Welcome to this week’s Pulse. Google is laying more groundwork for agent-led shopping, Google Trends is getting a Gemini helper inside Explore, and Google appears to have responded to a report we covered last week on AI Overviews health queries.
Google introduced the Universal Commerce Protocol as an open standard meant to help AI agents complete shopping tasks across merchants and platforms. The announcement landed around NRF and was framed as agent-based shopping infrastructure, not a consumer feature on its own.
Key facts: This story got attention for two reasons. First, it shows where Google wants AI Mode shopping to go next. Second, it triggered a familiar debate about personalization and pricing after critics connected Google’s “personalized upselling” language to surveillance pricing narratives. Google has pushed back on that framing, saying upselling means showing premium options and that its Direct Offers pilot cannot raise prices.
The question for ecommerce practitioners is which parts of the journey you still influence with classic SEO, which parts come down to feeds and structured data hygiene, and which parts are product decisions made inside Google’s surfaces. UCP doesn’t answer that question yet, but it clarifies the direction.
What SEO Professionals Are Saying
The most useful social commentary this week falls into “consumer risk” versus “plumbing and implementation.”
On the critique side, Lindsay Owens, executive director of Groundwork Collaborative, helped set the tone for the surveillance pricing argument around “personalized upselling.” Lee Hepner, senior legal counsel at the American Economic Liberties Project, posted along similar lines, treating individualized pricing as the bigger policy risk sitting behind these kinds of systems.
On the implementation side, Mani Fazeli, VP of Product at Shopify, described what Shopify sees as the point of UCP. He said it “models the entire shopping journey, not just payments” and that “merchants keep their business critical checkout customizations.”
Heiko Hotz, Generative AI Global Blackbelt at Google Cloud, framed it more bluntly from an agent-builder perspective. “Agents are great at reasoning, but they are terrible at navigating a visual website.” Eric Seufert, analyst and publisher of Mobile Dev Memo, weighed in from an incentives angle, arguing the endgame is keeping discovery, conversion, and optimization economically connected to paid media.
Google Trends is redesigning the Explore page with a Gemini-powered side panel that suggests related terms and makes comparisons easier.
Key facts: Google says the update can “automatically identify and compare relevant trends,” with the ability to compare up to eight terms and see more “top and rising” queries per term. The update is rolling out now.
Why This Matters
Google keeps making Trends more useful for the discovery phase of keyword research.
Trends has always been valuable, but it can be slow when you start with a vague idea and need to find the right comparison terms. The Gemini panel looks designed to reduce that friction. For practitioners who use Trends early in content planning, this could speed up the process of clustering related topics and spotting seasonal patterns.
What People Are Saying
Yossi Matias, vice president and head of Google Research, emphasized the Gemini side panel, which suggests related terms, supports comparisons of up to eight queries, and expands the “top” and “rising” query views.
In the SEO community, the initial framing is that this reduces friction in the Explore workflow by surfacing comparison terms faster, but there hasn’t been much detailed feedback yet beyond first impressions.
Health AI Overviews Face Fresh Scrutiny After Guardian Reporting
After the Guardian published examples of AI Overviews giving misleading or potentially risky guidance on medical queries, Google stopped showing AI Overviews for some health searches.
Key facts: The Guardian’s reporting included examples involving pancreatic cancer diet advice and “normal range” explanations for liver tests that reviewers said lacked context. In follow-up coverage, multiple outlets reported that Google removed AI Overviews for certain medical searches after the reporting circulated. Google’s response leaned on two themes: Some examples were missing context or based on incomplete screenshots, and it says most AI Overviews are supported by reputable sources.
Why This Matters
I wrote about the Guardian investigation earlier this month, and it fits a pattern that keeps resurfacing as AI Overviews expand into sensitive categories. You also have independent data showing medical Your Money or Your Life (YMYL) queries have some of the highest AI Overview exposure rates.
The issue for SEO practitioners is measurement. You can’t easily verify what AI Overviews say about topics you cover, and the summaries can change or disappear between queries. For anyone working in health, finance, or other YMYL categories, the question is whether AI Overviews help or complicate the trust signals you’ve built through traditional content.
What People Are Saying
Patient Information Forum highlighted the investigation and pointed to a quote from Sophie Randall, Director of PIF, saying AI Overviews can put inaccurate health information “at the top of online searches, presenting a risk to people’s health.”
Pancreatic Cancer UK also posted about participating in the investigation and reiterated that one example summary was “incorrect.” Individual commentary from clinicians and researchers shared the Guardian link and framed it as a higher-stakes version of earlier AI Overview failures.
Theme Of The Week: The “Done For You” Layer Keeps Growing
Each story this week shows Google building more layers between the query and the destination.
UCP moves checkout into Google’s surfaces. The Trends update makes discovery more guided inside Google’s tools. And the health reporting shows what happens when AI summaries sit at the top of results for sensitive queries.
For practitioners, the common theme is control. The more Google handles inside its own interfaces, the harder it becomes to measure what you influenced and what happened upstream of your site.
Welcome to this week’s PPC Pulse. This week’s news centers around quite a few Google updates.
Google rolled out campaign total budgets in open beta, introduced a new Direct Offers pilot inside AI Mode, and confirmed several Shopping promotion policy updates taking effect in early 2026.
The updates affect how advertisers manage fixed promotional spend, how offers surface closer to purchase decisions, and which promotion types are eligible across Shopping campaigns. None of these changes fundamentally alter PPC strategy, but they do change how much manual effort is required to execute it.
Here’s what matters for advertisers and how these updates may show up in your accounts.
Google Ads Campaign Total Budgets Enter Open Beta
Google announced that campaign total budgets are now available in open beta for Search, Performance Max, and Shopping campaigns.
Instead of managing spend through daily budgets, advertisers can now set a fixed total budget for a campaign running between three and 90 days. Google will automatically pace spend to utilize the full budget by the end date, adjusting delivery based on demand rather than forcing spend at the beginning or end of the campaign.
This option is designed for short-term initiatives like promotions, seasonal pushes, and limited-time tests. Campaign total budgets are selected during campaign creation under the Budget settings.
Why This Matters For Advertisers
For advertisers running time-bound campaigns, this removes one of the most common operational pain points.
Promotional campaigns often require frequent budget adjustments to stay on pace. Teams check spend daily, increase budgets when delivery lags, and pull back when performance spikes unexpectedly. That process is time-consuming and introduces risk.
Total budgets move that work upstream. Advertisers commit to a spend ceiling upfront and allow the system to manage pacing across the campaign window.
This is especially relevant for:
Retail promotions tied to approved media budgets.
Short-term tests where overspend is not an option.
Teams managing multiple campaigns with limited hands-on time.
That said, total budgets do not guarantee delivery. If demand is limited due to targeting, bids, or inventory, spend may still fall short. Advertisers should monitor early performance signals and be ready to adjust inputs if pacing lags.
What PPC Professionals Are Saying
Early reactions have been largely positive. Jyll Saskin Gales, Google Ads Coach, is “excited to see this launch,” while Sarah Stemen, president at Paid Search Association, emphasized her support if she were still working at a large agency, stating “her media planners would’ve loved this.”
Slight critiques came from Alexandru Stambari, performance marketing specialist at ASBC Moldova, stating:
Yes, this is certainly interesting. However, it would be much more valuable to have the ability in PMax to allocate budget across the placements that are most relevant to us, rather than being limited to YouTube and Search only.
Google Tests Direct Offers Inside AI Mode
Google announced a new pilot called Direct Offers, allowing advertisers to surface exclusive discounts directly within AI Mode experiences.
As more users turn to AI-powered search for product discovery, Google is testing ways to introduce offers at the moment when purchase intent is present but not fully committed.
Advertisers participating in the pilot can set up discounts within their campaign settings. Google’s AI determines when an offer is relevant enough to display based on the query and shopping context. The initial rollout focuses on discounts, with plans to support other value-based incentives such as bundles or free shipping.
Early partners include brands like Petco, e.l.f. Cosmetics, Samsonite, Rugs USA, and Shopify merchants.
Why This Matters For Advertisers
Direct Offers push promotions closer to the point of decision.
In traditional search flows, users often click through to evaluate price, shipping, and discounts on the site itself. Direct Offers reduce that friction by bringing the incentive into the discovery experience.
This pilot also ties into Google’s broader push toward streamlined commerce infrastructure, including its recent announcements around Universal Commerce Protocol (UCP). UCP is designed to standardize how product data, pricing, and checkout signals work across Google surfaces.
Direct Offers appear to be one of the visible layers built on top of that foundation. If Google can reliably combine intent, availability, and incentives within AI-driven results, promotions become part of the buying signal rather than a post-click persuader.
For advertisers, this raises new questions:
How often do offers influence visibility, and not just conversions?
Will discounts become more tightly linked to eligibility?
How can retailers balance promotional pressure with margin control?
This is not an indication that every brand needs to discount. But it does suggest that offer strategy is becoming more intertwined with how AI surfaces commerce results.
What PPC Professionals Are Saying
Early commentary among PPC professionals reflects both interest and practical questions about Direct Offers and how it will work in real accounts.
In her LinkedIn announcement, Ginny Marvin, Ads Product liaison at Google, described Direct Offers as a way for advertisers to present exclusive deals “less like a standard ad and more like a salesperson negotiating a deal on your behalf,” emphasizing that the system uses intent and context signals to decide when to surface offers.
A lot of questions came in around reporting, measurement, and control. Mark Preston, performance director at Herd, asked how much control advertisers will have over the discount, as well as if “context around variables like margin or inventory be layered in i.e. via feeds?” Heidi Sturrock, lead Google strategist at OMG Commerce, asked if advertisers could “see a glimpse of what types of reporting there will be.”
These early reactions suggest that while there is interest in what Direct Offers might enable, PPC professionals are already thinking about the practical mechanics of measuring impact, retaining control, and understanding the conditions under which offers appear.
Allowing common promotional abbreviations such as BOGO, B1G1, MSRP, and MRP.
Support for payment method-based promotions in Brazil.
Subscription-based businesses can now promote discounted plans or free trials by selecting “Subscribe and save” as the eligibility requirement in Merchant Center.
Examples include:
First-month free subscription trials.
Percentage discounts on multi-month subscription plans.
The abbreviation update allows advertisers to use commonly recognized promotional language without triggering policy issues. The payment method promotion update applies only to Brazil and includes incentives like cashback to digital wallets.
Why This Matters For Advertisers
These changes reflect a more practical approach to promotions.
Subscription businesses have historically faced limitations when promoting trials or discounted plans through Shopping. This update brings Shopping policies closer to how modern commerce operates.
The abbreviation support is also meaningful from an execution standpoint. Many advertisers already use these terms across paid social, email, and onsite messaging. Aligning Shopping policies reduces setup friction and approval delays.
For advertisers operating in Brazil, payment method promotions introduce a localized incentive lever worth testing.
None of these changes overhaul Shopping strategy, but they do make promotions easier to implement without workarounds.
Theme Of The Week: Spend Control Moves Upstream
This week’s updates show Google continuing to shift how and when advertisers control spend, particularly for promotions and short-term campaigns.
Total budgets ask advertisers to commit spend upfront while relying on automated pacing. Direct Offers test whether promotions can be injected closer to purchase without manual rules. Promotion policy updates remove friction around how offers are expressed and approved.
In each case, the mechanics are being smoothed out, but the strategic inputs still matter. Budget allocation, offer design, and eligibility choices continue to shape outcomes, even as the platforms handle more of the execution.
Remarketing lists continue to be one of the more dependable tools inside PPC accounts, especially for search campaigns. They give advertisers clearer control over who sees ads, how bids are adjusted, and how messaging aligns with prior brand interaction.
As tracking becomes more constrained and audience signals less granular, first-party data carries more weight in day-to-day performance.
Remarketing allows you to act on what users have already done, rather than relying entirely on inferred intent or broad audience definitions.
Where many accounts fall short is in how those lists are actually applied. Lists get created, added at observation, and then largely ignored.
Without a clear purpose tied to bidding, exclusions, or messaging, remarketing ends up being underutilized.
The strategies below focus on remarketing lists that directly influence PPC decisions. Each example is designed to support how users move through the funnel and how accounts are realistically managed, not how they look in theory.
Top-Of-Funnel & Awareness Remarketing Strategies
These three remarketing strategies cover the basics of top-of-funnel marketing and utilize different campaign types to help leverage your RLSAs.
1. Target Users Who Have Engaged With A Video Campaign And Encourage Them To Take Action
If you’ve tried YouTube Ads in any form and have struggled to determine or quantify success, then this strategy might be for you.
YouTube ads are a great way to gain awareness of a product, service, or brand – but how do you get a new user to take action from that first touchpoint?
Enter in remarketing lists.
Google Ads allows you to create different types of remarketing lists based on your YouTube videos. There are two key requirements for using this list type:
These lists can only be used in other YouTube or Search campaigns – not Display.
Your YouTube channel must be linked to your Google Ads account.
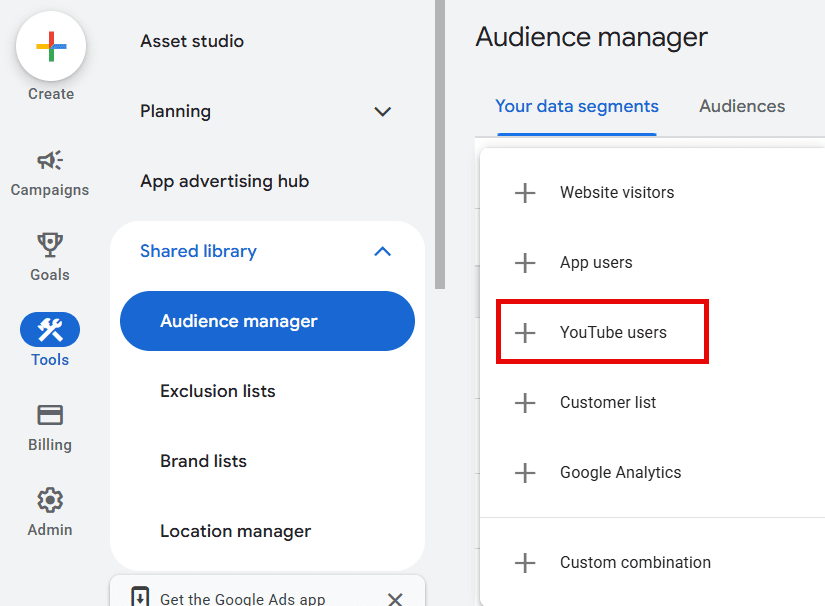
To set up YouTube remarketing lists, navigate to Tools > Shared Library > Audience Manager.
In Audience Manager, hit the “+” button to start segmenting your YouTube remarketing lists.
Screenshot by author, January 2026
From there, Google gives a multitude of options to start leveraging your YouTube video engagement for remarketing. These options include engagement from:
Views to videos.
Subscribes to the channel.
Visits to the channel.
Likes on videos.
Add videos to playlist.
Shares of videos.
Further, you’re able to segment further to make your remarketing lists as specific as possible:
Screenshot by author, January 2026
To leverage these newly created YouTube remarketing lists, try adding them to your existing Search campaigns as “Observation Only” at first to understand if these users are more likely to interact with your campaigns versus someone who hasn’t seen your YouTube videos.
Taking it a step further, you can create new Search campaigns that specifically target these users.
The benefit is that you can provide different messaging to these users who have already interacted with your brand.
2. Exclude Low Quality Or Irrelevant Website Traffic From Search Campaigns
If you’ve run any type of awareness campaign, you’ve likely seen a boost in traffic overall, including irrelevant webpages or low-quality visitors.
What do we constitute as low-quality or irrelevant webpages?
Any page that wouldn’t result in a purchase, such as:
Careers page.
Investors page.
Advertise with us page.
Customer Service page.
Users who stayed on the website for less than one second.
Excluding these types of website visitors from the get-go can help make your remarketing efforts more cost-efficient in the long run.
3. Create Lookalike Audiences From Your Own First-Party Data
Using Google’s affinity audiences or attributes that consider someone at the top of funnel for your product or service can be daunting, especially if you’re a small business or have a limited budget.
It may feel that you don’t have a lot of options to reach new users without paying dearly for it.
But, have you ever thought about using your most valuable assets to build awareness?
Leveraging your own first-party data to create Lookalike audiences gives you more leverage than third-party data, such as Google’s affinity audiences, to reach like-minded people of users who already love your brand.
To create an audience like this, there are a few options to consider:
Create a remarketing list of past purchasers using Google Ads or Google Analytics.
Upload a list of past purchasers to Google Ads.
Depending on the size of these lists, you’ll have the option to create a Lookalike audience and use it for either YouTube, Display, or Search.
The example below shows what a remarketing list based on a completed purchase URL looks like when created in Google Ads:
Screenshot by author, January 2026
I personally like to use Google Analytics when creating remarketing lists because you have many more segmentation or filtering options to be as specific as you need to be.
As a reminder, your site must be tagged and linked with either your Google Analytics property or Google Ads tag.
Consideration Stage Remarketing Strategies
These four remarketing strategies help move the user from the consideration to the purchase phase quicker using different bidding strategies and offers.
4. Increase Bids For Qualified Visitors Of Your Site Who Haven’t Made A Purchase
An easy way to leverage qualified users in your existing Search campaigns is to increase the bid on those users simply.
You don’t need to create separate campaigns for these users if you don’t want to. Segmenting these users and manipulating the bids on them keeps your account management under control.
To use this strategy, you’ll first need to create a remarketing list of users who haven’t made a purchase yet. You can use qualifications only to include people who:
Have made it to the cart checkout.
Visited a certain number of pages.
Spent a certain amount of time on site.
Visited certain categories/high-value product pages.
Once you have created those, it’s time to add them to an existing Search campaign and increase the bid.
What this means is that you’re willing to pay more for their click because they’ve already interacted with your brand in some way.
In your Search campaign, navigate to “Audiences” on the left-hand side.
In this example, I’m setting the audience at the campaign level, but you can set it at the ad group level as well.
Make sure to choose “Observation,” so you’re still able to capture other new users who are researching your brand.
Screenshot by author, January 2026
Once you’ve added your qualified remarketing list, it’s time to increase your bid adjustment.
Still, in the Audiences tab, you’ll see your remarketing list added.
In the columns, you’ll see “Bid Adjustment.” Choose the “pencil” icon to change the bid as you see fit. In this example, I’m going to increase the bid by 15%.
Screenshot by author, January 2026
Once you’ve implemented this change, be sure to continuously check back on the audience performance and determine if bids need to be changed based on performance.
5. Increase Bids For Users Who Have Completed A Micro-Conversion
This strategy is similar to the example above, except for the type of user you want to target.
If a user has completed a micro-conversion of any sort, they’re likely a high-qualified user to make a purchase.
What are examples of a micro-conversion? Depending on your product or service, these could include:
Signing up for emails or newsletters.
Downloading an ebook.
Signing up for a webinar.
Requesting a free sample.
These types of conversions show a user is active in research mode and seriously considering your brand.
By increasing the bid in your search campaigns for these users, you’re saying you’re willing to pay more for their clicks because they’re that much more likely to convert.
The process of setting this strategy up is the same as above, with the exception of creating a remarketing list based on the success of these micro-conversions.
6. Test Maximize Conversion Value With Cart Abandoners
This remarketing strategy would require you to create a separate campaign targeting only cart abandoners.
You may be asking, “Why not just use Maximize Conversion Value for everyone?”
If you’ve ever tested out the Maximize Conversion Value bidding strategy in Google Ads, you’ll know exactly why.
The reasons I don’t recommend using this for all campaigns include:
You can’t set any maximum ceiling values.
Not all users are ready to purchase.
By segmenting a search campaign specifically for cart abandoners, you can test this bidding strategy at a lower threshold – and with the most qualified users who are most likely to make a purchase.
Similar to the above examples, this strategy tells Google that you’re willing to be more flexible in how much you pay for someone to make a purchase.
And what better way to test this than with users who were almost ready to make that purchase?
To set this strategy into motion, you first need to create a remarketing list of “Cart Abandoners.”
This will look different for everyone, but it will likely be URL-based and able to be created in either Google Analytics or Google Ads.
After that list has been created, it’s time to set up your new search campaign.
This campaign can be a duplicate of any other search campaign. Just make sure to exclude your Cart Abandoner list from that existing campaign. We don’t want any crossover here!
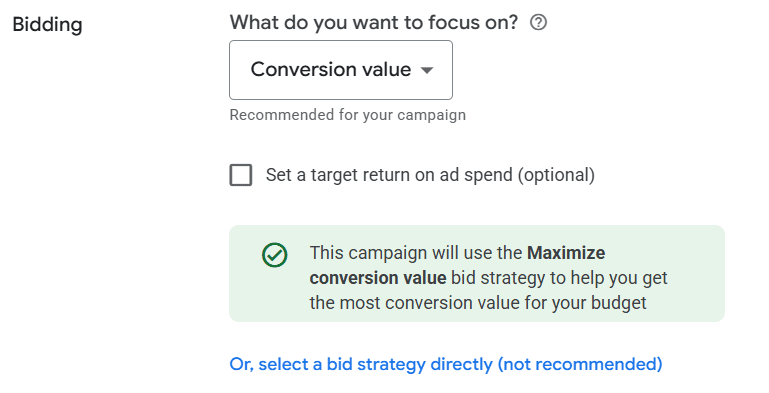
When creating the new campaign, this is where you’ll set the bid strategy to “Maximize Conversion Value” in the settings.
Screenshot by author, January 2026
Google Ads does give you the option to set a target return on ad spend, giving you somewhat control over campaign performance.
Depending on how much flexibility you have in your marketing budget, you can either leave that blank or set a target.
If you do set a target ROAS, make sure not to set it too high right away. Otherwise, the campaign won’t be able to effectively learn.
7. Create Offers Based On The User’s Interaction Timeline
Did you know you can create the same remarketing list of users, but segment them by the number of days?
Say you had a cart abandoner and wanted to move them toward purchase ASAP. You may be willing to give them a higher discount since the purchase was still new in their mind.
If they still haven’t purchased within three days, you may choose to still give them a discount, but not as high as the first offer.
After seven days, you still want them to keep your product top-of-mind, but that discount or offer may change again because they’ve waited so long.
So, how do you go about setting up this strategy?
First, you’ll want to create three different remarketing lists (for this example only).
Create cart abandoner audiences separated out by one day, three days, and seven days.
In Google Ads, you simply change the “membership duration” for each list. An example of where to change that during list creation is below:
Screenshot by author, January 2026
Once these lists are created, I recommend setting up different ad groups for each list. You’ll want different ad groups because the offer will be different for each list.
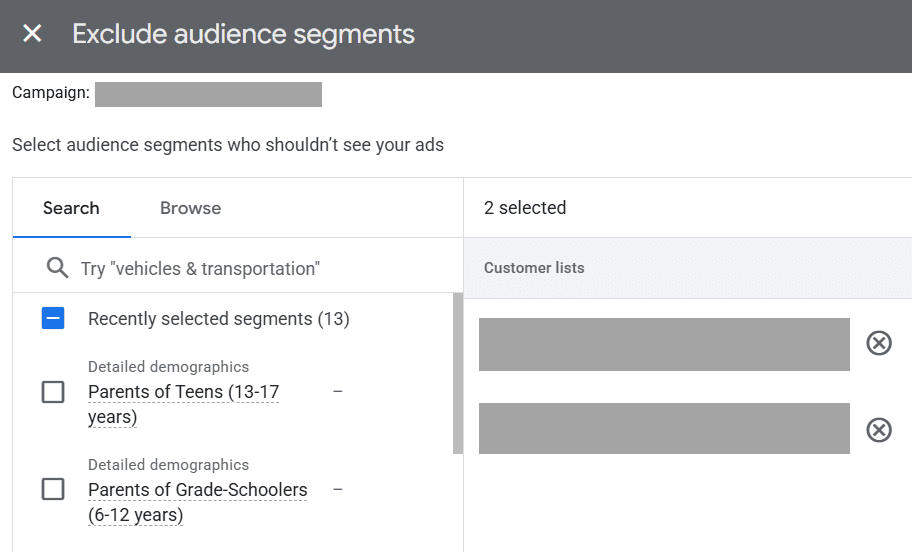
The last crucial piece of targeting cart abandoners is to exclude purchasers from your campaign. You will do this in the “Audiences” tab of your campaign and add your “Purchasers” remarketing list as an exclusion.
Post-Purchase Journey Remarketing Strategies
Once a user has made a purchase, that’s not necessarily the end of their journey!
These remarketing strategies enable past purchasers to become your most valuable asset and opportunities for repeat purchasers to become brand advocates.
8. Cross-Promote Other Products Based On A User’s Purchase Behavior
One of the best ways to create a repeat purchaser is to recommend complementing products based on a user’s purchase.
For example, say you’re a makeup brand, and a user just purchased their first tube of lipstick and mascara from you.
An effective remarketing strategy would include creating lists of past purchasers segmented by product category. This enables you to cross-promote other products and exclude product types they’ve just purchased.
In this example, you may create a remarketing list of users who have bought lipstick or mascara. You can then use that list to remarket products like foundation or eye shadow to encourage a repeat purchase.
These lists and strategies would work well in Dynamic Remarketing Ads or Google Shopping Ads. Because these products are much more visible, you’d want to use those campaign types to your advantage.
9. Exclude Past Purchasers To Maximize Spend Efficiency
As mentioned in strategy No. 7, you’ll want to exclude past purchasers from current acquisition campaigns to maximize spending efficiency.
An example of lazy remarketing is for a user to see an ad for a product they have already purchased.
Not only does that create a bad taste for the user, but that means you’re wasting valuable marketing money on people who have already purchased.
Now, there are certainly times when you’d not want to exclude past purchasers, especially if your product is a repeat purchase.
But, in these examples, your search campaigns are likely going after new users.
To exclude past purchasers, go to Audiences on the left-hand side of your campaign, then find the “Exclusions” table.
Screenshot by author, January 2026
10. Create Brand Advocates From Your Existing High-Value Customers
It’s true when they say that your customers are your best advocates. They have put their trust in you to deliver a high-value product or service that they have come to know and trust.
So, how do you turn them into advocates?
This remarketing strategy still includes utilizing that same past purchaser list. A few different options you could potentially offer past purchasers:
Create a referral program and give discounts to each person who purchases.
Offer discounts based on providing a positive public review.
Just because someone has purchased from you once does not mean they become a loyal customer. Sometimes it takes additional motivation to want to purchase again.
Loyalty or referral discounts are a great way to keep your existing customers coming back to you, as well as utilizing their own referral vehicles to generate new customers.
Creating referral programs is a low-cost and efficient multi-channel awareness strategy that is mutually beneficial for you – the brand and the customer.
Using Remarketing Lists With Intent, Not Just Coverage
Remarketing lists are most effective when they are built to support specific decisions inside your account. That includes how aggressively you bid, who you exclude, and where you shift budget based on user behavior.
Rather than treating remarketing as a single tactic, it works better as a system layered throughout the funnel. Lists tied to meaningful actions, like product views, cart activity, or prior purchases, tend to deliver far more value than broad, catch-all audiences.
As broader targeting becomes less reliable, remarketing offers a level of control that is increasingly hard to replace. When lists are thoughtfully segmented and actively used, they help PPC managers spend more efficiently and act with more confidence.
The real impact of remarketing does not come from how many lists you create. It comes from how intentionally those lists shape your bidding, targeting, and messaging decisions.
Choosing an SEO plugin like Yoast SEO impacts your online presence and future growth.
Yoast offers reliability with over 15 years of experience and millions of active installations, unlike newer competitors.
Innovations such as AI integration and a unified schema graph set Yoast apart from other plugins.
Yoast provides comprehensive support, education, and a multi-platform ecosystem tailored for long-term success.
Trust industry leaders like Microsoft and Spotify who use Yoast SEO to enhance their online visibility.
Estimated reading time: 11 minutes
Selecting an SEO plugin for your WordPress site is one of the most important decisions you’ll make for your online presence. It’s not just about installing software; it’s about choosing a long-term partner that will grow with your business, adapt to changing search algorithms, and support you in the age of AI. While the market offers several options, understanding what truly matters is key. Two of the most popular plugins in the market today are Yoast and Rank Math. Therefore, factors such as reliability, innovation, ecosystem, and trust help you make a choice that will serve your business for years to come.
This guide provides an in-depth comparison of the key differentiating factors between Yoast and Rank Math. We will understand why millions of websites worldwide have made Yoast their trusted comrade in the search business.
What really matters when choosing an SEO plugin
When evaluating WordPress SEO plugins, it’s easy to get distracted by feature lists and flashy interfaces. But experienced marketers, agencies, and business owners know that the best tools are defined by much more than what they promise on paper.
The questions that matter most:
Can you trust this plugin to work reliably as your business scales?
Will the company behind it still be innovating five years from now?
What happens when you need help before a critical deadline?
Does the plugin anticipate future SEO trends, or just react to them?
Is this a tool you install, or an ecosystem that supports your growth and development?
These aren’t trivial questions. Your SEO plugin touches essential pages on your site, influences the content you publish, and directly impacts your ability to be found by potential customers. Choosing poorly can lead to migration headaches, compatibility issues, and lost rankings. Choosing wisely means peace of mind, ongoing innovation, and a solid foundation to build upon.
Why legacy and proven trust matter in SEO plugins
Trust isn’t given. It’s earned. Yoast has defined the WordPress SEO landscape for over 15 years, with more than 13 million active installations and over 850 million downloads. This extensive legacy reflects a consistent track record of innovation, stability, and trust. Brands such as The Guardian, Microsoft, Spotify, and others rely on Yoast SEO as a foundation for their SEO strategies. This depth of experience is invaluable as SEO requires ongoing adaptation to algorithm changes and new technologies.
While Rank Math is an ambitious and feature-rich plugin with a growing user base, its presence in the market is relatively recent. For businesses seeking a proven solution with a long-standing heritage, Yoast’s established positioning offers confidence that the plugin will continue to evolve and provide reliable support for years to come.
Innovation that shapes the industry
Yoast has always been at the forefront of defining what modern SEO looks like. This isn’t a reactive development; it’s proactive innovation that anticipates where search is heading. Both plugins invest in innovation, but Yoast’s leadership in integrating AI and collaboration with Google sets it apart.
AI and Automation
We have introduced an industry-first AI-powered optimization toolset, including:
AI Generate: Creates multiple optimized title and meta description variations instantly, giving you professionally crafted options in seconds instead of struggling for the perfect phrasing.
AI Optimize: Scans your content and provides precise, actionable suggestions to improve keyphrase placement, sentence structure, and readability, teaching you SEO best practices while you write.
AI Summarize: Instantly generates bullet-point summaries of your content, making it more scannable and engaging for readers who skim before diving deep.
AI Brand Insights: This is where Yoast truly separates from the pack. As AI platforms like ChatGPT reshape how people find information, AI Brand Insights tracks how your brand appears in AI-generated responses. You can monitor your AI visibility, compare it against competitors, and ensure AI platforms accurately represent your business.
While Rank Math includes helpful automation features such as AI keyword suggestions, Yoast’s AI integration is more comprehensive and positioned as a core pillar of modern SEO strategy.
Schema markup that search engines can understand
While many plugins output disconnected structured data, Yoast SEO automatically generates a unified semantic graph on every page, linking your organization, content, authors, and products through a single JSON-LD structure that search engines and AI platforms can interpret consistently.
What makes this different
Automatic and invisible: Yoast outputs rich structured data representing your content, business, and relationships without requiring technical configuration. You focus on creating content; Yoast handles the complexity of structured data behind the scenes.
Single unified graph format: Instead of fragmented schema markup, Yoast creates one cohesive graph structure per page, connecting all entities with unique IDs. When plugins output conflicting schema, search engines can’t reliably interpret your site. Yoast’s unified graph ensures consistent interpretation at scale, whether Google, ChatGPT, or any API is reading your content.
Minimal configuration: Choose whether your site represents a person or organization; Yoast handles the rest automatically. Specialized blocks like FAQ and How-To map directly to correct schema types and link into the graph without additional setup.
Why this matters for AI-driven search
As AI platforms increasingly rely on structured data to understand websites, Yoast’s approach of creating a full semantic model of your site positions you for how search and discovery are evolving. The framework scales reliably from 100 to 100,000 pages while maintaining valid entity relationships. For developers, Yoast’s Schema API provides clean filters to extend or customize the graph without breaking its integrity.
Rank Math and other plugins support Schema markup, but Yoast’s unified graph framework represents a fundamentally different approach: automatic generation, consistent entity relationships, and architecture built for scale.
Continuous algorithm adaptation
Search engines make thousands of updates every year. Google alone rolls out over 5,000 algorithm changes annually. Now, as search engines evolve to incorporate AI tooling and platforms like ChatGPT reshape the way people discover information, the SEO landscape is changing faster than ever.
Most website owners can’t possibly track these shifts across traditional search AND emerging AI platforms, let alone understand their implications. Yoast’s dedicated SEO team monitors every significant update, from Google algorithm changes to how AI platforms index and reference content, and proactively adjusts the plugin to ensure your site stays optimized for both traditional and AI-driven discovery.
When you use Yoast, you’re not just getting software. You’re getting a team of experts working behind the scenes to keep your SEO strategy current across the entire discovery ecosystem.
An ecosystem built to support your SEO workflow
Yoast offers an ecosystem beyond the plugin. While Yoast SEO itself is a plugin, Yoast provides a comprehensive ecosystem to support your growth:
24/7 real human expert support available for Yoast SEO Premium users. It ensures that you get fast, knowledgeable help when you need it.
Yoast SEO Academy offers comprehensive SEO education, covering a range of topics from basics to advanced, with accompanying certifications.
A massive knowledge base and community for continuous learning and troubleshooting.
Multi-Platform Support
Your business doesn’t exist on WordPress alone. That’s why Yoast extends beyond a single platform:
Yoast SEO for Shopify: Brings Yoast’s trusted optimization to Shopify stores, helping ecommerce businesses improve product visibility and drive more sales.
Yoast WooCommerce SEO: Specifically designed for WooCommerce stores with automated product schema, smart breadcrumbs, and ecommerce-focused content analysis.
This ecosystem approach means Yoast grows with your business, supporting you across platforms as your needs evolve. Rank Math primarily focuses on the WordPress environment with a strong feature set, but lacks the same breadth of educational resources and multi-platform reach.
Stability and reliability at enterprise-grade scale
Flashy features attract attention. Rock-solid reliability keeps businesses running. Yoast rigorously tests every update for compatibility and performance across different WordPress versions and server configurations. This commitment ensures:
Backward compatibility: Updates maintain existing functionality without requiring extensive reconfiguration
WordPress core integration: Seamless compatibility with new WordPress releases
Performance at any scale: Optimized for sites ranging from personal blogs to high-traffic enterprise installations
With over 15 years in the market and more than 13 million active installations, Yoast has proven its reliability across millions of sites, hosting environments, and various use cases.
Rigorous testing and quality assurance
Yoast maintains strict development standards that prioritize stability above rapid feature deployment. Every update undergoes extensive testing across the latest WordPress versions, most PHP configurations, and common plugin combinations before release.
This disciplined approach means Yoast users rarely experience plugin conflicts, broken updates, or compatibility issues that plague WordPress sites using less mature plugins.
Backward compatibility
Major updates usually shake the functionality of plugins and software. However, Yoast maintains backward compatibility, ensuring that updating your plugin doesn’t suddenly break critical SEO features or require extensive reconfiguration.
WordPress core compatibility
As a plugin deeply integrated with WordPress development, Yoast maintains close relationships with the WordPress core team. This ensures seamless compatibility with new WordPress releases, often supporting new versions on launch day while other plugins scramble to catch up.
Performance optimized for scale
Whether you run a small blog or an enterprise site with millions of pages, Yoast performs efficiently without slowing down your site. The plugin is engineered for performance, using best practices for database queries, resource loading, and caching integration.
Enterprises trust Yoast precisely because it scales reliably. Small teams appreciate that the same plugin powering major corporations works flawlessly on their modest sites, too.
Ready to make a difference with Yoast SEO Premium?
Explore Yoast SEO Premium and the Yoast SEO AI+ package to discover advanced tools built for serious marketers.
Where Yoast takes the lead
While comprehensive feature-by-feature comparisons can be overwhelming, certain capabilities distinguish truly professional SEO plugins from the rest. Here’s where Yoast’s innovation and depth shine through.
AI-powered optimization
Yoast leads the industry in AI integration for SEO optimization:
AI Brand Insights for tracking your presence in AI search platforms
No competing plugin offers this comprehensive AI integration designed specifically for modern SEO workflows.
Schema Graph
Yoast’s Schema implementation creates a complete structured data graph connecting your organization, content, authors, and brand identity. This goes far beyond basic Schema markup, providing search engines with rich context that improves your chances of appearing in knowledge panels, rich results, and AI-generated answers.
Smart internal linking
Yoast SEO Premium includes intelligent internal linking suggestions that analyze your content and recommend relevant pages to link to. This isn’t just a list of posts; it’s context-aware suggestions that strengthen your site architecture and improve crawlability.
Advanced redirect manager
Managing redirects is critical when restructuring sites, changing URLs, or handling broken links. Yoast’s redirect manager offers:
Duplicate content prevention for product variations
Comprehensive crawl settings
Advanced users appreciate Yoast’s granular control over crawl optimization, robots.txt management, and indexation settings, giving technical SEO professionals the precision they need without overwhelming casual users.
Bot blocker for LLM training control
As AI companies scrape the web to train large language models, Yoast gives you control over whether your content is used for AI training via Bot Blocker. This cutting-edge feature addresses a concern most plugins haven’t even acknowledged yet.
Recognized and trusted by industry leaders
The company you keep says a lot about who you are. When the world’s most recognized brands trust Yoast to power their WordPress SEO, it’s a powerful testament to the quality, reliability, and effectiveness of our solutions.
Global brands* using Yoast include:
The Guardian
Microsoft
Spotify
Rolling Stones
Taylor Swift
Facebook
eBay
These organizations have teams of developers, SEO experts, and decision-makers who have evaluated every available option. They chose Yoast, not because it was the newest, but because it was the best.
*Disclaimer: Based on third party data sources.
Industry Recognition:
Global Search Awards Finalist: Recognized among the world’s leading SEO solutions
Yoast isn’t just popular, it’s the default choice for WordPress SEO professionals worldwide.
Understanding what you really need
Before making your final decision, consider what matters most for your specific situation:
If you value reliability and stability: Choose a plugin with a proven track record of consistent updates, compatibility, and performance. Longevity matters because it signals the company will be around to support you for years to come.
If innovation matters to your strategy: Look for a plugin that anticipates SEO trends rather than reacting to them. AI integration, Schema excellence, and algorithm adaptation separate forward-thinking tools from those playing catch-up.
If support is critical: Consider whether you need community forums or access to real SEO experts who can troubleshoot complex issues quickly. When your business relies on organic traffic, response time is crucial.
If education is important: Some plugins provide features; others teach you how to use them effectively. Comprehensive training resources and certifications demonstrate a commitment to your success.
If you’re building for the long term: Think about whether this plugin will grow with your business. Multi-platform support, scalability, and an ecosystem approach ensure that your investment pays dividends for years to come.
Make the choice that drives real growth
Choosing an SEO plugin isn’t about finding the tool with the longest feature list; it’s about finding the one that best suits your needs. It’s about partnering with a company that shares your commitment to long-term growth, innovation, and excellence.
Over 13 million websites trust Yoast SEO because it delivers on these promises:
Reliability: 15+ years of consistent innovation and stability
Trust: Used by global brands and industry leaders
Innovation: Leading the industry in AI integration and Schema excellence
Support: 24/7 access to real SEO professionals
Education: Comprehensive training through Yoast Academy
Ecosystem: Multi-platform support and continuous learning resources
Stability: Enterprise-grade performance at any scale
When you choose Yoast, you’re not just installing a plugin; you’re joining millions of websites that have made the strategic decision to partner with the most trusted name in WordPress SEO.
A smarter analysis in Yoast SEO Premium
Yoast SEO Premium has a smart content analysis that helps you take your content to the next level!
Aman Soni
Yoast has been synonymous with the word digital marketing since the beginning of everything SEO. It has been an ever-present, like an omnipotent, all-knowing SEO plugin, the first one I ever used. Now, I am delighted and also in awe that I work for the very brand which I so revered! I work, read, write, swim, hike and make things happen.
An advisory was published about a vulnerability discovered in the Membership Plugin By StellarWP which exposes sensitive Stripe payment setup data on WordPress sites using the plugin. The flaw enables unauthenticated attackers to launch attacks and is rated 8.2 (High).
Membership Plugin By StellarWP
The Membership Plugin – Restrict Content By StellarWP is used by WordPress sites to manage paid and private content. It enables site owners to restrict access to pages, posts, or other resources so that only logged-in users or paying members can view them and manage what non-paying site visitors can see. The plugin is commonly deployed on membership and subscription-based sites.
Vulnerable to Unauthenticated Attackers
The Wordfence advisory states that the vulnerability can be exploited by unauthenticated attackers, meaning no login or WordPress user account is required to launch an attack. User permission roles do not factor into whether the issue can be triggered, and that’s what makes this particular vulnerability more dangerous because it’s easier to trigger.
What the Vulnerability Is
The issue stems from missing security checks related to Stripe payment handling. Specifically, the plugin failed to properly protect Stripe SetupIntent data.
A Stripe SetupIntent is used during checkout to collect and save a customer’s payment method for future use. Each SetupIntent includes a client_secret value that is intended to be shared during a checkout or account setup flow.
“The Membership Plugin – Restrict Content plugin for WordPress is vulnerable to Missing Authentication in all versions up to, and including, 3.2.16 via the ‘rcp_stripe_create_setup_intent_for_saved_card’ function due to missing capability check.
Additionally, the plugin does not check a user-controlled key, which makes it possible for unauthenticated attackers to leak Stripe SetupIntent client_secret values for any membership.”
According to Stripe’s official documentation, the Setup Intents API is used to set up a payment method for future charges without creating an immediate payment. A SetupIntent includes a client_secret. Stripe’s documentation states that client_secret values should not be stored, logged, or exposed to anyone other than the intended customer.
This is how Stripe’s documentation explains what the purpose is for the Setup Intents API:
“Use the Setup Intents API to set up a payment method for future payments. It’s similar to a payment, but no charge is created.
The goal is to have payment credentials saved and optimized for future payments, meaning the payment method is configured correctly for any scenario. When setting up a card, for example, it may be necessary to authenticate the customer or check the card’s validity with the customer’s bank. Stripe updates the SetupIntent object throughout that process.”
Stripe documentation also explains that client_secret values are used client-side to complete payment-related actions and are intended to be passed securely from the server to the browser. Stripe states that these values should not be stored, logged, or exposed to anyone other than the relevant customer.
This is how Stripe’s documentation explains the client_secret value:
“client_secret The client secret of this Customer Session. Used on the client to set up secure access to the given customer.
The client secret can be used to provide access to customer from your frontend. It should not be stored, logged, or exposed to anyone other than the relevant customer. Make sure that you have TLS enabled on any page that includes the client secret.”
Because the plugin did not enforce the appropriate protections, Stripe SetupIntent client_secret values could be exposed.
What this means in real life is that Stripe payment setup data associated with memberships was accessible beyond its intended scope.
Affected Versions
The vulnerability affects all versions of the plugin up to and including version 3.2.16. Wordfence assigned the issue a CVSS score of 8.2, reflecting the sensitivity of the exposed data and the fact that no authentication is required to trigger the issue.
A score in this range indicates a high-severity vulnerability that can be exploited remotely without special access, increasing the importance of timely updates for sites that rely on the plugin for managing paid memberships or restricted content.
Patch Availability
The plugin has been updated with a patch and is available now. The issue was fixed in version 3.2.17 of the plugin. The update adds missing nonce and permission checks related to Stripe payment handling, addressing the conditions that allowed SetupIntent client_secret values to be exposed. A nonce is a temporary security token that ensures a specific action on a WordPress website was intentionally requested by the user and not by a malicious attacker.
The official Membership Plugin changelog responsibly discloses the updates:
“3.2.17 Security: Added nonce and permission checks for adding Stripe payment methods. 3.2.16 Security: Improved escaping and sanitization for [restrict] and [register_form] shortcode attributes.”
What Site Owners Should Do
Sites using Membership Plugin – Restrict Content should update to version 3.2.17 or newer.
Failure to update the plugin will leave the Stripe SetupIntent client_secret data exposed to unauthenticated attackers.
Google’s AI Overviews may be relying on YouTube more than official medical sources when answering health questions, according to new research from SEO platform SE Ranking.
The study analyzed 50,807 German-language health prompts and keywords, captured in a one-time snapshot from December using searches run from Berlin.
The report lands amid renewed scrutiny of health-related AI Overviews. Earlier this month, The Guardian published an investigation into misleading medical summaries appearing in Google Search. The outlet later reported Google had removed AI Overviews for some medical queries.
What The Study Measured
SE Ranking’s analysis focused on which sources Google’s AI Overviews cite for health-related queries. In that dataset, the company says AI Overviews appeared on more than 82% of health searches, making health one of the categories where users are most likely to see a generated summary instead of a list of links.
The report also cites consumer survey findings suggesting people increasingly treat AI answers as a substitute for traditional search, including in health. It cites figures including 55% of chatbot users trusting AI for health advice and 16% saying they’ve ignored a doctor’s advice because AI said otherwise.
YouTube Was The Most Cited Source
Across SE Ranking’s dataset, YouTube accounted for 4.43% of all AI Overview citations, or 20,621 citations out of 465,823.
The next most cited domains were ndr.de (14,158 citations, 3.04%) and MSD Manuals (9,711 citations, 2.08%), according to the report.
The authors argue that the ranking matters because YouTube is a general-purpose platform with a mixed pool of creators. Anyone can publish health content there, including licensed clinicians and hospitals, but also creators without medical training.
To check what the most visible YouTube citations looked like, SE Ranking reviewed the 25 most-cited YouTube videos in its dataset. It found 24 of the 25 came from medical-related channels, and 21 of the 25 clearly noted the content was created by a licensed or trusted source. It also warned that this set represents less than 1% of all YouTube links cited by AI Overviews.
Government & Academic Sources Were Rare
SE Ranking categorized citations into “more reliable” and “less reliable” groups based on the type of organization behind each source.
It reports that 34.45% of citations came from the more reliable group, while 65.55% came from sources “not designed to ensure medical accuracy or evidence-based standards.”
Within the same breakdown, academic research and medical journals accounted for 0.48% of citations, German government health institutions accounted for 0.39%, and international government institutions accounted for 0.35%.
AI Overview Citations Often Point To Different Pages Than Organic Search
The report compared AI Overview citations to organic rankings for the same prompts.
While SE Ranking found that 9 out of 10 domains overlapped between AI citations and frequent organic results, it says the specific URLs frequently diverged. Only 36% of AI-cited links appeared in Google’s top 10 organic results, 54% appeared in the top 20, and 74% appeared somewhere in the top 100.
The biggest domain-level exception in its comparison was YouTube. YouTube ranked first in AI citations but only 11th in organic results in its analysis, appearing 5,464 times as an organic link compared to 20,621 AI citations.
How This Connects To The Guardian Reporting
The SE Ranking report explicitly frames its work as broader than spot-checking individual responses.
“The Guardian investigation focused on specific examples of misleading advice. Our research shows a bigger problem,” the authors wrote, arguing that AI health answers in their dataset relied heavily on YouTube and other sites that may not be evidence-based.
Following The Guardian’s reporting, the outlet reported that Google removed AI Overviews for certain medical queries.
Google’s public response, as reported by The Guardian, emphasized ongoing quality work while also disputing aspects of the investigation’s conclusions.
Why This Matters
This report adds a concrete data point to a problem that’s been easier to talk about in the abstract.
Visibility in AI Overviews may depend on more than being the most prominent “best answer” in organic search. SE Ranking found many cited URLs didn’t match top-ranking pages for the same prompts.
The source mix also raises questions about what Google’s systems treat as “good enough” evidence for health summaries at scale. In this dataset, government and academic sources barely showed up compared to media platforms and a broad set of less reliability-focused sites.
That’s relevant beyond SEO. The Guardian reporting showed how high-stakes the failure modes can be, and Google’s pullback on some medical queries suggests the company is willing to disable certain summaries when the scrutiny gets intense.
Looking Ahead
SE Ranking’s findings are limited to German-language queries in Germany and reflect a one-time snapshot, which the authors acknowledge may vary over time, by region, and by query phrasing.
Even with that caveat, the combination of this source analysis and the recent Guardian investigation puts more focus on two open questions. The first is how Google weights authority versus platform-level prominence in health citations. The second is how quickly it can reduce exposure when specific medical query patterns draw criticism.
Happy New Year! I know it’s a bit late to say, but it never quite feels like the year has started until the new edition of our 10 Breakthrough Technologies list comes out.
For 25 years, MIT Technology Review has put together this package, which highlights the technologies that we think are going to matter in the future. This year’s version has some stars, including gene resurrection (remember all the dire wolf hype last year?) and commercial space stations.
I’ve been covering sodium-ion batteries for years, but this moment feels like a breakout one for the technology.
Today, lithium-ion cells power everything from EVs, phones, and computers to huge stationary storage arrays that help support the grid. But researchers and battery companies have been racing to develop an alternative, driven by the relative scarcity of lithium and the metal’s volatile price in recent years.
Sodium-ion batteries could be that alternative. Sodium is much more abundant than lithium, and it could unlock cheaper batteries that hold a lower fire risk.
There are limitations here: Sodium-ion batteries won’t be able to pack as much energy into cells as their lithium counterparts. But it might not matter, especially for grid storage and smaller EVs.
In recent years, we’ve seen a ton of interest in sodium-based batteries, particularly from major companies in China. Now the new technology is starting to make its way into the world—CATL says it started manufacturing these batteries at scale in 2025.
Next-generation nuclear
Nuclear reactors are an important part of grids around the world today—massive workhorse reactors generate reliable, consistent electricity. But the countries with the oldest and most built-out fleets have struggled to add to them in recent years, since reactors are massive and cost billions. Recent high-profile projects have gone way over budget and faced serious delays.
Next-generation reactor designs could help the industry break out of the old blueprint and get more nuclear power online more quickly, and they’re starting to get closer to becoming reality.
There’s a huge variety of proposals when it comes to what’s next for nuclear. Some companies are building smaller reactors, which they say could make it easier to finance new projects, and get them done on time.
Other companies are focusing on tweaking key technical bits of reactors, using alternative fuels or coolants that help ferry heat out of the reactor core. These changes could help reactors generate electricity more efficiently and safely.
Kairos Power was the first US company to receive approval to begin construction on a next-generation reactor to produce electricity. China is emerging as a major center of nuclear development, with the country’s national nuclear company reportedly working on several next-gen reactors.
Hyperscale data centers
This one isn’t quite what I would call a climate technology, but I spent most of last year reporting on the climate and environmental impacts of AI, and the AI boom is deeply intertwined with climate and energy.
Data centers aren’t new, but we’re seeing a wave of larger centers being proposed and built to support the rise of AI. Some of these facilities require a gigawatt or more of power—that’s like the output of an entire conventional nuclear power plant, just for one data center.
(This feels like a good time to mention that our Breakthrough Technologies list doesn’t just highlight tech that we think will have a straightforwardly positive influence on the world. I think back to our 2023 list, which included mass-market military drones.)
There’s no denying that new, supersize data centers are an important force driving electricity demand, sparking major public pushback, and emerging as a key bit of our new global infrastructure.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Meet the man hunting the spies in your smartphone
In April 2025, Ronald Deibert left all electronic devices at home in Toronto and boarded a plane. When he landed in Illinois, he bought a new laptop and iPhone. He wanted to reduce the risk of having his personal devices confiscated, because he knew his work made him a prime target for surveillance. “I’m traveling under the assumption that I am being watched, right down to exactly where I am at any moment,” Deibert says.
Deibert directs the Citizen Lab, a research center he founded in 2001 to serve as “counterintelligence for civil society.” Housed at the University of Toronto, it’s one of the few institutions that investigate cyberthreats exclusively in the public interest, and in doing so, it has exposed some of the most egregious digital abuses of the past two decades.
For many years, Deibert and his colleagues have held up the US as the standard for liberal democracy. But that’s changing. Read the full story.
—Finian Hazen
This story is from the latest issue of our print magazine. If you subscribe now to receive future copies when they land you’ll benefit from some big discounts, and get a free tote bag!
Three climate technologies breaking through in 2026
—Casey Crownhart
Happy New Year! I know it’s a bit late to say, but it never quite feels like the year has started until the new edition of our 10 Breakthrough Technologies list comes out.
This story ran in The Spark, our weekly newsletter all about the technologies we can use to combat climate change. Sign up to get it in your inbox first every Wednesday.
And, if you’re keen to learn more about why AI companies are betting big on next-gen nuclear, join us for an exclusive subscriber-only Roundtable event on Wednesday January 28 at 2pm ET.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 AI companies are now deeply entwined with the US military And it looks like they’re only set to get closer. (Wired $) + Three open questions about the Pentagon’s push for generative AI. (MIT Technology Review)
2 Grok will comply with local laws, X has said A global backlash over users creating ‘undressing’ images of real people seems to have forced its hand. (BBC) + So far there’s no evidence it’s actually following through on that promise though. (The Verge) + Elon Musk could stop it all instantly if he wanted to. (Engadget)
3 The risks of using AI in schools outweigh the benefits According to a sweeping new study by the Brookings Institution’s Center for Universal Education. (NPR) + AI’s giants are trying to take over the classroom. (MIT Technology Review)
4 Trump is imposing new tariffs on high-end chips They’re pretty narrow though, and leave plenty of room for exports to China. (WP $) + Zhipu AI says it’s trained its first major model entirely on Chinese chips. (South China Morning Post)
5 A UK police force blamed Microsoft Copilot for an intelligence error After spending weeks denying it was using AI tools at all. (Ars Technica) + Worried about police and lawyers using AI? Well, judges are at it too. (MIT Technology Review)
6 Inside the compounds where the fraud industry makes its billions The details are grim—for example the fact workers struck a gong every time they scammed someone out of $5,000. (NYT $) + Inside a romance scam compound—and how people get tricked into being there. (MIT Technology Review)
7 Bandcamp has banned purely AI-generated music from its platform It’s the first online music platform to take this step. (Billboard) + Can AI generate new ideas? (NYT $)
8 Remember Havana Syndrome? The US may have found the device that causes it It was acquired for millions of dollars under the last administration, and it’s still being studied. (CNN)
9 This study failed to prove social media time causes teens’ mental health issues It’s a common assumption, but there’s still remarkably little evidence to back it up. (The Guardian)
10 The UK is planning to build a record-breaking number of wind farms Its government is pushing for the vast majority of the country’s electricity to come from clean sources by 2030. (BBC)
Quote of the day
“Women and girls are far more reluctant to use AI. This should be no surprise to any of us. Women don’t see this as exciting new technology, but as simply new ways to harass and abuse us and try and push us offline.”
—Clare McGlynn, a law professor at Durham University, tells The Guardian she fears that the use of AI to harm women and girls is only going to grow.
One more thing
DANIEL STOLLE
Inside the little-known group setting the corporate climate agenda
As thousands of companies trumpet their plans to cut carbon pollution, a small group of sustainability consultants has emerged as the go-to arbiter of corporate climate action.
The Science Based Targets initiative, or SBTi, helps businesses develop a timetable for action to shrink their climate footprint through some combination of cutting greenhouse-gas pollution and removing carbon dioxide from the atmosphere. After years of small-scale sustainability work, SBTi is growing rapidly, and governments are paying attention.
But while the group has earned praise for reeling the private sector into constructive conversations about climate emissions, its rising influence has also attracted scrutiny and raised questions about why a single organization is setting the standards for many of the world’s largest companies. Read the full story.
—Ian Morse
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ The leaders of Japan and South Korea drummed up a viral moment with a jam session this week. + Struggle during the cold, dark winter months? Here’s how to make things easier for yourself. + If you like getting lost in the depths of Wikipedia, Freakpages is for you. + From Pluribus to Stranger Things, we really can’t get enough of hive mindsin stories lately. ($)
In this exclusive subscriber-only eBook, you’ll learn about how the idea that machines will be as smart as—or smarter than—humans has hijacked an entire industry.
Several American lawmakers have expressed an interest in limiting or prohibiting data-driven price changes. The recent activity dates back to at least 2021 and may stem from inflation concerns and increased AI usage.
For example, in December 2025, Instacart drew strong criticism from Democratic Senator Charles Schumer of New York after it permitted grocery stores to test AI-powered, dynamic pricing.
The experiment showed an average variation of about 7% between the lowest and highest prices for specific grocery items. But there were standouts, according to Consumer Reports, with Wheat Thins ranging from $3.99 per box to $4.89, 23% higher.
Schumer likened the price differences to gouging and asked for an investigation by the Federal Trade Commission.
Personalized dynamic pricing leads to profitable merchants and satisfied shoppers.
Tennessee Bill
Meanwhile, a proposal from Tennessee state representative John Ray Clemmons, a Democrat, illustrates how the dynamic pricing debate could shift from headlines to law.
Clemmons’ House Bill 1468 would prohibit “personalized algorithmic pricing,” which it defines as “dynamic pricing set by an algorithm that uses personal data.”
That definition targets any system that adjusts prices based on information tied to an individual shopper, including purchase history, browsing behavior, loyalty status, location signals, and other attributes. Conceivably, it could include aggregate data applied to individuals.
Tennessee HB 1468’s enforcement mechanism is also notable. It makes personalized algorithmic pricing an “unfair or deceptive act or practice” under the state’s consumer protection statute. That approach gives the state’s attorney general broad enforcement power and exposes retailers to legal liability, even if no consumer can point to a false claim or deception.
For ecommerce merchants, the risk is clear. If bills such as Tennessee’s spread, dynamic pricing could become legally hazardous not because prices are changing, but because the systems doing the changing rely on customer behavioral data — the same data that powers modern online merchandising, email marketing, loyalty programs, and conversion optimization.
Unfair?
The criticism of Instacart’s AI-pricing and the political momentum behind bills such as Tennessee’s HB 1468 incorrectly assumes that prices determined by data and software are somehow less legitimate than those set by a manager with a clipboard.
Put another way, to some lawmakers, dynamic pricing feels unfair.
But not every shopper cares to pay the same price. Consider coupons, which manufacturers and grocery stores routinely issue. Every shopper knows coupons exist. But not all use them, nor do they care that they are paying a different price.
Optimization
And that is the point. Optimization drives ecommerce price changes.
Vaidotas Juknys is chief commercial officer at Decodo, a web data infrastructure provider. He told me, “Dynamic pricing is widely used across modern commerce to help businesses align prices with demand, manage inventory more efficiently, and remain competitive in fast-moving markets.
“Broad restrictions risk limiting those benefits and may ultimately lead to higher average prices if companies lose the ability to adapt in real time.”
To be sure, dynamic optimization results in different prices across shoppers, who can accept or reject offers.
Algorithm-based pricing is likely a key component of ecommerce in the emerging AI world, presenting many opportunities for merchants:
Relevant discounts. Customer-level pricing enables merchants to offer discounts to shoppers who would not convert otherwise.
Conversion rate optimization. Algorithms can detect purchase intent signals (repeat visits, cart additions, time on site) and trigger pricing to close the sale.
No wasted discount. Blanket promotions reduce margins companywide. Personalized pricing can limit discounts to specific segments, preserving profit while still driving growth.
Customer retention. Pricing tied to loyalty status or purchasing history can reward and encourage repeat customers.
Inventory efficiency. Merchants can use shopper behavior to promote overstock items to likely buyers.
Smart acquisition offers. Personalized pricing can support first-time buyer promotions, helping brands compete with marketplaces without permanently lowering prices.
Boost marketing ROI. Personalized incentives can link to traffic sources, campaigns, and shopper cohorts, helping merchants measure the profitability of paid acquisition at the order level.
Yet shoppers benefit, too. Dynamic systems can reduce prices when supply is abundant and demand is weak. The result is more discounts, better availability, and fewer shortages than a rigid one-price approach.