Google released Gemini 3 Flash, expanding its Gemini 3 model family with a faster model that’s now the default in the Gemini app.
Gemini 3 Flash is also rolling out globally as the default model for AI Mode in Search.
The release builds on Google’s recent Gemini 3 rollout, which introduced Gemini 3 Pro in preview and also announced Gemini 3 Deep Think as an enhanced reasoning mode.
What’s New
Gemini 3 Flash replaces Gemini 2.5 Flash as the default model in the Gemini app globally, which means free users get the Gemini 3 experience by default.
In Search, Gemini 3 Flash is rolling out globally as AI Mode’s default model starting today.
For developers, Gemini 3 Flash is available in preview via the Gemini API, including access through Google AI Studio, Google Antigravity, Vertex AI, Gemini Enterprise, plus tools such as Gemini CLI and Android Studio.
Pricing
Gemini 3 Flash pricing is listed at $0.50 per million input tokens and $3.00 per million output tokens on Google’s Gemini API pricing documentation.
On the same pricing page, Gemini 2.5 Flash is listed at $0.30 per million input tokens and $2.50 per million output tokens.
Google says Gemini 3 Flash uses 30% fewer tokens on average than Gemini 2.5 Pro for typical tasks, and citing third-party benchmarking for a “3x faster” comparison versus 2.5 Pro.
Why This Matters
The default language model in the Gemini app has changed, and users have access at no extra cost.
If you build on Gemini, Gemini 3 Flash offers a new option for high-volume workflows, priced well below Pro-tier rates.
Looking Ahead
Gemini 3 Flash is rolling out now. In Search, Gemini 3 Pro is also available in the U.S. via the AI Mode model menu.
The updated documentation focuses on a timing issue specific to JavaScript sites: canonicalization can happen twice during Google’s processing.
Google evaluates canonical signals once when it first crawls the raw HTML, then again after rendering the JavaScript. If your raw HTML contains one canonical URL and your JavaScript sets a different one, Google may receive conflicting signals.
The documentation notes that injecting canonical tags via JavaScript is supported but not recommended. When JavaScript sets a canonical URL, Google can pick it up during rendering, but incorrect implementations can cause issues.
Multiple canonical tags, or changes to an existing canonical tag during rendering, can lead to unexpected indexing results.
Best Practices
Google recommends two best practices depending on your site’s architecture.
The preferred method is setting the canonical URL in the raw HTML response to match the URL your JavaScript will ultimately render. This gives Google consistent signals before and after rendering.
If JavaScript must set a different canonical URL, Google recommends leaving the canonical tag out of the initial HTML. This can help avoid conflicting signals between the crawl and render phases.
The documentation also reminds developers to ensure only one canonical tag exists on any given page after rendering.
Why This Matters
This guidance addresses a subtle detail that can be easy to miss when managing JavaScript-rendered sites.
The gap between when Google crawls your raw HTML and when it renders your JavaScript creates an opportunity for canonical signals to diverge.
If you use frameworks like React, Vue, or Angular that handle routing and page structure client-side, it’s worth checking how your canonical tags are implemented. Look at whether your server response includes a canonical tag and whether your JavaScript modifies or duplicates it.
In many cases, the fix is to coordinate your server-side and client-side canonical implementations so they send the same signal at both stages of Google’s processing.
Looking Ahead
This documentation update clarifies behavior that may not have been obvious before. It doesn’t change how Google processes canonical tags.
If you’re seeing unexpected canonical selection in Search Console’s Page indexing reporting, check for mismatches between your raw HTML and rendered canonical tags. The URL Inspection tool shows both the raw and rendered HTML, which makes it possible to compare canonical implementations across both phases.
Trust is commonly understood to be a standalone quality that is passed between sites regardless of link neighborhood or topical vertical. What I’m going to demonstrate is that “trust” is not a thing that trickles down from a trusted site to another site. The implication for link building is that many may have been focusing on the wrong thing.
Six years ago I was the first person to write about link distance ranking algorithms that are a way to create a map of the Internet that begins with a group of sites that are judged to be trustworthy. These sites are called the seed set. The seed set links to other sites, which in turn link to ever increasing groups of other sites. The sites closer to the original seed set tend to be trustworthy websites. The sites that are furthest away from the seed set tend to be not trustworthy.
Google still counts links as part of the ranking process so it’s likely that there continues to be a seed set that is considered trustworthy from which the further away you a site is linked from the seeds the likelier it is considered to be spam.
Circling back to the idea of trust as a ranking related factor, trust is not a thing that is passed from one site to another. Trust, in this context, is not even a part of the conversation. Sites are said to be trustworthy by the link distance between the site in question and the original seed set. So you see, there is no trust that is conveyed from one site or another.
The word Trustworthiness is even a part of the E-E-A-T standard of what constitutes a quality website. So trust should never be considered as a thing that is passed from one site to another because it does not exist.
The takeaway is that link building decisions based on the idea of trust propagated through links are built on an outdated premise. What matters is whether a site sits close to trusted seed sites within the same topical neighborhood, not whether it receives a link from a widely recognized or authoritative domain. This insight transforms link evaluation into a relevance problem rather than a reputation problem. This insight should encourage site owners to focus on earning links that reinforce topical alignment instead of chasing links that appear impressive but have little, if any, ranking value.
Why Third Party Authority Metrics Are Inaccurate
The second thing about the link distance ranking algorithms that I think is quite cool and elegant is that websites naturally coalesce around each other according to their topics. Some topics are highly linked and some, like various business association verticals, are not well linked at all. The consequence is that those poorly linked sites that are nevertheless close to the original seed set do not acquire much “link equity” because their link neighborhoods are so small.
What that means is that a low-linked vertical can be a part of the original seed set and display low third-party authority metrics scores. The implication is that the third-party link metrics that measure how many inbound links a site has fail. They fail because third-party authority metrics follow the old and outdated PageRank scoring method that counts the amount of inbound links a site has. PageRank was created around 1998 and is so old that the patent on it has expired.
The seed set paradigm does not measure inbound links. It measures the distance from sites that are judged to be trustworthy. That has nothing to do with how many links those seed set sites have and everything to do with them being trustworthy, which is a subjective judgment.
That’s why I say that third-party link authority metrics are outdated. They don’t follow the seed set paradigm, they follow the old and outdated PageRank paradigm. The insight to take away from this is that many highly trustworthy sites are being overlooked for link building purposes because link builders are judging the quality of a site by outdated metrics that incorrectly devalue sites in verticals that aren’t well linked but are actually very close to the trustworthy seed set.
The Important Of Link Neighborhoods
Let’s circle back to the observation that websites tend to naturally link to other sites that are on the same topic. What’s interesting about this is that the seed sets can be chosen according to topic verticals. Some verticals have a lot of inbound links and some verticals are in their own little corner of the Internet and aren’t link to from outside of their clique.
A link distance ranking algorithm can thus be used to calculate the relevance according to whatever neighbhorhood a site is located in. Majestic does something like that with their Trust Flow and Topical Trust Flow metrics that actually start with trusted seed sites. Topical Trust Flow breaks that score down into specific topic categories. The Topical Trust Flow metric shows how relevant a website is for a given metric.
My point isn’t that you should use that metric, although I think it’s the best one available today. The point is that there is no context for thinking about trustworthiness as something that spreads from link to link.
Once you can think of links in the paradigm of distance within a topic category it becomes easier to understand why a link from a university website or some other so-called “high trust” site isn’t necessarily that good or useful. I know for certain because there was a time before distance ranking where the topic of the site didn’t matter but now it does matter very much and it has mattered for a long time now.
The takeaways here are:
It is counterproductive to go after so-called “high trust” links from verticals that are well outside of the topic of the website you’re trying to get a link to.
This means that it’s more important to get links from sites that are in the right topic or from a context that exactly matches the topic, from a website that’s in an adjacent topical category.
For example, a site like The Washington Post is not a part of the Credit Repair niche. Any “trust” that may be calculated from a New York Times link to a Credit Repair site will likely be dampened to zero. Of course it will. Remember, seed set trust distance is calculated within groups within a niche. There is no trust passed from one link to another link. It is only the distance that is counted.
Logically, it makes sense to assume that there will be no validating effect between irrelevant sites. relevant website for the purposes of the seed set trust calculations.
Takeaways
Trust is not something that’s passed by links Link distance ranking algorithms do not deal with “trust.” They only measure how close a site is to a trusted seed set within a topic.
Link distance matters more than link volume Ranking systems based on link distance assess proximity to trusted seed sites, not how many inbound links a site has.
Topic-based link neighborhoods shape relevance Websites naturally cluster by topic, and link value is likely evaluated within those topical clusters rather than across the entire web. A non-relevant link can still have some small value but irrelevant links stopped working almost twenty years ago.
Third-party authority metrics are misaligned with modern link ranking systems Some third-party metrics rely on outdated Page Rank-style link counting and fail to account for seed set distance and topical context.
Low-link verticals are undervalued by SEOs Entire niches that are lightly linked can still sit close to trusted seed sets, yet appear weak in third-party metrics, causing them to be overlooked in link builders.
Relevance outweighs perceived link strength Links from well-known but topically irrelevant sites likely contribute little or nothing compared to links from closely related or adjacent topic sites.
Modern link evaluation is about topical proximity, not “trust” or raw link counts. Search systems measure how close a site is to trusted seed sites within its own topic neighborhood, which means relevant links from smaller, niche sites can matter more than links from famous but unrelated domains.
This knowledge should enable smarter link building by focusing efforts on contextually relevant websites that may actually strengthen relevance and rankings, instead of chasing outdated link authority scores that no longer reflect how search works.
Link building outreach is not just blasting out emails. There’s also a conversation that happens when someone emails you back with a skeptical question. The following are tactics to use for overcoming skeptical responses.
In my opinion it’s always a positive sign when someone responds to an email, even if they’re skeptical. I consider nearly all email responses to be indicators that a link is waiting to happen. This is why a good strategy that anticipates common questions will help you convert skeptical responses into links.
Many responses tend to be questions. What they are asking, between the lines, is for you to help them overcome their suspicions. Anytime you receive a skeptical response, try to view it as them asking you, “Help me understand that you are legitimate and represent a legitimate website that we should be linking to.”
The question is asked between the lines. The answer should similarly be addressed between the lines. Ninety nine percent of the time, a between-the-lines question should not be answered directly. The perfect way to answer those questions, the perfect way to address an underlying concern, is to answer it in the same way you received it, between the lines.
Common and weird questions that I used to get were like:
Who are you?
Who do you work for?
How did get my email address?
Before I discuss how I address those questions, I want to mention something important that I do not do. I do not try to actively convert the respondent in the first response. In my response to their response to my outreach, I never ask them to link to the site.
The question of linking is already hanging in the air and is the object of their email to you- there is no need to bring that up. If in your response you ask them again to link to your site it will tilt them back to being suspicious of you, raising the odds of losing the link.
In trout fishing, the successful angler crouches so that the trout does not see you. The successful angler may even wear clothing that helps them blend into the background. The best anglers imitate the crane, a fish-eating bird that stands perfectly still, imperceptibly inching closer to its prey. This is done to avoid being noticed. Your response should imitate the crane or the camouflaged angler. You should put yourself into the mindset of anything but a marketer asking for a link.
Your response must not be to immediately ask for a link because that in my opinion will just lose the link. So don’t do it just yet.
Tribal Affinity
One approach that I used to use successful is what I called the Tribal Affinity approach. For a construction/home/real estate related campaign, I used to approach it with the mindset of a homeowner. I wouldn’t say that I’m a homeowner (even though I was), I would just think in terms of what would I say as a homeowner contacting a company to suggest a real estate or home repair type a link. In the broken link or suggest a link strategy, I would say that the three links I am suggesting for their links page have been useful to me.
Be A Mirror
A tribal affinity response that was useful to me is to mirror the person I’m outreaching to, to assume the mindset of the person I am responding to. So for example, if they are a toy collector then your mindset can also be a toy collector. If the outreach target is a club member then your outreach mindset can be an enthusiast of whatever the club is about. I never claim membership in any particular organization, club or association. I limit my affinity to mirroring the same shared mindset as the person I’m outreaching to.
Assume The Mindset
Another approach is to assume the mindset of someone who happened upon the links page with a broken link or missing a good quality link. When you get into the mindset the text of your email will be more natural.
Thus, when someone responds by challenging me by asking how I found their site or who am I working for my response is to just stick to my mindset of a homeowner and respond accordingly.
And really, what’s going on is that they’re not really asking how you found their site. What they’re really asking, between the lines, is if you’re a marketer of some kind. You can go ahead and say yes, you are. Or you can respond between the lines and say that you’re just a homeowner. Up to you.
There are many variations to this approach. The important points are:
Responses that challenge you are not necessarily hostile but are often link conversions waiting to happen.
Never respond to a response by asking for a link.
Put yourself into the right mindset. Thinking like a marketer will usually lead to a conversion dampening response.
Put yourself into the mindset that mirrors the person you outreach to.
Get into the mindset that gives you a plausible reason for finding their site and the best words for asking for a link will write themselves.
Informational sites can easily decline into a crisis of search visibility. No site is immune. Here are five ways to manage content to maintain steady traffic, increase the ability to adapt to changing audiences, and make confident choices that help the site maintain growth momentum over time.
1. Create A Mix Of Content Types
Publishers are in a constant race to publish what’s latest because being first to publish can be a source of massive traffic. The main problem with these kinds of sites is that publishing content about current events can run into problems, putting into question the sustainability of the publication.
Current events quickly become stale and no longer relevant to an audience.
Unforeseen events like an industry strike, accidents, world events, and pandemics can disrupt interest in a topic.
The focus then is to identify content topics that are reliably relevant to the website’s current audience. This kind of content is called evergreen content, and it can form a safety net of reliable traffic that can sustain the business during slow cycles.
An example of the mixed approach to content that comes to mind is how the New York Times has a standalone recipes section on a subdomain of the main website. It also has a category-based section dedicated to gadget reviews called The Wirecutter.
Another example is the entertainment niche which in addition to industry news also publish interviews with stars and essays about popular movies. Music websites publish the latest news but also content based on snippets from interviews with famous musicians where the musicians make interesting statements about songs, inspirations, and cultural observations.
Rolling Stone magazine publishes content about music but also about current events like politics that align with their reader interests.
All three of those examples expand their topics to adjacent topics in order to bulk up their ability to attract steady and consistent traffic that is reliable.
2. Evergreen Content Also Needs Current Event Topics
Conversely, evergreen topics can generate new audience reach and growth by expanding to cover current events. Content sites about recipes, gardening, home repairs, DIY, crafts, parenting, personal finance, and fitness are all examples of topics that feature evergreen content and can also expand to cover current events. The flow of traffic derived from trending topics is an excellent source of devoted readers who return to read evergreen content and end up recommending the site to friends for both current events and evergreen topics.
Current events can be related to products and even to statements by famous people. If you enjoy creating content or making discoveries, then you’ll enjoy the challenge of discovering new sources of trending topics.
If you don’t already have a mix of evergreen and ephemeral content, then I would encourage you to seek opportunities to focus on those kinds of articles. They can help sustain traffic levels while feeding growth and life into the website.
3. Beware Of Old Content
Google evaluates the total content of a website in order to generate a quality score. Google is vague about these whole-site evaluations. We only know that they do it and that a good evaluation can have a positive effect on traffic.
However, what happens when the site becomes top-heavy with old, stale content that’s no longer relevant to site visitors? This can become a drag on a website. There are multiple ways of handling this situation.
Content that is absolutely out of date and of no interest to anyone and is therefore no longer useful should be removed. The criteria to judge content with is usefulness, not the age of the content. The reason to prune this content is because it’s possible that a whole-site evaluation may conclude that most of the website is comprised of unhelpful, outdated web pages. This could be a negative drag on site performance.
There’s nothing inherently wrong with old content as long as it’s useful. For example, the New York Times keeps old movie reviews in archives that are organized by year, month, day, category, and article title.
The URL slug for the movie review of E.T. looks like this: /1982/06/11/movies/et-fantasy-from-spielberg.html
Screenshot Of Archived Article
Take Decisive Steps
Useful historical content can be archived.
Older content that is out of date can be rehabilitated.
Content that’s out of date and has been superseded by new content can be redirected with a 301 response code to the new content.
Content that is out of date and objectively useless should be removed from the website and allowed to show a 404 response code.
4. Topic Interest
Something that can cause traffic to decline on an informational site is waning interest. Technological innovation can cause the popularity of another product to decline, dragging website traffic along with it. For example, I consulted for a website that reported its traffic was declining. The site still ranked for its keywords, but a quick look at Google Trends showed that interest in the website topic was declining. This was several months after the introduction of the iPhone, which negatively impacted a broad category of products that the website was centered on.
Always keep track of how interested your audience is in your topic. Follow influencers in your niche topic on social media to gauge what they are talking about and whether there are any shifts in the conversation that indicate waning interest or growing interest in a related topic.
Always try out new subcategories of your topic that cross over with your readership to see if there is an audience there that can be cultivated.
Another nuance to consider is the difference between temporary dips in interest and long-term structural decline. Some topics experience predictable cycles driven by seasons, economic conditions, or news coverage, while others face permanent erosion as user needs change or alternatives emerge. Misreading a cyclical slowdown as a permanent decline can lead to unnecessary pivots, while ignoring structural shifts can leave a site over-invested in content that no longer aligns with how people search, buy, or learn.
Monitoring topic interest is less about reacting to short-term fluctuations and more about keeping aware of topical interest and trends. By monitoring audience behavior, tracking broader trends, and experimenting at the edges of the core topic, an informational site can adjust gradually rather than being forced into abrupt changes after traffic has already declined. This ongoing attention helps ensure that content decisions remain grounded in how interest evolves over time.
5. Differentiate
Something that happens to a lot of informational websites is that competitors in a topic tend to cover the exact same stories and even have similar styles of photos, about pages, and bios.
B2B software sites have images of people around a laptop, images of a serious professional, and people gesturing at a computer or a whiteboard.
Recipe sites feature the Flat Lay (food photographed from above), the Ingredient Still Life portrait, and action shots of ingredients grated, sprinkled, or in mid air.
Websites tend to converge into homogeneity in the images they use and the kind of content that’s shared, based on the idea that if it’s working for competitors, then it may be a good approach. But sometimes it’s best to step out of the pack and do things differently.
Evolve your images so that they stand out or catch the eye, try a different way of communicating your content, identify the common concept that everyone uses, and see if there’s an alternate approach that makes your site more authentic.
For example, a recipe site can show photographic bloopers or discuss what can go wrong and how to fix or avoid it. Being real is authentic. So why not show what underbaked looks like? Instagram and Pinterest are traffic drivers, but does that mean all images must be impossibly perfect? Maybe people might respond to the opposite of homogeneity and fake perfection.
The thing that’s almost always missing from product reviews is photos of the testers actually using the products. Is it because the reviews are fake? Hm… Show images of the products with proof that they’ve been used.
Takeaways
Sustainable traffic can be cultivated with a mix of evergreen and timely content. Find the balance that works for your website.
Evergreen content performs best when it is periodically refreshed with up-to-date details.
Outdated content that lacks utility or meaning in people’s lives can quietly grow to suppress site-wide performance. Old pages should be reviewed for usefulness and then archived, updated, redirected, or removed.
Audience interest in a topic can decline even if rankings remain stable. Monitoring search demand and cultural shifts helps publishers know when it’s time to expand into adjacent topics before traffic erosion becomes severe.
Differentiation matters as much as coverage. Sites that mirror competitors in visuals, formats, and voice risk blending into sameness, while original presentation and proof of authentic experience build trust and attention.
Search visibility declines are not caused by a single technical flaw or isolated content mistake but by gradual misalignment between what a site publishes and what audiences continue to value. Sites that rely too heavily on fleeting interest, allow outdated material to accumulate, or follow competitors into visual and editorial homogeneity risk signaling mediocrity rather than relevance and inspiring enthusiasm. Sustained performance depends on actively managing content, balancing evergreen coverage with current events, pruning what’s no longer useful, and making deliberate choices that distinguish the site as useful, authentic, and credible.
Safari 26.2 adds support for measuring Largest Contentful Paint (LCP) and the Event Timing API, which is used to calculate Interaction to Next Paint (INP). This enables site owners to collect Largest Contentful Paint (LCP) and Interaction to Next Paint (INP) data from Safari users through the browser Performance API using their own analytics and real user monitoring tools.
LCP And INP In Apple Safari Browser
LCP is a Core Web Vital and a ranking signal. Interaction To Next Paint (INP), also a Core Web Vitals metric, measures how quickly your website responds to user interactions. Native Safari browser support enables accurate measurement, which closes a long-standing blind spot for performance diagnostics of site visitors using Apple devices.
INP is a particularly critical measurement because it reports on the total time between a user’s action (click, tap, or key press) and the visual update on the screen. It tracks the slowest interaction observed during a user’s visit. INP is important because it enables site owners to know if the page feels “frozen” or laggy for site visitors. Fast INP scores translate to a positive user experience for site visitors who are interacting with the website.
This change will have no effect on public tools like PageSpeed Insights and CrUX data because they are Chrome-based.
However, Safari site visitors can now be included in field performance data where site owners have configured measurement, such as in Google Analytics or other performance monitoring platforms.
The following analytics packages can now be configured to surface these metrics from Safari browser site visitors:
Google Analytics (GA4, via Web Vitals or custom event collection)
Adobe Analytics
Matomo
Amplitude (with performance instrumentation)
Mixpanel (with custom event pipelines)
Custom / In-House Monitoring
Apple Safari’s update also enables Real User Monitoring (RUM) platforms to surface this data for site owners:
“Safari 26.2 adds support for two tools that measure the performance of web applications, Event Timing API and Largest Contentful Paint.
The Event Timing API lets you measure how long it takes for your site to respond to user interactions. When someone clicks a button, types in a field, or taps on a link, the API tracks the full timeline — from the initial input through your event handlers and any DOM updates, all the way to when the browser paints the result on screen. This gives you insight into whether your site feels responsive or sluggish to users. The API reports performance entries for interactions that take longer than a certain threshold, so you can identify which specific events are causing delays. It makes measuring “Interaction to Next Paint” (INP) possible.
Largest Contentful Paint (LCP) measures how long it takes for the largest visible element to appear in the viewport during page load. This is typically your main image, a hero section, or a large block of text — whatever dominates the initial view. LCP gives you a clear signal about when your page feels loaded to users, even if other resources are still downloading in the background.”
Safari 26.2 provides new data that is critical for SEO and for monitoring the user experience, information that site owners rely on. Safari traffic represents a significant share of site visits. These improvements make it possible for site owners to have a more complete view of the real user experience across more devices and browsers.
There are multiple reasons why a site can drop in rankings due to a core algorithm update. The reasons may reflect specific changes to the way Google interprets content, a search query, or both. The change could also be subtle, like an infrastructure update that enables finer relevance and quality judgments. Here are eight commonly overlooked reasons for why a site may have lost rankings after a Google core update.
Ranking Where It’s Supposed To Rank?
If the site was previously ranking well and now it doesn’t, it could be what I call “it’s ranking where it’s supposed to rank.” That means that some part of Google’s algorithm has caught up to a loophole that the page was intentionally or accidentally taking advantage of and is currently ranking it where it should have been ranking in the first place.
This is difficult to diagnose because a publisher might believe that the web pages or links were perfect the way they previously were, but in fact there was an issue.
Topic Theming Defines Relevance
A part of the ranking process is determining what the topic of a web page is. Google admitted a year ago that a core topicality system is a part of the ranking process. The concept of topicality as part of the ranking algorithm is real.
The so-called Medic Update of 2018 brought this part of Google’s algorithm into sharp focus. Suddenly, sites that were previously relevant for medical keywords were nowhere to be found because they dealt in folk remedies, not medical ones. What happened was that Google’s understanding of what keyword phrases were about became more topically focused.
Bill Slawski wrote about a Google patent (Website representation vector) that describes a way to classify websites by knowledge domains and expertise levels that sounds like a direct match to what the Medic Update was about.
The patent describes part of what it’s doing:
“The search system can use information for a search query to determine a particular website classification that is most responsive to the search query and select only search results with that particular website classification for a search results page. For example, in response to receipt of a query about a medical condition, the search system may select only websites in the first category, e.g., authored by experts, for a search results page.”
Google’s interpretation of what it means to be relevant became increasingly about topicality in 2018 and continued to be refined in successive updates over the years. Instead of relying on links and keyword similarity, Google introduced a way to identify and classify sites by knowledge domain (the topic) in order to better understand how search queries and content are relevant to each other.
Returning to the medical queries, the reason many sites lost rankings during the Medic Update was that their topics were outside the knowledge domain of medical remedies and science. Sites about folk and alternative healing were permanently locked out of ranking for medical phrases, and no amount of links could ever restore their rankings. The same thing happened across many other topics and continues to affect rankings as Google’s ability to understand the nuances of topical relevance is updated.
Example Of Topical Theming
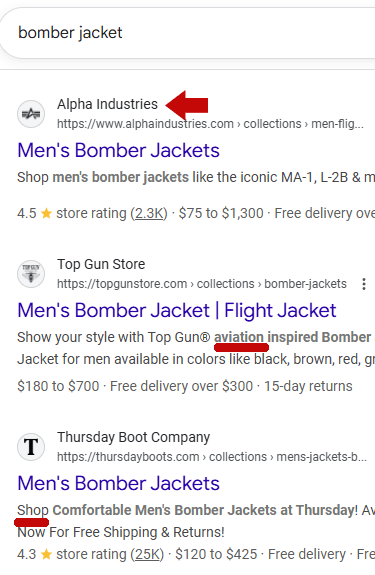
A way to think of topical theming is to consider that keyword phrases can be themed by topic. For example, the keyword phrase “bomber jacket” is related to both military clothing, flight clothing, and men’s jackets. At the time of writing, Alpha Industries, a manufacturer of military clothing, is ranked number one in Google. Alpha Industries is closely related to military clothing because the company not only focuses on selling military style clothing, it started out as a military contractor producing clothing for America’s military, so it’s closely identified by consumers with military clothing.
Screenshot Showing Topical Theming
So it’s not surprising that Alpha Industries ranks #1 for bomber jacket because it ticks both boxes for the topicality of the phrase Bomber Jacket:
Shopping > Military clothing
Shopping > Men’s clothing
If your page was previously ranking and now it isn’t, then it’s possible that the topical theme was redefined more sharply. The only way to check this is to review the top ranked sites, focusing, for example, on the differences between ranges such as position one and two, or sometimes positions one through three or positions one through five. The range depends on how the topic is themed. In the example of the Bomber Jacket rankings, positions one through three are themed by “military clothing” and “Men’s clothing.” Position three in my example is held by the Thursday Boot Company, which is themed more closely with “men’s clothing” than it is with military clothing. Perhaps not coincidentally, the Thursday Boot Company is closely identified with men’s fashion.
This is a way to analyze the SERPs to understand why sites are ranking and why others are not.
Topic Personalization
Sometimes the topical themes are not locked into place because user intents can change. In that case, opening a new browser or searching a second time in a different tab might cause Google to change the topical theme to a different topical intent.
In the case of the “bomber jacket” search results, the hierarchy of topical themes can change to:
Informational > Article About Bomber Jackets
Shopping > Military clothing
Shopping > Men’s clothing
The reason for that is directly related to the user’s information need which informs the intent and the correct topic. In the above case it looks like the military clothing theme may be the dominant user intent for this topic but the informational/discovery intent may be a close tie that’s triggered by personalization. This can vary by previous searches but also by geographic location, a user’s device, and even by the time of day.
The takeaway is that there may not be anything wrong with a site. It’s just ranking for a more specific topical intent. So if the topic is getting personalized so that your page no longer ranks, a solution may be to create another page to focus on the additional topic theme that Google is ranking.
Authoritativeness
In one sense, authoritativeness can be seen as an external validation of expertise of a website as a go-to source for a product, service, or content topic. While the expertise of the author contributes to authoritativeness and authoritativeness in a topic can be inherent to a website, ultimately it’s third-party recognition from readers, customers, and other websites (in the form of citations and links) that communicate a website’s authoritativeness back to Google as a validating signal.
The above can be reduced to these four points:
Expertise and topical focus originate within the website.
Authoritativeness is the recognition of that expertise.
Google does not assess that recognition directly.
Third-party signals can validate a site’s authoritativeness.
To that we can add the previously discussed Website Representation Vector patent that shows how Google can identify expertise and authoritativeness.
What’s going on then is that Google selects relevant content and then winnows that down by prioritizing expert content.
“Google’s automated systems are designed to use many different factors to rank great content. After identifying relevant content, our systems aim to prioritize those that seem most helpful. To do this, they identify a mix of factors that can help determine which content demonstrates aspects of experience, expertise, authoritativeness, and trustworthiness, or what we call E-E-A-T.”
Authoritativeness is not about how often a site publishes about a topic; any spammer can do that. It has to be about more than that. E-E-A-T is a standard to hold your site up to.
Stuck On Page Two Of Search Results? Try Some E-E-A-T
Speaking of E-E-A-T, many SEOs have the mistaken idea that it’s something they can add to websites. That’s not how it works. At the 2025 New York City Search Central Live event, Google’s John Mueller confirmed that E-E-A-T is not something you add to web pages.
He said:
“Sometimes SEOs come to us or like mention that they’ve added EEAT to their web pages. That’s not how it works. Sorry, you can’t sprinkle some experiences on your web pages. It’s like, that doesn’t make any sense.”
Clearly, content reflects qualities of authoritativeness, trustworthiness, expertise, and experience, but it’s not something that you add to content. So what is it?
E-E-A-T is just a standard to hold your site up to. It’s also a subjective judgment made by site visitors. A subjective judgment is like how a sandwich can taste great, with the “great” part being the subjective judgment. It is a matter of opinion.
One thing that is difficult for SEOs to diagnose is when their content is missing that extra something to push their site onto the first page of the SERPs. It can feel unfair to see competitors ranking on the first page of the SERPs even though your content is just as good as theirs.
Those differences indicate that their top-ranked web pages are optimized for people. Another reason is that more people know about them because they have a multimodal approach to content, whereas the site on page two of the SERPs mainly communicates via textual content.
In SERPs where Google prefers to rank government and educational sites for a particular keyword phrase, except for one commercial site, I almost always find evidence that their content and their outreach are resonating with site visitors in ways that the competitor websites do not. Websites that focus on multimodal, people-optimized content and experiences are usually what I find in those weird outlier rankings.
So if your site is stuck on page two, revisit the top-ranked web pages and identify ways that those sites are optimized for people and multimodal content. You may be surprised to see what makes those sites resonate with users.
Temporary Rankings
Some rankings are not made to last. This is the case with a new site or new page ranking boost. Google has a thing where it tastes a new site to see how it fits with the rest of the Internet. A lot of SEOs crow about their client’s new website conquering the SERPs right out of the gate. What you almost never hear about is when those same sites drop out of the SERPs.
This isn’t a bad thing. It’s normal. It simply means that Google has tried the site and now it’s time for the site to earn its place in the SERPs.
There’s Nothing Wrong With The Site?
Many site publishers find it frustrating to be told that there’s nothing wrong with their site even though it lost rankings. What’s going on may be that the site and web page are fine, but that the competitors’ pages are finer. These kinds of issues are typically where the content is fine and the competitors’ content is about the same but is better in small ways.
This is the one form of ranking drop that many SEOs and publishers easily overlook because SEOs generally try to identify what’s “wrong” with a site, and when nothing obvious jumps out at them, they try to find something wrong with the backlinks or something else.
This inability to find something wrong leads to recommendations like filing link disavows to get rid of spam links or removing content to fix perceived but not actual problems (like duplicate content). They’re basically grasping at straws to find something to fix.
But sometimes it’s not that something is wrong with the site. Sometimes it’s just that there’s something right with the competitors.
What can be right with competitors?
Links
User experience
Image content (for example, site visitors are reflected in image content).
Multimodal approach
Strong outreach to potential customers
In-person marketing
Cultivate word-of-mouth promotion
Better advertising
Optimized for people
SEO Secret Sauce: Optimized For People
Optimizing for people is a common blind spot. Optimizing for people is a subset of conversion optimization. Conversion optimization is about subtle signals that indicate a web page contains what the site visitor needs.
Sometimes that need is to be recognized and acknowledged. It can be reassurance that you’re available right now or that the business is trustworthy.
For example, a client’s site featured a badge at the top of the page that said something like “Trusted by over 200 of the Fortune 500.” That badge whispered, “We’re legitimate and trustworthy.”
Another example is how a business identified that most of their site visitors were mothers of boys, so their optimization was to prioritize images of mothers with boys. This subtly recognized the site visitor and confirmed that what’s being offered is for them.
Nobody loves a site because it’s heavily SEO’d, but people do love sites that acknowledge the site visitor in some way. This is the secret sauce that’s invisible to SEO tools but helps sites outrank their competitors.
It may be helpful to avoid mimicking what competitors are doing and increase ways that differentiate the site and outreach in ways that make people like your site more. When I say outreach, I mean actively seeking out places where your typical customer might be hanging out and figuring out how you can make your pitch there. Third-party signals have long been strong ranking factors at Google, and now, with AI Search, what people and other sites say about your site are increasingly playing a role in rankings.
Takeaways
Core updates sometimes correct over-ranking, not punish sites Ranking drops sometimes reflect Google closing loopholes and placing pages where they should have ranked all along rather than identifying new problems.
Topical theming has become more precise Core updates sometimes make existing algorithms more precise. Google increasingly ranks content based on topical categories and intent, not just keywords or links.
Topical themes can change dynamically Search results may shift between informational and commercial themes depending on context such as prior searches, location, device, or time of day.
Authoritativeness is externally validated Recognition from users, citations, links, and broader awareness can be the difference why one site ranks and another does not.
SEO does not control E-E-A-T and can’t be reduced to an on-page checklist While concepts of expertise and authoritativeness are inherent in content, they’re still objective judgments that can be inferred from external signals, not something that can be directly added to content by SEOs.
Temporary ranking boosts are normal New pages and sites are tested briefly, then must earn long-term placement through sustained performance and reception.
Competitors may simply be better for users Ranking losses often occur because competitors outperform in subtle but meaningful ways, not because the losing site is broken.
People-first optimization is a competitive advantage Sites that resonate emotionally, visually, and practically with visitors often outperform purely SEO-optimized pages.
Ranking changes after a core update sometimes reflect clearer judgments about relevance, authority, and usefulness rather than newly discovered web page flaws. As Google sharpens how it understands topics, pages increasingly compete on how well they align with what users are actually trying to accomplish and which sources people already recognize and trust. The lasting advantage comes from building a site that resonates with actual visitors, earns attention beyond search, and gives Google consistent evidence that users prefer it over alternatives. Marketing, the old-fashioned tell-people-about-a-business approach to promoting it, should not be overlooked.
Featured Image by Shutterstock/Silapavet Konthikamee
Google’s AI Mode and AI Overviews can produce answers with similar meaning while citing different sources, according to new data from Ahrefs.
The report, published on the Ahrefs blog, analyzed September 2025 U.S. data from Ahrefs’ Brand Radar tool and compared AI Mode and AI Overview responses for the same queries.
The authors looked at 730,000 query pairs for content similarity and 540,000 query pairs for citation and URL analysis.
What The Study Found
Ahrefs reports that AI Mode and AI Overviews cited the same URLs only 13% of the time. When comparing only the top three citations in each response, overlap increased to 16%.
The language in the responses also varied. Ahrefs reports 16% overlap in unique words and states that AI Mode and AI Overviews share the exact same first sentence only 2.5% of the time.
Ahrefs reported strong semantic alignment, with an average semantic similarity score of 86%, and 89% of response pairs scoring above 0.8 on a scale where 1.0 indicates identical meaning.
Despina Gavoyannis, Senior SEO Specialist at Ahrefs, writes:
“Put simply: 9 out of 10 times, AI Mode and AI Overview agreed on what to say. They just said it differently and cited different sources.”
Different Source Preferences
Ahrefs reports differences in which websites and content types each feature tends to cite.
For example, Wikipedia appears in 28.9% of AI Mode citations compared to 18.1% in AI Overviews. The data also finds that AI Mode cited Quora 3.5x more often and cited health sites at roughly double the rate of AI Overviews.
AI Overviews, by contrast, leaned more heavily on video content. YouTube was the most frequently cited source for AI Overviews, whereas Reddit was cited at similar rates in both AI Mode and AI Overviews.
Ahrefs also reports that AI Overviews cited videos and core pages (such as homepages) nearly twice as often as AI Mode. At the same time, both features showed a strong preference for article-format pages overall.
Entity And Brand Mentions
Ahrefs found AI Mode responses were about four times longer than AI Overviews on average and included more entities.
In the dataset, AI Mode averaged 3.3 entity mentions per response compared to 1.3 for AI Overviews. Approximately 61% of the time, AI Mode included all entities mentioned in the AI Overview response and then added additional entities.
Many responses didn’t include brands or entities. Ahrefs reports that 59.41% of AI Overview responses and 34.66% of AI Mode responses contained no mentions of persons or brands, which the authors associate with informational queries in which named entities are not typically part of the answer.
Citation Gaps
The data finds that AI Mode was more likely to include citations than AI Overviews.
Only 3% of AI Mode responses lacked sources, compared to 11% of AI Overviews. Ahrefs reports that missing citations typically occur in cases such as calculations, sensitive queries, help center redirects, or unsupported languages.
Why This Matters
This report suggests that AI Mode and AI Overviews can differ in the sources they credit, even when they reach similar conclusions for the same query.
For monitoring purposes, this can affect how you interpret “visibility” across experiences. A citation (or a mention) in AI Overviews does not necessarily imply you will be cited in AI Mode for the same query, and AI Mode’s longer responses may include additional entities and competitors compared to the shorter AI Overview format.
Google’s documentation states that both AI Overviews and AI Mode may use “query fan-out,” which issues multiple related searches across subtopics and data sources while a response is being generated.
Google also notes that AI Mode and AI Overviews may use different models and techniques, so the responses and links they display will vary.
Looking Ahead
Ahrefs notes this analysis compares single generations of AI Mode and AI Overview responses. In related research, Ahrefs reported that 45.5% of AI Overview citations change when AI Overviews update, suggesting that overlap can appear different across repeated runs.
Even with that caveat, the low overlap observed in this dataset indicates that AI Mode and AI Overviews frequently select different URLs as supporting sources for the same query.
Google’s John Mueller recently answered a question about how Google responds to staggered site moves where a site is partially moved from one domain to another. He said a standard site move is generally fine, but clarified his position when it came to partial site moves.
Straight Ahead Site Move?
Someone asked about doing a site move, initially giving the impression that they were moving the entire site. The question was in the context of using Google Search Console’s change of address feature.
“Do you have any thoughts on this GSC Change of Address question?
Can we submit the new domain if a few old URLs still get traffic and aren’t redirected yet, or should we wait until all redirects are live?”
Mueller initially answered that it should be fine:
“It’s generally fine (for example, some site moves keep the robots.txt on the old domain with “allow: /” so that all URLs can be followed). The tool does check for the homepage redirect though.”
Google Explains Why Partial Site Moves Are Problematic
His opinion changed however after the OP responded with additional information indicating that the home page has been moved while many of the product and category pages on the old domain will stay put for now, meaning that they want to move parts of the site now and other parts later, retaining one foot in on a new domain and the other firmly planted on the old one.
That’s a different scenario entirely. Unsurprisingly, Mueller changed his opinion.
He responded:
“Practically speaking, it’s not going to be seen as a full site move. You can still use the change of address tool, but it will be a messy situation until you’ve really moved it all over. If you need to do this (sometimes it’s not easy, I get it :)), just know that it won’t be a clean slate.
…You’ll have a hard time tracking things & Google will have a hard time understanding your sites. My recommendation would be to clean it up properly as soon as you can. Even properly planned & executed site migrations can be hard, and this makes it much more challenging.”
Google’s Site Understanding
Something that I find intriguing is Mueller’s occasional reference to Google’s understanding of a website. He’s mentioned this factor in other contexts in the past and it seems to be a catchall for things that are related to quality but also to something else that he’s referred to in the past as a relevance topic related to understanding where a site fits in the Internet.
In this context, Mueller appears to be using the phrase to mean understanding the site relative to the domain name.