Sometimes geothermal hot spots are obvious, marked by geysers and hot springs on the planet’s surface. But in other places, they’re obscured thousands of feet underground. Now AI could help uncover these hidden pockets of potential power.
A startup company called Zanskar announced today that it’s used AI and other advanced computational methods to uncover a blind geothermal system—meaning there aren’t signs of it on the surface—in the western Nevada desert. The company says it’s the first blind system that’s been identified and confirmed to be a commercial prospect in over 30 years.
Historically, finding new sites for geothermal power was a matter of brute force. Companies spent a lot of time and money drilling deep wells, looking for places where it made sense to build a plant.
Zanskar’s approach is more precise. With advancements in AI, the company aims to “solve this problem that had been unsolvable for decades, and go and finally find those resources and prove that they’re way bigger than previously thought,” says Carl Hoiland, the company’s cofounder and CEO.
To support a successful geothermal power plant, a site needs high temperatures at an accessible depth and space for fluid to move through the rock and deliver heat. In the case of the new site, which the company calls Big Blind, the prize is a reservoir that reaches 250 °F at about 2,700 feet below the surface.
As electricity demand rises around the world, geothermal systems like this one could provide a source of constant power without emitting the greenhouse gases that cause climate change.
The company has used its technology to identify many potential hot spots. “We have dozens of sites that look just like this,” says Joel Edwards, Zanskar’s cofounder and CTO. But for Big Blind, the team has done the fieldwork to confirm its model’s predictions.
The first step to identifying a new site is to use regional AI models to search large areas. The team trains models on known hot spots and on simulations it creates. Then it feeds in geological, satellite, and other types of data, including information about fault lines. The models can then predict where potential hot spots might be.
One strength of using AI for this task is that it can handle the immense complexity of the information at hand. “If there’s something learnable in the earth, even if it’s a very complex phenomenon that’s hard for us humans to understand, neural nets are capable of learning that, if given enough data,” Hoiland says.
Once models identify a potential hot spot, a field crew heads to the site, which might be roughly 100 square miles or so, and collects additional information through techniques that include drilling shallow holes to look for elevated underground temperatures.
In the case of Big Blind, this prospecting information gave the company enough confidence to purchase a federal lease, allowing it to develop a geothermal plant. With that lease secured, the team returned with large drill rigs and drilled thousands of feet down in July and August. The workers found the hot, permeable rock they expected.
Next they must secure permits to build and connect to the grid and line up the investments needed to build the plant. The team will also continue testing at the site, including long-term testing to track heat and water flow.
“There’s a tremendous need for methodology that can look for large-scale features,” says John McLennan, technical lead for resource management at Utah FORGE, a national lab field site for geothermal energy funded by the US Department of Energy. The new discovery is “promising,” McLennan adds.
Big Blind is Zanskar’s first confirmed discovery that wasn’t previously explored or developed, but the company has used its tools for other geothermal exploration projects. Earlier this year, it announced a discovery at a site that had previously been explored by the industry but not developed. The company also purchased and revived a geothermal power plant in New Mexico.
And this could be just the beginning for Zanskar. As Edwards puts it, “This is the start of a wave of new, naturally occurring geothermal systems that will have enough heat in place to support power plants.”
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
OpenAI has trained its LLM to confess to bad behavior
What’s new: OpenAI is testing a new way to expose the complicated processes at work inside large language models. Researchers at the company can make an LLM produce what they call a confession, in which the model explains how it carried out a task and (most of the time) own up to any bad behavior.
Why it matters: Figuring out why large language models do what they do—and in particular why they sometimes appear to lie, cheat, and deceive—is one of the hottest topics in AI right now. If this multitrillion-dollar technology is to be deployed as widely as its makers hope it will be, it must be made more trustworthy. OpenAI sees confessions as one step toward that goal. Read the full story. —Will Douglas Heaven
How AI is uncovering hidden geothermal energy resources
Sometimes geothermal hot spots are obvious, marked by geysers and hot springs on Earth’s surface. But in other places, they’re obscured thousands of feet underground. Now AI could help uncover these hidden pockets of potential power.
A startup company called Zanskar announced today that it’s used AI and other advanced computational methods to uncover a blind geothermal system—meaning there aren’t signs of it on the surface—in the western Nevada desert. The company says it’s the first blind system that’s been identified and confirmed to be a commercial prospect in over 30 years. Read the full story.
—Casey Crownhart
Why the grid relies on nuclear reactors in the winter
In the US, nuclear reactors follow predictable seasonal trends. Summer and winter tend to see the highest electricity demand, so plant operators schedule maintenance and refueling for other parts of the year.
This scheduled regularity might seem mundane, but it’s quite the feat that operational reactors are as reliable and predictable as they are. Now we’re seeing a growing pool of companies aiming to bring new technologies to the nuclear industry. Read the full story.
—Casey Crownhart
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Donald Trump has scrapped Biden’s fuel efficiency requirements It’s a major blow for green automobile initiatives. (NYT $) + Trump maintains that getting rid of the rules will drive down the price of cars. (Politico)
2 RFK Jr’s vaccine advisers may delay hepatitis B vaccines for babies The shots are a key part in combating acute cases of the infection. (The Guardian) + Former FDA commissioners are worried by its current chief’s vaccine views. (Ars Technica) + Meanwhile, a fentanyl vaccine is being trialed in the Netherlands. (Wired $)
3 Amazon is exploring building its own US delivery network Which could mean axing its long-standing partnership with the US Postal Service. (WP $)
4 Republicans are defying Trump’s orders to block states from passing AI laws They’re pushing back against plans to sneak the rule into an annual defense bill. (The Hill)+ Trump has been pressuring them to fall in line for months. (Ars Technica) + Congress killed an attempt to stop states regulating AI back in July. (CNN)
5 Wikipedia is exploring AI licensing deals It’s a bid to monetize AI firms’ heavy reliance on its web pages. (Reuters) + How AI and Wikipedia have sent vulnerable languages into a doom spiral. (MIT Technology Review)
6 OpenAI is looking to the stars—and beyond Sam Altman is reportedly interested in acquiring or partnering with a rocket company. (WSJ $)
7 What we can learn from wildfires This year’s Dragon Bravo fire defied predictive modelling. But why? (New Yorker $) + How AI can help spot wildfires. (MIT Technology Review)
8 What’s behind America’s falling birth rates? It’s remarkably hard to say. (Undark)
9 Researchers are studying whether brain rot is actually real Including whether its effects could be permanent. (NBC News)
10 YouTuber Mr Beast is planning to launch a mobile phone service Beast Mobile, anyone? (Insider $) + The New York Stock Exchange could be next in his sights. (TechCrunch)
Quote of the day
“I think there are some players who are YOLO-ing.”
—Anthropic CEO Dario Amodei suggests some rival AI companies are veering into risky spending territory, Bloomberg reports.
One more thing
The quest to show that biological sex matters in the immune system
For years, microbiologist Sabra Klein has painstakingly made the case that sex—defined by biological attributes such as our sex chromosomes, sex hormones, and reproductive tissues—can influence immune responses.
Klein and others have shown how and why male and female immune systems respond differently to the flu virus, HIV, and certain cancer therapies, and why most women receive greater protection from vaccines but are also more likely to get severe asthma and autoimmune disorders.
Klein has helped spearhead a shift in immunology, a field that long thought sex differences didn’t matter—and she’s set her sights on pushing the field of sex differences even further. Read the full story.
—Sandeep Ravindran
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ Digital artist Beeple’s latest Art Basel show features Elon Musk, Jeff Bezos and Mark Zuckerberg robotic dogs pooping out NFTs + If you’ve always dreamed of seeing the Northern Lights, here’s your best bet at doing so. + Check out this fun timeline of fashion’s hottest venues. + Why monkeys in ancient Roman times had pet piglets
Most organizations feel the imperative to keep pace with continuing advances in AI capabilities, as highlighted in a recent MIT Technology Review Insights report. That clearly has security implications, particularly as organizations navigate a surge in the volume, velocity, and variety of security data. This explosion of data, coupled with fragmented toolchains, is making it increasingly difficult for security and data teams to maintain a proactive and unified security posture.
Data and AI teams must move rapidly to deliver the desired business results, but they must do so without compromising security and governance. As they deploy more intelligent and powerful AI capabilities, proactive threat detection and response against the expanded attack surface, insider threats, and supply chain vulnerabilities must remain paramount. “I’m passionate about cybersecurity not slowing us down,” says Melody Hildebrandt, chief technology officer at Fox Corporation, “but I also own cybersecurity strategy. So I’m also passionate about us not introducing security vulnerabilities.”
That’s getting more challenging, says Nithin Ramachandran, who is global vice president for data and AI at industrial and consumer products manufacturer 3M. “Our experience with generative AI has shown that we need to be looking at security differently than before,” he says. “With every tool we deploy, we look not just at its functionality but also its security posture. The latter is now what we lead with.”
Our survey of 800 technology executives (including 100 chief information security officers), conducted in June 2025, shows that many organizations struggle to strike this balance.
This content was produced by Insights, the custom content arm of MIT Technology Review. It was not written by MIT Technology Review’s editorial staff. It was researched, designed, and written by human writers, editors, analysts, and illustrators. AI tools that may have been used were limited to secondary production processes that passed thorough human review.
In 2024, a Democratic congressional candidate in Pennsylvania, Shamaine Daniels, used an AI chatbot named Ashley to call voters and carry on conversations with them. “Hello. My name is Ashley, and I’m an artificial intelligence volunteer for Shamaine Daniels’s run for Congress,” the calls began. Daniels didn’t ultimately win. But maybe those calls helped her cause: New research reveals that AI chatbots can shift voters’ opinions in a single conversation—and they’re surprisingly good at it.
A multi-university team of researchers has found that chatting with a politically biased AI model was more effective than political advertisements at nudging both Democrats and Republicans to support presidential candidates of the opposing party. The chatbots swayed opinions by citing facts and evidence, but they were not always accurate—in fact, the researchers found, the most persuasive models said the most untrue things.
The findings, detailed in a pair of studies published in the journals Nature and Science, are the latest in an emerging body of research demonstrating the persuasive power of LLMs. They raise profound questions about how generative AI could reshape elections.
“One conversation with an LLM has a pretty meaningful effect on salient election choices,” says Gordon Pennycook, a psychologist at Cornell University who worked on the Nature study. LLMs can persuade people more effectively than political advertisements because they generate much more information in real time and strategically deploy it in conversations, he says.
For the Nature paper, the researchers recruited more than 2,300 participants to engage in a conversation with a chatbot two months before the 2024 US presidential election. The chatbot, which was trained to advocate for either one of the top two candidates, was surprisingly persuasive, especially when discussing candidates’ policy platforms on issues such as the economy and health care. Donald Trump supporters who chatted with an AI model favoring Kamala Harris became slightly more inclined to support Harris, moving 3.9 points toward her on a 100-point scale. That was roughly four times the measured effect of political advertisements during the 2016 and 2020 elections. The AI model favoring Trump moved Harris supporters 2.3 points toward Trump.
In similar experiments conducted during the lead-ups to the 2025 Canadian federal election and the 2025 Polish presidential election, the team found an even larger effect. The chatbots shifted opposition voters’ attitudes by about 10 points.
Long-standing theories of politically motivated reasoning hold that partisan voters are impervious to facts and evidence that contradict their beliefs. But the researchers found that the chatbots, which used a range of models including variants of GPT and DeepSeek, were more persuasive when they were instructed to use facts and evidence than when they were told not to do so. “People are updating on the basis of the facts and information that the model is providing to them,” says Thomas Costello, a psychologist at American University, who worked on the project.
The catch is, some of the “evidence” and “facts” the chatbots presented were untrue. Across all three countries, chatbots advocating for right-leaning candidates made a larger number of inaccurate claims than those advocating for left-leaning candidates. The underlying models are trained on vast amounts of human-written text, which means they reproduce real-world phenomena—including “political communication that comes from the right, which tends to be less accurate,” according to studies of partisan social media posts, says Costello.
In the other study published this week, in Science, an overlapping team of researchers investigated what makes these chatbots so persuasive. They deployed 19 LLMs to interact with nearly 77,000 participants from the UK on more than 700 political issues while varying factors like computational power, training techniques, and rhetorical strategies.
The most effective way to make the models persuasive was to instruct them to pack their arguments with facts and evidence and then give them additional training by feeding them examples of persuasive conversations. In fact, the most persuasive model shifted participants who initially disagreed with a political statement 26.1 points toward agreeing. “These are really large treatment effects,” says Kobi Hackenburg, a research scientist at the UK AI Security Institute, who worked on the project.
But optimizing persuasiveness came at the cost of truthfulness. When the models became more persuasive, they increasingly provided misleading or false information—and no one is sure why. “It could be that as the models learn to deploy more and more facts, they essentially reach to the bottom of the barrel of stuff they know, so the facts get worse-quality,” says Hackenburg.
The chatbots’ persuasive power could have profound consequences for the future of democracy, the authors note. Political campaigns that use AI chatbots could shape public opinion in ways that compromise voters’ ability to make independent political judgments.
Still, the exact contours of the impact remain to be seen. “We’re not sure what future campaigns might look like and how they might incorporate these kinds of technologies,” says Andy Guess, a political scientist at Princeton University. Competing for voters’ attention is expensive and difficult, and getting them to engage in long political conversations with chatbots might be challenging. “Is this going to be the way that people inform themselves about politics, or is this going to be more of a niche activity?” he asks.
Even if chatbots do become a bigger part of elections, it’s not clear whether they’ll do more to amplify truth or fiction. Usually, misinformation has an informational advantage in a campaign, so the emergence of electioneering AIs “might mean we’re headed for a disaster,” says Alex Coppock, a political scientist at Northwestern University. “But it’s also possible that means that now, correct information will also be scalable.”
And then the question is who will have the upper hand. “If everybody has their chatbots running around in the wild, does that mean that we’ll just persuade ourselves to a draw?” Coppock asks. But there are reasons to doubt a stalemate. Politicians’ access to the most persuasive models may not be evenly distributed. And voters across the political spectrum may have different levels of engagement with chatbots. “If supporters of one candidate or party are more tech savvy than the other,” the persuasive impacts might not balance out, says Guess.
As people turn to AI to help them navigate their lives, they may also start asking chatbots for voting advice whether campaigns prompt the interaction or not. That may be a troubling world for democracy, unless there are strong guardrails to keep the systems in check. Auditing and documenting the accuracy of LLM outputs in conversations about politics may be a first step.
A new book from a noted economist seeks to explain the rise of global tariffs and trade barriers.
Branko Milanovic is a former lead economist at the World Bank and currently teaches at the City University of New York and the London School of Economics. He’s an authority on income inequality.
The book draws on the author’s original research to argue that the world’s two leading economies — the U.S. and China — have changed in opposite directions over the past 50 years, resulting in “the greatest reshuffling of incomes since the Industrial Revolution,” and that, in turn, is causing political changes that reverse the trend towards globalization.
Trade Wars
First, he demonstrates the relative changes in income between the U.S. and China, as well as Asia and the West generally. He illuminates the data with 35 charts and graphs. Then he analyzes past economic theories, showing they can’t explain whether trade promotes or reduces conflict between nations.
The Great Global Transformation
The theories, he says, failed to foresee that U.S. wage earners and investors would merge into a new labor class that combines high salaries with investment returns via equity stakes such as stock options.
Next, he provides an overview of China’s internal economic and political evolution, especially under Xi Jinping, its president. Milanovic sees China’s opening to private enterprise as different from that of the former communist regimes in Russia and Eastern Europe. He believes China will continue to stand apart on the international stage.
He believes these factors lead to increased nationalism and a retreat from globalization, resulting in trade wars, tariffs, sanctions, and border walls. In Milanovic’s view, “Economic coercion is now considered a normal part of the foreign policy toolkit.”
Despite specialized terminology, Milanovic’s writing is clear even for lay readers. He offers many provocative ideas in just under 200 pages, but no practical business guidance.
However, the book steps back from simplistic daily news bites and places them in the context of a bigger picture. Milanovic draws parallels in political trends across countries and points out that what seems like flip-flopping or policy reversals by Xi and others may be “course corrections” towards a long-term goal. He notes that U.S. nostalgia for post-war dominance is an exception, not the norm.
Merchants who sell or source internationally may find “The Great Global Transformation” fresh and useful as they navigate growth.
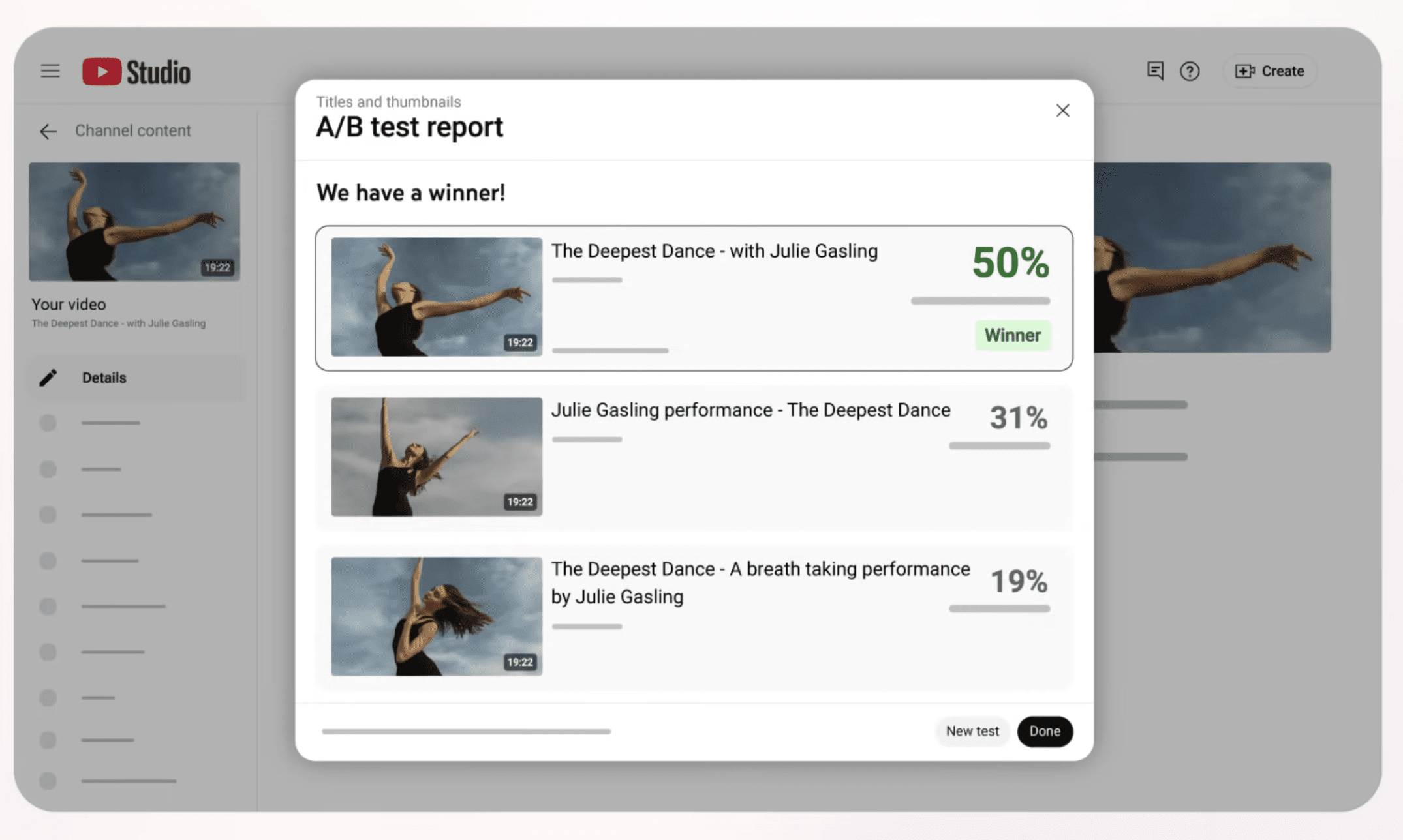
YouTube is rolling out title A/B testing globally to all creators with access to advanced features, expanding the testing capability beyond the select group that had early access.
The announcement came via the platform’s Creator Insider channel, clarifying how the feature works and addressing common questions from creators.
Title A/B testing joins thumbnail testing in YouTube’s “Test and Compare” tool. You can test up to three titles, three thumbnails, or combinations of both on a single video.
How Title A/B Testing Works
The A/B testing tool compares performance across experiment variations over a set period of up to two weeks.
After testing concludes, YouTube notifies creators of the results. If there’s a clear winner, that option becomes the default shown to all viewers. If all options performed similarly, the first combination becomes the default.
You can override the automatic selection at any time through the metadata editor or YouTube analytics page.
Why YouTube Uses Watch Time Over CTR
YouTube optimizes test results based on watch time rather than click-through rate.
In the Creator Insider video, the company explained:
“We want to ensure that your A/B test experiment gets the highest viewer engagement, so we’re optimizing for overall watch time over other metrics like CTR. We believe that this metric will best inform our creators content strategy decisions and support their chances of success.”
Understanding Test Results
YouTube tests deliver one of three possible outcomes.
“Winner” means one version outperformed others at driving watch time per impression. YouTube believes this version will lead to better performance.
“Performed the same” indicates all options earned similar shares of watch time. While small differences may appear, they aren’t statistically meaningful. You can choose whichever option you prefer.
“Inconclusive” can occur when no clear performance difference exists between options, or when the video doesn’t generate enough impressions for a reliable comparison. Higher view counts increase the likelihood of a decisive result.
Screenshot from: YouTube.com/CreatorInsider, December 2025.
Impression Distribution & Viewer Experience
YouTube distributes impressions as evenly as possible across test variations, though identical distribution isn’t guaranteed.
During active tests, viewers consistently see the same title-thumbnail combination across their home feed, watch page, and other YouTube surfaces. This prevents confusion from seeing different versions of the same video.
YouTube addressed a common concern about tests making previously-watched videos appear new. The company notes that watch history and the red progress bar on thumbnails remain the reliable indicators of what you’ve already watched.
Why This Matters
Title testing gives you data to inform creative decisions. Combined with thumbnail testing, you can now optimize both elements that influence whether viewers click on your videos.
The watch time metric means successful titles attract viewers who actually engage with your content, not just those who click and leave.
Looking Ahead
Title A/B testing requires access to YouTube’s advanced features, which you can enable through account verification. The feature works on long-form videos and is currently desktop-only.
YouTube first announced title A/B testing alongside thumbnail testing at Made on YouTube in September.
The strategies that worked in 2025 will not carry your campaigns through the new year.
Buyer behavior is evolving, budgets demand tighter discipline, and channels like calls, text, and voice agents are becoming essential conversion paths. As the marketing landscape shifts, the question is no longer whether you should adapt but how fast.
The Strategic Shifts Every Marketer Needs To Refine By Q2
Join Emily Popson, VP of Marketing at CallRail, for a clear and data-driven look at the five marketing priorities that will shape performance in 2026 and what PPC teams must adjust now to stay competitive.
You’ll Learn How To
Allocate marketing and advertising budgets in ways that drive measurable revenue
Google Maps now lets users leave business reviews under a custom nickname instead of their real name. The feature is part of a four-feature Maps update and is rolling out globally on Android, iOS, and desktop.
Local SEO agency Whitespark was among the first to document the change in detail, describing it as one of the more notable shifts to Google’s review system in years.
What Changed
Google’s support documentation outlines the new setting. Users can enable a custom display name and picture for posting through their Maps or Google profile. Once enabled, that identity appears on reviews, photos, videos, and Q&A posts across Maps.
The feature works retroactively. If you edit your nickname later, past contributions update to show the new name.
Whitespark notes that people have long created Google accounts with aliases. This is the first time Google has offered a dedicated posting identity separate from your main account profile and documented it officially.
How It Affects Spam Detection
Google’s blog post says its existing review protections remain in place. Reviews written under a nickname are still tied to an account and its history. Businesses can still report reviews they believe violate policies.
Whitespark calls this “pseudonymous rather than truly anonymous.” The public display name differs, but Google still sees the underlying account and contribution history.
Why This Matters
Expect to see more nicknames and illustration-based profile pictures in review feeds. Whitespark highlights industries like legal, medical, and financial services where clients often hesitate to post under their real name. This could increase review volume in those categories.
If you work with businesses in privacy-sensitive categories, you may want to update review request templates to mention the nickname option.
Looking Ahead
The nickname feature is live or rolling out for most users, though some local SEOs, such as Joy Hawkins, report they don’t yet see it in their own profiles.
Google is rolling out an experimental feature that lets Search Console users configure the Search results Performance report using natural language instead of manual filter selection.
The feature, called AI-powered configuration, translates plain-language requests into the appropriate filters and settings. You can describe the analysis you want to see, and the system handles the technical setup.
What’s New
The AI-powered configuration feature handles three types of report setup:
1. Filters
You can narrow data by query, page, country, device, search appearance, or date range through natural language.
A request like “Show me queries on phone searches that contain the word ‘sports’ in the last 6 months” applies the relevant filters automatically.
2. Comparisons
Complex date range comparisons that previously required manual configuration can now be set up through prompts like “Compare traffic for my pages that contain ‘/blog’ in this quarter to the same quarter last year.”
3. Metric Selection
The feature can display specific combinations of the four available metrics (Clicks, Impressions, Average CTR, and Average Position) based on your requests.
For example, you can ask, “Show me the Average CTR and Average Position of my queries in Spain in the last 28 days.”
Limitations
Google noted several limitations.
The feature works only with Performance reports for Search results, it doesn’t support Discover or News reports.
AI-powered configuration is designed only for configuring filters, comparisons, and metrics. It can’t sort tables or export data.
Google also cautioned that the AI can misinterpret requests. You should review suggested filters before analyzing data to make sure they match the query you intended.
Why This Matters
This feature could reduce the manual effort required to set up complex filter combinations in Search Console.
The ability to request custom date comparisons or multi-filter configurations through natural language removes several steps from the reporting process.
The accuracy caveat matters, especially for higher-stakes reporting. You’ll want to verify that the AI understood your request correctly before you rely on the data for decisions or client reporting.
Looking Ahead
Google is rolling out AI-powered configuration to a limited set of websites and will expand availability over time. No timeline for broader access was provided.
People keep asking me what it takes to show up in AI answers. They ask in conference hallways, in LinkedIn messages, on calls, and during workshops. The questions always sound different, but the intent is the same. People want to know how much of their existing SEO work still applies. They want to know what they need to learn next and how to avoid falling behind. Mostly, they want clarity (hence my new book!). The ground beneath this industry feels like it moved overnight, and everyone is trying to figure out if the skills they built over the last twenty years still matter.
They do. But not in the same proportions they used to. And not for the same reasons.
When I explain how GenAI systems choose content, I see the same reaction every time. First, relief that the fundamentals still matter. Then a flicker of concern when they realize how much of the work they treated as optional is now mandatory. And finally, a mix of curiosity and discomfort when they hear about the new layer of work that simply did not exist even five years ago. That last moment is where the fear of missing out turns into motivation. The learning curve is not as steep as people imagine. The only real risk is assuming future visibility will follow yesterday’s rules.
That is why this three-layer model helps. It gives structure to a messy change. It shows what carries over, what needs more focus, and what is entirely new. And it lets you make smart choices about where to spend your time next. As always, feel free to disagree with me, or support my ideas. I’m OK with either. I’m simply trying to share what I understand, and if others believe things to be different, that’s entirely OK.
This first set contains the work every experienced SEO already knows. None of it is new. What has changed is the cost of getting it wrong. LLM systems depend heavily on clear access, clear language, and stable topical relevance. If you already focus on this work, you are in a good starting position.
You already write to match user intent. That skill transfers directly into the GenAI world. The difference is that LLMs evaluate meaning, not keywords. They ask whether a chunk of content answers the user’s intent with clarity. They no longer care about keyword coverage or clever phrasing. If your content solves the problem the user brings to the model, the system trusts it. If it drifts off topic or mixes multiple ideas in the same chunk/block, it gets bypassed.
Featured snippets prepared the industry for this. You learned to lead with the answer and support it with context. LLMs treat the opening sentences of a chunk as a kind of confidence score. If the model can see the answer in the first two or three sentences, it is far more likely to use that block. If the answer is buried under a soft introduction, you lose visibility. This is not stylistic preference. It is about risk. The model wants to minimize uncertainty. Direct answers lower that uncertainty.
This is another long-standing skill that becomes more important. If the crawler cannot fetch your content cleanly, the LLM cannot rely on it. You can write brilliant content and structure it perfectly, and none of it matters if the system cannot get to it. Clean HTML, sensible page structure, reachable URLs, and a clear robots.txt file are still foundational. Now they also affect the quality of your vector index and how often your content appears in AI answers.
Updating fast-moving topics matters more today. When a model collects information, it wants the most stable and reliable view of the topic. If your content is accurate but stale, the system will often prefer a fresher chunk from a competitor. This becomes critical in categories like regulations, pricing, health, finance, and emerging technology. When the topic moves, your updates need to move with it.
This has always been at the heart of SEO. Now it becomes even more important. LLMs look for patterns of expertise. They prefer sources that have shown depth across a subject instead of one-off coverage. When the model attempts to solve a problem, it selects blocks from sources that consistently appear authoritative on that topic. This is why thin content strategies collapse in the GenAI world. You need depth, not coverage for the sake of coverage.
This second group contains tasks that existed in old SEO but were rarely done with discipline. Teams touched them lightly but did not treat them as critical. In the GenAI era, these now carry real weight. They do more than polish content. They directly affect chunk retrieval, embedding quality, and citation rates.
Scanning used to matter because people skim pages. Now chunk boundaries matter because models retrieve blocks, not pages. The ideal block is a tight 100 to 300 words that covers one idea with no drift. If you pack multiple ideas into one block, retrieval suffers. If you create long, meandering paragraphs, the embedding loses focus. The best performing chunks are compact, structured, and clear.
This used to be a style preference. You choose how to name your product or brand and try to stay consistent. In the GenAI era, entity clarity becomes a technical factor. Embedding models create numeric patterns based on how your entities appear in context. If your naming drifts, the embeddings drift. That reduces retrieval accuracy and lowers your chances of being used by the model. A stable naming pattern makes your content easier to match.
Teams used to sprinkle stats into content to seem authoritative. That is not enough anymore. LLMs need safe, specific facts they can quote without risk. They look for numbers, steps, definitions, and crisp explanations. When your content contains stable facts that are easy to lift, your chances of being cited go up. When your content is vague or opinion-heavy, you become less usable.
Links still matter, but the source of the mention matters more. LLMs weigh training data heavily. If your brand appears in places known for strong standards, the model builds trust around your entity. If you appear mainly on weak domains, that trust does not form. This is not classic link equity. This is reputation equity inside a model’s training memory.
Clear writing always helped search engines understand intent. In the GenAI era, it helps the model align your content with a user’s question. Clever marketing language makes embeddings less accurate. Simple, precise language improves retrieval consistency. Your goal is not to entertain the model. Your goal is to be unambiguous.
This final group contains work the industry never had to think about before. These tasks did not exist at scale. They are now some of the largest contributors to visibility. Most teams are not doing this work yet. This is the real gap between brands that appear in AI answers and brands that disappear.
The LLM does not rank pages. It ranks chunks. Every chunk competes with every other chunk on the same topic. If your chunk boundaries are weak or your block covers too many ideas, you lose. If the block is tight, relevant, and structured, your chances of being selected rise. This is the foundation of GenAI visibility. Retrieval determines everything that follows.
Your content eventually becomes vectors. Structure, clarity, and consistency shape how those vectors look. Clean paragraphs create clean embeddings. Mixed concepts create noisy embeddings. When your embeddings are noisy, they lose queries by a small margin and never appear. When your embeddings are clean, they align more often and rise in retrieval. This is invisible work, but it defines success in the GenAI world.
Simple formatting choices change what the model trusts. Headings, labels, definitions, steps, and examples act as retrieval cues. They help the system map your content to a user’s need. They also reduce risk, because predictable structure is easier to understand. When you supply clean signals, the model uses your content more often.
LLMs evaluate trust differently than Google or Bing. They look for author information, credentials, certifications, citations, provenance, and stable sourcing. They prefer content that reduces liability. If you give the model clear trust markers, it can use your content with confidence. If trust is weak or absent, your content becomes background noise.
Models need structure to interpret relationships between ideas. Numbered steps, definitions, transitions, and section boundaries improve retrieval and lower confusion. When your content follows predictable patterns, the system can use it more safely. This is especially important in advisory content, technical content, and any topic with legal or financial risk.
The shift to GenAI is not a reset. It is a reshaping. People are still searching for help, ideas, products, answers, and reassurance. They are just doing it through systems that evaluate content differently. You can stay visible in that world, but only if you stop expecting yesterday’s playbook to produce the same results. When you understand how retrieval works, how chunks are handled, and how meaning gets modeled, the fog lifts. The work becomes clear again.
Most teams are not there yet. They are still optimizing pages while AI systems are evaluating chunks. They are still thinking in keywords while models compare meaning. They are still polishing copy while the model scans for trust signals and structured clarity. When you understand all three layers, you stop guessing at what matters. You start shaping content the way the system actually reads it.
This is not busywork. It is strategic groundwork for the next decade of discovery. The brands that adapt early will gain an advantage that compounds over time. AI does not reward the loudest voice. It rewards the clearest one. If you build for that future now, your content will keep showing up in the places your customers look next.
My new book, “The Machine Layer: How to Stay Visible and Trusted in the Age of AI Search,” is now on sale at Amazon.com. It’s the guide I wish existed when I started noticing that the old playbook (rankings, traffic, click-through rates) was quietly becoming less predictive of actual business outcomes. The shift isn’t abstract. When AI systems decide which content gets retrieved, cited, and trusted, they’re also deciding which expertise stays visible and which fades into irrelevance. The book covers the technical architecture driving these decisions (tokenization, chunking, vector embeddings, retrieval-augmented generation) and translates it into frameworks you can actually use. It’s built for practitioners whose roles are evolving, executives trying to make sense of changing metrics, and anyone who’s felt that uncomfortable gap opening between what used to work and what works now.