5 Google Analytics Reports PPC Marketers Should Actually Use via @sejournal, @brookeosmundson
Google Analytics has never been perfect, but it used to feel familiar.
The shift to Google Analytics 4 forced PPC marketers to rethink how they pull insights, not just where to click.
Reports that once lived front and center now take more effort to find. Some require extra setup. Others feel less intuitive than before and that creates a real problem for PPC managers who need answers quickly.
You are expected to explain performance, justify spend, and make optimization decisions, often without the luxury of rebuilding reports or navigating multiple menus.
This article focuses on five Google Analytics reports that still deliver real value for PPC. These are the reports that help you understand audience behavior, uncover expansion opportunities, and connect paid traffic to outcomes the business actually cares about.
1. Audiences Report
As keyword match types continue to loosen and automation plays a larger role in campaign delivery, audience signals matter more than ever.
The Audiences report in GA4 replaces what many marketers previously relied on interest-based reports for, but with a more practical twist. Instead of inferred intent, this report is built on real user behavior.
This report shows how predefined and custom audiences perform across key engagement and conversion metrics. For PPC marketers, the value lies in analyzing audiences tied to meaningful actions, not generic demographic traits.
Use this report to:
- Identify which audiences are driving actual conversions, not just traffic.
- Compare performance between converters, cart viewers, repeat visitors, or high-engagement users.
- Validate which audiences deserve more aggressive bidding or budget allocation.
- Build and export high-performing audiences directly into Google Ads.
This report is far more actionable than legacy interest segments and aligns better with how PPC campaigns are structured today.
To find this report, navigate to: Reports > User > User Attributes > Audiences.

This report will only be useful if you have custom audiences set up in GA4. These are behavior-based audiences you define yourself, not prebuilt segments like In-Market or Affinity audiences you may be used to seeing in Google Ads.
GA4 audiences are built from first-party actions such as page views, events, or conversion behavior, which makes them more relevant for PPC optimization but requires upfront configuration.
2. Site Search Report
The Site Search report remains one of the most underused tools for PPC expansion.
By analyzing what users search for once they land on your site, you gain direct insight into unmet expectations and intent gaps.
In GA4, Site Search data lives under event tracking rather than a standalone report.
For PPC teams, this report can:
- Inform keyword expansion using real user language.
- Highlight product or content gaps affecting conversion rates.
- Reveal mismatches between ad messaging and on-site expectations.
Speaking of gaps, the Site Search report can also help product teams understand if additional demands exist for the products offered.
For example, say you have a wedding invitation website that has a decent product assortment for different themed weddings.
When using the Site Search report, you see an increasing number of searches for “rustic” – but none of the website designs have that rustic feel!
This can inform product marketing that there is a demand for this type of product, and they can take action accordingly.
To find the Site Search report, navigate to Reports > Engagement > Events.
Look for the event “view_search_results” and click on it.
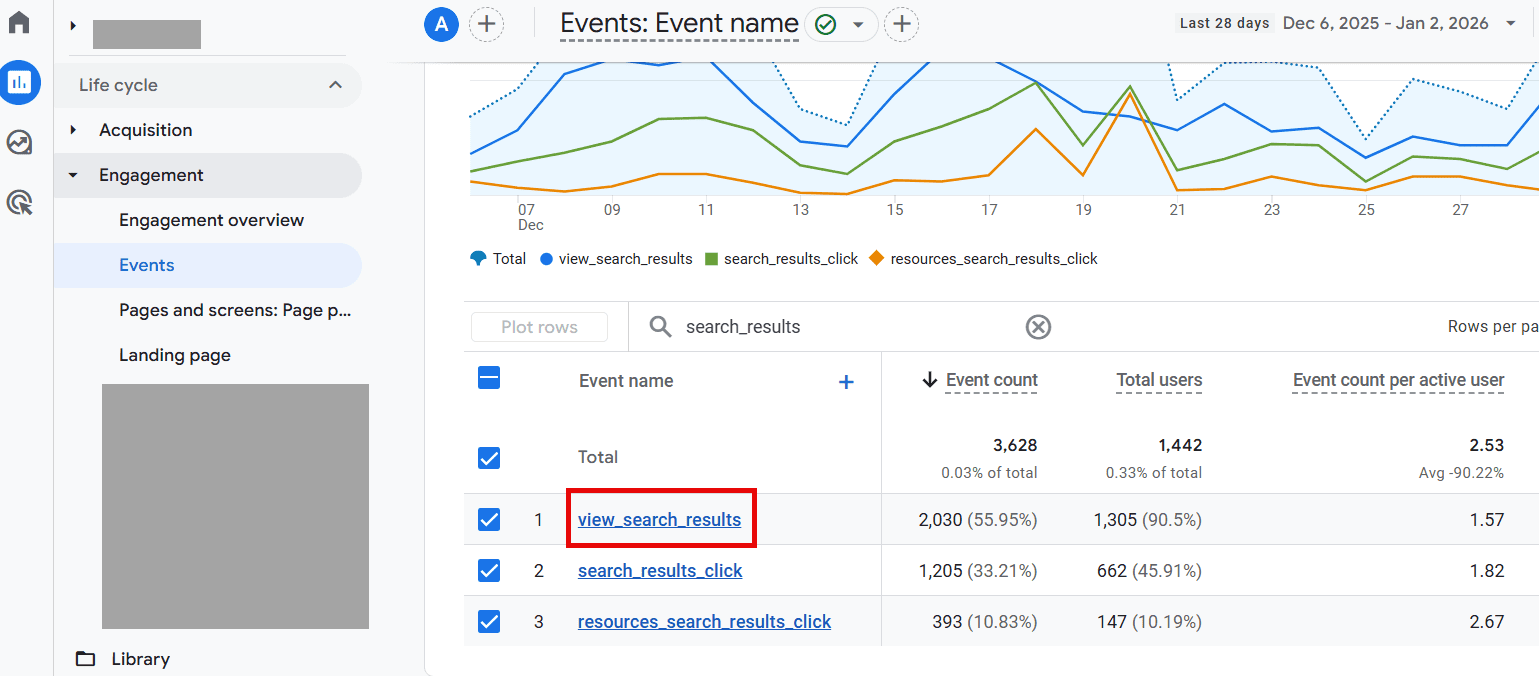
Once clicked, find the “search_term” custom parameter card on the page.
A few important notes on search terms data:
- Before using this report, you must create a new custom dimension (event-scoped) for the search term results to populate.
- Google Analytics will only show data once it meets a minimum aggregation threshold.
While it’s not as robust as the previous Site Search report in Universal Analytics, it does provide basic data on the number of events and total users per search term.
3. Referrals Report
Referral traffic is often ignored by PPC teams, which is a missed opportunity.
The Referrals report shows which external sites send users to your website and how those users behave once they arrive.
To find this report, navigate to Reports > Acquisition > Traffic Acquisition.
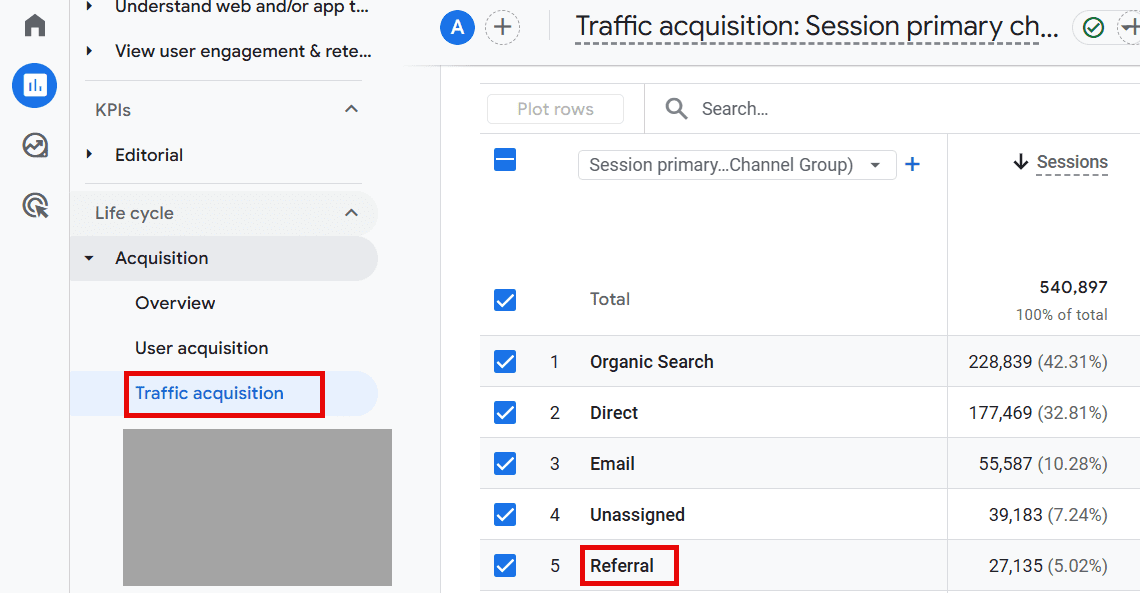
To view the websites from the Referral channel, click the “+” in the default channel group and choose “Session source/medium.”
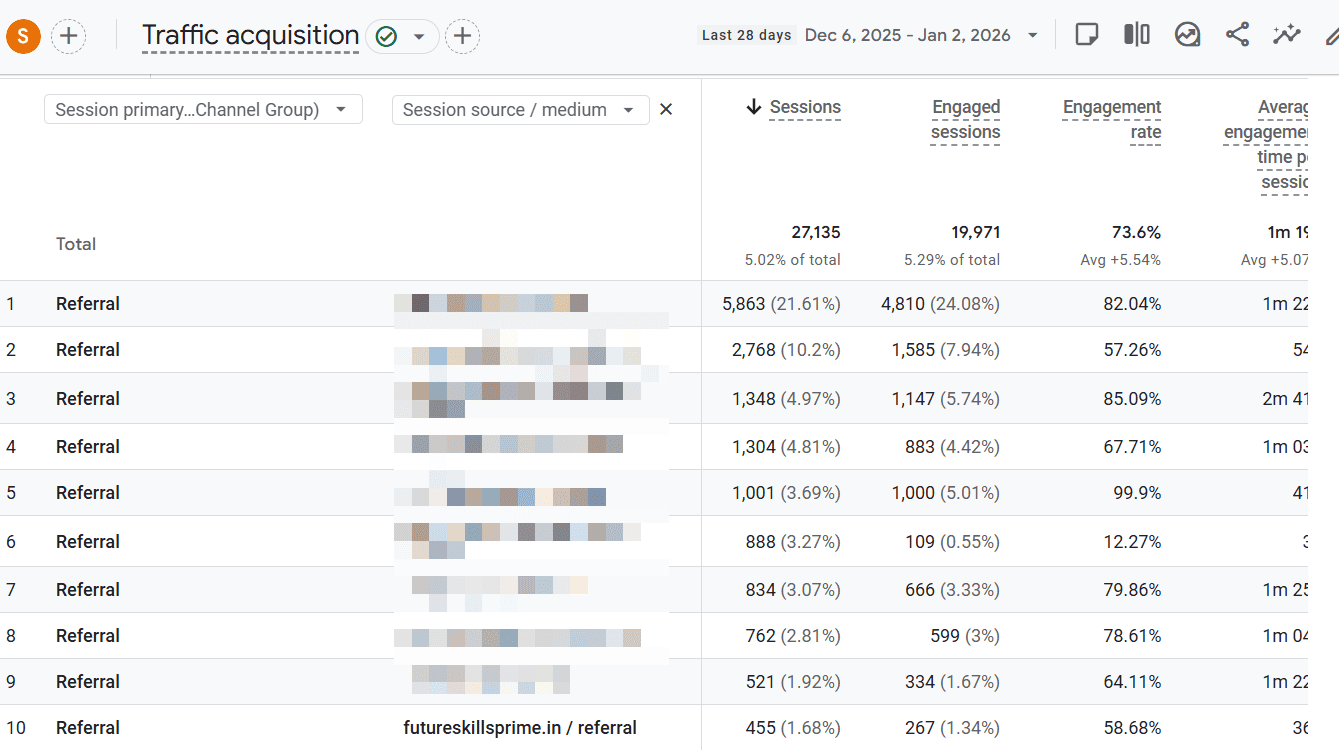
The key features of this report can:
- Identify third-party sites sending high-quality traffic.
- Distinguish between low-intent and high-intent referral sources.
- Build placement-based audiences for Display or Demand Gen testing.
Testing Display placements based on proven referral sources can be a cost-efficient way to expand reach without sacrificing traffic quality.
This is a cost-efficient way to test expanding new PPC efforts responsibly because the referral websites chosen are known to provide high-quality traffic to your website.
4. Top Conversion Paths Report
As marketers, we’re often asked how “Top of Funnel” (TOFU) or brand awareness campaigns are performing.
Leadership typically prioritizes channels that are proven to perform. So, they want to make sure marketing dollars are spent efficiently.
In today’s economy, this is more important than ever.
This Google Analytics report helps analyze and interpret TOFU behavior.
If you’re running any type of campaign beyond Search, this report is absolutely necessary.
Campaigns like YouTube and Display and other paid channels like social media (Meta, Instagram, TikTok, etc.) naturally have different goals and objectives.
TOF campaigns are undoubtedly criticized for “not performing” at the same rate as a Search campaign.
As marketers, this can be frustrating to hear over and over.
Using the Conversions Path report provides a holistic view of how long it takes a user to eventually make a purchase from the initial interaction.
To find this report, navigate to Advertising > Attribution > Conversion paths.
When drilling down to specific campaign performance, I recommend:
- Add a filter that contains “Session source/medium” to the specific paid channel in question (“google/cpc”, for example).
- Include an “AND” statement to the filter for “Session campaign” specific to the TOF campaigns in question.

In the example above, we found that our Paid Social campaigns should have been credited in more of the early and mid touchpoints!
The key features of this report can:
- Identify how many touchpoints to final conversion.
- Analyze complex user journey interactions when multiple channels are involved (especially for longer sale cycles).
- Report on credited conversions based on the attribution model.
This report can uncover necessary data to support the request for additional marketing dollars in TOF channels.
A win-win for all parties involved.
5. Conversion Events Report
Most PPC accounts optimize toward a single primary conversion. That makes sense for bidding, but it rarely tells the full story of how paid traffic actually contributes to revenue.
The Conversion Events report in Google Analytics 4 allows you to step back and evaluate all meaningful actions users take, not just the final one that gets credit in-platform.
For PPC decision-making, this report helps answer questions that Google Ads alone cannot, such as:
- Which actions consistently happen before a purchase or lead submission.
- Whether certain campaigns drive strong intent but fail to close immediately.
- How different paid channels influence early-stage engagement versus final conversion.
This becomes especially important when evaluating Display, YouTube, Demand Gen, or paid social campaigns. These campaigns often look inefficient when judged solely on last-click performance, but they may drive key actions like product views, pricing page visits, form starts, or repeat sessions.
To find this report, navigate to: Reports > Engagement > Events.

Conversion analysis in GA4 depends on which events you explicitly mark as conversions in Admin settings. GA4 does not provide a standalone “conversion-only” filter inside the Events report, so accuracy starts with proper event configuration.
Another practical use of this report is diagnosing drop-off points. If a campaign drives high volumes of early conversion events but struggles to generate final conversions, the issue may lie in landing page experience, form friction, or follow-up timing rather than targeting or bidding.
When paired with campaign-level filters from Google Ads, the Conversion Events report helps PPC managers explain why a campaign matters, even when it is not the last touch.
That context is often the difference between cutting a campaign too early and scaling one that is quietly doing its job.
Turn Analytics Into Better PPC Decisions
Google Analytics is not where most PPC optimizations happen day to day. That work still lives inside ad platforms.
But these reports serve a different purpose. They help PPC managers step back and understand how paid traffic behaves once it reaches the site, how users move across channels, and which actions actually signal intent.
Used monthly or quarterly, these reports surface patterns that daily account reviews often miss. They support smarter targeting decisions, clearer performance explanations, and more confident budget conversations.
When you focus on the reports that consistently answer real PPC questions, Google Analytics becomes less of a chore and more of a strategic asset.
More Resources:
Featured Image: MR Chalee/Shutterstock