Why Is Organic Traffic Down? Here’s How To Segment The Data via @sejournal, @torylynne
As an SEO, there are few things that stoke panic like seeing a considerable decline in organic traffic. People are going to expect answers if they don’t already.
Getting to those answers isn’t always straightforward or simple, because SEO is neither of those things.
The success of an SEO investigation hinges on the ability to dig into the data, identify where exactly the performance decline is happening, and connect the dots to why it’s happening.
It’s a little bit like an actual investigation: Before you can catch the culprit or understand the motive, you have to gather evidence. In an SEO investigation, that’s a matter of segmenting data.
In this article, I’ll share some different ways to slice and dice performance data for valuable evidence that can help further your investigation.
Using Data To Confirm There’s An SEO Issue
Just because organic traffic is down doesn’t inherently mean that it’s an SEO problem.
So, before we dissect data to narrow down problem areas, the first thing we need to do is determine whether there’s actually an SEO issue at play.
After all, it could be something else altogether. In which case, we’re wasting unnecessary resources chasing a problem that doesn’t exist.
Is This A Tracking Issue?
In many cases, what looks like a big traffic drop is just an issue with tracking on the site.
To determine whether tracking is functioning correctly, there are a couple of things we need to look for in the data.
The first is consistent drops across channels.
Zoom out of organic search and see what’s happening in other sources and channels.
If you’re seeing meaningful drops across email, paid, etc., that are consistent with organic search, then it’s more than likely that tracking isn’t working correctly.
The other thing we’re looking for here is inconsistencies between internal data and Google Search Console.
Of course, there’s always a bit of inconsistency between first-party data and GSC-reported organic traffic. But if those differences are significantly more pronounced for the time period in question, that hints at a tracking problem.
Is This A Brand Issue?
Organic search traffic from Google falls into two primary camps:
- Brand traffic: Traffic driven by user queries that include the brand name.
- Non-brand traffic: Traffic driven by brand-agnostic user queries.
Non-brand traffic is directly affected by SEO work. Whereas, brand traffic is mostly impacted by the work that happens in other channels.
When a user includes the brand in their search, they’re already brand-aware. They’re a return user or they’ve encountered the brand through marketing efforts in channels like PR, paid social, etc.
When marketing efforts in other channels are scaled back, the brand reaches fewer users. Since fewer people see the brand, fewer people search for it.
Or, if customers sour on the brand, there are fewer people using search to come back to the site.
Either way, it’s not an SEO problem. But in order to confirm that, we need to filter the data down.
Go to Performance in Google Search Console and exclude any queries that include your brand. Then compare the data against a previous period – usually YoY if you need to account for seasonality. Do the same for queries that don’t include the brand name.
If non-brand traffic has stayed consistent, while brand traffic has dropped, then this is a brand issue.
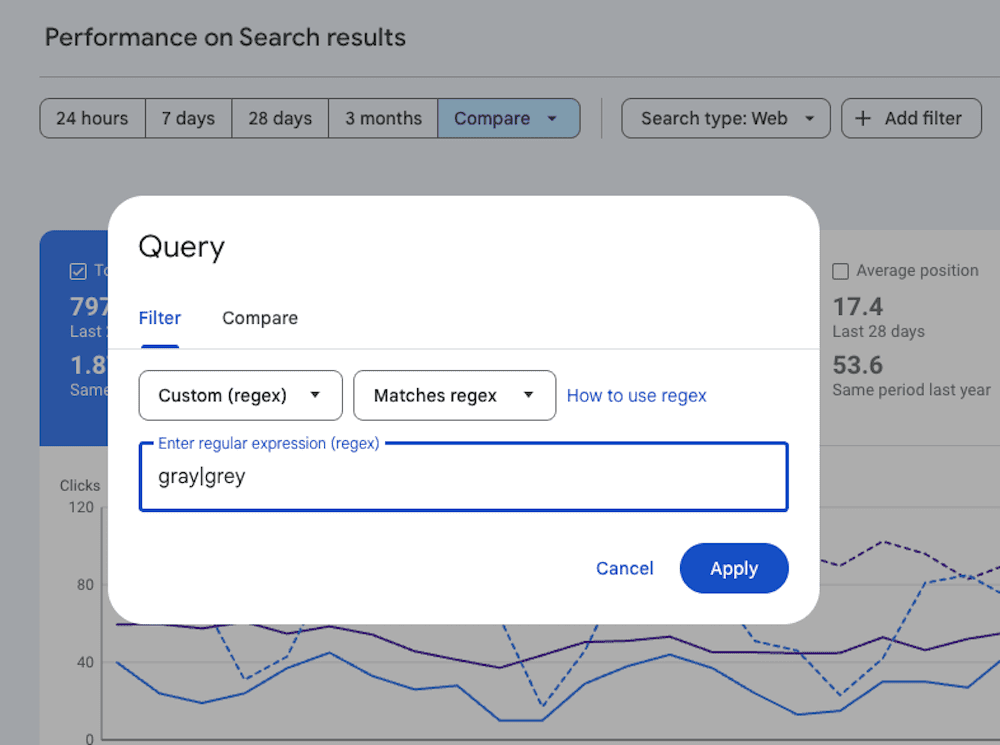
Tip: Account for users misspelling your brand name by filtering queries using fragments. For example, at Gray Dot Co, we get a lot of brand searches for things like “Gray Company” and “Grey Dot Company.” By using the simple regex expression “gray|grey” I can catch brand search activity that would otherwise fall through the cracks.
Is It Seasonal Demand?
The most obvious example of seasonal demand is holiday shopping on ecommerce sites.
Think about something like jewelry. Most people don’t buy jewelry every day; they buy it for special occasions. We can confirm that seasonality by looking at Google Trends.
Zooming out to the past five years of interest in “jewelry,” it clearly peaks in November and December.
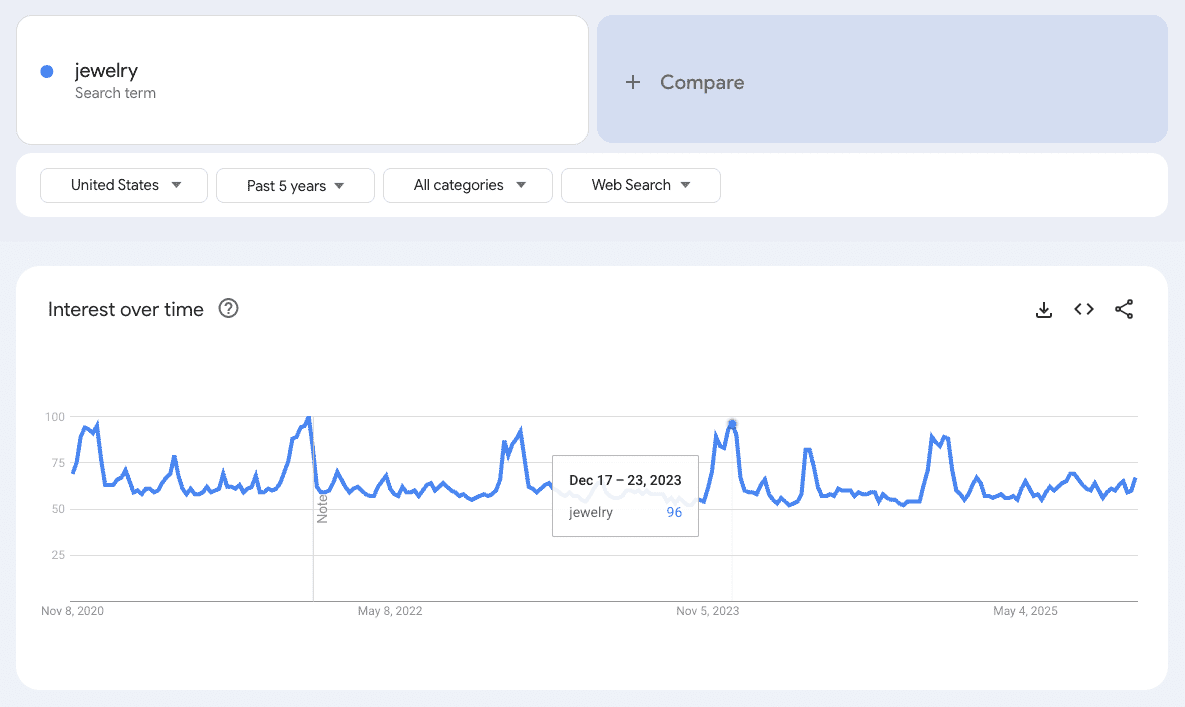
As a site that sells jewelry, of course, traffic in Q1 is going to be down from Q4.
I use a pretty extreme example here to make my point, but in reality, seasonality is widespread and often more subtle. It impacts businesses where you might not expect much seasonality at all.
The best way to understand its impact is to look at organic search data year-over-year. Do the peaks and valleys follow the same patterns?
If so, then we need to compare data YoY to get a true sense of whether there’s a potential SEO problem.
Is It Industry Demand?
SEOs need to keep tabs on not just what’s happening internally, but also what’s going on externally. A big piece of that is checking the pulse of organic demand for the topics and products that are central to the brand.
Products fall out of vogue, technologies become obsolete, and consumer behavior changes – that’s just the reality of business. When there are fewer potential customers in the landscape, there are fewer clicks to win, and fewer sessions to drive.
Take cameras, for instance. As the cameras on our phones got more sophisticated, digital cameras became less popular. And as they became less popular, searches for cameras dwindled.
Now, they’re making a comeback with younger generations. More people searching, more traffic to win.

You can see all of this at play in the search landscape by turning to Google Trends. The downtrend in interest caused by advances in technology, AND the uptrend boosted by shifts in societal trends.
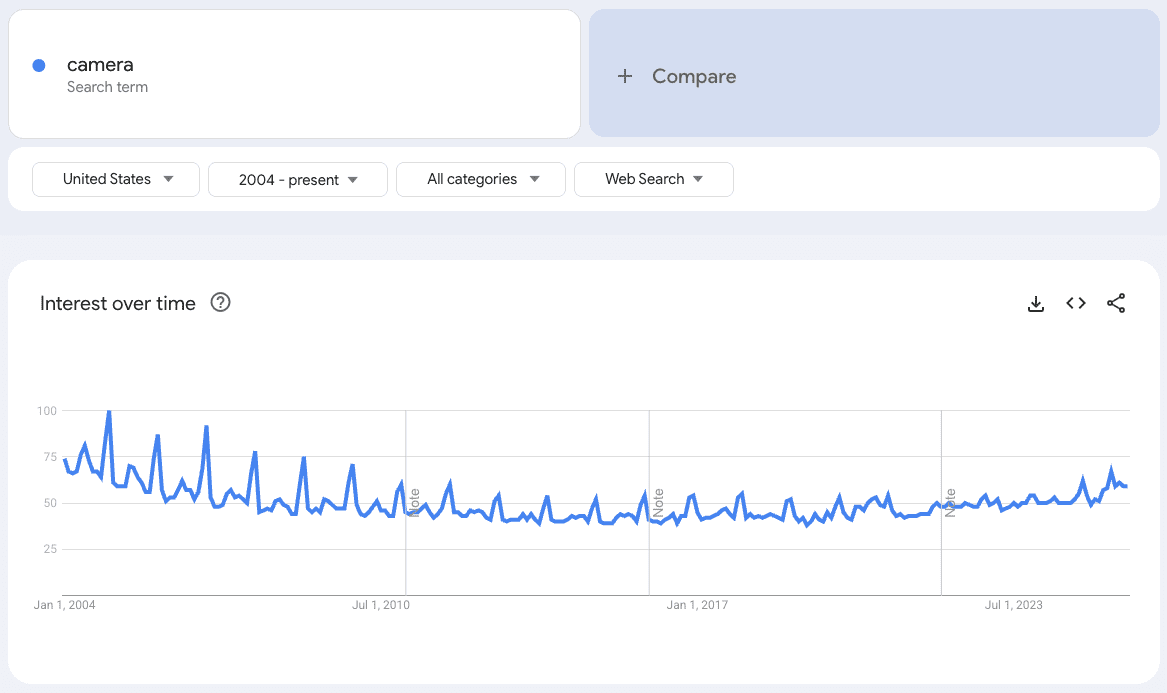
When there are drops in industry, product, or topic demand within the landscape, we need to ask ourselves whether the brand’s organic traffic loss is proportional to the overall loss in demand.
Is Paid Search Cannibalizing Organic Search?
Even if a URL on the site ranks well in organic results, ads are still higher on the SERP. So, if a site is running an ad for the same query it already ranks for, then the ad is going to get more clicks by nature.
When businesses give their PPC budgets a boost, there’s potential for this to happen across multiple, key SERPs.
Let’s say a site drives a significant chunk of its organic traffic from four or five product landing pages. If the brand introduces ads to those SERPs, clicks that used to go to the organic result start going to the ad.
That can have a significant impact on organic traffic numbers. But search users are still getting to the same URLs using the same queries.
To confirm, pull sessions by landing pages from both sources. Then, compare the data from before the paid search changes to the period following the change.
If major landing pages consistently show a positive delta that cancels out the negative delta in organic search, you’re not losing organic traffic; you’re lending it.
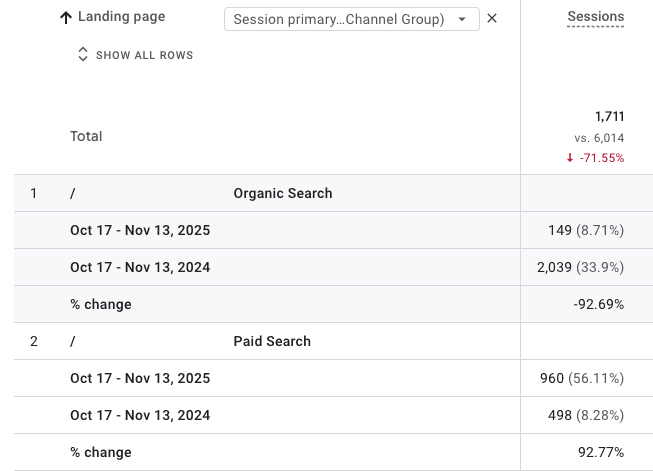
Segmenting Data To Find SEO Issues
Once we have confirmation that the organic traffic declines point to an SEO issue, we can start zooming in.
Segmenting data in different ways helps pinpoint problem areas and find patterns. Only then can we trace those issues to the cause and craft a strategy for recovery.
URL
Most SEOs are going to filter their organic traffic down by URL. It lets us see which pages are struggling and analyze those pages for potential improvements.
It also helps find patterns across pages that make it easier to isolate the cause of more widespread issues. For example, if the site is losing traffic across its product listing pages, it could signal that there’s a problem with the template for that page.
But segmenting by URL also helps us answer a very important question when we pair it with conversion data.
Do We Really Care About This Traffic?
Clicks are only helpful if they help drive business-valuable user interactions like conversions or ad views. For some sites, like online publications, traffic is valuable in and of itself because users coming to the site are going to see ads. The site still makes money.
But for brands looking to drive conversions, it could just be empty traffic if it’s not helping drive that primary key performance indicator (KPI).
A top-of-funnel blog post might drive a lot of traffic because it ranks for very high-volume keywords. If that same blog post is a top traffic-driving organic landing page, a slip in rankings means a considerable organic traffic drop.
But the users entering those high-volume keywords might not be very qualified potential customers.
Looking at conversions by landing page can help brands understand whether the traffic loss is ultimately hurting the bottom line.
The best way to understand is to turn to attribution.
First-touch attribution quantifies an organic landing page’s value in terms of the conversions it helps drive down the line. For most businesses, someone isn’t likely to convert the first time they visit the site. They usually come back and purchase.
Whereas, last-touch attribution shows the organic landing pages that people come to when they’re ready to make a purchase. Both are valuable!
Query
Filtering performance by query can help understand which terms or topic areas to focus improvements on. That’s not new news.
Sometimes, it’s as easy as doing a period-over-period comparison in GSC, ordering by clicks lost, and looking for obvious patterns, i.e., are the queries with the most decline just subtle variants of one another?
If there aren’t obvious patterns and the queries in decline are more widespread, that’s where topic clustering can come into the mix.
Topic Clustering With AI
Using AI for topic clustering helps quickly identify any potential relationships between queries that are seeing performance dips.
Go to GSC and filter performance by query, looking for any YoY declines in clicks and average position.
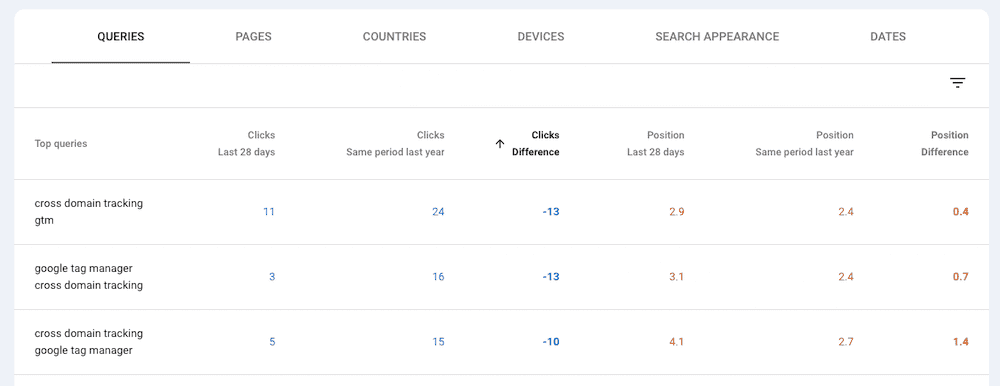
Then export this list of queries and use your favorite ML script to group the keywords into topic clusters.
The resulting list of semantic groupings can provide an idea of topics where a site’s authority is slipping in search.
In turn, it helps narrow the area of focus for content improvements and other optimizations to potentially build authority for the topics or products in question.
Identifying User Intent
When users search using specific terms, the type of content they’re looking for – and their objective – differs based on the query. These user expectations can be broken out into four different high-level categories:
| User Intent | Objective |
| Informational
(Top of funnel) |
Users are looking for answers to questions, explanations, or general knowledge about topics, products, concepts, or events. |
| Commercial
(Middle of funnel) |
Users are interested in comparing products, reading reviews, and gathering information before making a purchase decision. |
| Transactional
(Bottom of funnel) |
Users are looking to perform a specific action, such as making a purchase, signing up for a service, or downloading a file. |
| Navigational | Brand-familiar users are using the search engine as a shortcut to find a specific website or webpage. |
By leveraging user intent, we identify user objectives for which the site or pages on the site are falling short. It gives us a lens into performance decline, making it easier to identify possible causes from the perspective of user experience.
If the majority of queries losing clicks and positionality are informational, it could signal shortcomings in the site’s blog content. If the queries are consistently commercial, it might call for an investigation into how the site approaches product detail and/or listing pages.
GSC doesn’t provide user intent in its reporting, so this is where a third-party SEO tool can come into play. If you have position tracking set up and GSC connected, you can use the tool’s rankings report to identify queries in decline and their user intent.
If not, you can still get the data you need by using a mix of GSC and a tool like Ahrefs.
Device
This view of performance data is pretty simple, but it’s equally easy to overlook!
When the large majority of performance declines are attributed to ONLY desktop or mobile, device data helps identify potential tech or UX issues within the mobile or desktop experience.
The important thing to remember is that any declines need to be considered proportionally. Take the metrics for the site below…
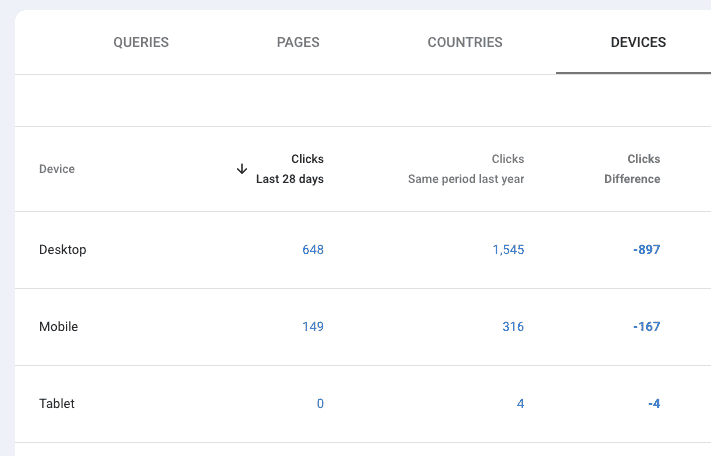
At first glance, the data makes it look like there might be an issue with the desktop experience. But we need to look at things in terms of percentages.
Desktop: 1 – (648/1545) x 100 = 58% decline
Mobile: 1 – (149/316) x 100 = 52% decline
While desktop shows a much larger decline in terms of click count, the percentage of decline YoY is fairly similar across both desktop and mobile. So we’re probably not looking for anything device-specific in this scenario.
Search Appearance
Rich results and SERP features are an opportunity to stand out on the SERP and drive more traffic through enhanced results. Using the search appearance filter in Google Search Console, you can see traffic from different types of rich results and SERP features:
- Forums.
- AMP Top Story (AMP page + Article markup).
- Education Q&A.
- FAQ.
- Job Listing.
- Job Details.
- Merchant Listing.
- Product Snippet.
- Q&A.
- Review Snippet.
- Recipe Gallery.
- Video.
This is the full list of possible features with rich results (courtesy of SchemaApp), though you’ll only see filters for search appearances where the domain is currently positioned.
In most cases, Google is able to generate these types of results because there is structured data on pages. The notable exceptions are Q&A, translated results, and video.
So when there are significant traffic drops coming from a specific type of search appearance, it signals that there’s potentially a problem with the structured data that enables that search feature.
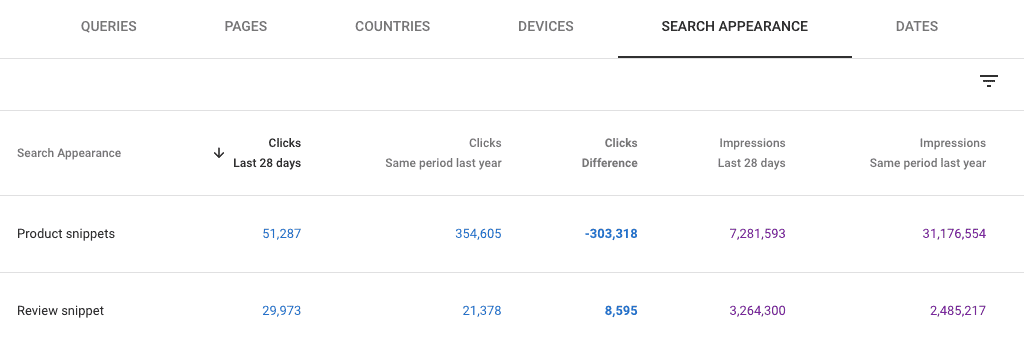
You can investigate structured data issues in the Enhancements reports in GSC. The exception is product snippets, which nest under the Shopping menu. Either way, the reports only show up in your left-hand nav if Google is aware of relevant data on the site.
For example, the product snippets report shows why some snippets are invalid, as well as ways to potentially improve valid results.
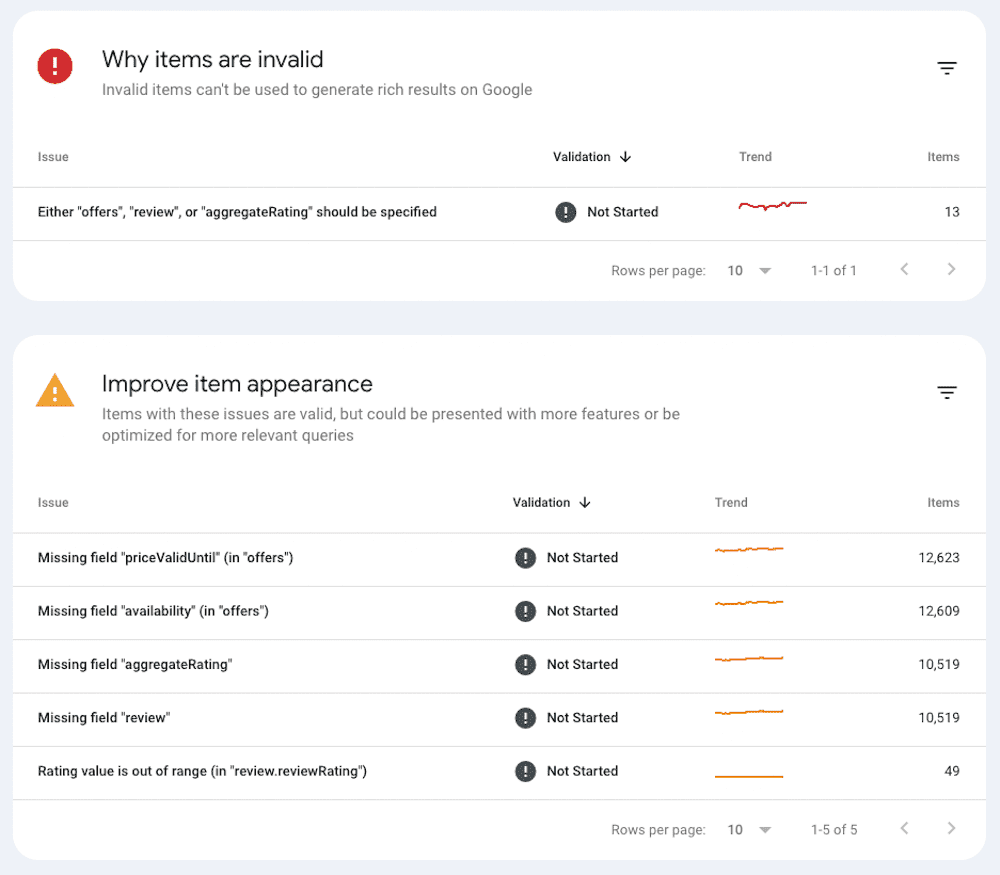
This context is valuable as you begin to investigate the technical causes of traffic drops from specific search features. In this case, it’s clear that Google is able to crawl and utilize product schema on most pages – but there are some opportunities to improve that schema with additional data.
Featured Snippets
When featured snippets originally came on the scene, it was a major change to the SERP structure that resulted in a serious hit to traditional organic results.
Today, AI Overviews are doing the same. In fact, research from Seer shows that CTR has dropped 61% for queries that now include an AI overview (21% of searches). And that impact is outsized for informational queries.
In cases where rankings have remained relatively static, but traffic is dropping, there’s good reason to investigate whether this type of SERP change is a driver of loss.
While Google Search Console doesn’t report on featured snippets (example: PAA questions) and AI Overviews, third-party tools do.
In the third-party tool Semrush, you can use the Domain Overview report to check for featured snippet availability across keywords where the site ranks.
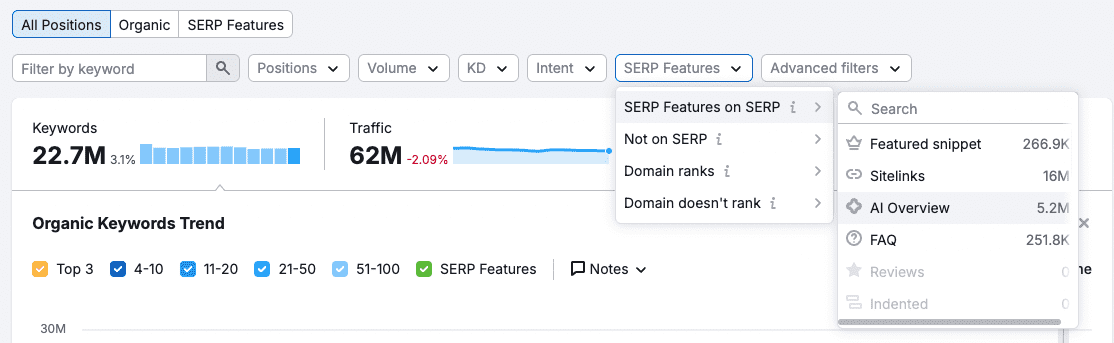
Do the keywords where you’re losing traffic have AI overviews? If you’re not cited, it’s time to start thinking about how you’re going to win that placement.
Search Type
Search type is another way to filter GSC data, where you’re seeing traffic declines despite healthy and consistent rankings.
After all, web search is just one prong of Google Search. Think about it: How often do you use Google Image search? At least in my case, that’s fairly often.
Filter performance data by each of these search types to understand which one(s) are having the biggest impact on performance decline. Then use that insight to start connecting the dots to the cause.
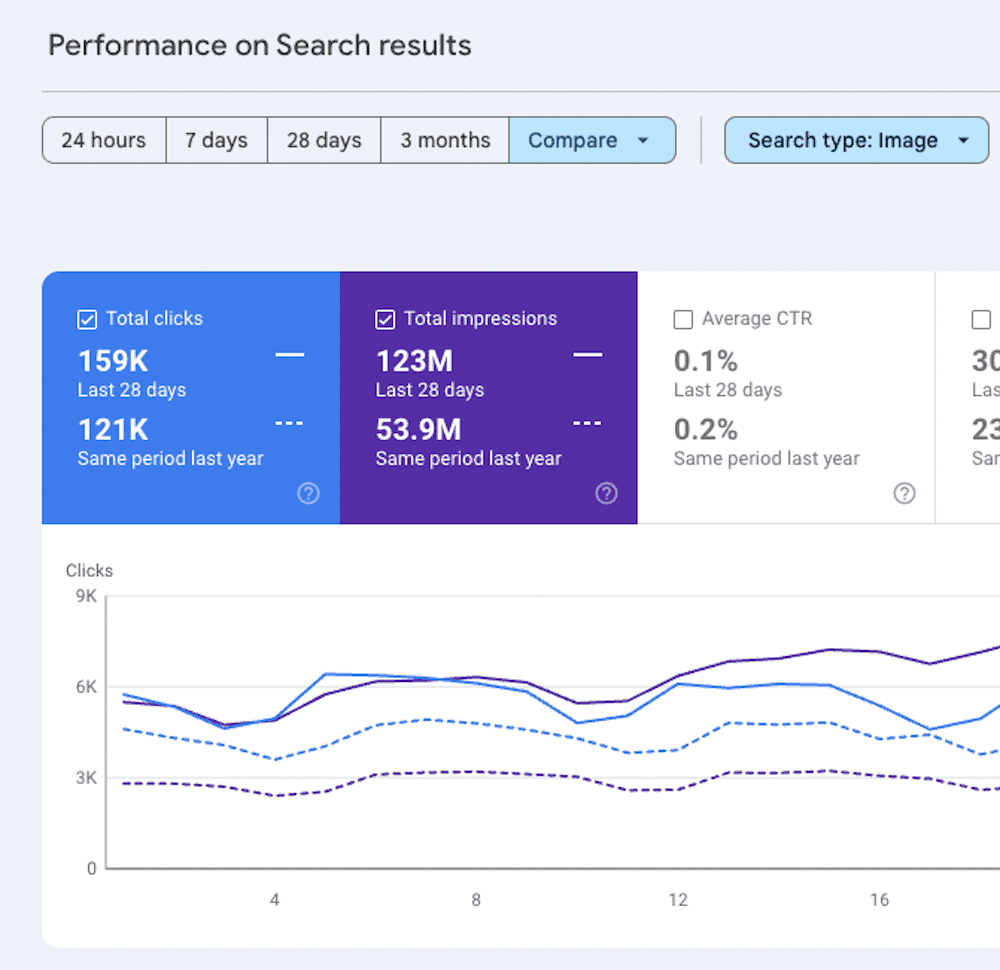
Images are a great example. One simple line in the robots.txt can block Google from crawling a subfolder that hosts multitudes of images. As those images disappear from image search results, any clicks from those results disappear in tandem.
We don’t know to look for this issue until we slice the data accordingly!
Geography
If the business operates physically in specific cities and states, then it likely already has geo-specific performance tracking set up through a tool.
But domains for online-only businesses shouldn’t dismiss geographic data – even at the city/state level! Declines are still a trigger to check geo-specific performance data.
Country
Just because the brand only sells and operates in one country doesn’t mean that’s where all the domain’s traffic is coming from. Drilling down by country in GSC allows you to see whether declines are coming from the country the brand is focused on or, potentially, another country altogether.
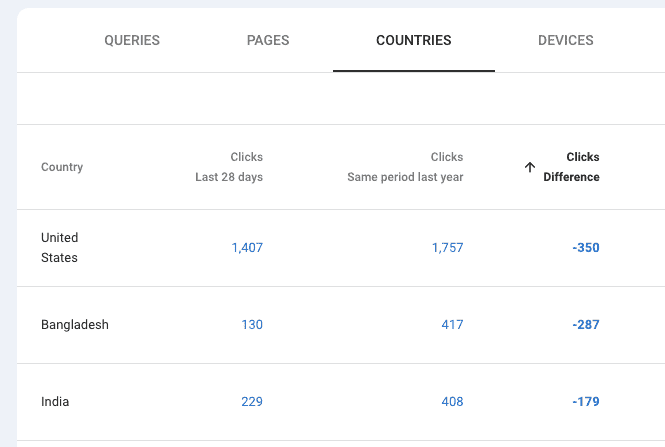
If it’s another country, it’s time to decide whether that matters. If the site is a publisher, it probably cares more about that traffic than an ecommerce brand that’s more focused on purchases in its country of operation.
Localization
When tools are reporting positionality at the country level, then rankings shifts in specific markets fly under the radar. It certainly happens, and major markets can have major traffic impact!
Tools like BrightLocal, Whitespark, and Semrush let you analyze SERP rankings one level deeper than GSC, providing data down to the city.
Checking for rankings discrepancies across cities is possible by checking a small sample of keywords with the greatest declines in clicks.
If I’m an SEO at the University of Phoenix, which is an online university, I’m probably pretty excited about ranking #1 in the United States for “online business degree.”
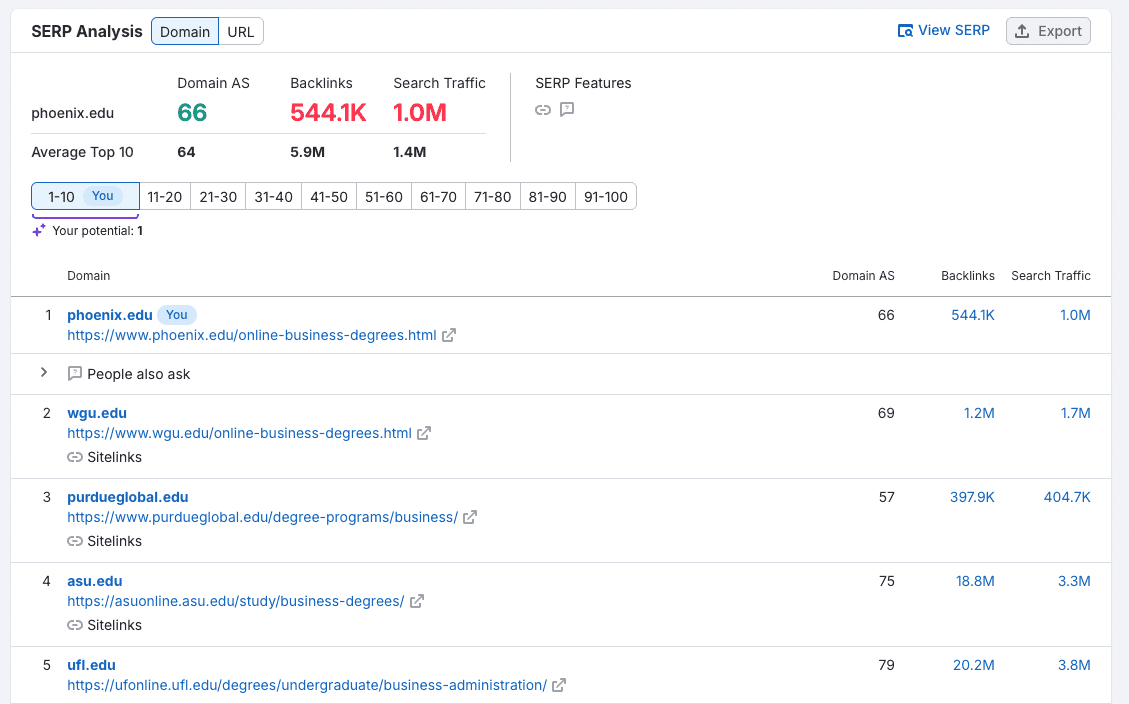
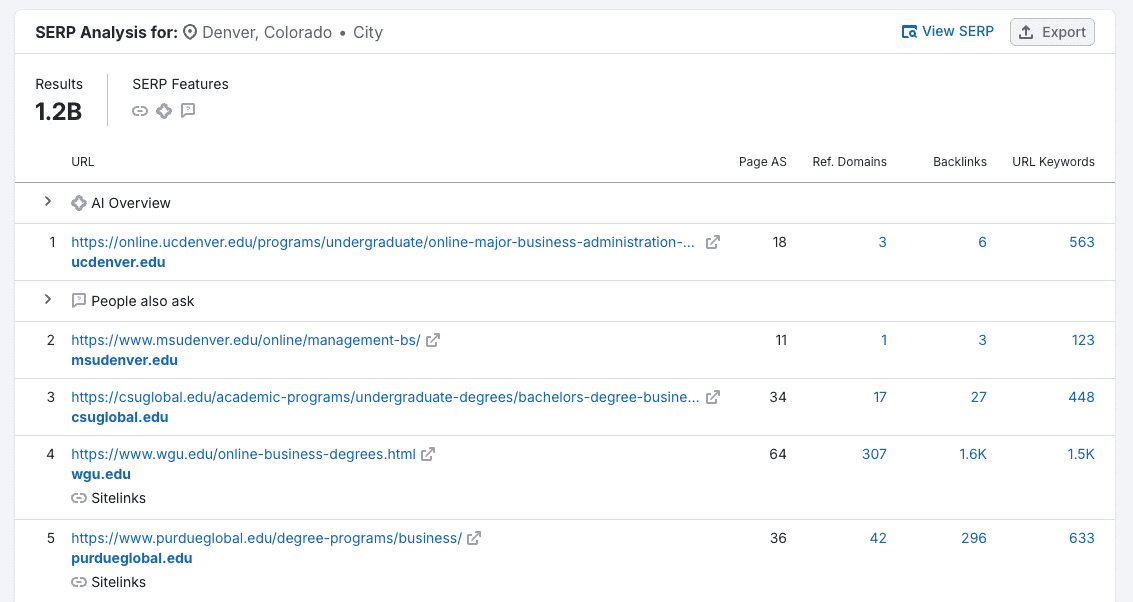
But if I drill down further, I might be a little distraught to find that the domain isn’t in the top five SERP results for users in Denver, CO…
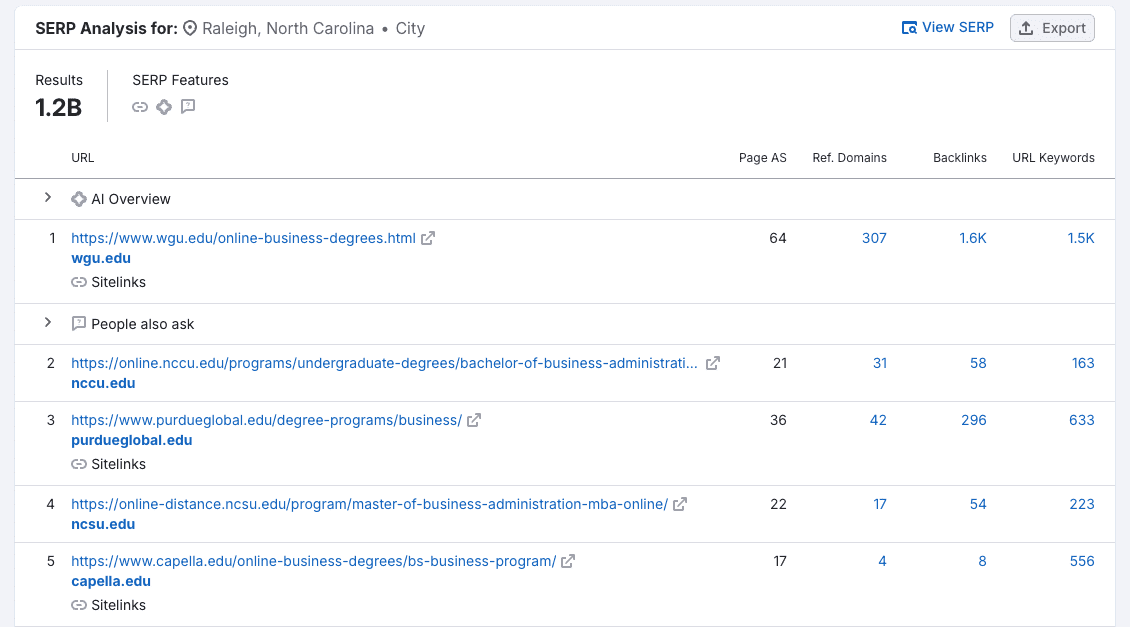
…or Raleigh, North Carolina.
Catch Issues Faster By Leveraging AI For Data Analysis
Data segmentation is an important piece of any traffic drop investigation, because humans can see patterns in data that bots don’t.
However, the opposite is true too. With anomaly detection tooling, you get the best of both worlds.
When combined with monitoring and alert notifications, anomaly detection makes it possible to find and fix issues faster. Plus, it enables you to find data patterns in any after-the-impact investigations
All of this helps ensure that your analysis is comprehensive, and might even point out gaps for further investigation.
This Colab tool from Sam Torres can help get your site set up!
Congrats, You’re Close To Closing This Case
As Sherlock Holmes would say about an investigation, “It is a capital mistake to theorize before one has data.” With the right data in hand, the culprits start to reveal themselves.
Data segmentation empowers SEOs to uncover leads that point to possible causes. By narrowing it down based on the evidence, we ensure more accuracy, less work, faster answers, and quicker recovery.
And while leadership might not love a traffic drop, they’re sure to love that.
More Resources:
Featured Image: Vanz Studio/Shutterstock