LinkedIn published findings from its internal testing on what drives visibility in AI-generated search results.
The company, reportedly among the most-cited sources in AI responses, shared what worked for improving its presence in LLMs and AI Overviews. For practitioners adjusting to AI search, this is a rare look at what a heavily-cited source tested and measured.
In a blog post, Inna Meklin, Director of Digital Marketing at LinkedIn, and Cassie Dell, Group Manager, Organic Growth at LinkedIn, detailed the tactics that got results.
Content Structure And Markup
LinkedIn found that how you organize content affects whether LLMs can extract and surface it. The authors wrote that headings and information hierarchy matter because “the more structured and logical your content is, the easier it is for LLMs to understand and surface.”
Semantic HTML markup also played a role, with clear structure helping LLMs interpret what each section is for. The authors called this “AI readability.”
The takeaway is that content structure isn’t just a UX consideration anymore. Proper heading hierarchy and clean markup may affect whether your content gets cited.
Expert Authorship And Timestamps
LinkedIn’s testing also pointed to credibility signals. The authors wrote:
“LLMs favor content that signals credibility and relevance, authored by real experts, clearly time-stamped, and written in a conversational, insight-driven style.”
Named authors with visible credentials and clear publication dates appeared to perform better in LinkedIn’s testing than anonymous or undated content.
The Measurement Change
LinkedIn added new KPIs alongside traffic for awareness-stage content, tracking citation share, visibility rate, and LLM mentions using AI visibility software. The company also said it’s creating a new traffic source in its internal analytics specifically for LLM-driven visits, and monitoring LLM bot behavior in CMS logs.
The authors acknowledged the measurement challenge:
“We simply couldn’t quantify how visibility within LLM responses impacts the bottom line.”
For teams still reporting traffic as the primary SEO metric, there’s a gap here. If non-brand informational content is increasingly consumed inside AI answers rather than on your site, traffic may undercount your actual reach.
Why This Matters
What caught my attention is how much this overlaps with what AI platforms themselves are saying.
SEJ’s Roger Montti recently interviewed Jesse Dwyer from Perplexity about what drives AI search visibility. Dwyer explained that Perplexity retrieves content at the sub-document level, pulling granular fragments rather than reasoning over full pages. That means how you structure content affects whether it gets extracted at all.
LinkedIn’s findings point in the same direction from the publisher side. Structure and markup matter because LLMs parse content in fragments. The credibility signals LinkedIn identified, like expert authorship and timestamps, appear to affect which fragments get surfaced.
When a heavily-cited source and an AI search platform land on the same conclusions independently, you have something to work with beyond speculation.
Looking Ahead
The authors are adopting a different mindset that practitioners can learn from:
“We are moving away from ‘search, click, website’ thinking toward a new model: Be seen, be mentioned, be considered, be chosen.”
LinkedIn indicated Part 3 of the series will include a guide on optimizing owned content for AI search, covering answer blocks and explicit definitions.
Natural language is quickly becoming the default way people interact with online tools. Instead of typing a few keywords, users now ask full questions, give detailed instructions, and are starting to expect clear, conversational answers. So, how can you make sure your content provides the answer to their question? Or better yet, how can you make it possible for them to interact with your website in a similar way? That’s where Microsoft’s NLWeb comes in.
Meet NLWeb, Microsoft’s new open project
NLWeb, short for Natural Language Web, is an open project recently launched by Microsoft. The aim of this project is to bring conversational interfaces directly to websites, rather than users having to use an external chatbot that’s in control of what’s shown. Instead of relying on traditional navigation or search bars, NLWeb is designed to allow users to ask questions and explore content in a more personal, conversational way.
At its core, NLWeb connects website content to AI-powered tools. It enables AI to understand what a website is about, what information it contains, and how that information should be interpreted for the purpose of returning personalized results. With this project, Microsoft is moving toward a more interoperable, standards-based, and open web that allows everyone to prepare their website for the future of search.
This project was initiated and realized by R.V. Guha, CVP and Technical Fellow at Microsoft. Guha is one of the creators of widely used web standards such as RSS and Schema.org.
How NLWeb works
NLWeb works by combining structured data, standardized APIs and AI models capable of understanding natural language. Every NLWeb instance acts as a Model Context Protocol (MCP) server, which makes your content discoverable for all the agents operating in the MCP ecosystem. This makes it easy for these agents to find your website.
Using structured data, website owners then present their content in a machine-readable way. AI applications can then consume this data and answer user questions accurately by matching them to the most relevant information. The result is a conversational experience powered by existing content, either directly on a website or through using an online search tool. A conversational interface for both human users and AI agents collecting information.
An important thing to note is that NLWeb is an open project. It’s not a closed ecosystem, meaning that Microsoft wants to make it accessible to everyone. The idea is to make it easy for any website owner to create an intelligent, natural language experience for their site, while also preparing their content to interact with and be discovered by other online agents, such as AI tools and search engines.
How does natural language work?
Natural language simply refers to the way we speak and write. This means using full sentences that allow room for intent, context and nuance. More than keywords or short commands, natural language reflects how people think and what they are looking for exactly.
To give you an example: a focus keyphrase might be running shoes trail. But using natural language, the request would look more like this: What are the best running shoes for trail running in wet conditions?
Natural language in AI tools
Modern AI tools are designed to understand this kind of input. The large language models behind these tools can analyze intent and context to generate responses that fulfill the given request. This is why conversational interfaces feel more intuitive than traditional search or forms.
Tools like AI chat assistants, voice search, and even traditional search engines rely heavily on natural language understanding and users have quickly adapted to it.
The current state of search
The way people find information online is changing fast. A change that is heavily influenced by the use of AI-powered tools. We now expect personalized answers instead of a list of results to sort through ourselves. AI chatbots also give us the option to follow up on our original search query, which turns search into a conversation instead of a series of clicks.
Research from McKinsey & Company shows that AI adoption and natural language interfaces are becoming mainstream, with 50% of consumers already using AI-driven tools for information discovery. The majority even say it’s the top digital source they use to make buying decisions. As these habits continue to grow, websites that aren’t optimized for natural language risk becoming invisible in AI-generated answers.
Why this is interesting for you
The shift to natural language isn’t just a technical trend. As discussed above, it directly impacts your online visibility and competitive position.
If users ask an AI system for information, only a handful of sources will be referenced in the response. This is because, like search engines, AI platforms also need to be able to read the information on your website. Being one of those sources can be the difference between being discovered or being overlooked.
NLWeb collaborates with Yoast
With NLWeb, you are communicating your website’s content clearly and in a standardized way. That means your brand, products, or expertise can appear in AI-powered answers instead of your competitors. To help as many website owners as possible benefit from this shift, Yoast is collaborating with NLWeb.
The best part? If you’re a user of any of our Yoast plans designed for WordPress, you’re well ahead here. Yoast’s integration with NLWeb will roll out in phases, starting with functionality that helps our users using WordPress express their content in ways AI systems can interpret accurately, without any additional setup required. So sit tight and let us help you prepare your website for the new world of search!
NLWeb aims to make your content understandable not just for people, but for the AI systems that are increasingly relevant to your website’s discovery.
Every January, YouTube’s CEO publishes a letter outlining where the platform is headed. In most years, these updates read like a product roadmap. Neal Mohan’s 2026 letter reads more like a strategic manifesto.
“YouTube is the epicenter of culture,” Mohan writes, arguing that creators are now “reinventing entertainment and building the media companies of the future,” while YouTube becomes the infrastructure powering that transformation.
For digital marketers, this matters because YouTube is no longer simply a distribution channel for video ads or brand content. It is simultaneously:
A global television network.
A creator marketplace.
A commerce platform.
A discovery engine powered by AI.
Each of these identities has direct implications for how SEOs, content marketers, social media managers, and executives should plan their video strategies in 2026 and beyond.
Mohan organizes YouTube’s priorities around four themes: reinventing entertainment, building the best place for kids and teens, powering the creator economy, and supercharging and safeguarding creativity. When examined through a marketing lens, these themes reveal a clear message: The future of video marketing is integrated, creator-led, commerce-enabled, and increasingly measurable.
Creators Are Now Studios – And Brands Must Think Like Co-Producers
Mohan states bluntly that the era of dismissing YouTube content as “UGC” is over. Many creators now operate like full-scale studios, purchasing production facilities, hiring teams, and developing episodic series that rival traditional television.
This is more than a branding exercise. It represents a structural shift in how entertainment is financed, produced, and distributed.
Historically, brands approached creators as distribution partners. A product placement, a sponsored segment, or a one-off integration was often sufficient. But when creators control their own intellectual property and audience relationships, that transactional model breaks down.
The more effective model is co-production.
In a co-production model, brands are involved from the very beginning in shaping content formats, creative development is approached as a collaborative process, and campaigns are designed to unfold across multiple episodes or even entire seasons rather than as one-off executions.
This approach aligns with my coverage of the rising performance of long-term creator partnerships compared to short-term influencer activations.
From a business standpoint, this also improves efficiency. Instead of briefing dozens of creators on the same campaign, brands can focus on a smaller number of deep partnerships that generate recurring assets usable across organic, paid, and owned channels.
Practical actions:
Identify creators whose content themes align with your product category and brand values.
Propose multi-video or episodic collaborations rather than single integrations.
Negotiate usage rights so creator content can be repurposed in paid media.
Why this helps you work smarter:
One strong partnership can outperform 10 shallow ones.
Shorts At 200 Billion Daily Views Has Redefined Discovery
Mohan revealed that YouTube Shorts now average 200 billion daily views and that YouTube plans to integrate additional formats, such as image posts, directly into the Shorts feed. This confirms what many marketers have already observed: Shorts are now YouTube’s primary discovery surface. But the strategic implication goes deeper.
Shorts are not just a short-form video product. They are evolving into a multi-format social feed that blends elements of TikTok, Instagram Reels, and traditional social posts. For marketers, this means Shorts should be treated as the front end of a larger content system.
A high-performing ecosystem works by guiding audiences through different layers of engagement: short-form content introduces an idea, long-form videos explore it in depth, community posts and livestreams sustain engagement, and paid ads are used strategically to amplify what’s already working.
My guidance on optimizing YouTube Shorts emphasizes hook-driven openings, concise storytelling, and native formatting. Mohan’s roadmap reinforces that these are not “nice to have” best practices; they are essential for visibility.
Practical actions:
Build Shorts in clusters around a single topic.
Include subtle prompts directing viewers to long-form content.
Repurpose Shorts into vertical ads.
Why this helps you work smarter:
One long-form video can generate dozens of Shorts that extend its lifespan.
YouTube Is The New TV – Plan Accordingly
Mohan cites Nielsen data showing YouTube has been #1 in streaming watchtime in the U.S. for nearly three years. He also highlights YouTube TV innovations like customizable multiview and specialized subscription plans.
This reinforces a critical point: YouTube now dominates living-room viewing. For marketers, this collapses the old distinction between digital video and television.
If YouTube is increasingly functioning like television, production quality starts to matter again, long-form storytelling becomes a more viable format, and episodic content begins to make far more sense as a sustainable strategy.
This does not mean every brand needs a Netflix-style series. But it does mean brands should consider developing signature formats rather than only campaign-based videos.
Examples of this approach include monthly shows hosted by subject-matter experts, structured series focused on product education, and documentary-style content that showcases real customer success stories.
YouTube ads increasingly resemble connected TV buys, making YouTube an essential component of omnichannel planning.
Practical actions:
Develop at least one recurring video series.
Test YouTube Select or CTV placements.
Optimize thumbnails and titles for large-screen browsing.
Why this helps you work smarter:
A consistent series builds audience equity over time.
YouTube’s Commerce Push Turns Video Into A Direct Revenue Channel
Mohan’s emphasis on YouTube Shopping and frictionless in-app purchases signals a major evolution: YouTube is becoming a transactional platform. Historically, video excelled at awareness and consideration. Conversions often happened elsewhere. That model is changing.
With in-app purchasing, attribution becomes clearer, funnels shorten and return on investment (ROI) improves.
For performance marketers, this means YouTube deserves a seat alongside search and social in lower-funnel planning.
I previously covered YouTube’s shoppable ad formats and best practices for measuring performance-driven video campaigns.
Practical actions:
Integrate product feeds with YouTube.
Tag videos with product links.
Use retargeting to reach viewers who watched product-related content.
Why this helps you work smarter:
Video can now drive measurable revenue, not just brand lift.
AI Will Multiply Output – But Strategy Will Separate Winners
Mohan notes that over 1 million channels use YouTube’s AI creation tools daily and that new capabilities will allow creators to generate Shorts using their own likeness and experiment with music and games. At the same time, YouTube is actively combating low-quality “AI slop.”
AI excels at handling many of the executional tasks in content creation, such as drafting scripts, generating multiple variations, translating content into different languages, and automating captions at scale.
Humans, however, continue to lead where deeper judgment and creativity are required, understanding audiences, crafting compelling narratives, and defining a clear, authentic brand voice.
AI reduces production time so you can focus on strategy.
Measurement Is Shifting Toward Business Impact
Mohan’s focus on diversified monetization signals YouTube’s broader emphasis on outcomes. For marketers, this means moving beyond surface-level metrics.
Rather than defaulting to surface-level questions like “How many views did we get?”, it’s more useful to ask whether watch time increased, brand lift improved, and conversions actually rose.
I’ve previously outlined frameworks for measuring video ROI that connect engagement to revenue.
Practical actions:
Track watch time and retention.
Use brand lift studies.
Attribute conversions where possible.
Why this helps you work smarter:
You optimize based on results, not vanity metrics.
The Strategic Bottom Line
Neal Mohan’s 2026 roadmap reveals that YouTube is evolving into a unified ecosystem where creators, commerce, AI, and entertainment converge. For digital marketers, the opportunity is not to chase every new feature. It is to design integrated systems that:
Use Shorts for discovery.
Use long form for depth.
Use creators for trust.
Use paid media for scale.
Use commerce integrations for conversion.
The marketers who succeed in 2026 will not be the ones who produce the most videos. They will be the ones who build the smartest video ecosystems.
Many Google Ads accounts generate steady traffic but struggle to turn that traffic into outcomes the business actually values, such as purchases, qualified leads, or demo requests.
That disconnect usually isn’t caused by a lack of demand or a broken platform. It’s more often the result of small, fixable issues across the account that quietly compound over time.
Keyword targeting drifts. Ad copy loses alignment with landing pages. Bid strategies stop matching how users actually convert.
None of these problems feel dramatic on their own, but together they can pull conversion rates down and make performance harder to scale.
The good news?
Improving conversion rates in Google Ads rarely requires rebuilding an account from scratch. In most cases, it comes down to tightening fundamentals, being more intentional with the levers already in place, and using performance data with a bit more discipline.
This article walks through 15 practical ways PPC managers can improve Google Ads conversion rates using changes that are realistic to implement and straightforward to test. The goal isn’t more traffic. It’s getting better results from the traffic you already pay for.
1. Implement Proper Conversion Tracking
This first one seems like a no-brainer, but it’s often overlooked by many accounts.
The only way to understand whether your Google Ads campaigns are performing or not performing is to properly set up conversion tracking.
The most common ways Google Ads conversion tracking is implemented are through:
The other key component to proper conversion tracking is identifying what conversions make sense to track.
Oftentimes, brands have one big conversion in mind. For ecommerce, that is likely a purchase or a sale. For B2B companies, it’s likely a lead or a demo signup.
But what about all the other available touchpoints before a customer makes that leap?
Consider tracking “micro” conversions on your sites to really identify the positive impact your PPC campaigns have.
Examples of “micro” conversions to track include:
Email newsletter signups.
Free samples.
Whitepaper download.
Webinar signup.
And more.
Taking a step back from the ins and outs of the platforms helps you hone in through the lens of a consumer. Setting up accurate measurements from the purchase journey can make a big impact on how you structure and optimize your Google Ads campaigns.
2. Optimize Keyword Lists
The second way to help increase Google Ads conversion rates is continuous optimization of keyword lists.
The Google Ads search terms report is a perfect tool for this. Not only can you see what users are searching for, in their own words, that leads to conversions, but you can also see what is not converting.
Keep in mind which match types you’re using throughout the keyword optimization process.
Broad match keywords have the biggest leniency when it comes to what types of searches will show for your ad. It also has the largest reach because of its flexible nature.
Turning some of your top-performing Broad match keywords into Exact match can help increase those Quality Scores, which can lead to lower cost per click (CPCs) and better efficiency for your campaigns.
3. Match Ad Copy To Landing Pages
Alright, so you’ve gotten a user to click on your ad. Great!
But you’re finding that not a lot of people are actually purchasing. What gives?
Surely, it must be a problem with the PPC campaigns.
Not always.
Typically, one of the most common reasons users leave a website right after clicking on an ad has to do with a mismatch of expectations.
Simply put, what the user was promised in an ad was not present or prominent on the landing page.
A great way to optimize conversion rates is to ensure the landing page copy is tailored to match your PPC ad copy.
Doing this ensures a relatively seamless user experience, which can help speed up the purchase process.
4. Use Clear Call-To-Action
If a user isn’t performing the actions you’d expect to after clicking on an ad, it may be time to review your ad copy.
Since the emergence of Responsive Search Ads (RSAs), I’ve seen many redundant headlines and generic calls-to-action (CTAs).
No wonder a user doesn’t know what you want them to do!
When creating CTAs either in ad copy or on the landing page, keep these principles in mind:
Use action-oriented language that clearly communicates what you want them to do.
For landing pages, make sure the CTA button is visually distinct and easily clickable. It helps if a CTA is shown before a user has to scroll down to find it.
Test different CTAs to determine what resonates best with users.
Examples of action-oriented CTA language could sound like:
“Download Now.”
“Request A Quote.”
“Shop Now.”
Try steering away from generic language such as “Learn More” unless you’re truly running a more top-of-funnel (TOF) campaign.
Creating a landing page with desktop top-of-mind should really be revisited, given that mobile traffic has overtaken desktop.
So, what can you do to help increase your conversion rates on mobile?
Use a responsive web design to accommodate different mobile layouts.
Make sure the site speed has fast loading times.
Create any mobile-specific features, like CTA placement, to make sure it’s easily viewable for users.
Optimize form fills on mobile devices.
6. Experiment With Ad Copy Testing
Ad copy is one of the biggest levers you can control in your PPC campaigns.
Even slight changes or tweaks to a headline or description can have a big impact on CTR and conversion rates.
Having multiple ad copy variants is crucial when trying to understand what resonates most with users.
Part of the beauty of Google’s Responsive Search Ads is the number of headline inputs you can have at once. Google’s algorithm then determines the best-performing ad copy combinations to increase conversion rates.
Google Ads also has tools built into the platform for more controlled testing if that is a route you want to take.
You can create ad variants or create an experiment directly in Google Ads for more precise A/B testing.
Screenshot taken by author, January 2026
It’s also important to test one element at a time to isolate the impact of each change. Testing too many elements at once can muddy up analysis.
7. Utilize Ad Assets
Ad assets are a great way to help influence a click to your website, which can help improve conversion rates.
Assets like callouts, structured snippets, and sitelinks can provide additional detail that couldn’t be shown in headlines or descriptions.
When your Ad Rank is higher, you have a better likelihood of showing ad assets, which helps increase the overall visibility of your ad.
Your ad assets can be customized to fit your campaign goals, and can even show specific promotions, special product features, and social proof like seller ratings.
8. Don’t Be Shy With Negative Keywords
A sound negative keyword strategy is one of the best ways to improve Google Ads conversion rates.
You may be wasting your paid search budget on keywords that aren’t producing conversions.
You may also notice that some broad keywords have gone rogue and are triggering your ads for terms they definitely shouldn’t be showing up for!
As mentioned earlier, the search terms report can help mitigate a lot of these types of keywords.
You can choose to add negative keywords at the following levels:
Ad group.
Campaign.
Negative keyword lists to apply to campaigns.
You also have the ability to add negative keywords as broad, phrase, or exact match.
Alleviating poor-performing keywords allows your budget to optimize for your core keyword sets that lead to conversions.
9. Set Proper Bid Strategies
The type of bid strategy you choose for your Google Ads campaigns can make or break performance.
In recent years, Google has moved towards its fully automated bidding strategies, using machine learning to align performance with the chosen goal and bid strategy.
Currently, Google has four Smart Bidding strategies focused on conversion-based goals:
Target CPA (Cost-Per-Action): Helps increase conversions while targeting a specific CPA.
Target ROAS (Return on Ad Spend): Helps increase conversions while targeting a specific ROAS.
Maximize Conversions: Optimizes for conversions, not focused on a target ROAS outcome, and spends the entire budget.
Maximize Conversion Value: Optimizes for conversion value, not focused on a target ROAS outcome, and spends the entire budget.
Choosing the right bidding strategy is just one piece of the puzzle.
The inputs of the chosen bid strategy are just as important, where more context is needed to have a successful campaign.
For example, suppose you choose a Target CPA bid strategy for a search campaign and set the target CPA to $50.
However, in that campaign, you notice that your average CPC ranges anywhere from $10-$20.
Suddenly, your impressions go down, and you’re not sure what’s happening!
It could be your bid strategy inputs.
In the example above, if you have high CPCs but set your target CPA to just slightly higher than the CPCs, that means you need to have a stellar conversion rate in order to stay within that $50 CPA threshold.
Additionally, many make the mistake of setting the same target CPA for all campaigns, regardless of brand or non-brand intent.
Most often, non-brand keywords will have much higher CPAs than brand terms, so the inputs should be set accordingly based on performance.
Make sure you set your Target CPA thresholds high enough initially for the campaigns to gather information to meet expectations.
10. Add Audience Segmentation
As keyword match types tend to get looser, there is more emphasis on leveraging audience segmentation to reach the right people.
Using audience segments allows you to tailor your ads towards specific groups or utilize audiences as exclusions so your ads aren’t triggered.
Examples of audience segments within Google Ads include:
Demographics: Can be based on gender, age, household income, education, and other areas.
Interests and behaviors: Based on hobbies, lifestyle choices, website browsing behavior, and purchase history.
Actively researching or planning: Based on a user’s past or recent purchase intent.
Past interactions with your business: Can be based on previous engagements like website visits, add-to-cart, other online interactions, existing customer relationship management (CRM) data, and more.
By segmenting audiences within your PPC campaigns, you can customize ad messaging based on those segments.
This can lead to maximizing relevance and engagement, ultimately increasing conversion rates.
You can also use insights from GA4 to inform your segmentation strategy to identify high-value audience segments.
11. Create A Retargeting Strategy
On average, ecommerce conversion rates range from 2.5-3%.
That means 97% of people leave a website without purchasing. Talk about a missed opportunity!
With a retargeting strategy in place, you have the opportunity to win back those missed customers and turn them into your brand champions.
Retargeting keeps track of website or app visitors who don’t take the desired action you’d like them to. You can create retargeting lists as niche or as broad as you prefer, but keep in mind that audiences must be a certain size before they’re eligible to use.
Examples of utilizing retargeting could be:
Creating segmented lists of users based on certain category pages of a website.
Users who have added an item to their cart but didn’t purchase it.
Users who have viewed at least three to five pages.
These segments can be used to create retargeting campaigns, which show those users ads to help increase the likelihood of them converting. Be sure to set those ad frequencies within the campaign so you don’t annoy your audience, though!
12. Offer Incentives
These days, shoppers are more accustomed to expecting a discount whenever they purchase.
There’s certainly an argument that programming people to buy only during a sale can diminish a product’s value perception.
However, there are strategies that can boost sales and conversion rates without devaluing the product.
If possible, try making the offers more personal towards the user and their behavior.
Additionally, you can set smaller windows of sale times and incorporate real-time purchase behavior so users can see how many people have taken advantage of the sale.
13. Choose The Right Location Settings
One of the easiest ways to waste precious PPC dollars is to set up location targeting wrong.
Google Ads offers multiple ways to geo-target locations within the campaign settings to help reach your goals.
Location targeting allows you to set specific locations for your ads to show, including:
City.
Region.
State.
Country.
Radius.
For example, if you have products that can only be purchased in the United States, you would likely target “United States” within the campaign setting.
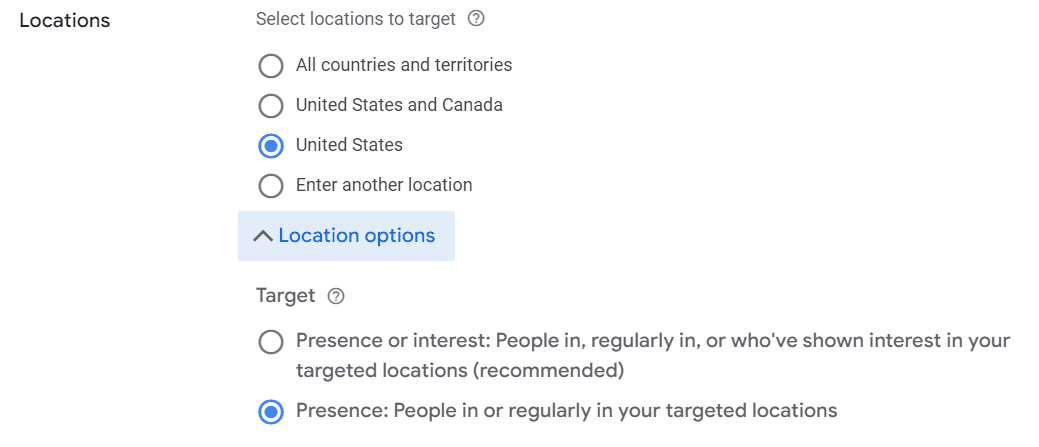
Nowadays, it’s not as easy as just choosing “United States” (in this example). This is where advanced settings come in.
Within the Google campaign settings, you have two location-targeting options:
Presence or interest: People in, regularly in, or who’ve shown interest in your targeted location.
Presence: People in or regularly in your targeted locations.
Screenshot taken by author, January 2026
In the example above, it would make sense to choose “Presence” – otherwise, the campaign could show ads in areas where the products aren’t available.
If users in those countries click on the ad but see they can’t purchase when they get to the website, that is a recipe for poor conversion rates.
14. Use Social Proof To Build Trust
Brands can leverage social proof in their Google Ads campaigns to help boost conversion rates.
The goal of using social proof is to incorporate elements that demonstrate positive sentiment from customers, endorsements, or validation that the customer’s needs will be met.
There are many ways brands can add social proof to their campaigns:
Seller ratings ad asset.
Callout ad assets.
Adding customer reviews and testimonials to the landing page.
Share case studies and success stories on the landing page.
Additionally, strategies like creating limited-time offers with an emphasis on social proof can help boost sales and conversion rates.
This could mean showing in real-time how many customers have taken advantage of the offer, which creates urgency for the customer to act.
Focusing on social proof and validation can build trust, credibility, and confidence among potential customers – ultimately leading to higher conversion rates.
15. Schedule Your Ads Based On Performance
Ad scheduling is an underestimated tool in Google Ads that helps improve conversion rates.
The beauty of ad scheduling is that you can control when your ad will or will not show.
Make sure to have ample budget and schedule ads when potential customers are most actively searching and are more engaged.
This can lead to higher effectiveness of the campaign and increased conversion rates.
For example, if you run a B2B software company, it’s highly unlikely that potential customers are searching in the middle of the night.
Optimize your spend by not showing ads at certain times of the day (such as the middle of the night) or days of the week (like weekends).
Screenshot taken by author, January 2026
If you’re not sure how to start optimizing campaigns by time, consider the following:
Use tools like GA4 to understand when most purchases are happening on the website.
Look for trends like website traffic, conversion times, engagement rates, etc., by time.
Align your ad schedule with peak business operations times, especially if customer service is involved.
Adjust ad schedules around key events like holidays or peak seasonality.
Turning Conversion Rate Optimization Into A Habit
Improving conversion rates in Google Ads is rarely tied to a single optimization or setting change. Strong performance usually comes from a series of small decisions that are reviewed, tested, and refined over time.
When those decisions stop getting attention, efficiency tends to slip, even in accounts with solid traffic and budgets.
The most effective PPC teams treat conversion rate optimization as an ongoing process rather than a one-time project. They regularly question assumptions, revisit historical decisions, and adjust based on how users behave today, not how the account was originally built.
If there’s one takeaway from these 15 tactics, it’s that better results don’t always come from spending more. They come from making the traffic you already earn more relevant, more intentional, and easier to convert.
A new proposal was published for creating an HTML attribute that can be helpful for notifying crawlers what part of a web page is generated by AI. The proposal is quickly becoming relevant because of new rules coming into effect in Europe this summer, but some are questioning whether this is the right solution to that problem.
AI Disclosure
The proposal was created by David E. Weekly (LinkedIn profile), who noted that there are currently proposals that provide a more general signal that an entire web page is AI generated but nothing that labels only a section of a web page in a page that is otherwise authored by a human.
Weekly’s proposal acknowledges the reality that many web pages are partially AI generated. One example is the AI generated summaries of news content. The proposal specifically mentions news sites that contain a sidebar with AI generated summaries.
The proposal suggests creating an HTML attribute that can be applied at the section level using the
Google added new documentation to Search Central covering their Preferred Sources program that helps news websites get into the Top Stories feature. The documentation explains what publishers can do to make it more likely to be ranked in Top Stories and get more traffic.
Top Stories
Given that Top Stories is about breaking news, freshness may be a factor for ranking.Top Stories surfaces local news as well as breaking news. Schema structured data is not necessary to rank in Top Stories but adding Schema.org Article structured data helps Google better understand what the page is about. While the Top Stories display resembles Google’s carousel feature, the ItemList structured data for Carousel displays has no effect.
Source Preferences Tool
The preferred sources program is available only to English language web pages globally. Google also states that sites that are already in the Preferred Sources tool are eligible to deep link to encourage users to add your site as a preferred source. https://www.google.com/preferences/source
If your site appears in the source preferences tool, you can use the following methods to guide your readers to select your site as a preferred source:
Add the deeplink to your social posts or promotions. Use the following URL format, which takes users directly to your site in the source preferences tool:
As AI Overviews and shopping agents divert organic traffic, ecommerce marketers may turn to advertising for predictable growth in 2026.
Artificial intelligence is reshaping how people discover, evaluate, and buy products. It may be early days, but the pace of change is accelerating.
For example, an October 2025 Harvard Business Review survey revealed that 74% of U.S. adults aged 18-30 had used an AI chatbot in the previous month. That’s up from 58% of young adults in a February 2025 survey.
Audiences
Search engines increasingly answer questions within the results. Shopping agents compare products before a shopper ever visits a website. The result is declining organic traffic.
Seemingly every industry is experiencing what might be a once-in-a-generation change in how it operates.
Yet the same AI tools creating disruption also offer opportunity. If organic traffic is less reliable, ad targeting becomes more valuable, and audience intelligence becomes a competitive advantage.
But marketers are not limited to retargeting their own shoppers or even lookalike audiences.
Merchants can buy pre-built audiences based on purchase behavior, device usage, location history, and other signals, then activate those same audiences across major advertising platforms, including social, programmatic display, connected TV, and video.
Better ad targeting can dramatically improve performance.
4 Tactics
Beyond demographics
The first step toward audience and advertising optimization might be to move beyond demographics.
“There are standard audiences that have been around forever, like age, gender, and interest, but we find a lot of our more interesting data sets in purchase history, what we call the Shopping Graph,” explained Mike Ford, CEO of Skydeo, a predictive audience firm.
This optimization is simple enough: target consumers who have recently purchased adjacent products, perhaps from competitors or in similar product categories.
To be sure, focusing on buy signals — transactional data — can cost more than broad demographic targeting. But those audiences often convert at significantly higher rates, which may more than offset the higher cost.
Hand-pick attributes
A second way to target audiences is to hand-pick attributes, or at least understand the lookalikes, thus adding human intelligence to the algorithmic mix.
Lookalike modeling is often obscure, hidden in the platform or the provider’s systems.
Instead of uploading a customer list and relying solely on an algorithm, marketers can build audiences based on explicit traits. Examples include buyers of premium dog food or folks who installed fitness apps and purchase athletic apparel.
Refresh
Another optimization tactic is to update the audience regularly.
“Sometimes audiences get stale. Sometimes they time out, and we have to refresh them,” said Ford.
Many marketers treat audiences as static assets. They build once and reuse indefinitely. This approach becomes ineffective when buying intent is sudden and short-lived.
Treat high-performing audiences like advertising creative. Rebuild or refresh audiences regularly. Ask platforms or vendors about the audience updates. Pick daily or weekly refresh cycles where possible.
Leverage AI
The fourth audience-targeting optimization Ford recommended was to leverage AI.
Ford’s Skydeo and many other data businesses, such as Adstra, Starcount, or AlikeAudience, have massive amounts of targeting data and established, off-the-shelf audiences.
Instead of hunting through taxonomies, ecommerce marketers can review, test, and validate machine-ranked audiences. The AI proposes options. Humans decide what to keep.
This does not undercut the idea of hand-picking audience attributes or demanding some level of algorithmic transparency. Rather, it is the idea of using AI not to replace human insights, but to accelerate them.
Traffic in 2026
When traffic is abundant, marketers can afford inefficiency. When traffic becomes scarce, waste is a problem.
Audience targeting optimization does not solve every challenge with AI-driven product discovery. But it can improve advertising effectiveness. And advertising is among the best ways to market in 2026.
WordPress announced wp-playground, a new AI agent skill designed to be used with the Playground CLI so AI agents can run WordPress for testing and check their work as they write code. The skill helps agents test code quickly while they work.
Playground CLI
Playground is a WordPress sandbox that enables users to run a full WordPress site without setting it all up on a traditional server. It is used for testing plugins, creating and adjusting themes, and experimenting safely without affecting a live site.
The new AI agent skill is for use with Playground CLI, which runs locally and requires knowledge of terminal commands, Node.js, and npm to manage local WordPress environments.
The wp-playground skill starts WordPress automatically and determines where generated code should exist inside the installation. The skill then mounts the code into the correct directory, which allows the agent to move directly from generated code to a running the WordPress site without manual setup.
Once WordPress is running, the agent can test behavior and verify results using common tools. In testing, agents interacted with WordPress through tools like curl and Playwright, checked outcomes, applied fixes, and then re-tested using the same environment. This process creates a repeatable loop where the agent can confirm whether a change works before making further changes.
The skill also includes helper scripts that manage startup and shutdown. These scripts reduce the time it takes for WordPress to become ready for testing from about a minute to only a few seconds. The Playground CLI can also log into WP-Admin automatically, which removes another manual step during testing.
The creator of the AI agent skill, Brandon Payton, is quoted explaining how it works:
“AI agents work better when they have a clear feedback loop. That’s why I made the wp-playground skill. It gives agents an easy way to test WordPress code and makes building and experimenting with WordPress a lot more accessible.”
The WordPress AI agent skill release also introduces a new GitHub repository dedicated to hosting WordPress agent skill. Planned ideas include persistent Playground sites tied to a project directory, running commands against existing Playground instances, and Blueprint generation.
For the last couple of years, I’ve been following the progress of a group of individuals who believe death is humanity’s “core problem.” Put simply, they say death is wrong—for everyone. They’ve even said it’s morally wrong.
Vitalism is more than a philosophy, though—it’s a movement for hardcore longevity enthusiasts who want to make real progress in finding treatments that slow or reverse aging. Not just through scientific advances, but by persuading influential people to support their movement, and by changing laws and policies to open up access to experimental drugs.
And they’re starting to make progress.
Vitalism was founded by Adam Gries and Nathan Cheng—two men who united over their shared desire to find ways to extend human lifespan. I first saw Cheng speak back in 2023, at Zuzalu, a pop-up city in Montenegro for people who were interested in life extension and some other technologies. (It was an interesting experience—you can read more about it here.)
Zuzalu was where Gries and Cheng officially launched Vitalism. But I’ve been closely following the longevity scene since 2022. That journey took me to Switzerland, Honduras, and a compound in Berkeley, California, where like-minded longevity enthusiasts shared their dreams of life extension.
It also took me to Washington, DC, where, last year, supporters of lifespan extension presented politicians including Mehmet Oz, who currently leads the Centers for Medicare & Medicaid Services, with their case for changes to laws and policies.
The journey has been fascinating, and at times weird and even surreal. I’ve heard biohacking stories that ended with smoking legs. I’ve been told about a multi-partner relationship that might be made possible through the cryopreservation—and subsequent reanimation—of a man and the multiple wives he’s had throughout his life. I’ve had people tell me to my face that they consider themselves eugenicists, and that they believe that parents should select IVF embryos for their propensity for a long life.
I’ve been shouted at and threatened with legal action. I’ve received barefoot hugs. One interviewee told me I needed Botox. It’s been a ride.
My reporting has also made me realize that the current interest in longevity reaches beyond social media influencers and wellness centers. Longevity clinics are growing in number, and there’s been a glut of documentaries about living longer or even forever.
At the same time, powerful people who influence state laws, giant federal funding budgets, and even national health policy are prioritizing the search for treatments that slow or reverse aging. The longevity community was thrilled when longtime supporter Jim O’Neill was made deputy secretary of health and human services last year. Other members of Trump’s administration, including Oz, have spoken about longevity too. “It seems that now there is the most pro-longevity administration in American history,” Gries told me.
I recently spoke to Alicia Jackson, the new director of ARPA-H. The agency, established in 2022 under Joe Biden’s presidency, funds “breakthrough” biomedical research. And it appears to have a new focus on longevity. Jackson previously founded and led Evernow, a company focused on “health and longevity for every woman.”
“There’s a lot of interesting technologies, but they all kind of come back to the same thing: Could we extend life years?” she told me over a Zoom call a few weeks ago. She added that her agency had “incredible support” from “the very top of HHS.” I asked if she was referring to Jim O’Neill. “Yeah,” she said. She wouldn’t go into the specifics.
Gries is right: There is a lot of support for advances in longevity treatments, and some of it is coming from influential people in positions of power. Perhaps the field really is poised for a breakthrough.
And that’s what makes this field so fascinating to cover. Despite the occasional weirdness.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
DHS is using Google and Adobe AI to make videos
The news: The US Department of Homeland Security is using AI video generators from Google and Adobe to make and edit content shared with the public, a new document reveals. The document, released on Wednesday, provides an inventory of which commercial AI tools DHS uses for tasks ranging from generating drafts of documents to managing cybersecurity.
Why it matters: It comes as immigration agencies have flooded social media with content to support President Trump’s mass deportation agenda—some of which appears to be made with AI—and as workers in tech have put pressure on their employers to denounce the agencies’ activities. Read the full story.
—James O’Donnell
How the sometimes-weird world of lifespan extension is gaining influence
—Jessica Hamzelou
For the last couple of years, I’ve been following the progress of a group of individuals who believe death is humanity’s “core problem.” Put simply, they say death is wrong—for everyone. They’ve even said it’s morally wrong.
Vitalism is more than a philosophy, though—it’s a movement for hardcore longevity enthusiasts who want to make real progress in finding treatments that slow or reverse aging. Not just through scientific advances, but by persuading influential people to support their movement, and by changing laws and policies to open up access to experimental drugs. And they’re starting to make progress.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
The AI Hype Index: Grok makes porn, and Claude Code nails your job
Separating AI reality from hyped-up fiction isn’t always easy. That’s why we’ve created the AI Hype Index—a simple, at-a-glance summary of everything you need to know about the state of the industry. Take a look at this month’s edition of the index here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Capgemini is no longer tracking immigrants for ICE After the French company was queried by the country’s government over the contract. (WP $) + Here’s how the agency typically keeps tabs on its targets. (NYT $) + US senators are pushing for answers about its recent surveillance shopping spree. (404 Media) + ICE’s tactics would get real soldiers killed, apparently. (Wired $)
2 The Pentagon is at loggerheads with Anthropic The AI firm is reportedly worried its tools could be used to spy on Americans. (Reuters) + Generative AI is learning to spy for the US military. (MIT Technology Review)
3 It’s relatively rare for AI chatbots to lead users down harmful paths But when it does, it can have incredibly dangerous consequences. (Ars Technica) + The AI doomers feel undeterred. (MIT Technology Review)
4 GPT-4o’s days are numbered OpenAI says just 0.1% of users are using the model every day. (CNBC) + It’s the second time that it’s tried to turn the sycophantic model off in under a year. (Insider $) + Why GPT-4o’s sudden shutdown left people grieving. (MIT Technology Review)
5 An AI toy company left its chats with kids exposed Anyone with a Gmail account was able to simply access the conversations—no hacking required. (Wired $) + AI toys are all the rage in China—and now they’re appearing on shelves in the US too. (MIT Technology Review)
6 SpaceX could merge with xAI later this year Ahead of a planned blockbuster IPO of Elon Musk’s companies. (Reuters) + The move would be welcome news for Musk fans. (The Information $) + A SpaceX-Tesla merger could also be on the cards. (Bloomberg $)
7 We’re still waiting for a reliable male contraceptive Take a look at the most promising methods so far. (Bloomberg $)
8 AI is bringing traditional Chinese medicine to the masses And it’s got the full backing of the country’s government. (Rest of World)
9 The race back to the Moon is heating up Competition between the US and China is more intense than ever. (Economist $)
10 What did the past really smell like? AI could help scientists to recreate history’s aromas—including mummies and battlefields. (Knowable Magazine)
Quote of the day
“I think the tidal wave is coming and we’re all standing on the beach.”
—Bill Zysblat, a music business manager, tells the Financial Times about the existential threat AI poses to the industry.
One more thing
Therapists are secretly using ChatGPT. Clients are triggered.
Declan would never have found out his therapist was using ChatGPT had it not been for a technical mishap. The connection was patchy during one of their online sessions, so Declan suggested they turn off their video feeds. Instead, his therapist began inadvertently sharing his screen.
For the rest of the session, Declan was privy to a real-time stream of ChatGPT analysis rippling across his therapist’s screen, who was taking what Declan was saying, putting it into ChatGPT, and then parroting its answers.
But Declan is not alone. In fact, a growing number of people are reporting receiving AI-generated communiqués from their therapists. Clients’ trust and privacy are being abandoned in the process. Read the full story.
—Laurie Clarke
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ Sinkholes are seriously mysterious. Is there a way to stay one step ahead of them? + This beautiful pixel art is super impressive. + Amid the upheaval in their city, residents of Minneapolis recently demonstrated both their resistance and community spirit in the annual Art Sled Rally (thanks Paul!) + How on Earth is Tomb Raider30 years old?!