This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Desalination plants in the Middle East are increasingly vulnerable
As the conflict in Iran has escalated, a crucial resource is under fire: the desalinization technology that supplies water in the region.
President Donald Trump has threatened to destroy “possibly all desalinization plants” in Iran if the Strait of Hormuz is not reopened. The impact on farming, industry, and—crucially—drinking in the Middle East could be severe. Find out why.
—Casey Crownhart
This story is part of MIT Technology Review Explains, our series untangling the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
AI is changing how small online sellers decide what to make
For small entrepreneurs, deciding what to sell and where to make it has traditionally been a slow, labor-intensive process. Now that work is increasingly being done by AI.
Tools like Alibaba’s Accio compress weeks of product research and supplier hunting into a single chat. Business owners and e-commerce experts say they’re making sourcing more accessible—and slashing the time from product idea to launch.
The gig workers who are training humanoid robots at home
When Zeus, a medical student in Nigeria, returns to his apartment from a long day at the hospital, he straps his iPhone to his forehead and records himself doing chores.
Zeus is a data recorder for Micro1, which sells the data he collects to robotics firms. As these companies race to build humanoids, videos from workers like Zeus have become the hottest new way to train them.
Micro1 has hired thousands of them in more than 50 countries, including India, Nigeria, and Argentina. The jobs pay well locally, but raise thorny questions around privacy and informed consent. The work can be challenging—and weird. Read the full story.
—Michelle Kim
This is our latest story to be turned into an MIT Technology Review Narrated podcast, which we’re publishing each week on Spotify and Apple Podcasts. Just navigate to MIT Technology Review Narrated on either platform, and follow us to get all our new content as it’s released.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Anthropic’s new model found security problems in every OS and browser Claude Mythos has been heralded as a cybersecurity “reckoning.” (The Verge) + Anthrophic is limiting the rollout over hacking fears. (CNBC) + It’s also launching a project that lets Mythos flag vulnerabilities. (Gizmodo) + Apple, Google, and Microsoft have joined the initiative. (ZDNET)
2 Iranian hackers are targeting American critical infrastructure Their focus is on energy and water infrastructure.(Wired) + They’re targeting industrial control devices. (TechCrunch)
3 Google’s AI Overviews deliver millions of incorrect answers per hour Despite a 90% accuracy rate. (NYT $) + AI means the end of internet search as we’ve known it. (MIT Technology Review)
4 Elon Musk is trying to oust OpenAI CEO Sam Altman in a lawsuit As remedies for Altman allegedly defrauding him. (CNBC) + Musk wants any damages given to OpenAI’s nonprofit arm. (WSJ $)
5 ICE has admitted it’s using powerful spyware The tools that can intercept encrypted messages. (NPR) + Immigration agencies are also weaponizing AI videos. (MIT Technology Review)
6 Greece has joined the countries banning kids from social media Under-15s will be blocked from 2027. (Reuters) + Australia introduced the world’s first social media ban for children. (Guardian) + Indonesia recently rolled out the first one in Southeast Asia. (DW) + Experts say they’re a lazy fix. (CNBC)
7 Intel will help Elon Musk build his Terafab in Texas They aim to manufacture chips for AI projects. (Engadget) + Musk says it will be the largest-ever semiconductor factory. (Engadget) + Future AI chips could be built on glass. (MIT Technology Review)
8 TikTok is building a second billion-euro data center in Finland It’s moving data storage for European users. (Reuters) + Finland has become a magnet for data centers. (Bloomberg $) + But nobody wants one in their backyard. (MIT Technology Review)
9 Plans for Canada’s first “virtual gated community” have sparked a row The AI-powered surveillance system has divided neighbors. (Guardian) + Is the Pentagon allowed to surveil Americans with AI? (MIT Technology Review)
10 The high-tech engineering of the “space toilet” has been revealed Artemis II is the first mission to carry one around the world. (Vox)
Quote of the day
“This case has always been about Elon generating more power and more money for what he wants. His lawsuit remains nothing more than a harassment campaign that’s driven by ego, jealousy and a desire to slow down a competitor.”
—OpenAI criticizes Musk’s legal action in an X post.
One More Thing
USWDS
Inside the US government’s brilliantly boring websites
You may not notice it, but your experience on every US government website is carefully crafted.
Each site aligns an official web design and a custom typeface. They aim to make government websites not only good-looking but accessible and functional for all.
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ Rejoice in the splendor of the “Earthset” image captured by Artemis II. + Meet the fearless cat chasing off bears. + This document vividly explains what makes the octopus so unique. + Revealed: the rhythmic secret that makes emo music so angsty.
We evolved for a linear world. If you walk for an hour, you cover a certain distance. Walk for two hours and you cover double that distance. This intuition served us well on the savannah. But it catastrophically fails when confronting AI and the core exponential trends at its heart.
From the time I began work on AI in 2010 to now, the amount of training data that goes into frontier AI models has grown by a staggering 1 trillion times—from roughly 10¹⁴ flops (floating-point operations‚ the core unit of computation) for early systems to over 10²⁶ flops for today’s largest models. This is an explosion. Everything else in AI follows from this fact.
The skeptics keep predicting walls. And they keep being wrong in the face of this epic generational compute ramp. Often, they point out that Moore’s Law is slowing. They also mention a lack of data, or they cite limitations on energy.
But when you look at the combined forces driving this revolution, the exponential trend seems quite predictable. To understand why, it’s worth looking at the complex and fast-moving reality beneath the headlines.
Think of AI training as a room full of people working calculators. For years, adding computational power meant adding more people with calculators to that room. Much of the time those workers sat idle, drumming their fingers on desks, waiting for the numbers to come through for their next calculation. Every pause was wasted potential. Today’s revolution goes beyond more and better calculators (although it delivers those); it is actually about ensuring that all those calculators never stop, and that they work together as one.
Three advances are now converging to enable this. First, the basic calculators got faster. Nvidia’s chips have delivered an over sevenfold increase in raw performance in just six years, from312 teraflops in 2020 to2,250 teraflops today. Our ownMaia 200 chip, launched this January, delivers 30% better performance per dollar than any other hardware in our fleet. Second, the numbers arrive faster thanks to a technology called HBM, or high bandwidth memory, which stacks chips vertically like tiny skyscrapers; the latest generation, HBM3, triples the bandwidth of its predecessor, feeding data to processors fast enough to keep them busy all the time. Third, the room of people with calculators became an office and then a whole campus or city. Technologies likeNVLink andInfiniBand connect hundreds of thousands of GPUs into warehouse-size supercomputers that function as single cognitive entities. A few years ago this was impossible.
These gains all come together to deliver dramatically more compute. Where training a language model took 167 minutes on eight GPUs in 2020, it now takes under four minutes on equivalent modern hardware. To put this in perspective: Moore’s Law would predict only about a 5x improvement over this period. We saw 50x. We’ve gone from two GPUs training AlexNet, the image recognition model that kicked off the modern boom in deep learning in 2012, to over 100,000 GPUs in today’s largest clusters, each one individually far more powerful than its predecessors.
Then there’s the revolution in software. Research fromEpoch AI suggests that the compute required to reach a fixed performance level halves approximately every eight months, much faster than the traditional 18-to-24-month doubling of Moore’s Law. The costs of serving some recent models have collapsed by a factor of up to 900 on an annualized basis. AI is becoming radically cheaper to deploy.
The numbers for the near future are just as staggering. Consider that leading labs are growing capacity at nearly 4x annually. Since 2020, the compute used to train frontier models has grown5x every year. Global AI-relevant compute is forecast to hit 100 million H100-equivalents by 2027, a tenfold increase in three years. Put all this together and we’re looking at something like another 1,000x in effective compute by the end of 2028. It’s plausible that by 2030 we’ll bring an additional200 gigawatts of compute online every year—akin to the peak energy use of the UK, France, Germany, and Italy put together.
What does all this get us? I believe it will drive the transition from chatbots to nearly human-level agents—semiautonomous systems capable of writing code for days, carrying out weeks- and months-long projects, making calls, negotiating contracts, managing logistics. Forget basic assistants that answer questions. Think teams of AI workers that deliberate, collaborate, and execute. Right now we’re only in the foothills of this transition, and the implications stretch far beyond tech. Every industry built on cognitive work will be transformed.
The obvious constraint here is energy. A single refrigerator-size AI rack consumes 120 kilowatts, equivalent to 100 homes. But this hunger collides with another exponential: Solar costs have fallen by a factor of nearly 100 over 50 years;battery prices have dropped 97% over three decades. There is a pathway to clean scaling coming into view.
The capital is deployed. The engineering is delivering. The $100 billion clusters, the 10-gigawatt power draws, the warehouse-scale supercomputers … these are no longer science fiction. Ground is being broken for these projects now across the US and the world. As a result, we are heading toward true cognitive abundance. At Microsoft AI, this is the world our superintelligence lab is planning for and building.
Skeptics accustomed to a linear world will continue predicting diminishing returns. They will continue being surprised. The compute explosion is the technological story of our time, full stop. And it is still only just beginning.
This week’s rundown of new services for ecommerce merchants includes updates on B2B tools, fulfillment, AI reporting, advertising platforms, agentic commerce, payments, affiliate marketing, and business formation services.
Got an ecommerce product release? Email updates@practicalecommerce.com.
New Tools for Merchants
Shopify extends native B2B features to all merchants. Merchants on Shopify can now manage wholesale and direct-to-consumer operations without plugins or patchwork. Shopify is extending its foundational B2B features to merchants on Basic, Grow, and Advanced plans, at no extra cost. Also, merchants on those plans can access native features, including company profiles for wholesale buyers, up to three custom catalogs with tailored pricing, volume discounts and quantity rules, vaulted credit cards, and payment terms.
Shopify: B2B and D2C management
ShipMonk opens fulfillment center designed for apparel brands.ShipMonk, a global fulfillment provider for ecommerce brands, has opened a center in Louisville, Kentucky. The facility has 406,000 square feet, 60 dock doors, and more than 300,000 storage locations. Per ShipMonk, the facility optimizes layouts for high-SKU density, dedicated rework stations, on-site embroidery services for premium customization, specialized workflows for wholesale complexity, and floor-ready presentation, as well as bespoke fulfillment services.
Swyft Filings launches an app to start an LLC inside ChatGPT.Swyft Filings, a provider of business formation services, has launched its OpenAI app, enabling entrepreneurs to form a business, start an LLC, register a corporation, and handle formation tasks. According to Swyft Filings, the app leverages generative AI for real-time guidance, faster filings, and more intuitive access to business formation services. The app is now available in the ChatGPT store.
Affiliate platform Levanta acquires Perch+ for Amazon sellers.Levanta, an affiliate and creator platform for ecommerce, has acquired Perch+, an affiliate network for Amazon sellers. According to Levanta, the move enables Perch+ brands to work directly with 60,000 partners in Levanta’s marketplace, with support for Amazon attribution and creator connections. Brands can run paid placement campaigns, automate product sampling, and surface who’s talking about their brand across social, per Levanta.
Miva releases 26 R1 with an embedded AI reporting assistant. Ecommerce platform Miva has released its 26 R1 update, with an embedded reporting assistant to help merchants make smarter, data-driven decisions. At the center of the release is AI Insights, an in-line reporting assistant. Merchants can use natural-language prompts to query store data, generate performance summaries, analyze conversion rates, and identify top-performing products by category or date range, all without exporting reports or building complex dashboards, according to Miva.
Miva
Commercetools partners with TradeCentric on B2B commerce.TradeCentric, a B2B e-procurement provider, has partnered with Commercetools, an ecommerce platform for global enterprises. Together, Commercetools and TradeCentric state that they enable seamless integration capabilities to eliminate manual order processing, reduce errors, and accelerate order-to-cash cycles. Commercetools customers gain access to these capabilities while integrating with major e-procurement systems, including the 220 procurement platforms supported by TradeCentric.
Bitly introduces AI-powered features for marketing analytics.Bitly, the URL shortener, has launched Assist and Weekly Insights for marketing. Bitly Assist is an AI-powered chat assistant built directly into the platform. It enables customers to ask questions conversationally about link and QR code performance. Weekly Insights highlights meaningful changes in link and QR code activity, identifying patterns across referrers, geographies, and devices.
Durable launches Discoverability for AI search.Durable, an AI business builder, has launched Discoverability, a feature that helps businesses get found on generative AI platforms such as ChatGPT, Gemini, Grok, and Perplexity. According to Durable, Discoverability provides (i) a single measure of how findable a business is across all online channels, (ii) guided suggestions to improve results over time, and (iii) rankings against competitors in genAI visibility.
Goflow introduces Order-Level P&L for real-time profit tracking.Goflow, a multichannel operating system for Amazon-first merchants, has launched Order-Level P&L for real-time profit tracking across orders, analytics, and reporting. The new feature estimates margins using inputs such as inventory batch costs and shipping rates. Each value is labeled by source, ensuring transparency between actual and estimated figures. By making profit and margin visible at the order, SKU, and channel level, sellers can identify issues quickly, per Goflow.
Goflow
BitRail launches merchant payment suite to help eliminate fees. Fintech company BitRail has announced an expanded suite of merchant payment services in partnership with Payment Lock, an enterprise security and payment processing platform. These tools build on BitRail’s core platform, which gives merchants branded checkout, branded digital wallets, and branded payment infrastructure. The features include compliant pricing for cash and credit, checkout and pay-now buttons, API integration, customer card vault, and reporting.
BQool brings Amazon AI advertising solutions to growing brands.BQool, a platform for Amazon sellers to automate operations, has announced the availability of its AI-powered advertising feature, designed to simplify campaign management and improve performance. The feature provides a one-click system that continuously analyzes large volumes of data, automates repetitive advertising tasks, and optimizes campaigns. The feature includes “auto-harvesting,” which identifies and adds high-performing keywords, and enables sellers to adopt intelligent automation while maintaining control and visibility, per BQool.
SDLC Corp launches free Odoo-WooCommerce connector.SDLC Corp, a technology integration provider, has launched a free connector that enables data synchronization between WooCommerce storefronts and Odoo back-office systems. According to SDLC Corp, the connector includes features to support day-to-day performance, including webhook-based event processing, scheduled jobs for inventory and catalog synchronization, configurable field mapping inside Odoo, and centralized logging with error-handling capabilities — all across single- and multi-store environments.
Criteo expands its Go self-service ad platforms to SMBs.Criteo, an advertising retargeting platform, has expanded its Go self-service ad tool with full access for small and midsize businesses. Criteo Go unifies display, video, native, and social within a single campaign environment. The platform optimizes spend, while built-in genAI creative tools produce and adapt ad formats, including video, to maintain consistent messaging across channels. Advertisers can create an account, enter billing details, and launch campaigns in as few as five clicks, according to Criteo.
The dashboard updated at 6:12 AM PDT on April 8 with the completion note: “The rollout was complete as of April 8, 2026.” The update began on March 27 at 2:00 AM PT, making the total rollout 12 days.
That’s within Google’s original two-week estimate and faster than the December 2025 core update, which took 18 days.
What Google Said About This Update
Google called the March 2026 core update “a regular update designed to better surface relevant, satisfying content for searchers from all types of sites.”
The company didn’t publish a companion blog post or announce specific goals for this update. It also didn’t share new guidance with the completion notice.
Core updates involve broad changes to Google’s ranking systems. They aren’t targeted at specific types of content or policy violations. Pages can move up or down based on how the update reassesses quality across the web.
Three Updates In One Month
March was unusually active for Google’s ranking systems. The core update was the third confirmed update in roughly five weeks.
The February Discover core update finished rolling out on February 27 after 22 days. That was the first time Google publicly labeled a core update as Discover-only.
The March 2026 spam update rolled out and completed in under 20 hours on March 24-25. That was the shortest confirmed spam update in the dashboard’s history.
The core update followed two days later on March 27.
Roger Montti, writing for Search Engine Journal, noted that the spam-then-core sequencing may not have been a coincidence. He wrote that spam fighting is logically part of the broader quality reassessment in a core update, comparing it to “clearing the table” before recalibrating the core ranking signals.
How The Rollout Compared To Recent Core Updates
The March rollout was the second-shortest of the past five broad core updates.
Only the December 2024 update finished faster.
Why This Matters
The completed rollout means you can now compare pre-update and post-update performance in Search Console across a full window. Google recommends waiting at least one full week after completion before drawing conclusions from the data.
Your baseline period should be the weeks before March 27, compared against performance after April 8. Keep in mind that the March spam update completed on March 25, so any ranking changes between March 24-27 could be from either update.
A drop in rankings after a core update doesn’t mean your site violated a policy. Core updates reassess content quality across the web, and some pages move up while others move down.
Looking Ahead
Google will likely continue making smaller, unannounced core updates between the larger confirmed rollouts. The company updated its core updates documentation in December to say that smaller core updates happen on an ongoing basis.
Not because the argument is hard to make – it isn’t – but because the behavior it’s about has been a fixture of the SEO industry for as long as I’ve worked in it. The shiny new object arrives, the FOMO kicks in, the conference decks update, and an entire professional class reshuffles its vocabulary to match whatever acronym landed that quarter. I wrote recently about how AI content scaling is just content spinning with better grammar – the tools change, the qualitative wall doesn’t. The acronym cycle runs on the same engine.
But this time, the shiny object didn’t emerge from practitioners observing a genuine shift and trying to name it. It was manufactured upstream – by venture capital, amplified by engagement farming, and adopted by professionals whose primary motivation isn’t “this is real” but “I can’t afford to look like I’m not keeping up.”
So here we are.
The Investment Thesis
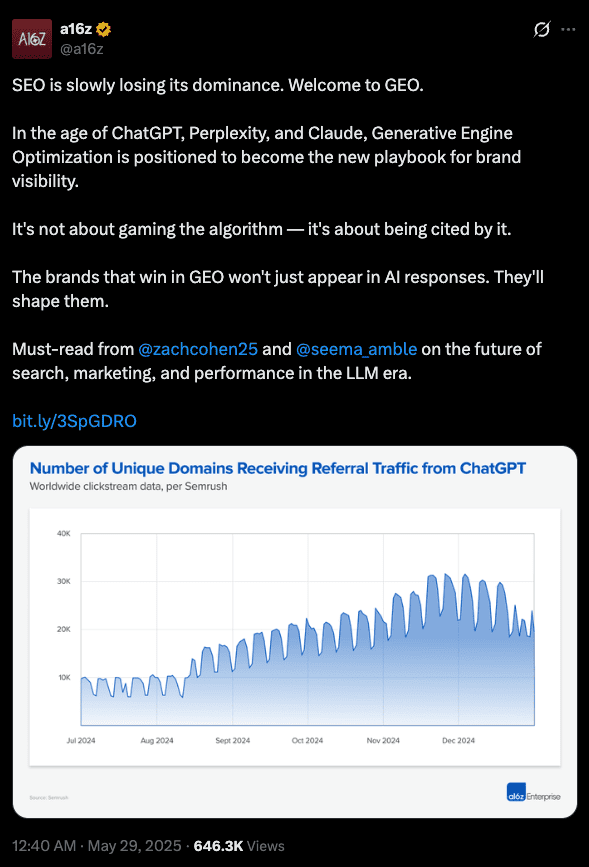
In May 2025, Andreessen Horowitz published a blog post titled “How Generative Engine Optimization (GEO) Rewrites the Rules of Search.” It appeared in their enterprise newsletter, written by two a16z partners, Zach Cohen and Seema Amble. Public, on their website, available to anyone with a browser.
The post declared that the “$80 billion+ SEO market just cracked” and that “a new paradigm is emerging.” It name-dropped three GEO tools – Profound, Goodie, and Daydream – as platforms enabling brands to track how they appear in AI-generated responses. It described a future where GEO companies would “fine-tune their own models” and “own the loop” between insight and iteration. a16z promoted it across their social channels, including a post from the firm’s official account: “SEO is slowly losing its dominance. Welcome to GEO.”
The blog post creates demand for the category. The category creates demand for the tools. The tools are in their portfolio. A sales funnel with a byline.
Marc Andreessen’s “Software is eating the world” wasn’t just an essay – it was a prospectus dressed in editorial clothing. The GEO post follows the same logic: identify the wave, position your bets as the inevitable response, publish the narrative that makes both feel like settled truth. Even sympathetic coverage noticed. The Alts.co write-up noted plainly that “a16z is drawing attention to GEO because it’s a chance to peddle/pump their own investments.”
What Happens When Nobody Checks The Source
Ten months later, in March 2026, someone on X described the blog post as “a 34-page internal memo” that a16z had “quietly published” and which had received only “200 views.” It cited a specific statistic: portfolio companies ranking No.1 on Google saw “a 34% drop in organic traffic in 12 months.” I’m not interested in the individual. This post is one of hundreds following the same pattern, and the pattern is what matters.
None of this is real.
The blog post isn’t 34 pages. It isn’t internal. It wasn’t quietly published. The specific opening line and the 34% stat don’t appear in the actual piece. You can verify this yourself right now.
This isn’t a16z’s doing. An engagement farmer found an old blog post and repackaged it with fictional scaffolding because that format performs better on social media. A “leaked internal memo” is sexier than a newsletter. “200 views” creates scarcity. Invented statistics create authority.
And it worked. People shared it, built threads around it, didn’t check whether the memo existed. Why would they? The narrative was too good.
Two independent forces – a VC firm doing standard narrative-building, and an engagement farmer doing standard engagement farming – converge on the same result. The VC seeds the category. The farmer, months later, independently amplifies a distorted version. Professionals absorb the distortion because nobody goes back to check the primary source.
Not coordination. Convergence. And a category becomes “real” without anybody establishing that it is.
The Willing Participants
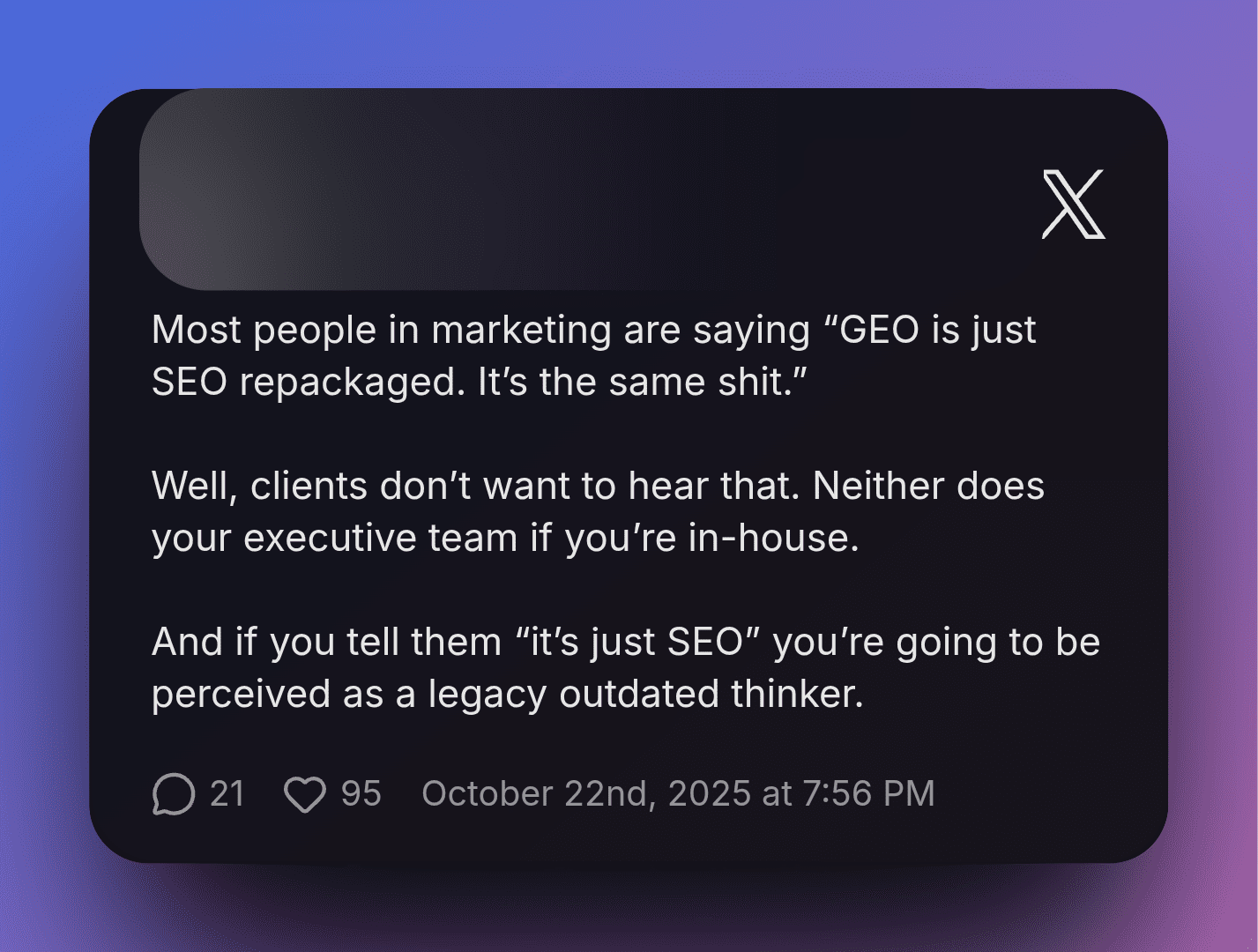
VCs and engagement farmers can’t take all the credit. SEO professionals are the most culpable link in the chain.
One widely-shared post on X captures the mentality – and I’m citing the behavior, not the person, because this position is everywhere in the industry right now. The argument: Clients don’t want to hear that GEO is “just SEO repackaged.” Neither does your executive team. Tell them “it’s just SEO,” and you’ll be “perceived as a legacy outdated thinker.” You might even be “replaced by a GEO agency.” The conclusion: “whether you like it or not… it’s in your best interest to get aboard the AI train.”
Image Credit: Pedro Dias
The argument is not that GEO works. Not that it measures anything meaningful. Not that it produces better outcomes for clients. The argument is that if you don’t adopt the label, you will lose your job.
Ambulance chasing dressed as career advice.
And here’s what makes SEO professionals more culpable than the VCs or the engagement farmers: they don’t just absorb the fear. They market it. They repackage the anxiety about their own relevance and sell it downstream to clients and executives who are even less equipped to evaluate the claims. The VC creates the narrative. The engagement farmer amplifies it. The SEO professional walks into a client meeting and says, “You need a GEO strategy, or you’ll be invisible to AI,” knowing full well they can’t define what that means in terms the client could verify.
This is how SEO professionals undermine their own credibility. Not by being wrong about the technical shift, but by selling certainty they don’t have about a category they didn’t bother to verify, using someone else’s terminology to paper over their own lack of understanding.
Nobody held a gun to anyone’s head and said, “Put GEO on your LinkedIn headline.” SEO professionals are choosing to adopt terminology they haven’t evaluated, from sources they haven’t verified, for tools they can’t validate; and then surfing that same fear factor into client budgets. If the only way you can sell your expertise is by rebranding it every eighteen months, the problem isn’t the label. It’s the confidence.
The people most capable of evaluating whether GEO is a real discipline are the same people adopting it fastest. Every hour they spend chasing the vocabulary is an hour not spent building the understanding that would make them impossible to replace. I’ve written about how AI is hollowing out the junior pipeline: the apprenticeship layer where practitioners actually learn judgment. The acronym treadmill accelerates that. It replaces depth with breadth, understanding with terminology, and professional development with professional performance.
What’s Actually Underneath
Strip away the a16z framing, the fabricated memos, and the professional anxiety, and ask the boring question: what would you actually do differently if you took GEO seriously?
I’ve argued before that grounding is just retrieval: When an AI system cites a source, it’s running a search task, not exercising editorial judgment. Indexing, vector search, relevance scoring. The same principles we’ve been working with for two decades, with a generative interface on top. GEO isn’t a second discipline standing alongside SEO. It’s old retrieval visibility in a trench coat pretending to be two disciplines. And your data interpretation skills – perched comfortably atop Mount Dunning-Kruger – don’t trump the clear, demonstrable logic of how a retrieval engine works. If you can’t explain why a result appeared, you have no business selling a service that claims to optimize for it.
The a16z post itself confirms this, perhaps accidentally. The advice it gives brands pursuing GEO is a greatest hits of SEO best practices: structured content, authoritative backlinks (rebranded as “earned media”), schema markup, topical authority. It even recommends “short, dense, citation-worthy paragraphs” and “specific claims with verifiable numbers” – which is, and I cannot stress this enough, just competent writing.
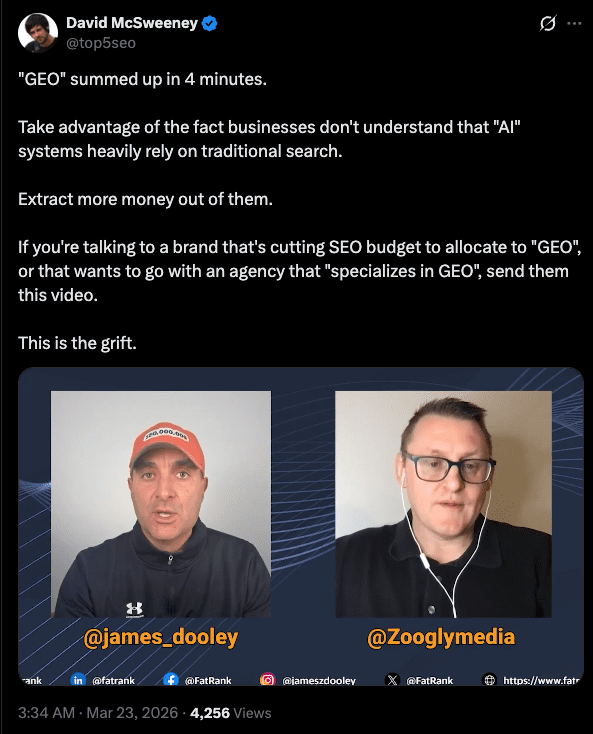
David McSweeney has been doing SEO since before some of these GEO startups’ founders graduated. He’s spent years writing about the same tactics now being repackaged under the GEO label (content freshness, digital PR, community participation, link building) and has the publication dates to prove it. His summary of the GEO pitch: take advantage of the fact that businesses don’t understand AI systems rely on traditional search, and extract more money from them.
He called it the grift. I think that’s generous. A grift implies individual con artists. This is structural: a category manufactured at the top, distorted in the middle, and adopted at the bottom. Not because it describes anything new, but because the professional cost of ignoring it feels higher than the professional cost of pretending it’s real.
You’re Not In The Driver’s Seat
Your job as a competent professional is to understand what these abbreviations actually mean, where they come from, and what – if anything – they change about your work.
If you can explain to your clients and your leadership what AI systems actually do, how they retrieve information, what’s genuinely measurable, and what isn’t – you will never be in a reactive position. You will never be the person scrambling to add “GEO” to a slide deck because someone on X told you it was the future.
If instead you let yourself be dragged around by whatever narrative venture capitalists need you to believe this quarter, you will always be reacting. One blog post away from a strategy pivot. Buying tools sold by people who benefit from your insecurity. That’s a choice. Not a fate.
The underlying mechanics of how content gets discovered – search engine crawler, LLM grounding system, RAG pipeline – haven’t undergone a paradigm shift. The interface has shifted. Users get answers synthesized from sources rather than a list of links.
But “the interface changed” doesn’t sell software. “Everything you know is obsolete and you need our dashboard” does.
Follow The Money
a16z benefits because the GEO narrative creates demand for their portfolio companies. The tool startups benefit because the narrative creates their market. The engagement farmers benefit because fabricated memos drive impressions. The agencies that rebrand as “GEO specialists” benefit because they can charge more for the same services with a shinier label.
Who doesn’t benefit? The practitioners doing solid, foundational work. Those people don’t need a new acronym. They need the industry to stop mistaking marketing for methodology.
And the clients. The clients are where the fear chain terminates, and the invoices begin. A new line item for work that should have been happening already under the SEO retainer, or that can’t be reliably measured in the first place. The VC manufactures the category. The SEO professional absorbs it and marks it up. The client pays for it. A game of telephone where the bill lands on the last person in the room who doesn’t speak the language.
I’ve written separately about the measurement problem with these tools – the non-determinism, the gap between parametric and retrieved knowledge, the dashboards built on methodological sand. The tools a16z promotes in that blog post have the same structural limitations. The dashboards look great. The numbers move. Whether the numbers mean anything is a question nobody selling the dashboard has an incentive to answer.
Meanwhile, the actual crisis gets no airtime. Organic search traffic across major U.S. publishers dropped 42% after AI Overviews expanded. Rankings didn’t change. Traffic did. That’s the real problem. Not which three-letter acronym to put on your slide deck, but the fact that the economic model underpinning content production on the open web is breaking. GEO doesn’t address that. It doesn’t even pretend to. It just gives everyone something to be busy with while the floor drops out.
The cycle time is getting shorter. We went from “AEO” to “GEO” in about eighteen months. Give it another year, and there’ll be another acronym, another VC blog post, another fabricated memo, and another round of professionals trying to decide whether the latest three letters are worth putting on their LinkedIn headline.
Or you could just do good work and understand what you’re doing well enough to explain it without borrowed terminology. But I suppose that doesn’t have the same ring to it on a pitch deck.
More Resources:
This post was originally published on The Inference.
Most ecommerce brands obsess over category pages and backlinks or product optimizations, while their product feeds remain auto-generated and underoptimized. Product feeds act as the backbone of ecommerce site catalogs and have long been the sole remit of PPC teams, but in the new era of AI Search, this is changing.
These changes are pulling product feed visibility directly into the SEO performance ecosystem and aligning it as general “search infrastructure,” not just “ads infrastructure.”
In this article, we’ll be talking you through the value that product feeds can bring to businesses and how SEO aligns with this.
SEO’s Role In Product Feeds
In ecommerce, product feeds are often seen as “set it and forget it” assets, but treating these feeds as simply raw data is an immediate missed opportunity to boost visibility across organic search, shopping, and agentic commerce in the future.
While a standard product feed provides basic data to search bots, an optimized feed enhances attribute accuracy to ensure your products appear for high-intent search queries. By refining your product data, you bridge the gap between technical specs and consumer needs, increasing both visibility and click-through rates.
SEO can help to optimize feeds across four main pillars:
1. Semantic Query Mapping
SEOs don’t just use basic product names. They use consumer language built out of query mapping and intent-matching.
By front-loading titles with high-intent keywords and “long-tail” descriptions that include attributes like color, material, or use-case, products are more likely to appear where the user’s intent is highest.
Example:
Instead of “Men’s Waterproof Jacket Black”
SEO Driven Product Feed: “Brand X Men’s Waterproof Running Jacket – Black Lightweight Performance Shell”
2. Taxonomy Logic
Taxonomy is important to stop your products from being lost in the void. A misplaced product can quickly become a lost sale.
By refining categorization and product grouping, general terms like “tactical hiking boots” won’t get buried under generalized categories like “general footwear.”
Building a logical hierarchy allows algorithms to crawl and understand the catalog with higher confidence of exactly who the product is targeting. All products within your feed will be automatically assigned a product category.
Ensuring your taxonomy, as well as the titles, descriptions, and GTIN information, will help to ensure that products are correctly categorized according to [google_product_category] attribute.
3. Structured Data
In Google Shopping, structured data acts as the anchor of “truth” that connects your website to your Merchant Center feed.
Structured data allows Google and other bots to directly pull product data from your HTML, creating a form of automated data validation. If, for example, your feed says a product is $50, but your schema says $60, Google will likely disapprove the listing.
In many cases, high-performing feeds rely on structured data to update price and availability in real-time. If you run a flash sale, Google’s crawler can detect the change via schema and updates your Shopping Ads, preventing “out of stock” clicks.
When it comes to agentic commerce, agents will query schema properties to see if your product fits the user’s specific constraints.
Structured data provides hard facts and allows agents to see if a product is “agent-ready” for checkout.
4. Analytical Review
Having a highly analytical mind that is always looking for opportunity, SEOs can help to identify any “ghost products” and diagnose whether the issues are down to attributes, images, or descriptions, providing ongoing optimization recommendations.
As we move into an era of AI-driven discovery, the quality of a brand’s feed data can quickly become a reflection of a brand’s reputation.
By providing more context within the feed, you are more likely to see your brand get recommended in conversational search and show up in organic shopping.
What Ecommerce Brands Get Wrong With Product Feed Optimization
The majority of issues that we see in product feeds come from inconsistencies and a lack of depth within the feed.
From conversations with brand managers, this seems to stem from a lack of ownership within a channel and a lack of understanding of the impact of what these inconsistencies can have.
In some cases, feeds can be disapproved due to having inaccurate price status due to inconsistency between the feed and a landing page.
Other common issues include:
Auto-generated Shopify titles.
No keyword layering.
Inconsistent variants.
Missing GTIN/MPN.
Thin descriptions.
Feed data not aligned with on-page SEO.
This is where having the eyes of an SEO who is used to ongoing technical auditing and hygiene maintenance, and understands the value of structured data and content for context, can be vital in product feed performance.
How Product Feeds Directly Impact Organic & AI Visibility
Quite simply, the more context you can provide in your product feed, the more chances you have of being shown or cited in traditional search and in AI engines.
If a product feed is missing critical attributes like size, color, material, compatibility, or use case, the product won’t just rank lower; it will become ineligible for more specific, high-intent queries.
As search queries grow longer and intent becomes more nuanced, i.e., searchers looking for “men’s waterproof trail running jacket black medium” rather than just “men’s trail running jacket,” feeds need to evolve past being simple descriptors.
They need to properly layer structured attributes that mirror how real customers search and filter online. The more complete the product feed, the more opportunities there will be for your products to appear online across Shopping to AI-generated citations.
What Product Feed Optimization Actually Looks Like
There are a few stages of product feed optimization that SEOs need to be both aware of and able to deliver.
Keyword & Intent Architecture
SEOs should approach product feeds the same way they approach category and content strategy.
Keyword research should be conducted at a product level, identifying high-intent modifiers such as size, material, compatibility, and demographic, and layer those attributes both into product titles and feed data.
Rather than relying on generic exports from Shopify or another ecommerce platform, product titles should reflect real organic search behavior around how customers actually query products.
Structured Data Alignment
SEOs should also make sure that feed attributes match on-page schema.
Keeping a close eye on Merchant Center for any potential issues, such as missing GTINs or prices not matching, and making any necessary adjustments to schema/structured data, will help to ensure that the feed is consistent and context is fully delivered to bots.
Variant Consolidation Strategy
This leans heavily into faceted navigation – which ecommerce SEOs have been battling for years.
By determining when product variations should be grouped under a single parent entity versus a standalone URL, SEOs can have more control over any unnecessary duplication and cannibalization.
This can also help to protect crawl efficiencies across large product catalogs and declutter product feeds.
Feed Health Monitoring
Similar to how SEOs regularly run technical crawls of websites to maintain hygiene and pick up any issues, SEOs should also treat feed governance as part of their regular checks.
This includes actively monitoring feed errors and addressing any Merchant Center issues that might limit visibility.
Prioritizing AI Search Readiness
A large opportunity for the future of search comes with agentic commerce, and product feeds are going to align directly with this.
By ensuring feeds are clearly structured and contain complete and accurate attributes, SEOs can reinforce strong product entity signals and provide clarity, which AI systems rely on to determine what to display in comparisons and recommendations.
Final Thoughts
Product feeds are no longer just paid media assets; they are core search infrastructure that directly impacts organic shopping visibility and AI-driven discovery.
Even the strongest category pages can’t compensate for inconsistent or poorly structured data at scale.
As search becomes more conversational and comparative, structured product clarity is going to be the difference between brands that are cited and brands that are not.
Google’s John Mueller answered a question about duplicate URLs appearing after a site structure change. His response offers clarity about how Google handles duplicate content and what actually influences indexing and ranking decisions.
Concern About Duplicate URLs And Ranking Impact
A site owner had changed the URL structure of their web pages then later discovered that older versions of those URLs were still accessible and appearing in Google Search Console.
The person asking the question on Reddit was concerned that requesting recrawls of the older URLs might confuse Google or lead to ranking issues.
“I switched over themes a while back and did some redesign and at some point …I changed all my recipes urls by taking the /recipe/ part out of site.com/recipe/actualrecipe so it’s now just site.com/actualrecipe but there are urls that still work when you put the /recipe/ back in the url.
I went to GSC and panicked that a bunch of my recipes weren’t indexed due to a 5xx error (I think it was when my site was down for a few days).
Now I’ve requested a bunch of them already to be recrawled, but realizing maybe google was ignoring them for a reason, like it didn’t want the duplicates.
Are my recrawl requests for /recipe/ urls going to confuse google who might penalize my ranking for the duplicates?”
The question reflects a reasonable concern that duplicate URLs and content might negatively affect rankings, especially when the error is surfaced through the search console indexing reports.
Google Is Able To Handle Duplicate URLs
Google’s John Mueller answered the question by explaining that multiple URLs pointing to the same content do not trigger a penalty or loss of search visibility. He also noted that this kind of duplication is common across the web, implying that Google’s systems are experienced with handling this kind of problem.
He explained:
“It’s fine, but you’re making it harder on yourself (Google will pick one to keep, but you might have preferences).
There’s no penalty or ranking demotion if you have multiple URLs going to the same content, almost all sites have it in variations. A lot of technical SEO is basically search-engine whispering, being consistent with hints, and monitoring to see that they get picked up.”
What Mueller is referring to is Google’s ability to canonicalize a single URL as the one that’s representative of the various similar URLs. As Mueller said, multiple URLs for essentially the same content is a frequent issue on the web.
Google’s documentation lists five reasons duplicate content happens:
“Region variants: for example, a piece of content for the USA and the UK, accessible from different URLs, but essentially the same content in the same language
Device variants: for example, a page with both a mobile and a desktop version
Protocol variants: for example, the HTTP and HTTPS versions of a site
Site functions: for example, the results of sorting and filtering functions of a category page
Accidental variants: for example, the demo version of the site is accidentally left accessible to crawlers”
The point is that duplicate content is something that happens often on the the web and is something that Google is able to handles.
Technical SEO Signals
Mueller said Google will pick one URL to keep, but added that the site owner might have preferences. That means Google will canonicalize the duplicates on its own, but the site owner or SEO can still signal which URL is the best choice (the canonical one) for ranking in the search results.
That is where technical SEO comes in. Internal linking, redirects, the proper use of rel=”canonical”, sitemap consistency, and consistency in 301 redirects all work as hints that help Google identify on the version you actually want indexed.
The Real Problem Is Mixed Signals
Mueller’s remark about making it harder on yourself was about the site owner/SEO spending time requesting URLs to be recrawled and noting that Google will figure it out on its own. But then he also referenced preferences, which alluded to all the signals I previously mentioned, in particular the rel=”canonical”.
Technical SEO Is Often About Reinforcing Preferences
Mueller’s description of technical SEO as “search-engine whispering” is useful because it captures how much of SEO involves reinforcing your preferences for what URLs are crawled, which content is chosen to rank, and indicating which pages of a website are the most important. Google may still choose a canonical on its own, but consistent signals increase the chance that it chooses the version the site owner wants.
That makes this a good example of what SEO is all about: Making it easy for Google to crawl, index, and understand the content. That’s really the essence of SEO. It is about being clear and consistent in the content, URLs, internal linking, overall site navigation, and even in showing the cleanest HTML, including semantic HTML (which makes it easier for Google to annotate a web page).
Semantic HTML can be used to clearly identify the main content of a web page. It can directly help Google zero in on what’s called the Centerpiece content, which is likely used for Google’s Centerpiece Annotation. The centerpiece annotation is a summary of the main topic of the web page.
Google’s canonicalization documentation explains:
“When Google indexes a page, it determines the primary content (or centerpiece) of each page. If Google finds multiple pages that seem to be the same or the primary content very similar, it chooses the page that, based on the factors (or signals) the indexing process collected, is objectively the most complete and useful for search users, and marks it as canonical. The canonical page will be crawled most regularly; duplicates are crawled less frequently in order to reduce the crawling load on sites.”
Technical SEO And Being Consistent
Stepping back to take a forest level view, duplicate URLs are really about a website not being consistent. Being consistent is not often seen as having to do with SEO but it actually is, on a general level. Every time I have created a new website I always had a plan for how to make it consistent, from the URLs to the topics, and also how to be able to expand that in a consistent manner as the website grows to cover more topics, to build that in.
Takeaways
Multiple URLs to the same content do not cause a penalty or ranking demotion
Google will usually pick one version to keep
Site owners can influence that choice through consistent technical signals
The real issue is mixed signals, not duplicate content itself
Technical SEO often comes down to reinforcing clear preferences and monitoring whether Google picks them up
The forest-level view of SEO can be seen as being consistent
AI search is dominating the strategy conversation right now, and every SEO director is fielding the same pressure from leadership: “What’s our AI search plan?”
The instinct is to optimize everywhere: close every citation gap, refresh every page, pursue every placement. But before you reallocate budget or rebuild your GEO roadmap, there’s a more useful question to ask first:
Which AI search signals are actually driving citations for your brand, and do you have a system to act on them?
Join us for an upcoming expert webinar where we’ll dive into exactly that.
What You’ll Learn
In this webinar, Sam Garg, Founder and CEO of Writesonic, will break down what 500M+ AI conversations reveal about citation signals, and show how that data should shape your GEO execution strategy.
Specifically, you’ll walk away with:
The signals behind AI citations: which content types, sources, and placements actually get cited in ChatGPT, Perplexity, and Gemini, and why it differs from traditional ranking logic
A GEO prioritization framework: so you stop spreading effort equally across citation outreach, content refresh, and third-party placements, and focus on what moves the needle for your specific gaps
An execution model powered by AI agents: including free open-source tools you can deploy right away to automate GEO tasks at scale
Why Attend?
Most SEO teams already have dashboards showing where they’re invisible in AI search. Few have a process to fix it. This session gives you both the diagnostic framework and the execution playbook to close those gaps, and the data to make the case for AI search investment internally.
Join us live to get your questions answered directly by the expert.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The one piece of data that could actually shed light on your job and AI
Within Silicon Valley’s orbit, an AI-fueled jobs apocalypse is spoken about as a given. Now even economists who have downplayed the threat are coming around to the idea.
Alex Imas, based at the University of Chicago, is one of them. He believes that any plan to address AI’s impact will depend on collecting one vital piece of data: price elasticity.
This article is from The Algorithm, our weekly newsletter giving you the inside track on all things AI. Sign up to receive it in your inbox every Monday.
Four things we’d need to put data centers in space
In January, Elon Musk’s SpaceX applied to launch up to 1 million data centers into Earth’s orbit. The goal? To fully unleash the potential of AI—without triggering an environmental crisis on Earth.
This story is part of MIT Technology Review Explains, our series untangling the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Trump has again proposed major cuts to US science and tech spending He wants to slash nearly every science-focused agency. (Ars Technica) + If Trump gets his way, the US could face a costly brain drain. (NYT $) + Top research talent is already fleeing the country. (Guardian) + Basic science deserves our boldest investment. (MIT Technology Review)
2 Sam Altman lobbied against AI regulations he publicly welcomed A bombshell report reveals many OpenAI insiders don’t trust him. (The New Yorker $) + Some have called him a sociopath. (Futurism) + OpenAI’s CFO fears it won’t be IPO-ready this year.(The Information $) + A war over AI regulation is brewing in the US. (MIT Technology Review)
3 NASA’s Artemis II has broken humanity’s all-time distance record The astronauts have flown farther than any humans before them. (BBC) + Their mission includes MIT-developed technology. (Axios)
4 Chinese tech firms are selling intel “exposing” US forces It comes from combining AI with open-source data.. (WP $) + AI is turning the Iran conflict into theater. (MIT Technology Review)
5 War is pushing countries to ditch hyperscalers Driven by Iran naming tech giants as military targets. (Rest of World) + No one wants a data center in their backyard. (MIT Technology Review)
6 OpenAI, Anthropic, and Google have united against China’s AI copying They’re sharing information on “adversarial distillation” (Bloomberg $)
7 Anduril and Impulse Space are working on Trump’s “Golden Dome” They’re developing space-based missile tracking for the project. (Gizmodo)
8 OpenAI has urged California to probe Elon Musk’s “anti-competitive behavior.” It accuses Musk of trying to “take control of the future of AGI.” (Reuters $) + And claims he coordinated attacks with Mark Zuckerberg. (CNBC) + A former Tesla president has revealed how he survived working for Musk. (WP $)
9 DeepSeek’s new AI model will run on Huawei chips It’s expected to launch in the next few weeks. (The Information $)
10 Memes have nuked our culture Internet “brain rot” has escaped our phones to take over everything. (NYT $)
Quote of the day
“I must say, it was actually quite nice.”
—Astronaut Victor Glover tells President Donald Trump what it was like when Artemis II was out of communication with the rest of humanity, The New York Times reports.
One More Thing
PABLO ALBARENGA
Inside the controversial tree farms powering Apple’s carbon-neutral goal
In 2020, Apple set a goal to become net zero by the end of the decade. To hit that target, the company is offsetting its emissions by planting millions of eucalyptus trees in Brazil.
Apple is betting that the strategy will lead to a greener future. But critics warn that the industrial tree farms will do more harm than good.
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ Japan’s automated bike garage is a cyclist’s dream come true. + This deep dive into bird behavior reveals the secrets of their dining habits. (Big thanks to reader Terry Gordon for the find!) + The first photo from the Artemis astronauts vividly captures the glow of our atmosphere. + There’s a new contender for the world’s most gorgeous website: RobertDeNiro.com.
Unlike static, rules-based systems, AI agents can learn, adapt, and optimize processes dynamically. As they interact with data, systems, people, and other agents in real time, AI agents can execute entire workflows autonomously.
But unlocking their potential requires redesigning processes around agents rather than bolting them onto fragmented legacy workflows using traditional optimization methods. Companies must become agent first.
In an agent-first enterprise, AI systems operate processes while humans set goals, define policy constraints, and handle exceptions.
“You need to shift the operating model to humans as governors and agents as operators,” says Scott Rodgers, global chief architect and U.S. CTO of the Deloitte Microsoft Technology Practice.
The agent-first imperative
With technology budgets for AI expected to increase more than 70% over the next two years, AI agents, powered by generative AI, are poised to fundamentally transform organizations and achieve results beyond traditional automation. These initiatives have the potential to produce significant performance gains, while shifting humans toward higher value work.
AI is advancing so quickly that static approaches to task automation will likely only produce incremental gains. Because legacy processes aren’t built for autonomous systems, AI agents require machine-readable process definitions, explicit policy constraints, and structured data flows, according to Rodgers.
Further complicating matters, many organizations don’t understand the full economic drivers of their business, such as cost to serve and per-transaction costs. As a result, they have trouble prioritizing agents that can create the most value and instead focus on flashy pilots. To achieve structural change, executives should think differently.
Companies must instead orchestrate outcomes faster than competitors. “The real risk isn’t that AI won’t work—it’s that competitors will redesign their operating models while you’re still piloting agents and copilots,” says Rodgers. “Nonlinear gains come when companies create agent-centric workflows with human governance and adaptive orchestration.”
Routine and repetitive tasks are increasingly handled automatically, freeing employees to focus on higher value, creative, and strategic work. This shift improves operational efficiency, fosters stronger collaboration, and generates faster decision-making—helping organizations modernize the workplace without sacrificing enterprise security.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.