The AI Consistency Paradox via @sejournal, @DuaneForrester
Doc Brown’s DeLorean didn’t just travel through time; it created different timelines. Same car, different realities. In “Back to the Future,” when Marty’s actions in the past threatened his existence, his photograph began to flicker between realities depending on choices made across timelines.
This exact phenomenon is happening to your brand right now in AI systems.
ChatGPT on Monday isn’t the same as ChatGPT on Wednesday. Each conversation creates a new timeline with different context, different memory states, different probability distributions. Your brand’s presence in AI answers can fade or strengthen like Marty’s photograph, depending on context ripples you can’t see or control. This fragmentation happens thousands of times daily as users interact with AI assistants that reset, forget, or remember selectively.
The challenge: How do you maintain brand consistency when the channel itself has temporal discontinuities?

The Three Sources Of Inconsistency
The variance isn’t random. It stems from three technical factors:
Probabilistic Generation
Large language models don’t retrieve information; they predict it token by token using probability distributions. Think of it like autocomplete on your phone, but vastly more sophisticated. AI systems use a “temperature” setting that controls how adventurous they are when picking the next word. At temperature 0, the AI always picks the most probable choice, producing consistent but sometimes rigid answers. At higher temperatures (most consumer AI uses 0.7 to 1.0 as defaults), the AI samples from a broader range of possibilities, introducing natural variation in responses.
The same question asked twice can yield measurably different answers. Research shows that even with supposedly deterministic settings, LLMs display output variance across identical inputs, and studies reveal distinct effects of temperature on model performance, with outputs becoming increasingly varied at moderate-to-high settings. This isn’t a bug; it’s fundamental to how these systems work.
Context Dependence
Traditional search isn’t conversational. You perform sequential queries, but each one is evaluated independently. Even with personalization, you’re not having a dialogue with an algorithm.
AI conversations are fundamentally different. The entire conversation thread becomes direct input to each response. Ask about “family hotels in Italy” after discussing “budget travel” versus “luxury experiences,” and the AI generates completely different answers because previous messages literally shape what gets generated. But this creates a compounding problem: the deeper the conversation, the more context accumulates, and the more prone responses become to drift. Research on the “lost in the middle” problem shows LLMs struggle to reliably use information from long contexts, meaning key details from earlier in a conversation may be overlooked or mis-weighted as the thread grows.
For brands, this means your visibility can degrade not just across separate conversations, but within a single long research session as user context accumulates and the AI’s ability to maintain consistent citation patterns weakens.
Temporal Discontinuity
Each new conversation instance starts from a different baseline. Memory systems help, but remain imperfect. AI memory works through two mechanisms: explicit saved memories (facts the AI stores) and chat history reference (searching past conversations). Neither provides complete continuity. Even when both are enabled, chat history reference retrieves what seems relevant, not everything that is relevant. And if you’ve ever tried to rely on any system’s memory based on uploaded documents, you know how flaky this can be – whether you give the platform a grounding document or tell it explicitly to remember something, it often overlooks the fact when needed most.
Result: Your brand visibility resets partially or completely with each new conversation timeline.
The Context Carrier Problem
Meet Sarah. She’s planning her family’s summer vacation using ChatGPT Plus with memory enabled.
Monday morning, she asks, “What are the best family destinations in Europe?” ChatGPT recommends Italy, France, Greece, Spain. By evening, she’s deep into Italy specifics. ChatGPT remembers the comparison context, emphasizing Italy’s advantages over the alternatives.
Wednesday: Fresh conversation, and she asks, “Tell me about Italy for families.” ChatGPT’s saved memories include “has children” and “interested in European travel.” Chat history reference might retrieve fragments from Monday: country comparisons, limited vacation days. But this retrieval is selective. Wednesday’s response is informed by Monday but isn’t a continuation. It’s a new timeline with lossy memory – like a JPEG copy of a photograph, details are lost in the compression.
Friday: She switches to Perplexity. “Which is better for families, Italy or Spain?” Zero memory of her previous research. From Perplexity’s perspective, this is her first question about European travel.
Sarah is the “context carrier,” but she’s carrying context across platforms and instances that can’t fully sync. Even within ChatGPT, she’s navigating multiple conversation timelines: Monday’s thread with full context, Wednesday’s with partial memory, and of course Friday’s Perplexity query with no context for ChatGPT at all.
For your hotel brand: You appeared in Monday’s ChatGPT answer with full context. Wednesday’s ChatGPT has lossy memory; maybe you’re mentioned, maybe not. Friday on Perplexity, you never existed. Your brand flickered across three separate realities, each with different context depths, different probability distributions.
Your brand presence is probabilistic across infinite conversation timelines, each one a separate reality where you can strengthen, fade, or disappear entirely.
Why Traditional SEO Thinking Fails
The old model was somewhat predictable. Google’s algorithm was stable enough to optimize once and largely maintain rankings. You could A/B test changes, build toward predictable positions, defend them over time.
That model breaks completely in AI systems:
No Persistent Ranking
Your visibility resets with each conversation. Unlike Google, where position 3 carries across millions of users, in AI, each conversation is a new probability calculation. You’re fighting for consistent citation across discontinuous timelines.
Context Advantage
Visibility depends on what questions came before. Your competitor mentioned in the previous question has context advantage in the current one. The AI might frame comparisons favoring established context, even if your offering is objectively superior.
Probabilistic Outcomes
Traditional SEO aimed for “position 1 for keyword X.” AI optimization aims for “high probability of citation across infinite conversation paths.” You’re not targeting a ranking, you’re targeting a probability distribution.
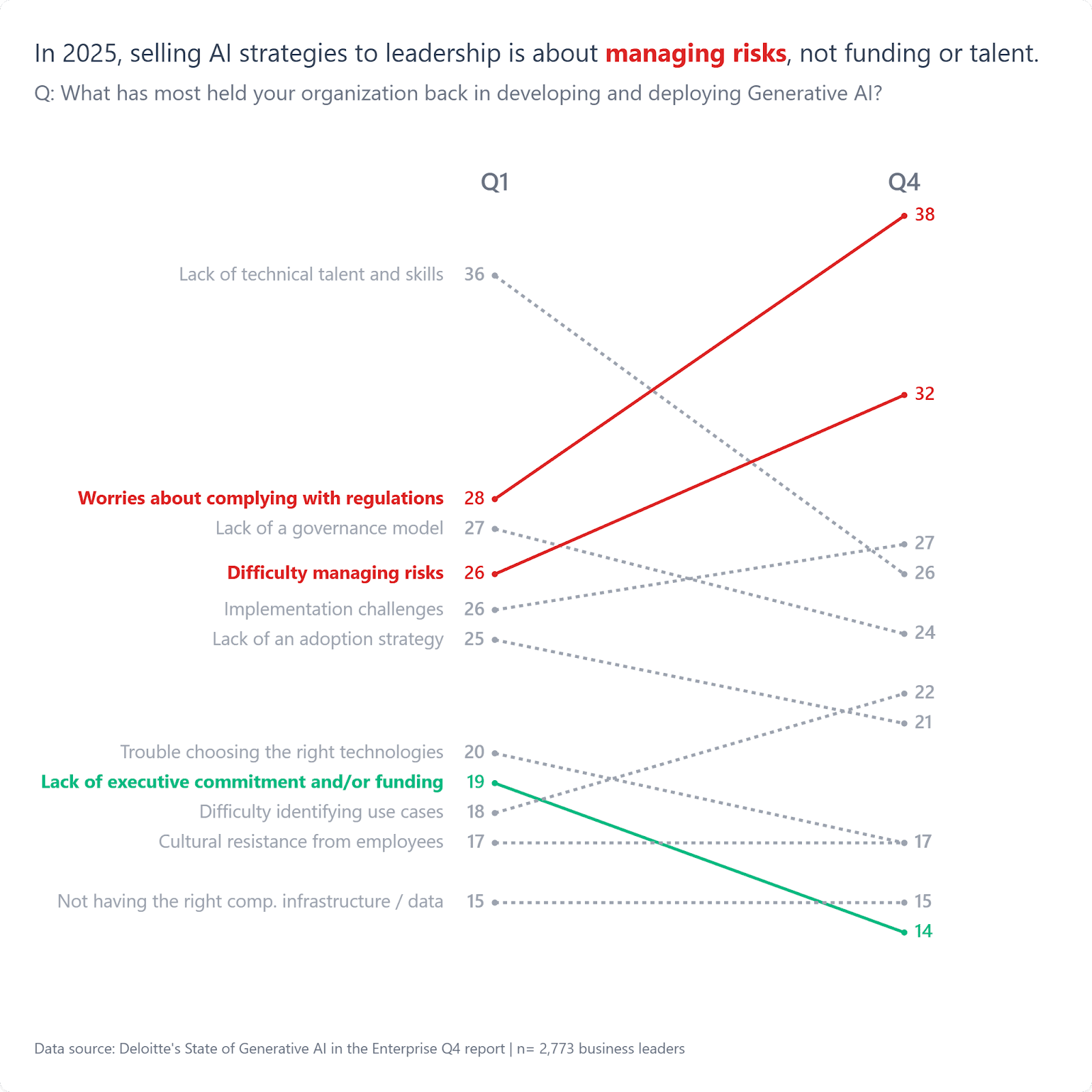
The business impact becomes very real. Sales training becomes outdated when AI gives different product information depending on question order. Customer service knowledge bases must work across disconnected conversations where agents can’t reference previous context. Partnership co-marketing collapses when AI cites one partner consistently but the other sporadically. Brand guidelines optimized for static channels often fail when messaging appears verbatim in one conversation and never surfaces in another.
The measurement challenge is equally profound. You can’t just ask, “Did we get cited?” You must ask, “How consistently do we get cited across different conversation timelines?” This is why consistent, ongoing testing is critical. Even if you have to manually ask queries and record answers.
The Three Pillars Of Cross-Temporal Consistency
1. Authoritative Grounding: Content That Anchors Across Timelines
Authoritative grounding acts like Marty’s photograph. It’s an anchor point that exists across timelines. The photograph didn’t create his existence, but it proved it. Similarly, authoritative content doesn’t guarantee AI citation, but it grounds your brand’s existence across conversation instances.
This means content that AI systems can reliably retrieve regardless of context timing. Structured data that machines can parse unambiguously: Schema.org markup for products, services, locations. First-party authoritative sources that exist independent of third-party interpretation. Semantic clarity that survives context shifts: Write descriptions that work whether the user asked about you first or fifth, whether they mentioned competitors or ignored them. Semantic density helps: keep the facts, cut the fluff.
A hotel with detailed, structured accessibility features gets cited consistently, whether the user asked about accessibility at conversation start or after exploring ten other properties. The content’s authority transcends context timing.
2. Multi-Instance Optimization: Content For Query Sequences
Stop optimizing for just single queries. Start optimizing for query sequences: chains of questions across multiple conversation instances.
You’re not targeting keywords; you’re targeting context resilience. Content that works whether it’s the first answer or the fifteenth, whether competitors were mentioned or ignored, whether the user is starting fresh or deep in research.
Test systematically: Cold start queries (generic questions, no prior context). Competitor context established (user discussed competitors, then asks about your category). Temporal gap queries (days later in fresh conversation with lossy memory). The goal is minimizing your “fade rate” across temporal instances.
If you’re cited 70% of the time in cold starts but only 25% after competitor context is established, you have a context resilience problem, not a content quality problem.
3. Answer Stability Measurement: Tracking Citation Consistency
Stop measuring just citation frequency. Start measuring citation consistency: how reliably you appear across conversation variations.
Traditional analytics told you how many people found you. AI analytics must tell you how reliably people find you across infinite possible conversation paths. It’s the difference between measuring traffic and measuring probability fields.
Key metrics: Search Visibility Ratio (percentage of test queries where you’re cited). Context Stability Score (variance in citation rate across different question sequences). Temporal Consistency Rate (citation rate when the same query is asked days apart). Repeat Citation Count (how often you appear in follow-up questions once established).
Test the same core question across different conversation contexts. Measure citation variance. Accept the variance as fundamental and optimize for consistency within that variance.
What This Means For Your Business
For CMOs: Brand consistency is now probabilistic, not absolute. You can only work to increase the probability of consistent appearance across conversation timelines. This requires ongoing optimization budgets, not one-time fixes. Your KPIs need to evolve from “share of voice” to “consistency of citation.”
For content teams: The mandate shifts from comprehensive content to context-resilient content. Documentation must stand alone AND connect to broader context. You’re not building keyword coverage, you’re building semantic depth that survives context permutation.
For product teams: Documentation must work across conversation timelines where users can’t reference previous discussions. Rich structured data becomes critical. Every product description must function independently while connecting to your broader brand narrative.
Navigating The Timelines
The brands that succeed in AI systems won’t be those with the “best” content in traditional terms. They’ll be those whose content achieves high-probability citation across infinite conversation instances. Content that works whether the user starts with your brand or discovers you after competitor context is established. Content that survives memory gaps and temporal discontinuities.
The question isn’t whether your brand appears in AI answers. It’s whether it appears consistently across the timelines that matter: the Monday morning conversation and the Wednesday evening one. The user who mentions competitors first and the one who doesn’t. The research journey that starts with price and the one that starts with quality.
In “Back to the Future,” Marty had to ensure his parents fell in love to prevent himself from fading from existence. In AI search, businesses must ensure their content maintains authoritative presence across context variations to prevent their brands from fading from answers.
The photograph is starting to flicker. Your brand visibility is resetting across thousands of conversation timelines daily, hourly. The technical factors causing this (probabilistic generation, context dependence, temporal discontinuity) are fundamental to how AI systems work.
The question is whether you can see that flicker happening and whether you’re prepared to optimize for consistency across discontinuous realities.
More Resources:
This post was originally published on Duane Forrester Decodes.
Featured Image: Inkoly/Shutterstock