Civitai—an online marketplace for buying and selling AI-generated content, backed by the venture capital firm Andreessen Horowitz—is letting users buy custom instruction files for generating celebrity deepfakes. Some of these files were specifically designed to make pornographic images banned by the site, a new analysis has found.
The study, from researchers at Stanford and Indiana University, looked at people’s requests for content on the site, called “bounties.” The researchers found that between mid-2023 and the end of 2024, most bounties asked for animated content—but a significant portion were for deepfakes of real people, and 90% of these deepfake requests targeted women. (Their findings have not yet been peer reviewed.)
The debate around deepfakes, as illustrated by the recent backlash to explicit images on the X-owned chatbot Grok, has revolved around what platforms should do to block such content. Civitai’s situation is a little more complicated. Its marketplace includes actual images, videos, and models, but it also lets individuals buy and sell instruction files called LoRAs that can coach mainstream AI models like Stable Diffusion into generating content they were not trained to produce. Users can then combine these files with other tools to make deepfakes that are graphic or sexual. The researchers found that 86% of deepfake requests on Civitai were for LoRAs.
In these bounties, users requested “high quality” models to generate images of public figures like the influencer Charli D’Amelio or the singer Gracie Abrams, often linking to their social media profiles so their images could be grabbed from the web. Some requests specified a desire for models that generated the individual’s entire body, accurately captured their tattoos, or allowed hair color to be changed. Some requests targeted several women in specific niches, like artists who record ASMR videos. One request was for a deepfake of a woman said to be the user’s wife. Anyone on the site could offer up AI models they worked on for the task, and the best submissions received payment—anywhere from $0.50 to $5. And nearly 92% of the deepfake bounties were awarded.
Neither Civitai nor Andreessen Horowitz responded to requests for comment.
It’s possible that people buy these LoRAs to make deepfakes that aren’t sexually explicit (though they’d still violate Civitai’s terms of use, and they’d still be ethically fraught). But Civitai also offers educational resources on how to use external tools to further customize the outputs of image generators—for example, by changing someone’s pose. The site also hosts user-written articles with details on how to instruct models to generate pornography. The researchers found that the amount of porn on the platform has gone up, and that the majority of requests each week are now for NSFW content.
“Not only does Civitai provide the infrastructure that facilitates these issues; they also explicitly teach their users how to utilize them,” says Matthew DeVerna, a postdoctoral researcher at Stanford’s Cyber Policy Center and one of the study’s leaders.
The company used to ban only sexually explicit deepfakes of real people, but in May 2025 it announced it would ban all deepfake content. Nonetheless, countless requests for deepfakes submitted before this ban now remain live on the site, and many of the winning submissions fulfilling those requests remain available for purchase, MIT Technology Review confirmed.
“I believe the approach that they’re trying to take is to sort of do as little as possible, such that they can foster as much—I guess they would call it—creativity on the platform,” DeVerna says.
Users buy LoRAs with the site’s online currency, called Buzz, which is purchased with real money. In May 2025, Civita’s credit card processor cut off the company because of its ongoing problem with nonconsensual content. To pay for explicit content, users must now use gift cards or cryptocurrency to buy Buzz; the company offers a different scrip for non-explicit content.
Civitai automatically tags bounties requesting deepfakes and lists a way for the person featured in the content to manually request its takedown. This system means that Civitai has a reasonably successful way of knowing which bounties are for deepfakes, but it’s still leaving moderation to the general public rather than carrying it out proactively.
A company’s legal liability for what its users do isn’t totally clear. Generally, tech companies have broad legal protections against such liability for their content under Section 230 of the Communications Decency Act, but those protections aren’t limitless. For example, “you cannot knowingly facilitate illegal transactions on your website,” says Ryan Calo, a professor specializing in technology and AI at the University of Washington’s law school. (Calo wasn’t involved in this new study.)
Civitai joined OpenAI, Anthropic, and other AI companies in 2024 in adopting design principles to guard against the creation and spread of AI-generated child sexual abuse material . This move followed a 2023 report from the Stanford Internet Observatory, which found that the vast majority of AI models named in child sexual abuse communities were Stable Diffusion–based models “predominantly obtained via Civitai.”
But adult deepfakes have not gotten the same level of attention from content platforms or the venture capital firms that fund them. “They are not afraid enough of it. They are overly tolerant of it,” Calo says. “Neither law enforcement nor civil courts adequately protect against it. It is night and day.”
Civitai received a $5 million investment from Andreessen Horowitz (a16z) in November 2023. In a video shared by a16z, Civitai cofounder and CEO Justin Maier described his goal of building the main place where people find and share AI models for their own individual purposes. “We’ve aimed to make this space that’s been very, I guess, niche and engineering-heavy more and more approachable to more and more people,” he said.
Civitai is not the only company with a deepfake problem in a16z’s investment portfolio; in February, MIT Technology Reviewfirst reported that another company, Botify AI, was hosting AI companions resembling real actors that stated their age as under 18, engaged in sexually charged conversations, offered “hot photos,” and in some instances described age-of-consent laws as “arbitrary” and “meant to be broken.”
Phillip Jackson’s media company, Future Commerce, focuses on trends and developments in business.
The company surveyed U.S. shoppers during the 2025 holiday season. He says one insight stood out: when AI recommends a product, 77% of respondents leave the platform to buy on the brand’s site.
Phillip first appeared on the podcast in early 2024. In this our latest conversation, he addressed the downsides of optimized ecommerce sites, the outlook of traditional search, and, yes, the rise of autonomous shopping agents.
The entire audio of our conversation is embedded below. The transcript is edited for length and clarity.
Eric Bandholz: Bring us up to date.
Phillip Jackson: Future Commerce is a media company exploring the culture of commerce through newsletters, podcasts, research, and events.
When you and I last spoke, I remember thinking, “I’m made for this.” It felt like everything I’ve learned over my entire career was in one place.
Ecommerce was difficult when I started in 1999. I spent more than a decade working for a direct-to-consumer seller of natural health products. We hand-coded sites in HTML, ran Google AdWords, and scaled multiple brands.
Bandholz: Is it better in 2026?
Jackson: I’ve been saying since around 2019 that we’ve reached the ideal website. We’ve optimized ecommerce experiences to death, and what’s left is efficiency and boredom.
We do a lot of consumer and executive research at Future Commerce. In one study published around 2022, we analyzed about 15 of the world’s highest-traffic ecommerce sites, excluding Amazon. Think brands like Bath & Body Works and Bed Bath & Beyond. We removed logos and navigation, then showed the pages to consumers. Most people couldn’t tell one site from another because they’re functionally identical.
That level of optimization is powerful, but it has a downside: it’s unmemorable. These sites are designed for conversion, not for recall or cultural impact. They’re slippery. You buy, you leave, and nothing sticks.
You see this everywhere in culture. Netflix is a great example. It’s incredible how they use data to maximize completion rates, which is why they release entire seasons at once. The data probably proves it works. But it doesn’t show what’s lost: cultural conversation. Shows released across many weeks remain part of the culture for extended periods.
The same thing has happened in ecommerce and product design. Websites, sport utility vehicles, smartphones, and even electric toothbrushes all converge on the same form.
Many industry folks hope AI will make ecommerce exciting again, but real innovation requires risk, which few companies are willing to take on.
Bandholz: Will marketplaces and AI replace brand websites?
Jackson: There’s a lot packed into that question, and we actually have data around it. On the practical side, the website isn’t going anywhere. Advertisers may shift platforms, and AI-driven discovery is clearly changing behavior, especially among Gen Zs. Generative AI sites have become a trusted source for product and brand discovery.
We researched consumer AI usage before and after the 2025 holidays. One insight stood out. When AI recommends a product, shoppers overwhelmingly prefer to leave the platform and visit the brand’s website. Across two studies, two cohorts, and multiple English-speaking countries, 77% said they would rather click through to the website than buy inside the AI interface.
That challenges the narrative that AI agents will handle all purchasing. I’m bullish on agents long term, but the website remains the center of context, trust, and information for generative engines.
Interestingly, AI may affect physical retail more quickly than digital. In our data, 35% of Gen Zs and 40% of Gen Xs said they’d rather buy based on an AI recommendation than go to a store.
More broadly, old and new systems always coexist. Markets don’t disappear; they evolve. The brands that survive will have durable products, a clear identity, and strong relationships. Almost certainly they will have websites. Everything else is still up for debate.
Bandholz: Will genAI replace traditional search?
Jackson: We’re seeing signs of that shift. However, there are economic questions to answer. What companies win the AI race? Which consumer products become dominant?
Yes, AI is disruptive, but it’s also introducing a new modality in our relationship with digital culture. It isn’t just a search box. It’s a different kind of interaction. I see it as complementary rather than exclusive. Traditional systems don’t vanish overnight; they adapt and coexist. AI changes behavior, but it layers onto existing habits rather than erasing them.
Bandholz: What’s your advice to folks starting in ecommerce?
Jackson: Some level of investment in genAI visibility is non-negotiable. Consumers are increasingly turning to engines like ChatGPT for product recommendations. If you’re not tracking whether your brand shows up there, you should be. It may be the closest thing we have to true organic discovery.
Beyond that, many newer providers aren’t living up to their promised disruption. TikTok Shop, for example, is essentially an affiliate channel. It’s powerful, but it’s not going to change fundamentally how everyone shops.
Bandholz: What major macro trends are you watching?
Jackson: The first is machine autonomy. Every business, from the smallest startup to the largest enterprise, is pushing for more automation and productivity. You see it with self-driving vehicles, delivery robots, and last-mile automation. You also see it in companies, with systems that operate without human intervention. That shift is happening fast.
The second force is human sovereignty, driven by mistrust in institutions. The Edelman Trust Barometer in early 2026 is at a 25-year low. People don’t trust governments, corporations, or systems the way they used to. At the same time, they now have tools to verify claims, build their own worldviews, and take control of decisions.
Healthcare is an example. Individuals can now monitor their own health and interpret data in ways that weren’t possible five years ago.
These two forces — autonomy and sovereignty — can complement each other, but they can also collide. Brands that understand how to navigate both, at any scale, will define the next era of commerce.
Bandholz: How can listeners follow you and reach out?
AI tools produce different brand recommendation lists nearly every time they answer the same question, according to a new report from SparkToro.
The data showed a <1-in-100 chance that ChatGPT or Google>
Rand Fishkin, SparkToro co-founder, conducted the research with Patrick O’Donnell from Gumshoe.ai, an AI tracking startup. The team ran 2,961 prompts across ChatGPT, Claude, and Google Search AI Overviews (with AI Mode used when Overviews didn’t appear) using hundreds of volunteers over November and December.
What The Data Found
The authors tested 12 prompts requesting brand recommendations across categories, including chef’s knives, headphones, cancer care hospitals, digital marketing consultants, and science fiction novels.
Each prompt was run 60-100 times per platform. Nearly every response was unique in three ways: the list of brands presented, the order of recommendations, and the number of items returned.
Fishkin summarized the core finding:
“If you ask an AI tool for brand/product recommendations a hundred times nearly every response will be unique.”
Claude showed slightly higher consistency in producing the same list twice, but was less likely to produce the same ordering. None of the platforms came close to the authors’ definition of reliable repeatability.
The Prompt Variability Problem
The authors also examined how real users write prompts. When 142 participants were asked to write their own prompts about headphones for a traveling family member, almost no two prompts looked similar.
The semantic similarity score across those human-written prompts was 0.081. Fishkin compared the relationship to:
“Kung Pao Chicken and Peanut Butter.”
The prompts shared a core intent but little else.
Despite the prompt diversity, the AI tools returned brands from a relatively consistent consideration set. Bose, Sony, Sennheiser, and Apple appeared in 55-77% of the 994 responses to those varied headphone prompts.
What This Means For AI Visibility Tracking
The findings question the value of “AI ranking position” as a metric. Fishkin wrote: “any tool that gives a ‘ranking position in AI’ is full of baloney.”
However, the data suggests that how often a brand appears across many runs of similar prompts is more consistent. In tight categories like cloud computing providers, top brands appeared in most responses. In broader categories like science fiction novels, the results were more scattered.
This aligns with other reports we’ve covered. In December, Ahrefs published data showing that Google’s AI Mode and AI Overviews cite different sources 87% of the time for the same query. That report focused on a different question: the same platform but with different features. This SparkToro data examines the same platform and prompt, but with different runs.
The pattern across these studies points in the same direction. AI recommendations appear to vary at every level, whether you’re comparing across platforms, across features within a platform, or across repeated queries to the same feature.
Methodology Notes
The research was conducted in partnership with Gumshoe.ai, which sells AI tracking tools. Fishkin disclosed this and noted that his starting hypothesis was that AI tracking would prove “pointless.”
The team published the full methodology and raw data on a public mini-site. Survey respondents used their normal AI tool settings without standardization, which the authors said was intentional to capture real-world variation.
The report is not peer-reviewed academic research. Fishkin acknowledged methodological limitations and called for larger-scale follow-up work.
Looking Ahead
The authors left open questions about how many prompt runs are needed to obtain reliable visibility data and whether API calls yield the same variation as manual prompts.
When assessing AI tracking tools, the findings suggest you should ask providers to demonstrate their methodology. Fishkin wrote:
“Before you spend a dime tracking AI visibility, make sure your provider answers the questions we’ve surfaced here and shows their math.”
On the first episode of the Google Ads Decoded podcast, host Ginny Marvin sat down with Eleanor Stribling, Group Product Manager for Google Analytics.
In the episode, Stribling noted an ambitious two-phase vision for the GA4 platform.
After acknowledging GA4’s rough transition from Universal Analytics, especially for marketers, she shared where the platform is headed over the next few years.
What Stribling Shared on Google Ads Decoded
After discussing the foundations of the importance of data strength, Stribling broke down the vision of GA4 into two timelines.
Over the next year or two, GA4 will focus on becoming a cross-channel, full-funnel measurement platform. She states the goal of this is:
To be that one place where you can really understand the impact of your media with data that makes sense and resonates and that you can take and make a business decision with.
This means moving beyond outdated siloed channel reporting to understand how all your media works together across the complete customer journey.
The longer-term vision she shared looks 3+ years beyond what GA4 is capable of today.
Stribling says GA4 will become a decision-making platform for businesses, essentially a growth engine that translates data into business outcomes.
“Making a world-class analyst available to every single person,” is how Stribling described this vision. AI will be the layer that makes this shift possible.
It will be interesting to see how Google’s vision for this will build out over the next few years. Considering they already have the reporting visualization tool, Looker Studio, my prediction is that there will be better or easier integration into it.
Beyond just better integration with Looker Studio, trying to become a growth engine or decision-making platform sounds like they’re trying to set themselves apart from the competition of other reporting platforms out there today, like Funnel or Power BI.
What’s Coming in the Advertising Workspace
Stribling pointed to the Advertising Workspace in GA4 as an area where marketers will see significant changes over the next year.
Expect improvements to reporting that better illustrate the user journey. Google is also building out budgeting and planning tools that let you upload cost data from other media buys and create spend plans based on your goals.
The platform will also suggest optimizations for in-flight campaigns, offering AI-powered recommendations to help you get closer to your campaign objectives.
Personally, I’m excited to see if they make the Explorer report building any more intuitive for marketers. I think it’s highly under-utilized right now because you’re essentially starting from a blank slate. It takes time, effort, and the right type of mindset to really sit down and try to re-learn an Analytics platform.
Why This Matters & Looking Ahead
GA4’s reputation amongst marketers hasn’t been stellar since it replaced Universal Analytics. In the podcast episode, Marvin reiterated that as a long-time marketer:
The platform felt designed for developers rather than marketers, and the transition left many advertisers frustrated.
Stribling’s comments signal that Google has been listening. Google seems to be heavily investing in making GA4 more accessible, while simultaneously building towards a future where the platform goes beyond its traditional reporting.
The two-phase vision shared is ambitious, particularly the long-term vision of GA4 as a business decision engine. Whether Google will move full steam ahead on this remains up in the air, but it seems that the direction GA4 is going is beyond just a measurement tool.
For now, the practical move for marketers is to keep working on your data strength. This includes auditing your tagging setup, testing the existing AI features that already exist today, and reviewing key conversion and event data.
Welcome to this week’s SEO Pulse: updates affect publisher control over AI features, how AI Overviews process queries, and what AI model tradeoffs mean for content workflows.
Here’s what matters for you and your work.
Google Explores Letting Sites Opt Out Of AI Search Features
Google says it’s exploring updates that could let websites opt out of AI-powered search features. The blog post came the same day the UK’s Competition and Markets Authority opened a consultation on potential new requirements for Google Search.
Key facts: Ron Eden, principal, product management at Google, wrote that the company is “exploring updates to our controls to let sites specifically opt out of Search generative AI features.” Google provided no timeline, technical specifications, or firm commitment.
Why This Matters For SEOs
Publishers and regulators have spent the past year pushing back on AI Overviews. The UK’s Independent Publishers Alliance, Foxglove, and Movement for an Open Web filed a complaint with the CMA last July, asking for the ability to opt out of AI summaries without being removed from search entirely.
A BuzzStream report we covered earlier this month found 79% of top news publishers block at least one AI training bot, and 71% block retrieval bots that affect AI citations. Publishers are already voting with their robots.txt files. Google’s post suggests it’s responding to pressure from the ecosystem by exploring controls it previously didn’t offer.
The practical question is what “opt out of AI search features” would mean technically. It’s unclear whether this would cover AI Overviews, AI Mode, or both, and whether sites would lose visibility in those experiences or only be excluded from summaries.
What People Are Saying
Early reactions on LinkedIn focused on the regulatory context and what this could mean for publishers.
David Skok, CEO & editor-in-chief at The Logic, wrote on LinkedIn:
“For the first time, a major regulator is publicly consulting on a requirement that would allow publishers to opt out of having their content used in Google’s AI Overviews or in training AI models without being removed from general search results.”
He added that the consultation would allow publishers to opt out of AI Overviews “without being removed from general search results.”
Matthew Allsop, the CMA’s principal digital markets adviser, framed it as a “meaningful choice” issue, pointing to measures that would allow publishers to opt out of AI Overviews.
In SEO and publisher discussions, the focus has been on whether any opt-out comes with tradeoffs, and whether Google will provide reporting that shows where content appears across AI surfaces.
Google is making Gemini 3 the default model for AI Overviews globally, in markets where the feature is available. The update also adds a direct path into AI Mode conversations.
Key facts: Robby Stein, VP of Product for Google Search, announced the rollout, saying AI Overviews now reach over 1 billion users. The Gemini 3 upgrade brings the same reasoning capabilities to AI Overviews that powers AI Mode.
Why This Matters For SEOs
The model upgrade and the seamless transition into AI Mode work together. Better reasoning means AI Overviews can handle more complex queries at the top of results. The follow-up prompt means those who want to go deeper can do so without leaving Google’s AI interfaces.
This creates a smoother path that keeps people inside Google’s AI experiences longer. Someone who sees your content cited in an AI Overview might previously have clicked through to your site. Now they can ask a follow-up question and stay in AI Mode, which may reduce click-through opportunities even when your content continues to be cited.
The seamless transition continues the pattern of Google handling more of the search journey within its own surfaces.
Sam Altman Says OpenAI “Screwed Up” GPT-5.2 Writing Quality
Sam Altman said OpenAI “screwed up” GPT-5.2’s writing quality during a developer town hall Monday evening. He said future GPT-5.x versions will address the gap.
Key facts: When asked about user feedback that GPT-5.2 produces writing that’s “unwieldy” and “hard to read” compared to GPT-4.5, Altman was blunt: “I think we just screwed that up.” He explained that OpenAI made a deliberate choice to focus GPT-5.2’s development on technical capabilities, putting “most of our effort in 5.2 into making it super good at intelligence, reasoning, coding, engineering, that kind of thing.”
Why This Matters For SEOs
If you use ChatGPT for content workflows, you may have noticed the change. GPT-5.2 handles complex reasoning tasks better but produces prose that reads more mechanical. Altman confirmed this wasn’t a bug but a tradeoff.
The admission clarifies what to expect from AI writing tools going forward. Model developers are making explicit choices about what to improve. Writing quality competes with coding, reasoning, and other technical benchmarks for development resources.
This means matching the tool to the task. GPT-5.2 might excel at research synthesis, data analysis, and technical documentation, but it can produce awkward prose for blog posts or marketing copy. GPT-4.5 often reads more naturally, even if it couldn’t handle the same complexity.
Altman said future GPT-5.x versions will “hopefully” be much better at writing than 4.5 was, but gave no timeline.
What People Are Saying
On social media, the reaction focused on what the admission reveals about AI development priorities. Some framed it as a transparency win, noting that most companies would have reframed the issue as a design choice rather than acknowledging a mistake. Others pointed to the tension between optimizing for benchmarks versus optimizing for practical writing quality.
Each story this week involves platforms making choices about what to prioritize and who gets to decide.
Google is exploring whether to give publishers more control over AI features, responding to a year of regulatory pressure and ecosystem pushback. The Gemini 3 rollout gives users a smoother AI experience while reducing control over where that journey ends. And Altman’s admission shows that even model development involves tradeoffs between competing capabilities.
This week, the theme is about understanding which levers you can pull. Publisher opt-out controls might eventually let you decide how your content appears in AI search. Model selection lets you match AI tools to specific tasks. But the broader direction of these platforms is outside your control, and the choices they make shape the environment you’re optimizing for.
Top Stories Of The Week:
This week’s coverage focused on three developments worth tracking.
More Resources:
For deeper context on the publisher and AI visibility dynamics behind these stories, check these related pieces.
Welcome to this week’s PPC Pulse. This week’s news is a continuation of last week’s announcements about ChatGPT ads and the Google Ads Decoded podcast.
ChatGPT announced premium-priced ads with limited data. The first episode of the Ads Decoded podcast, hosted by Ginny Marvin, Google’s Ads product liaison, featured Group Product Manager Eleanor Stribling to discuss Google Analytics.
Here’s what matters for advertisers and why.
ChatGPT Ads Reported To Start With $60 CPM Basis
While not directly reported from OpenAI, according to reporting from The Information, ChatGPT ads are slated to start around $60 per 1,000 impressions (CPM). This is roughly 3x higher than your typical Meta CPMs.
Despite the premium pricing from the start, advertisers won’t get the measurement tools they’re used to.
Reporting will be limited to high-level metrics like total impressions and clicks, with no visibility into conversion actions. OpenAI has indicated it may expand measurement capabilities later, but nothing is confirmed.
On the heels of last week’s announcement, ads will roll out in the coming weeks to users on ChatGPT’s Free and Go tiers. They’ll appear at the bottom of responses, only when OpenAI determines there’s a relevant product or service tied to the conversation.
Additionally, it’s been reported that initial buy-in for brands is $1 million ad spend.
Why This Matters For Advertisers
While CPM advertising is nothing new to advertisers, the lack of reporting that comes with a new platform is concerning. Especially when marketing budgets continue to get squeezed, and you’re on the hook for justifying every dollar spent.
While intent signal could prove strong with ChatGPT ads, the lack of measurement means advertisers have no way to prove that value or optimize toward it.
The high CPMs paired with minimal data categorize ChatGPT ads as more of a brand awareness play instead of a performance channel, at least initially.
Brands should be prepared to treat it like early-stage display or OTT advertising. You’re paying for attention and reach, not being able to prove ROI.
Another interesting snippet to ponder about the whole ChatGPT ads test is how they’re framing ad visibility. OpenAI already said that ads won’t influence answers. If it actually sticks to that, the only way to get placement is through genuine relevance to what someone is already trying to accomplish.
That framework is very different from how search and social ads work, and it could mean this platform stays small and selective with its advertisers, rather than becoming broadly accessible.
What PPC Professionals Are Saying
The reactions to the staggering $60 CPM starting point seem to be mixed.
Some marketers like Andrew Lolk, founder of SavvyRevenue, and Collin Slatterly, founder of Taikun Digital, aren’t necessarily phased by that number.
“$60 CPMs for ads in ChatGPT are probably a good deal. These ads are intent based which more akin to Google search and shopping ads than Meta or TV. Someone is asking chatGPT ‘What’s the best supplement for sleep?’ which is exactly how ads on Google are.”
Lolk, in a similar sentiment, provided his initial thoughts on the cost:
“Unpopular opinion: I don’t care what CPM ChatGPT set their ads to. I care about the return on those ads. The CPM is irrelevant. Obviously, the lower CPM, the better it is for advertisers. But before we know what the return is on a $60 CPM, then I will not say it’s good or bad.”
The conversation in the comments of Lolk’s post sparked a good debate, including an opposing viewpoint from Melissa Mackey, head of paid search at Compound Growth Marketing. Mackey mentioned that because ChatGPT ads aren’t set up as a performance channel, she’s “not paying $60 CPM for something with limited data and no conversion tracking.”
On top of the discussion around cost, it appears some marketers like Harrison Jack Hepp, owner of Industrious Marketing LLC, are already being pitched from agencies that have already run ChatGPT ads, which can’t be correct since they haven’t launched yet.
Screenshot from LinkedIn by author, January 2026
First Ads Decoded Episode Focuses On Google Analytics
The first episode of Ads Decoded launched on Jan. 28, 2026, featuring Eleanor Stribling, Group Product Manager at Google Analytics. The conversation laid a few basic foundations on data strength, as well as a candid look into where GA4 is headed in the next few years. If you’ve been frustrated with GA4 since it replaced Universal Analytics, this episode is worth your time.
Stribling didn’t dance around GA4’s rocky reputation. Instead, she acknowledged the transition challenges and spent the episode explaining where Google is taking the platform and why. The conversation covered two separate roadmaps: what’s changing in the next 12-24 months, and what Google is building toward over the next three-plus years.
Data strength came up repeatedly throughout the conversation, which makes sense given how central it is to everything Google is building. Stribling explained why it matters for AI performance and how it creates a competitive advantage for brands that get it right.
The episode also included practical guidance on setting up measurement correctly so the data you’re feeding into these systems is actually useful.
Why This Matters For Advertisers
The timing of this episode is smart. GA4 has been live for a while now, but a lot of advertisers still treat it like a downgrade from Universal Analytics. Marvin said as much during the episode that the platform felt built for developers, not marketers.
What makes this podcast episode useful isn’t just hearing Google’s vision for GA4. It’s hearing a product manager explain why certain decisions were made and what problems they’re actually trying to solve. That context helps when you’re trying to decide whether to invest time learning features that feel half-baked or waiting for something better.
The most actionable takeaway from the episode is to prioritize data strength. If your setup is messy now, the gap between what GA4 can do for you and what it could do for you is only going to widen.
What PPC Professionals Are Saying
The feedback from advertisers on LinkedIn has been overwhelmingly positive. It’s an early indicator of how much this type of communication has been asked for, and Google is providing it.
Susan Wenograd, Mixtape Digital’s senior director, paid media, commented, “Love that you’re doing this!”
John Sargent, Think VEN’s founder & managing director, showed his support, as well as asked a question about AI market share:
Congratulations Ginny! Keen to hear more in the future about AI advertising as well…Gemini going from 5% to >20% market share must be encouraging, but still early days with OpenAI sat at 60%+? How do you foresee this shifting over the next 12 months?
Alexandru Stambari, performance marketing specialist, acknowledged the good Google is doing with this information, while offering his critique on execution:
It’s good to see Google openly acknowledging that data strength is now a hard requirement for AI performance, not a “nice to have.” The focus on Analytics Advisor and transparency around Ads vs Analytics discrepancies is especially valuable for teams trying to scale automation responsibly.
That said, most of these ideas aren’t new for practitioners the real gap is still execution. Without clear implementation standards, CRM alignment, and ownership over data quality, even the best product updates risk staying at the storytelling level rather than driving measurable impact.
Theme Of The Week: Betting On What Advertisers Will Pay For
This week’s announcements are about two very different bets on what advertisers actually value.
ChatGPT is betting that access to high-intent conversations is worth $60 CPMs, even without the performance data advertisers have come to expect. They’re testing whether context and attention alone justify premium pricing when attribution and optimization are off the table.
Google is betting that transparency matters enough to build an entire podcast around it. Instead of launching another ad product or feature, they’re investing in helping advertisers understand what’s already there and what’s coming. It’s a bet that better communication and clearer explanations have value in themselves.
Both are asking advertisers to care about something that isn’t purely performance-driven. ChatGPT wants you to pay more for placement without proof. Google wants you to invest time learning about platform changes instead of just running campaigns.
A click drop in your Google Ads account can feel like the floor just moved under your account.
Not because clicks are considered more of a vanity metric. But because most sites still convert just a small slice of visitors.
Shopify, believe that 2.5-3% is an average benchmark for industry leaders (although not backed with data), whereas a recent study of Shopify sites by Littedata found the average CTR was just 1.4%.
So, when click volume drops, you’re not just losing traffic. You’re losing future conversions you were counting on, and you’re handing extra shots to competitors.
The fix usually is not one magic lever. You need a quick, disciplined diagnosis:
Did you lose eligibility (Quality Score)?
Did you lose reach (impressions)?
Were there disruptions in performance with changes (like testing new ads)?
Or did you get squeezed by competition?
This article walks through the four most common causes, plus what to do next.
What Is CTR?
One of the metric definitions that hasn’t changed over the years in Google Ads is CTR.
CTR is a relatively simple formula: The number of clicks that your ad receives divided by the number of times your ad is shown (clicks ÷ impressions).
While CTR is a simple calculation, this is one of the more vital metrics to help analyze performance.
Think again if you thought CTR could only be used to gauge compelling ad copy.
So, what is the purpose of CTR? Some applications of using CTR include:
Measuring the relevance and quality of ads.
Identifying the competitiveness of keywords and ads.
Analyzing gaps between campaign budgets and keyword bids.
When your CTR is suffering, this has a direct impact on click volume.
Now that CTR has been defined and we have use cases for the metric, you’re probably wondering, “What is a good CTR?”
A recent study from Wordstream by LocaliQ noted that the average CTR for search was 6.66% across all industries.
If your average CTR isn’t stacking up to industry averages, don’t fret! Follow these comprehensive tips to help get your CTR and click volume back up to par.
Why Is My Click Volume Decreasing?
Can’t explain the sudden dip in click performance? Here are some of the common reasons to help identify the cause.
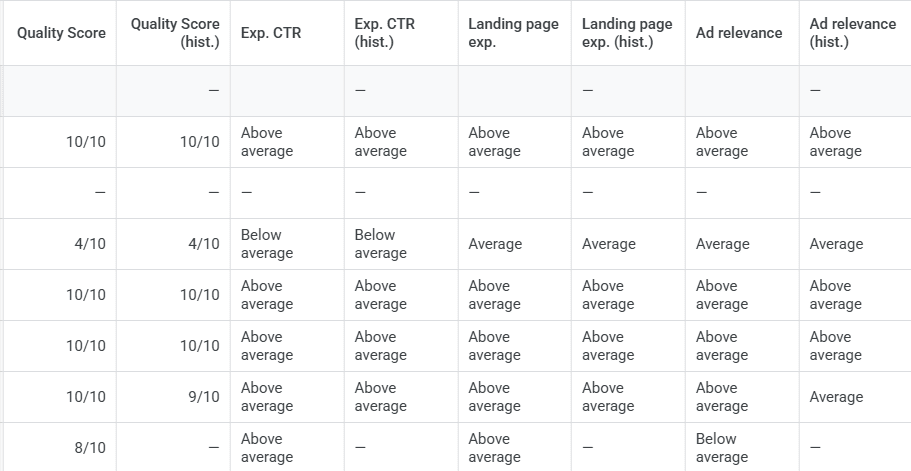
1. Did Your Quality Score Recently Drop?
While the Quality Score metric shouldn’t be considered the “end all be all,” this often underlooked metric may be a root cause of click volume decline.
Quality Score measures these key components of your ad:
Expected CTR.
Ad relevance.
Landing page relevance.
Google Ads shows you a relatively detailed view of each of these areas, so you’re not left guessing what you should focus on optimizing.
Screenshot taken from a Google Ads report, January 2026
Quality Score matters because it directly impacts how often your ads are eligible to show. Not only that, but it also affects how much you’re paying per click.
Solution: Optimize Quality Score based on the “grades” Google gives you for your keywords.
Some of these fixes may be easier to implement (such as new ad copy), but if you need to optimize your landing page, that may take time and other resources.
A thorough guide to optimizing Quality Score can be found here.
If your CTR has remained steady but is seeing click volume decrease, the main issue is this: decreased impressions.
There can be multiple factors for a sudden decrease in impressions, but here are the most common:
Seasonality
If you have a seasonal product, you’re naturally going to have dips and peaks in demand.
If searches go down for your particular industry, your keywords’ impressions will also decrease.
Updated Bidding Strategy
If you’ve recently modified your bidding strategy, there could be a misalignment between your daily budget vs. your target ROAS/CPA/CPC goal.
Any significant gaps in expectations here can cause a stark decline in impressions.
For example, if you set your bidding to a $50 CPA goal for competitive keywords but typically see a $150 CPA, this will cause almost instant volatility in impressions.
The way CPA and ROAS strategies work is to throttle impressions to users who are not likely to convert to your goal.
New Negative Keywords
Like many advertisers, you’ve had to tighten up your negative keywords. This is due to Google loosening restrictions on keyword match types.
However, you may have accidentally restricted too much on negative keywords. This can result in lost impressions because of conflicting negatives.
So, what can you do to combat low impressions?
Solution: Aside from any seasonality issues, review your current bidding strategies and ensure the targets are aligned (and realistic) to your performance goals.
Additionally, comb through your negative keyword lists to identify any conflicts that are hindering your ad from showing.
So you’ve written shiny new ad copy and implemented it across the board. You’re excited to see your improved ad copy outperform your previous ads.
But, you’ve discovered the opposite happens, and your click volume plummets.
What gives?
Essentially, any time you make an update to your campaigns, and especially ad copy, you’ve set your campaign back into learning mode. During this time, you may expect to see volatility in performance. You may see CTR drop while Google’s algorithm learns what resonates best with users.
Obviously, this is not ideal for any advertiser. You’ve spent the time to perfect a new copy and are watching it perform worse. So, what can we learn from this scenario?
Solution: A/B test your new ads before pausing all “old” ads. This can help reduce the inevitable performance volatility of pausing all old ads and replacing them with new ones.
Competition isn’t something that you can control. They may have a larger budget or more interesting ad copy than you. All of these items are out of your control.
What you can control is how you respond to competition.
Say your maximum CPC on a keyword is set to $5, but you notice a competitor is consistently showing above you. This most likely means that the competitor is outbidding you.
Solution: If you have the budget capacity, a simple remedy would be to be more aggressive in your bidding strategy. This can help increase impression and click volume as you show up more often.
Read more about how to use Smart Bidding effectively here.
Another example is if a competitor has a better ad copy than you. Say you’re selling a similar product, but a competitor has a promotion while you don’t. Which ad do you think will likely get more clicks?
Most likely, the promotional ad.
Solution: If you are not/cannot run a promotion, review your ad copy to identify how you can stand out from the competition.
Make sure you’re using all relevant ad extensions to help increase ad rank and real estate on the page. Consistently check the Ad Preview Tool to make sure your ad is still the most attractive on the page.
When clicks fall, your job is not to panic. Your job is to isolate the reason quickly, then act with intent. Here’s the simple mental checklist I use when I’m trying to get an account steady again:
If Quality Score slipped, focus on expected CTR, relevance, and landing page alignment before you touch bids.
If impressions dropped, sanity-check budgets, targets, and negative keyword conflicts first.
If new ads underperform, stop the “all at once” swap and move back to controlled testing.
If competitors get louder, tighten your message, improve your offer framing, and make sure assets are fully built out.
Click volume usually comes back when you stop treating it like a mystery and start treating it like a diagnosis. The goal is not “more clicks at any cost.” It’s restoring qualified visibility you can actually convert.
Google published a research paper about creating a challenging dataset for training AI agents for deep research. The paper offers insights into how agentic AI deep research works, which implies insights for optimizing content.
The acronym SAGE stands for Steerable Agentic Data Generation for Deep Search with Execution Feedback.
Synthetic Question And Answer Pairs
The researchers noted that the previous state of the art AI training datasets (like Musique and HotpotQA) required no more than four reasoning steps in order to answer the questions. On the number of searches needed to answer a question, Musique averages 2.7 searches per question and HotpotQA averaged 2.1 searches. Another commonly used dataset named Natural Questions (NQ) only required an average of 1.3 searches per question.
These datasets that are used to train AI agents created a training gap for deep search tasks that required more reasoning steps and a greater number of searches. How can you train an AI agent for complex real-world deep search tasks if the AI agents haven’t been trained to tackle genuinely difficult questions.
The researchers created a system called SAGE that automatically generates high-quality, complex question-answer pairs for training AI search agents. SAGE is a “dual-agent” system where one AI writes a question and a second “search agent” AI tries to solve it, providing feedback on the complexity of the question.
The goal of the first AI is to write a question that’s challenging to answer and requires many reasoning steps and multiple searches to solve.
The goal of the second AI is try to measure if the question is answerable and calculate how difficult it is (minimum number of search steps required).
The key to SAGE is that if the second AI solves the question too easily or gets it wrong, the specific steps and documents it found (the execution trace) is fed back to the first AI. This feedback enables the first AI to identify one of four shortcuts that enable the second AI to solve the question in fewer steps.
It’s these shortcuts that provide insights into how to rank better for deep research tasks.
Four Ways That Deep Research Was Avoided
The goal of the paper was to create a set of question and answer pairs that were so difficult that it took the AI agent multiple steps to solve. The feedback showed four ways that made it less necessary for the AI agent to do additional searches to find an answer.
Four Reasons Deep Research Was Unnecessary
Information Co-Location This is the most common shortcut, accounting for 35% of the times when deep research was not necessary. This happens when two or more pieces of information needed to answer a question are located in the same document. Instead of searching twice, the AI finds both answers in one “hop”.
Multi-query Collapse This happened in 21% of cases. The cause is when a single, clever search query retrieves enough information from different documents to solve multiple parts of the problem at once. This “collapses” what should have been a multi-step process into a single step.
Superficial Complexity This accounts for 13% of times when deep research was not necessary. The question looks long and complicated to a human, but a search engine (that an AI agent is using) can jump straight to the answer without needing to reason through the intermediate steps.
Overly Specific Questions 31% of the failures are questions that contain so much detail that the answer becomes obvious in the very first search, removing the need for any “deep” investigation.
The researchers found that some questions look hard but are actually relatively easy because the information is “co-located” in one document. If an agent can answer a 4-hop question in 1 hop because one website was comprehensive enough to have all the answers, that data point is considered a failure for training the agent for reasoning but it’s still something that can happen in real-life and the agent will take advantage of finding all the information on one page.
SEO Takeaways
It’s possible to gain some insights into what kinds of content satisfies the deep research. While these aren’t necessarily tactics for ranking better in agentic AI deep search, these insights do show what kinds of scenarios caused the AI agents to find all or most of the answers in one web page.
“Information Co-location” Could Be An SEO Win The researchers found that when multiple pieces of information required to answer a question occur in the same document, it reduces the number of search steps needed. For a publisher, this means consolidating “scattered” facts into one page prevents an AI agent from having to “hop” to a competitor’s site to find the rest of the answer.
Triggering “Multi-query Collapse” The authors identified a phenomenon where information from different documents can be retrieved using a single query. By structuring content to answer several sub-questions at once, you enable the agent to find the full solution on your page faster, effectively “short-circuiting” the long reasoning chain the agent was prepared to undertake.
Eliminating “Shortcuts” (The Reasoning Gap) The research paper notes that the data generator fails when it accidentally creates a “shortcut” to the answer. As an SEO, your goal is to be that shortcut—providing the specific data points like calculations, dates, or names that allow the agent to reach the final answer without further exploration.
The Goal Is Still To Rank In Classic Search
For an SEO and a publisher, these shortcuts underline the value of creating a comprehensive document because it will remove the need for an AI agent from getting triggered to hop somewhere else. This doesn’t mean it will be helpful to add all the information in one page. If it makes sense for a user it may be useful to link out from one page to another page for related information.
The reason I say that is because the AI agent is conducting classic search looking for answers, so the goal remains to optimize a web page for classic search. Furthermore, in this research, the AI agent is pulling from the top three ranked web pages for each query that it’s executing. I don’t know if this is how agentic AI search works in a live environment, but this is something to consider.
In fact, one of the tests that the researchers did was conducted using the Serper API to extract search results from Google.
So when it comes to ranking in agentic AI search, consider these takeaways:
It may be useful to consider the importance of ranking in the top three.
Do optimize web pages for classic search.
Do not optimize web pages for AI search
If it’s possible to be comprehensive, remain on-topic, and rank in the top three, then do that.
Interlink to relevant pages to help those rank in classic search, preferably in the top three (to be safe).
It could be that agentic AI search will consider pulling from more than the top three in classic search. But it may be helpful to set the goal of ranking for the top 3 in classic search and to focus on ranking other pages that may be a part of the multi-hop deep research.
“Who here believes involuntary death is a good thing?”
Nathan Cheng has been delivering similar versions of this speech over the last couple of years, so I knew what was coming. He was about to try to convince the 80 or so people in the audience that death is bad. And that defeating it should be humanity’s number one priority—quite literally, that it should come above all else in the social and political hierarchy.
“If you believe that life is good and there’s inherent moral value to life,” he told them, “it stands to reason that the ultimate logical conclusion here is that we should try to extend lifespan indefinitely.”
Solving aging, he added, is “a problem that has an incredible moral duty for all of us to get involved in.”
It was the end of April, and the crowd—with its whoops and yeahs—certainly seemed convinced. They’d gathered at a compound in Berkeley, California, for a three-day event called the Vitalist Bay Summit. It was part of a longer, two-month residency (simply called Vitalist Bay) that hosted various events to explore tools—from drug regulation to cryonics—that might be deployed in the fight against death. One of the main goals, though, was to spread the word of Vitalism, a somewhat radical movement established by Cheng and his colleague Adam Gries a few years ago.
No relation to the lowercase vitalism of old, this Vitalism has a foundational philosophy that’s deceptively simple: to acknowledge that death is bad and life is good. The strategy for executing it, though, is far more obviously complicated: to launch a longevity revolution.
Interest in longevity has certainly taken off in recent years, but as the Vitalists see it, it has a branding problem. The term “longevity” has been used to sell supplements with no evidence behind them, “anti-aging” has been used by clinics to sell treatments, and “transhumanism” relates to ideas that go well beyond the scope of defeating death. Not everyone in the broader longevity space shares Vitalists’ commitment to actually making death obsolete. As Gries, a longtime longevity devotee who has largely become the enthusiastic public face of Vitalism, said in an online presentation about the movement in 2024, “We needed some new word.”
“Vitalism” became a clean slate: They would start a movement to defeat death, and make that goal the driving force behind the actions of individuals, societies, and nations. Longevity could no longer be a sideshow. For Vitalism to succeed, budgets would need to change. Policy would need to change. Culture would need to change. Consider it longevity for the most hardcore adherents—a sweeping mission to which nothing short of total devotion will do.
“The idea is to change the systems and the priorities of society at the highest levels,” Gries said in the presentation.
To be clear, the effective anti-aging treatments the Vitalists are after don’t yet exist. But that’s sort of the point: They believe they could exist if Vitalists are able to spread their gospel, influence science, gain followers, get cash, and ultimately reshape government policies and priorities.
For the past few years, Gries and Cheng have been working to recruit lobbyists, academics, biotech CEOs, high-net-worth individuals, and even politicians into the movement, and they’ve formally established a nonprofit foundation “to accelerate Vitalism.” Today, there’s a growing number of Vitalists (some paying foundation members, others more informal followers, and still others who support the cause but won’t publicly admit as much), and the foundation has started “certifying” qualifying biotech companies as Vitalist organizations. Perhaps most consequentially, Gries, Cheng, and their peers are also getting involved in shaping US state laws that make unproven, experimental treatments more accessible. They hope to be able to do the same at the national level.
VITALISMFOUNDATION.ORG
VITALISMFOUNDATION.ORG
Vitalism cofounders Nathan Cheng and Adam Gries want to launch a longevity revolution.
All this is helping Vitalists grow in prominence, if not also power. In the past, people who have spoken of living forever or making death “optional” have been dismissed by their academic colleagues. I’ve been covering the broader field of aging science for a decade, and I’ve seen scientists roll their eyes, shrug their shoulders, and turn their backs on people who have talked this way. That’s not the case for the Vitalists.
Even the scientists who think that Vitalist ideas of defeating death are wacky, unattainable ones, with the potential to discredit their field, have shown up on stage with Vitalism’s founders, and these serious researchers provide a platform for them at more traditionally academic events.
I saw this collegiality firsthand at Vitalist Bay. Faculty members from Harvard, Stanford, and the University of California, Berkeley, all spoke at events. Eric Verdin, the prominent researcher who directs the Buck Institute for Research on Aging in Novato, California, had also planned to speak, although a scheduling clash meant he couldn’t make it in the end. “I have very different ideas in terms of what’s doable,” he told me. “But that’s part of the [longevity] movement—there’s freedom for people to say whatever they want.”
Many other well-respected scientists attended, including representatives of ARPA-H, the US federal agency for health research and breakthrough technologies. And as I left for a different event on longevity in Washington, DC, just after the Vitalist Bay Summit, a sizable group of Vitalist Bay attendees headed that way too, to make the case for longevity to US lawmakers.
The Vitalists feel that momentum is building, not just for the science of aging and the development of lifespan-extending therapies, but for the acceptance of their philosophy that defeating death should be humanity’s top concern.
This, of course, sparks some pretty profound questions. What would a society without death look like—and would we even want it? After all, death has become an important part of human culture the world over. And even if Vitalists aren’t destined to realize their lofty goal, their growing influence could still have implications for us all. As they run more labs and companies, and insert themselves into the making of laws and policy, perhaps they will discover treatments that really do slow or even reverse aging. In the meantime, though, some ethicists are concerned that experimental and unproven medicines—including potentially dangerous ones—are becoming more accessible, in some cases with little to no oversight.
Gries, ultimately, has a different view of the ethics here. He thinks that being “okay with death” is what disqualifies a person from being considered ethical. “Death is just wrong,” he says. “It’s not just wrong for some people. It’s wrong for all people.”
The birth of a revolution
When I arrived at the Vitalist Bay Summit on April 25, I noticed that the venue was equipped with everything a longevity enthusiast might need: napping rooms, a DEXA body-composition scanner, a sauna in a bus, and, for those so inclined, 24-hour karaoke.
I was told that around 300 people had signed up for that day’s events, which was more than had attended the previous week. That might have been because arguably the world’s most famous longevity enthusiast, Bryan Johnson, was about to make an appearance. (If you’re curious to know more about what Johnson was doing there, you can read about our conversation here.)
The key to Vitalism has always been that“death is humanity’s core problem, and aging its primary agent,” cofounder Adam Gries told me. “So it was, and so it has continued, as it was foretold.”
But Gries, another man in his 40s who doesn’t want to die, was the first to address the audience that day. Athletic and energetic, he bounded across a stage wearing bright yellow shorts and a long-sleeved shirt imploring people to “Choose Life: VITALISM.”
Gries is a tech entrepreneur who describes himself as a self-taught software engineer who’s “good at virality.” He’s been building companies since he was in college in the 2000s, and grew his personal wealth by selling them.
As with many other devotees to the cause, his deep interest in life extension was sparked by Aubrey de Grey, a controversial researcher with an iconic long beard and matching ponytail. He’s known widely both for his optimistic views about “defeating aging” and for having reportedly made sexual comments to two longevity entrepreneurs. (In an email, de Grey said he’s “never disputed” one of these remarks but denied having made the other. “My continued standing within the longevity community speaks for itself,” he added.)
In an influential 2005 TED Talk (which has over 4.8 million views), de Grey predicted that people would live to 1,000 and spoke of the possibility of new technologies that would continue to stave off death, allowing some to avoid it indefinitely. (In a podcast recorded last year, Cheng described a recording of this talk as “the OG longevity-pilling YouTube video.”)
Many Vitalists have been influenced by controversial longevity researcher Aubrey de Grey. Cheng called his 2005 TED Talk “the OG longevity-pilling YouTube video.”
PETER SEARLE/CAMERA PRESS/REDUX
“It was kind of evident to me that life is great,” says Gries. “So I’m kind of like, why would I not want to live?”
A second turning point for Gries came during the early stages of the covid-19 pandemic, when he essentially bet against companies that he thought would collapse. “I made this 50 [fold] return,” he says. “It was kind of like living through The Big Short.”
Gries and his wife fled from San Francisco to Israel, where he grew up, and later traveled to Taiwan, where he’d obtained a “golden visa” and which was, at the time, one of only two countries that had not reported a single case of covid. His growing wealth afforded him the opportunity to take time from work and think about the purpose of life. “My answer was: Life is the purpose of life,” he says. He didn’t want to die. He didn’t want to experience the “journey of decrepitude” that aging often involves.
So he decided to dedicate himself to the longevity cause. He went about looking up others who seemed as invested as he was. In 2021 his search led him to Cheng, a Chinese-Canadian entrepreneur based in Toronto. He had dropped out of a physics PhD a few years earlier after experiencing what he describes on his website as “a massive existential crisis” and shifted his focus to “radical longevity.” (Cheng did not respond to email requests for an interview.)
The pair “hit it off immediately,” says Gries, and they spent the following two years trying to figure out what they could do. The solution they finally settled on: revolution.
After all, Gries reasons, that’s how significant religious and social movements have happened in the past. He says they sought inspiration from the French and American Revolutions, among others. The idea was to start with some kind of “enlightenment,” and with a “hardcore group,” to pursue significant social change with global ramifications.
“We were convinced that without a revolution,” Gries says, “we were as good as dead.”
A home for believers
Early on, they wrote a Vitalist declaration, a white paper that lists five core statements for believers:
Life and health are good. Death is humanity’s core problem, and aging its primary agent.
Aging causes immense suffering, and obviating aging is scientifically plausible.
Humanity should apply the necessary resources to reach freedom from aging as soon as possible.
I will work on or support others to work on reaching unlimited healthy human lifespan.
I will carry the message against aging and death.
While it’s not an explicit part of the manifesto, it was important to them to think about it as a moral philosophy as well as a movement. As Cheng said at the time, morality “guides most of the actions of our lives.” The same should be true of Vitalism, he suggested.
Gries has echoed this idea. The belief that “death is morally bad” is necessary to encourage behavior change, he told me in 2024. It is a moral drive, or moral purpose, that pushes people to do difficult things, he added.
Revolution, after all, is difficult. And to succeed—to “get unlimited great health to the top of the priority list,” as Gries says—the movement would need to infiltrate the government and shape policy decisions and national budgets. The Apollo program got people to the moon with less than 1% of US GDP; imagine, Gries asks, what we could do to human longevity with a mere 1% of GDP?
It makes sense, then, that Gries and Cheng launched Vitalism in 2023 at Zuzalu, a “pop-up city” in Montenegro that provided a two-month home for like-minded longevity enthusiasts. The gathering was in some ways a loose prototype for what they wanted to accomplish. Cheng spoke there of how they wanted to persuade 10,000 or so Vitalists to move to Rhode Island. Not only was it close to the biotech hub of Boston, but they believed it had a small enough population for an influx of new voters sharing their philosophy to influence local and state elections. “Five to ten thousand people—that’s all we need,” he said. Or if not Rhode Island, another small-ish US state, where they could still change state policy from the inside.
The ultimate goal was to recruit Vitalists to help them establish a “longevity state”—a recognized jurisdiction that “prioritizes doing something about aging,” Cheng said, perhaps by loosening regulations on clinical trials or supporting biohacking.
Bryan Johnson, who is perhaps the world’s most famous longevity enthusiast, spoke at Vitalist Bay and is trying to start a Don’t Die religion.
AGATON STROM/REDUX PICTURES
This idea is popular among many vocal members of the Vitalism community. It borrows from the concept of the “network state” developed by former Coinbase CTO Balaji Srinivasan, defined as a new city or country that runs on cryptocurrency; focuses on a goal, in this case extending human lifespan; and “eventually gains diplomatic recognition from preexisting states.”
Some people not interested in dying have made progress toward realizing such a domain. Following the success of Zuzalu, one of the event’s organizers, Laurence Ion, a young cryptocurrency investor and self-proclaimed Vitalist, joined a fellow longevity enthusiast named Niklas Anzinger to organize a sequel in Próspera, the private “special economic zone” on the Honduran island of Roatán. They called their “pop-up city” Vitalia.
I visited shortly after it launched in January 2024. The goal was to create a low-regulation biotech hub to fast-track the development of anti-aging drugs, though the “city” was more like a gated resort that hosted talks from a mix of respected academics, biohackers, biotech CEOs, and straight-up eugenicists. There was a strong sense of community—many attendees were living with or near each other, after all. A huge canvas where attendees could leave notes included missives like “Don’t die,” “I love you,” and “Meet technoradicals building the future!”
But Vitalia was short-lived, with events ending by the start of March 2024. And while many of the vibes were similar to what I’d later see at Vitalist Bay, the temporary nature of Vitalia didn’t quite match the ambition of Gries and Cheng.
Patri Friedman, a 49-year-old libertarian and grandson of the economist Milton Friedman who says he attended Zuzalu, Vitalia, and Vitalist Bay, envisions something potentially even bolder. He’s the founder of the Seasteading Institute, which has the goal of “building startup communities that float on the ocean with any measure of political autonomy” and has received funding and support from the billionaire Peter Thiel. Friedman also founded Pronomos Capital, a venture capital fund that invests in projects focused on “building the cities of tomorrow.”
His company is exploring various types of potential network states, but he says he’s found that medical tourism—and, specifically, a hunger for life extension—dominates the field. “People do not want this ‘10 years and a billion dollars to pass a drug’ thing with the FDA,” says Friedman. (While he doesn’t call himself a Vitalist, partly because he’s “almost never going to agree with” any kind of decree, Friedman holds what you might consider similarly staunch sentiments about death, which he referred to as “murder by omission.” When I asked him if he has a target age he’d like to reach, he told me he found the question “mind-bogglingly strange” and “insane.” “How could you possibly be like: Yes, please murder me at this time?” he replied. “I can always fucking shoot myself in the head—I don’t need anybody’s help.”)
But even as Vitalists and those aligned with their beliefs embrace longevity states, Gries and Cheng are reassessing their former ambitions. The network-state approach has limits, Gries tells me. And encouraging thousands of people to move to Rhode Island wasn’t as straightforward as they’d hoped it might be.
Not because he can’t find tens of thousands of Vitalists, Gries stresses—but most of them are unwilling to move their lives for the sake of influencing the policy of another state. He compares Vitalism to a startup, with a longevity state as its product. For the time being, at least, there isn’t enough consumer appetite for that product, he says.
The past year shows that it may in fact be easier to lobby legislators in states that are already friendly to deregulation. Anzinger and a lobbying group called the Alliance for Longevity Initiatives (A4LI) were integral to making Montana the first US hub for experimental medical treatments, with a new law to allow clinics to sell experimental therapies once they have been through preliminary safety tests (which don’t reveal whether a drug actually works). But Gries and his Vitalist colleagues also played a role—“providing feedback, talking to lawmakers … brainstorming [and] suggesting ideas,” Gries says.
The Vitalist crew has been in conversation with lawmakers in New Hampshire, too. In an email in December, Gries and Cheng claimed they’d “helped to get right-to-try laws passed” in the state—an apparent reference to the recent expansion of a law to make more unapproved treatments accessible to people with terminal illnesses. Meanwhile, three other bills that expand access even further are under consideration.
Ultimately, Gries stresses, Vitalism is “agnostic to the fixing strategies” that will help them meet their goals. There is, though, at least one strategy he’s steadfast about: building influence.
Only the hardcore
To trigger a revolution, the Vitalists may need to recruit only around 3% or 4% of “society” to their movement, Gries believes. (Granted, that does still mean hundreds of millions of people.) “If you want people to take action, you need to focus on a small number of very high-leverage people,” he tells me.
That, perhaps unsurprisingly, includes wealthy individuals with “a net worth of $10 million or above,” he says. He wants to understand why (with some high-profile exceptions, including Thiel, who has been investing in longevity-related companies and foundations for decades) most uber-wealthy people don’t invest in the field—and how he might persuade them to do so. He won’t reveal the names of anyone he’s having conversations with.
These “high-leverage” people might also include, Gries says, well-respected academics, leaders of influential think tanks, politicians and policymakers, and others who work in government agencies.
A revolution needs to find its foot soldiers. And at the most basic level, that will mean boosting the visibility of the Vitalism brand—partly through events like Vitalist Bay, but also by encouraging others, particularly in the biotech space, to sign on. Cheng talks of putting out a “bat signal” for like-minded people, and he and Gries say that Vitalism has brought together people who have gone on to collaborate or form companies.
There’s also their nonprofit Vitalism International Foundation, whose supporters can opt to become “mobilized Vitalists” with monthly payments of $29 or more, depending on their level of commitment. In addition, the foundation works with longevity biotech companies to recognize those that are “aligned” with its goals as officially certified Vitalist organizations. “Designation may be revoked if an organization adopts apologetic narratives that accept aging or death,” according to the website. At the time of writing, that site lists 16 certified Vitalist organizations, including cryopreservation companies, a longevity clinic, and several research companies.
One of them is Shift Bioscience, a company using CRISPR and aging clocks—which attempt to measure biological age—to identify genes that might play a significant role in the aging process and potentially reverse it. It says it has found a single gene that can rejuvenate multiple types of cells.
Shift cofounder Daniel Ives, who holds degrees in mitochondrial and computational biology, tells me he was also won over to the longevity cause by de Grey’s 2005 TED Talk. He now has a countdown on his computer: “It’s my days till death,” he says—around 22,000 days left. “I’m using that to keep myself focused.”
Ives calls himself the “Vitalist CEO” of Shift Bioscience. He thinks the label is important first as a way for like-minded people to find and support each other, grow their movement, and make the quest for longevity mainstream. Second, he says, it provides a way to appeal to “hardcore” lifespan extensionists, given that others in the wellness and cosmetics industry have adopted the term “longevity” without truly applying themselves to finding rejuvenation therapies. He refers to unnamed companies and individuals who claim that drinking juices, for example, can reverse aging by five years or so.
“You don’t have to convince the mainstream,” says ARPA-H science and engineering advisor Mark Hamalainen. Though “kind of a terrible example,”he notes, Stalinism started small. “Sometimes you just have to convince the right people.”
“Somebody will make these claims and basically throw legitimate science under the bus,” he says. He doesn’t want spurious claims made on social media to get lumped in with the company’s serious molecular biology. Shift’s head of machine learning, Lucas Paulo de Lima Camillo, was recently awarded a $10,000 prize by the well-respected Biomarkers of Aging Consortium for an aging clock he developed.
Another out-and-proud Vitalist CEO is Anar Isman, the cofounder of AgelessRx, a telehealth provider that offers prescriptions for purported longevity drugs—and a certified Vitalist organization. (Isman, who is in his early 40s, used to work at a hedge fund but was inspired to join the longevity field by—you guessed it—de Grey.)
During a panel session at Vitalist Bay, he stressed that he too saw longevity as a movement—and a revolution—rather than an industry. But he also claimed his company wasn’t doing too badly commercially. “We’ve had a lot of demand,” he said. “We’ve got $60 million plus in annual revenue.”
Many of his customers come to the site looking for treatments for specific ailments, he tells me. He views each as an opportunity to “evangelize” his views on “radical life extension.” “I don’t see a difference between … dying tomorrow or dying in 30 years,” he says. He wants to live “at least 100 more” years.
CHRIS LABROOY
Vitalism, though, isn’t just appealing to commercial researchers. Mark Hamalainen, a 41-year-old science and engineering advisor at ARPA-H, describes himself as a Vitalist. He says he “kind of got roped into” Vitalism because he also works with Cheng—they founded the Longevity Biotech Fellowship, which supports new entrants to the field through mentoring programs. “I kind of view it as a more appealing rebranding of some of the less radical aspects of transhumanism,” he says. Transhumanism—the position that we can use technologies to enhance humans beyond the current limits of biology—covers a broad terrain, but “Vitalism is like: Can we just solve this death thing first? It’s a philosophy that’s easy to get behind.”
In government, he works with individuals like Jean Hébert, a former professor of genetics and neuroscience who has investigated the possibility of rejuvenating the brain by gradually replacing parts of it; Hébert has said that “[his] mission is to beat aging.” He spoke at Zuzalu and Vitalist Bay.
Andrew Brack, who serves as the program manager for proactive health at ARPA-H, was at Vitalist Bay, too. Both Brack and Hébert oversee healthy federal budgets—Hébert’s brain replacement project was granted $110 million in 2024, for example.
Neither Hébert nor Brack has publicly described himself as a Vitalist, and Hébert wouldn’t agree to speak to me without the approval of ARPA-H’s press office, which didn’t respond to multiple requests for an interview with him or Brack. Brack did not respond to direct requests for an interview.
Gries says he thinks that “many people at [the US Department of Health and Human Services], including all agencies, have a longevity-positive view and probably agree with a lot of the ideas Vitalism stands for.” And he is hoping to help secure federal positions for others who are similarly aligned with his philosophy. On both Christmas Eve and New Year’s Eve last year, Gries and Cheng sent fundraising emails describing an “outreach effort” to find applicants for six open government positions that, together, would control billions of dollars in federal funding. “Qualified, mission-aligned candidates we’d love to support do exist, but they need to be found and encouraged to apply,” the pair wrote in the second email. “We’re starting a systematic search to reach, screen, and support the best candidates.”
Hamalainen supports Gries’s plan to target high-leverage individuals. “You don’t have to convince the mainstream,” he says. Though “kind of a terrible example,” Hamalainen notes, Stalinism started small. “Sometimes you just have to convince the right people.”
One of the “right” people may be the man who inspired Gries, Hamalainen, Ives, Isman, and so many others to pursue longevity in the first place: de Grey. He’s now a paid-up Vitalist and even spoke at Vitalist Bay. Having been in the field for over 20 years, de Grey tells me, he’s seen various terms fall in and out of favor. Those terms now have “baggage that gets in the way,” he says. “Sometimes it’s useful to have a new term.”
The sometimes quiet (sometimes powerful, sometimes influential) Vitalists
Though one of the five principles of Vitalism is a promise to “carry the message,” some people who agree with its ideas are reluctant to go public, including some signed-up Vitalists. I’ve asked Gries multiple times over several years, but he won’t reveal how many Vitalists there are, let alone who makes up the membership.
Even some of the founders of Vitalism don’t want to be public about it. Around 30 people were involved in developing the movement, Gries says—but only 22 are named as contributors to the Vitalism white paper (with Gries as its author), including Cheng, Vitalia’s Ion, and ARPA-H’s Hamalainen. Gries won’t reveal the names of the others. He acknowledges that some people just don’t like to publicly affiliate with any organization. That’s certainly what I’ve found when I’ve asked members of the longevity community if they’re Vitalists. Many said they agreed with the Vitalist declaration, and that they liked and supported what Gries was doing. But they didn’t want the label.
Some people worry that associating with a belief system that sounds a bit religious—even cult-like, some say—won’t do the cause any favors. Others have a problem with the specific wording of the declaration.
For instance, Anzinger—the other Vitalia founder—won’t call himself a Vitalist. He says he respects the mission, but that the declaration is “a bit poetic” for his liking.
And Dylan Livingston, CEO of A4LI and arguably one of the most influential longevity enthusiasts out there, won’t describe himself as a Vitalist either.
Many other longevity biotech CEOs also shy away from the label—including Emil Kendziorra, who runs the human cryopreservation company Tomorrow Bio, even though that’s a certified Vitalist organization. Kendziorra says he agrees with most of the Vitalist declaration but thinks it is too “absolutist.” He also doesn’t want to imply that the pursuit of longevity should be positioned above war, hunger, and other humanitarian issues. (Gries has heard this argument before, and counters that both the vast spending on health care for people in the last years of their life and the use of lockdown strategies during the covid pandemic suggest that, deep down, lifespan extension is “society’s revealed preference.”)
Still, because Kendziorra agrees with almost everything in the declaration, he believes that “pushing it forward” and bringing more attention to the field by labeling his company a Vitalist organization is a good thing. “It’s to support other people who want to move the world in that direction,” he says. (He also offered Vitalist Bay attendees a discount on his cryopreservation services.)
“There’s a lot of closeted scientists working in our field, and they get really excited about lifespans increasing,” explains Ives of Shift Bioscience. “But you’ll get people who’ll accuse you of being a lunatic that wants to be immortal.” He claims that people who represent biotech companies tell him “all the time” that they are secretly longevity companies but avoid using the term because they don’t want funders or collaborators to be “put off.”
Ultimately, it may not really matter how much people adopt the Vitalist label as long as the ideas break through. “It’s pretty simple. [The Vitalist declaration] has five points—if you agree with the five points, you are a Vitalist,” says Hamalainen. “You don’t have to be public about it.” He says he’s spoken to others about “coming out of the closet” and that it’s been going pretty well.
Gries puts it more bluntly: “If you agree with the Vitalist declaration, you are a Vitalist.”
And he hints that there are now many people in powerful positions—including in the Trump administration—who share his views, even if they don’t openly identify as Vitalists.
Jim O’Neill, the deputy secretary of health and human services, is one of the highest-profile longevity enthusiasts serving in government. Gries says, “It seems that now there is the most pro-longevity administration in American history.”
AMY ROSSETTI/DEPARTMENT OF HEALTH AND HUMAN SERVICES VIA AP
O’Neill has long been interested in both longevity and the idea of creating new jurisdictions. Until March 2024, he served on the board of directors of Friedman’s Seasteading Institute. He also served as CEO of the SENS Research Foundation, a longevity organization founded by de Grey, between 2019 and 2021, and he represented Thiel as a board member there for many years. Many people in the longevity community say they know him personally, or have at least met him. (Tristan Roberts, a biohacker who used to work with a biotech company operating in Próspera, tells me he served O’Neill gin when he visited his Burning Man camp, which he describes as a “technology gay camp from San Francisco and New York.” Hamalainen also recalls meeting O’Neill at Burning Man, at a “techy, futurist” camp.) (Neither O’Neill nor representatives from the Department of Health and Human Services responded to a request to comment about this.)
O’Neill’s views are arguably becoming less fringe in DC these days. The day after the Vitalist Bay Summit, A4LI was hosting its own summit in the capital with the goal of “bringing together leaders, advocates, and innovators from around the globe to advance legislative initiatives that promote a healthier human lifespan.” I recognized lots of Vitalist Bay attendees there, albeit in more formal attire.
The DC event took place over three days in late April. The first two involved talks by longevity enthusiasts across the spectrum, including scientists, lawyers, and biotech CEOs. Vitalia’s Anzinger spoke about the success he’d had in Próspera, and ARPA-H’s Brack talked about work his agency was doing. (Hamalainen was also there, although he said he was not representing ARPA-H.)
But the third day was different and made me think Gries may be right about Vitalism’s growing reach. It began with a congressional briefing on Capitol Hill, during which Representative Gus Bilirakis, a Republican from Florida, asked, “Who doesn’t want to live longer, right?” As he explained, “Longevity science … directly aligns with the goals of the Make America Healthy Again movement.”
“There’s a lot of closeted scientists working in our field, and they get really excited about lifespans increasing,” says Daniel Ives of Shift Bioscience. “But you’ll get people who’ll accuse you of being a lunatic that wants to be immortal.”
Bilirakis and Representative Paul Tonko, a New York Democrat, were followed by Mehmet Oz, the former TV doctor who now leads the Centers for Medicare and Medicaid Services; he opened with typical MAHA talking points about chronic disease and said US citizens have a “patriotic duty” to stay healthy to keep medical costs down. The audience was enthralled as Oz talked about senescent cells, the zombie-like aged cells that are thought to be responsible for some age-related damage to organs and tissues. (The offices of Bilirakis and Tonko did not respond to a request for comment; neither did the Centers for Medicare and Medicaid Services.)
And while none of the speakers went anywhere near the concept of radical life extension, the Vitalists in the audience were suitably encouraged.
Gries is too: “It seems that now there is the most pro-longevity administration in American history.”
The fate of “immortality quests”
Whether or not Vitalism starts a revolution, it will almost always be controversial in some quarters. While believers see an auspicious future, others are far less certain of the benefits of a world designed to defeat death.
Gries and Cheng often make the case for deregulation in their presentations. But ethicists—and even some members of the longevity community—point out that this comes with risks. Some question whether it is ever ethical to sell a “treatment” without some idea of how likely it is to benefit the person buying and taking it. Enthusiasts counter with arguments about bodily autonomy. And they hope Montana is just the start.
Then there’s the bigger picture. Is it really that great not to die … ever? Some ethicists argue that for many cultures, death is what gives meaning to life.
Sergio Imparato, a moral philosopher and medical ethicist at Harvard University, believes that death itself has important moral meaning. We know our lives will end, and our actions have value precisely because our time is limited, he says. Imparato is concerned that Vitalists are ultimately seeking to change what it means to be human—a decision that should involve all members of society.
Alberto Giubilini, a philosopher at the University of Oxford, agrees. “Death is a defining feature of humanity,” he says. “Our psychology, our cultures, our rituals, our societies, are built around the idea of coping with death … it’s part of human nature.”
CHRIS LABROOY
Imparato’s family is from Naples, Italy, where poor residents were once laid to rest in shared burial sites, with no headstones to identify them. He tells me how the locals came to visit, clean, and even “adopt” the skulls as family members. It became a weekly ritual for members of the community, including his grandmother, who was a young girl at the time. “It speaks to what I consider the cultural relevance of death,” he says. “It’s the perfect counterpoint to … the Vitalist conception of life.”
Gries seems aware of the stigma around such “immortality quests,” as Imparato calls them. In his presentations, Gries shares lists of words that Vitalists should try to avoid—like “eternity,” “radical,” and “forever,” as well as any religious terms.
He also appears to be dropping, at least publicly, the idea that Vitalism is a “moral” movement. Morality was “never part of the Vitalist declaration,” Gries told me in September. When I asked him why he had changed his position on this, he dismissed the question. “Our point … was always that death is humanity’s core problem, and aging its primary agent,” he told me. “So it was, and so it has continued, as it was foretold.”
But despite these attempts to tweak and control the narrative, Vitalism appears to be opening the door to an incredibly wide range of sentiments in longevity science. A decade ago, I don’t think there would have been any way that the views espoused by Gries, Anzinger, and others who support Vitalist sentiments would have been accepted by the scientific establishment. After all, these are people who publicly state they hope to live indefinitely and who have no training in the science of aging, and who are open about their aims to find ways to evade the restrictions set forth by regulatory agencies like the FDA—all factors that might have rendered them outcasts not that long ago.
But Gries and peers had success in Montana. Influential scientists and policymakers attend Vitalism events, and Vitalists are featured regularly at more mainstream longevity events. Last year’s Aging Research and Drug Discovery (ARDD) conference in Copenhagen—widely recognized as the most important meeting in aging science—was sponsored in part by Anzinger’s new Próspera venture, Infinita City, as well as by several organizations that are either certified Vitalist or led by Vitalists.
“I was thinking that maybe what I was doing was very fringe or out there,” Anzinger, the non-Vitalist supporter of Vitalism, admits. “But no—I feel … loads of support.”
There was certainly an air of optimism at the Vitalist Bay Summit in Berkeley. Gries’s positivity is infectious. “All the people who want a fun and awesome surprise gift, come on over!” he called out early on the first day. “Raise your voice if you’re excited!” The audience whooped in response. He then proceeded to tell everyone, Oprah Winfrey–style, that they were all getting a free continuous glucose monitor. “You get a CGM! You get a CGM!” Plenty of attendees actually attached them to their arms on the spot.
Every revolution has to start somewhere, right?
This piece has been updated to clarify a quote from Mark Hamalainen.
The eastern half of the US saw a monster snowstorm over the weekend. The good news is the grid has largely been able to keep up with the freezing temperatures and increased demand. But there were some signs of strain, particularly for fossil-fuel plants.
One analysis found that PJM, the nation’s largest grid operator, saw significant unplanned outages in plants that run on natural gas and coal. Historically, these facilities can struggle in extreme winter weather.
Much of the country continues to face record-low temperatures, and the possibility is looming for even more snow this weekend. What lessons can we take from this storm, and how might we shore up the grid to cope with extreme weather?
Living in New Jersey, I have the honor of being one of the roughly 67 million Americans covered by the PJM Interconnection.
So I was in the thick of things this weekend, when PJM saw unplanned outages of over 20 gigawatts on Sunday during the height of the storm. (That’s about 16% of the grid’s demand that afternoon.) Other plants were able to make up the difference, and thankfully, the power didn’t go out in my area. But that’s a lot of capacity offline.
Typically, the grid operator doesn’t announce details about why an outage occurs until later. But analysts at Energy Innovation, a policy and research firm specializing in energy and climate, went digging. By examining publicly available grid mix data (a breakdown of what types of power plants are supplying the grid), the team came to a big conclusion: Fossil fuels failed during the storm.
The analysts found that gas-fired power plants were producing about 10 gigawatts less power on Sunday than the peak demand on Saturday, even while electricity prices were high. Coal- and oil-burning plants were down too. Because these plants weren’t operating, even when high prices would make it quite lucrative, they were likely a significant part of the problem, says Michelle Solomon, a manager in the electricity program at Energy Innovation.
PJM plans to share more details about the outages at an upcoming committee meeting once the cold snap passes, Dan Lockwood, a PJM spokesperson, told me via email.
Fossil-fuel plants can see reliability challenges during winter: When temperatures drop, pressures in natural-gas lines fall too, which can lead to issues for fuel supply. Freezing temperatures can throw compression stations and other mechanical equipment offline and even freeze piles of coal.
One of the starkest examples came in 2021, when Texas faced freezing temperatures that took many power plants offline and threw the grid into chaos. Many homes lost power for days, and at least 246 people died during that storm.
Texas fared much better this time around. After 2021, the state shored up its grid, adding winter weatherization for power plants and transmission systems. Texas has also seen a huge flood of batteries come online, which has greatly helped the grid during winter demand peaks, especially in the early mornings. Texas was also simply lucky that this storm was less severe there, as one expert told Inside Climate News this week.
Here on the East Coast, we’re not out of the woods yet. The snow has stopped falling, but grids are still facing high electricity demand because of freezing temperatures. (I’ve certainly been living under my heated blanket these last few days.)
PJM could see a peak power demand of 130 gigawatts for seven straight days, a winter streak that the local grid has never experienced, according to an update to the utility’s site on Tuesday morning.
The US Department of Energy issued emergency orders to several grid operators, including PJM, that allow power plants to run while basically ignoring emissions regulations. The department also issued orders allowing several grids to tell data centers and other facilities to begin using backup generators. (This is good news for reliability but bad news for clean air and the climate, since these power sources are often incredibly emissions-intensive.)
We here on the East Coast could learn a thing or two from Texas so we don’t need to resort to these polluting emergency measures to keep the lights on. More energy storage could be a major help in future winter storms, lending flexibility to the grid to help ride out the worst times, Solomon says. Getting offshore wind online could also help, since those facilities typically produce reliable power in the winter.
No one energy source will solve the massive challenge of building and maintaining a resilient grid. But as we face the continued threat of extreme storms, renewables might actually help us weather them.
This article is from The Spark, MIT Technology Review’s weekly climate newsletter. To receive it in your inbox every Wednesday, sign up here.