Google’s John Mueller answered a question on Reddit about heading elements, confirming a slight impact but downplaying its significance, saying a lot about how Google uses headings.
Hierarchical Heading Structure
Hierarchical and hierarchy in the context of heading elements (H1, H2, etc.) refers to the organization of headings in order of importance or structure. In this context, the word “importance” doesn’t mean importance as a ranking factor, it means importance to the structure of a web page.
Generally a web page could have one H1, indicative of the topic of the entire page and multiple H2 headings that signal what each section of a web page is about. For Google’s purposes, the first heading doesn’t have to be an H1, it can be an H2. Google isn’t mandated to use the first heading as the overall topic, it’s not a directive to their search algorithms where an SEO controls how Google interprets a heading.
The technical specifications of heading elements are found on the pages of the World Wide Web Consortium (W3C), the standards making body that, among many things, defines the purpose and use of HTML elements like headings.
Google generally follows the official W3C technical specifications of HTML elements but for practical purposes isn’t strict about it because many websites use headings for style not semantic purposes.
Are Incorrectly Ordered Headings Harmful To SEO?
The Redditor wanted to know if using the heading elements out of order was “harmful” and to what degree. They used the word “sequential” but the precise word is hierarchical.
They wanted to know how bad was it if the headings were out of order or if one of the headings was skipped entirely.
This is the question:
“How Harmful is having Non sequential header Tags? Like having a h4 title and h1 tags below Or Having a h4, h3 h5 but not h2 tags?”
H1, H2 Headings Have A Slight Impact
Google’s John Mueller confirmed that the heading order has a slight impact. He didn’t say it was a ranking factor nor did he say what kind of impact the heading order had. It could be that the heading order makes it easier for search engines to understand the web page, which is what I believe (meaning, it’s just my opinion and you’re entitled to yours).
This is Mueller’s answer:
“Doing things properly (right order headings) is a good practice, it helps search engines lightly to better understand your content, and it’s good for accessibility. If you’re setting up a new site, or making significant changes on your templates, or just bored :-), then why not take the extra 10 minutes to get this right.”
Sometimes it’s difficult to control the headings because a template might use headings to style sections of a web page, like in the footer or a sidebar. In the context of a WordPress site that means having to create a child template that controls the styles and change the CSS for those sections of the template so that they use CSS and not headings to style them.
Other than that, the heading structure is entirely under control of the publisher, site owner, or SEO.
Yet, having the keywords in the headings might not be enough because the purpose of heading elements is to communicate what a section of a web page is about and, as Mueller goes on to say, headings play a role for accessibility.
Google Says Fixing Headings Won’t Change Rankings
This is the part that some SEOs may find confusing because Google says that fixing the hierarchical structure of headings will not improve the rankings of a website.
A long time ago, like twenty four years ago, heading elements were a critical activity for ranking in Google. I know because I was an SEO in the early 2000s and experienced this first hand. By 2005 the impact to rankings had significantly diminished. I know it was diminished because I was a digital marketer when headings stopped making a critical impact and had evolved to become a signal of what a section of a web page is about.
The search results were full of sites that had no heading elements, it was hard not to notice the change.
But for some reason many in the SEO industry continued to believe that headings are a strong ranking factor. John Mueller’s statement about the diminished impact of heading elements to search rankings confirms the changed role that heading elements play today.
Mueller continued his answer:
“That said, if you have an existing site, fixing this isn’t going to change your site’s rankings; I suspect you’ll find much bigger value in terms of SEO by looking for ways to significantly up-value your site overall.”
What Mueller is talking about is the difference between making a web page for search engines (worrying about how Google will interpret heading elements) and creating a web page for users (worrying if the page contains useful information that is on-topic flows in a logical order).
His statement gives a clue to how Google uses heading elements and is good advice.
Google Chrome has officially ended support for the First Input Delay (FID) metric, marking a transition to prioritizing Interaction to Next Paint (INP).
The announcement by Rick Viscomi, who oversees web performance developer relations for the Chrome team, confirms INP as the core metric for evaluating interaction responsiveness.
Today’s the day: Chrome ends support for FID
If you’re still relying on it in Chrome tools, your workflows WILL BREAK
The following tools will stop reporting FID data over the next few days:
PageSpeed Insights
Chrome User Experience Report (CrUX)
web-vitals.js
Web Vitals extension
Background
The move to replace FID with INP stems from limitations in capturing the full scope of interaction responsiveness on the web.
FID only measured the delay between a user’s input and the browser’s response, overlooking other critical phases.
INP takes a more holistic approach by measuring the entire process, from user input to visual updates on the screen.
Transition Period
While the web-vitals.js library will receive a version bump (5.0) to accommodate the change, most other tools will stop reporting FID data without a version update.
The CrUX BigQuery project will remove FID-related fields from its schema starting with the 202409 dataset, scheduled for release in October.
To aid developers in the transition, the Chrome team is also retiring the “Optimize FID” documentation, redirecting users to the updated “Optimize INP” guidance.
We’re also shutting down the old Optimize FID article
Now with better APIs and metrics, there’s no reason to optimize ONLY the input delay phase of an interaction. Instead, focus on the entire UX from input to painthttps://t.co/DMzeFUelfm
Here are some steps to take to in light of the transition from FID to INP:
Familiarize yourself with the INP metric by reviewing the official documentation on web.dev. Understand how INP measures the full lifecycle of an interaction from input to visual update.
Audit your site’s current INP performance using tools like PageSpeed Insights or real-user monitoring services that support INP. Identify areas where interaction responsiveness needs improvement.
Consult the “Optimize INP” guidance on web.dev for best practices on reducing input delay, optimizing event handling, minimizing layout thrashing, and other techniques to enhance INP.
Update any performance monitoring tools or custom scripts that currently rely on the deprecated FID metric to use INP instead. For web-vitals.js users, be prepared for the breaking change in version 5.0.
If leveraging the CrUX BigQuery dataset, plan to update data pipelines to handle the schema changes, removing FID fields after the 202409 release in October.
By taking these steps, you can ensure a smooth migration to INP.
WordPress 6.6.2 introduces 26 bug fixes, including an important one that resolves a CSS issue affecting site appearance. Fifteen fixes address the WordPress core, while eleven focus on the Gutenberg block editor.
Maintenance Release – CSS Specificity
WordPress maintenance releases aren’t generally major updates to WordPress and are intended to fix issues that were introduced through new features from the last major update, in this case version 6.6.
This maintenance release is no different and contains a fix for a feature called CSS specificity that was introduced in WordPress 6.6.
CSS is the code that controls what a web page looks like in terms of colors, sizes, margins and spaces. Specificity means what style belongs to a web page element (like a section of page or something else more granular). CSS Specificity is a reference to a set of rules belonging to the WordPress core that determine which CSS property applies when there is ambiguity as to which property should apply. The purpose of CSS Specificity was initially developed as a way to make it simple for theme developers to overrule WordPress core styles with their own styles.
However it was discovered that the implementation of CSS Specificity introduced several issues that significantly affected what the web page looked like.
WordPress 6.6.2 fixes this issue and for that reason publishers who’ve had issues should consider updating.
Other Fixes
This maintenance release contains 15 fixes to the WordPress core and 11 fixes to the Gutenberg block editor.
Examples of fixes in the Core included in the maintenance release:
Sample Of Fixes In Gutenberg:
Reception Of 6.6.2
Publishers who haven’t experienced this update should feel confident about upgrading to this version. Initial reports in the private Dynamic WordPress Facebook Group is positive, with the admin of the group, David McCan, reporting he’d rolled it out to ten sites without experiencing any issues (link to discussion, must join the Facebook group to read).
Crawl budget is a vital SEO concept for large websites with millions of pages or medium-sized websites with a few thousand pages that change daily.
An example of a website with millions of pages would be eBay.com, and websites with tens of thousands of pages that update frequently would be user reviews and rating websites similar to Gamespot.com.
There are so many tasks and issues an SEO expert has to consider that crawling is often put on the back burner.
But crawl budget can and should be optimized.
In this article, you will learn:
How to improve your crawl budget along the way.
Go over the changes to crawl budget as a concept in the last couple of years.
(Note: If you have a website with just a few hundred pages, and pages are not indexed, we recommend reading our article on common issues causing indexing problems, as it is certainly not because of crawl budget.)
What Is Crawl Budget?
Crawl budget refers to the number of pages that search engine crawlers (i.e., spiders and bots) visit within a certain timeframe.
There are certain considerations that go into crawl budget, such as a tentative balance between Googlebot’s attempts to not overload your server and Google’s overall desire to crawl your domain.
Crawl budget optimization is a series of steps you can take to increase efficiency and the rate at which search engines’ bots visit your pages.
Why Is Crawl Budget Optimization Important?
Crawling is the first step to appearing in search. Without being crawled, new pages and page updates won’t be added to search engine indexes.
The more often that crawlers visit your pages, the quicker updates and new pages appear in the index. Consequently, your optimization efforts will take less time to take hold and start affecting your rankings.
Google’s index contains hundreds of billions of pages and is growing each day. It costs search engines to crawl each URL, and with the growing number of websites, they want to reduce computational and storage costs by reducing the crawl rate and indexation of URLs.
There is also a growing urgency to reduce carbon emissions for climate change, and Google has a long-term strategy to improve sustainability and reduce carbon emissions.
These priorities could make it difficult for websites to be crawled effectively in the future. While crawl budget isn’t something you need to worry about with small websites with a few hundred pages, resource management becomes an important issue for massive websites. Optimizing crawl budget means having Google crawl your website by spending as few resources as possible.
So, let’s discuss how you can optimize your crawl budget in today’s world.
Well, if you disallow URLs that are not important, you basically tell Google to crawl useful parts of your website at a higher rate.
For example, if your website has an internal search feature with query parameters like /?q=google, Google will crawl these URLs if they are linked from somewhere.
Similarly, in an e-commerce site, you might have facet filters generating URLs like /?color=red&size=s.
These query string parameters can create an infinite number of unique URL combinations that Google may try to crawl.
Those URLs basically don’t have unique content and just filter the data you have, which is great for user experience but not for Googlebot.
Allowing Google to crawl these URLs wastes crawl budget and affects your website’s overall crawlability. By blocking them via robots.txt rules, Google will focus its crawl efforts on more useful pages on your site.
Here is how to block internal search, facets, or any URLs containing query strings via robots.txt:
Each rule disallows any URL containing the respective query parameter, regardless of other parameters that may be present.
* (asterisk) matches any sequence of characters (including none).
? (Question Mark): Indicates the beginning of a query string.
=*: Matches the = sign and any subsequent characters.
This approach helps avoid redundancy and ensures that URLs with these specific query parameters are blocked from being crawled by search engines.
Note, however, that this method ensures any URLs containing the indicated characters will be disallowed no matter where the characters appear. This can lead to unintended disallows. For example, query parameters containing a single character will disallow any URLs containing that character regardless of where it appears. If you disallow ‘s’, URLs containing ‘/?pages=2’ will be blocked because *?*s= matches also ‘?pages=’. If you want to disallow URLs with a specific single character, you can use a combination of rules:
Disallow: *?s=*
Disallow: *&s=*
The critical change is that there is no asterisk ‘*’ between the ‘?’ and ‘s’ characters. This method allows you to disallow specific exact ‘s’ parameters in URLs, but you’ll need to add each variation individually.
Apply these rules to your specific use cases for any URLs that don’t provide unique content. For example, in case you have wishlist buttons with “?add_to_wishlist=1” URLs, you need to disallow them by the rule:
Disallow: /*?*add_to_wishlist=*
This is a no-brainer and a natural first and most important step recommended by Google.
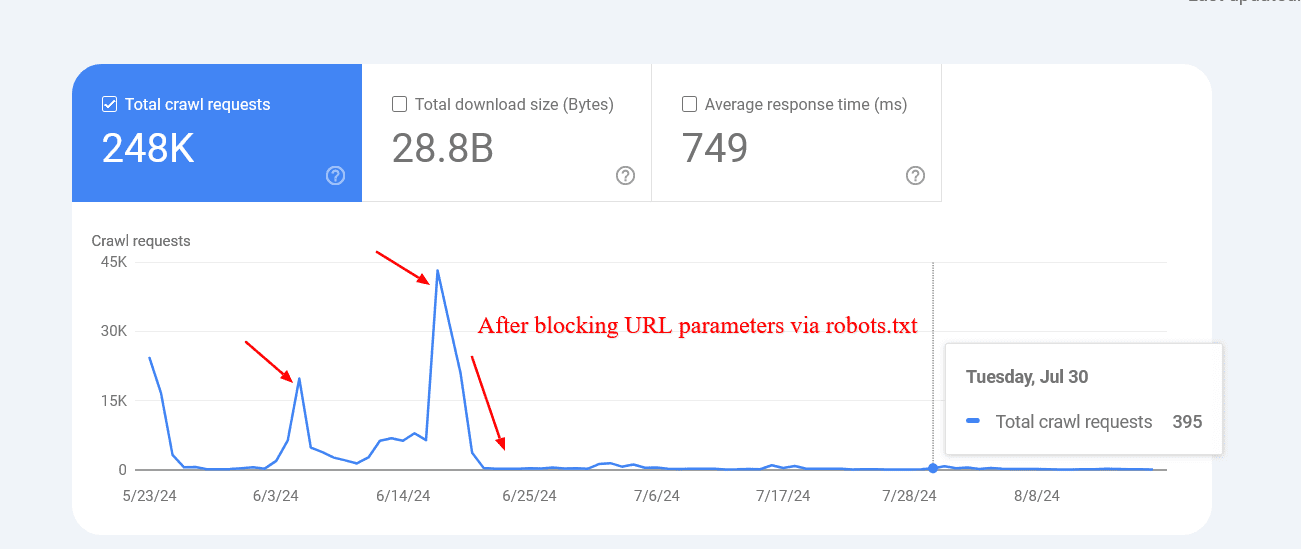
An example below shows how blocking those parameters helped to reduce the crawling of pages with query strings. Google was trying to crawl tens of thousands of URLs with different parameter values that didn’t make sense, leading to non-existent pages.
Reduced crawl rate of URLs with parameters after blocking via robots.txt.
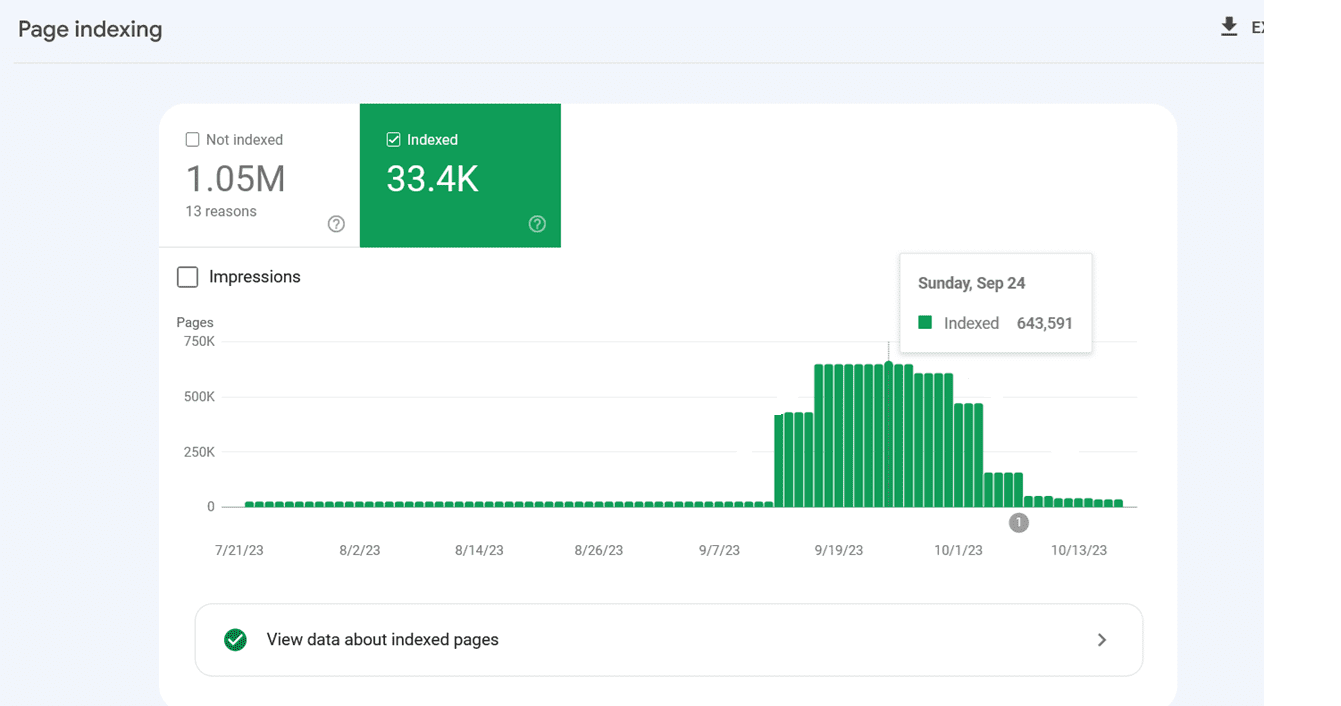
However, sometimes disallowed URLs might still be crawled and indexed by search engines. This may seem strange, but it isn’t generally cause for alarm. It usually means that other websites link to those URLs.
Indexing spiked because Google indexed internal search URLs after they were blocked via robots.txt.
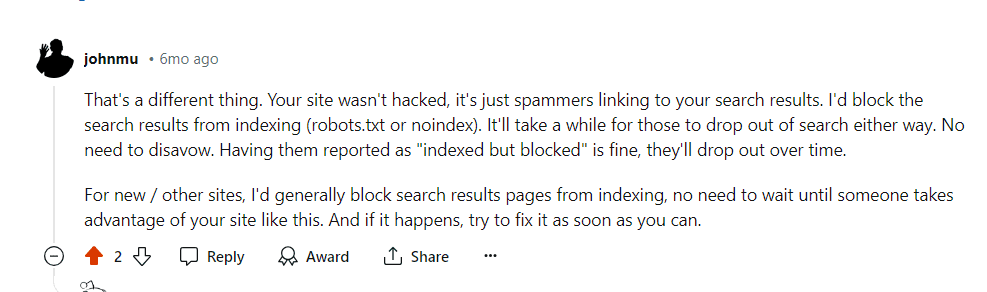
Google confirmed that the crawling activity will drop over time in these cases.
Google’s comment on Reddit, July 2024
Another important benefit of blocking these URLs via robots.txt is saving your server resources. When a URL contains parameters that indicate the presence of dynamic content, requests will go to the server instead of the cache. This increases the load on your server with every page crawled.
Please remember not to use “noindex meta tag” for blocking since Googlebot has to perform a request to see the meta tag or HTTP response code, wasting crawl budget.
1.2. Disallow Unimportant Resource URLs In Robots.txt
Besides disallowing action URLs, you may want to disallow JavaScript files that are not part of the website layout or rendering.
For example, if you have JavaScript files responsible for opening images in a popup when users click, you can disallow them in robots.txt so Google doesn’t waste budget crawling them.
Here is an example of the disallow rule of JavaScript file:
Disallow: /assets/js/popup.js
However, you should never disallow resources that are part of rendering. For example, if your content is dynamically loaded via JavaScript, Google needs to crawl the JS files to index the content they load.
Another example is REST API endpoints for form submissions. Say you have a form with action URL “/rest-api/form-submissions/”.
Potentially, Google may crawl them. Those URLs are in no way related to rendering, and it would be good practice to block them.
Disallow: /rest-api/form-submissions/
However, headless CMSs often use REST APIs to load content dynamically, so make sure you don’t block those endpoints.
In a nutshell, look at whatever isn’t related to rendering and block them.
2. Watch Out For Redirect Chains
Redirect chains occur when multiple URLs redirect to other URLs that also redirect. If this goes on for too long, crawlers may abandon the chain before reaching the final destination.
URL 1 redirects to URL 2, which directs to URL 3, and so on. Chains can also take the form of infinite loops when URLs redirect to one another.
Avoiding these is a common-sense approach to website health.
Ideally, you would be able to avoid having even a single redirect chain on your entire domain.
But it may be an impossible task for a large website – 301 and 302 redirects are bound to appear, and you can’t fix redirects from inbound backlinks simply because you don’t have control over external websites.
One or two redirects here and there might not hurt much, but long chains and loops can become problematic.
In order to troubleshoot redirect chains you can use one of the SEO tools like Screaming Frog, Lumar, or Oncrawl to find chains.
When you discover a chain, the best way to fix it is to remove all the URLs between the first page and the final page. If you have a chain that passes through seven pages, then redirect the first URL directly to the seventh.
Another great way to reduce redirect chains is to replace internal URLs that redirect with final destinations in your CMS.
Depending on your CMS, there may be different solutions in place; for example, you can use this plugin for WordPress. If you have a different CMS, you may need to use a custom solution or ask your dev team to do it.
3. Use Server Side Rendering (HTML) Whenever Possible
Now, if we’re talking about Google, its crawler uses the latest version of Chrome and is able to see content loaded by JavaScript just fine.
But let’s think critically. What does that mean? Googlebot crawls a page and resources such as JavaScript then spends more computational resources to render them.
Remember, computational costs are important for Google, and it wants to reduce them as much as possible.
So why render content via JavaScript (client side) and add extra computational cost for Google to crawl your pages?
Because of that, whenever possible, you should stick to HTML.
That way, you’re not hurting your chances with any crawler.
4. Improve Page Speed
As we discussed above, Googlebot crawls and renders pages with JavaScript, which means if it spends fewer resources to render webpages, the easier it will be for it to crawl, which depends on how well optimized your website speed is.
Google’s crawling is limited by bandwidth, time, and availability of Googlebot instances. If your server responds to requests quicker, we might be able to crawl more pages on your site.
So using server-side rendering is already a great step towards improving page speed, but you need to make sure your Core Web Vital metrics are optimized, especially server response time.
5. Take Care of Your Internal Links
Google crawls URLs that are on the page, and always keep in mind that different URLs are counted by crawlers as separate pages.
If you have a website with the ‘www’ version, make sure your internal URLs, especially on navigation, point to the canonical version, i.e. with the ‘www’ version and vice versa.
Another common mistake is missing a trailing slash. If your URLs have a trailing slash at the end, make sure your internal URLs also have it.
Otherwise, unnecessary redirects, for example, “https://www.example.com/sample-page” to “https://www.example.com/sample-page/” will result in two crawls per URL.
Another important aspect is to avoid broken internal links pages, which can eat your crawl budget and soft 404 pages.
And if that wasn’t bad enough, they also hurt your user experience!
In this case, again, I’m in favor of using a tool for website audit.
WebSite Auditor, Screaming Frog, Lumar or Oncrawl, and SE Ranking are examples of great tools for a website audit.
6. Update Your Sitemap
Once again, it’s a real win-win to take care of your XML sitemap.
The bots will have a much better and easier time understanding where the internal links lead.
Use only the URLs that are canonical for your sitemap.
Also, make sure that it corresponds to the newest uploaded version of robots.txt and loads fast.
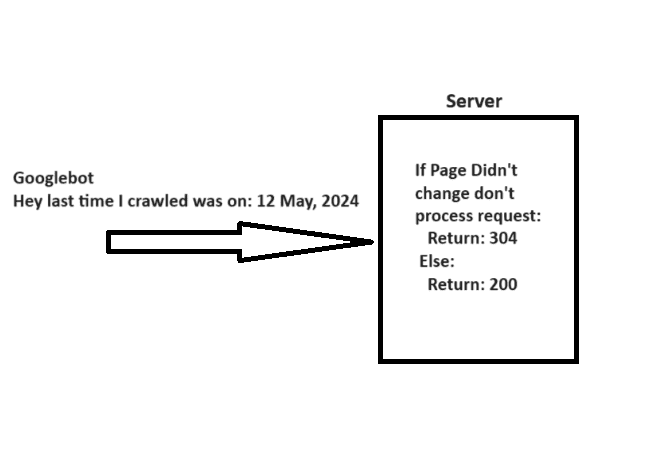
7. Implement 304 Status Code
When crawling a URL, Googlebot sends a date via the “If-Modified-Since” header, which is additional information about the last time it crawled the given URL.
If your webpage hasn’t changed since then (specified in “If-Modified-Since“), you may return the “304 Not Modified” status code with no response body. This tells search engines that webpage content didn’t change, and Googlebot can use the version from the last visit it has on the file.
A simple explanation of how 304 not modified http status code works.
Imagine how many server resources you can save while helping Googlebot save resources when you have millions of webpages. Quite big, isn’t it?
So be cautious. Server errors serving empty pages with a 200 status can cause crawlers to stop recrawling, leading to long-lasting indexing issues.
8. Hreflang Tags Are Vital
In order to analyze your localized pages, crawlers employ hreflang tags. You should be telling Google about localized versions of your pages as clearly as possible.
First off, use the lang_code" href="url_of_page" /> in your page’s header. Where “lang_code” is a code for a supported language.
You should use the element for any given URL. That way, you can point to the localized versions of a page.
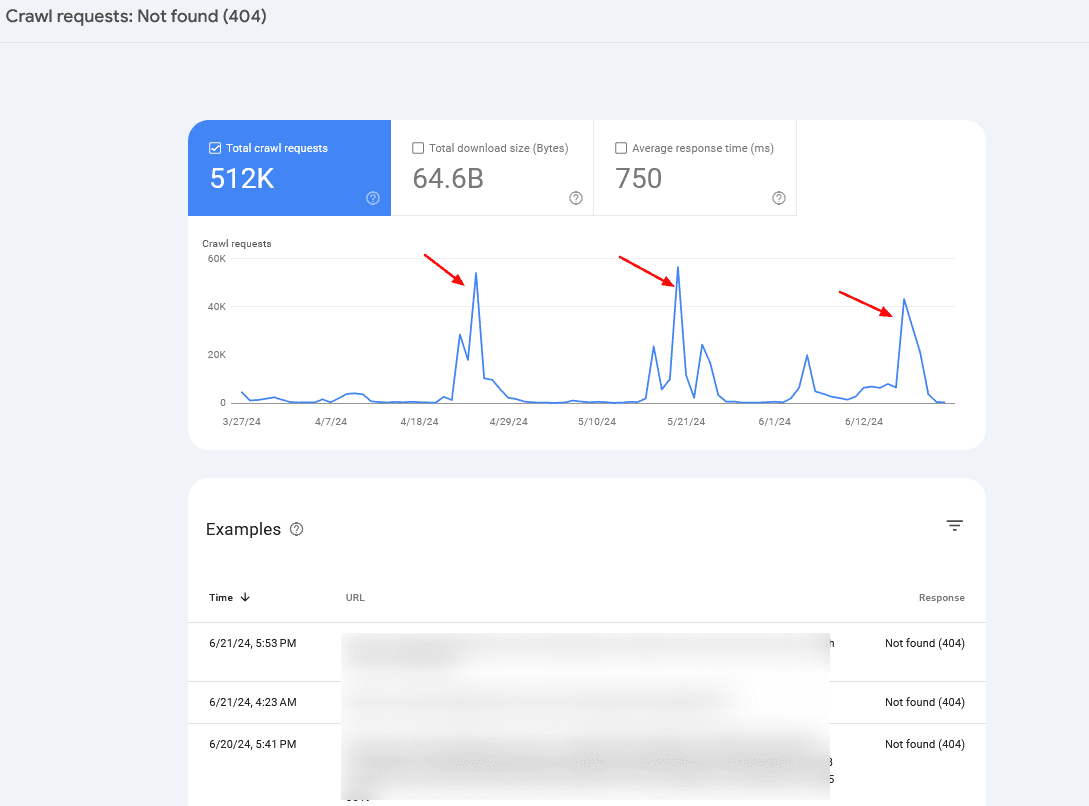
Check your server logs and Google Search Console’s Crawl Stats report to monitor crawl anomalies and identify potential problems.
If you notice periodic crawl spikes of 404 pages, in 99% of cases, it is caused by infinite crawl spaces, which we have discussed above, or indicates other problems your website may be experiencing.
Crawl rate spikes
Often, you may want to combine server log information with Search Console data to identify the root cause.
Summary
So, if you were wondering whether crawl budget optimization is still important for your website, the answer is clearly yes.
Crawl budget is, was, and probably will be an important thing to keep in mind for every SEO professional.
Hopefully, these tips will help you optimize your crawl budget and improve your SEO performance – but remember, getting your pages crawled doesn’t mean they will be indexed.
In case you face indexation issues, I suggest reading the following articles:
Featured Image: BestForBest/Shutterstock All screenshots taken by author
For better or worse, AI has become a dominant force in SEO.
SEO professionals have been grappling with AI for years in Google’s algorithms, but the technology has moved to the forefront of digital marketing. The largest tech companies are developing the technology quickly and pushing products out to customers, trying to stay ahead of the curve.
This has resulted in several AI and generative AI releases, including LLM chatbots, chatbot integrations into search platforms, and AI-based search and research products.
AI threatens to be one of the most disruptive forces in SEO and digital marketing.
SEJ’s latest ebook explores the recent history of AI and developments in the search and marketing industries. It also provides guides and expert advice on building AI into your strategy and workflows.
To compete in search environments built on AI algorithms and with user-facing generative AI features, SEO professionals must learn how the technology works. You need to know how to interact with AI on several fronts:
Optimizing for AI-powered search algorithms.
Building keyword and search strategies that take generative AI search features into account.
Employing AI tools to help improve productivity.
Understanding where AI needs human guidance and what tasks should not be delegated to it.
Differentiating your brand and content from competitors where AI tools have lowered the cost and barriers to marketing at scale.
Creating best practices that define your stance on and relationship to AI and generative AI will position you to succeed as the technology continues to develop and as user trends continue to change.
Look Back On AI Development To Predict Future Trends
Google spent many months rolling out AI products gradually, testing as it went. To understand how AI development will continue impacting SEO, study recent developments and releases, such as how Google has been changing SERP features and algorithms.
See where AI fits into these developments to predict how search might change.
The ebook collects almost a year of SEJ’s coverage of events in the industry and updates from Google, from product testing and releases to public reactions and studies about impact.
One key point is Google’s development of on-SERP features that give users answers without clicking through to a website. These features, including generative AI answers, can make it much more difficult to acquire traffic from certain queries.
That doesn’t mean you can’t make use of these queries, but it’s imperative that you correctly identify user intent for your target queries and build strategies specifically for acquiring SERP features.
SEO Professionals Must Focus On Authority, Brand, And Trust
While disruptive, new user interactions with AI present opportunities. Becoming a cited source can be a great way to power brand awareness. However, trust is also at a premium if you want to keep users’ attention and earn conversions.
Building your content and information architecture with AI in mind can help you stand out in multiple touchpoints of a user’s journey.
Understanding where you must differentiate yourself from automated marketing and build humanity into your brand is now a powerful way to stand out in the minds of users. Building content with AI-friendly organization but human-focused insights helps you serve the right audiences at the right time.
The ebook collects insights from SEJ contributors focused on how building AI into your content strategy goes beyond using it to create for you.
Effectively incorporating generative AI into your workflows requires that you understand how it works and what it’s good at.
You can use generative AI tools to build connections between ideas and words quickly, to parse a lot of data to find commonalities, and to draft and expand ideas, among many other things.
Generative AI can make some tasks much faster, but accuracy will always be an issue, so it’s best when the tasks involve redundancy or human checks.
For example, you could use generative AI to assist with internal linking. It’s ideal for quickly evaluating the pages of a website and suggesting semantic connections between pages. Then, a human can review for accuracy and execute the links that make sense.
We collected some of the best examples of how generative AI tools can improve human workflows in the SEO In The Age Of AI Ebook.
To learn about all this and more, download your copy of SEO In The Age Of AI.
This is today’s edition of The Download, our weekday newsletter that provides a daily dose of what’s going on in the world of technology.
Roblox is launching a generative AI that builds 3D environments in a snap
What’s new: Roblox has announced plans to roll out a generative AI tool that will let creators make whole 3D scenes just using text prompts. Users will also be able to modify scenes or expand their scope—say, to change a daytime scene to night or switch the desert for a forest.
How it works: Once it’s up and running, developers on the hugely popular online game platform will be able to simply write “Generate a race track in the desert,” for example, and the AI will spin one up.
Why it’s a big deal: Although developers can already create similar scenes like this manually in the platform’s creator studio, Roblox claims its new generative AI model will make the changes happen in a fraction of the time. It also claims that it will give developers with minimal 3D art skills the ability to craft more compelling environments. Read the full story.
—Scott J Mulligan
Ray Kurzweil: Technology will let us fully realize our humanity
—Ray Kurzweil is a technologist and futurist and the author, most recently, of The Singularity Is Nearer: When We Merge with AI. The views represented here are his own.
By the end of this decade, AI will likely surpass humans at all cognitive tasks, igniting the scientific revolution that futurists have long imagined. Our plodding progress in fields like robotics, nanotechnology, and genomics will become a sprint.
But our destiny isn’t a hollow Jetsons future of gadgetry and pampered boredom. By freeing us from the struggle to meet the most basic needs, technology will serve our deepest human aspirations to learn, create, and connect.
This sounds fantastically utopian, but humans have made such a leap before. Our hunter-gatherer ancestors lived on a razor’s edge of precarity. While modern life can often feel like a rat race, to our paleolithic ancestors, we would seem to enjoy impossible abundance and freedom. But what will the next leap look like? Read the full story.
Ray Kurzweil will be speaking at our flagship EmTech MIT conference, sharing his latest predictions on artificial general intelligence, singularity, and the infinite possibilities of an AI-integrated world.
Join us, either in-person at the MIT Media Lab in Cambridge or via our virtual livestream, between September 30 and October 1. Even better—The Download readers get 30% off tickets with the code DOWNLOADM24!
The must-reads
I’ve combed the internet to find you today’s most fun/important/scary/fascinating stories about technology.
1 Apple is hoping AI will help it sell more iPhones Today’s keynote is likely to focus on AI smarts over big hardware updates. (Bloomberg $) + AI isn’t really a motivator for consumers to upgrade their handsets, though. (WSJ $) + Apple is promising personalized AI in a private cloud. Here’s how that will work. (MIT Technology Review)
2 Google is facing yet another monopoly trial This time, it’s focusing on how the company dominates the online ad market. (WP $) + The US Department of Justice will issue other antitrust guidelines by December. (Reuters)
3 The jet stream appears to be shifting And climate change is likely to be the driving factor. (New Scientist $)
4 China is going all in on cracking nuclear fusion Startup Energy Singularity is fundraising to try and leapfrog Western rivals. (FT $) + This startup says its first fusion plant is five years away. Experts doubt it. (MIT Technology Review)
5 A growing number of European schools are banning smartphones But parents and teachers don’t always agree. (The Guardian) + Between phones and AI, educators are caught between a rock and a hard place. (The Information $) + Watermarking AI text could help teachers—but it’s not infallible. (Vox)
6 Pakistan’s internet firewall is disrupting its startups They’re struggling to raise funds amid the restrictions. (Rest of World)
7 The Arctic was a little-known testbed for military research The Cold War birthed a range of bizarre projects in the region. (Undark Magazine) + Russia has been testing its intelligence operations there too. (New Yorker $)
8 Inside the race to retrieve discarded bombs from the ocean The explosives the allies dumped following the World Wars are still dangerous. (The Atlantic $)
9 We could harness gravitational waves to detect alien ships The technology exists, we’re just learning how best to use it. (Wired $)
10 How to improve how driverless cars “see” in the dark Using a bit of inspiration from the human eye. (IEEE Spectrum) + The big new idea for making self-driving cars that can go anywhere. (MIT Technology Review)
Quote of the day
“Everyone is dealing with a sea of sameness.”
—Govind Balakrishnan, senior vice-president of creative platform Adobe Express, laments the growing trend for jobseekers to use the same AI tools to write their applications to the Financial Times.
The big story
The flawed logic of rushing out extreme climate solutions
April 2023
Early in 2022, entrepreneur Luke Iseman says, he released a pair of sulfur dioxide–filled weather balloons from Mexico’s Baja California peninsula, in the hope that they’d burst miles above Earth.
It was a trivial act in itself, effectively a tiny, DIY act of solar geoengineering, the controversial proposal that the world could counteract climate change by releasing particles that reflect more sunlight back into space.
Entrepreneurs like Iseman invoke the stark dangers of climate change to explain why they do what they do—even if they don’t know how effective their interventions are. But experts say that urgency doesn’t create a social license to ignore the underlying dangers or leapfrog the scientific process. Read the full story.
—James Temple
We can still have nice things
A place for comfort, fun and distraction to brighten up your day. (Got any ideas? Drop me a line or tweet ’em at me.)+ Life is full of pesky little tasks. These tips can help to make tackling them that bit easier. + The Eagles’ Don Felder and Joe Walsh would be so proud. + Bad news for Titanic fans: Jack and Rose’s famous railing is no more. + Congratulations to 10-year old Karin Tabira, Japan’s youngest expert in preparing deadly pufferfish!
In an era of unprecedented technological advancement, the health-care industry stands at a crossroad. As health expenditure continues to outpace GDP in many countries, health-care executives grapple with crucial decisions on investment prioritization for digitization, innovation, and digital transformation. The imperative to provide high-quality, patient-centric care in an increasingly digital world has never been more pressing. At the forefront of this transformation is imaging IT—a critical component that’s evolving to meet the challenges of modern health care.
The future of imaging IT is characterized by interconnected systems, advanced analytics, robust data security, AI-driven enhancements, and agile infrastructure. Organizations that embrace these trends will be well-positioned to thrive in the changing health-care landscape. But what exactly does this future look like, and how can health-care providers prepare for it?
Networked care models: The new paradigm
The adoption of networked care models is set to revolutionize health-care delivery. These models foster collaboration among stakeholders, making patient information readily available and leading to more personalized and efficient care. As we move forward, expect to see health-care organizations increasingly investing in technologies that enable seamless data sharing and interoperability.
Imagine a scenario where a patient’s entire medical history, including imaging data from various specialists, is instantly accessible to any authorized health-care provider. This level of connectivity not only improves diagnosis and treatment but also enhances the overall patient experience.
Data integration and analytics: Unlocking insights
True data integration is becoming the norm in health care. Robust integrated image and data management solutions (IDM) are consolidating patient data from diverse sources. But the real game-changer lies in the application of advanced analytics and AI to this treasure trove of information.
By leveraging these technologies, medical professionals can extract meaningful insights from complex data sets, leading to quicker and more accurate diagnoses and treatment decisions. The potential for improving patient outcomes through data-driven decision-making is immense.
A case in point is the implementation of Syngo Carbon Image and Data Management (IDM) at Tirol Kliniken GmbH in Innsbruck, Austria. This solution consolidates all patient-centric data points in one place, including different image and photo formats, DICOM CDs, and digitalized video sources from endoscopy or microscopy. The system digitizes all documents in their raw formats, enabling the distribution of native, actionable data throughout the enterprise.
Data privacy and edge computing: Balancing innovation and security
As health care becomes increasingly data-driven, concerns about data privacy remain paramount. Enter edge computing—a solution that enables the processing of sensitive patient data locally, reducing the risk of data breaches during processing and transmission.
This approach is crucial for health-care facilities aiming to maintain patient trust while adopting advanced technologies. By keeping data processing close to the source, health-care providers can leverage cutting-edge analytics without compromising on security.
Workflow integration and AI: Enhancing efficiency and accuracy
The integration of AI into medical imaging workflows is set to dramatically improve efficiency, accuracy, and the overall quality of patient care. AI-powered solutions are becoming increasingly common, reducing the burden of repetitive tasks and speeding up diagnosis.
From automated image analysis to predictive modeling, AI is transforming every aspect of the imaging workflow. This not only improves operational efficiency but also allows health-care professionals to focus more on patient care and complex cases that require human expertise.
A quantitative analysis at the Medical University of South Carolina demonstrates the impact of AI integration. With the support of deep learning algorithms fully embedded in the clinical workflow, cardiothoracic radiologists exhibited a reduction in chest CT interpretation times of 22.1% compared to workflows without AI support.
Virtualization: The key to agility
To future-proof their IT infrastructure, health-care organizations are turning to virtualization. This approach allows for modularization and flexibility, making it easier to adapt to rapidly evolving technologies such as AI-driven diagnostics.
Container technology is playing a pivotal role in optimizing resource utilization and scalability. By embracing virtualization, health-care providers can ensure their IT systems remain agile and responsive to changing needs.
Standardization and compliance: Ensuring long-term compatibility
As imaging IT systems evolve, adherence to industry standards and compliance requirements remains crucial. These systems need to seamlessly interact with Electronic Health Records (EHRs), medical devices, and other critical systems.
This adherence ensures long-term compatibility and the ability to accommodate emerging technologies. It also facilitates smoother integration of new solutions into existing IT ecosystems, reducing implementation challenges and costs.
Real-world success stories
The benefits of these technologies are not theoretical—they are being realized in health-care organizations around the world. For instance, the virtualization strategy implemented at University Hospital Essen (UME), one of Germany’s largest university hospitals, has dramatically improved the hospital’s ability to manage increasing data volumes and applications. UME’s critical clinical information systems now run on modular and virtualized systems, allowing experts to design and use innovative solutions, including AI tools that automate tasks previously done manually by IT and medical staff.
Similarly, the PANCAIM project leverages edge computing for pancreatic cancer detection. This EU-funded initiative uses Siemens Healthineers’ edge computing approach to develop and validate AI algorithms. At Karolinska Institutet, Sweden, an algorithm was implemented for a real pancreatic cancer case, ensuring sensitive patient data remains within the hospital while advancing AI validation in clinical settings.
Another innovative approach is the concept of a Common Patient Data Model (CPDM). This standardized framework defines how patient data is organized, stored, and exchanged across different health-care systems and platforms, addressing interoperability challenges in the current health-care landscape.
The road ahead: Continuous innovation
As we look to the future, it’s clear that technological advancements in radiology will continue at a rapid pace. To stay competitive and provide the best patient care, health-care organizations must prioritize ongoing innovation and the adoption of new technologies.
This includes not only IT systems but also medical devices and treatment methodologies. The health-care providers who embrace this ethos of continuous improvement will be best positioned to navigate the challenges and opportunities that lie ahead.
In conclusion, the future of imaging IT is bright, promising unprecedented levels of efficiency, accuracy, and patient-centricity. By embracing networked care models, leveraging advanced analytics and AI, prioritizing data security, and maintaining agile IT infrastructure, health-care organizations can ensure they’re prepared for whatever the future may hold.
The journey towards future-proof imaging IT may seem daunting, but it’s a necessary evolution in our quest to provide the best possible health care. As we stand on the brink of this new era, one thing is clear: the future of health care is digital, data-driven, and more connected than ever before.
If you want to learn more, you can find more information from Siemens Healthineers.
Syngo Carbon consists of several products which are (medical) devices in their own right. Some products are under development and not commercially available. Future availability cannot be ensured.
The results by Siemens Healthineers customers described herein are based on results that were achieved in the customer’s unique setting. Since there is no “typical” hospital and many variables exist (e.g., hospital size, case mix, level of IT adoption), it cannot be guaranteed that other customers will achieve the same results.
This content was produced by Siemens Healthineers. It was not written by MIT Technology Review’s editorial staff.
Robots perceive the world around them very differently from the way humans do.
When we walk down the street, we know what we need to pay attention to—passing cars, potential dangers, obstacles in our way—and what we don’t, like pedestrians walking in the distance. Robots, on the other hand, treat all the information they receive about their surroundings with equal importance. Driverless cars, for example, have to continuously analyze data about things around them whether or not they are relevant. This keeps drivers and pedestrians safe, but it draws on a lot of energy and computing power. What if there’s a way to cut that down by teaching robots what they should prioritize and what they can safely ignore?
That’s the principle underpinning “lazy robotics,” a field of study championed by René van de Molengraft, a professor at Eindhoven University of Technology in the Netherlands. He believes that teaching all kinds of robots to be “lazier” with their data could help pave the way for machines that are better at interacting with things in their real-world environments, including humans. Essentially, the more efficient a robot can be with information, the better.
Van de Molengraft’s lazy robotics is just one approach researchers and robotics companies are now taking as they train their robots to complete actions successfully, flexibly, and in the most efficient manner possible.
Teaching them to be smarter when they sift through the data they gather and then de-prioritize anything that’s safe to overlook will help make them safer and more reliable—a long-standing goal of the robotics community.
Simplifying tasks in this way is necessary if robots are to become more widely adopted, says Van de Molengraft, because their current energy usage won’t scale—it would be prohibitively expensive and harmful to the environment. “I think that the best robot is a lazy robot,” he says. “They should be lazy by default, just like we are.”
Learning to be lazier
Van de Molengraft has hit upon a fun way to test these efforts out: teaching robots to play soccer. He recently led his university’s autonomous robot soccer team, Tech United, to victory at RoboCup, an annual international robotics and AI competition that tests robots’ skills on the soccer field. Soccer is a tough challenge for robots, because both scoring and blocking goals require quick, controlled movements, strategic decision-making, and coordination.
Learning to focus and tune out distractions around them, much as the best human soccer players do, will make them not only more energy efficient (especially for robots powered by batteries) but more likely to make smarter decisions in dynamic, fast-moving situations.
Tech United’s robots used several “lazy” tactics to give them an edge over their opponents during the RoboCup. One approach involved creating a “world model” of a soccer pitch that identifies and maps out its layout and line markings—things that remain the same throughout the game. This frees the battery-powered robots from constantly scanning their surroundings, which would waste precious power. Each robot also shares what its camera is capturing with its four teammates, creating a broader view of the pitch to help keep track of the fast-moving ball.
Previously, the robots needed a precise, pre-coded trajectory to move around the pitch. Now Van de Molengraft and his team are experimenting with having them choose their own paths to a specified destination. This saves the energy needed to track a specific journey and helps the robots cope with obstacles they may encounter along the way.
The group also successfully taught the squad to execute “penetrating passes”—where a robot shoots toward an open region in the field and communicates to the best-positioned member of its team to receive it—and skills such as receiving or passing the ball within configurations such as triangles. Giving the robots access to world models built using data from the surrounding environment allows them to execute their skills anywhere on the pitch, instead of just in specific spots.
Beyond the soccer pitch
While soccer is a fun way to test how successful these robotics methods are, other researchers are also working on the problem of efficiency—and dealing with much higher stakes.
Making robots that work in warehouses better at prioritizing different data inputs is essential to ensuring that they can operate safely around humans and be relied upon to complete tasks, for example. If the machines can’t manage this, companies could end up with a delayed shipment, damaged goods, an injured human worker—or worse, says Chris Walti, the former head of Tesla’s robotics division.
Walti left the company to set up his own firm after witnessing how challenging it was to get robots to simply move materials around. His startup, Mytra, designs fully autonomous machines that use computer vision and an AI reinforcement-learning system to give them awareness of other robots closest to them, and to help them reason and collaborate to complete tasks (like moving a broken pallet) in much more computationally efficient ways.
The majority of mobile robots in warehouses today are controlled by a single central “brain” that dictates the paths they follow, meaning a robot has to wait for instructions before it can do anything. Not only is this approach difficult to scale, but it consumes a lot of central computing power and requires very dependable communication links.
Mytra believes it’s hit upon a significantly more efficient approach, which acknowledges that individual robots don’t really need to know what hundreds of other robots are doing on the other side of the warehouse. Its machine-learning system cuts down on this unnecessary data, and the computing power it would take to process it, by simulating the optimal route each robot can take through the warehouse to perform its task. This enables them to act much more autonomously.
“In the context of soccer, being efficient allows you to score more goals. In the context of manufacturing, being efficient is even more important because it means a system operates more reliably,” he says. “By providing robots with the ability to to act and think autonomously and efficiently, you’re also optimizing the efficiency and the reliability of the broader operation.”
While simplifying the types of information that robots need to process is a major challenge, inroads are being made, says Daniel Polani, a professor from the University of Hertfordshire in the UK who specializes in replicating biological processes in artificial systems. He’s also a fan of the RoboCup challenge—in fact, he leads his university’s Bold Hearts robot soccer team, which made it to the second round of this year’s RoboCup’s humanoid league.
“Organisms try not to process information that they don’t need to because that processing is very expensive, in terms of metabolic energy,” he says. Polani is interested in applying these lessons from biology to the vast networks that power robots to make them more efficient with their information. Reducing the amount of information a robot is allowed to process will just make it weaker depending on the nature of the task it’s been given, he says. Instead, they should learn to use the data they have in more intelligent ways.
Simplifying software
Amazon, which has more than 750,000 robots, the largest such fleet in the world, is also interested in using AI to help them make smarter, safer, and more efficient decisions. Amazon’s robots mostly fall into two categories: mobile robots that move stock, and robotic arms designed to handle objects. The AI systems that power these machines collect millions of data points every day to help train them to complete their tasks. For example, they must learn which item to grasp and move from a pile, or how to safely avoid human warehouse workers. These processes require a lot of computing power, which the new techniques can help minimize.
Generally, robotic arms and similar “manipulation” robots use machine learning to figure out how to identify objects, for example. Then they follow hard-coded rules or algorithms to decide how to act. With generative AI, these same robots can predict the outcome of an action before even attempting it, so they can choose the action most likely to succeed or determine the best possible approach to grasping an object that needs to be moved.
These learning systems are much more scalable than traditional methods of training robots, and the combination of generative AI and massive data sets helps streamline the sequencing of a task and cut out layers of unnecessary analysis. That’s where the savings in computing power come in. “We can simplify the software by asking the models to do more,” says Michael Wolf, a principal scientist at Amazon Robotics. “We are entering a phase where we’re fundamentally rethinking how we build autonomy for our robotic systems.”
Achieving more by doing less
This year’s RoboCup competition may be over, but Van de Molengraft isn’t resting on his laurels after his team’s resounding success. “There’s still a lot of computational activities going on in each of the robots that are not per se necessary at each moment in time,” he says. He’s already starting work on new ways to make his robotic team even lazier to gain an edge on its rivals next year.
Although current robots are still nowhere near able to match the energy efficiency of humans, he’s optimistic that researchers will continue to make headway and that we’ll start to see a lot more lazy robots that are better at their jobs. But it won’t happen overnight. “Increasing our robots’ awareness and understanding so that they can better perform their tasks, be it football or any other task in basically any domain in human-built environments—that’s a continuous work in progress,” he says.
Google Search Console is among the most helpful free tools for search engine optimization. GSC‘s popular “Performance” section shows a site’s rankings, sources of organic clicks, and other info, such as:
Yet the Performance section provides much more. Here are three little-used reports to improve SEO.
Visitors’ Devices
Smartphones are increasingly the top device for visitors and conversions. But sites vary. Some still have more desktop users than mobile.
Search Console reports the number of visitors searching and landing on your site on mobile and desktop devices. In “Performance” > “Search results”:
Click “New” to create a new filter,
Select “Device,”
Click the “Compare” tab,
Apply “Desktop” vs. “Mobile.”
The example below shows a site where visitors mostly search and click from desktop devices. Thus SEO for this site should focus on the desktop version.
Search Console’s Performance section shows visitors’ devices. In this report, most visitors use desktops. Click image to enlarge.
Traffic from Images
Google’s image results and image packs can generate many clicks. Yet there’s no easy way to identify the best performers. Search Console gives some insight at “Performance” > “Search results.”
Select “Search type: Image,”
Click to the “Queries” column
Sort results by “Clicks.”
Then search Google Images for those queries to find your image that ranks and produces clicks. There’s no better way in my experience to see a site’s performance in Image search.
Keep an eye on your image optimization techniques — e.g., alt text, file type, size —and adjust the strategy accordingly.
Filter by “Search type: Image” to view traffic (clicks) from that source. Click screenshot to enlarge.
Visitors’ Countries
Searchers landing on English-language sites are likely from the United States because it is the most populous English-speaking country. But other countries offer much ecommerce potential.
To see visitors’ countries, use “Performance” > “Search results”:
Click the “Countries” column,
Sort by “Clicks.”
Get deeper insight into this data by creating a filter to reveal the visitors who translate search results into their native language before accessing your site. Countries with substantial clicks from translated results suggest a market better served in that language.
Click “New” to create a filter,
Select “Search appearance,”
Choose “Translated results.”
In the example below, visitors from Indonesia translated search results the most.
Search Console can report the number of visitors that first translated in search. Click image to enlarge.
Approximately 300 million pairs of shoes are thrown away annually in the United States alone. Many could be reused or recycled. Brands are catching on to the importance of becoming sustainable and circular, launching recycling programs to extend the life of their products and keeping them out of landfills.
Here is a list of branded resale shops. Most launched during this recommerce boom of the last few years, though a few have been around longer. There are trade-in programs, peer-to-peer marketplaces, white-glove sustainability programs for luxury items, and more. Many are parts of broader sustainability initiatives from eco-conscious companies.
To follow the recommerce boom, check out ThreadUp’s The Recommerce 100, which ranks resale shops by the number of monthly product listings.
Branded Resale Sites
RE/AE is the popular resale site for American Eagle. The site is powered by ThredUp, a resale-as-a-service platform. American Eagle teamed up with Snapchat on Earth Day 2023 (April 22) for a shoppable AR Lens showcasing select styles from a specially curated inaugural 200-piece RE/AE collection. RE/AE lists nearly 40,000 resale products, enabling American Eagle to recirculate over 1 million items.
RE/AE by American Eagle
Renew is the resale shop for women’s apparel brand Eileen Fisher. The program began in 2009 as an opportunity for employees to return their unwanted clothes. It then launched nationwide in 2013. Customers can bring Eileen Fisher clothes back to any U.S. Eileen Fisher or Renew store and receive $5 in Renew Rewards for each piece, no matter the condition. Quality items are cleaned and resold; the rest are recycled or turned into art.
ReGear is the trade-in and resale hub of Arc’teryx, an outdoor apparel and equipment company. ReGear inspects, repairs, and rejuvenates used Arc’teryx gear before making it available for sale through the online store. ReGear is just one part of ReBird, the home for Arc’teryx circularity initiatives. The other parts are ReCare, with care and repair tools to make gear last, and ReCut, a program for creating new products from recycled materials.
Worn Wear is a set of tools from Patagonia that extends the use of its products through responsible care, repair, resale, and recycling at the end of a garment’s life. For trade-ins, Worn Wear provides customers with a credit of up to $100 per item (whether or not the item sells) to be used at Patagonia retail stores, WornWear.com, and Patagonia.com. Among the first resale programs from brands, Worn Wear started in 2013 at Patagonia pop-up events and became a permanent program in 2017.
Worn Wear by Patagonia
Like New is Lululemon’s trade-in program, which runs through resale technology provider Trove. The program allows customers to trade in used Lululemon clothing in exchange for an e-gift card to be used at the retail stores, online, or Likenew.lululemon.com. All profits on Like New go to the Apparel Impact Institute’s Fashion Climate Fund, with the goal of having an end-of-use solution for 100% of products by 2030. The program started in 2021 and expanded nationwide on Earth Day 2022.
Outerworn is a peer-to-peer resale marketplace for Outerknown, a sustainable clothing brand co-founded by surfing champion Kelly Slater. The brand’s mission, “For People & Planet,” is to make quality sustainable products that last a lifetime, keeping garments out of landfills. Launched in 2021, Outerworn enables the buying and selling of used pieces. Outerknown also pursues sustainability through socially responsible sourcing, organic materials, and upcycling textile waste.
Conscious Closet from Bergdorf Goodman is a service that extends the useful life of its customers’ luxury goods. The program has five focuses — edit, repair, alter, resell, and donate — and leverages a network of strategic partners and the retailer’s in-house services to assist clients at each stage. For the resell portion, Bergdorf Goodman has partnered with Fashionphile, a platform for pre-owned luxury accessories. The partnership offers customers circular services by enabling personal shoppers to facilitate the selling of clients’ luxury items in exchange for Bergdorf Goodman gift cards.
Conscious Closet by Bergdorf Goodman
Carhartt Reworked is a trade-in program for the workwear and outdoor apparel maker. Powered by Trove, the resale site is dedicated to extending the life of workwear and keeping previously worn, slightly imperfect gear out of landfills. Carhartt Reworked accepts trade-ins by mail and in participating Carhartt retail stores. In the first 12 months of the resale site’s launch, Carhartt says it extended the life of over 43,000 garments and kept more than 68,000 products out of landfills.
Re/Supply is a used gear program that outdoor equipment co-op REI started in 2017, though it hosted “garage sales” for many years. Re/Supply offers members a more sustainable and affordable way to purchase gear and apparel. The program consists of items customers have returned or traded in. Members can trade in gently used gear for gift cards to help extend a product’s life for fellow members. REI estimates that buying a used item avoids 50% or more CO2 emissions from new product manufacturing.
Canada Goose Generations is the recommerce platform for Canada Goose, the maker of performance luxury outdoor apparel. The site is powered by Trove. Building on the brand’s mission of making quality outerwear, Generations keeps long-lasting Canada Goose products in circulation, giving them additional life by inviting customers to trade in. Generations supports the brand’s Sustainable Impact Strategy, helping to achieve its goal of achieving net zero emissions by 2025, reducing scope 1 and 2 greenhouse gas emissions by 80% from its 2019 baseline.
Athleta Preloved is a partnership between fitness brand Athleta and resale platform provider ThredUp. Athleta Preloved offers gently used Athleta products at a discount. The site lists more than 30,000 resale products. Trade-in participants can earn Athleta credit for eligible items that sell in the listing window. Unsold items are reused or responsibly recycled. According to its website, approximately 525,000 Athleta clothing items have been recirculated and reused.
Athleta Preloved
Toms (re)Wear Good is a program from shoe company Toms, in partnership with ThredUp, that sells gently used shoes and accessories and allows customers to turn used clothes into a Toms shopping credit. Customers wishing to resell items on the resale platform can request a free “clean out” label via Toms website. The service determines which items are eligible for consignment. For the items sold, sellers get an e-gift card to use at Toms.com. Items not eligible for consignment will be reused or responsibly recycled.
Tea Rewear is a popular resale marketplace from San Francisco-based children’s clothing company Tea Collection. The Tea Rewear site is powered by Kidizen, a resale marketplace for kids’ fashion and essentials. Participants can list and sell items or work with Style Scouts, local representatives for parents who have merchandise but don’t want to list and sell it themselves.
Ikea Preowned is a new second-hand online marketplace where customers can sell Ikea products to each other rather than third-party marketplaces. The seller posts listings on Ikea Preowned, and Ikea’s algorithms generate the details of the item, including size and the original retail price. Ikea Preowned is up and running in Madrid and Oslo. The company plans a global roll-out by December.
Hanna-Me-Downs is a peer-to-peer marketplace to buy and sell pre-owned Hanna Andersson products. The marketplace is powered by Archive, a resale service platform, and is a part of Hanna Andersson’s sustainability drives that include (i) sourcing organic cotton, (ii) moving all cotton to regenerative farming by 2025, (iii) producing collections with at least 50% recycled content, and (iv) creating durable products with heavier-weight cotton and colors that last.