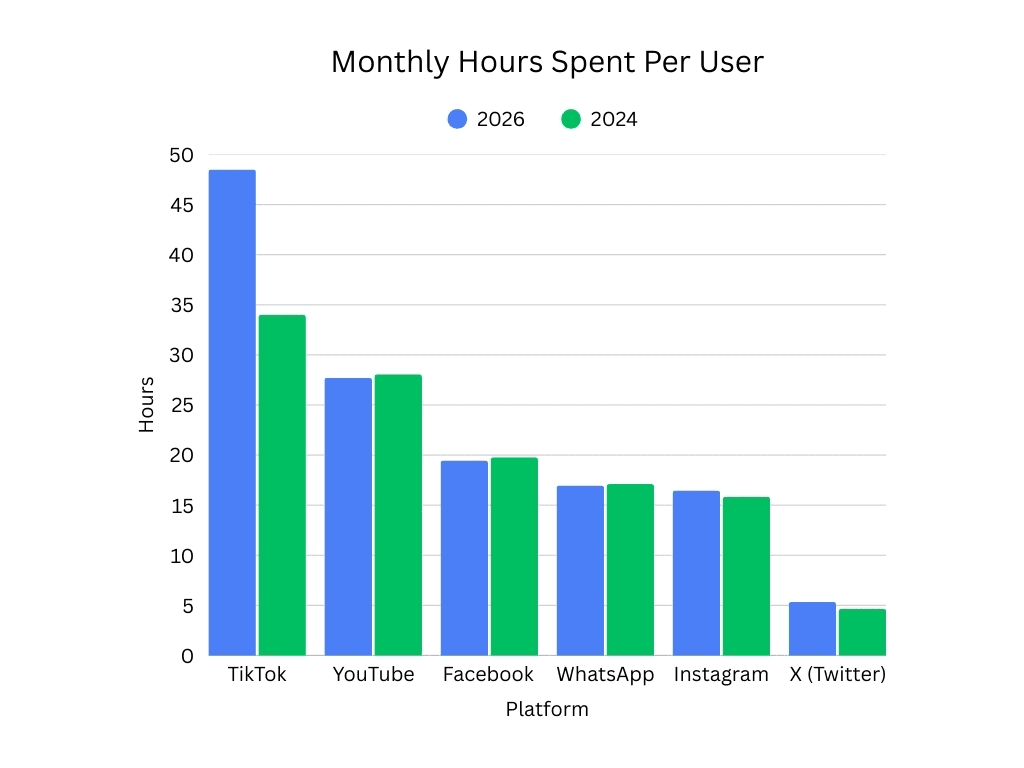
Every week we publish a rundown of new services for ecommerce merchants. This installment includes updates on product images, syndicated reviews, box-free returns, installment payments, marketplace integrations, agentic commerce, shipping intelligence, cross-border ecommerce, and affiliate partnerships.
Got an ecommerce product release? Email updates@practicalecommerce.com.
New Tools for Merchants
Designkit launches platform to streamline product visuals.Designkit has launched its product image platform. The AI-powered tool enables sellers to generate a full listing image set from a single prompt, including white-background shots, lifestyle scenes, and in-use visuals. It supports high-volume batch processing and localization across five languages. The AI Photo Editor Suite delivers refinement through five core tools: Background Remover, Background Generation, Object Remover, Image Enhancer, and Text & Element Integration.
Designkit
Ordoro and SPS Commerce partner to support brands on Amazon and Walmart.Ordoro, an ecommerce operations platform, has partnered with SPS Commerce, an intelligent supply chain network, to support scaling brands across retail and marketplace channels, including Amazon and Walmart. SPS Commerce helps brands recover revenue tied to retailer deductions, compliance fines, and marketplace reimbursement opportunities. Ordoro equips brands with the tools to manage inventory, shipping, and order workflows. Combined, the companies state they provide guidance for brands transitioning from early traction to operational maturity.
Shopware and Balance partner on B2B payments.Shopware, an open-source ecommerce platform, and Balance, an AI-powered financial infrastructure for B2B brands, have partnered to bring advanced B2B payment options to merchants in the Shopware ecosystem. Through the partnership, Shopware merchants can integrate Balance into checkout and buyer portals to offer and manage their pay-by-invoice and buy-now-pay-later programs. Balance automates the invoice-to-cash lifecycle with built-in fraud detection, credit management, and collection and reconciliation.
VisiGEO launches to make brands visible to AI. Focus Technology Co. has launched VisiGEO, a generative engine optimization platform. VisiGEO’s AI Visibility Analysis details mentions of your brand and competitors, along with the sentiment. VisiGEO’s Website GEO Audit corrects technical barriers blocking AI crawlers, from robots.txt misconfigurations to missing Schema.org markup. VisiGEO helps brands generate content and then provides publishing guidance to maximize AI impact.
Jliveo introduces AI-driven platform for B2B cross-border ecommerce.Jliveo, a B2B ecommerce solutions provider, has launched its AI-driven platform to support global wholesale and cross-border operations. The platform integrates sourcing, dropshipping, and fulfillment management into a single system — both wholesale purchasing and on-demand order fulfillment. Jliveo also incorporates automated content workflows and multilingual communication.
Jliveo
Shopify introduces Tinker app for AI tools.Shopify has debuted Tinker, a free mobile app that combines 100 specialized AI tools for creating images, videos, logos, and more. Tinker organizes tools by outcome, such as product photography, logo creation, social media videos, 360-degree views, and more. Each tool shows examples of what it creates and how to use it. Tinker brings models from providers such as OpenAI, Google, Anthropic, and others into a single app.
Amazon lets external websites offer Prime shipping without an Amazon login.Amazon is testing a program that lets shoppers access Prime shipping benefits on other websites without logging in to an Amazon account. The initiative includes a small group of test merchants who use Amazon’s multichannel fulfillment services to pick, pack, and deliver orders from their online store or other marketplaces and may have resisted deeper integration with Amazon’s ecosystem.
FedEx Office joins Amazon’s return network. Over 1,500 FedEx Office locations across the U.S. now offer Amazon’s free, label-free, box-free return option for eligible items. Customers begin the return process in their Amazon account, choose a nearby drop-off location, and receive a QR code. They can then bring their unpackaged item and its QR code to the selected location, where it is scanned and prepared for shipping — no shipping box or label required.
Meta expands Facebook affiliate partnerships.Meta is expanding Facebook affiliate partnerships to more test partners, including Amazon, eBay, and Temu in the U.S., Mercado Libre in Latin America, and Shopee in Asia. With affiliate partnerships, creators tag products from merchants in their Facebook posts to help their communities find and buy. Merchant partners choose which products to feature and set the commission for sales. Meta says it also plans to test similar affiliate experiences on Instagram.
Firmly launches Connect agentic marketing tool.Firmly, an agentic commerce platform, has introduced Connect, a no-code onboarding tool that autonomously integrates with merchants’ websites and commerce infrastructure to sell through agentic marketing channels. Firmly Connect allows merchants to quickly activate agentic commerce by verifying their business credentials, selecting where they want to sell, and publishing their product catalog while maintaining full control over pricing, inventory, and distribution.
Firmly
ShipperHQ launches AI-powered shipping intelligence platform.ShipperHQ, a shipping and checkout experience platform, has launched ShipperHQ.ai, a feature to give ecommerce merchants full visibility into their shipping operations. ShipperHQ.ai introduces an intelligence layer that combines real-time analytics with AI agents that analyze, test, and optimize shipping and checkout performance. Built on shipping logic refined across merchants, carrier integrations, and rate calculations, ShipperHQ.ai connects directly to an ecommerce store’s live shipping configuration and checkout data.
Thryv launches AI-powered sales automation for small businesses.Thryv, a provider of small-business marketing and sales software, launched AI Lead Flow. According to Thryv, the new tool connects online visibility, intelligent lead management, and automated sales follow-ups into a single experience. AI Lead Flow combines Thryv’s Marketing Center’s online visibility tools with its Keap sales automation engine to create a continuous, automated pipeline from the first online impression to the closed deal, eliminating the most common lead management failures for small businesses.
Shopify merchant brands are now available in ChatGPT.Shopify merchants can now sell to ChatGPT users via Shopify’s Agentic Storefronts, which provide access to genAI platforms such as ChatGPT, Microsoft Copilot, AI Mode in Google Search, and the Gemini app — all managed centrally from the Shopify admin. Brands not using Shopify for ecommerce can add products to the Shopify Catalog to reach shoppers and sell across these same AI channels.
Fair to say the majority of evergreen content will not drive the value it did five years ago. Hell, even one or two years ago. What we have done for the last decade will not be as profitable.
AIOs have eroded clicks. Answer engines have given people options. And to be fair, people are bored of the +2,000-word article answering “What time does X start?” Or recipes where the ingredient list is hidden below 1,500 words about why daddy didn’t like me.
So, you’ve got to be smart. This has to be framed as a commercial decision. Content needs to drive real business value. You’ve got to be confident in it delivering.
That doesn’t mean every article, video, or podcast has to drive a subscription or direct conversion. But it needs to play a clear part in the user’s journey. You need to be able to argue for its inclusion:
Is it a jumping-off point?
Will it drive a registration?
Or a free subscriber, save or follow on social
More commonly known as micro-conversions, these things really matter when it comes to cultivating and retaining an audience. People don’t want more bland, banal nonsense. They want something better.
The antithesis to AI slop will help your business be profitable.
Inherently, nothing. It’s a foundational part of the content pyramid.
In most cases, it’s been done to death, and AI is very effective at summarizing a lot of this bread-and-butter content.
The epitome of quantity over quality; it worked and made a fortune.
But I digress.
An authoritative enough site has been able to drive clicks and follow-up value with sub-par content for decades. That is, slowly diminishing. Rightly or wrongly.
And not because of the Helpful Content stuff. Google nerfed all the small sites long before the goliaths. Now they’ve gone after the big fish.
We have to make commercial decisions that help businesses make the right choice. Concepts like E-E-A-T have had an impact on the quality of content (a good thing). It’s also had an impact on the cost of creating quality content.
Working with experts.
Unique imagery.
Video.
Product and development costs.
Data.
This isn’t cheap. Once upon a time, we could generate value from authorless content full of stock images and no unique value. Unless you’re willing to bend the rules (which isn’t an option for most of us), you need an updated plan.
It depends.
You need to establish how much your content now costs to produce and the value it brings. Not everything is going to drive a significant conversion. That doesn’t mean you shouldn’t do it. It means you need to have a very clear reason for what you’re creating and why.
If particular topics are essential to your audience, service, and/or product, then they should at least be investigated.
One of the joys of creating evergreen content has always been that it adds value throughout the year(s). A couple of annual updates, even relatively light touch, could yield big results.
Commissioning something of quality in this space is likely more expensive. It needs to be worth it; it has to form part of your multi-channel experience to make it so.
Unique data and visuals that can be shared on socials.
Building campaigns around it (or it’s part of a campaign).
You can even build authors and your brand around it.
And if it resonates, you can rinse and repeat year after year.
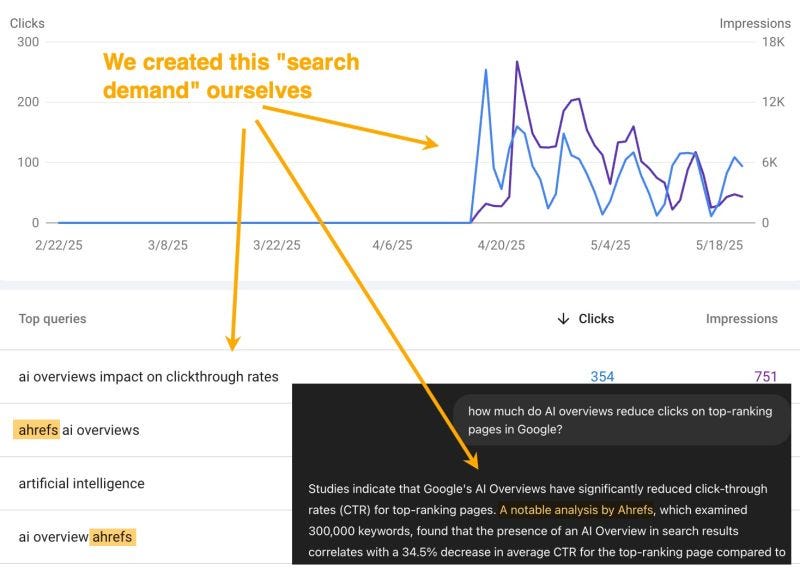
Ahrefs created demand for their brand + an evergreen topic – AIOs (Image Credit: Harry Clarkson-Bennett)
And this type of content or campaign can increase demand for a topic. You can become a thought leader by shifting the tide of public opinion.
For publishers and content creators, that is foundational.
I don’t – on both counts. We should want to be targeted on driving real value for the business.
Something like:
Tier 1: Value – core, revenue, and value-driving conversions.
Tier 2: Registrations (and things that help you build your owned properties), links, shares, and comments.
Tier 3: Page views, returning visits, and engagement metrics.
Micro-conversions over clicks. We’re focusing on registrations, free or lower-value subscriptions. Whatever gets the user into the ecosystem and one step closer to a genuinely valuable conversion.
The messy middle has changed, and it is largely unattributable (Image Credit: Harry Clarkson-Bennett)
Now, could a click be a micro-conversion? If you know that someone who reads a secondary article (by clicking a follow-up link) is 10x more likely to register, that follow-up click could be a sensible micro-conversion.
This type of conversion may not directly drive your bottom line. But it forces you and your team to focus on behaviors that are more likely to lead to a valuable conversion.
That is the point of a micro-conversion. It changes behaviors.
You can tweak the above tiers to better suit your content offering. Not all content is going to drive direct tier one or even two value. You just need to have a very clear idea of its purpose in the customer journey.
If what you’re creating already exists, you’d better make sure you add something extra. You’ve got to force your way into the conversation, and unless you can offer something unique, you’re (almost certainly) wasting your time IMO.
I’ll break all of these down, but I think (in order of importance):
Writing content for people.
Information gain.
Getting it found.
Creating it at the right time.
Structuring it for bots.
Everyone is obsessed with getting cited or being visible in AI.
I think this is completely the wrong way of framing this new era. Getting cited there, or being visible, is a happy byproduct of building a quality brand with an efficient, joined-up approach to marketing.
The more you understand your audience, the more likely you will be to create high-quality, relevant content that gets cited.
If you know your audience really cares about a topic, that’s step one taken care of. If you know where they spend time and how they’re influenced, that’s step two. And if you know how to cut through the noise, that’s step three.
Really, this is an evolution in SEO and the internet at large.
Invest in and create content that will resonate with your audience.
Create a cross-channel marketing strategy that will genuinely reach and influence them.
Share, share, share. Be impactful. Get out there.
Make sure it’s easy to read, share, and consume.
Your content still needs to reach and be remembered by the right people. Do that better than anybody else, and wider visibility will come.
In SEO, we have a different definition of information gain than more traditional information retrieval mechanics. I don’t know if that’s because we’re wrong (probably), or that we have a valid reason…
Maybe someone can enlighten me?
In more traditional machine learning, information gain measures how much uncertainty is reduced after observing new data. That uncertainty is captured by entropy, which is a way of quantifying how unpredictable a variable is based on its probability distribution.
Events with low probability are more surprising and therefore carry more information. High probability events are less surprising and novel. Therefore, entropy reflects the overall level of disorder and unpredictability across all possible outcomes.
Information gain, then, tells us how much that unpredictability drops when we split or segment the data. A higher information gain means the data has become more ordered and less uncertain – in other words, we’ve learned something useful.
To us in SEO, information gain means the addition of new, relevant information. Beyond what is already out there in the wider corpus.
A representative workflow of Google’s Contextual estimation of link information gain patent (Image Credit: Harry Clarkson-Bennett)
Google wants to reduce uncertainty. Reduce ambiguity. Content with a higher level of information gain isn’t only different, it elevates a user’s understanding. It raises the bar by answering the question(s) and topic more effectively than anyone else.
So, try something different, novel even, and watch Google test your content higher up in the SERPs to see if it satisfies a user.
This is such an important concept for evergreen content because so many of these queries have well-established answers. If you’re just parroting these answers because your competitors do it, you’re not forcing Google’s hand.
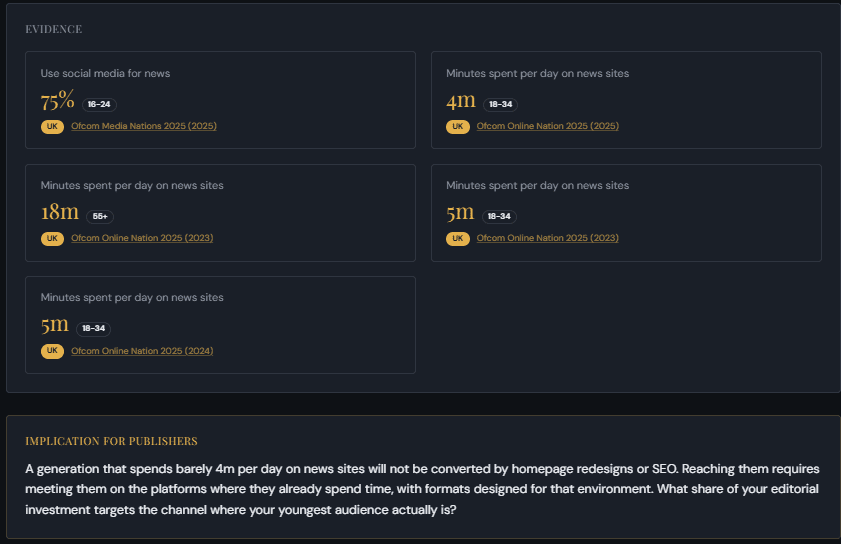
Particularly if you’re still just copying headers and FAQs from the top three results. Audiences are not arriving at publisher destinations through direct navigation at the same scale. They encounter journalism incidentally, through social feeds, not through habitual site visits.
Younger audiences spend less time on news sites and more time on social every year (Image Credit: Harry Clarkson-Bennett)
You’ve got to meet them there and force their hand.
According to this patent – contextual estimation of link information gain – Google scores documents based on the additional information they offer to a user, considering what the user has already seen.
“Based on the information gain scores of a set of documents, the documents can be provided to the user in a manner that reflects the likely information gain that can be attained by the user if the user were to view the documents.”
Bots, like people, need structure to properly “understand” content.
Elements like headings (h1 – h6), semantic HTML, and linking effectively between articles help search engines (and other forms of information retrieval) understand what content you deem important.
While the majority of semi-literates “understand” content, bots don’t. They fake it. They use engagement signals, NLP, and the vector model space to map your document against others.
They can only do this effectively if you understand how to structure a page.
Frontloading key information.
Effectively targeting highly relevant queries.
Using structured data formats like lists and tables, where appropriate (these are more cost-effective forms of tokenization).
The more clearly a page communicates its topic, subtopics, and relationships, the more likely it is to be consistently retrieved and reused across search and AI surfaces. This has a compounding effect.
Rank more effectively (great for RAG, obviously) – feature more heavily in versions of the internet – force your way into model training data.
If you need to get development work put through, frame it through the lens of assistive technology. Can people with specific needs fully access your pages?
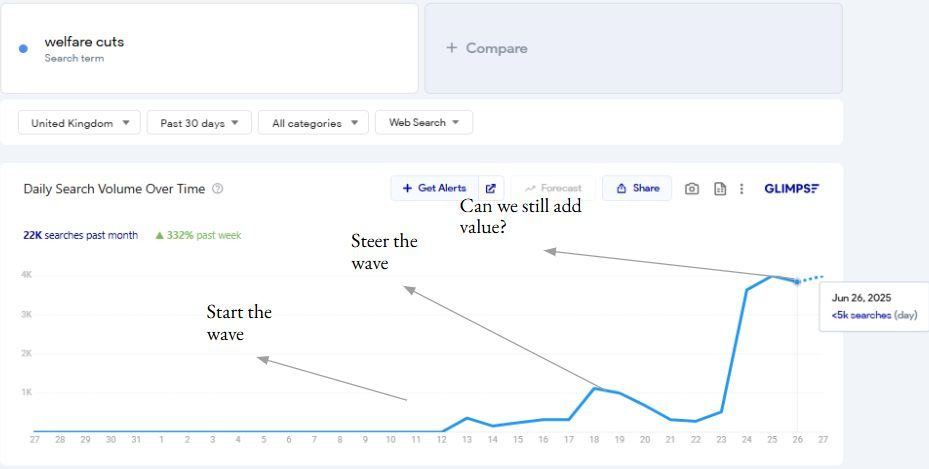
Track and pay very close attention to spikes in demand (Google Trends API being a very obvious option here).
Make sure you’re adding something of value to the wider corpus.
If quality content is already out there and you have nothing extra to add, consider whether it’s worth spending money on (SEO is not free).
Create and update timely evergreen content (Image Credit: Harry Clarkson-Bennett)
While this is primarily for news, you can apply a similar logic to evergreen content if you zoom out and follow macro trends.
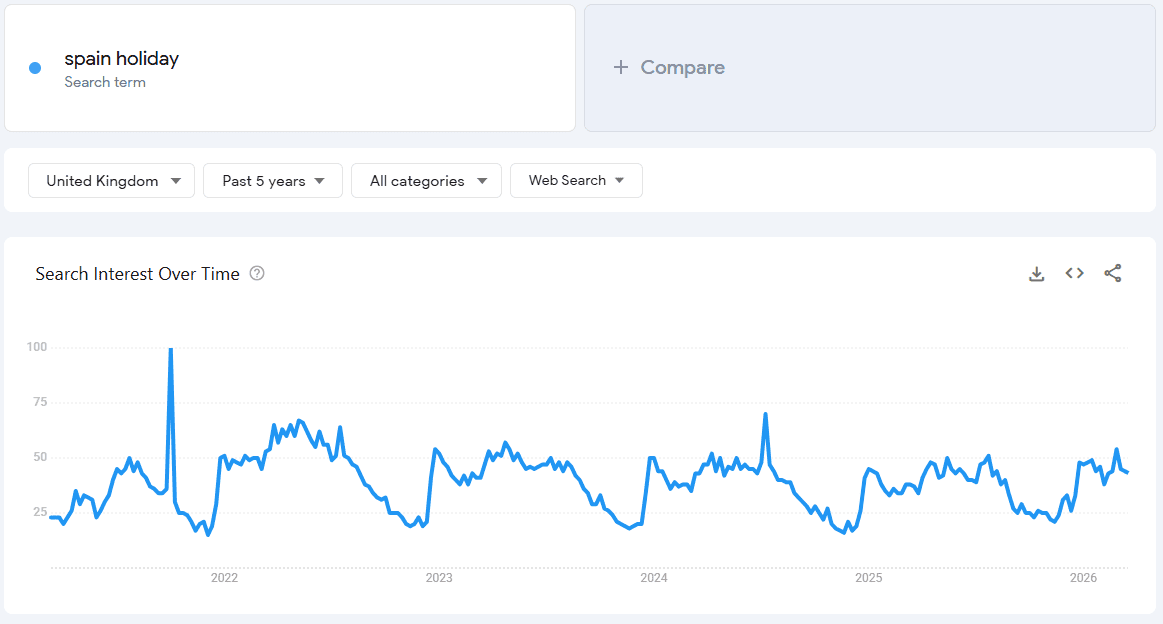
Evergreen content still spikes at different times throughout the year. Take Spain as an example. There’s much more limited interest in going to Spain in the Winter months from the UK. But January (holiday planning or weekend breaks) and summer (more immediate holiday-ing with the kids) provide better opportunities to generate traffic.
You’re capturing the spike in demand by updating content at the right time. Particularly if you understand the difference in user needs when this spike in demand happens.
In January, get your holiday planning content ready.
In the summer, get your family-friendly and last-minute holiday content up and running.
Image Credit: Harry Clarkson-Bennett
Demand for evergreen topics can be cyclical. In this example, you would want to capture the spike(s) with carefully planned updates, so you have up-to-date content when a user is really searching for that product, service, or information.
Well, what matters to your brand and your users? Have you asked them?
By the very nature of new and evolving topics and concepts, not everything “evergreen” has been done.
New topics rise. Old ones fall. Some are cyclical.
My rule(s) of thumb would be to establish:
Is the topic foundational to your product and service?
Does your current (and potential) audience demand it?
Do you have something new to add to the wider corpus of information?
If the answer to those three is a broad variation of yes, it’s almost certainly a good bet. Then, I would consider topic search volume, cross-platform demand, and whether the topic is trending up or down in popularity.
There are some things you should be doing “just for SEO.” Content isn’t one of them. You can yell topical authority until you’re blue in the face. If you’re creating stuff just for SEO – kill it.
IMO, these plays have been dead or dying for some time. The modern-day version of the internet (in particular search) demands disambiguation. It demands accuracy. Verification that you are an expert. Otherwise, you’re competing with those who have a level of legitimacy that you do not.
Social profiles, newsletters, real people sharing stories. You’re competing with people who aren’t polishing turds.
If all you’re thinking about is search volume or clicks, I don’t think it’s worth it.
And this brings me nicely onto rented land. Platforms you don’t own.
We’ve spent years creating assets (your websites) to deliver value in search. Owning all of your assets and prioritizing your site above all else. But that is changing. In many cases, people don’t reach your website until they’ve already made a purchasing decision.
I think Rand has managed this transition better than anybody (Image Credit: Harry Clarkson-Bennett)
So, you have to get your stuff out there. Create large, unique studies. Cut them into snippets and short-form videos. Use your individual platform to boost your profile and the content’s chances of soaring.
This is, IMO, particularly prescient for publishers. You’ve got to get out there. You’ve got to share and reuse your content. To make the most of what you’ve created.
Sweat your assets. Even if senior figures aren’t comfortable with this, you need to make it happen.
People have been espousing how important it is to feature as part of the answer. And that may be true. But you’re going to have to be good at selling your projects in if there’s no clear attribution or value.
It might not have the spikes of news, but evergreen interest still spikes at certain times in the year.
Get people – real people – to share it. To have their spin on it.
Outperform the expected early stage engagement and maximize your chance of appearing in platforms like Discover with wider platform engagement.
You have to work harder than before.
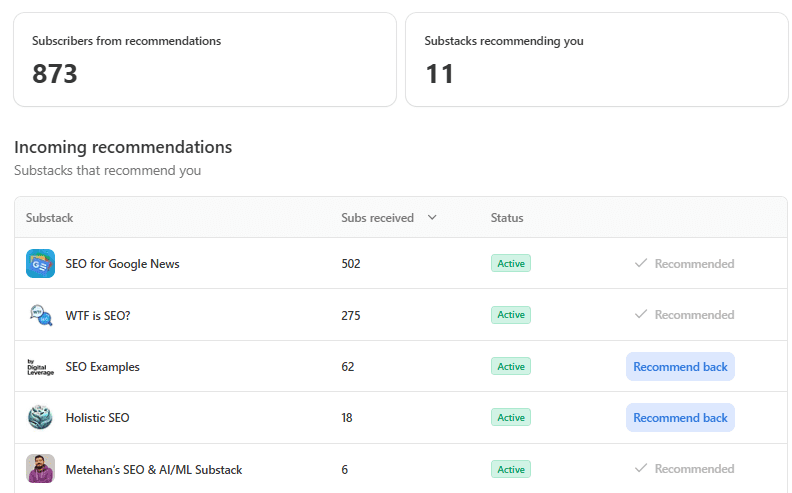
I shared an example of this around a year ago, but to revisit it, I now have 11 recommendations from other Substacks.
You can’t do this alone (Image Credit: Harry Clarkson-Bennett)
They have accounted for over 40% of my total subscribers. Admittedly, mainly from Barry, Shelby, and Jessie. But they are, if I may be so bold, superhumans.
And when our main driver of evergreen traffic to the site (Google) has really leaned into the evil that surrounds big tech, we’ve got to be cannier. We have to find ways to get people to share our content.
Even evergreen content.
If we’re being honest, a lot of SEO content has been rubbish. Churned out muck.
People are still churning out muck at an incredible rate. When what you’ve got is crap, more crap isn’t the answer. I think people are turned off. They’re tuning out of things at an alarming rate, especially young people.
It is all about getting the right people into the system. Evergreen content is still foundational here. You just have to make it work harder. Be more interesting. Be shareable.
Hopefully, this makes decisions over what we should and shouldn’t create easier.
AI and automation in ad platforms are well established. Google Ads and Microsoft Advertising are heavily invested in automated features, and the technical barrier to entry has never been lower. However, that accessibility comes with a tradeoff.
Two common challenges surface when bringing a PPC team in-house:
Campaigns are easier to launch than they are to explain and analyze.
Machine-driven decisions risk going unquestioned without an outside perspective.
Those challenges point to something CMOs probably already know: Automation doesn’t eliminate the need for human judgment. It raises the requirements for it. Even with strong AI tools in place, experienced PPC practitioners are still writing strategy, creating ad copy, and manually updating targeting.
This article covers two structural paths for managing that reality.
All in-house means your internal team manages PPC end-to-end, with no agency or external consultant involved.
Hybrid means your internal team handles day-to-day execution and internal oversight while an external specialist or consultant provides strategy, auditing, and a second set of eyes.
Both models can work. The goal is to match machine automation with human accountability and independent performance checks. Without that structure, an in-house team can end up in a bubble where the ad platform’s suggestions dictate all of the optimization decisions.
Is Your Organization Ready? What To Assess Before You Hire
Before you post a job description, determine whether your company is ready to manage the technical work that comes with modern PPC search ads. Hiring an internal team is a long-term commitment.
The Shift In Daily Tasks
The role of the search marketer is shifting from manual campaign creation to evaluating and guiding automated systems. The human role is increasingly about checking what the AI creates and stepping in to do the work the ad platform can’t do well on its own.
That last part matters so much more than most job descriptions reflect. In my experience, AI-generated ad copy is often not platform-ready, and strategy still requires a human who understands the brand, the profit model, and the customer. If your candidates are only talking about managing manual bids and features, they may not be ready for the current landscape. You need people who can navigate automated systems and know when to override them.
Input And Data Quality
Because AI success depends on signal strength, an in-house PPC team’s value is directly tied to their ability to connect and maintain clean data. Ad platforms rely on:
Conversion tracking.
CRM integration.
Audience modeling.
Bidding inputs.
Tools such as Google Ads Data Manager (connecting external products inside Google Ads) and offline conversion uploads mean managing data should be a core responsibility of in-house PPC specialists.
Poorly configured conversion tracking or incomplete data signals can lead automated bidding to optimize toward low-value actions, if the data isn’t managed effectively in-house. You can’t expect a machine to give you good results if you’re feeding it bad information.
If You Are Hiring, Look For These Skills
If you’ve decided to build fully in-house, hiring criteria should shift toward business data management and the ability to work alongside AI without taking every single suggestion.
1. Understanding Business Margins
Most PPC managers haven’t had to think in depth about COGS (Cost of Goods Sold) or return rates, but that’s changing.
The bar is rising for in-house hires. A team that can connect ad spend to net profit, not just revenue, is far better positioned to make smart decisions as automation takes over the mechanical work.
2. Owning The Post-Click Experience
The PPC team must care about what happens after the user lands on the site. Creative quality and landing page performance are directly tied to conversions and what the algorithm learns over time.
AI-driven traffic efficiency can be thrown off by a poor landing page experience. Your internal hires should have a working knowledge of landing page testing and website user experience.
3. Ad Copy And Strategic Judgment
AI can generate ad copy, but it can create variations that are missing marketing strategy or brand-ready messaging. Your team needs to evaluate, rewrite, and at times reject what the ad platform produces.
The same applies to strategy. Automated systems optimize toward the goals you set, but setting the right goals and interpreting performance still require a skilled human. Hire for that judgment, not just ad platform knowledge.
4. Technical Data Strategy
Your team needs to know how to build and maintain first-party data connections, such as CRM data and customer match uploads.
Your team’s job is to ensure the right signals are flowing to the right campaigns at the right time. Technical data competency should be a core requirement for the job.
Why A Hybrid Model May Work Better
Even when hiring and data processes are going well, blind spots can happen inside fully internal teams. Three issues can show up:
Brand blindness from working primarily inside a single account.
Lack of independent auditing on spend and profit.
Difficulty pushing back on ad platform pressure.
An external perspective adds accountability that internal teams can have trouble providing for themselves. In an environment where so many features are automated, that accountability matters more because teams don’t tend to deep dive into the automations.
1. The Problem With Brand Blindness
Internal teams are focused on one brand. That focus builds deep expertise, but it can limit perspective. For example, when performance changes, it’s difficult to determine whether the change reflects a platform-wide trend, an industry shift, or a campaign-specific issue.
Working across many industries gives specialist consultants a reference point that internal teams may not have. They can tell you if a performance drop is happening to everyone in the industry or just to you.
2. The Need For Independent Auditing
An external partner acts as an independent auditor for your search spend. They can help confirm that internal goals line up with actual business profit rather than ad platform metrics.
It’s easy for internal teams to grow comfortable and focus on vanity metrics like ROAS (Return on Ad Spend). An objective third party can help show you exactly how much actual profit your search spend is generating.
3. Managing Ad Platform Pressure
Internal teams are the primary target for PPC ad platform representatives. These reps frequently push recommendations such that are auto-applied and display network serving that eat up budgets and prioritize the platform’s revenue over your business.
Independent experts are less likely to follow these suggestions without questioning them. They provide the pushback needed to ensure spend is justified by performance, not the platform’s optimization score.
Structuring The Partnership For Success
Consider a division of labor that draws on internal brand knowledge and external expertise. This hybrid approach offers the most protection for your ad spend.
What The In-House Team Should Own
Data Ownership: Managing the privacy and quality of your customer signals.
Creative Guidance: Ensuring brand voice stays consistent across AI-generated ads.
Ad Copy and Strategy: Writing, evaluating, and refining what the ad platform produces.
Sales Coordination: Connecting PPC spend with internal inventory levels and sales cycles.
What The External Specialist Should Own
Strategic Roadmap: Providing a long-term view of where the search industry is heading.
Advanced Analysis: Proving the true value of your spend through profit-based measurement.
Objective Auditing: Serving as an independent check against ad platform recommendations.
Successful PPC teams in an AI-first search environment won’t be worried about who automated the fastest. They’ll be more thoughtful and strategic about defining what the machine does and what a human approves.
Matching Structure To Accountability
The decision to go fully in-house or hybrid isn’t permanent. What matters is that your structure matches the level of accountability your ad spend requires.
If your team has clean data, strong hiring, and the ability to question what the ad platform suggests, a fully in-house model can work. But if no one is challenging the machine’s recommendations, you have a gap that’s hard to fix from the inside.
A hybrid model doesn’t mean your internal team isn’t capable. It means you’re building in a check that protects your budget from blind spots.
Whatever you choose, the people managing your PPC need to understand your business at the profit level, not just the platform level. Automation handles the mechanics. Your team handles the judgment.
Enterprise SEO doesn’t fail because teams don’t care, lack expertise, or miss tactics. It fails because ownership is fractured.
In most large organizations, everyone controls a piece of SEO, yet no single group owns the outcome. Visibility, traffic, and discoverability depend on dozens of upstream decisions made across engineering, content, product, UX, legal, and local markets. SEO is measured on the result, but it does not control the system that produces it.
In smaller organizations, this problem is manageable. SEO teams can directly influence content, technical decisions, and site structure. In the enterprise, that control dissolves. Incentives diverge. Workflows fragment. Coordination becomes optional.
SEO success requires alignment, but enterprise structures reward isolation. That mismatch creates what I call the accountability gap – the silent failure mode behind most large-scale SEO underperformance.
SEO Is Measured By The Team That Doesn’t Control It
SEO is the only business function I am aware of that, judged by performance, cannot be delivered independently. This is especially true in the enterprise, where SEO performance is evaluated using familiar metrics: visibility, traffic, engagement, and increasingly AI-driven exposure. The irony is that the SEO function rarely controls the systems that generate those outcomes.
Function
Controls
SEO Dependency
Development
Templates, rendering, performance
Crawlability, indexability, structured data
Content Teams
Messaging, depth, updates
Relevance, coverage, AI eligibility
Product Teams
Taxonomy, categorization, naming
Entity clarity, internal structure
UX & Design
Navigation, layout, hierarchy
Discoverability, user engagement
Legal & Compliance
Claims, restrictions
Content completeness & trust signals
Local Markets
Localization & regional content
Cross-market consistency & intent alignment
SEO depends on all of these departments to do their job in an SEO-friendly manner for it to have a remote chance of success. This makes SEO unusual among business functions. It is judged by performance, yet it cannot deliver that performance independently. And because SEO typically sits downstream in the organization, it must request changes rather than direct them.
That structural imbalance is not a process issue. It is an ownership problem.
The Accountability Gap Explained
The accountability gap appears whenever a business-critical outcome depends on multiple teams, but no single team is accountable for the result.
SEO is a textbook example as fundamental search success requires development to implement correctly, content to align with demand, product teams to structure information coherently, markets to maintain consistency, and legal to permit eligibility-supporting claims. Failure occurs when even one link breaks.
Inside the enterprise, each of those teams is measured on its own key performance indicators. Development is rewarded for shipping. Content is rewarded for brand alignment. Product is rewarded for features. Legal is rewarded for risk avoidance. Markets are rewarded for local revenue. SEO lives in the cracks between them.
No one is incentivized to fix a problem that primarily benefits another department’s metrics. So issues persist, not because they are invisible, but because resolving them offers no local reward.
KPI Structures Encourage Metric Shielding
This is where enterprise SEO collides head-on with organizational design.
In practice, resistance to SEO rarely looks like resistance. No one says, “We don’t care about search.” Instead, objections arrive wrapped in perfectly reasonable justifications, each grounded in a different team’s success metrics.
Engineering teams explain that template changes would disrupt sprint commitments. Localization teams point to budgets that were never allocated for rewriting content. Product teams note that naming decisions are locked for brand consistency. Legal teams flag risk exposure in expanded explanations. And once something has launched, the implicit assumption is that SEO can address any fallout afterward.
Each of these responses makes sense on its own. None are malicious. But together, they form a pattern where protecting local KPIs takes precedence over shared outcomes.
This is what I refer to as metric shielding: the quiet use of internal performance measures to avoid cross-functional work. It’s not a refusal to help; it’s a rational response to how teams are evaluated. Fixing an SEO issue rarely improves the metric a given department is rewarded for, even if it materially improves enterprise visibility.
Over time, this behavior compounds. Problems persist not because they are unsolvable, but because solving them benefits someone else’s scorecard. SEO becomes the connective tissue between teams, yet no one is incentivized to strengthen it.
This dynamic is part of a broader organizational failure mode I call the KPI trap, where teams optimize for local success while undermining shared results. In enterprise SEO, the consequences surface quickly and visibly. In other parts of the organization, the damage often stays hidden until performance breaks somewhere far downstream.
The Myth: “SEO Is Marketing’s Job”
To simplify ownership, enterprises often default to a convenient fiction: SEO belongs to marketing.
On the surface, that assumption feels logical. SEO is commonly associated with organic traffic, and organic traffic is typically tracked as a marketing KPI. When visibility is measured in visits, conversions, or demand generation, it’s easy to conclude that SEO is simply another marketing lever.
In practice, that logic collapses almost immediately. Marketing may influence messaging and campaigns, but it does not control the systems that determine discoverability. It does not own templates, rendering logic, taxonomy, structured data pipelines, localization standards, release timing, or engineering priorities. Those decisions live elsewhere, often far upstream from where SEO performance is measured.
As a result, marketing ends up owning SEO on the organizational chart, while other teams own SEO in reality. This creates a familiar enterprise paradox. One group is held accountable for outcomes, while other groups control the inputs that shape those outcomes. Accountability without authority is not ownership. It is a guaranteed failure pattern.
The Core Reality
At its core, enterprise SEO failures are rarely tactical. They are structural, driven by accountability without authority across systems SEO does not control.
Search performance is created upstream through platform decisions, information architecture, content governance, and release processes. Yet SEO is almost always measured downstream, after those decisions are already locked. That separation creates the accountability gap.
SEO becomes responsible for outcomes shaped by systems it doesn’t control, priorities it can’t override, and tradeoffs it isn’t empowered to resolve. When success requires multiple departments to change, and no one owns the outcome, performance stalls by design.
Why This Breaks Faster In AI Search
In traditional SEO, the accountability gap usually expressed itself as volatility. Rankings moved. Traffic dipped. Teams debated causes, made adjustments, and over time, many issues could be corrected. Search engines recalculated signals, pages were reindexed, and recovery, while frustrating, was often possible. AI-driven search behaves differently because the evaluation model has changed.
This is where the accountability gap becomes fatal. When even one department blocks or weakens those elements – by fragmenting entities, constraining content, breaking templates, or enforcing inconsistent standards – the system doesn’t partially reward the brand. It fails to form a stable representation. And when representation fails, exclusion follows. Visibility doesn’t gradually decline. It disappears.
AI systems default to sources that are structurally coherent and consistently reinforced. Competitors with cleaner governance and clearer ownership become the reference point, even if their content is not objectively better. Once those narratives are established, they persist. AI systems are far less forgiving than traditional rankings, and far slower to revise once an interpretation hardens.
This is why the accountability gap now manifests as a visibility gap. What used to be recoverable through iteration is now lost through omission. And the longer ownership remains fragmented, the harder that loss is to reverse.
A Note On GEO, AIO, And The Labeling Distraction
Much of the current conversation reframes these challenges under new labels GEO, AIO, AI SEO, generative optimization. The terminology isn’t wrong. It’s just incomplete.
These labels describe where visibility appears, not why it succeeds or fails. Whether the surface is a ranking, an AI Overview, or a synthesized answer, the underlying requirements remain unchanged: structural clarity, entity consistency, governed content, trustworthy signals, and cross-functional execution.
Renaming the outcome does not change the operating model required to achieve it.
Organizations don’t fail in AI search because they picked the wrong acronym. They fail because the same accountability gap persists, with faster and less forgiving consequences.
The Enterprise SEO Ownership Paradox
At its core, enterprise SEO operates under a paradox that most organizations never explicitly confront.
SEO is inherently cross-functional. Its performance depends on systems, processes, platforms, and decisions that span development, content, product, legal, localization, and governance. It behaves like infrastructure, not a channel. And yet, it is still managed as if it were a marketing function, a reporting line, or a service desk that reacts to requests.
That mismatch explains why even well-funded SEO teams struggle. They are held responsible for outcomes created by systems they do not control, processes they cannot enforce, and decisions they are rarely empowered to shape.
This paradox stays abstract until it’s reduced to a single, uncomfortable question:
Who is accountable when SEO success requires coordinated changes across three departments?
In most enterprises, the honest answer is simple. No one.
And when no one owns cross-functional success, initiatives stall by design. SEO becomes everyone’s dependency and no one’s priority. Work continues, meetings multiply, and reports are produced – but the underlying system never changes.
That is not a failure of execution. It is a failure of ownership.
They establish executive sponsorship for search visibility, shared accountability across development, content, and product, and mandatory requirements embedded into platforms and workflows. Governance replaces persuasion. Standards are enforced before launch, not debated afterward.
SEO shifts from requesting fixes to defining requirements teams must follow. Ownership becomes structural, not symbolic.
The Final Reality
This perspective isn’t theoretical. It’s grounded in my nearly 30 years of direct experience designing, repairing, and operating enterprise website search programs across large organizations, regulated industries, complex platforms, and multi-market deployments.
I’ve sat in escalation meetings where launches were declared successful internally, only for visibility to quietly erode once systems and signals reached the outside world. I’ve watched SEO teams inherit outcomes created months earlier by decisions they were never part of. And more recently, I’ve worked with leadership teams who didn’t realize they had a search problem until AI-driven systems stopped citing them altogether. These are not edge cases. They are repeatable organizational failure modes.
What ultimately separated failure from recovery was never better tactics, better tools, or better acronyms. It was ownership. Specifically, whether the organization recognized search as a shared system-level responsibility and structured itself accordingly.
Enterprise SEO doesn’t break because teams aren’t trying hard enough. It breaks when accountability is assigned without authority, and when no one owns the outcomes that require coordination across the organization.
That is the problem modern search exposes. And ownership is the only durable fix.
Coming Next
The Modern SEO Center Of Excellence: Governance, Not Guidelines
We’ll close the loop by showing how enterprises institutionalize ownership through a Center of Excellence that governs standards, enforcement, entity governance, and cross-market consistency, the missing layer that prevents the accountability gap from recurring.
Google’s John Mueller responded to a question about whether core updates roll out in stages or follow a fixed sequence. His answer offers some clarity about how core updates are rolled out and also about what some core updates actually are.
Question About Core Update Timing And Volatility
An SEO asked on Bluesky whether core updates behave like a single rollout that is then refined over time or if the different parts being updated are rolled out at different stages.
The question reflects a common observation that rankings tend to shift in waves during a rollout period, often lasting several weeks. This has led to speculation that updates may be deployed incrementally rather than all at once.
“Given the timing, I want to ask a core update related question. Usually, we see waves of volatility throughout the 2-3 weeks of a rollout. Broadly, are different parts of core updated at different times? Or is it all reset at the beginning then iterated depending on the results?”
Core Updates Can Require Step-By-Step Deployment
Mueller explained that Google does not formally define or announce stages for core updates. He noted that these updates involve broad changes across multiple systems, which can require a step-by-step rollout rather than a single deployment.
He responded:
“We generally don’t announce “stages” of core updates.. Since these are significant, broad changes to our search algorithms and systems, sometimes they have to work step-by-step, rather than all at one time. (It’s also why they can take a while to be fully live.)”
Updates Depend On Systems And Teams Involved
Mueller next added that there is no single mechanism that governs how all core updates are released. Instead, updates reflect the work of different teams and systems, which can vary from one update to another.
He explained:
“I guess in short there’s not a single “core update machine” that’s clicked on (every update has the same flow), but rather we make the changes based on what the teams have been working on, and those systems & components can change from time to time.”
Core Updates May Roll Out Incrementally Rather Than All At Once
Mueller’s explanation suggests that the waves of volatility observed during core updates may correspond to incremental changes across different systems rather than a single reset followed by adjustments. Because updates are tied to multiple components, the rollout may progress in parts as those systems are updated and brought fully live.
This reflects a process where some changes are complex and require a more nuanced step-by-step rollout, rather than being released all at once, which may explain why ranking shifts can appear uneven during the rollout period.
Connection To Google’s Spam Update?
I don’t think that it was a coincidence that the March Core update followed closely after the recent March 2026 Spam Update. The reason I think that is because it’s logical for spam fighting to be a part of the bundle of changes made in a core algorithm update. That’s why Googlers sometimes say that a core update should surface more relevant content and less of the content that’s low quality.
So when Google announces a Spam Update, that stands out because either Google is making a major change to the infrastructure that Google’s core algorithm runs on or the spam update is meant to weed out specific forms of spam prior to rolling out a core algorithm update, to clear the table, so to speak. And that is what appears to have happened with the recent spam and core algorithm updates.
Comparison With Early Google Updates
Way back in the early days, around 25 years ago, Google used to have an update every month, offering a chance to see if new pages are indexed and ranked as well as seeing how existing pages are doing. The initial first days of the update saw widescale fluctuations which we (the members of WebmasterWorld forum) called the Google Dance.
Back then, it felt like updates were just Google adding more pages and re-ranking them. Then around the 2003 Florida update it became apparent that the actual ranking systems were being changed and the fluctuations could go on for months. That was probably the first time the SEO community noticed a different kind of update that was probably closer a core algorithm update.
In my opinion, one way to think of it is that Google’s indexing and ranking algorithms are like software. And then, there’s also hardware and software that are a part of the infrastructure that the indexing and ranking algorithms run on (like the operating system and hardware of your desktop or laptop).
That’s an oversimplification but it’s useful to me for visualizing what a core algorithm update might be. Most, if not all of it, is related to the indexing and ranking part. But I think sometimes there’s infrastructure-type changes going on that improve the indexing and ranking part.
For decades, artificial intelligence has been evaluated through the question of whether machines outperform humans. From chess to advanced math, from coding to essay writing, the performance of AI models and applications is tested against that of individual humans completing tasks.
This framing is seductive: An AI vs. human comparison on isolated problems with clear right or wrong answers is easy to standardize, compare, and optimize. It generates rankings and headlines.
But there’s a problem: AI is almost never used in the way it is benchmarked. Although researchers and industry have started to improve benchmarking by moving beyond static tests to more dynamic evaluation methods, these innovations resolve only part of the issue. That’s because they still evaluate AI’s performance outside the human teams and organizational workflows where its real-world performance ultimately unfolds.
While AI is evaluated at the task level in a vacuum, it is used in messy, complex environments where it usually interacts with more than one person. Its performance (or lack thereof) emerges only over extended periods of use. This misalignment leaves us misunderstanding AI’s capabilities, overlooking systemic risks, and misjudging its economic and social consequences.
To mitigate this, it’s time to shift from narrow methods to benchmarks that assess how AI systems perform over longer time horizons within human teams, workflows, and organizations. I have studied real-world AI deployment since 2022 in small businesses and health, humanitarian, nonprofit, and higher-education organizations in the UK, the United States, and Asia, as well as within leading AI design ecosystems in London and Silicon Valley. I propose a different approach, which I call HAIC benchmarks—Human–AI, Context-Specific Evaluation.
What happens when AI fails
For governments and businesses, AI benchmark scores appear more objective than vendor claims. They’re a critical part of determining whether an AI model or application is “good enough” for real-world deployment. Imagine an AI model that achieves impressive technical scores on the most cutting-edge benchmarks—98% accuracy, groundbreaking speed, compelling outputs. On the strength of these results, organizations may decide to adopt the model, committing sizable financial and technical resources to purchasing and integrating it.
But then, once it’s adopted, the gap between benchmark and real-world performance quickly becomes visible. For example, take the swathe of FDA-approved AI models that can read medical scans faster and more accurately than an expert radiologist. In the radiology units of hospitals from the heart of California to the outskirts of London, I witnessed staff using highly ranked radiology AI applications. Repeatedly, it took them extra time to interpret AI’s outputs alongside hospital-specific reporting standards and nation-specific regulatory requirements. What appeared as a productivity-enhancing AI tool when tested in a vacuum introduced delays in practice.
It soon became clear that the benchmark tests on which medical AI models are assessed do not capture how medical decisions are actually made. Hospitals rely on multidisciplinary teams—radiologists, oncologists, physicists, nurses—who jointly review patients. Treatment planning rarely hinges on a static decision; it evolves as new information emerges over days or weeks. Decisions often arise through constructive debate and trade-offs between professional standards, patient preferences, and the shared goal of long-term patient well-being. No wonder even highly scored AI models struggle to deliver the promised performance once they encounter the complex, collaborative processes of real clinical care.
The same pattern emerges in my research across other sectors: When embedded within real-world work environments, even AI models that perform brilliantly on standardized tests don’t perform as promised.
When high benchmark scores fail to translate into real-world performance, even the most highly scored AI is soon abandoned to what I call the “AI graveyard.”The costs are significant: Time, effort and money end up being wasted. And over time, repeated experiences like this erode organizational confidence in AI and—in critical settings such as health—may erode broader public trust in the technology as well.
When current benchmarks provide only a partial and potentially misleading signal of an AI model’s readiness for real-world use, this creates regulatory blind spots: Oversight is shaped by metrics that do not reflect reality. It also leaves organizations and governments to shoulder the risks of testing AI in sensitive real-world settings, often with limited resources and support.
How to build better tests
To close the gap between benchmark and real-world performance, we must pay attention to the actual conditions in which AI models will be used. The critical questions: Can AI function as a productive participant within human teams? And can it generate sustained, collective value?
Through my research on AI deployment across multiple sectors, I have seen a number of organizations already moving—deliberately and experimentally—toward the HAIC benchmarks I favor.
HAIC benchmarks reframe current benchmarking in four ways:
1. From individual and single-task performance to team and workflow performance (shifting the unit of analysis)
2. From one-off testing with right/wrong answers to long-term impacts (expanding the time horizon)
3. From correctness and speed to organizational outcomes, coordination quality, and error detectability (expanding outcome measures)
4. From isolated outputs to upstream and downstream consequences (system effects)
Across the organizations where this approach has emerged and started to be applied, the first step is shifting the unit of analysis.
For example, in one UK hospital system in the period 2021–2024, the question expanded from whether a medical AI application improves diagnostic accuracy to how the presence of AI within the hospital’s multidisciplinary teams affects not only accuracy but also coordination and deliberation. The hospital specifically assessed coordination and deliberation in human teams using and not using AI. Multiple stakeholders (within and outside the hospital) decided on metrics like how AI influences collective reasoning, whether it surfaces overlooked considerations, whether it strengthens or weakens coordination, and whether it changes established risk and compliance practices.
This shift is fundamental. It matters a lot in high-stakes contexts where system-level effects matter more than task-level accuracy. It also matters for the economy. It may help recalibrate inflated expectations of sweeping productivity gains that are so far predicated largely on the promise of improving individual task performance.
Once that foundation is set, HAIC benchmarking can begin to take on the element of time.
Today’s benchmarks resemble school exams—one-off, standardized tests of accuracy. But real professional competence is assessed differently. Junior doctors and lawyers are evaluated continuously inside real workflows, under supervision, with feedback loops and accountability structures. Performance is judged over time and in a specific context, because competence is relational. If AI systems are meant to operate alongside professionals, their impact should be judged longitudinally, reflecting how performance unfolds over repeated interactions.
I saw this aspect of HAIC applied in one of my humanitarian-sector case studies. Over 18 months, an AI system was evaluated within real workflows, with particular attention to how detectable its errors were—that is, how easily human teams could identify and correct them. This long-term “record of error detectability” meant the organizations involved could design and test context-specific guardrails to promote trust in the system, despite the inevitability of occasional AI mistakes.
A longer time horizon also makes visible the system-level consequences that short-term benchmarks miss. An AI application may outperform a single doctor on a narrow diagnostic task yet fail to improve multidisciplinary decision-making. Worse, it may introduce systemic distortions: anchoring teams too early in plausible but incomplete answers, adding to people’s cognitive workloads, or generating downstream inefficiencies that offset any speed or efficiency gains at the point of the AI’s use. These knock-on effects—often invisible to current benchmarks—are central to understanding real impact.
The HAIC approach, admittedly promises to make benchmarking more complex, resource-intensive, and harder to standardize. But continuing to evaluate AI in sanitized conditions detached from the world of work will leave us misunderstanding what it truly can and cannot do for us. To deploy AI responsibly in real-world settings, we must measure what actually matters: not just what a model can do alone, but what it enables—or undermines—when humans and teams in the real world work with it.
Angela Aristidou is a professor at University College London and a faculty fellow at the Stanford Digital Economy Lab and the Stanford Human-Centered AI Institute. She speaks, writes, and advises about the real-life deployment of artificial-intelligence tools for public good.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
There are more AI health tools than ever—but how well do they work?
In the last few months alone, Microsoft, Amazon, and OpenAI have all launched medical chatbots.
There’s a clear demand for these tools, given how hard it is for many people to access advice through the existing medical system—and they could make safe and useful recommendations. But concerns have surfaced about how little external evaluation they undergo before being released to the public.
The Pentagon’s culture war tactic against Anthropic has backfired
A judge has temporarily blocked the Pentagon from labeling Anthropic a supply chain risk and ordering government agencies to stop using its AI. Her intervention suggests that the feud never needed to reach such a frenzy.
This story is from The Algorithm, our weekly newsletter giving you the inside track on all things AI. Sign up to receive it in your inbox every Monday.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 California has defied Trump to impose new AI regulations Governor Newsom signed off on the new standards yesterday. (Guardian) + Firms seeking state contracts will need extra safeguards. (Reuters $) + States are installing guardrails despite Trump’s order to stop. (NYT $) + An AI regulation war is brewing in the US. (MIT Technology Review)
2 Experiments have verified quantum simulations for the first time It’s a breakthrough for quantum computing applications. (Nature) + Which could one day help solve healthcare problems. (MIT Technology Review)
3 The new White House app is a security and privacy nightmare It extensively tracks users and relies on external code. (Gizmodo) + The new app promises “unparalleled access” to Trump. (CNET) + It also invites users to report people to ICE. (The Verge)
4 Big Tech’s $635 billion AI spending faces an energy shock test The Middle East crisis is clouding prospects for growth. (Reuters $) + Here are three big unknowns about AI’s energy burden. (MIT Technology Review)
5 Meta and Google have been accused of breaking child safety rules Australia suspects they flouted a social media ban. (Bloomberg $) + Indonesia is also investigating non-compliance. (Reuters $)
6 Nebius is building a $10 billion AI data center in Finland The company is rapidly expanding Europe’s AI infrastructure. (CNBC)
7 South Korea’s chipmakers’ helium stocks will last until June Beyond that? Who knows. (Reuters $) + Shortages caused by the Iran war threaten the chip industry. (NYT $)
8 Another Starlink satellite has inexplicably exploded SpaceX suffered a similar episode in December. (The Verge) + We went inside Ukraine’s largest Starlink repair shop. (MIT Technology Review)
9 Bluesky’s new AI tool is already its most blocked account—after JD Vance About 83 times as many users have blocked it as have followed it. (TechCrunch)
10 An AI agent banned from Wikipedia has lashed out in angry blogs The bot accused its human editors of “uncivil behavior.” (404 Media)
Quote of the day
“Is any of this illegal? Probably not. Is it what you’d expect from an official government app? Probably not either.”
—Security researcher Thereallo reviews the White House’s new app.
One More Thing
CHANTAL JAHCHAN
Inside Amsterdam’s high-stakes experiment to create fair welfare AI
When Hans de Zwart, a digital rights advocate, saw Amsterdam’s plan to have an algorithm evaluate every welfare applicant for potential fraud, he nearly fell out of his chair. He believed the system had “unfixable problems.”
Meanwhile, Paul de Koning, a consultant to the city, was excited. He saw immense potential to improve efficiencies and remove biases.
These opposing viewpoints epitomize a global debate about whether algorithms can ever make fair decisions that shape people’s lives. Read the full story.
—Eileen Guo, Gabriel Geiger, and Justin-Casimir Braun
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line.)
In the early days of large language models (LLMs), we grew accustomed to massive 10x jumps in reasoning and coding capability with every new model iteration. Today, those jumps have flattened into incremental gains. The exception is domain-specialized intelligence, where true step-function improvements are still the norm.
When a model is fused with an organization’s proprietary data and internal logic, it encodes the company’s history into its future workflows. This alignment creates a compounding advantage: a competitive moat built on a model that understands the business intimately. This is more than fine-tuning; it is the institutionalization of expertise into an AI system. This is the power of customization.
Intelligence tuned to context
Every sector operates within its own specific lexicon. In automotive engineering, the “language” of the firm revolves around tolerance stacks, validation cycles, and revision control. In capital markets, reasoning is dictated by risk-weighted assets and liquidity buffers. In security operations, patterns are extracted from the noise of telemetry signals and identity anomalies.
Custom-adapted models internalize the nuances of the field. They recognize which variables dictate a “go/no-go” decision, and they think in the language of the industry.
Domain expertise in action
The transition from general-purpose to tailored AI centers on one goal: encoding an organization’s unique logic directly into a model’s weights.
Mistral AI partners with organizations to incorporate domain expertise into their training ecosystems. A few use cases illustrate customized implementations in practice:
Software engineering and assisting at scale: A network hardware company with proprietary languages and specialized codebases found that out-of-the-box models could not grasp their internal stack. By training a custom model on their own development patterns, they achieved a step function in fluency. Integrated into Mistral’s software development scaffolding, this customized model now supports the entire lifecycle—from maintaining legacy systems to autonomous code modernization via reinforcement learning. This turns once-opaque, niche code into a space where AI reliably assists at scale.
Automotive and the engineering copilot: A leading automotive company uses customization to revolutionize crash test simulations. Previously, specialists spent entire days manually comparing digital simulations with physical results to find divergences. By training a model on proprietary simulation data and internal analyses, they automated this visual inspection, flagging deformations in real time. Moving beyond detection, the model now acts as a copilot, proposing design adjustments to bring simulations closer to real-world behavior and radically accelerating the R&D loop.
Public sector and sovereign AI: In Southeast Asia, a government agency is building a sovereign AI layer to move beyond Western-centric models. By commissioning a foundation model tailored to regional languages, local idioms, and cultural contexts, they created a strategic infrastructure asset. This ensures sensitive data remains under local governance while powering inclusive citizen services and regulatory assistants. Here, customization is the key to deploying AI that is both technically effective and genuinely sovereign.
The blueprint for strategic customization
Moving from a general-purpose AI strategy to a domain-specific advantage requires a structural rethinking of the model’s role within the enterprise. Success is defined by three shifts in organizational logic.
1. Treat AI as infrastructure, not an experiment. Historically, enterprises have treated model customization as an ad hoc experiment—a single fine-tuning run for a niche use case or a localized pilot. While these bespoke silos often yield promising results, they are rarely built to scale. They produce brittle pipelines, improvised governance, and limited portability. When the underlying base models evolve, the adaptation work must often be discarded and rebuilt from scratch.
In contrast, a durable strategy treats customization as foundational infrastructure. In this model, adaptation workflows are reproducible, version-controlled, and engineered for production. Success is measured against deterministic business outcomes. By decoupling the customization logic from the underlying model, firms ensure that their “digital nervous system” remains resilient, even as the frontier of base models shifts.
2. Retain control of your own data and models. As AI migrates from the periphery to core operations, the question of control becomes existential. Reliance on a single cloud provider or vendor for model alignment creates a dangerous asymmetry of power regarding data residency, pricing, and architectural updates.
Enterprises that retain control of their training pipelines and deployment environments preserve their strategic agency. By adapting models within controlled environments, organizations can enforce their own data residency requirements and dictate their own update cycles. This approach transforms AI from a service consumed into an asset governed, reducing structural dependency and allowing for cost and energy optimizations aligned with internal priorities rather than vendor roadmaps.
3. Design for continuous adaptation. The enterprise environment is never static: regulations shift, taxonomies evolve, and market conditions fluctuate. A common failure is treating a customized model as a finished artifact. In reality, a domain-aligned model is a living asset subject to model decay if left unmanaged.
Designing for continuous adaptation requires a disciplined approach to ModelOps. This includes automated drift detection, event-driven retraining, and incremental updates. By building the capacity for constant recalibration, the organization ensures that its AI does not just reflect its history, but it evolves in lockstep with its future. This is the stage where the competitive moat begins to compound: the model’s utility grows as it internalizes the organization’s ongoing response to change.
Control is the new leverage
We have entered an era where generic intelligence is a commodity, but contextual intelligence is a scarcity. While raw model power is now a baseline requirement, the true differentiator is alignment—AI calibrated to an organization’s unique data, mandates, and decision logic.
In the next decade, the most valuable AI won’t be the one that knows everything about the world; it will be the one that knows everything about you. The firms that own the model weights of that intelligence will own the market.
This content was produced by Mistral AI. It was not written by MIT Technology Review’s editorial staff.
Delivery is the primary barrier to completing an ecommerce sale in Africa. I’ve described the challenges posed by landmark-based addresses and the consumer preference to pay on receipt.
The result is high return rates across Nigeria, Kenya, and other large markets, where a refused package means the merchant pays for logistics twice for zero revenue.
However, the industry is moving from managing these failures to adopting a tech stack to avoid them.
Data-based Delivery
Rather than relying on a driver’s local knowledge, a growing cohort of venture-backed fulfillment companies, such as Gig Logistics, Loop, and Faramove, leverage data to predict the likelihood of a successful delivery before an order is dispatched.
Address verification. To solve the “landmark address” problem, logistics firms are integrating tools such as OkHi’s AI-powered verification. It allows customers to verify their location at checkout via a global positioning system, a GPS. Merchants can flag non-verified addresses as high risk.
OkHi’s API enables customers to verify their location at checkout. Image: OkHi
Risk scoring. Logistics engines now plug into APIs such as VerifyMe’s QoreID. The tool provides a confidence score based on location data and past delivery behavior. A phone number with a history of refusing orders is high risk.
Automated WhatsApp flows. Flagged orders trigger automated communication to the customers via WhatsApp from APIs on platforms such as Termii (Nigeria) or Talksasa (Kenya). The system automatically redirects orders to a local pickup point for customers who do not respond.
The success of these tactics is evident in Jumia’s financial statements. According to its February 2026 report, the dominant African marketplace lowered its 2025 fulfillment expense per order by 12% year-over-year to $1.97, largely by shifting much of its delivery volume to PUDO (Pick Up, Drop Off) locations. This strategy is anchored by its JForce network of over 40,000 local consultants who act as trusted pickup points, bypassing high-risk doorstep delivery in congested capitals.
Investments in Logistics
In February 2026, funding for logistics and transport startups in Africa ($119.6 million) surpassed fintech ($54.1 million). Logistics infrastructure is becoming a competitive difference maker.
Warehouses in East Africa
On March 11, 2026, Africa Logistics Properties listed the region’s first real estate investment trust on the Nairobi Securities Exchange. The U.K. government committed $24 million to the listing through its MOBILIST program for sustainable development in emerging markets.
According to the Exchange’s CEO Frank Mwiti during the bell-ringing ceremony, “The debut of the dollar-denominated Industrial I-REIT is a historic milestone for our market. We are providing investors with a seamless gateway to Africa’s industrial logistics sector, combining hard currency stability with regional growth potential.”
Automation in North Africa
In January 2026, Egypt-based carrier Bosta launched a large automated sorting center in Cairo, the largest such facility in the Middle East. Capable of processing 11,000 parcels per hour, the center aims to reduce manual errors as Bosta prepares to handle 80 million parcels this year.
“This sorting machine alone required an investment of $5 million,” said Bosta CEO Mohamed Ezzat. “It directly contributes to improving delivery speed and operational accuracy.”
Lockers in Southern Africa
In South Africa, carriers are transitioning the last mile to 24/7 automated lockers. Ship-and-collect provider Pargo leads with over 4,000 points, followed by The Courier Guy’s network of 1,100 lockers as of March 2026. Merchants are seeing a significant reduction in “theft-related” losses and failed doorstep attempts.
Digital Trade
The African Continental Free Trade Area (AfCFTA) is a 2018 agreement among 55 member countries establishing the world’s largest free trade zone. AfCFTA’s Digital Trade Protocol provides rules for data protection and cross-border digital payments. It mandates that African governments recognize electronic trade documents as legally equivalent to paper, enabling merchants to insure and track goods across borders with legal certainty.
A major catalyst for this system is the integration of Kenya’s Pesalink, an instant payment network, with the Pan-African Payment and Settlement System (PAPSS). More than 80 Kenyan financial institutions now sync with 160-plus banks across Africa.
This integration, for example, allows a merchant in Nigeria to settle logistics fees in Naira for a delivery in Kenya instantly, removing a primary barrier to intra-African trade.
Foreign Merchants
For merchants looking to sell goods in Africa:
Connect to (i) a logistics-as-a-service (Gig Logistics, Loop, Faramove) that offers real-time delivery probability and (ii) an address verification provider (OkHi, QoreID) to flag risk early.
Incentivize PUDO options at checkout, a successful tactic for Jumia.
Use PAPSS-integrated channels for cross-border settlement to preserve margins.
Google’s Gary Illyes published a blog post explaining how Googlebot’s crawling systems work. The post covers byte limits, partial fetching behavior, and how Google’s crawling infrastructure is organized.
The post references episode 105 of the Search Off the Record podcast, where Illyes and Martin Splitt discussed the same topics. Illyes adds more details about crawling architecture and byte-level behavior.
What’s New
Googlebot Is One Client Of A Shared Platform
Illyes describes Googlebot as “just a user of something that resembles a centralized crawling platform.”
Google Shopping, AdSense, and other products all send their crawl requests through the same system under different crawler names. Each client sets its own configuration, including user agent string, robots.txt tokens, and byte limits.
When Googlebot appears in server logs, that’s Google Search. Other clients appear under their own crawler names, which Google lists on its crawler documentation site.
How The 2 MB Limit Works In Practice
Googlebot fetches up to 2 MB for any URL, excluding PDFs. PDFs get a 64 MB limit. Crawlers that don’t specify a limit default to 15 MB.
Illyes adds several details about what happens at the byte level.
He says HTTP request headers count toward the 2 MB limit. When a page exceeds 2 MB, Googlebot doesn’t reject it. The crawler stops at the cutoff and sends the truncated content to Google’s indexing systems and the Web Rendering Service (WRS).
Those systems treat the truncated file as if it were complete. Anything past 2 MB is never fetched, rendered, or indexed.
Every external resource referenced in the HTML, such as CSS and JavaScript files, gets fetched with its own separate byte counter. Those files don’t count toward the parent page’s 2 MB. Media files, fonts, and what Google calls “a few exotic files” are not fetched by WRS.
Rendering After The Fetch
The WRS processes JavaScript and executes client-side code to understand a page’s content and structure. It pulls in JavaScript, CSS, and XHR requests but doesn’t request images or videos.
Illyes also notes that the WRS operates statelessly, clearing local storage and session data between requests. Google’s JavaScript troubleshooting documentation covers implications for JavaScript-dependent sites.
Best Practices For Staying Under The Limit
Google recommends moving heavy CSS and JavaScript to external files, since those get their own byte limits. Meta tags, title tags, link elements, canonicals, and structured data should appear higher in the HTML. On large pages, content placed lower in the document risks falling below the cutoff.
Illyes flags inline base64 images, large blocks of inline CSS or JavaScript, and oversized menus as examples of what could push pages past 2 MB.
The 2 MB limit “is not set in stone and may change over time as the web evolves and HTML pages grow in size.”
The platform description explains why different Google crawlers behave differently in server logs and why the 15 MB default differs from Googlebot’s 2 MB limit. These are separate settings for different clients.
HTTP header details matter for pages near the limit. Google states headers consume part of the 2 MB limit alongside HTML data. Most sites won’t be affected, but pages with large headers and bloated markup might hit the limit sooner.
Looking Ahead
Google has now covered Googlebot’s crawl limits in documentation updates, a podcast episode, and a dedicated blog post within a two-month span. Illyes’ note that the limit may change over time suggests these figures aren’t permanent.
For sites with standard HTML pages, the 2 MB limit isn’t a concern. Pages with heavy inline content, embedded data, or oversized navigation should verify that their critical content is within the first 2 MB of the response.