Google released another Core Update to its search algorithm over the holidays. It was the most comprehensive update of 2025.
Google changes its algorithm frequently. Some are more widespread than others. Unlike Spam Updates, Core Updates generally do not penalize but, instead, alter how the algorithm treats certain queries and their intent.
For example, a Core Update may result in more “best of” listings (rather than product categories) in search results. Ecommerce sites may lose traffic, but not because of anything they’ve done, so no fix is required.
Yet a Core Update may result in higher rankings for certain types of content, which could prompt merchants to add those pages.
Core Updates can elevate a wide range of queries. The recent holiday update lowered the listings of large publishers and elevated niche sites. Search Engine Journal reported that Macy’s rankings decreased, while those of Columbia, The North Face, and Fragrance Market increased.
Content helpfulness
Google’s infamous Helpful Content algorithm is now part of its Core Updates and can, in theory, target an “unhelpful” site.
Google provides guidelines to human evaluators for what makes content helpful. It’s the best indicator for search optimizers as to Google’s definition of that term. To paraphrase from the guidelines:
Websites should place the most useful portions at the top of a page.
The amount of effort, originality, and skill determines the quality of the content.
Avoid unnecessary fluff or “filler” content that obscures what visitors are looking for.
Use clear titles and headings that inform, not oversell.
If a Core Update resulted in lost traffic, scrutinize your content helpfulness and on-page engagement.
How to recover
It’s often difficult to know why a Core Update lowered a site’s rankings. To diagnose, I typically start with the helpfulness of its pages and its overall engagement.
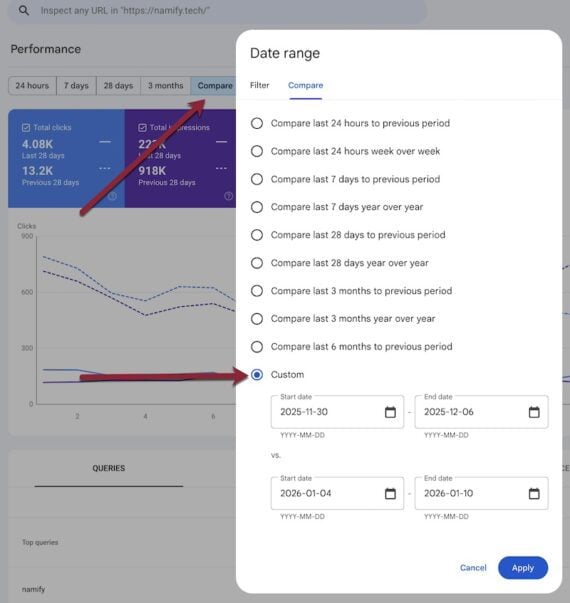
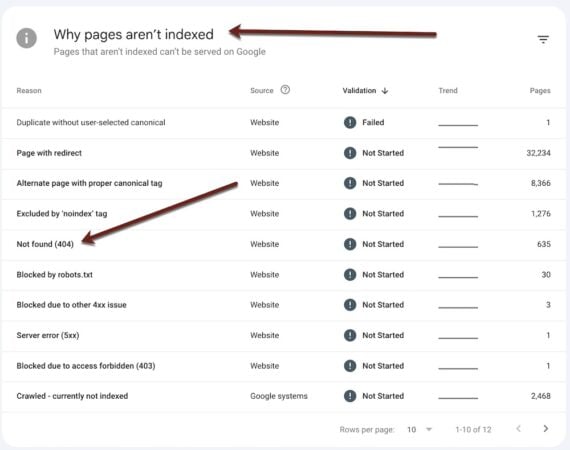
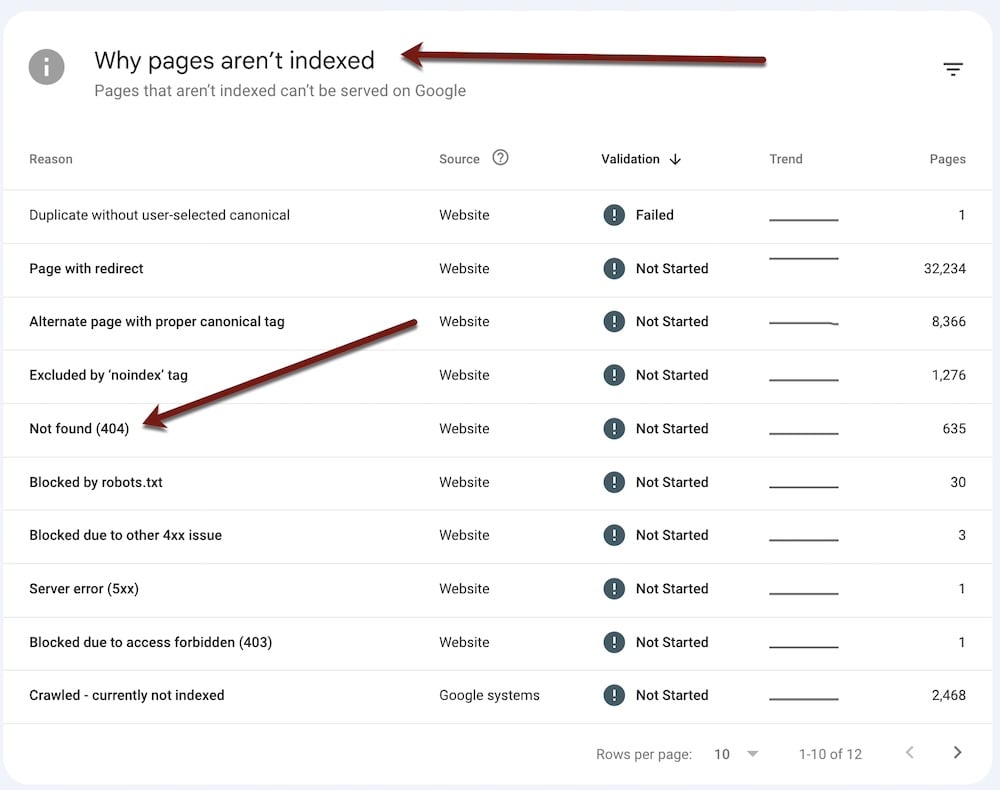
The first step is always to identify what was lost. Search Console will reveal the impacted queries:
Go to the full “Performance” report.
Choose “Compare” in the “More” filter.
Choose “Custom” and set start and end dates to expose the week before the change (early December for the most recent update) and the week after (beginning of January). Click “Apply.”
Sort the ensuing “Queries” column and the “Clicks Difference” column to see queries that now generate fewer clicks.
Select a before and after date range in Search Console to identify queries that generate fewer organic clicks.
Next, manually search Google for each affected query to determine if results shifted broadly or only for your page. The appearance of many new listings that answer a query in a new way may indicate a broad shift.
Semrush provides monthly snapshots of ranking URLs for each query. Refer to its archive to see how your overall SERPs have changed. If you see a widespread shift (i.e., 80% of listings are new for a given query), there is likely no fix needed. It’s Google changing its algorithm.
If only your site is downranked, most definitely look at the impacted pages and how to make them more helpful and engaging, such as:
Move the main portion, such as a quick answer to a search query, to the top.
Improve page structure and subheadings.
Remove ads, such as intrusive pop-ups, that block users from interacting with a page.
Add jump-to links that help visitors navigate the page.
Include social proof on the page.
Show the author’s name and bio.
Link to trusted sources.
Add helpful images and videos.
Update the page with recent data, trends, and stats (with sources).
Add explanatory sections, such as FAQs and definitions, tailored to the page’s purpose.
Helpfulness is subjective and vague. Nonetheless, consider your target audience and tailor your content accordingly.
Google announces only substantial Core Updates, those that affect many users. Lesser, unannounced updates occur more often and can result in recoveries.
Google’s John Mueller recently answered a question about phantom noindex errors reported in Google Search Console. Mueller asserted that these reports may be real.
Noindex In Google Search Console
A noindex robots directive is one of the few commands that Google must obey, one of the few ways that a site owner can exercise control over Googlebot, Google’s indexer.
And yet it’s not totally uncommon for search console to report being unable to index a page because of a noindex directive that seemingly does not have a noindex directive on it, at least none that is visible in the HTML code.
When Google Search Console (GSC) reports “Submitted URL marked ‘noindex’,” it is reporting a seemingly contradictory situation:
The site asked Google to index the page via an entry in a Sitemap.
The page sent Google a signal not to index it (via a noindex directive).
It’s a confusing message from Search Console that a page is preventing Google from indexing it when that’s not something the publisher or SEO can observe is happening at the code level.
“For the past 4 months, the website has been experiencing a noindex error (in ‘robots’ meta tag) that refuses to disappear from Search Console. There is no noindex anywhere on the website nor robots.txt. We’ve already looked into this… What could be causing this error?”
Noindex Shows Only For Google
Google’s John Mueller answered the question, sharing that there were always a noindex showing to Google on the pages he’s examined where this kind of thing was happening.
Mueller responded:
“The cases I’ve seen in the past were where there was actually a noindex, just sometimes only shown to Google (which can still be very hard to debug). That said, feel free to DM me some example URLs.”
While Mueller didn’t elaborate on what can be going on, there are ways to troubleshoot this issue to find out what’s going on.
How To Troubleshoot Phantom Noindex Errors
It’s possible that there is a code somewhere that is causing a noindex to show just for Google. For example, it may have happened that a page at one time had a noindex on it and a server-side cache (like a caching plugin) or a CDN (like Cloudflare) has cached the HTTP headers from that time, which in turn would cause the old noindex header to be shown to Googlebot (because it frequently visits the site) while serving a fresh version to the site owner.
Checking the HTTP Header is easy, there are many HTTP header checkers like this one at KeyCDN or this one at SecurityHeaders.com.
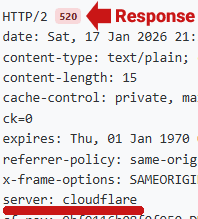
A 520 server header response code is one that’s sent by Cloudflare when it’s blocking a user agent.
Screenshot: 520 Cloudflare Response Code
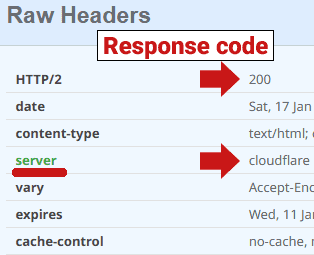
Below is a screenshot of a 200 server response code generated by cloudflare:
Screenshot: 200 Server Response Code
I checked the same URL using two different header checkers, with one header checker returning a a 520 (blocked) server response code and the other header checker sending a 200 (OK) response code. That shows how differently Cloudflare can respond to something like a header checker. Ideally, try checking with several header checkers to see if there’s a consistent 520 response from Cloudflare.
In the situation where a web page is showing something exclusively to Google that is otherwise not visible to someone looking at the code, what you need to do is to get Google to look at the page for you using an actual Google crawler and from a Google IP address. The way to do this is by dropping the URL into Google’s Rich Results Test. Google will dispatch a crawler from a Google IP address and if there’s something on the server (or a CDN) that’s showing a noindex, this will catch it. In addition to the structured data, the Rich Results test will also provide the HTTP response and a snapshot of the web page showing exactly what the server shows to Google.
When you run a URL through the Google Rich Results Test, the request:
Originates from Google’s Data Centers: The bot uses an actual Google IP address.
Passes Reverse DNS Checks: If the server, security plugin, or CDN checks the IP, it will resolve back to googlebot.com or google.com.
If the page is blocked by noindex, the tool will be unable to provide any structured data results. It should provide a status saying “Page not eligible” or “Crawl failed”. If you see that, click a link for “View Details” or expand the error section. It should show something like “Robots meta tag: noindex” or ‘noindex’ detected in ‘robots’ meta tag”.
This approach does not send the GoogleBot user agent, it uses the Google-InspectionTool/1.0 user agent string. That means if the server block is by IP address then this method will catch it.
Another angle to check is for the situation where a rogue noindex tag is specifically written to block GoogleBot, you can still spoof (mimic) the GoogleBot user agent string with Google’s own User Agent Switcher extension for Chrome or configure an app like Screaming Frog set to identify itself with the GoogleBot user agent and that should catch it.
Screenshot: Chrome User Agent Switcher
Phantom Noindex Errors In Search Console
These kinds of errors can feel like a pain to diagnose but before you throw your hands up in the air take some time to see if any of the steps outlined here will help identify the hidden reason that’s responsible for this issue.
A common question among search optimizers is whether a “404” HTTP status code conveys negative ranking signals for the site as a whole.
The answer is yes, but indirectly.
Impact of 404s
For starters, a 404 error is not a direct ranking signal. Broken links or deleted pages do not impact sitewide rankings in Google search results. Former Google Webmaster Trends Analyst Susan Moskwa confirmed this in 2011. She called 404 errors a natural occurrence on the web, one that search engines are aware of.
She also stated that Google prefers 404 status codes (or 410s for pages intentionally removed) because they clearly inform that the page is unavailable.
Google’s Search Console guidelines also address 404s, stating they “won’t impact your site’s search performance.”
Google’s John Mueller recently confirmed this on Reddit (“johnmu” ): “Just to be clear: 404s/410s are not a negative quality signal. It’s how the web is supposed to work.”
Yet 404 status codes can result in a loss of organic rankings through other signals:
Poor usability. Clicking a broken link is a poor user experience, which can prompt visitors to abandon a site. Clicks and engagementare Google ranking factors. Visitors who land on a site and quickly leave suggest to Google that they are dissatisfied.
Loss of link equity. Internal and external links to deleted pages pass no link equity.
Detecting 404s
Hence detecting and fixing broken links and deleted pages is a key step in diagnosing organic traffic drops. I typically use three methods: Search Console, Google Analytics, and third-party tools.
Search Console
Search Console’s “Pages” report includes unindexed URLs and the reasons, such as 404 and 410 status codes. Review the list and confirm:
You removed the pages intentionally.
No internal links point to those pages. To verify, click the 404 page in the list, then “Inspect URL” to the right for referring sitemaps or pages.
Search Console’s “Pages” report includes unindexed URLs and the reasons. Click image to enlarge.
Google Analytics
First, note the default title of your 404 pages. Load a meaningless, non-existent URL on your site, such as yoursite.com/iuyhtgf. View the page title. (Bookmark the page, view the title in “Edit bookmark” or similar.)
In my case, it’s “404 – Page Not Found.”
View the page title, such as “404 – Page Not Found” in this example.
Next, go to the “Pages and screens: Landing page” report in Google Analytics:
Keep the primary dimension as “Page title and screen name.”
Add a secondary dimension “Page URL.”
Search for your 404 page title.
Go to the “Pages and screens: Landing page” report on Google Analytics. Click image to enlarge.
Third-party tools
Platforms such as Ahrefs and Semrush can identify external links pointing to error pages on your site. Access Semrush’s tool in the “Backlink Audit” section:
Enter your domain.
Go to the “Backlink Audit” in the right-hand panel.
Click “Indexed pages.”
Check the box for “Broken links.”
The Semrush report shows the number of domains linking to each broken page. Ahrefs’ report is similar.
Web crawlers such as Screaming Frog can identify broken internal links.
301-redirect the link to another internal page. Google will pass link equity via a 301 only if the destination page’s content is identical or very similar to the deleted version.
Don’t mass-redirect all 404 pages to the home or unrelated page. It’s a poor user experience because visitors were expecting different content.
Instead, optimize 404s by redirecting to similar pages, or do not redirect at all and encourage visitors on the 404 page to use internal search.
Magento, now officially Adobe Commerce (but still known as Magento with SEOs), remains a powerful but demanding ecommerce platform, especially in the Magento 2 era.
Adobe Commerce can deliver strong organic performance when built and optimized correctly, but it requires careful attention to technical SEO, site speed, and structured data. This guide outlines key Magento/Adobe Commerce SEO challenges and how to set your store up for long-term success in 2026.
It offers deep flexibility, strong product catalog capabilities, and enterprise-grade customization, which is why major brands like RadioShack and The National Gallery still rely on it today. But technical SEO on Magento can be challenging if the build, theme, and extensions are not handled with care.
Modern Magento builds must go beyond legacy SEO thinking. Alongside fundamentals like crawl efficiency and URL handling, store owners now need to consider Core Web Vitals, mobile-first indexing, structured data for product discovery, and visibility in AI-driven search experiences.
Magento can perform very well for organic search when implemented correctly, but out of the box, it is not optimized. Many of the known issues are fixable with the proper development and SEO process in place.
General Magento/Adobe Commerce SEO Issues
Magento 2 can deliver strong performance, but it requires the right hosting stack, theme, and caching setup. In a mobile-first and Core Web Vitals world, speed and stability are not optional, as they influence rankings, conversion rates, and how efficiently Google can crawl your store.
To build a fast Magento site, focus on solid hosting, full-page caching, Varnish, and Redis. Reducing JavaScript bloat from extensions, compressing images into modern formats like WebP or AVIF, and lazy-loading heavy assets also help keep load times low. Regular audits in tools like Lighthouse and PageSpeed Insights make sure you stay aligned with Core Web Vitals.
Crawl efficiency is another important consideration. Your mobile version needs to load all core content and links, since Google now uses mobile crawling. It helps to maintain a clear category structure and server-side rendering for critical templates, so search engines can discover and interpret key content easily. Log file analysis is also useful to understand what Googlebot sees and where it may be wasting crawl budget.
On the infrastructure side, a CDN helps with serving assets quickly globally, while running PHP 8+ and MySQL 8 ensures stronger performance and security. Server-side caching layers further support speed and consistency.
Magento/Adobe Commerce Site Speed Issues
In my experience, Magento sites often become slow due to heavy themes and unnecessary extensions. Always question whether a module is needed and consider its impact on JavaScript and DOM complexity.
A slow site can cost both traffic and sales. Faster sites convert better and get crawled more frequently by Google.
There is more to performance than these points, but focusing on hosting, caching, and efficient rendering gives your store a strong foundation.
Key priorities to keep in mind:
Optimize hosting and caching so your store responds quickly at all times, especially during peak traffic.
Minimize JavaScript and extension load to reduce render delays and maintain healthy Core Web Vitals.
Ensure content and navigation are fully accessible on mobile, supporting crawl efficiency and user experience.
Use modern image formats and lazy loading to keep pages fast, even with rich visuals.
Common Magento/Adobe Commerce Product SEO Issues
Modern Magento product SEO is not just about fixing duplication. The goal is to help search engines understand products as entities, scale content efficiently, and support both shoppers and AI-driven discovery.
Simple Vs. Configurable Products
Configurable products should hold the primary authority. Simple SKUs used for variations (color, size, style) should:
Canonical to the parent configurable product.
Avoid indexation unless they serve a unique search intent (rare cases).
Carry structured data that matches the parent.
This prevents duplicate content, consolidates ranking signals, and aligns with Google’s preference for primary entity pages.
You need to ensure canonicals are server-side rendered and not dependent on JavaScript.
Product Titles & On-Page Content
Magento default document titles are still too generic, and leave a lot of opportunity for optimization.
Your title strategy should scale but remain meaningful. For scale, it’s easy enough to use a template (such as the one below), and then modify key pages with bespoke titles as needed.
[Type] [Key Attribute] [Brand] [Variant]
Which would generate a title like: Men’s Navy Wool Sweater – Medium
For larger catalogs, you should:
Set smart naming conventions.
Optimize high-value SKUs manually.
Avoid keyword stuffing; clarity wins.
Header Tags
Header tags shape how both users and search engines understand a product page. I’ve seen Magento themes sometimes misuse or duplicate headers, which weakens content structure and confuses algorithms trying to interpret page hierarchy.
A clean structure with one H1 for the product name helps search engines immediately identify the primary entity.
Supporting sections such as details, reviews, and shipping information should use H2 tags so AI systems and Google can parse the content into digestible, meaningful blocks. A structured hierarchy also improves accessibility and user experience, which, in turn, supports better engagement metrics and signals that modern AI‑enhanced ranking systems increasingly factor in.
Structured Data
Magento provides a basic layer of schema, but modern search and AI systems require richer, more complete product data. Enhanced product schema gives search engines precise information about what the product is, how it is priced, whether it is in stock, and what other attributes define it.
This matters because AI‑driven search experiences rely heavily on structured data to understand products as entities. Including fields like brand, GTIN, SKU, material, and size helps AI classify products correctly and match them to user intent.
AI‑driven search platforms evaluate far more than keywords. They look for clarity, completeness, and consumer‑ready information. Systems like Google AI Overviews and Perplexity need clean specifications, descriptive language, review signals, and trustworthy product attributes to surface a product confidently. When Magento product pages include well‑structured attributes, FAQs, clear specifications, and real user feedback, AI models can better determine relevance and usefulness. This not only improves visibility in AI‑generated summaries but also increases the likelihood of being surfaced as a recommended product in conversational search flows.
Product URLs
The structure of your product URLs plays a significant role in crawl efficiency and clarity.
Magento allows both category‑based URLs and top‑level product URLs, but the latter is usually better for SEO and AI systems. Clean, stable URLs reduce duplication and consolidate ranking signals into one definitive version of the page. When URLs change based on category paths, search engines may split authority across multiple versions or waste crawl budget on unnecessary duplicates.
For AI search systems, predictable URLs make it easier to associate product data with a single entity across the web. Using top‑level URLs, supported by strong internal linking and accurate canonicals, helps ensure that both search engines and AI models reference the correct version of the product page.
Faceted Navigation & Crawl Efficiency
Filters can easily create thousands of thin or duplicate pages. In 2026, the focus is not on hiding parameters but managing crawl paths and preserving essential category pages.
Use “noindex, follow” on filter pages if they must be accessible.
Avoid infinite combinations of parameters.
The old Google Search Console parameter tool is deprecated. Handle parameters via:
Robots rules (carefully).
Canonical tags.
Internal linking logic.
Smart sitemap control.
AJAX filtering is fine if you pair it with crawlable fallback links.
Ensure stateful URLs exist for important filtered views (e.g., size filters for apparel).
Product Filters should not hide useful product attributes. AI systems still need to understand sizing, material, price, and availability.
URL Rewrites & Duplicate Paths
Magento’s rewrite system is powerful but prone to creating duplicates if not managed carefully. Duplicate URLs dilute authority, create confusion for crawlers, and introduce unnecessary complexity for AI systems that depend on consistent signals. Issues like category paths reappearing, /catalog/ versions resurfacing, or numbered duplicates often stem from misconfigured rewrites or bulk product imports.
For SEO, duplicate paths waste crawl budget and risk indexing low‑quality or unintentional versions of a product page. For AI‑driven search, inconsistency makes it harder to map attributes, reviews, and pricing data to the correct canonical product. Regular rewrite table audits, strict redirect rules, and blocking system paths ensure search engines see only the correct version. Clean, predictable URL behavior is essential for long‑term organic stability.
Pagination
With Google no longer using rel=next/prev, the emphasis has shifted toward clarity, crawlability, and consistent content signals. Each paginated page should have its own unique title and H1, so search engines understand that these pages represent distinct sections of a category, not duplicates. Self‑canonicals prevent incorrect consolidation while still allowing discovery of deeper product listings.
For infinite scroll implementations, providing paginated fallbacks ensures that Google and AI systems can access all products, not just the first batch loaded on scroll. Proper pagination protects category visibility, prevents orphaned products, and ensures that AI models can access a full and accurate representation of your catalog.
Adobe Commerce Page Builder (ACP)
Adobe Commerce Page Builder (ACP) is becoming a central part of the Adobe Commerce ecosystem, offering a more streamlined and flexible way to manage content.
ACP could play a growing role in SEO and AI visibility because it supports cleaner markup, more consistent content structures, and modular components that search engines can interpret more easily. As AI-driven systems rely more on structured, reliable, and semantically organized content, ACP provides a foundation for producing consistent product pages, category templates, and merchandising blocks.
For merchants, ACP also reduces the risk of layout bloat since content blocks are standardized and optimized. This helps with performance and keeps Core Web Vitals healthy, a key factor for rankings and AI-driven discovery. Even if you cannot access ACP yet, planning for its adoption ensures your store remains future-ready.
Agentic Commerce Protocol (ACP)
The Agentic Commerce Protocol (ACP) is one of the most important emerging technologies for ecommerce, and Adobe Commerce merchants should begin preparing for its impact. Unlike Page Builder, this ACP refers to a protocol designed to help AI agents interact directly with online stores.
Screenshot from acp-magento.com, November 2025
AI agents, such as those in ChatGPT, Perplexity, and Google’s agentic systems, will increasingly handle tasks like comparing products, checking availability, and completing purchases on behalf of users. The Agentic Commerce Protocol standardizes how product data, pricing, stock status, and checkout operations are communicated to these agents.
For SEO and AI visibility, ACP represents a major shift. It allows AI systems to:
Access real‑time product information.
Evaluate product suitability based on user needs.
Complete actions such as adding products to carts.
Ensure product data is accurate and trustworthy.
For merchants, adopting ACP in the future means your products can be recommended, compared, and purchased through AI interfaces, not only through traditional search. Stores that implement ACP early will have a competitive advantage in AI‑driven discovery, especially as conversational shopping becomes normalized.
Even though ACP adoption is still developing, Adobe Commerce teams should begin preparing for:
Cleaner, more structured product data.
Accurate, machine‑readable availability and pricing.
Consistent taxonomy and attributes.
Technical readiness for API exposure and agent interactions.
Magento/Adobe Commerce can be a high-performing platform for search when built with technical SEO in mind. The key is to set strong foundations, efficient crawl paths, fast performance, structured data, and clarity for both users and AI systems.
Whether you are building yourself or working with developers, use this guide as a framework to ensure your Adobe Commerce store is set up for organic success in 2026 and beyond.
Ever clicked a link and landed on a “Page Not Found” error? Redirects prevent that. They send visitors and search engines to the right page automatically. Redirects are crucial for both SEO and user experience. For SEO, they preserve link equity and keep your rankings intact. Additionally, it enhances the user experience, as no one likes dead ends.
Table of contents
Key takeaways
A redirect automatically sends users and search engines from one URL to another, preventing errors like ‘Page Not Found.’
Redirects are crucial for SEO and user experience, preserving link equity and maintaining rankings.
Different types of redirects exist: 301 for permanent moves and 302 for temporary ones.
Avoid client-side redirects, such as meta refresh or JavaScript, as they can harm SEO.
Use Yoast SEO Premium to easily set up and manage redirects on your site.
What is a redirect?
A redirect is a method that automatically sends users and search engines from one URL to another. For example, if you delete a page, a redirect can send visitors to a new or related page instead of a 404 error.
How redirects work
A user or search engine requests a URL (e.g., yoursite.com/page-old).
The server responds with a redirect instruction.
The browser or search engine follows the redirect to the new URL (e.g., yoursite.com/page-new).
Redirects can point to any URL, even on a different domain.
Why redirects matter
Redirects keep your website running smoothly. Without them, visitors hit dead ends, links break, and search engines get lost. They’re not just technical fixes, because they protect your traffic, preserve rankings, and make sure users land where they’re supposed to. Whether you’re moving a page, fixing a typo in a URL, or removing old content, redirects make sure that nothing gets left behind.
When to use a redirect
Use redirects in these scenarios:
Deleted pages: Redirect to a similar page to preserve traffic.
Domain changes: Redirect the old domain to the new one.
HTTP→HTTPS: Redirect insecure URLs to secure ones.
URL restructuring: Redirect old URLs to new ones (e.g., /blog/post → /articles/post).
Temporary changes: Use a 302 for A/B tests or maintenance pages.
Types of redirects
There are various types of redirects, each serving a distinct purpose. Some are permanent, some are temporary, and some you should avoid altogether. Here’s what you need to know to pick the right one.
Not all redirects work the same way. A 301 redirect tells search engines a page has moved permanently, while a 302 redirect signals a temporary change. Client-side redirects, like meta refresh or JavaScript, exist because they’re sometimes the only option on restrictive hosting platforms or static sites, but they often create more problems than they solve. Below, we break down each type, explain when to use it, and discuss its implications for your SEO.
Redirect types at a glance
Redirect type
Use case
When to use
Browser impact
SEO impact
SEO risk
301
Permanent move
Deleted pages, domain changes, HTTP→HTTPS
Cached forever
Passes (almost) all link equity
None if used correctly
302
Temporary move
A/B testing, maintenance pages
Not cached
May not pass link equity
Can dilute SEO if used long-term
307
Temporary move (strict)
API calls, temporary content shifts
Not cached
Search engines may ignore
High if misused
308
Permanent move (strict)
Rare; use 301 instead
Cached forever
Passes link equity
None
Meta Refresh
Client-side redirect
Avoid where possible
Slow, not cached
Unreliable
High (hurts UX/SEO)
JavaScript
Client-side redirect
Avoid where possible
Slow, not cached
Unreliable
High (hurts UX/SEO)
301 redirects: Permanent moves
A 301 redirect tells browsers and search engines that a page has moved permanently. Use it when:
You delete a page and want to send visitors to a similar one.
You change your domain name.
You switch from HTTP to HTTPS.
SEO impact: 301 redirects pass virtually all link equity to the new URL. But be sure to never redirect to irrelevant pages, as this can confuse users and hurt SEO. For example, redirecting a deleted blog post about “best running shoes” to your homepage, instead of a similar post about running gear. This wastes link equity and frustrates visitors.
A 302 redirect tells browsers and search engines that a move is temporary. Use it for:
A/B testing different versions of a page.
Temporary promotions or sales pages.
Maintenance pages.
SEO impact: 302 redirects typically don’t pass ranking power like 301s. Google treats them as temporary, so they may not preserve SEO value. For permanent moves, always use a 301 to ensure link equity transfers smoothly.
Examples of when to use a 301 and 302 redirect:
Example 1: Temporary out-of-stock product (302): An online store redirects example.com/red-sneakers to example.com/blue-sneakers while red sneakers are restocked. A 302 redirect keeps the original URL alive for future use.
Example 2: A permanent domain change (301): A company moves from old-site.com to new-site.com. A 301 redirect makes sure visitors and search engines land on the new domain while preserving SEO rankings.
307 and 308 redirects: Strict rules
These redirects follow HTTP rules more strictly than 301 or 302:
Same method: If a browser sends a POST request, the redirect must also use POST.
Caching:
307: Never cached (temporary).
308: Always cached (permanent).
When to use them:
307: For temporary redirects where you must keep the same HTTP method (e.g., forms or API calls).
308: Almost never, use a 301 instead.
For most sites: Stick with 301 (permanent) or 302 (temporary). These are for specific technical cases only.
What to know about client-side redirects:
Client-side redirects, such as meta refresh or JavaScript, execute within the browser instead of on the server. They’re rarely the right choice, but here’s why you might encounter them:
Meta refresh: A HTML tag that redirects after a delay (e.g., “You’ll be redirected in 5 seconds…”).
JavaScript redirects: Code that changes the URL after the page loads.
Why should you avoid them?
Slow: The browser must load the page first, then redirect.
Unreliable: Search engines may ignore them, hurting SEO.
Bad UX: Users see a flash of the original page before redirecting.
Security risks: JavaScript redirects can be exploited for phishing.
When they’re used (despite the risks):
Shared hosting with no server access.
Legacy systems or static HTML sites.
Ad tracking or A/B testing tools.
Stick with server-side redirects (301/302) whenever possible. If you must use a client-side redirect, test it thoroughly and monitor for SEO issues.
How redirects impact SEO
Redirects do more than just send users to a new URL. They shape how search engines crawl, index, and rank your site. A well-planned redirect preserves traffic and rankings. A sloppy one can break both. Here’s what you need to know about their impact.
Ranking power
301 redirects pass most of the link equity from the old URL to the new one. This helps maintain your rankings. 302 redirects may not pass ranking power, especially if used long-term.
Crawl budget
Too many redirects can slow down how quickly search engines crawl your site. Avoid redirect chains (A→B→C) to save crawl budget.
User experience
Redirects prevent 404 errors and keep users engaged. A smooth redirect experience can reduce bounce rates.
Common redirect mistakes
Redirects seem simple, but small errors can cause big problems. Here are the most common mistakes and how to avoid them.
Redirect chains
A redirect chain happens when one URL redirects to another, which redirects to another, and so on. For example:
old-page → new-page → updated-page → final-page
Why it’s bad:
Slows down the user experience.
Wastes crawl budget, as search engines may stop following the chain before reaching the final URL.
When a page is deleted, some sites redirect all traffic to the homepage. For example:
Redirecting old-blog-post to example.com instead of a relevant blog post.
Why it’s bad:
Confuses users who expected specific content.
Search engines may see this as a “soft 404” and ignore the redirect.
Wastes ranking power that could have been passed to a relevant page.
How to fix it:
Redirect to the most relevant page available.
If no relevant page exists, return a 404 or 410 error.
Forgetting to update sitemaps
After setting up redirects, many sites forget to update their XML sitemaps. For example:
Keeping the old URL in the sitemap while redirecting it to a new URL.
Why it’s bad:
Sends mixed signals to search engines.
Wastes crawl budget on outdated URLs.
How to fix it:
Remove old URLs from the sitemap.
Add the new URLs to help search engines discover them faster.
Using redirects for thin or duplicate content
Some sites use redirects to hide thin or duplicate content. For example, redirecting multiple low-quality pages to a single high-quality page to “clean up” the site.
Why it’s bad:
Search engines may see this as manipulative.
Doesn’t address the root problem, which is low-quality content.
How to fix it:
Improve or consolidate content instead of redirecting.
Use canonical tags if duplicate content is unavoidable.
Not monitoring redirects over time
Redirects aren’t a set-it-and-forget-it task. For example:
Setting up a redirect and never checking if it’s still needed or working.
Why it’s bad:
Redirects can break over time (e.g., due to site updates or server changes).
Unnecessary redirects waste crawl budget.
How to fix it:
Audit redirects regularly (e.g., every 6 months).
Remove redirects that are no longer needed.
How to set up a redirect
Setting up redirects isn’t complicated, but the steps vary depending on your platform. Below, you’ll find straightforward instructions for the most common setups, whether you’re using WordPress, Apache, Nginx, or Cloudflare.
Pick the method that matches your setup and follow along. If you’re unsure which to use, start with the platform you’re most comfortable with.
WordPress (using Yoast SEO Premium)
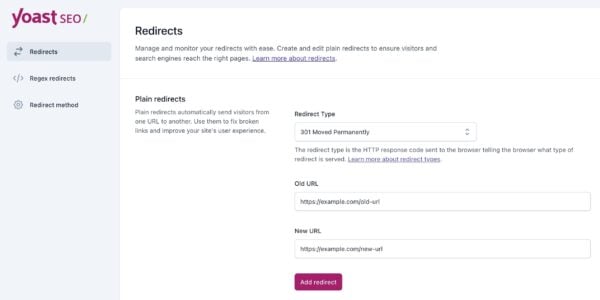
Yoast SEO Premium makes it easy to set up redirects, especially when you delete or move content. Here’s how to do it:
Option 1: Manual redirects
Go to Yoast SEO → Redirects in your WordPress dashboard.
Enter the old URL (the one you want to redirect from).
Enter the new URL (the one you want to redirect to).
Select the redirect type:
301 (Permanent): For deleted or permanently moved pages.
302 (Found): For short-term changes.
Click Add Redirect.
Manually redirecting a URL in Yoast’s redirect manager
Option 2: Automatic redirects when deleting content
Yoast SEO can create redirects automatically when you delete a post or page. Here’s how:
Go to Posts or Pages in your WordPress dashboard.
Find the post or page you want to delete and click Trash.
Yoast SEO will show a pop-up asking what you’d like to do with the deleted content. You’ll see two options:
Redirect to another URL: Enter a new URL to send visitors to.
Return a 410 Content Deleted header: Inform search engines that the page is permanently deleted and should be removed from their index.
Select your preferred option and confirm.
This feature saves time and ensures visitors land on the right page. No manual setup required.
Need help with redirects? Try Yoast SEO Premium
No code, no hassle. Just smarter redirects and many other invaluable tools.
Apache (.htaccess file)
Apache uses the .htaccess file to manage redirects. If your site runs on Apache, this is the simplest way to set them up. Add the rules below to your .htaccess file, ensuring it is located in the root directory of your site.
Nginx handles redirects in the server configuration file. If your site runs on Nginx, add these rules to your server block and then reload the service to apply the changes.
Cloudflare allows you to set up redirects without modifying server files. Create a page rule to forward traffic from one URL to another, without requiring any coding. Simply enter the old and new URLs, select the redirect type, and click Save.
Redirects don’t always work as expected. A typo, a cached page, or a conflicting rule can break them, or worse, create loops that frustrate users and search engines. Below are the most common issues and how to fix them.
If something’s not working, start with the basics: check for errors, test thoroughly, and clear your cache. The solutions are usually simpler than they seem.
Why isn’t my redirect working?
Check for typos: Ensure the URLs are correct.
Clear your cache: Browsers cache 301 redirects aggressively.
Use Screaming Frog to crawl your site for 404s and redirects.
What’s the difference between a 301 and 308 redirect?
301: Most common for permanent moves. Broad browser support.
308: Strict permanent redirect. Rarely used. Same SEO impact as 301.
What is a proxy redirect?
A proxy redirect keeps the URL the same in the browser but fetches content from a different location. Used for load balancing or A/B testing. Avoid for SEO, as search engines may not follow them.
Conclusion about redirects
Redirects are a simple but powerful tool. A redirect automatically sends users and search engines from one URL to another. As a result, they keep your site running smoothly and preserve SEO value and ranking power. Remember:
Use 301 redirects for permanent moves.
Use 302 redirects for temporary changes.
Avoid client-side redirects, such as meta refresh or JavaScript.
Edwin is an experienced strategic content specialist. Before joining Yoast, he worked for a top-tier web design magazine, where he developed a keen understanding of how to create great content.
The updated documentation focuses on a timing issue specific to JavaScript sites: canonicalization can happen twice during Google’s processing.
Google evaluates canonical signals once when it first crawls the raw HTML, then again after rendering the JavaScript. If your raw HTML contains one canonical URL and your JavaScript sets a different one, Google may receive conflicting signals.
The documentation notes that injecting canonical tags via JavaScript is supported but not recommended. When JavaScript sets a canonical URL, Google can pick it up during rendering, but incorrect implementations can cause issues.
Multiple canonical tags, or changes to an existing canonical tag during rendering, can lead to unexpected indexing results.
Best Practices
Google recommends two best practices depending on your site’s architecture.
The preferred method is setting the canonical URL in the raw HTML response to match the URL your JavaScript will ultimately render. This gives Google consistent signals before and after rendering.
If JavaScript must set a different canonical URL, Google recommends leaving the canonical tag out of the initial HTML. This can help avoid conflicting signals between the crawl and render phases.
The documentation also reminds developers to ensure only one canonical tag exists on any given page after rendering.
Why This Matters
This guidance addresses a subtle detail that can be easy to miss when managing JavaScript-rendered sites.
The gap between when Google crawls your raw HTML and when it renders your JavaScript creates an opportunity for canonical signals to diverge.
If you use frameworks like React, Vue, or Angular that handle routing and page structure client-side, it’s worth checking how your canonical tags are implemented. Look at whether your server response includes a canonical tag and whether your JavaScript modifies or duplicates it.
In many cases, the fix is to coordinate your server-side and client-side canonical implementations so they send the same signal at both stages of Google’s processing.
Looking Ahead
This documentation update clarifies behavior that may not have been obvious before. It doesn’t change how Google processes canonical tags.
If you’re seeing unexpected canonical selection in Search Console’s Page indexing reporting, check for mismatches between your raw HTML and rendered canonical tags. The URL Inspection tool shows both the raw and rendered HTML, which makes it possible to compare canonical implementations across both phases.
AI Overviews change how clicks flow through search results. Position 1 organic results that previously captured 30-35% CTR might see rates drop to 15-20% when an AI Overview appears above them.
Industry observations indicate that AI Overviews appear 60-80% of the time for certain query types. For these keywords, traditional CTR models and traffic projections become meaningless. The entire click distribution curve shifts, but we lack the data to model it accurately.
Brands And Agencies Need To Know: How Often AIO Appears For Their Keywords
Knowing how often AI Overviews appear for your keywords can help guide your strategic planning.
Without this data, teams may optimize aimlessly, possibly focusing resources on keywords dominated by AI Overviews or missing chances where traditional SEO can perform better.
Check For Citations As A Metric
Being cited can enhance brand authority even without direct clicks, as people view your domain as a trusted source by Google.
Many domains with average traditional rankings lead in AI Overview citations. However, without citation data, sites may struggle to understand what they’re doing well.
How CTR Shifts When AIO Is Present
The impact on click-through rate can vary depending on the type of query and the format of the AI Overview.
To accurately model CTR, it’s helpful to understand:
Whether an AI Overview is present or not for each query.
The format of the overview (such as expanded, collapsed, or with sources).
Your citation status within the overview.
Unfortunately, Search Console doesn’t provide any of these data points.
Without Visibility, Client Reporting And Strategy Are Based On Guesswork
Currently, reporting relies on assumptions and observed correlations rather than direct measurements. Teams make educated guesses about the impact of AI Overview based on changes in CTR, but they can’t definitively prove cause and effect.
Without solid data, every choice we make is somewhat of a guess, and we miss out on the confidence that clear data can provide.
How To Build Your Own AIO Impressions Dashboard
One Approach: Manual SERP Checking
Since Google Search Console won’t show you AI Overview data, you’ll need to collect it yourself. The most straightforward approach is manual checking. Yes, literally searching each keyword and documenting what you see.
This method requires no technical skills or API access. Anyone with a spreadsheet and a browser can do it. But that accessibility comes with significant time investment and limitations. You’re becoming a human web scraper, manually recording data that should be available through GSC.
Here’s exactly how to track AI Overviews manually:
Step 1: Set Up Your Tracking Infrastructure
Create a Google Sheet with columns for: Keyword, Date Checked, Location, Device Type, AI Overview Present (Y/N), AI Overview Expanded (Y/N), Your Site Cited (Y/N), Competitor Citations (list), Screenshot URL.
Build a second sheet for historical tracking with the same columns plus Week Number.
Create a third sheet for CTR correlation using GSC data exports.
Step 2: Configure Your Browser For Consistent Results
Open Chrome in incognito mode.
Install a VPN if tracking multiple locations (you’ll need to clear cookies and switch locations between each check).
Set up a screenshot tool that captures full page length.
Disable any ad blockers or extensions that might alter SERP display.
Step 3: Execute Weekly Checks (Budget 2-3 Minutes Per Keyword)
Search your keyword in incognito.
Wait for the page to fully load (AI Overviews sometimes load one to two seconds after initial results).
Check if AI Overview appears – note that some are collapsed by default.
If collapsed, click Show more to expand.
Count and document all cited sources.
Take a full-page screenshot.
Upload a screenshot to cloud storage and add a link to the spreadsheet.
Clear all cookies and cache before the next search.
Step 4: Handle Location-specific Searches
Close all browser windows.
Connect to VPN for target location.
Verify IP location using whatismyipaddress.com.
Open a new incognito window.
Add “&gl=us&hl=en” parameters (adjust country/language codes as needed).
Repeat Step 3 for each keyword.
Disconnect VPN and repeat for the next location.
Step 5: Process And Analyze Your Data
Export last week’s GSC data (wait two to three days for data to be complete).
Match keywords between your tracking sheet and GSC export using VLOOKUP.
Calculate AI Overview presence rate: COUNT(IF(D:D=”Y”))/COUNTA(D:D)
Compare the average CTR for keywords with vs. without AI Overviews.
Create pivot tables to identify patterns by keyword category.
Step 6: Maintain Data Quality
Re-check 10% of keywords to verify consistency.
Document any SERP layout changes that might affect tracking.
Archive screenshots weekly (they’ll eat up storage quickly).
Update your VPN locations if Google starts detecting and blocking them.
For 100 keywords across three locations, this process takes approximately 15 hours per week.
The Easy Way: Pull This Data With An API
If ~15 hours a week of manual SERP checks isn’t realistic, automate it. An API call gives you the same AIO signal in seconds, on a schedule, and without human error. The tradeoff is a little setup and usage costs, but once you’re tracking ~50+ keywords, automation is cheaper than people.
Here’s the flow:
Step 1: Set Up Your API Access
Sign up for SerpApi (free tier includes 250 searches/month).
Get your API key from the dashboard and store it securely (env var, not in screenshots).
Install the client library for your preferred language.
Step 2, Easy Version: Verify It Works (No Code)
Paste this into your browser to pull only the AI Overview for a test query:
Replace PAGE_TOKEN with the value from the first response.
Replace spaces in queries and locations with +.
Step 2, Low-Code Version
If you don’t want to write code, you can call this from Google Sheets (see the tutorial), Make, or n8nand log three fields per keyword: AIO present (true/false), AIO position, and AIO sources.
No matter which option you choose, the:
Total setup time: two to three hours.
Ongoing time: five minutes weekly to review results.
What Data Becomes Available
The API returns comprehensive AI Overview data that GSC doesn’t provide:
Presence detection: Boolean flag for AI Overview appearance.
Content extraction: Full AI-generated text.
Citation tracking: All source URLs with titles and snippets.
Positioning data: Where the AI Overview appears on page.
Interactive elements: Follow-up questions and expandable sections.
This structured data integrates directly into existing SEO workflows. Export to Google Sheets for quick analysis, push to BigQuery for historical tracking, or feed into dashboard tools for client reporting.
Demo Tool: Building An AIO Reporting Tool
Understanding The Data Pipeline
Whether you build your own tracker or use existing tools, the data pipeline follows this pattern:
Input: Your keyword list (from GSC, rank trackers, or keyword research).
Collection: Retrieve SERP data (manually or via API).
Processing: Extract AI Overview information.
Storage: Save to database or spreadsheet.
Analysis: Calculate metrics and identify patterns.
Let’s walk through implementing this pipeline.
You Need: Your Keyword List
Start with a prioritized keyword set.
Include categorization to identify AI Overview patterns by intent type. Informational queries typically show higher AI Overview rates than navigational ones.
Instantly. (This returns structured data instantly.)
Step 2: Store Results In Sheets, BigQuery, Or A Database
View the full tutorial for:
Step 3: Report On KPIs
Calculate the following key metrics from your collected data:
AI Overview Presence Rate.
Citation Success Rate.
CTR Impact Analysis.
Combine with GSC data to measure CTR differences between keywords with and without AI Overviews.
These metrics provide the visibility GSC lacks, enabling data-driven optimization decisions.
Clear, transparent ROI reporting for clients
With AI Overview tracking data, you can provide clients with concrete answers about their search performance.
Instead of vague statements, you can present specific metrics, such as: “AI Overviews appear for 47% of your tracked keywords, with your citation rate at 23% compared to your main competitor’s 31%.”
This transparency transforms client relationships. When they ask why impressions increased 40% but clicks only grew 5%, you can show them exactly how many queries now trigger AI Overviews above their organic listings.
More importantly, this data justifies strategic pivots and budget allocations. If AI Overviews dominate your client’s industry, you can make the case for content optimization targeting AI citation.
Early Detection Of AIO Volatility In Your Industry
Google’s AI Overview rollout is uneven, occurring in waves that test different industries and query types at different times.
Without proper tracking, you might not notice these updates for weeks or months, missing crucial optimization opportunities while competitors adapt.
Continuous monitoring of AI Overviews transforms you into an early warning system for your clients or organization.
Data-backed Strategy To Optimize For AIO Citations
By carefully tracking your content, you’ll quickly notice patterns, such as content types that consistently earn citations.
The data also reveals competitive advantages. For example, traditional ranking factors don’t always predict whether a page will be cited in an AI Overview. Sometimes, the fifth-ranked page gets consistently cited, while the top result is overlooked.
Additionally, tracking helps you understand how citations relate to your business metrics. You might find that being cited in AI Overviews improves your brand visibility and direct traffic over time, even if those citations don’t result in immediate clicks.
Stop Waiting For GSC To Provide Visibility – It May Never Arrive
Google has shown no indication of adding AI Overview filtering to Search Console. The API roadmap doesn’t mention it. Waiting for official support means flying blind indefinitely.
Start Testing SerpApi’s Google AI Overview API Today
If manual tracking isn’t sustainable, we offer a free tier with 250 searches/month so you can validate your pipeline. For scale, our published caps are clear: 20% of plan volume per hour on plans under 1M/month, and 100,000 + 1% of plan volume per hour on plans ≥1M/month.
We also support enterprise plans up to 100M searches/month. Same production infrastructure, no setup.
Build Your Own AIO Analytics Dashboard And Give Your Team Or Clients The Insights They Need
Whether you choose manual tracking, build your own scraping solution, or use an existing API, the important thing is to start measuring. Every day without AI Overview visibility is a day of missed optimization opportunities.
The tools and methods exist. The patterns are identifiable. You just need to implement tracking that fills the gap Google won’t address.
Get started here →
For those interested in the automated approach, access SerpApi’s documentation and test the playground to see what data becomes available. For manual trackers, download our spreadsheet template to begin tracking immediately.
Google Search Advocate John Mueller says large video files loading in the background are unlikely to have a noticeable SEO impact if page content loads first.
A site owner on Reddit’s r/SEO asked whether a 100MB video would hurt SEO if the page prioritizes loading a hero image and content before the video. The video continues loading in the background while users can already see the page.
Mueller responded:
“I don’t think you’d notice an SEO effect.”
Broader Context
The question addresses a common concern for sites using large hero videos or animated backgrounds.
The site owner described an implementation where content and images load within seconds, displaying a “full visual ready” state. The video then loads asynchronously and replaces the hero image once complete.
This method aligns with Google’s documentation on lazy loading, which recommends deferring non-critical content to improve page performance.
Google’s help documents state that lazy loading is “a common performance and UX best practice” for non-critical or non-visible content. The key requirement is ensuring content loads when visible in the viewport.
Why This Matters
If you’re running hero videos or animated backgrounds on landing pages, this suggests that background loading strategies are unlikely to harm your rankings. The critical factor is ensuring your primary content reaches users quickly.
Google measures page experience through Core Web Vitals metrics like Largest Contentful Paint. In many cases, a video that loads after visible content is ready shouldn’t block these measurements.
Implementation Best Practices
Google’s web.dev documentation recommends using preload=”none” on video elements to avoid unnecessary preloading of video data. Adding a poster attribute provides a placeholder image while the video loads.
For videos that autoplay, the documentation suggests using the Intersection Observer API to load video sources only when the element enters the viewport. This lets you maintain visual impact without affecting initial page load performance.
Looking Ahead
Site owners using background video can generally continue doing so without major SEO concerns, provided content loads first. Focus on Core Web Vitals metrics to verify your implementation meets performance thresholds.
Test your setup using Google Search Console’s URL Inspection Tool to confirm video elements appear correctly in rendered HTML.
Imagine telling someone that www.mysite.com/blog/myarticle and www.mysite.com/myarticle are actually the same page. To you, they’re the same, but to Google, even a small difference in the URL makes them separate pages. That is where the canonical tag steps in. In this guide, we will walk you through what a canonical URL is, how URL canonicalization works, when to use it, and which mistakes to avoid so that search engines always understand your preferred page version.
Table of contents
What is a canonical URL?
A canonical URL is the main, preferred, or official version of a webpage that you want search engines like Google to crawl and index. It helps search engines determine which version of a page to treat as the primary one when multiple URLs lead to similar or duplicate content. As a result, it avoids duplicate content and protects your SEO ranking signals.
All of the following URLs can show the same page, but you should set only one as the canonical URL:
https://www.mysite.com/product/shoes
https://mysite.com/product/shoes?ref=instagram
https://m.mysite.com/product/shoes
https://www.mysite.com/product/shoes?color=black
What is a canonical tag?
A canonical tag (also called a rel="canonical" tag) is a small HTML snippet placed inside the section of a webpage to tell search engines which URL is the canonical or master version. It acts like a clear label saying, “Index this page, not the others.” This prevents duplicate content issues, consolidates ranking signals, and supports proper canonicalization across your site.
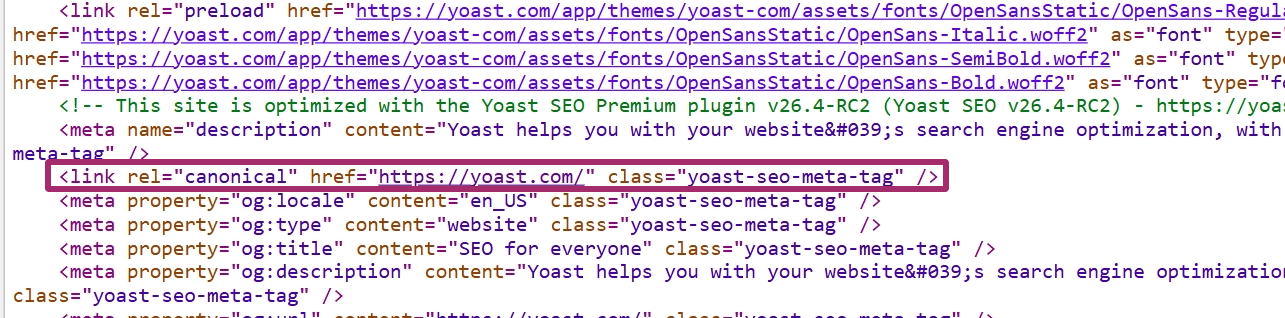
Here’s an example of a canonical tag in action:
This tag should be placed on any alternate or duplicate versions that point back to the main page you want indexed.
How does URL canonicalization work?
Canonicalization is the process of selecting the representative or canonical URL of a piece of content. From a group of identical or nearly identical URLs, this is the version that search engines treat as the main page for indexing and ranking.
Once you understand that, canonicalization becomes much easier to visualize. Think of it as a three-step workflow.
How the canonicalization process works
Here’s how the canonicalization works:
Search engines detect duplicate or similar URLs
Google groups URLs that return the same (or almost the same) content. These could come from:
URL parameters
HTTP vs. HTTPS versions
Desktop vs. mobile URLs
Filtered or sorted pages
Regional versions
Accidental duplicates like staging URLs
You signal which URL is canonical
You can guide search engines using canonical signals like:
The rel="canonical" tag
301 redirects
Internal links pointing to one preferred version
Consistent hreflang usage
XML sitemaps listing the preferred URL
HTTPS over HTTP
The strongest and clearest hint is the canonical tag placed in the head of the page.
Google selects one canonical URL
Google uses your signals, along with its own evaluation, to determine the primary URL. While Google typically follows canonical tags, it may override them if it detects stronger signals such as redirects, internal linking patterns, or user behaviour.
Once Google settles on the canonical URL, search engines will:
Consolidate link equity into the canonical page
Index the canonical URL
Treat all non-canonical URLs as duplicates
Reduce crawl waste
Avoid showing similar pages in search results
Canonical tags are a hint, not a directive. Google may still distribute link equity differently if it deems the canonical tag unreliable.
Reasons why canonicalization happens
Canonicalization becomes necessary when different URLs lead to the same content. Some common reasons are:
Region variants
For example, you have one product page for the USA and one for the UK, like: https://example.com/product/shoes-us and https://example.com/product/shoes-uk.
If the content is almost identical, use one canonical link or a clear regional setup to avoid confusion.
Pro tip: For regional variants, combine canonical tags with hreflang to specify language/region targeting.
Device variants
When you serve separate URLs for mobile and desktop, such as: https://m.example.com/product/shoes and https://www.example.com/product/shoes.
Canonical tags help search engines understand which URL is the primary version.
Protocol variants
Sorting and filtering often create many URLs that show similar content, like:
https://example.com/shoes?sort=price or https://example.com/shoes?color=black&size=7
A single canonical URL, such as https://example.com/shoes, tells search engines which page should carry the main ranking signals.
Maybe a staging or demo version of the site is left crawlable, or both https://example.com/page and https://example.com/page/ return the same content
Canonical tags and proper URL canonicalization help avoid these unintentional duplicates.
Some duplicate content on a site is normal. The goal of canonicalization in SEO is not to eliminate every duplicate, but to show search engines which URL you want them to treat as the primary one.
In practical aspects
In practice, canonicalization comes down to a few key things:
Placement
The canonical tag is placed in the head of the HTML, for example:
link rel="canonical" href="https://www.example.com/preferred-page" /
Each page should have at most one canonical tag, and it should point to the clean, preferred canonical URL.
Identification
Search engines examine several signals to determine the canonical version of a page. The rel="canonical" tag is important, but they also consider 301 redirects, internal links, sitemaps, hreflang, and whether the page is served on HTTPS. When these signals are consistent, it is easier for Google to pick the right canonicalized URL.
Crawling and indexing
Once search engines understand which URL is canonical, they primarily crawl and index that version, folding duplicates into it. Link equity and other signals are consolidated to the canonical page, which improves stability in rankings and makes your canonical tag SEO setup more effective.
The main rule for canonicalization is simple: if multiple URLs display the same content, choose one, make it your canonical URL, and clearly signal that choice with a proper canonical tag.
Google’s John Mueller puts it simply: ‘I recommend doing this kind of self-referential rel=canonical because it really makes it clear for us which page you want to have indexed or what this URL should be when it’s indexed.’
And that’s exactly why canonical tags matter; they tell search engines which version of a page is the real one. This keeps your SEO signals clean and prevents your site from competing with itself.
They’re important because they:
Avoid duplicate content issues: Canonical tags inform Google which URL should be indexed, preventing similar or duplicate pages from confusing crawlers or diluting rankings
Consolidate link equity: Canonicalization works similarly to internal linking; both are techniques used to direct authority to the page that matters most. Instead of splitting ranking signals across duplicate URLs, all information is consolidated into a single canonical URL
Improve crawl efficiency: Search engines don’t waste time crawling unnecessary duplicate pages, which helps them discover your important content faster
Enhance user experience: Users land on the correct, up-to-date version of your page, not a filtered, parameterized, or accidental duplicate
Canonical tags are useful in various everyday SEO scenarios. Here are the most common scenarios where you’ll want to use a rel=canonical tag to signal your preferred URL.
URL versions
If your page loads under multiple URL formats, with or without “www,” HTTP vs. HTTPS, and with or without a trailing slash, search engines may index each version separately. A canonical tag helps you standardize the preferred version so Google doesn’t treat them as separate pages.
Duplicate content
Ecommerce sites, blogs with tag archives, and category-driven pages often generate duplicate or near-duplicate content by design. If the same product or article appears under multiple URLs (filters, parameters, tracking codes, etc.), canonical tags help Google understand which canonical URL is the authoritative one. This prevents cannibalization and protects your canonical SEO setup.
If your content is republished on partner sites or aggregators, always use a canonical tag that points back to your original version. This ensures your page retains the ranking signals, not the syndicated copy, and search engines know exactly where the content was originally published.
If syndication partners don’t honor your canonical tag, consider using noindex or negotiating link attribution.
Paginated pages
Long lists or multi-page articles often create a chain of URLs like /page/2/, /page/3/, and so on. These pages contribute to the same topic but shouldn’t be indexed individually. Adding canonical tags to the paginated sequence (typically pointing to page 1 or a “view-all” version) helps consolidate indexing and keeps rankings focused on the primary page.
Pro tip: For paginated content, use self-referencing canonicals (each page points to itself) unless you have a ‘view-all’ page that loads quickly and is crawlable.
When you change domains, restructure URLs, or move from HTTP to HTTPS, using consistent canonical tags helps reinforce which pages replace the old ones. It signals to search engines which canonicalized URL should inherit ranking power. During migrations, canonical tags act as a safety net to prevent duplicate versions from competing with each other.
URL canonicalization is all about giving search engines a clear signal about which version of a page is the preferred or canonical URL. You can implement it in several simple steps.
Using the rel=”canonical” tag
The most common way (as shown multiple times in this blog post) to set a canonical URL is by adding a rel="canonical" tag in the head section of your page. It looks like this:
link rel="canonical" href="https://www.example.com/preferred-url"/
This tag tells search engines which URL should carry all ranking signals and appear in search results. Ensure that every duplicate or alternate version links to the same preferred URL, and that the canonical tag is consistent throughout the site.
You can also use rel="canonical" in HTTP headers for non-HTML content such as PDFs. This is helpful when you cannot place a tag in the page itself.
Pro tip: While supported for PDFs, Google may not always honor canonical HTTP headers. Use them in conjunction with other signals (e.g., sitemaps).
Also, ensure the canonical tag is as close to the top of the head section as possible so that search engines can see it early. Each page should have only one canonical tag, and it should always point to a clean, accessible URL. Avoid mixing signals. The canonical URL, your internal links, and your sitemap entries should all match.
Setting a preferred domain in Google Search Console
Google lets you choose whether you prefer your URLs to appear with or without www. Setting this preference helps reinforce your canonical signals and prevents search engines from treating www and non-www versions as different URLs.
To set your preferred domain, open your property in Google Search Console, go to Settings, and choose the version you want to treat as your primary domain.
Redirects (301 redirects)
A 301 redirect is one of the strongest signals you can send. It permanently informs browsers and search engines that one URL has been redirected to another and that the new URL should be considered the canonical URL.
Use 301 redirects when:
You merge duplicate URLs
You change your site structure
You migrate to HTTPS
You want to consolidate link equity from outdated pages
Of course, redirects replace the old URL, while canonical tags suggest a preference without removing the duplicate.
With Yoast SEO Premium, you can manage redirects effortlessly right inside your WordPress dashboard. The built-in redirect manager feature of the SEO plugin helps you avoid unnecessary 404s and prevents visitors from landing on dead ends, keeping your site structure clean and your user experience smooth.
A smarter analysis in Yoast SEO Premium
Yoast SEO Premium has a smart content analysis that helps you take your content to the next level!
Additional canonicalization techniques
There are a few more ways to support your canonical setup.
XML sitemaps: Always include only canonical URLs in your sitemap. This helps search engines understand which URLs you want indexed
Hreflang annotations: For multi-language or multi-region sites, hreflang tags help search engines serve the correct regional version while still respecting your canonical preference
Link HTTP headers: For files like PDFs or other non-HTML content, using a rel="canonical" HTTP header helps you specify the preferred URL server-side
Each of these methods reinforces your canonical signals. When you use them together, search engines have a much clearer understanding of your canonicalized URLs.
Implementing canonicalization in WordPress with Yoast
Manually adding a rel="canonical" tag to the head of every duplicate page can be fiddly and error prone. You need to edit templates or theme files, keep tags consistent with your sitemap and internal linking, and remember special cases, such as PDFs or paginated series. Modifying site code and HTML is risky when you have numerous pages or multiple editors working on the site.
Yoast SEO makes this easier and safer. The plugin automatically generates sensible canonical URL tags for all your pages and templates, eliminating the need for manual theme file edits or code additions. You can still override that choice on a page-by-page basis in the Yoast SEO sidebar: open the post or page, go to Advanced, and paste the full canonical URL in the Canonical URL field, then save.
Automatic coverage: Yoast automatically adds canonical tags to pages and archives by default, which helps prevent many common duplicate content issues
Manual override: For special cases, use the Yoast sidebar > Advanced > Canonical URL field to set a custom canonical. This accepts full URLs and updates when you save the post
Edge cases handled: Yoast will not output a canonical tag on pages set to noindex, and it follows best practices for paginated series and archives
Developer options: If you need custom behavior, you can filter the canonical output programmatically using the wpseo_canonical filter or use Yoast’s developer API
Cross-domain and non-HTML: Yoast supports cross-site canonicals, and you can use rel=”canonical” in HTTP headers for non-HTML files when needed
Both Yoast SEO and Yoast SEO Premium include canonical URL handling, and the Premium version adds extra automation and controls to streamline larger sites.
Canonical URLs may seem like a small technical detail, but they play a huge role in helping search engines understand your site. When Google finds multiple URLs displaying the same content, it must select one version to index. If you do not guide that choice, Google will make the decision on its own, and that choice is not always the version you intended. That can lead to split ranking signals, wasted crawl activity, and frustrating drops in visibility.
Using canonical URLs gives you back that control. It tells search engines which page is the primary version, which ones are duplicates, and where all authority signals should be directed. From filtering URLs to regional variants to accidental duplicates that slip through the cracks, canonicals keep everything tidy and predictable.
The good news is that canonicalization does not have to be complicated. A simple rel=”canonical” tag, consistent URL handling, smart redirects, and clean sitemap signals are enough to prevent most issues. And if you are working in WordPress, Yoast SEO takes care of almost all of this automatically, so you can focus on creating content instead of wrestling with code.
At the end of the day, canonical URLs are about clarity. Show search engines the version that matters, remove the noise, and keep your authority consolidated in one place. When your signals are clear, your rankings have a solid foundation to grow.
Joost is an internet entrepreneur and the founder of Yoast. He has a long history in WordPress and digital marketing. On our blog, he has written a lot about SEO in general, technical SEO and important topics related to SEO.