This week we heard that eight babies have been born in the UK following an experimental form of IVF that involves DNA from three people. The approach was used to prevent women with genetic mutations from passing mitochondrial diseases to their children. You can read all about the results, and the reception to them, here.
But these eight babies aren’t the first “three-parent” children out there. Over the last decade, several teams have been using variations of this approach to help people have babies. This week, let’s consider the other babies born from three-person IVF.
I can’t go any further without talking about the term we use to describe these children. Journalists, myself included, have called them “three-parent babies” because they are created using DNA from three people. Briefly, the approach typically involves using the DNA from the nuclei of the intended parents’ egg and sperm cells. That’s where most of the DNA in a cell is found.
But it also makes use of mitochondrial DNA (mtDNA)—the DNA found in the energy-producing organelles of a cell—from a third person. The idea is to avoid using the mtDNA from the intended mother, perhaps because it is carrying genetic mutations. Other teams have done this in the hope of treating infertility.
mtDNA, which is usually inherited from a person’s mother, makes up a tiny fraction of total inherited DNA. It includes only 37 genes, all of which are thought to play a role in how mitochondria work (as opposed to, say, eye color or height).
That’s why some scientists despise the term “three-parent baby.” Yes, the baby has DNA from three people, but those three can’t all be considered parents, critics argue. For the sake of argument, this time around I’ll use the term “three-person IVF” from here on out.
So, about these babies. The first were reported back in the 1990s. Jacques Cohen, then at Saint Barnabas Medical Center in Livingston, New Jersey, and his colleagues thought they might be able to treat some cases of infertility by injecting the mitochondria-containing cytoplasm of healthy eggs into eggs from the intended mother. Seventeen babies were ultimately born this way, according to the team. (Side note: In their paper, the authors describe potential resulting children as “three-parental individuals.”)
But two fetuses appeared to have genetic abnormalities. And one of the children started to show signs of a developmental disorder. In 2002, the US Food and Drug Administration put a stop to the research.
The babies born during that study are in their 20s now. But scientists still don’t know why they saw those abnormalities. Some think that mixing mtDNA from two people might be problematic.
Newer approaches to three-person IVF aim to include mtDNA from just the donor, completely bypassing the intended mother’s mtDNA. John Zhang at the New Hope Fertility Center in New York City tried this approach for a Jordanian couple in 2016. The woman carried genes for a fatal mitochondrial disease and had already lost two children to it. She wanted to avoid passing it on to another child.
Zhang took the nucleus of the woman’s egg and inserted it into a donor egg that had had its own nucleus removed—but still had its mitochondria-containing cytoplasm. That egg was then fertilized with the woman’s husband’s sperm.
Because it was still illegal in the US, Zhang controversially did the procedure in Mexico, where, as he told me at the time, “there are no rules.” The couple eventually welcomed a healthy baby boy. Less than 1% of the boy’s mitochondria carried his mother’s mutation, so the procedure was deemed a success.
There was a fair bit of outrage from the scientific community, though. Mitochondrial donation had been made legal in the UK the previous year, but no clinic had yet been given a license to do it. Zhang’s experiment seemed to have been conducted with no oversight. Many questioned how ethical it was, although Sian Harding, who reviewed the ethics of the UK procedure, then told me it was “as good as or better than what we’ll do in the UK.”
The scandal had barely died down by the time the next “three-person IVF” babies were announced. In 2017, a team at the Nadiya Clinic in Ukraine announced the birth of a little girl to parents who’d had the treatment for infertility. The news brought more outrage from some quarters, as scientists argued that the experimental procedure should only be used to prevent severe mitochondrial diseases.
It wasn’t until later that year that the UK’s fertility authority granted a team in Newcastle a license to perform mitochondrial donation. That team launched a trial in 2017. It was big news—the first “official” trial to test whether the approach could safely prevent mitochondrial disease.
But it was slow going. And meanwhile, other teams were making progress. The Nadiya Clinic continued to trial the procedure in couples with infertility. Pavlo Mazur, a former embryologist who worked at that clinic, tells me that 10 babies were born there as a result of mitochondrial donation.
Mazur then moved to another clinic in Ukraine, where he says he used a different type of mitochondrial donation to achieve another five healthy births for people with infertility. “In total, it’s 15 kids made by me,” he says.
But he adds that other clinics in Ukraine are also using mitochondrial donation, without sharing their results. “We don’t know the actual number of those kids in Ukraine,” says Mazur. “But there are dozens of them.”
In 2020, Nuno Costa-Borges of Embryotools in Barcelona, Spain, and his colleagues described another trial of mitochondrial donation. This trial, performed in Greece, was also designed to test the procedure for people with infertility. It involved 25 patients. So far, seven children have been born. “I think it’s a bit strange that they aren’t getting more credit,” says Heidi Mertes, a medical ethicist at Ghent University in Belgium.
The newly announced UK births are only the latest “three-person IVF” babies. And while their births are being heralded as a success story for mitochondrial donation, the story isn’t quite so simple. Three of the eight babies were born with a non-insignificant proportion of mutated mitochondria, ranging between 5% and 20%, depending on the baby and the sample.
Dagan Wells of the University of Oxford, who is involved in the Greece trial, says that two of the seven babies in their study also appear to have inherited mtDNA from their intended mothers. Mazur says he has seen several cases of this “reversal” too.
This isn’t a problem for babies whose mothers don’t carry genes for mitochondrial disease. But it might be for those whose mothers do.
I don’t want to pour cold water over the new UK results. It was great to finally see the results of a trial that’s been running for eight years. And the births of healthy babies are something to celebrate. But it’s not a simple success story. Mitochondrial donation doesn’t guarantee a healthy baby. We still have more to learn, not only from these babies, but from the others that have already been born.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
There are many businesses relatively new to SEO that eventually face the decision to build or buy links because they are told that links are important, which, of course, links are important. But the need to buy links presupposes that buying them is the only way to acquire them. Links are important, but less important than at any time in the history of SEO.
How Do I Know So Much About Links?
I have been doing SEO for 25 years, at one time specializing in links. I did more than links, but I was typecast as a “links guy” because I was the moderator of the Link Building Forum at WebmasterWorld under the martinibuster nickname. WebmasterWorld was at one time the most popular source of SEO information in the world. Being a WebmasterWorld moderator was an honor, and only the best of the very best were invited to become one. Many top old-school SEOs were moderators there, like Jennifer Slegg, Greg Boser, Todd Friesen, Dixon Jones, Ash Nallawalla, and many more.
That’s not to brag, but to explain that my opinion comes from decades-long experience starting from the very dawn of link building. There are very few people who have as deep hands-on experience with links. So this is my advice based on my experience.
Short History Of Link Building
Google’s link algorithms have steadily improved since the early days. As early as 2003, I was told by Google engineer Marissa Mayer (then at Google, before becoming CEO of Yahoo) that Google was able to distinguish that a link in the footer was a “built by” link and to not count it for PageRank. This crushed sites that relied on footer links to power their rankings.
2005 – Statistical Analysis In 2005, Google engineers announced at the Pubcon New Orleans search conference that they were using statistical analysis to catch unnatural linking patterns. Their presentation featured graphs showing a curve representing normal linking patterns and then a separate cloud of red dots that represented unnatural links.
Links That “Look” Natural If you’ve ever read the phrase “links that look natural” or “natural-looking links” and wondered where that came from, statistical analysis algorithms is the answer. After 2005, the goal for manipulative links was to look natural, which meant doing things like alternating the anchor text, putting links into context, and being careful about outbound link targets.
Demise Of Easy Link Tactics By 2006, Google had neutralized the business of reciprocal links, traffic counter link building, and was winding down the business of link directories.
WordPress Was Good For Link Building WordPress was a boon to link builders because it made it possible for more people to get online and build websites, increasing the ability to obtain links by asking or throwing money at them. There were also sites like Geocities that hosted mini-sites, but most of the focus was on standalone sites, maybe because of PageRank considerations (PageRank was visible in the Google Toolbar).
Rise Of Paid Links Seemingly everyone built websites on virtually any topic, which made link building easier to do simply by asking for a link. Companies like Text-Link-Ads came along and built huge networks of thousands of independent websites on virtually every topic, and they made a ton of money. I knew some people who sold links from their network of sites who were earning $40,000/month in passive income. White hat SEOs celebrated link selling because they said it was legitimate advertising (wink, wink), and therefore Google wouldn’t penalize it.
Fall Of Paid Links The paid links party ended in the years leading up to 2012, when paid links began losing their effectiveness. As a link building moderator, I had access to confidential information and was told by insiders that paid links were having less and less effect. Then 2012’s Penguin Update happened, and suddenly thousands of websites got hit by manual actions for paid links and guest posting links.
Ranking Where You’re Supposed To Rank
The Penguin Algorithm marked a turning point in the business of building links. Internally at Google there must have been a conversation about the punitive aspect of catching links and at some point not long after Google started ranking sites where they were supposed to rank instead of penalizing them.
In fact, I coined the phrase “ranking where you’re supposed to rank” in 2014 to show that while sites with difficulty ranking may not technically have a penalty, their links are ineffective and they are ranking where they are supposed to rank.
There’s a class of link sellers that sell what they call Private Blog Network links. PBN sellers depend on Google to not penalize a site and depend on Google to give a site a temporary boost which happens for many links. But the sites inevitably return to ranking where they’re supposed to rank.
Ranking poorly is not a big deal for churn and burn affiliate sites designed to rank high for a short period of time. But it’s a big deal for businesses that depend on a website to be ranking well every day.
Consequences Of Poor SEO
Receiving a manual action is a big deal because it takes a website out of action until Google restores the rankings. Recovering from a manual action is difficult and requires a site to go above and beyond by removing every single low-quality link they are responsible for, and sometimes more than that. Publishers are often disappointed after a manual action is lifted because their sites don’t return to their former high rankings. That’s because they’re ranking where they’re supposed to rank.
For that reason, buying links is not an option for B2B sites, personal injury websites, big-brand websites, or any other businesses that depend on rankings. An SEO or business owner will have to answer for a catastrophic loss in traffic and earnings should their dabbling in paid links backfire.
Personal injury SEO is a good example of why relying on links can be risky. It’s a subset of local search, where rankings are determined by local search algorithms. While links may help, the algorithm is influenced by other factors like local citations, which are known to have a strong impact on rankings. Even if a site avoids a penalty, links alone won’t carry it, and the best-case scenario is that the site ends up ranking where it’s supposed to rank. The worst-case scenario is a manual action for manipulative links.
I’ve assisted businesses with their reconsideration requests to get out of a manual action, and it’s a major hassle. In the old days, I could just send an email to someone at Google or Yahoo and get the penalty lifted relatively quickly. Getting out of a manual action today is not easy. It’s a big, big deal.
The point is that if the consequences of a poor SEO strategy are catastrophic, then buying links is not an option.
Promotion Is A Good Strategy
Businesses can still promote their websites without depending heavily on links. SEOs tend to narrow their views of promotion to just links. Link builders will turn down an opportunity to publish an article for distribution to tens of thousands of potential customers because the article is in an email or a PDF and doesn’t come with a link on a web page.
How dumb is that, right? That’s what thinking in the narrow terms of SEO does: it causes people to avoid promoting a site in a way that builds awareness in customers—the people who may be interested in a business. Creating awareness and building love for a business is the kind of thing that, in my opinion, leads to those mysterious external signals of trustworthiness that Google looks for.
Promotion is super important, and it’s not the kind of thing that fits into the narrow “get links” mindset. Any promotional activity a business undertakes outside the narrow SEO paradigm is going to go right over the head of the competition. Rather than obsessing over links, it may be a turning point for all businesses to return to thinking of ways to promote the site, because links are less important today than they ever have been, while external signals of trust, expertise, and authoritativeness are quite likely more important today than at any other time in SEO history.
Takeaways
Link Building’s Declining Value: Links are still important, but less so than in the past; their influence on rankings has steadily decreased.
Google’s Increasingly Sophisticated Link Algorithms: Google has increasingly neutralized manipulative link strategies through algorithm updates and statistical detection methods.
Rise and Fall of Paid Link Schemes: Paid link networks once thrived but became increasingly ineffective by 2012, culminating in penalties via the Penguin update.
Ranking Where You’re Supposed to Rank: Google now largely down-ranks or ignores manipulative links, meaning sites rank based on actual quality and relevance. Sites can still face manual actions, so don’t depend on Google continuing to down-rank manipulative links.
Risks of Link Buying: Manual actions are difficult to recover from and can devastate sites that rely on rankings for revenue.
Local SEO Factors Rely Less On Links: For industries like personal injury law, local ranking signals (e.g., citations) often outweigh link impact.
Promotion Beyond Links: Real promotion builds brand awareness and credibility, often in ways that don’t involve links but may influence user behavior signals. External user behavior signals have been a part of Google’s signals since the very first PageRank algorithm, which itself models user behavior.
Learn more about Google’s external user behavior signals and ranking without links:
Google’s John Mueller and Martin Splitt discussed making changes to a web page, observing the SEO effect, and the importance of tracking those changes. There has been long-standing hesitation around making too many SEO changes because of a patent filed years ago about monitoring frequent SEO updates to catch attempts to manipulate search results, so Mueller’s answer to this question is meaningful in the context of what’s considered safe.
Does this mean it’s okay now to keep making changes until the site ranks well? Yes, no, and probably. The issue was discussed on a recent Search Off the Record podcast.
Is It Okay To Make Content Changes For SEO Testing?
The context of the discussion was a hypothetical small business owner who has a website and doesn’t really know much about SEO. The situation is that they want to try something out to see if it will bring more customers.
Martin Splitt set up the discussion as the business owner asking different people for their opinions on how to update a web page but receiving different answers. Splitt then asks whether going ahead and changing the page is safe to do.
Martin asked:
“And I want to try something out. Can I just do that or do I hurt my website when I just try things out?”
Mueller affirmed that it’s okay to get ahead and try things out, commenting that most content management systems (CMS) enable a user to easily make changes to the content.
He responded:
“…for the most part you can just try things out. One of the nice parts about websites is, often, if you’re using a CMS, you can just edit the page and it’s live, and it’s done. It’s not that you have to do some big, elaborate …work to put it live.”
In the old days, Google used to update its index once a month. So SEOs would make their web page changes and then wait for the monthly update to see if those changes had an impact. Nowadays, Google’s index is essentially on a rolling update, responding to new content as it gets indexed and processed, with SERPs being re-ranked in reaction to changes, including user trends where something becomes newsworthy or seasonal (that’s where the freshness algorithm kicks in).
Making changes to a small site that doesn’t have much traffic is an easy thing. Making changes to a website responsible for the livelihood of dozens, scores, or even hundreds of people is a scary thing. So when it comes to testing, you really need to balance the benefits against the possibility that a change might set off a catastrophic chain of events.
Monitoring The SEO Effect
Mueller and Splitt next talked about being prepared to monitor the changes.
Mueller continued his answer:
“It’s very easy to try things out, let it sit for a couple of weeks, see what happens and kind of monitor to see is it doing what you want it to be doing. I guess, at that point, when we talk about monitoring, you probably need to make sure that you have the various things installed so that you actually see what is happening.
Perhaps set up Search Console for your website so that you see the searches that people are doing. And, of course, some way to measure the goal that you want, which could be something perhaps in Analytics or perhaps there’s, I don’t know, some other way that you track in person if you have a physical store, like are people actually coming to my business after seeing my website, because it’s all well and good to do SEO, but if you have no way of understanding has it even changed anything, you don’t even know if you’re on the right track or recognize if something is going wrong.”
Something that Mueller didn’t mention is the impact on user behavior on a web page. Does the updated content make people scroll less? Does it make them click on the wrong thing? Do people bounce out at a specific part of the web page?
That’s the kind of data Google Analytics does not provide because that’s not what it’s for. But you can get that data with a free Microsoft Clarity account. Clarity is a user behavior analytics SaaS app. It shows you where (anonymized) users are on a page and what they do. It’s an incredible window on web page effectiveness.
Martin Splitt responded:
“Yeah, that’s true. Okay, so I need a way of measuring the impact of my changes. I don’t know, if I make a new website version and I have different texts and different images and everything is different, will I immediately see things change in Search Console or will that take some time?”
Mueller responded that the amount of time it takes for changes to show up in Search Console depends on how big the site is and the scale of the changes.
Mueller shared:
“…if you’re talking about something like a homepage, maybe one or two other pages, then probably within a week or two, you should see that reflected in Search. You can search for yourself initially.
That’s not forbidden to search for yourself. It’s not that something will go wrong or anything. Searching for your site and seeing, whatever change that you made, has that been reflected. Things like, if you change the title to include some more information, you can see fairly quickly if that got picked up or not.”
When Website Changes Go Wrong
Martin next talks about what I mentioned earlier: when a change goes wrong. He makes the distinction between a technical change and changes for users. A technical change can be tested on a staging site, which is a sandboxed version of the website that search engines or users don’t see. This is actually a pretty good thing to do before updating WordPress plugins or doing something big like swapping out the template. A staging site enables you to test technical changes to make sure there’s nothing wrong. Giving the staged site a crawl with Screaming Frog to check for broken links or other misconfigurations is a good idea.
Mueller said that changes for SEO can’t be tested on a staged site, which means that whatever changes are made, you have to be prepared for the consequences.
Listen to The Search Off The Record from about the 24 minute mark:
Millions of images of passports, credit cards, birth certificates, and other documents containing personally identifiable information are likely included in one of the biggest open-source AI training sets, new research has found.
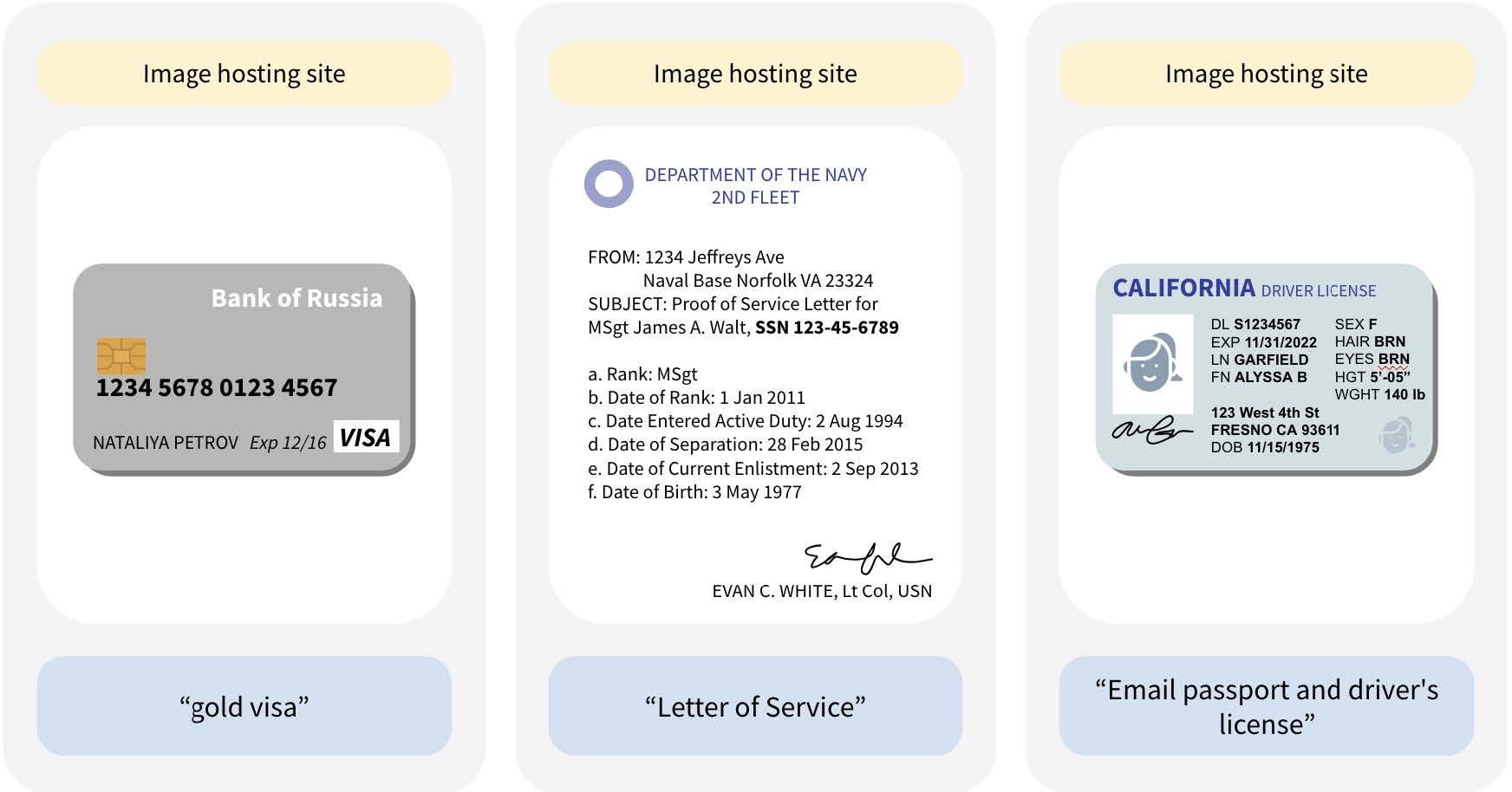
Thousands of images—including identifiable faces—were found in a small subset of DataComp CommonPool, a major AI training set for image generation scraped from the web. Because the researchers audited just 0.1% of CommonPool’s data, they estimate that the real number of images containing personally identifiable information, including faces and identity documents, is in the hundreds of millions. The study that details the breach was published on arXiv earlier this month.
The bottom line, says William Agnew, a postdoctoral fellow in AI ethics at Carnegie Mellon University and one of the coauthors, is that “anything you put online can [be] and probably has been scraped.”
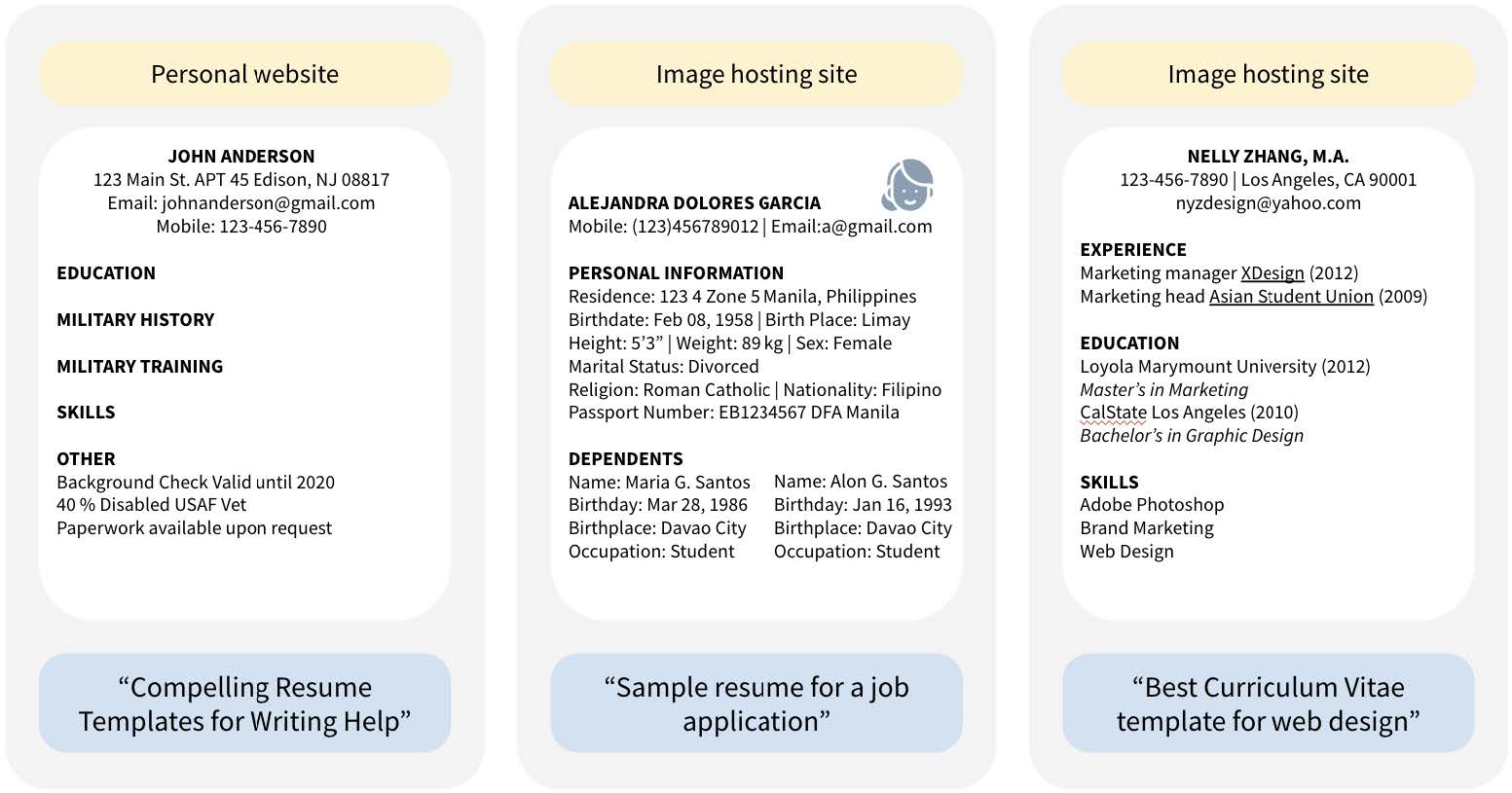
The researchers found thousands ofinstances of validated identity documents—including images of credit cards, driver’s licenses, passports, and birth certificates—as well as over 800 validated job application documents (including résumés and cover letters), which were confirmed through LinkedIn and other web searches as being associated with real people. (In many more cases, the researchers did not have time to validate the documents or were unable to because of issues like image clarity.)
A number of the résumés disclosed sensitive information including disability status, the results of background checks, birth dates and birthplaces of dependents, and race. When résumés were linked to people with online presences, researchers also found contact information, government identifiers, sociodemographic information, face photographs, home addresses, and the contact information of other people (like references).
Examples of identity-related documents found in CommonPool’s small-scale data set show a credit card, a Social Security number, and a driver’s license. For each sample, the type of URL site is shown at the top, the image in the middle, and the caption in quotes below. All personal information has been replaced, and text has been paraphrased to avoid direct quotations. Images have been redacted to show the presence of faces without identifying the individuals.
COURTESY OF THE RESEARCHERS
When it was released in 2023, DataComp CommonPool, with its 12.8 billion data samples, was the largest existing data set of publicly available image-text pairs, which are often used to train generative text-to-image models. While its curators said that CommonPool was intended for academic research, its license does not prohibit commercial use as well.
CommonPool was created as a follow-up to the LAION-5B data set, which was used to train models including Stable Diffusion and Midjourney. It draws on the same data source: web scraping done by the nonprofit Common Crawl between 2014 and 2022.
While commercial models often do not disclose what data sets they are trained on, the shared data sources of DataComp CommonPool and LAION-5B mean that the data sets are similar, and that the same personally identifiable information likely appears in LAION-5B, as well as in other downstream models trained on CommonPool data. CommonPool researchers did not respond to emailed questions.
And since DataComp CommonPool has been downloaded more than 2 million times over the past two years, it is likely that “there [are]many downstream models that are all trained on this exact data set,” says Rachel Hong, a PhD student in computer science at the University of Washington and the paper’s lead author. Those would duplicate similar privacy risks.
Good intentions are not enough
“You can assume that any large-scale web-scraped data always contains content that shouldn’t be there,” says Abeba Birhane, a cognitive scientist and tech ethicist who leads Trinity College Dublin’s AI Accountability Lab—whether it’s personally identifiable information (PII), child sexual abuse imagery, or hate speech (which Birhane’s own research into LAION-5B has found).
Indeed, the curators of DataComp CommonPool were themselves aware it was likely that PII would appear in the data set and did take some measures to preserve privacy, including automatically detecting and blurring faces. But in their limited data set, Hong’s team found and validated over 800 faces that the algorithm had missed, and they estimated that overall, the algorithm had missed 102 million faces in the entire data set. On the other hand, they did not apply filters that could have recognized known PII character strings, like emails or Social Security numbers.
“Filtering is extremely hard to do well,” says Agnew. “They would have had to make very significant advancements in PII detection and removal that they haven’t made public to be able to effectively filter this.”
Examples of résumé documents and personal disclosures found in CommonPool’s small-scale data set. For each sample, the type of URL site is shown at the top, the image in the middle, and the caption in quotes below. All personal information has been replaced, and text has been paraphrased to avoid direct quotations. Images have been redacted to show the presence of faces without identifying the individuals. Image courtesy of the researchers.
COURTESY OF THE RESEARCHERS
There are other privacy issues that the face blurring doesn’t address. While the blurring filter is automatically applied, it is optional and can be removed. Additionally, the captions that often accompany the photos, as well as the photos’ metadata, often contain even more personal information, such as names and exact locations.
Another privacy mitigation measure comes from Hugging Face, a platform that distributes training data sets and hosts CommonPool, which integrates with a tool that theoretically allows people to search for and remove their own information from a data set. But as the researchers note in their paper, this would require people to know that their data is there to start with. When asked for comment, Florent Daudens of Hugging Face said that “maximizing the privacy of data subjects across the AI ecosystem takes a multilayered approach, which includes but is not limited to the widget mentioned,” and that the platform is “working with our community of users to move the needle in a more privacy-grounded direction.”
In any case, just getting your data removed from one data set probably isn’t enough. “Even if someone finds out their data was used in a training data sets and … exercises their right to deletion, technically the law is unclear about what that means,” says Tiffany Li, an associate professor of law at the University of San Francisco School of Law. “If the organization only deletes data from the training data sets—but does not delete or retrain the already trained model—then the harm will nonetheless be done.”
The bottom line, says Agnew, is that “if you web-scrape, you’re going to have private data in there. Even if you filter, you’re still going to have private data in there, just because of the scale of this. And that’s something that we [machine-learning researchers], as a field, really need to grapple with.”
Reconsidering consent
CommonPool was built on web data scraped between 2014 and 2022, meaning that many of the images likely date to before 2020, when ChatGPT was released. So even if it’s theoretically possible that some people consented to having their information publicly available to anyone on the web, they could not have consented to having their data used to train large AI models that did not yet exist.
And with web scrapers often scraping data from each other, an image that was originally uploaded by the owner to one specific location would often find its way into other image repositories. “I might upload something onto the internet, and then … a year or so later, [I] want to take it down, but then that [removal] doesn’t necessarily do anything anymore,” says Agnew.
The researchers also found numerous examples of children’s personal information, including depictions of birth certificates, passports, and health status, but in contexts suggesting that they had been shared for limited purposes.
“It really illuminates the original sin of AI systems built off public data—it’s extractive, misleading, and dangerous to people who have been using the internet with one framework of risk, never assuming it would all be hoovered up by a group trying to create an image generator,” says Ben Winters, the director of AI and privacy at the Consumer Federation of America.
Finding a policy that fits
Ultimately, the paper calls for the machine-learning community to rethink the common practice of indiscriminate web scraping and also lays out the possible violations of current privacy laws represented by the existence of PII in massive machine-learning data sets, as well as the limitations of those laws’ ability to protect privacy.
“We have the GDPR in Europe, we have the CCPA in California, but there’s still no federal data protection law in America, which also means that different Americans have different rights protections,” says Marietje Schaake, a Dutch lawmaker turned tech policy expert who currently serves as a fellow at Stanford’s Cyber Policy Center.
Besides, these privacy laws apply to companies that meet certain criteria for size and other characteristics. They do not necessarily apply to researchers like those who were responsible for creating and curating DataComp CommonPool.
And even state laws that do address privacy, like California’s consumer privacy act, have carve-outs for “publicly available” information. Machine-learning researchers have long operated on the principle that if it’s available on the internet, then it is public and no longer private information, but Hong, Agnew, and their colleagues hope that their research challenges this assumption.
“What we found is that ‘publicly available’ includes a lot of stuff that a lot of people might consider private—résumés, photos, credit card numbers, various IDs, news stories from when you were a child, your family blog. These are probably not things people want to just be used anywhere, for anything,” says Hong.
Hopefully, Schaake says, this research “will raise alarm bells and create change.”
This article previously misstated Tiffany Li’s affiliation. This has been fixed.
Ray Reddy is a two-time mobile commerce entrepreneur, a Google veteran, and, now, the head of Shopify POS, the company’s in-store platform. He says the future of retail is location-agnostic, where shoppers can easily transition from online to brick-and-mortar without losing account details, order history, and similar info.
That, he says, is the path of Shopify POS.
In our recent conversation, he addressed Shopify’s physical-store penetration, the needs of modern shoppers, backend complexities, and more.
Our entire audio is embedded below. The transcript is edited for length and clarity.
Eric Bandholz: Give us a rundown of what you do.
Ray Reddy: I lead Shopify’s retail product team, focused on evolving Shopify POS into an all-in-one system for in-person commerce, from pop-ups to large multi-store enterprises.
Before Shopify, I built two commerce companies. The first, PushLife, was a mobile commerce platform acquired by Google, which I then joined and led the company’s mobile commerce products. Later, I founded Ritual, a social ordering app for restaurants and businesses. My team and I left Ritual in January this year and joined Shopify.
Shopify serves online and offline merchants in over 170 countries across nearly every vertical.
In online commerce, workflows are largely standardized, including product pages, carts, and checkout flows. But in-person retail varies drastically. A coffee shop operates nothing like a furniture store or a spa. Each vertical has distinct workflows, such as table management, appointment scheduling, or barcode scanning.
Historically, success in physical retail meant focusing on a single niche. However, many verticals also sell online and want one unified system for inventory, customers, and transaction data. They’d rather use a single platform than patch together disconnected tools.
Shopify POS’s flexibility and ecosystem are a long-term fit for many growing businesses.
Bandholz: Tell us about your target audience.
Reddy: Our core point-of-sale customers tend to fall into a few categories: apparel, sporting goods, beauty and cosmetics, and gift or novelty retailers. We’re also seeing growth in pet stores, bike shops, and jewelry retailers.
We now serve brands with over 1,000 stores. That’s been a considerable shift over the last couple of years, from a system that works for a single store to one that also meets the complex needs of large chains.
Point-of-sale capability at Shopify was originally a lightweight add-on to ecommerce. No more. Over 10% of POS users are brick-and-mortar only.
Our vision remains a POS system that’s simple enough for a single store and robust enough to support thousands. We’re making progress, but there’s a lot of work ahead.
Bandholz: How can direct-to-consumer brands use POS?
Reddy: We refer to individuals selling at pop-ups or farmers’ markets as “casual sellers.” That’s often the first offline step for online brands. We’ve seen companies such as Allbirds start small with Shopify and scale into publicly traded businesses with dozens of stores. That kind of journey — from side hustle to national brand — is something we’re proud to support.
Contactless payments — tap to pay — are widespread. We’ve integrated the technology into the entire POS experience. But selling in person is more than taking payments. Sellers need lightweight inventory tools, stock counts, and real-time syncing between online and offline. Something as simple as buying a mattress in-store and having it shipped requires more than a basic payment app.
The key is minimizing friction. A good POS platform shouldn’t force sellers to fumble through screens. It should handle all the backend complexity — inventory, fulfillment, compliance — so sellers can stay present and build relationships with customers.
Bandholz: What’s the POS experience of placing in-person orders for shipment?
Reddy: One of our most recent improvements in Shopify POS is “mixed baskets,” orders that include in-store and shipped items. Merchants previously had to create multiple orders or use workarounds. With the launch of POS 10 in April, in-store staff can process a single mixed-basket order and payment. It simplifies complex workflows.
We look for opportunities to reduce friction by monitoring how customers use POS. For example, POS 10 reduced cart-building times by 5% across the board. Some merchants with complex carts saw up to a 10% improvement in speed.
We’ve also overhauled search. Previously, it required exact text matches, which was frustrating for staff with extensive catalogs. We’ve now introduced fuzzy matching that behaves more like Google Search. One home goods retailer with 47,000 SKUs reported it was a game-changer.
We also focus on ease of use for temporary or seasonal staff. Many stores don’t have time for extensive training. One pop-up apparel brand reported that their seasonal employees were able to learn the POS system in a single shift.
Bandholz: Does Shopify POS link with Shop Pay?
Reddy: Shopify POS integrates with Shop Pay at many retailers, though not all. This integration is a key area of ongoing investment. The future of retail combines the convenience of online shopping with the tangible in-store experience. One common frustration for in-store shoppers is the time it takes to find products or wait for staff assistance, unlike the quick, one-click experience online.
Our goal is to merge online profiles and capabilities with in-store shopping. For example, customers who want items shipped to their homes often have to provide their full address at checkout — information already stored in their Shop Pay profile. Transferring that data instantly to the store system would remove friction and speed up the checkout.
Beyond payment, there’s a huge opportunity to enhance the buyer experience by linking online activity to in-store shopping. Imagine seeing items you added to your online cart just a few feet away in a physical store, ready for purchase. Connecting customers’ online intent with their in-store experience offers a significant advantage and exciting possibilities.
Bandholz: Where can people learn about POS and connect with you?
The CEO of Conductor started a LinkedIn discussion about the future of AI SEO platforms, suggesting that the established companies will dominate and that 95 percent of the startups will disappear. Others argued that smaller companies will find their niche and that startups may be better positioned to serve user needs.
Besmertnik published his thoughts on why top platforms like Conductor, Semrush, and Ahrefs are better positioned to provide the tools users will need for AI chatbot and search visibility. He argued that the established companies have over a decade of experience crawling the web and scaling data pipelines, with which smaller organizations cannot compete.
Conductor’s CEO wrote:
“Over 30 new companies offering AI tracking solutions have popped up in the last few months. A few have raised some capital to get going. Here’s my take: The incumbents will win. 95% of these startups will flatline into the SaaS abyss.
…We work with 700+ enterprise brands and have 100+ engineers, PMs, and designers. They are all 100% focused on an AI search only future. …Collectively, our companies have hundreds of millions of ARR and maybe 1000x more engineering horsepower than all these companies combined.
Sure we have some tech debt and legacy. But our strengths crush these disadvantages…
…Most of the AEO/GEO startups will be either out of business or 1-3mm ARR lifestyle businesses in ~18 months. One or two will break through and become contenders. One or two of the largest SEO ‘incumbents’ will likely fall off the map…”
Is There Room For The “Lifestyle” Businesses?
Besmertnik’s remarks suggested that smaller tool companies earning one to three million dollars in annual recurring revenue, what he termed “lifestyle” businesses, would continue as viable companies but stood no chance of moving upward to become larger and more established enterprise-level platforms.
Rand Fishkin, cofounder of SparkToro, defended the smaller “lifestyle” businesses, saying that it feels like cheating at business, happiness, and life.
He wrote:
“Nothing better than a $1-3M ARR “lifestyle” business.
…Let me tell you what I’m never going to do: serve Fortune 500s (nevermind 100s). The bureaucracy, hoops, and friction of those orgs is the least enjoyable, least rewarding, most avoid-at-all-costs thing in my life.”
Not to put words into Rand’s mouth but it seems that what he’s saying is that it’s absolutely worthwhile to scale a business to a point where there’s a work-life balance that makes sense for a business owner and their “lifestyle.”
Case For Startups
Not everyone agreed that established brands would successfully transition from SEO tools to AI search, arguing that startups are not burdened by legacy SEO ideas and infrastructure, and are better positioned to create AI-native solutions that more accurately follow how users interact with AI chatbots and search.
Daniel Rodriguez, cofounder of Beewhisper, suggested that the next generation of winners may not be “better Conductors,” but rather companies that start from a completely different paradigm based on how AI users interact with information. His point of view suggests that legacy advantages may not be foundations for building strong AI search tools, but rather are more like anchors, creating a drag on forward advancement.
He commented:
“You’re 100% right that the incumbents’ advantages in crawling, data processing, and enterprise relationships are immense.
The one question this raises for me is: Are those advantages optimized for the right problem? All those strengths are about analyzing the static web – pages, links, and keywords.
But the new user journey is happening in a dynamic, conversational layer on top of the web. It’s a fundamentally different type of data that requires a new kind of engine.
My bet is that the 1-2 startups that break through won’t be the ones trying to build a better Conductor. They’ll be the ones who were unburdened by legacy and built a native solution for understanding these new conversational journeys from day one.”
Venture Capital’s Role In The AI SEO Boom
Mike Mallazzo, Ads + Agentic Commerce @ PayPal, questioned whether there’s a market to support multiple breakout startups and suggested that venture capital interest in AEO and GEO startups may not be rational. He believes that the market is there for modest, capital-efficient companies rather than fund-returning unicorns.
Mallazzo commented:
“I admire the hell out of you and SEMRush, Ahrefs, Moz, etc– but y’all are all a different breed imo– this is a space that is built for reasonably capital efficient, profitable, renegade pirate SaaS startups that don’t fit the Sand Hill hyper venture scale mold. Feels like some serious Silicon Valley naivete fueling this funding run….
Even if AI fully eats search, is the analytics layer going to be bigger than the one that formed in conventional SEO? Can more than 1-2 of these companies win big?”
New Kinds Of Search Behavior And Data?
Right now it feels like the industry is still figuring out what is necessary to track, what is important for AI visibility. For example, brand mentions is emerging as an important metric, but is it really? Will brand mentions put customers in the ecommerce checkout cart?
And then there’s the reality of zero click searches, the idea that AI Search significantly wipes out the consideration stage of the customer’s purchasing journey, the data is not there, it’s swallowed up in zero click searches. So if you’re going to talk about tracking user’s journey and optimizing for it, this is a piece of the data puzzle that needs to be solved.
Michael Bonfils, a 30-year search marketing veteran, raised these questions in a discussion about zero click searches and what to do to better survive it, saying:
“This is, you know, we have a funnel, we all know which is the awareness consideration phase and the whole center and then finally the purchase stage. The consideration stage is the critical side of our funnel. We’re not getting the data. How are we going to get the data?
So who who is going to provide that? Is Google going to eventually provide that? Do they? Would they provide that? How would they provide that?
But that’s very important information that I need because I need to know what that conversation is about. I need to know what two people are talking about that I’m talking about …because my entire content strategy in the center of my funnel depends on that greatly.”
There’s a real question about what type of data these companies are providing to fill the gaps. The established platforms were built for the static web, keyword data, and backlink graphs. But the emerging reality of AI search is personalized and queryless. So, as Michael Bonfils suggested, the buyer journeys may occur entirely within AI interfaces, bypassing traditional SERPs altogether, which is the bread and butter of the established SEO tool companies.
AI SEO Tool Companies: Where Your Data Will Come From Next
If the future of search is not about search results and the attendant search query volumes but a dynamic dialogue, the kinds of data that matter and the systems that can interpret them will change. Will startups that specialize in tracking and interpreting conversational interactions become the dominant SEO tools? Companies like Conductor have a track record of expertly pivoting in response to industry needs, so how it will all shake out remains to be seen.
I’ve spent years working with Google’s SEO tools, and while there are countless paid options out there, Google’s free toolkit remains the foundation of my optimization workflow.
These tools show you exactly what Google considers important, and that offers invaluable insights you can’t get anywhere else.
Let me walk you through the five Google tools I use daily and why they’ve become indispensable for serious SEO work.
1. Lighthouse
Screenshot from Chrome DevTool, July 2025
When I first discovered Lighthouse tucked away in Chrome’s developer tools, it felt like finding a secret playbook from Google.
This tool has become my go-to for quick site audits, especially when clients come to me wondering why their perfectly designed website isn’t ranking.
Getting Started With Lighthouse
Accessing Lighthouse is surprisingly simple.
On any webpage, press F12 (Windows) or Command+Option+C (Mac) to open developer tools. You’ll find Lighthouse as one of the tabs. Alternatively, right-click any page, select “Inspect,” and navigate to the Lighthouse tab.
What makes Lighthouse special is its comprehensive approach. It evaluates five key areas: performance, progressive web app standards, best practices, accessibility, and SEO.
While accessibility might not seem directly SEO-related, I’ve learned that Google increasingly values sites that work well for all users.
Real-World Insights From The Community
The developer community has mixed feelings about Lighthouse, and I understand why.
As _listless noted, “Lighthouse is great because it helps you identify easy wins for performance and accessibility.”
However, CreativeTechGuyGames warned about the trap of chasing perfect scores: “There’s an important trade-off between performance and perceived performance.”
I’ve experienced this firsthand. One client insisted on achieving a perfect 100 score across all categories.
We spent weeks optimizing, only to find that some changes actually hurt user experience. The lesson? Use Lighthouse as a guide, not gospel.
Why Lighthouse Matters For SEO
The SEO section might seem basic as it checks things like meta tags, mobile usability, and crawling issues, but these fundamentals matter.
I’ve seen sites jump in rankings just by fixing the simple issues Lighthouse identifies. It validates crucial elements like:
Proper viewport configuration for mobile devices.
Title and meta description presence.
HTTP status codes.
Descriptive anchor text.
Hreflang implementation.
Canonical tags.
Mobile tap target sizing.
One frustrating aspect many developers mention is score inconsistency.
As one Redditor shared, “I ended up just re-running the analytics WITHOUT changing a thing and I got a performance score ranging from 33% to 90%.”
I’ve seen this too, which is why I always run multiple tests and focus on trends rather than individual scores.
Making The Most Of Lighthouse
My best advice? Use the “Opportunities” section for quick wins. Export your results as JSON to track improvements over time.
And remember what one developer wisely stated: “You can score 100 on accessibility and still ship an unusable [website].” The scores are indicators, not guarantees of quality.
2. PageSpeed Insights
Screenshot from pagespeed.web.dev, July 2025
PageSpeed Insights transformed from a nice-to-have tool to an essential one when Core Web Vitals became ranking considerations.
What sets PageSpeed Insights apart is its combination of lab data (controlled test results) and field data (real user experiences from the Chrome User Experience Report).
This dual approach has saved me from optimization rabbit holes more times than I can count.
The field data is gold as it shows how real users experience your site over the past 28 days. I’ve had situations where lab scores looked terrible, but field data showed users were having a great experience.
This usually means the lab test conditions don’t match your actual user base.
Community Perspectives On PSI
The Reddit community has strong opinions about PageSpeed Insights.
NHRADeuce perfectly captured a common frustration: “The score you get from PageSpeed Insights has nothing to do with how fast your site loads.”
While it might sound harsh, there’s truth to it since the score is a simplified representation of complex metrics.
Practical Optimization Strategies
Through trial and error, I’ve developed a systematic approach to PSI optimization.
Arzishere’s strategy mirrors mine: “Added a caching plugin along with minifying HTML, CSS & JS (WP Rocket).” These foundational improvements often yield the biggest gains.
DOM size is another critical factor. As Fildernoot discovered, “I added some code that increased the DOM size by about 2000 elements and PageSpeed Insights wasn’t happy about that.” I now audit DOM complexity as part of my standard process.
Mobile optimization deserves special attention. A Redditor asked the right question: “How is your mobile score? Desktop is pretty easy with a decent theme and Litespeed hosting and LScaching plugin.”
In my experience, mobile scores are typically 20-30 points lower than desktop, and that’s where most of your users are.
The Diminishing Returns Reality
Here’s the hard truth about chasing perfect PSI scores: “You’re going to see diminishing returns as you invest more and more resources into this,” as E0nblue noted.
I tell clients to aim for “good” Core Web Vitals status rather than perfect scores. The jump from 50 to 80 is much easier and more impactful than 90 to 100.
3. Safe Browsing Test
Screenshot from transparencyreport.google.com/safe-browsing/search, July 2025
The Safe Browsing Test might seem like an odd inclusion in an SEO toolkit, but I learned its importance the hard way.
A client’s site got hacked, flagged by Safe Browsing, and disappeared from search results overnight. Their organic traffic dropped to zero in hours.
Understanding Safe Browsing’s Role
Google’s Safe Browsing protects users from dangerous websites by checking for malware, phishing attempts, and deceptive content.
As Lollygaggindovakiin explained, “It automatically scans files using both signatures of diverse types and uses machine learning.”
The tool lives in Google’s Transparency Report, and I check it monthly for all client sites. It shows when Google last scanned your site and any current security issues.
The integration with Search Console means you’ll get alerts if problems arise, but I prefer being proactive.
Community Concerns And Experiences
The Reddit community has highlighted some important considerations.
One concerning trend expressed by Nextdns is false positives: “Google is falsely flagging apple.com.akadns.net as malicious.” While rare, false flags can happen, which is why regular monitoring matters.
Privacy-conscious users raise valid concerns about data collection.
As Mera-beta noted, “Enhanced Safe Browsing will send content of pages directly to Google.” For SEO purposes, standard Safe Browsing protection is sufficient.
Why SEO Pros Should Care
When Safe Browsing flags your site, Google may:
Remove your pages from search results.
Display warning messages to users trying to visit.
Drastically reduce your click-through rates.
Impact your site’s trust signals.
I’ve helped several sites recover from security flags. The process typically takes one to two weeks after cleaning the infection and requesting a review.
That’s potentially two weeks of lost traffic and revenue, so prevention is infinitely better than cure.
Best Practices For Safe Browsing
My security checklist includes:
Weekly automated scans using the Safe Browsing API for multiple sites.
Immediate investigation of any Search Console security warnings.
Regular audits of third-party scripts and widgets.
Monitoring of user-generated content areas.
4. Google Trends
Screenshot from Google Trends, July 2025
Google Trends has evolved from a curiosity tool to a strategic weapon in my SEO arsenal.
With updates now happening every 10 minutes and AI-powered trend detection, it’s become indispensable for content strategy.
Beyond Basic Trend Watching
What many SEO pros miss is that Trends isn’t just about seeing what’s popular. I use it to:
Validate content ideas before investing resources.
The Reddit community offers balanced perspectives on Google Trends.
Maltelandwehr highlighted its unique value: “Some of the data in Google Trends is really unique. Even SEOs with monthly 7-figure budgets will use Google Trends for certain questions.”
However, limitations exist. As Dangerroo_2 clarified, “Trends does not track popularity, but search demand.”
This distinction matters since a declining trend doesn’t always mean fewer total searches, just decreasing relative interest.
For niche topics, frustrations mount. iBullyDummies complained, “Google has absolutely ruined Google Trends and no longer evaluates niche topics.” I’ve found this particularly true for B2B or technical terms with lower search volumes.
Advanced Trends Strategies
My favorite Trends hacks include:
The Comparison Method: I always compare terms against each other rather than viewing them in isolation. This reveals relative opportunity better than absolute numbers.
Category Filtering: This prevents confusion between similar terms. The classic example is “jaguar” where without filtering, you’re mixing car searches with animal searches.
Rising Trends Mining: The “Rising” section often reveals opportunities before they become competitive. I’ve launched successful content campaigns by spotting trends here early.
Geographic Arbitrage: Finding topics trending in one region before they spread helps you prepare content in advance.
Addressing The Accuracy Debate
Some prefer paid tools, as Contentwritenow stated: “I prefer using a paid tool like BuzzSumo or Semrush for trends and content ideas simply because I don’t trust Google Trends.”
While I use these tools too, they pull from different data sources. Google Trends shows actual Google search behavior, which is invaluable for SEO.
“A line trending downward means that a search term’s relative popularity is decreasing. But that doesn’t necessarily mean the total number of searches for that term is decreasing.”
I always combine Trends data with absolute volume estimates from other tools.
No list of Google SEO tools would be complete without Search Console.
If the other tools are your scouts, Search Console is your command center, showing exactly how Google sees and ranks your site.
Why Search Console Is Irreplaceable
Search Console provides data you literally cannot get anywhere else. As Peepeepoopoobutler emphasized, “GSC is the accurate real thing. But it doesn’t really give suggestions like ads does.”
That’s exactly right. While it won’t hold your hand with optimization suggestions, the raw data it provides is gold.
The tool offers:
Actual search queries driving traffic (not just keywords you think matter).
True click-through rates by position.
Index coverage issues before they tank your traffic.
Core Web Vitals data for all pages.
Manual actions and security issues that could devastate rankings.
I check Search Console daily, and I’m not alone.
Successful site owner ImportantDoubt6434 shared, “Yes monitoring GSC is part of how I got my website to the front page.”
The Performance report alone has helped me identify countless optimization opportunities.
Setting Up For Success
Getting started with Search Console is refreshingly straightforward.
As Anotherbozo noted, “You don’t need to verify each individual page but maintain the original verification method.”
I recommend domain-level verification for comprehensive access since you can “verify ownership by site or by domain (second level domain),” but domain gives you data across all subdomains and protocols.
The verification process takes minutes, but the insights last forever. I’ve seen clients discover they were ranking for valuable keywords they never knew about, simply because they finally looked at their Search Console data.
Hidden Powers Of Search Console
What many SEO pros miss are the advanced capabilities lurking in Search Console.
Seosavvy revealed a powerful strategy: “Google search console for keyword research is super powerful.” I couldn’t agree more.
By filtering for queries with high impressions but low click-through rates, you can find content gaps and optimization opportunities your competitors miss.
The structured data reports have saved me countless hours. CasperWink mentioned working with schemas, “I have already created the schema with a review and aggregateRating along with confirming in Google’s Rich Results Test.”
Search Console will tell you if Google can actually read and understand your structured data in the wild, something testing tools can’t guarantee.
Sitemap management is another underutilized feature. Yetisteve correctly stated, “Sitemaps are essential, they are used to give Google good signals about the structure of the site.”
I’ve diagnosed indexing issues just by comparing submitted versus indexed pages in the sitemap report.
The Reality Check: Limitations To Understand
Here’s where the community feedback gets really valuable.
An experienced SimonaRed warned, “GSC only shows around 50% of the reality.” This is crucial to understand since Google samples and anonymizes data for privacy. You’re seeing a representative sample, not every single query.
Some find the interface challenging. As UncleFeather6000 admitted, “I feel like I don’t really understand how to use Google’s Search Console.”
I get it because the tool has evolved significantly, and the learning curve can be steep. My advice? Start with the Performance report and gradually explore other sections.
Recent changes have frustrated users, too. “Google has officially removed Google Analytics data from the Search Console Insights tool,” Shakti-basan noted.
This integration loss means more manual work correlating data between tools, but the core Search Console data remains invaluable.
Making Search Console Work Harder
Through years of daily use, I’ve developed strategies to maximize Search Console’s value:
The Position 11-20 Gold Mine: Filter for keywords ranking on page two. These are your easiest wins since Google already thinks you’re relevant. You just need a push to page one.
Click-Through Rate Optimization: Sort by impressions, then look for low CTR. These queries show demand but suggest your titles and descriptions need work.
Query Matching: Compare what you think you rank for versus what Search Console shows. The gaps often reveal content opportunities or user intent mismatches.
Page-Level Analysis: Don’t just look at site-wide metrics. Individual page performance often reveals technical issues or content problems.
Integrating Search Console With Other Tools
The magic happens when you combine Search Console data with the other tools:
Use Trends to validate whether declining traffic is due to ranking drops or decreased search interest.
Cross-reference PageSpeed Insights recommendations with pages showing Core Web Vitals issues in Search Console.
Verify Lighthouse mobile-friendliness findings against Mobile Usability reports.
Monitor Safe Browsing status directly in the Security Issues section.
Mr_boogieman asked rhetorically, “How are you tracking results without looking at GSC?” It’s a fair question.
Without Search Console, you’re flying blind, relying on third-party estimations instead of data straight from Google.
Bringing It All Together
These five tools form the foundation of effective SEO work. They’re free, they’re official, and they show you exactly what Google values.
While specialized SEO platforms offer additional features, mastering these Google tools ensures your optimization efforts align with what actually matters for rankings.
My workflow typically starts with Search Console to identify opportunities, using Trends to validate content ideas, employing Lighthouse and PageSpeed Insights to optimize technical performance, and includes Safe Browsing checks to protect hard-won rankings.
Remember, these tools reflect Google’s current priorities. As search algorithms evolve, so do these tools. Staying current with their features and understanding their insights keeps your SEO strategy aligned with Google’s direction.
The key is using them together, understanding their limitations, and remembering that tools are only as good as the strategist wielding them. Start with these five, master their insights, and you’ll have a solid foundation for SEO success.
Google’s June 2025 Core Update just finished. What’s notable is that while some say it was a big update, it didn’t feel disruptive, indicating that the changes may have been more subtle than game changing. Here are some clues that may explain what happened with this update.
Two Search Ranking Related Breakthroughs
Although a lot of people are saying that the June 2025 Update was related to MUVERA, that’s not really the whole story. There were two notable backend announcements over the past few weeks, MUVERA and Google’s Graph Foundation Model.
Google MUVERA
MUVERA is a Multi-Vector via Fixed Dimensional Encodings (FDEs) retrieval algorithm that makes retrieving web pages more accurate and with a higher degree of efficiency. The notable part for SEO is that it is able to retrieve fewer candidate pages for ranking, leaving the less relevant pages behind and promoting only the more precisely relevant pages.
This enables Google to have all of the precision of multi-vector retrieval without any of the drawbacks of traditional multi-vector systems and with greater accuracy.
Google’s MUVERA announcement explains the key improvements:
“Improved recall: MUVERA outperforms the single-vector heuristic, a common approach used in multi-vector retrieval (which PLAID also employs), achieving better recall while retrieving significantly fewer candidate documents… For instance, FDE’s retrieve 5–20x fewer candidates to achieve a fixed recall.
Moreover, we found that MUVERA’s FDEs can be effectively compressed using product quantization, reducing memory footprint by 32x with minimal impact on retrieval quality.
These results highlight MUVERA’s potential to significantly accelerate multi-vector retrieval, making it more practical for real-world applications.
…By reducing multi-vector search to single-vector MIPS, MUVERA leverages existing optimized search techniques and achieves state-of-the-art performance with significantly improved efficiency.”
Google’s Graph Foundation Model
A graph foundation model (GFM) is a type of AI model that is designed to generalize across different graph structures and datasets. It’s designed to be adaptable in a similar way to how large language models can generalize across different domains that it hadn’t been initially trained in.
Google’s GFM classifies nodes and edges, which could plausibly include documents, links, users, spam detection, product recommendations, and any other kind of classification.
This is something very new, published on July 10th, but already tested on ads for spam detection. It is in fact a breakthrough in graph machine learning and the development of AI models that can generalize across different graph structures and tasks.
It supersedes the limitations of Graph Neural Networks (GNNs) which are tethered to the graph on which they were trained on. Graph Foundation Models, like LLMs, aren’t limited to what they were trained on, which makes them versatile for handling new or unseen graph structures and domains.
Google’s announcement of GFM says that it improves zero-shot and few-shot learning, meaning it can make accurate predictions on different types of graphs without additional task-specific training (zero-shot), even when only a small number of labeled examples are available (few-shot).
Google’s GFM announcement reported these results:
“Operating at Google scale means processing graphs of billions of nodes and edges where our JAX environment and scalable TPU infrastructure particularly shines. Such data volumes are amenable for training generalist models, so we probed our GFM on several internal classification tasks like spam detection in ads, which involves dozens of large and connected relational tables. Typical tabular baselines, albeit scalable, do not consider connections between rows of different tables, and therefore miss context that might be useful for accurate predictions. Our experiments vividly demonstrate that gap.
We observe a significant performance boost compared to the best tuned single-table baselines. Depending on the downstream task, GFM brings 3x – 40x gains in average precision, which indicates that the graph structure in relational tables provides a crucial signal to be leveraged by ML models.”
What Changed?
It’s not unreasonable to speculate that integrating both MUVERA and GFM could enable Google’s ranking systems to more precisely rank relevant content by improving retrieval (MUVERA) and mapping relationships between links or content to better identify patterns associated with trustworthiness and authority (GFM).
Integrating Both MUVERA and GFM would enable Google’s ranking systems to more precisely surface relevant content that searchers would find to be satisfying.
Google’s official announcement said this:
“This is a regular update designed to better surface relevant, satisfying content for searchers from all types of sites.”
This particular update did not seem to be accompanied by widespread reports of massive changes. This update may fit into what Google’s Danny Sullivan was talking about at Search Central Live New York, where he said they would be making changes to Google’s algorithm to surface a greater variety of high-quality content.
Search marketer Glenn Gabe tweeted that he saw some sites that had been affected by the “Helpful Content Update,” also known as HCU, had surged back in the rankings, while other sites worsened.
Although he said that this was a very big update, the response to his tweets was muted, not the kind of response that happens when there’s a widespread disruption. I think it’s fair to say that, although Glenn Gabe’s data shows it was a big update, it may not have been a disruptive one.
So what changed? I think, I speculate, that it was a widespread change that improved Google’s ability to better surface relevant content, helped by better retrieval and an improved ability to interpret patterns of trustworthiness and authoritativeness, as well as to better identify low-quality sites.
I’ll admit that I’ve rarely hesitated to point an accusing finger at air-conditioning. I’ve outlined in manystoriesand newsletters that AC is a significant contributor to global electricity demand, and it’s only going to suck up more power as temperatures rise.
But I’ll also be the first to admit that it can be a life-saving technology, one that may become even more necessary as climate change intensifies. And in the wake of Europe’s recent deadly heat wave, it’s been oddly villainized.
We should all be aware of the growing electricity toll of air-conditioning, but the AC hate is misplaced. Yes, AC is energy intensive, but so is heating our homes, something that’s rarely decried in the same way that cooling is. Both are tools for comfort and, more important, for safety. So why is air-conditioning cast as such a villain?
In the last days of June and the first few days of July, temperatures hit record highs across Europe. Over 2,300 deaths during that period were attributed to the heat wave, according to early research from World Weather Attribution, an academic collaboration that studies extreme weather. And human-caused climate change accounted for 1,500 of the deaths, the researchers found. (That is, the number of fatalities would have been under 800 if not for higher temperatures because of climate change.)
We won’t have the official death toll for months, but these early figures show just how deadly heat waves can be. Europe is especially vulnerable, because in many countries, particularly in the northern part of the continent, air-conditioning is not common.
Popping on a fan, drawing the shades, or opening the windows on the hottest days used to cut it in many European countries. Not anymore. The UK was 1.24 °C (2.23 °F) warmer over the past decade than it was between 1961 and 1990, according to the Met Office, the UK’s national climate and weather service. One recent study found that homes across the country are uncomfortably or dangerously warm much more frequently than they used to be.
The reality is, some parts of the world are seeing an upward shift in temperatures that’s not just uncomfortable but dangerous. As a result, air-conditioning usage is going up all over the world, including in countries with historically low rates.
The reaction to this long-term trend, especially in the face of the recent heat wave, has been apoplectic. People are decrying AC across social media and opinion pages, arguing that we need to suck it up and deal with being a little bit uncomfortable.
Now, let me preface this by saying that I do live in the US, where roughly 90% of homes are cooled with air-conditioning today. So perhaps I am a little biased in favor of AC. But it baffles me when people talk about air-conditioning this way.
I spent a good amount of my childhood in the southeastern US, where it’s very obvious that heat can be dangerous. I was used to many days where temperatures were well above 90 °F (32 °C), and the humidity was so high your clothes would stick to you as soon as you stepped outdoors.
For some people, being active or working in those conditions can lead to heatstroke. Prolonged exposure, even if it’s not immediately harmful, can lead to heart and kidney problems. Older people, children, and those with chronic conditions can be more vulnerable.
In other words, air-conditioning is more than a convenience; in certain conditions, it’s a safety measure. That should be an easy enough concept to grasp. After all, in many parts of the world we expect access to heating in the name of safety. Nobody wants to freeze to death.
And it’s important to clarify here that while air-conditioning does use a lot of electricity in the US, heating actually has a higher energy footprint.
In the US, about 19% of residential electricity use goes to air-conditioning. That sounds like a lot, and it’s significantly more than the 12% of electricity that goes to space heating. However, we need to zoom out to get the full picture, because electricity makes up only part of a home’s total energy demand. A lot of homes in the US use natural gas for heating—that’s not counted in the electricity being used, but it’s certainly part of the home’s total energy use.
When we look at the total, space heating accounts for a full 42% of residential energy consumption in the US, while air conditioning accounts for only 9%.
I’m not letting AC off the hook entirely here. There’s obviously a difference between running air-conditioning (or other, less energy-intensive technologies) when needed to stay safe and blasting systems at max capacity because you prefer it chilly. And there’s a lot of grid planning we’ll need to do to make sure we can handle the expected influx of air-conditioning around the globe.
But the world is changing, and temperatures are rising. If you’re looking for a villain, look beyond the air conditioner and into the atmosphere.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday,sign up here.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Researchers announce babies born from a trial of three-person IVF
Eight babies have been born in the UK thanks to a technology that uses DNA from three people: the two biological parents plus a third person who supplies healthy mitochondrial DNA. The babies were born to mothers who carry genes for mitochondrial diseases and risked passing on severe disorders.
In the team’s approach, patients’ eggs are fertilized with sperm, and the DNA-containing nuclei of those cells are transferred into donated fertilized eggs that have had their own nuclei removed. The new embryos contain the DNA of the intended parents along with a tiny fraction of mitochondrial DNA from the donor, floating in the embryos’ cytoplasm.
The study, which makes use of a technology called mitochondrial donation, has been described as a “tour de force” and “a remarkable accomplishment” by others in the field. But not everyone sees the trial as a resounding success. Read the full story.
—Jessica Hamzelou
These four charts show where AI companies could go next in the US
No one knows exactly how AI will transform our communities, workplaces, and society as a whole. Because it’s hard to predict the impact AI will have on jobs, many workers and local governments are left trying to read the tea leaves to understand how to prepare and adapt.
A new interactive report released by the Brookings Institution attempts to map how embedded AI companies and jobs are in different regions of the United States in order to prescribe policy treatments to those struggling to keep up. Here are four charts to help understand the issues.
—Peter Hall
In defense of air-conditioning
—Casey Crownhart
I’ll admit that I’ve rarely hesitated to point an accusing finger at air-conditioning. I’ve outlined in many stories and newsletters that AC is a significant contributor to global electricity demand, and it’s only going to suck up more power as temperatures rise.
But I’ll also be the first to admit that it can be a life-saving technology, one that may become even more necessary as climate change intensifies. And in the wake of Europe’s recent deadly heat wave, it’s been oddly villainized. Read our story to learn more.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Donald Trump is cracking down on “dangerous science” But the scientists affected argue their work is essential to developing new treatments. (WP $) + How MAHA is infiltrating states across the US. (The Atlantic $)
2 The US Senate has approved Trump’s request to cancel foreign aid The White House is determined to reclaim around $8 billion worth of overseas aid. (NYT $) + The bill also allocates around $1.1 billion to public broadcasting. (WP $) + HIV could infect 1,400 infants every day because of US aid disruptions. (MIT Technology Review)
3 American air strikes only destroyed one Iranian nuclear site The remaining two sites weren’t damaged that badly, and could resume operation within months. (NBC News)
4 The US is poised to ban Chinese technology in submarine cables The cables are critical to internet connectivity across the world. (FT $) + The cables are at increasing risk of sabotage. (Bloomberg $)
5 The US measles outbreak is worsening Health officials’ tactics for attempting to contain it aren’t working. (Wired $) + Vaccine hesitancy is growing, too. (The Atlantic $) + Why childhood vaccines are a public health success story. (MIT Technology Review)
6 A new supercomputer is coming The Nexus machine will search for new cures for diseases. (Semafor)
7 Elon Musk has teased a Grok AI companion inspired by Twilight No really, you shouldn’t have… (The Verge) + Inside the Wild West of AI companionship. (MIT Technology Review)
8 Future farms could be fully autonomous Featuring AI-powered tractors and drone surveillance. (WSJ $) + African farmers are using private satellite data to improve crop yields. (MIT Technology Review)
9 Granola is Silicon Valley’s favorite new tool No, not the tasty breakfast treat. (The Information $)
10 WeTransfer isn’t going to train its AI on our files after all After customers reacted angrily on social media. (BBC)
Quote of the day
“He’s doing the exact opposite of everything I voted for.”
—Andrew Schulz, a comedian and podcaster who interviewed Donald Trump last year, explains why he’s starting to lose faith in the President to Wired.
One more thing
The open-source AI boom is built on Big Tech’s handouts. How long will it last?
In May 2023 a leaked memo reported to have been written by Luke Sernau, a senior engineer at Google, said out loud what many in Silicon Valley must have been whispering for weeks: an open-source free-for-all is threatening Big Tech’s grip on AI.
In many ways, that’s a good thing. AI won’t thrive if just a few mega-rich companies get to gatekeep this technology or decide how it is used. But this open-source boom is precarious, and if Big Tech decides to shut up shop, a boomtown could become a backwater. Read the full story.
—Will Douglas Heaven
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)
+ Happy birthday David Hasselhoff, 73 years young today! + The trailer for the final season of Stranger Things is here, and things are getting weird. + Windows 95, you will never be bettered. + I don’t know about you, but I’m ready for a fridge cigarette.