Google’s Search Engine Market Share Drops As Competitors’ Grows via @sejournal, @MattGSouthern
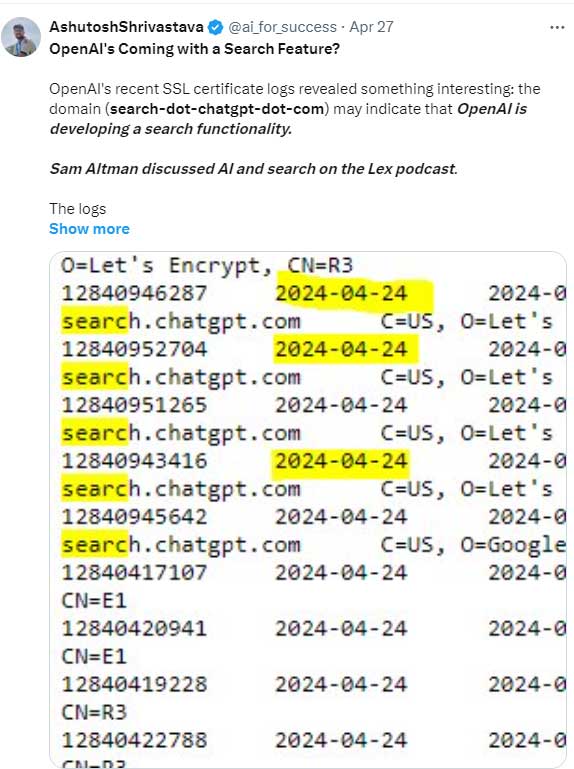
According to data from GS Statcounter, Google’s search engine market share has fallen to 86.99%, the lowest point since the firm began tracking search engine share in 2009.
The drop represents a more than 4% decrease from the previous month, marking the largest single-month decline on record.
 Screenshot from: https://gs.statcounter.com/search-engine-market-share/, May 2024.
Screenshot from: https://gs.statcounter.com/search-engine-market-share/, May 2024.U.S. Market Impact
The decline is most significant in Google’s key market, the United States, where its share of searches across all devices fell by nearly 10%, reaching 77.52%.
 Screenshot from: https://gs.statcounter.com/search-engine-market-share/, May 2024.
Screenshot from: https://gs.statcounter.com/search-engine-market-share/, May 2024.Concurrently, competitors Microsoft Bing and Yahoo Search have seen gains. Bing reached a 13% market share in the U.S. and 5.8% globally, its highest since launching in 2009.
Yahoo Search’s worldwide share nearly tripled to 3.06%, a level not seen since July 2015.
 Screenshot from: https://gs.statcounter.com/search-engine-market-share/, May 2024.
Screenshot from: https://gs.statcounter.com/search-engine-market-share/, May 2024.Search Quality Concerns
Many industry experts have recently expressed concerns about the declining quality of Google’s search results.
A portion of the SEO community believes that the search giant’s results have worsened following the latest update.
These concerns have begun to extend to average internet users, who are increasingly voicing complaints about the state of their search results.
Alternative Perspectives
Web analytics platform SimilarWeb provided additional context on X (formerly Twitter), stating that its data for the US for March 2024 suggests Google’s decline may not be as severe as initially reported.
From our data (Search Engine website category, US, March 2024) it doesn’t look like we’re there yet: pic.twitter.com/RBUJp4ZLeb
— Similarweb (@Similarweb) May 1, 2024
SimilarWeb also highlighted Yahoo’s strong performance, categorizing it as a News and Media platform rather than a direct competitor to Google in the Search Engine category.
Don’t underestimate Yahoo. They’re doing great. On our platform they’re categorized as News and Media, and hence not a direct competitor to Google in the Search Engine category. But they rank #10 worldwide, #6 in the US, and #1 in their category. Much higher than Bing and OpenAI. pic.twitter.com/O4yJu5QEK6
— Similarweb (@Similarweb) May 2, 2024
At the same time, Google is slightly declining 👀 pic.twitter.com/9i7paeU1QG
— Similarweb (@Similarweb) May 2, 2024
Why It Matters
The shifting search engine market trends can impact businesses, marketers, and regular users.
Google has been on top for a long time, shaping how we find things online and how users behave.
However, as its market share drops and other search engines gain popularity, publishers may need to rethink their online strategies and optimize for multiple search platforms besides Google.
Users are becoming vocal about Google’s declining search quality over time. As people start trying alternate search engines, the various platforms must prioritize keeping users satisfied if they want to maintain or grow their market position.
It will be interesting to see how they respond to this boost in market share.
What It Means for SEO Pros
As Google’s competitors gain ground, SEO strategies may need to adapt by accounting for how each search engine’s algorithms and ranking factors work.
This could involve diversifying SEO efforts across multiple platforms and staying up-to-date on best practices for each one.
The increased focus on high-quality search results emphasizes the need to create valuable, user-focused content that meets the needs of the target audience.
SEO pros must prioritize informative, engaging, trustworthy content that meets search engine algorithms and user expectations.
Remain flexible, adaptable, and proactive to navigate these shifts. Keeping a pulse on industry trends, user behaviors, and competing search engine strategies will be key for successful SEO campaigns.
Featured Image: Tada Images/Shutterstock