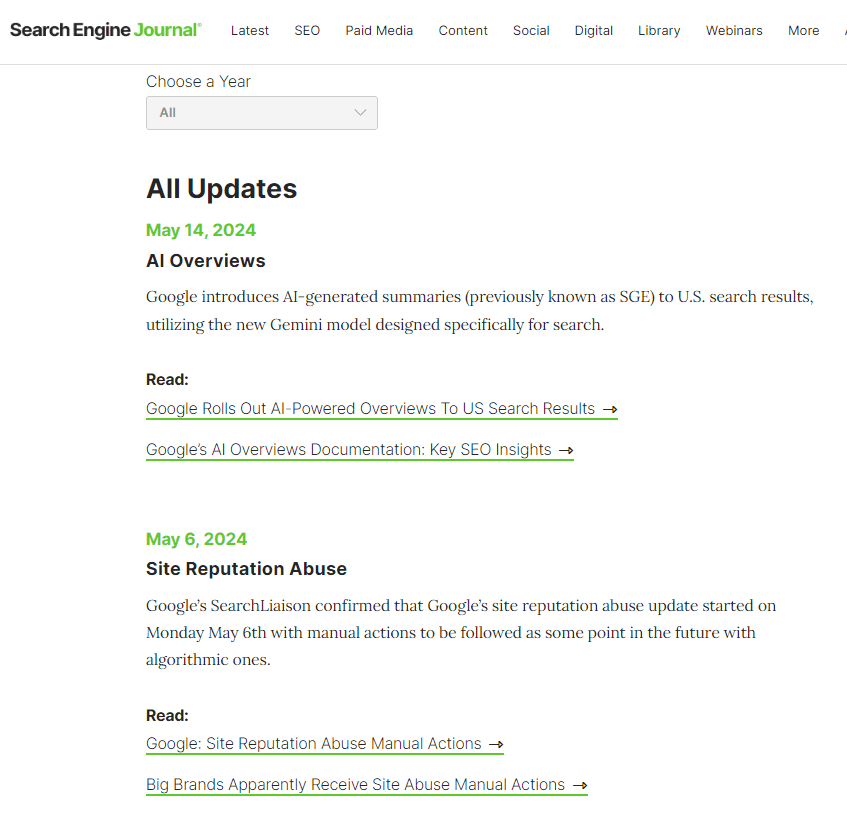
In the world of SEO, URL parameters pose a significant problem.
While developers and data analysts may appreciate their utility, these query strings are an SEO headache.
Countless parameter combinations can split a single user intent across thousands of URL variations. This can cause complications for crawling, indexing, visibility and, ultimately, lead to lower traffic.
The issue is we can’t simply wish them away, which means it’s crucial to master how to manage URL parameters in an SEO-friendly way.
To do so, we will explore:
What Are URL Parameters?
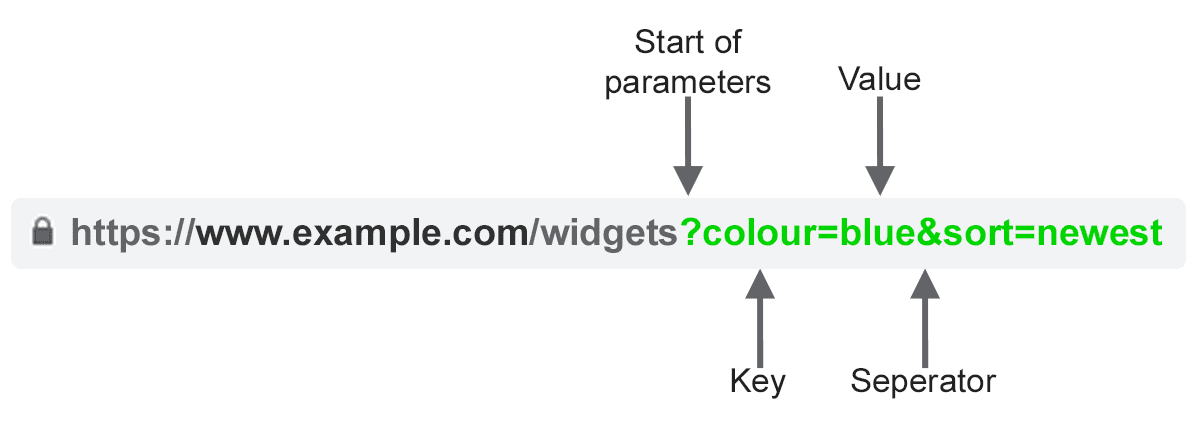
URL parameters, also known as query strings or URI variables, are the portion of a URL that follows the ‘?’ symbol. They are comprised of a key and a value pair, separated by an ‘=’ sign. Multiple parameters can be added to a single page when separated by an ‘&’.
The most common use cases for parameters are:
- Tracking – For example ?utm_medium=social, ?sessionid=123 or ?affiliateid=abc
- Reordering – For example ?sort=lowest-price, ?order=highest-rated or ?so=latest
- Filtering – For example ?type=widget, colour=purple or ?price-range=20-50
- Identifying – For example ?product=small-purple-widget, categoryid=124 or itemid=24AU
- Paginating – For example, ?page=2, ?p=2 or viewItems=10-30
- Searching – For example, ?query=users-query, ?q=users-query or ?search=drop-down-option
- Translating – For example, ?lang=fr or ?language=de
SEO Issues With URL Parameters
1. Parameters Create Duplicate Content
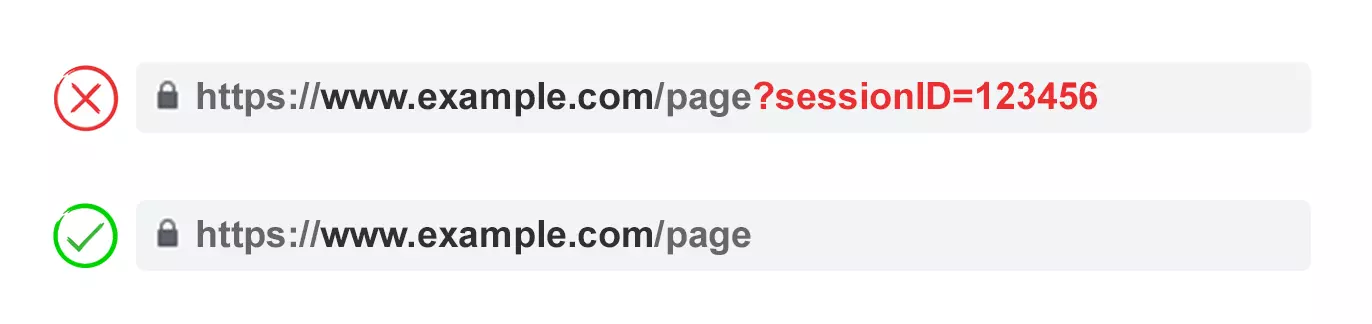
Often, URL parameters make no significant change to the content of a page.
A re-ordered version of the page is often not so different from the original. A page URL with tracking tags or a session ID is identical to the original.
For example, the following URLs would all return a collection of widgets.
- Static URL: https://www.example.com/widgets
- Tracking parameter: https://www.example.com/widgets?sessionID=32764
- Reordering parameter: https://www.example.com/widgets?sort=latest
- Identifying parameter: https://www.example.com?category=widgets
- Searching parameter: https://www.example.com/products?search=widget
That’s quite a few URLs for what is effectively the same content – now imagine this over every category on your site. It can really add up.
The challenge is that search engines treat every parameter-based URL as a new page. So, they see multiple variations of the same page, all serving duplicate content and all targeting the same search intent or semantic topic.
While such duplication is unlikely to cause a website to be completely filtered out of the search results, it does lead to keyword cannibalization and could downgrade Google’s view of your overall site quality, as these additional URLs add no real value.
2. Parameters Reduce Crawl Efficacy
Crawling redundant parameter pages distracts Googlebot, reducing your site’s ability to index SEO-relevant pages and increasing server load.
Google sums up this point perfectly.
“Overly complex URLs, especially those containing multiple parameters, can cause a problems for crawlers by creating unnecessarily high numbers of URLs that point to identical or similar content on your site.
As a result, Googlebot may consume much more bandwidth than necessary, or may be unable to completely index all the content on your site.”
3. Parameters Split Page Ranking Signals
If you have multiple permutations of the same page content, links and social shares may be coming in on various versions.
This dilutes your ranking signals. When you confuse a crawler, it becomes unsure which of the competing pages to index for the search query.
4. Parameters Make URLs Less Clickable
Let’s face it: parameter URLs are unsightly. They’re hard to read. They don’t seem as trustworthy. As such, they are slightly less likely to be clicked.
This may impact page performance. Not only because CTR influences rankings, but also because it’s less clickable in AI chatbots, social media, in emails, when copy-pasted into forums, or anywhere else the full URL may be displayed.
While this may only have a fractional impact on a single page’s amplification, every tweet, like, share, email, link, and mention matters for the domain.
Poor URL readability could contribute to a decrease in brand engagement.
Assess The Extent Of Your Parameter Problem
It’s important to know every parameter used on your website. But chances are your developers don’t keep an up-to-date list.
So how do you find all the parameters that need handling? Or understand how search engines crawl and index such pages? Know the value they bring to users?
Follow these five steps:
- Run a crawler: With a tool like Screaming Frog, you can search for “?” in the URL.
- Review your log files: See if Googlebot is crawling parameter-based URLs.
- Look in the Google Search Console page indexing report: In the samples of index and relevant non-indexed exclusions, search for ‘?’ in the URL.
- Search with site: inurl: advanced operators: Know how Google is indexing the parameters you found by putting the key in a site:example.com inurl:key combination query.
- Look in Google Analytics all pages report: Search for “?” to see how each of the parameters you found are used by users. Be sure to check that URL query parameters have not been excluded in the view setting.
Armed with this data, you can now decide how to best handle each of your website’s parameters.
SEO Solutions To Tame URL Parameters
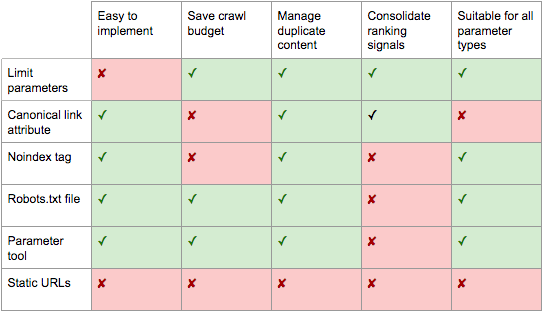
You have six tools in your SEO arsenal to deal with URL parameters on a strategic level.
Limit Parameter-based URLs
A simple review of how and why parameters are generated can provide an SEO quick win.
You will often find ways to reduce the number of parameter URLs and thus minimize the negative SEO impact. There are four common issues to begin your review.
1. Eliminate Unnecessary Parameters
Ask your developer for a list of every website’s parameters and their functions. Chances are, you will discover parameters that no longer perform a valuable function.
For example, users can be better identified by cookies than sessionIDs. Yet the sessionID parameter may still exist on your website as it was used historically.
Or you may discover that a filter in your faceted navigation is rarely applied by your users.
Any parameters caused by technical debt should be eliminated immediately.
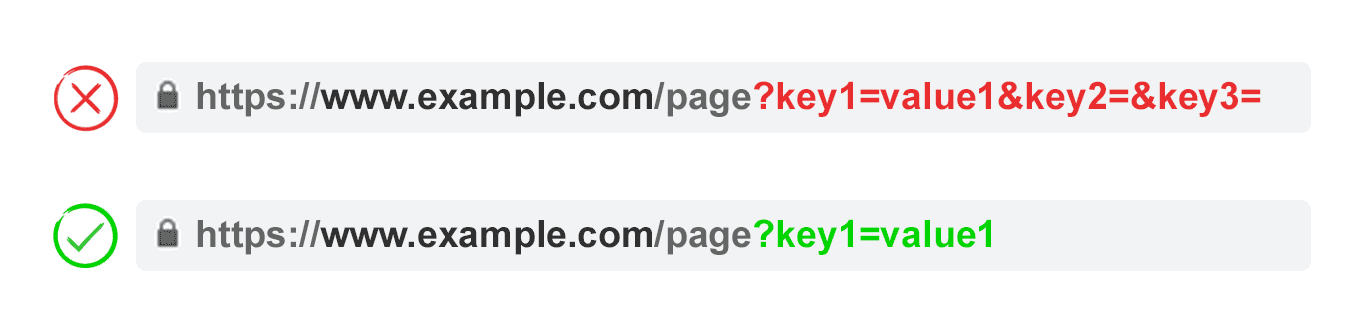
2. Prevent Empty Values
URL parameters should be added to a URL only when they have a function. Don’t permit parameter keys to be added if the value is blank.
In the above example, key2 and key3 add no value, both literally and figuratively.
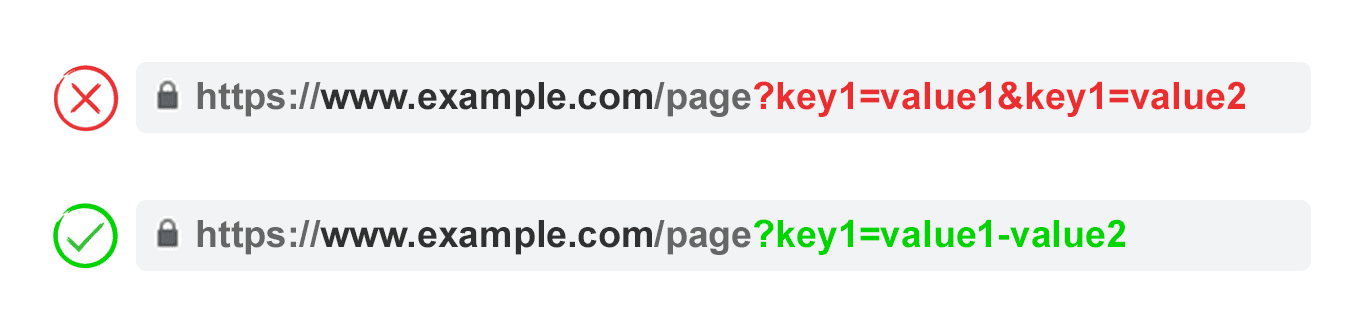
3. Use Keys Only Once
Avoid applying multiple parameters with the same parameter name and a different value.
For multi-select options, it is better to combine the values after a single key.
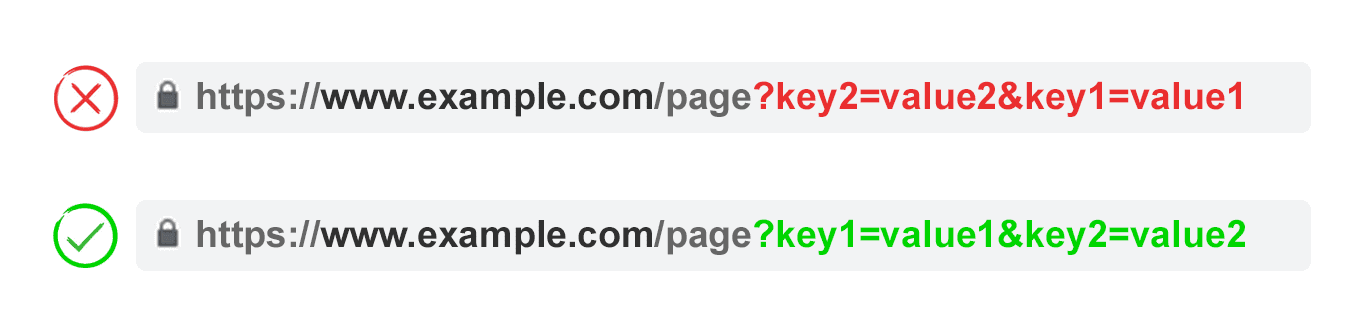
4. Order URL Parameters
If the same URL parameter is rearranged, the pages are interpreted by search engines as equal.
As such, parameter order doesn’t matter from a duplicate content perspective. But each of those combinations burns crawl budget and split ranking signals.
Avoid these issues by asking your developer to write a script to always place parameters in a consistent order, regardless of how the user selected them.
In my opinion, you should start with any translating parameters, followed by identifying, then pagination, then layering on filtering and reordering or search parameters, and finally tracking.
Pros:
- Ensures more efficient crawling.
- Reduces duplicate content issues.
- Consolidates ranking signals to fewer pages.
- Suitable for all parameter types.
Cons:
- Moderate technical implementation time.
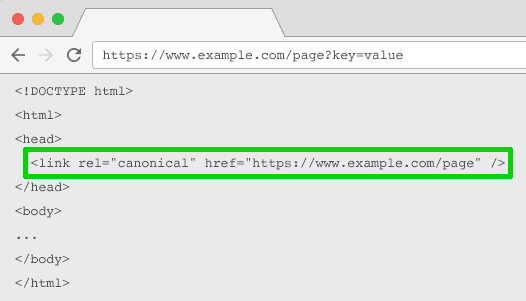
Rel=”Canonical” Link Attribute
The rel=”canonical” link attribute calls out that a page has identical or similar content to another. This encourages search engines to consolidate the ranking signals to the URL specified as canonical.
You can rel=canonical your parameter-based URLs to your SEO-friendly URL for tracking, identifying, or reordering parameters.
But this tactic is not suitable when the parameter page content is not close enough to the canonical, such as pagination, searching, translating, or some filtering parameters.
Pros:
- Relatively easy technical implementation.
- Very likely to safeguard against duplicate content issues.
- Consolidates ranking signals to the canonical URL.
Cons:
- Wastes crawling on parameter pages.
- Not suitable for all parameter types.
- Interpreted by search engines as a strong hint, not a directive.
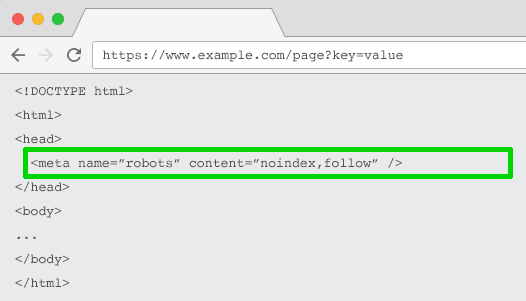
Meta Robots Noindex Tag
Set a noindex directive for any parameter-based page that doesn’t add SEO value. This tag will prevent search engines from indexing the page.
URLs with a “noindex” tag are also likely to be crawled less frequently and if it’s present for a long time will eventually lead Google to nofollow the page’s links.
Pros:
- Relatively easy technical implementation.
- Very likely to safeguard against duplicate content issues.
- Suitable for all parameter types you do not wish to be indexed.
- Removes existing parameter-based URLs from the index.
Cons:
- Won’t prevent search engines from crawling URLs, but will encourage them to do so less frequently.
- Doesn’t consolidate ranking signals.
- Interpreted by search engines as a strong hint, not a directive.
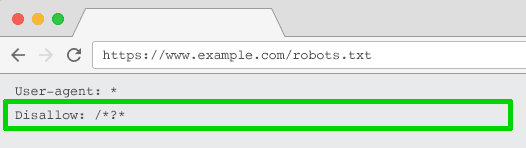
Robots.txt Disallow
The robots.txt file is what search engines look at first before crawling your site. If they see something is disallowed, they won’t even go there.
You can use this file to block crawler access to every parameter based URL (with Disallow: /*?*) or only to specific query strings you don’t want to be indexed.
Pros:
- Simple technical implementation.
- Allows more efficient crawling.
- Avoids duplicate content issues.
- Suitable for all parameter types you do not wish to be crawled.
Cons:
- Doesn’t consolidate ranking signals.
- Doesn’t remove existing URLs from the index.
Move From Dynamic To Static URLs
Many people think the optimal way to handle URL parameters is to simply avoid them in the first place.
After all, subfolders surpass parameters to help Google understand site structure and static, keyword-based URLs have always been a cornerstone of on-page SEO.
To achieve this, you can use server-side URL rewrites to convert parameters into subfolder URLs.
For example, the URL:
www.example.com/view-product?id=482794
Would become:
www.example.com/widgets/purple
This approach works well for descriptive keyword-based parameters, such as those that identify categories, products, or filters for search engine-relevant attributes. It is also effective for translated content.
But it becomes problematic for non-keyword-relevant elements of faceted navigation, such as an exact price. Having such a filter as a static, indexable URL offers no SEO value.
It’s also an issue for searching parameters, as every user-generated query would create a static page that vies for ranking against the canonical – or worse presents to crawlers low-quality content pages whenever a user has searched for an item you don’t offer.
It’s somewhat odd when applied to pagination (although not uncommon due to WordPress), which would give a URL such as
www.example.com/widgets/purple/page2
Very odd for reordering, which would give a URL such as
www.example.com/widgets/purple/lowest-price
And is often not a viable option for tracking. Google Analytics will not acknowledge a static version of the UTM parameter.
More to the point: Replacing dynamic parameters with static URLs for things like pagination, on-site search box results, or sorting does not address duplicate content, crawl budget, or internal link equity dilution.
Having all the combinations of filters from your faceted navigation as indexable URLs often results in thin content issues. Especially if you offer multi-select filters.
Many SEO pros argue it’s possible to provide the same user experience without impacting the URL. For example, by using POST rather than GET requests to modify the page content. Thus, preserving the user experience and avoiding SEO problems.
But stripping out parameters in this manner would remove the possibility for your audience to bookmark or share a link to that specific page – and is obviously not feasible for tracking parameters and not optimal for pagination.
The crux of the matter is that for many websites, completely avoiding parameters is simply not possible if you want to provide the ideal user experience. Nor would it be best practice SEO.
So we are left with this. For parameters that you don’t want to be indexed in search results (paginating, reordering, tracking, etc) implement them as query strings. For parameters that you do want to be indexed, use static URL paths.
Pros:
- Shifts crawler focus from parameter-based to static URLs which have a higher likelihood to rank.
Cons:
- Significant investment of development time for URL rewrites and 301 redirects.
- Doesn’t prevent duplicate content issues.
- Doesn’t consolidate ranking signals.
- Not suitable for all parameter types.
- May lead to thin content issues.
- Doesn’t always provide a linkable or bookmarkable URL.
Best Practices For URL Parameter Handling For SEO
So which of these six SEO tactics should you implement?
The answer can’t be all of them.
Not only would that create unnecessary complexity, but often, the SEO solutions actively conflict with one another.
For example, if you implement robots.txt disallow, Google would not be able to see any meta noindex tags. You also shouldn’t combine a meta noindex tag with a rel=canonical link attribute.
Google’s John Mueller, Gary Ilyes, and Lizzi Sassman couldn’t even decide on an approach. In a Search Off The Record episode, they discussed the challenges that parameters present for crawling.
They even suggest bringing back a parameter handling tool in Google Search Console. Google, if you are reading this, please do bring it back!
What becomes clear is there isn’t one perfect solution. There are occasions when crawling efficiency is more important than consolidating authority signals.
Ultimately, what’s right for your website will depend on your priorities.
Personally, I take the following plan of attack for SEO-friendly parameter handling:
- Research user intents to understand what parameters should be search engine friendly, static URLs.
- Implement effective pagination handling using a ?page= parameter.
- For all remaining parameter-based URLs, block crawling with a robots.txt disallow and add a noindex tag as backup.
- Double-check that no parameter-based URLs are being submitted in the XML sitemap.
No matter what parameter handling strategy you choose to implement, be sure to document the impact of your efforts on KPIs.
More resources:
Featured Image: BestForBest/Shutterstock