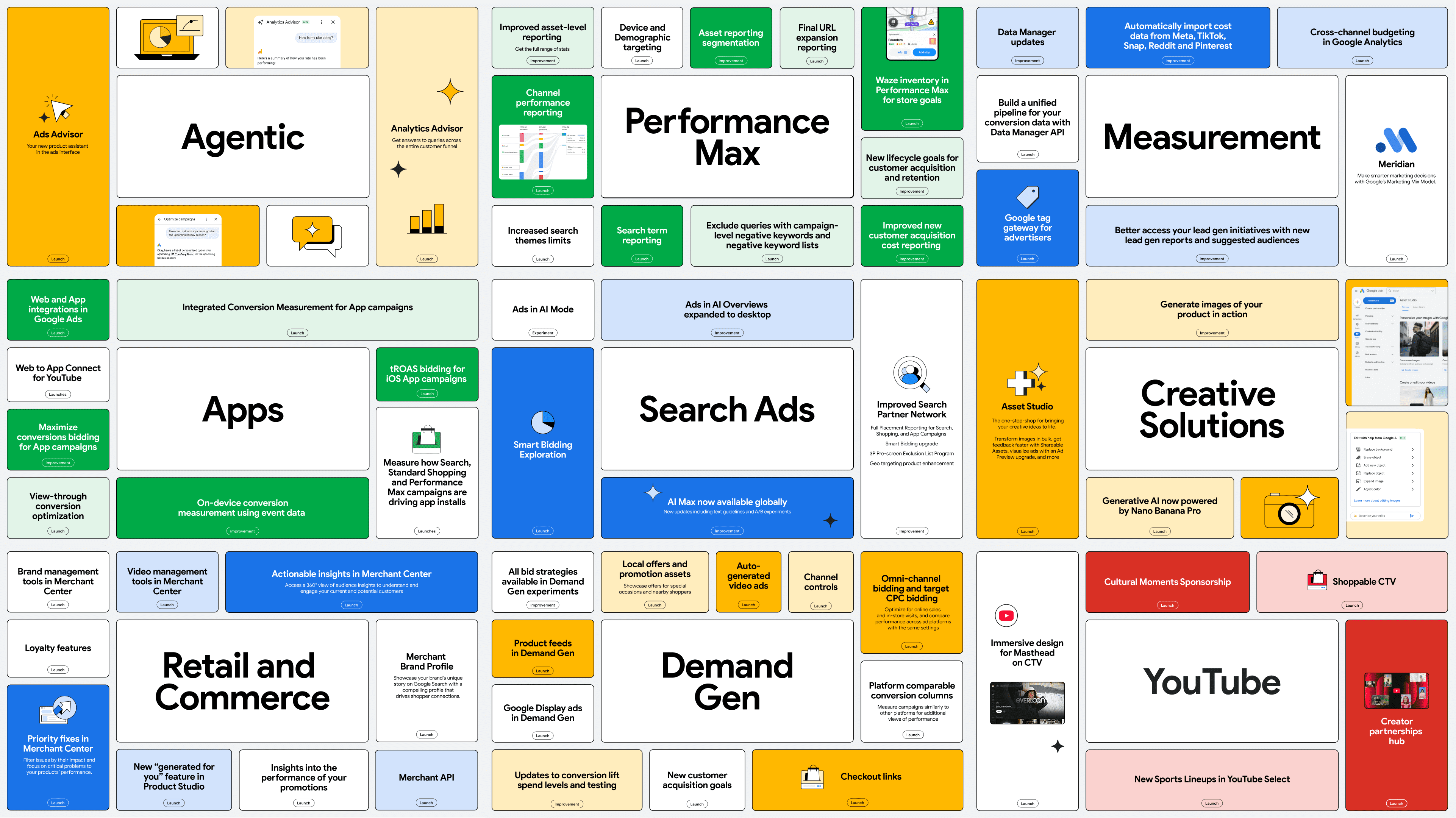
As December is quickly coming to a close, Google released its 2025 Year in Review, with a thorough list of product launches, upgrades, improvements all driven by AI.
These updates showed up across the board in Search, YouTube, Demand Gen, Performance Max, Merchant Center, and more.
Some updates felt like natural progressions from earlier releases. Others pushed Google’s vision for a more automated, more visual, and more data-informed ad system into clearer view.
For PPC managers and directors who spent the year testing generative AI, adjusting to new reporting controls, and rethinking creative workflows, Google’s recap is a useful way to understand what actually shaped paid media in 2025 and what still needs refinement.
The Biggest Releases of 2025
Before breaking down the themes and implications, here is a snapshot of the major updates Google highlighted in its year-end recap:
Ads in AI Overviews expanded to desktop and new global markets
AI Mode opened new mid-funnel inventory for deeper conversational queries
The launch of AI Max for Search, with new beta features being released in Q1 2026
Smart Bidding Exploration allowed for flexible ROAS targets
Full placement reporting expanded across the Search Partner Network
YouTube released Shoppable CTV, new Cultural Moments Sponsorship, new sports lineups, and a creator partnerships hub
Demand Gen added product feeds, target CPC bidding, campaign-level experiments, and channel controls
PMax gained channel-level reporting, full Search Terms, asset-level metrics, negative keyword lists, device targeting, and expanded search themes
Merchant Center gained brand profiles, AI-powered visuals, loyalty tools, and priority fixes
Meridian introduced an open-sourced MMM approach with lower lift thresholds
Data Manager and Google tag gateway made data accuracy and consolidation easier
Asset Studio launched inside Google Ads with Nano Banana Pro powering image and video creation
Ads Advisor and Analytics Advisor delivered guided support for campaign building and analysis
Taken together, these updates show Google’s ongoing effort to blend automation with advertiser control, though some areas are maturing faster than others.
Below are details of some of the key updates worth digging into more.
How Google Repositioned Search for the Next Era
Google spent much of 2025 redefining how Search works, particularly around discovery moments and conversational intent. These shifts matter because they determine where ads can appear and how early advertisers can influence a buying journey.
Ads in AI Overviews
Google expanded Ads in AI Overviews across desktop and global markets. This placement sits inside AI-generated summaries and gives advertisers a chance to appear before users have clicked into a traditional results page. While Ads in AI Overviews was announced earlier this year, it wasn’t until the later part of 2025 where users were sharing their screenshots in the wild.
AI Mode
Still in testing, AI Mode answers multi-step or nuanced queries with structured responses. Google now allows ads to appear below and within these responses when relevant. These moments previously had no paid inventory, so this is a new mid-funnel opportunity for advertisers who want to influence complex decision-making.
AI Max for Search
AI Max extended its feature set and remains one of Google’s fastest-growing Search products. Experiments, creative guidelines, and text customization give advertisers more agency over AI-generated assets. The challenge is managing expectations. AI Max simplifies setup but still requires strategic human oversight to shape relevance and cost efficiency.
Smart Bidding Exploration
Google cited an average 18 percent increase in unique converting query categories and a 19 percent conversion lift when advertisers used flexible ROAS targets. For brands that struggle to expand reach without overspending, this may become one of the most practical levers in 2026.
YouTube and Demand Gen Continued Their Growth Spurt
YouTube delivered some of Google’s most impactful upgrades this year. Shoppable CTV allows viewers to browse products directly on the big screen or pass the experience to their phone.
Cultural Moments Sponsorships created a packaged approach for brands that want presence during tentpole events. With new sports lineups across college and women’s leagues, Google is betting heavily on live and fandom-driven environments.
Demand Gen also saw meaningful improvement. Google noted a 26 percent increase in conversions per dollar driven by more than 60 AI-powered enhancements.
Combined with product feeds, channel controls, and full compatibility with Custom Experiments, Demand Gen now feels like a maturing format rather than an experimental successor to Discovery.
Performance Max Became More Transparent and More Controllable
Performance Max received a set of long overdue reporting and control features that changed how many advertisers worked inside the platform.
Channel reporting, full Search terms, asset-level insights, customer acquisition visibility, and segmentation options let PPC managers understand where performance originates. Negative keyword lists, device targeting, demographic controls, and expanded search themes finally gave advertisers the ability to tighten or expand performance intentionally rather than reactively.
For many teams, this was the year PMax felt less like a ‘take-it-or-leave-it’ automation tool and more like a high-powered campaign framework that needs guidance rather than blind trust.
Creativity Became a Central Focus
One theme that Google emphasized more strongly this year was creative quality and workflow efficiency. With Asset Studio and Nano Banana Pro, Google is signaling that creative is no longer a side component of performance. It is a core lever.
Asset Studio
The new in-platform creative workspace lets advertisers generate, edit, and review creative directly inside Google Ads. Nano Banana Pro now supports:
Natural language editing
Seasonal variations
Photorealistic product scenes
Multi-product compositions
Bulk image generation
Shareable assets for team review
For lean teams that struggle to produce enough visual variation for PMax, Demand Gen, or YouTube, this removes a major bottleneck. The quality still varies depending on brand style, texture, or lighting, but Google is clearly positioning AI-assisted creative as a foundational element in campaign setup.
Ad Preview and Workflow Support
Updated previews show ads across channels without guesswork, and shareable previews remove a lot of friction with internal stakeholders. This is one of Google’s more underrated releases because it directly solves a common workflow challenge: aligning creative teams and media teams without lengthy back-and-forth.
Google also introduced Ads Advisor, a guided AI assistant for campaign building and troubleshooting, which reduces operational burden for teams who manage multiple accounts or frequent experiments.
Why the iOS Measurement Updates Are More Important Than It Looks
Buried within Google’s 2025 recap was an update most marketers will skim past, but app-focused advertisers immediately saw as one of the most meaningful improvements of the year.
Google expanded Web-to-App acquisition measurement for iOS, allowing advertisers to track when a user moves from a web campaign into an app install that ultimately leads to a valuable in-app action.
On the surface, this reads like a small reporting enhancement. In practice, it solves one of the most frustrating gaps in iOS app advertising since ATT went live in 2021.
For most advertisers who run traditional lead-gen or ecommerce campaigns, this update will feel distant. But for app marketers, it finally closes the loop on a user journey that used to look fragmented, inconsistent, or completely invisible.
Here’s what makes it so important:
It brings back visibility that app advertisers lost years ago. After Apple’s App Tracking Transparency rollout, many advertisers lost the ability to see how web campaigns influenced app installs. That meant paid Search, Shopping, and even PMax often undervalued app growth, because installs and in-app actions didn’t get attributed correctly. Google’s new iOS Web-to-App measurement begins restoring that path, which helps app campaigns receive credit where it was previously impossible.
It allows advertisers to optimize for higher-value actions, not just installs. Before this update, the disconnect between web traffic and app conversions often pushed advertisers toward shallow optimization goals. Now, Google can tie in-app action quality back to upstream campaigns. For app marketers, that means smarter bidding. For finance teams, it means cleaner forecasting.
It makes cross-surface strategy practical again. Many app brands advertise across Search, YouTube, Shopping, and PMax but had to treat those touchpoints separately. This update reopens the door to a unified approach, where creative, bidding strategies, and budgets can align with actual user behavior instead of being fragmented by platform limitations.
App-focused teams have been navigating blind spots for years. They know how often web traffic influences app installs. They’ve seen how many high-value users start on mobile web before downloading. Without visibility, they’ve had to rely on directional data, blended reporting, or costly workarounds through MMP partners.
This update doesn’t solve every attribution limitation on iOS, but it does give app advertisers something they’ve wanted since ATT: a path to understanding the real value of web-driven app conversions.
It creates a more complete and realistic measurement loop, which is exactly what Google needs if it wants advertisers to invest confidently in App campaigns across Search, YouTube, Demand Gen, and Performance Max in 2026.
Where There’s Room for Improvement
A year-in-review should not only highlight progress but also acknowledge where advertisers still experience friction. My goal here is objective critique without negativity.
AI Overviews need clearer consistency
Advertisers still struggle to predict when AI Overviews will appear and how often ads surface within them. Before this becomes a must-have surface, Google needs more stability and clearer guidelines.
Creative control in AI Max is not fully predictable
Google is expanding customization settings, but advertisers still see unexpected rewrites or over-simplifications. More transparency around why AI chooses certain variations would help creative teams align expectations.
Asset Studio output varies by category
While the new tools are fast and flexible, certain product types still generate inconsistent or overly stylized visuals. This will improve, but brands that rely on strict visual identity may need hybrid workflows for now.
Measurement unification is still a challenge
Meridian is promising, but advertisers want easier alignment between Google’s lift results and those from Meta, Amazon, or independent MMM tools. The industry needs consistency, not isolated attribution logic.
These gaps do not diminish the significance of Google’s updates, but they remind us that AI-led advertising is still developing and requires both experimentation and skepticism.
Wrapping Up the Year
Google’s 2025 recap showed a platform that is evolving quickly but maturing steadily. Automation is no longer something advertisers fear or resist. The conversation has shifted to how PPC teams can direct these systems with clearer insight, smarter testing, and more intentional creative work.
If 2025 was about unlocking visibility and control, 2026 will be about applying those tools with discipline. Marketers who lean into experimentation, creative differentiation, and data strength will be the ones who stay ahead as Google’s ad ecosystem continues to change.
What was your biggest takeaway from Google’s updates this year?
For two decades, the arrangement between search engines and publishers was a symbiotic relationship where publishers allowed crawling, and search engines sent referral traffic back. That traffic helped to fund content creation for publishers through ads and subscriptions.
AI features are changing this, and the deal is starting to break down.
AI Overviews, ChatGPT, and answer engines keep users within their platform instead of sending them to source sites. The result is publishers are watching their traffic decline while AI companies crawl more content than ever.
New payment models are emerging to replace the old economics. some involve usage-based revenue sharing, others are flat licensing deals worth millions, and a few have ended in court settlements. But the terms vary widely, and it’s unclear whether any model can sustain the content ecosystem that AI depends on.
This article examines the payment models taking shape, how different publishers are responding, and what SEO professionals should consider as the industry figures out sustainable economics.
The crawl-to-referral ratio shows how unbalanced this is. Cloudflare’s analysis tracks Google Search maintaining roughly a 10:1 ratio, crawling about 10 pages for every referral sent back. OpenAI’s ratio was estimated at around 1,200:1 to 1,700:1.
Fewer pageviews mean fewer ad impressions, lower subscription conversions, and reduced affiliate revenue.
Payment Models Taking Shape
Three payment models are emerging.
1. Usage-Based Revenue Sharing
Perplexity launched its Comet Plus program in 2025. The company shares subscription revenue with publishers after keeping a cut for compute costs, though the exact split isn’t disclosed.
These models tie pay to usage, but the pools stay small compared to traditional search revenue and scaling depends on converting free users to paid subscribers.
These arrangements bundle three rights: training data access using archives to improve models, real-time content display with attribution in ChatGPT, and technology access letting publishers use OpenAI tools.
AI companies need both historical archives and current content, but this creates tiers where publishers with vast archives can negotiate deals while smaller publishers lack leverage.
Anthropic settled with authors for $1.5 billion after Judge William Alsup’s June ruling in Bartz v. Anthropic. The ruling said training on legally purchased books was fair use. Downloading from pirate sites was infringement.
The settlement shows AI companies can afford to pay even while arguing in court they shouldn’t have to, and it provides a public benchmark other negotiations may reference, though specific terms remain sealed.
Publishers accepting deals cite new revenue streams, legal protection from copyright claims, influence over AI development, and recognition that AI search adoption appears inevitable, with many viewing early partnerships as positioning for future leverage.
Publishers Pursuing Litigation
The New York Times sued OpenAI and Microsoft in 2023. The complaint argues the companies created “a multi-billion-dollar for-profit business built in large part on the unlicensed exploitation of copyrighted works.”
Publishers refusing deals say the money’s too low and worry that accepting bad terms now legitimizes them going forward, plus AI summaries directly compete with their work.
Trade Organization Positions
Danielle Coffey, CEO of News/Media Alliance, called Google’s AI Mode practices “parasitic, unsustainable and pose a real existential threat.” She suggests that AI systems are only as good as the content they use to train them.
Jason Kint of Digital Content Next noted that despite Google sending large monthly revenue checks through advertising, 78% of member digital revenue still comes from ads. Every point of search traffic lost “squeezes the budgets that fund investigative reporting.”
Both organizations demand that AI systems provide transparency, clearly attribute content, respect publishers’ roles, comply with competition laws, and not misrepresent original works.
The Emerging Division: Licensed Web Vs. Open Web
The payment model differences are creating two tiers of web content with different economics.
A “Licensed Web” consists of premium content behind APIs and licensing agreements. Publishers with vast archives, specialized expertise, or unique data sets are negotiating direct access deals with LLM companies. This content gets used for training and real-time retrieval with attribution and compensation.
The “Open Web” includes crawlable pages without licensing agreements. User-generated content, marketing material, commodity information, and sites lacking leverage to negotiate terms. This content may still get crawled and used, but without direct compensation beyond minimal referral traffic.
This setup can lead to mismatched incentives. Publishers investing in differentiated, high-quality content may have licensing options to support their work. Meanwhile, those creating more easily replaceable information might struggle with commoditization, making it harder to find clear ways to earn revenue.
For practitioners, focus on developing your own research, unique data sets, specialized expertise, and original reporting. This increases both traditional search value and potential licensing value to AI platforms.
How Payment Models Are Reshaping SEO And Content Strategy
The shift from traffic to licensing is forcing changes across SEO.
The Citation Vs. Click Problem
Traditional SEO centered on rankings that drove clicks, but LLM citations work differently as content appears in AI answers with attribution, but fewer click-throughs. Lily Ray believes SEO is no longer just about ranking and traffic.
Practitioners are now tracking engagement quality, conversion rates, branded search, and direct traffic alongside traditional metrics. Some are quantifying AI citations across ChatGPT, Perplexity, and other platforms. This provides visibility into brand mentions even when referrals don’t materialize.
Bot Access Becomes A Business Decision
Publishers today find themselves making decisions about blocking content via robots.txt. These choices weren’t even considered two years ago. The decision weighs AI visibility with concerns about potential traffic loss and the benefits of licensing.
Many content publishers are open to allowing bot access, valuing their presence in AI results more than guarding content that competitors also produce. News organizations prioritize speed and broad coverage for breaking stories, aiming to reach as many people as possible.
On the other hand, some publishers choose to restrict access to their high-value research and specialized insights, knowing that scarcity can give them stronger negotiating power. Those with paywalled analysis often block AI crawlers to protect their subscription models, ensuring they maintain control over their most valuable content.
ProRata and TollBit offer selective licensing as a middle ground. Publishers maintain AI visibility while getting paid. But AI companies haven’t widely adopted these platforms.
Measurement Systems Under Pressure
Traffic declines may trigger discussions with stakeholders who expect a recovery, and for sites that rely solely on advertising, this can be a challenging discussion to have.
Publishers are exploring alternative revenue models such as subscriptions, memberships, consulting, events, and affiliate partnerships, while also prioritizing email, newsletters, and apps.
Branded search remains more stable than overall traffic levels, emphasizing the importance of brand-building beyond search rankings.
Content Investment Questions
Payment uncertainty can make it hard to decide what content is worth investing in. Publishers with licensing deals might focus on what AI companies need for training or retrieval, while those without deals have to consider different factors.
The division between Licensed Web and Open Web influences these choices. Original research, unique data, and specialized expertise may justify different levels of investment compared to more common material.
Smaller publishers often lack the leverage of licensing. Creating high-quality content while competing with AI-generated summaries that don’t drive traffic raises ongoing questions about sustainability.
Content Sustainability Concerns
Revenue declines are forcing news organizations to cut staff, reducing investigative capacity and the production of original reporting.
The Society of Authors reports 12,000+ members have written letters saying they “do not consent” to AI training. That signals creative professionals reconsidering publication if compensation doesn’t materialize.
More content is moving behind paywalls, which protects revenue but limits free information access. The News/Media Alliance warns that without fair compensation for publisher content, AI practices pose a significant threat to ongoing investment in journalism.
The challenge is that AI companies really rely on publishers to provide high-quality training data. But AI systems that don’t generate traffic can make it harder for publishers to fund their content creation efforts.
Right now, payment models might work well for big publishers who have more power, but mid-sized and small publishers face more uncertain financial situations.
Those with direct relationships to their audience and multiple sources of income are generally in a stronger position compared to those mainly relying on ads.
What’s Likely Next
Current LLM payment models don’t match what publishers earned from search traffic, and they also don’t reflect what AI companies extract through crawling.
Publishers are dividing into distinct camps, with some angling for deals while others are betting litigation will establish better terms than individual negotiations.
Trade organizations are pushing for regulatory solutions, but AI companies maintain their current approach works. OpenAI points to expanding partnerships and says deals provide fair value. Perplexity argues its revenue-sharing model aligns incentives. Google hasn’t announced plans beyond existing traffic-sharing arrangements.
What happens next depends on litigation outcomes, regulatory action, and whether market pressure forces AI platforms to improve terms.
Multiple paths forward remain possible, and for now, publishers face immediate decisions about bot access, content strategy, and revenue diversification without clarity on which approach will prove sustainable.
A few weeks ago, I was given access to review a confidential OpenAI partner-facing report, the kind of dataset typically made available to a small group of publishers.
For the first time, from the report, we have access to detailed visibility metrics from inside ChatGPT, the kind of data that only a select few OpenAI site partners have ever seen.
This isn’t a dramatic “leak,” but rather an unusual insight into the inner workings of the platform, which will influence the future of SEO and AI-driven publishing over the next decade.
The consequences of this dataset far outweigh any single controversy: AI visibility is skyrocketing, but AI-driven traffic is evaporating.
This is the clearest signal yet that we are leaving the era of “search engines” and entering the era of “decision engines,” where AI agents surface, interpret, and synthesize information without necessarily directing users back to the source.
This forces every publisher, SEO professional, brand, and content strategist to fundamentally reconsider what online visibility really means.
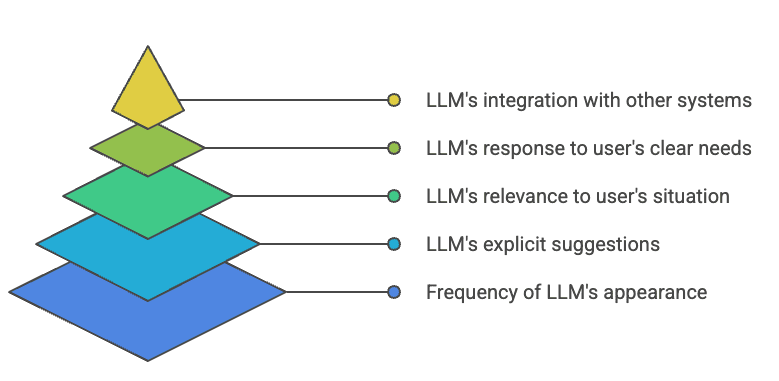
1. What The Report Data Shows: Visibility Without Traffic
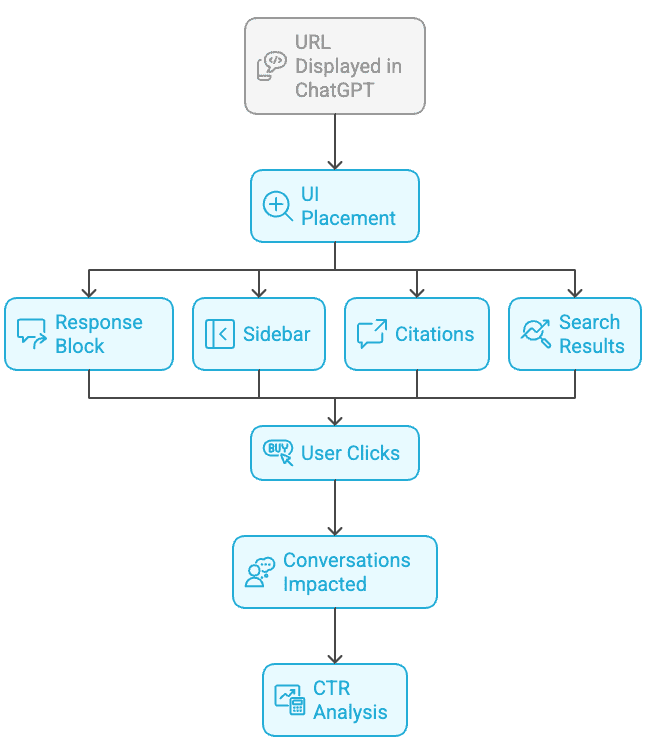
The report dataset gives a large media publisher a full month of visibility. With surprising granularity, it breaks down how often a URL is displayed inside ChatGPT, where it appears inside the UI, how often users click on it, how many conversations it impacts, and the surface-level click-through rate (CTR) across different UI placements.
URL Display And User Interaction In ChaGPT
Image from author, November 2025
The dataset’s top-performing URL recorded 185,000 distinct conversation impressions, meaning it was shown in that many separate ChatGPT sessions.
Of these impressions, 3,800 were click events, yielding a conversation-level CTR of 2%. However, when counting multiple appearances within conversations, the numbers increase to 518,000 total impressions and 4,400 total clicks, reducing the overall CTR to 0.80%.
This is an impressive level of exposure. However, it is not an impressive level of traffic.
Most other URLs performed dramatically worse:
0.5% CTR (considered “good” in this context).
0.1% CTR (typical).
0.01% CTR (common).
0% CTR (extremely common, especially for niche content).
This is not a one-off anomaly; it’s consistent across the entire dataset and matches external studies, including server log analyses by independent SEOs showing sub-1% CTR from ChatGPT sources.
We have experienced this phenomenon before, but never on this scale. Google’s zero-click era was the precursor. ChatGPT is the acceleration. However, there is a crucial difference: Google’s featured snippets were designed to provide quick answers while still encouraging users to click through for more information. In contrast, ChatGPT’s responses are designed to fully satisfy the user’s intent, rendering clicks unnecessary rather than merely optional.
2. The Surface-Level Paradox: Where OpenAI Shows The Most, Users Click The Least
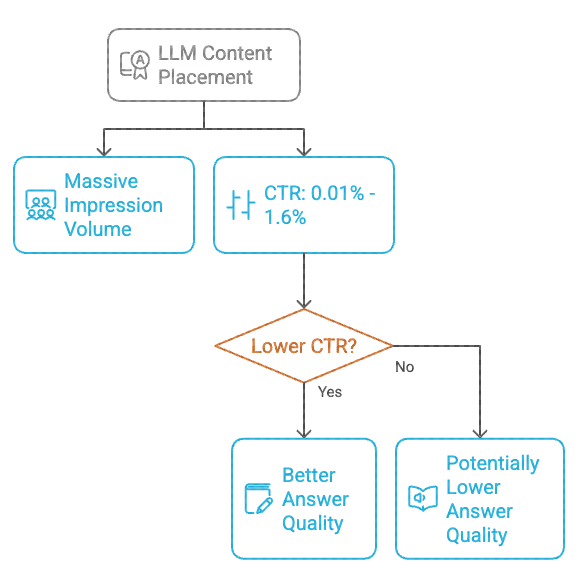
The report breaks down every interaction into UI “surfaces,” revealing one of the most counterintuitive dynamics in modern search behavior. The response block, where LLMs place 95%+ of their content, generates massive impression volume, often 100 times more than other surfaces. However, CTR hovers between 0.01% and 1.6%, and curiously, the lower the CTR, the better the quality of the answer.
LLM Content Placement And CTR Relationship
Image from author, November 2025
This is the new equivalent of “Position Zero,” except now it’s not just zero-click; it’s zero-intent-to-click. The psychology is different from that of Google. When ChatGPT provides a comprehensive answer, users interpret clicking as expressing doubt about the AI’s accuracy, indicating the need for further information that the AI cannot provide, or engaging in academic verification (a relatively rare occurrence). The AI has already solved its problem.
The sidebar tells a different story. This small area has far fewer impressions, but a consistently strong CTR ranging from 6% to 10% in the dataset. This is higher than Google’s organic positions 4 through 10. Users who click here are often exploring related content rather than verifying the main answer. The sidebar represents discovery mode rather than verification mode. Users trust the main answer, but are curious about related information.
Citations at the bottom of responses exhibit similar behavior, achieving a CTR of between 6% and 11% when they appear. However, they are only displayed when ChatGPT explicitly cites sources. These attract academically minded users and fact-checkers. Interestingly, the presence of citations does not increase the CTR of the main answer; it may actually decrease it by providing verification without requiring a click.
Search results are rarely triggered and usually only appear when ChatGPT determines that real-time data is needed. They occasionally show CTR spikes of 2.5% to 4%. However, the sample size is currently too small to be significant for most publishers, although these clicks represent the highest intent when they occur.
The paradox is clear: The more frequently OpenAI displays your content, the fewer clicks it generates. The less frequently it displays your content, the higher the CTR. This overturns 25 years of SEO logic. In traditional search, high visibility correlates with high traffic. In AI-native search, however, high visibility often correlates with information extraction rather than user referral.
“ChatGPT’s ‘main answer’ is a visibility engine, not a traffic engine.”
3. Why CTR Is Collapsing: ChatGPT Is An Endpoint, Not A Gateway
The comments and reactions on LinkedIn threads analyzing this data were strikingly consistent and insightful. Users don’t click because ChatGPT solves their problem for them. Unlike Google, where the answer is a link, ChatGPT provides the answer directly.
This means:
Satisfied users don’t click (they got what they needed).
Curious users sometimes click (they want to explore deeper).
Skeptical users rarely click (they either trust the AI or distrust the entire process).
Very few users feel the need to leave the interface.
As one senior SEO commented:
“Traffic stopped being the metric to optimize for. We’re now optimizing for trust transfer.”
Another analyst wrote:
“If ChatGPT cites my brand as the authority, I’ve already won the user’s trust before they even visit my site. The click is just a formality.”
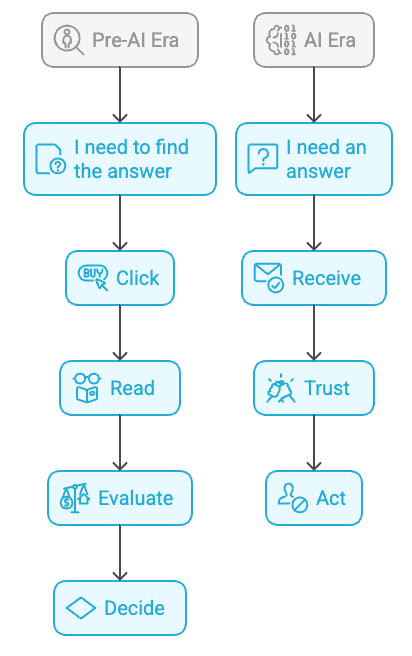
This represents a fundamental shift in how humans consume information. In the pre-AI era, the pattern was: “I need to find the answer” → click → read → evaluate → decide. In the AI era, however, it has become: “I need an answer” → “receive” → “trust” → “act”, with no click required. AI becomes the trusted intermediary. The source becomes the silent authority.
Shift In Information Consumption
Image from author, November 2025
This marks the beginning of what some are calling “Inception SEO”: optimizing for the answer itself, rather than for click-throughs. The goal is no longer to be findable. The goal is to be the source that the AI trusts and quotes.
4. Authority Over Keywords: The New Logic Of AI Retrieval
Traditional SEO relies on indexation and keyword matching. LLMs, however, operate on entirely different principles. They rely on internal model knowledge wherever possible, drawing on trained data acquired through crawls, licensed content, and partnerships. They only fetch external data when the model determines that its internal knowledge is insufficient, outdated, or unverified.
When selecting sources, LLMs prioritize domain authority and trust signals, content clarity and structure, entity recognition and knowledge graph alignment, historical accuracy and factual consistency, and recency for time-sensitive queries. They then decide whether to cite at all based on query type and confidence level.
This leads to a profound shift:
Entity strength becomes more important than keyword coverage.
Consistency and structured content matter more than content volume
Model trust becomes the single most important ranking factor
Factual accuracy over long periods builds cumulative advantage
“You’re no longer competing in an index. You’re competing in the model’s confidence graph.”
This has radical implications. The old SEO logic was “Rank for 1,000 keywords → Get traffic from 1,000 search queries.” The new AI logic is “Become the authoritative entity for 10 topics → Become the default source for 10,000 AI-generated answers.”
In this new landscape, a single, highly authoritative domain has the potential to dominate AI citations across an entire topic cluster. “Long-tail SEO” may become less relevant as AI synthesizes answers rather than matching specific keywords. Topic authority becomes more valuable than keyword authority. Being cited once by ChatGPT can influence millions of downstream answers.
5. The New KPIs: “Share Of Model” And In-Answer Influence
As CTR is declining, brands must embrace metrics that reflect AI-native visibility. The first of these is “share of model presence,” which is how often your brand, entity, or URLs appear in AI-generated answers, regardless of whether they are clicked on or not. This is analogous to “share of voice” in traditional advertising, but instead of measuring presence in paid media, it measures presence in the AI’s reasoning process.
LLM Decision Hierarchy
Image from author, November 2025
How to measure:
Track branded mentions in AI responses across major platforms (ChatGPT, Claude, Perplexity, Google AI Overviews).
Monitor entity recognition in AI-generated content.
Analyze citation frequency in AI responses for your topic area.
LLMs are increasingly producing authoritative statements, such as “According to Publisher X…,” “Experts at Brand Y recommend…,” and “As noted by Industry Leader Z…”
This is the new “brand recall,” except it happens at machine speed and on a massive scale, influencing millions of users without them ever visiting your website. Being directly recommended by an AI is more powerful than ranking No. 1 on Google, as the AI’s endorsement carries algorithmic authority. Users don’t see competing sources; the recommendation is contextualized within their specific query, and it occurs at the exact moment of decision-making.
Then, there’s contextual presence: being part of the reasoning chain even when not explicitly cited. This is the “dark matter” of AI visibility. Your content may inform the AI’s answer without being directly attributed, yet still shape how millions of users understand a topic. When a user asks about the best practices for managing a remote team, for example, the AI might synthesize insights from 50 sources, but only cite three of them explicitly. However, the other 47 sources still influenced the reasoning process. Your authority on this topic has now shaped the answer that millions of users will see.
High-intent queries are another crucial metric. Narrow, bottom-of-funnel prompts still convert, showing a click-through rate (CTR) of between 2.6% and 4%. Such queries usually involve product comparisons, specific instructions requiring visual aids, recent news or events, technical or regulatory specifications requiring primary sources, or academic research requiring citation verification. The strategic implication is clear: Don’t abandon click optimization entirely. Instead, identify the 10-20% of queries where clicks still matter and optimize aggressively for those.
Finally, LLMs judge authority based on what might be called “surrounding ecosystem presence” and cross-platform consistency. This means internal consistency across all your pages; schema and structured data that machines can easily parse; knowledge graph alignment through presence in Wikidata, Wikipedia, and industry databases; cross-domain entity coherence, where authoritative third parties reference you consistently; and temporal consistency, where your authority persists over time.
This holistic entity SEO approach optimizes your entire digital presence as a coherent, trustworthy entity, not individual pages. Traditional SEO metrics cannot capture this shift. Publishers will require new dashboards to track AI citations and mentions, new tools to measure “model share” across LLM platforms, new attribution methodologies in a post-click world, and new frameworks to measure influence without direct traffic.
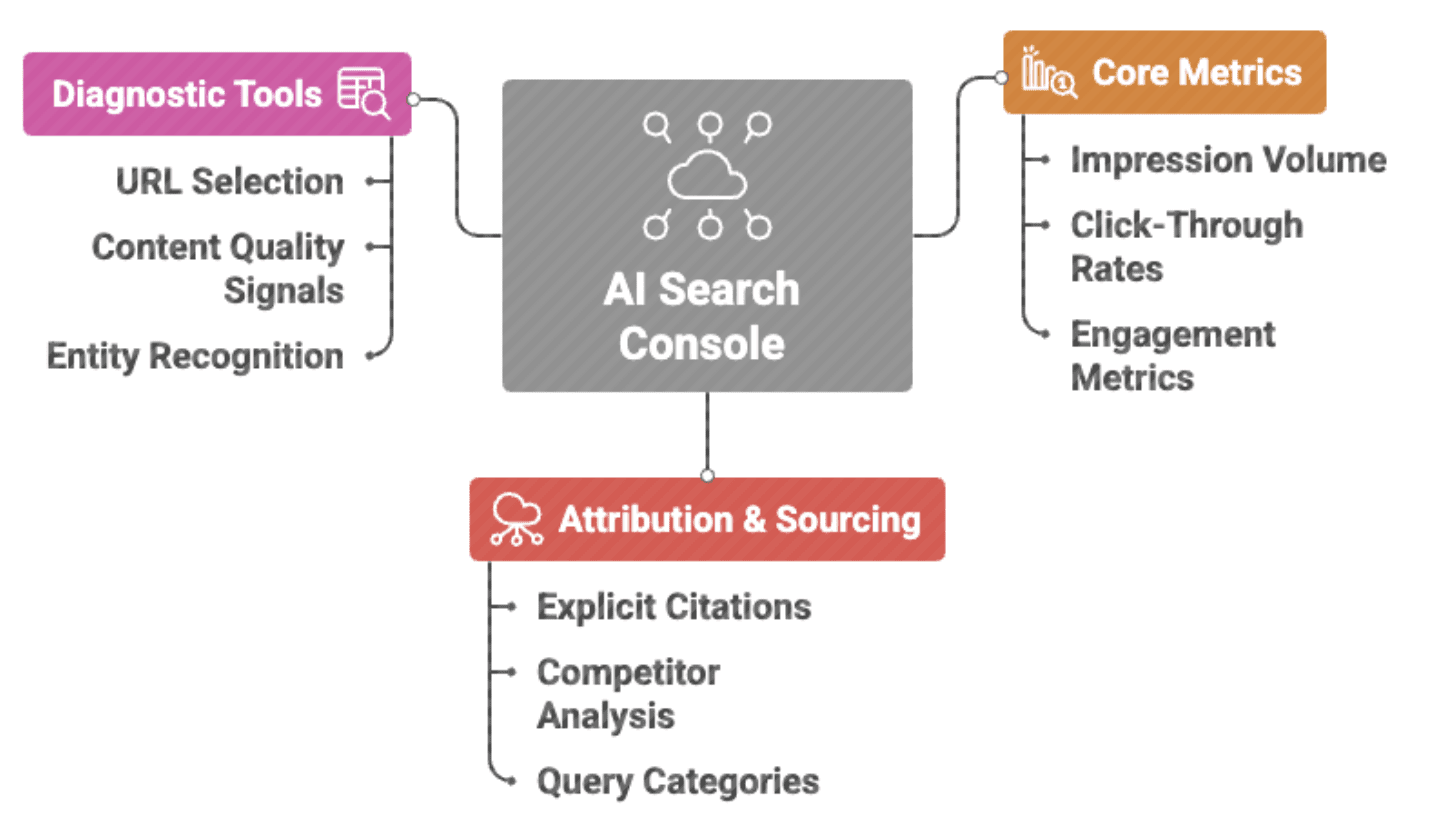
6. Why We Need An “AI Search Console”
Many SEOs immediately saw the same thing in the dataset:
“This looks like the early blueprint for an OpenAI Search Console.”
Right now, publishers cannot:
See how many impressions they receive in ChatGPT.
Measure their inclusion rate across different query types.
Understand how often their brand is cited vs. merely referenced.
Identify which UI surfaces they appear in most frequently.
Correlate ChatGPT visibility with downstream revenue or brand metrics.
Track entity-level impact across the knowledge graph.
Measure how often LLMs fetch real-time data from them.
Understand why they were selected (or not selected) for specific queries.
Compare their visibility to competitors.
Google had “Not Provided,” hiding keyword data. AI platforms may give us “Not Even Observable,” hiding the entire decision-making process. This creates several problems. For publishers, it’s impossible to optimize what you can’t measure; there’s no accountability for AI platforms, and asymmetric information advantages emerge. For the ecosystem, it reduces innovation in content strategy, concentrates power in AI platform providers, and makes it harder to identify and correct AI bias or errors.
Based on this leaked dataset and industry needs, an ideal “AI Search Console” would provide core metrics like impression volume by URL, entity, and topic, surface-level breakdowns, click-through rates, and engagement metrics, conversation-level analytics showing unique sessions, and time-series data showing trends. It would show attribution and sourcing details: how often you’re explicitly cited versus implicitly used, which competitors appear alongside you, query categories where you’re most visible, and confidence scores indicating how much the AI trusts your content.
Diagnostic tools would explain why specific URLs were selected or rejected, what content quality signals the AI detected, your entity recognition status, knowledge graph connectivity, and structured data validation. Optimization recommendations would identify gaps in your entity footprint, content areas where authority is weak, opportunities to improve AI visibility, and competitive intelligence.
OpenAI and other AI platforms will eventually need to provide this data for several reasons. Regulatory pressure from the EU AI Act and similar regulations may require algorithmic transparency. Media partnerships will demand visibility metrics as part of licensing deals. Economic sustainability requires feedback loops for a healthy content ecosystem. And competitive advantage means the first platform to offer comprehensive analytics will attract publisher partnerships.
The dataset we’re analyzing may represent the prototype for what will eventually become standard infrastructure.
AI Search Console
Image from author, November 2025
7. Industry Impact: Media, Monetization, And Regulation
The comments raised significant concerns and opportunities for the media sector. The contrast between Google’s and OpenAI’s economic models is stark. Google contributes to media financing through neighbouring rights payments in the EU and other jurisdictions. It still sends meaningful traffic, albeit declining, and has established economic relationships with publishers. Google also participates in advertising ecosystems that fund content creation.
By contrast, OpenAI and similar AI platforms currently only pay select media partners under private agreements, send almost no traffic with a CTR of less than 1%, extract maximum value from content while providing minimal compensation, and create no advertising ecosystem for publishers.
AI Overviews already reduce organic CTR. ChatGPT takes this trend to its logical conclusion by eliminating almost all traffic. This will force a complete restructuring of business models and raise urgent questions: Should AI platforms pay neighbouring rights like search engines do? Will governments impose compensatory frameworks for content use? Will publishers negotiate direct partnerships with LLM providers? Will new licensing ecosystems emerge for training data, inference, and citation? How should content that is viewed but not clicked on be valued?
Several potential economic models are emerging. One model is citation-based compensation, where platforms pay based on how often content is cited or used. This is similar to music streaming royalties, though transparent metrics are required.
Under licensing agreements, publishers would license content directly to AI platforms, with tiered pricing based on authority and freshness. This is already happening with major outlets such as the Associated Press, Axel Springer, and the Financial Times. Hybrid attribution models would combine citation frequency, impressions, and click-throughs, weighted by query value and user intent, in order to create standardized compensation frameworks.
Regulatory mandates could see governments requiring AI platforms to share revenue with content creators, based on precedents in neighbouring rights law. This could potentially include mandatory arbitration mechanisms.
This would be the biggest shift in digital media economics since Google Ads. Platforms that solve this problem fairly will build sustainable ecosystems. Those that do not will face regulatory intervention and publisher revolts.
8. What Publishers And Brands Must Do Now
Based on the data and expert reactions, an emerging playbook is taking shape. Firstly, publishers must prioritize inclusion over clicks. The real goal is to be part of the solution, not to generate a spike in traffic. This involves creating comprehensive, authoritative content that AI can synthesize, prioritizing clarity and factual accuracy over tricks to boost engagement, structuring content so that key facts can be easily extracted, and establishing topic authority rather than chasing individual keywords.
Strengthening your entity footprint is equally critical. Every brand, author, product, and concept must be machine-readable and consistent. Publishers should ensure their entity exists on Wikidata and Wikipedia, maintain consistent NAP (name, address, phone number) details across all properties, implement comprehensive schema markup, create and maintain knowledge graph entries, build structured product catalogues, and establish clear entity relationships, linking companies to people, products, and topics.
Building trust signals for retrieval is important because LLMs prioritize high-authority, clearly structured, low-ambiguity content. These trust signals include:
Authorship transparency, with clear author bios, credentials, and expertise.
Editorial standards, covering fact-checking, corrections policies, and sourcing.
Domain authority, built through age, backlink profile, and industry recognition.
Structured data, via schema implementation and rich snippets.
Factual consistency, maintaining accuracy over time without contradictions.
Expert verification, through third-party endorsements and citations.
Publishers should not abandon click optimization entirely. Instead, they should target bottom-funnel prompts that still demonstrate a measurable click-through rate (CTR) of between 2% and 4%, since AI responses are insufficient.
Examples of high-CTR queries:
“How to configure [specific technical setup]” (requires visuals or code).
“Latest news on [breaking event]” (requires recency).
“Where to buy [specific product]” (transactional intent).
“[Company] careers” (requires job portal access).
Strategy: Identify the 10–20% of your topic space where AI cannot fully satisfy user intent, and optimize those pages for clicks.
In terms of content, it is important to lead with the most important information, use clear and definitive language, cite primary sources, avoid ambiguity and hedging unless accuracy requires it, and create content that remains accurate over long timeframes.
Perhaps the most important shift is mental: Stop thinking in terms of traffic and start thinking in terms of influence. Value has shifted from visits to the reasoning process itself. New success metrics should track how often you are cited by AI, the percentage of AI responses in your field that mention you, how your “share of model” compares with that of your competitors, whether you are building cumulative authority that persists across model updates, and whether AI recognizes you as the definitive source for your core topics.
The strategic focus shifts from “drive 1 million monthly visitors” to “influence 10 million AI-mediated decisions.”
Publishers must also diversify their revenue streams so that they are not dependent on traffic-based monetization. Alternative models include building direct relationships with audiences through email lists, newsletters, and memberships; offering premium content via paywalls, subscriptions, and exclusive access; integrating commerce through affiliate programmes, product sales, and services; forming B2B partnerships to offer white-label content, API access, and data licensing; and negotiating deals with AI platforms for direct compensation for content use.
Publishers that control the relationship with their audience rather than depending on intermediary platforms will thrive.
The Super-Predator Paradox
A fundamental truth about artificial intelligence is often overlooked: these systems do not generate content independently; they rely entirely on the accumulated work of millions of human creators, including journalism, research, technical documentation, and creative writing, which form the foundation upon which every model is built. This dependency is the reason why OpenAI has been pursuing licensing deals with major publishers so aggressively. It is not an act of corporate philanthropy, but an existential necessity. A language model that is only trained on historical data becomes increasingly disconnected from the current reality with each passing day. It is unable to detect breaking news or update its understanding through pure inference. It is also unable to invent ground truth from computational power alone.
This creates what I call the “super-predator paradox”: If OpenAI succeeds in completely disrupting traditional web traffic, causing publishers to collapse and the flow of new, high-quality content to slow to a trickle, the model’s training data will become increasingly stale. Its understanding of current events will degrade, and users will begin to notice that the responses feel outdated and disconnected from reality. In effect, the super-predator will have devoured its ecosystem and will now find itself starving in a content desert of its own creation.
The paradox is inescapable and suggests two very different possible futures. In one, OpenAI continues to treat publishers as obstacles rather than partners. This would lead to the collapse of the content ecosystem and the AI systems that depend on it. In the other, OpenAI shares value with publishers through sustainable compensation models, attribution systems, and partnerships. This would ensure that creators can continue their work. The difference between these futures is not primarily technological; the tools to build sustainable, creator-compensating AI systems largely exist today. Rather, it is a matter of strategic vision and willingness to recognize that, if artificial intelligence is to become the universal interface for human knowledge, it must sustain the world from which it learns rather than cannibalize it for short-term gain. The next decade will be defined not by who builds the most powerful model, but by who builds the most sustainable one by who solves the super-predator paradox before it becomes an extinction event for both the content ecosystem and the AI systems that cannot survive without it.
Note: All data and stats cited above are from the Open AI partner report, unless otherwise indicated.
In a recent interview with the BBC, Sundar Pichai emphasized that AI is not a standalone source of information. He affirmed that AI works together with search and that AI and Search have their uses. Pichai also said that AI is not a replacement for either search, the information ecosystem, or actual subject matter experts.
A number of tweets and articles mischaracterized Pichai’s remarks, including a BBC News social media post summarizing the interview with the line, “Don’t blindly trust what AI tells you.”
That phrasing misleadingly suggests that Pichai said don’t trust AI. But that’s not what Pichai meant. His full answer emphasized that AI is not a standalone source of information, that the information ecosystem is greater than that.
AI Makes Mistakes, That’s Why There’s Grounding
Sundar Pichai had just finished describing how AI will, in a few years time, usher in new opportunities and create new kinds of jobs based on what humans can do with AI. He used the example of envisioning a feature-length movie.
In response to that statement, the interviewer challenged Pichai with a question about the fallibility of AI, saying that what Pichai described is built on the assumption that AI works.
Pichai’s statement was broadly about how people will use AI in a few years time. The interviewer’s question was narrowly focused on the accuracy and truth of AI. The conversation between the interviewer and Pichai contained this dynamic, where the interviewer kept narrowing the focus to AI in isolation and Pichai kept broadening the focus to the wider information ecosystem within which AI exists.
The interviewer keeps pressing Pichai with variations of the same narrow question:
Is AI reliable?
Doesn’t AI make information less reliable?
Shouldn’t Google be held responsible because this model was invented there?
Pichai repeatedly answers by placing AI within a wider context:
AI is not the only system people use.
Search and other grounded sources remain essential.
Journalism, doctors, teachers, and other experts matter.
The information ecosystem is larger than AI.
The interviewer kept zooming in to look at the AI “tree,” and Pichai responded by zooming out to explain AI within the context of the information ecosystem “forest.” This is the key to understanding what Pichai means by his answers.
In response to Pichai’s statements of how AI will transform society in the coming years, the interviewer asked about the truthfulness of AI today:
“So all of the hopes, the hype, the valuations, the social benefit of this transformation you’ve just described, you’ve built on a central assumption that the technology functions, that it works.
Let me propose one simple test of Gemini, which is your booming ChatGPT kind of competitor. Is it accurate always? Does it tell the truth?”
Pichai explained that generative AI is not a source of truth, it’s simply making a statistical prediction of how to respond. In that context he said that Google Search is what grounds AI in facts and truth. Grounding is a system for anchoring generative AI with real-world facts instead of relying on its training data.
Pichai responded:
“Look, we are working hard from a scientific standpoint to ground it in real world information. And there are areas, part of what we’ve done with Gemini is we’ve brought the power of Google Search. So it uses Google Search as a tool to try and answer, to give answers more accurately. But there are moments, these AI models fundamentally have a technology by which they’re predicting what’s next, and they are prone to errors.”
Use Tools For What They’re Good At
The next part of Pichai’s answer underlines the fact that AI and Search are tools that people use for different purposes. The point he is making is that AI is not a standalone technology that has replaced Search. He said to use each tool for “what they’re good at.”
Pichai explained:
“Today, I think, we take pride in the amount of work we put in to give as accurate information as possible. But the current state-of-the-art AI technology is prone to some errors.
This is why people also use Google Search, and we have other products which are more grounded in providing accurate information, right? But the same tools are helpful if you want to creatively write something.
So you have to learn to use these tools for what they’re good at and not blindly trust everything they say.”
Not One Standalone System: The Information Ecosystem Matters
The interviewer echoed Pichai’s statement about not blindly trusting then challenged him again about reliability.
The interviewer asked:
“OK, don’t blindly trust.
But let me suggest to you that you have a special responsibility because this whole model, type of model, transformer model, the T in ChatGPT, was invented here under you. And you know that it’s a probability. And I just wonder if you accept the end result of all this fantastic investment is the information is less reliable?”
Pichai returned to his first answer, that AI is not all that there is, that AI is just one source of information from a great many sources, including from actual human experts. The interviewer was trying to pin Pichai down to talking about generative AI and Pichai was answering by saying that it’s not just AI.
Pichai explained:
“I think if you only construct systems standalone, and you only rely on that, that would be true.
Which is why I think we have to make the information ecosystem… has to be much richer than just having AI technology being the sole product in it.
…Truth matters. Journalism matters. All of the surrounding things we have today matters, right?
So if you’re a student, you’re talking to your teacher.
If as a consumer, you’re going to a doctor, you want to trust your doctor.
Yeah, all of that matters.”
Pichai’s point is that AI exists within a larger world tools, human knowledge and expertise, not as a replacement for it. His emphasis on teachers, doctors, and journalism shows that human expertise remains a high standard for truth and accuracy. Pichai declined to answer questions in a way that treated AI as the sole system for answers. Instead, he kept emphasizing that AI is only one part of where we get information.
This is why Pichai’s answer cannot be reduced to a click-baity line like “Don’t blindly trust what AI tells you, says Google’s Sundar Pichai.” The deeper message is about how he, and by extension, Google, views AI as one tool out of many.
Google Ads quietly unveiled a tool in October called “Investment Strategy” that suggests short-term tactics to improve performance. Located in the Recommendations tab, the feature shows all campaigns and the impact of various budget changes.
Investment Strategy is akin to Google’s existing budget simulators, with two main differences. First, it focuses on the next seven days rather than a long-term forecast.
Second, it’s centralized at the account level; bid simulators apply to specific campaigns or portfolios. It displays all budget-restricted campaigns in one view and can run projections accordingly.
To launch Investment Strategy, first choose your primary campaign metric:
Conversions,
Conversion value [revenue],
Clicks.
You’ll then see the projected impact on your account if all campaigns are unrestricted by budget.
The new Investment Strategy tool projects the performance impact assuming campaigns have unlimited budgets.
Choose which campaign changes are appropriate, as many likely won’t apply. The example below showcases the projected changes to “Avg. ROAS” and “Weekly conversion value” from Google’s recommendations.
Choose which campaign changes are appropriate, as many likely won’t apply.
I may or may not implement Google’s suggestions. I could instead toggle for the impact of varying budgets.
For example, say a client allocates an extra $10,000 for the remainder of the month. I can revise Google’s recommended budgets to determine which campaigns receive the spend.
Projection Tools
Google has long offered Performance Planner to recommend spending for a long-term outcome. Advertisers can view performance projections up to one year and optionally simulate the impact of custom conversion rates.
Thus Performance Planner is worthwhile for extended planning, while Investment Strategy recommendations are immediate and highly beneficial during, for instance, Cyber Week or back-to-school promotions.
Here’s an overview of Google Ads budget and strategy tools:
Campaign budget and bid strategy. On-demand recommendations in individual campaigns.
Performance Planner. Projections up to one year of performance by spend.
Investment Strategy. The seven-day performance impact of budget changes to a campaign based on an advertiser’s primary goal.
I’m encouraged by the Investment Strategy tool because it’s quick and easy to understand. It projects the metrics that matter most: spend vs. performance. What’s missing are fields for target cost per conversion (tCPA) and target return on ad spend (tROAS). Both would help advertisers project incremental gains within their goals.
Google will likely consolidate all budgeting and bid strategy recommendations under Investment Strategy, resulting in a single portal for tactical and budgeting guidance.
Nonetheless, I advise caution. Google’s projections may not apply to your products, budget, or goals. Carefully determine which, if any, to implement and then monitor closely.
In January 2024, the phone rang in homes all around New Hampshire. On the other end was Joe Biden’s voice, urging Democrats to “save your vote” by skipping the primary. It sounded authentic, but it wasn’t. The call was a fake, generated by artificial intelligence.
Today, the technology behind that hoax looks quaint. Tools like OpenAI’s Sora now make it possible to create convincing synthetic videos with astonishing ease. AI can be used to fabricate messages from politicians and celebrities—even entire news clips—in minutes. The fear that elections could be overwhelmed by realistic fake media has gone mainstream—and for good reason.
But that’s only half the story. The deeper threat isn’t that AI can just imitate people—it’s that it can actively persuade people. And new research published this week shows just how powerful that persuasion can be. In two large peer-reviewed studies, AI chatbots shifted voters’ views by a substantial margin, far more than traditional political advertising tends to do.
In the coming years, we will see the rise of AI that can personalize arguments, test what works, and quietly reshape political views at scale. That shift—from imitation to active persuasion—should worry us deeply.
The challenge is that modern AI doesn’t just copy voices or faces; it holds conversations, reads emotions, and tailors its tone to persuade. And it can now command other AIs—directing image, video, and voice models to generate the most convincing content for each target. Putting these pieces together, it’s not hard to imagine how one could build a coordinated persuasion machine. One AI might write the message, another could create the visuals, another could distribute it across platforms and watch what works. No humans required.
A decade ago, mounting an effective online influence campaign typically meant deploying armies of people running fake accounts and meme farms. Now that kind of work can be automated—cheaply and invisibly. The same technology that powers customer service bots and tutoring apps can be repurposed to nudge political opinions or amplify a government’s preferred narrative. And the persuasion doesn’t have to be confined to ads or robocalls. It can be woven into the tools people already use every day—social media feeds, language learning apps, dating platforms, or even voice assistants built and sold by parties trying to influence the American public. That kind of influence could come from malicious actors using the APIs of popular AI tools people already rely on, or from entirely new apps built with the persuasion baked in from the start.
And it’s affordable. For less than a million dollars, anyone can generate personalized, conversational messages for every registered voter in America. The math isn’t complicated. Assume 10 brief exchanges per person—around 2,700 tokens of text—and price them at current rates for ChatGPT’s API. Even with a population of 174 million registered voters, the total still comes in under $1 million. The 80,000 swing voters who decided the 2016 election could be targeted for less than $3,000.
Although this is a challenge in elections across the world, the stakes for the United States are especially high, given the scale of its elections and the attention they attract from foreign actors. If the US doesn’t move fast, the next presidential election in 2028, or even the midterms in 2026, could be won by whoever automates persuasion first.
The 2028 threat
While there have been indications that the threat AI poses to elections is overblown, a growing body of research suggests the situation could be changing. Recent studies have shown that GPT-4 can exceed the persuasive capabilities of communications experts when generating statements on polarizing US political topics, and it is more persuasive than non-expert humans two-thirds of the time when debating real voters.
Two major studies published yesterday extend those findings to real election contexts in the United States, Canada, Poland, and the United Kingdom, showing that brief chatbot conversations can move voters’ attitudes by up to 10 percentage points, with US participant opinions shifting nearly four times more than it did in response to tested 2016 and 2020 political ads. And when models were explicitly optimized for persuasion, the shift soared to 25 percentage points—an almost unfathomable difference.
While previously confined to well-resourced companies, modern large language models are becoming increasingly easy to use. Major AI providers like OpenAI, Anthropic, and Google wrap their frontier models in usage policies, automated safety filters, and account-level monitoring, and they do sometimes suspend users who violate those rules. But those restrictions apply only to traffic that goes through their platforms; they don’t extend to the rapidly growing ecosystem of open-source and open-weight models, which can be downloaded by anyone with an internet connection. Though they’re usually smaller and less capable than their commercial counterparts, research has shown with careful prompting and fine-tuning, these models can now match the performance of leading commercial systems.
All this means that actors, whether well-resourced organizations or grassroots collectives, have a clear path to deploying politically persuasive AI at scale. Early demonstrations have already occurred elsewhere in the world. In India’s 2024 general election, tens of millions of dollars were reportedly spent on AI to segment voters, identify swing voters, deliver personalized messaging through robocalls and chatbots, and more. In Taiwan, officials and researchers have documented China-linked operations using generative AI to produce more subtle disinformation, ranging from deepfakes to language model outputs that are biased toward messaging approved by the Chinese Communist Party.
It’s only a matter of time before this technology comes to US elections—if it hasn’t already. Foreign adversaries are well positioned to move first. China, Russia, Iran, and others already maintain networks of troll farms, bot accounts, and covert influence operators. Paired with open-source language models that generate fluent and localized political content, those operations can be supercharged. In fact, there is no longer a need for human operators who understand the language or the context. With light tuning, a model can impersonate a neighborhood organizer, a union rep, or a disaffected parent without a person ever setting foot in the country. Political campaigns themselves will likely be close behind. Every major operation already segments voters, tests messages, and optimizes delivery. AI lowers the cost of doing all that. Instead of poll-testing a slogan, a campaign can generate hundreds of arguments, deliver them one on one, and watch in real time which ones shift opinions.
The underlying fact is simple: Persuasion has become effective and cheap. Campaigns, PACs, foreign actors, advocacy groups, and opportunists are all playing on the same field—and there are very few rules.
The policy vacuum
Most policymakers have not caught up. Over the past several years, legislators in the US have focused on deepfakes but have ignored the wider persuasive threat.
Foreign governments have begun to take the problem more seriously. The European Union’s 2024 AI Act classifies election-related persuasion as a “high-risk” use case. Any system designed to influence voting behavior is now subject to strict requirements. Administrative tools, like AI systems used to plan campaign events or optimize logistics, are exempt. However, tools that aim to shape political beliefs or voting decisions are not.
By contrast, the United States has so far refused to draw any meaningful lines. There are no binding rules about what constitutes a political influence operation, no external standards to guide enforcement, and no shared infrastructure for tracking AI-generated persuasion across platforms. The federal and state governments have gestured toward regulation—the Federal Election Commission is applying old fraud provisions, the Federal Communications Commission has proposed narrow disclosure rules for broadcast ads, and a handful of states have passed deepfake laws—but these efforts are piecemeal and leave most digital campaigning untouched.
In practice, the responsibility for detecting and dismantling covert campaigns has been left almost entirely to private companies, each with its own rules, incentives, and blind spots. Google and Meta have adopted policies requiring disclosure when political ads are generated using AI. X has remained largely silent on this, while TikTok bans all paid political advertising. However, these rules, modest as they are, cover only the sliver of content that is bought and publicly displayed. They say almost nothing about the unpaid, private persuasion campaigns that may matter most.
To their credit, some firms have begun publishing periodic threat reports identifying covert influence campaigns. Anthropic, OpenAI, Meta, and Google have all disclosed takedowns of inauthentic accounts. However, these efforts are voluntary and not subject to independent auditing. Most important, none of this prevents determined actors from bypassing platform restrictions altogether with open-source models and off-platform infrastructure.
What a real strategy would look like
The United States does not need to ban AI from political life. Some applications may even strengthen democracy. A well-designed candidate chatbot could help voters understand where the candidate stands on key issues, answer questions directly, or translate complex policy into plain language. Research has even shown that AI can reduce belief in conspiracy theories.
Still, there are a few things the United States should do to protect against the threat of AI persuasion. First, it must guard against foreign-made political technology with built-in persuasion capabilities. Adversarial political technology could take the form of a foreign-produced video game where in-game characters echo political talking points, a social media platform whose recommendation algorithm tilts toward certain narratives, or a language learning app that slips subtle messages into daily lessons. Evaluations, such as the Center for AI Standards and Innovation’s recent analysis of DeepSeek, should focus on identifying and assessing AI products—particularly from countries like China, Russia, or Iran—before they are widely deployed. This effort would require coordination among intelligence agencies, regulators, and platforms to spot and address risks.
Second, the United States should lead in shaping the rules around AI-driven persuasion. That includes tightening access to computing power for large-scale foreign persuasion efforts, since many actors will either rent existing models or lease the GPU capacity to train their own. It also means establishing clear technical standards—through governments, standards bodies, and voluntary industry commitments—for how AI systems capable of generating political content should operate, especially during sensitive election periods. And domestically, the United States needs to determine what kinds of disclosures should apply to AI-generated political messaging while navigating First Amendment concerns.
Finally, foreign adversaries will try to evade these safeguards—using offshore servers, open-source models, or intermediaries in third countries. That is why the United States also needs a foreign policy response. Multilateral election integrity agreements should codify a basic norm: States that deploy AI systems to manipulate another country’s electorate risk coordinated sanctions and public exposure.
Doing so will likely involve building shared monitoring infrastructure, aligning disclosure and provenance standards, and being prepared to conduct coordinated takedowns of cross-border persuasion campaigns—because many of these operations are already moving into opaque spaces where our current detection tools are weak. The US should also push to make election manipulation part of the broader agenda at forums like the G7 and OECD, ensuring that threats related to AI persuasion are treated not as isolated tech problems but as collective security challenges.
Indeed, the task of securing elections cannot fall to the United States alone. A functioning radar system for AI persuasion will require partnerships with our partners and allies. Influence campaigns are rarely confined by borders, and open-source models and offshore servers will always exist. The goal is not to eliminate them but to raise the cost of misuse and shrink the window in which they can operate undetected across jurisdictions.
The era of AI persuasion is just around the corner, and America’s adversaries are prepared. In the US, on the other hand, the laws are out of date, the guardrails too narrow, and the oversight largely voluntary. If the last decade was shaped by viral lies and doctored videos, the next will be shaped by a subtler force: messages that sound reasonable, familiar, and just persuasive enough to change hearts and minds.
For China, Russia, Iran, and others, exploiting America’s open information ecosystem is a strategic opportunity. We need a strategy that treats AI persuasion not as a distant threat but as a present fact. That means soberly assessing the risks to democratic discourse, putting real standards in place, and building a technical and legal infrastructure around them. Because if we wait until we can see it happening, it will already be too late.
Tal Feldman is a JD candidate at Yale Law School who focuses on technology and national security. Before law school, he built AI models across the federal government and was a Schwarzman and Truman scholar. Aneesh Pappu is a PhD student and Knight-Hennessy scholar at Stanford University who focuses on agentic AI and technology policy. Before Stanford, he was a privacy and security researcher at Google DeepMind and a Marshall scholar.
One day this fall, I watched an electronic sign outside the Broadway-Lafayette subway station in Manhattan switch seamlessly between an ad for makeup and one promoting the website Pickyourbaby.com, which promises a way for potential parents to use genetic tests to influence their baby’s traits, including eye color, hair color, and IQ.
Inside the station, every surface was wrapped with more ads—babies on turnstiles, on staircases, on banners overhead. “Think about it. Makeup and then genetic optimization,” exulted Kian Sadeghi, the 26-year-old founder of Nucleus Genomics, the startup running the ads. To his mind, one should be as accessible as the other.
Nucleus is a young, attention-seeking genetic software company that says it can analyze genetic tests on IVF embryos to score them for 2,000 traits and disease risks, letting parents pick some and reject others. This is possible because of how our DNA shapes us, sometimes powerfully. As one of the subway banners reminded the New York riders: “Height is 80% genetic.”
The day after the campaign launched, Sadeghi and I had briefly sparred online. He’d been on X showing off a phone app where parents can click through traits like eye color and hair color. I snapped back that all this sounded a lot like Uber Eats—another crappy, frictionless future invented by entrepreneurs, but this time you’d click for a baby.
I agreed to meet Sadeghi that night in the station under a banner that read, “IQ is 50% genetic.” He appeared in a puffer jacket and told me the campaign would soon spread to 1,000 train cars. Not long ago, this was a secretive technology to whisper about at Silicon Valley dinner parties. But now? “Look at the stairs. The entire subway is genetic optimization. We’re bringing it mainstream,” he said. “I mean, like, we are normalizing it, right?”
Normalizing what, exactly? The ability to choose embryos on the basis of predicted traits could lead to healthier people. But the traits mentioned in the subway—height and IQ—focus the public’s mind toward cosmetic choices and even naked discrimination. “I think people are going to read this and start realizing: Wow, it is now an option that I can pick. I can have a taller, smarter, healthier baby,” says Sadeghi.
Entrepreneur Kian Sadeghi stands under advertising banner in the Broadway-Lafayette subway station in Manhattan, part of a campaign called “Have Your Best Baby.”
COURTESY OF THE AUTHOR
Nucleus got its seed funding from Founders Fund, an investment firm known for its love of contrarian bets. And embryo scoring fits right in—it’s an unpopular concept, and professional groups say the genetic predictions aren’t reliable. So far, leading IVF clinics still refuse to offer these tests. Doctors worry, among other things, that they’ll create unrealistic parental expectations. What if little Johnny doesn’t do as well on the SAT as his embryo score predicted?
The ad blitz is a way to end-run such gatekeepers: If a clinic won’t agree to order the test, would-be parents can take their business elsewhere. Another embryo testing company, Orchid, notes that high consumer demand emboldened Uber’s early incursions into regulated taxi markets. “Doctors are essentially being shoved in the direction of using it, not because they want to, but because they will lose patients if they don’t,” Orchid founder Noor Siddiqui said during an online event this past August.
Sadeghi prefers to compare his startup to Airbnb. He hopes it can link customers to clinics, becoming a digital “funnel” offering a “better experience” for everyone. He notes that Nucleus ads don’t mention DNA or any details of how the scoring technique works. That’s not the point. In advertising, you sell the sizzle, not the steak. And in Nucleus’s ad copy, what sizzles is height, smarts, and light-colored eyes.
It makes you wonder if the ads should be permitted. Indeed, I learned from Sadeghi that the Metropolitan Transportation Authority had objected to parts of the campaign. The metro agency, for instance, did not let Nucleus run ads saying “Have a girl” and “Have a boy,” even though it’s very easy to identify the sex of an embryo using a genetic test. The reason was an MTA policy that forbids using government-owned infrastructure to promote “invidious discrimination” against protected classes, which include race, religion and biological sex.
Since 2023, New York City has also included height and weight in its anti-discrimination law, the idea being to “root out bias” related to body size in housing and in public spaces. So I’m not sure why the MTA let Nucleus declare that height is 80% genetic. (The MTA advertising department didn’t respond to questions.) Perhaps it’s because the statement is a factual claim, not an explicit call to action. But we all know what to do: Pick the tall one and leave shorty in the IVF freezer, never to be born.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
AI chatbots can sway voters better than political advertisements
The news: Chatting with a politically biased AI model is more effective than political ads at nudging both Democrats and Republicans to support presidential candidates of the opposing party, new research shows.
The catch: The chatbots swayed opinions by citing facts and evidence, but they were not always accurate—in fact, the researchers found, the most persuasive models said the most untrue things. The findings are the latest in an emerging body of research demonstrating the persuasive power of LLMs. They raise profound questions about how generative AI could reshape elections. Read the full story.
—Michelle Kim
The era of AI persuasion in elections is about to begin
—Tal Feldman is a JD candidate at Yale Law School who focuses on technology and national security. Aneesh Pappu is a PhD student and Knight-Hennessy scholar at Stanford University who focuses on agentic AI and technology policy.
The fear that elections could be overwhelmed by AI-generated realistic fake media has gone mainstream—and for good reason.
But that’s only half the story. The deeper threat isn’t that AI can just imitate people—it’s that it can actively persuade people. And new research published this week shows just how powerful that persuasion can be. AI chatbots can shift voters’ views by a substantial margin, far more than traditional political advertising tends to do.
In the coming years, we will see the rise of AI that can personalize arguments, test what works, and quietly reshape political views at scale. That shift—from imitation to active persuasion—should worry us deeply. Read the full story.
The ads that sell the sizzle of genetic trait discrimination
—Antonio Regalado, senior editor for biomedicine
One day this fall, I watched an electronic sign outside the Broadway-Lafayette subway station in Manhattan switch seamlessly between an ad for makeup and one promoting the website Pickyourbaby.com, which promises a way for potential parents to use genetic tests to influence their baby’s traits, including eye color, hair color, and IQ.
Inside the station, every surface was wrapped with more of its ads—babies on turnstiles, on staircases, on banners overhead. “Think about it. Makeup and then genetic optimization,” exulted Kian Sadeghi, the 26-year-old founder of Nucleus Genomics, the startup running the ads.
The day after the campaign launched, Sadeghi and I had briefly sparred online. He’d been on X showing off a phone app where parents can click through traits like eye color and hair color. I snapped back that all this sounded a lot like Uber Eats—another crappy, frictionless future invented by entrepreneurs, but this time you’d click for a baby.
This story first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 The metaverse’s future looks murkier than ever OG believer Mark Zuckerberg is planning deep cuts to the division’s budget. (Bloomberg $) + However some of that money will be diverted toward smart glasses and wearables. (NYT $) + Meta just managed to poach one of Apple’s top design chiefs. (Bloomberg $)
2 Kids are effectively AI’s guinea pigs And regulators are slowly starting to take note of the risks. (The Economist $) + You need to talk to your kid about AI. Here are 6 things you should say. (MIT Technology Review)
3 How a group of women changed UK law on non-consensual deepfakes It’s a big victory, and they managed to secure it with stunning speed. (The Guardian) + But bans on deepfakes take us only so far—here’s what else we need. (MIT Technology Review) + An AI image generator startup just leaked a huge trove of nude images. (Wired $)
4 OpenAI is acquiring an AI model training startup Its researchers have been impressed by the monitoring and de-bugging tools built by Neptune. (NBC) + It’s not just you: the speed of AI deal-making really is accelerating. (NYT $)
5 Russia has blocked Apple’s FaceTime video calling feature It seems the Kremlin views any platform it doesn’t control as dangerous. (Reuters $) + How Russia killed its tech industry. (MIT Technology Review)
6 The trouble with AI browsers This reviewer tested five of them and found them to be far more effort than they’re worth. (The Verge $) + AI means the end of internet search as we’ve known it. (MIT Technology Review)
7 An anti-AI activist has disappeared Sam Kirchner went AWOL after failing to show up at a scheduled court hearing, and friends are worried. (The Atlantic$)
8 Taiwanese chip workers are creating a community in the Arizona desert A TSMC project to build chip factories is rapidly transforming this corner of the US. (NYT $)
9 This hearing aid has become a status symbol Rich people with hearing issues swear by a product made by startup Fortell. (Wired $) + Apple AirPods can be a gateway hearing aid. (MIT Technology Review)
10 A plane crashed after one of its 3D-printed parts melted Just because you can do something, that doesn’t mean you should. (BBC)
Quote of the day
“Some people claim we can scale up current technology and get to general intelligence…I think that’s bullshit, if you’ll pardon my French.”
—AI researcher Yann LeCun explains why he’s leaving Meta to set up a world-model startup, Sifted reports.
One more thing
ILLUSTRATION SOURCES: NATIONAL HUMAN GENOME RESEARCH INSTITUTE
What to expect when you’re expecting an extra X or Y chromosome
Sex chromosome variations, in which people have a surplus or missing X or Y, occur in as many as one in 400 births. Yet the majority of people affected don’t even know they have them, because these conditions can fly under the radar.
As more expectant parents opt for noninvasive prenatal testing in hopes of ruling out serious conditions, many of them are surprised to discover instead that their fetus has a far less severe—but far less well-known—condition.
And because so many sex chromosome variations have historically gone undiagnosed, many ob-gyns are not familiar with these conditions, leaving families to navigate the unexpected news on their own. Read the full story.
—Bonnie Rochman
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
The past year has marked a turning point in the corporate AI conversation. After a period of eager experimentation, organizations are now confronting a more complex reality: While investment in AI has never been higher, the path from pilot to production remains elusive. Three-quarters of enterprises remain stuck in experimentation mode, despite mounting pressure to convert early tests into operational gains.
“Most organizations can suffer from what we like to call PTSD, or process technology skills and data challenges,” says Shirley Hung, partner at Everest Group. “They have rigid, fragmented workflows that don’t adapt well to change, technology systems that don’t speak to each other, talent that is really immersed in low-value tasks rather than creating high impact. And they are buried in endless streams of information, but no unified fabric to tie it all together.”
The central challenge, then, lies in rethinking how people, processes, and technology work together.
Across industries as different as customer experience and agricultural equipment, the same pattern is emerging: Traditional organizational structures—centralized decision-making, fragmented workflows, data spread across incompatible systems—are proving too rigid to support agentic AI. To unlock value, leaders must rethink how decisions are made, how work is executed, and what humans should uniquely contribute.
“It is very important that humans continue to verify the content. And that is where you’re going to see more energy being put into,” Ryan Peterson, EVP and chief product officer at Concentrix.
Much of the conversation centered on what can be described as the next major unlock: operationalizing human-AI collaboration. Rather than positioning AI as a standalone tool or a “virtual worker,” this approach reframes AI as a system-level capability that augments human judgment, accelerates execution, and reimagines work from end to end. That shift requires organizations to map the value they want to create; design workflows that blend human oversight with AI-driven automation; and build the data, governance, and security foundations that make these systems trustworthy.
“My advice would be to expect some delays because you need to make sure you secure the data,” says Heidi Hough, VP for North America aftermarket at Valmont. “As you think about commercializing or operationalizing any piece of using AI, if you start from ground zero and have governance at the forefront, I think that will help with outcomes.”
Early adopters are already showing what this looks like in practice: starting with low-risk operational use cases, shaping data into tightly scoped enclaves, embedding governance into everyday decision-making, and empowering business leaders, not just technologists, to identify where AI can create measurable impact. The result is a new blueprint for AI maturity grounded in reengineering how modern enterprises operate.
“Optimization is really about doing existing things better, but reimagination is about discovering entirely new things that are worth doing,” says Hung.
This webcast is produced in partnership with Concentrix.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.