Google updated its Discussion Forum and Q&A Page structured data documentation, adding several new supported properties to both markup types.
The most notable addition is digitalSourceType, a property that lets forum and Q&A sites indicate when content was created by a trained AI model or another automated system.
Content Source Labeling Comes To Forum Markup
The new digitalSourceType property uses IPTC digital source enumeration values to indicate how content was created. Google supports two values:
TrainedAlgorithmicMediaDigitalSource for content created by a trained model, such as an LLM.
AlgorithmicMediaDigitalSource for content created by a simpler algorithmic process, such as an automatic reply bot.
The property is listed as recommended, not required, for both the DiscussionForumPosting and Comment types in the Discussion Forum docs, and for Question, Answer, and Comment types in the Q&A Page docs.
Google already uses similar IPTC source type values in its image metadata documentation to identify how images were created. The update extends that concept to text-based forum and Q&A content.
New Comment Count Property
Google added commentCount as a recommended property across both documentation pages. It lets sites declare the total number of comments on a post or answer, even when not all comments appear in the markup.
The Q&A Page documentation includes a new formula: answerCount + commentCount should equal the total number of replies of any type. This gives Google a clearer picture of thread activity on pages where comments are paginated or truncated.
Expanded Shared Content Support
The Discussion Forum documentation expanded its sharedContent property. Previously, sharedContent accepted a generic CreativeWork type. The updated docs now explicitly list four supported subtypes:
WebPage for shared links.
ImageObject for posts where an image is the primary content.
VideoObject for posts where a video is the primary content.
DiscussionForumPosting or Comment for quoted or reposted content from other threads.
The addition of DiscussionForumPosting and Comment as accepted types is new. Google’s updated documentation includes a code example showing how to mark up a referenced comment with its URL, author, date, and text.
The image property description was also updated across both docs with a note about link preview images. Google now recommends placing link preview images inside the sharedContent field’s attached WebPage rather than in the post’s image field.
Why This Matters
For sites that publish a mix of human and machine-generated content, the digitalSourceType addition provides a structured way to communicate that to Google. The new properties are optional, and no existing implementations will break.
Google has not said how it will use the digitalSourceType data in its ranking or display systems. The documentation only describes it as a way to indicate content origin.
Looking Ahead
The update does not include changes to required properties, so existing forum and Q&A structured data implementations remain valid. Sites that want to adopt the new properties can add them incrementally.
A good XML sitemap serves as a roadmap for your website, guiding Google to all your important pages. XML sitemaps can be beneficial for SEO, helping Google find your essential pages quickly, even if your internal linking isn’t perfect. This post explains what they are and how they help you rank better and get surfaced by AI agents.
Table of contents
Key takeaways
An XML sitemap is crucial for SEO, as it guides search engines to your important pages, improving crawl efficiency
XML sitemaps list essential URLs and provide metadata, helping search engines understand content and prioritize crawling
With Yoast SEO, you can automatically generate and manage XML sitemaps, keeping them up to date
XML sitemaps support faster indexing of new content and help discover orphan pages that aren’t linked elsewhere
Add your XML sitemap to Google Search Console to help Google find it quickly and monitor indexing status
What are XML sitemaps?
An XML sitemap is a file that lists a website’s essential pages, ensuring Google can find and crawl them. It also helps search engines understand your website structure and prioritize important content.
💡 Fun fact:
XML is not the only type of sitemap; there are several sitemap formats, each serving a slightly different purpose:
RSS, mRSS, and Atom 1.0 feeds: These are typically used for content that changes frequently, such as blogs or news sites. They automatically highlight recently updated content
Text sitemaps: The simplest format. These contain a plain list of URLs, one per line, without additional metadata
These are HTML sitemaps that are created for visitors, not search engines. They list and link to important pages in a clear, hierarchical structure to improve user navigation. An XML sitemap, however, is specifically designed for search engines.
XML sitemaps include additional metadata about each URL, helping search engines better understand your content. For example, it can indicate:
When a page was last meaningfully updated
How important is a URL relative to other URLs
Whether the page includes images or videos, using sitemap extensions
Search engines use this information to crawl your site more intelligently and efficiently, especially if your website is large, new, or has complex navigation.
Looking to expand your knowledge of technical SEO? We have a course in the Yoast SEO Academy focusing on crawlability and indexability. One of the topics we tackle is how to use XML sitemaps properly.
What does an XML sitemap look like?
An XML sitemap follows a standardized format. It is a text file written in Extensible Markup Language (XML) that search engines can easily read and process. As it follows a structured format, search engines like Google can quickly understand which URLs exist on your website and when they were last updated.
Here is a very simple example of an XML sitemap that contains a single URL:
https://www.yoast.com/wordpress-seo/2024-01-01
Each URL in a sitemap is wrapped in specific XML tags that provide information about that page. Some of these tags are required, while others are optional but helpful for search engines.
Below is a breakdown of the most common XML sitemap tags:
Tag
Requirement
Description
<?xml>
Mandatory
Declares the XML version and character encoding used in the file.
Mandatory
The container for the entire sitemap. It defines the sitemap protocol and holds all listed URLs.
Mandatory
Represents a single URL entry in the sitemap. Each page must be enclosed within its own tag.
Mandatory
Specifies the full canonical URL of the page you want search engines to crawl and index.
Optional
Indicates the date when the page was last meaningfully updated, helping search engines know when to re-crawl the page.
Optional
Suggests how frequently the content on the page is expected to change, such as daily, weekly, or monthly.
Optional
Suggests the relative importance of a page compared to other pages on the same site, using a scale from 0.0 to 1.0.
Note: While sitemaps.org supports optional tags like and , Google and Bing generally ignore them. Google has officially discarded them. Instead, it prefers to signal (last modified) when content actually updates.
What is an XML sitemap index?
A sitemap index is a file that lists multiple XML sitemap files. Instead of containing individual page URLs, it acts as a directory that points search engines to several separate sitemaps.
This becomes useful when a website has a large number of URLs or when the site owner wants to organize sitemaps by content type. For example, a site may have separate sitemaps for pages, blog posts, products, or categories.
Here’s a breakdown of how XML sitemap and XML sitemap index differ:
Feature
XML Sitemap
XML Sitemap Index
Purpose
Lists individual URLs on a website
Lists multiple sitemap files
Content
Contains page URLs and optional metadata
Contains links to sitemap files
Use case
Suitable for small or medium-sized sites
Useful when a site has multiple sitemaps
Structure
Uses and tags
Uses and tags.
Search engines support sitemap limits. A single sitemap can contain up to 50,000 URLs or be up to 50 MB in size. If your website exceeds these limits, you can create multiple sitemaps and group them together using a sitemap index.
Submitting a sitemap index to search engines allows them to discover and process all your sitemaps from a single file.
In short, an XML sitemap helps search engines discover pages, while a sitemap index helps search engines discover multiple sitemaps.
Below is a simple example of what a sitemap index file looks like:
In this example, the sitemap index references two separate sitemaps. Each one can contain thousands of URLs. This structure helps search engines efficiently discover and crawl large websites.
Why do you need an XML sitemap?
Technically, you don’t need an XML sitemap. Search engines can often discover your pages through internal links and backlinks from other websites. However, having an XML sitemap is highly recommended because it helps search engines crawl and understand your site more efficiently.
Here are some key benefits of using an XML sitemap:
Improved crawl efficiency
Sitemaps help search engines like Google and Bing crawl large or complex websites more efficiently. By listing your important URLs in one place, you make it easier for crawlers to find and prioritize valuable pages.
Faster indexing of new content
When you update or add new pages to your site, including them in your sitemap helps search engines discover them sooner. This can lead to faster indexing, especially for websites that publish content frequently, such as blogs, news sites, or e-commerce stores with changing product listings.
Discovery of orphan pages
Orphan pages are pages that are not linked from other parts of your website. Because crawlers typically follow links to discover content, these pages can sometimes be missed. An XML sitemap can help ensure these pages are still discovered.
Additional metadata signals
XML sitemaps can include additional metadata about each URL, such as the tag. This information helps search engines understand when a page was last updated and whether it may need to be crawled again.
Support for specialized content
Sitemaps can also be extended to include specific types of content, such as images or videos. These specialized sitemaps help search engines better understand and surface media content in results like Google Images or video search.
Better understanding of site structure
A well-organized sitemap gives search engines a clearer overview of your website’s structure and the relationship between different sections or content types.
Indexing insights through Search Console
When you submit your sitemap to tools like Google Search Console, you can monitor how many URLs are discovered and indexed. This also helps you identify crawl issues or indexing errors.
Support for multilingual websites
For websites targeting multiple languages or regions, XML sitemaps can include alternate language versions of pages using hreflang annotations. This helps search engines serve the correct language version to users in different locations.
Do XML sitemaps matter for AI search?
Yes, but indirectly. AI-powered search experiences like AI Overviews or Bing Copilot still rely on the traditional search index to discover and retrieve content. That means your pages usually need to be crawled and indexed first before they can appear in AI-generated answers.
This is where XML sitemaps still help. By listing your important URLs in one place, a sitemap makes it easier for search engines to discover and index your content. Keeping the value accurate can also help search engines prioritize recently updated pages, which is especially useful for AI systems that aim to surface fresh information.
In short, a sitemap won’t make your content appear in AI answers by itself. But it helps ensure your pages are discoverable, indexed, and up to date, which increases their chances of being used in AI-powered search results.
Adding XML sitemaps to your site with Yoast
Because XML sitemaps play an important role in helping search engines discover and crawl your content, Yoast SEO automatically generates XML sitemaps for your website. This feature is available in both the free and premium versions (Yoast SEO Premium, Yoast WooCommerce SEO, and Yoast SEO AI+) of the plugin.
A smarter analysis in Yoast SEO Premium
Yoast SEO Premium has a smart content analysis that helps you take your content to the next level!
Instead of requiring you to manually create or maintain sitemap files, Yoast SEO handles everything automatically. As you publish, update, or remove content, the plugin updates your sitemap index and the individual sitemaps in real time. This ensures search engines always have an up-to-date overview of the pages you want them to crawl and index.
Yoast SEO also organizes your sitemaps intelligently. Rather than placing every URL in a single file, the plugin creates a sitemap index that groups separate sitemaps for different content types, such as posts, pages, and other public content types, with just one click.
Another important advantage is that Yoast SEO only includes content that should actually appear in search results. Pages set to noindex are automatically excluded from the XML sitemap. This helps keep your sitemap clean and focused on the URLs that matter for SEO.
Controlling what appears in your sitemap
While the plugin automatically manages sitemaps, you still have full control over which content is included.
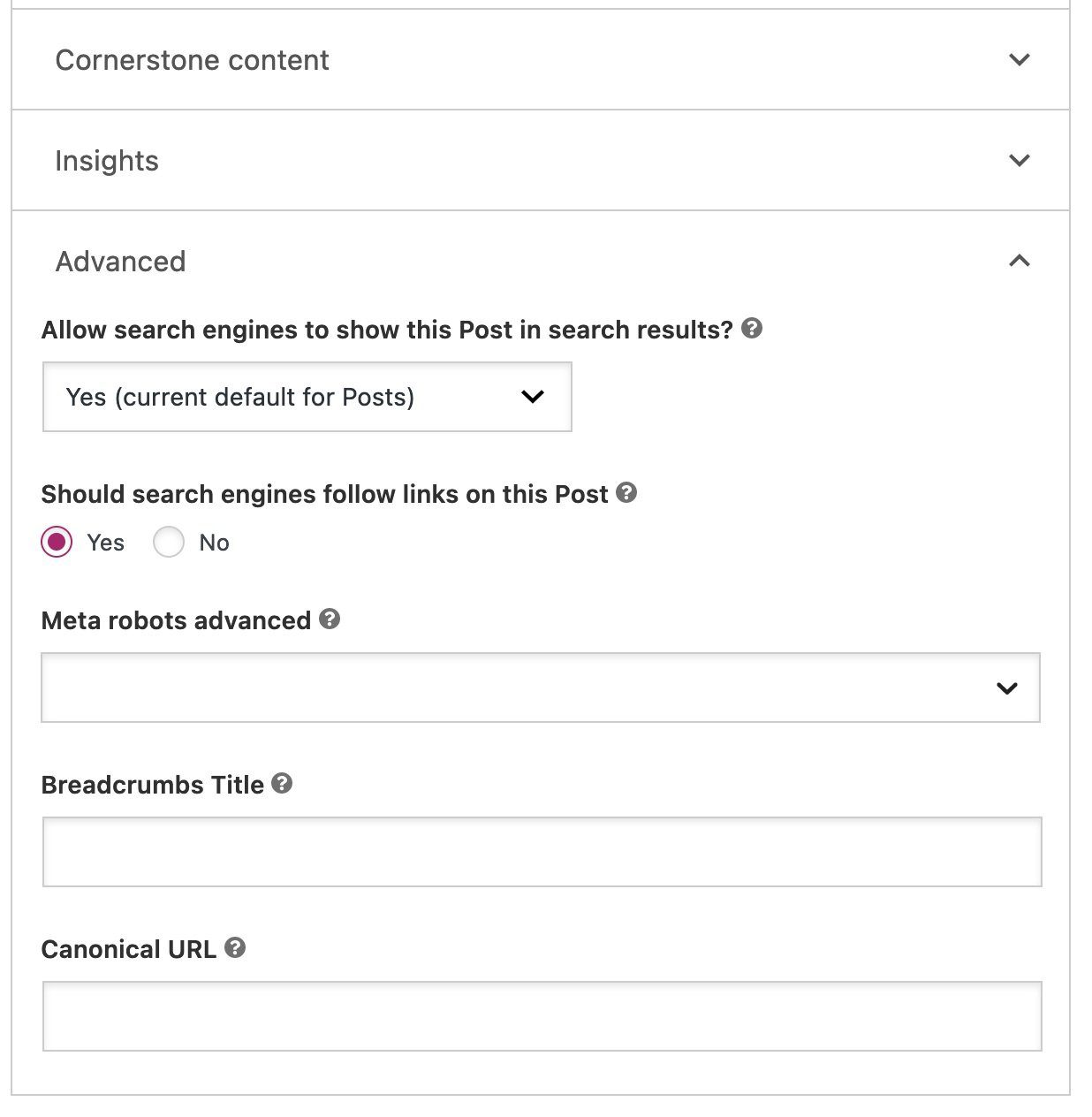
For example, if you don’t want a specific post or page to appear in search results, you can change the setting “Allow search engines to show this content in search results?” in the Yoast SEO sidebar under the Advanced tab. When this option is set to No, the content will be marked as noindex and automatically excluded from the XML sitemap. When set to Yes, the content remains eligible to appear in search results and is included in the sitemap.
This makes it easy to keep your sitemap focused on the pages you actually want search engines to crawl and index. In some cases, developers can further customize sitemap behavior. For example, filters can be used to limit the number of URLs per sitemap or to programmatically exclude certain content types.
Because all of this happens automatically, most website owners never need to manage sitemap files manually. Yoast SEO keeps your XML sitemap clean, up to date, and optimized for search engines as your site grows.
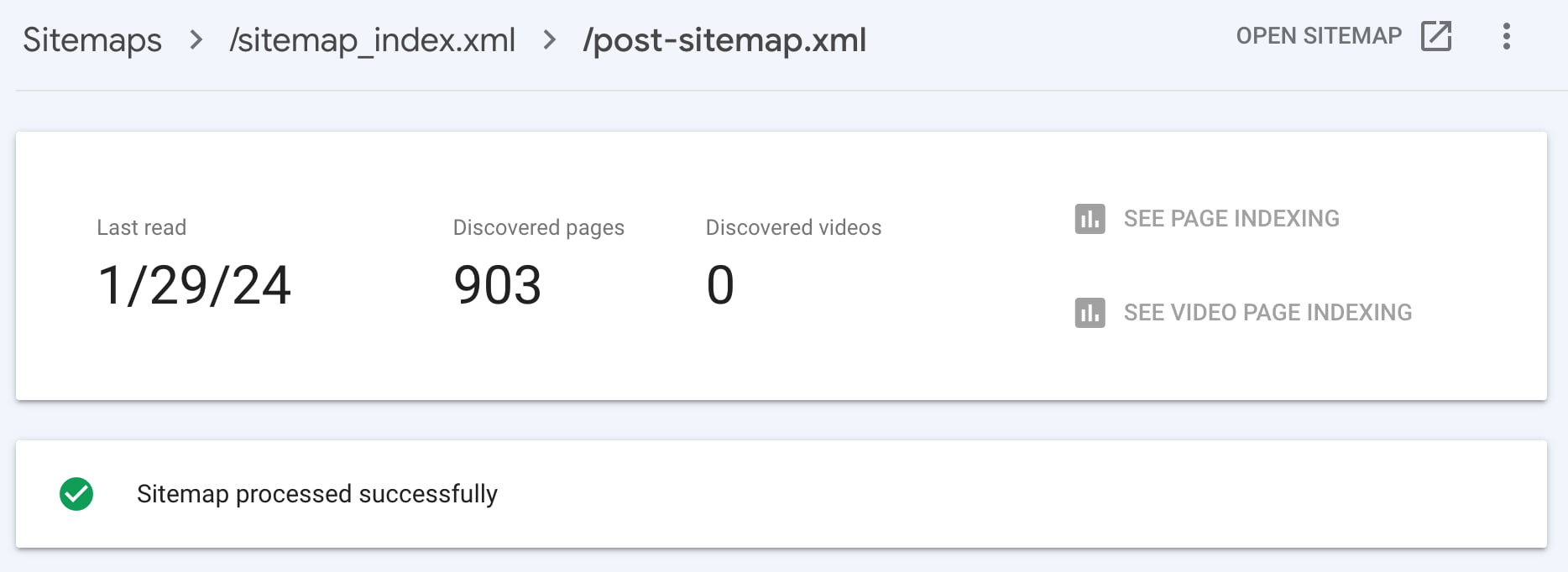
If you want Google to find your XML sitemap quicker, you’ll need to add it to your Google Search Console account. You can find your sitemaps in the ‘Sitemaps’ section. If not, you can add your sitemap at the top of the page.
Adding your sitemap helps check whether Google has indexed all pages in it. We recommend investigating this further if there is a significant difference between the ‘submitted’ and ‘indexed’ counts for a particular sitemap. Maybe there’s an error that prevents some pages from indexing? Another option is to add more links pointing to content that has not yet been indexed.
Google correctly processed all URLs in a post sitemap
What websites need an XML sitemap?
Google’s documentation says sitemaps are beneficial for “really large websites,” “websites with large archives,” “new websites with just a few external links to them,” and “websites which use rich media content.” According to Google, proper internal linking should allow it to find all your content easily. Unfortunately, many sites do not properly link their content logically.
While we agree that these websites will benefit the most from having one, at Yoast, we think XML sitemaps benefit every website. As the web grows, it’s getting harder and harder to index sites properly. That’s why you should provide search engines with every available option to have it found. In addition, XML sitemaps make search engine crawling more efficient.
Every website needs Google to find essential pages easily and know when they were last updated. That’s why this feature is included in the Yoast SEO plugin.
Which pages should be in your XML sitemap?
How do you decide which pages to include in your XML sitemap? Always start by thinking of the relevance of a URL: when a visitor lands on a particular URL, is it a good result? Do you want visitors to land on that URL? If not, it probably shouldn’t be in it. However, if you don’t want that URL to appear in the search results, you must add a ‘noindex’ tag. Leaving it out of your sitemap doesn’t mean Google won’t index the URL. If Google can find it by following links, Google can index the URL.
Example: A new blog
For example, you are starting a new blog. Of course, you want to ensure your target audience can find your blog posts in the search results. So, it’s a good idea to immediately include your posts in your XML sitemap. It’s safe to assume that most of your pages will also be relevant results for your visitors. However, a thank you page that people will see after they’ve subscribed to your newsletter is not something you want to appear in the search results. In this case, you don’t want to exclude all pages from your sitemap, only this one.
Let’s stay with the example of the new blog. In addition to your blog posts, you create some categories and tags. These categories and tags will have archive pages that list all posts in that specific category or tag. However, initially, there might not be enough content to fill these archive pages, making them ‘thin content’.
For example, tag archives that show just one post are not that valuable to visitors yet. You can exclude them from the sitemap when starting your blog and include them once you have enough posts. You can even exclude all your tag pages or category pages simultaneously using Yoast SEO.
However, this kind of page could also be excellent ranking material. So, if you think: well, yes, this tag page is a bit ‘thin’ right now, but it could be a great landing page, then enrich it with additional information and images. And don’t exclude it from your sitemap in this case.
Frequently asked questions about XML sitemaps
There are a lot of questions regarding XML sitemaps, so we’ve answered a couple in the FAQ below:
What happens when Google Search Console says an XML sitemap has errors?
An invalid or improperly read XML sitemap usually indicates a specific error that needs investigation. Check the reported issue to understand what is causing the problem. Make sure the sitemap has been submitted through the search engine’s webmaster tools. When the sitemap is marked as invalid, review the listed errors and apply the appropriate fixes for each one.
How can I check whether a website has an XML sitemap?
In most cases, you can find out if sites have an XML sitemap by adding sitemap.xml to the root domain. So, that would be example.com/sitemap.xml. If a site has Yoast SEO installed, you’ll notice that it’s redirected to example.com/sitemap_index.xml. sitemap_index.xml is the base sitemap that collects all the sitemaps on your site into a single page.
How can I update an XML sitemap?
There are ways to create and update your sitemaps by hand, but you shouldn’t. Also, there are static generators that let you generate a sitemap whenever you want. But, again, this process would need to repeat itself every time you add or update content. The best way to do this is by simply using Yoast SEO. Turn on the XML sitemap in Yoast SEO, and all your updates will be applied automatically.
Can I use in my XML sitemap?
In the past, people believed that adding the attribute to sitemaps would signal to Google that specific URLs should be prioritized. Unfortunately, it doesn’t do anything, as Google has often said it doesn’t use this attribute to read or prioritize content in sitemaps.
Check your own XML sitemap!
Now you know how important it is to have an XML sitemap: it can help your site’s SEO. If you add the correct URLs, Google can easily access your most important pages and posts. Google will also find updated content easily, so it knows when a URL needs to be crawled again. Lastly, adding your XML sitemap to Google Search Console helps Google find it quickly and lets you check for sitemap errors.
So check your XML sitemap and find out if you’re doing it right!
I’m a Computer Science grad who accidentally stumbled into writing—and stayed because I fell in love with it. Over the past six years, I’ve been deep in the world of SEO and tech content, turning jargon into stories that actually make sense. When I’m not writing, you’ll probably find me lifting weights to balance my love for food (because yes, gym and biryani can coexist) or catching up with friends over a good cup of chai.
If more than half the web runs on a content management system, then the majority of technical SEO standards are being positively shaped before an SEO even starts work on it. That’s the lens I took into the 2025 Web Almanac SEO chapter (for clarity, I co-authored the 2025 Web Almanac SEO chapter referenced in this article).
Rather than asking how individual optimization decisions influence performance, I wanted to understand something more fundamental: How much of the web’s technical SEO baseline is determined by CMS defaults and the ecosystems around them.
SEO often feels intensely hands-on – perhaps too much so. We debate canonical logic, structured data implementation, crawl control, and metadata configuration as if each site were a bespoke engineering project. But when 50%+ of pages in the HTTP Archive dataset sit on CMS platforms, those platforms become the invisible standard-setters. Their defaults, constraints, and feature rollouts quietly define what “normal” looks like at scale.
How CMS adoption trends track with core technical SEO signals.
Where plugin ecosystems appear to shape implementation patterns.
And how emerging standards like llms.txt are spreading as a result.
The question is not whether SEOs matter. It’s whether we’ve been underestimating who sets the baseline for the modern web.
The Backbone Of Web Design
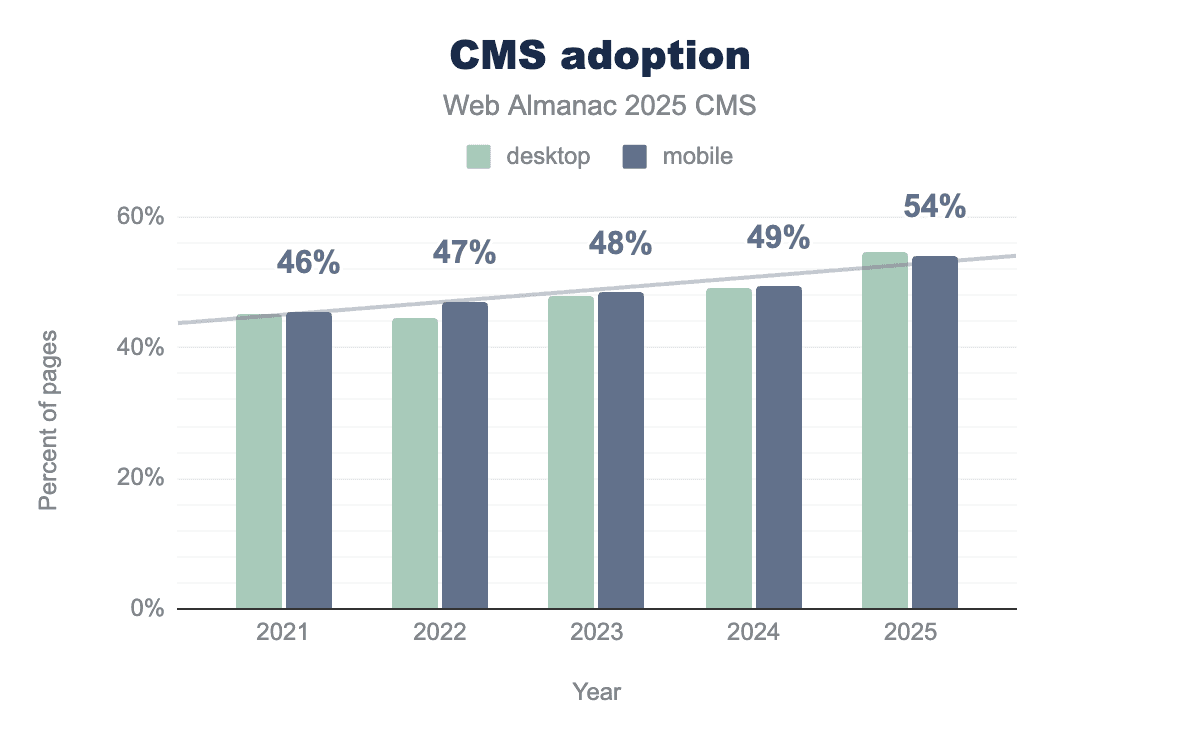
The 2025 CMS chapter of the Web Almanac saw a milestone hit with CMS adoption; over 50% of pages are on CMSs. In case you were unsold on how much of the web is carried by CMSs, over 50% of 16 million websites is a significant amount.
WordPress is still the most used CMS, by a long way, even if it has dropped marginally in the 2024 data. Shopify, Wix, Squarespace, and Joomla trail a long way behind, but they still have a significant impact, especially Shopify, on ecommerce specifically.
SEO Functions That Ship As Defaults In CMS Platforms
CMS platform defaults are important, this – I believe – is that a lot of basic technical SEO standards are either default setups or for the relatively small number of websites that have dedicated SEOs or people who at least build to/work with SEO best practice.
When we talk about “best practice,” we’re on slightly shaky ground for some, as there isn’t a universal, prescriptive view on this one, but I would consider:
Descriptive “SEO-friendly” URLs.
Editable title and meta description.
XML sitemaps.
Canonical tags.
Meta robots directive changing.
Structured data – at least a basic level.
Robots.txt editing.
Of the main CMS platforms, here is what they – self-reportedly – have as “default.” Note: For some platforms – like Shopify – they would say they’re SEO-friendly (and to be honest, it’s “good enough”), but many SEOs would argue that they’re not friendly enough to pass this test. I’m not weighing into those nuances, but I’d say both Shopify and those SEOs make some good points.
CMS
SEO-friendly URLs
Title & meta description UI
XML sitemap
Canonical tags
Robots meta support
Basic structured data
Robots.txt
WordPress
Yes
Partial (theme-dependent)
Yes
Yes
Yes
Limited (Article, BlogPosting)
No (plugin or server access required)
Shopify
Yes
Yes
Yes
Yes
Limited
Product-focused
Limited (editable via robots.txt.liquid, constrained)
Wix
Yes
Guided
Yes
Yes
Limited
Basic
Yes (editable in UI)
Squarespace
Yes
Yes
Yes
Yes
Limited
Basic
No (platform-managed, no direct file control)
Webflow
Yes
Yes
Yes
Yes
Yes
Manual JSON-LD
Yes (editable in settings)
Drupal
Yes
Partial (core)
Yes
Yes
Yes
Minimal (extensible)
Partial (module or server access)
Joomla
Yes
Partial
Yes
Yes
Yes
Minimal
Partial (server-level file edit)
Ghost
Yes
Yes
Yes
Yes
Yes
Article
No (server/config level only)
TYPO3
Yes
Partial
Yes
Yes
Yes
Minimal
Partial (config or extension-based)
Based on the above, I would say that most SEO basics can be covered by most CMSs “out of the box.” Whether they work well for you, or you cannot achieve the exact configuration that your specific circumstances require, are two other important questions – ones which I am not taking on. However, it often comes down to these points:
It is possible for these platforms to be used badly.
It is possible that the business logic you need will break/not work with the above.
There are many more advanced SEO features that aren’t out of the box, that are just as important.
We are talking about foundations here, but when I reflect on what shipped as “default” 15+ years ago, progress has been made.
Fingerprints Of Defaults In The HTTP Archive Data
Given that a lot of CMSs ship with these standards, do these SEO defaults correlate with CMS adoption? In many ways, yes. Let’s explore this in the HTTP Archive data.
Canonical Tag Adoption Correlates With CMS
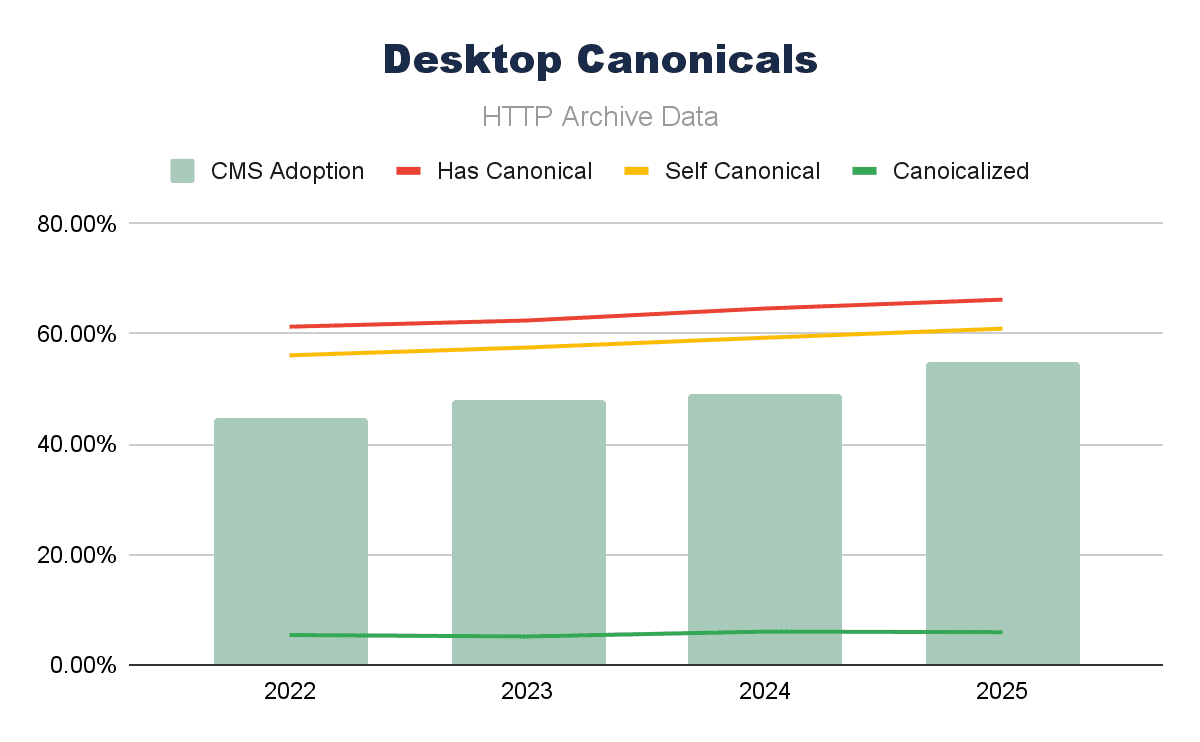
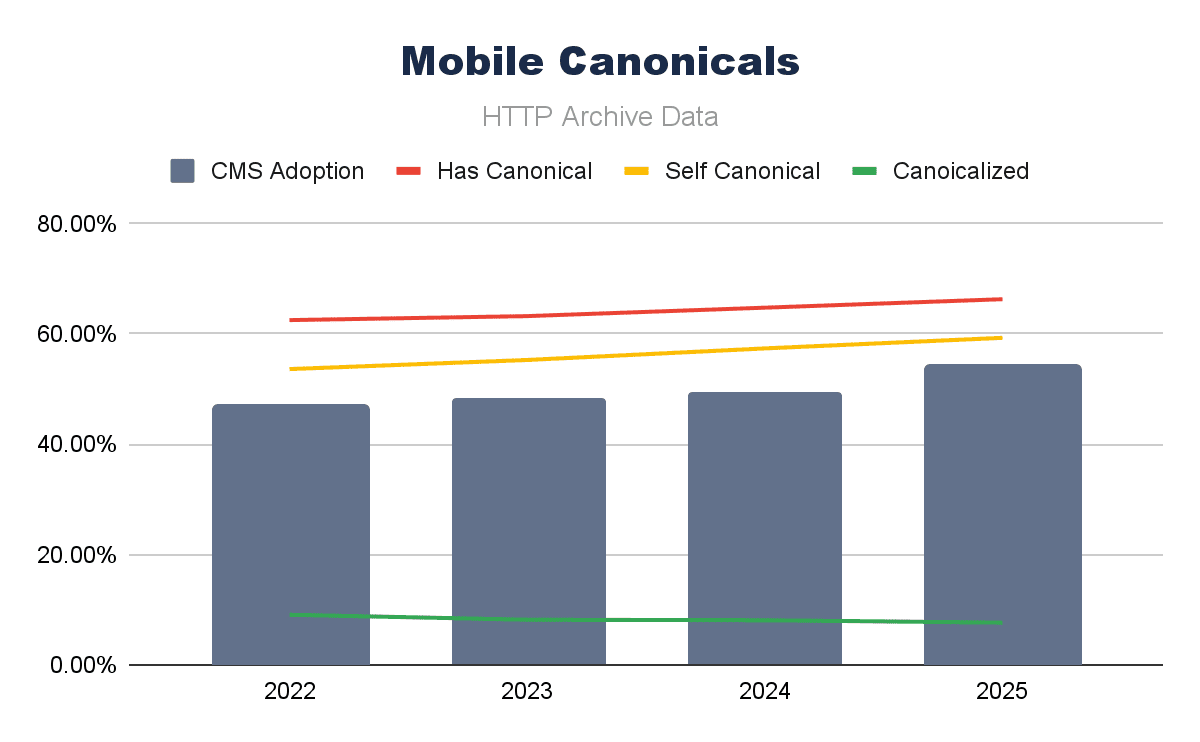
Combining canonical tag adoption data with (all) CMS adoption over the last four years, we can see that for both mobile and desktop, the trends seem to follow each other pretty closely.
Image by author, February 2026Image by author, February 2026
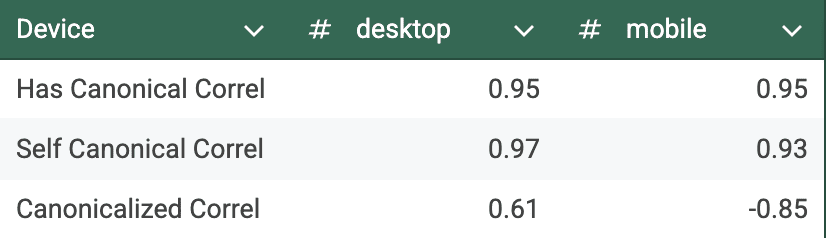
Running a simple Pearson correlation over these elements, we can see this strong correlation even clearer, with canonical tag implementation and the presence of self-canonical URLs.
Image by author, February 2026
What differs is the mobile correlation of canonicalized URLs; that seems to be a negative correlation on mobile and a lower (but still positive) correlation on desktop. A drop in canonicalized pages is largely causing this negative correlation, and the reasons behind this could be many (and harder to be sure of).
Canonical tags are a crucial element for technical SEO; their continued adoption does certainly seem to track the growth in CMS use, too.
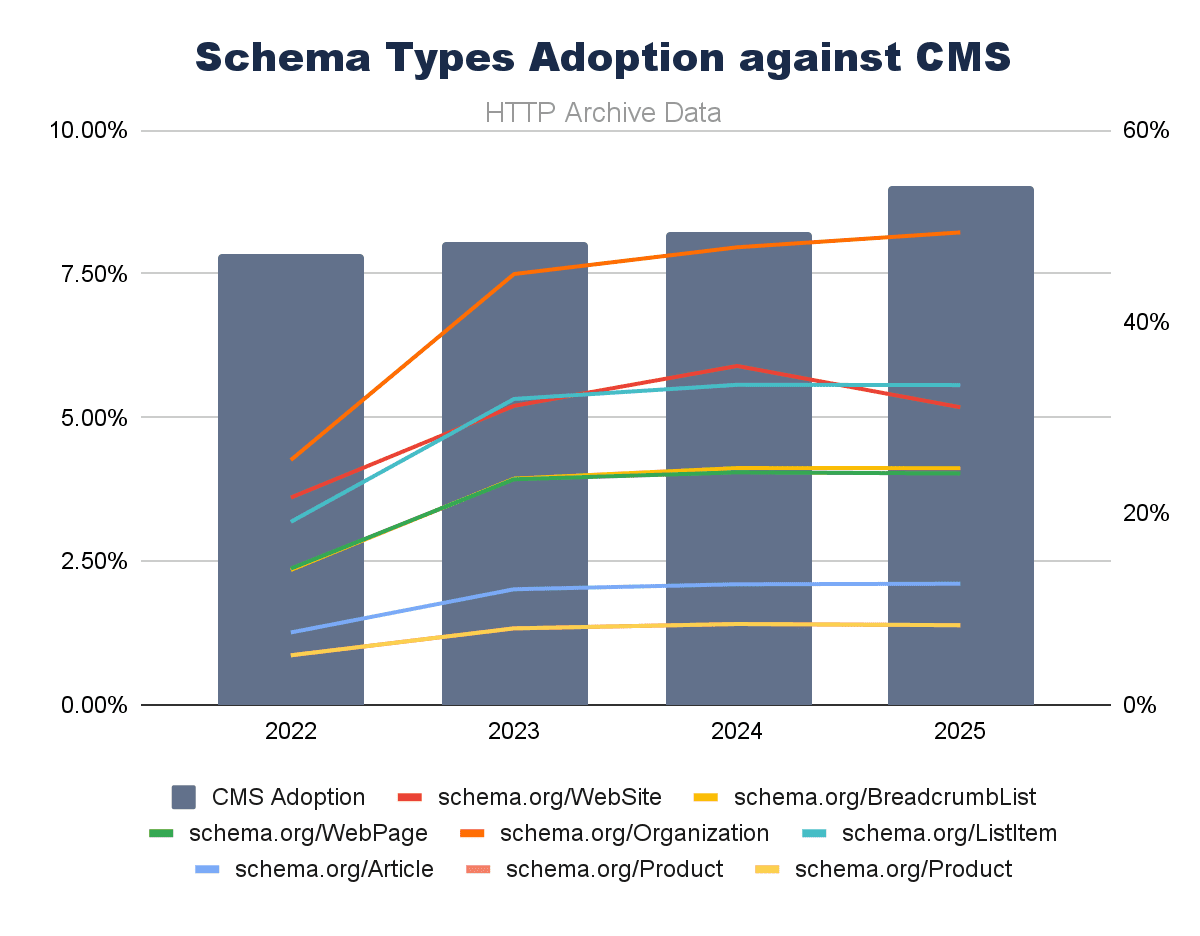
Schema.org Data Types Correlate With CMS
Schema.org types against CMS adoption show similar trends, but are less definitive overall. There are many different types of Schema.org, but if we plot CMS adoption against the ones most common to SEO concerns, we can observe a broadly rising picture.
Image by author, February 2026
With the exception of Schema.org WebSite, we can see CMS growth and structured data following similar trends.
But we must note that Schema.org adoption is quite considerably lower than CMSs overall. This could be due to most CMS defaults being far less comprehensive with Schema.org. When we look at specific CMS examples (shortly), we’ll see far-stronger links.
Schema.org implementation is still mostly intentional, specialist, and not as widespread as it could be. If I were a search engine or creating an AI Search tool, would I rely on universal adoption of these, seeing the data like this? Possibly not.
Robots.txt
Given that robots.txt is a single file that has some agreed standards behind it, its implementation is far simpler, so we could anticipate higher levels of adoption than Schema.org.
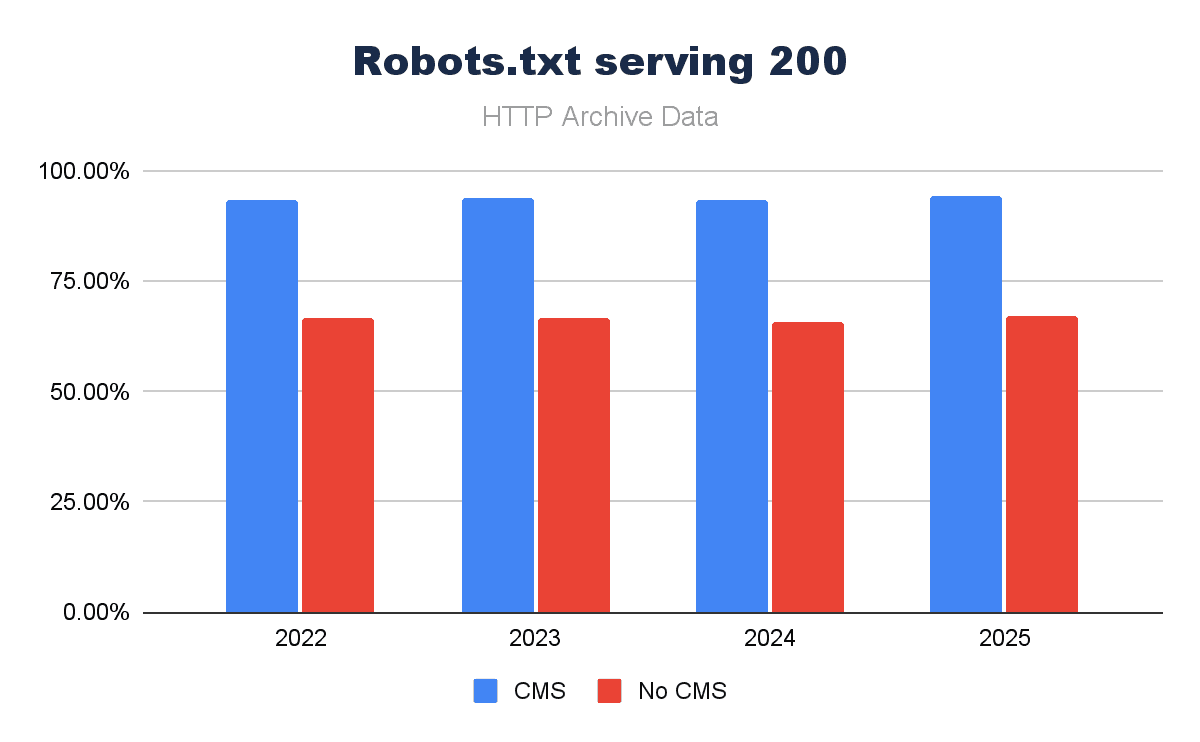
The presence of a robots.txt is pretty important, mostly to limit crawl of search engines to specific areas of the site. We are starting to see an evolution – we noted in the 2025 Web Almanac SEO chapter – that the robots.txt is used even more as a governance piece, rather than just housekeeping. A key sign that we’re using our key tools differently in the AI search world.
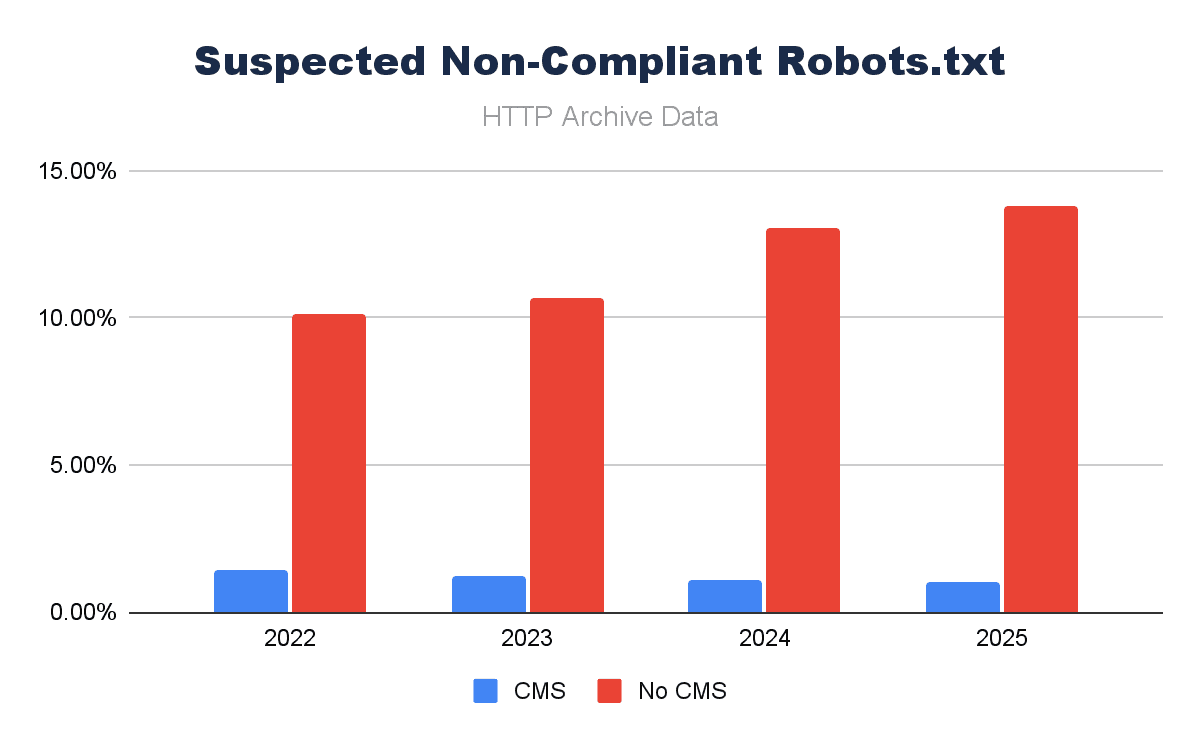
But before we consider the more advanced implementations, how much of a part does a CMS have in ensuring a robots.txt is present? Looks like over the last four years, CMS platforms are driving a significant amount more of robots.txt files serving a 200 response:
Image by author, February 2026
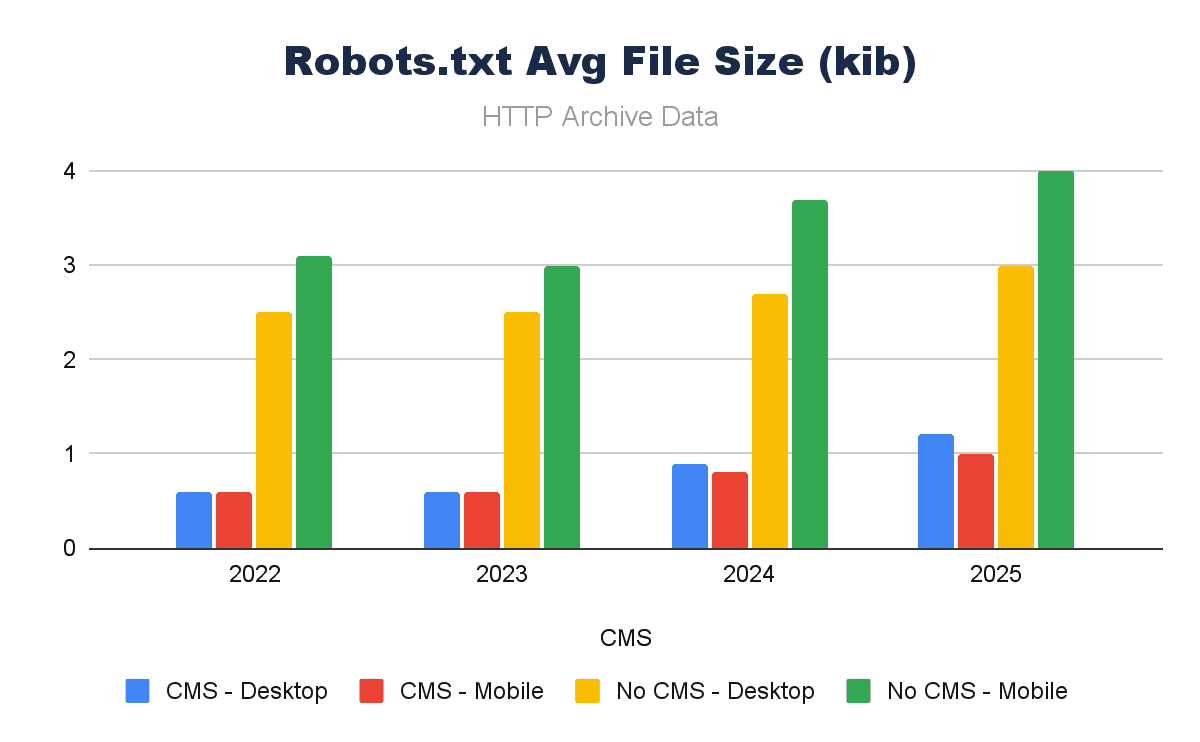
What is more curious, however, is when you consider the file of the robots.txt files. Non-CMS platforms have robots.txt files that are significantly larger.
Image by author, February 2026
Why could this be? Are they more advanced in non-CMS platforms, longer files, more bespoke rules? Most probably in some cases, but we’re missing another impact of a CMSs standards – compliant (valid) robots.txt files.
A lot of robots.txt files serve a valid 200 response, but often they’re not txt files, or they’re redirecting to 404 pages or similar. When we limit this list to only files that contain user-agent declarations (as a proxy), we see a different story.
Image by author, February 2026
Approaching 14% of robots.txt files served on non-CMS platforms are likely not even robots.txt files.
A robots.txt is easy to set up, but it is a conscious decision. If it’s forgotten/overlooked, it simply won’t exist. A CMS makes it more likely to have a robots.txt, and what’s more, when it is in place, it makes it easier to manage/maintain – which IS key.
WordPress Specific Defaults
CMS platforms, it seems, cover the basics, but more advanced options – which still need to be defaults – often need additional SEO tools to enable.
Interrogating WordPress-specific sites with the HTTP Archive data will be easiest as we get the largest sample, and the Wapalizer data gives a reliable way to judge the impact of WordPress-specific SEO tools.
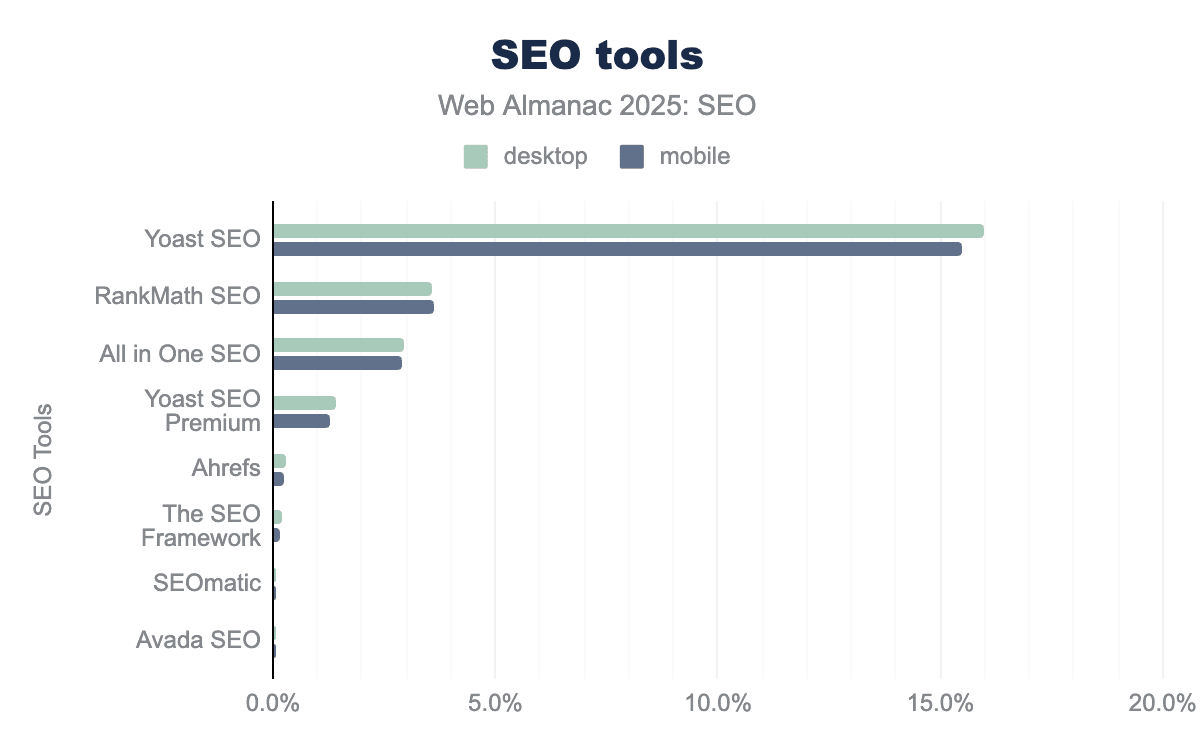
From the Web Almanac, we can see which SEO tools are the most installed on WordPress sites.
Screenshot from Web Almanac, February 2026
For anyone working within SEO, this is unlikely to be surprising. If you are an SEO and worked on WordPress, there is a high chance you have used either of the top three. What IS worth considering right now is that while Yoast SEO is by far the most prevalent within the data, it is seen on barely over 15% of sites. Even the most popular SEO plugin on the most popular CMS is still a relatively small share.
Of these top three plugins, let’s first consider what the differences of their “defaults” are. These are similar to some of WordPress’s, but we can see many more advanced features that come as standard.
Editable metadata, structured data, robots.txt, sitemaps, and, more recently, llms.txt are the most notable. It is worth noting that a lot of the functionality is more “back-end,” so not something we’d be as easily able to see in the HTTP Archive data.
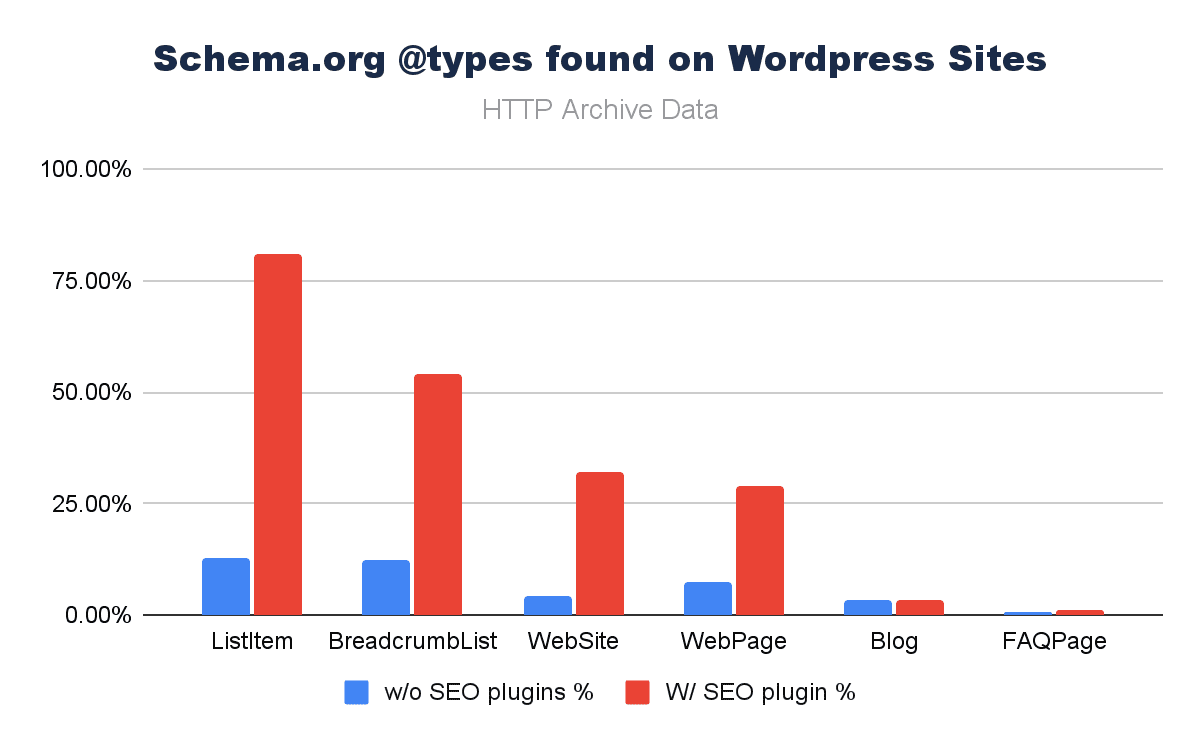
Structured Data Impact From SEO Plugins
We can see (above) that structured data implementation and CMS adoption do correlate; what is more interesting here is to understand where the key drivers themselves are.
Viewing the HTTP Archive data with a simple segment (SEO plugins vs. no SEO plugins), from the most recent scoring paints a stark picture.
Image by author, February 2026
When we limit the Schema.org @types to the most associated with SEO, it is really clear that some structured data types are pushed really hard using SEO plugins. They are not completely absent. People may be using lesser-known plugins or coding their own solutions, but ease of implementation is implicit in the data.
Robots Meta Support
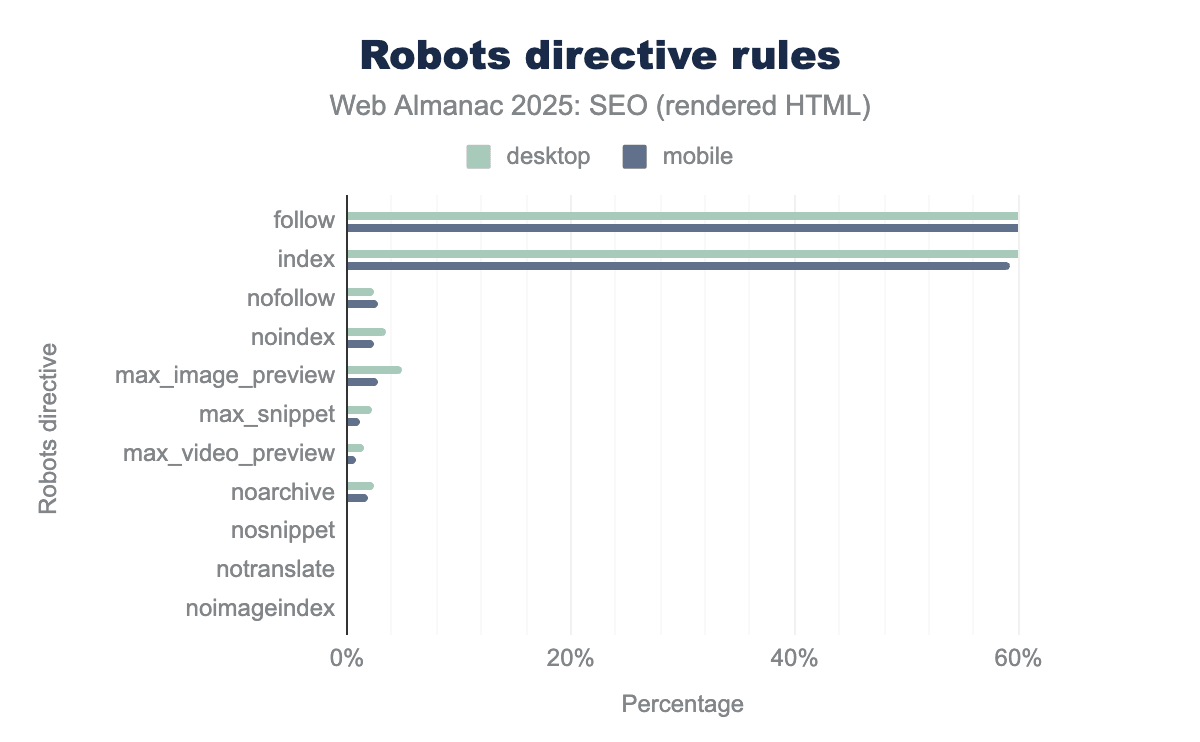
Another finding from the SEO Web Almanac 2025 chapter was that “follow” and “index” directives were the most prevalent, even though they’re technically redundant, as having no meta robots directives is implicitly the same thing.
Screenshot from Web Almanac 2025, February 2026
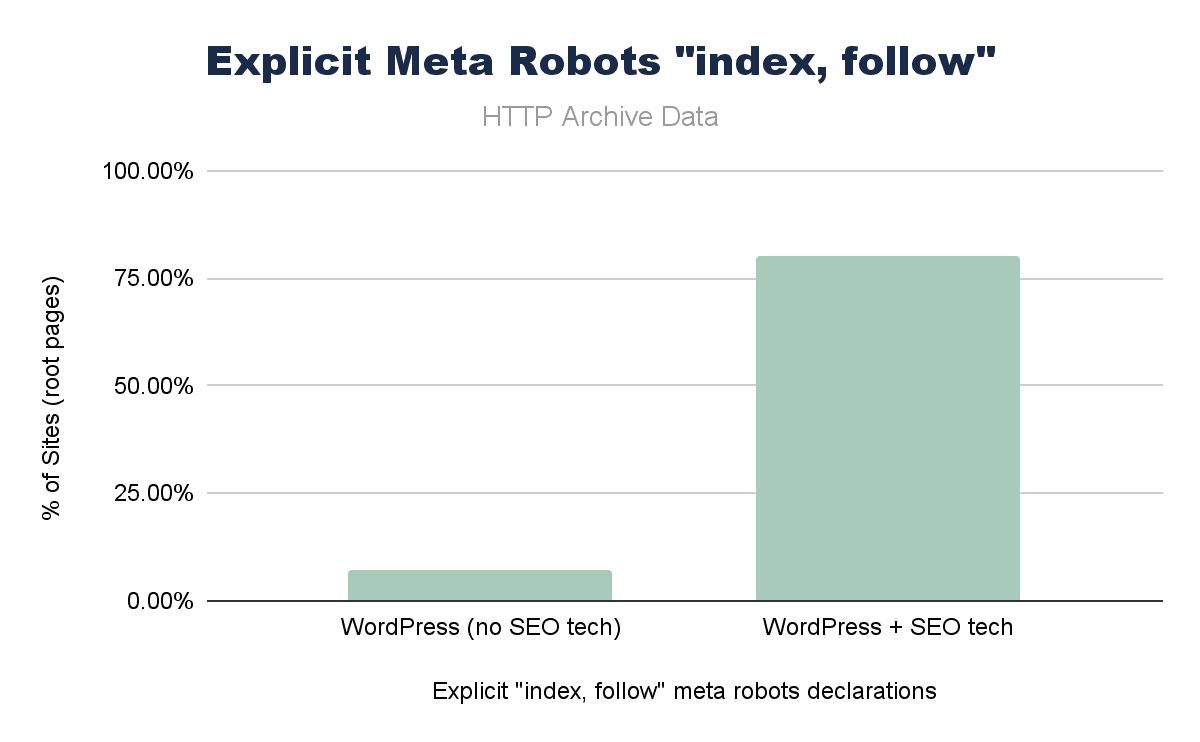
Within the chapter number crunching itself, I didn’t dig in much deeper, but knowing that all major SEO WordPress plugins have “index,follow” as default, I was eager to see if I could make a stronger connection in the data.
Where SEO plugins were present on WordPress, “index, follow” was set on over 75% of root pages vs. <5% of WordPress sites without SEO plugins>
Image by author, February 2026
Given the ubiquity of WordPress and SEO plugins, this is likely a huge contributor to this particular configuration. While this is redundant, it isn’t wrong, but it is – again – a key example of whether one or more of the main plugins establish a de facto standard like this, it really shapes a significant portion of the web.
Diving Into LLMs.txt
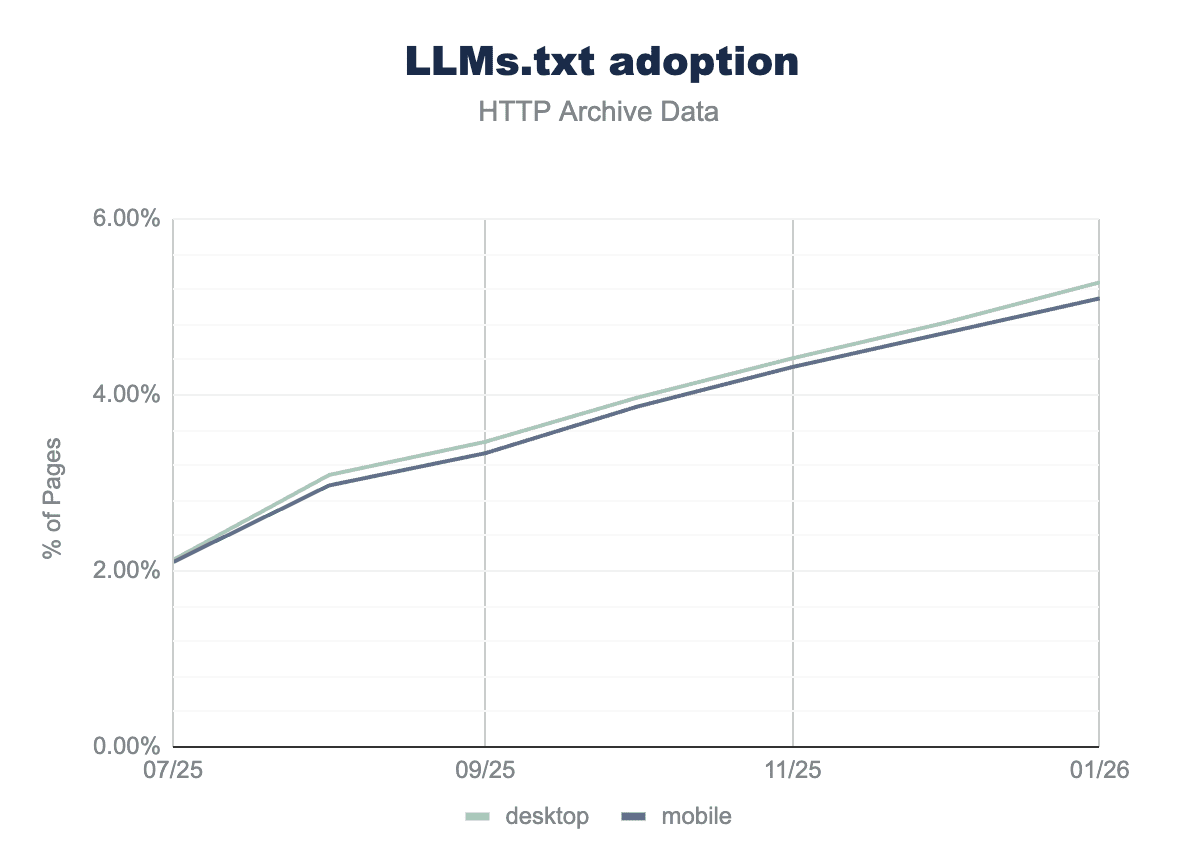
Another key area of change from the 2025 Web Almanac was the introduction of the llms.txt file. Not an explicit endorsement of the file, but rather a tacit acknowledgment that this is an important data point in the AI Search age.
From the 2025 data, just over 2% of sites had a valid llms.txt file and:
39.6% of llms.txt files are related to All-in-One SEO.
3.6% of llms.txt files are related to Yoast SEO.
This is not necessarily an intentional act by all those involved, especially as Rank Math enables this by default (not an opt-in like Yoast and All-in-One SEO).
Image by author, February 2026
Since the first data was gathered on July 25, 2025 if we take a month-by-month view of the data, we can see further growth since. It is hard not to see this as growing confidence in this markup OR at least, that it’s so easy to enable, more people are likely hedging their bets.
Conclusion
The Web Almanac data suggests that SEO, at a macro level, moves less because of individual SEOs and more because WordPress, Shopify, Wix, or a major plugin ships a default.
Canonical tags correlate with CMS growth.
Robots.txt validity improves with CMS governance.
Redundant “index,follow” directives proliferate because plugins make them explicit.
Even llms.txt is already spreading through plugin toggles before it even gets full consensus.
This doesn’t diminish the impact of SEO; it reframes it. Individual practitioners still create competitive advantage, especially in advanced configuration, architecture, content quality, and business logic. But the baseline state of the web, the technical floor on which everything else is built, is increasingly set by product teams shipping defaults to millions of sites.
Perhaps we should consider that if CMSs are the infrastructure layer of modern SEO, then plugin creators are de facto standards setters. They deploy “best practice” before it becomes doctrine
This is how it should work, but I am also not entirely comfortable with this. They normalize implementation and even create new conventions simply by making them zero-cost. Standards that are redundant have the ability to endure because they can.
So the question is less about whether CMS platforms impact SEO. They clearly do. The more interesting question is whether we, as SEOs, are paying enough attention to where those defaults originate, how they evolve, and how much of the web’s “best practice” is really just the path of least resistance shipped at scale.
An SEO’s value should not be interpreted through the amount of hours they spend discussing canonical tags, meta robots, and rules of sitemap inclusion. This should be standard and default. If you want to have an out-sized impact on SEO, lobby an existing tool, create your own plugin, or drive interest to influence change in one.
In January, I wrote about the birth of agentic commerce through both Agentic Commerce Protocol (ACP) and Universal Commerce Protocol (UCP), and how this could impact us all as consumers, business owners, and SEOs. As we still sit on waitlists for both, this doesn’t mean that we can’t prepare for it.
UCP fixes a real-life problem for many, minimizing the fragmented commerce journey. Instead of building separate integrations for every agent platform as we have been mostly doing in the past, you can now [theoretically] integrate once and will integrate seamlessly with other tools and platforms.
But note here that, as opposed to ACP which focuses more so on the checkout → fulfillment → payment journey, UCP goes beyond this with six capabilities covering the entire commerce lifecycle.
This, of course, will impact an SEO’s ambit. As we shift from optimizing for clicks to optimizing for selection, we also need to ensure that it’s you/your client that is selected through data integrity, product signals, and AI-readable commerce capabilities. Structured data has always served an important role for the internet as a whole and will continue to be the driving force on how you can serve agents, crawlers, and humans in the best way possible.
I allude to a possible new acronym “ACO” – Agentic Commerce Optimization – and the following could be considered the closest we can get to guidelines on how we undertake it.
Identity Linking – OAuth 2.0 authorization for personalized experiences and loyalty.
Checkout – session creation, tax calculation, payment handling.
Order Management – webhook-based lifecycle and logistical updates.
Vertical Capabilities – extensible modules for specialized use cases like travel booking windows or subscription schedules.
UCP’s schema authoring guide shows how capabilities are defined through versioned JSON schemas, which act as the foundation of the protocol. When it comes to considering this as an SEO, properties such as offers, aggregateRating, and shippingDetails aren’t just for surfacing rich snippets, etc., for product discovery, they’re now what agents query during the entire process.
Schema Is, And Will Continue To Be, Essential
UCP’s technical specification uses its own JSON schema-based vocabulary. Whilst it doesn’t build on schema.org directly, it remains critical in the broader ecosystem. As Pascal Fleury Fleury said at Google Search Central Live in December, “schema is the glue that binds all these ontologies together”. UCP handles the transaction; schema.org helps agents decide who to transact with.
Ensure you’re on top of and populate product schema as much as you can. It may seem like SEO 101. Regardless, audit all of this now to ensure you’re not missing anything when UCP really rolls out.
This includes checks on:
Product schema (with complete coverage): All core fields: name, description, SKU, GTIN, brand, related images, and offers.
Offers must include: Price, priceCurrency, availability, URL, seller. Add aggregateRating and review to ensure you have positive third-party perspective.
Ensure all product variants output correctly.
Include shippingDetails with delivery estimates.
Organization and Brand: Assists with “Merchant of Record” verification. If you’re not an Organization, then fallback to Person.
Designated FAQPage: Ensure you have an FAQpage as these can be incorporated alongside product-level FAQs and used as part of its decision-making.
Prepare Your Merchant Center Feed
UCP will utilize your existing Merchant Center feed as the discovery layer. This means that beyond the normal on-site schema you provide, Merchant Center itself requires more details that you can populate within its platform.
Return policies (required to be a Merchant of Record): Complete all return costs, return windows, and policy links. These will be used not just within the checkout and transactional areas, but again a consideration for selection at all. Advanced accounts need policies at each sub-account level.
Customer support information: Not only would initial information be offered to the customer, but there may be ways in which entry-level customer support queries can be completely managed, thus increasing customer satisfaction while minimizing customer support agent capacity.
Agentic checkout eligibility: Add the native_commerce attribute to your feed, as products are only eligible here if this is set up.
Product identifiers: Each product must have an ID, and correlate to the product ID when using the checkout API.
Product consumer warnings: Any product warning should assert the consumer_notice attribute.
Google recommends that this be done through a supplemental data source in Merchant Center rather than modifying your primary feed, which would prevent incorrect formatting or other invalidation.
Lastly, double-check if the products you’re selling aren’t included within its product restrictions list, as there are several that, if you do offer those things, you should consider how to manage alongside the abilities of UCP.
Optimizing Conversational Commerce Attributes
Within the UCP blog post announcement, Srinivasan introduced a way for more clarity with conversational commerce attributes:
“…we’re announcing dozens of new data attributes in Merchant Center designed for easy discovery in the conversational commerce era, on surfaces like AI Mode, Gemini and Business Agent. These new attributes complement retailers’ existing data feeds and go beyond traditional keywords to include things like answers to common product questions, compatible accessories or substitutes.”
These provide further clarity (and therefore minimize hallucinations) during the discovery process in order to be selected or ruled out.
Not only would this incorporate product and brand-related FAQs, but take this a step further to also consider:
Compatibility: Potential up-sell opportunities.
Substitution: An opportunity for dealing with out-of-stock items.
Related products: Great for cross-sell opportunities.
Furthermore, this can be used to become even more specific, moving beyond basic attributes to agent-parseable details. Now, if a product is “purple” on a basic level, “dark purple” or even something unobvious, such as “Wolf” (real example below), may be more appropriate for finer detail while still falling under “purple.” The same can be considered for sizes, materials (or a mixture of materials), etc.
Multi-Modal Fan-Out Selection
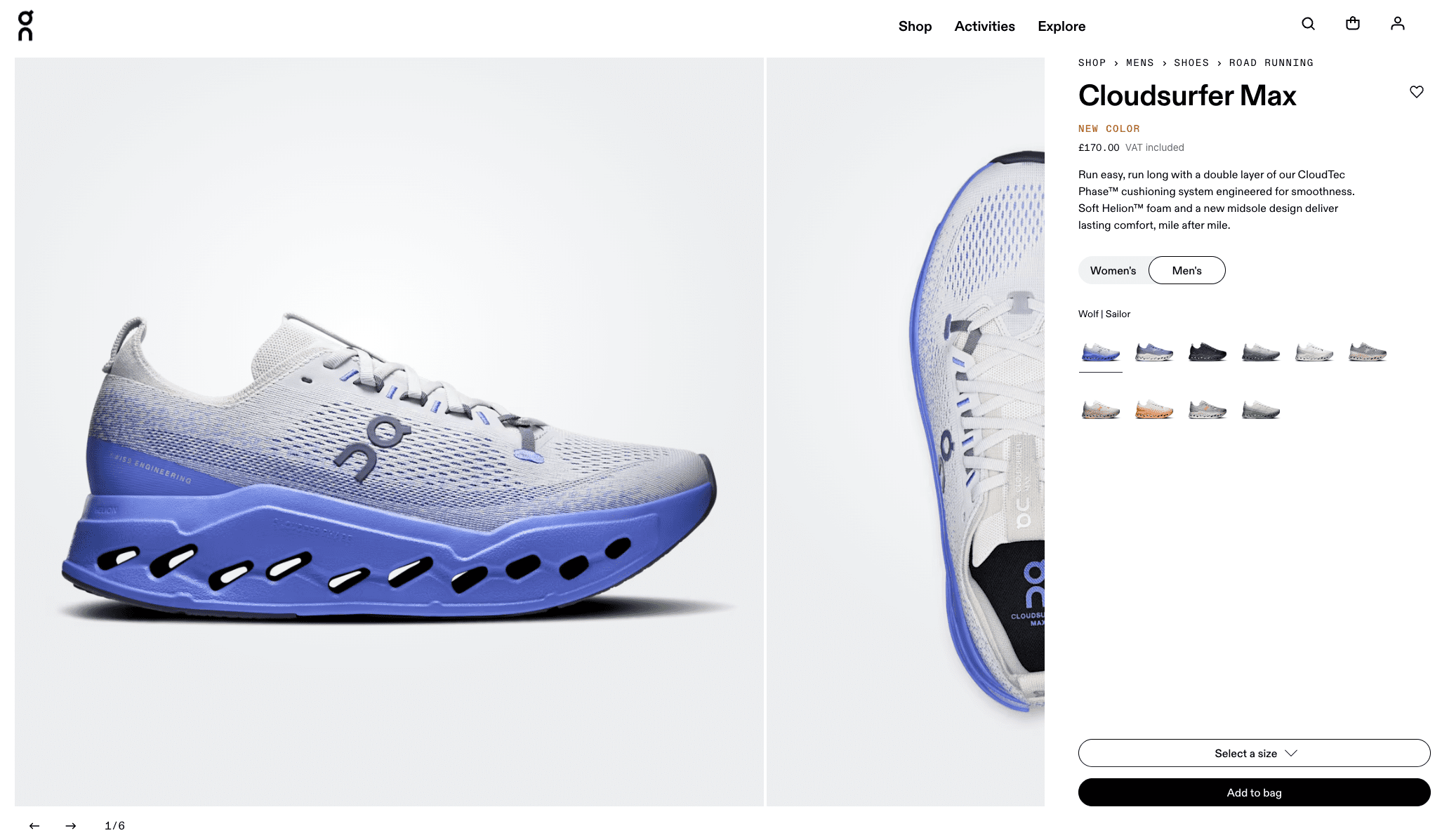
When executed well, optimizing for conversational commerce attributes will increase the possibility of selection within fan-out query results. When considering some of these attributes, it is worth looking at tools, such as WordLift’s Visual Fan-Out simulator, which illustrates how a single image decomposes into multiple search intents, revealing which attributes agents may prioritize when performing query fan-out. But how would this look?
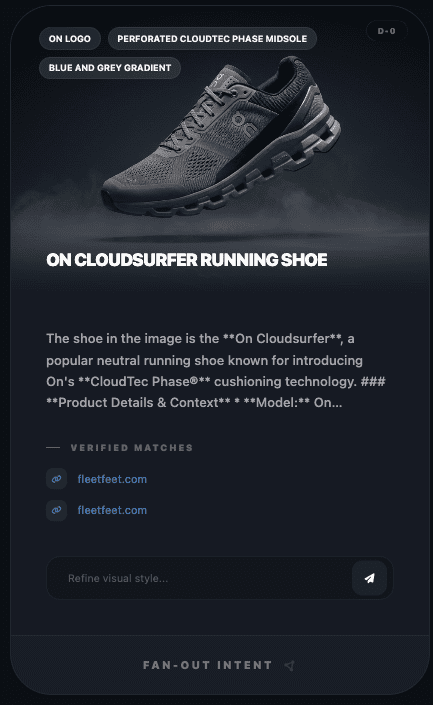
As an example, I used one product image and browsed downward three horizons. Using On’s Cloudsurfer Max as an example (used with permission):
Using just one product image, this is what is presented on the surface:
Screenshot from WordLift’s Visual Fan-Out simulator, February 2026
It immediately noticed that the product was On, and specifically from the Cloudsurfer range. Great start! Now let’s see what it sees over the horizon:
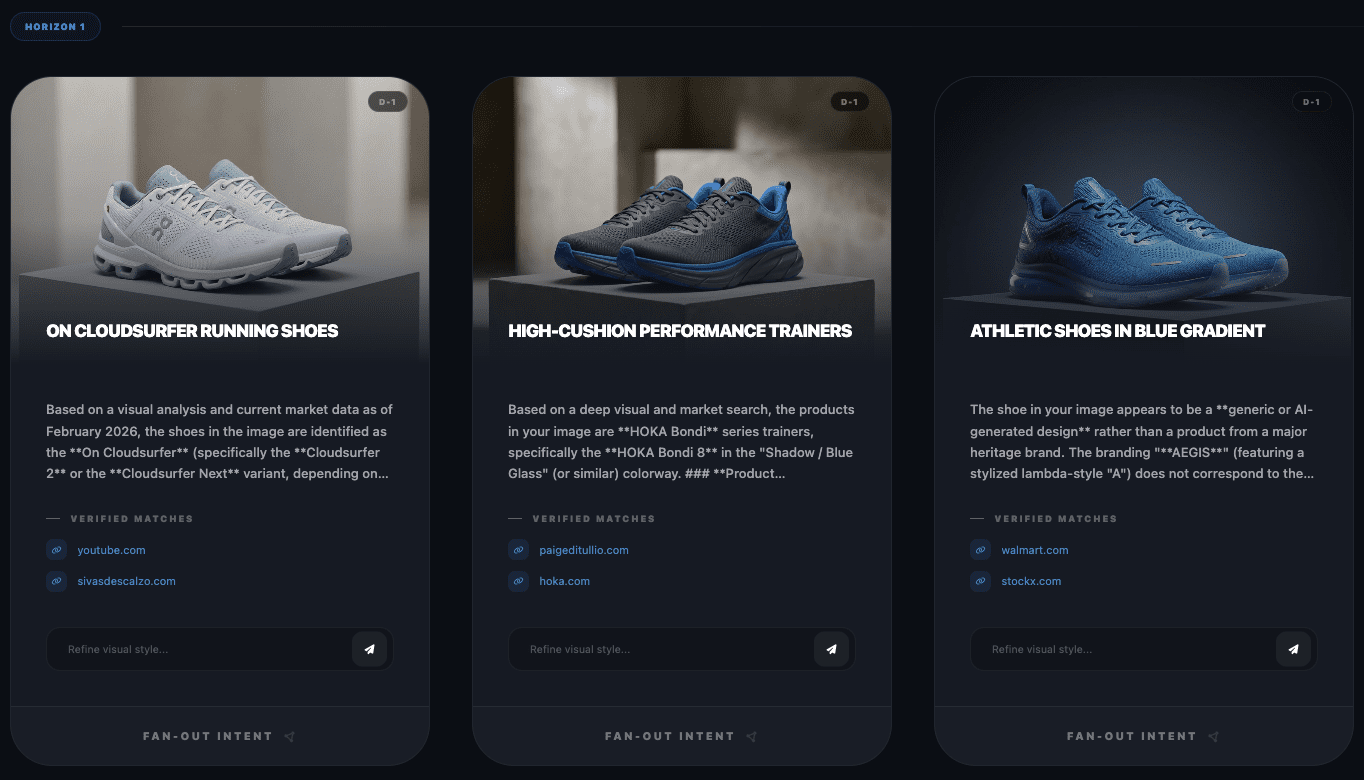
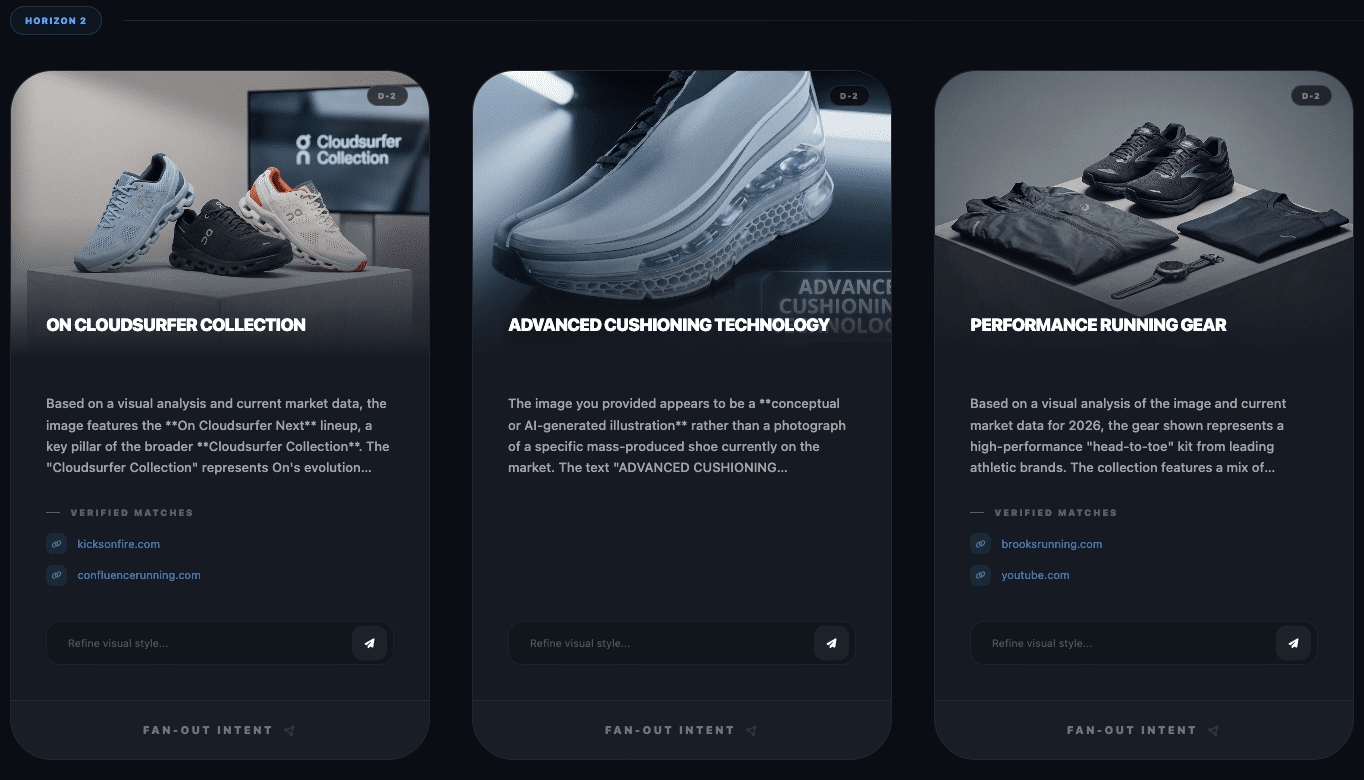
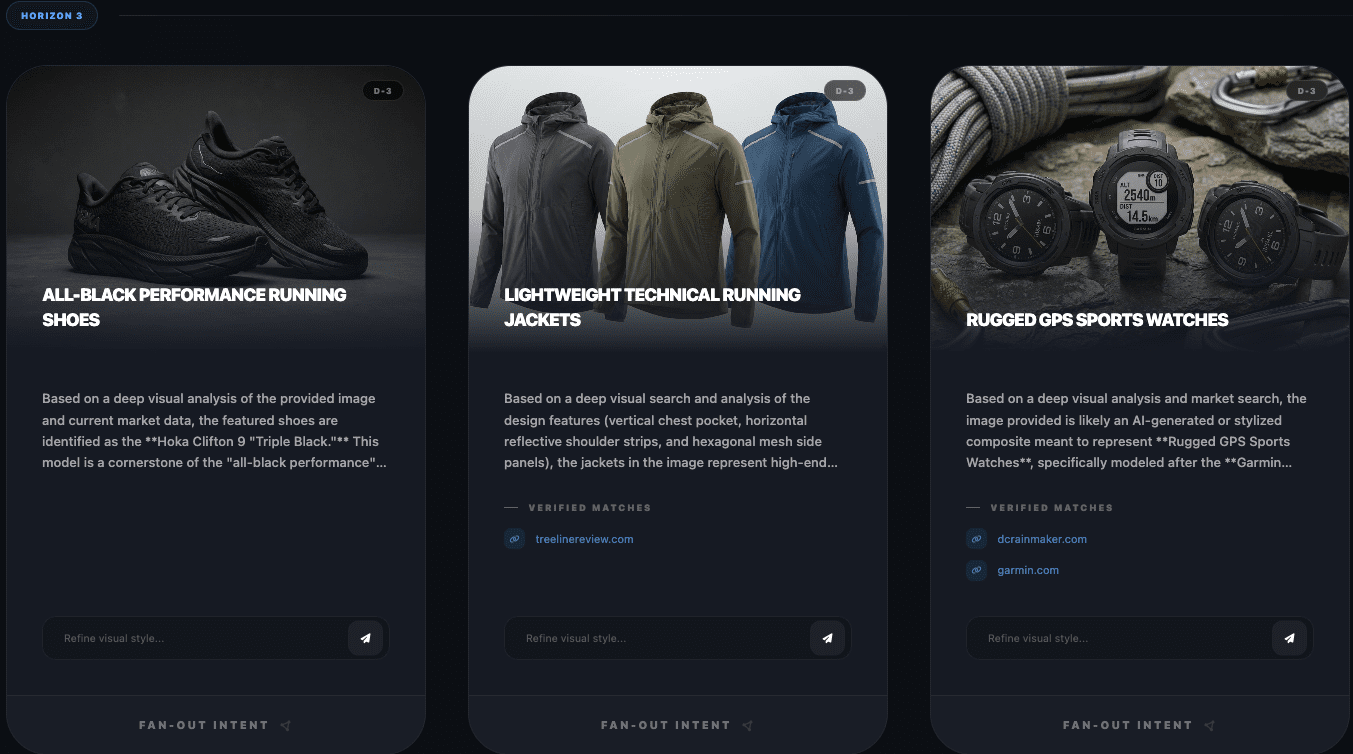
Screenshot from WordLift’s Visual Fan-Out simulator, February 2026Screenshot from WordLift’s Visual Fan-Out simulator, February 2026Screenshot from WordLift’s Visual Fan-Out simulator, February 2026
Here, you can draw inspiration or direction on how best to place yourself for potential and likely fan-out queries. With this example, I found it interesting that Horizon 2 mentions performance running gear as a large category, then when performing fan-out on that showed the related products around gear in general. This shows how wide LLMs consider selection and how you can present attributes to attract selection.
UCP’s Roadmap Is Expanding Into Multi-Verticals
UCP is already planning to go beyond one single purchase but expands beyond retail into travel, services, and other verticals. Its roadmap details several priorities over the coming year, including:
Multi‑item carts and complex baskets: Moving beyond single‑item checkout to native multi‑item carts, bundling, promotions, tax/shipping logic, and more realistic fulfillment handling.
Loyalty and account linking: Standardized loyalty program management and account linking so agents can apply points, member pricing, and benefits across merchants.
Post‑purchase support: Support for order tracking, returns, and customer‑service handoff so agents can manage customer support post-sale.
Personalization signals: Richer signals for cross‑sell/upsell, wishlists, history, and context‑based recommendations.
New verticals: Expansion beyond retail into travel, services, digital goods, and food/restaurant use cases via extensions to the protocol.
Each of the points above is worth further reading and consideration if this is something your brand may offer. Furthermore, its plans to expand beyond retail into travel, services, digital goods, and hospitality mean that, if you’re working within any of these verticals, you need to be even more prepared to ensure eligibility.
Social Proof And Third-Party Perspective
Regardless of how well you may optimize on-site to prepare for UCP, all this data integrity still needs to be validated by trusted third-party sources.
Third-party platforms, such as Trustpilot and G2, appear to be frequently cited and trusted among most of the LLMs, so I’d still advise that you continue to collect those positive brand and product reviews in order to satisfy consensus, resulting in more opportunities to be selected during product discovery.
TL;DR – Prepare Now
If you own or manage any form of ecommerce site, now is the time to ensure you’re preparing for UCP’s rollout as soon as possible. It’s only a matter of time, and with AI Mode spreading into default experiences, getting ahead of the rollout is essential.
This is moving faster than most previous commerce shifts, and brands that wait for full rollout signals will already be behind. This isn’t a short-term LLM gimmick but is part of the largest change in the ecommerce space.
This post was sponsored by WP Engine. The opinions expressed in this article are the sponsor’s own.
In the race for audience attention, digital marketers at media companies often have one hand tied behind their backs. The mission is clear: drive sustainable revenue, increase engagement, and stay ahead of technological disruptions such as LLMs and AI agents.
Yet, for many media organizations, execution is throttled by a “Sticky-taped stack,” which is a fragile, patchwork legacy CMS structure and ad-hoc plugins. For a digital marketing leader, this isn’t just a technical headache; it’s a direct hit to the bottom line.
Fragmentation Tax: How A Siloed CMS, Disconnected Data & Tech Debt Are Costing You Growth
The Fragmentation Tax is the hidden cost of operational inefficiency. It drains budgets, burns out teams, and stunts the ability to scale. For digital marketing and growth leads, this tax is paid in three distinct “currencies”:
1. Siloed Data & Strategic Blindness.
When your ad server, subscriber database, and content tools exist as siloed work streams, you lose the ability to see the full picture of the reader’s journey.
Without integrated attribution, marketers are forced to make strategic pivots based on vanity metrics like generic pageviews rather than true business intelligence, such as conversion funnels or long-term reader retention.
2. The Editorial Velocity Gap.
In the era of breaking news, being second is often the same as being last. If an editorial team is forced into complex, manual workflows because of a fragmented tech stack, content reaches the market too late to capture peak search volume or social trends. This friction creates a culture of caution precisely when marketing needs a culture of velocity to capture organic traffic.
3. Tech Debt vs. Innovation.
Tech debt is the future cost of rework created by choosing “quick-and-dirty” solutions. This is a silent killer of marketing budgets. Every hour an engineering team spends fixing plugin conflicts or managing security fires caused by a cobbled-together infrastructure is an hour stolen from innovation.
The 4 Publishing Pillars That Improve SEO & Monetization
To stop paying this tax, media organizations are moving away from treating their workflows as a collection of disparate parts. Instead, they are adopting a unified system that eliminates the friction between engineering, editorial, and growth.
A modern publishing standard addresses these marketing hurdles through four key operational pillars:
Pillar 1: Automated Governance (Built-In SEO & Tracking Integrity)
Marketing integrity relies on consistency.
In a fragmented system, SEO metadata, tracking pixels, and brand standards are often managed manually, leading to human error.
A unified approach embeds governance directly into the workflow.
By using automated checklists, organizations ensure that no article goes live until it meets defined standards, protecting the brand and ensuring every piece of content is optimized for discovery from the moment of publication.
Pillar 2: Fearless Iteration (Continuous SEO & CRO Optimization Without Risk)
High-traffic articles are a marketer’s most valuable asset. However, in a legacy stack, updating a live story to include, for instance, a Call-to-Action (CTA), is often a high-risk maneuver that could break site layouts.
A modern unified approach allows for “staged” edits, enabling teams to draft and review iterations on live content without forcing those changes live immediately. This allows for a continuous improvement cycle that protects the user experience and site uptime.
Pillar 3: Cross-Functional Collaboration (Reducing Workflow Bottlenecks Between Editorial, SEO & Engineering)
Any type of technology disruption requires a team to collaborate in real-time. The “Sticky-taped” approach often forces teams to work in separate tools, creating bottlenecks.
A modern unified standard utilizes collaborative editing, separating editorial functions into distinct areas for text, media, and metadata. This allows an SEO specialist or a growth marketer to optimize a story simultaneously with the journalist, ensuring the content is “market-ready” the instant it’s finished.
Late-breaking or real-time events, such as global geopolitical shifts or live sports, require in-the-moment storytelling to keep audiences informed, engaged, and on-site. Traditionally, “Live Blogs” relied on clunky third-party embeds that fragmented user data and slowed page loads.
A unified standard treats breaking news as a native capability, enabling rapid-fire updates that keep the audience glued to the brand’s own domain, maximizing ad impressions and subscription opportunities.
Conclusion: Trading Toil for Agility
Ultimately, shifting to a unified standard is about reducing inefficiencies caused by “fighting the tools.” By removing the technical toil that typically hides insights in siloed tools, media organizations can finally trade operational friction for strategic agility.
When your site’s foundation is solid and fast, editors can hit “publish” without worrying about things breaking. At the same time, marketers can test new ways to grow the audience without waiting weeks for developers to update code. This setup clears the way for everyone to move faster and focus on what actually matters: telling great stories and connecting with readers.
The era of stitching software together with “sticky tape” is over. For modern media companies to thrive amid constant digital disruption, infrastructure must be a launchpad, not a hindrance. By eliminating the Fragmentation Tax, marketing leaders can finally stop surviving and start growing.
Jason Konen is director of product management at WP Engine, a global web enablement company that empowers companies and agencies of all sizes to build, power, manage, and optimize their WordPressⓇ websites and applications with confidence.
Google’s John Mueller shared a case where a leftover HTTP homepage was causing unexpected site-name and favicon problems in search results.
The issue, which Mueller described on Bluesky, is easy to miss because Chrome can automatically upgrade HTTP requests to HTTPS, making the HTTP version easy to overlook.
What Happened
Mueller described the case as “a weird one.” The site used HTTPS, but a server-default HTTP homepage was still accessible at the HTTP version of the domain.
“A hidden homepage causing site-name & favicon problems in Search. This was a weird one. The site used HTTPS, however there was a server-default HTTP homepage remaining.”
The tricky part is that Chrome can upgrade HTTP navigations to HTTPS, which makes the HTTP version easy to miss in normal browsing. Googlebot doesn’t follow Chrome’s upgrade behavior.
“Chrome automatically upgrades HTTP to HTTPS so you don’t see the HTTP page. However, Googlebot sees and uses it to influence the sitename & favicon selection.”
Google’s site name system pulls the name and favicon from the homepage to determine what to display in search results. The system reads structured data from the website, title tags, heading elements, og:site_name, and other signals on the homepage. If Googlebot is reading a server-default HTTP page instead of the actual HTTPS homepage, it’s working with the wrong signals.
How To Check For This
Mueller suggested two ways to see what Googlebot sees.
First, he joked that you could use AI. Then he corrected himself.
“No wait, curl on the command line. Or a tool like the structured data test in Search Console.”
Running curl http://yourdomain.com from the command line would show the raw HTTP response without Chrome’s auto-upgrade. If the response returns a server-default page instead of your actual homepage, that’s the problem.
If you want to see what Google retrieved and rendered, use the URL Inspection tool in Search Console and run a Live Test. Google’s site name documentation also notes that site names aren’t supported in the Rich Results Test.
This case introduces a new complication. The problem wasn’t in the structured data or the HTTPS homepage itself. It was a ghost page in the HTTP version, which you’d have no reason to check because your browser never showed it.
Google’s site name documentation explicitly mentions duplicate homepages, including HTTP and HTTPS versions, and recommends using the same structured data for both. Mueller’s case shows what can go wrong when an HTTP version contains content different from the HTTPS homepage you intended to serve.
The takeaway for troubleshooting site-name or favicon problems in search results is to check the HTTP version of your homepage directly. Don’t rely on what Chrome shows you.
Looking Ahead
Google’s site name documentation specifies that WebSite structured data must be on “the homepage of the site,” defined as the domain-level root URI. For sites running HTTPS, that means the HTTPS homepage is the intended source.
If your site name or favicon looks wrong in search results and your HTTPS homepage has the correct structured data, check whether an HTTP version of the homepage still exists. Use curl or the URL Inspection tool’s Live Test to view it directly. If a server-default page is sitting there, removing it or redirecting HTTP to HTTPS at the server level should resolve the issue.
Google’s crawl team has been filing bugs directly against WordPress plugins that waste crawl budget at scale.
Gary Illyes, Analyst at Google, shared the details on the latest Search Off the Record podcast. His team filed an issue against WooCommerce after identifying its add-to-cart URL parameters as a top source of crawl waste. WooCommerce picked up the bug and fixed it quickly.
Not every plugin developer has been as responsive. An issue filed against a separate action-parameter plugin is still sitting unclaimed. And Google says its outreach to the developer of a commercial calendar plugin that generates infinite URL paths fell on deaf ears.
What Google Found
The details come from Google’s internal year-end crawl issue report, which Illyes reviewed during the podcast with fellow Google Search Relations team member Martin Splitt.
Action parameters accounted for roughly 25% of all crawl issues reported in 2025. Only faceted navigation ranked higher, at 50%. Together, those two categories represent about three-quarters of every crawl issue Google flagged last year.
The problem with action parameters is that each one creates what appears to be a new URL by adding text like ?add_to_cart=true. Parameters can stack, doubling or tripling the crawlable URL space on a site.
Illyes said these parameters are often injected by CMS plugins rather than built intentionally by site owners.
The WooCommerce Fix
Google’s crawl team filed a bug report against the plugin, flagging the add-to-cart parameter behavior as a source of crawl waste affecting sites at scale.
Illyes describes how they identified the issue:
“So we would try to dig into like where are these coming from and then sometimes you can identify that perhaps these action parameters are coming from WordPress plug-ins because WordPress is quite a popular CMS content management system. And then you would find that yes, these plugins are the ones that add to cart and add to wish list.”
And then what you would do if you were a Gary is to try to see if they are open source in the sense that they have a repository where you can report bugs and issues and in both of these cases the answer was yes. So we would file issues against these uh plugins.”
WooCommerce responded and shipped a fix. Illyes noted the turnaround was fast, but other plugin developers with similar issues haven’t responded. Illyes didn’t name the other plugins.
He added:
“What I really, really loved is that the good folks at Woolcommerce almost immediately picked up the issue and they solved it.”
The data shows those warnings and documentation updates didn’t solve the problem because the same issues still dominate crawl reports.
The crawl waste is often baked into the plugin layer. That creates a real bind for websites with ecommerce plugins. Your crawl problems may not be your fault, but they’re still your responsibility to manage.
Illyes said Googlebot can’t determine whether a URL space is useful “unless it crawled a large chunk of that URL space.” By the time you notice the server strain, the damage is already happening.
Google consistently recommends robots.txt, as blocking parameter URLs proactively is more effective than waiting for symptoms.
Looking Ahead
Google filing bugs against open-source plugins could help reduce crawl waste at the source. The full podcast episode with Illyes and Splitt is available with a transcript.
Natural language is quickly becoming the default way people interact with online tools. Instead of typing a few keywords, users now ask full questions, give detailed instructions, and are starting to expect clear, conversational answers. So, how can you make sure your content provides the answer to their question? Or better yet, how can you make it possible for them to interact with your website in a similar way? That’s where Microsoft’s NLWeb comes in.
Meet NLWeb, Microsoft’s new open project
NLWeb, short for Natural Language Web, is an open project recently launched by Microsoft. The aim of this project is to bring conversational interfaces directly to websites, rather than users having to use an external chatbot that’s in control of what’s shown. Instead of relying on traditional navigation or search bars, NLWeb is designed to allow users to ask questions and explore content in a more personal, conversational way.
At its core, NLWeb connects website content to AI-powered tools. It enables AI to understand what a website is about, what information it contains, and how that information should be interpreted for the purpose of returning personalized results. With this project, Microsoft is moving toward a more interoperable, standards-based, and open web that allows everyone to prepare their website for the future of search.
This project was initiated and realized by R.V. Guha, CVP and Technical Fellow at Microsoft. Guha is one of the creators of widely used web standards such as RSS and Schema.org.
How NLWeb works
NLWeb works by combining structured data, standardized APIs and AI models capable of understanding natural language. Every NLWeb instance acts as a Model Context Protocol (MCP) server, which makes your content discoverable for all the agents operating in the MCP ecosystem. This makes it easy for these agents to find your website.
Using structured data, website owners then present their content in a machine-readable way. AI applications can then consume this data and answer user questions accurately by matching them to the most relevant information. The result is a conversational experience powered by existing content, either directly on a website or through using an online search tool. A conversational interface for both human users and AI agents collecting information.
An important thing to note is that NLWeb is an open project. It’s not a closed ecosystem, meaning that Microsoft wants to make it accessible to everyone. The idea is to make it easy for any website owner to create an intelligent, natural language experience for their site, while also preparing their content to interact with and be discovered by other online agents, such as AI tools and search engines.
How does natural language work?
Natural language simply refers to the way we speak and write. This means using full sentences that allow room for intent, context and nuance. More than keywords or short commands, natural language reflects how people think and what they are looking for exactly.
To give you an example: a focus keyphrase might be running shoes trail. But using natural language, the request would look more like this: What are the best running shoes for trail running in wet conditions?
Natural language in AI tools
Modern AI tools are designed to understand this kind of input. The large language models behind these tools can analyze intent and context to generate responses that fulfill the given request. This is why conversational interfaces feel more intuitive than traditional search or forms.
Tools like AI chat assistants, voice search, and even traditional search engines rely heavily on natural language understanding and users have quickly adapted to it.
The current state of search
The way people find information online is changing fast. A change that is heavily influenced by the use of AI-powered tools. We now expect personalized answers instead of a list of results to sort through ourselves. AI chatbots also give us the option to follow up on our original search query, which turns search into a conversation instead of a series of clicks.
Research from McKinsey & Company shows that AI adoption and natural language interfaces are becoming mainstream, with 50% of consumers already using AI-driven tools for information discovery. The majority even say it’s the top digital source they use to make buying decisions. As these habits continue to grow, websites that aren’t optimized for natural language risk becoming invisible in AI-generated answers.
Why this is interesting for you
The shift to natural language isn’t just a technical trend. As discussed above, it directly impacts your online visibility and competitive position.
If users ask an AI system for information, only a handful of sources will be referenced in the response. This is because, like search engines, AI platforms also need to be able to read the information on your website. Being one of those sources can be the difference between being discovered or being overlooked.
NLWeb collaborates with Yoast
With NLWeb, you are communicating your website’s content clearly and in a standardized way. That means your brand, products, or expertise can appear in AI-powered answers instead of your competitors. To help as many website owners as possible benefit from this shift, Yoast is collaborating with NLWeb.
The best part? If you’re a user of any of our Yoast plans designed for WordPress, you’re well ahead here. Yoast’s integration with NLWeb will roll out in phases, starting with functionality that helps our users using WordPress express their content in ways AI systems can interpret accurately, without any additional setup required. So sit tight and let us help you prepare your website for the new world of search!
NLWeb aims to make your content understandable not just for people, but for the AI systems that are increasingly relevant to your website’s discovery.
The open web is the part of the internet built on open standards that anyone can use. This concept creates a democratic digital space where people can build on each other’s work without restrictions, just like how WordPress.org is built. For website owners, understanding and leveraging the open web is increasingly crucial. Especially with the rise of AI-powered systems and the general direction that online search is taking. So, let’s explore what the open web is and what it means for your website.
What is the open web?
The open web refers to the part of the internet built on open, shared standards that are available to everyone. It’s powered by technologies like HTTP, HTML, RSS, and Schema.org, which make it easy for websites and online systems to interact with each other. But it is more than just technical protocols. It also includes open‑source code, public APIs, and the free flow of data and content across sites, services, and devices. Creating a democratic digital space where people can build on each other’s work without heavy restrictions.
Because these standards are not owned or patented, the open web remains largely decentralized. This allows content to be accessed, understood, and reused across devices and platforms. This not only encourages innovation but also ensures that information is discoverable without being locked behind proprietary ecosystems.
The benefits of an open web
The open web is built on publicly available protocols that enable access, collaboration, and innovation at a global scale.
The most important benefits include:
Collaboration and innovation: Open protocols enable developers to build on each other’s work without proprietary restrictions.
Accessibility: Users and AI agents alike can access and interact with web content regardless of device, platform, or underlying technology.
Democratization: No single company controls access to information, giving publishers greater autonomy.
Inclusion: The open web creates a more level playing field, where everyone gets a chance to participate in the digital economy.
The open web vs the deep web
To give you a better idea of what the open web is, it helps to know about the “deep web” and closed or “walled garden” platforms. The deep web covers content not indexed by search engines, while closed systems or walled gardens restrict access and keep data siloed.
On the open web, anyone can access information freely. A good example of that is Wikipedia. Accessible to anyone looking for information on a topic and anyone who wants to contribute to its content. Closed-off platforms, like proprietary apps or social media ecosystems, create places where content is only available if you pay or use a specific service. Well-known examples of this are social media platforms such as Facebook and Instagram. Another example is a news website that requires a paid subscription to get access.
In essence, the open web keeps information discoverable, accessible, and interoperable – instead of locked inside a handful of platforms.
AI and the open web
The popularity of AI-powered search makes open web principles more important than ever. Decentralized and accessible information allows AI tools to interact with content directly and use it freely to generate an answer for a user.
“We believe the future of AI is grounded in the open web.”
Ramanathan Guha, CVP and Technical Fellow at Microsoft.
Microsoft’s open project NLWeb is a prime example. It provides a standardized layer that enables AI agents to discover, understand, and interact with websites efficiently, without needing separate integrations for every platform.
What this means for website owners
For website owners, including small business owners, embracing the open web means making your content freely available in ways that AI can interpret. By using structured data standards like Schema.org, your website becomes discoverable to AI tools. Increasing your reach and ensuring that your content remains part of the future of search.
Yoast and Microsoft: collaborating towards a more open web
Yoast is proud to collaborate with NLWeb, a Microsoft project that makes your content easier to understand for AI agents without extra effort from website owners. Allowing your content to remain discoverable, reach a wider audience with and show up in AI-powered search results.
The open web strives towards an accessible web where content is available for everyone. A web where it doesn’t matter how big your website or marketing budget is. Giving everyone the chance to be found and represented in AI-powered search. NLWeb helps turn this vision into reality by connecting today’s open web with tomorrow’s AI-driven search ecosystem
This post was sponsored by WP Media. The opinions expressed in this article are the sponsor’s own.
You’ve built a WordPress site you’re proud of. The design is sharp, the content is solid, and you’re ready to compete. But there’s a hidden cost you might not have considered: a slow site doesn’t just hurt your SEO-it now affects your AI visibility too.
With AI-powered search platforms such as ChatGPT and Google’s AI Overviews and AI Mode reshaping how people discover information, speed has never mattered more. And optimizing for it might be simpler than you think.
The conventional wisdom? “Speed optimization is technical and complicated.” “It requires a developer.” “It’s not that big a deal anyway.” These myths spread because performance optimization is genuinely challenging. But dismissing it because it’s hard? That’s leaving lots of untapped revenue on the table.
Here’s what you need to know about the speed-SEO-AI connection-and how to get your site up to speed without having to reinvent yourself as a performance engineer.
Why Visitors Won’t Wait For Your Site To Load (And What It Costs You)
Let’s start with the basics. When’s the last time you waited patiently for a slow website to load? Exactly.
Google’s research shows that as page load time increases from one second to three seconds, the probability of a visitor bouncing increases by 32%. Push that to five seconds, and bounce probability jumps to 90%.
Think about it. You’re spending money on ads, content, and SEO to get people to your site-and then losing nearly half of them before they see anything because your pages load too slowly.
For e-commerce, the stakes are even higher:
A site loading in 1 second has a conversion rate 5x higher than one loading in 5 seconds.
79% of shoppers who experience performance issues say they won’t return to buy again.
Every 1-second delay reduces customer satisfaction by 16%.
A slow site isn’t just losing one sale. It’s potentially losing you customers for life.
Website Speeds That AI and Visitors Expect
Google stopped being subtle about this in 2020. With the introduction of Core Web Vitals, page speed became an official ranking factor. If your WordPress site meets these benchmarks, you’re signaling quality to Google. If it doesn’t, you’re handing competitors an advantage.
Here’s the challenge: only 50% of WordPress sites currently meet Google’s Core Web Vitals standards.
That means half of WordPress websites have room to improve-and an opportunity to gain ground on competitors who haven’t prioritized performance.
The key metric to watch is Largest Contentful Paint (LCP)-how qhttps://wp-rocket.me/blog/website-load-time-speed-statistics/uickly your main content loads. Google wants this under 2.5 seconds. Hit that target, and you’re in good standing.
What most site owners miss: speed improvements compound. Better Core Web Vitals leads to better rankings, which leads to more traffic, which leads to more conversions. The sites that optimize first capture that momentum.
The AI Visibility Advantage: Why Speed Matters More Than Ever
Here’s where it gets really interesting-and where early movers have an edge.
The rise of AI-powered search tools like ChatGPT, Perplexity, and Google’s AI Overviews is fundamentally changing how people discover information. And here’s what most haven’t realized yet: page speed influences AI visibility too.
A recent study by SE Ranking analyzed 129,000 domains across over 216,000 pages to identify what factors influence ChatGPT citations. The findings on page speed were striking:
Fast pages (FCP under 0.4 seconds): averaged 6.7 citations from ChatGPT
Slow pages (FCP over 1.13 seconds): averaged just 2.1 citations
That’s a threefold difference in AI visibility based largely on how fast your pages load.
Why does this matter? Because 50% of consumers use AI-powered search today in purchase decisions. Sites that load fast are more likely to be cited, recommended, and discovered by a growing audience that starts their search with AI.
The opportunity: Speed optimization now serves double duty-it boosts your traditional SEO and positions you for visibility in an AI-first search landscape.
How To Improve Page Speed Metrics & Increase AI Citations
Speed, SEO, and AI visibility are now deeply connected.
Every day your site underperforms, you’re missing opportunities.
Your Page Speed Optimization Roadmap
Here’s your action plan:
Audit your current speed.
Identify the bottlenecks.
Implement a comprehensive solution. Rather than patching issues one plugin at a time, use an all-in-one performance tool that addresses caching, code optimization, and media loading together.
Monitor and maintain. Speed isn’t a one-time fix. Track your metrics regularly to ensure you’re maintaining performance as you add content and features.
Step 1: Audit Your Current Website Speed
To best identify where the source of your slow website lies and build a baseline to test against, you must perform a website speed test audit.
Compare your Core Web Vitals results scores to your industry’s CWV baseline.
Identify which scores are lowest before moving to step 2.
Step 2: Identify Your Page Speed Bottlenecks
Is it unoptimized images? Render-blocking JavaScript? Too many plugins? Understanding the issue helps you choose the right solution.
In fact, this is where most of your competitors drop the ball, allowing you to pick it up and outperform their websites on SERPs. For business owners focused on running their company, this often falls to the bottom of the priority list.
Why? Because traditional website speed optimization involves a daunting technical website testing checklist that includes, but isn’t limited to:
Rather than piecing together multiple plugins and manually tweaking settings, you get an all-in-one approach that handles the heavy lifting automatically. This is where purpose-built performance technology can change the game.
The endgame is to remove the complexity from WordPress optimization:
Instant results. For example, upon activation, WP Rocket implements 80% of web performance best practices without requiring any configuration. Page caching, GZIP compression, CSS and JS minification, and browser caching are just a few of the many optimizations that run in the background for you.
No coding required. Advanced features such as lazy-loading images, removing unused CSS, and delaying JavaScript are available via simple toggles.
Built-in compatibility. It’s designed to work with popular themes, plugins, page builders, and WooCommerce.
Performance tracking included. Built-in tool lets you monitor your speed improvements and Core Web Vitals scores without leaving your dashboard.
The goal isn’t to become a performance expert. It’s to have a fast website that supports your business objectives. When optimization happens in the background, you’re free to focus on what you actually do best.
For many, shifting tactics can cause confusion and unnecessary complexity. Utilizing the right technology makes implementing them so much easier and ensures you maximize AI visibility and website revenue.
A three-minute fix can make a huge difference to how your WordPress site performs.