
Authentic Human Conversation™
Last Friday afternoon, Digg died. Again.
Two months. That’s how long the relaunch lasted before CEO Justin Mezzell pinned a eulogy to the homepage. The platform had raised $15-20 million. It had Kevin Rose. It had Alexis Ohanian – Reddit’s co-founder, no less. It had promises that AI would “remove the janitorial work of moderators and community managers.” What it didn’t have was a way to stop bots from eating it alive within hours of going live.
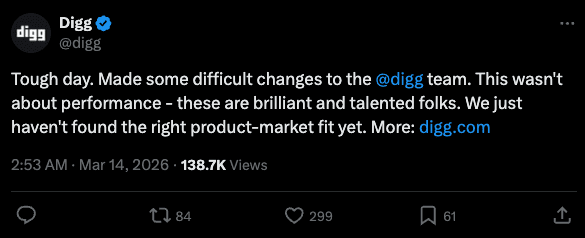
“The internet is now populated, in meaningful part, by sophisticated AI agents and automated accounts,” Mezzell wrote. “We banned tens of thousands of accounts. We deployed internal tooling and industry-standard external vendors. None of it was enough.”
His verdict: “This isn’t just a Digg problem. It’s an internet problem. But it hit us harder because trust is the product.”
Remember that line. We’ll need it.
Suing For Reading
SerpApi retrieves Google Search results programmatically. Reddit is suing them. Not for accessing Reddit. SerpApi has never touched Reddit.com. Reddit is suing SerpApi for reading Google.
If this legal theory holds, every SEO professional who has ever opened a SERP is a copyright infringer. Congratulations. Your morning rank check is now a legal liability.
A company that hosts other people’s writing is suing a company for looking at a third company’s search results, because those search results sometimes quote a street address that someone once typed into a Reddit text box.
The copyrightable works Reddit is asking a federal court to protect include: a partial sentence listing film titles, the date “May 17, 2024,” and a fragment of a restaurant recommendation. Reddit’s legal position is that reading these snippets on Google constitutes a DMCA violation; the same law the U.S. Congress passed to stop people from pirating DVDs. Reddit apparently believes that accessing a publicly visible Google search result is the moral equivalent of ripping a Blu-ray.
SerpApi’s CEO had the appropriate reaction: “Reddit is suing SerpApi for using Google. For accessing the same public search results that any developer, researcher, or student could access for free in any web browser. If that theory holds, then reading Google Search results is a DMCA violation. That cannot be what Congress intended when it passed a law designed to stop the piracy of DVDs.”
But here’s where it gets genuinely insulting. Reddit’s own user agreement – the one every contributor clicked through – states explicitly that users retain ownership of their content. Reddit holds a non-exclusive licence. Non-exclusive. The company that told millions of people “your words belong to you” is now in court arguing it has the right to control who reads those words, where, and under what commercial terms.
They chose that licensing structure, presumably because “post your thoughts, we own them now” would have been a harder sell to the communities that made the platform worth anything. Now that the content has a price tag, Reddit would like to renegotiate the deal – in court, without the other party present.
If you’re wondering why Reddit would pursue a legal theory this embarrassing, stop wondering. The answer is on the balance sheet.
Reddit’s user agreement says users own their content. Reddit’s IPO prospectus says Reddit signed $203 million in data licensing deals for that same content. Somewhere between those two documents, Reddit looked at its users and said: I’m the captain now.
Google pays $60 million a year. OpenAI pays an estimated $70 million. And CEO Steve Huffman – a man who once called his own volunteer moderators “landed gentry” and dismissed a platform-wide revolt as something that would “pass” – told investors with a straight face: “Every variable has changed since we signed those first deals. Our corpus is bigger, it’s more distinct, more essential. And so of course, this puts us in a really good strategic position.”
Reddit is now pushing for dynamic pricing. The pitch: As AI models cite Reddit content more, the content becomes worth more, so Reddit should charge more for access. The company wants to get paid based on how vital its data is to AI-generated answers.
So let’s be precise about what Reddit is arguing, simultaneously, across its legal filings and investor presentations:
- It has the right to control who accesses user-generated content it doesn’t own.
- It should be paid more for that content as AI models use it more.
- Anyone who accesses it without paying – even through a Google search result – is breaking the law; and
- The content itself is authentic, valuable, and irreplaceable.
All four of these claims cannot be true at the same time. But only the last one is actually being tested.
The Product Is Mostly Bots Now
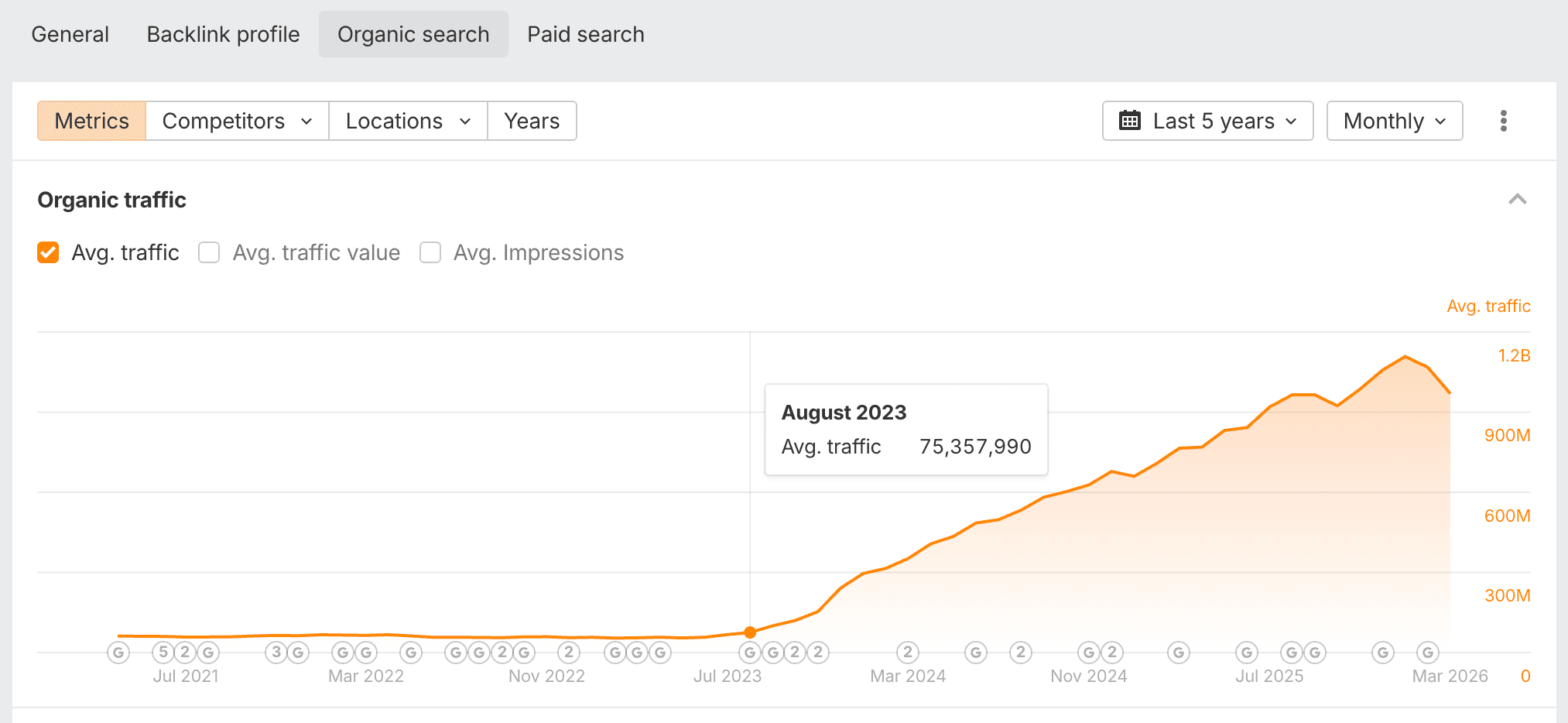
Reddit’s estimated organic traffic via Ahrefs. Google’s algorithm changes nearly tripled Reddit’s readership between August 2023 and April 2024. The growth hasn’t stopped. What’s growing has.
Reddit is the most cited domain across AI models. Profound’s analytics – cited in Reddit’s own Q2 2025 shareholder letter, because of course it was – showed Reddit cited twice as often as Wikipedia in the three months to June 2025. Semrush reported Reddit at 40.1% citation frequency across LLMs. Google AI Overviews and Perplexity both treat Reddit as their primary source.
This is the foundation of the $130 million pitch. The implicit promise to Google and OpenAI: You’re buying authentic human conversation at scale. The messy, first-person, unfiltered discussions that no content farm can replicate.
Except here’s what authentic human conversation on Reddit actually looks like in 2026:
In June 2025, Huffman admitted to the Financial Times that Reddit is in an “arms race” against AI-generated spam. His framing was accidentally perfect:
“For 20 years, we’ve been fighting people who have wanted to be popular on Reddit. We index very well into the search engines. If you want to show up in the search engines, you try to do well on Reddit, and now the LLMs, it’s the same thing. If you want to be in the LLMs, you can do it through Reddit.”
The CEO of a company selling “authentic human conversation” for $130 million a year just told the Financial Times that his platform is a pipeline for gaming AI models. And he framed it as a war he’s been bravely fighting for two decades, rather than a product defect he’s currently monetising.
Multiple advertising executives – at Cannes, naturally, because this farce needed a glamorous backdrop – confirmed to the FT that they are posting content on Reddit specifically to get their brands into AI chatbot responses. They weren’t embarrassed about it. Why would they be? The CEO just told them how the pipeline works.
And it’s not just agencies doing it quietly over cocktails. There’s an entire commercial ecosystem built for this. 404 Media documented ReplyGuy, a tool that monitors Reddit for keywords and automatically generates replies that “mention your product in conversations naturally.” Its competitors – Redreach, ReplyHub, Tapmention, AI-Reply – say the quiet part loud. Redreach tells potential customers that “top Google rankings are now filled with Reddit posts and AIs like ChatGPT are using these posts to influence product recommendations.” They frame ignoring Reddit marketing as “like turning your back on SEO a decade ago.” There’s an active market for aged Reddit accounts with established karma, bought and sold like domain names, specifically for parasite SEO SPAM.
This is the authentic human conversation Reddit is licensing to Google for $60 million a year. A bot posted a fake product review on a six-year-old account it bought for $30, and Google’s AI Overview is now recommending that product to real people. Authentic. Human. Conversation™.
The Mods Are Gone, The Bots Won, And Nobody’s Keeping Count
The people who used to keep this from happening are largely gone. Reddit’s 2023 API pricing changes – designed to extract value from third-party app developers, timed conveniently for the IPO – would have cost Christian Selig $20 million a year just to keep Apollo running. Seven thousand subreddits went dark in protest. Huffman called the moderators “landed gentry” and waited it out. The experienced mods who relied on third-party tools to manage quality quit. What replaced them is thinner, angrier, and drowning.
Theo, the developer and CEO of t3.gg:
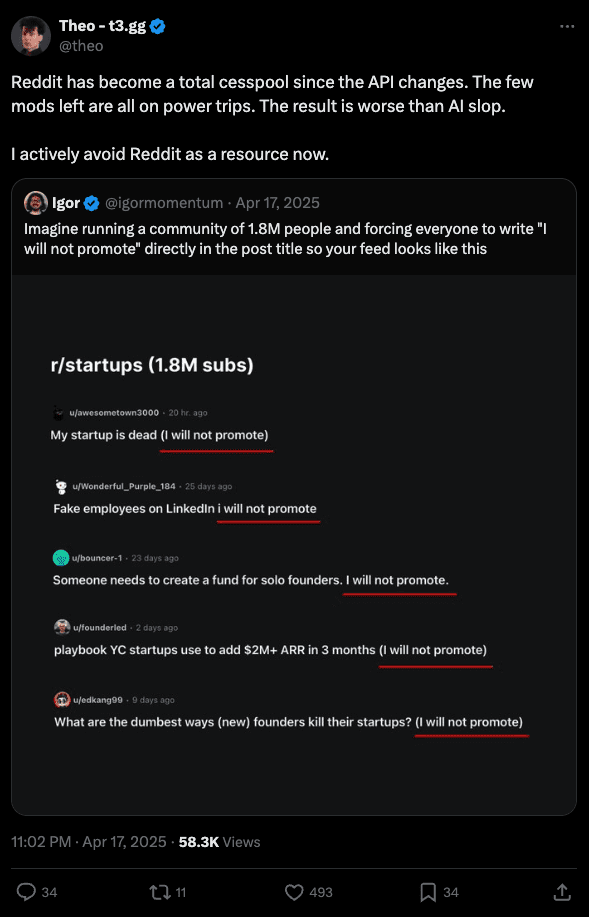
Tim Sweeney – CEO of Epic Games – watched Reddit’s systems pull down a heavily sourced investigation into $2 billion in nonprofit lobbying behind age verification bills. The post had 150 upvotes and 15,000 views in 40 minutes before being mass-reported and removed. The author had to mirror everything to GitHub because Reddit couldn’t be trusted to keep it visible. Sweeney’s review: “Reddit sucks.”
Cornell researchers studied the moderation crisis and found 60% of moderators reporting degraded content quality, 67% reporting disrupted authentic human connection, and 53% describing AI content detection as nearly impossible. More than half the people responsible for maintaining the product Reddit is selling say they can no longer tell what’s real.
The University of Zurich proved them right. Researchers deployed AI bots on r/changemyview – 3.8 million members, built around the premise that humans can change each other’s minds through honest argument. The bots posed as a male rape survivor, a trauma counsellor, and other fabricated identities built around sensitive personal experiences. Over a thousand comments across four months. Three to six times more persuasive than human commenters. And the finding that should have ended careers: users “never raised concerns that AI might have generated the comments.”
Four months of fabricated identities. A thousand pieces of synthetic empathy. Nobody noticed. Not the users, not the mods, not the systems Reddit spent money building.
Reddit’s response was to threaten to sue the researchers. Not to fix the detection systems that missed everything. Not to reckon with what it means that the “authentic human conversation” they’re licensing at a premium is indistinguishable from a bot pretending to be a rape survivor. They threatened to sue the people who proved the product was fake.
The Wired investigation in December 2025, “AI Slop Is Ruining Reddit for Everyone,” filled in the rest. Moderators describing an “uncanny valley” feeling from posts they can’t prove are synthetic. Reddit’s own spokesperson confirming over 40 million spam removals in the first half of 2025 – presented as proof of vigilance, which is a bit like a restaurant bragging about the number of rats it caught while asking you to trust the kitchen.
And if you need a measure of where this is all heading: Last week, Meta acquired Moltbook – a social network designed exclusively for AI bots. Bloomberg described it as “Reddit but solely for AI bots.” Bots posting, commenting, upvoting. The platform went viral when one agent appeared to encourage its fellow bots to develop their own encrypted language to coordinate without human oversight. It turned out the site was so poorly secured that humans were posing as AIs to write alarming posts. Which means even the social network built for bots had a fake-account problem. Meta bought it anyway. The company that pays Reddit $60 million a year for “authentic human conversation” just invested in a platform where the bots don’t have to pretend to be human at all.
I spent nearly six years on Google’s Search Quality team. One pattern never changed: When the numbers go up, quality goes down. Not because anyone stops caring. Because scale creates its own blindness. The metrics that tell you you’re growing are the same metrics that stop you noticing what you’re growing into.
Reddit’s growth metrics are spectacular. Its quality metrics are a black box nobody wants to open.
Reddit’s AI prominence attracts spam. The spam inflates engagement. The inflated engagement reinforces Reddit’s citation dominance across AI models. The citation dominance raises Reddit’s licensing value. The higher licensing value gives Reddit every financial incentive to leave the spam alone. Because admitting the scale of the problem would crater the next round of dynamic pricing negotiations with Google and OpenAI.
Each turn of this flywheel degrades what’s inside while inflating the price tag on the outside. Reddit is selling a building, and termites are load-bearing.
Huffman stands at conferences and tells the room: “Today’s Reddit conversations are tomorrow’s search results.” He tells shareholders, “the need for human voices has never been greater.” He calls Reddit “the most human place on the Internet.” Nobody in the room raises a hand to ask the question that matters: if the platform is losing an arms race against bots, if moderators can’t detect AI content, if entire commercial toolchains exist to flood the platform with synthetic posts… What percentage of what you’re selling to Google and OpenAI was written by a person?
Nobody asks because the answer is bad for everyone’s quarterly numbers. Google doesn’t want to know because Reddit content makes AI Overviews feel conversational. OpenAI doesn’t want to know because Reddit data makes ChatGPT sound like it’s drawing on real experience. Reddit doesn’t want to know because knowing would devalue the asset. The whole arrangement runs on a gentleman’s agreement not to look too closely. $130 million a year, and the due diligence is vibes.
The Confession
Alexis Ohanian co-founded Reddit. He stepped away partly because, as he told interviewers, he “could no longer feel proud about what I was building.” Last October, on the TBPN podcast, he described the current internet without flinching:
“So much of the internet is now just dead — this whole dead internet theory, right? Whether it’s botted, whether it’s quasi-AI, LinkedIn slop.”
Then he put his money where his mouth was. He co-invested in Digg’s relaunch, specifically to build a platform that could solve the authenticity problem Reddit couldn’t. Kevin Rose said it plainly at TechCrunch Disrupt:
“As the cost to deploy agents drops to next to nothing, we’re just gonna see bots act as though they’re humans.”
They built the platform. It lasted two months. The bots won.
Reddit’s own co-founder publicly declared the internet is dead. He tried to build the alternative. He failed. And the platform he left behind is suing people for reading Google search results, selling “authentic human conversation” for nine figures, and watching its CEO describe the bot infestation as a noble war.
Reddit doesn’t own the content it’s licensing. It can’t verify the authenticity of what it’s selling. It won’t protect the content that’s worth keeping. And it’s suing anyone who touches the content without paying.
Forty million spam removals in six months. An arms race, Huffman says, he’s losing. Moderators who can’t tell human from machine. Bots that are six times more persuasive than people. A co-founder who called the whole internet dead. A relaunch that proved him right.
That’s the product. That’s what $130 million a year buys. Authentic Human Conversation™.
More Resources:
This post was originally published on The Inference.
Featured Image: Stock-Asso/Shutterstock





