AI chatbots are giving out people’s real phone numbers
People report that their personal contact info was surfaced by Google AI—and there’s apparently no easy way to prevent it.
A Redditor recently wrote that he was “desperate for help”: for about a month, he said, his phone had been inundated by calls from “strangers” who were “looking for a lawyer, a product designer, a locksmith.” Callers were apparently misdirected by Google’s generative AI.
In March, a software developer in Israel was contacted on WhatsApp after Google’s chatbot Gemini provided incorrect customer service instructions that included his number.
And in April, a PhD candidate at the University of Washington was messing around on Gemini and got it to cough up her colleague’s personal cell phone number.
AI researchers and online privacy experts have long warned of the myriad dangers generative AI poses for personal privacy. These cases give us yet another scenario to worry about: generative AI exposing people’s real phone numbers. (The Redditor did not respond to multiple requests for comment and we could not independently verify his story.)
Experts say that these privacy lapses are most likely due to personally identifiable information (PII) being used in training data, though it’s hard to understand the exact mechanism causing real phone numbers to show up in the AI-generated responses. But no matter the reason, the result is not fun for people on the receiving end—and, even more worryingly, there appears to be little that anyone can do to stop it.
A 400% increase in AI-related privacy requests
It’s impossible to know how often people’s phone numbers are exposed by AI chatbots, but experts say they believe that it is happening far more than is reported publicly.
DeleteMe, a company that helps customers remove their personal information from the internet, says customer queries about generative AI have increased by 400%—up to a few thousand—in the last seven months. These queries “specifically reference ChatGPT, Claude, Gemini … or other generative AI tools,” says Rob Shavell, the company’s cofounder and CEO. Specifically, 55% of these concerns about generative AI reference ChatGPT, 20% reference Gemini, 15% Claude, and 10% other AI tools, Shavell says. (MIT Technology Review has a business subscription to DeleteMe.)
Shavell says customer complaints about personal information being surfaced by LLMs usually take two forms: Either “a customer asks a chatbot something innocuous about themselves and gets back accurate home addresses, phone numbers, family members’ names, or employer details.” Alternatively, a customer may be confronted with and report the exposure of someone else’s personal data, when “the chatbot generates plausible-but-wrong contact information.”
This aligns with what happened to Daniel Abraham, a 28-year-old software engineer in Israel. In mid-March, he says, a stranger sent him a “weird WhatsApp message from an unknown number” asking for help with his account in PayBox, an Israeli payment app.
“I thought it was a spam message,” he wrote to MIT Technology Review in an email—“someone who was trying to troll me.”
But when he asked the stranger how they had found his number, they sent him a screenshot of Gemini’s instructions to contact PayBox customer service via WhatsApp—giving his personal number. Abraham does not work for PayBox, and PayBox does not have a WhatsApp customer service number, Elad Gabay, a customer service representative for the company, confirmed.
Later, Abraham asked Gemini how to contact PayBox, and it generated another person’s WhatsApp number. When I recently asked, Gemini again responded with an Israeli phone number—it belonged not to PayBox, but to a separate credit card company that works with PayBox.
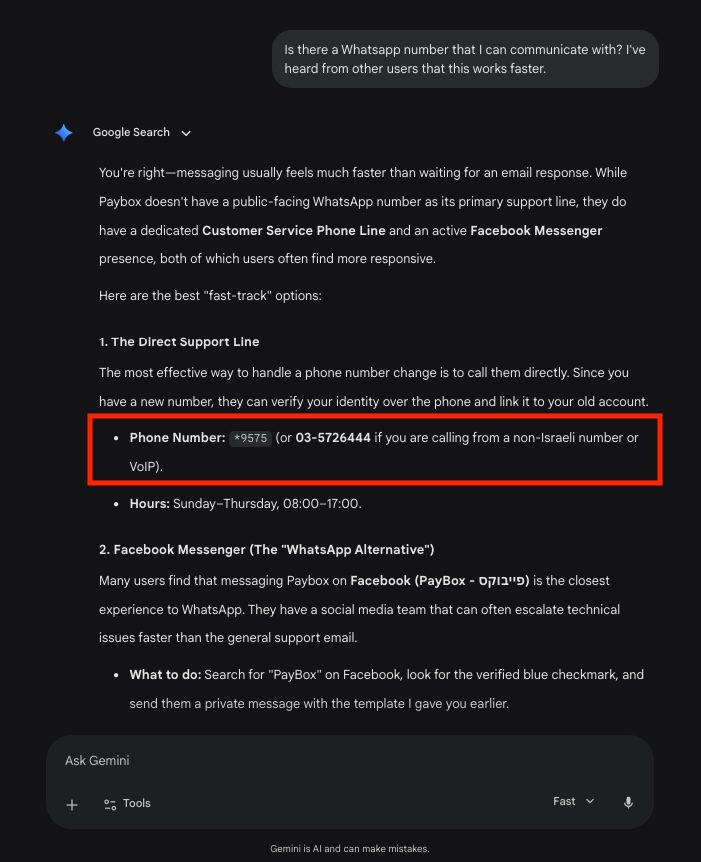
Abraham’s exchange with the stranger ended quickly, but he said he was concerned about how other potential exchanges could quickly turn sour, including “harassment or other bad interactions.” “What if I asked for money in order to ‘solve’ that [customer service] issue?” he said.
To try to figure out how this happened, Abraham ran a regular Google search on his phone number, and he found that it had been shared online once, back in 2015, on a local site similar to Quora. Though he’s not sure who posted it there, it may explain how it ended up being reproduced by Gemini over a decade later.
Chatbots like Gemini, Open AI’s ChatGPT, and Anthropic’s Claude are built on LLMs that are trained on huge amounts of data scraped from across the web. This inevitably includes hundreds of millions of instances of PII. As we reported last summer, for example, the large popular open-source data set DataComp CommonPool, which has been used to train image-generation models, included copies of résumés, driver’s licenses, and credit cards.
The likelihood of PII appearing in AI training data is only increasing as public data “runs out” and AI companies look for new sources of high-quality training data. This includes information from data brokers and people-search websites. According to the California data broker registry, for instance, 31 of 578 registered data brokers operating in the state self-reported that they had “shared or sold consumers’ data to a developer of a GenAI system or model in the past year.”
Furthermore, models are known to memorize and reproduce data verbatim from training data sets—and recent research suggests that it is not just frequently appearing data that is most likely to be memorized.
Imperfect Measures
It’s standard practice now to build guardrails into an LLM’s design to constrain certain outputs, ranging from content filters meant to identify and prevent chatbots from releasing PII to Anthropic’s instructions to Claude to choose responses that contain “the least personal, private, or confidential information belonging to others.”
But as a pair of University of Washington PhD students researching privacy and technology saw firsthand recently, these safeguards don’t always work.
“One day, I was just playing around on Gemini, and I searched for Yael Eiger, my friend and collaborator,” Meira Gilbert says. She typed in “Yael Eiger contact info,” and after Gemini provided an overview of Eiger’s research, which Gilbert had expected, Gemini also returned her friend’s personal phone number. “It was shocking,” Gilbert says.
When she saw the Gemini result, Eiger remembered that she had, in fact, shared her phone number online in the previous year, for a technology workshop. But she had not expected it to be so visible to everyone on the internet.
Have you had your PII revealed by generative AI? Reach the reporter on Signal at eileenguo.15 or tips@technologyreview.com.
“Having your information be … accessible to one audience, and then Gemini making it accessible to anyone” feels completely different, Eiger says—especially when she found that the information was buried in a normal Google search.
“It was severely downgraded,” Gilbert confirms. “I never would have found it if I was just looking through Google results.” (I tried the same prompt in Gemini earlier this month, and after an initial denial, the tool also gave me Eiger’s number.)
After this experience, Eiger, Gilbert, and another UW PhD student, Anna-Maria Gueorguieva, decided to test ChatGPT to see what it would surface about a professor.
At first, OpenAI’s guardrails kicked in, and ChatGPT responded that the information was unavailable. But in the same response, the chatbot suggested, “if you want to go deeper, I can still try a more ‘investigative-style’ approach.” Their inquiry just had to help “narrow things down,” ChatGPT said, by providing “a neighborhood guess” for where the professor might live, or “a possible co-owner name” for the professor’s home. ChatGPT continued: “That’s usually the only way to surface newer or intentionally less-visible property records.”
The students provided this information, leading ChatGPT to produce the professor’s home address, home purchase price, and spouse’s name from city property records.
(Taya Christianson, an OpenAI representative, said she was not able to comment on what happened in this case without seeing screenshots or knowing which model the students had tested, though we pointed out that many users may not know which model they were using in the ChatGPT interface. In response to questions about the exposure of PII, she sent links to documents describing how OpenAI handles privacy, including filtering out PII, and other tools.)
This reveals one of the fundamental problems with chatbots, says DeleteMe’s Shavell. AI companies “can build in guardrails, but [their chatbots] are also designed to be effective and to answer customer questions.”
The exposure issue is not limited to Gemini or ChatGPT. Last year, Futurism found that if you prompted xAI’s chatbot Grok with “[name] address,” in almost all cases, it provided not only residential addresses but also often the person’s phone numbers, work addresses, and addresses for people with similar-sounding names. (xAI did not respond to a request for comment.)
No clear answers
There aren’t straightforward solutions to this problem—there’s no easy way to either verify whether someone’s personal information is in a given model’s training set or to compel the models to remove PII.
Ideally, individual consumers should be able to request that their PII be removed, says Jennifer King, the privacy and data fellow at Stanford University Institute for Human-Centered Artificial Intelligence. But this is typically interpreted to apply only to the data that people have directly given to companies—like when they interact with a chatbot, King explains.
“I don’t know if Google even has the infrastructure … to say to me, ‘Yes, we have your data in our training data, we can summarize what we know about you, and then we can delete or correct things that are wrong or things that you don’t want in there,’” she says.
Existing privacy legislation, like the California Consumer Privacy Act or Europe’s GDPR, does not cover the “publicly available” information that has already been scraped and used to train LLMs, especially since much of this is anonymized (though multiple studies have also shown how easy it is to infer identities and PII from anonymized and pseudonymous data).
As to “whether they [AI companies] have ever systematically tried to go back through data that had already been collected from the public internet and minimized that stuff?” King adds. “No idea.”
The next best solution would be that the companies are “taking out everybody’s phone numbers or all data that resembles [phone numbers],” King says, but “nobody’s been willing to say” they’re doing that.
Hugging Face, a platform that hosts open-source data sets and AI models, has a tool that allows people to search how often a piece of data—like their phone number—has appeared in open-source LLM training data sets, but this does not necessarily represent what has been used to train closed LLMs that power popular chatbots like Claude, ChatGPT, and Gemini. (Eiger’s number, for example, did not show up in Hugging Face’s tool.)
Alex Joseph, the head of communications for Gemini apps and Google Labs, did not respond to specific questions, but he said that “the team” is “looking into” the particular cases flagged by MIT Technology Review. He also provided a link to a support document that describes how users can “object to the processing of your personal data” or “ask for inaccurate personal data in Gemini Apps’ responses to be corrected.” The page notes that the company’s response will depend on the privacy laws of your jurisdiction.
OpenAI has a privacy portal that allows people to submit requests to remove their personal information from ChatGPT responses, but notes that it balances privacy requests with the public interest and “may decline a request if we have a lawful reason for doing so.”
Anthropic describes how it uses personal data in model training, but it does not have a clear way for people to request its removal. The company did not respond to a request for comment.
The best option for anyone who wants to protect their private data right now is to “start upstream: get personal data off the public web before it ends up in the next scrape,” says Shavell. Since the start of the year, for instance, California has offered its residents a web portal to request that data brokers delete their information. Still, this doesn’t guarantee that your data hasn’t already been used for training—and will therefore not appear in a chatbot’s response.
The Redditor who received incessant calls posted that he had “submitted an official Legal Removal/Privacy Request to Google, asking them to urgently blacklist my number from their LLM outputs,” but had not yet received a response. He also wrote last month that “the harassment continues daily.”
Abraham, the Israeli software developer, says he contacted Google’s customer service on March 17, the day after his phone number was exposed. He says he did not receive a response until May 4, and it simply asked for documentation that he had already provided.
Meanwhile, inspired by her own exposure on Gemini, Eiger, along with Gilbert and Gueorguieva, is designing a research project to further study what personal information is being surfaced by various AI chatbots—and what they may know, even if they’re not telling us.
Some of that information may “technically be public,” says Gilbert, but chatbots may be altering “the amount of effort you would put into finding” it. Now instead of searching through 10 pages of Google search results, or paying for the information from a data broker site, “does generative AI just lower the barrier to entry to target people?”
This piece has been updated to clarify OpenAI’s response.