Core Web Vitals: WordPress, Wix, Squarespace, Joomla, Duda, & Drupal via @sejournal, @martinibuster

The Core Web Vitals technology report shows that five out of six of the most popular content management systems performed worse in April 2024 when compared to the beginning of the year. The real-world performance data collected by HTTPArchive offers some clues about why performance scores are trending downward.
Core Web Vitals Technology Report
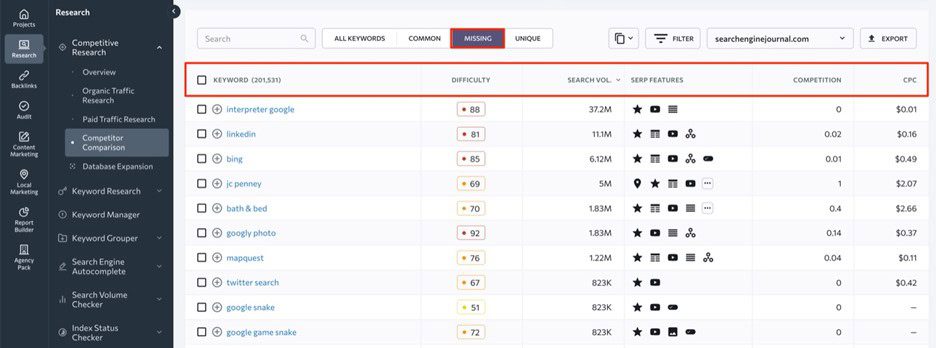
The rankings for Core Web Vitals (CWV) are a mix of real-world and lab data. The real-world data comes from the Chrome User Experience Report (CrUX) and the lab data is from an HTTP Archive public dataset (lab data based on the websites included in the CrUX report).
The data is used to create the Core Web Vitals technology report which can be sliced and diced to measure the mobile and desktop performances for a wide variety of content management systems in any combination, as well as provide data on JavaScript, CSS HTML and image weight data.
The data reported in the Search Engine Journal articles are based on measurements of mobile data. The scores are in the form of percentages which represent the percentages of website visits that resulted in a good Core Web Vitals (CWV) score.
This is the background on the HTTP Archive scoring for CWV:
“Core Web Vitals
There may be different approaches to measure how well a website or group of websites performs with CWV. The approach used by this dashboard is designed to most closely match the CWV assessment in PageSpeed Insights”
This is the background information about the HTTP Archive lab data:
“HTTP Archive measures individual web pages, not entire websites. And due to capacity limitations, HTTP Archive is limited to testing one page per website. The most natural page to test for a given website is its home page, or the root page of the origin.”
Source of quotes, HTTP Archive.
Top Core Web Vitals Performance
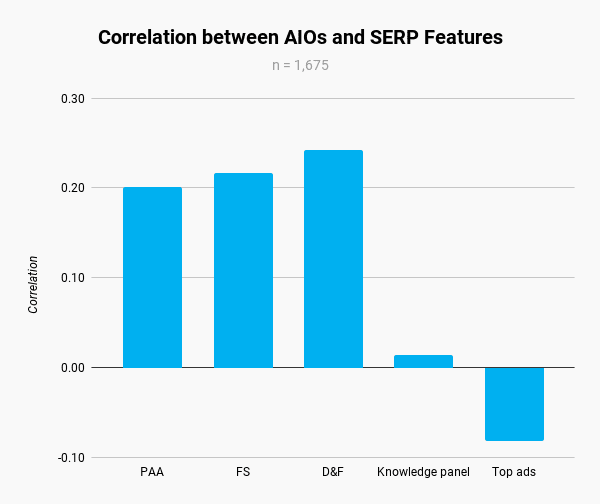
The highest performing content management system (CMS) of the six CMS under comparison is Duda, a closed-source website builder platform that is used by agencies and developers for creating and managing large portfolios of client sites. 71% of website visits resulted in a good core web vitals score. Duda’s score is 13 percentage points ahead of the second place winner, Squarespace, another closed source website building platform.
Sites built with Duda consistently have higher CWV performance rates than any other CMS, by a wide margin. Squarespace, Drupal and Wix are bunched together with similar performance scores, with the Joomla and WordPress scoring in fifth and sixth place.
WordPress Is Faster But Other Factors Slowing It Down
Although WordPress is ranked in sixth place, it’s performance did not drop as much as the other leading content management systems, quite possibly reflecting the many performance improvements in
present in each new version of WordPress. WordPress 6.5, released in early April 2024, featured over 100 performance improvements to the backend and the front end.
The performance score for WordPress was slightly lower in April 2024 than in the beginning of the year, but less than one percentage point. However, that percentage drop is lower than the top ranked CMS, Duda, which experienced a drop of 5.41 percentage points.
Chrome Lighthouse is an automated tool for measuring website performance. The Lighthouse scores for WordPress in January of this year was 35%, which means that 35% of measured WordPress sites had a good Lighthouse CWV score. The CWV score took a dip in February and March but it zipped back to 35% in April, perhaps reflecting the many performance improvements in WordPress version 6.5.
The scores for the average Page Weight is likely where the performance lagged. Page Weight is the average number of bytes sent over the network, which could be compressed. The average Page Weight of WordPress sites started out at 568.48 in January and increased to 579.92, an increase of 11.44.
The average download size of images when compared from January to April 2024 increased by 49.5 Kilobytes but that’s something that has more to do with how publishers use WordPress and not how WordPress is being used. These could be contributing to the essentially flat performance change this year. But again, virtually no change in performance is better than what’s going on with other content management systems which experienced larger drops in their performance rates.
Top CWV Performance By CMS
The list of CWV performance represents the percentage of sites using a given CMS that has a good CWV score. Here is the list of the top performers with their respective percentage rates:
- Duda 71%
- Squarespace 58%
- Drupal 54%
- Wix 52%
- Joomla 43%
- WordPress 38%
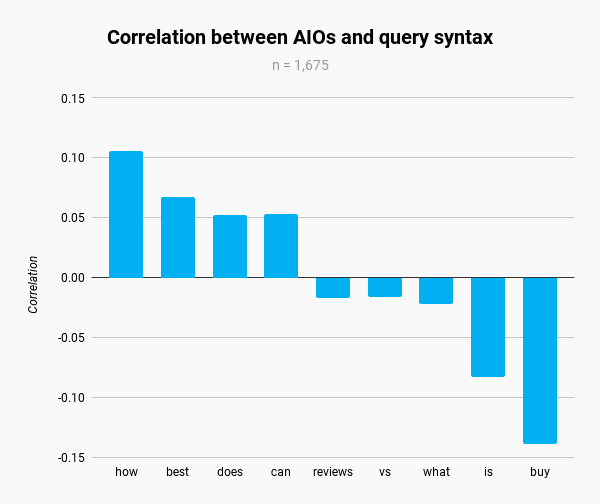
Performance Drops By CMS
Comparing the performance drop by CMS shows a weird trend in that four out of six content management systems had relatively high drops in performance. The following is a comparison of performance drops by percentage points, indicated with a minus sign.
List By Performance Change
- Wix -7.11
- Duda -5.41
- Joomla -2.84
- Drupal -2.58
- WordPress -0.71
As can be seen above, WordPress had the lowest drop in performance. Wix and Duda had the steepest drops in performance while Squarespace was the only CMS with an increase in performance, with a positive score of +3.92.
Core Web Vitals Scores – Takeaways
Duda is clearly the Core Web Vitals performance champ, outscoring every content management system in this comparison. Squarespace, Wix and Drupal are close behind in a tight pack. Out of the six platforms in this comparison only Squarespace managed to improve their scores this year.
All of the other platforms in this comparison scored less well in April compared to the beginning of the year, possibly due to increases in page weight, particularly in images but there might be something else that accounts for this anomaly that isn’t accounted for in the HTTP Archive reports.
The WordPress performance team continues to score notable improvements to the WordPress core and the slight performance drop of less than one percent may be because of how publishers are using the platform.
It’s safe to say that all the platforms in this comparison are winners because all of them show steady improvements in general.
Explore the HTTP Archive Core Web Vitals report here.
Featured Image by Shutterstock/Roman Samborskyi