In Q2 2025, MrBeast has retained his top spot as the most-subscribed YouTube individual on the social media platform.
After MrBeast overtook PewDiePie in late 2022 to shake up the top-most subscribed on YouTube leaderboard, there has been even more movement in the second quarter of 2025.
At the beginning of YouTube, it was a long journey for individuals to reach 100 million subscribers, but now MrBeast is the first individual YouTuber to crack 200 million subscribers.
On YouTube, way back in 2006, Judson Laipply was the first recorded individual to have the most subscribers, with mere thousands.
In the same year, Brookers was the first channel and individual to reach 10,000 subscribers – and that was a big deal.
Today, MrBeast is the most-subscribed individual, just above T-Series – an Indian record label and film studio that was once the number one most-subscribed channel on YouTube.
T-Series was the first channel to reach 100 million subscribers in 2019 and the first to reach 200 million in 2021.
While T-Series held twice as many subscribers as the top individual YouTuber last year, it has now been overtaken by the most popular content creator.
Being an influencer is big business.
Who Is The No. 1 Most Subscribed YouTuber?
As of June 2025, MrBeast is the most-subscribed YouTuber, with 399 million subscribers.
Kid-friendly content channel Like Nastya is now the second most-subscribed YouTube individual with 128 million subscribers.
PewDiePie has retained third place with 110 million.
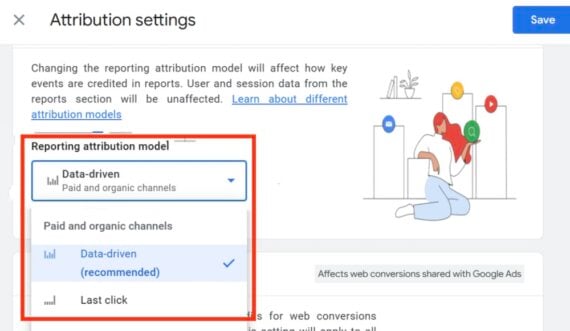
The Top 30 Most-Subscribed YouTubers, June 2025
|
Channel |
Videos |
Language |
Subscribers (In Millions) |
| 1 |
MrBeast |
874 |
English |
399 |
| 2 |
Like Nastya |
952 |
English |
128 |
| 3 |
PewDiePie |
4,820 |
English |
110 |
| 4 |
김프로KIMPRO |
3,200 |
Korean |
106 |
| 5 |
Alan’s Universe |
1,370 |
English |
92.7 |
| 6 |
A4 |
1,000 |
Russian |
80.8 |
| 7 |
Justin Bieber |
249 |
English |
75.4 |
| 8 |
UR · Cristiano |
102 |
European Portuguese |
75.2 |
| 9 |
KL BRO Biju Rithvik |
3,100 |
Hindi |
72.8 |
| 10 |
Mark Rober |
212 |
English |
68.5 |
| 11 |
Fede Vigevani |
1,510 |
Spanish |
67.3 |
| 12 |
Topper Guild |
1,170 |
English |
65.8 |
| 13 |
EminemMusic |
198 |
English |
65 |
| 14 |
Alejo Igoa |
1,190 |
Spanish |
64.5 |
| 15 |
ISSEI / いっせい |
3,630 |
Japanese |
61.5 |
| 16 |
Taylor Swift |
285 |
English |
61 |
| 17 |
PANDA BOI |
1,180 |
Multilingual |
58.6 |
| 18 |
Zhong |
1,950 |
English |
58.3 |
| 19 |
Marshmello |
534 |
English |
57.9 |
| 20 |
Acharya Prashant |
13,700 |
Hindi |
56.7 |
| 21 |
Ed Sheeran |
607 |
English |
56.4 |
| 22 |
Mikecrack |
2,120 |
Spanish |
56.4 |
| 23 |
Ariana Grande |
229 |
English |
56.1 |
| 24 |
Billie Eilish |
161 |
English |
55.8 |
| 25 |
Bispo Bruno Leonardo |
7,530 |
Portuguese |
55.5 |
| 26 |
Jess No Limit |
2,680 |
Indonesian |
54.2 |
| 27 |
JuegaGerman |
2,310 |
Spanish |
53.4 |
| 28 |
Alfredo Larin |
1,900 |
Spanish |
52.8 |
| 29 |
LUCCAS TOON – LUCCAS NETO |
3,200 |
Portugese |
52.1 |
| 30 |
BETER BÖCÜK |
1,900 |
Turkish |
51.5 |
*Data Sources (SocialBlade, YouTube), June 2025
Please note that this is a list of the most subscribed individuals, not the most subscribed channels. It excludes “brand” channels that don’t focus on an individual personality, artist, or influencer.
Who Are The Top 10 Most-Subscribed YouTubers?
The list of the top 30 most-subscribed individuals features many successful music artists but has a majority of native YouTube influencers.
With the channel becoming an integral part of marketing and distribution for music artists, it’s no surprise that top artists feature highly.
Justin Bieber, the top individual artist, leveraged YouTube from an early age to gain mainstream attention on his own terms.
MrBeast has over 323.6 million more subscribers than Bieber, which highlights just how much attention the channel can achieve – and that, today, being a YouTube influencer is the same as being a traditional celebrity.
To get a better understanding of who all the influencers are, we’ve included a summary of the top 10 most-subscribed YouTuber influencers below.
1. MrBeast
U.S.-based Jimmy Donaldson started MrBeast as MrBeast6000 in 2012 when he was only 13.
He also holds five other channels, including Beast Reacts, MrBeast 2, Beast Philanthropy, and MrBeast 3 (inactive). MrBeast Gaming also sits in the top 100, with just under 47.5 million subscribers.
MrBeast’s early videos include counting to 10,000 non-stop (a 44-hour stunt), which quickly went viral but is now best known for videos that involve elaborate stunts, charity donations, or cash giveaways.
In one video, he gave away $1 million and has done several big philanthropic stunts, such as “I Built 100 Wells in Africa” and “I Rescued 100 Abandoned Dogs.”
When reaching the 200-million subscriber milestone in October 2023, MrBeast took to X (Twitter) to say how stunned his 13-year-old self would be and that he planned to continue making content for decades.
When he reached 300 million subscribers in July 2024, he posted on X (Twitter) to say he remembered freaking out when he hit 300 subscribers 11 years ago.
In his usual philanthropic style, he also gave away a private island for his 100-million subscriber milestone, which is probably part of the reason he originally took the top position from PewDiePie in December 2022.
Jimmy Donaldson’s channel brings in between $600 and $ 700 million a year, but his mother is the person who looks after his bank accounts.
He still resides in his hometown of Greenville, North Carolina, and employs many local people in the production of his videos.
2. Like Nastya
Anastasia Sergeyevna Radzinskaya is the only individual child YouTuber on the list. She was born in January 2014 and is the youngest influencer with the most followers, now overtaking PewDiePie by 18 million to take the No. 2 spot.
It’s worth noting that another channel, Vlad and Niki, is very popular with 140 million subscribers – but as a duo rather than an individual, they aren’t included in this list. Despite being featured in last year’s rankings, Ryan’s World has now fallen out of the rankings.
Although Radzinskaya was born in Russia, she has since moved to the U.S., and her videos are produced in English. The channel is for children and covers educational entertainment and vlogging.
Some of her success is down to the channel being dubbed in several languages, enabling her to reach a wide audience.
Radzinskaya’s parents help her manage the Like Nastya channel, but she is the face and star of the show.
3. PewDiePie
PewDiePie, otherwise known as Felix Arvid Ulf Kjellberg, held the most-subscribed position on YouTube for nearly 10 years until 2022. He was the original YouTube influencer who crossed over from online to be famous offline.
Swedish Kjellberg registered PewDiePie in 2010, and started out with play-by-plays of video games – a genre known as “Let’s Play.” It only took three years for him to be the most-subscribed channel on YouTube, and he was the highest-earning YouTuber in 2016.
Alongside “Let’s Play” content, PewDiePie has also experimented with comedy, commentary, music, and shows.
Following the rising success of his channel, Kjellberg also released his own game and published a book.
In 2022, his content shifted more towards lifestyle content after moving to Japan, with another shift in 2023 as he became a father. These changes to the types of videos PewDiePie produces could be the reason for his slightly waning subscriber count.
4. 김프로KIMPRO
KIMPRO (real name: Kim Dong-jun) is a South Korean content creator who is best known for his comedic and financial content. His two sisters often appear as guest stars in his videos.
His channel exploded in popularity in recent years, thanks primarily to his comedy clips. Meanwhile, his TikTok account, kimpro828, gained a massive following of 4.3 million followers in recent years.
He started in August 2022, which makes these numbers all the more impressive. Using special effects, viewers are drawn to his mix of viral recreations, including mukbangs, vlogs, challenges, and video reactions.
Though all of his content is in Korean, his relatable comedy has earned him a large and loyal subscriber base. His success demonstrates that niche content, particularly when made entertaining, can compete with the gaming and music genres on YouTube.
5. Alan’s Universe
Alan Chikin Chow is an American content creator, actor, and producer who became famous for his simple yet comedic sketches and bold storytelling.
His channel, “Alan’s Universe,” is a high school collective series. His videos feature himself and his classmates as recurring main characters, facing bullies and winning with the power of love. This theme has resonated with younger audiences.
His success has been largely driven by YouTube Shorts, where his high-quality production and positive energy align well with viewer expectations.
Alan has also appeared in TV shows and commercial ads, and he continues to bridge the gap between social media and traditional entertainment.
He has partnered up with streaming platform, Roku, and his series has been available since March 24, 2025, bringing his universe to new platforms and broader audiences.
6. A4
Belarusian content creator Vladislav Andreyevich Bumaga, known online as Vlad A4 or simply A4, holds the position of one of the most popular Russian-speaking YouTubers.
He created his channel back in 2014, with A4 being a play on his last name, Bumaga, meaning “paper.”
In 2016, he released a video called “24 Hours in a Trampoline Centre,” which took his subscriber count from 200,000 to his first 1 million.
Now, with just over 80.8 million subscribers, he continues to upload a wide variety of challenges and vlog content featuring his friends, as well as promoting his branded products.
7. Justin Bieber
Canadian Justin Bieber is the musical artist with the most followers on YouTube. He joined YouTube in 2007 and, after coming second in a local singing competition, began posting himself performing song covers.
After his channel started to grow, he got the attention of his now manager and his record label. In 2008, he signed a recording contract.
Bieber continued to focus on his YouTube channel and growing his followers, known as “Beliebers.”
This most likely contributed to his early and continued success. He continues to post videos on YouTube alongside his music videos and promotional content, although his last upload was now over two years ago.
8. UR · Cristiano
No surprises here – Cristiano Ronaldo was already the most legendary footballer possibly of all time, way before YouTube.
Being very social savvy, he has cultivated a massive following across social platforms, and YouTube is no exception.
His channel features a mix of personal highlights, behind-the-scenes training footage, interviews, commentaries, and sponsored content. Additionally, his collaboration with the number one most subscribed YouTuber, Mr. Beast, amassed 59 million views.
While he is not a traditional vlogger or influencer, Ronaldo’s global fan base ensures that any content he posts gets millions of views.
As a newcomer in this top 10 list, he demonstrates the power of celebrity, and that in itself can drive subscriber numbers, even with infrequent uploads.
9. KL BRO Biju Rithvik
KL BRO Biju Rithvik is an Indian content creator from Kerala, featuring his daily life. The channel features family-friendly short films and skits.
They are a family-centered content that features relatable and silly moments, resonating with a wide audience in India.
The rise of YouTube Shorts in India has played a significant role in its massive growth, with each Short amassing millions of views. YouTube CEO Neal Mohan notes the milestone for Shorts in India:
“YouTube is number one in reach and watch time in India. And we just passed a huge milestone. Shorts, which we first launched in India, now have trillions of views here.”
10. Mark Rober
Science can be fun and suitable for everyone, as former NASA engineer turned YouTuber Mark Rober proves with his spot on this top 10 list.
As the current founder of Crunchlabs, a STEM subscription box and learning platform for kids and adults. His science-focused videos do combine education with entertainment.
From jumping on a moving train (a la Tom Cruise) and building his own indoor rollercoaster to glitterbombs for car thieves, each video documents and explains how the engineering works.
Not to mention, every project is unique, with a step-by-step process that makes it accessible for aspirants to do the same.
With high-quality production, he says he leans heavily on his community to support his initiatives. Back in 2019, he partnered up with MrBeast for his #TeamTrees project to help raise $20 million for 20 million trees.
Why YouTubers Are Significantly Influential For Online Marketers
Achieving a most-subscribed status on YouTube cements you as an influencer and enables you to make serious income.
Not only can YouTubers earn from ads on the videos, but they are also in demand as brand ambassadors for product placements, product reviews, and product collaborations.
Mere mentions of products and brands by an influencer can drive traffic and sales for brands.
Smart influencers use the exposure to diversify into many mainstream areas of collaboration and business to supplement their income and ensure longevity.
Much like top-level sports stars have always been in demand as brand ambassadors, influencers can be used for brand alignment.
Influencer marketing doesn’t have to be just for the big brands; influencers with only a few thousand engaged followers can help spread messages.
And for smaller brands, elevated exposure on social media can be a major benefit.
More Resources:
Featured Image: Roman Samborskyi/Shutterstock