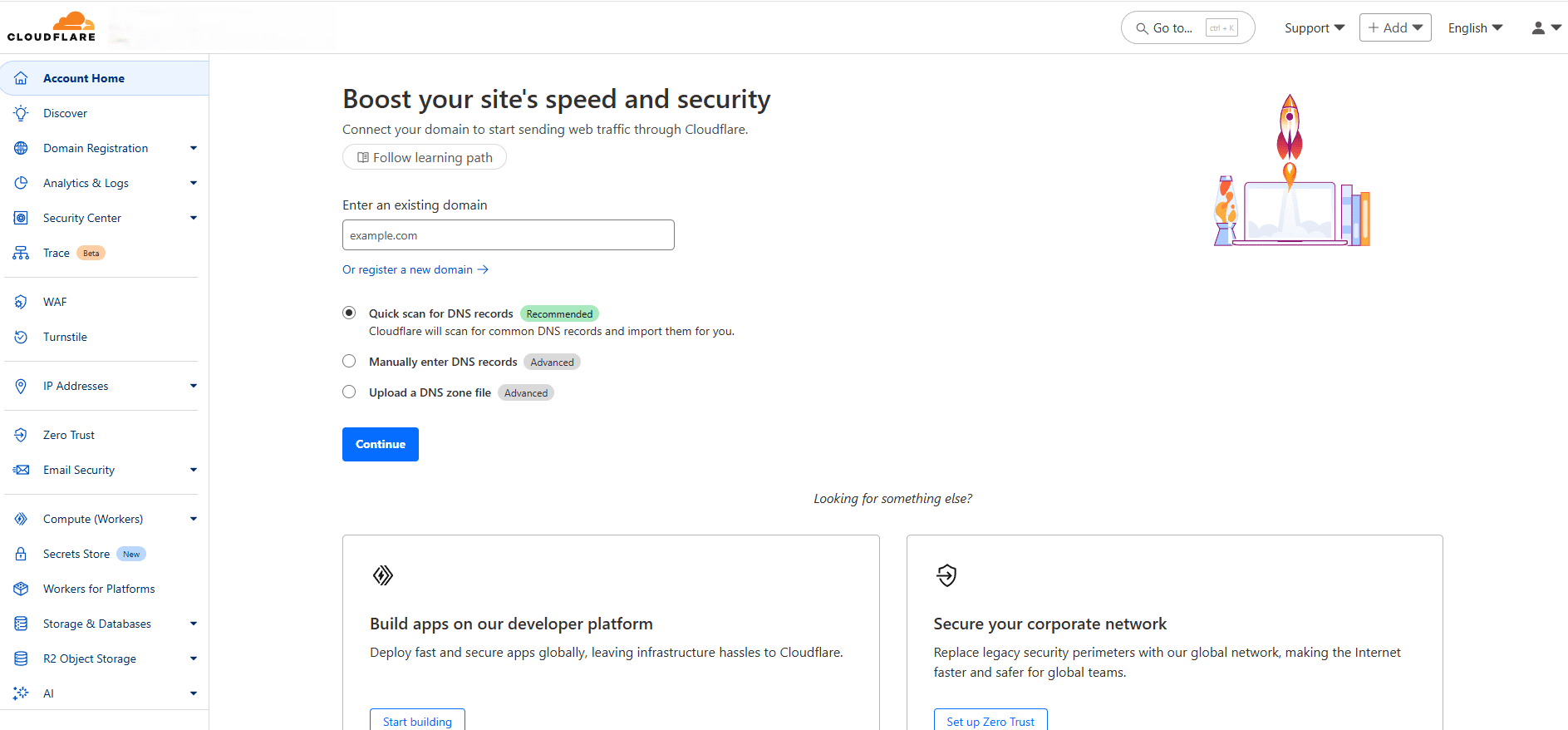
Google now supports structured data that allows businesses to show loyalty program benefits in search results.
Businesses can use two new types of structured data. One type defines the loyalty program itself, while the other illustrates the benefits members receive for specific products.
Here’s what you need to know.
Loyalty Structured Data
When businesses use this new structured data for loyalty programs, their products can display member benefits directly in Google. This allows shoppers to view the perks before clicking on any listings.
Google recognizes four specific types of loyalty benefits that can be displayed:
Loyalty Points: Points earned per purchase
Member-Only Prices: Exclusive pricing for members
Special Returns: Perks like free returns
Special Shipping: Benefits like free or expedited shipping
This is a new way to make products more visible. It may also result in higher clicks from search results.
The announcement states:
“… member benefits, such as lower prices and earning loyalty points, are a major factor considered by shoppers when buying products online.”
Details & Requirements
The new feature needs two steps.
First, add loyalty program info to your ‘Organization’ structured data.
Then, add loyalty benefits to your ‘Product’ structured data.
Bonus step: Check if your markup works using the Rich Results Test tool.
With valid markup in place, Google will be aware of your loyalty program and the perks associated with each product.
Important implementation note: Google recommends placing all loyalty program information on a single dedicated page rather than spreading it across multiple pages. This helps ensure proper crawling and indexing.
Multi-Tier Programs Now Supported
Businesses can define multiple membership tiers within a single loyalty program—think bronze, silver, and gold levels. Each tier can have different requirements for joining, such as:
This flexibility allows businesses to create sophisticated loyalty structures that match their existing programs.
Merchant Center Takes Priority
Google Shopping software engineers Irina Tuduce and Pascal Fleury say this feature is:
“… especially important if you don’t have a Merchant Center account and want the ability to provide a loyalty program for your business.”
It’s worth reiterating: If your business already uses Google Merchant Center, keep using that for loyalty programs.
In fact, if you implement both structured data markup and Merchant Center loyalty programs, Google will prioritize the Merchant Center settings. This override ensures there’s no confusion about which data source takes precedence.
Looking Ahead
The update seems aimed at helping smaller businesses compete with larger retailers, which often have complex Merchant Center setups.
Now, smaller sites can share similar information using structured data, including sophisticated multi-tier programs that were previously difficult to implement without Merchant Center.
Small and medium e-commerce sites without Merchant Center accounts should strongly consider adopting this markup.
Solution: Hosting with NVMe storage and sufficient RAM improves these metrics.
Crawl Budget
Your website’s visibility to search engines can be affected by limited server resources, wrong settings, and firewalls that restrict access.
When search engines encounter these issues, they index fewer pages and visit your site less often.
Solution: Upgrade to a hosting provider that’s built for SEO performance and consistent uptime.
Indexation Success
Proper .htaccess rules for redirects, error handling, and DNS configurations are essential for search engines to index your content effectively.
Many hosting providers limit your ability to change this important file, restricting you from:
– Editing your .htaccess file.
– Installing certain SEO or security plugins.
– Adjusting server settings.
These restrictions can hurt your site’s ability to be indexed and affect your overall SEO performance.
Solution: VPS and dedicated hosting solutions give you full access to these settings.
SERP Stability During Traffic Spikes
If your content goes viral or experiences a temporary surge in traffic, poor hosting can cause your site to crash or slow down significantly. This can lead to drops in your rankings if not addressed right away.
Google warns users about sites with security issues in Search Console. Warnings like “Social Engineering Detected” can erode user trust and hurt your rankings.
The location of your server affects how fast your site loads for different users, which can influence your rankings.
Solution: Find a web host that operates data centers in multiple server locations, such as two in the United States, one in Amsterdam, and, soon, one in Singapore. This helps reduce loading times for users worldwide.
Load Times
Faster-loading pages lead to lower bounce rates, which can improve your SEO. [Server-side optimizations], such as caching and compression, are vital for achieving fast load times.
These factors have always been important, but they are even more critical now that AI plays a role in search engine results.
Image created by InMotion Hosting, 2025.
2025 Update: Search Engines Are Prioritizing Hosting & Technical Performance More Than Ever
In 2025, search engines have fully embraced AI-driven results, and with this shift has come an increased emphasis on technical performance signals that only proper hosting can deliver.
How 2025 AI Overview SERPs Affect Your Website’s Technical SEO
Google is doubling down on performance signals. Its systems now place even greater weight on:
Uptime: Sites with frequent server errors due to outages experience more ranking fluctuations than in previous years. 99.99% uptime guarantees are now essential.
Server-Side Rendering: As JavaScript frameworks become more prevalent, servers that efficiently handle rendering deliver a better user experience and improved Core Web Vitals scores. Server-optimized JS rendering can make a difference.
Trust Scores: Servers free of malware with healthy dedicated IP addresses isolated to just your site (rather than shared with potentially malicious sites) receive better crawling and indexing treatment. InMotion Hosting’s security-first approach helps maintain these crucial trust signals.
Content Freshness: Server E-Tags and caching policies affect how quickly Google recognizes and indexes new or updated content.
TTFB (Time To First Byte): Server location, network stability, and input/output speeds all impact TTFB. Servers equipped with NVMe storage technology excel at I/O speeds, delivering faster data retrieval and improved SERP performance.
Created by InMotion Hosting. May, 2025
Modern search engines utilize AI models that prioritize sites that deliver consistent, reliable, and fast data. This shift means hosting that can render pages quickly is no longer optional for competitive rankings.
What You Can Do About It (Even If You’re Not Into Technical SEO)
You don’t need to be a server administrator to improve your website’s performance. Here’s what you can do.
1. Choose Faster Hosting
Upgrade from shared hosting to VPS or dedicated hosting with NVMe storage. InMotion Hosting’s plans are specifically designed to boost SEO performance.
2. Use Monitoring Tools
Free tools like UptimeRobot.com, WordPress plugins, or cPanel’s resource monitoring can alert you to performance issues before they affect your rankings.
3. Implement Server-Side Caching
Set up caching with Redis or Memcached using WordPress plugins like W3 Total Cache, or through cPanel.
4. Add a CDN
Content Delivery Networks (CDNs) can enhance global performance without needing server changes. InMotion Hosting makes CDN integration easy.
5. Utilize WordPress Plugins
Use LLMS.txt files to help AI tools crawl your site more effectively.
6. Work with Hosting Providers Who Understand SEO
InMotion Hosting offers managed service packages for thorough server optimization, tailored for optimal SEO performance.
Small Business: VPS Hosting Is Ideal for Reliable Performance on a Budget
VPS hosting is every growing business’s secret SEO weapon.
Imagine two competing local service businesses, both with similar content and backlink profiles, but one uses shared hosting while the other uses a VPS.
When customers search for services, the VPS-hosted site consistently appears higher in results because it loads faster and delivers a smoother user experience.
What Counts as an SMB
Small to medium-sized businesses typically have fewer than 500 employees, annual revenue under $100 million, and websites that receive up to 50,000 monthly visitors.
If your business falls into this category, VPS hosting offers the ideal balance of performance and cost.
What You Get With VPS Hosting
1. Fast Speeds with Less Competition
VPS hosting gives your website dedicated resources, unlike shared hosting where many sites compete for the same resources. InMotion Hosting’s VPS solutions ensure your site runs smoothly with optimal resource allocation.
2. More Control Over SEO
With VPS hosting, you can easily set up caching, SSL, and security features that affect SEO. Full root access enables you to have complete control over your server environment.
3. Affordable for Small Businesses Focused on SEO
VPS hosting provides high-quality performance at a lower cost than dedicated servers, making it a great option for growing businesses.
4. Reliable Uptime
InMotion Hosting’s VPS platform guarantees 99.99% uptime through triple replication across multiple nodes. If one node fails, two copies of your site will keep it running.
5. Better Performance for Core Web Vitals
Dedicated CPU cores and RAM lead to faster loading times and improved Core Web Vitals scores. You can monitor server resources to keep track of performance.
6. Faster Connections
Direct links to major internet networks improve TTFB (Time To First Byte), an important SEO measure.
7. Strong Security Tools
InMotion Hosting provides security measures to protect your site against potential threats that could harm it and negatively impact your search rankings. Their malware prevention systems keep your site safe.
How To Set Up VPS Hosting For Your SEO-Friendly Website
Assess your website’s current performance using tools like Google PageSpeed Insights and Search Console
Choose a VPS plan that matches your traffic volume and resource needs
Work with your provider’s migration team to transfer your site (InMotion Hosting offers Launch Assist for seamless transitions)
Implement server-level caching for optimal performance
Configure your SSL certificate to ensure secure connections
Set up performance monitoring to track improvements
Update DNS settings to point to your new server
Large & Enterprise Businesses: Dedicated Hosting Is Perfect For Scaling SEO
What Counts As An Enterprise Business?
Enterprise businesses typically have complex websites with over 1,000 pages, receive more than 100,000 monthly visitors, operate multiple domains or subdomains, or run resource-intensive applications that serve many concurrent users.
Benefits of Dedicated Hosting
Control Over Server Settings
Dedicated hosting provides you with full control over how your server is configured. This is important for enterprise SEO, which often needs specific settings to work well.
Better Crawlability for Large Websites
More server resources allow search engines to crawl more pages quickly. This helps ensure your content gets indexed on time. Advanced server logs provide insights to help you improve crawl patterns.
Reliable Uptime for Global Users
Enterprise websites need to stay online. Dedicated hosting offers reliable service that meets the expectations of users around the world.
Strong Processing Power for Crawlers
Dedicated CPU resources provide the power needed to handle spikes from search engine crawlers when they index your site. InMotion Hosting uses the latest Intel Xeon processors for better performance.
Multiple Dedicated IP Addresses
Having multiple dedicated IP addresses is important for businesses and SaaS platforms that offer API microservices. IP management tools make it easier to manage these addresses.
Custom Security Controls
You can create specific firewall rules and access lists to manage traffic and protect against bots. DDoS protection systems enhance your security.
Real-Time Server Logs
You can watch for crawl surges and performance issues as they happen with detailed server logs. Log analysis tools help you find opportunities to improve.
Load Balancing for Traffic Management
Load balancing helps spread traffic evenly across resources. This way, you can handle increases in traffic without slowing down performance. InMotion Hosting provides strong load balancing solutions.
Future Scalability
You can use multiple servers and networks to manage traffic and resources as your business grows. Scalable infrastructure planning keeps your performance ready for the future.
Fixed Pricing Plans
You can manage costs effectively as you grow with predictable pricing plans.
How To Migrate To Dedicated Hosting
Conduct a thorough site audit to identify all content and technical requirements.
Document your current configuration, including plugins, settings, and custom code.
Work with InMotion Hosting’s migration specialists to plan the transition
Set up a staging environment to test the new configuration before going live
Configure server settings for optimal SEO performance
Implement monitoring tools to track key metrics during and after migration
Create a detailed redirect map for any URL changes
Roll out the migration during low-traffic periods to minimize impact
Why Shared Hosting Can Kill Your SERP Rankings & Core Web Vitals
If you’re serious about SEO in 2025, shared hosting is a risk that doesn’t come with rewards.
Shared Hosting Issues & Risks
Capped Resource Environments
Shared hosting plans typically impose strict limits on CPU usage, memory, and connections. These limitations directly impact Core Web Vitals scores and can lead to temporary site suspensions during traffic spikes.
Resource Competition
Every website on a shared server competes for the same limited resources.
A resource-intensive website on your shared server can degrade performance for all sites, including yours. Isolated hosting environments eliminate this risk.
Collateral Damage During Outages
When a shared server becomes overwhelmed, not only does your website go down, but so do connected services like domains and email accounts. InMotion Hosting’s VPS and dedicated solutions provide isolation from these cascading failures.
Limited Access to Server Logs
Without detailed server logs, diagnosing and resolving technical SEO issues becomes nearly impossible. Advanced log analysis is essential for optimization.
Restricted Configuration Access
Shared hosting typically prevents modifications to server-level configurations that are essential for optimizing technical SEO.
Inability to Adapt Quickly
Shared environments limit your ability to implement emerging SEO techniques, particularly those designed to effectively handle AI crawlers. Server-level customization is increasingly important for SEO success.
In 2025, Reliable Hosting Is a Competitive Advantage
As search engines place greater emphasis on technical performance, your hosting choice is no longer just an IT decision; it’s a strategic marketing investment.
InMotion Hosting’s VPS and Dedicated Server solutions are engineered specifically to address the technical SEO challenges of 2025 and beyond. With NVMe-powered storage, optimized server configurations, and 24/7 expert human support, we provide the foundation your site needs to achieve and maintain top rankings.
Ready to turn your hosting into an SEO advantage? Learn more about our SEO-first hosting solutions designed for performance and scale.
Redirects are essential to every website’s maintenance, and managing redirects becomes really challenging when SEO pros deal with websites containing millions of pages.
Examples of situations where you may need to implement redirects at scale:
An ecommerce site has a large number of products that are no longer sold.
Outdated pages of news publications are no longer relevant or lack historical value.
Listing directories that contain outdated listings.
Job boards where postings expire.
Why Is Redirecting At Scale Essential?
It can help improve user experience, consolidate rankings, and save crawl budget.
You might consider noindexing, but this does not stop Googlebot from crawling. It wastes crawl budget as the number of pages grows.
From a user experience perspective, landing on an outdated link is frustrating. For example, if a user lands on an outdated job listing, it’s better to send them to the closest match for an active job listing.
At Search Engine Journal, we get many 404 links from AI chatbots because of hallucinations as they invent URLs that never existed.
We use Google Analytics 4 and Google Search Console (and sometimes server logs) reports to extract those 404 pages and redirect them to the closest matching content based on article slug.
When chatbots cite us via 404 pages, and people keep coming through broken links, it is not a good user experience.
404 urls report in GSC, May 2025
404 visits from AI chatbots, May 2025
Prepare Redirect Candidates
First of all, read this post to learn how to create a Pinecone vector database. (Please note that in this case, we used “primary_category” as a metadata key vs. “category.”)
To make this work, we assume that all your article vectors are already stored in the “article-index-vertex” database.
Prepare your redirect URLs in CSV format like in this sample file. That could be existing articles you’ve decided to prune or 404s from your search console reports or GA4.
Sample file with URLs to be redirected (Screenshot from Google Sheet, May 2025)
Optional “primary_category” information is metadata that exists with your articles’ Pinecone records when you created them and can be used to filter articles from the same category, enhancing accuracy further.
In case the title is missing, for example, in 404 URLs, the script will extract slug words from the URL and use them as input.
Generate Redirects Using Google Vertex AI
Download your Google API service credentials and rename them as “config.json,” upload the script below and a sample file to the same directory in Jupyter Lab, and run it.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from google.auth import load_credentials_from_file
from google.cloud import aiplatform
from google.api_core.exceptions import GoogleAPIError
from pinecone import Pinecone, PineconeException
from vertexai.language_models import TextEmbeddingModel, TextEmbeddingInput
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter).
# This is useful for interactive environments to show progress without cluttering the output.
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-vertex" # The name of the Pinecone index where article vectors are stored.
GOOGLE_CRED_PATH = "config.json" # Path to your Google Cloud service account credentials JSON file.
EMBEDDING_MODEL_ID = "text-embedding-005" # Identifier for the Vertex AI text embedding model to use.
TASK_TYPE = "RETRIEVAL_QUERY" # The task type for the embedding model. Try with RETRIEVAL_DOCUMENT vs RETRIEVAL_QUERY to see the difference.
# This influences how the embedding vector is generated for optimal retrieval.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List[int] = [] # Optional: List of years to filter Pinecone results by 'publish_year' metadata.
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (Vertex AI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE GOOGLE VERTEX AI ───────────────────────────────────────────────
# Set the GOOGLE_APPLICATION_CREDENTIALS environment variable to point to the
# service account key file. This allows the Google Cloud client libraries to
# authenticate automatically.
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = GOOGLE_CRED_PATH
try:
# Load credentials from the specified JSON file.
credentials, project_id = load_credentials_from_file(GOOGLE_CRED_PATH)
# Initialize the Vertex AI client with the project ID and credentials.
# The location "us-central1" is specified for the AI Platform services.
aiplatform.init(project=project_id, credentials=credentials, location="us-central1")
logging.info("Vertex AI initialized.")
except Exception as e:
# Log an error if Vertex AI initialization fails and re-raise the exception
# to stop script execution, as it's a critical dependency.
logging.error(f"Failed to initialize Vertex AI: {e}")
raise
# Initialize the embedding model once globally.
# This is a crucial optimization for "Resource Management for Embedding Model".
# Loading the model takes time and resources; doing it once avoids repeated loading
# for every URL processed, significantly improving performance.
try:
GLOBAL_EMBEDDING_MODEL = TextEmbeddingModel.from_pretrained(EMBEDDING_MODEL_ID)
logging.info(f"Text Embedding Model '{EMBEDDING_MODEL_ID}' loaded.")
except Exception as e:
# Log an error if the embedding model fails to load and re-raise.
# The script cannot proceed without the embedding model.
logging.error(f"Failed to load Text Embedding Model: {e}")
raise
# ─── INITIALIZE PINECONE ──────────────────────────────────────────────────────
# Initialize the Pinecone client and connect to the specified index.
try:
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
1. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
2. Handling URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)[0].split('#', 1)[0]
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Determine if the original URL path ended with a trailing slash.
has_slash = urlparse(temp).path.endswith('/')
# Remove any trailing slash temporarily for consistent processing.
temp = temp.rstrip('/')
# Re-add the trailing slash if it was originally present.
return temp + ('/' if has_slash else '')
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = [seg for seg in path.split('/') if seg] # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for GoogleAPIError. This makes the embedding generation
# more resilient to transient issues like network problems or Vertex AI rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(GoogleAPIError), # Only retry if a GoogleAPIError occurs.
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional[List[float]]:
"""
Generates a vector embedding for the given text using the globally initialized
Vertex AI Text Embedding Model. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional[List[float]]: A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
# Use the globally initialized model to get embeddings.
# This is the "Resource Management for Embedding Model" optimization.
inp = TextEmbeddingInput(text, task_type=TASK_TYPE)
vectors = GLOBAL_EMBEDDING_MODEL.get_embeddings([inp], output_dimensionality=768)
return vectors[0].values # Return the embedding vector (list of floats).
except GoogleAPIError as e:
# Log a warning if a GoogleAPIError occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"Vertex AI error during embedding generation (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
except Exception as e:
# Catch any other unexpected exceptions during embedding generation.
logging.error(f"Unexpected error generating embedding: {e}")
return None # Return None for non-retryable or final failed attempts.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev["URL"].iloc[-1]
# Find the index of this last URL in the original input DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == last].tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs[0] + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List[Dict[str, Any]] = [] # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
category = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
slug = slug_from_url(raw_url)
if not slug:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context for embedding.")
continue
text = slug.replace('-', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except GoogleAPIError as e:
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding generated.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict[str, Any] = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = [c.strip() for c in category.split(",") if c.strip()]
if cats:
filt["primary_category"] = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt["publish_year"] = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt["id"] = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", []):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# 1. It exists (cid is not None).
# 2. It's not the original URL itself (to prevent self-redirects).
# 3. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode = 'a' if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
# clear_output(wait=True) # Uncomment if running in Jupyter and want to clear output
clear_output(wait=True)
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode = 'a' if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
You will see a test run with only five records, and you will see a new file called “redirect_map.csv,” which contains redirect suggestions.
Once you ensure the code runs smoothly, you can set the TEST_MODE boolean to true False and run the script for all your URLs.
Test run with only five records (Image from author, May 2025)
If the code stops and you resume, it picks up where it left off. It also checks each redirect it finds against the CSV file.
This check prevents selecting a database URL on the pruned list. Selecting such a URL could cause an infinite redirect loop.
Redirect candidates using Google Vertex AI’s task type RETRIEVAL_QUERY (Image from author, May 2025)
We can now take this redirect map and import it into our redirect manager in the content management system (CMS), and that’s it!
You can see how it managed to match the outdated 2013 news article “YouTube Retiring Video Responses on September 12” to the newer, highly relevant 2022 news article “YouTube Adopts Feature From TikTok – Reply To Comments With A Video.”
Also for “/what-is-eat/,” it found a match with “/google-eat/what-is-it/,” which is a 100% perfect match.
This is not just due to the power of Google Vertex LLM quality, but also the result of choosing the right parameters.
When I use “RETRIEVAL_DOCUMENT” as the task type when generating query vector embeddings for the YouTube news article shown above, it matches “YouTube Expands Community Posts to More Creators,” which is still relevant but not as good a match as the other one.
For “/what-is-eat/,” it matches the article “/reimagining-eeat-to-drive-higher-sales-and-search-visibility/545790/,” which is not as good as “/google-eat/what-is-it/.”
If you wanted to find redirect matches from your fresh articles pool, you can query Pinecone with one additional metadata filter, “publish_year,” if you have that metadata field in your Pinecone records, which I highly recommend creating.
In the code, it is a PUBLISH_YEAR_FILTER variable.
If you have publish_year metadata, you can set the years as array values, and it will pull articles published in the specified years.
Generate Redirects Using OpenAI’s Text Embeddings
Let’s do the same task with OpenAI’s “text-embedding-ada-002” model. The purpose is to show the difference in output from Google Vertex AI.
Simply create a new notebook file in the same directory, copy and paste this code, and run it.
import os
import time
import logging
from urllib.parse import urlparse
import re
import pandas as pd
from pandas.errors import EmptyDataError
from typing import Optional, List, Dict, Any
from openai import OpenAI
from pinecone import Pinecone, PineconeException
# Import tenacity for retry mechanism. Tenacity provides a decorator to add retry logic
# to functions, making them more robust against transient errors like network issues or API rate limits.
from tenacity import retry, wait_exponential, stop_after_attempt, retry_if_exception_type
# For clearing output in Jupyter (optional, keep if running in Jupyter)
from IPython.display import clear_output
# ─── USER CONFIGURATION ───────────────────────────────────────────────────────
# Define configurable parameters for the script. These can be easily adjusted
# without modifying the core logic.
INPUT_CSV = "redirect_candidates.csv" # Path to the input CSV file containing URLs to be redirected.
# Expected columns: "URL", "Title", "primary_category".
OUTPUT_CSV = "redirect_map.csv" # Path to the output CSV file where the generated redirect map will be saved.
PINECONE_API_KEY = "YOUR_PINECONE_API_KEY" # Your API key for Pinecone. Replace with your actual key.
PINECONE_INDEX_NAME = "article-index-ada" # The name of the Pinecone index where article vectors are stored.
OPENAI_API_KEY = "YOUR_OPENAI_API_KEY" # Your API key for OpenAI. Replace with your actual key.
OPENAI_EMBEDDING_MODEL_ID = "text-embedding-ada-002" # Identifier for the OpenAI text embedding model to use.
CANDIDATE_FETCH_COUNT = 3 # Number of potential redirect candidates to fetch from Pinecone for each input URL.
TEST_MODE = True # If True, the script will process only a small subset of the input data (MAX_TEST_ROWS).
# Useful for testing and debugging.
MAX_TEST_ROWS = 5 # Maximum number of rows to process when TEST_MODE is True.
QUERY_DELAY = 0.2 # Delay in seconds between successive API queries (to avoid hitting rate limits).
PUBLISH_YEAR_FILTER: List[int] = [] # Optional: List of years to filter Pinecone results by 'publish_year' metadata eg. [2024,2025].
# If empty, no year filtering is applied.
LOG_BATCH_SIZE = 5 # Number of URLs to process before flushing the results to the output CSV.
# This helps in saving progress incrementally and managing memory.
MIN_SLUG_LENGTH = 3 # Minimum length for a URL slug segment to be considered meaningful for embedding.
# Shorter segments might be noise or less descriptive.
# Retry configuration for API calls (OpenAI and Pinecone).
# These parameters control how the `tenacity` library retries failed API requests.
MAX_RETRIES = 5 # Maximum number of times to retry an API call before giving up.
INITIAL_RETRY_DELAY = 1 # Initial delay in seconds before the first retry.
# Subsequent retries will have exponentially increasing delays.
# ─── SETUP LOGGING ─────────────────────────────────────────────────────────────
# Configure the logging system to output informational messages to the console.
logging.basicConfig(
level=logging.INFO, # Set the logging level to INFO, meaning INFO, WARNING, ERROR, CRITICAL messages will be shown.
format="%(asctime)s %(levelname)s %(message)s" # Define the format of log messages (timestamp, level, message).
)
# ─── INITIALIZE OPENAI CLIENT & PINECONE ───────────────────────────────────────
# Initialize the OpenAI client once globally. This handles resource management efficiently
# as the client object manages connections and authentication.
client = OpenAI(api_key=OPENAI_API_KEY)
try:
# Initialize the Pinecone client and connect to the specified index.
pinecone = Pinecone(api_key=PINECONE_API_KEY)
index = pinecone.Index(PINECONE_INDEX_NAME)
logging.info(f"Connected to Pinecone index '{PINECONE_INDEX_NAME}'.")
except PineconeException as e:
# Log an error if Pinecone initialization fails and re-raise.
# Pinecone is a critical dependency for finding redirect candidates.
logging.error(f"Pinecone init error: {e}")
raise
# ─── HELPERS ───────────────────────────────────────────────────────────────────
def canonical_url(url: str) -> str:
"""
Converts a given URL into its canonical form by:
1. Stripping query strings (e.g., `?param=value`) and URL fragments (e.g., `#section`).
2. Handling URL-encoded fragment markers (`%23`).
3. Preserving the trailing slash if it was present in the original URL's path.
This ensures consistency with the original site's URL structure.
Args:
url (str): The input URL.
Returns:
str: The canonicalized URL.
"""
# Remove query parameters and URL fragments.
temp = url.split('?', 1)[0]
temp = temp.split('#', 1)[0]
# Check for URL-encoded fragment markers and remove them.
enc_idx = temp.lower().find('%23')
if enc_idx != -1:
temp = temp[:enc_idx]
# Determine if the original URL path ended with a trailing slash.
preserve_slash = temp.endswith('/')
# Strip trailing slash if not originally present.
if not preserve_slash:
temp = temp.rstrip('/')
return temp
def slug_from_url(url: str) -> str:
"""
Extracts and joins meaningful, non-numeric path segments from a canonical URL
to form a "slug" string. This slug can be used as text for embedding when
a URL's title is not available.
Args:
url (str): The input URL.
Returns:
str: A hyphen-separated string of relevant slug parts.
"""
clean = canonical_url(url) # Get the canonical version of the URL.
path = urlparse(clean).path # Extract the path component of the URL.
segments = [seg for seg in path.split('/') if seg] # Split path into segments and remove empty ones.
# Filter segments based on criteria:
# - Not purely numeric (e.g., '123' is excluded).
# - Length is greater than or equal to MIN_SLUG_LENGTH.
# - Contains at least one alphanumeric character (to exclude purely special character segments).
parts = [seg for seg in segments
if not seg.isdigit()
and len(seg) >= MIN_SLUG_LENGTH
and re.search(r'[A-Za-z0-9]', seg)]
return '-'.join(parts) # Join the filtered parts with hyphens.
# ─── EMBEDDING GENERATION FUNCTION ─────────────────────────────────────────────
# Apply retry mechanism for OpenAI API errors. This makes the embedding generation
# more resilient to transient issues like network problems or API rate limits.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10), # Exponential backoff for retries.
stop=stop_after_attempt(MAX_RETRIES), # Stop retrying after a maximum number of attempts.
retry=retry_if_exception_type(Exception), # Retry on any Exception from OpenAI client (can be refined to openai.APIError if desired).
reraise=True # Re-raise the exception if all retries fail, allowing the calling function to handle it.
)
def generate_embedding(text: str) -> Optional[List[float]]:
"""
Generate a vector embedding for the given text using OpenAI's text-embedding-ada-002
via the globally initialized OpenAI client. Includes retry logic for API calls.
Args:
text (str): The input text (e.g., URL title or slug) to embed.
Returns:
Optional[List[float]]: A list of floats representing the embedding vector,
or None if the input text is empty/whitespace or
if an unexpected error occurs after retries.
"""
if not text or not text.strip():
# If the text is empty or only whitespace, no embedding can be generated.
return None
try:
resp = client.embeddings.create( # Use the globally initialized OpenAI client to get embeddings.
model=OPENAI_EMBEDDING_MODEL_ID,
input=text
)
return resp.data[0].embedding # Return the embedding vector (list of floats).
except Exception as e:
# Log a warning if an OpenAI error occurs, then re-raise to trigger the `tenacity` retry mechanism.
logging.warning(f"OpenAI embedding error (retrying): {e}")
raise # The `reraise=True` in the decorator will catch this and retry.
# ─── MAIN PROCESSING FUNCTION ─────────────────────────────────────────────────
def build_redirect_map(
input_csv: str,
output_csv: str,
fetch_count: int,
test_mode: bool
):
"""
Builds a redirect map by processing URLs from an input CSV, generating
embeddings, querying Pinecone for similar articles, and identifying
suitable redirect candidates.
Args:
input_csv (str): Path to the input CSV file.
output_csv (str): Path to the output CSV file for the redirect map.
fetch_count (int): Number of candidates to fetch from Pinecone.
test_mode (bool): If True, process only a limited number of rows.
"""
# Read the input CSV file into a Pandas DataFrame.
df = pd.read_csv(input_csv)
required = {"URL", "Title", "primary_category"}
# Validate that all required columns are present in the DataFrame.
if not required.issubset(df.columns):
raise ValueError(f"Input CSV must have columns: {required}")
# Create a set of canonicalized input URLs for efficient lookup.
# This is used to prevent an input URL from redirecting to itself or another input URL,
# which could create redirect loops or redirect to a page that is also being redirected.
input_urls = set(df["URL"].map(canonical_url))
start_idx = 0
# Implement resume functionality: if the output CSV already exists,
# try to find the last processed URL and resume from the next row.
if os.path.exists(output_csv):
try:
prev = pd.read_csv(output_csv)
except EmptyDataError:
# Handle case where the output CSV exists but is empty.
prev = pd.DataFrame()
if not prev.empty:
# Get the last URL that was processed and written to the output file.
last = prev["URL"].iloc[-1]
# Find the index of this last URL in the original input DataFrame.
idxs = df.index[df["URL"].map(canonical_url) == last].tolist()
if idxs:
# Set the starting index for processing to the row after the last processed URL.
start_idx = idxs[0] + 1
logging.info(f"Resuming from row {start_idx} after {last}.")
# Determine the range of rows to process based on test_mode.
if test_mode:
end_idx = min(start_idx + MAX_TEST_ROWS, len(df))
df_proc = df.iloc[start_idx:end_idx] # Select a slice of the DataFrame for testing.
logging.info(f"Test mode: processing rows {start_idx} to {end_idx-1}.")
else:
df_proc = df.iloc[start_idx:] # Process all remaining rows.
logging.info(f"Processing rows {start_idx} to {len(df)-1}.")
total = len(df_proc) # Total number of URLs to process in this run.
processed = 0 # Counter for successfully processed URLs.
batch: List[Dict[str, Any]] = [] # List to store results before flushing to CSV.
# Iterate over each row (URL) in the DataFrame slice to be processed.
for _, row in df_proc.iterrows():
raw_url = row["URL"] # Original URL from the input CSV.
url = canonical_url(raw_url) # Canonicalized version of the URL.
# Get title and category, handling potential missing values by defaulting to empty strings.
title = row["Title"] if isinstance(row["Title"], str) else ""
category = row["primary_category"] if isinstance(row["primary_category"], str) else ""
# Determine the text to use for generating the embedding.
# Prioritize the 'Title' if available, otherwise use a slug derived from the URL.
if title.strip():
text = title
else:
raw_slug = slug_from_url(raw_url)
if not raw_slug or len(raw_slug) < MIN_SLUG_LENGTH:
# If no meaningful slug can be extracted, skip this URL.
logging.info(f"Skipping {raw_url}: insufficient slug context.")
continue
text = raw_slug.replace('-', ' ').replace('_', ' ') # Prepare slug for embedding by replacing hyphens with spaces.
# Attempt to generate the embedding for the chosen text.
# This call is wrapped in a try-except block to catch final failures after retries.
try:
embedding = generate_embedding(text)
except Exception as e: # Catch any exception from generate_embedding after all retries.
# If embedding generation fails even after retries, log the error and skip this URL.
logging.error(f"Failed to generate embedding for {raw_url} after {MAX_RETRIES} retries: {e}")
continue # Move to the next URL.
if not embedding:
# If `generate_embedding` returned None (e.g., empty text or unexpected error), skip.
logging.info(f"Skipping {raw_url}: no embedding.")
continue
# Build metadata filter for Pinecone query.
# This helps narrow down search results to more relevant candidates (e.g., by category or publish year).
filt: Dict[str, Any] = {}
if category:
# Split category string by comma and strip whitespace for multiple categories.
cats = [c.strip() for c in category.split(",") if c.strip()]
if cats:
filt["primary_category"] = {"$in": cats} # Filter by categories present in Pinecone metadata.
if PUBLISH_YEAR_FILTER:
filt["publish_year"] = {"$in": PUBLISH_YEAR_FILTER} # Filter by specified publish years.
filt["id"] = {"$ne": url} # Exclude the current URL itself from the search results to prevent self-redirects.
# Define a nested function for Pinecone query with retry mechanism.
# This ensures that Pinecone queries are also robust against transient errors.
@retry(
wait=wait_exponential(multiplier=INITIAL_RETRY_DELAY, min=1, max=10),
stop=stop_after_attempt(MAX_RETRIES),
retry=retry_if_exception_type(PineconeException), # Only retry if a PineconeException occurs.
reraise=True # Re-raise the exception if all retries fail.
)
def query_pinecone_with_retry(embedding_vector, top_k_count, pinecone_filter):
"""
Performs a Pinecone index query with retry logic.
"""
return index.query(
vector=embedding_vector,
top_k=top_k_count,
include_values=False, # We don't need the actual vector values in the response.
include_metadata=False, # We don't need the metadata in the response for this logic.
filter=pinecone_filter # Apply the constructed metadata filter.
)
# Attempt to query Pinecone for redirect candidates.
try:
res = query_pinecone_with_retry(embedding, fetch_count, filt)
except PineconeException as e:
# If Pinecone query fails after retries, log the error and skip this URL.
logging.error(f"Failed to query Pinecone for {raw_url} after {MAX_RETRIES} retries: {e}")
continue
candidate = None # Initialize redirect candidate to None.
score = None # Initialize relevance score to None.
# Iterate through the Pinecone query results (matches) to find a suitable candidate.
for m in res.get("matches", []):
cid = m.get("id") # Get the ID (URL) of the matched document in Pinecone.
# A candidate is suitable if:
# 1. It exists (cid is not None).
# 2. It's not the original URL itself (to prevent self-redirects).
# 3. It's not another URL from the input_urls set (to prevent redirecting to a page that's also being redirected).
if cid and cid != url and cid not in input_urls:
candidate = cid # Assign the first valid candidate found.
score = m.get("score") # Get the relevance score of this candidate.
break # Stop after finding the first suitable candidate (Pinecone returns by relevance).
# Append the results for the current URL to the batch.
batch.append({"URL": url, "Redirect Candidate": candidate, "Relevance Score": score})
processed += 1 # Increment the counter for processed URLs.
msg = f"Mapped {url} → {candidate}"
if score is not None:
msg += f" ({score:.4f})" # Add score to log message if available.
logging.info(msg) # Log the mapping result.
# Periodically flush the batch results to the output CSV.
if processed % LOG_BATCH_SIZE == 0:
out_df = pd.DataFrame(batch) # Convert the current batch to a DataFrame.
# Determine file mode: 'a' (append) if file exists, 'w' (write) if new.
mode = 'a' if os.path.exists(output_csv) else 'w'
# Determine if header should be written (only for new files).
header = not os.path.exists(output_csv)
# Write the batch to the CSV.
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
batch.clear() # Clear the batch after writing to free memory.
if not test_mode:
clear_output(wait=True) # Clear output in Jupyter for cleaner progress display.
print(f"Progress: {processed} / {total}") # Print progress update.
time.sleep(QUERY_DELAY) # Pause for a short delay to avoid overwhelming APIs.
# After the loop, write any remaining items in the batch to the output CSV.
if batch:
out_df = pd.DataFrame(batch)
mode = 'a' if os.path.exists(output_csv) else 'w'
header = not os.path.exists(output_csv)
out_df.to_csv(output_csv, mode=mode, header=header, index=False)
logging.info(f"Completed. Total processed: {processed}") # Log completion message.
if __name__ == "__main__":
# This block ensures that build_redirect_map is called only when the script is executed directly.
# It passes the user-defined configuration parameters to the main function.
build_redirect_map(INPUT_CSV, OUTPUT_CSV, CANDIDATE_FETCH_COUNT, TEST_MODE)
While the quality of the output may be considered satisfactory, it falls short of the quality observed with Google Vertex AI.
Below in the table, you can see the difference in output quality.
When it comes to SEO, even though Google Vertex AI is three times more expensive than OpenAI’s model, I prefer to use Vertex.
The quality of the results is significantly higher. While you may incur a greater cost per unit of text processed, you benefit from the superior output quality, which directly saves valuable time on reviewing and validating the results.
From my experience, it costs about $0.04 to process 20,000 URLs using Google Vertex AI.
While it’s said to be more expensive, it’s still ridiculously cheap, and you shouldn’t worry if you’re dealing with tasks involving a few thousand URLs.
In the case of processing 1 million URLs, the projected price would be approximately $2.
If you still want a free method, use BERT and Llama models from Hugging Face to generate vector embeddings without paying a per-API-call fee.
The real cost comes from the compute power needed to run the models, and you must generate vector embeddings of all your articles in Pinecone or any other vector database using those models if you will be querying using vectors generated from BERT or Llama.
In Summary: AI Is Your Powerful Ally
AI enables you to scale your SEO or marketing efforts and automate the most tedious tasks.
This doesn’t replace your expertise. It’s designed to level up your skills and equip you to face challenges with greater capability, making the process more engaging and fun.
Mastering these tools is essential for success. I’m passionate about writing about this topic to help beginners learn and feel inspired.
As we move forward in this series, we will explore how to use Google Vertex AI for building an internal linking WordPress plugin.
Google has confirmed that most websites still don’t need to worry about crawl budget unless they have over one million pages. However, there’s a twist.
Google Search Relations team member Gary Illyes revealed on a recent podcast that how quickly your database operates matters more than the number of pages you have.
This update comes five years after Google shared similar guidance on crawl budgets. Despite significant changes in web technology, Google’s advice remains unchanged.
The Million-Page Rule Stays The Same
During the Search Off the Record podcast, Illyes maintained Google’s long-held position when co-host Martin Splitt inquired about crawl budget thresholds.
Illyes stated:
“I would say 1 million is okay probably.”
This implies that sites with fewer than a million pages can stop worrying about their crawl budget.
What’s surprising is that this number has remained unchanged since 2020. The web has grown significantly, with an increase in JavaScript, dynamic content, and more complex websites. Yet, Google’s threshold has remained the same.
Your Database Speed Is What Matters
Here’s the big news: Illyes revealed that slow databases hinder crawling more than having a large number of pages.
Illyes explained:
“If you are making expensive database calls, that’s going to cost the server a lot.”
A site with 500,000 pages but slow database queries might face more crawl issues than a site with 2 million fast-loading static pages.
What does this mean? You need to evaluate your database performance, not just count the number of pages. Sites with dynamic content, complex queries, or real-time data must prioritize speed and performance.
The Real Resource Hog: Indexing, Not Crawling
Illyes shared a sentiment that contradicts what many SEOs believe.
He said:
“It’s not crawling that is eating up the resources, it’s indexing and potentially serving or what you are doing with the data when you are processing that data.”
Consider what this means. If crawling doesn’t consume many resources, then blocking Googlebot may not be helpful. Instead, focus on making your content easier for Google to process after it has been crawled.
How We Got Here
The podcast provided some context about scale. In 1994, the World Wide Web Worm indexed only 110,000 pages, while WebCrawler indexed 2 million. Illyes called these numbers “cute” compared to today.
This helps explain why the one-million-page mark has remained unchanged. What once seemed huge in the early web is now just a medium-sized site. Google’s systems have expanded to manage this without altering the threshold.
Why The Threshold Remains Stable
Google has been striving to reduce its crawling footprint. Illyes revealed why that’s a challenge.
He explained:
“You saved seven bytes from each request that you make and then this new product will add back eight.”
This push-and-pull between efficiency improvements and new features helps explain why the crawl budget threshold remains consistent. While Google’s infrastructure evolves, the basic math regarding when crawl budget matters stays unchanged.
What You Should Do Now
Based on these insights, here’s what you should focus on:
Sites Under 1 Million Pages: Continue with your current strategy. Prioritize excellent content and user experience. Crawl budget isn’t a concern for you.
Larger Sites: Enhance database efficiency as your new priority. Review:
Query execution time
Caching effectiveness
Speed of dynamic content generation
All Sites: Redirect focus from crawl prevention to indexing optimization. Since crawling isn’t the resource issue, assist Google in processing your content more efficiently.
However, the insight regarding database efficiency shifts the conversation for larger sites. It’s not just about the number of pages you have; it’s about how efficiently you serve them.
For SEO professionals, this means incorporating database performance into your technical SEO audits. For developers, it underscores the significance of query optimization and caching strategies.
Five years from now, the million-page threshold might still exist. But sites that optimize their database performance today will be prepared for whatever comes next.
A Google engineer has warned that AI agents and automated bots will soon flood the internet with traffic.
Gary Illyes, who works on Google’s Search Relations team, said “everyone and my grandmother is launching a crawler” during a recent podcast.
The warning comes from Google’s latest Search Off the Record podcast episode.
AI Agents Will Strain Websites
During his conversation with fellow Search Relations team member Martin Splitt, Illyes warned that AI agents and “AI shenanigans” will be significant sources of new web traffic.
Illyes said:
“The web is getting congested… It’s not something that the web cannot handle… the web is designed to be able to handle all that traffic even if it’s automatic.”
This surge occurs as businesses deploy AI tools for content creation, competitor research, market analysis, and data gathering. Each tool requires crawling websites to function, and with the rapid growth of AI adoption, this traffic is expected to increase.
How Google’s Crawler System Works
The podcast provides a detailed discussion of Google’s crawling setup. Rather than employing different crawlers for each product, Google has developed one unified system.
Google Search, AdSense, Gmail, and other products utilize the same crawler infrastructure. Each one identifies itself with a different user agent name, but all adhere to the same protocols for robots.txt and server health.
Illyes explained:
“You can fetch with it from the internet but you have to specify your own user agent string.”
This unified approach ensures that all Google crawlers adhere to the same protocols and scale back when websites encounter difficulties.
The Real Resource Hog? It’s Not Crawling
Illyes challenged conventional SEO wisdom with a potentially controversial claim: crawling doesn’t consume significant resources.
Illyes stated:
“It’s not crawling that is eating up the resources, it’s indexing and potentially serving or what you are doing with the data.”
He even joked he would “get yelled at on the internet” for saying this.
This perspective suggests that fetching pages uses minimal resources compared to processing and storing the data. For those concerned about crawl budget, this could change optimization priorities.
From Thousands to Trillions: The Web’s Growth
The Googlers provided historical context. In 1994, the World Wide Web Worm search engine indexed only 110,000 pages, whereas WebCrawler managed to index 2 million. Today, individual websites can exceed millions of pages.
This rapid growth necessitated technological evolution. Crawlers progressed from basic HTTP 1.1 protocols to modern HTTP/2 for faster connections, with HTTP/3 support on the horizon.
“You saved seven bytes from each request that you make and then this new product will add back eight.”
Every efficiency gain is offset by new AI products requiring more data. This is a cycle that shows no signs of stopping.
What Website Owners Should Do
The upcoming traffic surge necessitates action in several areas:
Infrastructure: Current hosting may not support the expected load. Assess server capacity, CDN options, and response times before the influx occurs.
Access Control: Review robots.txt rules to control which AI crawlers can access your site. Block unnecessary bots while allowing legitimate ones to function properly.
Database Performance: Illyes specifically pointed out “expensive database calls” as problematic. Optimize queries and implement caching to alleviate server strain.
Monitoring: Differentiate between legitimate crawlers, AI agents, and malicious bots through thorough log analysis and performance tracking.
The Path Forward
Illyes pointed to Common Crawl as a potential model, which crawls once and shares data publicly, reducing redundant traffic. Similar collaborative solutions may emerge as the web adapts.
While Illyes expressed confidence in the web’s ability to manage increased traffic, the message is clear: AI agents are arriving in massive numbers.
Websites that strengthen their infrastructure now will be better equipped to weather the storm. Those who wait may find themselves overwhelmed when the full force of the wave hits.
There’s a lot to know about search intent, from using deep learning to infer search intent by classifying text and breaking down SERP titles using Natural Language Processing (NLP) techniques, to clustering based on semantic relevance, with the benefits explained.
Not only do we know the benefits of deciphering search intent, but we also have a number of techniques at our disposal for scale and automation.
So, why do we need another article on automating search intent?
Search intent is ever more important now that AI search has arrived.
While more was generally in the 10 blue links search era, the opposite is true with AI search technology, as these platforms generally seek to minimize the computing costs (per FLOP) in order to deliver the service.
SERPs Still Contain The Best Insights For Search Intent
The techniques so far involve doing your own AI, that is, getting all of the copy from titles of the ranking content for a given keyword and then feeding it into a neural network model (which you have to then build and test) or using NLP to cluster keywords.
What if you don’t have time or the knowledge to build your own AI or invoke the Open AI API?
While cosine similarity has been touted as the answer to helping SEO professionals navigate the demarcation of topics for taxonomy and site structures, I still maintain that search clustering by SERP results is a far superior method.
That’s because AI is very keen to ground its results on SERPs and for good reason – it’s modelled on user behaviors.
There is another way that uses Google’s very own AI to do the work for you, without having to scrape all the SERPs content and build an AI model.
Let’s assume that Google ranks site URLs by the likelihood of the content satisfying the user query in descending order. It follows that if the intent for two keywords is the same, then the SERPs are likely to be similar.
For years, many SEO professionals compared SERP results for keywords to infer shared (or shared) search intent to stay on top of core updates, so this is nothing new.
The value-add here is the automation and scaling of this comparison, offering both speed and greater precision.
How To Cluster Keywords By Search Intent At Scale Using Python (With Code)
Assuming you have your SERPs results in a CSV download, let’s import it into your Python notebook.
1. Import The List Into Your Python Notebook
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
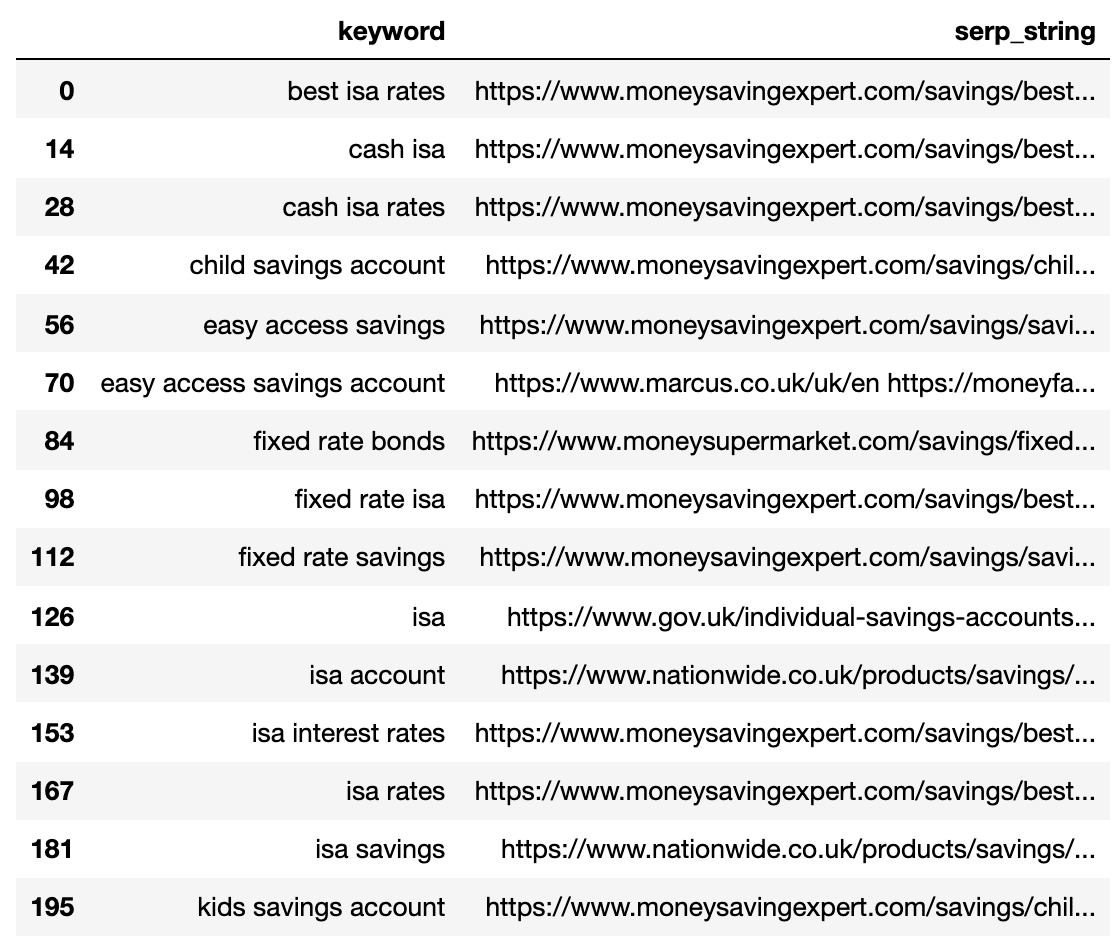
Below is the SERPs file now imported into a Pandas dataframe.
Image from author, April 2025
2. Filter Data For Page 1
We want to compare the Page 1 results of each SERP between keywords.
We’ll split the dataframe into mini keyword dataframes to run the filtering function before recombining into a single dataframe, because we want to filter at the keyword level:
The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]
Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
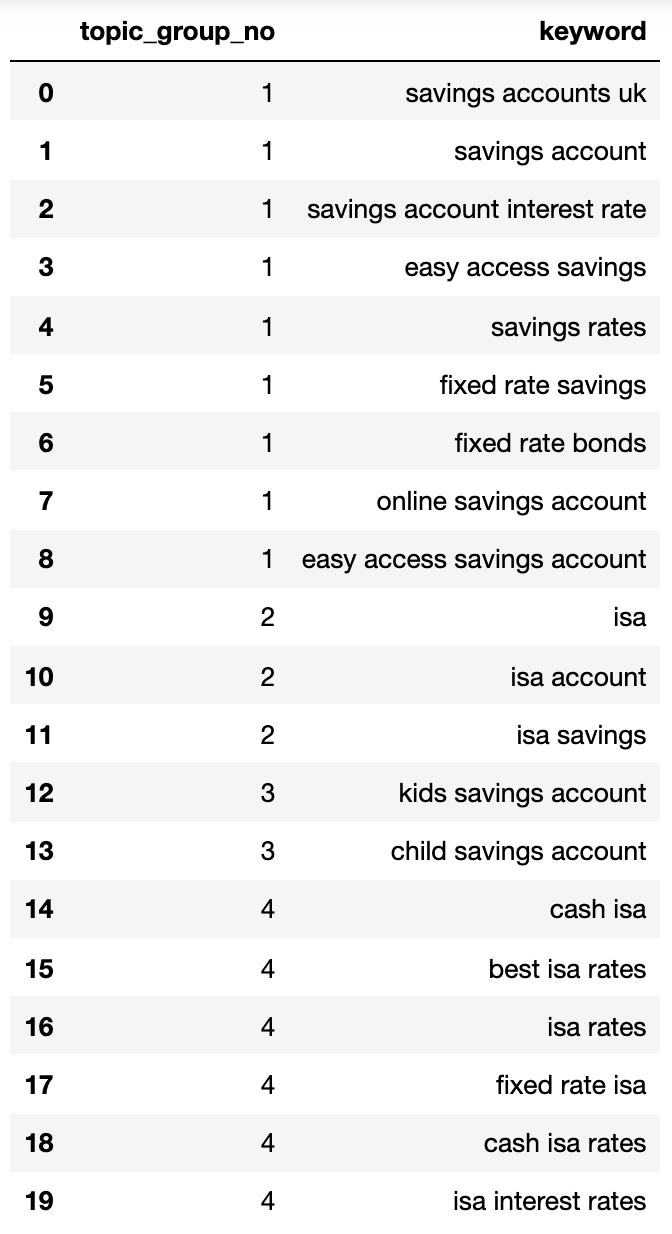
We now have the potential topic name, keywords SERP similarity, and search volumes of each.
You’ll note that keyword and keyword_b have been renamed to topic and keyword, respectively.
Now we’re going to iterate over the columns in the dataframe using the lambda technique.
The lambda technique is an efficient way to iterate over rows in a Pandas dataframe because it converts rows to a list as opposed to the .iterrows() function.
Here goes:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
Below shows a dictionary containing all the keywords clustered by search intent into numbered groups:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
Image from author, April 2025
The search intent groups above show a good approximation of the keywords inside them, something that an SEO expert would likely achieve.
Although we only used a small set of keywords, the method can obviously be scaled to thousands (if not more).
Activating The Outputs To Make Your Search Better
Of course, the above could be taken further using neural networks, processing the ranking content for more accurate clusters and cluster group naming, as some of the commercial products out there already do.
For now, with this output, you can:
Incorporate this into your own SEO dashboard systems to make your trends and SEO reporting more meaningful.
Build better paid search campaigns by structuring your Google Ads accounts by search intent for a higher Quality Score.
Merge redundant facet ecommerce search URLs.
Structure a shopping site’s taxonomy according to search intent instead of a typical product catalog.
I’m sure there are more applications that I haven’t mentioned – feel free to comment on any important ones that I’ve not already mentioned.
In any case, your SEO keyword research just got that little bit more scalable, accurate, and quicker!
Google’s Search Relations team recently shared insights about how the search engine handles HTTP status codes during a “Search Off the Record” podcast.
Gary Illyes and Martin Splitt from Google discussed several status code categories commonly misunderstood by SEO professionals.
How Google Views Certain HTTP Status Codes
While the podcast didn’t cover every HTTP status code (obviously, 200 OK remains fundamental), it focused on categories that often cause confusion among SEO practitioners.
Splitt emphasized during the discussion:
“These status codes are actually important for site owners and SEOs because they tell a story about what happened when a particular request came in.”
The podcast revealed several notable points about how Google processes specific status code categories.
The 1xx Codes: Completely Ignored
Google’s crawlers ignore all status codes in the 1xx range, including newer features like “early hints” (HTTP 103).
Illyes explained:
“We are just going to pass through [1xx status codes] anyway without even noticing that something was in the 100 range. We just notice the next non-100 status code instead.”
This means implementing early hints might help user experience, but won’t directly benefit your SEO.
Redirects: Simpler Than Many SEOs Believe
While SEO professionals often debate which redirect type to use (301, 302, 307, 308), Google’s approach focuses mainly on whether redirects are permanent or temporary.
Illyes stated:
“For Google search specifically, it’s just like ‘yeah, it was a redirection.’ We kind of care about in canonicalization whether something was temporary or permanent, but otherwise we just [see] it was a redirection.”
This doesn’t mean redirect implementation is unimportant, but it suggests the permanent vs. temporary distinction is more critical than the specific code number.
Client Error Codes: Standard Processing
The 4xx range of status codes functions largely as expected.
Google appropriately processes standard codes like 404 (not found) and 410 (gone), which remain essential for proper crawl management.
The team humorously mentioned status code 418 (“I’m a teapot”), an April Fool’s joke in the standards, which has no SEO impact.
Network Errors in Search Console: Looking Deeper
Many mysterious network errors in Search Console originate from deeper technical layers below HTTP.
Illyes explained:
“Every now and then you would get these weird messages in Search Console that like there was something with the network… and that can actually happen in these layers that we are talking about.”
When you see network-related crawl errors, you may need to investigate lower-level protocols like TCP, UDP, or DNS.
What Wasn’t Discussed But Still Matters
The podcast didn’t cover many status codes that definitely matter to Google, including:
200 OK (the standard successful response)
500-level server errors (which can affect crawling and indexing)
Continue to implement standard status codes correctly, including those not specifically discussed
As web technology evolves with HTTP/3 and QUIC, understanding how Google processes these signals can help you build more effective technical SEO strategies without overcomplicating implementation.
ChatGPT is more than just a prompting and response platform. You can send prompts to ask for help with SEO, but it becomes more powerful the moment that you make your own agent.
I conduct many SEO audits – it’s a necessity for an enterprise site – so I was looking for a way to streamline some of these processes.
How did I do it? By creating a ChatGPT agent that I’m going to share with you so that you can customize and change it to meet your needs.
I’ll keep things as “untechnical” as possible, but just follow the instructions, and everything should work.
I’m going to explain the following steps”
Configuration of your own ChatGPT.
Creating your own Cloudflare code to fetch a page’s HTML data.
Putting your SEO audit agents to work.
At the end, you’ll have a bot that provides you with information, such as:
Custom ChatGPT for SEO (Image from author, May 2025)
You’ll also receive a list of actionable steps to take to improve your SEO based on the agent’s findings.
Creating A Cloudflare Pages Worker For Your Agent
Cloudflare Pages workers help your agent gather information from the website you’re trying to parse and view its current state of SEO.
You can use a free account to get started, and you can register by doing the following:
Going to http://pages.dev/
Creating an account
I used Google to sign up because it’s easier, but choose the method you’re most comfortable with. You’ll end up on a screen that looks something like this:
Cloudflare Dashboard (Screenshot from Cloudfare, May 2025)
Navigate to Add > Workers.
Add a Cloudflare Worker (Screenshot from Cloudfare, May 2025)
You can then select a template, import a repository, or start with Hello World! I chose the Hello World option, as it’s the easiest one to use.
Selecting Cloudflare Worker (Screenshot from Cloudfare, May 2025)
Go through the next screen and hit “Deploy.” You’ll end up on a screen that says, “Success! Your project is deployed to Region: Earth.”
Don’t click off this page.
Instead, click on “Edit code,” remove all of the existing code, and enter the following code into the editor:
addEventListener('fetch', event => {
event.respondWith(handleRequest(event.request));
});
async function handleRequest(request) {
const { searchParams } = new URL(request.url);
const targetUrl = searchParams.get('url');
const userAgentName = searchParams.get('user-agent');
if (!targetUrl) {
return new Response(
JSON.stringify({ error: "Missing 'url' parameter" }),
{ status: 400, headers: { 'Content-Type': 'application/json' } }
);
}
const userAgents = {
googlebot: 'Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/121.0.6167.184 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)',
samsung5g: 'Mozilla/5.0 (Linux; Android 13; SM-S901B) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Mobile Safari/537.36',
iphone13pmax: 'Mozilla/5.0 (iPhone14,3; U; CPU iPhone OS 15_0 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Version/10.0 Mobile/19A346 Safari/602.1',
msedge: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/42.0.2311.135 Safari/537.36 Edge/12.246',
safari: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/601.3.9 (KHTML, like Gecko) Version/9.0.2 Safari/601.3.9',
bingbot: 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; bingbot/2.0; +http://www.bing.com/bingbot.htm) Chrome/',
chrome: 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36',
};
const userAgent = userAgents[userAgentName] || userAgents.chrome;
const headers = {
'User-Agent': userAgent,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Encoding': 'gzip',
'Cache-Control': 'no-cache',
'Pragma': 'no-cache',
};
try {
let redirectChain = [];
let currentUrl = targetUrl;
let finalResponse;
// Follow redirects
while (true) {
const response = await fetch(currentUrl, { headers, redirect: 'manual' });
// Add the current URL and status to the redirect chain only if it's not already added
if (!redirectChain.length || redirectChain[redirectChain.length - 1].url !== currentUrl) {
redirectChain.push({ url: currentUrl, status: response.status });
}
// Check if the response is a redirect
if (response.status >= 300 && response.status < 400 && response.headers.get('location')) { const redirectUrl = new URL(response.headers.get('location'), currentUrl).href; currentUrl = redirectUrl; // Follow the redirect } else { // No more redirects; capture the final response finalResponse = response; break; } } if (!finalResponse.ok) { throw new Error(`Request to ${targetUrl} failed with status code: ${finalResponse.status}`); } const html = await finalResponse.text(); // Robots.txt const domain = new URL(targetUrl).origin; const robotsTxtResponse = await fetch(`${domain}/robots.txt`, { headers }); const robotsTxt = robotsTxtResponse.ok ? await robotsTxtResponse.text() : 'robots.txt not found'; const sitemapMatches = robotsTxt.match(/Sitemap:s*(https?://[^s]+)/gi) || []; const sitemaps = sitemapMatches.map(sitemap => sitemap.replace('Sitemap: ', '').trim());
// Metadata
const titleMatch = html.match(/]*>s*(.*?)s*/i);
const title = titleMatch ? titleMatch[1] : 'No Title Found';
const metaDescriptionMatch = html.match(//i);
const metaDescription = metaDescriptionMatch ? metaDescriptionMatch[1] : 'No Meta Description Found';
const canonicalMatch = html.match(//i);
const canonical = canonicalMatch ? canonicalMatch[1] : 'No Canonical Tag Found';
// Open Graph and Twitter Info
const ogTags = {
ogTitle: (html.match(//i) || [])[1] || 'No Open Graph Title',
ogDescription: (html.match(//i) || [])[1] || 'No Open Graph Description',
ogImage: (html.match(//i) || [])[1] || 'No Open Graph Image',
};
const twitterTags = {
twitterTitle: (html.match(//i) || [])[2] || 'No Twitter Title',
twitterDescription: (html.match(//i) || [])[2] || 'No Twitter Description',
twitterImage: (html.match(//i) || [])[2] || 'No Twitter Image',
twitterCard: (html.match(//i) || [])[2] || 'No Twitter Card Type',
twitterCreator: (html.match(//i) || [])[2] || 'No Twitter Creator',
twitterSite: (html.match(//i) || [])[2] || 'No Twitter Site',
twitterLabel1: (html.match(//i) || [])[2] || 'No Twitter Label 1',
twitterData1: (html.match(//i) || [])[2] || 'No Twitter Data 1',
twitterLabel2: (html.match(//i) || [])[2] || 'No Twitter Label 2',
twitterData2: (html.match(//i) || [])[2] || 'No Twitter Data 2',
twitterAccountId: (html.match(//i) || [])[2] || 'No Twitter Account ID',
};
// Headings
const headings = {
h1: [...html.matchAll(/
A recent exchange between SEO professional Neil McCarthy and Google Search Advocate John Mueller has highlighted how Google treats hreflang tags.
McCarthy observed pages intended for Belgian French users (fr-be) appearing in France. Mueller clarified that hreflang is a suggestion, not a guarantee.
Here’s what this interaction shows us about hreflang, canonical tags, and international SEO.
French-Belgian Pages in French Search Results
McCarthy noticed that pages tagged for French-Belgian audiences were appearing in searches conducted from France.
In a screenshot shared on Bluesky, Google stated the result:
Contains the search terms
Is in French
“Seems coherent with this search, even if it usually appears in searches outside of France”
McCarthy asked whether Google was ignoring his hreflang instructions.
“hreflang doesn’t guarantee indexing, so it can also just be that not all variations are indexed. And, if they are the same (eg fr-fr, fr-be), it’s common that one is chosen as canonical (they’re the same).”
In a follow-up, he added:
“I suspect this is a ‘same language’ case where our systems just try to simplify things for sites. Often hreflang will still swap out the URL, but reporting will be on the canonical URL.”
Key Takeaways
Hreflang is a Hint, Not a Command
Google uses hreflang as a suggestion for which regional URL to display. It doesn’t require that each version be indexed or shown separately.
Canonical Tags Can Override Variations
Google may select one as the canonical URL when two pages are nearly identical. That URL then receives all the indexing and reporting.
“Same Language” Simplification
If two pages share the same language, Google’s systems may group them. Even if hreflang presents the correct variant to users, metrics often consolidate into the canonical version.
What This Means for International SEO Teams
Add unique elements to each regional page. The more distinct the content, the less likely Google is to group it under one canonical URL.
In Google Search Console, verify which URL is shown as canonical. Don’t assume that hreflang tags alone will generate separate performance data.
Use VPNs or location-based testing tools to search from various countries. Ensure Google displays the correct pages for the intended audience.
Review Google’s official documentation on hreflang, sitemaps, and HTTP headers. Remember that hreflang signals are hints that work best alongside a solid site structure.
Next Steps for Marketers
International SEO can be complex, but clear strategies help:
Audit Your hreflang Setup: Check tag syntax, XML sitemaps, and HTTP header configurations.
Review Page Similarity: Ensure each language-region version serves a unique user need.
Monitor Continuously: Set up alerts for unexpected traffic patterns or drops in regional performance.
SEO teams can set realistic goals and fine-tune their international strategies by understanding hreflang’s limits and Google’s approach to canonical tags. Regular testing, precise localization, and vigilant monitoring will keep regional campaigns on track.