This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
The one piece of data that could actually shed light on your job and AI
Within Silicon Valley’s orbit, an AI-fueled jobs apocalypse is spoken about as a given. Now even economists who have downplayed the threat are coming around to the idea.
Alex Imas, based at the University of Chicago, is one of them. He believes that any plan to address AI’s impact will depend on collecting one vital piece of data: price elasticity.
This article is from The Algorithm, our weekly newsletter giving you the inside track on all things AI. Sign up to receive it in your inbox every Monday.
Four things we’d need to put data centers in space
In January, Elon Musk’s SpaceX applied to launch up to 1 million data centers into Earth’s orbit. The goal? To fully unleash the potential of AI—without triggering an environmental crisis on Earth.
This story is part of MIT Technology Review Explains, our series untangling the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Trump has again proposed major cuts to US science and tech spending He wants to slash nearly every science-focused agency. (Ars Technica) + If Trump gets his way, the US could face a costly brain drain. (NYT $) + Top research talent is already fleeing the country. (Guardian) + Basic science deserves our boldest investment. (MIT Technology Review)
2 Sam Altman lobbied against AI regulations he publicly welcomed A bombshell report reveals many OpenAI insiders don’t trust him. (The New Yorker $) + Some have called him a sociopath. (Futurism) + OpenAI’s CFO fears it won’t be IPO-ready this year.(The Information $) + A war over AI regulation is brewing in the US. (MIT Technology Review)
3 NASA’s Artemis II has broken humanity’s all-time distance record The astronauts have flown farther than any humans before them. (BBC) + Their mission includes MIT-developed technology. (Axios)
4 Chinese tech firms are selling intel “exposing” US forces It comes from combining AI with open-source data.. (WP $) + AI is turning the Iran conflict into theater. (MIT Technology Review)
5 War is pushing countries to ditch hyperscalers Driven by Iran naming tech giants as military targets. (Rest of World) + No one wants a data center in their backyard. (MIT Technology Review)
6 OpenAI, Anthropic, and Google have united against China’s AI copying They’re sharing information on “adversarial distillation” (Bloomberg $)
7 Anduril and Impulse Space are working on Trump’s “Golden Dome” They’re developing space-based missile tracking for the project. (Gizmodo)
8 OpenAI has urged California to probe Elon Musk’s “anti-competitive behavior.” It accuses Musk of trying to “take control of the future of AGI.” (Reuters $) + And claims he coordinated attacks with Mark Zuckerberg. (CNBC) + A former Tesla president has revealed how he survived working for Musk. (WP $)
9 DeepSeek’s new AI model will run on Huawei chips It’s expected to launch in the next few weeks. (The Information $)
10 Memes have nuked our culture Internet “brain rot” has escaped our phones to take over everything. (NYT $)
Quote of the day
“I must say, it was actually quite nice.”
—Astronaut Victor Glover tells President Donald Trump what it was like when Artemis II was out of communication with the rest of humanity, The New York Times reports.
One More Thing
PABLO ALBARENGA
Inside the controversial tree farms powering Apple’s carbon-neutral goal
In 2020, Apple set a goal to become net zero by the end of the decade. To hit that target, the company is offsetting its emissions by planting millions of eucalyptus trees in Brazil.
Apple is betting that the strategy will lead to a greener future. But critics warn that the industrial tree farms will do more harm than good.
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
+ Japan’s automated bike garage is a cyclist’s dream come true. + This deep dive into bird behavior reveals the secrets of their dining habits. (Big thanks to reader Terry Gordon for the find!) + The first photo from the Artemis astronauts vividly captures the glow of our atmosphere. + There’s a new contender for the world’s most gorgeous website: RobertDeNiro.com.
Unlike static, rules-based systems, AI agents can learn, adapt, and optimize processes dynamically. As they interact with data, systems, people, and other agents in real time, AI agents can execute entire workflows autonomously.
But unlocking their potential requires redesigning processes around agents rather than bolting them onto fragmented legacy workflows using traditional optimization methods. Companies must become agent first.
In an agent-first enterprise, AI systems operate processes while humans set goals, define policy constraints, and handle exceptions.
“You need to shift the operating model to humans as governors and agents as operators,” says Scott Rodgers, global chief architect and U.S. CTO of the Deloitte Microsoft Technology Practice.
The agent-first imperative
With technology budgets for AI expected to increase more than 70% over the next two years, AI agents, powered by generative AI, are poised to fundamentally transform organizations and achieve results beyond traditional automation. These initiatives have the potential to produce significant performance gains, while shifting humans toward higher value work.
AI is advancing so quickly that static approaches to task automation will likely only produce incremental gains. Because legacy processes aren’t built for autonomous systems, AI agents require machine-readable process definitions, explicit policy constraints, and structured data flows, according to Rodgers.
Further complicating matters, many organizations don’t understand the full economic drivers of their business, such as cost to serve and per-transaction costs. As a result, they have trouble prioritizing agents that can create the most value and instead focus on flashy pilots. To achieve structural change, executives should think differently.
Companies must instead orchestrate outcomes faster than competitors. “The real risk isn’t that AI won’t work—it’s that competitors will redesign their operating models while you’re still piloting agents and copilots,” says Rodgers. “Nonlinear gains come when companies create agent-centric workflows with human governance and adaptive orchestration.”
Routine and repetitive tasks are increasingly handled automatically, freeing employees to focus on higher value, creative, and strategic work. This shift improves operational efficiency, fosters stronger collaboration, and generates faster decision-making—helping organizations modernize the workplace without sacrificing enterprise security.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. This includes the writing of surveys and collection of data for surveys. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
Water as a weapon: Desalination plants supplying drinking water to millions across the Middle East have become targets in the escalating US-Iran conflict, with plants in Iran, Bahrain, and Kuwait already reporting damage.
Gulf states are most at risk: While Iran gets just 3% of its municipal fresh water from desalination, Bahrain, Qatar, and Kuwait depend on it for over 90% of their drinking water—making them far more exposed to attacks.
Bigger plants mean bigger consequences: The average desalination facility is now ten times larger than it was 15 years ago. Taking one offline could impact the water supplies of many people in the area.
The danger doesn’t end with the war: Climate change, oil spills, and algae blooms pose growing threats to these facilities—and experts warn the conflict may teach future actors just how effectively water infrastructure can be weaponized.
MIT Technology Review Explains: Let our writers untangle the complex, messy world of technology to help you understand what’s coming next. You can read more from the series here.
As the conflict in Iran has escalated, a crucial resource is under fire: the desalination technology that supplies water across much of the region.
In early March, Iran’s foreign minister accused the US of attacking a desalination plant on Qeshm Island in the Strait of Hormuz and disrupting the water supply to nearly 30 villages. (The US denied responsibility.) In the weeks since, both Bahrain and Kuwait have reported damage to desalination plants and blamed Iran, though Iran also denied responsibility.
In late March, President Donald Trump threatened the destruction of “possibly all desalinization plants” in Iran if the Strait of Hormuz was not reopened. Since then, he’s escalated his threats against Iran, warning of plans to attack other crucial civilian infrastructure like power plants and bridges.
Countries in the Middle East, particularly the Gulf states, rely on the technology to turn salt water into fresh water for farming, industry, and—crucially—drinking. The mounting attacks and threats to date highlight just how vital the industry is to the region—a situation made even more precarious by rising temperatures and extreme weather driven by climate change.
Right now, 83% of the Middle East is under extremely high water stress, says Liz Saccoccia, a water security associate at the World Resources Institute. Future projections suggest that’s going to increase to about 100% by 2050, she adds: “This is a continuing trend, and it’s getting worse, not better.”
Here’s a look at desalination technology in the Middle East and what wartime threats to the critical infrastructure could mean for people in the region.
A vital resource
Desalination technology has helped provide water supplies in the Middle East since the early 20th century and became widespread in the 1960s and 1970s.
There are two major categories of desalination plants. Thermal plants use heat to evaporate water, leaving salt and other impurities behind. The vapor can then be condensed into usable fresh water. The alternative is membrane-based technology like reverse osmosis, which pushes water through membranes that have tiny pores—so small that salt can’t get through.
Early desalination plants in the Middle East were the first type, burning fossil fuels to evaporate water, leaving the salt behind. This technique is incredibly energy-intensive, and over time, processes that rely on filters became the dominant choice.
Membrane technologies have made up essentially all new desalination capacity in recent years; the last major thermal plant built in the Gulf came online in 2018. Many reverse osmosis plants still rely on fossil fuels, but they’re more efficient. Since then, membrane technologies have added more than 15 million cubic meters of daily capacity—enough to supply water to millions of people.
Capacity has expanded quickly in recent years; between 2006 and 2024, countries across the Middle East collectively spent over $50 billion building and upgrading desalination facilities, and nearly that much operating them.
Today, there are nearly 5,000 desalination plants operational across the Middle East.
And looking ahead, growth is continuing. Between 2024 and 2028, daily capacity is expected to grow from about 29 million cubic meters to 41 million cubic meters.
Uneven vulnerabilities
Some countries rely on the technology more than others. Iran, for example, uses desalination for about 3% of its municipal fresh water. The country has access to groundwater and some surface water, including rivers, though these resources are being stretched thin by agriculture and extreme drought.
Other nations in the region, particularly the Gulf countries (Bahrain, Qatar, Kuwait, the United Arab Emirates, Saudi Arabia, and Oman), have much more limited water resources and rely heavily on desalination. Across these six nations, all but the UAE get more than half their drinking water from desalination, and for Bahrain, Qatar, and Kuwait the figure is more than 90%.
“The Gulf countries are much, much more vulnerable to attacks on their desalination plants than Iran is,” says David Michel, a senior associate in the global food and water security program at the Center for Strategic and International Studies.
There are thousands of desalination facilities across the region, so the system wouldn’t collapse if a small number were taken offline, Michel says. However, in recent years there’s been a trend toward larger, more centralized plants.
The average desalination plant is about 10 times larger than it was 15 years ago, according to data from the International Energy Agency. The largest desalination plants today can produce 1 million cubic meters of water daily, enough for hundreds of thousands of people. Taking one or more of these massive facilities offline could have a significant effect on the system, Michel says.
Escalating threats
Desalination facilities are quite linear, meaning there are multiple steps and pieces of equipment that work in sequence—and the failure of a component in that chain can take an entire facility down. Attacks on water inlets, transportation networks, and power supplies can also disrupt the system, Michel says.
During the Gulf War in 1991, Iraqi forces pumped oil into the gulf, contaminating the water and shutting down desalination plants in Kuwait.
The facilities are also generally located close to other targets in this conflict. Desalination is incredibly energy intensive, so about three-quarters of facilities in the region are next to power plants. Trump has repeatedly threatened power plants in Iran. In response, Iran’s military has said that if civilian targets are hit, the country will respond with strikes that are “much more devastating and widespread.” Other governments and organizations, including the United Nations, the European Union, and the Red Cross, have broadly condemned threats to infrastructure as illegal.
But war isn’t the only danger facing these plants, even if it is the most immediate. Some studies have suggested that global warming could strengthen cyclones in the region, and these extreme weather events could force shutdowns or damage equipment.
Water pollution could also cause shutdowns. Oil spills, whether accidental or intentional, as in the case of the Gulf War, can wreak havoc. And in 2009, a red algae bloom closed desalination plants in Oman and the United Arab Emirates for weeks. The algae fouled membranes and blocked the plants from being able to take water in from the Persian Gulf and the Gulf of Oman.
Desalination facilities could become more resilient to threats in the future, and they may need to as their importance continues to grow.
There’s increasing interest in running desalination facilities at least partially on solar power, which could help reduce dependence on the oil that powers most facilities today. The Hassyan seawater desalination project in the UAE, currently under construction, would be the largest reverse osmosis plant in the world to operate solely with renewable energy.
Another way to increase resilience is for countries to build up more strategic water storage to meet demand. Qatar recently issued new policies that aim to improve management and storage of desalinated water, for example. Countries could also work together to invest in shared infrastructure and policies that help strengthen the water supply through the region.
Preparedness, resilience, and cooperation will be key for the Middle East broadly as critical infrastructure, including the water supply, is increasingly under threat.
“The longer the conflict goes on, the more likely we’ll see significant water infrastructure damage,” says Ginger Matchett, an assistant director at the Atlantic Council. “What worries me is that after this war ends, some of the lessons will show how water can be weaponized more strategically than previously imagined.”
May 2026 offers ecommerce content marketers a mix of cultural milestones, seasonal buying moments, and fun creative hooks. The challenge is not finding topics, but producing content that stands out in search, earns visibility in feeds, and contributes to revenue.
Content marketing has long been foundational for overall visibility, but it is changing.
Marketers in 2026 should create content that is discoverable in organic search and Google Discover-like feeds, easy for genAI platforms to summarize and cite, and capable of influencing buying decisions.
With this in mind, here are five content marketing ideas to try in May 2026.
First American in Space
Alan B. Shepard Jr. in his space suit, inside the Mercury capsule. Source: NASA.
Roughly 65 years ago, on May 5, 1961, NASA’s Mercury-Redstone 3, Freedom 7, flight marked a milestonein American innovation.
The 15 minutes, 28 seconds journey into space orbit, took astronaut Alan Shepard 116.5 miles over the Earth, making him the first American in space. The Mercury rocket topped out at 5,134 miles per hour. It was a meaningful accomplishment.
The Freedom 7 anniversary offers content marketers a chance to connect products with themes of precision, durability, and engineering.
A workwear shop, for example, might publish a timeline showing how fabrics and clothing have evolved since the early days of the space program. The shop might even add a “then vs. now” comparison that highlights how modern products outperform their historical counterparts.
The key is to move beyond a simple historical recap. Use diagrams, product breakdowns, or side-by-side comparisons to make the content useful and easy to understand.
Mother’s Day Gift Guides
Consider niche gift guides, such as pickleball how-to, for Mother’s Day.
Mother’s Day on Sunday, May 10, 2026, is the most important U.S. retail holiday in the month. The occasion typically generates more than $30 billion in retail sales, mostly for flowers, candy, and small gifts.
Ecommerce businesses can go beyond traditional gifts and promote unusual products in niche gift guides. Here are a couple of examples.
Pickleball mom. Upwards of 5 million American moms play pickleball each year. Consider guides to paddles, bags, court shoes, and recovery tools.
Homesteading mom. Millions of U.S. households are engaged in gardening, food preservation, or small-scale farming. The Mother’s Day home-gardening gift guide, anyone?
Memorial Day How-to
A guide to help shoppers plan a Memorial Day gathering can include products that make the experience easier.
Content that helps a reader or viewer complete a task or learn a skill remains one of the most powerful forms of marketing.
Consider publishing checklists for backyard events, guides to planning a cookout, or packing lists for a weekend trip. Step-by-step formats are easy to follow and easy to share. Don’t be afraid to include specific product recommendations.
National Paper Airplane Day
National Paper Airplane Day is an opportunity to add fun to content marketing.
Celebrated on May 26, 2026, National Paper Airplane Day is a minor occasion to entertain and have some fun.
A simple approach is to publish instructions for building paper airplanes. These could include tutorials, design variations, and performance tips to make the content relatively more valuable.
Power tool retailer: Publish plans for a fan-powered backyard paper airplane race course.
Stationary shop: Create a checklist for selecting aeronautical paper.
A STEM products seller: Provide a guide to the aerodynamics of paper airplanes.
Even a fun topic like paper airplanes can become useful content that engages shoppers and supports product discovery.
Miles Davis at 100
Miles Davis playing a gig in Antibes, France, in July 1963. Photo by Mallory1180.
Born on May 26, 1926, Miles Davis was a renowned American trumpet player who helped define jazz.
Content marketers promoting music, culture, or nostalgia could examine how Davis reinvented his style over time and connect that idea to various product categories. Frame apparel, audio equipment, or lifestyle goods around themes of craftsmanship and expression.
A vinyl record store could publish “The Beginner’s Guide to Miles Davis. Where to Start and What to Buy.” Or a wine and spirit retail might make “5 Cocktails Inspired by Miles Davis Albums.”
Artificial intelligence powers Google Ads. With the right data and prompts, AI helps advertisers get more from their accounts, from improving bid strategies to predicting searchers’ intent. Among the top time-savers, however, are tools for creative assets.
Common creative challenges for advertisers include:
Finding the right images and sizes
Editing existing images for greater appeal
Creating engaging videos
Trimming video length
Advertisers aren’t typically graphic designers or video producers. That’s the purpose of Google’s Asset Studio, where advertisers can quickly find and edit images and videos.
Create images
Google can generate images from a single descriptive prompt. An advertiser selling cushioned socks could state:
Create a variety of images that showcase comfortable, cushioned socks. The images should be a mix of close-ups, people in action with the socks, and product images.
I entered that prompt, received multiple images, and selected this one:
The first image of socks also contained a coffee mug with steam.
I prefer no coffee mug, so I prompted the tool to remove it and received this version:
The second version removed the mug but not the steam.
The steam remained. I then requested another edit and received another image, which I’ll use:
The final sock image has no mug and no steam.
Asset Studio also provides aspect ratios for easy resizing in other campaigns, such as Performance Max and Demand Gen.
Product images
Asset Studio can liven existing product images. For example, an advertiser selling a “GOAT” t-shirt could prompt:
Feature a man wearing this shirt walking on a sidewalk.
Here is the resulting image:
Asset Studio converted a static t-shirt image into a compelling lifestyle shot.
Videos from images
Videos are critical for engagement, yet many advertisers cannot easily create them. With Asset Studio, advertisers can upload a single photo to receive a 5-second clip or two photos for 10 seconds.
Advertisers can then customize the video with a template, key messages, and a logo. Asset Studio then places the completed version in the advertiser’s YouTube channel to use with all video-based campaign types.
Advertisers can upload a single photo to receive a 5-second clip or two photos for 10 seconds.
Create videos
Advertisers can create videos from Asset Studio templates, which vary in length and asset type. Some templates require only text, though each includes default scenes to customize.
For example, scene 1 may require only a business name, while scene 2 requires expanded text. These videos won’t win awards, but they do fulfill inventory needs.
Asset Studio templates vary in length and asset type, with default scenes to customize.
Trim videos
Consumers’ attention is notoriously short. Generally, the longer the video, the fewer consumers engage with it. Hence shorter videos (that get to the point) typically perform better.
Via Asset Studio, advertisers can trim longer videos to any length or use the default options:
6 seconds (for bumper ads)
10 seconds (for non-skippable in-stream ads)
15 seconds (for non-skippable in-stream ads)
As with all AI, ensure the trimmed videos are brand-appropriate and accurately showcase your message.
Google CEO Sundar Pichai said AI models could break widely used software and that prices for black-market zero-day exploits may be falling. The comments came during a conversation on the Cheeky Pint podcast with Stripe CEO Patrick Collison.
What Pichai Said
The discussion touched on constraints facing AI infrastructure buildout when Pichai turned to security as a less visible risk.
Pichai said:
“These models are definitely like really going to break pretty much all software out there. Maybe already we don’t know as we sit here and speak.”
Elad Gil mentioned hearing that black market zero-day prices were falling because AI was increasing the supply of discoverable vulnerabilities. Pichai said he was “not at all surprised,” though neither cited specific pricing data.
Pichai framed security threats as a hidden constraint on AI deployment, alongside memory supply and energy. He said the situation would require “more coordination, which is not happening today” and predicted a potential “sharp moment” ahead.
“I don’t think you can wish them away,” Pichai said.
What The Data Shows
Google’s Threat Intelligence Group tracked 90 zero-day exploits used in attacks during 2025, up from 78 in 2024. Nearly half targeted enterprise software, an all-time high.
The GTIG report predicted that AI would “accelerate the ongoing race between attackers and defenders” in 2026. It said adversaries are likely to use AI to accelerate reconnaissance, vulnerability discovery, and exploit development.
While Pichai and Gil described falling black-market prices, industry reporting on the separate commercial-exploit market has shown prices holding or rising in some categories as vendors harden their products.
Why This Matters
Every website runs on software with potential vulnerabilities. WordPress plugins, server configurations, third-party scripts, and authentication systems are all part of the attack surface that AI-assisted exploit discovery could target faster.
If AI is accelerating the pace at which vulnerabilities are found and weaponized, the window between a flaw existing and an attacker using it gets shorter. That puts more pressure on maintaining current patches and auditing their dependencies.
Google’s threat data shows exploit volume rising and AI accelerating discovery, even if the pricing claim lacks specifics.
Looking Ahead
Pichai’s comments were conversational, not a formal Google policy statement. But they came from someone who oversees both the company’s AI models and its threat intelligence operation.
The gap between AI capability and security readiness is a theme Google’s threat researchers have been documenting with increasing urgency. The GTIG report expects AI to speed both offense and defense going forward.
Boost your skills with Growth Memo’s weekly expert insights. Subscribe for free!
AI Mode is compressing the stage where buyers compare, reject, and discover brands on their own. Our new usability study of 185 documented purchase tasks shows that 74% of AI Mode final shortlists came directly from the AI’s output – no external check, no triangulation, no second opinion.
This analysis will cover:
How the comparison search phase has collapsed.
What this means for brands competing in categories with high competitor AI Mode saturation.
The three levers that determine whether your brand shows up.
Why We Conducted The Study
AI transforms Search from a list of results to a list of recommendations (shortlist). Until now, we have no idea how users treat AI shortlists. Do they take it at face value or thoroughly validate it?
That’s why I partnered with Citation Labs and Clickstream Solutions to record real users and their interactions when facing high-stakes purchases. This usability study of 48 participants completing 185 major-purchase tasks reveals that AI Mode operates as a recommendation environment, not a comparison one.
In traditional search, people click through results, comparing across sources to assemble a candidate set. In AI Mode, they accept the AI’s candidates and move on. 74% of AI Mode shortlists came directly from the AI’s output with no external check. In traditional search, more than half of users built their own shortlist from scratch.
The study covers four categories (televisions, laptops, washer/dryer sets, and car insurance). Participants completed tasks using both AI Mode and traditional search in a within-subjects A/B design, producing 149 AI Mode task observations and 36 search observations. The behavioral patterns are consistent enough across categories and participants to carry weight. (Full study design is at the end.)
“In AI Mode, buyers often use a shortlist synthesis to shortcut the cognitive effort of Standard Searching and comparing. This raises the value of onsite decision assets and third-party sources that provide AI with clear trade-offs, specific evidence, and sufficient contextual structure to describe a brand’s offering with confidence.”
The absence of narrowness frustration is the most intellectually significant finding. 15% in AI Mode vs 11% in Search, with no meaningful statistical difference. That’s the finding that rules out the obvious alternative explanation: that users accepted the AI’s shortlist because they felt trapped. They didn’t push back. They weren’t frustrated. They were satisfied. That makes the acceptance harder to dismiss.
Here’s what happened.
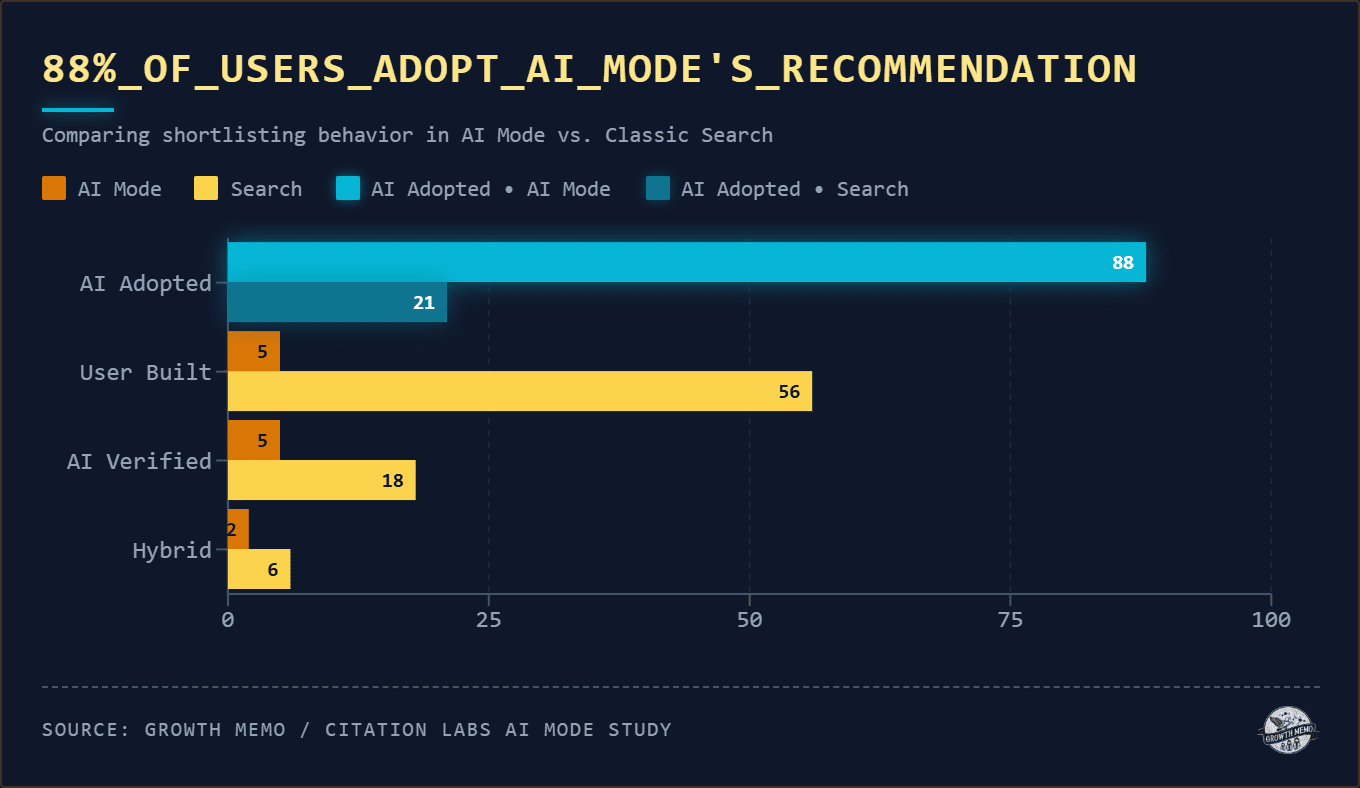
1. 88% Of Users Took The AI’s Shortlist Outright
Across the laptop and insurance tasks, where participants used both search surfaces (classic search and AI Mode), the gap in constructing a product shortlist was stark.
Image Credit: Kevin Indig
Definitions:
AI Adopted: The participant took the AI’s recommended candidates as their shortlist with no changes or external verification.
User Built: The participant ignored the AI’s (or Search’s) suggestions and assembled their own candidate list from independent sources.
AI Verified: The participant started with the AI’s candidates but checked them against an outside source (a retailer site, a review, a manufacturer page) before finalizing.
Hybrid: The participant combined AI-suggested candidates with at least one candidate they found independently.
In classic search, 56% of participants built their own shortlist from multiple sources. In AI Mode, only 8 out of 147 codeable tasks produced a genuinely self-built shortlist. The user’s comparison process didn’t just shrink when using AI Mode. For most participants, it didn’t happen at all.
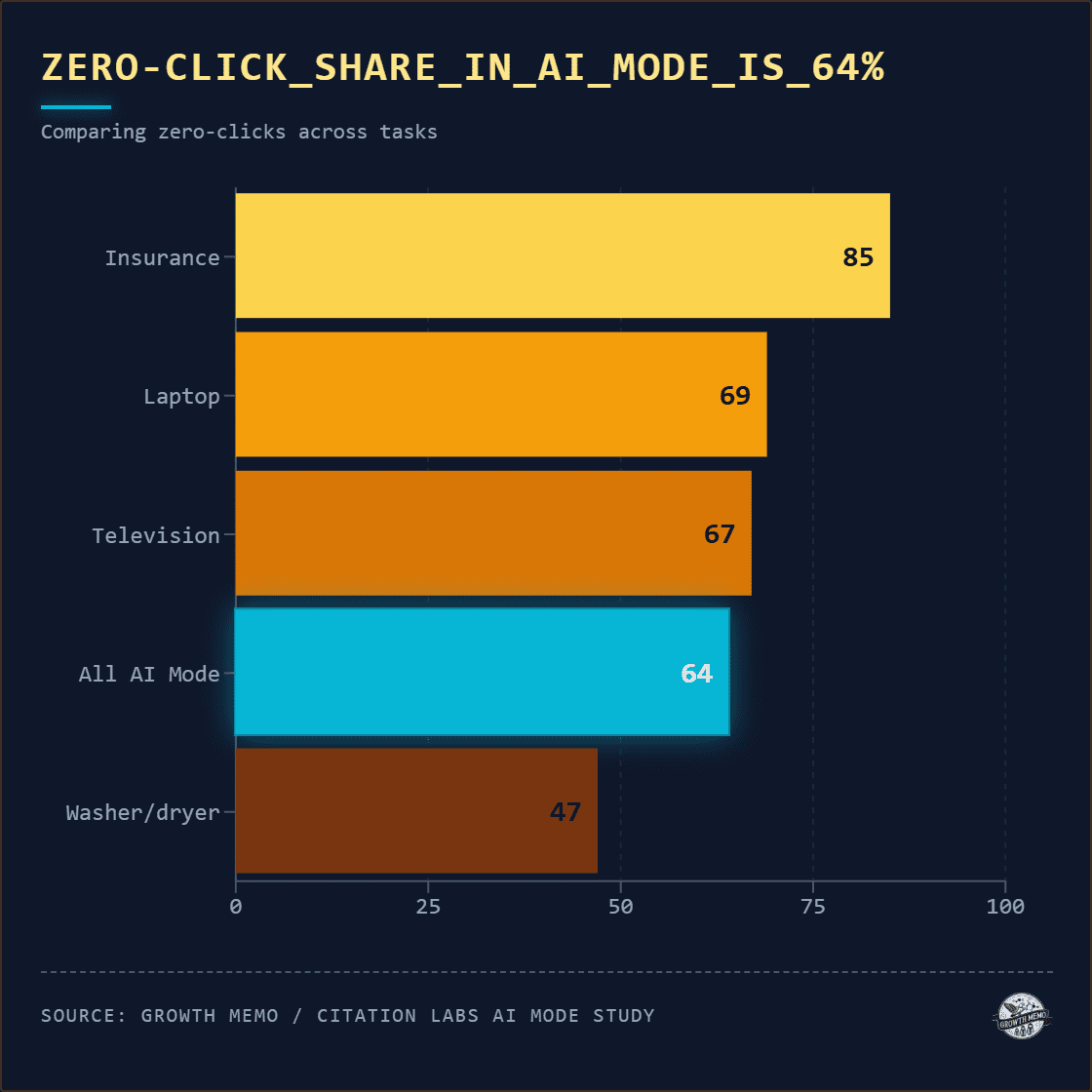
64% of AI Mode participants clicked nothing at all during their task. They read the AI’s text, sometimes scrolled through inline product snippets, and declared their finalists. The no-click rate varied by category:
Image Credit: Kevin Indig
Insurance participants delegated most heavily. Washer/dryer participants clicked the most, likely because appliance decisions involve specific physical constraints (capacity, stacking compatibility, dimensions) that the AI summary didn’t always resolve.
The 36% who did interact with individual results within AI Mode broke into 2 groups:
About 15% of the AI Adopted group (17 of 117 participants) verified inside AI Mode: They opened inline product cards or merchant pop-ups to check a price or spec, then returned to the AI’s list.
Others used follow-up prompts as verification tools, asking the AI for prices or narrowing by constraints.
A separate 23% of all AI Mode tasks involved at least one visit to an external website, mostly retailers (Best Buy appeared in 10 of 34 tasks with external visits) and manufacturer sites. The destination pattern matters: Users left AI Mode to confirm a candidate they’d already accepted from the AI’s list, not to find new ones.
Of the 117 participants who adopted the AI’s shortlist directly, roughly 85% showed no internal verification behavior at all. Participants who built their own lists took an average of 89 seconds longer and consulted more than twice as many sources.
“Given that the first paragraph says Lenovo or Apple… going with that,” said one user about laptops when searching via AI Mode. Position one in the AI response was the entire decision.
Another AI Mode user remarked: “I liked it more than anything else I’ve ever used for product searching. It made it a lot quicker to find the options.” They experienced speed as a valuable feature, not a shortcut.
In classic search, the pattern reversed. Nearly 89% of participants clicked on something.
One insurance participant clicked out to Progressive and GEICO independently, read both landing pages, consulted an Experian article, and then arrived at a shortlist.
A laptop participant applied hardware filters and flagged a review score discrepancy: “It shows 4.6 out of 5 stars for the reviews, but when you actually click the link: not reviewed yet.” Active skepticism of aggregated data was a behavior absent from AI Mode transcripts.
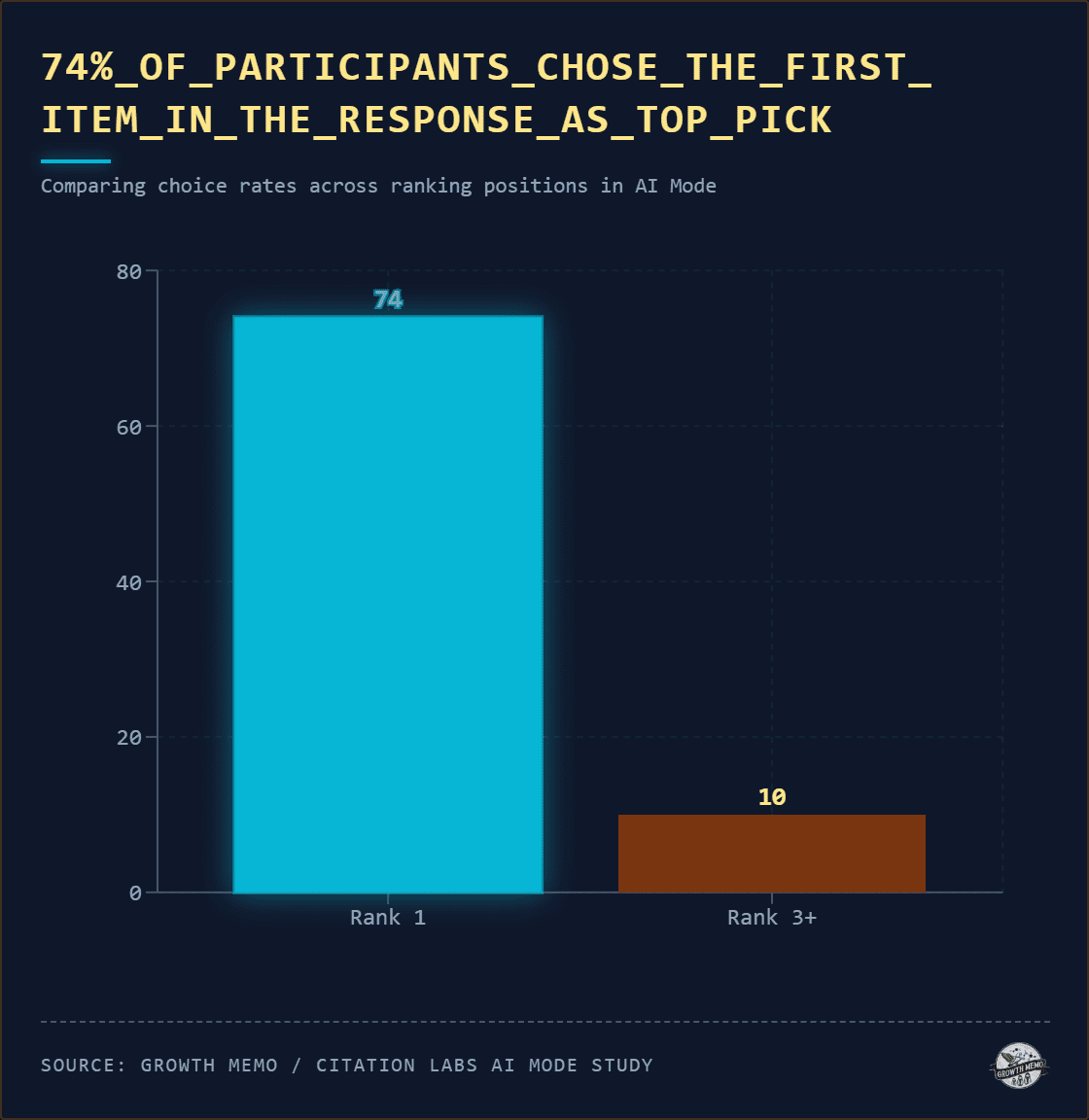
2. The AI’s Top Pick Becomes The User’s Top Pick 74% Of The Time
Just like in classic search, the top answer carries outsized weight. 74% of participants chose the item ranked first in the AI’s response as their top pick. The mean rank of the final choice was 1.35. Only 10% chose something ranked third or lower.
Image Credit: Kevin Indig
Position one in the AI’s output carries an outsized advantage because of where it sits: inside a curated section that typically contains two to five items, after the AI has already done the filtering. The first item is the AI’s top pick. When people engage with AI mode, we know they read almost all of the output: The first AI Mode study found users spend 50 to 80 seconds reading AI Mode output, more than double the dwell time on AI Overviews. Users are reading carefully. They just read within a set the AI already narrowed.
However, 26% of participants in this study overrode rank order. The driver: brand recognition. They spotted a brand lower on the list and preferred it regardless of where the AI placed it. TV and laptop categories saw this most, where participants arrived with existing preferences for Samsung, LG, Apple, or Lenovo. But overriding rank did not mean rejecting the AI’s output: 81% of rank-override participants still chose from the AI’s candidate set.
3. The AI’s Words Become The Trust Signal
“Travelers and USAA actually tell me how much, whereas State Farm and GEICO give percentages. Just knowing the exact amount makes me want to pick Travelers or USAA right off the bat.”
That quote captures a core pattern in AI Mode trust. The AI’s formatting shaped the decision: Dollar amounts versus percentage discounts determined which brands made the shortlist.
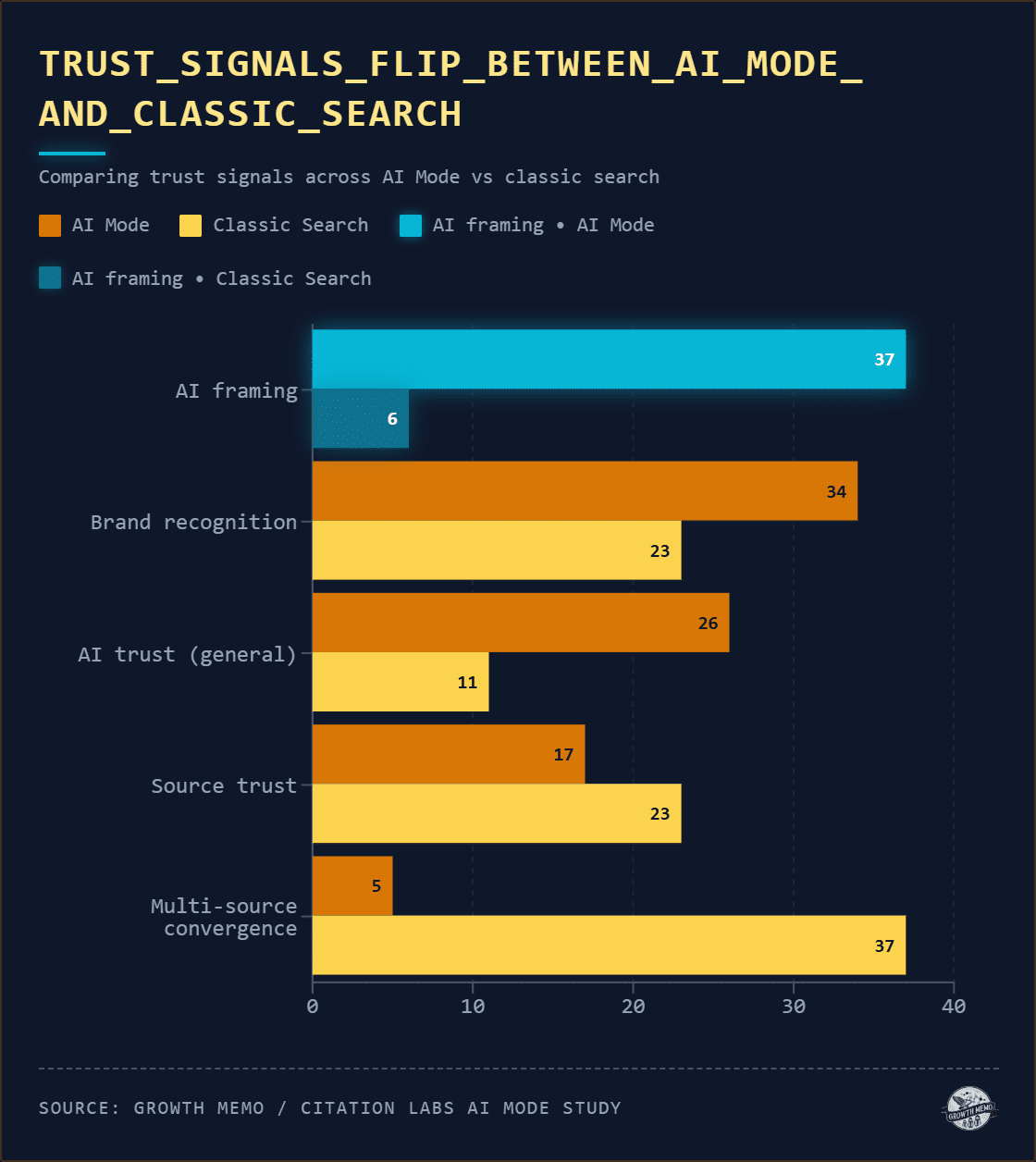
AI framing (37%), meaning how AI talks about the product, and brand recognition (34%) were the top 2 trust drivers in AI Mode. They run nearly even:
Brand recognition led when participants arrived with brand preferences.
AI’s wording filled the gaps where participants didn’t already have preferences.
Image Credit: Kevin Indig
In classic search, the dominant trust mechanism was multi-source convergence: Participants built confidence by checking whether multiple independent sources agreed about a product.
Essentially, users triangulated. One checked Progressive, then GEICO, then an Experian article. Another compared aggregated star ratings against reviews on the actual site. They were building a case from separate inputs.
That behavior was almost absent in AI Mode (5%). Instead, AI framing (how the AI worded its description of a product) and brand recognition were the top 2 trust drivers.
The split between these two signals tracked closely with product category:
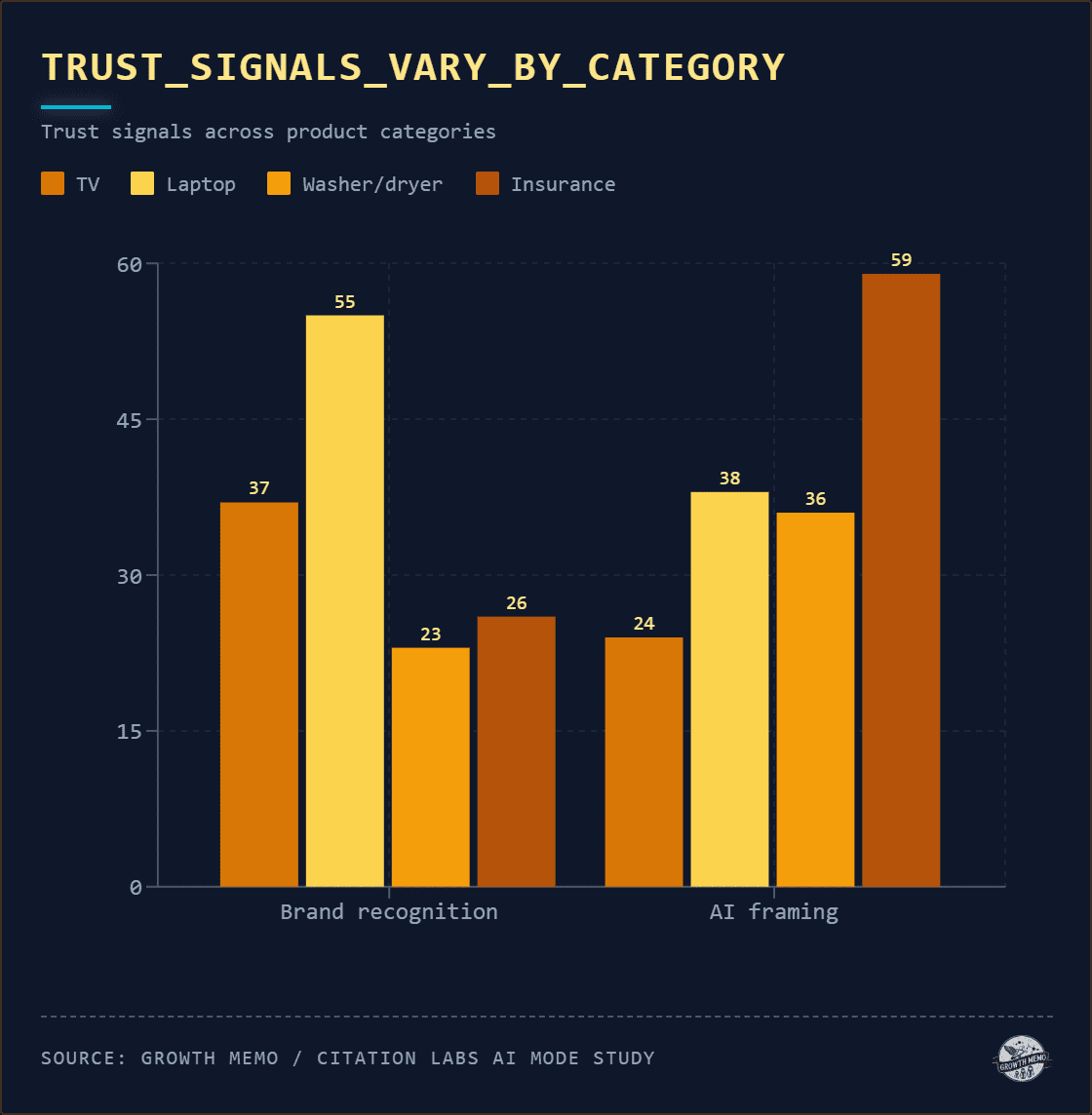
Image Credit: Kevin Indig
For televisions and laptops, where most participants arrived with existing brand preferences, brand recognition dominated. For insurance and washer/dryer, where participants had less prior knowledge, AI framing dominated.
When you lack a prior view, the AI’s description becomes the trust signal. In AI Mode, the synthesis is the corroboration. Participants treated the AI’s summary as if the cross-checking had already been done for them.
The first study showed a related pattern from the supply side: AI Mode matches site type to intent, surfacing brands for transactional queries and review sites for comparisons. This study shows the demand side of the same behavior: When the AI surfaces a brand the user already knows, brand recognition drives the decision; when it doesn’t, the AI’s own framing fills that role. The site-type matching and the trust mechanism reinforce each other.
4. If You’re Not In The List, You Don’t Exist
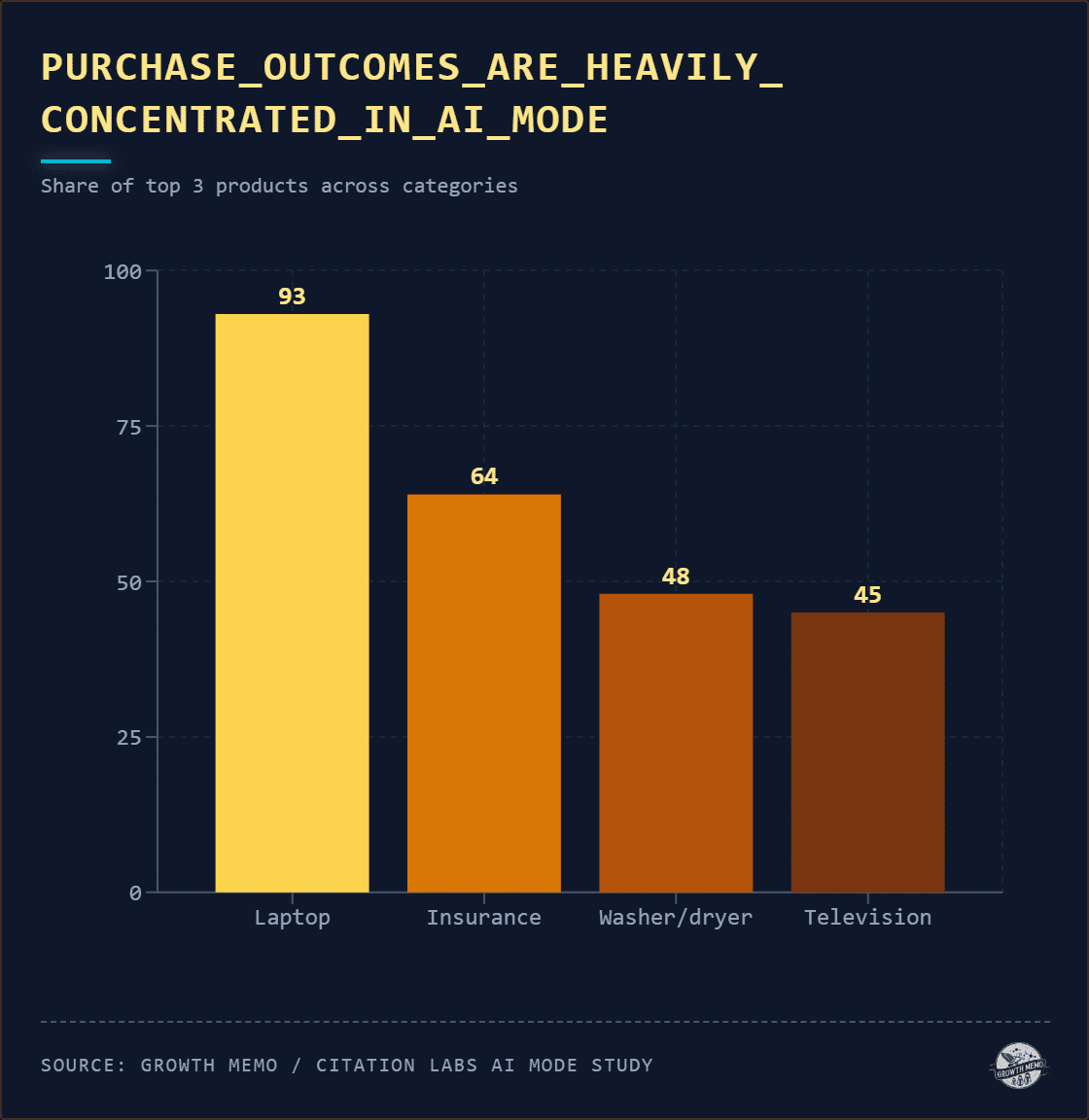
Purchase outcomes in AI Mode concentrated heavily. For laptops, three brands captured 93% of all AI Mode final choices. In classic search, the distribution was broader: HP EliteBook variants appeared three times, ASUS once, and other brands got consideration they never received in AI Mode.
Image Credit: Kevin Indig
Two distinct problems emerged:
Brands that never appeared in the AI’s output were never considered. Participants didn’t see them, so they couldn’t evaluate them. The AI decided who made the list, not the buyer.
Brands that did appear but lacked recognition faced a different problem: They weren’t seriously considered. Erie Insurance showed up in AI Mode results, but multiple participants eliminated it on name recognition alone. The brand was present but hadn’t built enough awareness to survive the moment of selection. One participant dropped a brand because it lacked a hyperlink in the AI output, reading that formatting gap as a credibility signal: “There’s not even a link there.”
Another participant said when using AI Mode: “I’m already eager to believe these are good recommendations because it mentions LG and Samsung, two brands I consider very reliable.” The AI didn’t say those brands were better. The participant inferred it from familiarity.
Participants didn’t feel constrained by the narrower set. Narrowness frustration appeared in 15% of AI Mode tasks and 11% of classic search tasks, statistically indistinguishable. The option set shrank, but the feeling of having enough options didn’t change. The most skeptical AI Mode participant in the comparison set, who complained the AI kept pointing to “teen drivers, teen drivers, teen drivers,” still chose GEICO and Travelers: the consensus AI result.
5. Users Leave To Buy, Not To Research
23% of AI Mode tasks involved an external site visit, but keep in mind these prompts reflect high-stakes situations. In standard search, that figure was 67%.
Image Credit: Kevin Indig
The volume difference matters less than the intent difference:
AI Mode participants who left went to retailer sites and manufacturer pages to verify a price or spec for a candidate they’d already selected.
Standard Search participants left to discover candidates: Reddit for peer opinions, editorial review sites for expert takes, insurance aggregators for comparison.
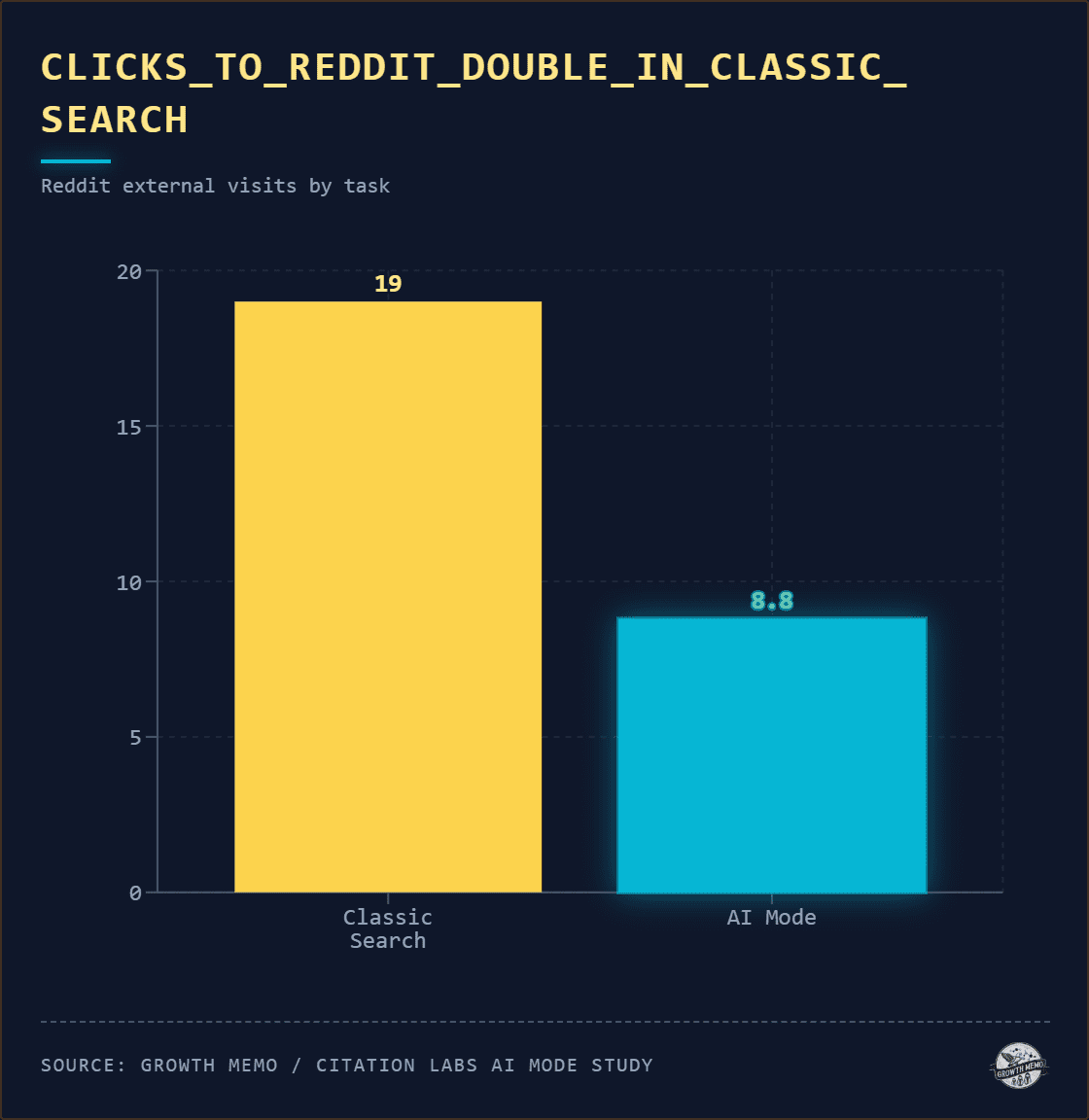
In the first AI Overviews study, we found that high risk leads users to verify AI claims more and reference against answers from other users on UGC platforms (like Reddit).
In this study, Reddit appeared in 19% of standard search tasks and only twice across all 149 AI Mode sessions. The peer-opinion layer that shapes a large share of traditional Search barely exists in AI Mode behavior.
There’s irony in that pattern. Google leans heavily on Reddit content to train its models. However, the source that users rely on most in standard search is the one they almost never visit when the AI synthesizes those same sources for them.
The first study found the same pattern at a different scale. Across 250 sessions, clicks were “reserved for transactions:” Shopping prompts drove the highest exit share, while comparison prompts drove the lowest. The exit destinations were retailers and brand sites, not editorial or peer-opinion sources. Six months and a different task set later, the pattern holds: When users leave AI Mode, they leave to buy.
6. 3 Levers: Visibility, Framing, And Pricing Data
Three things that excite me most about the study:
First, we can apply the mental model of rankings (higher = better) to AI Mode as well. Most users choose the first product. Now, we can apply this to prompt tracking by focusing more on prompts that lead to shortlists and use our position as a goalpost.
Second, trust trumps rank. We know this since the first user behavior studies I published, but this study reinforces the importance of building trust with users before they search. It’s the ultimate cheat code.
Third, we now know buyers trust AI’s recommendations. Obviously, there’s a high risk here if the AI is wrong, but seeing how quickly buyers take the AI’s recommendation also shows us how fast consumers adopt AI. It truly is the future of Search.
Keep in mind:
1. Visibility at the model layer is the new threshold. If AI Mode doesn’t surface your brand, you have a visibility problem at the model layer. Query your own category the way a buyer would (i.e., “best car insurance for a family with a teen driver,” “best washer dryer set under $2,000”) and document which brands appear, in what order, and with what framing. Do this across multiple prompt variations. Do it regularly, because AI responses shift over time.
2. How the AI describes you matters as much as whether it appears. Brands cited with concrete attributes (specific model, specific price, named use case) held stronger positions than brands described generically. The content on your site that the AI draws from not only affects whether you show up, but also how confidently and specifically you show up. A brand with structured pricing data, clear product specs, and explicit use cases gives the AI better material to work with.
3. For categories with context-dependent pricing, AI Mode creates a false-confidence problem. 63% of insurance participants were rated overconfident about pricing. They accepted AI-quoted rate estimates without checking whether the figures applied to their actual state, driving record, or current insurer. They made elimination decisions based on numbers that may not have applied to them. Where shopping panels showed explicit retailer-confirmed prices (washer/dryer), 85% of participants understood pricing clearly. Where they didn’t (insurance, laptops), confusion and overconfidence filled the gap. Structured pricing data through Merchant Center feeds and schema markup is the most direct lever for brands selling physical products. For services, the lever is editorial: Make sure your landing pages and FAQ content frame pricing as conditional (“your rate depends on X, Y, Z”) so the AI has that framing to draw from.
Study Design
Citation Labs and Clickstream Solutions ran this as a remote, unmoderated usability study with 48 U.S.-based participants recruited through Prolific. Each participant completed up to four major-purchase shortlisting tasks across televisions, laptops, washer/dryer sets, and car insurance.
The comparison between AI Mode and traditional standard search used a within-subjects A/B design: Participants used both surfaces, not one or the other. Significance calculations were normalized for the exact number of participants in each group (149 AI Mode task observations, 36 standard search task observations). This matters because the groups are unequal in size, and raw percentage comparisons between them would overstate confidence without that correction.
Sessions were screen-recorded with think-aloud audio. Trained analysts annotated each recording for behavioral markers (click-through, shortlist origin, trust signals, external site visits) and qualitative markers (stated reasoning, brand mentions, frustration signals). The 185 task-level observations provide a larger analytical base than the 48-participant headcount suggests, but confidence intervals remain wider than a large-scale survey. Findings are directional, not population-level estimates.
Notes on terminology used throughout this report:
Shortlist: The final set of brands a user would consider buying from.
AI Adopted: The participant took the AI’s recommended candidates as their shortlist with no changes or external verification.
User Built: The participant ignored the AI’s (or Search’s) suggestions and assembled their own candidate list from independent sources. In Search, when there was no AIO present, they had no option for relying on AI suggestions.
AI Verified: The participant started with the AI’s candidates but checked them against an outside source (a retailer site, a review, a manufacturer page, further prompting, or interaction with a panel outside the main AI text block ) before finalizing.
Hybrid: The participant combined AI-suggested candidates with at least one candidate they found independently.
AI framing: The specific words and structure the AI used to describe a product, such as labels like “best for affordability” or explicit price comparisons.
Brand recognition: The user chose or eliminated a brand based on prior familiarity, not the AI’s description or any external research.
AI trust (general): The user accepted the AI’s output as credible without citing a specific reason, such as a particular label or description.
Source trust: The user trusted a recommendation because of where it came from, such as a retailer, manufacturer, or named publication surfaced in results.
Multi-source convergence: The user built confidence by checking whether multiple independent sources agreed on the same recommendation.
Rank override rate: The share of users who chose a brand other than the AI’s top-ranked option, regardless of whether they stayed within the AI’s candidate list.
Featured Image: Tapati Rinchumrus/Shutterstock; Paulo Bobita/Search Engine Journal
Ask any PPC professional what career shape they are working toward, and most will say T-shaped. One deep specialism, broad supporting knowledge across adjacent areas. It became the dominant career framework in marketing over the last decade, and for good reason. In a world where platforms were simpler and clients valued versatility, the T-shaped practitioner was exactly what the market wanted.
That model is no longer enough.
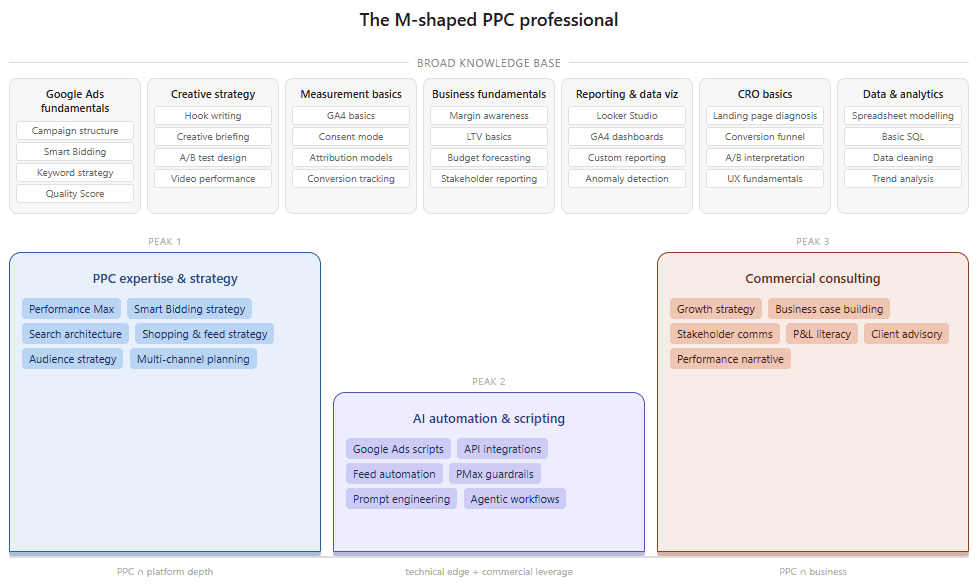
Not because T-shaped practitioners are bad at their jobs or the model does not work anymore. Most are excellent. But the conditions that made T-shaped the right target have changed fundamentally, and the practitioners commanding the highest compensation in 2026 are not T-shaped. They are something more evolved: M-shaped. Two or three deep pillars of expertise, sitting on a broad foundation of knowledge across five to seven adjacent domains. It looks like a generalist from a distance and like a specialist up close, depending on which conversation you are in.
I want to make the case that M-shaped is not just an incremental upgrade on T-shaped. It is a fundamentally different career posture, built for a fundamentally different market.
Why T-Shaped Made Sense, And Why It Is No Longer Enough
The T-shaped model solved a real problem. Early in a career, being good at one thing gets you hired. Being good at only one thing gets you stuck. T-shaped gave practitioners a path: Go deep first, then build outward. It worked particularly well in agency environments where account managers needed enough breadth to have intelligent conversations across channels without needing to own them all.
The problem is that AI has quietly made T-shaped the new floor, not the ceiling. The State of PPC 2026 report, with over 1,306 responses, suggests that the skills now expected of a competent PPC manager include data analysis, first-party data activation, creative testing strategy, attribution modeling, prompt engineering, and scripting. That is not a job description for a specialist. It is the broad knowledge layer of a T-shaped practitioner, repackaged as the baseline requirement.
When the broad layer of your T becomes everyone’s minimum viable requirement, the T itself stops being a differentiator. What differentiates you now is what sits on top of it.
There is also a structural issue that the T-shaped model was never designed to address. A single deep specialism creates a single point of failure. If your specialism is automated, commoditised, or simply stops being valued by clients, you are exposed. Practitioners who built their identity around a single skill have already felt this. The M-shaped model spreads that risk across multiple pillars without sacrificing depth.
What M-Shaped Actually Means In PPC
M-shaped is not a new term, but it has barely been applied to paid media specifically. In talent and HR circles, it describes a senior professional with multiple areas of genuine depth connected by a wide base of contextual knowledge. Think of the shape literally: two or three peaks, not one, all sitting on the same broad foundation.
In a PPC context, the broad foundation could cover seven domains. Not mastery of each, but enough fluency to be credible, to ask the right questions, and to connect dots across them:
Broad knowledge layer (the base of the M)
What fluency looks like in practice
Google Ads and paid search fundamentals
Understanding platform mechanics, bid strategy, and campaign architecture at a working level.
Creative strategy
Briefing creative from a performance hypothesis, not an aesthetic preference.
Data and analytics fundamentals
Enough to interpret a dataset, build a basic model in Google Sheets or Looker Studio, and know when the numbers you are looking at are telling you something real versus something misleading.
Audience and first-party data
Knowing what signals matter and how first-party data integrate.
Business fundamentals
Reading a P&L, understanding margin, talking to a CFO.
Reporting and data visualisation
Turning raw data into a decision, not just a dashboard.
CRO basics
Enough to understand where paid traffic lands and why conversion rate affects the economics of every campaign you run.
On top of that base, the M-shaped PPC professional has two or three peaks. These are not sub-specializations within PPC. They are complementary disciplines that sit alongside it. The difference matters. Going deeper on Smart Bidding or Performance Max is valuable, but it is still PPC. Building genuine expertise in data engineering, CRO, SEO, business consulting, or marketing attribution is something different. It takes you into rooms and conversations that pure PPC expertise does not open. That is what the second and third peaks are for.
My own peaks are measurement and attribution strategy, AI-driven automation and scripting, and high-value commercial consulting. Importantly, these are not just deeper layers within PPC. They are distinct disciplines in their own right, each requiring a different knowledge base and opening access to different conversations. Attribution sits at the intersection of PPC and broader data strategy. Automation and scripting sit at the intersection of PPC and engineering. Consulting sits at the intersection of all of it and commercial strategy. That is the point. The peaks of an M-shaped profile should take you somewhere your PPC foundation alone cannot reach.
The specific peaks will differ for every practitioner. What matters is that they are genuinely deep, that they are visible, and that they are connected to each other and to the broad base in a way that makes sense commercially.
A sample M-shaped skillset could look like this:
Image from author, March 2026
Why M-Shaped Is Where The Premium Compensation Actually Lives
The salary data backs this up in a way that is hard to ignore. Duane Brown’s PPC Salary Survey 2026 shows that U.S. freelancers with 10 to 15 years of experience earn a median of $202,895, compared to $123,545 for agency practitioners at the same experience level. That is a gap of nearly $80,000 for the same years on the clock.
That premium is not explained by experience alone. It is explained by the ability to operate across disciplines. The practitioners earning at that level are not running campaigns for retainer fees. They are being engaged as experts who can bridge PPC with adjacent high-value problems: a consultant who understands both automation and business strategy, a specialist who can speak to attribution in a language the CFO recognises, a practitioner who can connect first-party data infrastructure to paid media outcomes. The peaks make that possible. The base alone does not.
The in-house data tells a similar story. The same survey shows a median of $170,000 for in-house practitioners with six to nine years of experience, against $90,000 for their agency counterparts at the same stage. That $80,000 gap reflects something structural: in-house senior roles, particularly growth-oriented ones, tend to be built around practitioners who own multiple critical functions rather than managing a portfolio of client accounts. They are hired for their peaks, not their base.
Agencies have to spread expertise across too many clients to let anyone go truly deep. In-house is where M-shaped profiles find the room to build.
This is worth sitting with if you work in an agency. Agency environments are excellent for building a range. You see more campaigns, more industries, more budget levels in two years at a good agency than you would in five years in-house. But agencies have a structural ceiling on depth: there are too many clients, too many accounts, too much context-switching for any one practitioner to genuinely own a problem from end to end. The practitioners who break through that ceiling are the ones who build their peaks outside the day job, through side projects, consulting work, speaking, writing, and building tools, and use the agency as the base, not the destination.
The Counterargument Worth Addressing
The obvious pushback to all of this is that M-shaped sounds good in theory but is unrealistic in practice. Most practitioners do not have the time or the organizational support to develop multiple genuine areas of deep expertise while also managing a full workload. And they are right that it cannot happen overnight.
But I think this objection confuses building M-shaped with being M-shaped. You do not arrive at M-shaped by trying to become an expert in three things simultaneously. You arrive there by going deep in one area first, then, once that pillar is solid enough to be commercially useful, identifying a second area where your first pillar gives you a natural edge. Measurement and attribution, for example, becomes a much more tractable second pillar once you already understand automation. If you know how Performance Max actually allocates budget, what signals Smart Bidding consumes, and where platform reporting diverges from reality, you are not approaching attribution as an abstract measurement problem. You are solving a specific one: how do you build a framework that accounts for what you already know the platform is doing wrong? That prior knowledge makes you faster, more credible, and harder to replace than someone who learned attribution in isolation.
The progression is not linear, and it is not fast. But the practitioners commanding $150,000 to $200,000 in this industry did not get there by deepening a single specialism forever. They got there by building a second peak, and then finding a way to connect the two.
What This Means For Where You Invest Next
If the argument holds that T-shaped is the new floor and M-shaped is where the premium lives, then the practical question is how to identify which second or third peak to build.
My honest advice is to start from your first peak and ask what adjacent problems your clients or employers consistently struggle with that you are currently not equipped to solve. If your peak is campaign automation, the adjacent problem is probably measurement: clients who have great automation in place but no reliable way to attribute outcomes to it. If your peak is creative performance, the adjacent problem is probably first-party data and audience strategy: clients who are producing great creative but targeting it at the wrong signals.
The peaks that compound best are the ones that are genuinely complementary, where depth in one makes you better at the other and more valuable to the businesses you work with. That is what separates M-shaped from simply having two T-shapes that happen to coexist in the same person.
The State of PPC 2026 report is unambiguous on the wider context: the performance gap between sophisticated advertisers and the average is wider than it has ever been. Platforms are not becoming more transparent, privacy constraints are not loosening, and competition is not decreasing. In that environment, the practitioners who will win are not the ones who are good at everything. They are the ones who are indispensable at two or three things that matter deeply to the businesses they serve.
T-shaped got a lot of us to where we are. M-shaped is what gets us to where the market is heading, and to a point where your career becomes genuinely difficult to commoditise or replace.
One last thing worth saying clearly: Do not be discouraged by this. M-shaped is not a certification you earn or a checklist you complete in a training sprint. It is the professional identity you build over a career.
The practitioners I know who have reached it did not set out to become M-shaped. They went deep on one thing, got good enough that it opened a door to something adjacent, walked through it, and repeated the process. That takes years, sometimes a decade or more. The fact that it takes that long is precisely why it is worth building. Anything that can be acquired in two or three years can be acquired by everyone. What you are working toward is something that cannot.
A recent podcast by Google called attention to the fact that websites are getting larger than ever before. Google’s Gary Illyes and Martin Splitt explained that the idea that websites are getting “larger” is a bad thing is not necessarily true. The takeaway for publishers and SEOs is that Page Weight is not a trustworthy metric because the cause of the “excess” weight might very well be something useful.
Page Size Depends On What ‘s Being Measured
Google’s Martin Splitt explained that what many people think of as page size depends on what is being measured.
Is it measured by just the HTML?
Or are you talking about total page size, including images, CSS, and JavaScript?
It’s an important distinction. For example, many SEOs were freaked out when they heard that Googlebot was limiting their page crawl to just 2 megabytes of HTML per page. To put that into perspective, two megabytes of HTML equals about two million characters (letters, numbers, and symbols). That’s the equivalent of one HTML page with the same number of letters as two Harry Potter books.
But when you include CSS, images, and JavaScript along with the HTML, now we’re having a different conversation that’s related to page speed for users, not for the Googlebot crawler.
Martin discussed an article on HTTPArchive’s Web Almanac, which is a roundup of website trends. The article appeared to be mixing up different kinds of page weight, and that makes it confusing because there are at least two versions of page weight.
He noted:
“See that’s where I’m not so clear about their definition of page weight.
…they have a paragraph where they are trying to like explain what they mean by page weight. …I don’t understand the differences in what these things are. So they say page weight (also called page size) is the total volume of data measured in kilobytes or megabytes that a user must download to view a specific page. In my book that includes images and whatnot because I have to download that to see.
And that’s why I was surprised to hear that in 2015 that was 845 kilobytes. That to me was surprising. …Because I would have assumed that with images it would be more than 800 kilobytes.
… In July 2025, the same median page is now 2.3 megabytes.”
Data Gets Compressed
But that is only one way to understand page size. Another way to consider page size is by focusing on what is transferred over the network, which can be smaller due to compression. Compression is an algorithm on the server side that minimizes the size of the file that is sent from the server and downloaded by the browser. Most servers use a compression algorithm called Brotli.
Martin Splitt explains:
“I ask this question publicly that different people had very different notions of how they understood page size. Depending on the layer you are looking at, it gets confusing as well because there’s also compression.
…So some people are like, ah, but this website downloads 10 megabytes onto my disk.
And I’m like, yes. …but maybe if you look at what actually goes over the wire, you might find that this is five or six megabytes, not the whole 10 megabytes. Because you can compress things on the network level and then you decompress them on the client side level…”
Technically, the page size in Martin’s example is actually five or six megabytes because of compression, and it’s able to download faster. But on the user’s side, that five or six megabytes gets decompressed, and it turns back into ten megabytes, which occupies that much space on a user’s phone, desktop, or wherever.
And that introduces an ambiguity. Is your web page ten megabytes or five megabytes?
That illustrates a wider problem: different people are talking about different things when they talk about page size.
Even widely used definitions don’t fully resolve the ambiguity. Page weight is described as “the total volume of data measured in kilobytes or megabytes that a user must download,” but as the discussion makes clear, there is no one clear definition.
Martin asserts:
“When you ask people what they think, if this is big or not, you start getting very different answers depending on how they think about page size. And there is no one true definition of it.”
What About Ratio Of Markup To Content?
One of the most interesting distinctions made in the podcast is that a large page is not necessarily inefficient. For example, a 15 MB HTML document is considered acceptable because “pretty much most of these 15 megabytes are actually useful content.” The size reflects the value being delivered.
By contrast, what if the ratio of content to markup were the other way around, where there was a little bit of content but the overwhelming amount of the page weight was markup.
Martin discussed the ratio example:
“…what if the markup is the only overhead? And I mean like what do you mean? It’s like, well, you know, if it’s like five megabytes but it’s only very little content, is that bad? Is that worse as in this case, the 15 megabytes.
And I’m like, that’s tricky because then we come into this weird territory of the ratio between content and markup. Yeah.
And I said, well, but what if a lot of it is markup that is metadata for some third party tool or for some service or for regulatory reasons or licensing reasons or whatever. Then that’s useful content, but not necessarily for the end user, but you still kind of have to have it.
It would be weird to say that that is worse than the page where the weight is mostly content.”
What Martin is doing here is shifting the idea of page weight away from raw size toward what the data actually represents.
Why Pages Include Data Users Never See
A major contributor to page weight is content that users never see.
Gary Illyes points to structured data as an example of content that is specifically meant for machines and not for users. While it can be useful for search engines, it also adds to the overall size of the page. If a publisher adds a lot of structured data to their page in order to take advantage of all the different options that are available, that’s going to add to the page size even though the user will never see it.
This calls attention to a structural reality of the web: pages are not just built for human readers. They are also built for search engines, tools, AI agents, and other systems, all of which add their own requirements to the weight of a web page.
When Overhead Is Justified
Not all non-user-facing content is unnecessary.
Martin talked about how markup may include “metadata” or a tool, regulatory, or licensing purpose, creating a kind of gray area. Even if the additional data does not improve the user experience directly, it does serve a purpose, including helping the user find the page through a search engine.
The point that Martin was getting at is that these considerations of page weight complicate attempts to label page weight as good if it is under this threshold or bad if the page weight exceeds it.
Why Separating Content and Metadata Doesn’t Work
One possible solution that Gary Illyes discussed is separating human-facing content from machine-facing data. While Gary didn’t specifically mention the LLMs.txt proposal, what he discussed kind of resembles it in that it serves content to a machine minus all the other overhead that goes with the user-facing content.
What he actually discussed was a way to separate all of the machine-facing data from what the user will download, thus, in theory, making the user’s version of a web page smaller.
Gary quickly dismisses that idea as “utopic” because there will always be hordes of spammers who will find a way to take advantage of that.
He explained:
“But then unfortunately this is an utopic thing. Because not everyone on the internet is playing nice.
We know how much spam we have to deal with. On our blog we say somewhere that we catch like 40 billion URLs per day that’s spam or some insane number, I don’t remember exactly, but it’s some insane number and definitely billions. That will just exacerbate the amount of spam that search engines receive and other machines receive maybe like I would bet $1 and 5 cents that will actually increase the amount of spam that search engines and LLMs and others ingest.”
Gary also said that Google’s experience is that, historically, when you have separate kinds of content, there will always be differences between the two kinds. He used the example of when websites had mobile and desktop pages, where the two versions of content were generally different, which in turn caused issues for search and also for usability when a site ranks a web page for content on one version of a page, then sends the user to a different version of the page where that content does not exist.
Although he didn’t explicitly mention it, that explanation of Google’s experience may shed more light on why Google will not adopt LLMS.txt.
As a result, search engines have largely settled on a single-document model, even if it is inefficient.
Website Size vs Page Size Is the Real World
The discussion ultimately challenges the original concept of the problem, that heavy web pages are bad.
Gary observes:
“The first question is, are websites getting fat? I think this question is not even meaningful.
Because it does not matter in the context of a website if it’s fat. In the context of a single page, yes.
But in the context of a website, it really doesn’t matter.”
So now Gary and Martin change the focus to web pages that are getting heavier, a more meaningful way to look at the issue of how web pages and websites are evolving.
This moves the discussion from an abstract idea to something more measurable and actionable.
Heavier Pages Still Carry Real Costs
Even with faster connections and better infrastructure, larger pages still have consequences, and smaller weighted pages have positive benefits.
Martin explains:
“I think we are wasting a lot of resources. And I mean we, we had that in another episode where we said that we know that there are studies that show that websites that are faster have better retention and better conversion rates. Yeah. And speed is in part also based on size. Because the more data I ship, the longer it takes for the network to actually transfer that data and the longer it takes for the processor of whatever device you’re on to actually process it and display it to you.”
From a broader perspective, the issue is not just performance but efficiency. As Illyes puts it, “we are wasting a lot of resources.”
The web may be getting heavier, but the more important takeaway is why. Pages are carrying more than just user-facing content, and that design choice shapes both their size and their impact.
Eligible Yoast customers can now run a free Yoast AI Brand Insights scan and get a personalized report showing how ChatGPT, Perplexity, and Gemini see your brand. Your brand is part of the AI conversation whether you’re monitoring it or not. Yoast AI Brand Insights, part of the Yoast SEO AI+ plan gives you visibility into what AI tools say about you, how often you appear, and whether the picture they paint matches reality. To help you see that for yourself, we’re offering eligible customers a free, one-time scan.
What you’ll see
Your AI Visibility Index: a clear score showing how present your brand is across ChatGPT, Perplexity, and Gemini
Sentiment analysis: whether AI describes you positively, neutrally, or in a way that needs attention
Competitor benchmarking: how often your competitors appear alongside you, so you know where you stand
Citation tracking: which sources AI is drawing on when it talks about your brand
How it works
Add your brand details, set your location, and generate your queries. Your personalized report is ready in minutes.
Current customers can locate Yoast AI Brand Insights inside their MyYoast account
Who is eligible
Existing customers on one of the following plans can log in and try a brand scan for free today.
Yoast SEO Premium
Yoast WooCommerce SEO
Yoast SEO Google Docs add-on
Look out for your invitation inside the product the next time you log in.
Beth is Product Marketing Manager at Yoast. Before joining the company, she honed her digital marketing and project management skills in various in-house and agency environments.