Optimizing For Attention: How Eye Tracking Can Help Your International Strategy via @sejournal, @SequinsNsearch
SEO has been given different names in the past couple of years, usually based on whatever it’s trying to optimize for at the time: LEO (LLM engine optimization), AEO, GEO, and so on.
That is, before Google came out with new AI search guidance and said the quiet part out loud: It’s all still just SEO.
With all of these acronyms, one thing that still seems to escape our goals is, as usual, the user behind it all. One thing people often miss is that we should be optimizing for attention, not just for labels and new three-letter terms.
It’s often said that attention is the primary commodity in marketing. While I have reservations about this (trust is the ultimate mover, and without it, it’s hard to get a transaction), attention is the first gateway to our content being considered at all, and a key part of the customer journey, particularly in a world that is saturated with results that are all potentially relevant.
We have many ways to get attention at different stages of the journey (I covered this briefly in my previous article), and most of them are generally “universal,” like making sure your content is relevant and aligned with intent.
However, when we hear about “scaling internationally,” businesses operate under the (wrong) assumption that what works for people in one market will automatically work for a similar audience in another location. This hardly makes international strategy a thoughtful or efficient one.
Why Should We Care About Capturing Attention?
Getting attention is paramount because what doesn’t get seen doesn’t get consumed – and what doesn’t get consumed does not get served by the algorithm.
Humans have limited attention at their disposal, and it seems to have decreased significantly in recent years. Research by Gloria Mark, for example, suggests the average attention span on a screen is around 47 seconds (down from several minutes in earlier decades). And it’s likely even less on marketing channels, especially the ones serving short-form content.
There are, in fact, experimental studies showing that certain kinds of short‑form content can actively disrupt our ability to remember what we were supposed to do after a break. In one experiment comparing content across different platforms, people who watched TikTok during a pause were much more likely to forget their original task or intention afterward, while those who watched YouTube showed little or no such impairment.
This points to an even bigger challenge: Even when we are inherently relevant for the user, this is often not enough to make sure they pay early attention to us, especially if they’re already engaged in a task that is already taking some of their cognitive resources. In short, we can’t take attention for granted.
This makes “catching the eye” vital not only for the algorithm, which uses dwell time and engagement signals to determine what to show next, but also for humans, who might need to be quickly re‑oriented to what they were looking for after opening an app and getting sidetracked.
And beyond the algorithm, attention is also the first gateway to human persuasion. So, as budgets shrink while expectations remain the same, understanding how to capture and direct attention becomes the first step in optimizing content performance.
How Does Attention Differ Across Locales?
When you localize an experience, your goal should be going beyond basic translations: You also want to adapt it to the cultural background of the country, which includes content format preferences, shared knowledge and references, and attentional patterns. And different attention patterns shape different behaviors.
English‑speaking readers learn to read from left to right, and this shapes how they scan text and visual layouts. We tend to enter a page from the left side and top, then move rightward and downward, often skimming more as we go.
In practice, this means early elements on the left and top get more visual attention, while elements placed toward the right‑hand edge and bottom are more likely to be overlooked when people are browsing quickly.
This often results in the “corner of death“, where logos placed in the right bottom side are less likely to be seen (and thus remembered).
And Western natural reading direction is reflected in the”F” scanning pattern many of us are familiar with.
However, there are more text scanning patterns, depending on the goal of the user and the layout of the page, from a “Spotted pattern” to a “Layer‑cake pattern” and several others that describe how people jump between points of interest rather than sticking to every line in order.
So, it’s clear that if different pages call for different attention patterns, different locales (and different reading directions) most definitely do as well.
A quick study I ran as a proof of concept showed me how, on average, left-to-right readers (e.g., Spain) and right-to-left readers (e.g., Egypt) consume visual content very differently. Averaged data from 30 participants returned heatmaps where the Spanish cohort very often focused on the left side of the ad, whereas the Egyptian one largely ignored the bottom left corner.

Why is this important?
Not only to isolate important elements that a different audience might not see at all, but also because it helps us frame the page for the goal we want to achieve.
For example, we often use the first option in a series of items as a baseline to make all subsequent judgments. Think about it: When we land on a category page, and the first item is the most expensive, it makes everything else look like a good deal.
This is a phenomenon called “anchoring,” which is widely used to direct persuasion behaviors, like in this example from the ecommerce Noon.

And you know what Noon does particularly well? When you change the locale to UAE, the elements flip on the page, so that the most expensive phone is now on the right side. This is a great example of correct localization, since the first item seen by an Arabic-speaking reader will be the one on the right, not on the left.

Beyond reading patterns, it is worth noting that certain cultures also tend to focus on different elements of a page – for example, some audiences are more drawn to bold imagery while others spend relatively more time on text and contextual details. And while I’ve focused here on left‑to‑right and right‑to‑left readers, there are also vertical writing systems where people read top‑to‑bottom, adding yet another habitual scan pattern into the mix and reinforcing that you can’t assume a single “universal” layout will work everywhere. Eye‑tracking helps you see these biases in practice, so you can decide whether to lead with visuals, copy, or supporting context for each locale instead of guessing it.
How Does Eye Tracking Work?
Traditional analytics can tell us something about attention, but it’s normally a byproxy of other metrics. Think about the heatmaps you can get from Microsoft Clarity. They’re really good at bringing out where the user scrolls, clicks, and where the journey fails – but all of this is a measure of explicit behavior. Attention patterns often don’t leave a trace in our analytics. We can infer that what doesn’t get scrolled doesn’t get seen, and that, conversely, what gets a click is something that has caught the eye.
Eye tracking goes deeper than that and isolates data that can give us an understanding of what gets seen and what does not, as well as some indication about emotional engagement and cognitive load (which is often a reason for abandonment).
It produces scanpaths and heatmaps based on metrics like:
- Fixations: Moments when the eyes briefly stop and focus on a specific point, indicating where attention is actually landing.
- Saccades: The rapid jumps the eyes make between fixations, showing how people move their gaze across the page or screen.
- Pupil dilation: Changes in pupil size that can reflect arousal or mental effort while someone is looking at your content.
- K‑coefficient: A combined measure of fixation duration and saccade length that indicates whether someone is broadly scanning (ambient) or closely focusing (focal) on what they see.
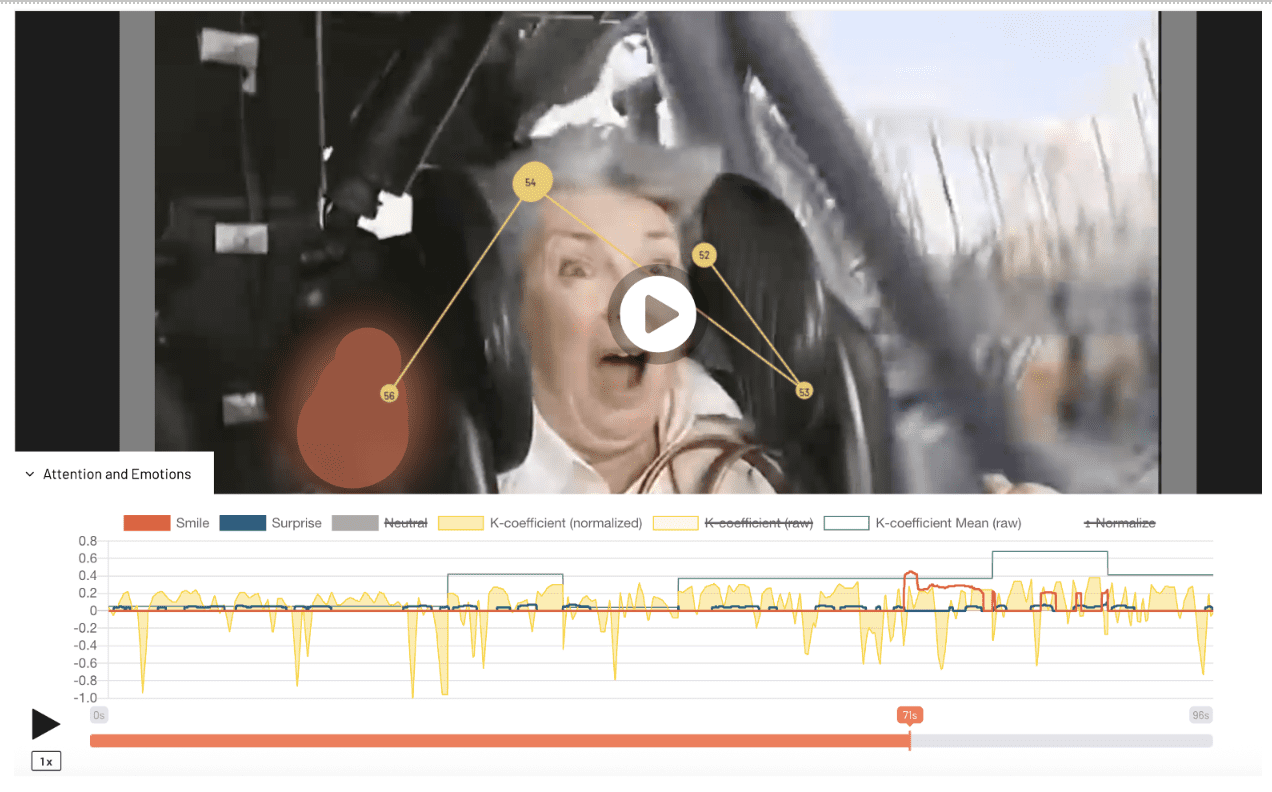
This information can be used for optimizing the position of elements and messages, and guiding attention in landing pages and creatives.
Research-grade options are very precise (and very expensive), but there are light-weight, web-based eye-trackers that you can leverage to run attention studies at a fraction of the cost and remotely. Tools like GazeRecorder record where people look on a page or screen in real time, then turn that into scanpaths and heatmaps so you can see which elements attract attention first, and which are ignored.
RealEye combines webcam-based eye tracking with facial coding, tagging expressions such as smiles or surprise, so you can see not just where people look, but also whether their emotional response skews more positive or negative, which can be useful when testing ads or landing pages.
And if you don’t want to collect “real” gaze data from participants at all, you can also use synthetic attention predictions. Platforms like EyeQuant use trained models to simulate how a typical viewer might look at a page and generate predicted heatmaps within seconds. These aren’t a substitute for actual eye‑tracking studies, but they can be a fast, low‑effort way to spot major attention issues before you invest in full testing.
Leveraging Eye Tracking Insights To Optimize Content Internationally
The insights you get about attention from eye‑tracking studies largely surpass what we can get from explicit behavioral metrics, and they can guide how we design experiences far beyond just where we place logos and calls-to-action.
Here are some practical ways to use them:
- Identify competing elements. Use heatmaps and scanpaths to spot parts of the page that pull attention away from what matters (e.g., busy background images stealing focus from the product, or a large secondary button outshining the primary CTA). You can then simplify, resize, or reposition those elements so attention flows more cleanly toward your key goals.
- Strengthen the visual hierarchy. Check whether people actually look at content in the order you intended (for example, headline → key benefit → product → CTA). If their gaze jumps around or skips crucial information, adjust layout, typography, color, and whitespace until the scanpath matches the story you want the page to tell.
- Refine creative per market. Run the same layout across different countries and compare where people look first and how long they stay there. Swap imagery, colors, or copy directionally (e.g., left–right, top–bottom) to match local reading patterns and visual habits, then re‑test to see whether attention on key elements improves.
- Iterate on messaging and visuals. Test variations of headlines, hero images, and CTA labels while tracking not only clicks but also how quickly eyes land on them and how long they remain there. If people only skim over your main message, sharpen the copy and adjust its positioning until it earns a longer fixation.
You can even use these insights to build simple predictive models to forecast early campaign success across different markets and cultures. For instance, you might find that earlier fixations on the brand or logo predict better recall, that longer dwell time on CTAs correlates with higher conversion intent, or that emotional faces consistently drive cross‑cultural engagement.
Always keep in mind that one size does not fit all – not across cultures, and not across page types or user goals either. A product page will be scanned very differently from a Help page or a blog post, and your design should respect those intent differences.
So, next time you get asked to scale internationally, keep an eye (no pun intended) on where the attention goes, because it can tell you more than dozens of A/B tests – and help you ship experiences that work with human perception instead of against it.
More Resources:
Featured Image: RobinRmD/Shutterstock