Rethinking Audience Targeting In A Signal-Loss Era (With The R.E.M. Framework) via @sejournal, @SequinsNsearch
Do you know who your audience is and what they want?
Over the last 20 years or so, we used to rely almost purely on data to answer that question. But as cookie tracking and user signals declined and analytics shifted toward sampling (what we refer to as the “signal-loss era”), we’ve lost some of that superpower. On top of this, we’ve handed over control to hyper-personalized platforms with “black box” targeting algorithms to find our audiences, leaving us less able to truly understand what is going on. And in doing so, we have lost track of the user.
In a way, the abundance of data made us complacent: “Data-informed” became the standard, while “user-informed” strategies progressively faded.
The problem with that over-reliance on data is that it made it “okay” to forget we are fundamentally communicating with humans and creating connections. We focused on the outcome and lost the drive to know who we’re connecting with and what leads us to acquire certain users or lose some.
And while signal loss and AI targeting might be perceived as a constraint, in reality, it is actually a great opportunity to go back to basics of marketing. It means we can focus on really understanding the user as a person, and not as trace fragments of data they leave in our web analytics.
Ultimately, getting to know them means we can serve them better – and find stronger, long-lasting ways to connect.
The Opportunity: Understanding Users And How We Reach Them
Even if we still had the data we had before, would it even be enough? I don’t think so, because it assumes user behavior is limited to what we can observe. In reality, behavior is shaped by a series of small, automatic decisions that happen below the surface, often driving outcomes before any action is even initiated – let alone tracked.
On top of this, when we talk about “understanding the user,” this is often reduced to understanding their needs and a rough demographic, but that’s only part of the picture. Users are people, with unique needs and patterns of thoughts at every stage of their consideration journey.
Now more than ever, we need to truly know who we are talking to and interacting with. What makes them favor us over a competitor? What media and channels are they using so we can reach them? What emotional triggers are really relevant to them? What is important to them at every stage of the journey? Only after answering these questions can we claim to have at least scratched the surface.
I’ve said before that human decision-making is inherently imperfect, shaped by cognitive biases and heuristics that help us navigate complexity without analyzing every option in detail. And that’s the reason why knowing what they want is often not enough to get the full picture – you need to know how they make decisions too.
When we fully understand the user, we can shape our approach ahead of outcomes, inform testing and platform targeting, and even anticipate results before execution.
A Practical Alternative To Cookie-Based Strategies: The R.E.M. Framework
To make sure you can reach the right audience, even when data is scarce and tracking unreliable, you should work with three simple things to aim for: Being Relevant, Everywhere, and Memorable in your strategy, from creatives, messaging, and channel choices.
This is what I call the R.E.M. Framework.

1. Be Relevant (And Relatable)
Relevancy is the first gateway to attention. In a world saturated with competing stimuli, it’s one of the primary filters the brain uses to decide what deserves focus.
Think about it: You might be having a great conversation with a friend in a group full of other people talking, and pay attention only to what they say. And yet, if your name is mentioned by someone else in a conversation you are not listening to, it’s very likely that you will automatically start paying attention to that instead.
This is what is commonly referred to as “the cocktail party effect,” a great example of how stimuli that are relevant to our personal experience, context, and goals can automatically capture our attention even when we are engaged in another task – something that happens consistently on social media, for example.
Today, we often refer to attention as “marketing’s primary currency,” and for a good reason. In a market so saturated, we only have a few seconds to pique our users’ interest before they move on to the next thing. And any content that won’t result in early engagement is likely to be dropped by the algorithm, which won’t serve it to other users as deemed not a good fit for our audience.
This is known by the industry as “the three-second rule,” and might in fact even be optimistic for newer platforms where short-form video prevails, like TikTok videos and Instagram reels. Short-form videos tend to make people forget what they came to the platform for in the first place much faster than long-form videos, and it’s exceptionally easy to lose a viewer on these formats if the hook isn’t instantly strong enough.
But in order to understand how to capture interest early, we need to take a step back and understand how attention works.
As humans, we are consistently exposed to a lot of stimuli at the same time, and we don’t have the cognitive resources to process each one of them, so we select some of them for further processing while ignoring others. We do so via a process called “selective attention” that can be driven by internal motivations (“endogenous orienting”) or external drivers (“exogenous orienting”). In other words, we tend to allocate attention based on our own goals (for example, when we have a deadline and we need to focus on a deliverable) or on the perceptual features of the objects around us (for example, the sound of the phone ringing or a stand-out word in a sentence).
That means that we have two ways to engage someone’s attention: by connecting with their goals, or presenting them with something that stands out in a sea of other similar things.
We can argue that relevancy sits in between these processes and can engage them both. As a matter of fact, when we are researching something, we are already deciding to filter out all the results that seem relevant to our own goal. But it works the other way too: Something relevant to our needs, goals, and context will jump out when we are doomscrolling on socials, even when we are not engaged in a search.
So relevancy is a sort of “catch-all” for attention.
How do you make sure you are immediately relevant?
By identifying what your audience needs, and leading with the solution in the hook. Don’t waste time with obscure messaging or secondary angles that you can elaborate on once you’ve anchored attention.
Strong tests and creatives are the ones that don’t focus on the business, but focus on the user and what they are trying to solve instead. And hyper-personalized platforms make this even more layered. Make the audience see themselves in what you offer, and you’ll shorten the time it takes for them to recognize you as the right choice.
2. Be Everywhere (Your Audience Is)
But can you be relevant to everyone? Of course not. So it’s imperative you understand your audience and their motivations to capture existing demand. And beyond that, you need to be present where they can find you, with the message they’re looking for in that moment.
This is one of the main challenges, now that journeys are so scattered across different platforms and search experiences. There are so many channels people discover us by, that it’s virtually impossible to track where certain journeys even start from. We might get a user from an LLM query, or a social post, or a Google search. Most likely, it’s all of them. A consideration journey is not linear, and it’s in fact the result of a continuous loop of discovery and evaluation, something we know now as “The Messy Middle.” Even the best attribution models rarely capture this.
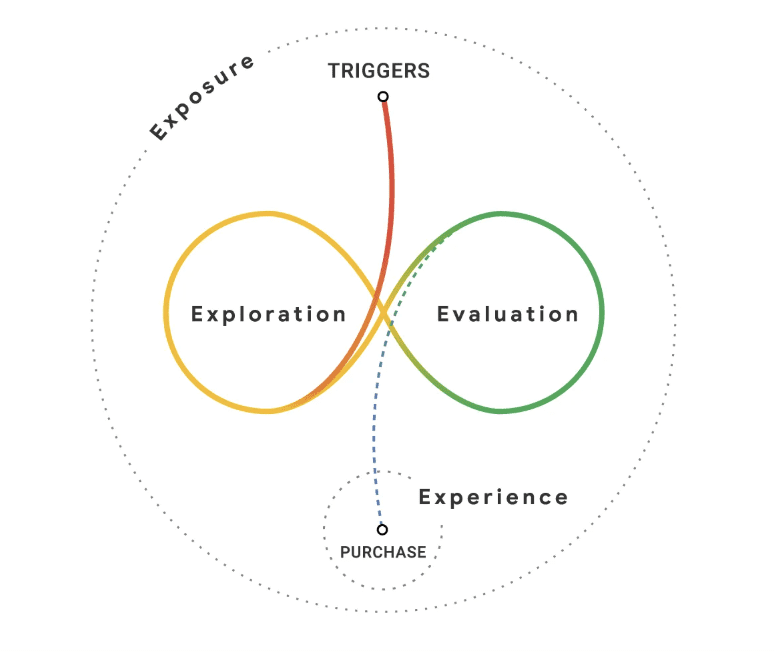
So, the solution is to work cross-functionally to cast a wide net across different channels, because visibility builds trust. “Out of sight, out of mind”: Our brain forms associations that strengthen with repeated exposure, and drops whatever is not used. If you’re consistently present where your audience is, with relevant content, you create the perception that you are indeed everywhere – without actually having to be.
And that matters, because repeated exposure is part of how we cast a choice in a sea of options. We call this “availability heuristic,” a decision-making shortcut that makes us favor what comes to mind easily: what we’ve seen often, recently, or remember clearly. Think about recommending a movie. You’re far more likely to mention something you’ve just watched, or keep seeing suggested, than something from years ago.
So, while relevance gets you noticed, presence keeps you top of mind. That means that when someone is ready to act, you’re already part of the consideration set, often before they even start a search.
Of course, going omnichannel is a beast in itself. Creatives and messages in one platform won’t work on another – you still need to test and iterate – but if you do it from a customer lens, your work is much simpler, and the benefits are two-fold: You can target different moments in the journey and stay top of mind.
But how do you prioritize channels when resources are limited?
You can rely on demographic research, personas, and early discovery data to establish a rough baseline, although that only gets you so far. Mapping who they are doesn’t tell you what they do when they make a choice, and how those behaviors shift across the journey. That’s the piece you have to find out for yourself: How do they make decisions? Who do they rely on for information, and where do they go to find it? And just as importantly, where are they when they’re not actively looking, and how can you meet them there?
And this is where personas fall short. They might tell you what people need and who they are, but not how they feel when making a decision. Often, what gets labeled as a bad strategy is simply incomplete research.
To really understand your audience, you need all of this information, which brings us to the next part.
3. Be Memorable
Being memorable is the one variable that still carries the most weight – yet is the hardest one to achieve. Why? Because it relies on creating a meaningful connection with the audience. And what that connection looks like can vary a lot across different individuals.
The general playbook to produce an emotion in marketing has often relied on the assumption that we share the same set of basic reactions, something that is based on Paul Ekman’s studies isolating fear, anger, happiness, surprise, disgust, and sadness as the “six basic emotions.”
And while it is true that some of these can be shared, the reality of the human emotional experience is much more nuanced and is often modulated by personal context, expectation, cultural values, and much more.
While attention works similarly across different individuals, memorability relies on personal context, values, and experiences. Think about an ad that stayed with you. What was the reason why you remember it so well? Chances are, it is because of the way it made you feel. Another reader of this article will have chosen a completely different ad.
Some brands, messages, or creatives stay with us because they elicit an emotional reaction. They make us laugh, they trigger nostalgia, sometimes they outrage us. But they all make us feel a certain way. And even when we choose employing rules of thumb like going for what we already know (“familiarity bias”) or what our peers suggest (“social proof”), it’s often because these are choices that are validated and make us feel safe.
We often hear that people make decisions emotionally, then they justify them rationally. This idea is reflected in early theories like Damasio’s “Somatic Marker Hypothesis,” which proposes that emotional signals influence decision-making, and is supported by neurophysiological evidence showing that physiological arousal varies between liked and disliked brands, pointing to the involvement of emotional processes in brand evaluation.
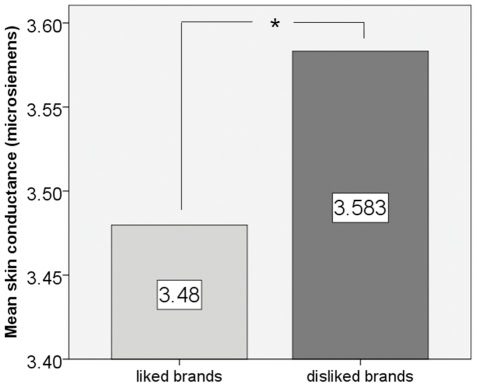
And that’s important, because the way we feel about a brand determines not only our perceptions but it’s pervasive of the entire experience with them, including trust and willingness to engage with their messaging and offer. We remember experiences for how they made us feel; we connect with some brands and ethos, and we disconnect wildly from some. Once you gain that memorability with your audience, you have an easier time retaining it – as well as guiding them to choose you.
What does this mean for you? Get acquainted not only with what your user needs or what is most likely to catch their eye, but with their personal and cultural context, how they feel, and what their expectations and values are – because these are all aspects that influence the relationship between brand and consumer. A genuine connection will make the user bypass any intermediate evaluation, and make you stand out from competitors, looping us back to our R – the relevancy you aim for in the first step of this framework.
Takeaways
Catching attention isn’t the only metric of success in the signal loss and hyper-personalization era. You need to be everywhere, and to stay top of mind when your audience is looking for the solution you can offer. So it’s imperative you know your users, their motivations, and their emotional states to capture existing demand and connect with them, wherever they are.
Easy, right?
Not really, but here are some starting points:
- Find what your audience needs by collating data that goes beyond search, and takes into account customer service logs, user interviews, and social scraping (both for your brands and your competitors), so that you can capture both the pre-purchase and post-purchase journeys. Use that data to inform your USP and messaging in your test and creatives. Make it all about them, not you.
- Don’t take channels for granted, or ignore them just because they’re not useful to your immediate key performance indicators (KPIs). Visibility is often the result of compound actions and cross-functional collaboration. Map out your discoverability across different channels, content formats, and ways to consume content, so that you can target different moments in your audience’s journey. Let this be your guiding light when you pick your battles.
- Get to know your audience at a granular level: What do they feel when they search? What are their values? What are their expectations? If they know us, how do they feel about us? Use those emotional drivers to understand what creatives, messaging, and format might be best to use as a gateway to create a meaningful connection.
In summary, start with finding your audience, learn how they decide and understand their underlying needs; all of this will inform your unique selling proposition (USP) and product value proposition, your messaging and creatives, as well as your distribution channels and the choice of formats.
It’s time we go beyond personas and start looking at the real people behind the screen.
More Resources:
Featured Image: ImageFlow/Shutterstock