The SEO industry has spent the last couple of decades perfecting the art of looking productive while delivering value some might describe as questionable.
Armed with an extensive suite of analytical tools, SEO is an incredibly data-rich and metric-rich industry. It was easy to generate reports that, on the surface at least, looked impressive to a C-suite eager for more of that “data-led decision making” everyone kept talking about.
These days, the C-suite is less interested in metrics like rankings, traffic, and sessions. They’re finally asking: “So what?”
It’s the same question that killed the “likes and followers” era of social media marketing. Eventually, boards stopped caring about follower counts and started demanding conversion rates, customer acquisition costs, and a measurable return on their investment.
Now it’s SEO’s turn for a reckoning. And answering that question requires a very different skill set from how many SEOs have been trained. Too many SEOs lack that wider business awareness and marketing aptitude to understand how they fit into the bigger picture.
In short, we’re faced with an SEO skills gap which, if left unaddressed, risks SEO teams and agencies falling out of step with the expectations of senior leadership and clients.
Rankings and traffic are still important, don’t get me wrong. But they’re not business outcomes; they’re contributory factors. Yet SEOs continue to cross their fingers in the hope that growth in these metrics will magically translate into sales or some other form of measurable business value. Who measures that value and how it comes about is usually someone else’s problem.
Sales and marketing can fret over the wider strategy. If the vanity metrics continue to show growth, the SEO team sits back, content they’ve done their bit.
Except, with zero-click search on the rise as customers turn increasingly to AI tools, many organizations are seeing their search traffic trending down. That focus on volume over strategy is no longer working.
Connecting The Dots To Business Outcomes
I’ve been watching this shift play out in real time. Over the past few years, I’ve noticed clients focus less on “Can you improve our rankings,” and more on “Can you prove how this contributes to our business growth.”
But as much as I’d like to trust my gut, personal experience hardly qualifies as unequivocal evidence. Unfortunately, I lack the resources to conduct a comprehensive five-year longitudinal analysis to see how employer/client expectations might have changed. So, I conducted a quick straw poll of my network instead.
It’s a small data sample, so apply the appropriate pinch of salt. I simply wanted to get a sense of whether what I’m seeing holds true beyond my business.
It seems it does.
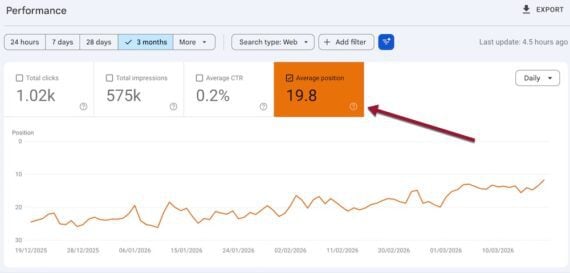
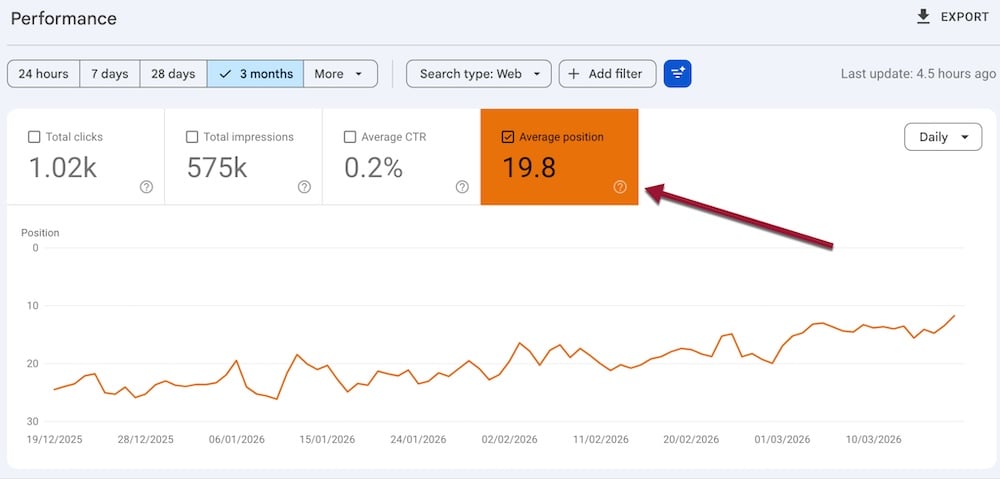
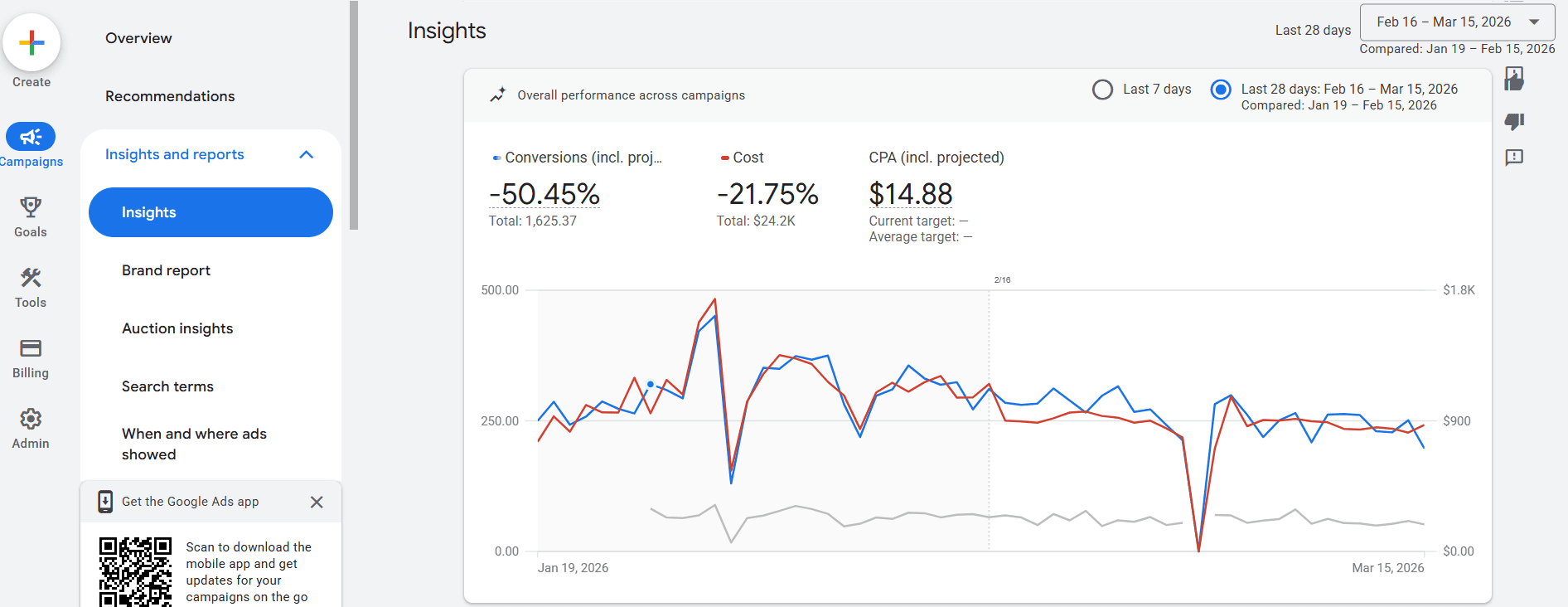
I asked respondents how confident they were in their SEO team’s ability to explain SEO’s contribution to business outcomes like customer acquisition cost (CAC), lifetime value (LTV), and pipeline. Scored on a scale of 1 to 10, the overall average is a smidge over 6.7. Not terrible, but not great either.
But in an environment where budgets are shrinking, a score of just “okay” when it comes to demonstrating business value is potentially fatal.
Simply saying, “Trust us, it helps,” will never survive a CFO review.
SEO’s New Critical Skills
I also asked respondents which skills they consider to be most critical when hiring future SEOs. Unsurprisingly, the top result was:
1. Technical SEO (83%)
Of course, it is. You can’t tune a car without knowing your way around an engine. So no; crawling, indexing, load times, schema … none of it is going away.
But that near-ubiquitousness also means that technical SEO is the price of admission. It’s table stakes. It’s the bare minimum requirement. Being great with technical SEO will get you in the door, but it won’t keep you in the room.
What’s more telling is how many respondents selected critical skills that most SEO teams I encounter still treat as “someone else’s job.”
2. Content strategy and creation (61%)
3. Business acumen – CAC, LTV, revenue forecasting (50%)
4. Communication and stakeholder management (39%)
While the market still needs technicians, it’s increasingly hiring commercial operators. Knowing how to do something is only useful when you can also clearly articulate why.
Meanwhile, the skills that SEOs would normally consider part of their job description languished nearer the bottom of the results.
=5. Data analytics and reporting (33%)
=5. AI/machine‑learning and automation (33%)
That’s not to say SEOs don’t need to worry about these skills. It’s just that they’re less likely to sway an employer or client’s hiring decisions. Like vanity metrics, they’re simply the means to an end. An aptitude for data analytics isn’t a replacement for business acumen, but it helps inform those strategic decisions. AI and automation are useful tools, but they’re no replacement for human-led content creation.
Today, what separates high-performing teams from the rest isn’t their aptitude with technical SEO or their skill with data, but whether they can connect execution to outcomes and defend it in the language of business.
Marketing Fundamentals Matter Now More Than Ever
As SEO evolved into its own discipline, it apparently forgot that search visibility is just one component of a much larger strategic puzzle.
Most SEO teams operate as if their job is to “optimize websites.” It’s not. Their job is to help businesses grow profitably. And you can’t do that without understanding the fundamental building blocks of marketing strategy that have been hammered into every marketing graduate for over 60 years.
The four Ps of Marketing: Product, Price, Place, and Promotion.
Product: Do You Even Know What You’re Selling?
When brothers Michael and Marc Grondahl launched Planet Fitness in 1992, their strategy struck many as completely irrational. They set out to actively repel the industry’s most valuable customers.
The reason was actually quite simple. The brothers wanted to go after the 80-85% of people who didn’t belong to a gym. They realized that a gym full of well-muscled gym junkies lifting heavy weights and posing in front of mirrors is intimidating for casual users.
This insight completely shaped the gym’s launch strategy. Remove heavy weights. Ban string tank tops. No posing mirrors. And because casual users don’t overuse the facilities, gym memberships could be more affordable.
Every decision reinforced the same positioning: This is a judgment-free zone for normal people, not a stage for bodybuilders.
Most SEO teams create content without spending sufficient time trying to understand product positioning or brand messaging. With pressure on to show results quickly, they jump straight to execution, following the usual methodologies and repeatable processes to target the most obvious industry keywords.
And here’s the problem: while you can use SEO tools or AI to generate comprehensive and prioritized keyword lists, they can’t tell you who you should be selling to or how to position the product against competitors. That requires human insight, commercial understanding, and strategic thinking.
- What problem does this product solve?
- Who is it for (and who is it deliberately not for)?
- What differentiates it from the available alternatives?
- What’s the positioning strategy: premium, value, specialist, or generalist?
Price: Understanding Value, Not Just Cost
Pricing isn’t just a number. It’s a strategic signal about quality and positioning to your target market.
For example, the Van Westendorp Price Sensitivity Meter, introduced in 1976 by Dutch economist Peter van Westendorp, helps businesses to determine the price range customers will find most acceptable. It does this by asking four questions:
- At what price would the product be too cheap to trust?
- At what price is it a bargain?
- At what price is it getting expensive but still acceptable?
- At what price is it too expensive to consider?
This methodology is particularly useful when launching a new product that doesn’t (yet) have any obvious competitors. It gauges how much value consumers place on the innovation.
A pricing strategy can fundamentally change who to target and what messaging to use. Yet SEOs don’t always consider a client’s pricing strategy when deciding on an approach.
If the product is positioned as a premium expense, it makes no sense to chase high-volume keywords likely to attract price-sensitive customers. You’re bringing in people who won’t convert because they’re looking for the cheapest option, not the best option.
Place: Digital Shelves And Strategic Positioning
Place focuses on making the product available to customers in the right location and at the right time. In retail, this science is well-established.
According to recent NielsenIQ research, shoppers typically make in-store purchasing decisions in under six seconds. Hence, best-selling items are placed at eye level while less profitable products are relegated to higher or lower shelves.
Online, this decision window widens, as 44% of shoppers take at least three minutes to find a product. But while a website doesn’t have shelves, the principles are otherwise identical. By the time someone is ready to buy, they’re far more likely to default to a brand they’re already familiar with.
In search results, you’re effectively competing for digital eye level: a top three ranking, a featured snippet, an AI overview citation.
But placement extends far beyond search rankings. Can your content be cited by AI tools? Are your conversion paths obvious? Do you appear in comparison articles? Are you positioned alongside competitors in ways that favor your value proposition?
Effective placement isn’t just about identifying the channels where the business wants to be visible. It’s also about developing an interconnected content ecosystem. Just as supermarkets place complementary products together, your content should create logical pathways that guide customers forward.
Promotion: Where SEO Forgets It’s Supposed To Persuade
While Placement is about getting your content and messaging in front of the right people, Promotion is about influencing what happens next. Promotion is the persuasion part.
Imagine someone researching project management tools, comparing Asana, Monday.com, and Basecamp. A landing page titled “Asana vs. Monday.com for agencies” isn’t just informational; it’s promotional. You’re deliberately influencing how they evaluate options and steering them toward a specific conclusion.
Imagine you’re the CMO for a fictional project management tool called … oh, I don’t know … Taskaroo. (I’m no branding expert.) Someone researching project management tools would likely want to compare Taskaroo alongside other likely options: Asana, Monday.com, and Basecamp.
Comparison pages are popular SEO tactics because they target valuable keywords at a key part of the research journey. But a landing page titled “Asana vs. Taskaroo for agencies” has even more value as a promotional tactic. The content on that page is your opportunity to shape how potential customers evaluate their options, framed to favor your own value propositions, of course, in the hope that more people will put Taskaroo into active consideration.
That’s how promotional content should work: meeting people wherever they are in the customer journey and providing the ideal information and messaging to move them forward.
The Friction That Kills Conversion
Promotion is where I see most SEO strategies fall apart. Not because SEOs don’t create content, but because they’ve forgotten that promotion isn’t the same as visibility.
When SEOs don’t think in terms of content ecosystems, mapped to the customer journey, they create unnecessary friction at exactly the moment someone might be ready to move forward.
For example, an ecommerce site publishes an article about running shoes. It’s a handy primer for anyone who’s just getting interested in running, with brief overviews of all the different types: trail running shoes, track shoes, road running shoes. It’s well-written, ranks nicely, and targets someone at the top of the funnel.
But once the reader starts wondering whether they should get a pair of trail running shoes, there’s nowhere for them to go. No suggested further reading on trail running to develop the reader’s interest; no links to guides on what to look for in trail running shoes; no connection to product recommendations. In short, there’s no next step for someone entering the consideration phase of the journey.
Actually, if there is a link, it’s probably in the form of a CTA pointing to the product page in the hope of boosting that page’s rankings. But is it really likely that someone might miraculously jump from awareness to costly conversion in a single bound after only reading a hundred heavily optimized words?
The reader has hit friction. Any further research will mean leaving your site, searching again, and potentially landing on a competitor with a better understanding of their needs. Your SEO team may have done the hard work of attracting the right audience and exciting their interest, only to abandon them at the exact moment they’re ready to go deeper.
This is why content marketing strategy and business acumen are now considered essential SEO skills. While SEO is mostly about building rankings and attracting traffic, content marketing is about nurturing and directing that traffic towards genuine, measurable business outcomes.
And that requires a comprehensive ecosystem of interlinked content spanning the entire journey from initial awareness to conversion and beyond, addressing as many relevant questions, objections, and barriers to purchase as possible along the way.
Flipping The Script On SEO
At the heart of the SEO skills gap sits a fundamental misunderstanding:
The purpose of your content isn’t to boost your SEO. The purpose of SEO is to boost your content.
SEOs use content to rank. Marketers create content to convert. If it’s possible to tell which assets were created for SEO and which were created for Marketing, then you have a problem.
When an SEO creates content purely to rank for a keyword, they’re not thinking about what the customer ultimately hopes to achieve. They’re not thinking about the journey and what happens next. They’re not anticipating what questions might arise. They’re not proactively addressing barriers and concerns that might prevent a purchase decision.
By understanding the four Ps, SEO’s role becomes much clearer. Forget chasing volume with vanity metrics. Truly effective SEO is about building experiences tailored to the customer journey, removing friction at every touchpoint, so that the next step is always obvious and effortless.
The companies that understand this don’t just rank. They convert.
Stop hiring “SEO Specialists” and start hiring growth marketers with SEO expertise who understand how their work contributes to customer acquisition efficiency, pipeline growth, and profitability.
More Resources:
Featured Image: Na_Studio/Shutterstock