Millions of people argue with each other online every day, but remarkably few of them change someone’s mind. New research suggests that large language models (LLMs) might do a better job. The finding suggests that AI could become a powerful tool for persuading people, for better or worse.
A multi-university team of researchers found that OpenAI’s GPT-4 was significantly more persuasive than humans when it was given the ability to adapt its arguments using personal information about whoever it was debating.
Their findings are the latest in a growing body of research demonstrating LLMs’ powers of persuasion. The authors warn they show how AI tools can craft sophisticated, persuasive arguments if they have even minimal information about the humans they’re interacting with. The research has been published in the journal Nature Human Behavior.
“Policymakers and online platforms should seriously consider the threat of coordinated AI-based disinformation campaigns, as we have clearly reached the technological level where it is possible to create a network of LLM-based automated accounts able to strategically nudge public opinion in one direction,” says Riccardo Gallotti, an interdisciplinary physicist at Fondazione Bruno Kessler in Italy, who worked on the project.
“These bots could be used to disseminate disinformation, and this kind of diffused influence would be very hard to debunk in real time,” he says.
The researchers recruited 900 people based in the US and got them to provide personal information like their gender, age, ethnicity, education level, employment status, and political affiliation.
Participants were then matched with either another human opponent or GPT-4 and instructed to debate one of 30 randomly assigned topics—such as whether the US should ban fossil fuels, or whether students should have to wear school uniforms—for 10 minutes. Each participant was told to argue either in favor of or against the topic, and in some cases they were provided with personal information about their opponent, so they could better tailor their argument. At the end, participants said how much they agreed with the proposition and whether they thought they were arguing with a human or an AI.
Overall, the researchers found that GPT-4 either equaled or exceeded humans’ persuasive abilities on every topic. When it had information about its opponents, the AI was deemed to be 64% more persuasive than humans without access to the personalized data—meaning that GPT-4 was able to leverage the personal data about its opponent much more effectively than its human counterparts. When humans had access to the personal information, they were found to be slightly less persuasive than humans without the same access.
The authors noticed that when participants thought they were debating against AI, they were more likely to agree with it. The reasons behind this aren’t clear, the researchers say, highlighting the need for further research into how humans react to AI.
“We are not yet in a position to determine whether the observed change in agreement is driven by participants’ beliefs about their opponent being a bot (since I believe it is a bot, I am not losing to anyone if I change ideas here), or whether those beliefs are themselves a consequence of the opinion change (since I lost, it should be against a bot),” says Gallotti. “This causal direction is an interesting open question to explore.”
Although the experiment doesn’t reflect how humans debate online, the research suggests that LLMs could also prove an effective way to not only disseminate but also counter mass disinformation campaigns, Gallotti says. For example, they could generate personalized counter-narratives to educate people who may be vulnerable to deception in online conversations. “However, more research is urgently needed to explore effective strategies for mitigating these threats,” he says.
While we know a lot about how humans react to each other, we know very little about the psychology behind how people interact with AI models, says Alexis Palmer, a fellow at Dartmouth College who has studied how LLMs can argue about politics but did not work on the research.
“In the context of having a conversation with someone about something you disagree on, is there something innately human that matters to that interaction? Or is it that if an AI can perfectly mimic that speech, you’ll get the exact same outcome?” she says. “I think that is the overall big question of AI.”
The era of “40% off everything, today only” as a revenue driver is mostly gone. Nowadays, sophistication is key since repeat customers expect more than discounts.
For experienced marketers, the challenge isn’t just timing or promotion. It’s building urgency in a way that aligns with long-term goals, brand positioning, and channel constraints.
Urgency
Discounts alone no longer create urgency. Merchants need a mix of temporal, social, and product-based cues that build momentum throughout a campaign.
Consider:
Inventory scarcity. Communicate low stock thresholds dynamically. Tools such as Fomo and Convert inject real-time signals like “12 left in stock” or “selling fast.”
Tiered unlocks. Reward speed with value. For example: “First 100 customers get 30% off; next 200 get 20% off.”
Personalization. Segment by purchase behavior, and run a flash sale for your most loyal customers with unique timers per buyer cohort. Klaviyo and Iterable dynamically adjust expiration based on email open or site activity.
These approaches build urgency without sacrificing profits across all customers.
Paire, a sustainable clothing brand, teases limited-quantity gift-with-purchase offers that unlock at specific spending thresholds.
Paire unlocks limited-quantity gift-with-purchase offers at spending thresholds. Click image to enlarge.
Bombas, the sock and apparel company known for its one-for-one donations, deploys personalized flash sales for loyalty segments with precision. A bright yellow “Expires Tomorrow” banner creates urgency, while strategic messaging reinforces societal impact: “3 million pairs donated.”
Bombas combines a yellow “Expire tomorrow” banner with the social impact of “3 million pairs donated.” Click image to enlarge.
Both approaches — Paire and Bombas — demonstrate how discount messaging can reinforce brand purpose when properly segmented.
Channels
Flash sales can be effective beyond holidays or end-of-quarter pushes.
Lagging products. Got seasonal overstock or SKUs with poor velocity? Run a micro-flash sale triggered by inventory data — target customers who viewed or added those products but didn’t convert.
Lifecycle churns. If your average repurchase window is 45 days, schedule a flash sale on day 40 with a time-sensitive reorder incentive. Use your customer data platform or email service provider to identify likely churn cohorts.
List fatigue. If open or click rates dip by 20% across core segments, test a one-day flash event as a reactivation lever, especially if your emails emphasize content or brand rather than promos.
Flash sales affect multiple channels: email, SMS, and paid. Alignment is essential to avoid:
Inbox fatigue. Repeated discounts can lower click-to-open rates and prompt inbox filtering by internet service providers. Suppress habitual non-clickers (except for products with longer consideration cycles) or create a dedicated “sale-only” segment where users can opt in.
Ad dilution. Frequent promos can tank click-throughs. Use exclusions (e.g., customers who purchased in the last 30 days) to protect your evergreen campaigns.
List degradation. Flash-sale-only buyers are likely to churn. Consider delaying welcome offers after those subscribers convert organically.
Better Flash Sales
Here’s a three-phase approach integrating urgency and control.
Warm-up (1–2 days prior):
Tease the sale via SMS or email to high-value segments. Use early access as a loyalty perk.
Target visitors by deploying browse abandonment emails or early ad previews.
Launch (24–48 hours max):
Use a single call-to-action across channels.
Pull in zero-party data where possible (“You liked [product A]. It’s 20% off today only.”)
Embed social proof or low-inventory signals in product detail pages and ads.
Cool-down:
Use a final chance message for non-purchasers, then suppress or retarget based on funnel behavior.
Analyze performance by segment (e.g., new vs. returning, email vs. SMS) to understand who buys from urgency and who waits for discounts.
Beyond Revenue
A strategically executed flash sale can double as an insights tool.
Which channel drove the fastest conversions?
Who purchases early vs. last-call messaging?
Did discounts elevate average order values or only volume?
Tools such as Daasity, Triple Whale, and business intelligence dashboards can provide the post-sale data to answer those questions. Then refine not just your sales cadence but audience planning and creative strategy.
In short, flash sales should not compromise a brand. When planned with data, segmentation, and restraint, they can re-energize a list, clear inventory, and deliver real margin — much more than a short-term rush.
There’s a lot to know about search intent, from using deep learning to infer search intent by classifying text and breaking down SERP titles using Natural Language Processing (NLP) techniques, to clustering based on semantic relevance, with the benefits explained.
Not only do we know the benefits of deciphering search intent, but we also have a number of techniques at our disposal for scale and automation.
So, why do we need another article on automating search intent?
Search intent is ever more important now that AI search has arrived.
While more was generally in the 10 blue links search era, the opposite is true with AI search technology, as these platforms generally seek to minimize the computing costs (per FLOP) in order to deliver the service.
SERPs Still Contain The Best Insights For Search Intent
The techniques so far involve doing your own AI, that is, getting all of the copy from titles of the ranking content for a given keyword and then feeding it into a neural network model (which you have to then build and test) or using NLP to cluster keywords.
What if you don’t have time or the knowledge to build your own AI or invoke the Open AI API?
While cosine similarity has been touted as the answer to helping SEO professionals navigate the demarcation of topics for taxonomy and site structures, I still maintain that search clustering by SERP results is a far superior method.
That’s because AI is very keen to ground its results on SERPs and for good reason – it’s modelled on user behaviors.
There is another way that uses Google’s very own AI to do the work for you, without having to scrape all the SERPs content and build an AI model.
Let’s assume that Google ranks site URLs by the likelihood of the content satisfying the user query in descending order. It follows that if the intent for two keywords is the same, then the SERPs are likely to be similar.
For years, many SEO professionals compared SERP results for keywords to infer shared (or shared) search intent to stay on top of core updates, so this is nothing new.
The value-add here is the automation and scaling of this comparison, offering both speed and greater precision.
How To Cluster Keywords By Search Intent At Scale Using Python (With Code)
Assuming you have your SERPs results in a CSV download, let’s import it into your Python notebook.
1. Import The List Into Your Python Notebook
import pandas as pd
import numpy as np
serps_input = pd.read_csv('data/sej_serps_input.csv')
del serps_input['Unnamed: 0']
serps_input
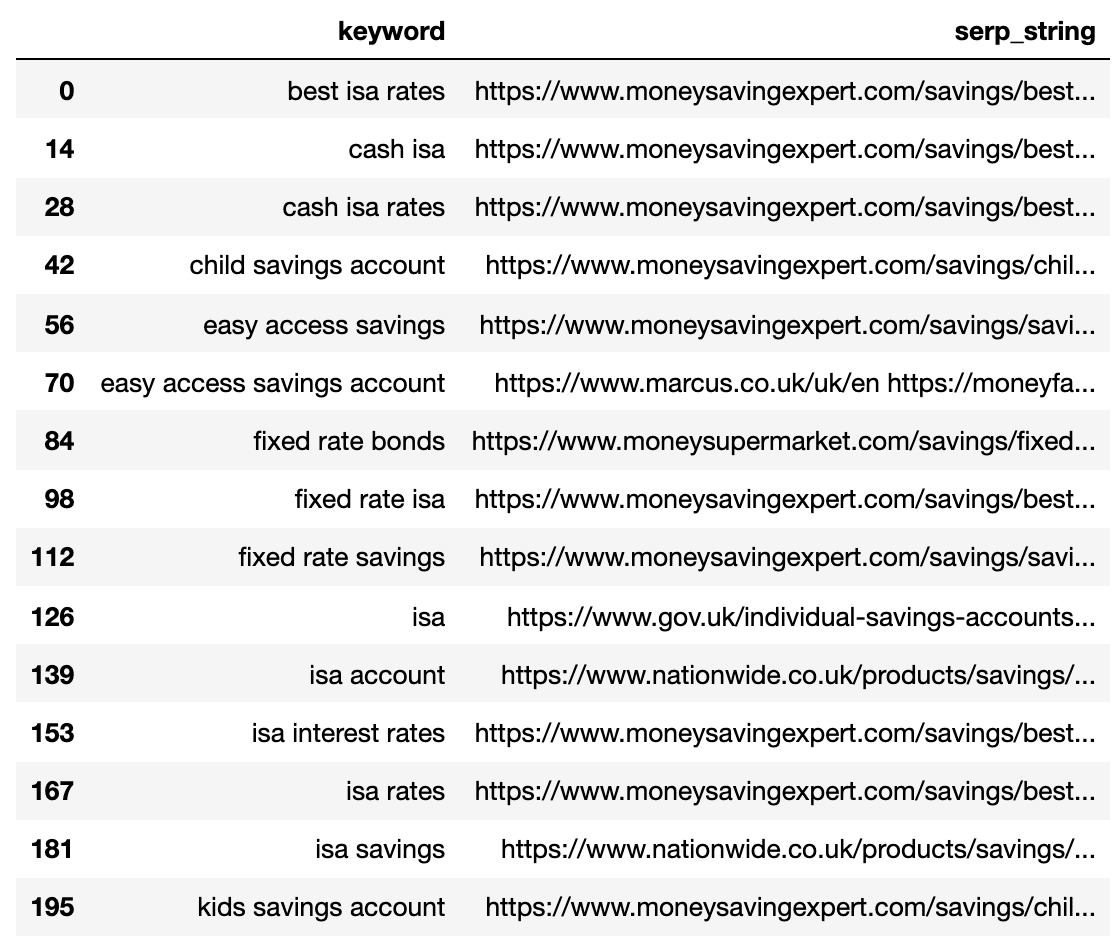
Below is the SERPs file now imported into a Pandas dataframe.
Image from author, April 2025
2. Filter Data For Page 1
We want to compare the Page 1 results of each SERP between keywords.
We’ll split the dataframe into mini keyword dataframes to run the filtering function before recombining into a single dataframe, because we want to filter at the keyword level:
The above shows all of the keyword SERP pair combinations, making it ready for SERP string comparison.
There is no open-source library that compares list objects by order, so the function has been written for you below.
The function “serp_compare” compares the overlap of sites and the order of those sites between SERPs.
import py_stringmatching as sm
ws_tok = sm.WhitespaceTokenizer()
# Only compare the top k_urls results
def serps_similarity(serps_str1, serps_str2, k=15):
denom = k+1
norm = sum([2*(1/i - 1.0/(denom)) for i in range(1, denom)])
#use to tokenize the URLs
ws_tok = sm.WhitespaceTokenizer()
#keep only first k URLs
serps_1 = ws_tok.tokenize(serps_str1)[:k]
serps_2 = ws_tok.tokenize(serps_str2)[:k]
#get positions of matches
match = lambda a, b: [b.index(x)+1 if x in b else None for x in a]
#positions intersections of form [(pos_1, pos_2), ...]
pos_intersections = [(i+1,j) for i,j in enumerate(match(serps_1, serps_2)) if j is not None]
pos_in1_not_in2 = [i+1 for i,j in enumerate(match(serps_1, serps_2)) if j is None]
pos_in2_not_in1 = [i+1 for i,j in enumerate(match(serps_2, serps_1)) if j is None]
a_sum = sum([abs(1/i -1/j) for i,j in pos_intersections])
b_sum = sum([abs(1/i -1/denom) for i in pos_in1_not_in2])
c_sum = sum([abs(1/i -1/denom) for i in pos_in2_not_in1])
intent_prime = a_sum + b_sum + c_sum
intent_dist = 1 - (intent_prime/norm)
return intent_dist
# Apply the function
matched_serps['si_simi'] = matched_serps.apply(lambda x: serps_similarity(x.serp_string, x.serp_string_b), axis=1)
# This is what you get
matched_serps[['keyword', 'keyword_b', 'si_simi']]
Now that the comparisons have been executed, we can start clustering keywords.
We will be treating any keywords that have a weighted similarity of 40% or more.
We now have the potential topic name, keywords SERP similarity, and search volumes of each.
You’ll note that keyword and keyword_b have been renamed to topic and keyword, respectively.
Now we’re going to iterate over the columns in the dataframe using the lambda technique.
The lambda technique is an efficient way to iterate over rows in a Pandas dataframe because it converts rows to a list as opposed to the .iterrows() function.
Here goes:
queries_in_df = list(set(matched_serps['keyword'].to_list()))
topic_groups = {}
def dict_key(dicto, keyo):
return keyo in dicto
def dict_values(dicto, vala):
return any(vala in val for val in dicto.values())
def what_key(dicto, vala):
for k, v in dicto.items():
if vala in v:
return k
def find_topics(si, keyw, topc):
if (si >= simi_lim):
if (not dict_key(sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, topc)):
if (not dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
sim_topic_groups[keyw] = [keyw]
sim_topic_groups[keyw] = [topc]
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (dict_values(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, keyw)
sim_topic_groups[d_key].append(topc)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
if (not dict_values(sim_topic_groups, keyw)) and (dict_values(sim_topic_groups, topc)):
d_key = what_key(sim_topic_groups, topc)
sim_topic_groups[d_key].append(keyw)
if dict_key(non_sim_topic_groups, keyw):
non_sim_topic_groups.pop(keyw)
if dict_key(non_sim_topic_groups, topc):
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (not topc in sim_topic_groups):
sim_topic_groups[keyw].append(topc)
sim_topic_groups[keyw].append(keyw)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (not keyw in sim_topic_groups) and (topc in sim_topic_groups):
sim_topic_groups[topc].append(keyw)
sim_topic_groups[topc].append(topc)
if keyw in non_sim_topic_groups:
non_sim_topic_groups.pop(keyw)
if topc in non_sim_topic_groups:
non_sim_topic_groups.pop(topc)
elif (keyw in sim_topic_groups) and (topc in sim_topic_groups):
if len(sim_topic_groups[keyw]) > len(sim_topic_groups[topc]):
sim_topic_groups[keyw].append(topc)
[sim_topic_groups[keyw].append(x) for x in sim_topic_groups.get(topc)]
sim_topic_groups.pop(topc)
elif len(sim_topic_groups[keyw]) < len(sim_topic_groups[topc]):
sim_topic_groups[topc].append(keyw)
[sim_topic_groups[topc].append(x) for x in sim_topic_groups.get(keyw)]
sim_topic_groups.pop(keyw)
elif len(sim_topic_groups[keyw]) == len(sim_topic_groups[topc]):
if sim_topic_groups[keyw] == topc and sim_topic_groups[topc] == keyw:
sim_topic_groups.pop(keyw)
elif si < simi_lim:
if (not dict_key(non_sim_topic_groups, keyw)) and (not dict_key(sim_topic_groups, keyw)) and (not dict_values(sim_topic_groups,keyw)):
non_sim_topic_groups[keyw] = [keyw]
if (not dict_key(non_sim_topic_groups, topc)) and (not dict_key(sim_topic_groups, topc)) and (not dict_values(sim_topic_groups,topc)):
non_sim_topic_groups[topc] = [topc]
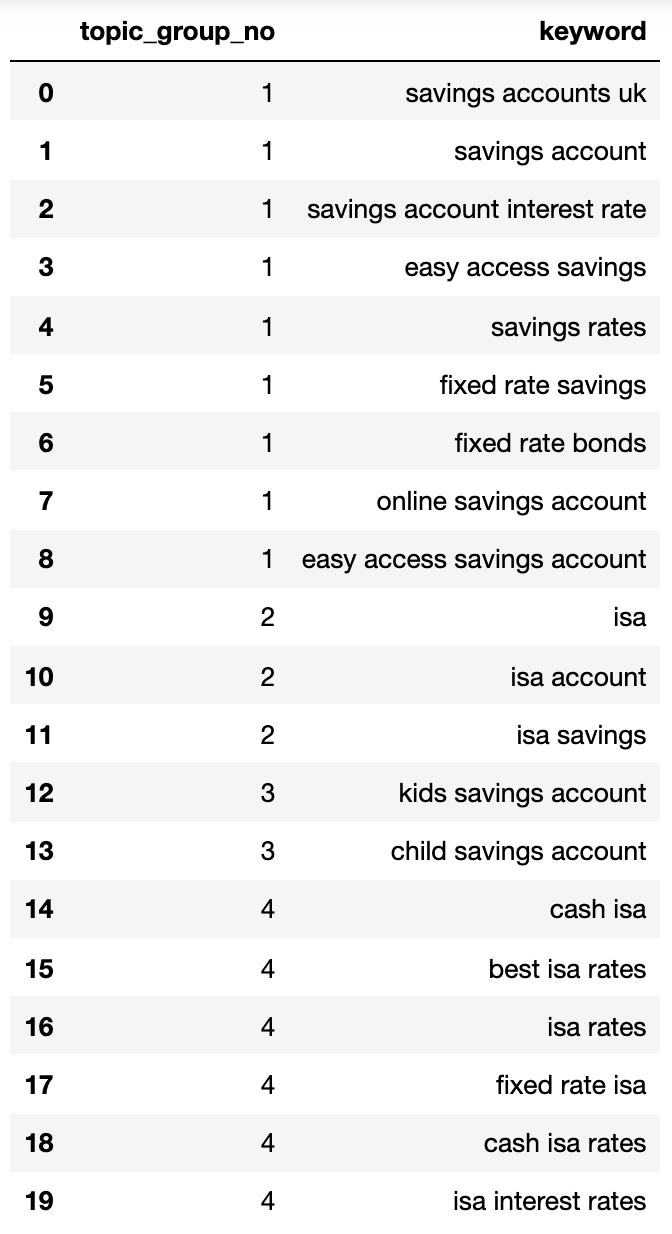
Below shows a dictionary containing all the keywords clustered by search intent into numbered groups:
topic_groups_lst = []
for k, l in topic_groups_numbered.items():
for v in l:
topic_groups_lst.append([k, v])
topic_groups_dictdf = pd.DataFrame(topic_groups_lst, columns=['topic_group_no', 'keyword'])
topic_groups_dictdf
Image from author, April 2025
The search intent groups above show a good approximation of the keywords inside them, something that an SEO expert would likely achieve.
Although we only used a small set of keywords, the method can obviously be scaled to thousands (if not more).
Activating The Outputs To Make Your Search Better
Of course, the above could be taken further using neural networks, processing the ranking content for more accurate clusters and cluster group naming, as some of the commercial products out there already do.
For now, with this output, you can:
Incorporate this into your own SEO dashboard systems to make your trends and SEO reporting more meaningful.
Build better paid search campaigns by structuring your Google Ads accounts by search intent for a higher Quality Score.
Merge redundant facet ecommerce search URLs.
Structure a shopping site’s taxonomy according to search intent instead of a typical product catalog.
I’m sure there are more applications that I haven’t mentioned – feel free to comment on any important ones that I’ve not already mentioned.
In any case, your SEO keyword research just got that little bit more scalable, accurate, and quicker!
The search landscape undergoes its biggest shift in a generation.
If you’ve been in SEO long enough to remember the glory days of the all-organic search engine results pages (SERP), you’ll know how much of this real estate has been gradually taken over by paid ads, other first-party products, and rich snippets.
Now, the most aggressive transition of all: AI Overviews (as well as search-based large language model platforms).
At BrightonSEO last month, I explored how this evolution is forcing us to rethink what SEO means and why discoverability, not just ranking, is the new north star.
The “Dawn” Of The Zero-Click Isn’t Just Over – It’s Now Assumed
We’ve been reading about the rise of zero-click searches for some time now, but this “takeover” has been much more noticeable over the past 12 months.
I recently searched [how to teach my child to tell the time], and after scrolling through a parade of paid product ads, Google-owned assets, and the AI Overview summaries, I scrolled a good three pages down the SERP.
Google and other search and discovery platforms want to keep users in their ecosystems. For SEO pros, this means traditional metrics such as click-through rate (CTR) are becoming less valuable by the day.
From Answer Engines To Assistant Engines
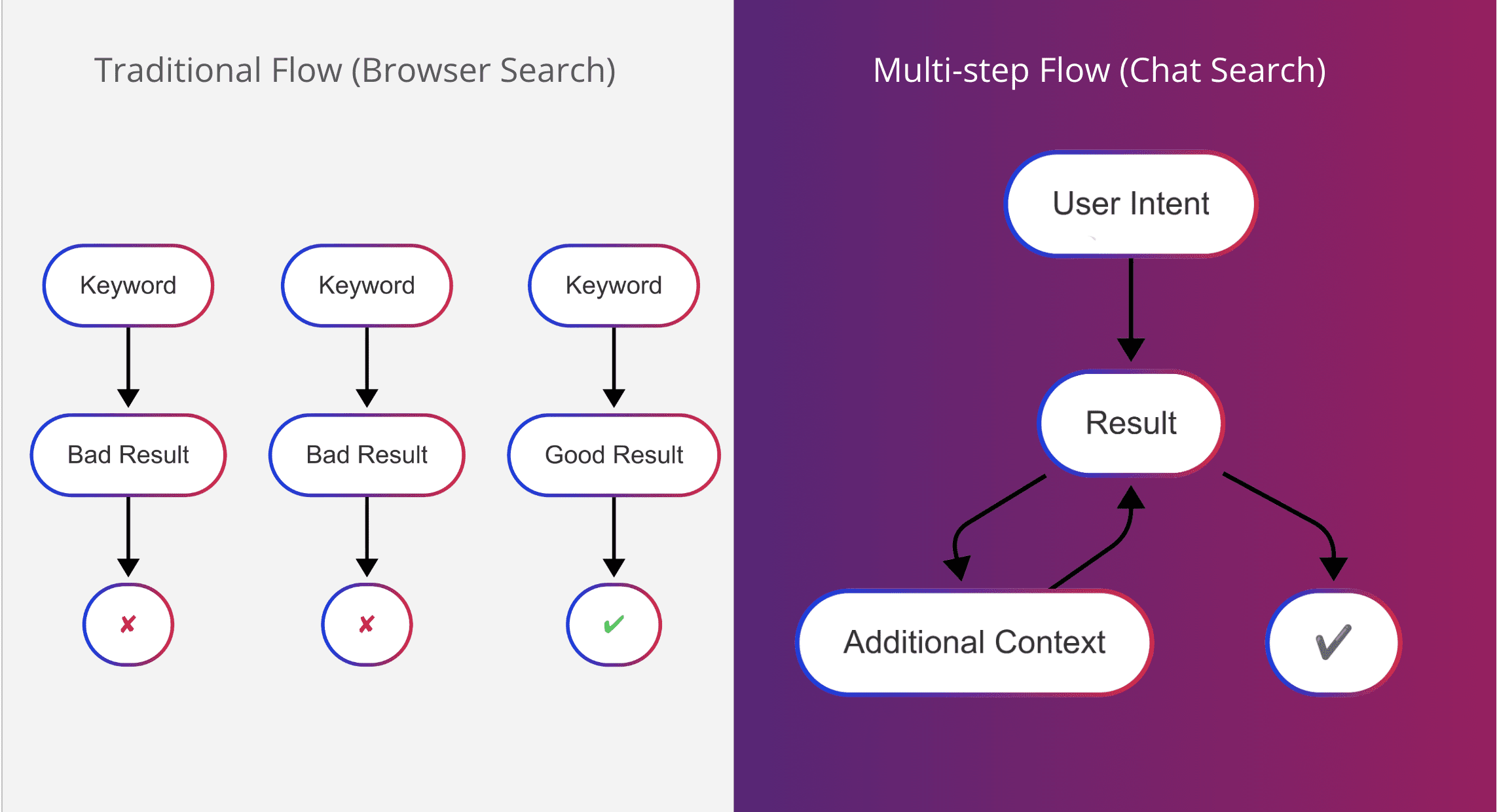
LLMs have changed not just the way a result is displayed to the user but also changed the traditional search flow born within the browser into a multi-step flow that the native SERP simply cannot support in the same way.
The research process is collapsing into a single, seamless exchange.
But as technology accelerates, our own curiosity and research skills are at risk of declining or disappearing completely as the evolution of technology exponentially grows.
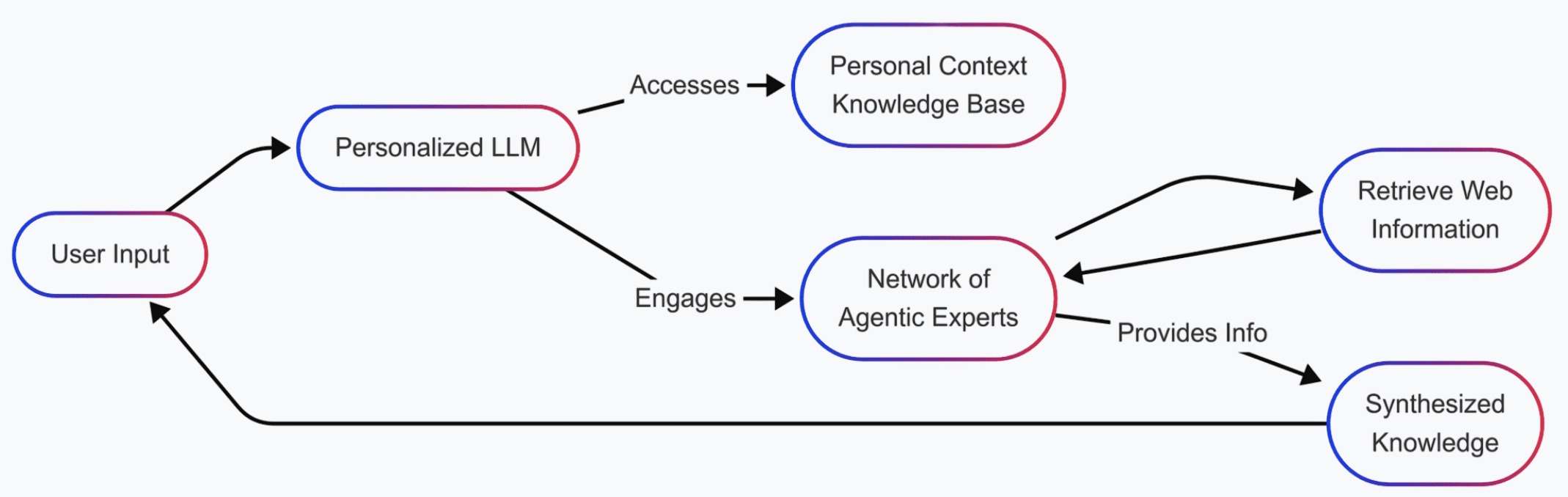
Assistant engines and wider LLMs are the new gatekeepers between our content and the person discovering that content – our potential “new audience.”
They parse, consume, understand, and then synthesize content, which is the deciding factor in what it mentions to whom/what it interacts with.
Structured data is still crucial, as context, transparency, and sentiment matter more than ever.
Personal LLM agent flow diagram by Alain Schlesser, used with permission, May 2025
Challenges Are Different, But Also The Same
As an SEO, our challenges with this new behavior affect the way we do – and report on – our jobs.
In reality, many are just old headaches in shiny new wrappers:
Attribution is a mess: With AI Overviews and LLMs synthesizing content, it’s harder than ever to see where your traffic comes from – or if you’re getting any at all. There are some tools out there that do monitor, but we’re in the early days to see a standard. Even Google said they have no plans on adding insights on AIO within Search Console.
Traffic is fragmenting (again): We saw this with social media platforms at the beginning, where discovery happened outside the organic SERPs. Discovery is now happening everywhere, all at once. With attribution also harder to ascertain, this is a bigger challenge today.
Budgets are under scrutiny from fear, uncertainty, and doubt (FUD): The native SERP is changing too much, so some may assume there’s less (or no) value in doing SEO much anymore (untrue!).
The Shift Of Success Metrics
The days of our current success metrics are dwindling. The days of vanity-led metrics are coming to an end.
Similar to how our challenges are the same but different, this also applies to how we redefine success metrics:
Old Hat
New Hat
Content
Context + sentiment
Keywords
Intent
Brand
Brand + sentiment
Rankings
Mentions
Links from external sources
Citations across various channels
SERP monopoly
Share of voice
E-E-A-T
Still E-E-A-T
Structured data
Entities, knowledge graph & vector embeds
Answering
Assisting
What Can You Do About It?
Information can be aggregated, but personality can’t. This is why it’s still our responsibility to help “assist the assistant” to consider and include you as part of that aggregated information and synthesized answer.
Stick to the fundamentals: Never neglect SEO 101.
Third-party perspective is increasingly important, so ensure this is maintained and managed well to ensure positive brand sentiment.
Embrace structured data: Even if some say it’s becoming less crucial for LLMs to understand entities, structured data is being used right now inside major LLMs to output structured data within responses, giving them an established and standardised way to understand your content.
Educate stakeholders: Shift the conversation from rankings and clicks to discoverability and brand presence. The days of the branded unlinked mention suddenly have more value than “acquiring X followed non-branded anchor text links pcm.”
Experiment with your content: Try new ways to produce and market your content beyond the traditional word. Here, video is useful not only for humans but also for LLMs, who are now “watching” and understanding them to aid their response.
Create helpful, unique content: To add to the above, don’t produce for the sake of production.
LLMs.txt: The Potential To Be The New Standard
Keep an eye on emerging standards proposals, such as llms.txt, which is one way some are adapting and contributing to how LLMs ingest our content beyond our traditional approaches offered with robots.txt and XML sitemaps.
While some are skeptical about this standard, I believe it is still something worth implementing now, and I understand its true benefits for the future.
There is (virtually) non-existent risk in implementing something that doesn’t take too much time or resources to produce, so long as you’re doing so with a white hat approach.
Conclusion: Embrace Discoverability And New Metrics
SEO isn’t dead. It’s expanding, but at a rate we haven’t experienced before.
Discoverability is the new go-to success metric, but it’s not without flaws, especially as the way we search continues to change.
This is no longer about “ranking well” anymore. This is now about being understood, surfaced, trusted, and discovered across every platform and assistant that matters.
Embrace and adapt to the changes, as it’s going to continue for some time.
More Resources:
Featured Image: PeopleImages.com – Yuri A/Shutterstock
Search marketers assert that Google’s new long-form AI Overviews answers have become the very thing Google’s documentation advises publishers against: scraped content lacking originality or added value, at the expense of content creators who are seeing declining traffic.
Why put the effort into writing great content if it’s going to be rewritten into a complete answer that removes the incentive to click the cited source?
Rewriting Content And Plagiarism
Google previously showed Featured Snippets, which were excerpts from published content that users could click on to read the rest of the article. Google’s AI Overviews (AIO) expands on that by presenting entire articles that answer a user’s questions and sometimes anticipates follow-up questions and provides answers to those, too.
And it’s not an AI providing answers. It’s an AI repurposing published content. That action is called plagiarism when a student does the same thing by repurposing an existing essay without adding unique insight or analysis.
The thing about AI is that it is incapable of unique insight or analysis, so there is zero value-add in Google’s AIO, which in an academic setting would be called plagiarism.
Example Of Rewritten Content
Lily Ray recently published an article on LinkedIn drawing attention to a spam problem in Google’s AIO. Her article explains how SEOs discovered how to inject answers into AIO, taking advantage of the lack of fact checking.
Lily subsequently checked on Google, presumably to see if her article was ranking and discovered that Google had rewritten her entire article and was providing an answer that was almost as long as her original.
She tweeted:
“It re-wrote everything I wrote in a post that’s basically as long as my original post “
It re-wrote everything I wrote in a post that’s basically as long as my original post ☠️ pic.twitter.com/ucNCSMHsY4
An algorithm that search engines and LLMs may use to analyze content is to determine what questions the content answers. This way the content can be annotated according to what answers it provides, making it easier to match a query to a web page.
I used ChatGPT to analyze Lily’s content and also AIO’s answer. The number of questions answered by both documents were almost exactly the same, twelve. Lily’s article answered 13 questions while AIO provided answeredo twelve.
Both articles answered five similar questions:
Spam Problem In AI Overviews AIO: “s there a spam problem affecting Google AI Overviews? Lily Ray: What types of problems have been observed in Google’s AI Overviews?
Manipulation And Exploitation of AI Overviews AIO: How are spammers manipulating AI Overviews to promote low-quality content? Lily Ray: What new forms of SEO spam have emerged in response to AI Overviews?
Accuracy And Hallucination Concerns AIO: Can AI Overviews generate inaccurate or contradictory information? Lily Ray: Does Google currently fact-check or validate the sources used in AI Overviews?
Concern About AIO In The SEO Community AIO: What concerns do SEO professionals have about the impact of AI Overviews? Lily Ray: Why is the ability to manipulate AI Overviews so concerning?
Deviation From Principles of E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) AIO: What kind of content is Google prioritizing in response to these issues? Lily Ray: How does the quality of information in AI Overviews compare to Google’s traditional emphasis on E-E-A-T and trustworthy content?
Plagiarizing More Than One Document
Google’s AIO system is designed to answer follow-up and related questions, “synthesizing” answers from more than one original source and that’s the case with this specific answer.
Whereas Lily’s content argues that Google isn’t doing enough, AIO rewrote the content from another document to say that Google is taking action to prevent spam. Google’s AIO differs from Lily’s original by answering five additional questions with answers that are derived from another web page.
This gives the appearance that Google’s AIO answer for this specific query is “synthesizing” or “plagiarizing” from two documents to answer the question Lily Ray’s search query, “spam in ai overview google.”
Takeaways
Google’s AI Overviews is repurposing web content to create long-form content that lacks originality or added-value.
Google’s AIO answers mirror the content they summarize, copying the structure and ideas to answer identical questions inherent in the articles.
Google’s AIO arguably deviates from Google’s own quality standards, using rewritten content in a manner that mirrors Google’s own definitions of spam.
Google’s AIO features apparent plagiarism of multiple sources.
The quality and trustworthiness of AIO responses may not reach the quality levels set by Google’s principles of Experience, Expertise, Authoritativeness, and Trustworthiness because AI lacks experience and apparently there is no mechanism for fact-checking.
The fact that Google’s AIO system provides essay-length answers arguably removes any incentive for users to click through to the original source and may help explain why many in the search and publisher communities are seeing less traffic. The perception of AIO traffic is so bad that one search marketer quipped on X that ranking #1 on Google is the new place to hide a body, because nobody would ever find it there.
Google could be said to plagiarize content because AIO answers are rewrites of published articles that lack unique analysis or added value, placing AIO firmly within most people’s definition of a scraper spammer.
A combination of fear and necessity may create a renaissance of sorts for brand marketing.
Many retail and direct-to-consumer companies that have essentially ignored branding now worry that generative AI is merging their advertising and marketing copy into a single, industry-wide sameness. Yet these businesses also recognize genAI’s importance.
Source of the Fear
Consider the decline of regional accents in America.
Years ago, such accents were common. Texans had a drawl. Georgians sounded Southern. Bostonians didn’t pronounce the letter “r.”
The accents still exist to some degree, but multiple studies attribute their decline to mass media and improved transportation. The rise of nationwide television in the 1950s and affordable cross-country vacations and relocations prompted Americans to sound the same.
AI does something similar. It learns patterns of writing from the web and also contributes content to it. AI-generated sentences and paragraphs reside on the same web that instructs the writing patterns.
Careful observers have recognized some of these repeated patterns. For example, many suspect that the noble em dash (—) was a sure sign of AI copy. The assertion is untrue. The em dash, en dash, and hyphen are versatile forms of punctuation dating to the 1700s.
Nonetheless, this humble line (the em dash) represented what at least some believed to be an AI glitch that made all writing similar. If AI could overuse the em dash, it could also homogenize brand copy.
The em dash is a longstanding punctuation mark, as shown here in the author’s article from 2008.
It is the 2025 equivalent of the generic brand video that Dissolve, a video and photography licensing company, released in 2014. Based on a McSweeney’s poem, the video began, “We think first of vague words that are synonyms for progress and pair them with footage of a high-speed train.”
The video looked and sounded like many corporate videos of the era and pointed out just how funny and bad generic branding can be.
Necessity
AI’s capacity to process vast datasets, learn from patterns, and generate readable text offers seemingly unprecedented opportunities for marketers.
AI can produce ad copy, social media posts, product descriptions, and more. The quality is not perfect, but the cost, ubiquity, speed, and scale make it attractive.
Some ecommerce marketers even use AI to generate personalized customer messages at scale. Others create dozens of ad variations and multivariate tests to drive conversions.
These capabilities mean generative AI is a competitive necessity for many businesses.
Branding
In an attempt to balance the benefits of AI with concerns of a generic voice, marketers may focus on their company’s brand and what makes it distinct.
For example, fractional CMO Derrick Hicks now offers AI prompting services for adding brand context. The aim is a consistent voice across all marketing channels for recognition and trust.
Hicks’s offering is similar (but more developed) to the brand voice features in AI tools such as Copy.ai and Content Hub. It’s traditional brand development applied to AI.
The key is to develop a compelling written and spoken brand. It’s a strategic investment requiring time, repetition, and deliberate choices.
Good branding begins with clarity: how the company speaks, what it stands for, and who it speaks to. This means defining tone and vocabulary through collaboration and iteration, and codifying those decisions into a brand voice document.
The document should include examples, preferred and banned words, and guidelines by channel and customer persona. It’s the reference point for every prompt and marketing asset, AI-generated or not.
Expect to revise and sharpen the document over time. Train the AI tools. Provide examples, instructions, and corrections. The more specific and consistent the inputs, the stronger the brand expression.
A marketing team should test messages, observe how prospects respond, and adjust.
None of this is easy. But for ecommerce companies in a noisy, AI-driven marketplace, a strong verbal brand is a differentiator, making the business recognizable, memorable, and trustworthy.
A couple of weeks ago I was in Washington, DC, for a gathering of scientists, policymakers, and longevity enthusiasts. They had come together to discuss ways to speed along the development of drugs and other treatments that might extend the human lifespan.
One approach that came up was to simply make experimental drugs more easily accessible. Let people try drugs that might help them live longer, the argument went. Some groups have been pushing bills to do just that in Montana, a state whose constitution explicitly values personal liberty.
A couple of years ago, a longevity lobbying group helped develop a bill that expanded on the state’s existing Right to Try law, which allowed seriously ill people to apply for access to experimental drugs (that is, drugs that have not been approved by drug regulators). The expansion, which was passed in 2023, opened access for people who are not seriously ill.
Over the last few months, the group has been pushing further—for a new bill that sets out exactly how clinics can sell experimental, unproven treatments in the state to anyone who wants them. At the end of the second day of the event, the man next to me looked at his phone. “It just passed,” he told me. (The lobbying group has since announced that the state’s governor Greg Gianforte has signed the bill into law, but when I called his office, Gianforte’s staff said they could not legally tell me whether or not he has.)
In the US, drugs must be tested in human volunteers before they can be approved and sold. Early-stage clinical trials are small and check for safety. Later trials test both the safety and efficacy of a new drug.
The system is designed to keep people safe and to prevent manufacturers from selling ineffective or dangerous products. It’s meant to protect us from snake oil.
But people who are seriously ill and who have exhausted all other treatment options are often desperate to try experimental drugs. They might see it as a last hope. Sometimes they can volunteer for clinical trials, but time, distance, and eligibility can rule out that option.
Since the 1980s, seriously or terminally ill people who cannot take part in a trial for some reason can apply for access to experimental treatments through a “compassionate use” program run by the US Food and Drug Administration (FDA). The FDA authorizes almost all of the compassionate use requests it receives (although manufacturers don’t always agree to provide their drug for various reasons).
But that wasn’t enough for the Goldwater Institute, a libertarian organization that in 2014 drafted a model Right to Try law for people who are terminally ill. Versions of this draft have since been passed into law in 41 US states, and the US has had a federal Right to Try law since 2018. These laws generally allow people who are seriously ill to apply for access to drugs that have only been through the very first stages of clinical trials, provided they give informed consent.
Some have argued that these laws have been driven by a dislike of both drug regulation and the FDA. After all, they are designed to achieve the same result as the compassionate use program. The only difference is that they bypass the FDA.
Either way, it’s worth noting just how early-stage these treatments are. A drug that has been through phase I trials might have been tested in just 20 healthy people. Yes, these trials are designed to test the safety of a drug, but they are never conclusive. At that point in a drug’s development, no one can know how a sick person—who is likely to be taking other medicines— will react to it.
Now these Right to Try laws are being expanded even more. The Montana bill, which goes the furthest, will enable people who are not seriously ill to access unproven treatments, and other states have been making moves in the same direction.
Just this week, Georgia’s governor signed into law the Hope for Georgia Patients Act, which allows people with life-threatening illnesses to access personalized treatments, those that are “unique to and produced exclusively for an individual patient based on his or her own genetic profile.” Similar laws, known as “Right to Try 2.0,” have been passed in other states, too, including Arizona, Mississippi, and North Carolina.
And last year, Utah passed a law that allows health care providers (including chiropractors, podiatrists, midwives, and naturopaths) to deliver unapproved placental stem cell therapies. These treatments involve cells collected from placentas, which are thought to hold promise for tissue regeneration. But they haven’t been through human trials. They can cost tens of thousands of dollars, and their effects are unknown. Utah’s law was described as a “pretty blatant broadbrush challenge to the FDA’s authority” by an attorney who specializes in FDA law. And it’s one that could put patients at risk.
Laws like these spark a lot of very sensitive debates. Some argue that it’s a question of medical autonomy, and that people should have the right to choose what they put in their own bodies.
And many argue there’s a cost-benefit calculation to be made. A seriously ill person potentially has more to gain and less to lose from trying an experimental drug, compared to someone who is in good health.
But everyone needs to be protected from ineffective drugs. Most ethicists think it’s unethical to sell a treatment when you have no idea if it will work, and that argument has been supported by numerous US court decisions over the years.
There could be a financial incentive for doctors to recommend an experimental drug, especially when they are granted protections by law. (Right to Try laws tend to protect prescribing doctors from disciplinary action and litigation should something go wrong.)
On top of all this, many ethicists are also concerned that the FDA’s drug approval process itself has been on a downward slide over the last decade or so. An increasing number of drug approvals are fast-tracked based on weak evidence, they argue.
Scientists and ethicists on both sides of the debate are now waiting to see what unfolds under the new US administration.
In the meantime, a quote from Diana Zuckerman, president of the nonprofit National Center for Health Research, comes to mind: “Sometimes hope helps people do better,” she told me a couple of years ago. “But in medicine, isn’t it better to have hope based on evidence rather than hope based on hype?”
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
This baby boy was treated with the first personalized gene-editing drug
Doctors say they constructed a bespoke gene-editing treatment in less than seven months and used it to treat a baby with a deadly metabolic condition. The rapid-fire attempt to rewrite the child’s DNA marks the first time gene editing has been tailored to treat a single individual.
The baby who was treated, Kyle “KJ” Muldoon Jr., suffers from a rare metabolic condition caused by a particularly unusual gene misspelling. Researchers say their attempt to correct the error demonstrates the high level of precision new types of gene editors offer.
The project also highlights what some experts are calling a growing crisis in gene-editing technology. That’s because even though the technology could cure thousands of genetic conditions, most are so rare that companies could never recoup the costs of developing a treatment for them. Read the full story. —Antonio Regalado
Access to experimental medical treatments is expanding across the US
—Jessica Hamzelou
A couple of weeks ago I was in Washington, DC, for a gathering of scientists, policymakers, and longevity enthusiasts. They had come together to discuss ways to speed along the development of drugs and other treatments that might extend the human lifespan.
One approach that came up was to simply make experimental drugs more easily accessible. Now, the state of Montana has passed a new bill that sets out exactly how clinics can sell experimental, unproven treatments in the state to anyone who wants them.
The passing of the bill could make Montana something of a US hub for experimental treatments. But it represents a wider trend: the creep of Right to Try across the US. And a potentially dangerous departure from evidence-based medicine. Read the full story.
This article first appeared in The Checkup, MIT Technology Review’s weekly biotech newsletter. To receive it in your inbox every Thursday, and read articles like this first, sign up here.
Take a new look at AI’s energy use
Big Tech’s appetite for energy is growing rapidly as adoption of AI accelerates. But just how much energy does even a single AI query use? And what does it mean for the climate?
Join editor in chief Mat Honan, senior climate reporter Casey Crownhart, and AI reporter James O’Donnell at 1.30pm ET on Wednesday May 21 for a subscriber-only Roundtables conversation exploring AI’s energy demands now and in the future. Register here.
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 xAI has blamed Grok’s white genocide fixation on an ‘unauthorized modification’ Made by an unnamed employee at 3.15am. (TechCrunch) + The topic is one the far-right comes back to again and again. (The Atlantic $) + Memphis residents are struggling to live alongside xAI’s supercomputer. (CNBC)
2 Meta has delayed the launch of its next flagship AI model Its engineers are struggling to improve its Behemoth LLM enough. (WSJ $)
3Elon Musk is tapping up friends and allies for federal jobs It’s creating an unprecedented web of potential conflicts of interests. (WSJ $) + Musk is posting on X less than he used to. (Semafor)
4 The US is slashing funding for scientific research Such projects produced GPS, LASIK eye surgery, and CAPTCHAs. (NYT $) + US tech visa applicants are under seriously heavy scrutiny. (Wired $) + The foundations of America’s prosperity are being dismantled. (MIT Technology Review) 5 Big Tech wants its AI agents to remember everything about you They’re focusing on improving chatbots’ memory—but critics are worried. (FT $) + AI agents can spontaneously develop human-like behavior. (The Guardian) + Generative AI can turn your most precious memories into photos that never existed. (MIT Technology Review)
6 People keep making anti-DEI modifications for The Sims 4 And the gamemaker EA’s attempts to stamp them out aren’t working. (Wired $)
7 This chatbot promises to help you get over your ex Closure creates an AI version of ex-partners for users to vent their frustrations at. (404 Media) + The AI relationship revolution is already here. (MIT Technology Review)
8 How this AI song became a viral megahit in Japan YAJU&U is completely inescapable, and totally nonsensical. (Pitchfork) + AI is coming for music, too. (MIT Technology Review)
9 Your future overseas trip could be by zeppelin If these startups get their way. (WP $) + Welcome to the big blimp boom. (MIT Technology Review)
10 Are you a ‘dry texter’? It’s a conflict-averse teen’s worst nightmare. (Vox)
Quote of the day
“It’s OK to be Chinese overseas.”
—Chris Pereira, the CEO of iMpact, a communications firm advising Chinese companies expanding abroad, tells Rest of World that DeepSeek has given Chinese startups the confidence not to hide their origins.
One more thing
We’ve never understood how hunger works. That might be about to change.
When you’re starving, hunger is like a demon. It awakens the most ancient and primitive parts of the brain, then commandeers other neural machinery to do its bidding until it gets what it wants.
Although scientists have had some success in stimulating hunger in mice, we still don’t really understand how the impulse to eat works. Now, some experts are following known parts of the neural hunger circuits into uncharted parts of the brain to try and find out.
Their work could shed new light on the factors that have caused the number of overweight adults worldwide to skyrocket in recent years. And it could also help solve the mysteries around how and why a new class of weight-loss drugs seems to work so well. Read the full story.
—Adam Piore
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or skeet ’em at me.)+ Who knew—Harvard Law School’s Magna Carta may be the real deal after all. + Early relatives of reptiles might have walked the Earth much earlier than we realised. + New York University’s MFA Students are a talented bunch. + The Raines sandwich sounds unspeakably awful
For this week’s “Ecommerce Conversations,” I’m offering another master class on entrepreneurship. It’s my fourth this year, following episodes on hiring, branding, and profit-building.
My goal is to help existing and future entrepreneurs based on operating Beardbrand, my direct-to-consumer company, for a decade now. This installment is my most important master class to date. It’s about setting priorities for business and life.
My entire audio is embedded below. The transcript is edited for clarity and length.
Purpose
A common entrepreneurial mistake is building a business without intention or purpose. There are many ways to approach entrepreneurship, but I focus on creating a company that gives me freedom — doing what I want, when I want, with people I enjoy working with. That’s my North Star, and it influences every decision.
Your North Star might be different, but it’s important to define it early. For me, I lean toward less drama and more personal freedom. Bigger companies with rapid growth often have more lawsuits, employee issues, and general chaos. I keep things simpler to avoid unnecessary headaches.
If you aim to build a massive, high-growth company and sell it for millions as quickly as possible, this approach isn’t for you. But if you value a sustainable business that supports your lifestyle and aligns with your values, that’s what I’m here to share.
Profit Equals Freedom
A common mistake for entrepreneurs is chasing revenue instead of bottom-line profit. They obsess over gross sales, but the key is what you can keep, your net profit. High revenue with slim margins won’t give you freedom.
Money has never been important to me. My first job paid $11 an hour at a Dell call center. My parents were upper-middle class and supportive, but they were not investors in Beardbrand beyond buying products and cheering me on.
What kept me afloat was simple math: spend less than you earn. When income drops, cut expenses. When income rises, save aggressively. That cycle of living below my means has created financial stability over time.
Improving margins means lower costs (mostly for products and customer acquisition), higher prices to customers, or both. Entrepreneurs tend to focus on marketing, such as Facebook and Google ads and search engine optimization. But those channels can become more expensive over time and erode margins.
It’s just as important to lower the cost of goods while improving the end products so customers will pay more. Efficient supply chains and nonstop product improvement are critical.
A common trap is holding onto low-margin products because they generate top-line revenue. If a product doesn’t contribute to your bottom line, it’s not worth keeping — you’re working for free. But don’t abandon products too quickly. Test ways to cut costs, raise prices, or acquire customers more affordably. If those efforts fail, discontinue the item.
External Funds
Entrepreneurs often take on loans or seek investors, but the goal should always be to build the company without outside debt or equity.
The traditional route — bank loans, venture capital funding, or friends and family — means taking on debt or giving up ownership. A better option is customer financing. Crowdfunding platforms such as Kickstarter sell your product to consumers before it exists, providing seed money and real-world feedback while reducing risk and maintaining ownership. No debt payments. No investors telling you how to run your business.
Before borrowing money, ask if there’s another business to build first, perhaps a product launch in small batches. To start Beardbrand, I made 100 bottles of beard oil in my kitchen. Small beginnings can still lead to freedom.
Remember why you started. Is it for freedom, wealth, or ego? For those chasing freedom, avoid debt if possible. Fund your business in a way that keeps you in control.
Long-term
Too many business owners have a short-term mindset. We’re all bombarded with stories of entrepreneurs selling their businesses for millions. That narrative gets beaten into our heads: build fast, exit fast, make millions. But think long-term. Not just five or 10 years out, but 50 or 100 years — a multi-generational business.
For that to happen, you have to love showing up every day. And that usually starts with being profitable. Losing money is not fun. Cut unprofitable products, downsize, or humble your lifestyle to fix cash flow.
Beyond finances, entrepreneurs choose who they work with. That’s a gift.
Ultimately, think about your kids. Would they want to take over your business? If so, integrate them in a way they enjoy, not out of obligation. That requires investing time with your family now, away from the business, so they’ll want to be part of it later.
Self-invest
A long-term vision does not mean neglecting other aspects of life. I’m investing in my health and mindset — ensuring my body and mind are ready for my kids, grandkids, and the company as I age.
I exercise six days a week — three lifting and three rowing. I built a garage gym for time-saving convenience.
For my mental health, my family and I travel to Denmark every summer. It’s not a vacation — I still work — but being in a new place sparks adventure. For me, that’s travel. Others may value hobbies, gardening, or whatever keeps their lives interesting.
Priorities
How we spend our time is a key decision in life. It starts with knowing our priorities — serving our body, mind, business, spouse, kids, and friends.
I write in a Moleskine notebook what’s important to me. Then I rank them. No ties, no equals. For me, family ranks above business.
But above all, I prioritize my health and mindset. I can’t show up for my wife, kids, or company if I’m absent physically, mentally, or emotionally. You can’t pour from an empty cup. Get clear on your list.
A WordPress plugin that automatically posts content scraped from other websites has been discovered to contain a critical vulnerability that allows anyone to upload malicious files to affected websites. The severity of the vulnerability is rated at 9.8 on a scale of 1-10.
Crawlomatic Multisite Scraper Post Generator Plugin for WordPress
The Crawlomatic WordPress plugin is sold via the Envato CodeCanyon store for $59 per license. It enables users to crawl forums, weather statistics, articles from RSS feeds, and directly scrape the content from other websites and then automatically publish the content on the user’s website.
The plugin’s Envato CodeCanyon web page features a banner that notes that the author of the plugin has been recognized for having met “WordPress quality standards” and displays a badge indicating that it is “Envato WP Requirements Compliant,” an indication that it meets Envato’s “security, quality, performance and coding standards in WordPress plugins and themes.”
The plugin’s directory page explains that it it can crawl and scrape virtually any website, including JavaScript-based sites, promising that it can turn a user’s website into a “money making machine.”
Unauthenticated Arbitrary File Upload
The Crawlomatic WordPress plugin is missing a filetype validation check in all version prior to and including version 2.6.8.1.
According to a warning posted on Wordfence:
“The Crawlomatic Multipage Scraper Post Generator plugin for WordPress is vulnerable to arbitrary file uploads due to missing file type validation in the crawlomatic_generate_featured_image() function in all versions up to, and including, 2.6.8.1. This makes it possible for unauthenticated attackers to upload arbitrary files on the affected site’s server which may make remote code execution possible.”
Users of the plugin are recommended by Wordfence to update to at least version 2.6.8.2.