14 Things Executives And SEOs Need To Focus On In 2026 via @sejournal, @DuaneForrester
So many people spent 2025 arguing about whether SEO was dying. It was never dying. It was shifting into a new layer. Discovery continues to move from search boxes to AI systems. Answers now come from models that rewrite your work, summarize competitors, blend sources, and shape decisions before a browser window loads. In 2026, this shift becomes visible enough that executives and SEOs can no longer treat it like an edge case; percentages from sources will shift. The search stack that supported the last 20 years is now only one of several layers that shape customer decisions. (I talk about all this in my new book, “The Machine Layer” (non-affiliate link).)
This matters because the companies that win in 2026 will be the ones treating AI systems as new distribution channels. The companies that lose will be the ones waiting for their analytics dashboards to catch up. You no longer optimize for a single front door. You now optimize for many. Each one is powered by models that decide what to show, who to show it to, and how to describe you.
Here are 14 things that will define competitive advantage in 2026. Each one is already visible in real data. Together, they point to a year where discovery becomes more ambient, more conversational, and more dependent on how well a machine can parse and trust you. And at the end of this list is one heck of a prediction that I bet you didn’t see coming for next year! If I’m being honest, I’m sure a few of you did, but to this depth? Realizing it was all so close?
Grab a coffee or tea, find your favorite spot to read, and let’s get started!

1. AI Answer Surfaces Become The New Front Door
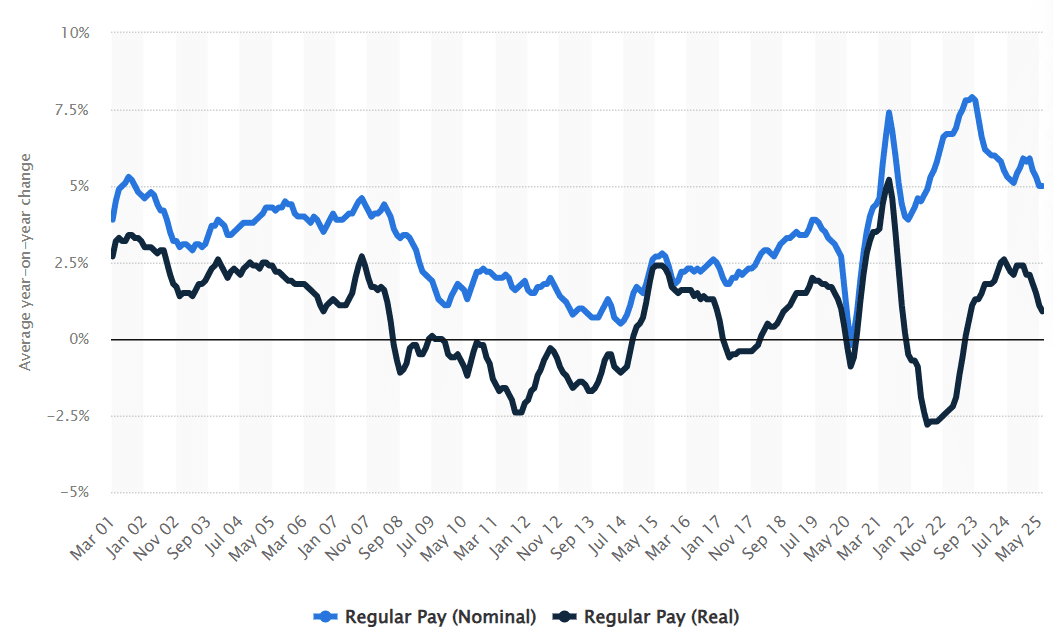
ChatGPT, Claude, Gemini, Meta AI, Perplexity, CoPilot, and Apple Intelligence now sit between customers and your website. More and more users ask questions inside these systems before they ever search. And the answers they get are inconsistent. BrightEdge’s analysis showed that AI engines disagree with each other 62% of the time. When engines disagree this much, brand visibility becomes unstable. Executives need reporting that reveals how often their brand appears inside these systems. SEOs need workflows that evaluate chunk retrieval, embedding strength, and citation presence across multiple answer engines.
2. Content Must Be Designed For Machine Retrieval
Microsoft’s 2025 Copilot study analyzed more than 200,000 work sessions. The most common AI-assisted tasks were gathering information, explaining information, and rewriting information. These are the core tasks modern content must support. AI models choose content that is structured, predictable, and easy to embed. If your content lacks clear sectioning, consistent patterns, or explicit definitions, it becomes harder for models to use. This impacts whether you appear in answers. In 2026, your formatting choices become ranking signals for machines.
3. On-Device LLMs Change How People Search
Apple Intelligence runs many tasks locally. It also rewrites queries in more natural conversational patterns. This pushes search activity away from browsers and deeper into the operating system. People will ask their device short, private questions that never hit the web. They will ask follow-up questions inside the OS. They will make decisions without ever visiting a page. This shifts both volume and structure. SEOs will need content designed for lightweight, edge device retrieval.
4. Wearables Start Steering The Discovery Funnel
Meta Ray Bans already support visual queries. The user points at something and asks what it is. Voice and camera replace typing. This increases micro queries tied to real-world context. Expect to see more identify this, what does this do, and how do I fix that queries. Wearables compress the distance between stimulus and search. Executives should invest in image quality, product clarity, and structured metadata. SEOs should treat visual search signals as core inputs.
5. Short-Form Video Becomes A Training Input For AI
Video is now a core training signal for modern multimodal models. V-JEPA 2 from Meta AI is trained on an unknown number of hours of raw video and images, but this still shows that large-scale video learning is becoming foundational for motion understanding, physical prediction, and video question answering. Gemini 2.5 from Google DeepMind explicitly supported video understanding, allowing the model to interpret video clips, extract visual and audio context, and reason over sequences. OpenAI’s Sora research demonstrates that state-of-the-art generative video models learn from diverse video inputs to understand motion, physical interactions, transitions, and real-world dynamics. In 2026, your short-form video becomes part of your broader signal footprint. Not only the transcript. The visuals, pacing, motion, and structure become vectors the model can interpret. When your video output and written content diverge, the model will default to whichever medium communicates more clearly and consistently.
6. Organic Search Signals Shift Toward Trust And Provenance
Traditional algorithms relied on links, keywords, and click patterns. AI systems shift that weight toward provenance and verification. Perplexity describes its model as retrieval-augmented, pulling from authoritative sources like articles, websites, and journals and surfacing citations to show where information comes from. Independent audits support this direction. A 2023 evaluation of generative search engines found that systems like Perplexity favored content that is factual, well-structured, and supported by external evidence when assembling cited answers. This remains true today as well. SEO industry analysis also shows that pages with clear metadata, consistent topical organization, and visible author identity are more likely to be cited. Naturally, all of this changes what trust looks like. Machines prioritize consistency, clarity, and verifiable sourcing. Executives should focus on data governance and content stability. SEOs should focus on structured citations, author attribution, and semantic coherence across their content ecosystem.
7. Real-Time Cohort Creation Replaces Static Personas
LLMs build temporary cohorts by clustering people with similar intent patterns. These clusters can form in seconds and dissolve just as fast. They are not tied to demographics or personas. They are based on what someone is trying to do right now. This is the basis of the experiential cohort concept. Marketers have not caught up yet. In 2026, cohort-based targeting will shift toward intent embeddings and away from persona documents. SEOs should tune content for intent patterns, not identity attributes.
8. Agent-To-Agent Commerce Becomes Real
Agents will schedule appointments, book travel, reorder supplies, compare providers, and negotiate simple agreements. Your content becomes instructions for another machine. To support that, it must be unambiguous. It must be explicit about requirements, constraints, availability, pricing rules, and exceptions. If you want an agent to pick your business, you need a content model that feeds the agent’s decision tree. Executives should map the top 10 agent-mediated tasks in their industry. SEOs should design content that makes those tasks easy for a machine to interpret.
9. Hardware Acceleration Pushes AI Into Every Routine
NVIDIA, Apple, and Qualcomm are all building hardware optimized for on-device and low-latency AI inference. These chips reduce friction, which increases the number of everyday questions people ask without ever opening a browser. NVIDIA’s data center inference platforms show how much compute is moving toward real-time model execution. Qualcomm’s AI Hub highlights how modern phones can run complex models locally, shrinking the gap between thought and action. Apple’s M-series chips include Neural Engines that support local model execution inside Apple Intelligence. Lower friction means people will ask more small, immediate questions as they move through their day instead of grouping everything into one session. SEOs should plan for discovery happening across many short, assistant-driven interactions rather than a single focused search moment.
10. Query Volume Expands As Voice And Camera Take Over
Voice input grows the long tail. Camera input grows contextual queries. The Microsoft Work Trend Index shows rising AI usage across everyday task categories, including personal information gathering. People ask more questions because speaking is easier than typing. The shape of demand widens, which increases ambiguity. SEOs need stronger intent classification workflows and a better understanding of how retrieval models cluster similar questions.
11. Brand Authority Becomes Machine Measurable
Models determine authority by measuring consistency across your content. They look for stable terminology, clear entity relationships, and patterns in how third parties reference you. They look for alignment between what you publish and how the rest of the web describes your work. This is not the old human quality framework. It is a statistical confidence score. Executives should invest in knowledge graphs. SEOs should map their entity network and tune the language around each entity for stability.
12. Zero-click Environments Become Your Primary Competitor
Answer engines pull from multiple sources and give the user a single synthesized answer. This reduces visits but increases influence. In 2026, the dominant competitors for organic attention are ChatGPT, Perplexity, Gemini, CoPilot, Meta AI, and Apple Intelligence. You do not win by resisting zero click. You win by being the source the engine prefers. Executives must adopt new performance metrics that reflect answer presence. SEOs should run monthly audits of brand visibility across all major platforms, tracking citations, mentions, paraphrases, and omissions.
13. Competitive Intelligence Shifts Into Prompt Space
Your competitors now live inside AI answers, whether they want to or not. Their content becomes part of the same retrieval memory that models use to answer your queries. In 2026, SEOs will evaluate competitor visibility by studying how platforms describe them. You will ask models to summarize competitors, benchmark capabilities, and compare offerings. The insights you get will shape strategy. This becomes a new research channel that executives can use for positioning and differentiation.
14. Your Website Becomes A Training Corpus
AI systems will digest your content many times before a human does. That means your site is now a data repository. It must be structured, stable, and consistent. Publishing sloppy structure or unaligned phrasing creates noise inside retrieval models. Executives should treat their content like a data pipeline. SEOs should think like information architects. The question shifts from how do we rank to how do we become the preferred reference source for a model.
The companies that succeed in 2026 will be the ones that understand this shift early. Visibility now lives in many places at once. Authority is measured by machines, not just people. Trust is earned through structure, clarity, and consistency. The winners will build for a world where discovery is ambient, and answers are synthesized. The losers will cling to dashboards built for a past that is not coming back.
Now, if you’ve read this far, thank you, and I have a surprise – an actual prediction for 2026! I think it’s a big, important one, so buckle up!
I’m calling this Latent Choice Signals, or these, I suppose, as it’s a grouping of signals that paint a picture for the platforms. From the consumer’s POV, this is the essential mental map they’re following: “I saw it, I felt something about it, and I decided not to continue.” This is the core. The user’s mind is making a choice, even if they never articulate it or click anything. That behavior generates meaning. And the system can interpret that meaning at scale. Let’s dig in…
The Prediction No One Sees Coming
By the end of 2026, AI systems will begin optimizing decisions around the patterns users never articulate. Not the queries they type. Not the questions they ask. But the choices they avoid.
This is the shift almost everyone misses, and you can see the edges of it forming across three different fields. When you pull them together, the picture becomes clearer.
First, operating system-level AI is already learning from behavior that is not explicitly expressed. Apple Intelligence is described as a personal intelligence layer that blends generative models with on device personal context to prioritize messages, summarize notifications, and suggest actions across apps. Apple built this for convenience and privacy, but it created something more important. The system must learn over time which suggestions people accept and which they quietly ignore. It sees which notifications get swiped away, which app actions never get used, and which prompts are abandoned. It does not need to read your mind. It only needs to see which proposed actions never earn a tap. Those patterns are already part of how it ranks what to surface next.
Second, recommender systems already treat non-actions as meaningful signals. You see it every time you skip a YouTube video, swipe past a TikTok in under a second, or close Netflix when the row of suggestions feels wrong. These platforms do not publish their exact mechanics, but implicit feedback is a well-established concept in the research world. Classic work on collaborative filtering for implicit feedback datasets shows how systems use viewing, skipping, and browsing behavior to model preference, even when users never rate anything directly. Newer work continues to refine how clicks, views, and avoidance patterns feed recommendation models at scale. It is reasonable to expect LLM-driven assistants to borrow from the same logic. The pattern is too useful to ignore. When you close an assistant, rephrase a question to avoid a certain brand, or scroll past a suggestion without engaging, that is data about what you did not want.
Third, alignment research already trains models to follow what humans prefer, not just what text predicts. OpenAI’s “Learning to summarize with human feedback” work shows how models can be tuned using human comparisons between outputs, with a reward model that learns which responses people think are better. This has been in play for years now. This kind of reinforcement learning from human feedback was built for tasks like summarization and style, but the underlying principle matters here. Models can be optimized around patterns of acceptance and rejection. Over time, conversational systems can extend this to live settings, where corrections, rewrites, and abandonments are treated as signals about what the user did not want, even when they never spell that out.
Put these three domains together, and a larger pattern emerges. As AI systems move into glasses, phones, laptops, cars, and operating systems, they will gain precise visibility into the choices people avoid. These avoidance patterns will become signals that inform how assistants rank options, choose providers, and recommend products.
This will not feel like surveillance. The model is not peeking into your private life. It is watching your interaction patterns with the system itself. It sees where you hesitate, which suggestions you skip, which tasks you hand off, which providers create follow-up questions, which prices cause users to pause, which explanations reduce confidence, and which interfaces break the chain of intent. These are all first-party behavioral signals the assistant is already allowed to use. And that platforms see these signals on a global scale.
In 2026, these Latent Choice Signals will become strong enough that they form a new optimization layer. A silent ranking system built around friction. If your brand generates hesitation, the assistant will reduce your visibility long before your analytics flag a problem. If your content creates confusion during synthesis, it will be bypassed during retrieval. If your policies trigger too many follow-up questions, the model will favor a competitor with clearer flows. The user will never know why. All they will see is the assistant presenting a different option.
This is the layer that will blindside executives. Dashboards will look normal. Rankings may appear stable. Traffic may hold steady. Yet conversions inside AI-mediated decisions will drift. Customers will stop choosing you, not because you lost traditional ranking signals, but because you introduced cognitive friction the model can detect and optimize against.
The winners will be the companies that treat avoidance as a measurable signal. They will analyze which parts of their product and content cause hesitation. They will refine policies to reduce ambiguity. They will simplify offerings. They will align explanations with how models process uncertainty. They will build experiences that reduce agent-level friction and improve confidence inside a retrieval sequence.
By late 2026, negative intent signals may become one of the strongest competitive filters in digital business. Not because users say anything, but because their silence now has structure the model can learn from. Anyone watching today’s data can see this shift forming, but almost no one is naming it. Yet the early indicators are already here, hiding between the interactions users never get far enough to complete.
This is the prediction that will define the next phase of AI-driven discovery. And the companies that understand it early will be the ones the assistants prefer.
More Resources:
This post was originally published on Duane Forrester Decodes.
Featured Image: Collagery/Shutterstock