How To Measure PPC Performance When AI Controls The Auction via @sejournal, @brookeosmundson
For most of the history of paid search, performance measurement followed a clear cause-and-effect relationship.
Advertisers controlled the inputs inside their campaigns like bid strategies, keyword and campaign structure, ad copy, and landing pages. All these factors contributed to conversion performance in some shape or form.
When performance changed, the explanation was usually traceable. For example, a new keyword theme improved conversion rates. Or, a bidding strategy increased efficiency.
That simple cause-and-effect framework is breaking down in real time, and has been for a while.
Over the past several months, Google has accelerated its transition toward AI-driven campaign types like Performance Max, Demand Gen, or assets inside those like AI Max or AI-driven ad creative components.
Not only do these change how campaigns are set up and managed, but they also change how performance must be measured.
Advertisers increasingly receive conversions from queries they did not explicitly target, from creative assets that are automatically assembled, and from placements distributed across multiple channels. In this environment, measuring performance by analyzing individual campaign inputs becomes less useful.
The real challenge is understanding how automated systems generate outcomes.
This article provides a measurement framework for that reality. It explains what has changed in advertising platforms, how PPC teams can evaluate performance when automation controls more of the auction, and how practitioners can communicate results clearly to leadership.
The Current Measurement Crisis In PPC
Right now, most discussions about AI in PPC tend to focus on automation features like campaign types, targeting capabilities, ad creative development, and bid strategy expansion.
But, there’s a deeper shift happening in measurement but not talked about as much.
Automation introduces a larger set of variables influencing each auction. When the platforms make targeting, bidding, placement decisions (and more) dynamically, isolating the impact of individual campaign inputs becomes difficult.
Recent platform updates have not only changed how campaigns are managed, but also how performance should be interpreted. The connection between action and outcome is less direct, and in many cases, partially obscured.
Several platform developments illustrate why traditional measurement methods are becoming less reliable.
AI Max Expands Queries Beyond Keyword Lists
In my opinion, AI Max represents Google’s most aggressive step toward intent-driven matching.
Instead of relying solely on advertiser-defined keywords, AI systems evaluate contextual signals, user behavior patterns, and historical performance data to match ads with queries that may not exist in the account.
Not only that, but AI Max goes beyond search terms. It also has the ability to change your ad assets for more tailored messaging when Google deems appropriate.
For PPC managers, this introduces a structural shift in how to measure performance. Conversions may originate from queries that were never explicitly targeted.
And we knew that something like this was coming. Back in 2023, Google first publicly used the word “keywordless” in communications when talking about Search and Performance Max.
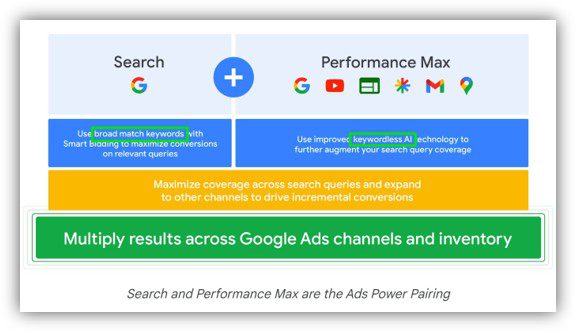
For example, a retailer who bids on “trail running shoes” may now appear for search terms like:
- “best shoes for rocky terrain running”
- “ultra marathon footwear”
- “durable hiking running hybrids”
These queries reflect the same intent, but they don’t map cleanly back to the original keyword strategy.
Instead of trying to force these queries into keyword-level reporting, try analyzing performance by grouping into intent clusters. By evaluating conversion rate and revenue at the category level, teams can maintain strategic clarity even as query matching expands.
Google Ads already does a decent job of this in the Insights tab within the platform. They have a “Search terms insights” report that groups queries into “Search category,” where you can see conversions and search volume.
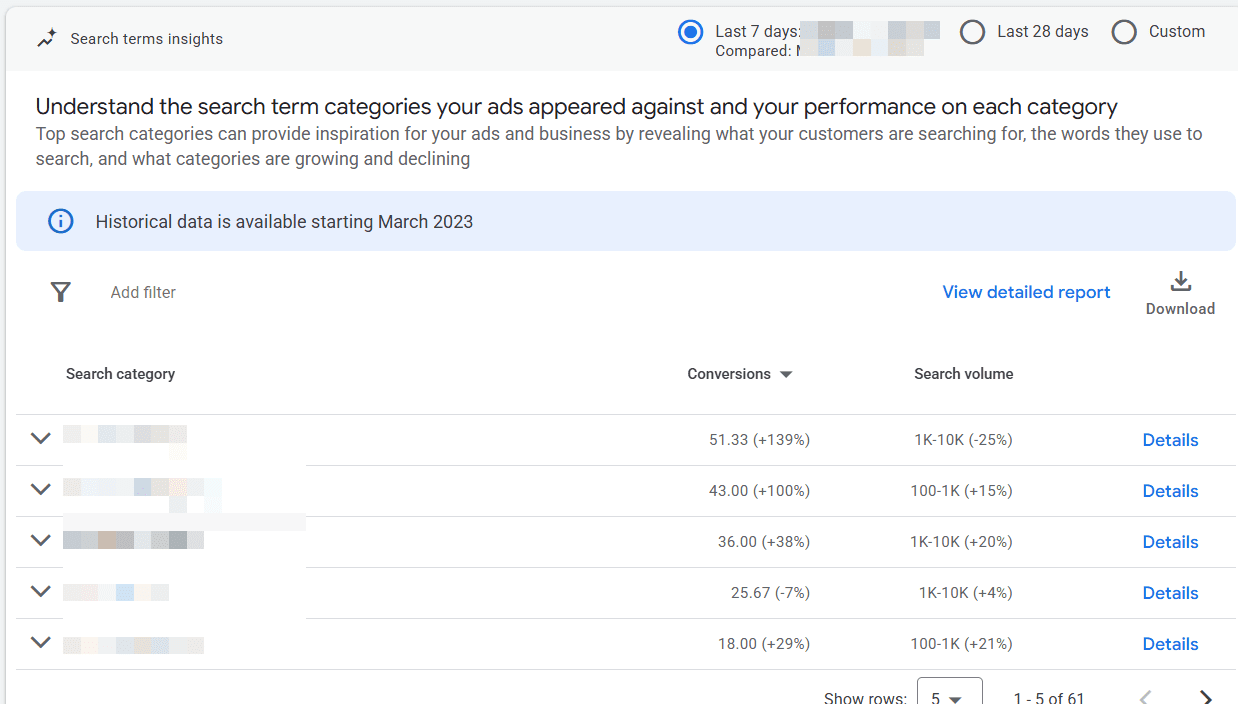
Performance Max Distributes Spend Across Multiple Channels
Performance Max can further complicate measurement by distributing budget across Search, YouTube, Display, Discover, Gmail, and Maps.
Up until last year, there was little-to-no transparency in how spend was allocated across those channels. Back in April 2025, Google launched the long-awaited feature of channel reporting to the PMax campaign type. It now shows channel-level reporting, better search terms data, and expanded asset performance metrics.
For example, say you have a $40,000 monthly PMax campaign budget and see this channel breakdown:
| Channel | Spend | Conversions |
| Search | $18,500 | 310 |
| YouTube | $10,200 | 82 |
| Display | $7,100 | 45 |
| Discover | $4,200 | 28 |
If Search drives the majority of conversions, but YouTube consumes a large portion of spend, PPC marketers could try the following:
- Test separating out branded search outside of PMax.
- Refine asset groups to improve search alignment.
- Run controlled experiments comparing PMax vs. Search.
Measurement becomes an exercise in interpreting how the system allocates spend rather than controlling each placement.
Ads Are Beginning To Appear Inside AI Conversations
Conversational search introduces an entirely new layer of complexity into PPC measurement.
Google is now testing shopping results embedded directly within AI Mode, allowing users to compare products without leaving the interface.
Google isn’t the only one doing this. ChatGPT announced on Jan. 16, 2026, that it would begin testing ads for its Free and Go users in the United States.
No matter which platform is running or testing ads in AI conversations, it’s clear that the measurement gap hasn’t been solved, and leaves many PPC managers with unanswered questions.
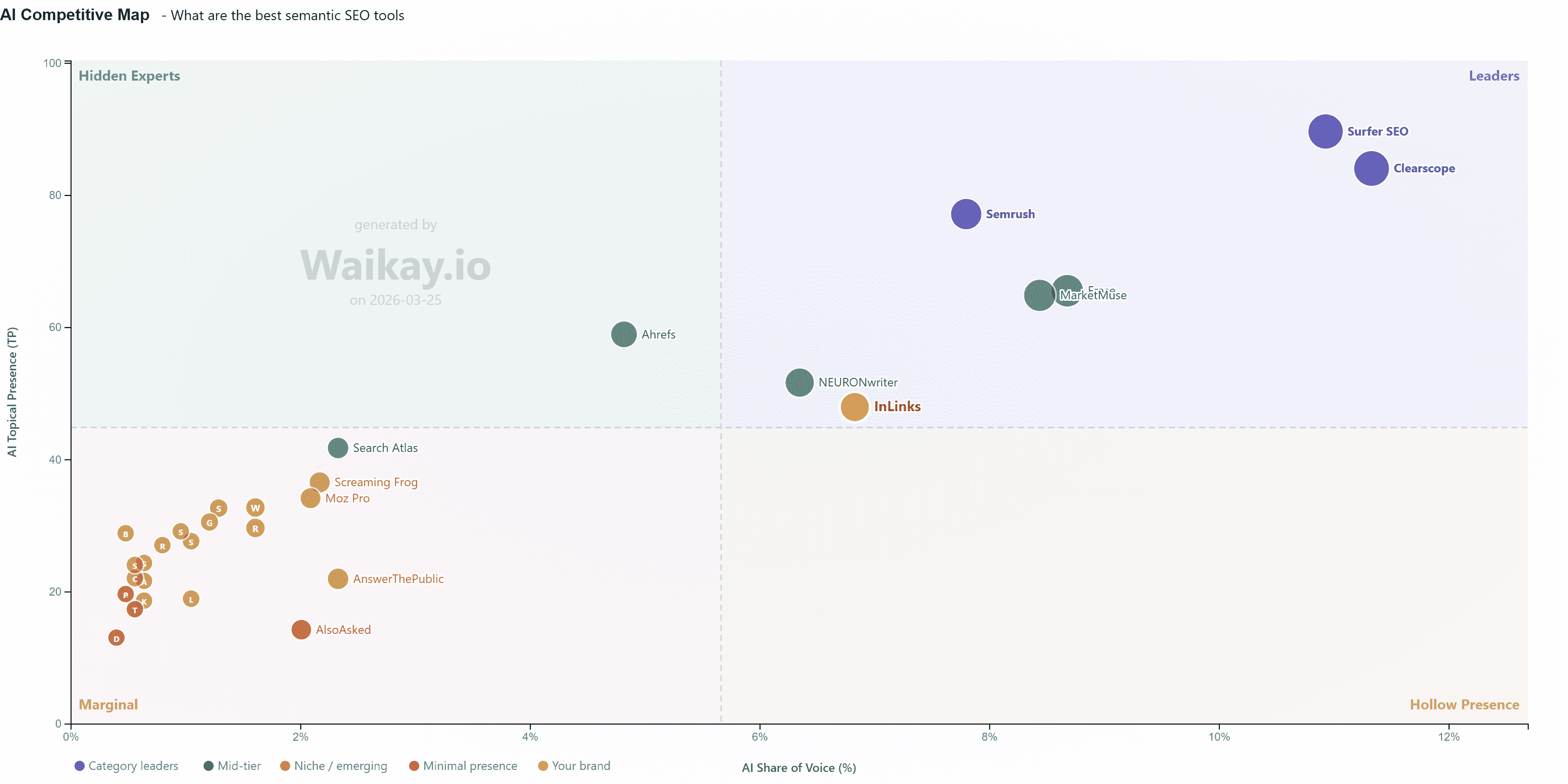
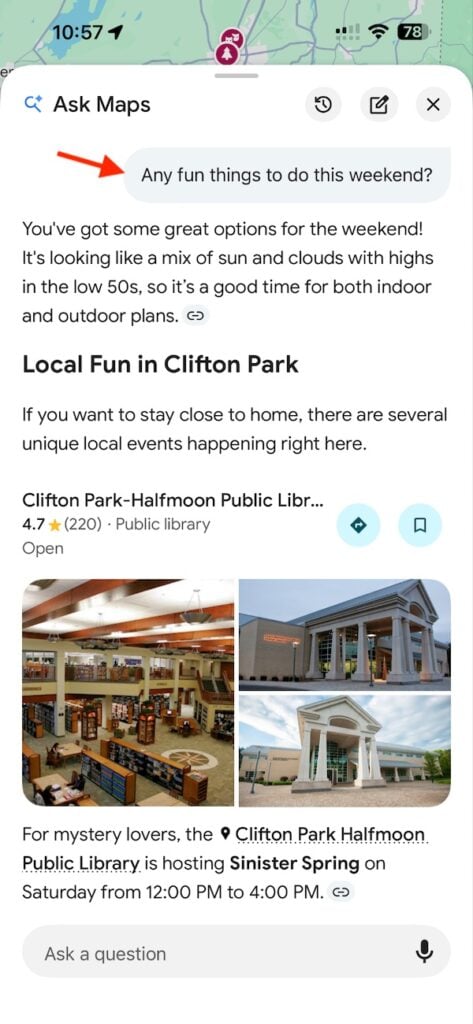
In my own recent search, I came across ads at the end of an AI Mode thread when I searched “noise cancelling headphones”:
So, if I were to click on one of those sponsored ads but convert at a later time, that attribution is unclear right now. Will my conversion be measured from the AI recommendation, the product listing click, or a later branded search?
These journeys challenge traditional attribution models, which were built around linear click paths rather than multi-step AI interactions.
Why Traditional PPC Metrics Are No Longer Enough
Many PPC reporting dashboards still rely on communicating metrics like impressions, clicks, conversion rate, and return on ad spend.
While some of those metrics remain useful, they no longer tell the full user story when bringing in automated and AI-driven environments.
These three shifts explain why.
1. Attribution Windows Are Expanding
AI-assisted search increases both the length and complexity of user journeys.
Research from Google and Boston Consulting Group show that “4S behaviors” (streaming, scrolling, searching, and shopping) have completely reshaped how users discover and engage with brands.
When AI introduces product recommendations earlier in a user’s journey, the time between initial interaction and conversion often grows. This could be because that user is still at the beginning of their research phase. Just because you’re introducing a product earlier, does not mean that they’ll be ready to purchase it any earlier.
So, what can marketers do about that gap now? Here are a few helpful tips to better understand how users are engaging with your business:
- Review conversion lag reports in Google Ads.
- Analyze time-to-conversion in GA4. Are there any differences or shifts in the last three, six, or nine months?
- Extend attribution windows to 60-90 days where appropriate.
This ensures automated systems receive more accurate feedback on what (and when they) drive conversions.
Organic Search Is Losing Click Share
Search results now include everything from AI Overviews, scrollable shopping modules at the top, and expanded ad placements across all devices.
Where does that leave organic listings?
A study conducted by SparkToro and Datos found that nearly 60% of Google searches end without a click.
This reduces organic traffic even more and shifts more demand capture towards paid media.
From a measurement standpoint, PPC should be evaluated alongside organic performance when possible.
Tracking blended search revenue provides a more accurate view of total search performance, rather than isolating paid channels.
AI Systems Optimize For Outcomes Rather Than Inputs
Traditional PPC management focused on inputs like keywords, bids, and ad copy to influence performance directly.
AI systems work differently. Instead of optimizing individual levers, they evaluate large sets of signals in real-time to determine which combinations are most likely to drive conversions.
This changes what measurement needs to do. Instead of asking which specific keyword or bid strategy adjustment improved performance, marketers need to evaluate whether the platform is producing the right business outcomes.
As platforms take over more of the execution, measurement has to focus less on the mechanics and more on whether automation is driving profitable, meaningful results.
The New Measurement Stack For AI-Driven PPC
If AI is now controlling more of the auction, then PPC teams need a different way to evaluate performance.
The old measurement stack was built around visibility into campaign inputs. You could look at keyword performance, search terms, ad copy, device segmentation, and bid adjustments to understand what was working. That model starts to fall apart when automation is making many of those decisions on your behalf.
The replacement becomes a new measurement stack that advertisers should look at in these four layers:
- Profitability.
- Incrementality.
- Blended acquisition efficiency.
- First-party conversion quality.
Together, these give marketers a more accurate picture of whether automation is actually helping the business grow.
Start With Profit, Not Just ROAS
ROAS still has value, but it should no longer be treated as the primary success metric in highly automated campaigns.
The problem is that AI-driven systems are often very good at capturing demand that already exists. That can make campaign efficiency look strong on paper, even if the business is not gaining much incremental value.
A campaign with a 700% ROAS may still be underperforming if it is primarily driving low-margin products, repeat purchasers, or orders that would have happened anyway.
That is why profitability should sit at the top of the measurement stack.
Instead of asking, “Did this campaign generate enough revenue?” marketers should be asking, “Did this campaign generate profitable revenue?”
For ecommerce brands, this could mean incorporating:
- Contribution margin.
- Product margin by category.
- Average order profitability.
- New customer revenue vs. returning customer revenue.
A simple starting point is to compare campaign revenue against both ad spend and cost of goods sold.
For lead gen advertisers, the same principle applies, just different incorporations:
- Qualified lead rate.
- Sales acceptance rate.
- Close rate by campaign.
- Revenue per opportunity.
If AI is optimizing toward cheap conversions that never turn into revenue, the system is learning the wrong lesson.
Add Incrementality To Separate Demand Capture From Demand Creation
The second layer of the stack is incrementality. This is where many PPC measurement frameworks still fall short.
Automation can be highly effective at finding conversions, but that does not automatically mean it is generating new business. In many cases, AI systems are simply getting better at intercepting users who were already on their way to converting.
If your campaign is mostly capturing existing demand, performance may look strong inside the ad platform while actual business lift remains modest.
This is why incrementality testing has become much more important in the AI era.
For PPC teams, this means at least part of measurement should be designed to answer: “Would this conversion have happened without the ad?”
You don’t need an enterprise-level media mix modeling to get started. A few practical approaches include:
- Geo holdout tests. Pause or reduce spend in a small set of markets while maintaining normal activity elsewhere.
- Use Google incrementality testing. Google reduced the minimum of testing incrementality in its platform to just $5,000, making it more affordable for many advertisers.
- Branded search suppression tests. In select markets or windows, test the impact of reducing branded spend where brand demand is already strong.
Answering this question does not mean automation is bad. It means PPC teams need a better way to distinguish between platform efficiency and true business lift.
Use Blended CAC To Measure Search More Realistically
The third layer of the new measurement stack is blended acquisition efficiency.
As AI Overviews, AI Mode, and other search changes continue to reduce traditional organic click opportunities, PPC should not be measured in a vacuum.
That is especially true for brands where paid and organic search are increasingly working together to capture the same demand.
A campaign may appear less efficient in-platform while still playing a critical role in maintaining total search visibility and revenue.
That is where blended customer acquisition cost (CAC) becomes useful.
Blended CAC looks at total acquisition spend across relevant channels and divides it by the total number of new customers acquired.
The formula for this is simple:
Total acquisition spend ÷ total new customers = blended CAC
This gives leadership a much more realistic picture of what it actually costs to grow the business.
It also helps PPC managers explain why paid search may need to carry more weight when organic search visibility declines due to AI-driven search features.
In other words, this metric helps move the conversation away from “Did Google Ads hit target ROAS?” and toward “What is it costing us to acquire a customer across modern search systems?”
Make First-Party Conversion Quality The Foundation
The final layer of the stack is first-party data quality. This is the part many advertisers still underestimate.
As platforms automate more of the targeting, bidding, and matching logic, the quality of the signals you send back becomes even more important. If the platform is deciding who to show ads to and which conversions to optimize toward, your job is to make sure it is learning from the right outcomes.
That means not all conversions should be treated equally.
If a lead form completion, low-value purchase, repeat customer order, and high-margin new customer sale are all fed back into the system the same way, automation will optimize toward volume, not value.
For PPC teams, that means the measurement stack should include a serious review of conversion quality inputs, including:
- Offline conversion imports.
- CRM-based revenue mapping.
- New vs. returning customer segmentation.
- Lead quality or opportunity-stage imports.
- Customer lifetime value indicators where available.
This is where measurement and optimization start to overlap.
If the wrong conversions are being measured, the wrong outcomes will be optimized.
That is why first-party data is not just a reporting issue. It is the foundation of the entire AI-era measurement stack.
What To Show Your CMO Or Clients
One of the most difficult aspects of managing automated campaigns is explaining performance to leadership teams.
Executives often expect reporting frameworks built around the mechanics of traditional campaign management. In automated environments, those indicators tell only a small part of the story.
A more effective reporting structure focuses on three layers that connect advertising performance to business outcomes.
The first layer should always focus on the metrics that leadership teams care about most. Revenue growth, contribution margin, and customer acquisition cost provide a direct connection between marketing activity and company performance. These indicators allow executives to evaluate marketing investments in the same framework they use to evaluate other business decisions.
Instead of presenting keyword-level reports, PPC leaders should begin with a clear summary of how paid media contributed to revenue and profit during the reporting period. If revenue increased by 18% quarter over quarter while customer acquisition costs remained stable, that outcome provides a far more meaningful signal than any individual campaign metric.
The second layer of reporting should explain how paid media contributes to the broader acquisition ecosystem. As AI-driven search experiences reshape the visibility of organic results, paid media often carries a larger share of the responsibility for capturing demand.
Blended customer acquisition cost provides an effective way to communicate this relationship. By combining marketing spend across channels and dividing it by the total number of new customers acquired, organizations gain a clearer understanding of the overall efficiency of their acquisition strategy.
This approach also helps executives understand how paid search interacts with organic search, social advertising, and other marketing channels. Rather than evaluating PPC in isolation, leadership can see how the entire acquisition system performs.
The final layer of reporting should focus on experimentation and strategic insights. Automated systems constantly evolve, and the best way to evaluate them is through structured experimentation.
Reports should include summaries of campaign experiments, including:
- The hypotheses tested.
- The metrics evaluated.
- The outcomes observed.
For example, if enabling AI-driven query expansion increased conversion volume while maintaining acceptable acquisition costs, that result provides valuable guidance for future campaign structure decisions.
Equally important is identifying metrics that are becoming less relevant.
Keyword-level performance reports, average ad position, and manual bid adjustments were once central components of PPC reporting. In automated campaign environments, those metrics often provide little strategic value. Continuing to emphasize them can distract leadership from the outcomes that truly matter.
Effective reporting in the AI era should emphasize growth, profitability, and strategic learning rather than operational mechanics.
Measurement Gaps That Still Exist
Despite improvements in automation and reporting transparency, several emerging advertising experiences remain difficult to measure.
One example is the growing presence of personalized offers within AI-driven shopping experiences. Google’s Direct Offers feature allows retailers to surface dynamic discounts during AI-generated shopping recommendations. While the feature may influence purchase decisions, advertisers currently have limited visibility into how frequently those offers appear or how strongly they influence conversion behavior.
Without that visibility, marketers cannot easily determine whether the discounts are generating incremental revenue or simply reducing margins on purchases that would have occurred anyway.
Another emerging measurement challenge involves conversational commerce. Google has begun exploring “agentic commerce” systems where AI assistants help users research and purchase products across multiple retailers.
In these environments, the user journey may involve several conversational prompts before a purchase occurs. The traditional concept of an ad impression or click may become less meaningful when AI systems guide the user through a multi-step research process.
As these experiences evolve, marketers will need new attribution models capable of evaluating influence across conversational journeys rather than isolated interactions.
These developments highlight the importance of ongoing experimentation and advocacy from advertisers. Measurement frameworks will need to evolve alongside the platforms themselves.
The Future Of PPC Measurement
Automation has changed the mechanics of paid advertising, but it has not eliminated the need for strategic oversight.
If anything, the role of human expertise has become more important.
AI systems are extremely effective at executing campaigns across large datasets and complex auctions. What they cannot do on their own is define the business outcomes that matter most or interpret performance within the broader context of organizational growth.
The most effective PPC teams are adapting to this reality. Instead of focusing exclusively on the mechanics of campaign management, they are investing more effort in defining profitability metrics, designing incrementality tests, and building reporting frameworks that connect advertising performance to business outcomes.
Measurement in the AI era will look different from the measurement frameworks that defined the early years of paid search. The focus will shift away from controlling individual campaign inputs and toward understanding how automated systems generate value for the business.
For PPC practitioners and marketing leaders alike, that shift represents the next stage in the evolution of paid media strategy.
More Resources:
Featured Image: Roman Samborskyi/Shutterstock