies to track site performance, analyze traffic patterns, and ensure sites are running at peak efficiency.
Conclusion
Managed hosting is not just a convenience. It’s a critical component of success for SEO agencies managing WordPress sites.
By leveraging the performance, security, and time-saving benefits of a managed hosting provider like Kinsta, agencies can improve client results, enhance their relationships, and streamline their operations.
When it comes to SEO, every second counts. A fast, secure, and well-maintained website will always perform better in search rankings. For agencies looking to deliver maximum value to their clients, investing in managed hosting is a smart, long-term decision.
Ready to make the switch?
Kinsta offers a guarantee of no-shared hosting, 99.99% uptime guarantee, and 24/7/365 support, so we’re here when you need us. Plus, we makes it easy, effortless, and free to move to Kinsta.
Our team of migration experts have experience switching from all web hosts. And when you make the switch to Kinsta, we’ll give you up to $10,000 in free hosting to ensure you avoid paying double hosting bills.
Alphabet Inc. reported its third-quarter earnings, with revenues reaching $88.3 billion, a 15% increase from last year.
The Google parent company’s operating margin expanded to 32% from 27.8% year-over-year, while net income rose 34% to $26.3 billion.
During the earnings call, the company highlighted the growing role of AI across its products and services.
Google Cloud revenue increased 35% to $11.4 billion, while YouTube surpassed $50 billion in combined advertising and subscription revenue over the past four quarters.
Several operational changes occurred during the quarter, including the reorganization of Google’s AI teams and the expansion of AI features across its products.
The company also reported improvements in AI infrastructure efficiency and increased deployment of AI-powered search capabilities.
Highlights
AI
CEO Sundar Pichai emphasized how AI transforms the search experience, telling investors that “new AI features are expanding what people can search for and how they search for it.”
Google’s AI infrastructure investments are yielding efficiency gains. According to Pichai, over a quarter of all new code at Google is now generated by AI and then reviewed by engineers, accelerating development cycles.
Google has reduced AI Overview query costs by 90% over 18 months while doubling the Gemini model size. These improvements extend across seven Google products, each serving over 2 billion monthly users.
Cloud
The Google Cloud division reported operating income of $1.95 billion, marking an increase from $266 million in the same quarter last year.
Company leadership attributed this growth to increased adoption of AI infrastructure and generative AI solutions among enterprise customers.
In an organizational move, Google announced it will transfer its Gemini consumer AI team to Google DeepMind, signaling a deeper integration of AI development across the company.
YouTube
YouTube achieved a notable milestone: its combined advertising and subscription revenues exceeded $50 billion over the past four quarters.
YouTube ads revenue grew to $8.9 billion in Q3, while the broader Google subscriptions, platforms, and devices segment reached $10.7 billion.
Financials
Net income increased 34% to $26.3 billion
Operating margin expanded to 32% from 27.8% last year
Earnings per share rose 37% to $2.12
Total Google Services revenue grew 13% to $76.5 billion
What This Means
Google’s Q3 results point to shifts in search that SEO professionals and businesses need to watch.
With AI Overviews now reaching over 1 billion monthly users, we’re seeing changes in search behavior.
According to CEO Sundar Pichai, users are submitting longer and more complex queries, exploring more websites, and increasing their search activity as they become familiar with AI features.
For publishers, the priorities are clear: create content that addresses complex queries and monitor how AI Overviews affect traffic patterns.
We can expect further advancements across services with Google’s heavy investment in AI. The key will be staying agile and continually testing new features as they roll out.
A British couple’s legal battle against Google’s search practices has concluded.
Europe’s highest court upheld a €2.4 billion fine against Google, marking a victory for small businesses in the digital marketplace.
Background
Shivaun and Adam Raff launched Foundem, a price comparison website, in June 2006.
On launch day, Google’s automated spam filters hit the site, pushing it deep into search results and cutting off its primary traffic source.
“Google essentially disappeared us from the internet,” says Shivaun Raff.
The search penalties remained in place despite Foundem later being recognized by Channel 5’s The Gadget Show as the UK’s best price comparison website.
From Complaint To Major Investigation
After two years of unanswered appeals to Google, the Raffs took their case to regulators.
Their complaint led to a European Commission investigation in 2010, which revealed similar issues affecting approximately 20 other comparison shopping services, including Kelkoo, Trivago, and Yelp.
The investigation concluded in 2017 with the Commission ruling that Google had illegally promoted its comparison shopping service while demoting competitors, resulting in the €2.4 billion fine.
Here’s a summary of what happened next.
Timeline: From Initial Fine to Final Ruling (2017-2024)
2017
European Commission issues €2.4 billion fine against Google
Google implements changes to its shopping search results
Google files initial appeal against the ruling
2021
General Court of the European Union upholds the fine
Google launches second appeal to the European Court of Justice
2024March
European Commission launches new investigation under Digital Markets Act
Probe examines whether Google continues to favor its services in search results
September
European Court of Justice rejects Google’s final appeal A fine of €2.4 billion is definitively upheld
Marks the end of main legal battle after 15 years
The seven-year legal process highlights the challenges small businesses face in seeking remedies for anti-competitive practices, despite having clear evidence.
Google’s Response
Google maintains its 2017 compliance changes resolved the issues.
A company spokesperson stated:
“The changes we made have worked successfully for more than seven years, generating billions of clicks for more than 800 comparison shopping services.”
What’s Next?
While the September 2024 ruling validates the Raffs’ claims, it comes too late for Foundem, which closed in 2016.
In March 2024, the European Commission launched a new investigation into Google’s current practices under the Digital Markets Act.
The Raffs are now pursuing a civil damages claim against Google, scheduled for 2026.
Why This Matters
This ruling confirms that Google’s search rankings can be subject to regulatory oversight and legal challenges.
The case has already influenced new digital marketplace regulations, including the EU’s Digital Markets Act.
Although Foundem’s story concluded with the company’s closure in 2016, the legal precedent it set will endure.
While everyone is looking at AI Overviews, Google launched a personalized shopping experience to build a foothold in the vertical that’s the least sensitive to LLM disruption.
AI could revive personalization and bring it to other areas of Google as well.
The new SERP layout shakes up ecommerce SEO by making Google the new category page and shifting the focus to product pages.
[…] today, we’re introducing a transformed Google Shopping — rebuilt from the ground up with AI. We’ve paired the 45 billion product listings in Google’s Shopping Graph with Gemini models to transform the online shopping experience with a new, personalized shopping home, which is rolling out in the U.S. over the coming weeks, starting today.
Users can try the new experience out on shopping.google.com or the shopping tab. I see this as a test that could replace the default experience for shopping queries.
In reality, shopping SERPs have been transforming for a while. I wrote about it back in December 2023 in Ecommerce Shifts:
Google’s metamorphosis into a shopping marketplace is complete. Two ingredients were missing: product filters that turn pure search pages into ecommerce search pages and direct checkout. Those ingredients have now been added, and the cake has been baked.
In the same article, I highlighted why:
Reality is that Google had few options. Amazon had been eating their lunch with a growing ad business that hits Google where it hurts: ecommerce. Shopping is lucrative in part because conversions and returns are easier to measure than in industries like SaaS.
Two things changed since I published the article that explains the urgency of Google pushing into shopping:
Google rolled AI Overviews out. In Phoenix, I outlined how often Google tried to personalize the search results without much success, but AI has a chance to make it work.
TikTok has stepped into the ring with Amazon, encouraging merchants to livestream and advertise. Everyone was looking at TikTok as a search competitor to Google when former head of search Prabhakar Raghavan publicly mentioned that “nearly half of Gen Z is using Instagram and TikTok for search instead of Google,” but we missed how aggressively TikTok was pushing into ecommerce. If Google competes harder with Amazon and Amazon competes against TikTok, then TikTok is a stronger competitor to Google than originally assumed.
LLMs and AI Overviews likely disrupt informational searches by making many clicks obsolete, but ecommerce search is still alive and kicking and one of the main contributors to revenue growth.
The exact impact of personalized, AI-based shopping Search will take a few more months to assess. But it makes a change in how Google:
Looks for different verticals.
Looks for different geos.
Looks for different users.
Aggregates websites.
Google’s Verticalization
Image Credit: Kevin Indig
Different queries trigger different experiences on Google across shopping, travel, local and information.
Search for [mens shoes], and you get a shopping marketplace. Search for [best flight between chicago and nyc], and you get a flight booking engine. Et cetera. Et cetera.
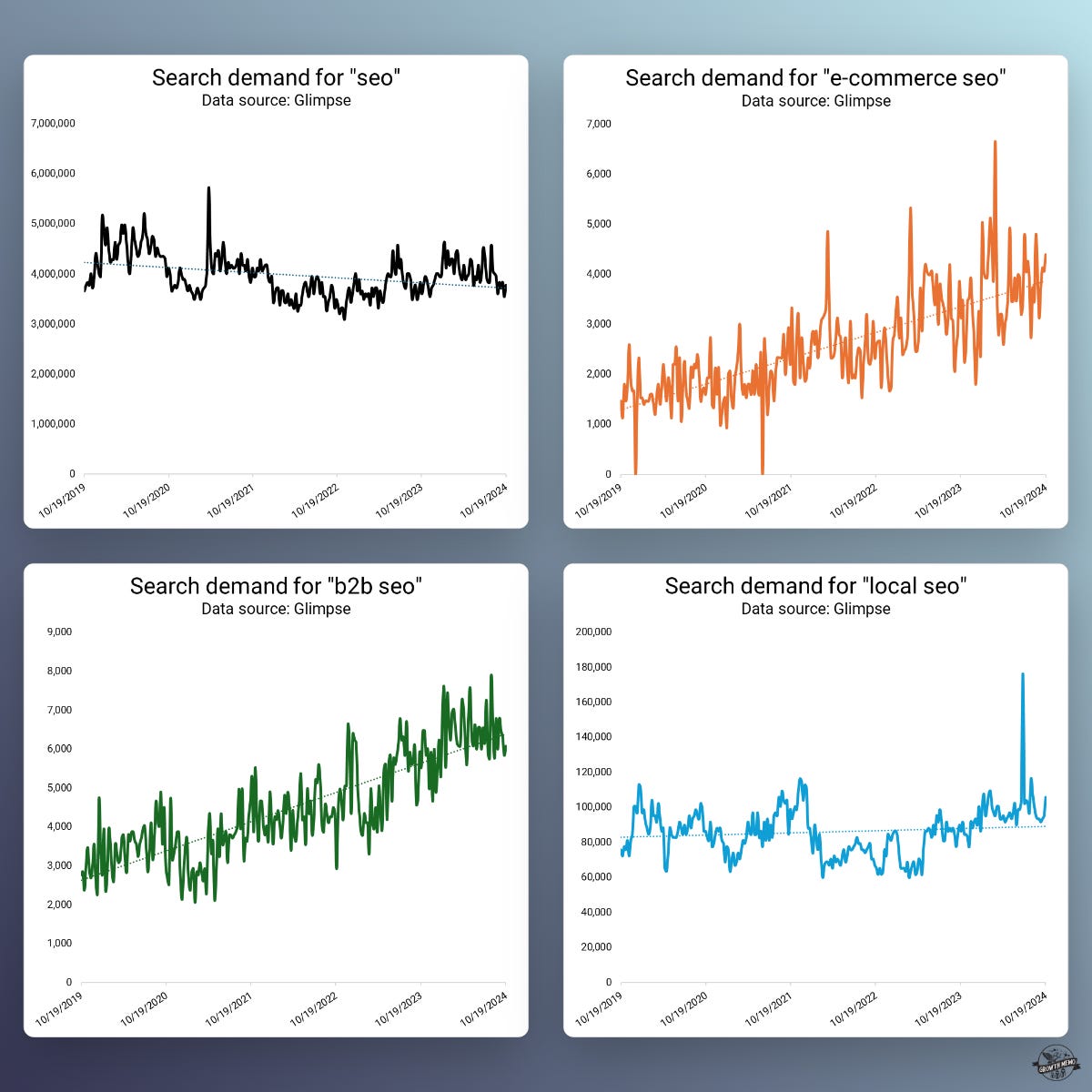
Google’s search demand for verticalized SEO reflects the trend: Searches for [seo] are flat while demand for verticalization, e.g., “B2B SEO,” is growing.
So, why do we still generalize SEO? There is no one SEO. There are many different types of SEO based on which vertical we talk about.
With different Google experiences grows the need to specialize skills by vertical. Ecommerce SEO, for example, centers around free listings and feed optimization in Google’s Merchant Center.
Our tools and insights are still far behind. There is no tool to run split tests for free listings in Merchant Center, but several tools handle feed optimization and experimentation for paid results.
Even worse, most companies still measure organic positions for success in ecommerce, but free listings show up above position 1 almost half of the time. Trend: growing.
Regulation splits the internet experience, aka Search, into a European and American version with stark differences. While Big Tech companies face complexity, Search players have an opportunity to compare SERP Features and AI Overviews in both internet versions and better understand their impact.
AI Overviews have not yet rolled out in EU markets, and it’s unclear if they will.
Since the new shopping experience heavily leans on AI Overviews, I am equally skeptical that it will come to the EU, especially with the strong personalization layer.
Personalization under the Digital Marketing Act (DMA) is not forbidden, but GDPR mandates that users consent to it.
YouGov surveyed thousands of people across 17 countries and found vast discrepancies in consent.
Google will almost certainly “burry” consent in its general terms of service, which no one reads. It will be up to legislators to evaluate whether that’s sufficient.
Just like AIOs, the non-personalized shopping experience in the EU might serve as a comparison for the U.S. and other countries to understand the impact of Google’s new experience better.
Google’s Personalization
Image Credit: Kevin Indig
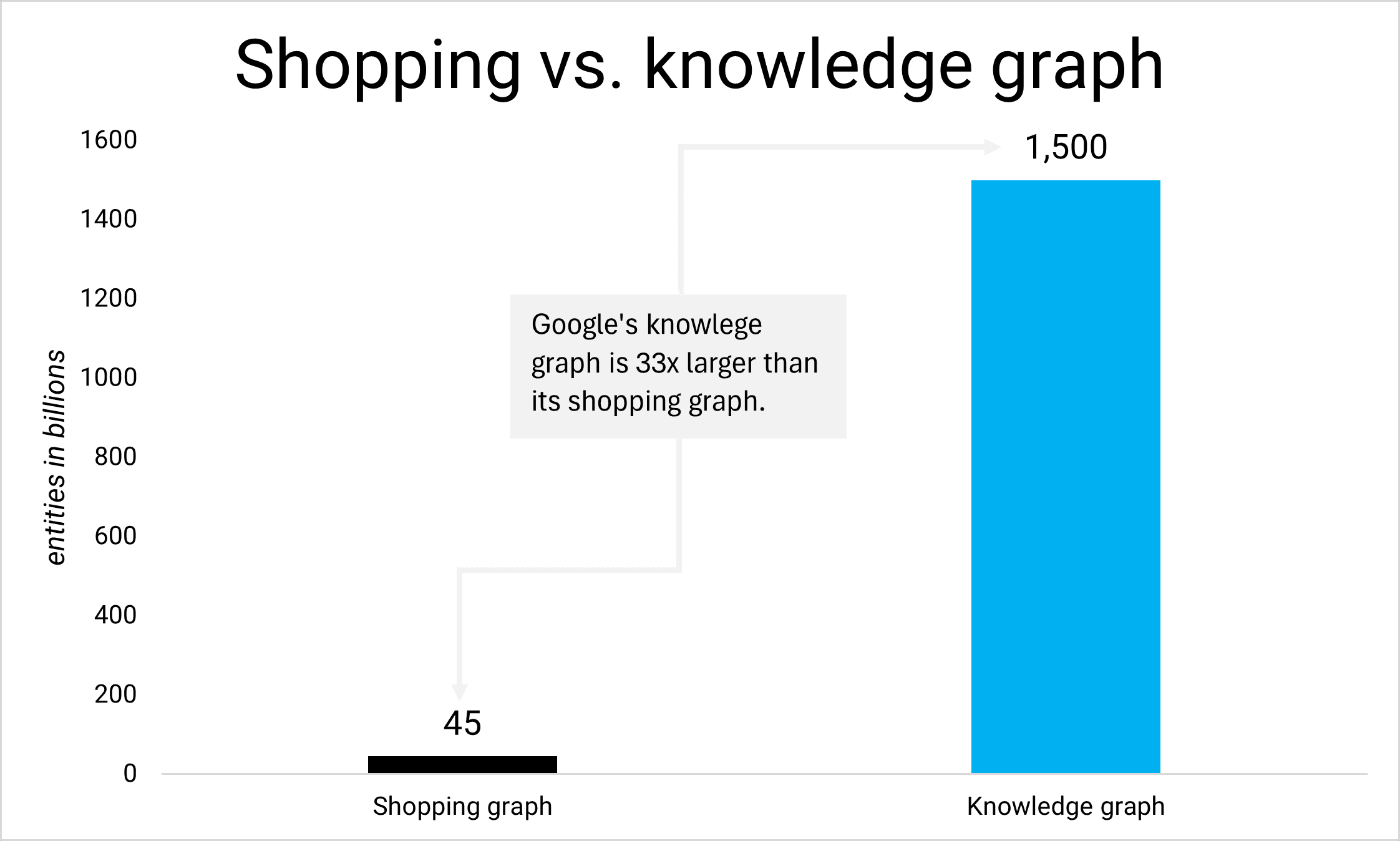
Google personalizes the new shopping experience based on user behavior and matches it with its vast shopping graph that covers over 45 billion entities.
Note that 45 billion entities include product variations, reviews, brands, categories, and more.
However, the Shopping Graph looks like a dwarf compared to Google’s knowledge graph with over 1.5 trillion entities.
If personalization is a question of graph size and AI capabilities, it’s only a matter of time until non-shopping results are more personalized.
Personalization also makes sense in the context that AI can answer long questions much better than Google’s old semantic search ever could, so Google might as well personalize results based on behavior.
Google also uses YouTube as a source to personalize shopping. I wonder: why not for regular Search as well? ~25% of queries show videos, and most of those are from YouTube.
Google could easily prefer videos from YouTube channels you subscribe to in the regular search results, as an example.
The challenge of personalization for marketers is optimizing for a uniform search experience.
When our experiences differ significantly, our data does as well, which means we’re losing a whole layer of insights to work with.
The result is that we need to rely more on aggregate data, post-purchase surveys and market research, like in the good ‘ol days.
Google’s Aggregation
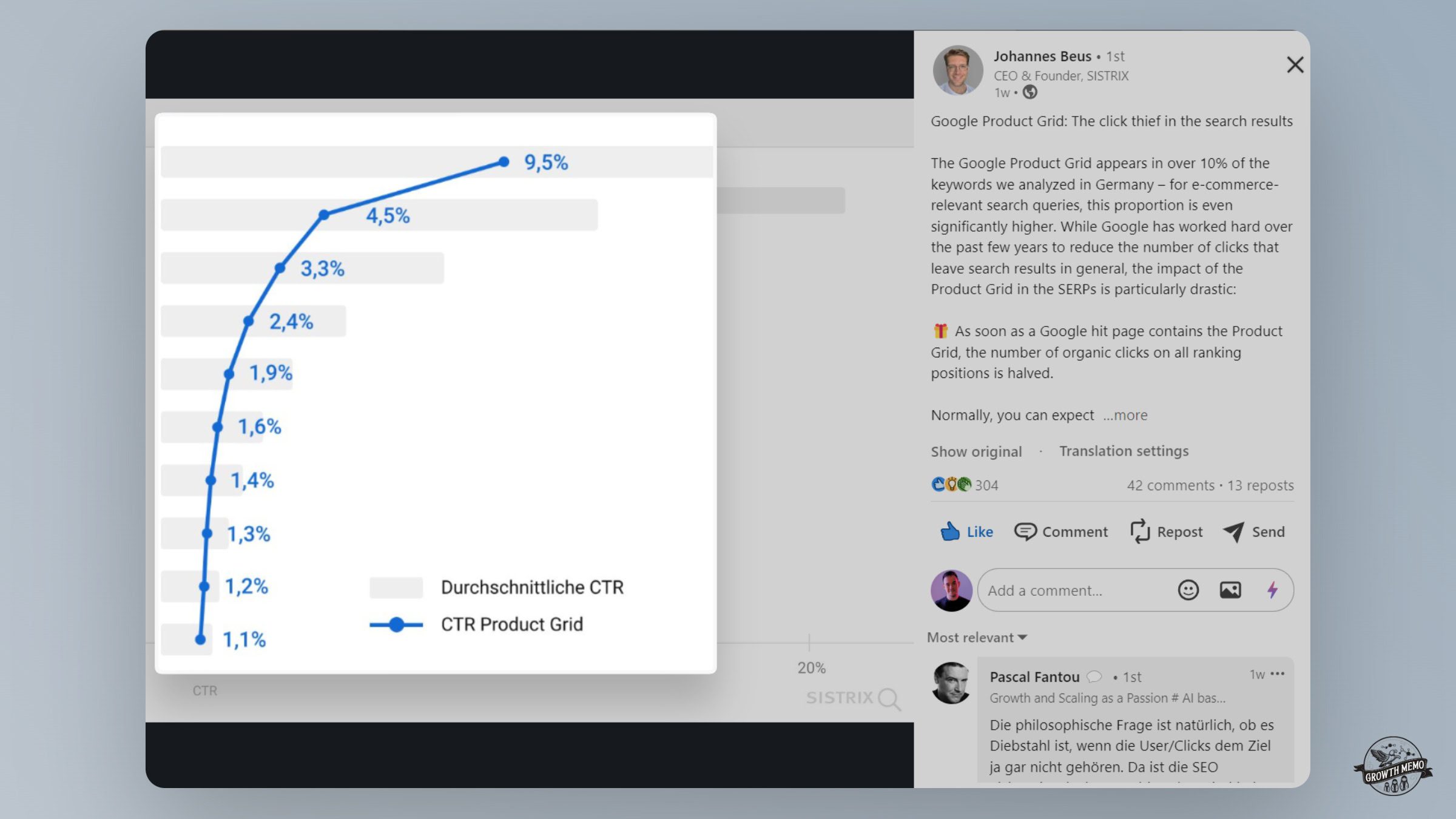
Free product listing click-through rates, according to Johannes Beus (link) Image Credit: Kevin Indig
The big question, of course, is how this new experience impacts organic clicks. Can websites still get clicks? We don’t know for sure until more data rolls in.
One reference point comes from Johannes Beus (Founder/CEO of Sistrix), who found that Free Listings cut clicks on organic results in half, e.g., position 1 drops from ~21% on average to 9.5%.
But based on the layout and my experience with layout changes in the past, I will say that I don’t see a threat here. I see a change.
Google’s new layout for shopping SERPs, the one it has been using for a year now, is essentially a category page that lists products from online stores. As a result, the focus of ecommerce SEO shifts from category to product page optimization.
Where I do see a negative impact is for sites that provide price comparison, tracking, or discounts. Chrome has been tracking price changes for over a year.
We know shoppers always want low prices, and the new Google Shopping not only includes deal-finding tools like price comparison, price insights and price tracking throughout, but also a new dedicated and personalized deals page where you can browse deals for you — just click the “Deals” link at the top of your page to explore.
I wouldn’t be shocked to hear that Google also uses Chrome data to inform the shopping graph and product recommendation in the personalized shopping experience.
If so, separating Chrome from Google in the context of the antitrust trial would also impact its personalization capabilities.
Above: “shopping tab” with Google’s new shopping experience; below: “all” tab (Image Credit: Kevin Indig)
Image Credit: Kevin Indig
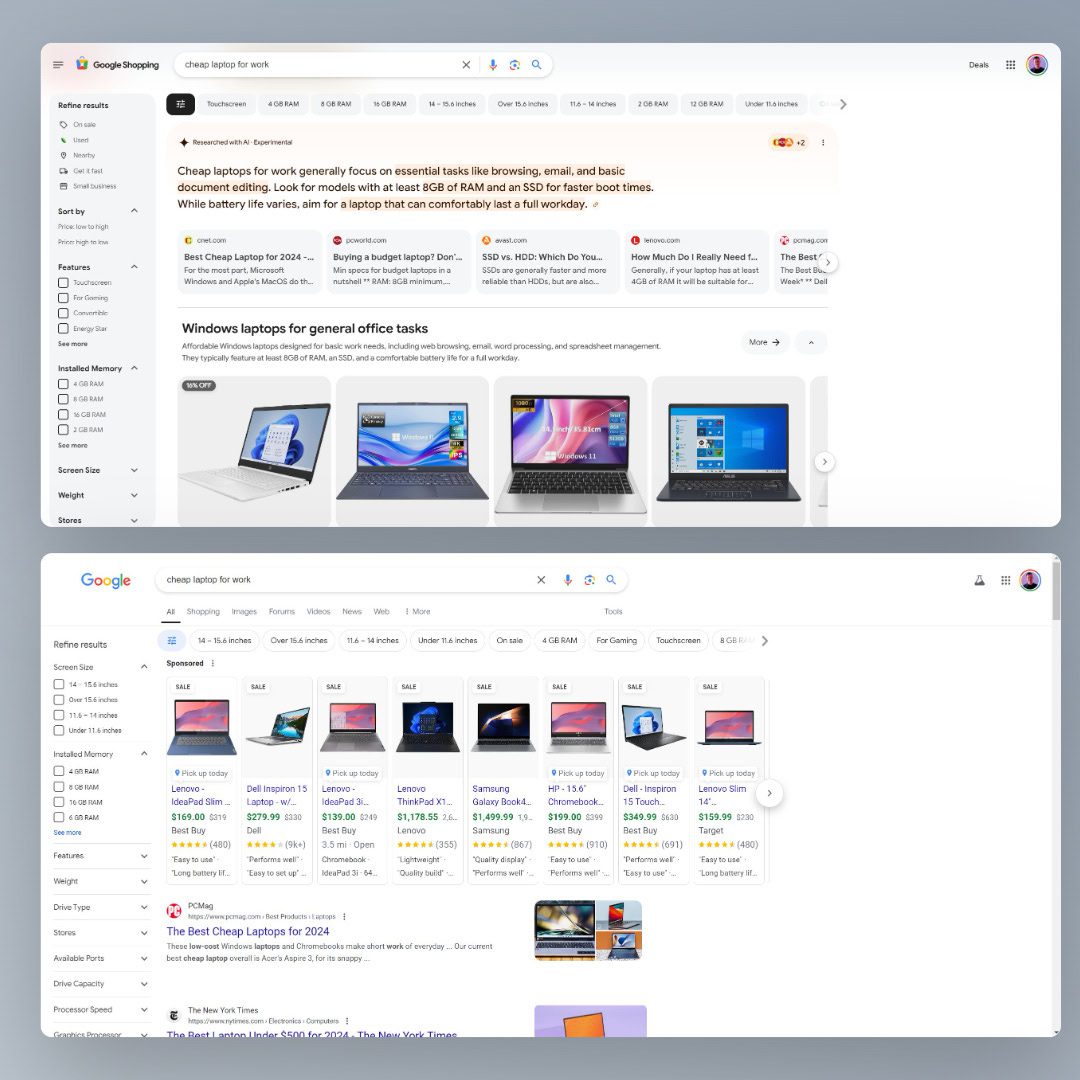
One improvement from the new experience is that editorial content doesn’t have to fight with product or category pages over positions anymore.
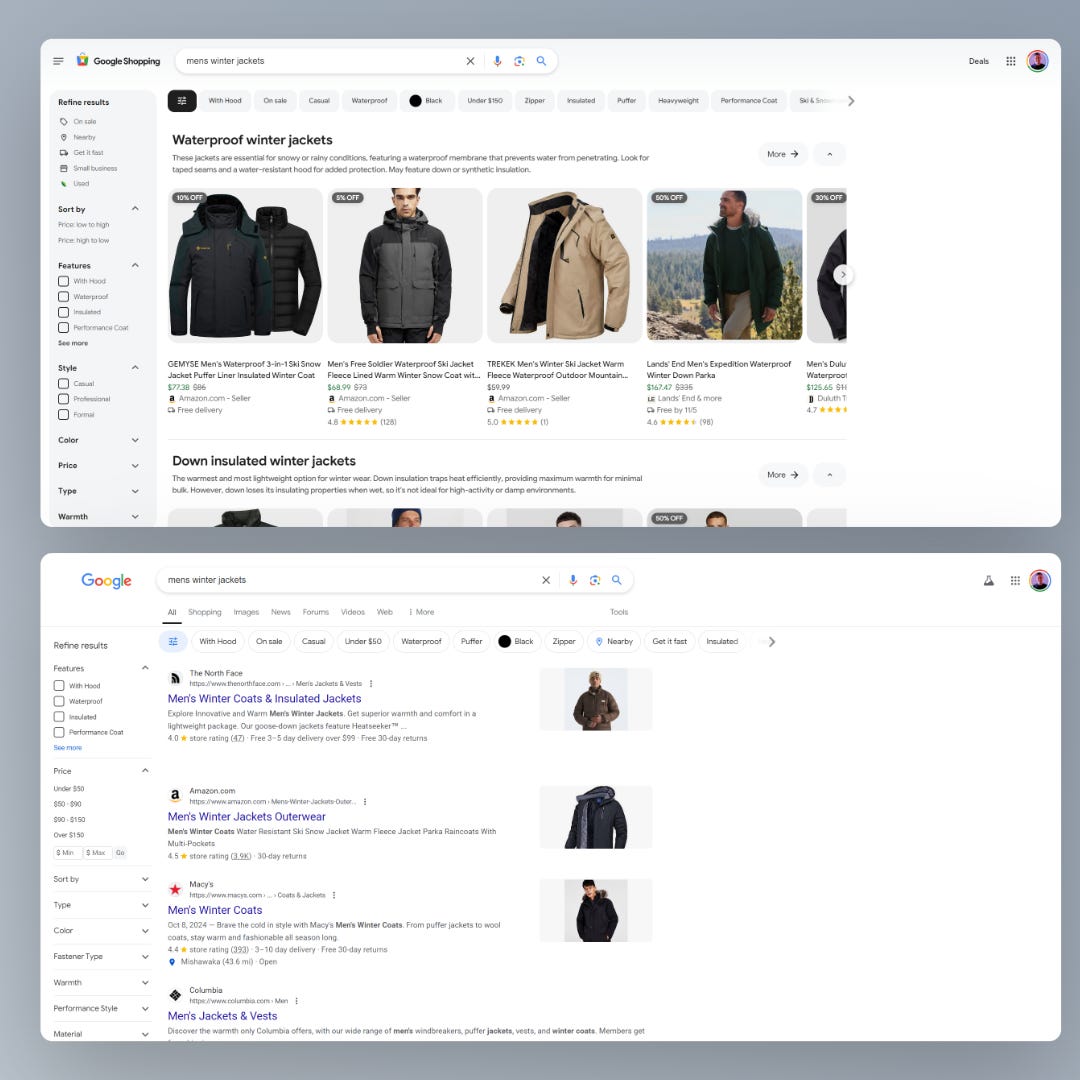
The layout constantly changes, but it seems some queries highlight links to editorial articles about products (like “cheap laptop for work”), others (like “mens winter jackets”) don’t.
At least, there seems to be a lifeline for publishers in ecommerce.
The official documentation for how Core Web Vitals are scored was recently updated with new insights into how Interaction to Next Paint (INP) scoring thresholds were chosen and offers a better understanding of Interaction To Next Paint.
Interaction to Next Paint (INP)
Interaction to Next Paint (INP) is a relatively new metric, officially becoming a Core Web Vitals in the Spring of 2024. It’s a metric of how long it takes a site to respond to interactions like clicks, taps, and when users press on a keyboard (actual or onscreen).
“INP observes the latency of all interactions a user has made with the page, and reports a single value which all (or nearly all) interactions were beneath. A low INP means the page was consistently able to respond quickly to all—or the vast majority—of user interactions.”
INP measures the latency of all the interactions on the page, which is different than the now retired First Input Delay metric which only measured the delay of the first interaction. INP is considered a better measurement than INP because it provides a more accurate idea of the actual user experience is.
INP Core Web Vitals Score Thresholds
The main change to the documentation is to provide an explanation for the speed performance thresholds that show poor, needs improvement and good.
One of the choices made for deciding the scoring was how to handle scoring because it’s easier to achieve high INP scores on a desktop versus a mobile device because external factors like network speed and device capabilities heavily favor desktop environments.
But the user experience is not device dependent so rather that create different thresholds for different kinds of devices they settled on one metric that is based on mobile devices.
The new documentation explains:
“Mobile and desktop usage typically have very different characteristics as to device capabilities and network reliability. This heavily impacts the “achievability” criteria and so suggests we should consider separate thresholds for each.
However, users’ expectations of a good or poor experience is not dependent on device, even if the achievability criteria is. For this reason the Core Web Vitals recommended thresholds are not segregated by device and the same threshold is used for both. This also has the added benefit of making the thresholds simpler to understand. Additionally, devices don’t always fit nicely into one category. Should this be based on device form factor, processing power, or network conditions? Having the same thresholds has the side benefit of avoiding that complexity.
The more constrained nature of mobile devices means that most of the thresholds are therefore set based on mobile achievability. They more likely represent mobile thresholds—rather than a true joint threshold across all device types. However, given that mobile is often the majority of traffic for most sites, this is less of a concern.”
These are scores Chrome settled on:
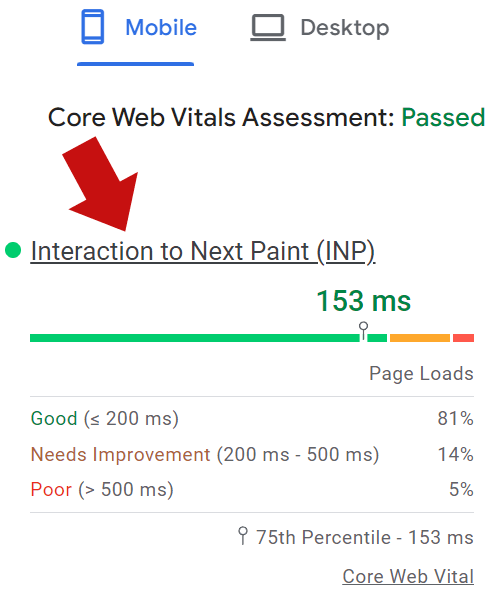
Scores of under 200 ms (milliseconds) were chosen to represent a “good” score.
Scores between 200 ms – 500 ms represent a “needs improvement” score.
Performance of over 500 ms represent a “poor” score.
Screenshot Of An Interaction To Next Paint Score
Lower End Devices Were Considered
Chrome was focused on choosing achievable metrics. That’s why the thresholds for INP had to be realistic for lower end mobile devices because so many of them are used to access the Internet.
They explained:
“We also spent extra attention looking at achievability of passing INP for lower-end mobile devices, where those formed a high proportion of visits to sites. This further confirmed the suitability of a 200 ms threshold.
Taking into consideration the 100 ms threshold supported by research into the quality of experience and the achievability criteria, we conclude that 200 ms is a reasonable threshold for good experiences”
Most Popular Sites Influenced INP Thresholds
Another interesting insight in the new documentation is that achievability of the scores in the real world were another consideration for the INP scoring metrics, measured in milliseconds (ms). They examined the performance of the top 10,000 websites because they made up the vast majority of website visits in order to dial in the right threshold for poor scores.
What they discovered is that the top 10,000 websites struggled to achieve performance scores of 300 ms. The CrUX data that reports real-world user experience showed that 55% of visits to the most popular sites were at the 300 ms threshold. That meant that the Chrome team had to choose a higher millisecond score that was achieveable by the most popular sites.
The new documentation explains:
“When we look at the top 10,000 sites—which form the vast majority of internet browsing—we see a more complex picture emerge…
On mobile, a 300 ms “poor” threshold would classify the majority of popular sites as “poor” stretching our achievability criteria, while 500 ms fits better in the range of 10-30% of sites. It should also be noted that the 200 ms “good” threshold is also tougher for these sites, but with 23% of sites still passing this on mobile this still passes our 10% minimum pass rate criteria.
For this reason we conclude a 200 ms is a reasonable “good” threshold for most sites, and greater than 500 ms is a reasonable “poor” threshold.”
Barry Pollard, a Web Performance Developer Advocate on Google Chrome who is a co-author of the documentation, added a comment to a discussion on LinkedIn that offers more background information:
“We’ve made amazing strides on INP in the last year. Much more than we could have hoped for. But less than 200ms is going to be very tough on low-end mobile devices for some time. While high-end mobile devices are absolute power horses now, the low-end is not increasing at anywhere near that rate…”
A Deeper Understanding Of INP Scores
The new documentation offers a better understanding of how Chrome chooses achievable metrics and takes some of the mystery out of the relatively new INP Core Web Vital metric.
Google published a proposal in the Schema.org Project GitHub instance that proposes proposing an update at Schema.org to expand the shopping structured data so that merchants can provide more shipping information that will likely show up in Google Search and other systems.
Shipping Schema.org Structured Data
The proposed new structured data Type can be used by merchants to provide more shipping details. It also suggests adding the flexibility of using a sitewide shipping structured data that can then be nested with the Organization structured data, thereby avoiding having to repeat the same information thousands of times across a website.
The initial proposal states:
“This is a proposal from Google to support a richer representation of shipping details (such as delivery cost and speed) and make this kind of data explicit. If adopted by schema.org and publishers, we consider it likely that search experiences and other consuming systems could be improved by making use of such markup.
This change introduces a new type, ShippingService, that groups shipping constraints (delivery locations, time, weight and size limits and shipping rate). Redundant fields from ShippingRateSettings are therefore been deprecated in this proposal.
As a consequence, the following changes are also proposed:
some fields in OfferShippingDetails have moved to ShippingService; ShippingRateSettings has more ways to specify the shipping rate, proportional to the order price or shipping weight; linking from the Offer should now be done with standard Semantic Web URI linking.”
The proposal is open for discussion and many stakeholders are offering opinions on how the updated and new structured data would work.
For example, one person involved in the discussion asked how a sitewide structured data type placed in the Organization level could be superseded by individual products had different information and someone else provided an answer.
A participant in the GitHub discussion named Tiggerito posted:
“I re-read the document and what you said makes sense. The Organization is a place where shared ShippingConditions can be stored. But the ShippingDetails is always at the ProductGroup or Product level.
This is how I currently deal with Shipping Details:
In the back end the owner can define a global set of shipping details. Each contains the fields Google currently support, like location and times, but not specifics about dimensions. Each entry also has conditions for what product the entry can apply to. This can include a price range and a weight range.
When I’m generating the structured data for a page I include the entries where the product matches the conditions.
This change looks like it will let me change from filtering out the conditions on the server, to including them in the Structured Data on the product page.
Then the consumers of the data can calculate which ShippingConditions are a match and therefore what rates are available when ordering a specific number of the product. Currently, you can only provide prices for shipping one.
The split also means it’s easier to provide product specific information as well as shared shipping information without the need for repetition.
Your example in the document at the end for using Organization. It looks like you are referencing ShippingConditions for a product that are on a shipping page. This cross-referencing between pages could greatly reduce the bloat this has on the product page, if supported by Google.”
The Googler responded to Tiggerito:
“@Tiggerito
The Organization is a place where shared ShippingConditions can be stored. But the ShippingDetails is always at the ProductGroup or Product level.
Indeed, and this is already the case. This change also separates the two meanings of eg. width, height, weight as description of the product (in ShippingDetails) and as constraints in the ShippingConditions where they can be expressed as a range (QuantitativeValue has min and max).
In the back end the owner can define a global set of shipping details. Each contains the fields Google currently support, like location and times, but not specifics about dimensions. Each entry also has conditions for what product the entry can apply to. This can include a price range and a weight range.
When I’m generating the structured data for a page I include the entries where the product matches the conditions.
This change looks like it will let me change from filtering out the conditions on the server, to including them in the Structured Data on the product page.
Then the consumers of the data can calculate which ShippingConditions are a match and therefore what rates are available when ordering a specific number of the product. Currently, you can only provide prices for shipping one.
Some shipping constraints are not available at the time the product is listed or even rendered on a page (eg. shipping destination, number of items, wanted delivery speed or customer tier if the user is not logged in). The ShippingDetails attached to a product should contain information about the product itself only, the rest gets moved to the new ShippingConditions in this proposal. Note that schema.org does not specify a cardinality, so that we could specify multiple ShippingConditions links so that the appropriate one gets selected at the consumer side.
The split also means it’s easier to provide product specific information as well as shared shipping information without the need for repetition.
Your example in the document at the end for using Organization. It looks like you are referencing ShippingConditions for a product that are on a shipping page. This cross-referencing between pages could greatly reduce the bloat this has on the product page, if supported by Google.
Indeed. This is where we are trying to get at.”
Discussion On LinkedIn
LinkedIn member Irina Tuduce (LinkedIn profile), software engineer at Google Shopping, initiated a discussion that received multiple responses that demonstrating interest for the proposal.
Andrea Volpini (LinkedIn profile), CEO and Co-founder of WordLift, expressed his enthusiasm for the proposal in his response:
“Like this Irina Tuduce it would streamline the modeling of delivery speed, locations, and cost for large organizations
“I already gave my feedback on the naming conventions to schema.org which they implemented. My concern for Google is how exactly merchants will get this data into the markup. It’s nearly impossible to get exact shipping rates in the SD if they fluctuate. Merchants can enter a flat rate that is approximate, but they often wonder if that’s acceptable. Are there consequences to them if the shipping rates are an approximation (e.g. a price mismatch in GMC disapproves a product)?”
Inside Look At Development Of New Structured Data
The ongoing LinkedIn discussion offers a peek at how stakeholders in the new structured data feel about the proposal. The official Schema.org GitHub discussion not only provides a view of how the proposal is progressing, it offers stakeholders an opportunity to provide feedback for shaping what it will ultimately look like.
With hindsight, the previous epoch could be called “The Age of the One-Trick Pony.” It began back in 2002 when Google passed more than a dozen crawlers and directories to become the dominant search engine.
If you learned how to improve a website’s visibility in Google’s natural or unpaid search results, then you could get a respectable job as a search engine optimizer.
Going forward, SEO specialists will need to invest more time in learning four additional disciplines: digital analytics, digital advertising, content marketing, and social media marketing.
SEO managers will also need to demonstrate critical thinking about digital marketing strategy if they ever hope to climb the ladder.
So, where should you begin?
Digital Analytics
You should start by learning more about digital analytics, which is the process of collecting, measuring, analyzing, and interpreting data from digital sources to understand how users interact with online content.
This will help you understand why traditional metrics like “keyword rankings” and “organic pageviews” – which are the top two performance metrics that SEO professionals use to measure success in 2024 – aren’t getting noticed anymore. This means they’re never going to help you get a promotion, let alone a seat at the big table.
“Keyword rankings and pageviews are not necessarily relevant to business goals. They’re the main metrics being disrupted right now, but it’s critical to lean into disruption to discover opportunities and change strategies.”
He used a clickstream panel from Datos to tackle a couple of critical questions:
What typically occurs after Americans and Europeans perform a Google search?
In 2024, what percentage of searches end without any clicks?
As the twin charts below indicate, close to 60% of Google searches result in zero clicks, while slightly more than 40% result in a click.
Image from Sparktoro, September 2024
Of the searches that result in a click, about 25-30% go to platforms that Google owns, including YouTube, Google Images, Google Maps, and Google News. Meanwhile, the other 70% to 75% go to a non-Google-owned, non-Google-ad-paying property.
For every 1,000 Google searches, only 360 clicks in the U.S. and just 374 clicks in Europe go to the open web.
That is why you should use digital analytics to measure the impact of visibility in Google’s natural or unpaid search results on raising brand awareness.
In the late 1980s, I was the director of corporate communications at Lotus Development Corporation and at Ziff-Davis during the 1990s. Back then, I began utilizing surveys to measure the impact of publicity on brand awareness.
Today, you can use a modified version of brand lift surveys to measure this KPI.
Brand lift surveys ask people questions about your brand and products – either before and after your target audience has been exposed to a new campaign or at regular intervals.
The questions can help you understand how your SEO efforts and other cross-channel programs are impacting your brand, including:
Awareness.
Consideration.
Favorability.
Purchase intent.
In other words, learning to use digital analytics to measure, analyze, and interpret data is significantly more valuable to your career than just using the same old web analytics metrics that SEO pros have been collecting and reporting for more than 20 years.
Digital Advertising
Next, I would recommend learning more about digital advertising, which includes pay-per-click (PPC) advertising.
Digital ads can appear in many forms, including text, images, audio, and video, and can be found on various platforms, such as search engines, social media, and websites.
You’re probably sharing your keyword research with colleagues in your advertising department or over at your ad agency. But that is just the front end of a longer process – you should learn more about the middle and back end, too.
For example, I had bet dollars to donuts that your colleagues in advertising are busy setting up audiences in Google Analytics 4, which lets them segment users in ways that are important to your business.
By linking your GA4 account to Google Ads, they can remarket to them.
Why does this represent a strategic opportunity for SEO pros?
“People don’t make decisions in a neat, linear fashion.”
Between the moment they realize they need or want something and the moment they make a purchase, a lot happens.
The research also found:
“People look for information about a category’s products and brands, and then weigh all the options.”
They go through two different mental modes in the messy middle: exploration, which is an expansive activity, and evaluation, which is a reductive activity.
It concluded:
“Whatever a person is doing, across a huge array of online sources, such as search engines, social media, and review sites, can be classified into one of these two mental modes.”
So, how do SEO professionals harness this insight?
What if you started building “SEO audiences” in GA4 to help people in the “messy middle” of their purchase journey?
You could then share your SEO audiences with your colleague in advertising, who could then create a remarketing campaign targeted at this specific group of users – and help them complete their purchase journey.
For example, if your SEO program builds an audience of 1,000 users who:
Begin the checkout process, then your colleague could use Google Ads to ask them to make a purchase.
Download a white paper, then your colleague could use Google Ads to ask them to complete a registration form.
Scroll to 90% of a blog post or article, then your colleague could use Google Ads to ask them to subscribe to a newsletter.
SEJ’s State of SEO 2025 says the biggest barrier to SEO success in the last 12 months was “budget and resources.” And that was followed by two other traditional barriers: “Google algorithm updates” and “competition in SERPs.”
But if you dig a little deeper, the fourth item on the list of the biggest barriers to SEO success was “alignment with other departments.”
So, imagine what would happen if the SEO and PPC people started working together to help people in the “messy middle” of their purchase journey?
Content Marketing, Social Media Marketing, And SEO
Speaking of alignment with other departments, SEO pros need to learn even more than they already know about content marketing and social media marketing.
Overlapping responsibilities can be a waste of time and frustrating for teams. So, these tend to be the first things that companies and clients trim when they tighten their purse strings.
Ironically, slightly overlapping roles can improve workflow integration. This is because each role’s activities impact the next process in the workflow.
Alignment with other departments isn’t just a way to keep your SEO budget and resources from being cut. It is also a way to overcome other barriers to SEO success, like “Google algorithm updates” and “competition in SERPs.”
The article by Kevin Indig dives into the latest data on AI Overviews (AIO) to understand domain visibility, citation trends, and effective search strategies crucial for SEO success.
What does he notice? The top three most cited domains in AIOs are:
YouTube.com.
Wikipedia.com.
LinkedIn.com.
What does he wonder?
“The fact that two social networks, YouTube and LinkedIn, are in the top three most cited domains raises the question of whether we can influence AIO answers with content on YouTube and LinkedIn more than our own.”
Indig also notes that videos take more effort to produce than LinkedIn answers, but videos might also be more defensible against copycats. So, “AIO-optimization strategies should include social and video content.”
Let us imagine that you are the SEO manager at a Fortune 500 company. What would happen if your chief marketing officer (CMO) decided to create a task force to develop AIO-optimization strategies?
If the task force included managers from the SEO, content marketing, and social media marketing departments, then how likely is it that you would be selected to head up this team?
Since then, SEJ’s State of SEO 2025 confirms that 46.3% of SEO professionals are “content goblins,” a term that the author coined to describe people “willing to eschew rules, morals, and good taste in exchange for eyeballs and mountains of cash.”
Another 25.2% of SEO pros are “alligator wrestlers,” another term coined by The Verge to describe the link spammers who want people to click on “WATCH: 10-foot Gator Prepares to Maul Digital Marketers.”
And 19.6% were confused by these descriptions, which indicates that they don’t get out of their silos very often.
So, how do you avoid the stereotype that SEO pros are hustlers, while simultaneously demonstrating that you have the education, expertise, and experience needed to lead an interdisciplinary team?
But you’d probably improve your chances of getting the new position by also reading:
In other words, the more you know about content marketing and social media marketing, the more likely it is that you will be chosen to head up a task force to develop AIO-optimization strategies.
And working collaboratively with other departments to leverage YouTube, LinkedIn, and cross-channel strategies will also increase your odds of getting promoted in the foreseeable future.
Digital Marketing Strategy
But when you climb the corporate ladder, don’t be surprised if your next job title doesn’t include the term “search engine optimization” or “SEO.”
“Over the last 18 months there has been a marked decline in the job market for senior SEO leadership roles across in-house and agency landscapes, and this trend is persisting.”
And he wondered:
“Maybe companies don’t believe SEO by itself is enough anymore. Job seekers need SEO plus something extra.”
As I mentioned earlier, the era of one-trick ponies is about to end. What comes next can only be described using Words of Estimative Probability (WEP), which are used by intelligence analysts in analytic reports to convey the likelihood of a future event occurring.
So, whether you’re called the VP of marketing, CMO, or chief growth officer (CGO), the challenge will be the same: Create successful digital marketing strategies when your global company or top brand is faced with unexpected opportunities or unanticipated threats in the unforeseeable future.
What are the odds that you can overcome that challenge?
You can increase the likelihood of success by reading case studies and then asking yourself two questions:
What do I notice?
What do I wonder?
I used this approach when I wrote the chapter on digital marketing strategy in the book, “Digital Marketing Fundamentals.” I shared two articles that I had written for Search Engine Journal:
Now, learning lessons from others is a good start, but you can significantly improve your chances of success by borrowing a big idea from my old friend and former colleague, Avinash Kaushik. He wrote an article titled, Stop Exceeding Expectations, Suck Less First.
He said that we should stop trying to “exceed the (often less-than-optimally informed) expectations of Wall Street Analysts” because “this desire to overachieve also comes at a very heavy cost – it drives sub-optimal behavior.”
Instead, he recommended this “as the #1 goal for your company: Suck less, every day.”
How does this incremental approach help a VP of marketing, CMO, or CGO achieve their business objectives?
“More often than not, magnificent success results from executing a business plan that is rooted in a strong understanding of the landscape of possibilities, and a deep self-awareness of business capabilities. These business plans will contain a structured approach…”
Then, he shared the Digital Marketing “Ladder of Awesomeness” below.
Image from Occam’s Razor by Kaushik, September 2024
Next, Kaushik shared the Digital Analytics “Ladder of Awesomeness” below, which outlines the KPIs for each step.
Image from Occam’s Razor by Kaushik, September 2024
Now, your twin ladders of awesomeness might look a little different than his because this is 2024 – not 2013.
And both digital marketing and digital analytics have evolved. But the step-by-step process that Kaushik outlined will help you make the hard choices that are the most relevant for your company or brand when it finds itself in an unexpected, unanticipated, or unforeseeable position.
So, the first step in this new era of SEO is developing digital marketing strategies that help you avoid the pitfalls, seize the opportunities, and climb the ladder of success.
In parallel, the second step should be learning how to measure incrementality, the conversions that would not have occurred without marketing influence.
Oh, it’s also smart to start climbing these twin ladders of awesomeness as quickly as you can.
Why? Because the clock is ticking.
According to Spencer Stuart’s most recent CMO Tenure Study, Fortune 500 CMOs had an average tenure of 4.2 years last year.
However, there are differences between diverse types of companies.
CMOs at B2B companies tend to stay in their roles for an average of 4.5 years; CMOs at B2C companies average 4.0 years; CMOs at the top 100 advertisers hand on to their jobs for just 3.1 years.
In the next couple of years, a significant percentage of CMO jobs are going to open suddenly. How likely is it that you’ll be ready to be interviewed for one of them?
Spencer Stuart also noticed that 34% of Fortune 500 CMOs lead functions in addition to marketing, such as communications. So, the “plus something extra” trend extends from the SEO manager level all the way up to the CMO level.
The Age Of Awesomeness
Take an expanded view of marketing leaders’ growing purview and start climbing the ladder as soon as humanly possible.
The only thing that’s left to do is coin a unique term for the new era we’re entering.
We could call it the “Age of Awesomeness” or the “Epoch of Twin Escalators.” But I’m open to other suggestions.
What have you noticed, and what have you wondered?
Google’s John Mueller answered a question on LinkedIn about how Google chooses canonicals, offering advice about what SEOs and publishers can do to encourage Google how to pick the right URL.
What Is A Canonical URL?
In the situation where multiple URLs (the addresses for multiple web pages) have the same content, Google will choose one URL that will be representative for all of the pages. The chosen page is referred to as the canonical URL.
Google Search Central has published documentation that explains how SEOs and publishes can communicate their preference of which URL to use. None of these methods force Google to choose the preferred URL, they mainly serve as a strong hint.
There are three ways to indicate the canonical URL:
Redirecting duplicate pages to the preferred URL (a strong signal)
Use the rel=canonical link attribute to specify the preferred URL (a strong signal)
List the preferred URL in the sitemap (a weak signal)
Some of Google’s canonicalization documentation incorrectly refers to the rel=canonical as a link element. The link tag, , is the element. The rel=canonical is an attribute of the link element. Google also calls rel=canonical an annotation, which might be an internal way Google refers to it but it’s not the proper way to refer to rel=canonical (it’s an HTML attribute of the link element).
There are two important things you need to know about HTML elements and attributes:
HTML elements are the building blocks for creating a web page.
An HTML attribute is something that adds more information about that building block (the HTML element).
The Mozilla Developer Network HTML documentation (an authoritative source for HTML specifications) notes that “link” is an HTML element and that “rel=” is an attribute of the link element.
Person Read The Manual But Still Has Questions
The person reading Google’s documentation which lists the above three ways to specify a canonical still had questions so he asked it on LinkedIn.
He referred to the documentation as “doc” in his question:
“The mentioned doc suggests several ways to specify a canonical URL.
1. Adding tag in
section of the page, and another, 2. Through sitemap, etc.
So, if we consider only point 2 of the above.
Which means the sitemap—Technically it contains all the canonical links of a website.
Then why in some cases, a couple of the URLs in the sitemap throws: “Duplicate without user-selected canonical.” ?”
As I pointed out above, Google’s documentation says that the sitemap is a weak signal.
Google Uses More Signals For Canonicalization
John Mueller’s answer reveals that Google uses more factors or signals than what is officially documented.
He explained:
“If Google’s systems can tell that pages are similar enough that one of them could be focused on, then we use the factors listed in that document (and more) to try to determine which one to focus on.”
Internal Linking Is A Canonical Factor
Mueller next explained that internal links can be used to give Google a strong signal of which URL is the preferred one.
This is how Mueller answered:
“If you have a strong preference, it’s best to make that preference very obvious, by making sure everything on your site expresses that preference – including the link-rel-canonical in the head, sitemaps, internal links, etc. “
He then followed up with:
“When it comes to search, which one of the pages Google’s systems focus on doesn’t matter so much, they’d all be shown similarly in search. The exact URL shown is mostly just a matter for the user (who might see it) and for the site-owner (who might want to monitor & track that URL).”
Takeaways
In my experience it’s not uncommon that a large website contains old internal links that point to the wrong URL. Sometimes it’s not old internal links that are the cause, it’s 301 redirects from an old page to another URL that is not the preferred canonical. That can also lead to Google choosing a URL that is not preferred by the publisher.
If Google is choosing the wrong URL then it may be useful to crawl the entire site (like with Screaming Frog) and then look at the internal linking patterns as well as redirects because it may very well be that forgotten internal links hidden deep within the website or chained redirects to the wrong URL are causing Google to choose the wrong URL.
Google’s documentation also notes that external links to the wrong page could influence which page Google chooses as the canonical, so that’s one more thing that needs to be checked for debugging why the wrong URL is being ranked.
The important takeaway here is that if the standard ways of specifying the canonical are not working then it’s possible that there is an external links, or unintentional internal linking, or a forgotten redirect that is causing Google to choose the wrong URL. Or, as John Mueller suggested, increasing the amount of internal links to the preferred URL may help Google to choose the preferred URL.
The concept of Compressibility as a quality signal is not widely known, but SEOs should be aware of it. Search engines can use web page compressibility to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords, making it useful knowledge for SEO.
Although the following research paper demonstrates a successful use of on-page features for detecting spam, the deliberate lack of transparency by search engines makes it difficult to say with certainty if search engines are applying this or similar techniques.
What Is Compressibility?
In computing, compressibility refers to how much a file (data) can be reduced in size while retaining essential information, typically to maximize storage space or to allow more data to be transmitted over the Internet.
TL/DR Of Compression
Compression replaces repeated words and phrases with shorter references, reducing the file size by significant margins. Search engines typically compress indexed web pages to maximize storage space, reduce bandwidth, and improve retrieval speed, among other reasons.
This is a simplified explanation of how compression works:
Identify Patterns: A compression algorithm scans the text to find repeated words, patterns and phrases
Shorter Codes Take Up Less Space: The codes and symbols use less storage space then the original words and phrases, which results in a smaller file size.
Shorter References Use Less Bits: The “code” that essentially symbolizes the replaced words and phrases uses less data than the originals.
A bonus effect of using compression is that it can also be used to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords.
Research Paper About Detecting Spam
This research paper is significant because it was authored by distinguished computer scientists known for breakthroughs in AI, distributed computing, information retrieval, and other fields.
Another of the co-authors is Dennis Fetterly, currently a software engineer at Google. He is listed as a co-inventor in a patent for a ranking algorithm that uses links, and is known for his research in distributed computing and information retrieval.
Those are just two of the distinguished researchers listed as co-authors of the 2006 Microsoft research paper about identifying spam through on-page content features. Among the several on-page content features the research paper analyzes is compressibility, which they discovered can be used as a classifier for indicating that a web page is spammy.
Detecting Spam Web Pages Through Content Analysis
Although the research paper was authored in 2006, its findings remain relevant to today.
Then, as now, people attempted to rank hundreds or thousands of location-based web pages that were essentially duplicate content aside from city, region, or state names. Then, as now, SEOs often created web pages for search engines by excessively repeating keywords within titles, meta descriptions, headings, internal anchor text, and within the content to improve rankings.
Section 4.6 of the research paper explains:
“Some search engines give higher weight to pages containing the query keywords several times. For example, for a given query term, a page that contains it ten times may be higher ranked than a page that contains it only once. To take advantage of such engines, some spam pages replicate their content several times in an attempt to rank higher.”
The research paper explains that search engines compress web pages and use the compressed version to reference the original web page. They note that excessive amounts of redundant words results in a higher level of compressibility. So they set about testing if there’s a correlation between a high level of compressibility and spam.
They write:
“Our approach in this section to locating redundant content within a page is to compress the page; to save space and disk time, search engines often compress web pages after indexing them, but before adding them to a page cache.
…We measure the redundancy of web pages by the compression ratio, the size of the uncompressed page divided by the size of the compressed page. We used GZIP …to compress pages, a fast and effective compression algorithm.”
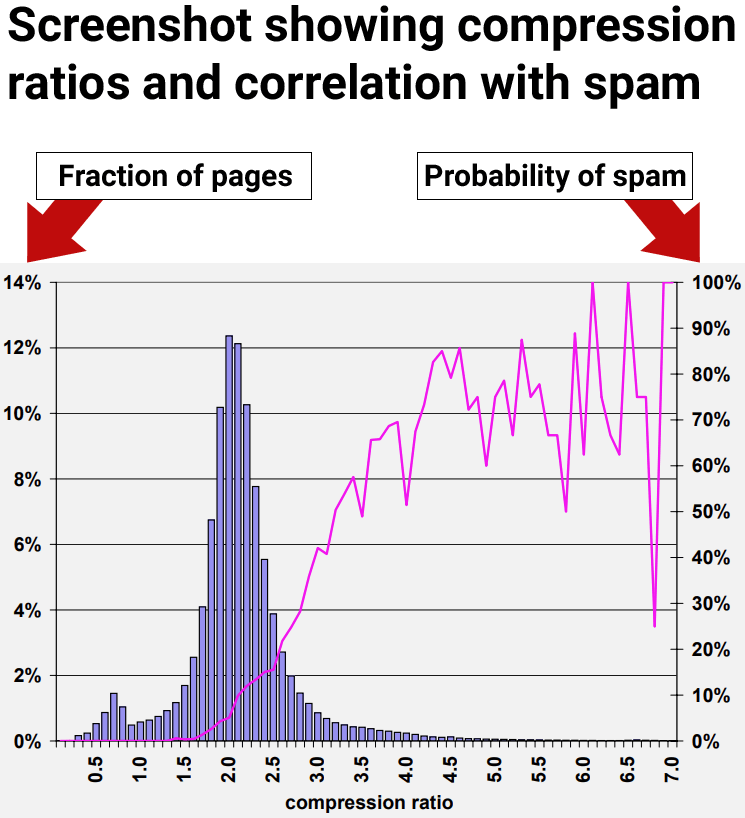
High Compressibility Correlates To Spam
The results of the research showed that web pages with at least a compression ratio of 4.0 tended to be low quality web pages, spam. However, the highest rates of compressibility became less consistent because there were fewer data points, making it harder to interpret.
Figure 9: Prevalence of spam relative to compressibility of page.
The researchers concluded:
“70% of all sampled pages with a compression ratio of at least 4.0 were judged to be spam.”
But they also discovered that using the compression ratio by itself still resulted in false positives, where non-spam pages were incorrectly identified as spam:
“The compression ratio heuristic described in Section 4.6 fared best, correctly identifying 660 (27.9%) of the spam pages in our collection, while misidentifying 2, 068 (12.0%) of all judged pages.
Using all of the aforementioned features, the classification accuracy after the ten-fold cross validation process is encouraging:
95.4% of our judged pages were classified correctly, while 4.6% were classified incorrectly.
More specifically, for the spam class 1, 940 out of the 2, 364 pages, were classified correctly. For the non-spam class, 14, 440 out of the 14,804 pages were classified correctly. Consequently, 788 pages were classified incorrectly.”
The next section describes an interesting discovery about how to increase the accuracy of using on-page signals for identifying spam.
Insight Into Quality Rankings
The research paper examined multiple on-page signals, including compressibility. They discovered that each individual signal (classifier) was able to find some spam but that relying on any one signal on its own resulted in flagging non-spam pages for spam, which are commonly referred to as false positive.
The researchers made an important discovery that everyone interested in SEO should know, which is that using multiple classifiers increased the accuracy of detecting spam and decreased the likelihood of false positives. Just as important, the compressibility signal only identifies one kind of spam but not the full range of spam.
The takeaway is that compressibility is a good way to identify one kind of spam but there are other kinds of spam that aren’t caught with this one signal. Other kinds of spam were not caught with the compressibility signal.
This is the part that every SEO and publisher should be aware of:
“In the previous section, we presented a number of heuristics for assaying spam web pages. That is, we measured several characteristics of web pages, and found ranges of those characteristics which correlated with a page being spam. Nevertheless, when used individually, no technique uncovers most of the spam in our data set without flagging many non-spam pages as spam.
For example, considering the compression ratio heuristic described in Section 4.6, one of our most promising methods, the average probability of spam for ratios of 4.2 and higher is 72%. But only about 1.5% of all pages fall in this range. This number is far below the 13.8% of spam pages that we identified in our data set.”
So, even though compressibility was one of the better signals for identifying spam, it still was unable to uncover the full range of spam within the dataset the researchers used to test the signals.
Combining Multiple Signals
The above results indicated that individual signals of low quality are less accurate. So they tested using multiple signals. What they discovered was that combining multiple on-page signals for detecting spam resulted in a better accuracy rate with less pages misclassified as spam.
The researchers explained that they tested the use of multiple signals:
“One way of combining our heuristic methods is to view the spam detection problem as a classification problem. In this case, we want to create a classification model (or classifier) which, given a web page, will use the page’s features jointly in order to (correctly, we hope) classify it in one of two classes: spam and non-spam.”
These are their conclusions about using multiple signals:
“We have studied various aspects of content-based spam on the web using a real-world data set from the MSNSearch crawler. We have presented a number of heuristic methods for detecting content based spam. Some of our spam detection methods are more effective than others, however when used in isolation our methods may not identify all of the spam pages. For this reason, we combined our spam-detection methods to create a highly accurate C4.5 classifier. Our classifier can correctly identify 86.2% of all spam pages, while flagging very few legitimate pages as spam.”
Key Insight:
Misidentifying “very few legitimate pages as spam” was a significant breakthrough. The important insight that everyone involved with SEO should take away from this is that one signal by itself can result in false positives. Using multiple signals increases the accuracy.
What this means is that SEO tests of isolated ranking or quality signals will not yield reliable results that can be trusted for making strategy or business decisions.
Takeaways
We don’t know for certain if compressibility is used at the search engines but it’s an easy to use signal that combined with others could be used to catch simple kinds of spam like thousands of city name doorway pages with similar content. Yet even if the search engines don’t use this signal, it does show how easy it is to catch that kind of search engine manipulation and that it’s something search engines are well able to handle today.
Here are the key points of this article to keep in mind:
Doorway pages with duplicate content is easy to catch because they compress at a higher ratio than normal web pages.
Groups of web pages with a compression ratio above 4.0 were predominantly spam.
Negative quality signals used by themselves to catch spam can lead to false positives.
In this particular test, they discovered that on-page negative quality signals only catch specific types of spam.
When used alone, the compressibility signal only catches redundancy-type spam, fails to detect other forms of spam, and leads to false positives.