
What is agentic commerce? A peek into the future of buying (with caveats)
Commerce has undergone several major shifts over the past few decades. What started with localized physical stores evolved into borderless, internet-driven ecommerce experiences.
Now, with the rise of AI, it is believed that commerce could be heading toward another transformation: agentic commerce, where AI agents help consumers discover products, compare options, and even complete purchases on their behalf.
Yet despite the excitement, many questions remain. Will consumers trust AI agents with buying decisions? Will businesses see enough return on investment to justify the costs? And does autonomous shopping solve a real problem, or simply add another layer of complexity to the buying journey?
Still, the technology is advancing rapidly. Imagine a shopping experience where consumers no longer jump between tabs, compare dozens of products on different websites, or manually research every purchase. Instead, AI agents understand intent, evaluate options, compare prices, and act within predefined rules to help users make purchasing decisions. What once sounded futuristic is already beginning to take shape.
In this article, we’ll explore what agentic commerce is, how it works, the technological developments driving it forward, and some of the challenges that could shape its future adoption.
Key takeaways
- Agentic commerce represents a shift where AI agents assist consumers in product discovery, comparisons, and purchases
- AI agents execute tasks based on user intent, simplifying the shopping journey and enhancing efficiency
- Consumer interest is growing, with over 60% expecting to use AI in their shopping experiences by 2026
- Technological developments like the Agentic Commerce Protocol (ACP) and Universal Commerce Protocol (UCP) are crucial for enabling agentic commerce
- Despite its potential, agentic commerce faces challenges related to consumer trust, security, and the need for business investments.
What is agentic commerce?
In simple terms, agentic commerce refers to a commerce model where AI agents act as decision-makers on behalf of customers.
Instead of manually searching for products, comparing options, filtering results, and completing purchases, users can rely on AI agents to handle these tasks based on their intent, preferences, constraints, and buying goals.
To paint a clearer and practical picture, here’s how Alex Moss explained agentic commerce in the SEO Unplugged: Agentic Commerce with Alex Moss podcast:
So everything’s connected.
I could literally say into the into a phone to my agent, go and buy me some new shoes with that jacket I bought last week, and that’s it.
And it would go away.
It would do the research.
And of course, you can have a say in an approval in terms of part of the journey.
At its core, agentic commerce works like a digital shopping proxy. Humans define the intent or goal, while AI agents execute the process behind the scenes. While the AI handles the heavy lifting, users still remain in control of the final decision-making process.
Also read: Ensuring continuous discoverability with agentic AI for SEO
Agentic commerce is the next big thing in ecommerce
The concept of agentic commerce may still sound futuristic, but the shift has already started. Consumer behavior, AI adoption, and industry forecasts all point to a future in which AI agents become an active part of the buying journey.
Here are some numbers that highlight why agentic commerce is emerging as the next major evolution in ecommerce.
Consumers already use AI in their buying journey
Consumers have already started relying on AI-powered tools to discover products and make purchasing decisions. According to a McKinsey & Company report, more than 70% of AI-powered search users ask top-of-the-funnel questions about categories, brands, products, or services.
The same report also found that nearly 50% of consumers already use AI-powered search experiences today. As AI increasingly becomes part of product discovery, traditional search-driven traffic may face growing disruption. In fact, the study suggests that businesses could see 20–50% of their traffic shift away from traditional search experiences over time.
This highlights an important shift: consumers are no longer just searching; they are increasingly asking AI systems to guide their decisions.
Shoppers are expecting agentic commerce
Consumer interest in AI-assisted shopping is also growing rapidly. The 2025 report titled “Agentic Commerce: From Brand Loyalty to Bot Logic” explored how shoppers feel about AI agents in retail experiences.
The report found that more than 60% of shoppers expect to use agentic AI in 2026. The findings also revealed a major behavioral shift: consumers increasingly prioritize convenience, speed, pricing, and trust over platform loyalty.

Instead of browsing individual retailer apps, shoppers may rely on AI agents that can compare products across multiple platforms, evaluate reviews, identify the best deals, and complete purchases more efficiently. This changes the competitive landscape from retailer-versus-retailer competition to AI-driven discovery ecosystems.
Analysts predict explosive growth for agentic commerce
Industry analysts also expect agentic commerce to become a massive economic opportunity over the next few years. Another McKinsey report suggests that agentic commerce could fundamentally reshape the shopping experience.
Based on the growing adoption of AI-powered discovery tools and increasing merchant readiness, the report estimates that by 2030, the US B2C retail market alone could unlock an orchestrated revenue opportunity of $900 billion to $1 trillion. Globally, that opportunity could range from $3 trillion to $5 trillion.
How does agentic commerce work?
At its core, agentic commerce combines human intent with AI-driven execution. Instead of manually browsing websites, comparing products, and completing purchases, users can delegate much of the shopping journey to AI agents. These agents understand goals, evaluate options, make decisions within defined constraints, and even complete transactions on behalf of users.
What makes this different from traditional AI assistants is the ability to act. While assistive AI tools mainly provide information or recommendations, agentic AI can independently execute tasks across the shopping journey.
Also read: What is the user journey in SEO?
Here’s a step-by-step look at how agentic commerce works:
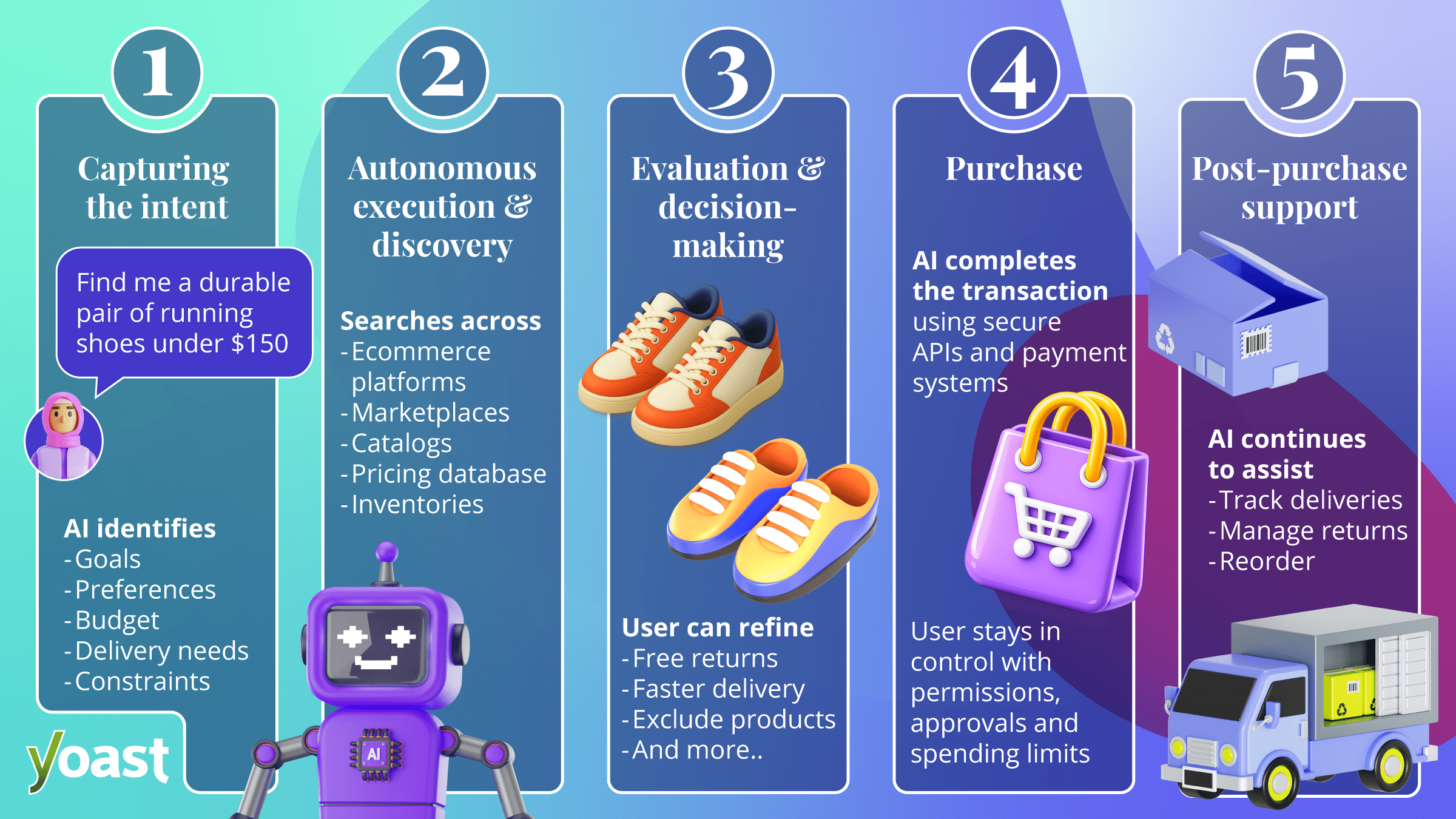
Step 1: Capturing the intent
Every agentic commerce journey begins with intent. Instead of typing short keywords into a search bar, users interact with AI agents conversationally.
For example, a shopper might say:
- “Find me a durable pair of running shoes under $150.”
- “Restock groceries for a vegetarian dinner party.”
- “Buy a formal shirt that matches the trousers I purchased last month.”
At this stage, the AI agent focuses on understanding the user’s goals, preferences, budget, delivery expectations, and constraints. If the request feels too broad, the agent may ask follow-up questions to refine the intent before moving forward.
Step 2: Autonomous instruction execution and brand discovery
Once the intent becomes clear, the AI agent begins executing the task autonomously. Instead of searching a single website, it scans multiple ecommerce platforms, marketplaces, product catalogs, reviews, pricing databases, and inventory systems simultaneously.
This is where agentic commerce begins to change traditional product discovery. Rather than showing endless product pages, the agent narrows down the most relevant options based on the shopper’s needs.
At the same time, brands with better-structured product data, accurate inventory information, transparent pricing, and machine-readable content are more likely to be discovered by AI agents.
Do read: Taxonomy SEO: How to optimize your categories and tags
Step 3: Evaluation and decision-making
After gathering options, the AI agent starts evaluating products and comparing tradeoffs. It may analyze factors such as:
- Price and discounts
- Product specifications
- Customer reviews and ratings
- Shipping timelines
- Return policies
- Brand trust and reputation
Instead of simply listing products, the agent reasons through the options and explains why certain products better meet the shopper’s requirements than others.
Users can also refine the decision-making process further by adding conditions such as:
- “Only show products with free returns.”
- “Prioritize faster delivery.”
- “Exclude refurbished products.”
This creates a feedback loop where the AI agent continuously improves its recommendations based on user preferences.
Step 4: Purchase
Once the shopper approves a product or sets predefined rules, the AI agent can move forward with the transaction. Using APIs, commerce protocols, and secure payment systems, the agent can add items to carts, apply discounts, authenticate payments, and complete purchases.
In some cases, the purchase may happen instantly. In others, the AI agent may wait for specific conditions, such as a price drop, stock availability, or faster delivery options, before completing the transaction.
Even though the AI handles execution, users still remain in control through permissions, approval settings, and spending limits.
Step 5: Post-purchase support
The role of AI agents does not end after checkout. Agentic commerce also extends into post-purchase experiences.
AI agents can continue assisting users by:
- Tracking deliveries
- Managing returns or exchanges
- Monitoring refunds
- Sending delivery updates
- Reordering recurring products
- Recommending complementary products or accessories
This turns shopping into an ongoing and intelligent experience rather than a one-time transaction.
Technological developments
Agentic commerce is not powered solely by AI models. Behind the scenes, it depends on a growing ecosystem of protocols, frameworks, APIs, and payment systems that help AI agents interact with digital commerce platforms securely and efficiently.
One important concept shaping agentic AI is the Model Context Protocol (MCP). In agentic AI, MCP enables AI models to connect with external systems, tools, databases, and applications via a standardized communication layer.
Instead of building separate integrations for every AI model and every software platform, MCP creates a common framework that allows AI agents to access information and execute actions more consistently. Think of it like creating a shared operating language between AI systems and digital tools, so they can work together without requiring completely custom connections every time.
As agentic commerce evolves as a use case of agentic AI, similar commerce-focused protocols are now emerging specifically for shopping ecosystems. These protocols help AI agents understand product information, communicate with merchants, compare inventory, and securely complete transactions on behalf of users.
Here are some important developments supporting agentic commerce:
Agentic Commerce Protocol (ACP)
One of the most important developments in this space is the Agentic Commerce Protocol (ACP), an open standard introduced by Stripe in collaboration with OpenAI.
ACP is designed to help AI agents interact more naturally with ecommerce systems by creating a standardized framework for product discovery, checkout, and payment execution. In simple terms, it provides the infrastructure that allows AI agents to move beyond simply recommending products and actually complete purchases securely on behalf of users.
The protocol is still in its early stages, but its first real-world implementations are already emerging. For example, ChatGPT users in the United States can already purchase products from Etsy merchants directly within the chat experience through Stripe-powered checkout. Shopify integrations are also expected to follow.
This matters because it signals a shift from AI-assisted discovery to AI-enabled transactions happening inside conversational interfaces themselves. Instead of redirecting users across multiple websites and checkout flows, ACP aims to make the entire shopping journey more seamless and agent-friendly.
Another important aspect of ACP is its open-standard approach. Rather than creating a closed ecosystem tied to a single platform, Stripe and OpenAI position ACP as a framework that developers, merchants, and ecommerce platforms can adopt more broadly as agentic commerce evolves.
Looking ahead, protocols like ACP could become foundational infrastructure for AI-driven shopping experiences, especially as more businesses begin to optimize their product catalogs, payment systems, and checkout experiences for AI agents rather than only human users.
Also read: Boost your checkout page UX: Vital tips for online stores
Universal Commerce Protocol (UCP)
As more AI agents enter the shopping journey, a new challenge emerges: how can these agents communicate with thousands of retailers, marketplaces, payment providers, and service platforms without requiring a custom integration for each one?
This is the problem that the Universal Commerce Protocol (UCP) aims to solve.
Introduced by Google, UCP is an open standard designed to create a common language for agentic commerce. Rather than building separate connections between every AI agent and every commerce platform, UCP provides a shared framework that allows them to communicate more efficiently throughout the shopping journey.
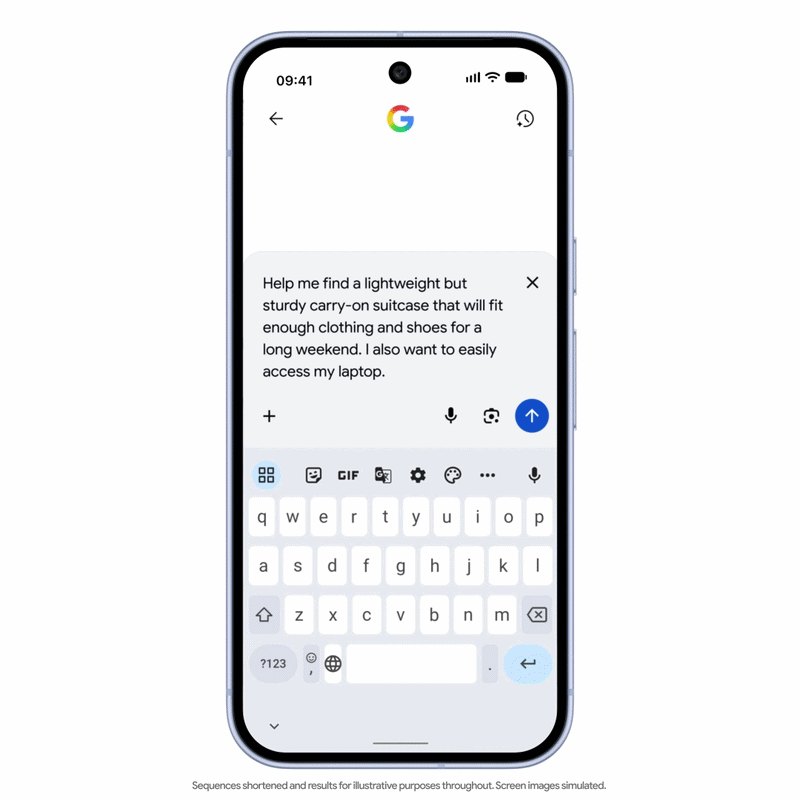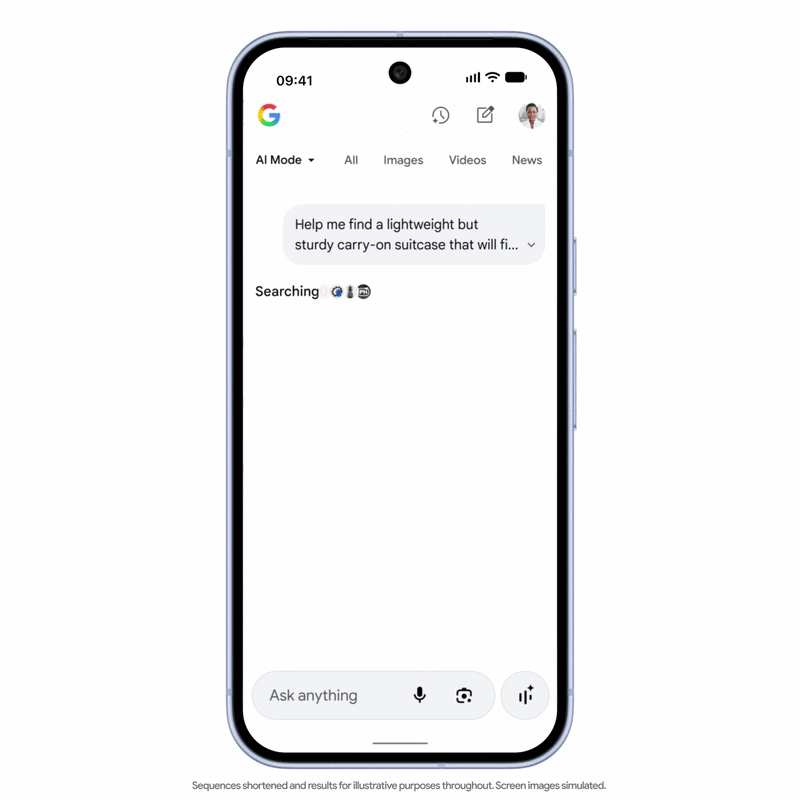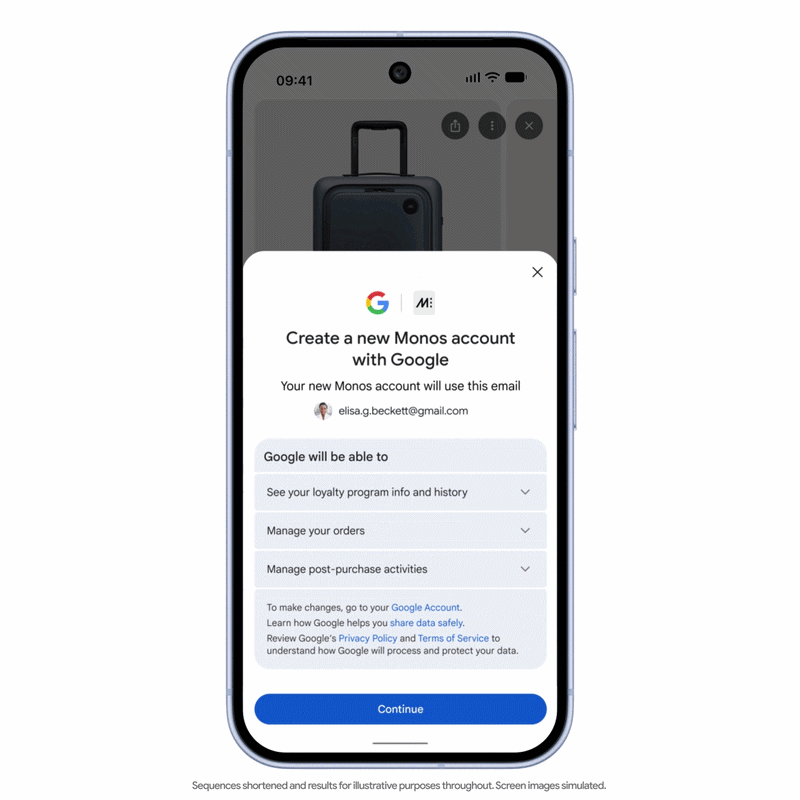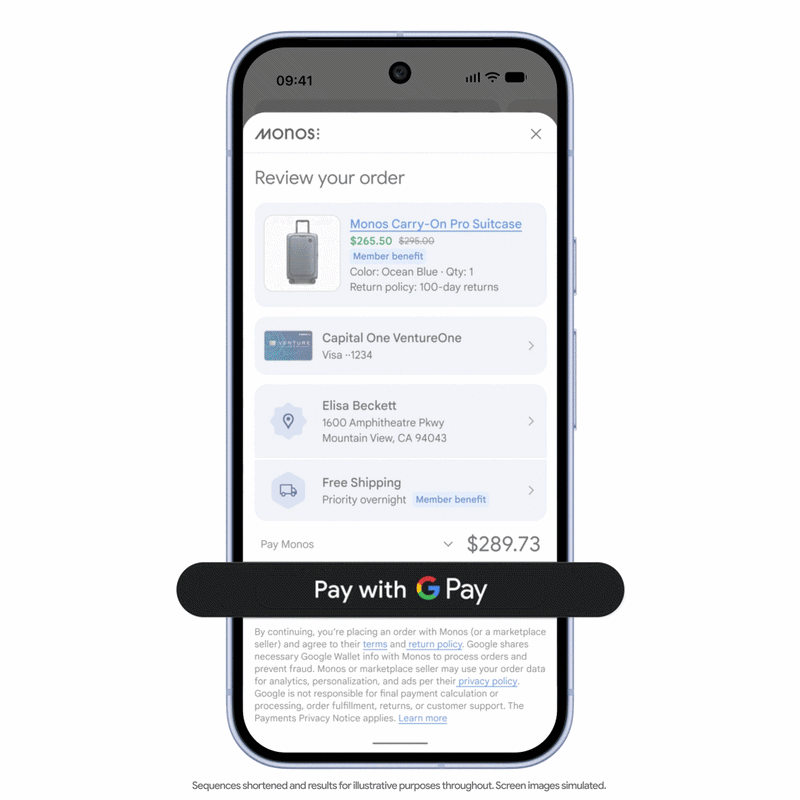
Think of it this way: if agentic commerce becomes mainstream, millions of AI agents could research products, check inventory, compare prices, place orders, and manage returns every day. Without a standardized framework, retailers and AI platforms would need to create and maintain countless one-to-one integrations. UCP aims to remove this complexity by providing a common set of rules for all participants to exchange commercial information.
What makes UCP particularly interesting is its broad scope. Unlike protocols that focus mainly on purchasing, UCP is designed to support the entire commerce lifecycle, including:
- Product discovery
- Product comparison
- Purchasing and checkout
- Order tracking
- Returns and post-purchase support
Google has also designed UCP to work alongside other emerging AI standards, including Agent2Agent (A2A), Agent Payments Protocol (AP2), and Model Context Protocol (MCP). This allows businesses to adopt agentic commerce without completely replacing their existing systems.
The initiative already has significant industry backing. Google co-developed UCP with major commerce companies, including Shopify, Etsy, Wayfair, Target, and Walmart. It has also received support from companies such as Mastercard, Visa, Stripe, and American Express.

While agentic commerce is still in its early stages, UCP represents an important step toward a future in which AI agents, merchants, and payment providers can operate within a single ecosystem rather than through isolated platforms. In many ways, it provides the foundational infrastructure needed to make agentic commerce scalable across the broader digital economy.
Mastercard Agent Pay
While protocols like ACP and UCP focus on communication and interoperability, Mastercard Agent Pay focuses on one of the most critical challenges in agentic commerce: trust and secure payment execution.
As AI agents gain the ability to discover products, compare options, and make purchasing decisions, they also need a secure way to complete transactions on behalf of users. Mastercard Agent Pay was introduced to provide the infrastructure for exactly that.
The platform is designed to allow AI agents to execute payments while operating within user-defined permissions, authentication requirements, and spending controls. Rather than giving AI systems unrestricted access to payment credentials, Agent Pay focuses on creating verified, traceable, and authorized payment flows for agent-driven commerce.
One of the most significant developments came through its collaboration with PayPal, where Mastercard Agent Pay is being integrated into PayPal’s wallet infrastructure. It allows AI agents to securely complete transactions on behalf of PayPal users while maintaining the security and trust mechanisms that consumers already expect from digital payments.
This partnership is particularly important because it moves agentic commerce closer to real-world adoption. Instead of existing only within experimental AI environments, agent-driven payments can potentially operate across a much larger ecosystem of merchants, consumers, and payment networks.
Together, ACP, UCP, and Agent Pay are helping lay the foundation for agentic commerce. While ACP focuses on enabling AI agents to interact with merchants and complete purchases, UCP creates a common language that allows agents, retailers, and platforms to work together at scale. Agent Pay adds the trust layer by enabling secure, authorized payments, bringing AI-driven shopping one step closer to reality.
FAQs: What is agentic commerce?
Agentic commerce benefits both businesses and consumers by making shopping more efficient and personalized.
For users
AI agents can reduce research time, provide tailored recommendations, monitor prices, and automate routine purchases.
For enterprises
Agentic commerce can streamline operations, improve personalization, automate repetitive workflows, support faster decision-making, and help products reach customers more quickly. Together, these benefits create a more convenient shopping experience while improving operational efficiency.
No, they are not the same. Agentic AI is the underlying technology that enables AI systems to understand goals, make decisions, and complete tasks autonomously. Agentic commerce is a specific application of agentic AI in shopping and commerce. In other words, agentic AI is the foundation, while agentic commerce is one of its real-world use cases.
In traditional commerce, the shopper remains the primary decision-maker and executor throughout the buying journey. Even when AI is present, its role is largely limited to recommending products or improving search experiences. In agentic commerce, AI agents actively participate in the shopping process by researching products, comparing options, and executing tasks on behalf of users, guided by predefined goals and preferences.
Several companies are already experimenting with agentic commerce. For example, Amazon has introduced its “Buy for Me” feature, which allows AI agents to purchase products from third-party websites when items are unavailable on Amazon.
Similarly, Google is testing AI-powered shopping experiences that can monitor prices and automatically purchase products when they meet user-defined conditions. Beyond consumer shopping, businesses are also using AI agents to monitor inventory levels and automatically reorder supplies when stock runs low.
Agentic commerce still faces important questions
While the technology behind agentic commerce is advancing quickly, widespread adoption is far from guaranteed. Many consumers may not feel comfortable giving AI agents the authority to make purchasing decisions or access payment methods on their behalf. Others may question whether autonomous shopping solves a real problem or simply makes it easier to buy more things, more often.
Businesses face their own uncertainties. Supporting agentic commerce may require investments in new protocols, structured data, integrations, and AI-ready commerce experiences. Whether those investments yield measurable returns remains unclear, especially given that consumer adoption is still in its early stages.
There are also broader challenges to solve, including security, fraud prevention, AI bias, platform dependency, and the potential loss of direct relationships between brands and customers. Agentic commerce may represent an exciting new direction for digital shopping, but its long-term success will depend on whether it can create value for consumers, merchants, and the broader ecommerce ecosystem, not just the AI platforms powering it.














